Embed Size (px)
Citation preview

Convolutional Neural Networks
Alex Conwayalex @ numberboost.com
& JHB Deep Learning Hackathon Info :)
For Computer Vision
Applications

Hands up!

Check out theDeep Learning Indaba
videos & practicals!
http://www.deeplearningindaba.com/videos.html
http://www.deeplearningindaba.com/practicals.html

Image Classification
4
http://yann.lecun.com/exdb/mnist/
https://github.com/fchollet/keras/blob/master/examples/mnist_cnn.py
(99.25% test accuracy in 192 seconds and 70 lines of code)

Image Classification
5

Image Classification
6

https://research.googleblog.com/2017/06/supercharg
e-your-computer-vision-models.html
Object detection

https://www.youtube.com/watch?v=VOC3huqHrss
Object detection

Image Captioning & Visual Attention
XXX
9
https://einstein.ai/research/knowing-when-to-look-adaptive-
attention-via-a-visual-sentinel-for-image-captioning

Image Q&A
10https://arxiv.org/pdf/1612.00837.pdf

Video Q&A
XXX
11
https://www.youtube.com/watch?v=UeheTiBJ0Io

Pix2Pix
https://affinelayer.com/pix2pix/
https://github.com/affinelayer/pix2pix-tensorflow 12

Pix2Pix
https://medium.com/towards-data-science/face2face-a-pix2pix-demo-that-mimics-the-facial-expression-of-the-german-chancellor-b6771d65bf66 13

14
Original input
Pix2pix output
Remastered
https://hackernoon.co
m/remastering-classic-
films-in-tensorflow-
with-pix2pix-
f4d551fa0503

Style Transfer
https://github.com/junyanz/CycleGAN15

Style Transfer
https://github.com/junyanz/CycleGAN16

1. What is a neural network?
2. What is a convolutional neural
network?
3. How to use a convolutional neural
network
4. More advanced methods
5. Practical tips
6. Hackathon Challenge Info 17

Big Shout Outs
Jeremy Howard & Rachel Thomas
http://course.fast.ai
Andrej Karpathy
http://cs231n.github.io
François Chollet (Keras lead dev)
https://keras.io/
18

1.What is a neural
network?

What is a single neuron?
20
• 3 inputs [x1,x2,x3]
• 3 weights [w1,w2,w3]
• Element-wise multiply and sum
• Apply activation function f
• Often add a bias too (weight of 1) – not
shown

What is an Activation Function?
21
Sigmoid Tanh ReLU
Nonlinearities … “squashing functions” … transform neuron’s output
NB: sigmoid output in [0,1]

What is a Deep Neural Network?
22
Inputs outputs
hidden
layer 1hidden
layer 2
hidden
layer 3
Outputs of one layer are inputs into the next layer

How does a neural network learn?
23
• You need labelled examples “training data”
• Initially, the network makes random predictions (weights initialized
randomly)
• For each training data point, we calculate the error between the
network’s predictions and the ground-truth labels (“loss function”
e.g. mean squared error)
• Using a method called ‘backpropagation’ (really just the chain rule
from calculus 1), we use the error to update the weights (using
‘gradient descent’) so that the error is a little bit smaller next time (it
learns from past errors)

http://playground.tensorflow.org

What is a Neural Network?
For much more detail, see:
1. Michael Nielson’s Neural Networks &
Deep Learning free online book http://neuralnetworksanddeeplearning.com/chap1.html
2. Anrej Karpathy’s CS231n Noteshttp://neuralnetworksanddeeplearning.com/chap1.html
25

2. What is a
convolutional
neural network?

What is a Convolutional Neural
Network?
27
“like a simple neural network but with
special types of layers that work well on
images”
(math works on numbers)
• Pixel = 3 colour channels (R, G, B)
• Pixel intensity = number in [0,255]
• Image has width w and height h
• Therefore image is w x h x 3 numbers

