Embed Size (px)
Citation preview

The Rise of Data Lakes Massimo Brignoli [email protected]

Title Slide Option 2 Click here to add speaker name and title

#MDBE16
Agenda
What is a Data Lake 01 Modern Enterprise Data Management Architecture
03 Why MongoDB? 02
Case Studies & Scenarios 04 Lessons Learned 05

The Big Data Promise

#MDBE16
How MuchData?
• One thing is not missing to the companies: data • Sensors StreamsFlussi dei sensori • Social Sentiment • Servers Logging • Mobile Apps
• Analists estimate a growth of 40% Y2Y, 90% of them are not structured or partially structured
• The legacy technologies (some of them designed 40 years ago) are not enough

#MDBE16
The “Big Data” Promise
• To explore the info collecting and analyzing the data, brings the promise of • Competitive Advantage • Lower Operating Costs
• One popular example of the Big Data technology is the “single view”: to aggregate all what is known about a customer to improve the contact and the revenues
• The legacy EDW is not able to substain the amount of traffic, overloaded by the volume and variety of data (e by high cost).

#MDBE16
The Rise of Data Lakes
• Many companies started to look at an architecture called “Data Lake”: • Platform to manage data in a flexible way • Platform to aggregate cross-silos data in one single place • Allow the exploration of all the data

#MDBE16
Hadoop Time
• The most popular platform nowadays is Hadoop: • Allow the horizontal scalability on commodity hardware • Allow a read-optimized schema of eterogeneous data • Include working layer in SQL and other common languages • Great references (Yahoo and Google in primis)

#MDBE16
Why Hadoop?
• Hadoop Distributed FileSystem is designed to scale on great batch operations • Provide a write-one read-many append-only model • Optmized for long scan of TB or PB of data • This ability to handle multi-structured data can be used:
• To segment customers for marketing campain • Recommendation systems • Predictive analytics • Risk Models

#MDBE16
New Requisites
• Data Lakes are designed to provide the Hadoop output to the online applications. These apps have some common requisites:
• Low latency (order of ms) • Random access to a small indexed subset of data • Support to expressive query language and aggregation queries • Update of data that change value very frequently in real-time

#MDBE16
Hadoop is the Answer to Everything?
• In our world driven by data, the milliseconds are important. • IBM researchers stated that 60% of the data lose their value after few milliseconds • For example to identify a fraud stock exchange transaction after some minutes is
useless
• Gartner predicted that 70% of the Hadoop installation will fail since will not reach of goal of cost reduction and revenue increase.

#MDBE16
Enterprise Data Management Pipeline
…
Siloed source databases
External feeds (batch)
Streams
Stream icon from: https://en.wikipedia.org/wiki/File:Activity_Streams_icon.png
Transform Store raw data
Analyze Aggregate Pub-sub, E
TL, file imports
Stream Processing
Users
Other Systems

#MDBE16
What are the problems? • Join non necessarie causano pessime performance • Costoso scalare verticalmente • Lo schema rigido rende difficile il consolidamento di datai
variabili o non strutturati • Ci sono differenze nei record da eliminare durante la fase di
aggregazione • I processi soventi durano ore durante la notte • I dati sono vecchi per prendere decisioni intraday

#MDBE16
Click to add title: keep it to 56 characters w/spaces
This is a typical content slide with full width body.
• First level bullet list • Second level bullet list
• Third level bullet list

Quick Overview of MongoDB

#MDBE16
Documents Enable Dynamic Schema & Optimal Performance
{ customer_id : 1,
first_name : "Mark",
last_name : "Smith",
city : "San Francisco",
phones: [
{
number : “1-212-777-1212”,
dnc : true,
type : “home”
},
number : “1-212-777-1213”,
type : “cell”
}]
}
CustomerID FirstName LastName City
0 John Doe NewYork1 Mark Smith SanFrancisco2 Jay Black Newark3 Meagan White London4 Edward Daniels Boston
PhoneNumber Type DNC CustomerID
1-212-555-1212 home T 0
1-212-555-1213 home T 0
1-212-555-1214 cell F 0
1-212-777-1212 home T 1
1-212-777-1213 cell (null) 1
1-212-888-1212 home F 2

#MDBE16
Document Model Benefits Agility and flexibility
Data model supports business change
Rapidly iterate to meet new requirements
Intuitive, natural data representation
Eliminates ORM layer
Developers are more productive
Reduces the need for joins, disk seeks
Programming is more simple
Performance delivered at scale
{ !customer_id : 1, !first_name : "Mark", !last_name : "Smith", !city : "San Francisco", !phones: [ !{ !
number : “1-212-777-1212”, !dnc : true, !type : “home” !
}, !number : “1-212-777-1213”,
!type : “cell” !
}] !} !

