Embed Size (px)
DESCRIPTION
Citation preview

WHITE PAPER
Best Practices in Data ManagementMeeting the Goal of an Enterprise Risk Management Platform

SAS White Paper
Table of Contents
Executive Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
A Unified Data Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
The Metadata Framework . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
Auditing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
A Common Security Framework . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
A Common Set of Native Access Engines . . . . . . . . . . . . . . . . . . . . . . 8
Data Quality . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
Planning for a Data Management System . . . . . . . . . . . . . . . . . . . . . . 9
Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
The content provider for this paper was Antonis Miniotis, Risk Product Manager,
SAS Global Risk Practice.
1
Best Practices in Data Management
Executive SummaryEver since enterprise risk management (ERM) systems first came to the forefront in the mid-1990s, financial institutions worldwide have been grappling with ERM principles and their viable implementation . In general, an ERM system should capture and analyze information across all lines of business on multiple topics (e .g ., exposures, limits on product lines and business units, etc .), provide analytic capabilities (e .g ., concentration analysis, stress testing, VaR calculations, etc .) and produce reports for a variety of internal and external constituents . It is now increasingly clear that data should be treated as an asset; not doing so can negatively affect a firm’s bottom line . For more information on this topic, see the SAS white paper Data as a Board-Level Issue: Effective Risk Management and Its Dependence on Accurate, High-Quality Data .
With constant performance pressures and changing regulatory demands, banks are being forced to collect more data and dig deeper into their databases in order to refine their analyses . As a result, banks are taking a closer look at their data management processes across the enterprise, from the back office to the front end .
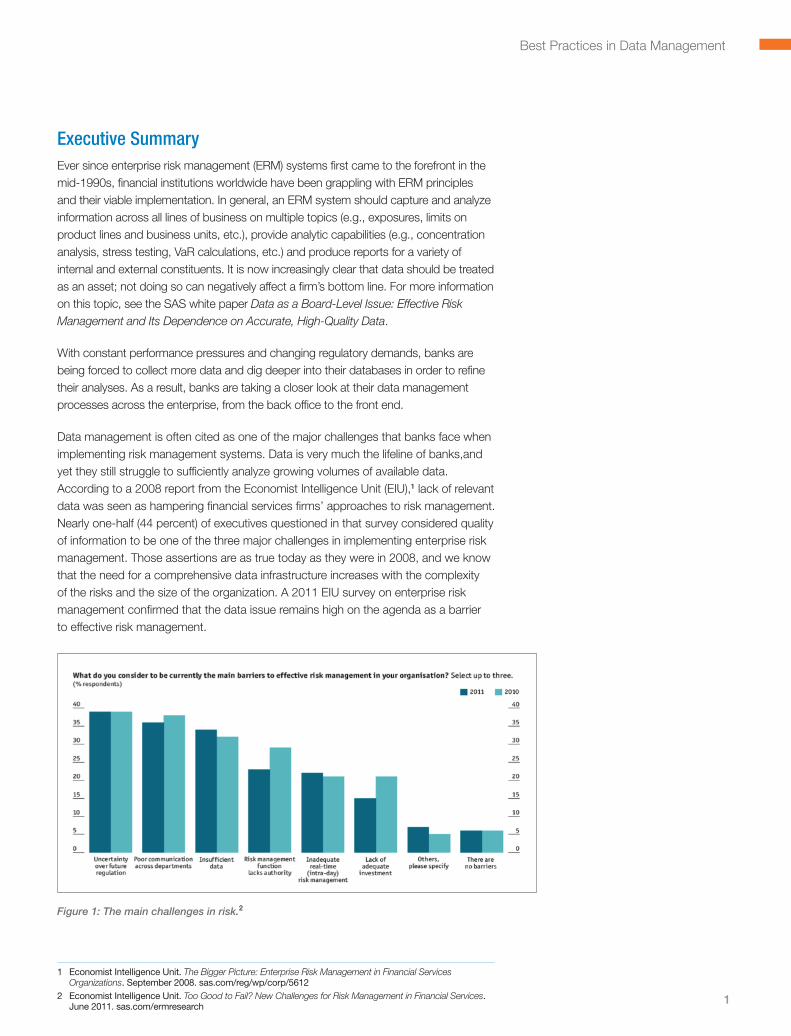
Data management is often cited as one of the major challenges that banks face when implementing risk management systems . Data is very much the lifeline of banks,and yet they still struggle to sufficiently analyze growing volumes of available data . According to a 2008 report from the Economist Intelligence Unit (EIU),1 lack of relevant data was seen as hampering financial services firms’ approaches to risk management . Nearly one-half (44 percent) of executives questioned in that survey considered quality of information to be one of the three major challenges in implementing enterprise risk management . Those assertions are as true today as they were in 2008, and we know that the need for a comprehensive data infrastructure increases with the complexity of the risks and the size of the organization . A 2011 EIU survey on enterprise risk management confirmed that the data issue remains high on the agenda as a barrier to effective risk management .
Figure 1: The main challenges in risk.2
1 Economist Intelligence Unit. The Bigger Picture: Enterprise Risk Management in Financial Services Organizations. September 2008. sas.com/reg/wp/corp/5612
2 Economist Intelligence Unit. Too Good to Fail? New Challenges for Risk Management in Financial Services. June 2011. sas.com/ermresearch

