Embed Size (px)
Citation preview

VIDEO RETRIEVAL OF SPECIFIC PERSONS IN SPECIFIC LOCATIONS
AUTHOR: ADVISORS:
Xavier Giró-i-Nieto
Eva Mohedano Kevin McGuinness
Andrea Calafell
Noel E. O’Connor
1

1. Motivation2. State of the art3. Framework for TRECVID4. Face detection5. Face representation6. Query expansion7. Annotation Tool8. Fusion and normalization strategies9. Conclusions and future work
OUTLINE
2

MOTIVATION
SURVEILLANCE PERSONAL VIDEO ORGANIZATION
3

TRECVID INSTANCE SEARCH 2016
PEOPLE AND LOCATION QUERY SET
Person visual
examples
Binary masks
Location visual
examples
TARGET DATABASE
1.5M keyframes
244 video files (300GB)
4

MOTIVATION: goals
● Obtain a baseline to participate in TRECVID Instance Search 2016 (July, 1).
● Improve the results obtained in TRECVID using the baseline.
5

1. Motivation2. State of the art3. Framework for TRECVID4. Face detection5. Face representation6. Query expansion7. Annotation Tool8. Fusion and normalization strategies9. Conclusions and future work
OUTLINE
6

STATE OF THE ART
Image of Eva Mohedano, D3L6 Image Retrieval, Deep Learning for Computer Vision (UPC 2016)
BASIC RETRIEVAL PIPELINE:
7

STATE OF THE ART
Image of Eva Mohedano, D3L6 Image Retrieval, Deep Learning for Computer Vision (UPC 2016)
BAG OF VISUAL WORDS:
8

STATE OF THE ART
Image: Alex Krizhevsky , Ilya Sutskever , Geoffrey E. Hinton, Imagenet classification with deep convolutional neural networks, 2012Ali Sharif Razavian, Josephine Sullivan, Atsuto Maki, and Stefan Carlsson. A baseline for visual instance retrieval with deep convolutional networks. ICLR 2015.
CNN REPRESENTATION:
9

STATE OF THE ART
Eva Mohedano, Amaia Salvador, Kevin McGuinness, Ferran Marqués, Noel E. O’Connor, and Xavier Giró i Nieto. Bags of local convolutional features for scalable instance search. ICMR 2016.
BAG OF LOCAL CONVOLUTIONAL FEATURES:
10

1. Motivation2. State of the art3. Framework for TRECVID4. Face detection5. Face representation6. Query expansion7. Annotation Tool8. Fusion and normalization strategies9. Conclusions and future work
OUTLINE
11

FRAMEWORK FOR TRECVID
12

FRAMEWORK FOR TRECVID
13Mohedano, et al. ICMR 2016

1. Motivation2. State of the art3. Framework for TRECVID4. Face detection5. Face representation6. Query expansion7. Annotation Tool8. Fusion and normalization strategies9. Conclusions and future work
OUTLINE
14

FRAMEWORK FOR TRECVID
15

FACE DETECTION: ReInspect
Russell Stewart, Mykhaylo Andriluka, and Andrew Y. Ng. End-to-end people detection in crowded scenes. CVPR 2016.
16

FACE DETECTION: ReInspectQUALITATIVE RESULTS OF REINSPECT:
Changing both the input size of the network and the image size
Changing only the image size
17
Bad detectionsFalse negatives

FACE DETECTION: ReInspect
PROBLEM: Images used to train ReInspect
18

FACE DETECTION: Menpo
1 https://github.com/menpo/menpodetect
Python wrapper for face detectors1:
● DLIB
● OPENCV
● Pixel Intensity Comparison-based
Object detection (PICO)
● FFLD2:
○ Based on Deformable Part
Models (DPM)
○ Use LUV color space
2 M. Mathias, R. Benenson, M. Pedersoli, and L. Van Gool. Face detection without bells and whistles. ECCV, 2014.
Examples of FFLD results
19

QUALITATIVE RESULTS OF MENPO:
DLIB
FACE DETECTION: Menpo
OPENCV
PICO 20
False negatives

QUALITATIVE RESULTS OF MENPO:
FACE DETECTION: Menpo
FFLD
Still some false negatives Solution: Equalize image
21

1. Motivation2. State of the art3. Framework for TRECVID4. Face detection5. Face representation6. Query expansion7. Annotation Tool8. Fusion and normalization strategies9. Conclusions and future work
OUTLINE
22

DEEP FACE RECOGNITION
FACE REPRESENTATION
Image: Simonyan, Karen, and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. ICLR 2015.O. M. Parkhi, A. Vedaldi, and A. Zisserman. Deep face recognition. BMVC 2015
VGG 16-layer
23

1. Motivation2. State of the art3. Framework for TRECVID4. Face detection5. Face representation6. Query expansion7. Annotation Tool8. Fusion and normalization strategies9. Conclusions and future work
OUTLINE
24