MongoDB Technical Capabilities Application
Driver
Mongos
Primary
Secondary
Secondary
Shard 1
Primary
Secondary
Secondary
Shard2
… Primary
Secondary
Secondary
ShardN
db.customer.insert({…})db.customer.find({ name: ”John Smith”})
1. Dynamic Document Schema
{ name: “John Smith”, date: “2013-08-01”, address: “10 3rd St.”, phone: {
home: 1234567890, mobile:
1234568138 } }
2. Native language drivers
5. High performance
- Data locality
- Indexes - RAM
3. High availability
6. Horizontal scalability - Sharding
4. Workload Isolation

Morphia
MEAN Stack
Java Python Perl Ruby
Drivers & Ecosystem

#MDBE16
3.2 Features Relevant for EDM
• WiredTiger as default storage engine • In-memory storage engine • Encryption at rest • Document Validation Rules • Compass (data viewer & query builder) • Connector for BI (Visualization) • Connector for Hadoop • Connector for Spark • $lookUp (left outer join)

Data Governance with Document Validation Implement data governance without
sacrificing agility that comes from dynamic
schema
• Enforce data quality across multiple
teams and applications
• Use familiar MongoDB expressions to
control document structure
• Validation is optional and can be as
simple as a single field, all the way to
every field, including existence, data
types, and regular expressions
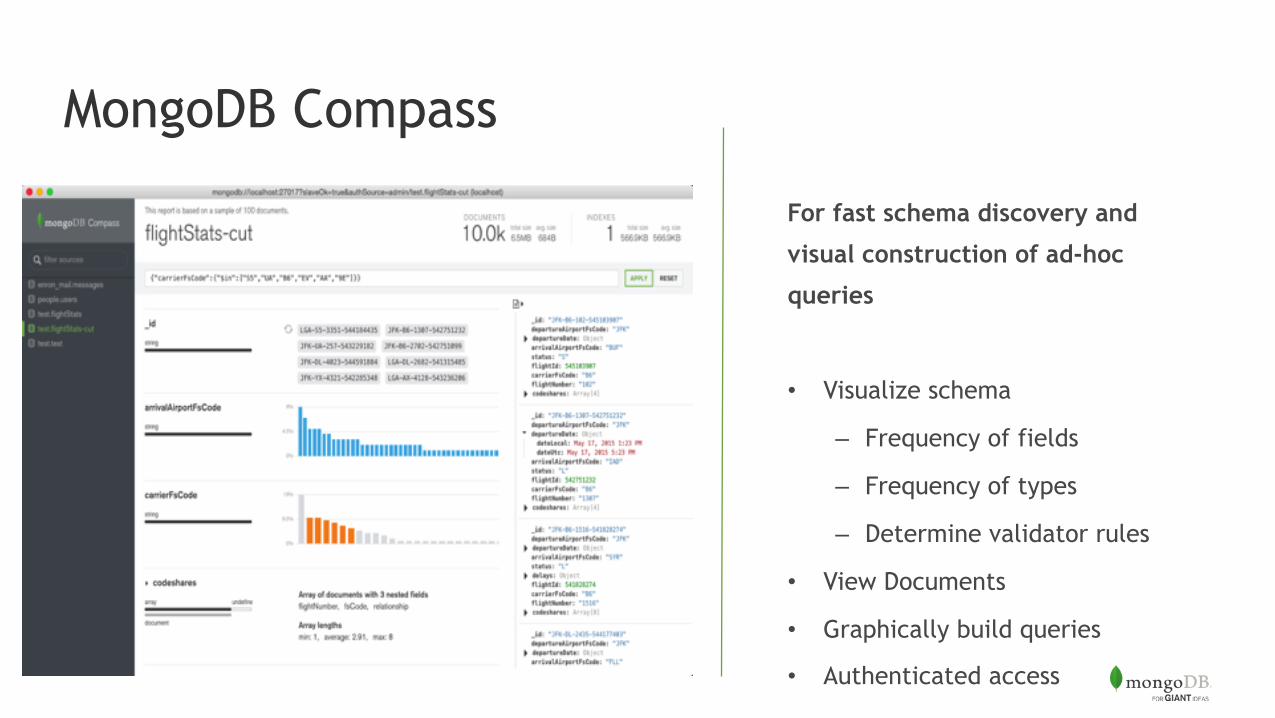
MongoDB Compass
For fast schema discovery and
visual construction of ad-hoc
queries
• Visualize schema
– Frequency of fields
– Frequency of types
– Determine validator rules
• View Documents
• Graphically build queries
• Authenticated access

#MDBE16
MongoDB Connector for BI
Visualize and explore multi-dimensional
documents using SQL-based BI tools. The
connector does the following:
• Provides the BI tool with the schema of the
MongoDB collection to be visualized
• Translates SQL statements issued by the BI
tool into equivalent MongoDB queries that are
sent to MongoDB for processing
• Converts the results into the tabular format
expected by the BI tool, which can then
visualize the data based on user requirements