2
SAS White Paper
Indeed, data management is – and will remain – a critical component of an ERM system, and a bank’s approach to data management should be holistic and unified, as data silos stymie the flow of information and prevent employees and managers from seeing a complete picture . For example, when a financial institution defines its risk profile and associated risk limits at the organizational, business and product levels, the value derived from those limits depends on whether they can be accessed seamlessly by corporate, retail investment banking business units and corporate risk management, which monitors adherence to the institution’s risk appetite (see the SAS white paper The Art of Balancing Risk and Reward: The Role of the Board in Setting, Implementing and Monitoring Risk Appetite3) . This example, however, isn’t just about the efficient and uninhibited flow of data among the various operational lines of business (LOBs), customer-facing desks (e .g ., capital market front-office trading rooms and retail banking branch offices) and corporate risk management . Rather, the focus is on the assurance that:
• Thedataisstructuredaccordingtoaspecificsetofbusinessrules.
• Dataqualityhasbeenevaluatedandreportedonagainsttheserules.
• Datafromdisparatesourcesisgroupedtogetherinaformthatsuitsanalysts and information consumers .
• Differentusershavethesameviewofthesametypeofdata(e.g.,asingleview of the customer, standardized exposure representation, companywide performance reports based on specific measures such as RAROC, etc .) .
For these assurances to be possible, an institution’s data management platform must be scalable, open and capable of supporting the needs of multiple risk management functions (e .g ., market risk, operational risk, credit risk, etc .) and applications (e .g ., exposure monitoring, VaR calculation, loss-event collection, RAROC reporting, reporting on adherence to KPIs, etc .), and should have the following characteristics:
• Aunifieddatamodelthatisbothflexibleandextensibleinordertomeettheevolving business needs of a vibrant financial organization .
• Acommonmetadataframeworkbasedonanopenindustrystandard.
• Acommonsecurityframework.
• Acommonsetofnativeaccessenginestothevariouspossiblesourcesystems(transaction systems, limits management systems, netting systems, etc .) .
• Commondataqualitycapabilities.
This paper will discuss each component both separately and together in order to demonstrate the benefits of the structure as a whole .
3 SAS Institute. The Art of Balancing Risk and Reward: The Role of the Board in Setting, Implementing and Monitoring Risk Appetite. December 2011 . sas.com/resources/whitepaper/wp_40392.pdf
The key ERM issue for many
banks is to get enriched data
in a single place so they can
actually report on it.

3
Best Practices in Data Management
A Unified Data ModelThe lifeline of any system that is designed to derive valuable business information and draw pertinent conclusions from processed data is the data itself, and that most certainly is true for banks . In fact, the structure of that data is of critical importance to the viability of an ERM system .
Figure 2: Enterprise risk management architecture.
A data model that caters to the needs of an ERM system should not only include all the elements of ERM – e .g ., exposures, mitigants and their relationships with exposures, counterparty and customer types, financial instruments, events and losses, market and credit risk factors, etc . – but should also be capable of extending these elements according to an organization’s particular needs . That is because a data model is an evolving entity that should be modified to reflect the changes that take place in the elements and business issues that affect the ERM platform .
The data model should include tools that allow the business to analyze gaps and/or change requirements against the evolving needs of ERM . These tools should enable the business to analyze the impact of both changing existing items in the data model or adding new ones to it, either upstream or downstream in the ETL flows that use an entity that has been earmarked for a change .
The data model should consistently represent different types of data – e .g ., source system codes, dates, regulatory exposure types, counterparties, etc . As such, the data model should include a thorough data dictionary that includes the rules and formats for every type of field stored in the data model .