28
This is VGGNet – don’t panic, we’ll break it down piece by piece
Example Architecture

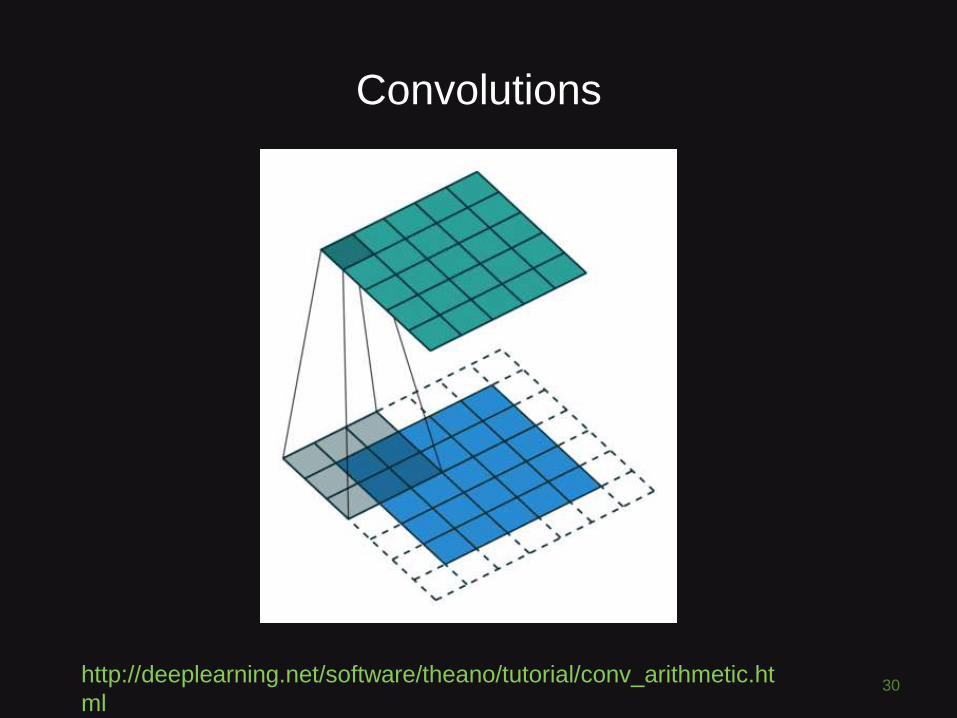
Convolutions
29
http://setosa.io/ev/image-kernels/
Convolutions
30http://deeplearning.net/software/theano/tutorial/conv_arithmetic.ht
ml
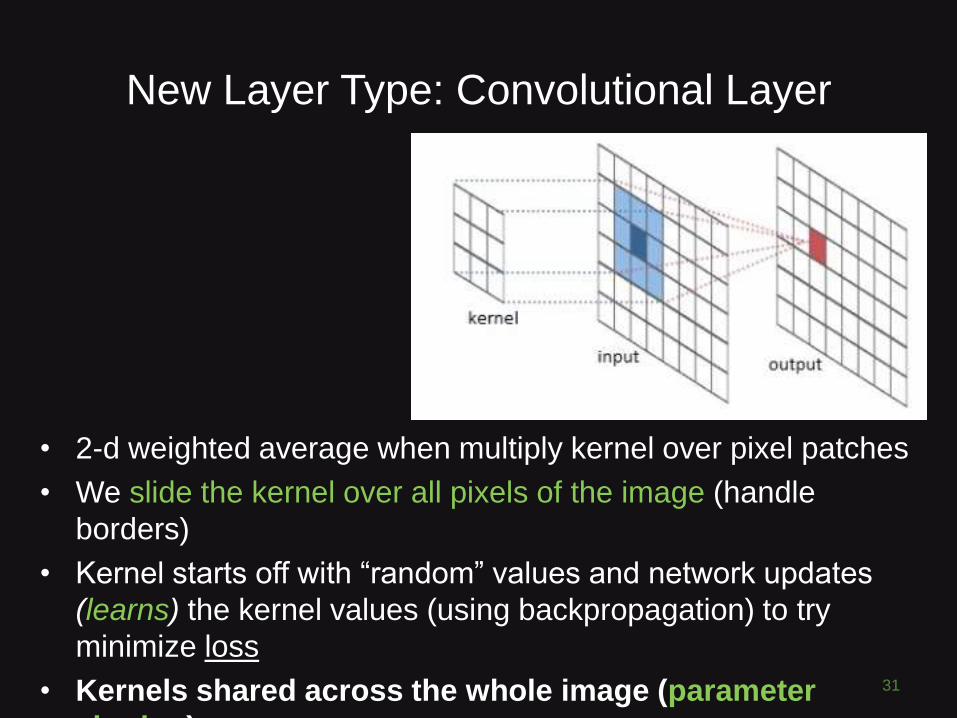
New Layer Type: Convolutional Layer
31
• 2-d weighted average when multiply kernel over pixel patches
• We slide the kernel over all pixels of the image (handle
borders)
• Kernel starts off with “random” values and network updates
(learns) the kernel values (using backpropagation) to try
minimize loss
• Kernels shared across the whole image (parameter
sharing)

