Embed Size (px)
Citation preview

Big Data, Big Challenge.
Puneet Kacker, Kanpur
08-OCT-2015

What is Big Data?

Big Data is data that is too large, complex and dynamic for any conventional data tools to capture, store, manage and analyze.
The right use of Big Data allows analysis to spot trends and gives niche insights that help create value and innovation much faster than conventional methods.
However, there is more to the big data deluge than mere volumes; in particular, increasing data heterogeneity and complexity makes it difficult to extract knowledge from such data.
If the use of big data for drug discovery should indeed open new frontiers, and not only be hype, new visions and concepts are required to reduce data complexity and increase data consistency from different sources.
What is Big Data?

What is the Challenge?
Three “V’s”, i.e., the Volume, Variety and Velocity of data coming in is what creates the challenge.
http://hlwiki.slais.ubc.ca/images/1/1a/Big_data_2013.jpg
1 PB = 1000 TB
big challenges in data storage, processing and analysis. Coordinated efforts from both experimental biologists and bioinformaticists are required to overcome these challenges.

Big Biological Data

Open Source

Chemical Compounds

Drug Targets
10,774 Targets

Drug Discovery Through Virtual Screening

One Target, One Compound
DiseaseEnzyme, Drug Target
Potential Drug Candidate
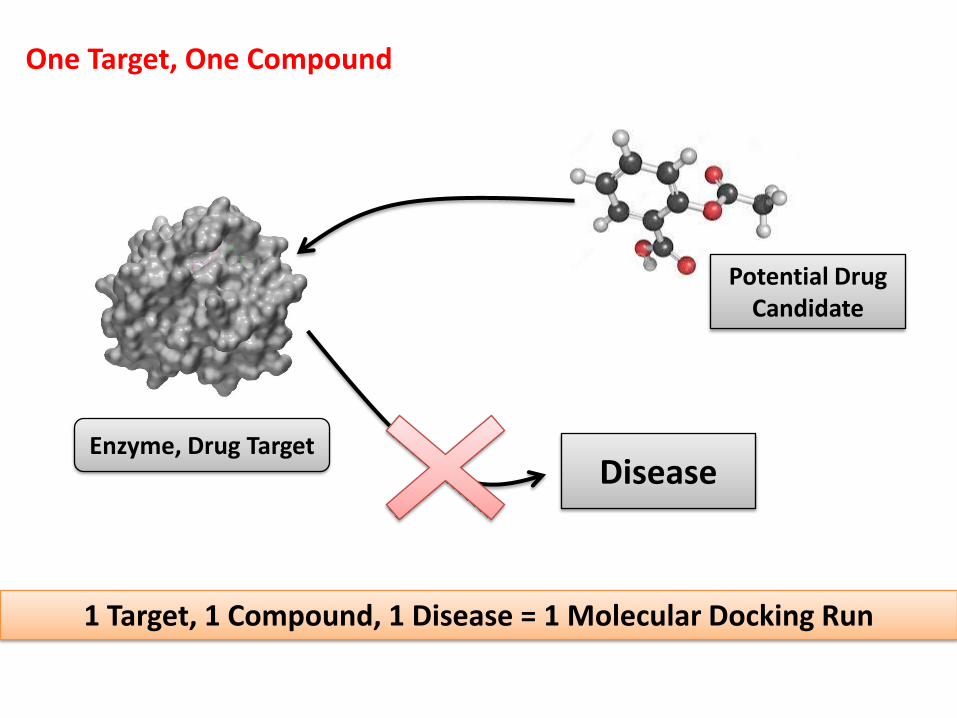
One Target, One Compound
DiseaseEnzyme, Drug Target
Potential Drug Candidate
1 Target, 1 Compound, 1 Disease = 1 Molecular Docking Run

One Compound to Many Targets
10,000 Protein Targets
Disease-1
Disease-2
Disease-N
Potential Drug Candidate
10,000 Targets, 1 Compound, 10,000 Diseases = Total 10,000 Molecular Docking Runs

One Compound to Many Targets and Their Conformations
10,000 Protein Targets
Disease-1
Disease-2
Disease-N
Potential Drug Candidate
10,000X2 Target Conformations, 1 Compound, 10,000 Diseases = Total 20,000 Molecular Docking Runs
Conf-1Conf-2

Many Compounds to Many Targets and Their Conformations
10,000 Protein Targets
Disease-1
Disease-2
Disease-N 60,826,590Potential Compounds
10,000X2 Target Conformations, 60,826,590Compounds, 10,000 Diseases = Total 1,216,531,800,000 Molecular Docking Runs
Conf-1Conf-2

Calculation
Suppose one docking run takes 1 min. time on single processor
1,216,531,800,000 /60 = 20275530000 Hours
1,216,531,800,000 /(60X24) = 844813750 Days
1,216,531,800,000 /(60X24X30) = 28160458 Months
1,216,531,800,000 /(60X24X30X12) = 2346704 Years
1,216,531,800,000 /(60X24X30X12X60) = 39111 Births
10 Crores Processors will be needed to complete all the docking runs in less than a day time
An excel sheet can accommodate 1048576 rows by 16384 columns

What if the same calculations are carried out by two different methods!

Big Data requires Big resources and smart data handling methods

Supporting Tools/Languages
R is a free software environment for statistical computing and graphics.
https://www.r-project.org/
Hadoop is an open-source framework that allows to store and process big data in a distributed environment across clusters of computers using simple programming models.
https://hadoop.apache.org/

Let’s Learn Programming Interactively
http://tryr.codeschool.com/levels/1/challenges/1

Further Reading

And After That

Thank You!
www.puneetsclassroom.in





