4
SAS White Paper
It should allow for the management of fast or slowly changing dimensions without any loss of history where appropriate . For example, the probability of default (PD) rating of a counterparty is a slowly changing attribute, and storing changes to this attribute is important in order for comparison calculations to be run and ratings migrations to be processed . An example of a fast changing attribute are the margin requirements on a futures transaction, which are evaluated every day .
It is best to codesign the ETL flows that will populate the data tables of the ERM platform together with the data model in order to ensure coordination and integration of what is processed and how . Therefore, the data model is best defined in a stratified manner, where there are two layers of data structure .
A global ERM data model that incorporates data items for all sources of risk should be at the highest level . This global data hub would feed the data to the respective sublevels of the ERM system . For example, information on counterparties and exposures would be stored for all sources of risk; however, within each subunit of the ERM system (i .e ., market risk, credit risk, etc .), these pieces of information would be processed differently because they address different forms of risk .
To reiterate, the design should follow a stratified structure, with a global data hub that facilitates the population and interchange of data among the various subunits of the ERM system (i .e ., the market, credit and operational risk units) . Such a design enables you to fix the ETL flows that populate the data marts that pertain to each subunit, so you only have to worry about bringing the data into the global data hub . Once the data is in there, you can quite easily and transparently move it to any respective data mart (e .g ., the credit risk data mart) . In doing so, you isolate the issue of managing your ERM data from the issue of making changes in data that take place at the source-level system because you only need to address these changes at the initial stage – that is, in populating the global data hub .
The Metadata FrameworkMetadata – information about the data itself – is usually classified as one of the following types:
• Physicalmetadata,whichdescribesthestructuresandpropertiesofthedata(e.g.,field descriptions for a DBMS table) .
• Businessmetadata,whichdescribesthephysicaldatausingrepresentationsthatare familiar to the information users (e .g ., in physical data, the client age could be defined as “Age_Client;” however, for reporting purposes, this field would be described in the metadata as “Current Age of Client .” The latter is the terminology that business users understand, as it directly represents the way they identify parts of their business .) .
• Applicationmetadata,whichdescribesthepropertiesofanobjectthatwascreatedusing an application (e .g ., an internal ratings model) .
A data model is an evolving
entity that should be modified
to reflect the changes that
take place in the elements and
business issues that affect the
ERM platform.

5
Best Practices in Data Management
Given that metadata is information about the underlying data and application objects, the importance of metadata in the context of an ERM system is clear . All the applications that constitute an ERM system must have access to the complete picture of a data item so it can be processed as required and correctly presented in the next application in the flow .
Without this very fundamental capability, there would be breaks in the flow, which would require the translation and transport of data from one application to the next . For example, if there were one common set of metadata, the economic capital calculation engine would read and process the same data that a performance management application would later use to report on KPIs and KRIs . Without common metadata, one application may process the data one way, while another may read the data differently .
As another example, take the use of metadata on a ratings modeling and risk-weighted assets (RWA) process . A quantitative analyst would define an internal ratings model using the relevant application, which would produce metadata about the model inputs and outputs, the model PD categories, etc . Where both applications used a common metadata framework based on open industry standards, such as the common warehouse metamodel of the OMG, the ratings model metadata would be accessible to the engine that performs RWA calculations, reducing the risk of errors in the calculations .
A common metadata framework should include both a structure and dictionary of properties for each object . The structure should adhere to rules governing groups of metadata objects, parent-child relationships, inheritance and data integrity:
• Groups of metadata objects: A group of metadata could be a set of metadata structures that describes a DBMS table .
• Parent-child relationships: A parent-child relationship is the relationship that exists between a supertype and a subordinate . For example, a data field is a child of its parent, the DBMS table .
• Inheritance: Inheritance defines how a child can carry the properties of the parent object, including the access rights . For example, a set of access rights could be identified for a DBMS table (the parent object) . The metadata framework should include rules that specify how a DBMS table column (the child) could inherit – if at all – the access rights from the parent .
• Data integrity: Similar to the data integrity of a DBMS schema, data integrity in terms of metadata pertains to all those rules that control the values associated with a metadata item and how an item relates to other metadata items in the same group or in a parent-child relationship . For example, the metadata for identifying application users could stipulate that each metadata identity is associated with a single first and last name .
Enterprise risk intelligence
data needed to drive an ERM
platform goes beyond that
maintained in a typical data
warehouse.