Many Kernels = Many “Activation Maps” = Volume
32http://cs231n.github.io/convolutional-networks/

Convolutions
33
https://github.com/fchollet/keras/blob/master/examples/conv_filter_visuali
zation.py

Convolutions
34
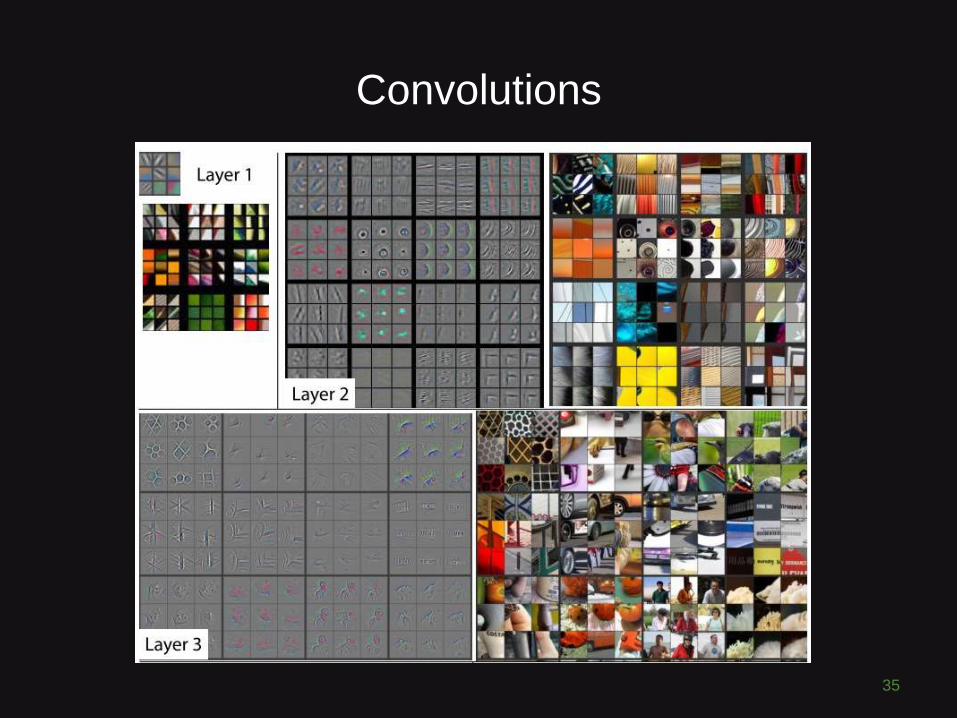
Convolutions
35

Convolutions
36

Great vid
37
https://www.youtube.com/watch?v=AgkfIQ4IGaM

New Layer Type: Max Pooling
38

New Layer Type: Max Pooling
• Reduces dimensionality from one layer to next
• By replacing NxN sub-area with max value
• Makes network “look” at larger areas of the image at a time e.g.
Instead of identifying fur, identify cat
• Reduces computational load
• Reduces overfitting since losing information helps the network
generalize
39

Softmax
• Convert scores ∈ ℝ to probabilities ∈ [0,1]
• Then predict the class with highest
probability
40

