Embed Size (px)
Citation preview

@2016 LinkedIn Corporation. All Rights Reserved.
KDD 16’ Tutorial
Business Applications of Predictive Modeling at Scale

@2016 LinkedIn Corporation. All Rights Reserved. 2
Instructors
Songtao GuoSr. Staff of Business Analytics Data Mining at LinkedIn
Yan LiuSr. Manager of Business Analytics Data Mining at LinkedIn
Paul OgilvieSr. Manager of Machine Learning Algorithms Team at LinkedIn
Qiang ZhuStaff of Business Analytics Data Mining at LinkedIn
@2016 LinkedIn Corporation. All Rights Reserved. 3
Outline
Introduction ❏ Why predictive modeling is important? ❏ Understanding of audience background and learning objectives
Predictive Modeling Overview
❏ End-to-end walkthrough of a production modeling solution❏ Common pitfalls and challenges❏ Case Study - LinkedIn Feed Ranking
❏ Considerations when choosing a framework❏ Overview of tools and platforms across industry❏ Modoop - example of a scaled framework
Choosing a Framework

@2016 LinkedIn Corporation. All Rights Reserved. 4
Outline
Introduction ❏ Why predictive modeling is important? ❏ Understanding of audience background and learning objectives
Predictive Modeling Overview
❏ End-to-end walkthrough of a production modeling solution❏ Common pitfalls and challenges❏ Case Study - LinkedIn Feed Ranking
❏ Considerations when choosing a framework❏ Overview of tools and platforms across industry❏ Modoop - example of a scaled framework
Choosing a Framework

@2016 LinkedIn Corporation. All Rights Reserved. 5
Example 1: Search Ranking

@2016 LinkedIn Corporation. All Rights Reserved. 6
Example 2: Recommendation
Job recommendations on LinkedIn
Movie recommendations on Netflix

@2016 LinkedIn Corporation. All Rights Reserved. 7
Example 3: User Intention Predictions
Predict which users are more likely to make certain actions, such as click, purchase, churn, etc.

@2016 LinkedIn Corporation. All Rights Reserved. 8
Example 4: B2B Predictive Analytics

@2016 LinkedIn Corporation. All Rights Reserved. 9
Example 5: Web Content Analytics
Social data
Customer feedback• Customer service• Group updates• Network updates
Survey results
Products Categorization
Sentiments
Group Subscription
Home Page Mobile Message
Text Classification
Relevance

@2016 LinkedIn Corporation. All Rights Reserved. 10
Other Applications...
Image RecognitionFraud/Spam Detection NLP Speech Recognition
and more...

@2016 LinkedIn Corporation. All Rights Reserved. 11
Outline
Introduction ❏ Why predictive modeling is important? ❏ Understanding of audience background and learning objectives
Predictive Modeling Overview
❏ End-to-end walkthrough of a production modeling solution❏ Common pitfalls and challenges❏ Case Study - LinkedIn Feed Ranking
❏ Considerations when choosing a framework❏ Overview of tools and platforms across industry❏ Modoop - example of a scaled framework
Choosing a Framework

@2016 LinkedIn Corporation. All Rights Reserved. 12
Outline
Introduction ❏ Why predictive modeling is important? ❏ Understanding of audience background and learning objectives
Predictive Modeling Overview
❏ End-to-end walkthrough of a production modeling solution❏ Common pitfalls and challenges❏ Case Study - LinkedIn Feed Ranking
❏ Considerations when choosing a framework❏ Overview of tools and platforms across industry❏ Modoop - example of a scaled framework
Choosing a Framework
@2016 LinkedIn Corporation. All Rights Reserved.
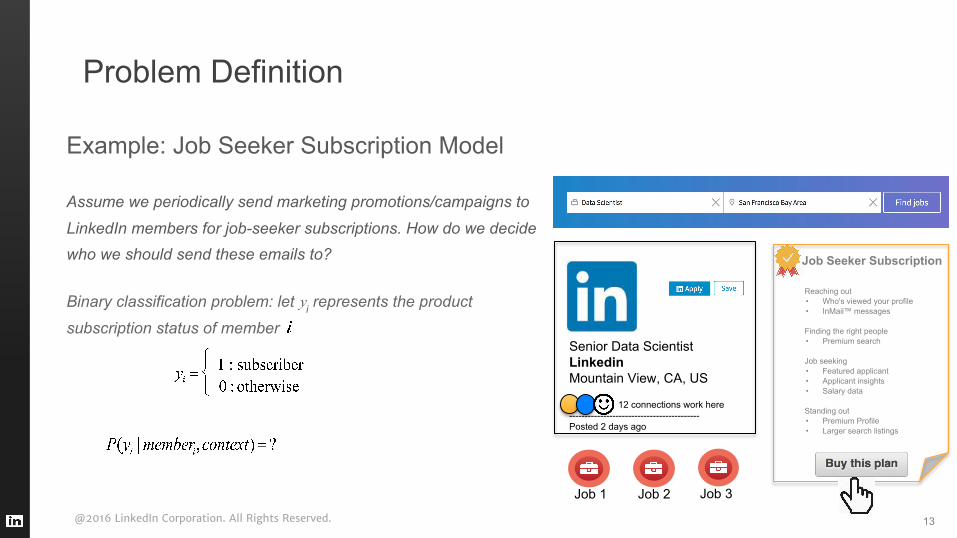
Problem Definition
13
Example: Job Seeker Subscription Model
Assume we periodically send marketing promotions/campaigns to
LinkedIn members for job-seeker subscriptions. How do we decide who we should send these emails to?
Binary classification problem: let i represents the product
subscription status of member
Job 1
Senior Data ScientistLinkedinMountain View, CA, US
12 connections work here------------------------------------------Posted 2 days ago
Job 2 Job 3
Job Seeker Subscription
Reaching out• Who's viewed your profile• InMail™ messages
Finding the right people• Premium search
Job seeking• Featured applicant• Applicant insights• Salary data
Standing out• Premium Profile• Larger search listings

@2016 LinkedIn Corporation. All Rights Reserved.
crowd and internal judgments
label preparation
raw features
features with label
log data
online A/B test random bucket
evaluate for model selection
data partitioning
model training+
-- -
-
+ +
best model
compute offline evaluation metrics
offline scoring and indexing
log data
a/b test reports
feature engineering
label
feature integration
trainingdata
testingdata
validationdata
model performance
raw features
feature integration
scoring features
-
raw data
-
online/offline systems

@2016 LinkedIn Corporation. All Rights Reserved.
crowd and internal judgments
label preparation
raw features
features with label
log data
online A/B test random bucket
evaluate for model selection
model training+
-- -
-
+ +
best model
compute offline evaluation metrics
offline scoring and indexing
a/b test reports
feature engineering
label
feature integration
trainingdata
testingdata
validationdata
model performance
raw features
feature integration
scoring features
-
raw data
-
data partitioning
online/offline systems
log data

