Embed Size (px)
Citation preview

Provenance Analysis and RDF Query Processing
Satya S. Sahoo, Praveen Rao October 12, 2015

Plan for the Tutorial
• 09:00 – 10:00: Provenance and its Applications o What is provenance? o W3C PROV specifications and applications
• 10:00– 10:30: Provenance Query and Analysis o Provenance queries o Graph operations to support provenance queries
• 10:30 – 11:00: Coffee Break, RBC Gallery, First Floor • 11:00 – 12:15: RDF Query Processing
o Centralized approaches o Parallel approaches
• 12:15 – 12:30: Discussion

Provenance in Application Domains: Healthcare
• Patient treatment often depends on their medical history o Past hospital visits o Current and past
medications
• Outcome of treatment also depends on patient history
• Medical history of patient - provenance

Provenance in Application Domains: Sensor Networks
• Sensor properties needed for data analysis o Location of sensor
(geo-spatial) o Temporal information
of sensor observations o Sensor capabilities (e.g.,
resolution, modality)
• Provenance in sensor networks o Find all sensors located in
geographical location? o Download data from wind
speed sensors for snowstorm
* Patni, H., Sahoo, S.S., Henson, C., Sheth, A., “Provenance aware linked sensor data”, Proceedings of the Second Workshop on Trust and Privacy on the Social and Semantic Web, 2010

Provenance in Application Domains: In silico Experiments
• Provenance information helps explain how results from in silico experiments are derived
• Supports scientific reproducibility • Helps ensure data quality
* Zhao, J., Sahoo, S.S., Missier, P., Sheth, A., Goble, C., “Extending semantic provenance into the web of data”, IEEE Internet Computing, 15(1), pp. 40-48. 2011

Research in Provenance Management
• Provenance: derived from the word provenir - “to come from”
• Provenance metadata is specific category of metadata • The W7 model: who, when, why, where, what, which, how • Provenance tracking in relational databases
o Result set → + query (constraints) + time value
• Provenance in scientific workflow
ID Name
1 Joe
2 Mary
GeneToPathway Gene Pathway

Provenance and Semantic Web Layer Cake
• Proof layer aka Provenance
• Trust is derived from provenance information

Provenance Management
• Provenance Modeling using Semantic Web technologies
• Provenance models used as input to the W3C PROV Data Model ! Open Provenance
Model (OPM) ! Provenir Ontology
! Proof Markup Language (PML)
! Dublin Core
! Provenance Vocabulary

Provenance Management
• Provenance Querying and Access using Semantic Web technologies
• Access provenance of resources on the Web using standard Web protocols (HTTP)
• Two access mechanisms o Direct access:
Dereferencing URIs o Provenance query
service • Mechanism for content
negotiation

W3C PROV Family of Specifications: Provenance Modeling
• W3C Recommendations o PROV Data Model (PROV-
DM) o PROV Ontology (PROV-O) o PROV-Constraints o PROV Notations (PROV-
N)
• PROV Working Group Notes (selected) o PROV-Access and Querying (AQ) o PROV Dictionary o PROV XML o PROV and Dublin Core Mappings
(PROV-DC) o PROV Semantics (using first-order logic)
(PROV-SEM)

W3C PROV: PROV Data Model
• Three primary terms • Entity: A real or
imaging thing with fixed aspects
• Activity: occurs over a period of time and acts on entities
• Agent: bears responsibility for activity, entity, or another agent

