Embed Size (px)
Citation preview

Vad är Swe-Clarin?
Lars BorinSpråkbanken/svenska språket, Göteborgs universitet
Swe-Clarin
Kulturarvet som ettor och nollor/1 • KB 9/10 2015

det korta svaret
Swe-Clarin
är densvenska delen
av deneuropeiska forskningsinfrastrukturen
CLARIN ERIC

CLARIN i ett nötskal(efter Steven Krauwer)
Common Language Resources and Technology Infrastructure<http://www.clarin.eu>)Grundidé:
◮ Europeisk federation av digitala arkiv med språkresurseroch språkverktyg (text, tal, multimodala, teckenspråk . . . )
◮ med tillgång till resurser och verktyg genom nättjänster föratt hämta, bearbeta, förädla, utforska och användaresurserna
◮ genom en samlad inloggningsprocedur för arkiv och verktyg
◮ med forskare inom humaniora och samhällsvetenskap sommålgrupp
◮ som ska täcka alla EU-länder samt associerade stater
◮ och alla språk som är relevanta för målgruppen

Mål och visioner – språkets roll(efter Steven Krauwer)
◮ Språket intar en central plats i många humanistiska ochsamhällsvetenskapliga discipliner. Exempelvis:
◮ som studieobjekt i sig◮ som mänskligt kommunikationsmedel◮ som mänskligt uttrycksmedel◮ som kunskapskälla om vår historia◮ som en del av vår kulturella identitet◮ som kunskaps- och informationsbärare

varför CLARIN?
◮ CLARIN anpassar och utvecklar språkteknologi ochspråkresurshantering som e-vetenskap – datorverktyg somforskningsstöd inom humaniora, samhällvetenskap ochandra discipliner där innehållet i text (och tal) utgörprimärdata för forskningen
◮ CLARIN bygger en basinfrastruktur för att möjliggöraforskning både på dagens enorma volymer ”primärtdigitala” språkliga data och på de snabbt ökandemängderna digitaliserade kulturarvsdata

språkteknologi ochspråkresurser i Sverige
◮ lång historia (från 1960-talet), många forskargrupper◮ svenska korpusar (Språkbanken [1975–], SUC, GSLC, många
inlärarkorpusar, . . . )◮ flerspråkiga korpusar (Uppsala, Linköping, Göteborg, . . . )◮ taldatabaser (KTH, Telia Research, . . . )◮ resurser för informationsåtkomst (SICS, KTH, . . . )◮ lexikondatabaser (Språkbanken, KTH, Språkrådet, . . . )◮ många olika verktyg för text och tal
◮ men i huvudsak bedriven som korta forskningsprojekt ochfragmenterad
◮ och i behov av harmonisering och integration

den svenska META-NET-vitboken(från META-NORD-projektet)
<http://www.meta-net.eu/whitepapers/overview>
Här får vi veta att svenska idag är större på internet än i den fysiska världen
men lämnar mycket övrigt att önska ifråga om språkteknologistöd.

SWE-CLARIN
◮ CLARIN: ESFRI-förberedelsefas 2008-01 – 2011-06
◮ CLARIN ERIC (European Research InfrastructureConsortium) startade 29/2 2012 med 9 medlemmar
◮ Swe-Clarin (∼50 MSEK från VR 2014–2018)startade 1/1 2014 med målen:
◮ att bilda en svensk nod i CLARIN ERIC(inträdet – som 10:e medlem – skedde 1/10 2014):
◮ Göteborgs universitet/Språkbanken◮ Göteborgs universitet/SND◮ KTH◮ Linköpings universitet◮ Lunds universitet◮ Stockholms universitet◮ Uppsala universitet◮ Språkrådet◮ DigiSam
◮ att bygga en basinfrastruktur för CLARIN i Sverige

CLARIN-conceptet
◮ e-vetenskap – i form av språkteknologi somforskningsverktyg – för discipliner där text (och tal) ärprimärdata:
◮ humaniora◮ samhällsvetenskap◮ (vissa sorters) medicin
◮ CLARINs betydelse växer i takt med digitaliseringen avkulturarvet och den elektroniska kommunikationensutbredning

digital spetsforskningspotential
Precis som vid gruvbrytning, kräver stora mängder ’informationsglest’ digitalttext- och talmaterial effektiv teknik för sökning, korrelering och korsindexeringi det språkliga innehållet – inte minst mellan olika språk – för att forskningenska få ut användbara primärdata ur det.

exempel 1: telefoner i Sverige

exempel 2: språkutveckling
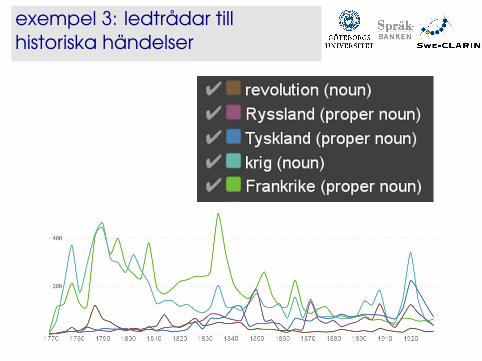
exempel 3: ledtrådar tillhistoriska händelser

användargrupperna i Sverige
◮ språkvetenskap (mycket långt kommen; e-vetenskap sen1960-talet!)
◮ medicin (långt kommen; flera projekt)
◮ historia (några projekt)
◮ litteraturvetenskap (enstaka projekt)
◮ statsvetenskap (ansatser)
I hela CLARIN-området är användningen betydande, ochCLARIN ERIC blir ett centralt forum för effektivt utbyte avexpertis och erfarenheter.
Swe-Clarin befinner sig i ett ”kontaktsökande” uppbyggnads-skede och evenemang som den här workshopen är viktiga föratt skapa Swe-Clarins framtid.