@2016 LinkedIn Corporation. All Rights Reserved.
Label Preparation
▪ A set of labels(“right answers”) is defined in advance
▪ Methods– Derive from data
▪ Historical transaction▪ User preference▪ User activity
– Domain expert– Scale up label collection
▪ Crowdsourcing
Example1: Job seeker model• user_id• Target: whether subscribed
JobSeeker product • {Yes,No} -> {1,0}
• timestamp
Example2: Churn prediction• Account + timestamp• Target: Close/Renew
Example3: sentiment analysis• Review• Target: sentiment types
• Strong negative• Negative• Neutral• Positive• Strong positive
16

@2016 LinkedIn Corporation. All Rights Reserved.
crowd and internal judgments
label preparation
raw features
features with label
log data
online A/B test random bucket
evaluate for model selection
model training+
-- -
-
+ +
best model
compute offline evaluation metrics
offline scoring and indexing
a/b test reports
feature engineering
label
feature integration
trainingdata
testingdata
validationdata
model performance
raw features
feature integration
scoring features
-
raw data
-
data partitioning
online/offline systems
log data

@2016 LinkedIn Corporation. All Rights Reserved.
Feature Engineering
Entity Features Social FeaturesBehavioral Features
• Multiple data sources, hundreds to billions of features• Multiple levels of granularity• Monitoring dynamic changes
18
• Demographics• Personal and
professional interest• …
• pageviews • searches• activities on external
sites• …
• Social network identity and behaviors
• …
The process of transforming raw data into features that better represent the underlying problem to the predictive models

@2016 LinkedIn Corporation. All Rights Reserved.
Feature Metadata
▪ Location▪ Description▪ Type
– numerical, categorical, ordinal, binary
▪ Granularity– snapshot, hourly, daily,
weekly, monthly...▪ Creation frequency
– hourly, daily, weekly, monthly…
19
▪ Aggregatable▪ Aggregation length
– snapshot, hourly, daily, weekly, monthly...
▪ Aggregation option– min, max, sum, avg,
median...▪ Transformation option
– log, binary, self…▪ Owner▪ Retention policy

@2016 LinkedIn Corporation. All Rights Reserved.
Feature Storage
▪ File format: one of the most essential drivers of functionality and performance for big data processing
▪ What must be considered?– How big are your files?– How important is file format “splitability”?– Does block compression matter?– Are you more concerned about read or write?
20

@2016 LinkedIn Corporation. All Rights Reserved.
Feature Storage Type
21
Storage Text Sequence File Avro Parquet ORC
type row based row based row based column-oriented column + row
block compression
X V V V V
splittable compression
X V V V V
schema support X X V V V
schema evolution
X X V V V

@2016 LinkedIn Corporation. All Rights Reserved.
Feature Representation
▪ Key-Value pair
▪ Full feature vector
▪ Sparse feature vector
22
entity_id feature1 feature2 ...
xx1 0 0.3
xx2 1 0.1
xx3 0 NA
… … 0.9
entity_id feature1 feature2 ...
xx1 0 0.3
xx2 1 0.1
xx3 0 NA
… … 0.9
entity_id feature1 feature2 ...
xx1 1 0.4
xx2 NA 0.2
xx3 0 NA
… … 0.7
2016-02-29
2016-03-31
Entity
Feature
Timestamp2016-01-31

@2016 LinkedIn Corporation. All Rights Reserved.
Raw Feature Schema Example
23
{ "type" : "record", "name" : "TUPLE", "fields" : [ { "name" : "id", "type" : [ "null", "long" ] }, { "name" : "timestamp", "type" : [ "null", "int" ] }, { "name" : "feature_name", "type" : [ "null", "string" ] }, { "name" : "feature_value", "type" : [ "null", "double" ] } ]}
▪ Key-value pair
entity_id timestamp name value1 t1 F1 0.41 t1 F2 01 t2 F4 52 t3 F1 1… … F5 ...

@2016 LinkedIn Corporation. All Rights Reserved.
Raw Feature Schema Example
24
{ "type": "record", "name": "TUPLE", "fields": [ { "name": "id", "type": [ "null", "long" ] }, { "name": "timestamp", "type": [ "null", "int" ] }, { "name": "feature1", "type": [ "null", "double" ] }, { "name": "feature1", "type": [ "null", "double" ] }, { "name": "feature3", "type": [ "null", "double" ] }, ... ]}
▪ Full feature vector
entity_id timestamp feature1 feature2 ...xx1 t1 1 0.4xx2 t1 NA 0.2xx3 t2 0 NA… ... … 0.7

@2016 LinkedIn Corporation. All Rights Reserved.
Raw Feature Schema Example
25
{ "type": "record", "name": "FeatureVector", "fields": [
{ "name": "entity_id", "type": [ "string" ]
},{
"name": "timestamp", "type": [ "null", "string" ]
},{
"name": "features", "type": { "type": "array", "items": { "type": "record", "name": "FeatureValue", "fields": [ { "name": "id", "type": "string", "doc": "identifier of a feature"}, { "name": "value", "type": "string", "doc": "text representation of a feature value" } ] }}, "default": []
} ]}
▪ Sparse feature vector
LIBSVMlabel index1:value1 index2:value2 ...

@2016 LinkedIn Corporation. All Rights Reserved.
Feature Monitoring
26
Labor Day
Typical metrics to monitor:● summation: e.g.: total page views, total
searches● coverage: e.g.: number of users who sent
inmails● percentiles: e.g.: top 95% of profile views
count
Methods to detect anomaly● Percentage change● T-test, Chi-square test● Generalized ESD (Extreme Studentized
Deviate) test, Seasonal Hybrid ESD.