Bringing it all together
xxx
41
Convolution + max pooling + fully connected +
softmax
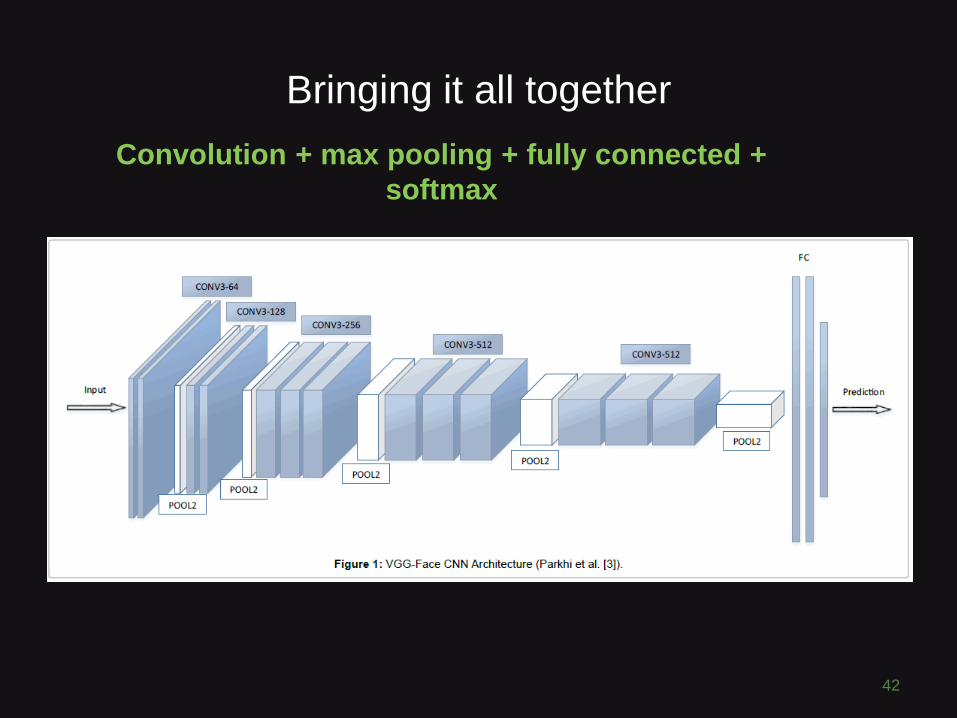
Bringing it all together
42
Convolution + max pooling + fully connected +
softmax

We need labelled training data!

