Embed Size (px)
Citation preview

A Scalable Implementa.on of a MapReduce-‐based Graph Processing Algorithm for Large-‐
scale Heterogeneous Supercomputers
Koichi Shirahata*1,Hitoshi Sato*1,*2, Toyotaro Suzumura*1,*2,*3,Satoshi Matsuoka*1
*1 Tokyo Ins;tute of Technology *2 CREST, Japan Science and Technology Agency
*3 IBM Research -‐ Tokyo
1
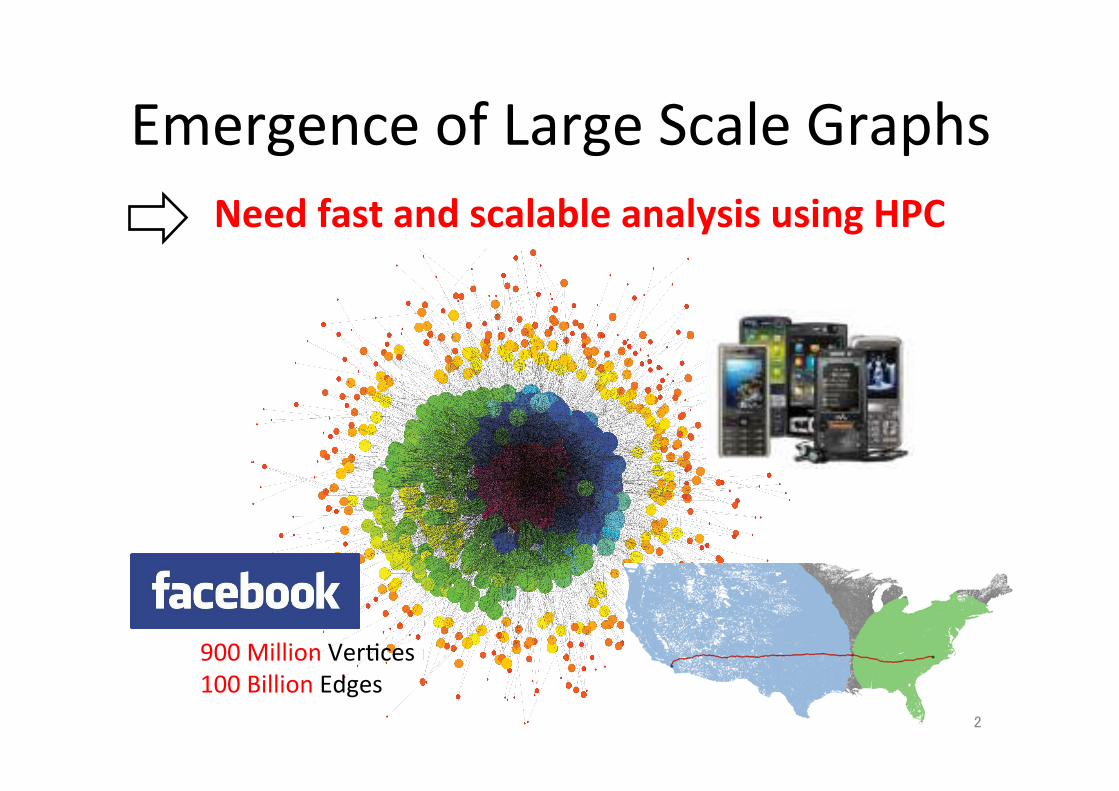
Emergence of Large Scale Graphs Need fast and scalable analysis using HPC
2
900 Million Ver;ces 100 Billion Edges
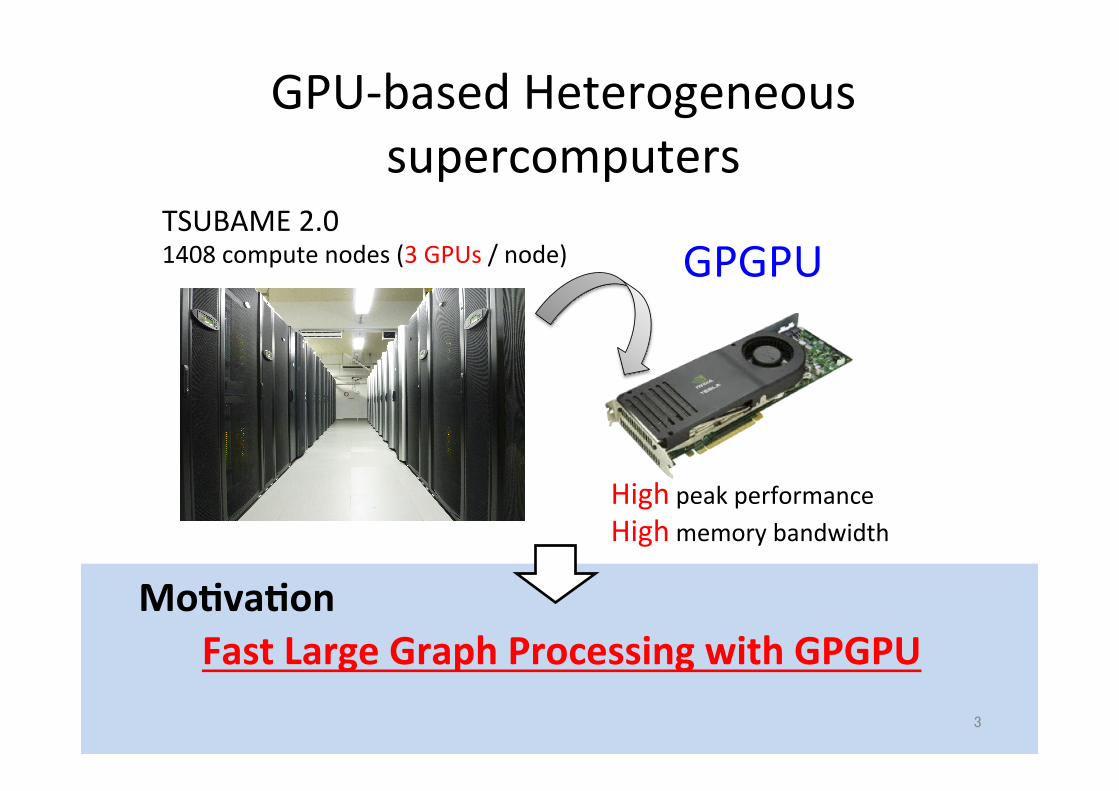
GPU-‐based Heterogeneous supercomputers
3
Fast Large Graph Processing with GPGPU
High peak performance High memory bandwidth
GPGPU
Mo.va.on
TSUBAME 2.0 1408 compute nodes (3 GPUs / node)
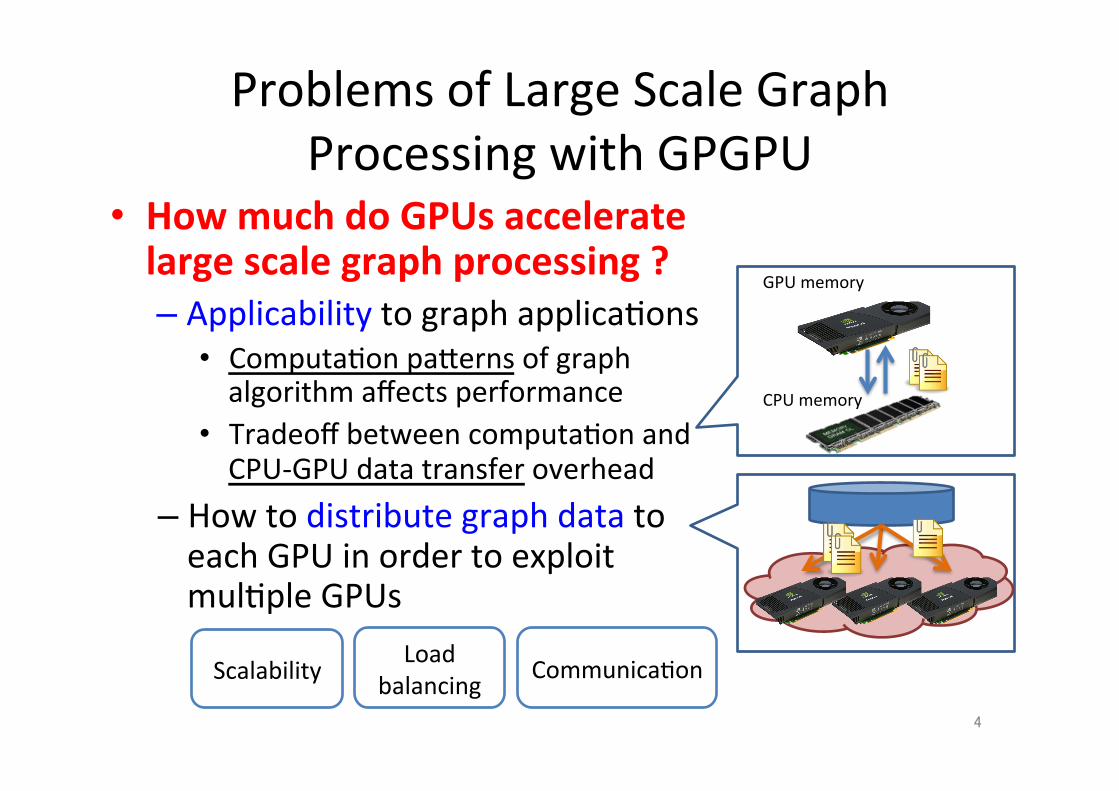
Problems of Large Scale Graph Processing with GPGPU
• How much do GPUs accelerate large scale graph processing ? – Applicability to graph applica;ons • Computa;on paXerns of graph algorithm affects performance
• Tradeoff between computa;on and CPU-‐GPU data transfer overhead
– How to distribute graph data to each GPU in order to exploit mul;ple GPUs
4
GPU memory
CPU memory
Scalability Load balancing Communica;on
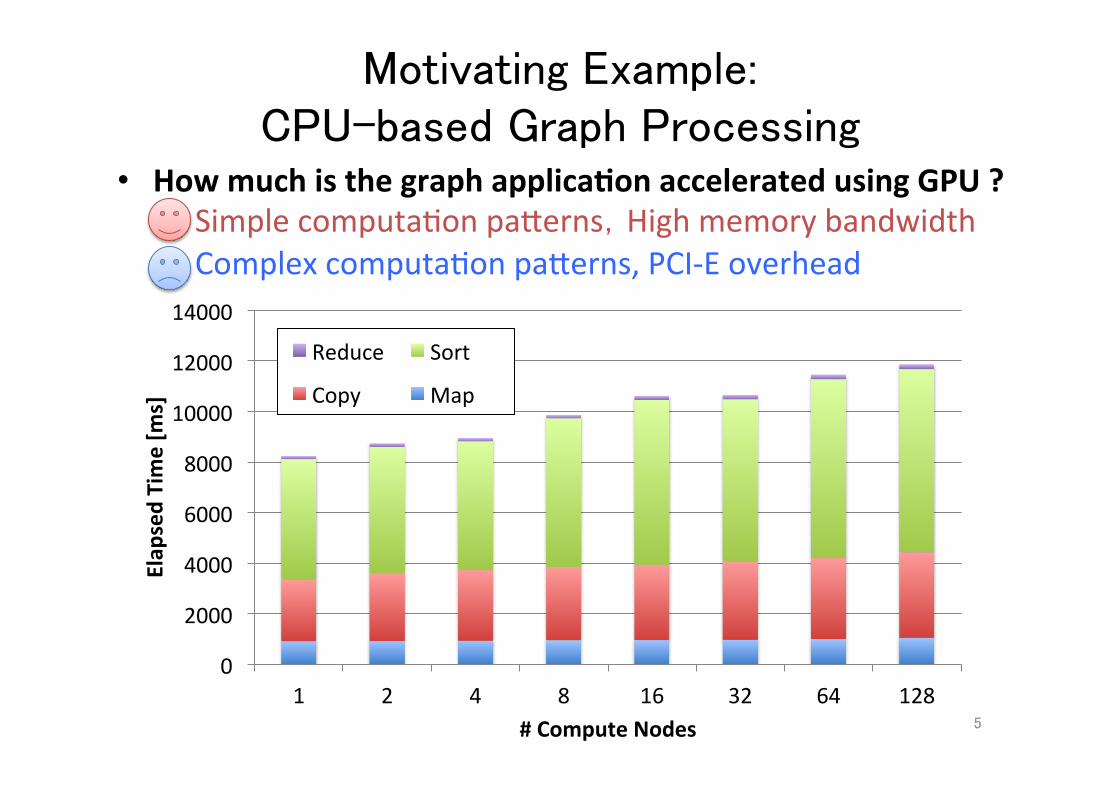
Motivating Example: CPU-based Graph Processing
• How much is the graph applica.on accelerated using GPU ? – Simple computa;on paXerns,High memory bandwidth – Complex computa;on paXerns, PCI-‐E overhead
5
0
2000
4000
6000
8000
10000
12000
14000
1 2 4 8 16 32 64 128
Elap
sed Time [m
s]
# Compute Nodes
Reduce Sort
Copy Map

Contribu;ons • Implemented a scalable mul.-‐GPU-‐based PageRank applica.on – Extend Mars (an exis;ng GPU MapReduce framework)
• Using the MPI library – Implement GIM-‐V on mul;-‐GPU MapReduce
• GIM-‐V: a graph processing algorithm – Load balance op;miza;on between GPU devices for large-‐scale graphs • Task scheduling-‐based graph par;;oning
6
• Scale well up to 256 nodes (768 GPUs) • 1.52x speedup compared with on CPUs