@2016 LinkedIn Corporation. All Rights Reserved.
crowd and internal judgments
label preparation
raw features
features with label
log data
online A/B test random bucket
evaluate for model selection
model training+
-- -
-
+ +
best model
compute offline evaluation metrics
offline scoring and indexing
a/b test reports
feature engineering
label
feature integration
trainingdata
testingdata
validationdata
model performance
raw features
feature integration
scoring features
-
raw data
-
data partitioning
online/offline systems
log data

@2016 LinkedIn Corporation. All Rights Reserved.
Feature Integration
28
user_id Label
xx1 0
xx2 1
xx3 0
… …
user_id pageviews searches …
xx1 97 5 …
xx2 27 2 …
xx4 58 4 …
user_id Tenure Is employed …
xx1 3876 1 …
xx2 60 0 …
xx3 2700 1 …
user_id connections Connect in …
xx1 60 4 …
xx2 5 5 …
xx3 120 30 …
user_id Label pageviews searches … Tenure Is employed … connections Connect in …
xx1 0 97 5 … 3876 1 … 60 4 …
xx2 1 27 2 … 60 0 … 5 5 …
xx3 0 null null null 2700 1 … 120 30 …
… …
Label setFeature set 1
Feature set 2
Feature set 3

@2016 LinkedIn Corporation. All Rights Reserved. 29
Feature Integration
Training data with timestamp
Feature Mart
presentweek 1
week 2week 3
week 4
mid Y X
xx1 0 Snapshot features Aggregated features
xx2 1 … …
xx3 0 … …
trans descself xsign sign(x)log sign(x)*log(abs(x)+1))isna 1:x==null; 0:x!=null
trans desc
sum sum(xi)
Weighted sum sum(wi*xi), wi=α^i
avg avg(xi)
Weighted avg sum(wi*xi)/sum(wi), wi=α^i
past

@2016 LinkedIn Corporation. All Rights Reserved.
Feature Transformation and Interactions
▪ Feature transformation important for linear models▪ Numeric values:
– binary buckets based on histograms of data– log transforms– scale to unit variance, mean of 0
▪ Categorical values – binary indicator for each categorical value
▪ Interactions– cross-products of feature types, e.g.
▪ {Skillsmember} X {Skillsjob}▪ {Skillsmember} X {Industryjob}
30

@2016 LinkedIn Corporation. All Rights Reserved.
crowd and internal judgments
label preparation
raw features
-
features with label
log data
online A/B test random bucket
evaluate for model selection
model training+
-- -
-
+ +
best model
compute offline evaluation metrics
offline scoring and indexing
a/b test reports
feature engineering label
feature integration
trainingdata
testingdata
validationdata
model performance
raw features
feature integration
scoring features
-
raw data
-
data partitioning
online/offline systems
log data

@2016 LinkedIn Corporation. All Rights Reserved.
Model Learning
32
Training Set
Validation Set
Testing Set
Model Validation
Model Training
Model Testing
Data Partitioning
Best Model
Model Selection
SolversLogistic regression L1/L2
Random Forest
Gradient Boosting Trees
SVM… ...

@2016 LinkedIn Corporation. All Rights Reserved.
Hyperparameter search▪ Modeling techniques must be tuned for best performance
– Regression▪ regularization methods (Ridge, Lasso, Elastic Net)▪ regularization weight
– Gradient boosted trees ▪ number trees▪ depth of tree▪ learning rate▪ sampling parameters
▪ Provide wrappers to ease hyperparameter search in early problem exploration
– Grid Search– Randomized Search, Bayesian Optimization
▪ Typically don’t want to rerun hyperparameter search for each retrain, do only periodically when there is a major change in data volume, features, etc.
33

@2016 LinkedIn Corporation. All Rights Reserved. 34
Measure Model Performance
▪ Precision/Recall– Precision = TP/(TP+FP)– Recall = TP/(TP+FN)
▪ true positive rate / sensitivity
▪ F1 score– 2 * (Precision * Recall) / (Precision + Recall)
▪ False positive rate:– FPR = FP/N = FP/(FP+TN)
▪ Specificity: true negative rate– SPC = TN/N = TN/(FP+TN)
▪ Accuracy– ACC = (TP+TN)/(P+N)
TruePositive
FalsePositive
FalseNegative
TrueNegative
Actual Value
p n
P N
Prediction Outcome
p’
n’
total

@2016 LinkedIn Corporation. All Rights Reserved. 35
Measure Model Performance

@2016 LinkedIn Corporation. All Rights Reserved.
crowd and internal judgments
label preparation
raw features
features with label
log data
online A/B test random bucket
evaluate for model selection
model training+
-- -
-
+ +
best model
offline scoring and indexing
a/b test reports
feature engineering
label
feature integration
trainingdata
testingdata
validationdata
model performance
raw features
feature integration
scoring features
-
raw data
-
data partitioning
compute offline evaluation metrics
online/offline systems
log data

@2016 LinkedIn Corporation. All Rights Reserved. 37
Model Testing
▪ Similar to model validation– Test on data NOT used in model selection– Scoring using the best model– Performance evaluation/comparison
Raw Testing Data Production Model
Best Model

@2016 LinkedIn Corporation. All Rights Reserved.
crowd and internal judgments
label preparation
raw features
features with label
log data
online A/B test random bucket
evaluate for model selection
model training+
-- -
-
+ +
best model
offline scoring and indexing
online/offline systems
a/b test reports
feature engineering
label
feature integration
trainingdata
testingdata
validationdata
model performance
raw features
feature integration
scoring features
-
raw data
-
data partitioning
compute offline evaluation metrics
log data

@2016 LinkedIn Corporation. All Rights Reserved.
Performance Measurement via A/B Test
39
Algorithm b20%
Algorithm a 80%
Collect results to determine which one is better

@2016 LinkedIn Corporation. All Rights Reserved.
Best Practices for Running A/B Test▪ Start testing on a small portion of users▪ Measure one change at a time▪ Be aware of potential biases (time, targeted population, etc.)▪ Avoid coupling a marketing campaign with an A/B test▪ Use a simple rule of thumb to address multiple testing problems
– 0.05 p-value cutoff for metrics that are expected to be impacted– a smaller cutoff, say 0.001, for metrics that are not
40

crowd and internal judgments
label preparation
raw features
features with label
log data
online A/B test random bucket
evaluate for model selection
model training+
-- -
-
+ +
best model
compute offline evaluation metrics
offline scoring and indexing
a/b test reports
feature engineering
label
feature integration
trainingdata
testingdata
validationdata
model performance
raw features
feature integration
scoring features
-
raw data
-
data partitioning
online/offline systems
log data
@2016 LinkedIn Corporation. All Rights Reserved. 42
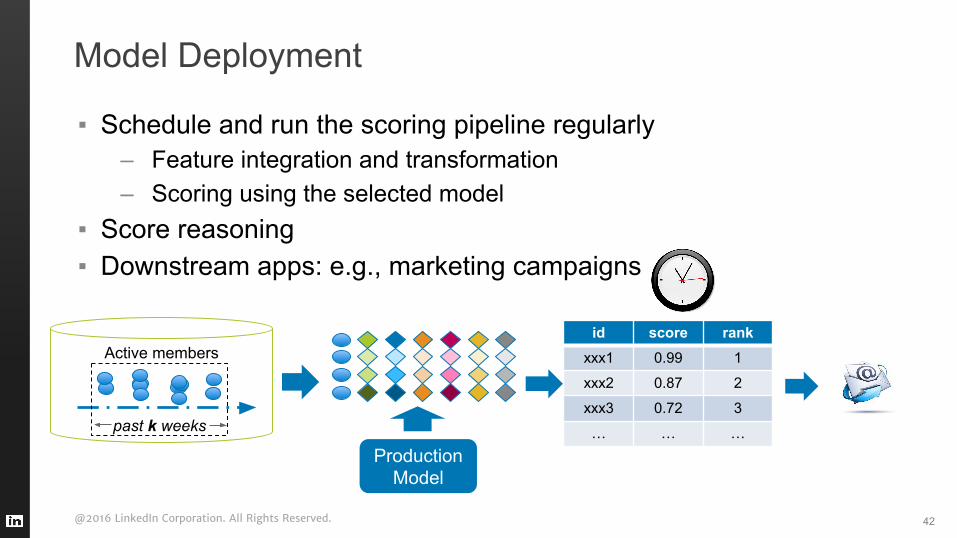
Model Deployment
▪ Schedule and run the scoring pipeline regularly– Feature integration and transformation– Scoring using the selected model
▪ Score reasoning▪ Downstream apps: e.g., marketing campaigns
Production Model
Active members
past k weeks
id score rankxxx1 0.99 1
xxx2 0.87 2
xxx3 0.72 3
… … …