PROV-DM: Additional Terms
• PROV core terms can be extended to model domain-specific provenance o Subtyping: programming is a specific type of activity
• PROV allows modeling provenance of provenance • Bundles: named set of provenance descriptions
o For example, provenance of medical record is important to evaluate its accuracy
• Collections: structured entities o For example, ranked query results
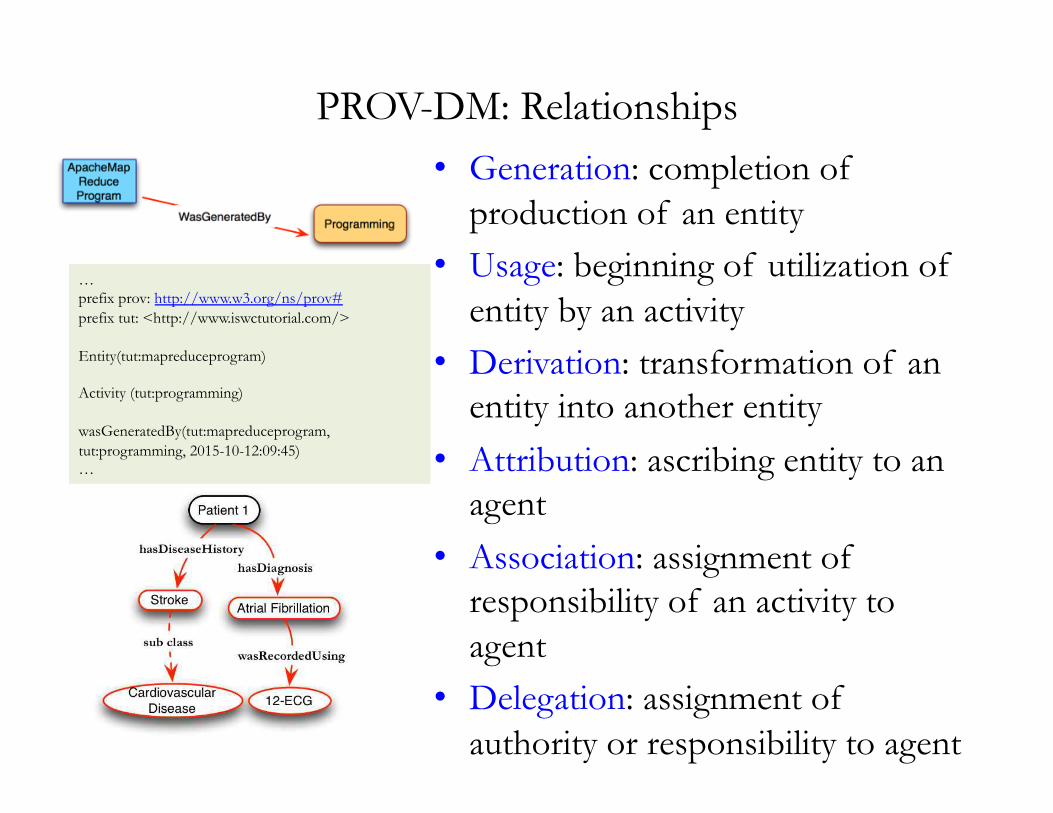
PROV-DM: Relationships • Generation: completion of
production of an entity • Usage: beginning of utilization of
entity by an activity • Derivation: transformation of an
entity into another entity • Attribution: ascribing entity to an
agent • Association: assignment of
responsibility of an activity to agent
• Delegation: assignment of authority or responsibility to agent
… prefix prov: http://www.w3.org/ns/prov# prefix tut: <http://www.iswctutorial.com/>
Entity(tut:mapreduceprogram)
Activity (tut:programming)
wasGeneratedBy(tut:mapreduceprogram, tut:programming, 2015-10-12:09:45) …

A Provenance Graph: Medical History of Patients
• Exercise: Identify subtypes of PROV terms in the graph
Class Instance

PROV Ontology (PROV-O) • Models the PROV Data Model using OWL2 • Enables creation of domain-specific provenance ontologies

PROV-O: Qualified Terms
• Qualified terms are used to model ternary relationships using the “Qualification Pattern”
• Uses an intermediate class to represent additional description associated with the relationship
• Additional qualifications: o Time of generation o Location

PROV Constraints: Provenance Validation and Inference
• PROV Constraints is used to validate PROV instances using a set of definitions, inferences, and constraints
• Support consistency checking and also reasoning over PROV dataset
• Also allow normalization of PROV data • For example,
o Uniqueness constraint: If two PROV statement describe the birth of a person twice, the two statements will have same timestamp
o Event ordering constraint: A person cannot be released from hospital before admission

PROV Constraints: Inference
• Support for simple and complex inferences
Inference 15: IF actedOnBehalfOf(id; ag2, ag1, _a, attrs) THEN wasInfluencedBy(id; ag2, ag1, attrs)
Inference 13: IF wasAttributedTo(_att; e, ag, attrs) THEN wasGeneratedBy(_gen; e, a, _t, attrs) AND wasAssociatedWith(_assoc; a, ag, _p1, []).

Summary of First Session
• We have covered: ! What is provenance? ! Why is provenance important? ! How does it fit into the Semantic Web? ! Which models of provenance can be used by domain
applications? ! When to use PROV Entity, Agent, and Process? ! Who delegates authority or responsibility to Agent
(PROV-DM Relationships)? ! Where can we apply PROV constraints and inference
rules to validate provenance data?