Performance on TSUBAME2.0 supercomputer
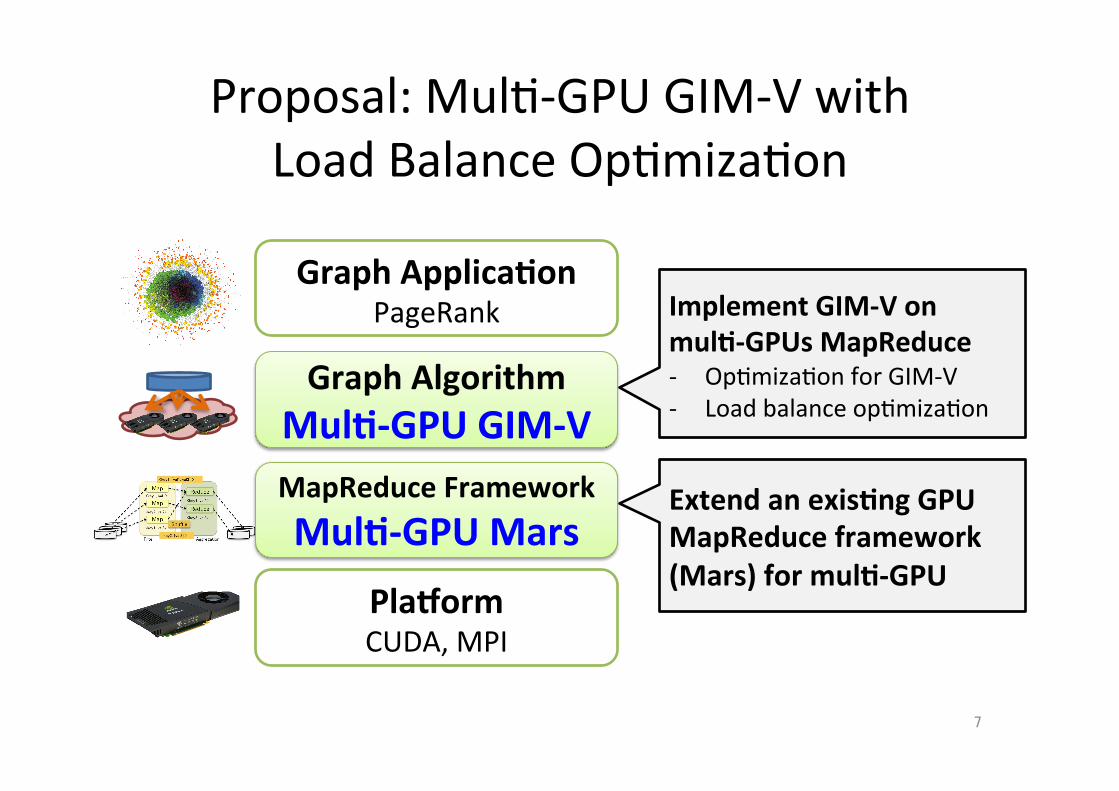
Proposal: Mul;-‐GPU GIM-‐V with Load Balance Op;miza;on
7
Graph Applica.on PageRank
Graph Algorithm Mul.-‐GPU GIM-‐V
MapReduce Framework Mul.-‐GPU Mars
PlaZorm CUDA, MPI
Implement GIM-‐V on mul.-‐GPUs MapReduce -‐ Op;miza;on for GIM-‐V -‐ Load balance op;miza;on
Extend an exis.ng GPU MapReduce framework (Mars) for mul.-‐GPU
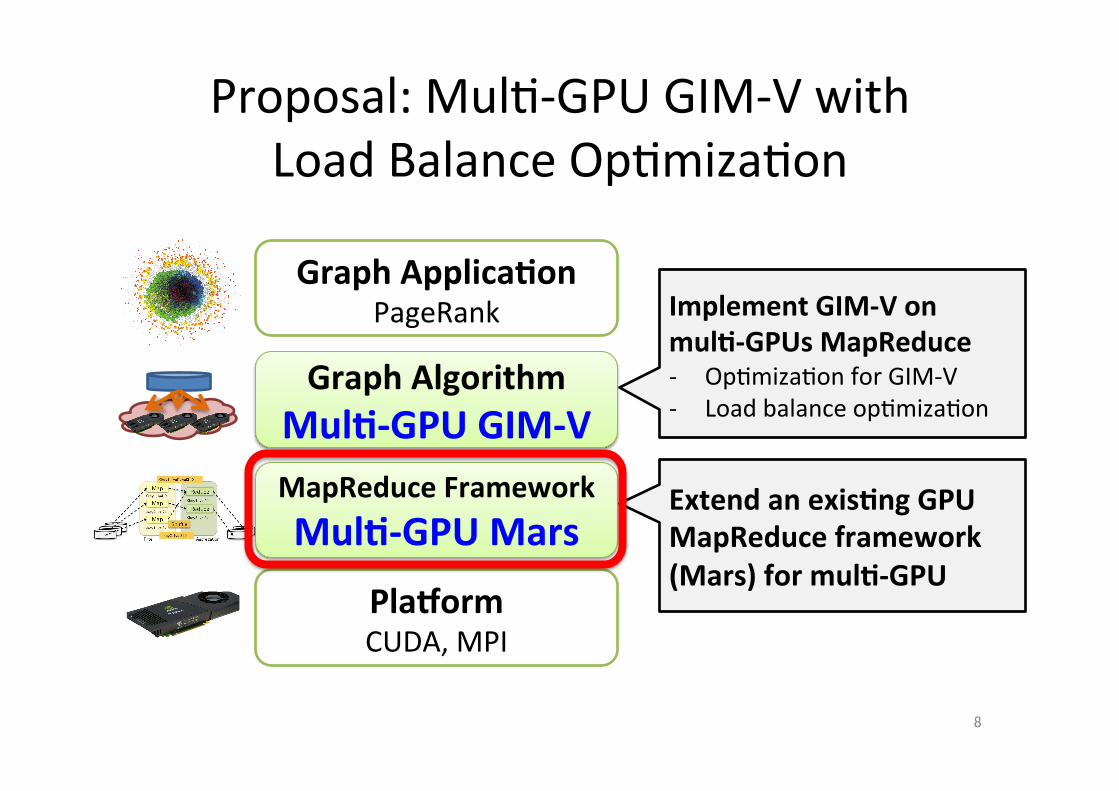
Proposal: Mul;-‐GPU GIM-‐V with Load Balance Op;miza;on
8
Graph Applica.on PageRank
Graph Algorithm Mul.-‐GPU GIM-‐V
MapReduce Framework Mul.-‐GPU Mars
PlaZorm CUDA, MPI
Implement GIM-‐V on mul.-‐GPUs MapReduce -‐ Op;miza;on for GIM-‐V -‐ Load balance op;miza;on
Extend an exis.ng GPU MapReduce framework (Mars) for mul.-‐GPU
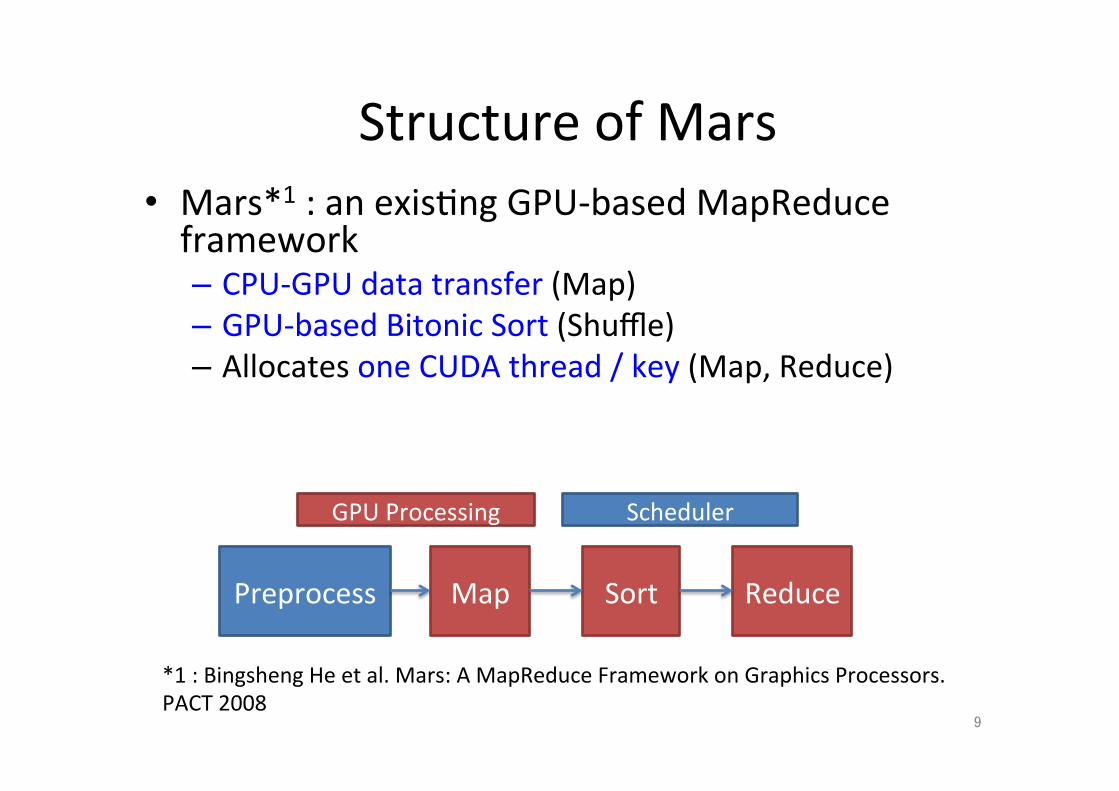
Structure of Mars • Mars*1 : an exis;ng GPU-‐based MapReduce framework – CPU-‐GPU data transfer (Map) – GPU-‐based Bitonic Sort (Shuffle) – Allocates one CUDA thread / key (Map, Reduce)
9
*1 : Bingsheng He et al. Mars: A MapReduce Framework on Graphics Processors. PACT 2008
Preprocess
GPU Processing
Map Sort Reduce
Scheduler
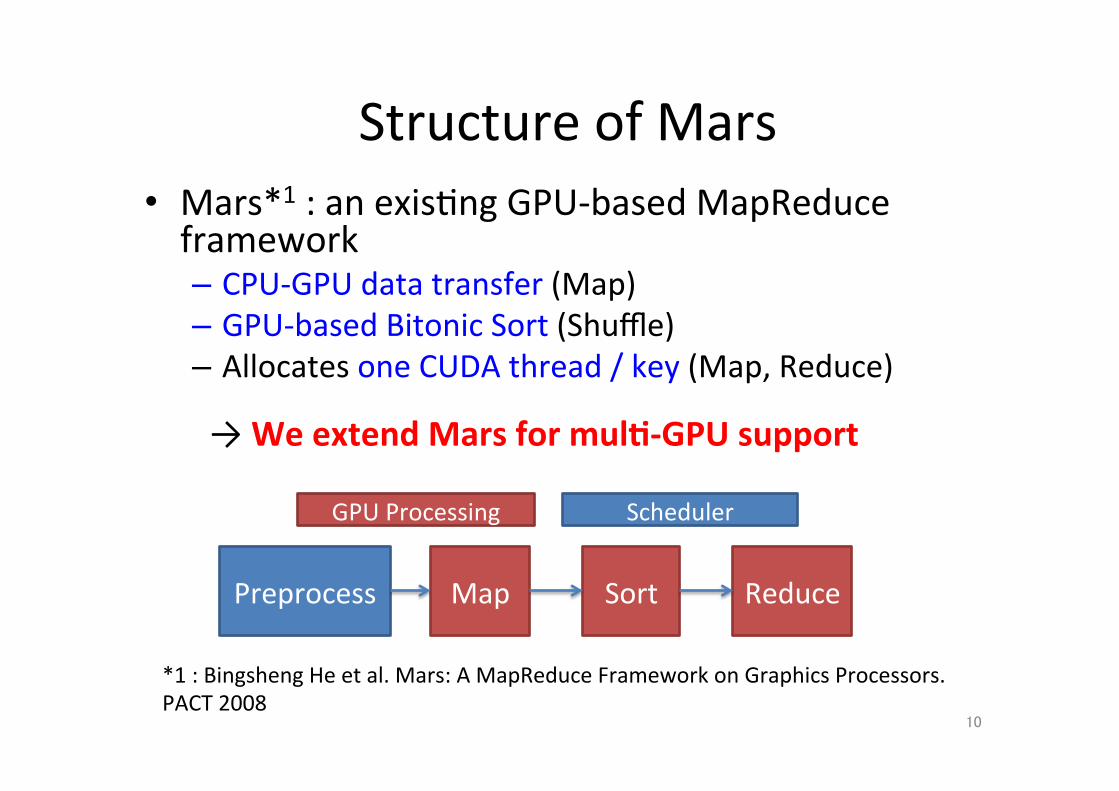
Structure of Mars • Mars*1 : an exis;ng GPU-‐based MapReduce framework – CPU-‐GPU data transfer (Map) – GPU-‐based Bitonic Sort (Shuffle) – Allocates one CUDA thread / key (Map, Reduce)
10
*1 : Bingsheng He et al. Mars: A MapReduce Framework on Graphics Processors. PACT 2008
→ We extend Mars for mul.-‐GPU support
Preprocess
GPU Processing
Map Sort Reduce
Scheduler
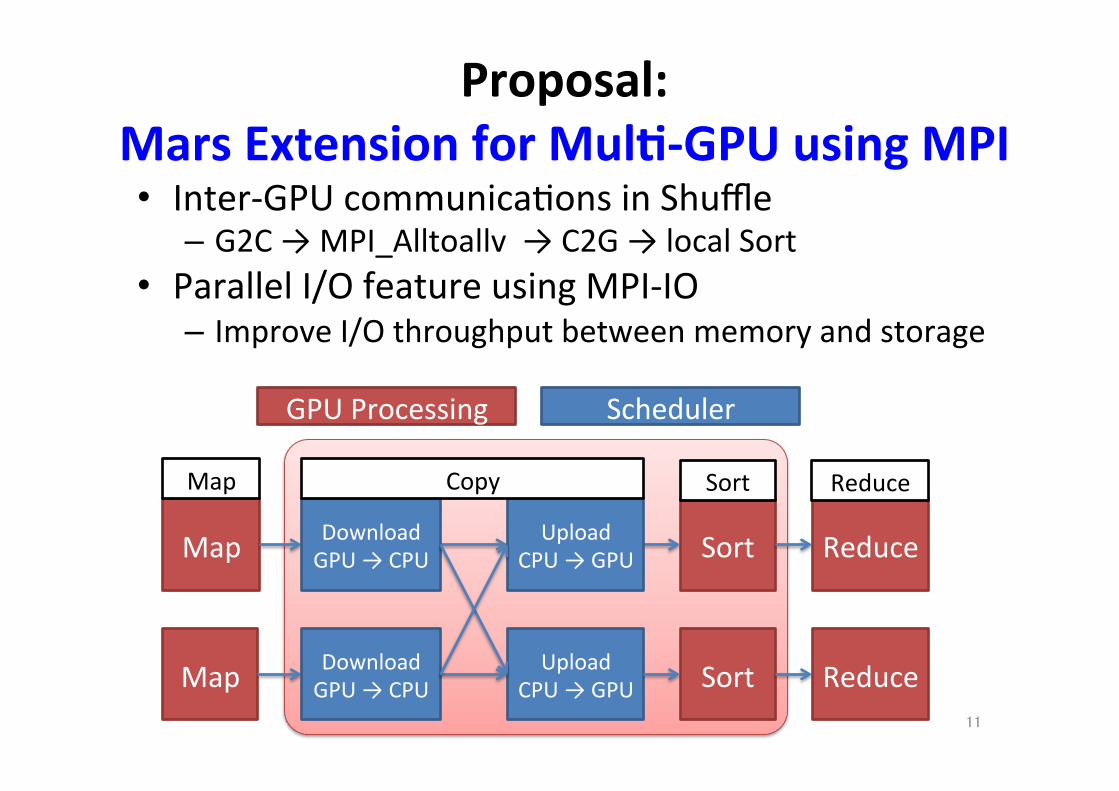
Proposal: Mars Extension for Mul.-‐GPU using MPI
Map Sort
Map Sort
Reduce
Reduce
GPU Processing Scheduler
Upload CPU → GPU
Download GPU → CPU
Download GPU → CPU
Upload CPU → GPU
• Inter-‐GPU communica;ons in Shuffle – G2C → MPI_Alltoallv → C2G → local Sort
• Parallel I/O feature using MPI-‐IO – Improve I/O throughput between memory and storage