@2016 LinkedIn Corporation. All Rights Reserved.
Model Management
43
Day 1 Day 30
Photo credit: asmfoto Marcell Mizik, photo license withDepositphotos File Purchase Agreement #41549281

@2016 LinkedIn Corporation. All Rights Reserved. 44
Model ManagementFeed in new training data to generate new model periodically
Monitor performance changes over time Keep model up to date
Ensemble historical models as one of the baseline models

@2016 LinkedIn Corporation. All Rights Reserved. 45
Outline
Introduction ❏ Why predictive modeling is important? ❏ Understanding of audience background and learning objectives
Predictive Modeling Overview
❏ End-to-end walkthrough of a production modeling solution❏ Common pitfalls and challenges❏ Case Study - LinkedIn Feed Ranking
❏ Considerations when choosing a framework❏ Overview of tools and platforms across industry❏ Modoop - example of a scaled framework
Choosing a Framework
@2016 LinkedIn Corporation. All Rights Reserved.
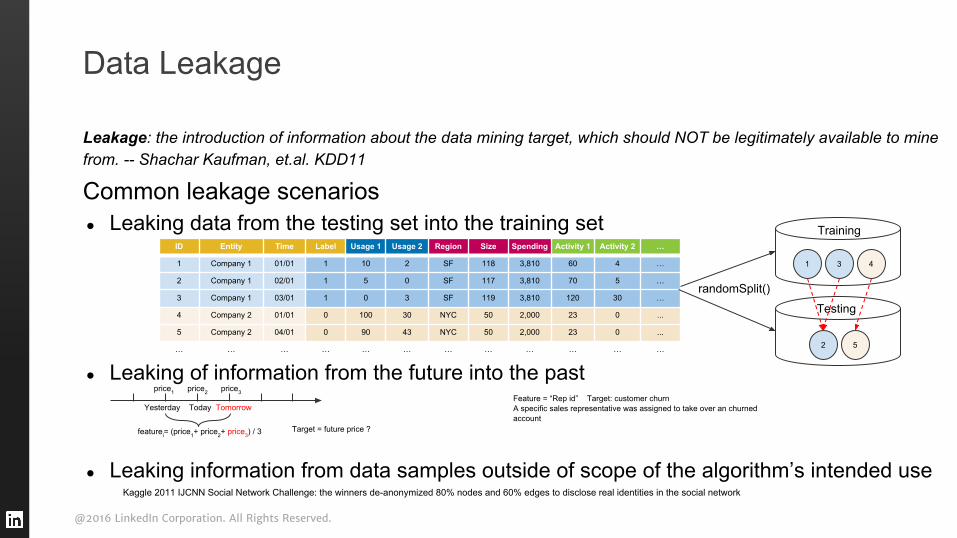
Leakage: the introduction of information about the data mining target, which should NOT be legitimately available to mine from. -- Shachar Kaufman, et.al. KDD11
Common leakage scenarios● Leaking data from the testing set into the training set
● Leaking of information from the future into the past
● Leaking information from data samples outside of scope of the algorithm’s intended use
Data Leakage
ID Entity Time Label Usage 1 Usage 2 Region Size Spending Activity 1 Activity 2 …
1 Company 1 01/01 1 10 2 SF 118 3,810 60 4 …
2 Company 1 02/01 1 5 0 SF 117 3,810 70 5 …
3 Company 1 03/01 1 0 3 SF 119 3,810 120 30 …
4 Company 2 01/01 0 100 30 NYC 50 2,000 23 0 ...
5 Company 2 04/01 0 90 43 NYC 50 2,000 23 0 ...
… … … … … … … … … … … …
1 3
2
4
5
Training
Testing
randomSplit()
price1 price2 price3
Yesterday Today Tomorrow
featurei= (price1+ price2+ price3) / 3Target = future price ?
Feature = “Rep id” Target: customer churnA specific sales representative was assigned to take over an churned account
Kaggle 2011 IJCNN Social Network Challenge: the winners de-anonymized 80% nodes and 60% edges to disclose real identities in the social network

@2016 LinkedIn Corporation. All Rights Reserved.
● Identify data leakage○ Exploratory data analysis (EDA)
■ An approach to analyzing data sets to summarize their main characteristics, often with visual methods
○ Model performance is too good to be true?
○ Early in-the-field testing
47
Data Leakage

@2016 LinkedIn Corporation. All Rights Reserved.
Class Imbalance
▪ A dataset is said to be imbalanced when the binomial or multinomial response variable has one or more classes that are underrepresented in the training data, with respect to the other classes
– “I have a binary classification problem and the label is distributed in 1:100 ratio in my training set. My results are overfit to majority class.”
▪ The class imbalance problem is pervasive and ubiquitous– e.g job recommendation, ads CTR, fraud detection
▪ Misclassify the minority class usually with high cost– rejecting a valid credit card transaction VS. approving a large fraudulent transaction
48
?