6
SAS White Paper
In addition to identifying the metadata framework’s structure and the rules for storing information within it, you must also identify the mechanism for exchanging this metadata information among applications . An open metadata framework requires the implementation of an open industry standard – such as XML – as the interchange mechanism . This facilitates the exchange of information not only among the components of the ERM platform, but also among other parts of the business and external regulatory bodies .
Auditing
A common metadata framework serves another important purpose – auditing . Internal auditors and external regulatory authorities require banks to provide detailed information on the flow of data, calculation results and reports throughout the business flows . For example, to qualify for IRB in either market risk or credit risk, a bank must demonstrate in a coherent way how the data flows from the data sources to the analytical applications, and how the quantitative models process this information and generate the results .
Regulators want to see how model parameters are managed, how risk factor distributions are modeled, how models are tested/validated, and how they are used in daily business (e .g ., how a point-in-time ratings model uses obligor-specific information to assign obligors to risk categories and how unstressed PDs are measured and modeled) . That is why it is vital to have a data management platform with an underlying metadata framework that stores metadata for all data, application objects and reports .
Metadata is stored in repositories like any other type of data and in structures that are conducive to fast querying and avoidance of unnecessary duplication . The structure should be able to associate repositories and enable the easy, transparent exchange and sharing of information among repositories .
To facilitate the sharing of metadata, it makes good business sense to allow the inheritance of metadata definitions from one repository to another (or more) in order to avoid duplication . Deduplication and sharing enable administrators to better manage the metadata by allowing them to collaborate with the business users to identify a set of global metadata that any application or user of ERM data must have . For example, users that manage the ETL flows would need to have access to the servers where the input data would be processed . These server definitions could form a set of global metadata that the metadata repositories of the various subgroups of ERM (e .g ., market risk, credit risk, operational risk) would inherit .
A data management platform
with an underlying metadata
framework that stores metadata
for all data, application objects
and reports is vital to an ERM
system.

7
Best Practices in Data Management
Every organization should
streamline access rights to the
data and its derivatives in order
to avoid both intentional and
erroneous mismanagement of
these resources.
A Common Security FrameworkThe metadata layer allows various personas or business user types to view a single version of the truth when it comes to available data, reports and application objects . However, every organization should streamline access rights to the data and its derivatives (i .e ., reports, performance diagrams, quantitative models, etc .) in order to avoid both intentional and erroneous mismanagement of these resources, which are among the most important assets of an ERM system .
As such, the data management platform should be managed centrally (remember that the elimination of isolated silos is one of the most important hallmarks of an ERM framework) . It should also allow for auditing and reporting on access patterns, access rights and the flow of data through ERM processes .
To facilitate auditing and reporting, security should be metadata-driven . After all, auditing is a fundamental part of most regulatory initiatives, and regulators and internal auditors alike want to see not only how data is processed, but also how it is accessed – in other words, who does what, when and how .
Data management security should address the issues of authentication and authorization . Authentication involves the acknowledgement of users as they attempt to log on to the data management platform . Typically, this is facilitated by an application server or operating system authentication mechanisms, and via LDAP or Active Server . The security platform should be flexible enough to support these mechanisms, enabling the business to leverage investments in existing security frameworks .
The concept of authorization is ERM-specific because it determines what set of actions an authenticated user is allowed to perform on a particular data resource (or any other application resource, for that matter), commensurate with the particular banking environment .
The security framework should accommodate various forms of access controls:
• Direct access controls specify which users and/or groups are allowed to access a particular object (e .g ., a DBMS table, a remote server, a quantitative model, an ETL flow, a KPI report, etc .) and in what way(s) .
• Direct access control templates are defined for a particular user and/or group and are associated with access to a particular resource, such as the ones described in the previous bullet point .
• Inherited access controls determine access to a resource by the access controls for its parent . For example, access to an ETL flow could be determined by the access rights to the group of ETL flows that encompass this particular flow, or access to a DBMS table could be determined by the access rights definitions that were defined for its parent DBMS schema .
The data management platform should generate ample user access logs . These logs should be in a user-friendly format and available to internal and external auditors at will . In addition, such logs should be readily available to the ERM platform’s querying and reporting tools to enable the efficient preparation of security/access reports .

