Embed Size (px)
Citation preview

Cloud Computing in the Cloud
Jeff Hung, Trend Micro SPN November 23, 2015

Jeff Hung
• Trend Micro – Manager of SPN-‐Infra Team – SPN compute/data infra like Hadoop
• Experience – Played Hadoop since 2009 – Distributed System, Cloud, and Big-‐data: 10+ years
• github.com/jeRung

#TrendInsight
Story of the Journey
3

Wheat and Chessboard problem
• The ruler of India would like to offer reward to the wise man, who invented the game of chess.
• The wise man just want one grain of rice on the first square of the chess board, double the grains of the second square, and so on…
4

Dat
a Vo
lum
e in
HD
FS
Data Volume Forecast
• Volume increases 1.5 ~ 2x every year

Solu\ons?
Migra\ng to another datacenter • Be^er infrastructure • Op\mized configura\on • Reduced running cost
Evaluate if AWS is a viable solu\on • Much cheaper storage cost • More elas\c than datacenter • No more CAPEX burst
6
Introduced in HadoopCon 2015:

Is it really a good idea?
Common Believe: Hadoop cluster running in virtual environment is significantly perform lower than the cluster running on physical machines
7 Reference: http://www.cs.wustl.edu/~jain/cse570-13/ftp/bigdatap/index.html

Hadoop on AWS: EC2 + EBS
Run exis\ng SPN Hadoop sodware stack as is on EC2 with EBS persistence. à Cost es\ma\on shows it is not prac\cal
8
Configuration EBS IOPS vs. Datacenter
Production workload with 3-year heavily reserved instances
300 5 x 2000 9 x 4000 14 x
Cost is too High!!

Hadoop on AWS: EMR + S3
Use AWS Elas\c MapReduce (EMR) managed service with data persist in S3.
Experiments: 1. Benchmark to compare current PROD and EMR 2. Evaluate business readiness by real applica\on
9
Computing Storage

#TrendInsight
Benchmarking
10

Benchmarks
• Server/OS Level – Disk I/O (fio) – Network I/O (iperf)
• Hadoop Level – TestDFSIO – mrbench – TeraSort – RandomWriter / RandomTextWriter

Disk I/O Comparison (fio)
• IOPS for sequen\al access • IOPS for random access
12
- 70% Read - 30% Write - File Size: 64 MB
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
Sequential Read
Sequential Write
Random Read
Random Write
Datacenter
EMR root: /
EMR SSD: /mnt

Network I/O Comparison (iperf)
• Run 30 minutes to see how fast it can be • Datacenter: cross rack communica\on
13
0
20
40
60
80
100
120
140
Datacenter #1
Datacenter #2
EMR #1 EMR #2 EMR #3
Mbi
ts /
Sec
A -> B
B -> A

TestDFSIO
• 70MB, 140MB, and 1GB files • Run in 70 mappers
14
Based on datacenter file size and block # distribution
0
10
20
30
40
50
60
70
80
90
100
(MBy
tes
/ Se
c)
70 MB 140 MB 1 GB
Datacenter
EMR: default
EMR: custom

mrbench
• 10 Runs, 70 DataLines • 70 Maps, 42 Reduces
15
Avg. Time (sec) Datacenter EMR
On Map Tasks 2.8 4.9
On Shuffle Tasks 4.6 7.3
On Reduce Tasks 1.0 1.0
Job Running Time 12.7 21.1
EMR is slower than Datacenter

TeraSort
• 70 Mappers, 1 Reducer • EMR with Local HDFS, S3, and S3-‐Encrypted
16
Avg. Time (sec) Datacenter EMR: HDFS EMR: S3 EMR: S3 Enc
On Map Tasks 6.9 13.4 12.6 12.4
On Shuffle Tasks 45.3 38.2 40.6 40.4
On Reduce Tasks 32.7 56.0 510.8 608.6
Job Running Time 110.8 755.4 836.0
EMR mappers is slower than Datacenter