@2016 LinkedIn Corporation. All Rights Reserved. 49
Solutions▪ Can You Collect More Data?▪ Consider different evaluation metrics
– “Accuracy” might be misleading for imbalanced training data– Confusion Matrix, Precision, Recall, F1, Kappa, ROC
▪ Re-sampling data set– Up-sampling (Over-sampling)– Down-sampling– Synthetic Minority Oversampling Technique (SMOTE)
▪ Use different learning algorithms– Decision tree, random forest– AUC-Maximizing Algorithms
▪ Cost-Sensitive Training
Class Imbalance

@2016 LinkedIn Corporation. All Rights Reserved.
Categorical Data
▪ Categorical feature– A variable that can take on one of a limited, and usually fixed, number of possible values,
thus assigning each individual to a particular group or "category” - The Practice of Statistics , 2003
▪ |SIGKDD Conference| = ?▪ |KDD workshop| = ?▪ |KDD host country| = ?
▪ High cardinality categorical features are common in the data– E.g. Industry, country, city
▪ Too many levels– Not all the levels (distinct values of the categorical feature) got enough support. Some are
less useful– Many Machine Learning tools can only handle certain amount of levels
▪ E.g. Random Forest implementation in R has a hard limit of 32-levels for a categorical feature
50

@2016 LinkedIn Corporation. All Rights Reserved. 51
▪ Solutions– Reduce cardinality by grouping categories into higher-level ones
– Transform a categorical feature into multiple binary ones
▪ Introduce an additional ‘others’ feature to represent all the new categories in the testing set
Cloud and Distributed Computing Dental
Hadoop Spark Hive Yarn ... others
1 1 0 0 ... 0
Categorical Data

@2016 LinkedIn Corporation. All Rights Reserved.
▪ Missing data scenarios– Missing Completely at Random (MCAR)
▪ Is not related to other variables AND is not related to value of missing variable▪ E.g. Computer crash
– Missing at Random (MAR)▪ Is related to other, known variables. BUT, is not related to value of missing
variable(s) once we take the above relation(s) into account▪ E.g. male participants are more likely to refuse to fill out the depression survey, but it does not
depend on the level of their depress
– Missing Not at Random (MNAR)▪ Is related to what the value of the missing data would have been even if we take
into consideration other variables▪ E.g. People with low high school GPA decline to report it
52
Missing Data

@2016 LinkedIn Corporation. All Rights Reserved.
Missing Data
▪ Solutions– Remove observations with missing values
▪ When values are missing at random and you have enough data
– Missing data imputation▪ Common imputation strategies
– Categorical: Choose the category with the most support– Numerical: Median, mean, or simply set to 0
▪ Predict missing data using a model
– Introduce a corresponding dummy feature to indicate its availability
– Use a model that are robust to missing data, e.g. tree-based model.
53

@2016 LinkedIn Corporation. All Rights Reserved.
Outliers
▪ Outliers can be introduced in response or predictors– Rare event (valid)– Erroneous metrics (invalid)
▪ Impact of the outliers– Outlier values can have a disproportionate weight on the model. – MSE will focus on handling outlier observations more to reduce square error– Boosting will spend considerable modeling effort fitting these observations
▪ Solutions– Whether the outlier value is valid or invalid? – Remove observation with outlier feature values– Apply transformation to reduce impact:
▪ log ▪ binning (e.g. based on distribution)▪ spline transforms▪ Impose a constraint on data range (cap values)
– Choose a more robust loss function (e.g. trees)54

@2016 LinkedIn Corporation. All Rights Reserved.
Model Interpretation
▪ Why? – Debug, diagnose, generate new hypotheses– Inevitable questions about why a prediction was made from your
business counterparts– for presenting reasons to users - may be output of a ML model itself
55
... With premium account, you get more search results and access to …
... Do you know 5 of your connections have started to use premium account …

@2016 LinkedIn Corporation. All Rights Reserved.
Model Interpretation
Univariate Feature InterpretationPros:▪ Get a sense of importance for each
feature▪ Many available algorithms: Random
Forest, Regularized linear models, various feature selection algorithms
Cons:▪ Bias, e.g. impurity evaluation of RF
is biased towards preferring variables with more categories
▪ Difficulty of interpreting the ranking of correlated variables
▪ Single feature may contain lots of noise.
56
Group-wise Feature InterpretationPros:▪ Easy to capture the overall look by
grouping massive features into a few buckets
▪ Strong semantic meanings▪ Inter-group correlation are less▪ Impact from noise is reduced by
analysing multiple features at the same time
Cons:▪ Domain knowledge required

@2016 LinkedIn Corporation. All Rights Reserved.
Model Interpretation
57
SOCIAL E-LEARNING
MARKETING
AFFILIATION
ENGAGEMENT SPENDING
GROWTH
PRODUCT USAGE
Provide high-level overview and insights
Deep dive to finer-level predictors

@2016 LinkedIn Corporation. All Rights Reserved. 58
Outline
Introduction ❏ Why predictive modeling is important? ❏ Understanding of audience background and learning objectives
Predictive Modeling Overview
❏ End-to-end walkthrough of a production modeling solution❏ Common pitfalls and challenges❏ Case Study - LinkedIn Feed Ranking
❏ Considerations when choosing a framework❏ Overview of tools and platforms across industry❏ Modoop - example of a scaled framework
Choosing a Framework

@2016 LinkedIn Corporation. All Rights Reserved. 59
Sponsored Ads
Updates from followed companies
Updates from connections
Case Study - LinkedIn Feed Ranking

@2016 LinkedIn Corporation. All Rights Reserved. 60
Case Study - LinkedIn Feed Ranking
Feed Events
➢ Sponsored Ads➢ Updates from connections➢ Updates from followed companies➢ Updates from joined groups➢ Articles shared / commented / liked by
connections ➢ Articles mentioned connections➢ Articles posted by influencers or
connections➢ News from followed channels➢ Job recommendations➢ People You May Know➢ ...

@2016 LinkedIn Corporation. All Rights Reserved.
Actor-Verb-Object Formalism and Activity Types
61

@2016 LinkedIn Corporation. All Rights Reserved. 62
Case Study - LinkedIn Feed Ranking
Actor
Object
Verb

@2016 LinkedIn Corporation. All Rights Reserved.
Case Study - LinkedIn Feed Ranking
63
▪ Context
▪ Questions
▪ Group Discussions
▪ Discuss LinkedIn Solutions
- 400+ million members- may have thousands of items to rank- focus on the modeling problem - assume that items are provided- skewed activity - some members very active, some not very active- ranking problem, online scoring
- How to formulate the feed ranking problem? - What are the suitable algorithms? - What kind of features are preferred here?- How to perform offline validation?