11
Map Copy Sort Reduce
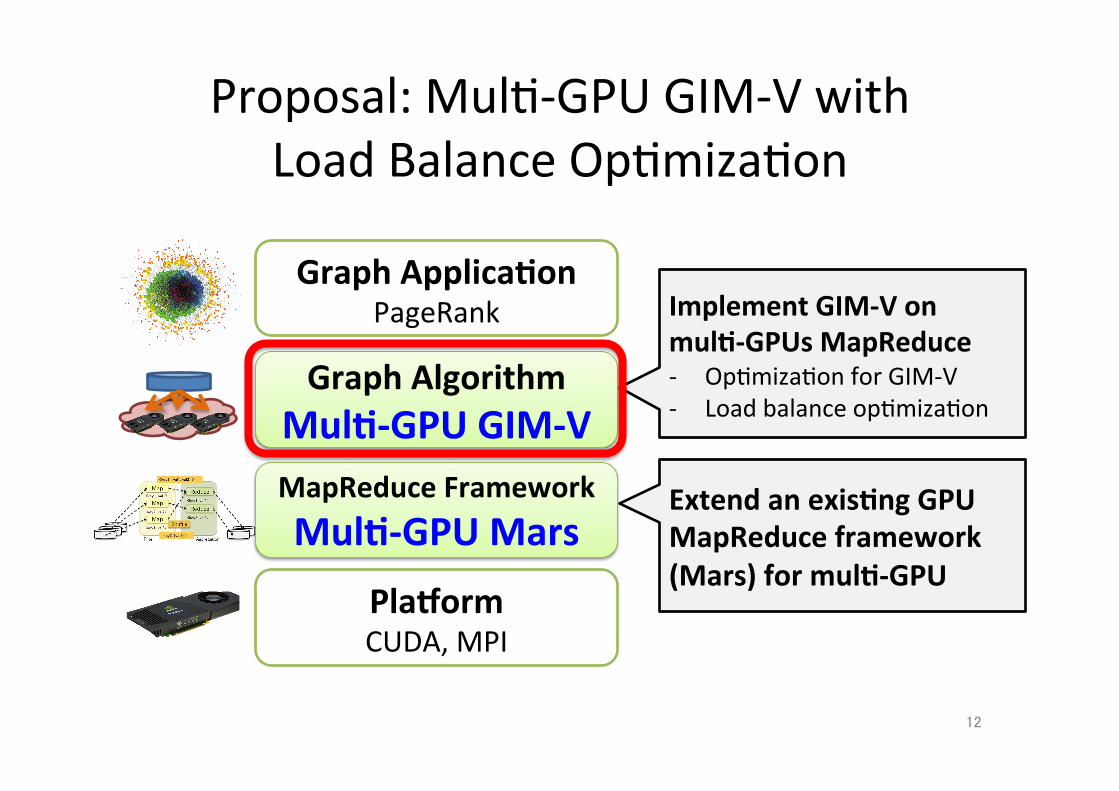
Proposal: Mul;-‐GPU GIM-‐V with Load Balance Op;miza;on
12
Graph Applica.on PageRank
Graph Algorithm Mul.-‐GPU GIM-‐V
MapReduce Framework Mul.-‐GPU Mars
PlaZorm CUDA, MPI
Implement GIM-‐V on mul.-‐GPUs MapReduce -‐ Op;miza;on for GIM-‐V -‐ Load balance op;miza;on
Extend an exis.ng GPU MapReduce framework (Mars) for mul.-‐GPU

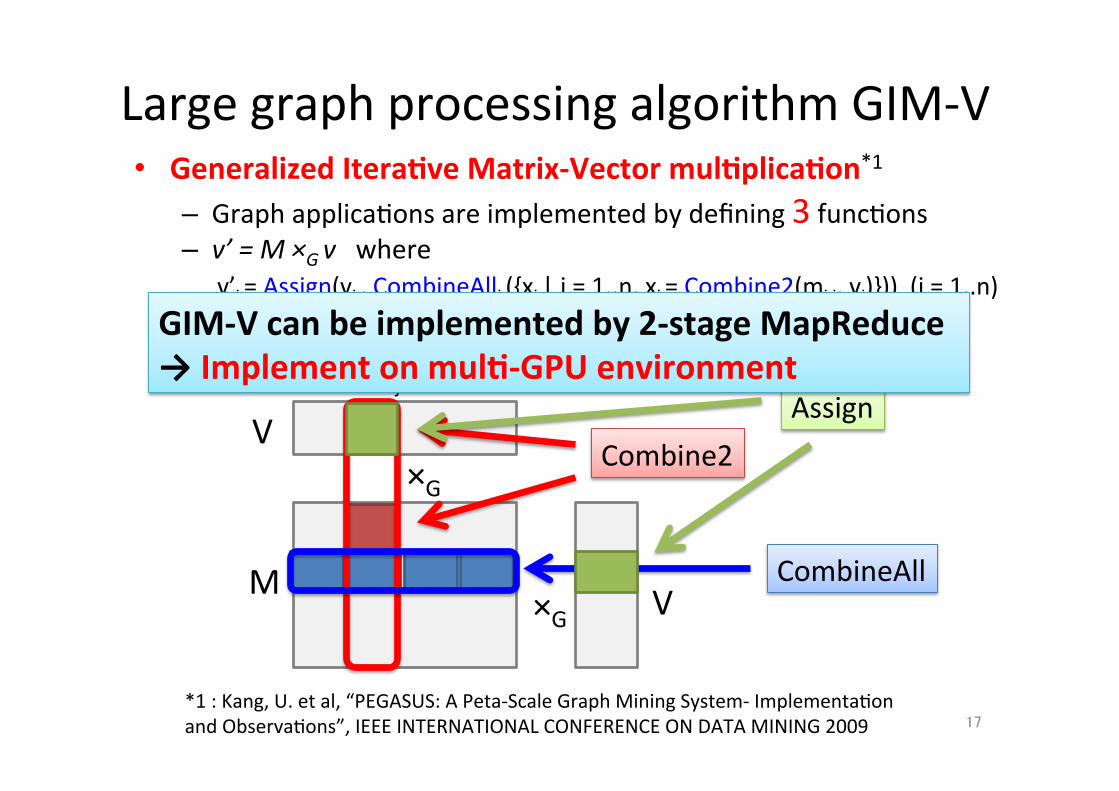
Large graph processing algorithm GIM-‐V
13 *1 : Kang, U. et al, “PEGASUS: A Peta-‐Scale Graph Mining System-‐ Implementa;on and Observa;ons”, IEEE INTERNATIONAL CONFERENCE ON DATA MINING 2009
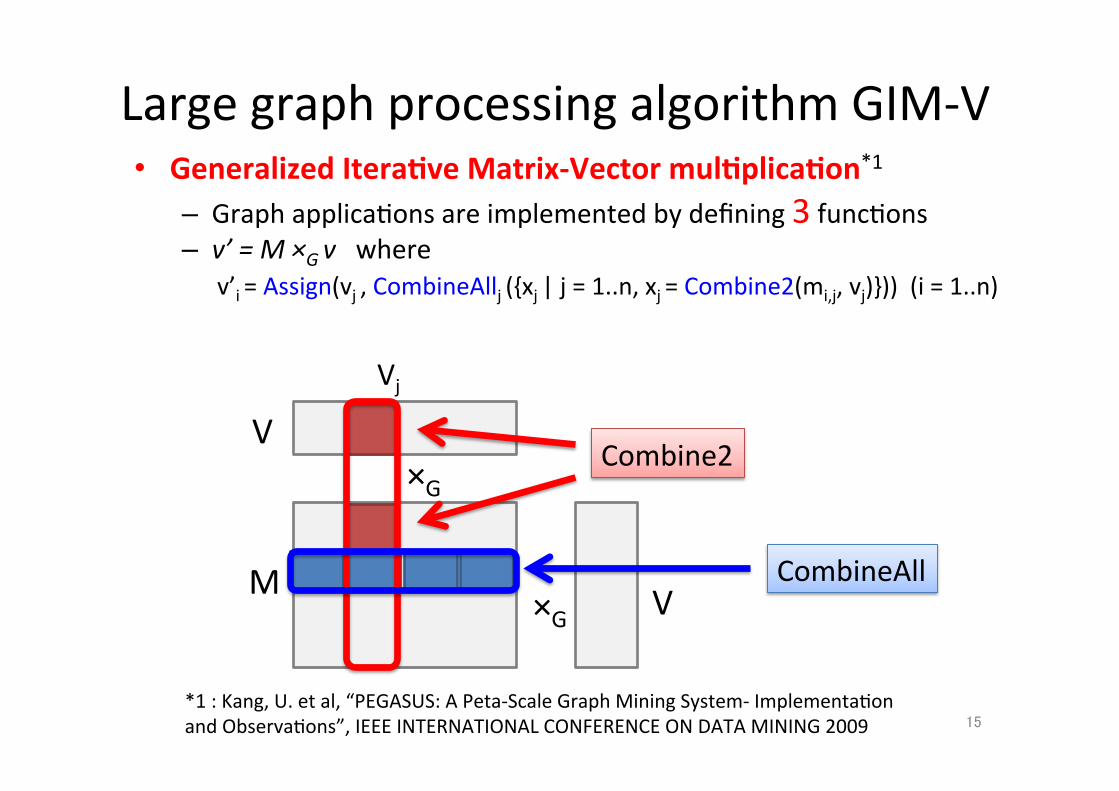
• Generalized Itera.ve Matrix-‐Vector mul.plica.on*1 – Graph applica;ons are implemented by defining 3 func;ons – v’ = M ×G v where
v’i = Assign(vj , CombineAllj ({xj | j = 1..n, xj = Combine2(mi,j, vj)})) (i = 1..n)
×G
Vj
V
M ×G
V

Large graph processing algorithm GIM-‐V
14 *1 : Kang, U. et al, “PEGASUS: A Peta-‐Scale Graph Mining System-‐ Implementa;on and Observa;ons”, IEEE INTERNATIONAL CONFERENCE ON DATA MINING 2009
×G
Vj
V
M ×G
Combine2
V
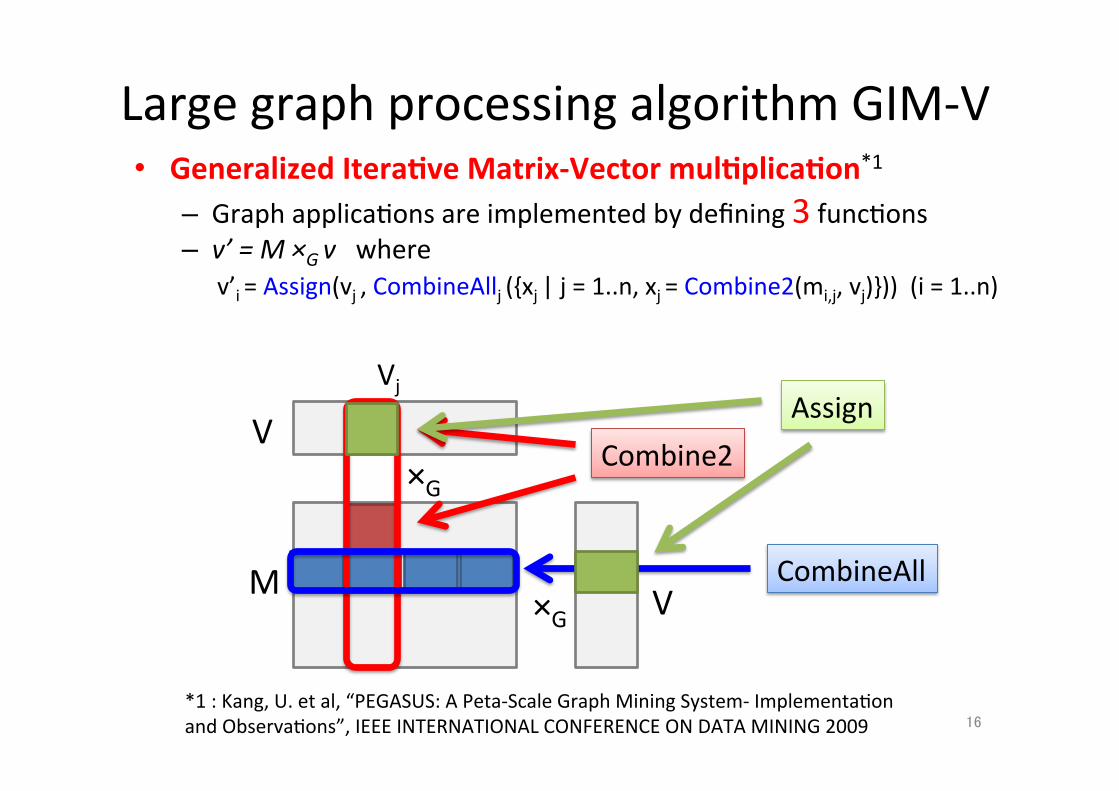
• Generalized Itera.ve Matrix-‐Vector mul.plica.on*1 – Graph applica;ons are implemented by defining 3 func;ons – v’ = M ×G v where
v’i = Assign(vj , CombineAllj ({xj | j = 1..n, xj = Combine2(mi,j, vj)})) (i = 1..n)
Large graph processing algorithm GIM-‐V
15 *1 : Kang, U. et al, “PEGASUS: A Peta-‐Scale Graph Mining System-‐ Implementa;on and Observa;ons”, IEEE INTERNATIONAL CONFERENCE ON DATA MINING 2009
×G
×G
Vj
V
M CombineAll V
Combine2
• Generalized Itera.ve Matrix-‐Vector mul.plica.on*1 – Graph applica;ons are implemented by defining 3 func;ons – v’ = M ×G v where
v’i = Assign(vj , CombineAllj ({xj | j = 1..n, xj = Combine2(mi,j, vj)})) (i = 1..n)
Large graph processing algorithm GIM-‐V