8
SAS White Paper
A Common Set of Native Access EnginesIt is very important for an ERM data management system to include an array of native access engines to other data sources . Only then can an ERM system be truly global in its scope and application . We stress the words “native access engine” in order to differentiate these engines from those that are generic (e .g ., ODBC) . A native access engine is designed to access and employ all the functionality of the particular DBMS optimizer that needs to be accessed . That includes crucial functionality in index processing, fast loads and writes, multithreaded partition capabilities (wherever available) and optimized SQL queries processed at the source itself . Native access becomes even more crucial when access to both the metadata of the ERP system and its underlying data structures are required .
It is important for these engines to be flexible in the way they allow a user to interact with the source data (which can be an RDBMS, ERP, legacy system, etc .) . That means that they should enable the user to submit SQL scripts in the native form understood by the input data source optimizer directly, or be capable of translating the user’s SQL to the form understood by the input source .
Through better data quality, reports would improve – variances could be explained and could increase revenue because they’d have much better information and more current info for more timely decisions .
Data QualityData quality is paramount for any system that operates for the sole purpose of producing valuable business information . No financial organization can ever be sure that its economic and/or regulatory capital calculations are accurate and reliable if the supporting data is not cleansed and validated according to defined business rules . Furthermore, data quality must be an integral part of the process not only to ensure the fast, seamless processing of the data, but also to satisfy the auditing requirements of regulators and independent auditors .
Because of its importance, a detailed description of data quality is beyond the scope of this paper . But at minimum, any ERM data management system should be able to perform these basic functions:
• Dataprofiling.
• Businessrulecreationandapplicationforimputingmissingdata.
• Businessrulecreationandapplicationforstandardizingandvalidatingcolumnvalues against a knowledge base .
• Deduplication.
An ERM data management
system must include an array
of native access engines to
other data sources in order to
be truly global in its scope and
application.

9
Best Practices in Data Management
Planning for a Data Management SystemAn ERM system should be able to process and integrate information from many sources that fall into one of three main categories – front-, middle- and back-office systems .
• Front-end systems – Includes investment banking trading systems used by traders to track positions and price and execute deals, and retail banking origination systems used by loan officers .
• Middle-office systems – Used by the ERM unit to measure and monitor risk exposure at various levels – from individual business units up to group level . LOBs (retail, corporate, investment banking) are compared with risk concentration limits (as defined against particular portfolio segments) and flagged as needed .
• Back-office systems – Where trade settlements take place and information is passed to accounting for crediting and debiting, as required by each transaction .
Even though these categories serve different purposes, there are overlapping activities that dictate the need for overlapping data access . For example, traders need real-time access to information on limits, and they must also perform some form of marginal or incremental VaR calculations to assess a position’s contribution to their portfolios . For the retail side, the single environment would support behavioral scoring, regulatory reporting and risk management best practices (simulation-based economic capital calculations) . From an ERM perspective, all three systems would interact (see Figure 3) .
Market Data• Bloomberg• Reuters
Current Data
Front Office
Trading Systems• Fixed Income• FX• Equities• Derivatives
ERM GlobalData Hub
Positions/ExposuresRepository, Limits
Default Data
Internal/ExternalRatings
Nettings, Collateral(physical, financial,guarantees etc.)
Customer/Counterparty data
Back Office
Risk Engine-Middle Office
Reports• Internal• Regulatory• Market
Operational RiskEvent-Loss Self-Assessment Data
Configuration Data
Data Marts (e.g. Credit Risk etc.)
ReportRepository
Figure 3: System interaction in an ERM environment.
Better data quality would
improve reports, explain
variances and lead to increased
revenue, as banks would have
better, more current information
for more timely decisions.