@2016 LinkedIn Corporation. All Rights Reserved.
▪ Binary classification problem: let it represent the interaction between viewer i and update t:
it =
▪ Assume using logistic regression model, let Xit be a vector of features characterizing viewers, feed update and the context, and be a vector of parameters:
log = ′Xit
which is equivalent to:
Problem Formulation
64
1, if viewer interacts with feed update
-1, otherwise
P( it = 1 | viewer, update)
1 - P( it = 1 | viewer, update)
P( it = 1 | viewer, update) = 1/ (1 + exp(- ′Xit))

@2016 LinkedIn Corporation. All Rights Reserved.
Model Training
▪ The parameter vector is estimated by maximizing the likelihood of the training data as a function of
L( ) = (1 + exp(- ′Xit))-1
▪ Add a regularization term (Euclidean norm on the parameter vector) to the log-likelihood function to mitigate overfitting
( ) = - ∑ log (1 + exp(- it ′Xit)) - || ||2
▪ Compute the gradient vector of the regularized log-likelihood function by using one of the standard computational tools for gradient-based maximization, for example, stochastic gradient descent.
65
it
it

@2016 LinkedIn Corporation. All Rights Reserved.
Potential Features ▪ Features in the feature vector Xit are classified into following categories:
– Viewer-only features Xi
▪ member industry, geo location, skills– Activity-only features Xt
▪ time of activity, verb type (like, comment, share, recommendation, ...)– Object-only features Xo
▪ position– Viewer-actor features Xij:
▪ number messages sent to actor from viewer, number shared connections, ...– Viewer-activity type features Xik
▪ viewer CTR for activity type– Viewer-actor-activity type features Xijk
▪ viewer CTR for actor - activity type combination– Viewer-object features Xio
▪ object same language as viewer profile, number previous interactions
▪ The inner product ′Xit can be decomposed to′Xit = i′Xi + t′Xt + ij′Xij + ik′Xik + ijk′Xijk + io′Xio
66

@2016 LinkedIn Corporation. All Rights Reserved.
Feature Design and Engineering
67
▪ Apply feature transformation to bypass the limitation from the linear models.
– log function on raw counts,– indicator function on raw counts,– bucketize a numerical feature as a set of categorical features concatenated as a binary
sub-vector

@2016 LinkedIn Corporation. All Rights Reserved.
Three-step Offline Evaluation
68
▪ AUC for model selection▪ Comparing the ratio of observed to expected (predictions) probabilities
for different activity types (denoted as the O/E ratio) and whether or not the data likelihood converged to the global maximum.
– The CTR model overestimates different pCTR probabilities if O/E<1 – The CTR model underestimates different pCTR probabilities if O/E>1
▪ The “Replay” tool – Takes a logistic regression model and runs it on historic (random bucket) data and
records the total interaction on “matched impressions”– Reorders them using the new model that we evaluate;– Count only clicks on matched impressions that appear in the first position.

@2016 LinkedIn Corporation. All Rights Reserved. 69
Outline
Introduction ❏ Why predictive modeling is important? ❏ Understanding of audience background and learning objectives
Predictive Modeling Overview
❏ End-to-end walkthrough of a production modeling solution❏ Common pitfalls and challenges❏ Case Study - LinkedIn Feed Ranking
❏ Considerations when choosing a framework❏ Overview of tools and platforms across industry❏ Modoop - example of a scaled framework
Choosing a Framework

@2016 LinkedIn Corporation. All Rights Reserved.
Scale of the problem
70
▪ Can it fit on one machine?– source: https://github.com/szilard/benchm-ml– Vowpal Wabbit can train linear model on a
▪ 1B example x 9 dense feature dataset in ~ 23 minutes on AWS r3.8xlarge instance
▪ 10M example dataset in 15 seconds – xgboost can train gradient boosted trees on a
▪ 10M example x 9 dense feature dataset in as little as 15 minutes using 6GB RAM
▪ Easier to explore a wide range of algorithms▪ Single machine algorithms often the most
robust, come with good tools
64"Green Globe In Child’s Hands" (CC BY-SA 2.0) by kenteegardin

@2016 LinkedIn Corporation. All Rights Reserved. 71
Integration with your company’s tech stack
▪ Data formats or sources– Avro, Parquet, Hive, SQL, Kafka ….– Build your own data converters
▪ Can be surprisingly difficult!▪ Character encoding▪ Sparse, text named features →
indexed features▪ Model deployment
– Model formats: PMML – Embeddable scorers: what
programming language?
?

@2016 LinkedIn Corporation. All Rights Reserved.
Modeling Techniques
▪ Linear regression models (linear, logistic, poisson) – Scale to the largest datasets – Can have useful model diagnostics– Are fast at scoring– Can be easily retrained or updated online– Require much more feature engineering
▪ Gradient boosted regression trees and random forests– Provide great model accuracy with minimal feature engineering– Are slower to train– Are slower to score
▪ Others?– Factorization machines– Deep learning
72
Σ

@2016 LinkedIn Corporation. All Rights Reserved.
▪ Sometimes efficient scoring is critical– ranking problems, recommender systems, edge prediction
▪ Pre-compute in batch– build your own candidate selection– feed into scoring utility– rank and store– scaling for very large numbers of candidate
pairs can be challenging– relatively expensive if not queried
▪ Compute on-demand– candidates provided by an underlying index
(e.g. search engine), database, or store– score online– rank and return– latency is critical– requires robust online infrastructure
Scoring Support
73
Σ
Σ

@2016 LinkedIn Corporation. All Rights Reserved.
▪ build– in-house building often only makes sense for large teams – allows specialization, innovation
▪ assemble– leverage open-source software – make it easier to use within your company’s tech stack– fill in gaps that open-source software doesn’t address: feature integration, model
updates, a/b testing, …▪ buy
– can get support contracts– makes sense if little to no engineering support within company or business unit– good for small teams– can be limiting in terms of techniques
74
"Brick laying" (CC BY 2.0) by hnnbz
"dollar-sign" (CC BY-SA 2.0) by Oldmaison
"LEGO house" (CC BY 2.0) by Atsushi Tadokoro

@2016 LinkedIn Corporation. All Rights Reserved.
Maturity of platform
▪ Leverage your network– Who is using it? in production?– Is it working for them?– What are its limits? scalability, stability, ease of use, ….
▪ Open source– How active is the development of the project?
▪ sometimes means lots of changes or instability ▪ usually a good sign
– From what companies? ▪ Diverse companies suggests broad adoption▪ Big companies suggests scale, maturity of engineering processes▪ Academic only may indicate weak points in scale or robustness (especially
with respect to scoring solutions)▪ Purchasing solutions or support
– Consider size of the company, amount of funding raised, your tolerance to risk– Pedigree of the ML experts and engineers at the company
75"Jersey City waterfront at night" (CC BY-SA 2.0) by mattk1979

@2016 LinkedIn Corporation. All Rights Reserved.
Anticipate evolving needs
▪ May start with buying a solution▪ But later need to integrate more tightly and move
toward assembling▪ Or later build major components yourself▪ Consider whether the solutions you buy are built on
open source and can help you transition to assembling solutions
76
"Butterfly" (CC BY-SA 2.0) by Salvatore Gerace

@2016 LinkedIn Corporation. All Rights Reserved. 77
Outline
Introduction ❏ Why predictive modeling is important? ❏ Understanding of audience background and learning objectives
Predictive Modeling Overview
❏ End-to-end walkthrough of a production modeling solution❏ Common pitfalls and challenges❏ Case Study - LinkedIn Feed Ranking
❏ Considerations when choosing a framework❏ Overview of tools and platforms across industry❏ Modoop - example of a scaled framework
Choosing a Framework