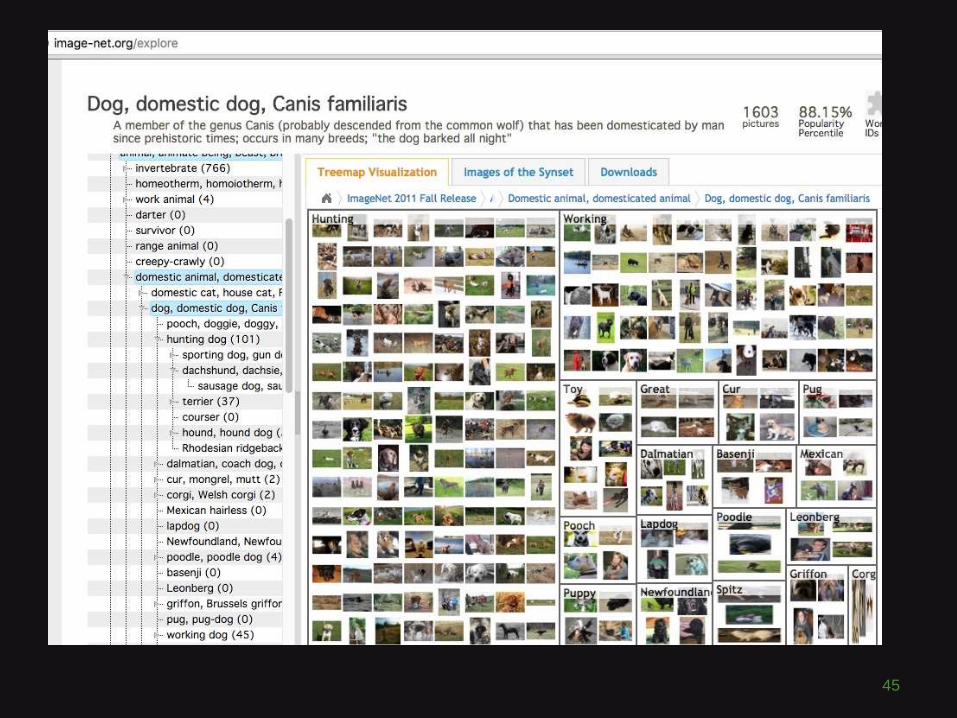
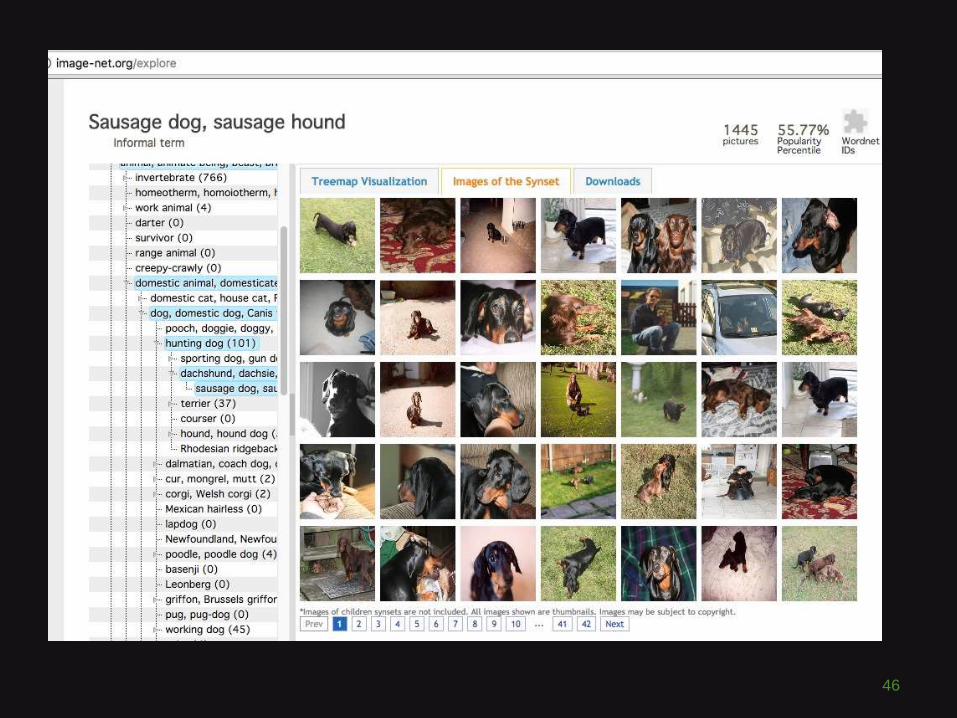
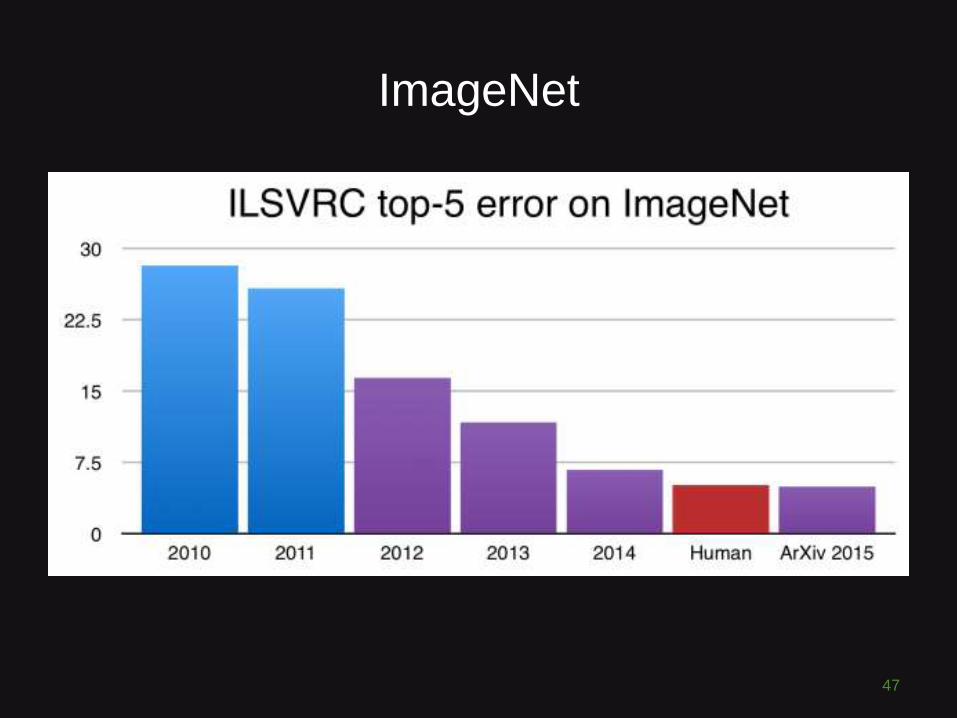
ImageNet
44
http://image-net.org/explore
ImageNet
45
ImageNet
46
ImageNet
47

3. How to use a
convolutional neural
network

Using a Pre-Trained ImageNet-Winning
CNN
49
• We’ve been looking at “VGGNet”
• Oxford Visual Geometry Group (VGG)
• The runner-up in ILSVRC 2014
• Network is 16 layers (deep!)
• Its main contribution was in showing that the depth of
the network is a critical component for good
performance.
• Only 3x3 (stride 1 pad 1) convolutions and 2x2 max
pooling
• Easy to fine-tune https://blog.keras.io/building-powerful-image-classification-
models-using-very-little-data.html