Dynamic Lookup Combine data from multiple
collections with left outer joins for
richer analytics & more flexibility in
data modeling
• Blend data from multiple sources for
analysis
• Higher performance analytics with
less application-side code and less
effort from your developers
• Executed via the new $lookup
operator, a stage in the MongoDB
Aggregation Framework pipeline

#MDBE16
Aggregation Framework – Pipelined Analysis Start with the original collection; each record
(document) contains a number of shapes (keys),
each with a particular color (value)
• $match filters out documents that don’t contain
a red diamond
• $project adds a new “square” attribute with a
value computed from the value (color) of the
snowflake and triangle attributes
• $lookup performs a left outer join with another
collection, with the star being the comparison
key
• Finally, the $group stage groups the data by the
color of the square and produces statistics for
each group
Partner Ecosystem (500+)
* BI Connector (ODBC driver) and $lookUp (left outer join) are planned to be released with v3.2 in Q4
#MDBE16
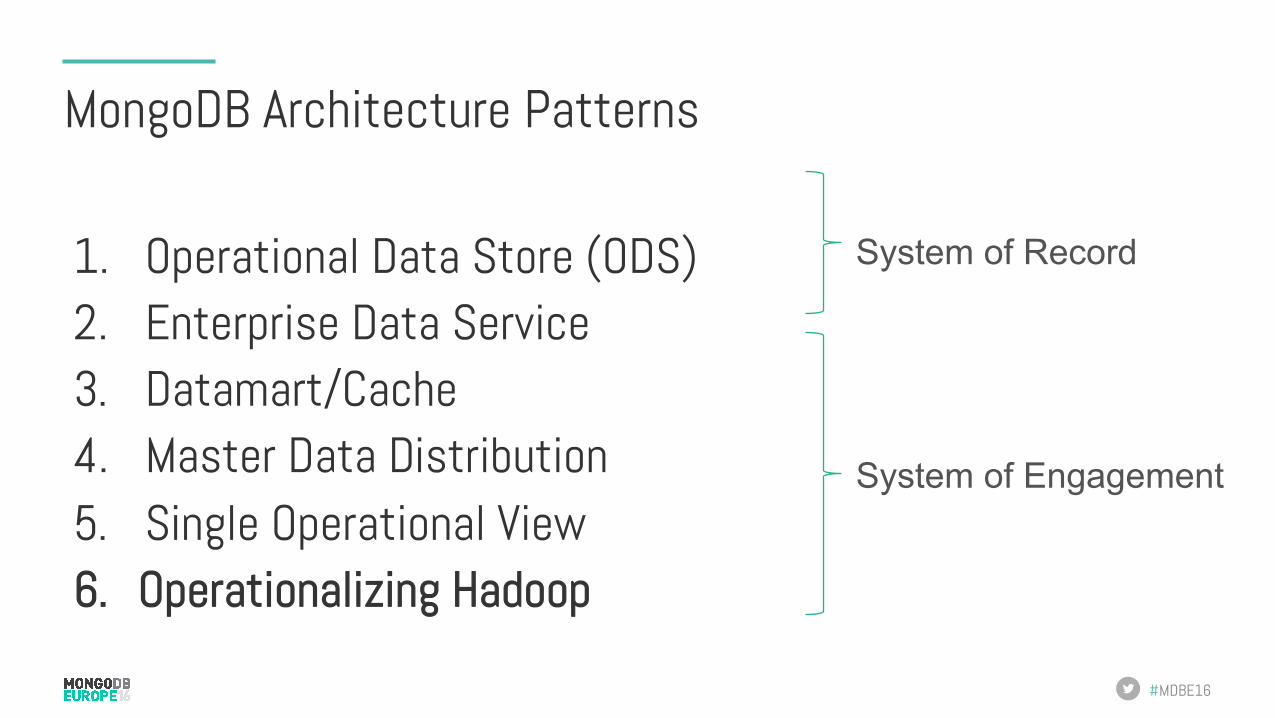
MongoDB Architecture Patterns
1. Operational Data Store (ODS) 2. Enterprise Data Service 3. Datamart/Cache 4. Master Data Distribution 5. Single Operational View 6. Operationalizing Hadoop
System of Record
System of Engagement