Plan for the Tutorial
• 09:00 – 10:00: Provenance and its Applications o What is provenance? o W3C PROV specifications and applications
• 10:00 – 10:30: Provenance Query and Analysis o Provenance queries o Graph operations to support provenance queries
• 10:30 – 11:00: Coffee Break, RBC Gallery, First Floor • 11:00 – 12:15: RDF Query Processing
o Centralized approaches o Parallel approaches
• 12:15 – 12:30: Discussion

Provenance Query and Analysis: Data-driven Research
Source: http://renewhamilton.ca
Source: www.comsoc.org/blog
Source: www.nature.com
Human Connectome Project
PAN-STARRS
Project Neptune

Provenance Query and Analysis
• Challenges in data-driven research o How to reliably store and transfer data between applications,
users, or across institutions? o How to integrate data while ensuring consistency and data
quality? o How to select subsets of data with relevant provenance
attributes o How to rank results of user queries based on provenance
values?
• Provenance queries o Directly query provenance o Query provenance of provenance

Classification Scheme for Provenance Queries
• Type 1: Querying for Provenance Metadata o Has this patient undergone a heart surgery in the
past 1 year? • Type 2: Querying for Specific Data Set
o Find all financial transactions conducted by John Doe in the past 3 years involving amount > $1 million?
• Type 3: Operations on Provenance Metadata o What are the difference in the medical history of two
patients – one had better outcome than other?
23

I. Provenance Trails: Query for Provenance of Entity
• Provenance trails consists of all the provenance related information of an entity o Hospital admissions of the patient o Medication information o Diagnosis information
• Involves graph traversal o May involve recursive graph traversal o All provenance information associated
with specific hospital admission

II. Query for Entity Satisfying Provenance
• Retrieve all entities that satisfy specific provenance constraints o Involves identification and extraction
of subgraph o Conforms to the provenance
constraints
• May involve multiple SPARQL queries
• Require aggregation of result subgraphs

III. Aggregation or Comparison of Provenance
• Compare the provenance trails of two sensor data entities to identify source of data error
• Provenance graph comparison can be related to subgraph isomorphism used in SPARQL query execution o Covered in the RDF query processing segment
• A patient’s medical history spans multiple hospital admissions o Requires aggregation of individual provenance graphs
corresponding to hospital admissions

RDF Reification Approach
lipoprotein inflammatory_cells affects

Provenance Context • Provenance contextual information defines the
interpretation of an entity • Provenance context is a formal object defined in terms
of Provenir ontology
lipoprotein inflammatory
_cells affects
derives_from
PubMed_Source
derives_from
Entity
rdf:type
derives_from
PROV-O
Provenance Context
* Sahoo et al., 22nd SSDBM Conference, Heidelberg, Germany, pp. 461-470, Jun 30 - Jul 2, 2010

Provenance Context Entity (PaCE) Approach
• A provenance context is used for entity generation - S, P, O of a RDF triple
• Allows an application to decide the level of provenance granularity
Exhaus've approach (E_PaCE) Minimal approach (M_PaCE)
Intermediate approach (I_PaCE)

PaCE Inferencing and Evaluation Result
• 85 million fewer RDF triples using PaCE
Asserted
Inferred
• Extends existing RDFS entailment
• Condition: Equivalence of provenance context
* Sahoo et al., 22nd SSDBM Conference, Heidelberg, Germany, pp. 461-470, Jun 30 -‐ Jul 2, 2010

Provenance Context Entity (PaCE) Results
Query: List all the RDF triples extracted from a given journal ar'cle
Query: List all the journal ar'cles from which a given RDF triple was extracted
Query: Count the number of triples in each source for the therapeu'c use of a given drug
Query: Count the number of journal ar'cles published between two dates for a given triple
* Sahoo et al., 22nd SSDBM Conference, Heidelberg, Germany, pp. 461-470, Jun 30 -‐ Jul 2, 2010

Time Series Analysis using Provenance Information
Query: Count the number of journal articles published over 10 years for a given triple (e.g., thalidomide → treats → multiple myeloma)
* Sahoo et al., 22nd SSDBM Conference, Heidelberg, Germany, pp. 461-470, Jun 30 -‐ Jul 2, 2010

Summary of Second Session
• We covered: ! Provenance queries ! Different categories of provenance queries ! Graph operations in context of provenance queries ! Provenance of RDF triples ! Comparison of Provenance Context Entity approach
and RDF Reification approach ! What’s next?