@2016 LinkedIn Corporation. All Rights Reserved.
Spark ML, MLlib
▪ ML– Usability through DataFrames and Pipelines– More polished implementations, often more scalable– Regression, Trees, k-Means, LDA
▪ MLlib– Old RDD API– More extensive set of methods– Matrix Factorization, Power Iteration Clustering, SVD, PCA, Frequent Pattern Mining,
… ▪ Extensive support for reading data sources via Spark: Amazon S3, Amazon Redshift,
mongoDB, mySQL, Shark, Hive, HDFS, byo, ...▪ Batch and streaming scoring support▪ PMML model export for some techniques
78

@2016 LinkedIn Corporation. All Rights Reserved.
Vowpal Wabbit
79
▪ Very fast SGD – hashing trick – scales to very large number of features and datasets
on a single machine– models less interpretable (can’t know the weight on any single feature)
▪ Allreduce server for distributed learning▪ Quadratic, cubic feature interaction▪ Most users run from command line▪ Also C++ and C# APIs▪ Linear, logistic, svm, quantile regression, online (contextual bandit),
LDA, matrix factorization▪ Batch, API, service scoring

@2016 LinkedIn Corporation. All Rights Reserved.
DMLC
▪ (mostly) research collaboration▪ Mixed language support across methods▪ XGBoost: Scalable GBDT▪ MXNet: flexible deep learning▪ DiFacto: factorization machines, logistic regression using
parameter server
80

@2016 LinkedIn Corporation. All Rights Reserved.
scikit-learn
▪ Popular python package for machine learning▪ SVM, regression, trees (RF, GBDT),
k-means, PCA, matrix factorization, …▪ Load easily from file, HDFS, Amazon S3▪ Batch, API scoring
81

@2016 LinkedIn Corporation. All Rights Reserved.
R
▪ Application for data mining, statistics, ML▪ Generally not considered “production” grade▪ Extensive packages▪ Among most popular: SVM, regression trees (GBRT, RF, ...),
PCA, Quadratic Programming, GLM, GBM, association rule mining, bagging, ...
▪ Packages for loading data from file, SQL, JDBC, HDFS, hive, Redshift, Amazon S3
▪ PMML model export for some packages
82

@2016 LinkedIn Corporation. All Rights Reserved.
TensorFlow
▪ Primarily used for Deep Learning▪ Python (first class), C++ (minimal) APIs▪ Designed from ground up for distributed ML▪ GPU support▪ Flexible modeling framework beyond deep learning▪ Auto-differentiation makes it easier to add new techniques▪ Designed for production learning and scoring▪ Batch scoring, model export
83

@2016 LinkedIn Corporation. All Rights Reserved.
AWS + Amazon Machine Learning
84
console, API
S3, Redshift, RDS (SQL)
limited transformations
logistic regression, multinomial regression,linear regression

@2016 LinkedIn Corporation. All Rights Reserved.
AWS + Spark
85
linear, logistic, multiclass, and survivalregression, trees (RF, GBDT), MF, survival regression, k-means, LDA
Scala, Java, R, python
MySQL, Shark, Hive, HDFS, ODBC, …
pipelines
console, API

@2016 LinkedIn Corporation. All Rights Reserved.
AWS + Spark + databricks
86
linear, logistic, multiclass, and survivalregression, trees (RF, GBDT), MF, survival regression, k-means, LDA
Scala, Java, R, python
MySQL, Shark, Hive, HDFS, ODBC, …
pipelines
notebooks,scheduled jobs,model deployment toscoring server
S3, Redshift, RDS (SQL)

@2016 LinkedIn Corporation. All Rights Reserved.
AWS + H2O
87
extensive regression & classification, GBDT, ensembles, deep learning
notebooks, model export (jar, JSON)
HDFS, file, URL download, Amazon S3

@2016 LinkedIn Corporation. All Rights Reserved.
AWS + H2O + Spark
88
extensive regression & classification, GBDT, ensembles, deep learning
notebooks, model export (jar, JSON)

@2016 LinkedIn Corporation. All Rights Reserved.
AWS + Turi
89
extensive regression & classification, recommenders (factorization machines, MF, …), k-means, LDA, deep learning
notebooks, C++, pythonHDFS, Amazon S3, file, ODBC, Avro, ...
API, batch scoring

@2016 LinkedIn Corporation. All Rights Reserved.
AWS + Turi + Spark
90
extensive regression & classification, recommenders (factorization machines, MF, …), k-means, LDA, deep learning
notebooks, C++, pythonHDFS, Amazon S3, file, ODBC, Avro, ...
Spark RDD <-> Dato SFrame data conversion

@2016 LinkedIn Corporation. All Rights Reserved.
Azure Cloud:dbs, batch computation,Power BI,stream analytics,...
Microsoft Azure Machine Learning
91
extensive regression & classification, k-means, Vowpal Wabbit
API, Notebooks, GUI Workflows, R, python
API, batch scoring
Hive, Azure, bulk upload, URL download,. ..

@2016 LinkedIn Corporation. All Rights Reserved.
Azure Cloud:dbs, batch computation,Power BI,stream analytics,...
Azure Machine Learning + Hadoop/Spark
92
extensive regression & classification, k-means, Vowpal Wabbit
API, Notebooks, GUI Workflows, R, python
HDInsight:run Hadoop and Spark on Azure
API, batch scoring
Hive, Azure, bulk upload, URL download,. ..

@2016 LinkedIn Corporation. All Rights Reserved.
Google Machine Learning (limited preview)
93
compute, app, networking,storage, big data, security, ...
TensorFlow: deep learning,flexible optimization framework
notebooks
Cloud Storage, BigQuery
model export, API, batch

@2016 LinkedIn Corporation. All Rights Reserved. 94
Outline
Introduction ❏ Why predictive modeling is important? ❏ Understanding of audience background and learning objectives
Predictive Modeling Overview
❏ End-to-end walkthrough of a production modeling solution❏ Common pitfalls and challenges❏ Case Study - LinkedIn Feed Ranking
❏ Considerations when choosing a framework❏ Overview of tools and platforms across industry❏ Modoop - example of a scaled framework
Choosing a Framework

@2016 LinkedIn Corporation. All Rights Reserved.
Intelligence Engine
HDFS Feature Mart
Application 1 Application 2 Application N… …
Workflows Workflows Workflows
Feature Engineering Libraries
Machine Learning Libraries
Workflow Scheduler & Manager
Ground Truth
DriversMetadata
Store
Web UI
95
Modoop - example of building/assembling a platform
Scores Models
MapReduce / Yarn
Pig, Hive, Python, Scala, Shell script, ...