Enterprise Data Management Pipeline
…
Siloed source databases
External feeds (batch)
Streams
Stream icon from: https://en.wikipedia.org/wiki/File:Activity_Streams_icon.png
Transform Store raw data
Analyze Aggregate Pub-sub, E
TL, file imports
Stream Processing
Users
Other Systems
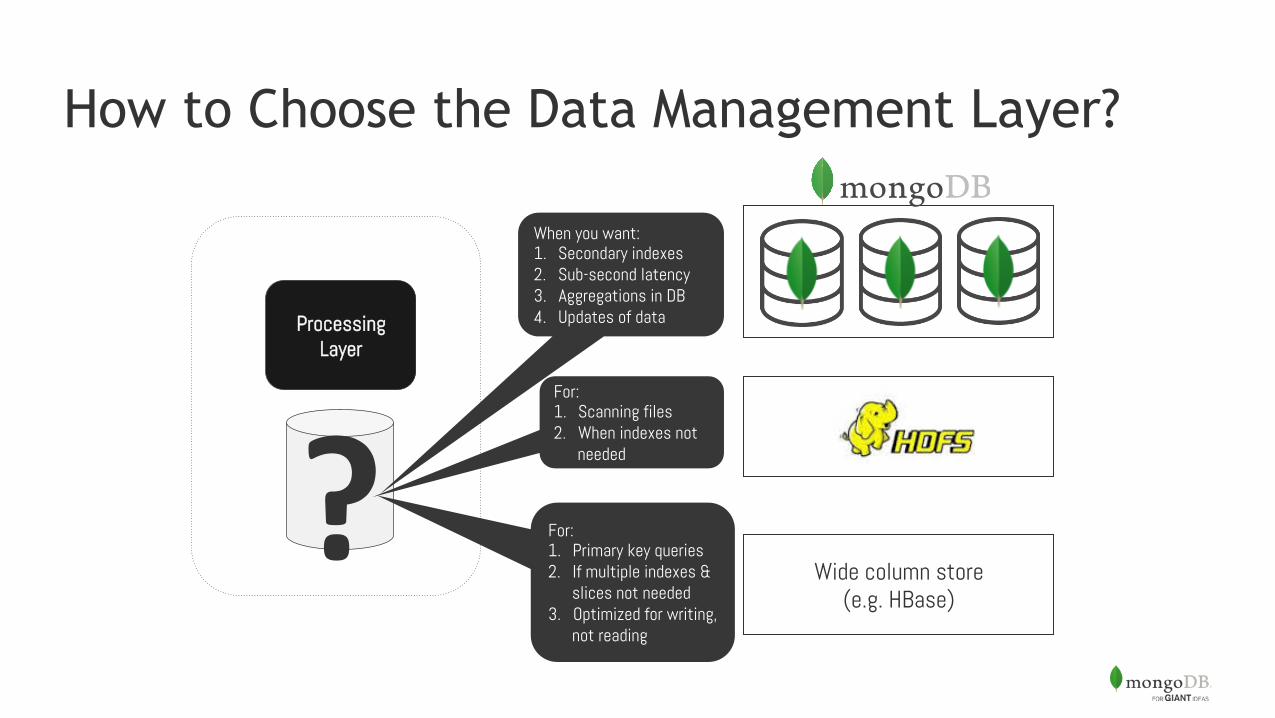
How to Choose the Data Management Layer?
Processing Layer
?
When you want: 1. Secondary indexes 2. Sub-second latency 3. Aggregations in DB 4. Updates of data
For: 1. Scanning files 2. When indexes not
needed
Wide column store (e.g. HBase)
For: 1. Primary key queries 2. If multiple indexes &
slices not needed 3. Optimized for writing,
not reading
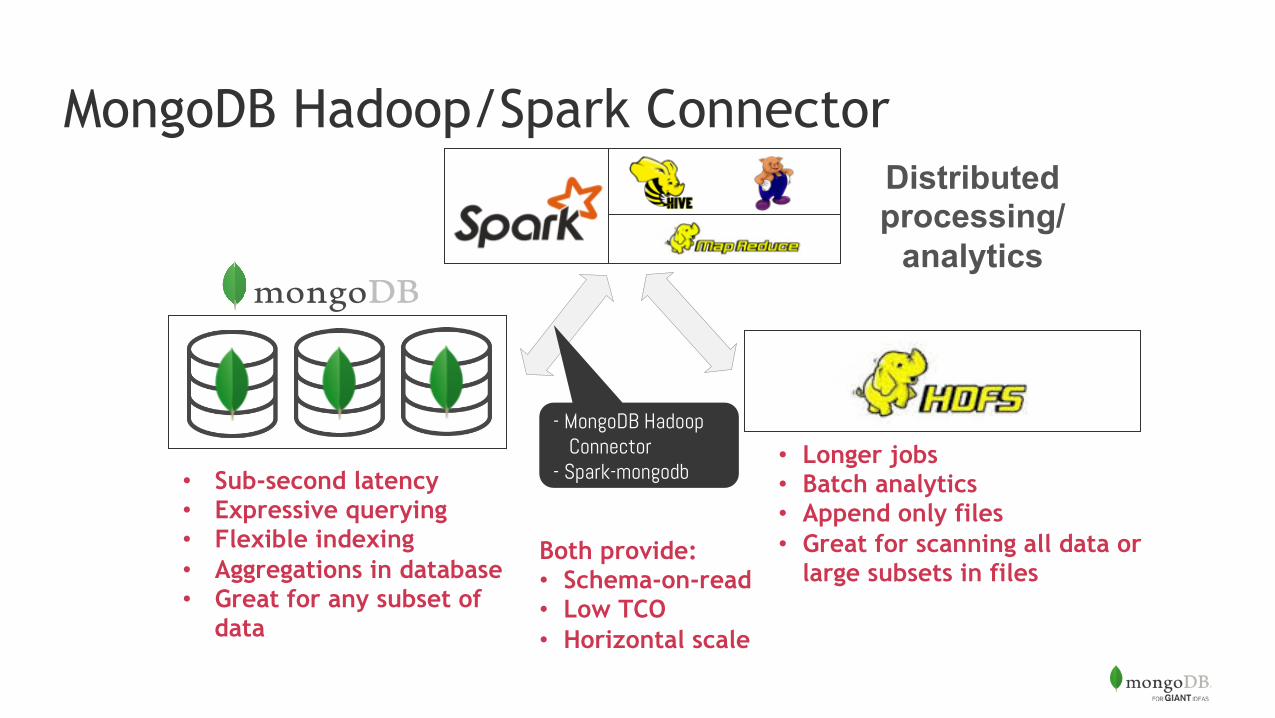
MongoDB Hadoop/Spark Connector Distributed processing/
analytics
• Sub-second latency • Expressive querying • Flexible indexing • Aggregations in database • Great for any subset of
data
• Longer jobs • Batch analytics • Append only files • Great for scanning all data or
large subsets in files
- MongoDB Hadoop Connector
- Spark-mongodb
Both provide: • Schema-on-read • Low TCO • Horizontal scale