16 *1 : Kang, U. et al, “PEGASUS: A Peta-‐Scale Graph Mining System-‐ Implementa;on and Observa;ons”, IEEE INTERNATIONAL CONFERENCE ON DATA MINING 2009
×G
×G
Vj
V
M CombineAll V
Assign
Combine2
• Generalized Itera.ve Matrix-‐Vector mul.plica.on*1 – Graph applica;ons are implemented by defining 3 func;ons – v’ = M ×G v where
v’i = Assign(vj , CombineAllj ({xj | j = 1..n, xj = Combine2(mi,j, vj)})) (i = 1..n)
• Generalized Itera.ve Matrix-‐Vector mul.plica.on*1 – Graph applica;ons are implemented by defining 3 func;ons – v’ = M ×G v where
v’i = Assign(vj , CombineAllj ({xj | j = 1..n, xj = Combine2(mi,j, vj)})) (i = 1..n)
Large graph processing algorithm GIM-‐V
17 *1 : Kang, U. et al, “PEGASUS: A Peta-‐Scale Graph Mining System-‐ Implementa;on and Observa;ons”, IEEE INTERNATIONAL CONFERENCE ON DATA MINING 2009
×G
×G
Vj
V
M CombineAll V
Assign
Combine2
GIM-‐V can be implemented by 2-‐stage MapReduce → Implement on mul.-‐GPU environment
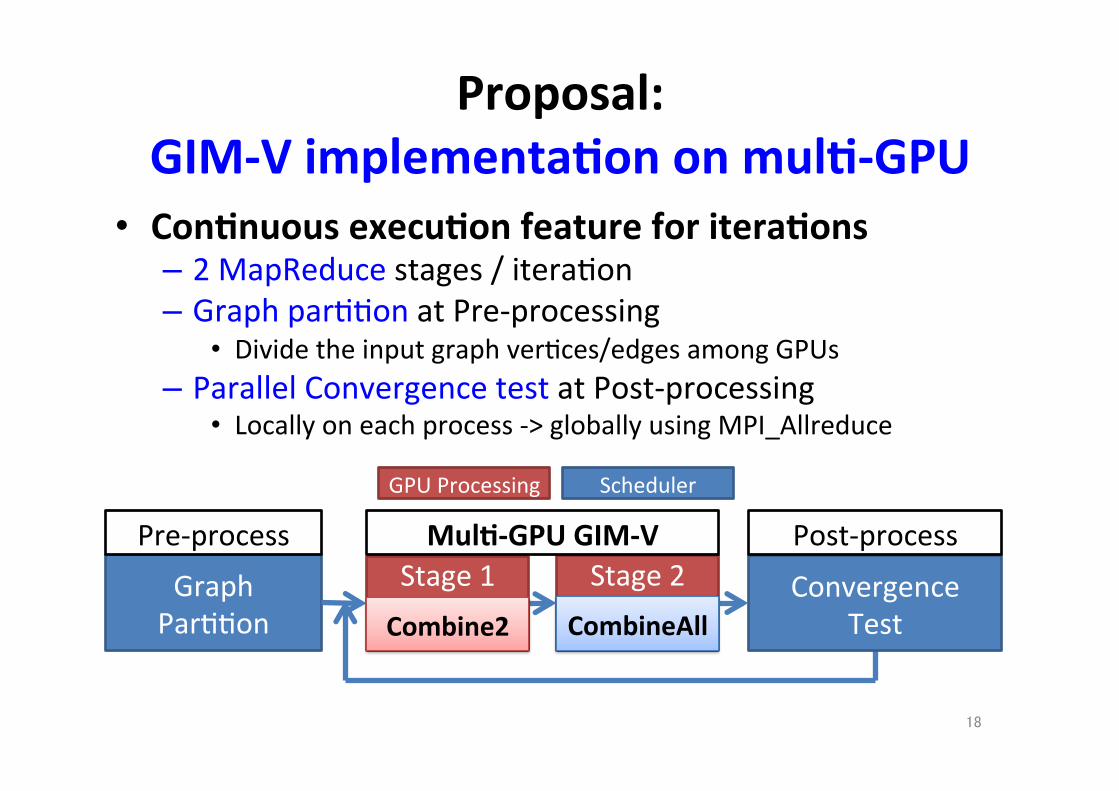
Proposal: GIM-‐V implementa.on on mul.-‐GPU
• Con.nuous execu.on feature for itera.ons – 2 MapReduce stages / itera;on – Graph par;;on at Pre-‐processing
• Divide the input graph ver;ces/edges among GPUs – Parallel Convergence test at Post-‐processing
• Locally on each process -‐> globally using MPI_Allreduce
18
Graph Par;;on
Stage 1
Stage 2
GPU Processing Scheduler
Pre-‐process
Convergence Test
Post-‐process Mul.-‐GPU GIM-‐V
Combine2 CombineAll
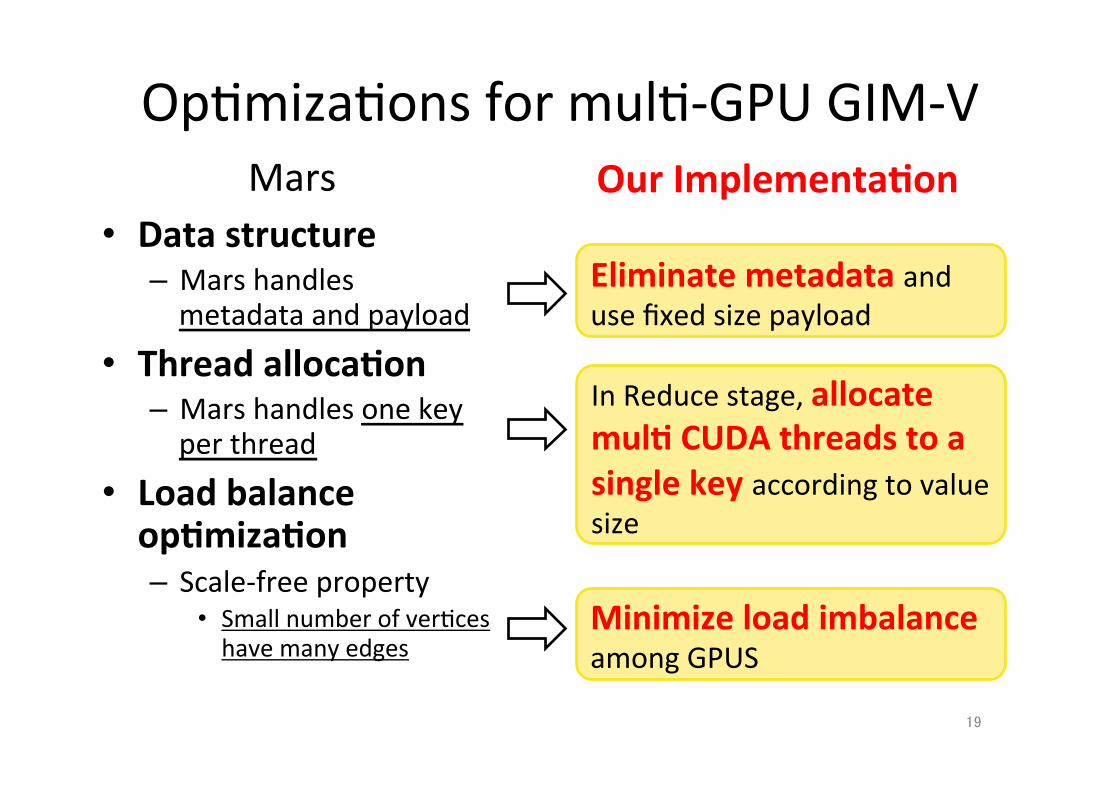
Eliminate metadata and use fixed size payload
Op;miza;ons for mul;-‐GPU GIM-‐V
• Data structure – Mars handles metadata and payload
• Thread alloca.on – Mars handles one key per thread
• Load balance op.miza.on – Scale-‐free property
• Small number of ver;ces have many edges
19
In Reduce stage, allocate mul. CUDA threads to a single key according to value size
Minimize load imbalance among GPUS
Mars Our Implementa.on
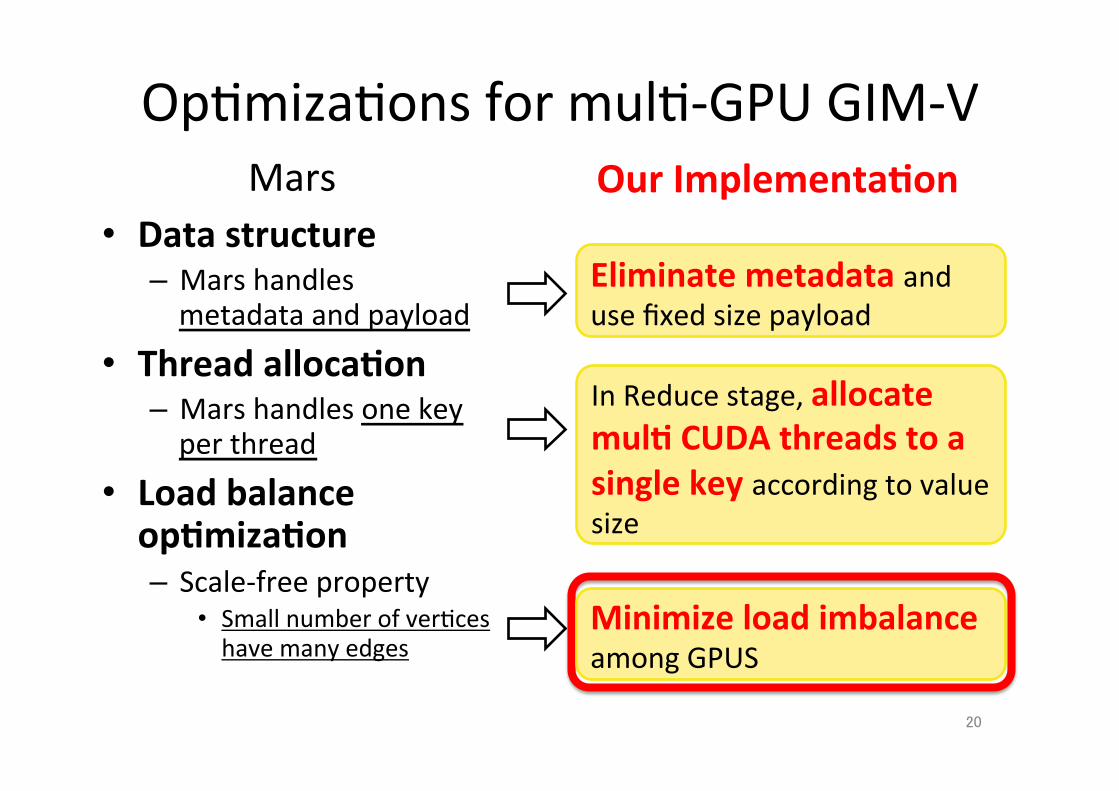
Eliminate metadata and use fixed size payload
Op;miza;ons for mul;-‐GPU GIM-‐V