RandomWriter / RandomTextWriter
• 70 Mappers, 1 Reducer • EMR with Local HDFS, S3, and S3-‐Encrypted
• Outliers are due to S3 hang – easy to reproduce – Ader repor\ng to AWS, this problem has been fixed
17
Avg. Time (sec) Datacenter EMR: HDFS EMR: S3 EMR: S3 Enc
On Map Tasks 110.6 134.4 101.7 116.8
Job Running Time 229.0 213.0 463.6 300.0

Observa\ons
• EC2 performs very well – Thanks to SSD – Current hardware vs. 4-‐year old cluster
• EMR is unexpected slower – Not mature enough when test – AWS evolve fast, in most of the \me
18

#TrendInsight
PoC: Real ApplicaBon

PoC with Real World Applica\on
• PE file metadata and distribu\on in real world – Analyzed 500 billion of log entries so far – Iden\fies 850 million of dis\nct files – Serves 750 million of requests per day
• One of the biggest applica\ons we have – Consumes huge amount of workload in primary cluster – Validates that AWS is a viable solu\on in terms of volume
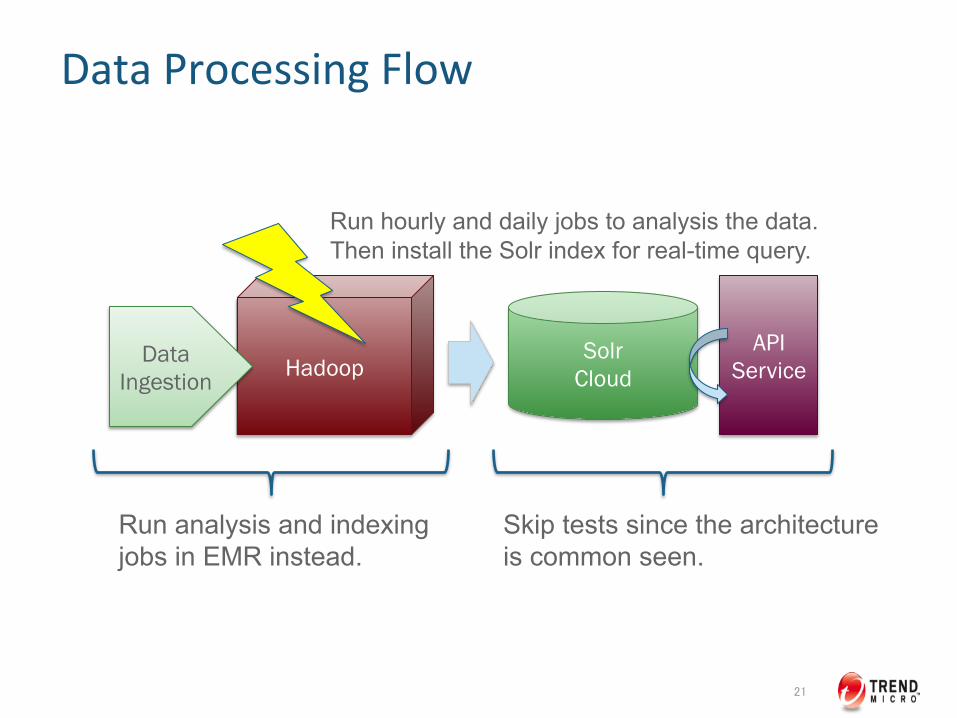
Data Processing Flow
21
Hadoop Data Ingestion
API Service
Solr Cloud
Run hourly and daily jobs to analysis the data. Then install the Solr index for real-time query.
Run analysis and indexing jobs in EMR instead.
Skip tests since the architecture is common seen.

EMR + S3
• Store persist data in S3 – low cost • Process in EMR – easy to upgrade
• Allow mul\ple cluster and resized cluster
22
EMR v1
Read Write
S3 S3 EMR v2

EMR Instance Groups
23
Master Node
Core Nodes
Task Nodes
AWS Cloud
Runs NN, RM No HA Support No KRB Security
Runs DN, NM Data is volatile Cannot scale-in
Runs NM only Resize cluster Spot Instance!