#MDBE16
Data Store for Raw Dataset
…
Siloed source databases
External feeds (batch)
Streams
Stream icon from: https://en.wikipedia.org/wiki/File:Activity_Streams_icon.png
Transform Store raw data
Analyze Aggregate Pub-sub, E
TL, file imports
Stream Processing
Users
Other Systems
Store raw data Transform
- Typically just writing record-by-record from source data
- Usually just need high write volumes
- All 3 options handle that
Transform read requirements - Benefits to reading multiple datasets sorted
[by index], e.g. to do a merge - Might want to look up across tables with
indexes (and join functionality in MDB v3.2) - Want high read performance while writes are
happening
Interactive querying on the raw data could use indexes with MongoDB

#MDBE16
Data Store for Transformed Dataset
…
Siloed source databases
External feeds (batch)
Streams
Stream icon from: https://en.wikipedia.org/wiki/File:Activity_Streams_icon.png
Transform Store raw data
Analyze Aggregate Pub-sub, E
TL, file imports
Stream Processing
Users
Other Systems
Aggregate Transform
Often benefits to updating data as merging multiple datasets
Dashboards & reports can have sub-second latency with indexes
Aggregate read requirements - Benefits to using indexes for grouping - Aggregations natively in the DB would help - With indexes, can do aggregations on slices of data - Might want to look up across tables with indexes to
aggregate
#MDBE16
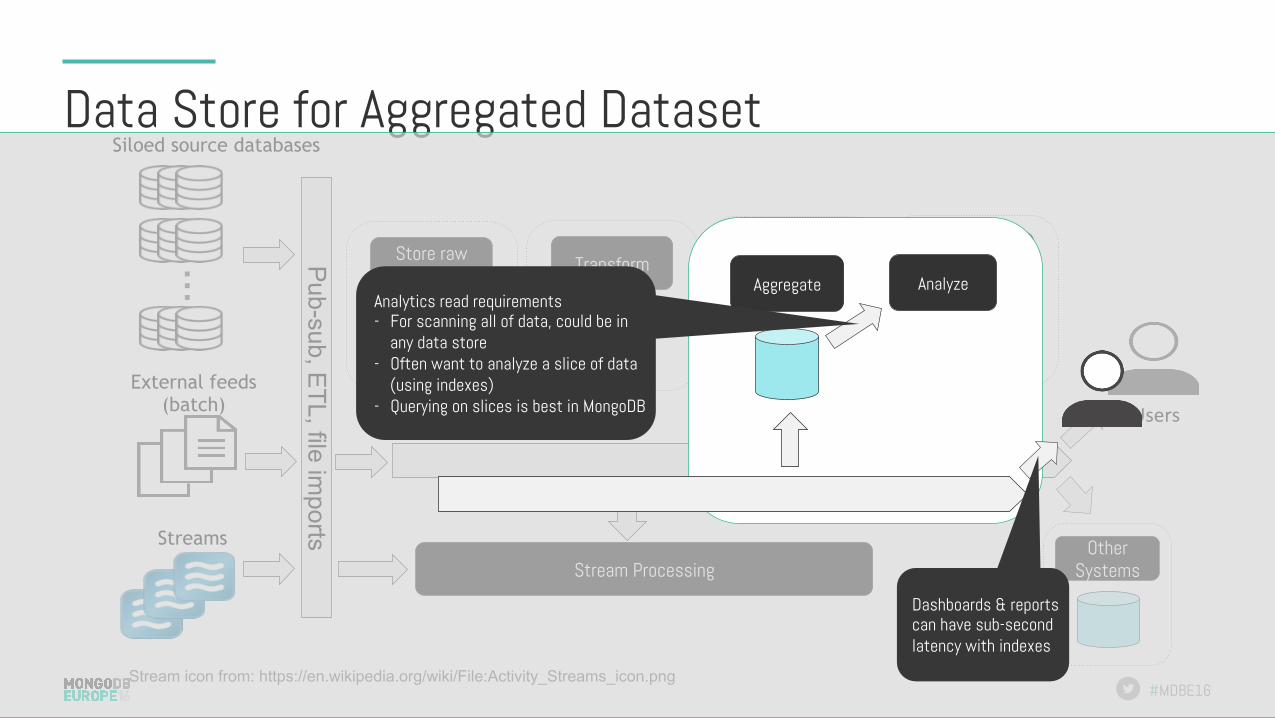
Data Store for Aggregated Dataset
…
Siloed source databases
External feeds (batch)
Streams
Stream icon from: https://en.wikipedia.org/wiki/File:Activity_Streams_icon.png
Transform Store raw data
Analyze Aggregate Pub-sub, E
TL, file imports
Stream Processing
Users
Other Systems
Analyze Aggregate
Dashboards & reports can have sub-second latency with indexes
Analytics read requirements - For scanning all of data, could be in
any data store - Often want to analyze a slice of data
(using indexes) - Querying on slices is best in MongoDB
#MDBE16
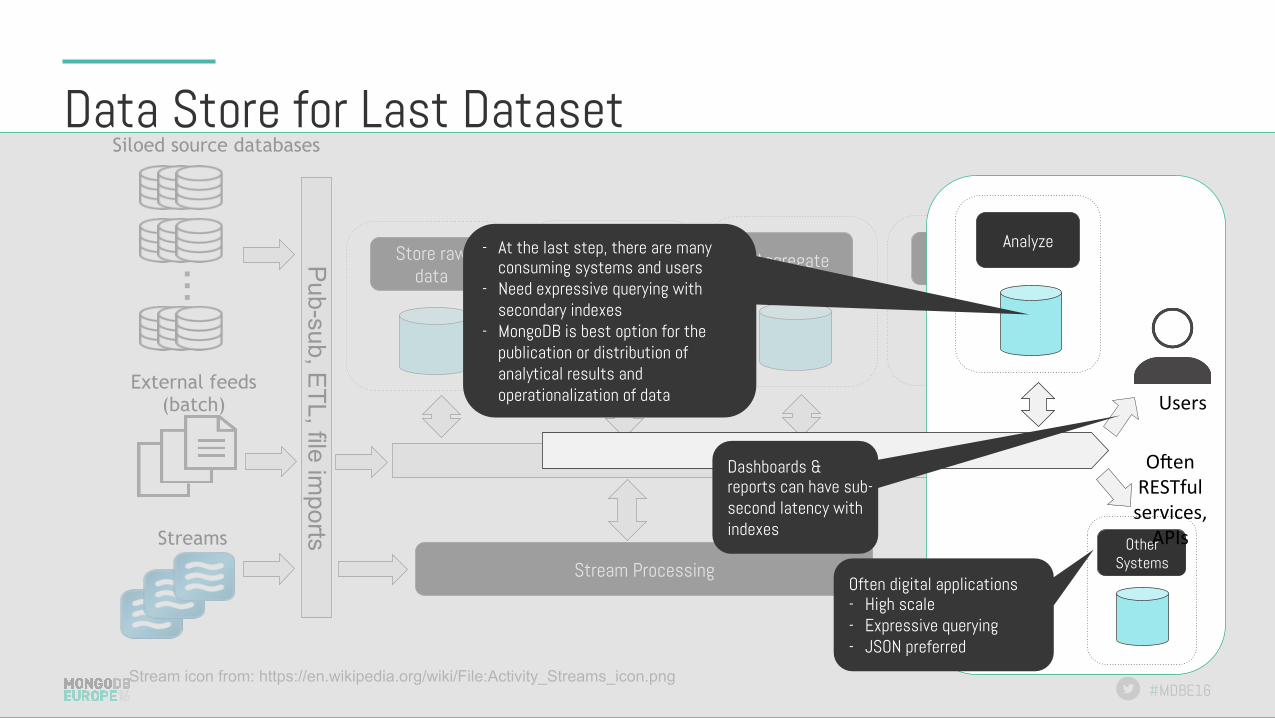
Data Store for Last Dataset
…
Siloed source databases
External feeds (batch)
Streams
Stream icon from: https://en.wikipedia.org/wiki/File:Activity_Streams_icon.png
