Embed Size (px)
Citation preview

© 2ndQuadrant 2016
Big Data & PostgreSQLUsing TABLESAMPLE to Analyze Very Large Datasets
By Umair Shahid

© 2ndQuadrant 2016
Who am I?Director, Products @ 2ndQuadrantGot “pushed” into PostgreSQL in
2004, ended up falling in love with it
Not a hardcore techie, yet passionate about open source software
Interested in Big Data, especially the newer PostgreSQL features supporting it
2011
2015

© 2ndQuadrant 2016
What is Big Data?Volume
Size: Text files to HD videosSources: Spreadsheets to sensorsFrom lakes to oceans
VelocityMore sources imply more speedFaster connectivity implies more speedHigh-paced world requires faster turnaround
Variety
© 2ndQuadrant 2016
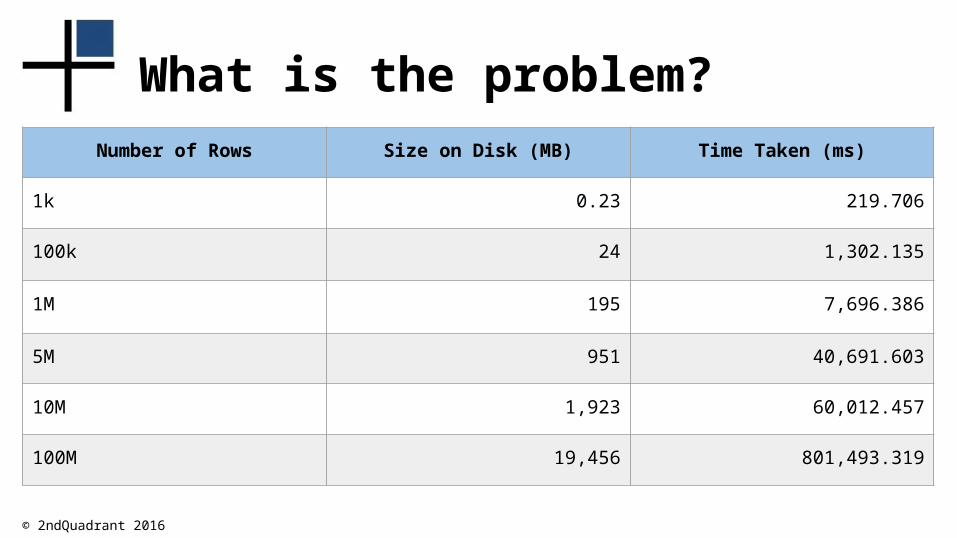
What is the problem?Number of Rows Size on Disk (MB) Time Taken (ms)
1k 0.23 219.706
100k 24 1,302.135
1M 195 7,696.386
5M 951 40,691.603
10M 1,923 60,012.457
100M 19,456 801,493.319

© 2ndQuadrant 2016
Why is this significant?Data mining has typically been a painful processMajor contributor to the pain has been the time it
takes for queries to returnMany false steps before the required data is
identifiedWaiting time is wasted timeSampling, count based or time based, reduces the
wasted time significantly

© 2ndQuadrant 2016
What is TABLESAMPLE?
Ability to read a random sample of data in a table
Defined in SQL:2003 (5th revision of SQL)
Implemented in PostgreSQL 9.5

© 2ndQuadrant 2016
Syntax
SELECT select_expression
FROM table_name
TABLESAMPLE sampling_method ( argument [, ...] )
[ REPEATABLE ( seed ) ]
...

© 2ndQuadrant 2016
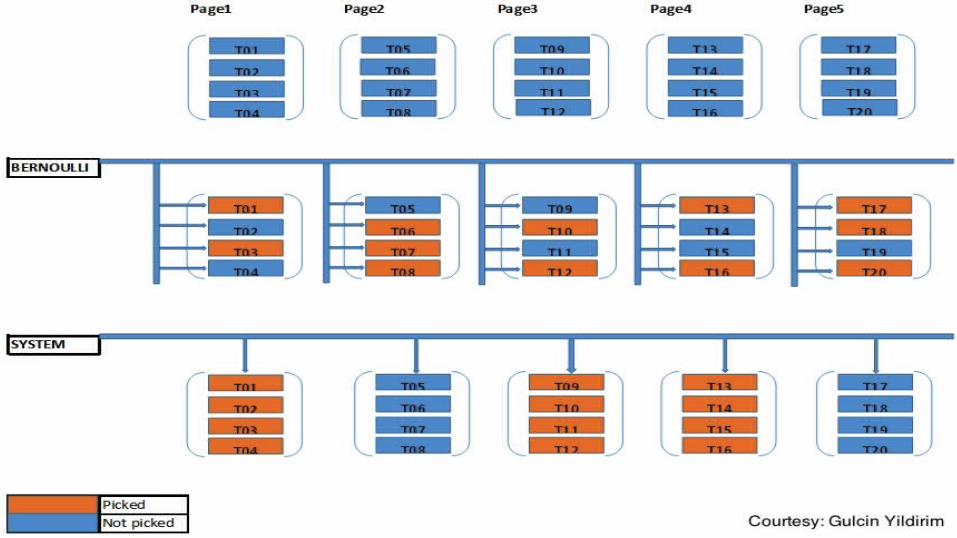
sampling_methodargument is percentage of rowsSYSTEM
Block level samplingVery fastNon-independent rows
BERNOULLIRow level samplingSlower than SYSTEMIndependent rows (uniformly random)
© 2ndQuadrant 2016

© 2ndQuadrant 2016
Demo sampling methods

© 2ndQuadrant 2016
REPEATABLE results(Reminder: [ REPEATABLE ( seed ) ])
Optional argumentUsed if random, yet repeatable results are
requiredseed and argument need to be the same to
produce repeatable resultsAny changes made to the table will result in a
different data set

© 2ndQuadrant 2016
Now it gets interesting … TABLESAMPLE allows for additional sampling methods via
extensionstsm_system_time specifies max number of milliseconds
to spend reading a tableImplements the syntax:
SELECT select_expression
FROM table_name
TABLESAMPLE SYSTEM_TIME (argument)

© 2ndQuadrant 2016
Demo tsm_system_time

© 2ndQuadrant 2016
Enter Orange ...Funded by AXLE (
http://axleproject.eu)Same project funded
TABLESAMPLEAvailable integrated with
PostgreSQL in 2UDA (http://2ndquadrant.com/2uda)
Uses TABLESAMPLE to very quickly create visualizations for data
Can quickly create predictive models

© 2ndQuadrant 2016
Demo OrangeYou can find a very helpful tutorial at
http://2ndquadrant.com/2uda

© 2ndQuadrant 2016
Other Big Data features in PostgreSQL● HSTORE
XML
JSON & JSONB
BRIN INDEXES
Parallel sequential scan
Parallel aggregates
FDWs
Horizontal Scalability
Check out Postgres-XL http://www.postgres-xl.org/

© 2ndQuadrant 2016
Features from the latest release
9.6 Beta3 announced last night
Added support to parallel query for TABLESAMPLE

© 2ndQuadrant 2016
Moving Forward … Next meetup: Tentatively August 19, 2016Please come forward and share your
PostgreSQL storiesToday’s refreshments are sponsored by
2ndQuadrant - THANK YOU!Need more sponsorsOR
Need to start charging for these sessions

Special Thanks!!

© 2ndQuadrant 2016
Umair ShahidEmail: [email protected]: @pg_umair
2ndQuadrant is hiring - All geographies!
Thank you for your time!





























