Embed Size (px)
Citation preview

Putting Compilers to Work
August 19th, 2015 Drew Paroski

Why do compilers and runtimes matter?
•Virtually all modern software is powered by compilers
•Compilers can have a huge effect on the efficiency and performance of software
•Also can affect how programmers develop software

Efficiency and Performance•Qualitative: •Change what user experiences are possible
•Quantitative: •Reduce CPU and resource usage•This often translates into reduced costs
and/or increased revenue

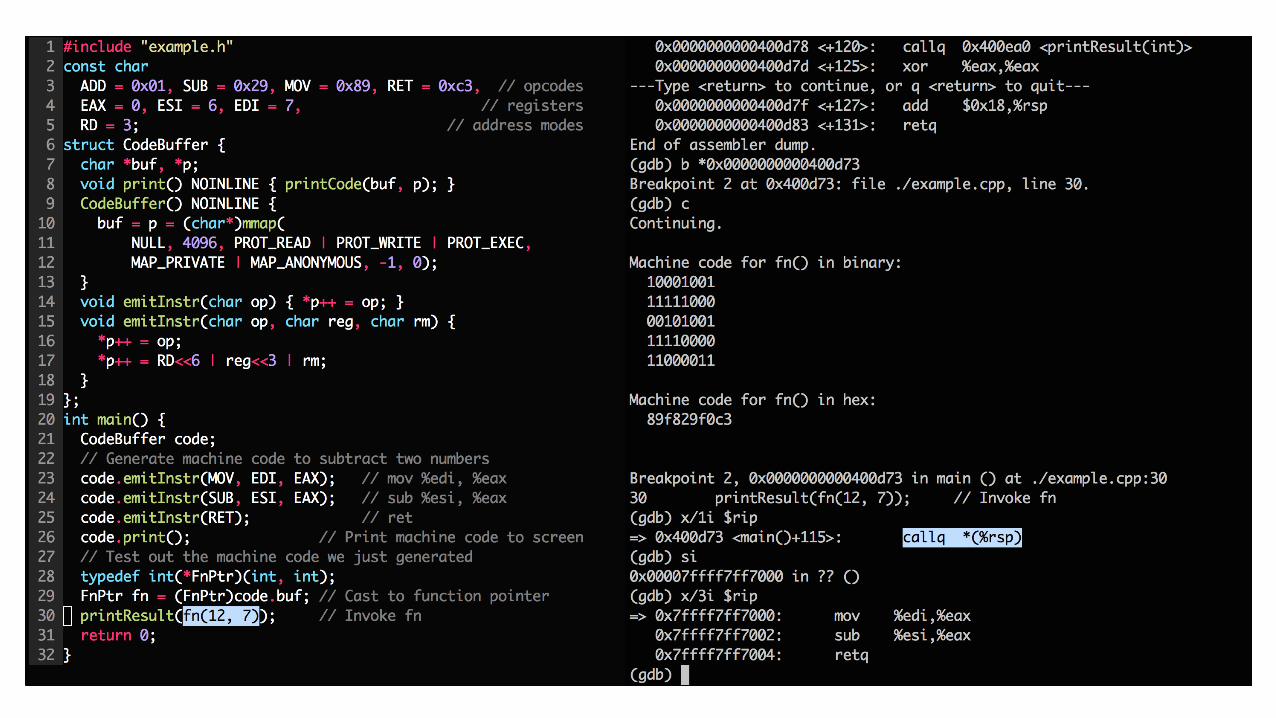
How do compilers work?•Demo: Demystifying machine code
Let’s look at a 50-line C++ program that generates machine code at run time and invokes it
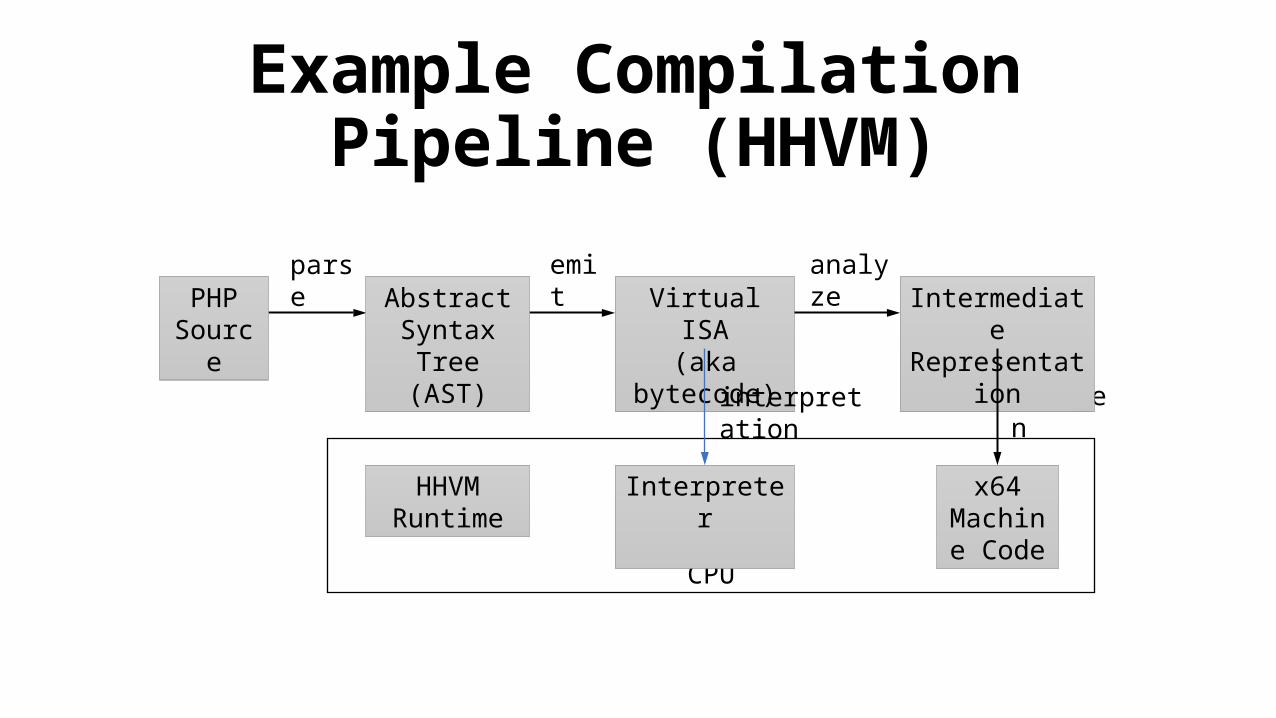
Example Compilation Pipeline (HHVM)
parse
codegen
Virtual ISA(aka bytecode)
emitIntermediate
Representation
analyzePHP
SourceAbstract
Syntax Tree (AST)
CPU
x64 Machine
Code
InterpreterHHVM Runtime
interpretation