10
SAS White Paper
The parameters that constitute configuration data are static throughout the process and are used as inputs in modeling, economic capital and/or regulatory capital calculations . In a regulatory environment, such data includes: supervisory haircuts, add-ons and CCFs, the confidence level and time horizon for VaR calculations, supervisory risk weights, etc .
Figure 3 shows how the data management process moves data through the following steps:
1 . Data requirements and gap analysis . Business users from various functions (e .g ., quantitative analysts that model VaR, internal auditors that want to check and validate the process, state supervisors making regulatory demands to check the validity of the calculations, etc .) have identified their data needs . The data management team can then evaluate the gaps, if any, in the source systems .
2 . Mapping inputs to outputs . Once any gaps are identified and substitute data tables/fields have been agreed upon with the business users, the data management team can begin mapping inputs to outputs . In this example, the outputs are the tables found in the data model of the ERM data hub .
3 . ETL process construction . Next, the ETL designers begin constructing the ETL processes that will move data from the source systems to the ERM data hub . ETL flows must be tested, validated and put into production . Flows can then be moved to the scheduler . This is done on the basis of data dependencies . For example, to perform regulatory capital calculations, you must first load parameters (such as haircuts, add-ons, etc .) and the MtM positions of the portfolio . In this example, the start of regulatory capital calculation flows should be dependent on the completion of the other two flows . This, of course, implies the need to integrate checks and balances into the scheduler to ensure the execution of flows according to business specifications .
4 . Transfer of data to the data marts . Once the data is loaded on the ERM data hub, it can then be transferred to the data marts using predefined ETL flows . Because you designed the ERM data hub and data marts, you also have control over the structure of the ETL flows, making this part of the process easier .

11
Best Practices in Data Management
5 . Analysis and modeling . Once the data is loaded into the data marts, analysts can begin analyzing and modeling the data . The risk engine should be flexible not only in terms of what models it allows you to implement (e .g ., EC using credit migration or contingent claims; VaR calculations using delta-normal, historical, MC simulation, etc .), but also in permitting the storage and batch or real-time submission of the scripted version of the modeling work . Once the analysts have finalized their modeling work, these scripts can be loaded into the scheduler to enable the submission of the entire process, end-to-end or in parts, as required . The scheduling of an ETL flow depends on how frequently data in the source systems change . For example, a financial account used as collateral for a loan will incur changes almost daily in terms of its balance . Another example would be the calculation of undrawn amounts against facilities . Customer information, however, does not change daily, at least in terms of demographic information .
6 . Report and output data generation . Report and output data generation processes are necessary post-processes to the risk engine scripts . Here again, the data management function of the ERM system will play the crucial role of defining the tables and columns of the report repository . The data management system should cater to multinational organizations and be able to generate reports in various structures and languages . Therefore, the data management and reporting subsystems must be able to work jointly, sharing metadata and data . Reports can be published in a portal that authorized users can access .
As previously mentioned, the data management subsystem should accommodate the reporting requirements of the various “personas” or user types throughout the organization, as demonstrated in the table below .
Personas Scope of Reports Report Content Format Frequency of
Updates
Upper Management
Groupwide Group KPIs/KRIs, group performance against risk appetite, aggregate positions & VaR.
Focus on strategic goals as defined in company policies and on scenarios or stress tests against critical risk factors.
VaR measures daily; others can be weekly, monthly or quarterly.
Risk Management
Groupwide, business units, banking & trading books
Group KPIs/KRIs, group performance against risk appetite, aggregate positions & VaR.
Aggregate OLAP type presentation over various hierarchies along with detailed model validation, back-testing, scenarios or stress testing.
Daily, intraday.
Trading Desk Staff
Trading books as per trading desk
Trading desk KPIs/KRIs, trading desk performance against risk appetite, aggregate positions & VaR.
Limits alerts, marginal or incremental VaR, MtM of portfolios, hedging information.
Real time, end of day.
The data management
subsystem should
accommodate the reporting
requirements of the various
user types throughout the
organization.
12
SAS White Paper
The data management system should maintain historical data in terms of the data used by the risk engine and the reporting repository . Historical data is vital for back-testing, historical simulations and comparison of calculation/analysis results between different time frames .
The data management system should generate ample logs and trace information throughout the flow of data from the point of extraction from the source systems all the way to report generation . This way, regulators and internal auditors can validate the path of the data, and internal developers can use this log information to iteratively improve process capacity .
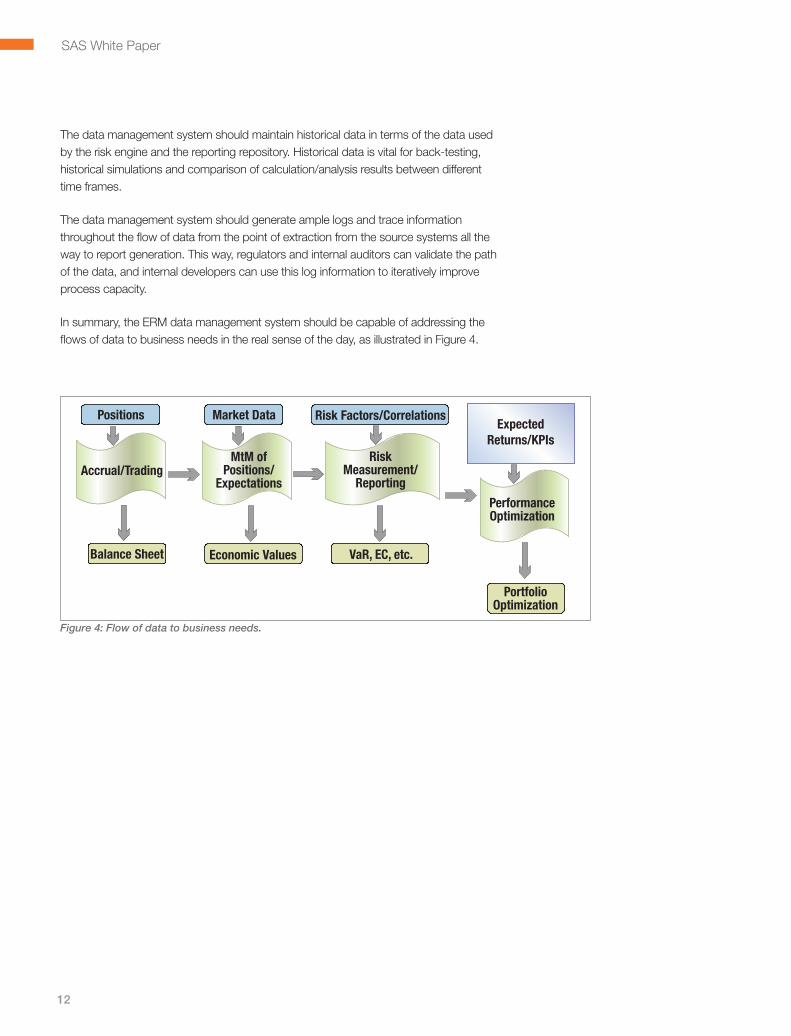
In summary, the ERM data management system should be capable of addressing the flows of data to business needs in the real sense of the day, as illustrated in Figure 4 .
Positions Market Data Risk Factors/Correlations
PortfolioOptimization
Balance Sheet Economic Values VaR, EC, etc.
ExpectedReturns/KPIs
Accrual/TradingMtM of
Positions/Expectations
RiskMeasurement/
Reporting
PerformanceOptimization
Figure 4: Flow of data to business needs.