Transform Store raw data
Analyze Aggregate Pub-sub, E
TL, file imports
Stream Processing
Users
Other Systems
Analyze
Users
Dashboards & reports can have sub-second latency with indexes
- At the last step, there are many consuming systems and users
- Need expressive querying with secondary indexes
- MongoDB is best option for the publication or distribution of analytical results and operationalization of data
Other Systems
Often digital applications - High scale - Expressive querying - JSON preferred
OMenRESTfulservices,APIs
#MDBE16
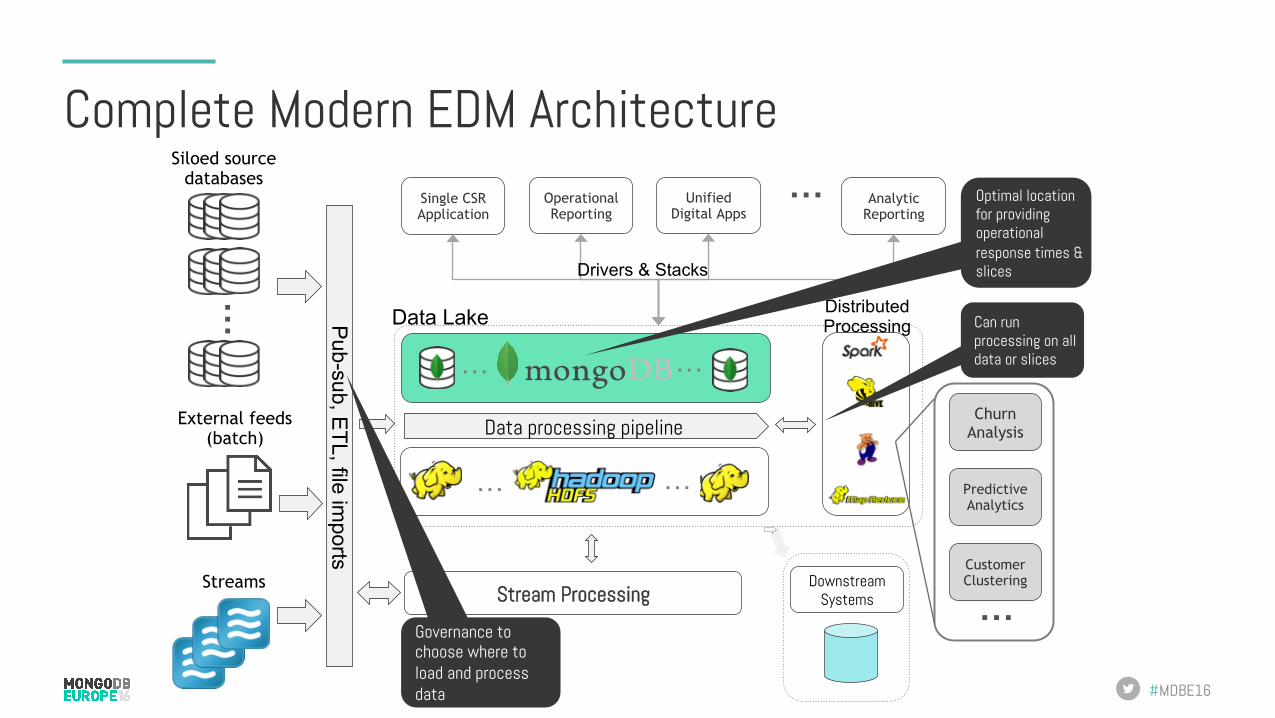
Complete Modern EDM Architecture
…
Siloed source databases
External feeds (batch)
Streams
Data processing pipeline
Pub-sub, E
TL, file imports
Stream Processing Downstream
Systems
… …
Single CSR Application
Unified Digital Apps
Operational Reporting
… … …
Analytic Reporting
Drivers & Stacks
Customer Clustering
Churn Analysis
Predictive Analytics
…
Distributed Processing
Governance to choose where to load and process data
Optimal location for providing operational response times & slices
Can run processing on all data or slices
Data Lake