The Rise of Web Programming
•1993: CGI scripting (Perl / C)•1995: Javascript, PHP, and Java applets•1996: Flash, ASP, and ActiveX•1999: JSP•2004: Ruby on Rails•2005: Django (Python)•2007: Silverlight (XAML / C#)

•Engines for most of these languages were interpreters•Often ~100x slower (or more) than C and C++
•Most interpreters don’t have a noticeable compilation delay•Supports a rapid iterative development
workflow (edit-save-run)
Web Programming Languages

•Websites grew in their complexity
•Developers started to bump against the limitations of early engines’ performance
•Bonus points: Try to preserve the rapid iterative development workflow of these languages (edit-save-run)
Building Efficient Compilers for
Dynamic Languages

Compiler Improvements in Web Programming
•2002: ASP.NET•2007: Cython•2008: JRuby•2009: TraceMonkey, WebKit SFX/Nitro, V8•2010: HipHop for PHP, PyPy 1.2•2011: HHVM•2014: Pyston

•Let’s talk about performance optimization in general
Improving software performance

Three Areas to Optimize
1) Data fetching and I/O in general2) How memory is used on an individual machine3) How computation is actually performed by the CPU
•Always measure using profiling tools to determine what areas you should focus your optimization efforts on

•Typically the biggest issue to look at •Does you application frequently stall while waiting for data?
Data Fetching and other I/O
CPU Blocked on I/O CPUCPU Blocked
on I/O
Wall time

•Are you fetching more data than you need to?•Are you making lots of round trips in a serial fashion?• Fetch data in batches to reduce # of round trips
• Is your application still blocking a lot?•Use async I/O APIs
Data Fetching and other I/O

•Are you taking a lot of cache misses?•Caches misses slow things down by making the CPU
stall•Pay attention to your application’s memory usage•Use as little memory as possible•Avoid pointer chasing
How is memory used?

• Is your application repeatedly re-computing something that could be memoized?•Are common operations as efficient as possible?• Is your application needlessly making lots of short-lived allocations?• Is there unnecessary contention with locks or interlocked operations?
How is computation performed on the CPU?