13
Best Practices in Data Management
ConclusionFinancial institutions are continuously seeking the ability to make better decisions – supported by data – faster . However, because most banks spend so much time gathering and cleaning data and creating reports, there’s little time left to explore data for insights that can have a positive impact on the bottom line .
That’s why a holistic, unified approach to data management – one that ensures a smooth flow of information throughout the organization – is a critical part of a true ERM system .
Using SAS® for data management enables decision makers at all levels to see a complete picture of enterprise risk . SAS Data Management supports the needs of multiple risk management functions and applications by providing:
• Ascalable,openplatform.
• Aunifieddatamodelthatisbothflexibleandextensible.
• Commonmetadataandsecurityframeworks.
• Acommonsetofnativeaccessengines.
• Embeddeddataqualitycapabilities.
SAS integrates quality control and automates the entire data management process – from data collection and aggregation to data validation and cleansing – to ensure data accuracy and consistency in a unified, quantitative risk management framework .
Using SAS to manage risk at the enterprise level enables decision makers to glean key insights from data and then combine those insights with information from other functions (e .g ., marketing, finance, HR) to facilitate true enterprisewide risk-based performance management .

SAS Institute Inc. World Headquarters +1 919 677 8000To contact your local SAS office, please visit: www.sas.com/offices
SAS and all other SAS Institute Inc. product or service names are registered trademarks or trademarks of SAS Institute Inc. in the USA and other countries. ® indicates USA registration. Other brand and product names are trademarks of their respective companies. Copyright © 2012, SAS Institute Inc. All rights reserved.103003_S83731_0312
About SASSAS is the leader in business analytics software and services, and the largest independent vendor in the business intelligence market . Through innovative solutions, SAS helps customers at more than 55,000 sites improve performance and deliver value by making better decisions faster . Since 1976, SAS has been giving customers around the world THE POWER TO KNOW® . For more information on SAS® Business Analytics software and services, visit sas.com .





























