Embed Size (px)
Citation preview

AN EFFICIENT APPROXIMATE PROTOCOL
FOR
PRIVACY PRESERVING ASSOCIATION RULE MINING
MURAT KANTARCIOGLU, ROBERT NIX AND JAIDEEP VAIDYA (2009)
- BY
PUSHPALANKA JAYAWARDHANA
158217G

CONTENTS
• Introduction
• Two Types of Techniques
• Problem
• Proposing Solution
• Related Work
• Bloom Filters
• Redefine the Problem
• Approximate Threshold Dot Product Algorithm
• Security
• Computational and Communicational Cost
• Experimental Results
• Accuracy
• Efficiency
• Conclusion

INTRODUCTION
• Association Rule Mining
• An important data mining model studied extensively by the database and data mining community
• A method for discovering interesting relations between variables in large databases
• "Beer and diaper" story
• Buying Diapers==> Buying Beer
• Privacy Preserving in Association Rule Mining
• More parties are interested in learning the global association rules
• None is willing to reveal the data at individual sites

TWO TYPES OF TECHNIQUES
• Perturbation Based methods
• Locally perturb data before delivering to the data miner
• Special techniques are used to reconstruct the original distribution
• Mining algorithm needs to be modified to consider that data is perturbed
• Have security concerns
• Secure Multiparty Computation Techniques
• Each party builds decision tree
• Only the final decision tree is shared, not any other data
• Use cryptographic techniques for security
• Computationally intensive

PROBLEM?
How can we mine data in an
efficient and provably secureway?

PROPOSING SOLUTION
An approximate protocol for computing the dot product of two
vectors owned by two different parties

RELATED WORK
• A similar approximation protocol is already proposed with sampling techniques
• A solution is present with bloom filters
• Rule mining is done centrally
• Goethals' s encryption mechanism
• simple and secured
• Calculate exact dot product
• Run time O(n)

BLOOM FILTERS
• A probabilistic data structure• Used to test on membership of
a set• False positives are possible• No false negatives• Can be used to approximate
the intersection size between two sets

REDEFINE PROBLEM
• Compute the scalar product
• Checks if the scalar product of two distributed vectors is greater than some threshold
X1 . X2 = |S1 ∩ S2| ≥ t

APPROXIMATE THRESHOLD DOT PRODUCT ALGORITHM
• Each party creates own bloom filter, using common parameters.
• size of the bloom filter - m
• hash functions - h1, h2, ..................., hk
• Participate in the secure dot product algorithm using private bloom filters and get the random shares of the dot product result
• each party participates in secure multiplication protocol using private dot product results to get the random share of the multiplication result
• Finally, each party participate in a secure comparison protocol to approximate the final result.

SECURITY
• Preserved under following assumptions
• Parties are semi-honest
• Dot product, multiplication and comparison protocols are secure

COMPUTATIONAL AND COMMUNICATIONAL COST
• O(nk) for hashing for bloom filters, rest is O(1)
• Hashing cost is negligible compared to public key operations
• m<<n --> faster
• Flexible to use if a better secure dot product computing protocol if found in the future
• communication cost propotional to m --> low cost