#MDBE16
Example scenarios
1. Single Customer View a. Operational b. Analytics on customer segments c. Analytics on all customers
2. Customer profiles & clustering
3. Presenting churn analytics on high value customers

#MDBE16
Single View of Customer Spanish bank replaces Teradata and Microstrategy to increase business and avoid significant cost
Problem Why MongoDB Results
Problem Solution Results
Took days to implement new functionality and business policies, inhibiting revenue growth Branches needed an app providing single view of the customer and real time recommendations for new products and services Multi-minute latency for accessing customer data stored in Teradata and Microstrategy
Built single view of customer on MongoDB – flexible and scalable app easy to adapt to new business needs Super fast, ad hoc query capabilities (milliseconds), and real-time analytics thanks to MongoDB’s Aggregation Framework Can now leverage distributed infrastructure and commodity hardware for lower total cost of ownership and greater availability
Cost avoidance of 10M$+ Application developed and deployed in less than 6 months. New business policies easily deployed and executed, bringing new revenue to the company Current capacity allows branches to load instantly all customer info in milliseconds, providing a great customer experience
Large Spanish Bank

#MDBE16
Case Study Insurance leader generates coveted single view of customers in 90 days – “The Wall”
Problem Why MongoDB Results Problem Solution Results
No single view of customer, leading to poor customer experience and churn 145 years of policy data, 70+ systems, 15+ apps that are not integrated Spent 2 years, $25M trying build single view with Oracle – failed
Built “The Wall” pulling in disparate data and serving single view to customer service reps in real time Flexible data model to aggregate disparate data into single data store Churn analysis done with Hadoop with relevant results output to MongoDB
Prototyped in 2 weeks Deployed to production in 90 days Decreased churn and improved ability to upsell/cross-sell


#MDBE16
Two content
Click to add text.
• First level bullet list • Second level bullet list
• Third level bullet list
Click to add text.
• First level bullet list • Second level bullet list
• Third level bullet list
#MDBE16
Left content
Click to add text.
• First level bullet list • Second level bullet list
#MDBE16
Left content
Click to add text.
• First level bullet list • Second level bullet list

#MDBE16
Pie Chart
64%
25%
11%
1st Qtr 2nd Qtr 3rd Qtr
1st Quarter Lorem ipsum dolor sit amet, onsectetur adipiscing elit. Praesent sodales odio sit amet odio tristique .
2nd Quarter Lorem ipsum dolor sit amet, onsectetur adipiscing elit. Praesent sodales odio sit amet odio tristique .
3rd Quarter Lorem ipsum dolor sit amet, onsectetur adipiscing elit. Praesent sodales odio sit amet odio tristique .

#MDBE16
Bar Graph
0
1
2
3
4
5
6
Category 1 Category 2 Category 3 Category 4
Chart Title
Series 1 Series 2 Series 3

#MDBE16
Column Header 1 Column Header 2 Column Header 3 Column Header 4 Column Header 5
Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet
Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet
Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet
Table

#MDBE16
Title only

#MDBE16
Coding Example – Light Background
// Retrieve var MongoClient = require('mongodb').MongoClient;
// Connect to the db
MongoClient.connect("mongodb://localhost:27017/exampleDb", function(err, db) {
if(err) { return console.dir(err); }
db.collection('test', function(err, collection) {});
db.collection('test', {w:1}, function(err, collection) {});
db.createCollection('test', function(err, collection) {});
db.createCollection('test', {w:1}, function(err, collection) {});
});

#MDBE16
Coding Example – Dark Background
// Retrieve var MongoClient = require('mongodb').MongoClient;
// Connect to the db
MongoClient.connect("mongodb://localhost:27017/exampleDb", function(err, db) {
if(err) { return console.dir(err); }
db.collection('test', function(err, collection) {});
db.collection('test', {w:1}, function(err, collection) {});
db.createCollection('test', function(err, collection) {});
db.createCollection('test', {w:1}, function(err, collection) {});
});




#MDBE16
Columns and icons with copy (option 1)
Lorem ipsum dolor sit amet, onsectetur
adipiscing elit. Praesent sodales odio sit amet odio tristique.
Linked Lorem ipsum dolor sit
amet, onsectetur adipiscing elit.
Praesent sodales odio sit amet odio tristique.
Planning Lorem ipsum dolor sit
amet, onsectetur adipiscing elit.
Praesent sodales odio sit amet odio tristique.
Writing Lorem ipsum dolor sit
amet, onsectetur adipiscing elit.
Praesent sodales odio sit amet odio tristique.
Research

#MDBE16
Columns and icons with copy (option 2)
Lorem ipsum dolor sit amet, onsectetur
adipiscing elit. Praesent sodales odio
sit amet odio tristique .
Linked Lorem ipsum dolor sit
amet, onsectetur adipiscing elit.
Praesent sodales odio sit amet odio tristique .
Planning Lorem ipsum dolor sit
amet, onsectetur adipiscing elit.
Praesent sodales odio sit amet odio tristique .
Writing Lorem ipsum dolor sit
amet, onsectetur adipiscing elit.
Praesent sodales odio sit amet odio tristique .
Research

#MDBE16
Timeline or progress
2013
Lorem ipsum dolor sit amet, onsectetur adipiscing elit. Praesent sodales odio sit amet odio tristique sit elit.
Lorem ipsum dolor sit amet, onsectetur adipiscing elit. Praesent sodales odio sit amet odio tristique sit elit.
2014
2015
Lorem ipsum dolor sit amet, onsectetur adipiscing elit. Praesent sodales odio sit amet odio tristique sit elit.
Lorem ipsum dolor sit amet, onsectetur adipiscing elit. Praesent sodales odio sit amet odio tristique sit elit.
2016

“ Quote sample. Lorem ipsum dolor sit amet, onsectetur adipiscing elit amet sodales. Praesent sodales odio sit amet odio tristique. Lorem ipsum dolor sit amet, onsectetur adipiscing elit. Praesent sodales odio sit amet odio tristique. Lorem ipsum dolor sit amet, onsectetur adipiscing elit.”






