Plan for the Tutorial
• 09:00 – 10:00: Provenance and its Applications o What is provenance? o W3C PROV specifications and applications
• 10:00 – 10:30: Provenance Query and Analysis o Provenance queries o Graph operations to support provenance queries
• 10:30 – 11:00: Coffee Break, RBC Gallery, First Floor • 11:00 – 12:15: RDF Query Processing
o Centralized approaches o Parallel approaches
• 12:15 – 12:30: Discussion

Semantic Web Layer Cake

What will we cover?
• Oracle-RDF, SW-Store • RDF-3X, Hexastore • BitMat • DB2RDF • TripleBit • RIQ
Centralized approaches
• Scalable SPARQL querying • HadoopRDF • Trinity.RDF • H2RDF+ • TriaD • DREAM
Parallel approaches
RDF query processing

Resource Description Framework (RDF)
• Each RDF statement is a (subject, predicate, object) triple o Represents an assertion or a fact
<http://xmlns.com/foaf/0.1/Alice> <http://xmlns.com/foaf/0.1/name> “Alice”

RDF Quadruples (Quads)
• A quad is denoted by (subject, predicate, object, context) o Context (a.k.a. graph name) can be used to capture provenance
information (e.g., origin/source of a statement) o Triples with the same context belong to the same RDF graph
@prefix foaf: <http://xmlns.com/foaf/0.1/>
foaf:Alice foaf:name “Alice” <http://ex.org/John/foaf.rdf> . foaf:Bob foaf:name “Bob” <http://ex.org/John/foaf.rdf> .
foaf:Alice foaf:knows foaf:Bob <http://ex.org/graphs/John> . foaf:Alice foaf:knows foaf:Bob <http://ex.org/graphs/Mary> .

SPARQL Query PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX movie: <http://data.linkedmdb.org/resource/movie/>
SELECT ?g ?producer ?name ?label ?page ?film WHERE { GRAPH ?g { ?producer movie:producer_name ?name . ?producer rdfs:label ?label . OPTIONAL { ?producer foaf:page ?page . } ?film movie:producer ?producer . }}
Basic Graph Pattern (BGP) matching
Triple pattern

Open-Source and Commercial Tools
Sesame, Apache Jena, 3store, Mulgara, Kowari, YARS2, …
Virtuoso, AllegroGraph, Garlik 4store/5store, …
SYSTAP’s Blazegraph, Stardog, Oracle 12c, Titan, Neo4j, MarkLogic, Ontotext’s GraphDB

Reported Large-scale Deployments
1+ trillion triples
Oracle 12c
8 database nodes (192 cores) and 14 storage nodes (168 cores), 2 TB total
RAM and 44.8 TB Flash Cache AllegroGraph
240 core Intel x5650, 2.66GHz, 1.28 TB RAM
10+ billion triples
OpenLink Virtuoso (15+ Billion)
8-node cluster, two quad-core processors per node, 16 GB RAM
Ontotext’s GraphDB (13 Billion)
Dual-CPU server with Xeon E5-2690 CPUs, 512 GB of RAM and SSD storage
array
Stardog (50 Billion)
Single server, 32 cores, 256 GB RAM Blazegraph (50 Billion)
Single server, GPU-acceleration
Source: http://www.w3.org/wiki/LargeTripleStores

Triples Table, Vertical Partitioning
• SQL-based RDF querying scheme [Chong et.al. VLDB ‘05]
o IDTriples table, URIMap table; use of self-joins; subject-property matrix
• SW-Store [Abadi et.al., VLDB ’07, VLDBJ ‘09]
o Vertical partitioning of RDF data • Triples with the same property are grouped together: (S,O)
o Use of a column-store; materialization of frequent joins
• MonetDB/SQL [Sidirourgos et.al., PVLDB ’08]
o Triplestore on a row-store vs vertical partitioning on column-store
D. J. Abadi, A. Marcus, S. R. Madden, K. Hollenbach, “Scalable Semantic Web Data Management Using Vertical Partitioning,” in Proc. of the 33rd VLDB Conference, 2007, pp. 411-422. L. Sidirourgos, R. Goncalves, M. Kersten, N. Nes, S. Manegold, “Column-store support for RDF data management: not all swans are white,” in PVLDB, 1(2), 2008.
E. I. Chong, S. Das, G. Eadon, J. Srinivasan, “An efficient SQL-based RDF querying scheme,” in Proc. of the 31st VLDB Conference, 2005, pp. 1216-1227.