•Compilers requires a fair amount of investment before it pays off
•Have you exhausted the low hanging fruit from other avenues of performance optimization?
•Are there better engines already out there you can use?
When to invest in compilers

•Before building anything, think about what your goals really are•How much better does execution performance need to be?
2x? 4x?•Do you need fast compile times? How fast?•Do you need to support a rapid iterative workflow?
•Do these goals help improve the user experience for your product or your company’s bottom line?
What are your goals?

•Everyone wants the best performance, but it doesn’t come for free
•Do you really need 5x better execution performance? Or would 2x be good enough for the next few years?
• Is it worth it for your company to pay one or more engineers to work on this instead of other things your company needs?
What are your goals?

•Does your use case require doing compilationon-line?
•On average, how big are the source programs that are being compiled?
•Does code your compiler outputs execute for short periods of time or are they longer running?
• Is your source language statically typed or dynamically typed?
What are the constraints of your use case?

• Do you need fine control over low-level / native stuff?
• Do you need to integrate with existing native code or data structures?
• Do you need to work on multiple processors/platforms?
• How quickly do you need a working solution?
• What’s the best fit for your use case?• Ahead of time (AOT) compilation• Just-in-time (JIT) compilation• Interpreted execution
What are the constraints of your use case?

•Full custom approach• Interpreter approach•Transpiler approach•Build on top of an existing backend (LLVM, JVM)•Meta-tracing / partial evaluation frameworks (PyPy, Truffle)
Approaches

•Easy to write, maintain, and debug
•Can be built relatively quickly
•Very low compile times
•Well-crafted interpreters can deliver better execution performance than you probably think
Interpreters

• Interpreters built to execute a virtual ISA (bytecode) tend to be faster than AST interpreters•Generally try to limit branches in your opcode
handlers• Common trick: split up an opcode into several separate
opcodes•Dispatch loop one of the major sources of
overhead, invest some time in optimizing it
Interpreters

•A transpiler converts one programming to another, and relies on an existing compiler to compile and run the target language (typically C or C++)
•Can be built fairly quickly, relatively easy to debug
•Can deliver better execution perf than interpreters
•Examples: Cython, HipHop for PHP
Transpiler approach

•Often has lower ceiling for best possible long-term performance vs. the full custom approach• Primitive operations the source language exposes often do not
cleanly map onto the primitive operations exposed by the target language
• Transpiler architecture can get unwieldy as your system evolves and you squeeze for more perf
• For use cases that involve compiling medium-sized programs or larger, transpiling to C/C++ effectively locks you into AOT-compilation-only model
Downsides of Transpilers

• LLVM is the backend for the clang C/C++ compiler•Unlike most compiler backends, LLVM has well
designed external facing APIs•Most suitable for compiling statically typed
languages where longer compile times are acceptable• LLVM is good when you need to tight integration
with existing native code where perf really matters
Building on top of LLVM

•Examples: Scala, JRuby•Works really well if the source language was designed with the JVM in mind•Not great if you need to tight integration with existing native code where perf matters•Suffers from some of the same problems as transpilers if your source language wasn’t designed with the JVM in mind
Building on top of the JVM

•Examples: PyPy, Truffle
•Takes an interpreter for your source language as input
•Analyzes the interpreter implementation, stitches together code from different opcode handlers, and then does optimization passes on these fragments and emits them to machine code
•New and therefore not as proven as otherapproaches
Meta-tracing and partial evaluation frameworks

•Most expensive option in terms of time/effort•Gives you maximum control over every part of your system, let’s you craft everything to your exact use case•Can produce the best possible execution performance and compile-time performance•Ex: JVM, .NET, gcc, clang, V8, HHVM
Full Custom Approach

•Major risks:•Can take too long to build•Can go off the rails if you don’t have the proper expertise
Full Custom Approach

•Depending on the approach you take, you’ll need to optimize different parts of the system
•Memory, memory, memory•Reduce memory usage and cache misses•Optimize your runtime’s binary layout•Try out jemalloc or tcmalloc•Try out Linux’s “huge pages” feature
Optimization Advice

What’s Next for Compilers?•Continued focus on engines that both deliver superior execution performance and support the rapid iterative development workflow

Predictions: What’s Next?•DB query compilation will be an interesting space to watch
•Disk is not the bottleneck anymore
•Growing demand for real-time analytics on huge, constantly-changing datasets
• I think we’ll see different database systems striving to deliver the highest quality SQL->machine code compilation

Questions?





