• Data structure – Mars handles metadata and payload
• Thread alloca.on – Mars handles one key per thread
• Load balance op.miza.on – Scale-‐free property
• Small number of ver;ces have many edges
20
In Reduce stage, allocate mul. CUDA threads to a single key according to value size
Mars Our Implementa.on
Minimize load imbalance among GPUS
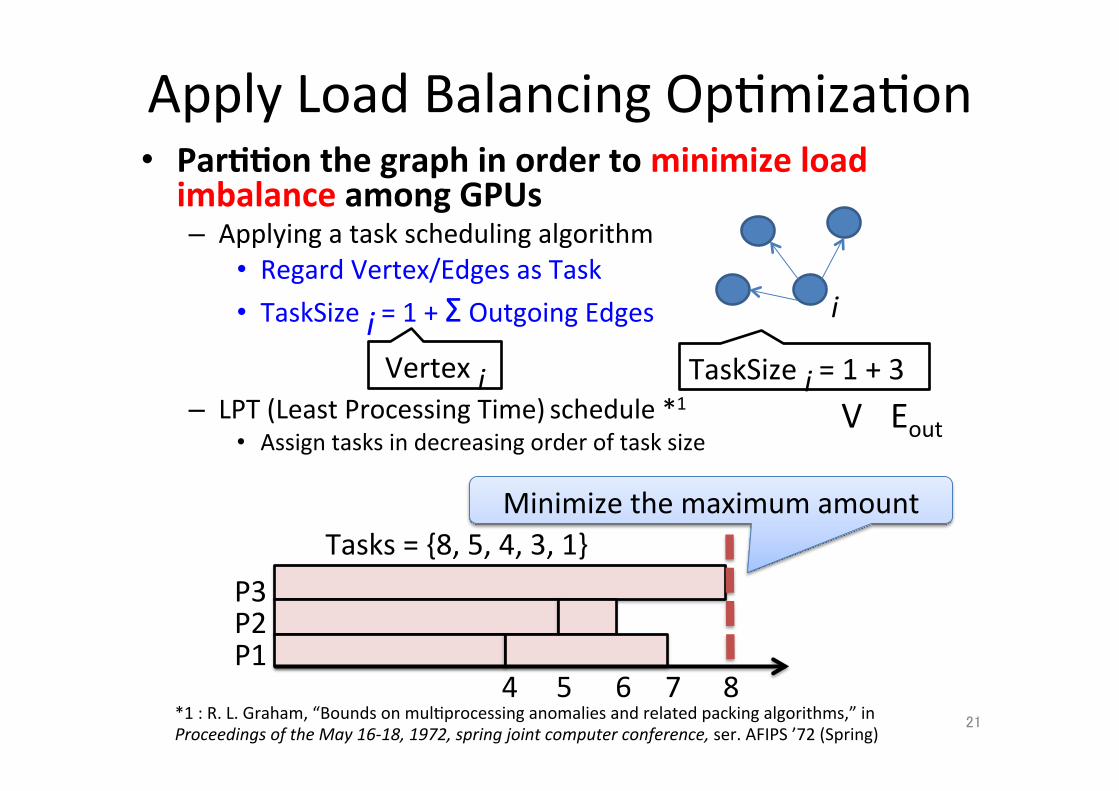
Apply Load Balancing Op;miza;on • Par..on the graph in order to minimize load imbalance among GPUs – Applying a task scheduling algorithm
• Regard Vertex/Edges as Task • TaskSize i = 1 + Σ Outgoing Edges
– LPT (Least Processing Time) schedule *1
• Assign tasks in decreasing order of task size
*1 : R. L. Graham, “Bounds on mul;processing anomalies and related packing algorithms,” in Proceedings of the May 16-‐18, 1972, spring joint computer conference, ser. AFIPS ’72 (Spring)
P3 P2 P1
4 5 6 8 7
Tasks = {8, 5, 4, 3, 1} Minimize the maximum amount
Vertex i
i
TaskSize i = 1 + 3 V Eout
21

Experiments
• Methods – A single round of itera;ons (w/o Preprocessing) – PageRank applica;on
• Measures rela;ve importance of web pages
– Input data • Ar;ficial Kronecker graphs
– Generated by generator in Graph 500 • Parameters
– SCALE: log 2 of #ver;ces (#ver;ces = 2SCALE) – Edge_factor: 16 (#edges = Edge_factor × #ver;ces)
22
16 4 3
2 1
8 12 4
8 6 4 2
12 3 2 1 4 3 2 1
G2 =G1⊗G1G1
Study the performance of our mul.-‐GPU GIM-‐V • Scalability • Comparison w/ a CPU-‐based implementa.on • Validity of the load balance op.miza.on
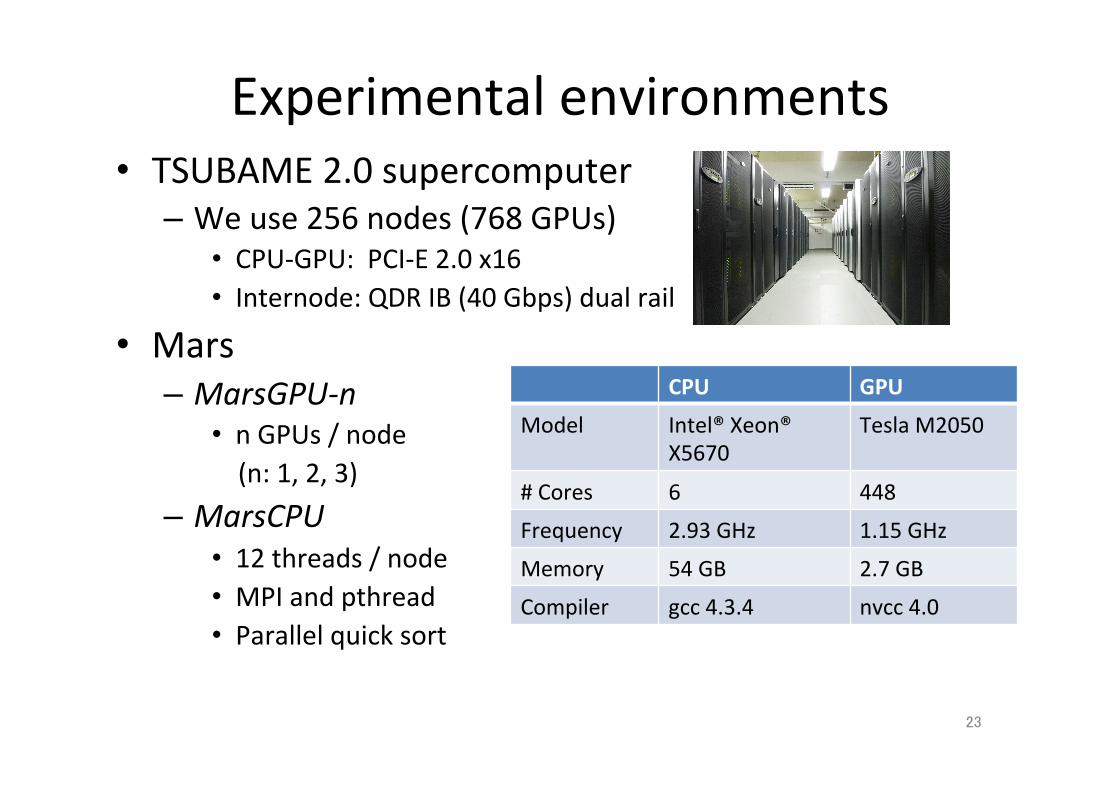
Experimental environments • TSUBAME 2.0 supercomputer – We use 256 nodes (768 GPUs)
• CPU-‐GPU: PCI-‐E 2.0 x16 • Internode: QDR IB (40 Gbps) dual rail
• Mars – MarsGPU-‐n
• n GPUs / node (n: 1, 2, 3)
– MarsCPU • 12 threads / node • MPI and pthread • Parallel quick sort
23
CPU GPU
Model Intel® Xeon® X5670
Tesla M2050
# Cores 6 448
Frequency 2.93 GHz 1.15 GHz
Memory 54 GB 2.7 GB