Exhaustive Indexing
• Early approaches o Kowari [Wood et.al., XTech ‘05], YARS [Harth et.al., LA-WEB ‘05]
• RDF-3X [Neuman et.al., PVLDB ‘08, VLDBJ ‘10]
o 6 permutations: (SPO), (SOP), (POS), (PSO), (OSP), (OPS) o Clustered B+-tree indexes; leverages merge joins; compression o New join ordering method using a cost model based on
selectivity estimates
• Hexastore also builds similar indexes [Weiss et.al., PVLDB ‘08] o Merge joins; no compression
T. Neumann, G. Weikum, “RDF-3X: a RISC-style engine for RDF,” in Proc. of the VLDB Endowment 1 (1) (2008), pp. 647-659.
C. Weiss, P. Karras, A. Bernstein, “Hexastore: Sextuple indexing for Semantic Web data management,” in Proc. VLDB Endow. 1 (1) (2008), pp. 1008-1019.

Reducing the Cost of Join Processing
• BitMat [Atre et.al., WWW ‘10]
o A triple is uniquely mapped to a cell in a 3D cube o Compressed bit matrices are loaded and processed in memory
during join processing • Intermediate join results are not materialized
• DB2RDF [Bornea et.al., SIGMOD ‘13]
o Direct Primary Hash, Reverse Primary Hash • Wide table layout to reduce joins for star-shaped queries • Only subject and object indexes
o SPARQL-to-SQL translation
M. A. Bornea, J. Dolby, A. Kementsietsidis, K. Srinivas, P. Dantressangle, O. Udrea, B. Bhattacharjee, “Building an efficient RDF store over a relational database,” in Proc. of 2013 SIGMOD Conference, 2013, pp. 121-132.
M. Atre, V. Chaoji, M. J. Zaki, J. A. Hendler, “Matrix "Bit" loaded: A scalable lightweight join query processor for RDF data,” in Proc. of the 19th WWW Conference, 2010, pp. 41-50.

Reducing the Cost of Join Processing
• TripleBit [Yuan et.al., PVLDB ‘13]
o Represents triples as a 2D bit matrix called Triple Matrix • Compression for compactness
o For each predicate • SO and OS ordered buckets of triples • Conceptually, only two indexes are needed instead of six: POS, PSO
o Reduction in the size of intermediate results during join processing
P. Yuan, P. Liu, B. Wu, H. Jin, W. Zhang, L. Liu, “TripleBit: A fast and compact system for large scale RDF data,” in Proc. VLDB Endow. 6 (7) (2013), pp. 517-528.

Join Processing on Large, Complex BGPs
Too many join operations "

RIQ
• Fast processing of SPARQL queries on RDF quads: (S,P,O,C)
Decrease-and-conquer
V. Slavov, A. Katib, P. Rao, S. Paturi, D. Barenkala, “Fast Processing of SPARQL Queries on RDF Quadruples,” in Proc. of the 17th International Workshop on the Web and Databases (WebDB 2014), Snowbird, UT, 2014.

