Embed Size (px)
Citation preview

Convolutional Neural Networks forNatural Language Processing
Adriaan Schakel
November 26, 2015

Google Trends
Query: convolutional neural networks
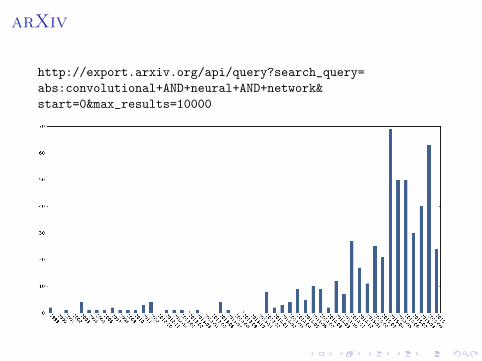
arXiv
http://export.arxiv.org/api/query?search_query=
abs:convolutional+AND+neural+AND+network&
start=0&max_results=10000

ILSVRC2012
I Challenge: identify main objects present in images (from 1000 objectcategories)
I Tranining data: 1,2 million labelled images
I October 13, 2012: results released
I Winner: Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton(University of Toronto)
I Score: top-5 test error rate of 15.3%, compared to 26.2% achievedby second-best entry

ILSVRC2012
Krizhevsky, Sutskever, and Hinton (2012)

ILSVRC2012
AlexNet:
I deep ConvNet trained on raw RGB pixel values
I 60 million parameters and 650,000 neurons
I 5 convolutional layers (some followed by max-pooling layers) and3 globally-connected layers
I a final 1000-way softmax
I trained on two NVIDIA GPUs for about a week
I use of dropout in the globally-connected layers
DNNResearch

Radical Change
Letter from Yann LeCun to editor of CVPR 2012:
Getting papers about feature learning accepted at visionconference has always been a struggle, and I’ve had more thanmy share of bad reviews over the years. I was very sure thatthis paper was going to get good reviews because:
I it uses no hand-crafted features (it’s all learned all the waythrough. Incredibly, this was seen as a negative point bythe reviewers!);
I it beats all published results on 3 standard datasets forscene parsing;
I it’s an order of magnitude faster than the competingmethods.
If that is not enough to get good reviews, I just don’t knowwhat is. So, I’m giving up on submitting to computer visionconferences altogether. (. . . ) Submitting our papers is just awaste of everyone’s time (and incredibly demoralizing to my labmembers).

Revolution?History:
I 1980: introduction of ConvNets by Fukushima
I late 1980s: further development by LeCun andcollaborators @ Bell Labs
I late 1990s: LeNet-5 was reading about 20% ofwritten checks in U.S.
Breakthrough due to:
I persistence of academic researchers
I improved algorithms
I increase in computing power
I increase in amount of data
I dissemination of knowledge
http://www.elitestreetsmagazine.com/magazine/2008/jan-mar/art.php

Neural Networks
1943 McCulloch and Pitts proposed first artificial neuron:
computes weighted sum of its binary input signals,xi = 0, 1
y = θ
(n∑
i=1
wixi − u
)1957 Rosenblatt developed a learning algorithm: the perceptron
(for linearly separable data only)
K Jain, J Mao, KM Mohiuddin - IEEE computer, 1996

Perceptron
The New York Times July 7, 1958:
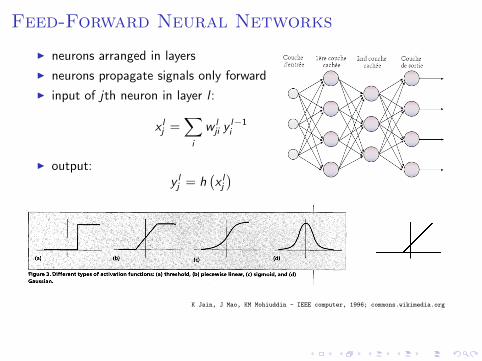
Feed-Forward Neural Networks
I neurons arranged in layers
I neurons propagate signals only forward
I input of jth neuron in layer l :
x lj =
∑i
w lji y l−1
i
I output:y lj = h
(x lj
)
K Jain, J Mao, KM Mohiuddin - IEEE computer, 1996; commons.wikimedia.org

Backpropagation
Paul Werbos (1974):
1. initialize weights to small random values
2. choose input pattern
3. propagate signal forward through network
4. determine error (E ) and propagate it backwards through network toassign credit/blame to each unit
5. update weights by means of gradient descent:
∆wji = −η ∂E
∂wji

ConvNetsFeed-forward nets w/:
I local receptive field
I shared weights
Applications:
I character recognition
I face recognition
I medical diagnosis
I self-driving cars
I object recognition(e.g. birds)