QUERY EXPANSION
Sequence of keyframes of one shot
dilate
Mask creation pipeline25
TEMPORAL QUERY EXPANSION:

Results of temporal query expansion
26
QUERY EXPANSIONTEMPORAL QUERY EXPANSION:

27
QUERY EXPANSIONPSEUDO-RELEVANCE FEEDBACK QUERY EXPANSION:
Top 20 retrieved keyframes

1. Motivation2. State of the art3. Framework for TRECVID4. Face detection5. Face representation6. Query expansion7. Annotation Tool8. Fusion and normalization strategies9. Conclusions and future work
OUTLINE
28

ANNOTATION TOOL
3.991 shots for persons
1.528 shots for locations
794 shots in common
29

1. Motivation2. State of the art3. Framework for TRECVID4. Face detection5. Face representation6. Query expansion7. Annotation Tool8. Fusion and normalization strategies9. Conclusions and future work
OUTLINE
30

FRAMEWORK FOR TRECVID
31

FUSION AND NORMALIZATION STRATEGIESNORMALIZATION:
● Z-score:
● Max-min:
● Extreme Value Theory:
FUSION:Linear combination, maximum, minimum.
32
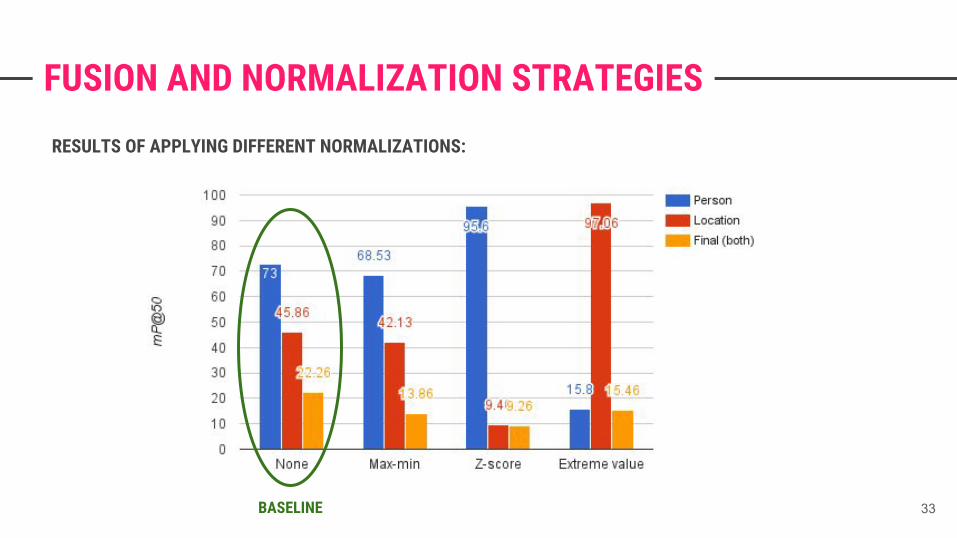
FUSION AND NORMALIZATION STRATEGIES
RESULTS OF APPLYING DIFFERENT NORMALIZATIONS:
BASELINE 33

FUSION AND NORMALIZATION STRATEGIES
Brad Person distribution Laundrette Location distribution
34
EXAMPLE DISTRIBUTION:

FUSION AND NORMALIZATION STRATEGIES
RESULTS OF APPLYING MAXIMUM OR MINIMUM FUSION
35

FUSION AND NORMALIZATION STRATEGIES
RESULTS OF WEIGHTING LINEAR COMBINATION
HIGHER THAN THE BASELINE 36

1. Motivation2. State of the art3. Framework for TRECVID4. Face detection5. Face representation6. Query expansion7. Annotation Tool8. Fusion and normalization strategies9. Conclusions and future work
OUTLINE
37

CONCLUSIONS
● FFLD, a simple approach using vanilla DPM combined with image equalization is the best option for TRECVID dataset
38

CONCLUSIONS● The temporal query expansion proposed works well, but the faces are very similar between them
However, using the top 20 faces in the ranking as new queries gives more diverse faces.
39

CONCLUSIONS● An annotation tool is needed in order to obtain quantitative results.
3.991 shots for persons
1.528 shots for locations
794 shots in common
TOTAL OF RELEVANT ANNOTATED SHOTS
● The best configuration is without applying normalization and combining the scores by weighting higher the location ranking
40

FUTURE WORK● Analyze deeper the location part
● Try to improve the location rankings
41

QUESTIONS?
42

FUSION AND NORMALIZATION STRATEGIES
RESULTS OF THE PARTS SEPARATELY OVER 50 KEYFRAMES
43

FUSION AND NORMALIZATION STRATEGIES
RESULTS OF APPLYING MAXIMUM, MINIMUM AND PRODUCT FUSION
44





