Compiler gcc 4.3.4 nvcc 4.0
24
0
10
20
30
40
50
60
70
80
90
100
0 50 100 150 200 250 300
MEgde
s / se
c
# Compute Nodes
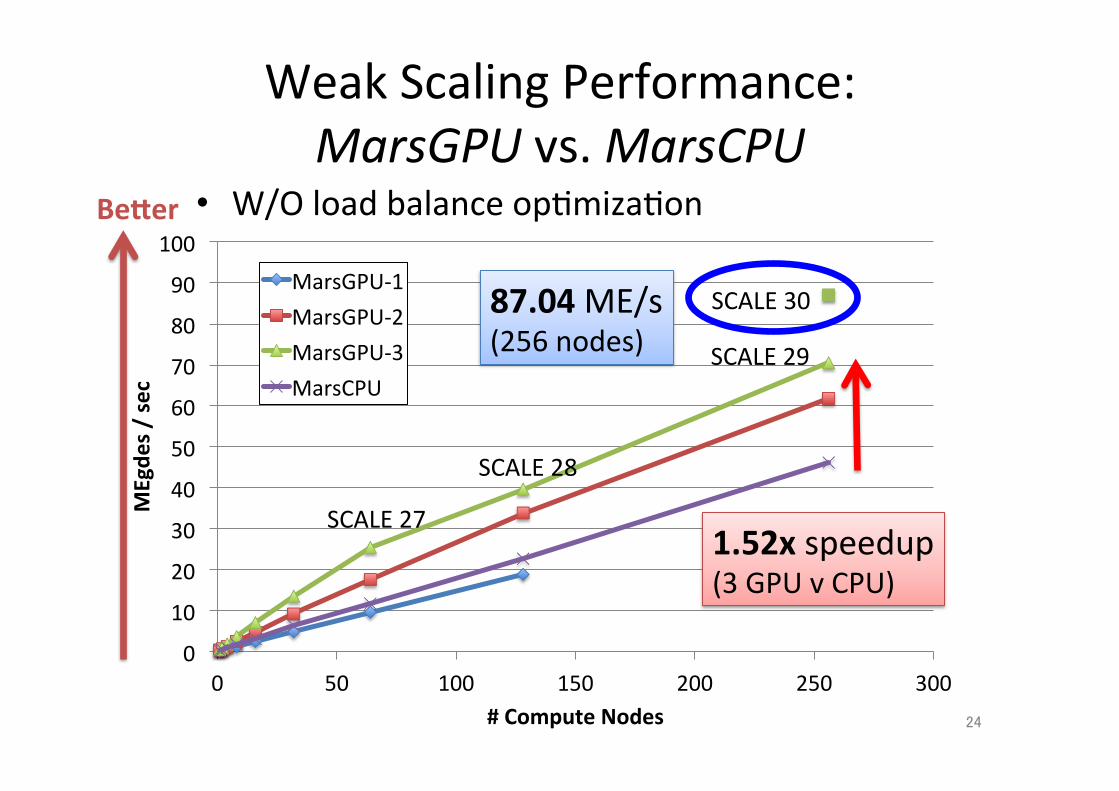
MarsGPU-‐1 MarsGPU-‐2 MarsGPU-‐3 MarsCPU
SCALE 30
SCALE 29
SCALE 28
SCALE 27
87.04 ME/s (256 nodes)
1.52x speedup (3 GPU v CPU)
Weak Scaling Performance: MarsGPU vs. MarsCPU
Becer • W/O load balance op;miza;on
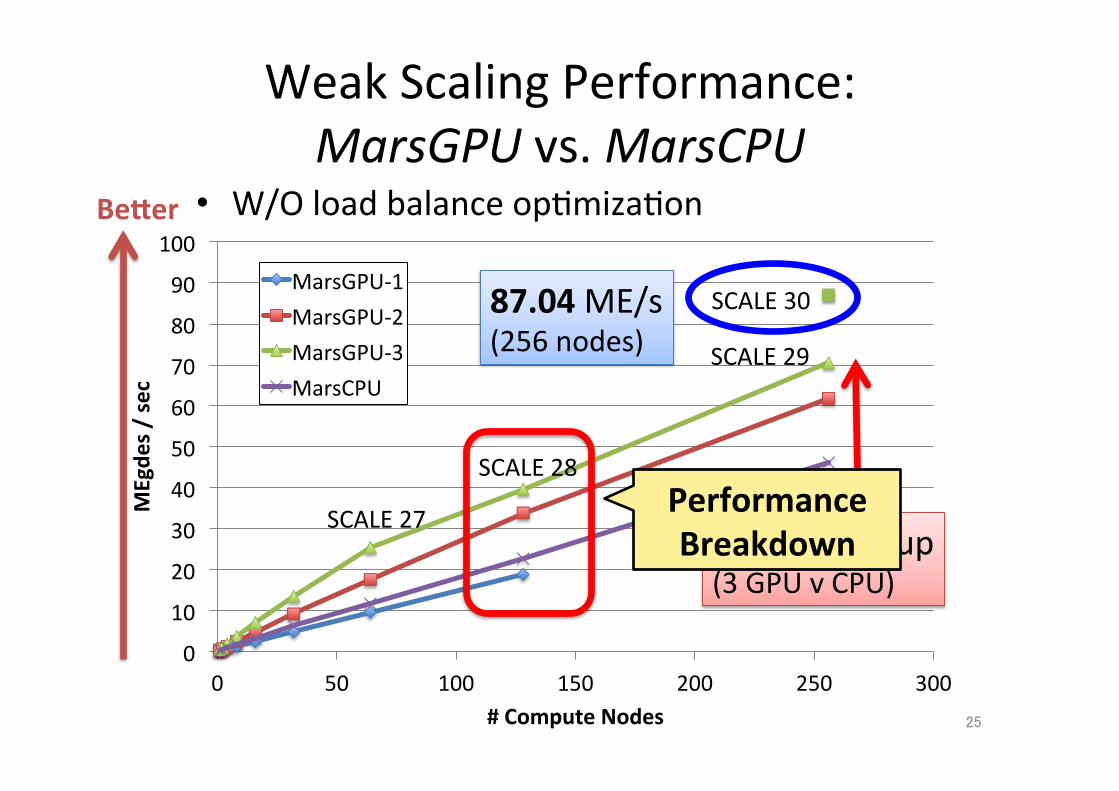
Weak Scaling Performance: MarsGPU vs. MarsCPU
25
0
10
20
30
40
50
60
70
80
90
100
0 50 100 150 200 250 300
MEgde
s / se
c
# Compute Nodes
MarsGPU-‐1 MarsGPU-‐2 MarsGPU-‐3 MarsCPU
SCALE 30
SCALE 29
SCALE 28
SCALE 27
Becer • W/O load balance op;miza;on
87.04 ME/s (256 nodes)
1.52x speedup (3 GPU v CPU)
Performance Breakdown
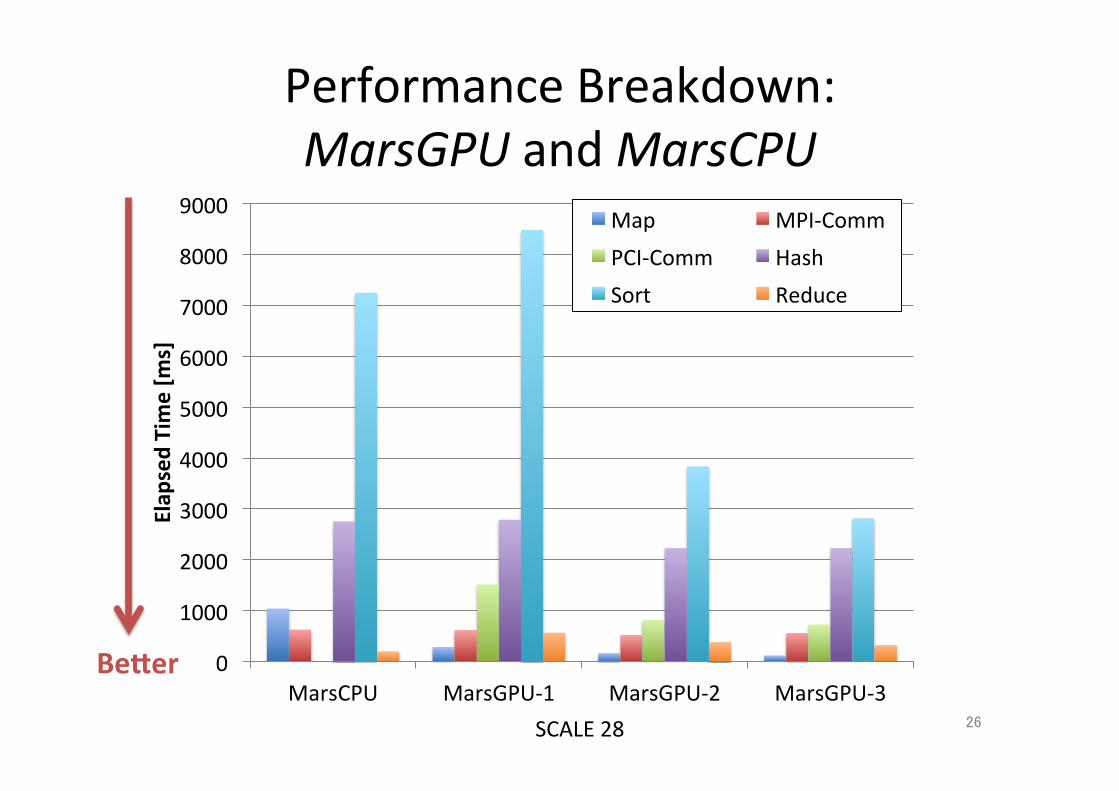
26
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
MarsCPU MarsGPU-‐1 MarsGPU-‐2 MarsGPU-‐3
Elap
sed Time [m
s]
Map MPI-‐Comm PCI-‐Comm Hash Sort Reduce
Performance Breakdown: MarsGPU and MarsCPU
Becer
SCALE 28
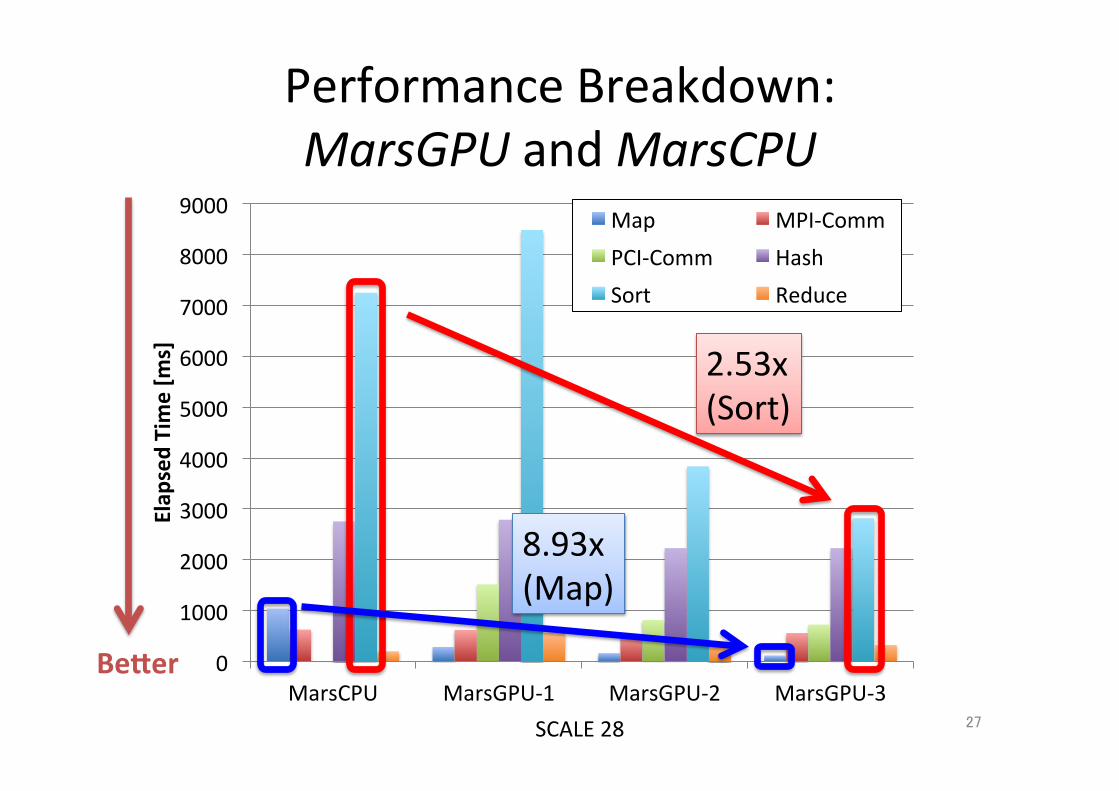
27
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
MarsCPU MarsGPU-‐1 MarsGPU-‐2 MarsGPU-‐3
Elap
sed Time [m
s]
Map MPI-‐Comm PCI-‐Comm Hash Sort Reduce
Performance Breakdown: MarsGPU and MarsCPU
8.93x (Map)
2.53x (Sort)
Becer
SCALE 28
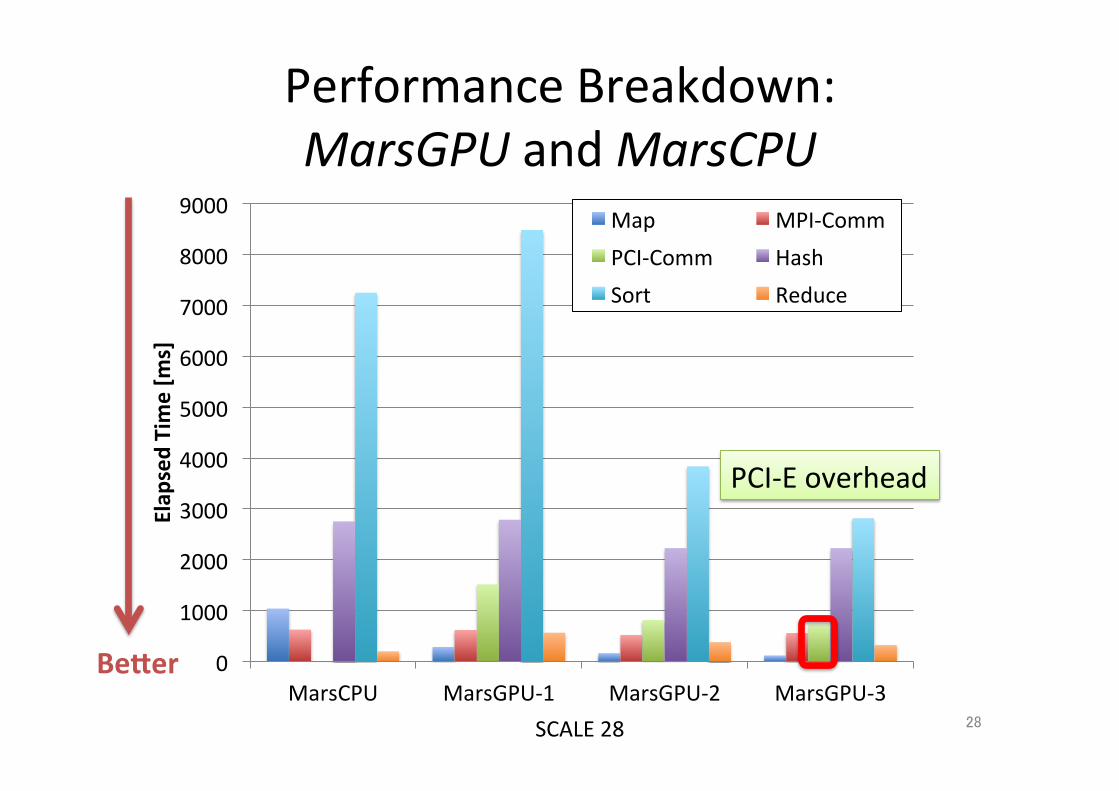
28
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
MarsCPU MarsGPU-‐1 MarsGPU-‐2 MarsGPU-‐3
Elap
sed Time [m
s]
Map MPI-‐Comm PCI-‐Comm Hash Sort Reduce
Performance Breakdown: MarsGPU and MarsCPU
Becer
SCALE 28
PCI-‐E overhead
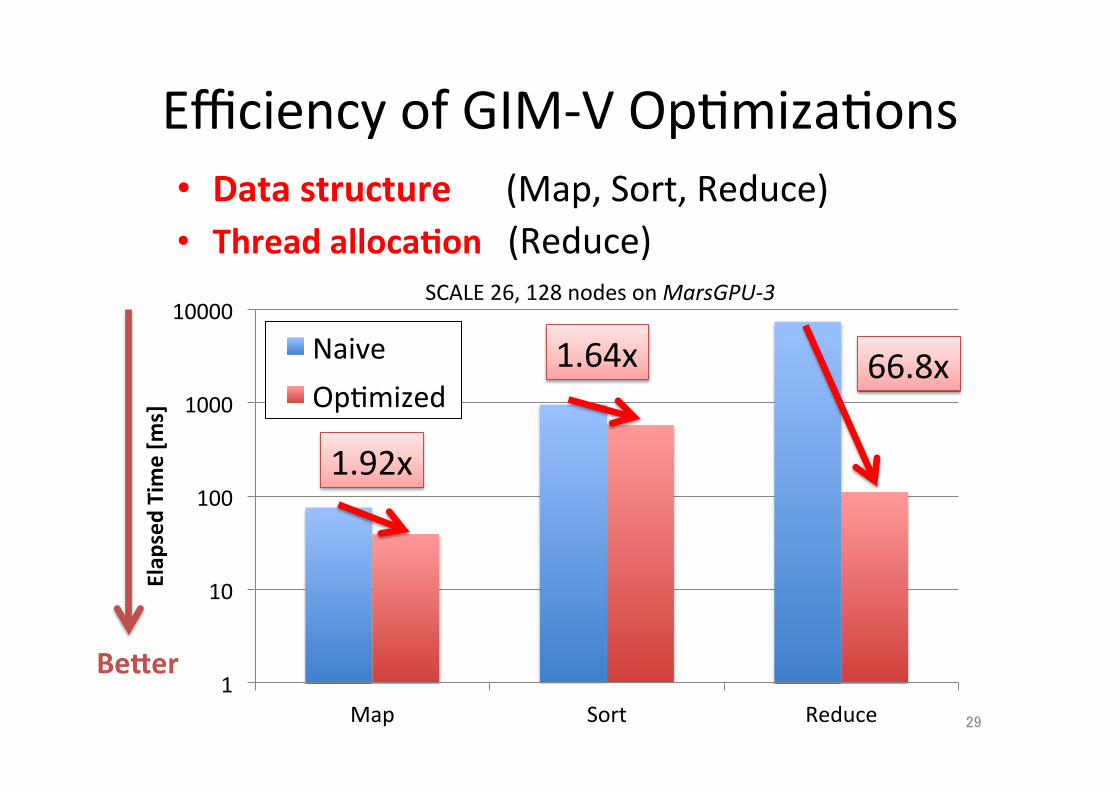
Efficiency of GIM-‐V Op;miza;ons • Data structure (Map, Sort, Reduce) • Thread alloca.on (Reduce)
29
1
10
100
1000
10000
Map Sort Reduce
Elap
sed Time [m
s]
Naive Op;mized
1.92x
1.64x 66.8x
SCALE 26, 128 nodes on MarsGPU-‐3
Becer
30
0
10
20
30
40
50
60
70
80
90
0 20 40 60 80 100 120 140
MEd
ges /
Sec
# Compute Nodes
MarsGPU-‐3 MarsGPU-‐3 LPT
1.16x
1.16x Speedup