några konkretaSwe-Clarin-samarbeten
◮ politisk opinionsbildning i sociala medier (statsvetenskap,Göteborg)
◮ kvinnors aktiviteter i tidigmodern tid (historia, Uppsala)◮ allusion och textåteranvändning i litteratur
(litteraturvetenskap, Göteborg)◮ språkliga signaler för tidig upptäckt av demens
(medicin/vårdvetenskap, Göteborg)◮ ”återupplivande” av traditionell matlagning (ISOF m.fl.,
KTH)◮ undersökning av diskriminerande gymnasiebetygssättning
(nationalekonomi, Stockholm)◮ förändring över tid i attityder till retorik avspeglade i ett
historiskt tidningsmaterial (litteraturvetenskap, Uppsala)◮ . . .
. . . och många fler önskas!

(Swe-)CLARINs fyra ben
1. en teknisk infrastruktur: PID, identitetsfederation, automatiskmetadatainhämtning, grid/moln
2. standardisering av data- och metadataformat samtinnehållsmodeller: ISO TC37/SC7 (SIS TK115), W3C;hantering av upphovsrättsfrågor
3. en administrativ struktur för underhåll och vidareutvecklingav infrastrukturen, samt för expertis och användarstöd:föreståndare, styrgrupp, referensgrupp,CLARIN-centra (⊂ CLARIN ERIC)
4. språkteknologiska basresurser: BLARK (Basic LAnguageResource Kit) och SNK (en svensk nationell korpus)

från kökkenmödding tillinfrastruktur
SWE-CLARIN

standarder är omfattande,petiga och osynliga . . .

. . . men de möjliggör fantastiskasaker

språkteknologi som forsknings-redskap och digitalisering (1)
◮ utveckling av sofistikerade språkverktyg kräver öppnalicenser (Open Content) för text och andra språkresurser(ordlistor, termbanker, tesaurer, etc.)
◮ detta beror bland annat på att den dominerandeutvecklingsmetodologin bygger på maskininlärning(”självlärande system”)
◮ som kräver stora mängder träningsdata
◮ (men även manuella ansatser bygger på generaliseringoch abstraktion från språkliga rådata)

språkteknologi som forsknings-redskap och digitalisering (2)
◮ det är ett oerhört slöseri med resurser att alltid nyskapaträningsdata istället för att kunna ackumulera dem
◮ forskningens logik (verifierbarhet och reproducerbarhet)kräver dessutom att forskningsrådata alltid är åtkomliga
◮ öppna data skapar en god cirkel med ständigt bättreredskap för informationsåtkomst sprungna ur forskningen,som i sin tur kan dra nytta av den högkvalitativareinformationen

med andra ord:
◮ den som för det allmännas räkning digitaliserar texter (i vidbemärkelse) och bygger databaser (t.ex. omkulturarvsobjekt) borde alltid (åtminstone) görainformationen i dess helhet så fritt tillgänglig som lagentillåter (d.v.s. fulltext, kompletta databasdumpar, etc.)
◮ (med licenser som CC0, CC BY eller CC BY-SA som tillåterbearbetning och återdistribution)
◮ ett sämre men möjligt alternativ (som CLARIN stödjer) ärdataåtkomst baserad på kategoritillhörighet (t.ex.”forskare anställd vid ett universitet i ett medlemsland”)som kontrolleras genom s.k. identitetsfederationer (jfr.Eduroam).

(enbart) ”titthålsaccess” räckerinte
◮ gör jag inte forskarsamhället en tjänst om jag struktureraråtkomsten och tillhandahåller ett sökgränssnitt och/eller ettAPI
◮ (kanske byggt på öppna standarder)
◮ (t.ex. till en digitaliserad brevsamling, en språktypologisk,lexikalisk, bibliografisk eller biografisk databas, geodataeller mina forskningsdata)?

◮ jo, absolut!
◮ men om jag gör enbart det,
◮ är alla andra utlämnade till vad jag vet och kan föreställamig,
◮ och jag stänger fler möjligheter än jag öppnar,
◮ eftersom det inte går att förutse framtidens forskningsfrågoroch forskningsmetoder
◮ och eftersom det blir svårt eller omöjligt attkombinera/korrelera material från olika källor
◮ eller generalisera över datamängderna (”data mining” /”text mining”)

vilka är hindren?
◮ juridiska:◮ integritet (t.ex. inspelade samtalsdata)◮ sekretess (t.ex. patientjournaler)◮ upphovsrätt (”moderna” textdata, teve/radioprogram):
inget undantag för forskning
◮ ekonomiska/ideologiska/politiska/tekniska:◮ trög och bristfällig digitalisering◮ ovana (omedvetenhet)/ovilja att dela med sig av
forskningsdata◮ data-, metadata- och innehållsstandarder under utveckling
(”rörliga mål”)

sammanfattningsvis
◮ Swe-Clarin är en e-vetenskapsinfrastruktur för humanioraoch samhällsvetenskap
◮ som är under uppbyggnad i Sverige
◮ som en del av det europeiska CLARIN ERIC-initiativet
◮ Två faktorer är avgörande för Swe-Clarins framtid:
1. koppling till faktiska forskningsfrågor hos målgruppen2. tillgång till digitala språkresurser på villkor som möjliggör
både fri forskning på resurserna och vidareutveckling avinfrastrukturen

tack för uppmärksamheten!