Example: Classifying Product Images
50
https://github.com/alexcnwy/CTDL_CNN_TALK_20
170620

51
https://blog.keras.io/building-powerful-image-classification-
models-using-very-little-data.html

Fine-tuning A CNN To Solve A New Problem
• Cut off last layer of pre-trained Imagenet winning
CNN
• Keep learned network but replace final layer
• Can learn to predict different classes
• Fine-tuning is re-training new final layer
52

53
Before

54
After

Fine-tuning A CNN To Solve A New Problem
• Fix weights in convolutional layers (set
trainable=False)
• Remove final dense layer that predicts 1000
imagenet
• Replace with new dense layer to predict 9
categories
55
Gets 88% accuracy in classifying products into
categories

Visual Similarity
56
• Chop off last 2 VGG layers
• Use dense layer with 4096 activations
• Compute nearest neighbours in the space of these
activations
https://memeburn.com/2017/06/spree-image-search/

57
https://github.com/alexcnwy/CTDL_CNN_TALK_20170620

58

4. More advanced topics

cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf
Lots of Computer Vision Tasks

Long, Shelhamer, and Darrell, “Fully Convolutional Networks for Semantic Segmentation” CVPR
2015
Noh et al, “Learning Deconvolution Network for Semantic Segmentation” CVPR 2015
Semantic Segmentation

http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf
Object detection

Object detection

https://www.youtube.com/watch?v=VOC3huqHrss
Object detection


http://blog.romanofoti.com/style_transfer/
https://github.com/fchollet/keras/blob/master/examples/neural_style_transfer.py
Style Transfer
Loss = content_loss + style_lossContent loss = convolutions from pre-trained network
Style loss = gram matrix from style image convolutions

5. Practical tips

http://blog.kaggle.com/2016/02/04/noaa-right-whale-recognition-
winners-interview-2nd-place-felix-lau/
Computer Vision Pipelines
https://flyyufelix.github.io/2017/04/16/kaggle-
nature-conservancy.html

Practical Tips
• use a GPU – AWS p2 instances (use spot!)
• when overfitting (validation_accuracy <<< training_accuracy)
– Increase dropout
– Early stopping
• when underfitting (low training_accuracy)
1. Add more data
2. Use data augmentation
– Flipping / stretching / rotating
– Slightly change hues / brightness
3. Use more complex model
– Resnet / Inception / Densenet
– Ensamble (average <<< weighted average with learned weights)
70

Hackathon Challenge
Info

POTHOLES!

POTHOLES!

Hackathon Details
Challenge: Detect potholes in images
Binary classification problem
Given +- 5000 training images with labels
Given number of potholes + bounding box annotations
Given convolutional output for each image (in train & test)
Submit predictions on held-out test images
MOST ACCURATE MODEL WINS!74

Hackathon Details
Can form teams of up to 4 people
You need to present your approach (2 min max)
Prizes for best presentation / most innovative approach
(even if not most accurate)
Don’t worry if you don’t know any of this stuff
– it’s a great opportunity to learn!
Hackathons are fun!!!!
75

Why this is an important problem
Potholes cause road deaths:
“The Automobile Association (AA) said that if there was proper
maintenance of our roads, then there could be an immediate
decrease in about 5% of road deaths … South Africa’s has
more than 700000 accidents occurring annually.”http://www.roadcover.co.za/potholes-how-they-worsen-our-roads/
35’000 lives!!
2 levels:
• Alert the road authorities where they are to fix quickly
• Real time pothole avoidance (much harder!)
76Big thanks to Dr. Steve Kroon for suggesting and helping with the
dataset

See you tomorrow!Same venue (THE DIZ 111 Smit Street)
9am – 830pm

QUESTIONS?Email me :)
Alex Conwayalex @ numberboost.com

















![Constrained Convolutional Neural Networks for …vgg/rg/slides/ccnn1.pdf · Constrained Convolutional Neural Networks for Weakly Supervised Segmentation ... [CCNN] Convolutional Neural](https://img.dokumen.tips/doc/110x75/5baa6a3809d3f2c9618bd4b3/constrained-convolutional-neural-networks-for-vggrgslidesccnn1pdf-constrained.jpg)