RIQ’s Architecture

Performance Comparison: Single Large, Complex BGP
BTC 20121
~ 1.4 billion quads LUBM
~ 1.4 billion RDF statements
1http://challenge.semanticweb.org
Y. Guo, Z. Pan, J. Heflin, “LUBM: A benchmark for OWL knowledge base systems,” Web Semantics: Science, Services and Agents on the World Wide Web 3 (2005) 158–182.
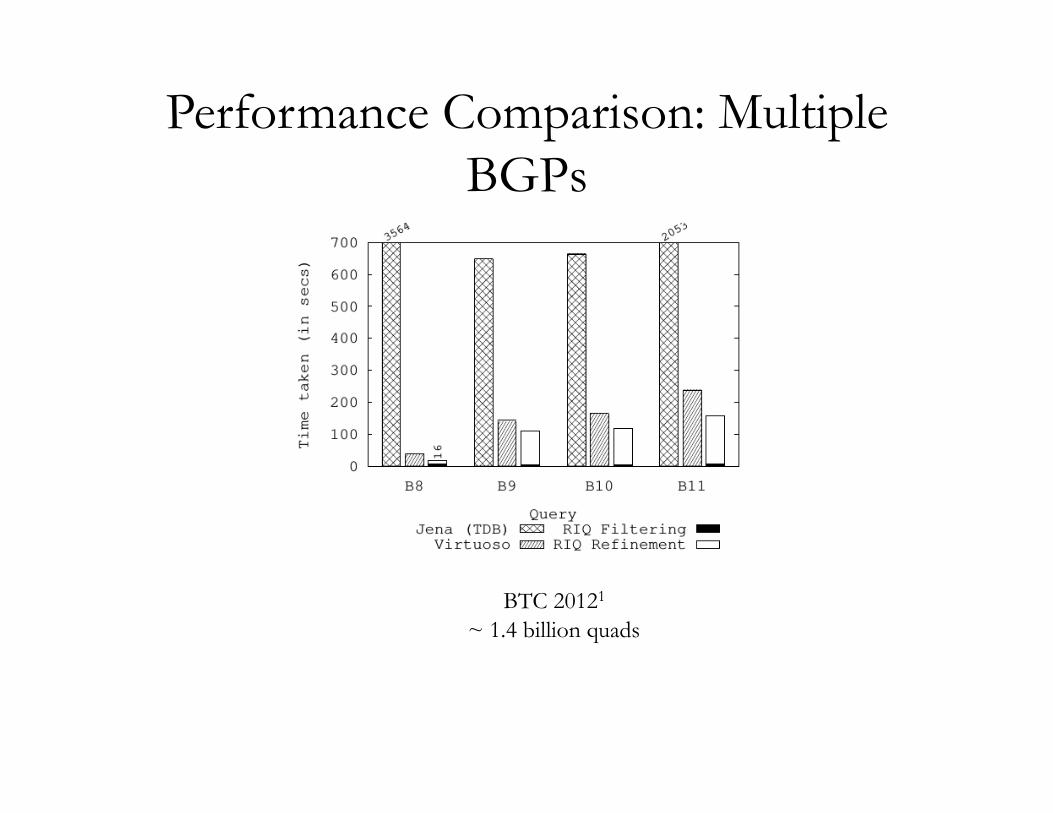
Performance Comparison: Multiple BGPs
BTC 20121
~ 1.4 billion quads

Parallel RDF Query Processing in a Cluster
• Early approaches o YARS2 [Harth et.al., ISWC/ASWC ’07], SHARD [Rohloff et.al., PSI
EtA ‘10], Virtuoso1
• Hash partition triples across multiple machines • Parallel access during query processing
o Work well for simple index lookup queries o For complex SPARQL queries, need to ship data during query
processing
K. Rohloff and R. Schantz, “High-performance, massively scalable distributed systems using the MapReduce software framework: The SHARD triple-store.” International Workshop on Programming Support Innovations for Emerging Distributed Applications, 2010.
1OpenLink Software. Towards Web-Scale RDF. http://virtuoso.openlinksw.com/dataspace/dav/wiki/Main/VOSArticleWebScaleRDF.
A. Harth, J. Umbrich, A. Hogan, S. Decker, “YARS2: A Federated Repository for Querying Graph Structured Data from the Web,” in Proc. of ISWC'07/ASWC'07, pp. 211-224, 2007.

Scalable SPARQL Querying
• Vertex partitioning using METIS1
• Triples in each partition are placed together on a machine o Replication of triples on the partition boundaries
• n-hop guarantee
o PWOC queries • No data shuffling between machines
o Uses RDF-3X on each machine
• Uses Hadoop for certain tasks o E.g., data partitioning, communication during query processing
J. Huang, D. J. Abadi, K. Ren, “Scalable SPARQL querying of large RDF graphs,” in Proc. of VLDB Endow. 4 (11) (2011), pp. 1123-1134. 1METIS. http://glaros.dtc.umn.edu/gkhome/views/metis

HadoopRDF
• Split triples by predicate • For rdf:type, split by distinct objects • Store the splits as HDFS files • MapReduce-based join processing to process SPARQL
queries o Heuristics-based cost model
M. Husain, J. McGlothlin, M. Masud, L. Khan, B. Thuraisingham, “Heuristics-Based Query Processing for Large RDF Graphs Using Cloud Computing,” in IEEE Transactions on Knowledge and Data Engineering 23(9), pp. 1312-1327 (2011).