@2016 LinkedIn Corporation. All Rights Reserved.
Intelligence Engine
HDFS Feature Mart
Application 1 Application 2 Application N… …
Workflows Workflows Workflows
Feature Engineering Libraries
Machine Learning Libraries
Workflow Scheduler & Manager
Ground Truth
DriversMetadata
Store
Web UI
96Scores Models
MapReduce / Yarn
Pig, Hive, Python, Scala, Shell script, ...
Leverage hadoop/Spark, Azkaban open source

@2016 LinkedIn Corporation. All Rights Reserved.
Intelligence Engine
HDFS Feature Mart
Application 1 Application 2 Application N… …
Workflows Workflows Workflows
Feature Engineering Libraries
Machine Learning Libraries
Workflow Scheduler & Manager
Ground Truth
DriversMetadata
Store
Web UI
97Scores Models
MapReduce / Yarn
Pig, Hive, Python, Scala, Shell script, ...
Feature mart and metadata store enable feature integration and feature engineering

@2016 LinkedIn Corporation. All Rights Reserved.
Intelligence Engine
HDFS Feature Mart
Application 1 Application 2 Application N… …
Workflows Workflows Workflows
Feature Engineering Libraries
Machine Learning Libraries
Workflow Scheduler & Manager
Ground Truth
DriversMetadata
Store
Web UI
98Scores Models
MapReduce / Yarn
Pig, Hive, Python, Scala, Shell script, ...
Leverage open source, augment with evaluation and model selection
Photon MLMetronome: internalML workflow tools

@2016 LinkedIn Corporation. All Rights Reserved.
Intelligence Engine
HDFS Feature Mart
Application 1 Application 2 Application N… …
Workflows Workflows Workflows
Feature Engineering Libraries
Machine Learning Libraries
Workflow Scheduler & Manager
Ground Truth
DriversMetadata
Store
Web UI
99Scores Models
MapReduce / Yarn
Pig, Hive, Python, Scala, Shell script, ...
Create end-to-end workflow based on user-provided label and configurations

@2016 LinkedIn Corporation. All Rights Reserved.
Intelligence Engine
HDFS Feature Mart
Application 1 Application 2 Application N… …
Workflows Workflows Workflows
Feature Engineering Libraries
Machine Learning Libraries
Workflow Scheduler & Manager
Ground Truth
DriversMetadata
Store
Web UI
100Scores Models
MapReduce / Yarn
Pig, Hive, Python, Scala, Shell script, ...
Custom user interface provides model understanding tools

@2016 LinkedIn Corporation. All Rights Reserved.
Summary
▪ Mining data to extract useful and enduring patterns remains a skill arguably more art than science
▪ Choose appropriate evaluation metrics for different audiences▪ A black box model is not enough▪ Consider scale, features, integration costs, maturity, and
flexibility of platforms
101

@2016 LinkedIn Corporation. All Rights Reserved.
Appendix
102

@2016 LinkedIn Corporation. All Rights Reserved. 103
Spark ML Vowpal Wabbit dmlc scikit-learn R TensorFlow
Interfaces python, Scala, Java, R command line, C#, C++ command line, xgboost: C++, Python, R, Java, Scala, Juliamxnet: Python, R, Julia, Scala, Go, Javascriptdifacto: C++
notebook, command line, python
gui, command line python
Data Sources Amazon S3, Amazon Redshift, mongoDB, mySQL, Shark, Hive, HDFS, byo, ...
file, API file, HDFS, Amazon S3 file, HDFS, Amazon S3, file, SQL, JDBC, HDFS, hive, Redshift, Amazon S3
file, API
Modeling Techniques
MLlib: linear, logistic, tree (RF, GBDT), MF, survival regression, multiclass, k-means, LDA
linear, logistic, svm, quantile regression, online (contextual bandit), LDA, MF
xgboost (gbrt), mxnet (deep learning), difacto (factorization machines, logistic regression)
SVM, regression, trees (RF, GBDT), k-means, PCA, matrix factorization, ...
SVM, regression trees (GBRT, RF, ..), PCA, QP, GLM, GBM, association rule mining, bagging, ...
deep learning, linear/logistic regression, flexible learning framework
Platforms Spark Single Machine, Custom AllReduce
parameter server, AllReduce (Rabit), Spark, YARN
- - Google Cloud Compute Engine
Scoring Batch, Streaming Batch, API Batch Batch, API PMML export for some packages
Batch, API
Open Source Software

@2016 LinkedIn Corporation. All Rights Reserved. 104
Microsoft Azure Machine Learning
Google Cloud Machine Learning Platform (alpha)
Amazon Machine Learning
Databricks H20 Turi
Interfaces API, Notebooks, GUI Workflows, R, python
API, Notebooks, Programmatic Workflows, Java, python (alpha)
API, console API, Notebooks, Programmatic Workflows, Java, Scala, python, R
API, Notebook, R, Java, Scala, python
Notebooks, C++, python
Cloud Microsoft Azure Google Cloud Compute Engine
Amazon AWS Amazon AWS Amazon AWS, Microsoft Azure*, Google Cloud*, your data center
Amazon AWS, Microsoft Azure*, Google Cloud*, your data center
Data Sources Hive, Azure blob storage, Azure table, Azure SQL OData feed, bulk upload, URL download
text (including JSON), Google Cloud Bigtable, Google Cloud Datastore, byo
Amazon S3, Amazon Redshift, Amazon RDS (SQL)
Amazon S3, Amazon Redshift, mongoDB, mySQL, Shark, Hive, HDFS, byo, ...
HDFS, file, URL download, Amazon S3
HDFS, Amazon S3, file, ODBC, Avro, SparkRDD, ...
Modeling Techniques
extensive regression & classification, k-means, Vowpal Wabbit
TensorFlow: flexible deep learning, regression, ...
binary, multiclass classification, regression
MLlib: linear, logistic, tree (RF, GBDT), MF, survival regression, multiclass, k-means, LDA
extensive regression & classification, GBDT, ensembles, deep learning
extensive regression & classification, recommenders (factorization machines, MF, …), k-means, LDA, deep learning
Limitations 10GB training datasetsfull info
ML in limited previewPrediciton API: 2.5GB training datasets
100GB training datasets1k input featuresfull info
Extensibility byo R, python, package imports TensorFlow SDK, Google Cloud Platform
byo AWS services pipelines, byo Spark byo on your platform python, C++, byo platform
Pretrained Models vision, speech, sentiment, ... speech, vision, translation, ...
Scoring API, batch API, batch, planned export API, batch API, batch, streaming, PMML export
API, JSON, POJO export API, Batch
Machine Learning Platforms





























![[Tutorial] building machine learning models for predictive maintenance applications - Yan Zhang](https://img.dokumen.tips/doc/110x75/586fba3f1a28abe57d8b86b5/tutorial-building-machine-learning-models-for-predictive-maintenance-applications.jpg)