Race to bring Deep Learning to the Masses
Major players:
I Google
I Facebook
I Baidu
I Microsoft
I Nvidia
I Apple
I Amazon
LeCun @ Facebook
http://www.popsci.com/facebook-ai

Fooling ConvNets
I fix trained network
I carry out backprop using wrong class label
I update input pixels:
Goodfellow, Shlens, and Szegedy, ICLR 2015

Dreaming ConvNets
I fix trained network
I initialize input byaverage image ofsome class
I carry out backpropusing that class’label
I update input pixels:
Simonyan, Vedaldi, and Zisserman, arXiv:1312.6034

ConvNets for NLP Tasks
2008:
Case study: sentiment analysis (classification)
Rationale: key phrases, that are indicative of class membership, canappear anywhere in a document

Applications
almost every image posted by MrsMerkel’s office of her in meetingsand summits has attractedcomments in Russian criticisingher and her policies.
Staff in Mrs Merkel’s office havebeen deleting comments but someremain despite the purge.
FAZ 07.06.2015:
Merkels Social-Media-Team, dessen Mitarbeiterzahl nichtbekanntgegeben wird, war heillos uberfordert.

Pre-trained Word VectorsWord embeddings:
I dense vectors (w/ dimension d of order 100)
I derived from word co-occurrences: a word is characterized by thecompany it keeps (Firth, 1957)
I GloVe [Pennington, Socher, and Manning (2014)]:I log-bilinear regression modelI learns word vectors, such that:
log(Xij) = wTi wj + bi + bj
I Xij the number of times word j occurs in the context of word iI wi ∈ Rd word vectorsI wj ∈ Rd context word vectors
I Word2vec (skip-gram algorithm) [Mikolov et al. (2013)]:I shallow feed-forward neural networkI learns word vectors, such that:
Xij∑j Xij
=ew
Ti wj∑
j ewTi wj

Pre-trained Word VectorsKim (2014): Sentence classification
Hyperparameters:
I filters of width (regionsize) 3, 4, and 5
I 100 feature maps each
I max-pooling layer
I penultimate layer: 300units
Datasets (average sentence length ∼ 20):
I movie reviews w/ one sentence perreview (pos/neg?)
I electronic product reviews (pos/neg?)
I TREC question dataset. Is questionabout a person, a location, numericinformation, etc.? (6 categories).
arXiv:1408.5882

One-Hot VectorsJohnson and Zhang (2015): Classification of larger pieces of text
(average size ∼ 200)
aardvark :
10...0
, zwieback :
0...01
Hyperparameters:
I filter width (region size) 3
I stack words in region
I 1000 feature maps
I max-pooling
I penultimate layer: 1000units
Performance:
I IMDB (|V | = 30k): error rate 8.74%
I Amazon Elec: error rate 7.74%
arXiv:1412.1058

Character InputZhang, Zhao, and LeCun (2015): Large datasets
Hyperparameters:
I alphabet of size 70
I 6 convolutional layers (all followed by max-pooling layers) and3 fully-connected layers
I filter width (region size) 7 or 3
I 1024 feature maps
Performance:Model AG Sogou DBP. Yelp P. Yelp F. Yah. A. Amz. F. Amz. P.
BoW 11.19 7.15 3.39 7.76 42.01 31.11 45.36 9.60BoW TFIDF 10.36 6.55 2.63 6.34 40.14 28.96 44.74 9.00ngrams 7.96 2.92 1.37 4.36 43.74 31.53 45.73 7.98ngrams TFIDF 7.64 2.81 1.31 4.56 45.20 31.49 47.56 8.46ConvNet 12.82 4.88 1.73 5.89 39.62 29.55 41.31 5.51
arXiv:1509.01626

OutlookI Convenient and powerful libraries:
I Theano (Lasagne, Keras) developed at LISA, University of MontrealI Torch primarily developed by Ronan Collobert (now @ Facebook),
used within Facebook, Google, Twitter, and NYUI TensorFlow by Google
I The new iPhone 6S shows great GPU performance. So, expect(more) deep learning coming to your phone.
I Embedded devices like Nvidia’s TX1, a tinysupercomputer w/ 256 CUDA cores and 4GBmemory, for driver-assistance systems and the like.
http://technonewschannel.com/tips-trick/5-hidden-features-of-android-camera-which-you-should-know/











![Constrained Convolutional Neural Networks for …vgg/rg/slides/ccnn1.pdf · Constrained Convolutional Neural Networks for Weakly Supervised Segmentation ... [CCNN] Convolutional Neural](https://img.dokumen.tips/doc/110x75/5baa6a3809d3f2c9618bd4b3/constrained-convolutional-neural-networks-for-vggrgslidesccnn1pdf-constrained.jpg)

