Trinity.RDF
• Uses a distributed in-memory key-value store o Hashing on vertex-ids, random partitioning on machines o RDF graphs are stored natively using key-value pairs
• Parallel graph exploration, optimized exploration o Lower communication cost o Reduction in the size of intermediate results
K. Zeng, J. Yang, H. Wang, B. Shao, Z. Wang, “A distributed graph engine for Web Scale RDF data,” Proc. VLDB Endow. 6 (4) (2013), pp. 265-276.
2 m
odel
s
(vertex-id, <in-adjacency-list, out-adjacency-list>)
(vertex-id, <in1, …, ink, out1, …, outk>), (ini, <adjacency-listi>), (outi, <adjacency-listi>)
Adjacency list is partitioned on i machines

H2RDF+
• Uses HBase to build indexes on triples o 6 permutations of (SPO)
• Triples are stored as rowkeys
o Aggressive compression
• MapReduce-based multi-way merge and sort-merge joins o Sort-merge join is used when joining unordered intermediate
results
N. Papailiou, D. Tsoumakos, I. Konstantinou, P. Karras, N. Koziris, “H2RDF+: An Efficient Data Management System for Big RDF Graphs,” in Proc. of the 2014 SIGMOD Conference, Snowbird, Utah, 2014, pp. 909-912.
N. Papailiou, I. Konstantinou, D. Tsoumakos, P. Karras, N. Koziris, “H2RDF+: High-performance Distributed Joins over Large-scale RDF Graphs,” in Proc. of the IEEE International Conference on Big Data, 2013.

TriAD
• Master node o Global summary graph – concise summary of RDF data
• Graph partitioning; a supernode per partition
• Worker/slave nodes o Locality-based sharding
• Triples belonging to a supernode are stored on the same horizontal partition
o Local indexes – 6 permutations of (SPO)
• Query processing o Use the summary graph for join-ahead pruning o Distributed query execution via asynchronous inter-node
communication (MPICH2) S. Gurajada, S. Seufert, I. Miliaraki, M. Theobald, “TriAD: A Distributed Shared-nothing RDF Engine Based on Asynchronous Asynchronous Message Passing,” in Proc. of the 2014 SIGMOD Conference, Snowbird, Utah, 2014, pp. 289-300.

DREAM
• RDF data is not partitioned across different machines o Each machine stores the entire RDF data
• Adaptive query planner o Partitions a query graph into sub-queries o Sub-queries are executed in parallel on M (≥1) machines o No data shuffling
• Machines exchange auxiliary data (e.g., ids of triples) for joining intermediate data and producing the final result
M. Hammoud, D. A. Rabbou, R. Nouri, S.M.R. Beheshti, S. Sakr, “DREAM: Distributed RDF Engine with Adaptive Query Planner and Minimal Communication,” in Proc. VLDB Endow. 8 (6) (2015), pp. 654-665.

What did we cover?
• Oracle-RDF, SW-Store • RDF-3X, Hexastore • BitMat • DB2RDF • TripleBit • RIQ
Centralized approaches
• Scalable SPARQL querying • HadoopRDF • Trinity.RDF • H2RDF+ • TriaD • DREAM
Parallel approaches
RDF query processing

Open Challenges in Provenance
• Large scale storage of provenance o Limited work in real world provenance management for Big
Data applications
• Standardization of provenance query APIs • Integration of provenance analysis with RDF query
processing systems • Efficient provenance analysis using state of the art
approaches in SPARQL query execution • Visualization of provenance data

Acknowledgement
• Tutorial Website o https://sites.google.com/site/provenancetutorial/
• Acknowledgements o National Science Foundation (NSF) Grant No. 1115871 o National Institutes of Health (NIH) Grant No. 1U01EB020955-01
• Contact o Satya Sahoo, [email protected] o Praveen Rao, [email protected]












![Web view), possible candidates are the W3C Evaluation and Report Language (EARL) [35] and the W3C Provenance Ontology (PROV-O) [34]. The latter candidate was](https://img.dokumen.tips/doc/110x75/5a9df1807f8b9ada718b893f/web-view-possible-candidates-are-the-w3c-evaluation-and-report-language-earl.jpg)
![Foundations of RDF Databasescgutierr/papers/foundationsR...The RDF model is specified in a series of W3C documents [32,27,11,34]. In this section, we introduce an abstract version](https://img.dokumen.tips/doc/110x75/6068dd4149562b4a0d43c1ee/foundations-of-rdf-databases-cgutierrpapersfoundationsr-the-rdf-model-is-speciied.jpg)