How to evaluate?
24
Scope (features, data-to-process)
Cost Time (processing time) (resource, money)
Given the same amount of data & work load…
Jobs must be finished within time constraints
Would the cost be competitive?
Optimize for...

The Jobs and Time Constraints
• There are 2 hourly jobs and 6 daily jobs:
• Find a combina\on of instance types and EMR cluster size that have low-‐enough cost
25
# Job Program Time Constraint
1 Hourly Jobs
census_hourly.pig 55 mins
2 census_index_hourly.pig
3
Daily Jobs
census_daily.pig 2 hours
4 census_index_daily.pig 6 hours
5 vsapi_stats.pig 30 mins
6 vsapi_index.pig 60 mins
7 vsapi_dname_stats.pig 20 mins
8 vsapi_dname_index.pig 10 mins

The combina\ons that failed
• It’s a try-‐n-‐error process…
26
Test #
EMR Instance Group
AMI Version
Job Finish Time (min)
Special Parameters Master Core Task #1 #2 #3 #4 #5 #6 #7 #8
1 i2.2xL i2.2xL * 30 -‐ 3.1.0 74 24 slowstart=0.05
2 c3.4xL c3.4xL * 60 -‐ (private) 96 32 slowstart=0.05
3 i2.2xL i2.2xL * 30 -‐ 3.1.0 60 23 slowstart=0.9
4 c3.4xL c3.4xL * 60 -‐ 3.1.0 30 19 17 17+ 14 24 27 4 slowstart=0.9
5 c3.4xL c3.4xL * 70 -‐ 3.1.0 35 18 slowstart=0.9
6 c3.4xL c3.4xL * 60 -‐ 3.1.0 (ba73a7d2) 96 29 slowstart=0.9
7 c3.4xL c3.4xL * 60 -‐ 3.1.1 (fcad7f94) 89 67 slowstart=0.9
8 c3.4xL c3.4xL * 60 -‐ 3.1.1 (fcad7f94) 32 16 16 xxx 16 21 10 2 slowstart=0.9, y.s.c.node-‐locality-‐delay = -‐1
9 c3.4xL c3.4xL * 60 -‐ 3.1.1 (fcad7f94) 30 17 15 95 17 22 17 21 slowstart=0.9, y.s.c.node-‐locality-‐delay = -‐1
10 c3.4xL c3.4xL * 60 -‐ 3.1.1 (fcad7f94) 26 17 slowstart=0.9, y.s.c.node-‐locality-‐delay = -‐1
11 c3.4xL c3.4xL * 40 -‐ 3.1.1 (fcad7f94) 27 17 slowstart=0.9, y.s.c.node-‐locality-‐delay = -‐1
12 c3.4xL c3.4xL * 100 -‐ 3.1.1 (fcad7f94) 19 16 slowstart=0.9, y.s.c.node-‐locality-‐delay = -‐1

AWS Bugs Discovered
Confiden\al | Copyright 2013 TrendMicro Inc. 27
Job Stage Job Stage Action
issue Status
Job launch
Job initialization
S3 reading
[Performance] The s3 access takes long time, for example, some census_hourly MR takes two to three minutes in this part.
Unsolved Fixed
Pig analysis
[Performance] The pig analysis takes long time, for example, some census_hourly MR takes four minutes in this part.
Unsolved Fixed
Submit job & assign AM
[Performance] The job already show on RM Web UI, but have not been assigned to any AM. It may take about 5 minutes pending on this status.
Fixed
Computation Mapper phase
[Performance] Mapper utilization very low while the job has been initialized
Fixed
Reducer phase
[Performance] Reducer startup too early
Fixed
[Bug] Census_daily_index.pig met 5G upload limitation while write output to S3. Job failed.
Not sure Fixed
[Bug] Most of the index pig script met multipleUpload error while write output to S3. Job failed in AMI 3.1.1.
Unsolved Fixed
Finalization [Performance] Even though all mapper/reducers are finished. The job still seek through all S3 files for long time. For example, some census_hourly MR takes three to four minutes in this part.
Unsolved Fixed