EXPERIMENTAL RESULTS
• Consider effect of,
• vector length (l),
• vector density (d)
• the actual intersection of the two vectors (i)
• the bloom filter parameters
• m (length of filter)
• k(number of hash functions)
on the performance of the algorithm.
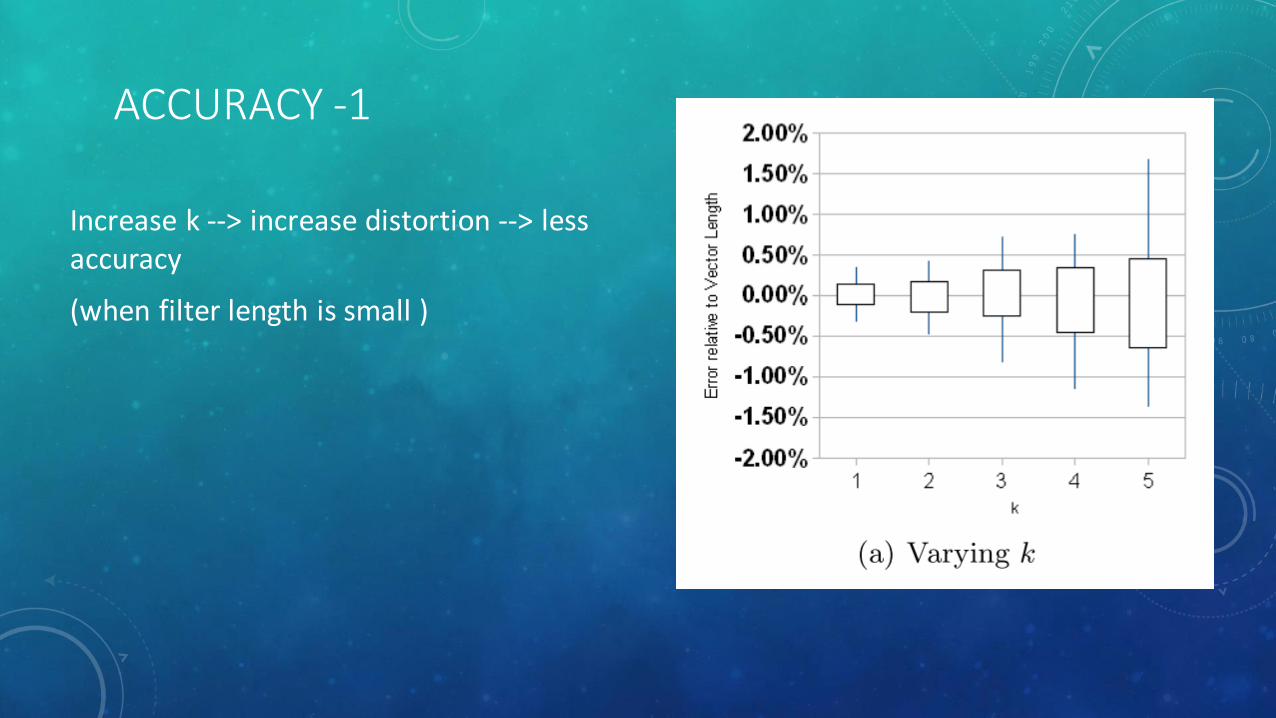
ACCURACY -1
Increase k --> increase distortion --> less accuracy
(when filter length is small )

ACCURACY -2
Increase filter length --> high accuracy
(Less distortion and collision )

ACCURACY -3
Even for a large vector, same accuracy can be achieved with sub-linear increase in filter length