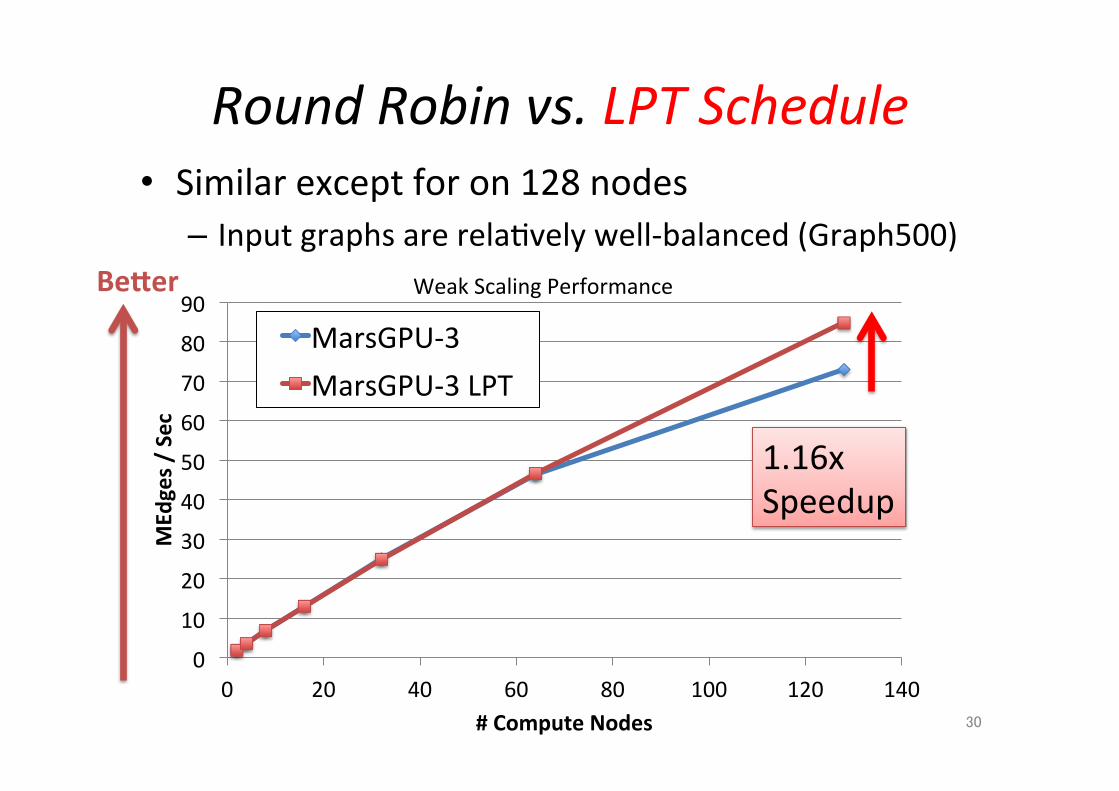
Round Robin vs. LPT Schedule • Similar except for on 128 nodes – Input graphs are rela;vely well-‐balanced (Graph500)
Weak Scaling Performance Becer
31
0
10
20
30
40
50
60
70
80
90
0 20 40 60 80 100 120 140
MEd
ges /
Sec
# Compute Nodes
MarsGPU-‐3 MarsGPU-‐3 LPT
1.16x
1.16x Speedup
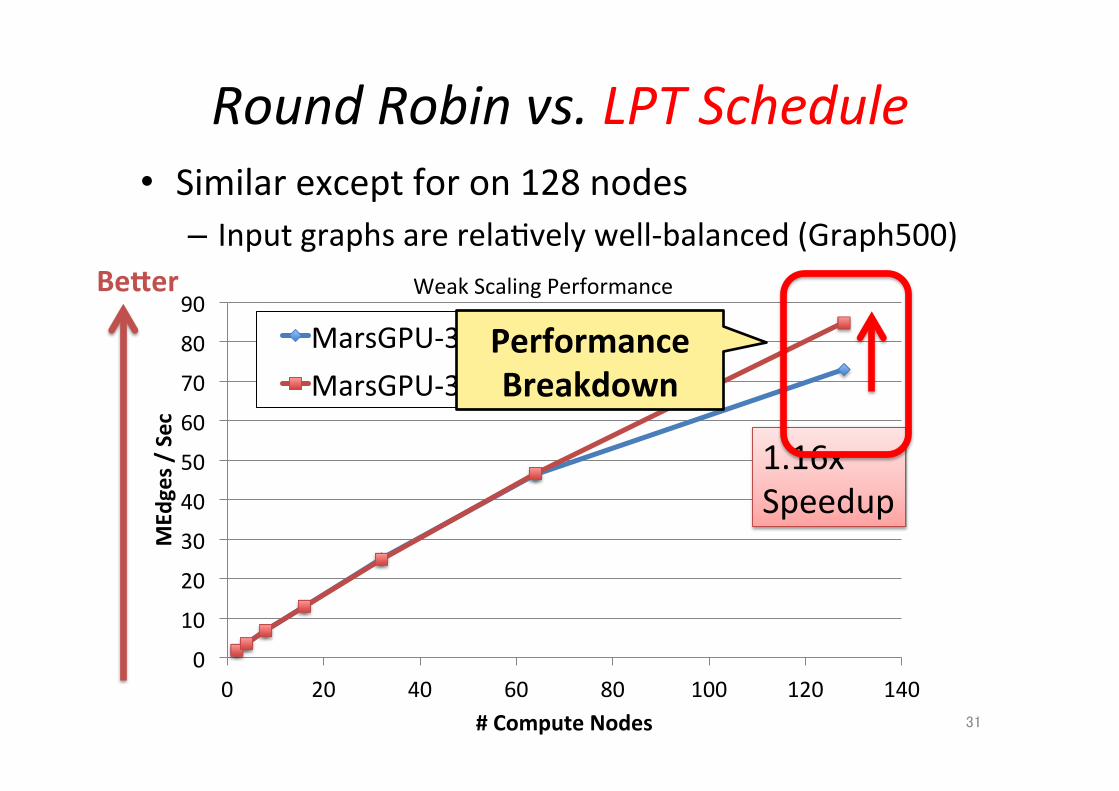
Performance Breakdown
• Similar except for on 128 nodes – Input graphs are rela;vely well-‐balanced (Graph500)
Weak Scaling Performance
Round Robin vs. LPT Schedule
Becer
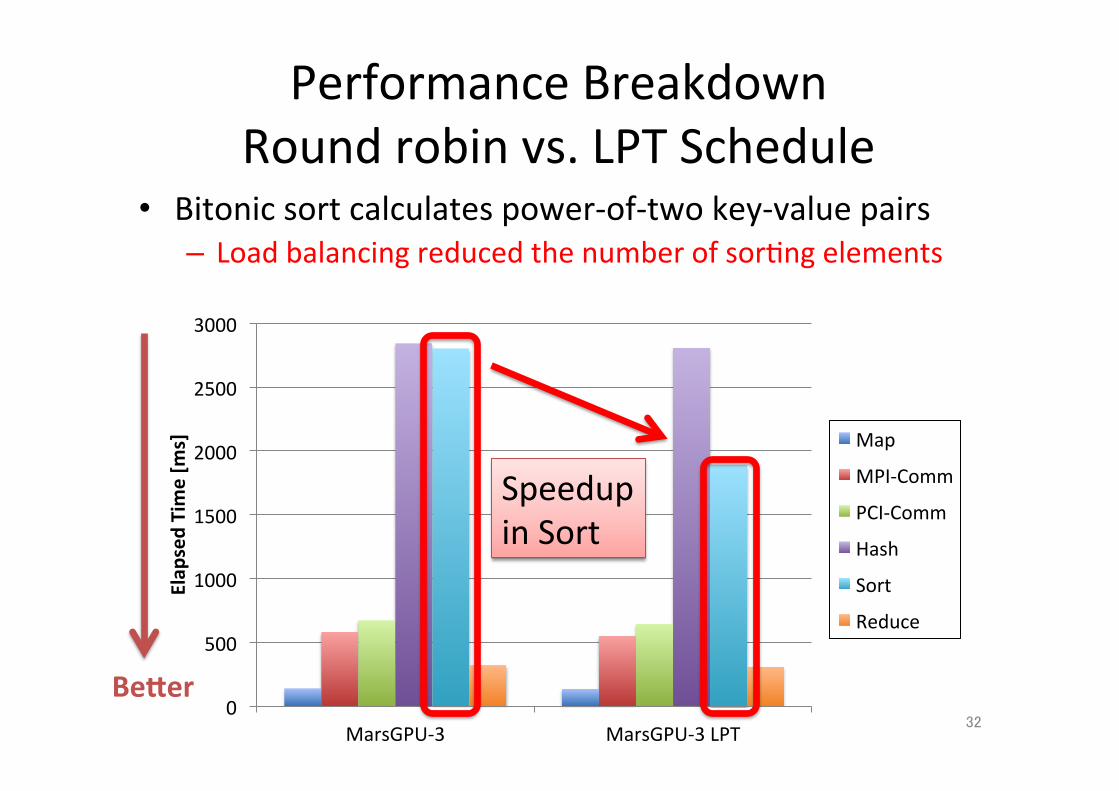
Performance Breakdown Round robin vs. LPT Schedule
• Bitonic sort calculates power-‐of-‐two key-‐value pairs – Load balancing reduced the number of sor;ng elements
32 0
500
1000
1500
2000
2500
3000
MarsGPU-‐3 MarsGPU-‐3 LPT
Elap
sed Time [m
s] Map
MPI-‐Comm
PCI-‐Comm
Hash
Sort
Reduce
Speedup in Sort
Becer
33
1
10
100
1000
10000
100000
PEGASUS MarsCPU MarsGPU-‐3
KEdges / Sec
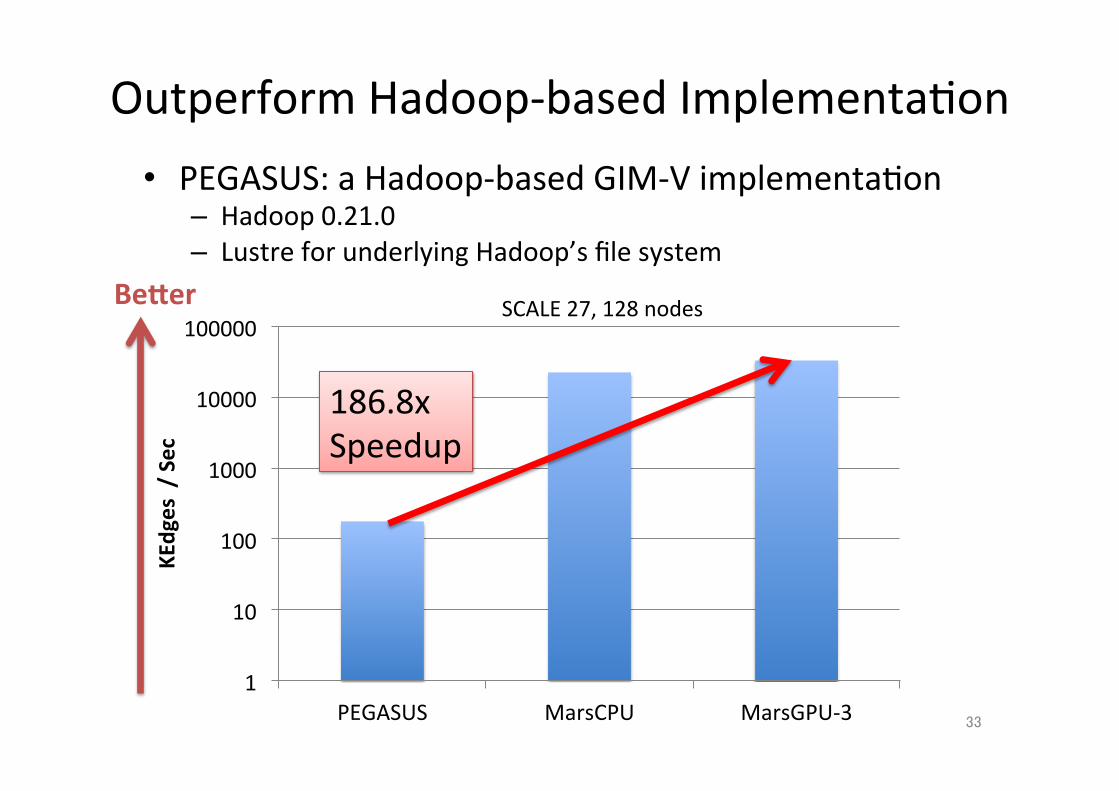
Outperform Hadoop-‐based Implementa;on
• PEGASUS: a Hadoop-‐based GIM-‐V implementa;on – Hadoop 0.21.0 – Lustre for underlying Hadoop’s file system
186.8x Speedup
SCALE 27, 128 nodes Becer

Related Work • Graph processing using GPU – Shortest path algorithms for GPU (BFS,SSSP, and APSP)*1
→ Not achieve compe;;ve performance • MapReduce implementa;ons on GPUs – GPMR*2 : MapReduce implementa;on on mul; GPUs → Not show scalability for large-‐scale processing
• Graph processing with load balancing – Load balancing while keeping communica;on low on R-‐MAT graphs*3
→ We show the task scheduling-‐based load-‐balancing
34
*1 : Harish, P. et al, “Accelera;ng Large Graph Algorithms on the GPU using CUDA”, HiPC 2007. *2 : Stuart, J.A. et al, “Mul;-‐GPU MapReduce on GPU Clusters”, IPDPS 2011. *3 : J. Chhugani, N. Sa;sh, C. Kim, J. Sewall, and P. Dubey, “Fast and Efficient Graph Traversal Algorithm for CPUs: Maximizing single-‐node efficiency,” in Parallel Distributed Processing Symposium (IPDPS), 2012