The final result
• c3.4xlarge – 40 core nodes running 24hr/day – 25 task nodes running 2hr/day
28
Only slightly greater than Datacenter Cost (but there are other hidden cost in DC)
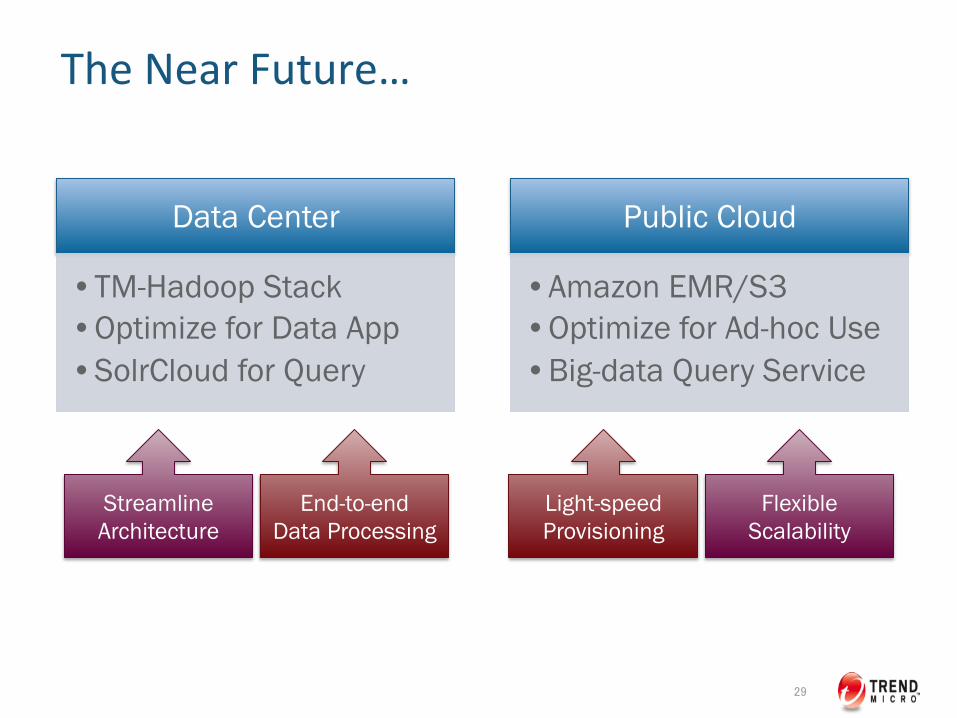
The Near Future…
29
Data Center
• TM-Hadoop Stack • Optimize for Data App • SolrCloud for Query
Public Cloud
• Amazon EMR/S3 • Optimize for Ad-hoc Use • Big-data Query Service
Streamline Architecture
End-to-end Data Processing
Light-speed Provisioning
Flexible Scalability

#TrendInsight
Lesson Learned

On-‐premises (physical) vs. EMR (virtual)
• The gap is not that big – EMR is a good choice for startups – There are other benefits like elas\city
• The key is op\miza\on – Engineers’ duty and nature is to op\mize!! – Apps op\mized for DC runs costly in AWS

AWS could be the way to go
• AWS evolves fast and listen to customers – Lots of issues being fixed during test period – New features are realized if there are true needs
• AWS model is more flexible in configura\ons – More low cost op\ons to leverage – Less lead \me for configura\on change
32

Mindset Change
• Think in terms of business goal – Instead of limited performance metrics – Hidden issues could be measured
• Op\mize for cost instead of \me – In on-‐premises DC we op\mize for \me – On AWS we op\mize for cost
33

#TrendInsight
QuesBons? THANKS YOU~
34





