ACCURACY -4
• At 0 density no error
• Drastically increase error at high densities
• Good for sparse vectors
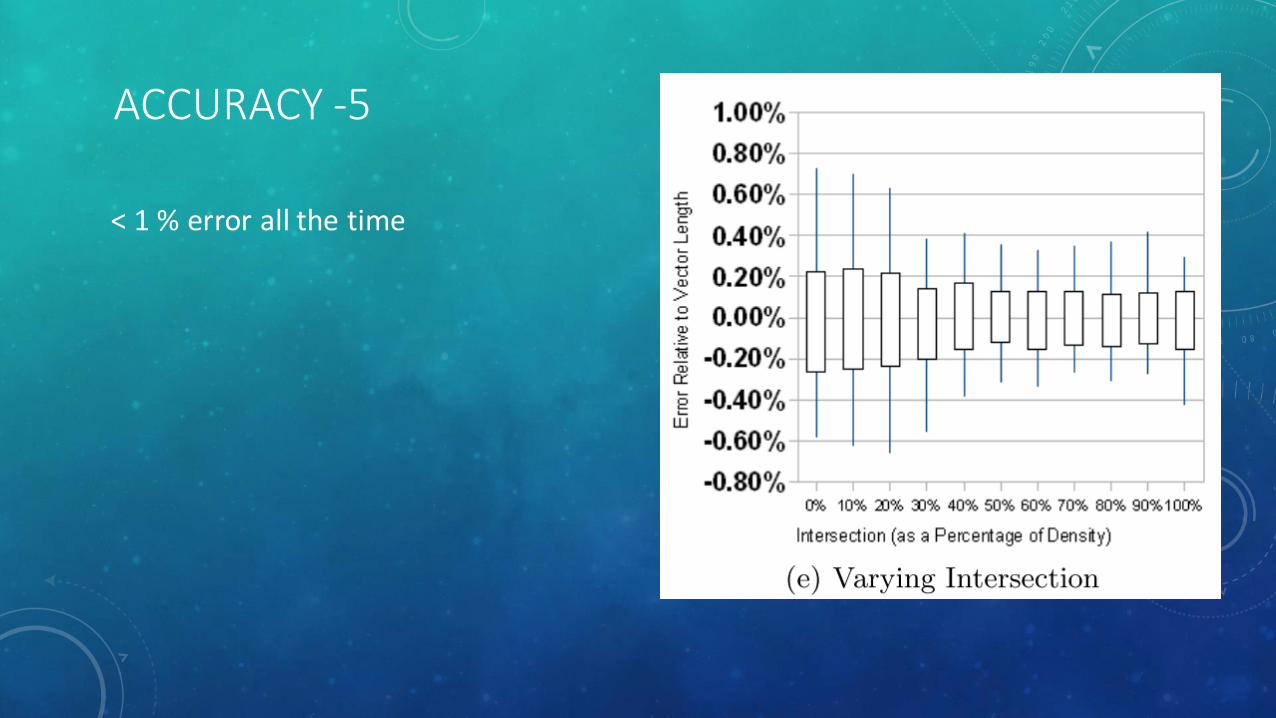
ACCURACY -5
< 1 % error all the time
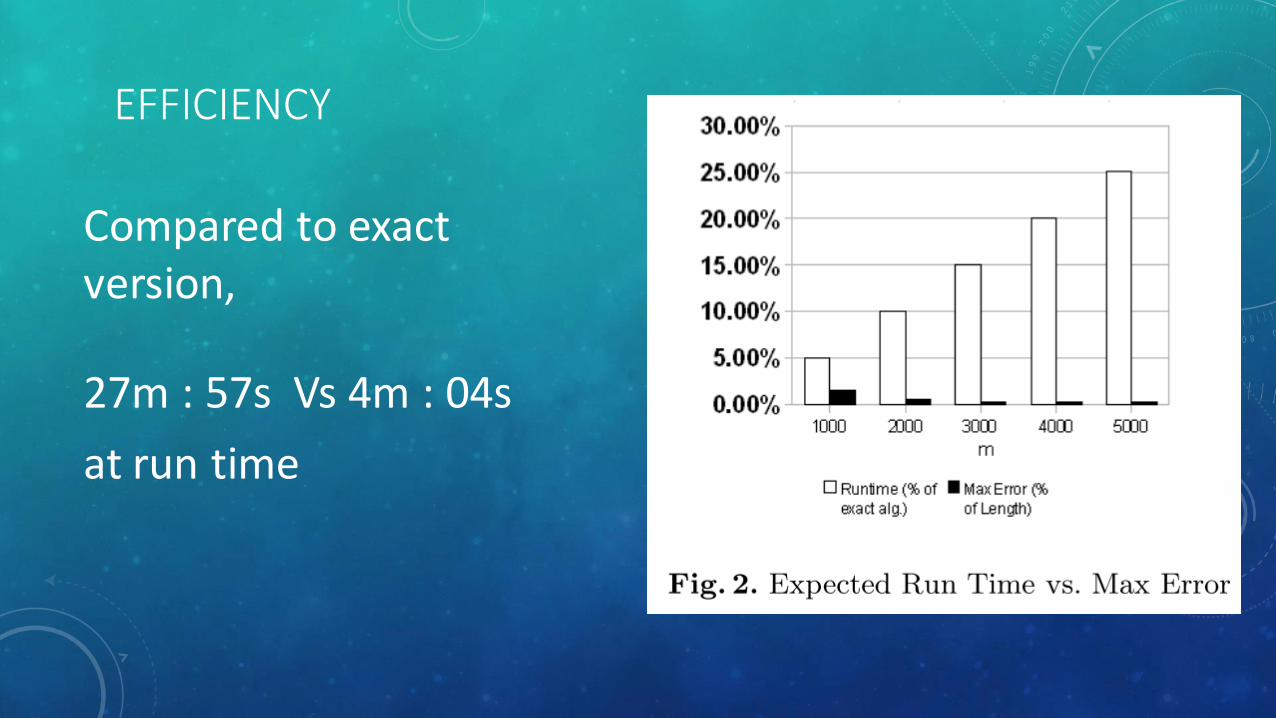
EFFICIENCY
Compared to exact version,
27m : 57s Vs 4m : 04s
at run time

CONCLUSIONS
• Propose an efficient and secure protocol to approximately compute scalar product in a privacy preserving manner.
• Efficiency is gained by allowing an approximation than an exact answer
• Extending to work with more than 2 parties is a future work

Q & A


![Efficient Privacy-Preserving Face Recognition · privacy-preserving face recognition systems [14]. 3 In this paper we concentrate on efficient privacy-preserving face recognition](https://img.dokumen.tips/doc/110x75/5f5537f760f4da560b622b51/eifcient-privacy-preserving-face-recognition-privacy-preserving-face-recognition.jpg)


![Privacy-Preserving Data Mining - users.cis.fiu.eduusers.cis.fiu.edu/~lpeng/Privacy/Privacy-preserving data mining.pdf · [Cra99b] [AC99] [LM99] [LEW99]). Paper Organization We discuss](https://img.dokumen.tips/doc/110x75/5b2d2dbd7f8b9abb6e8bb89e/privacy-preserving-data-mining-userscisfiu-lpengprivacyprivacy-preserving.jpg)