Conclusions • A scalable MapReduce-‐based GIM-‐V implementa.on using mul.-‐GPU – Methodology • Extend Mars to support mul;-‐GPU • GIM-‐V using mul;-‐GPU MapReduce • Load balance op;miza;on
– Performance • 87.04 ME/s on SCALE 30 (256 nodes, 768 GPUs) • 1.52x speedup than the CPU-‐based implementa;on
• Future work – Op;miza;on of our implementa;on
• Improve communica;on, locality – Data handling larger than GPU memory capacity
• Memory hierarchy management (GPU, DRAM, NVM, SSD) 35
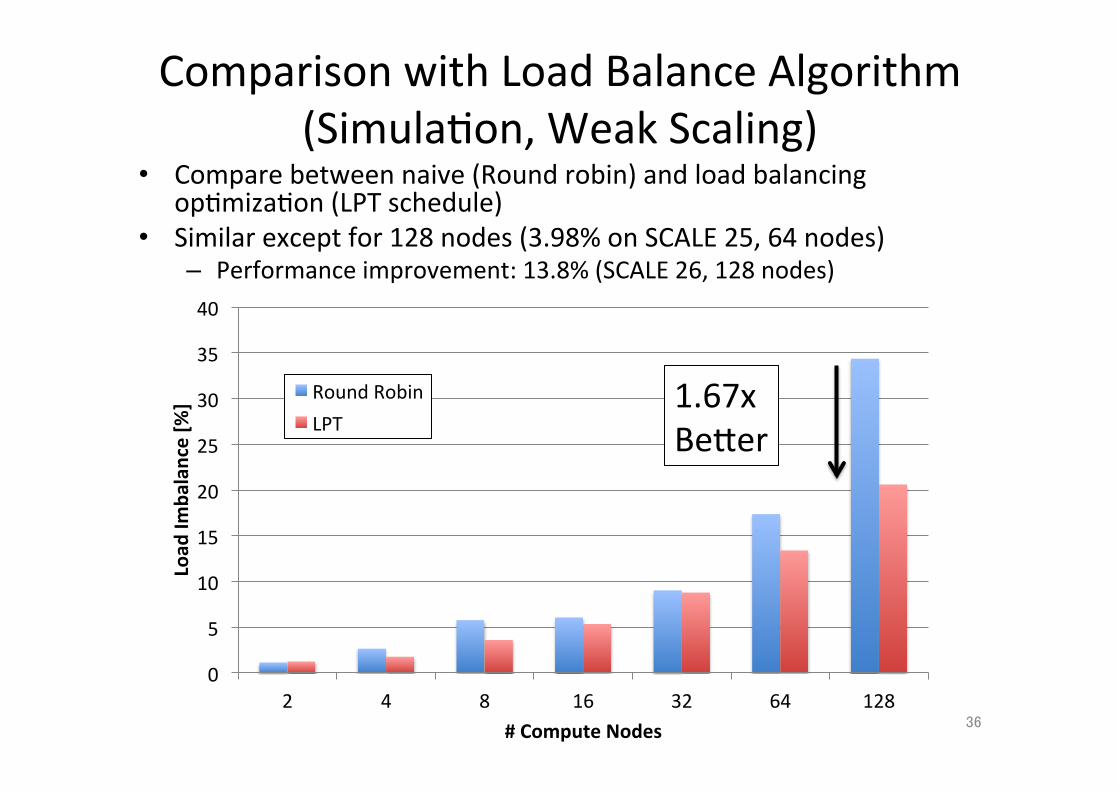
Comparison with Load Balance Algorithm (Simula;on, Weak Scaling)
• Compare between naive (Round robin) and load balancing op;miza;on (LPT schedule)
• Similar except for 128 nodes (3.98% on SCALE 25, 64 nodes) – Performance improvement: 13.8% (SCALE 26, 128 nodes)
36
0
5
10
15
20
25
30
35
40
2 4 8 16 32 64 128
Load
Imba
lance [%
]
# Compute Nodes
Round Robin LPT
1.67x BeXer
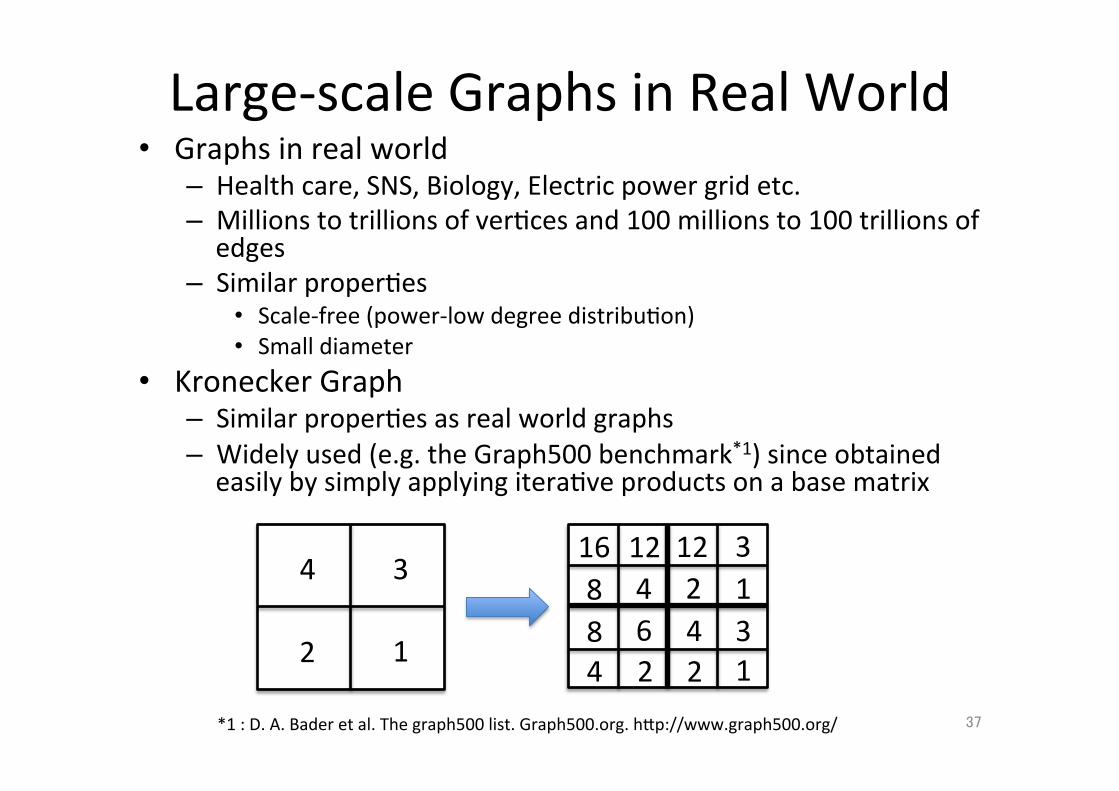
Large-‐scale Graphs in Real World • Graphs in real world
– Health care, SNS, Biology, Electric power grid etc. – Millions to trillions of ver;ces and 100 millions to 100 trillions of edges
– Similar proper;es • Scale-‐free (power-‐low degree distribu;on) • Small diameter
• Kronecker Graph – Similar proper;es as real world graphs – Widely used (e.g. the Graph500 benchmark*1) since obtained easily by simply applying itera;ve products on a base matrix
37 *1 : D. A. Bader et al. The graph500 list. Graph500.org. hXp://www.graph500.org/
16 4 3
2 1
8 12 4
8 6 4 2
12 3 2 1 4 3 2 1















![Mimir: Memory-Efficient and Scalable MapReduce for Large …balaji/pubs/2017/ipdps/ipdps17... · 2017-02-26 · example, supercomputers such as the IBM Blue Gene/Q [3] use specialized](https://img.dokumen.tips/doc/110x75/5e8f3efb6688c80a9f1ea088/mimir-memory-eficient-and-scalable-mapreduce-for-large-balajipubs2017ipdpsipdps17.jpg)













