Embed Size (px)
Citation preview

Modernização de código em
Xeon® e Xeon Phi™Programando para Multi-core e Many-core
Igor Freitas – Intel do Brasil

Agenda
2
Próximo passo para a Computação Exascale
Modernização de código em processadores Xeon®
Identificando oportunidades de otimização – Vetorização / SIMD
Otimizando de código com “semi-autovetorização”
Identificando oportunidades de Paralelismo (multi-threading)
Modernização de código em co-processadores Xeon® Phi™
Otimizações feitas no Xeon® aplicadas no Xeon Phi™

3
Próximo passo para a Computação Exascale

Over 15 GF/Watt1
~500 GB/s sustained memory bandwidth with integrated on-package memory
Next Step: KNL
Systems scalable to
>100 PFlop/s
~3X Flops and ~3X single-thread theoretical peak performance over Knights Corner1
Up to 100 Gb/s with Storm Lake integrated fabric
1 Projections based on internal Intel analysis during early product definition, as compared to prior generation Intel® Xeon Phi™ Coprocessors, and are provided for
informational purposes only. Any difference in system hardware or software design or configuration may affect actual performance.
I/O
MemoryProcessor
Performance
Resiliency Standard
Programming
Models
Power
Efficiency
Exascale Vision
Next Step on Intel’s Path to Exascale Computing

The Road Ahead
Transistors Fabric Integration
General Purpose Approach Standards
Performance
ROI
Secure Future
Optimized Hardware Choice Unified Software
Memory
You need the best To get the most
5

A Paradigm Shift for Highly-ParallelServer Processor and Integration are Keys to Future
Coprocessor
Fabric
Memory
Memory Bandwidth~500 GB/s STREAM
Memory CapacityOver 25x* KNC
ResiliencySystems scalable to >100 PF
Power EfficiencyOver 25% better than card1
I/OUp to 100 GB/s with int fabric
CostLess costly than discrete parts1
FlexibilityLimitless configurations
Density3+ KNL with fabric in 1U3
Knights Landing
*Comparison to 1st Generation Intel® Xeon Phi™ 7120P Coprocessor (formerly codenamed Knights Corner)1Results based on internal Intel analysis using estimated power consumption and projected component pricing in the 2015 timeframe. This analysis is provided for informational purposes only. Any difference in system hardware or software design or configuration may affect actual performance. 2Comparison to a discrete Knights Landing processor and discrete fabric component.3Theoretical density for air-cooled system; other cooling solutions and configurations will enable lower or higher density.
Server Processor

…
…
..
.
..
.
Integrated Intel® Omni-Path
Over 60 Cores
Processor Package
Compute
Intel® Xeon® Processor Binary-Compatible
3+ TFLOPS1, 3X ST2 (single-thread) perf. vs KNC
2D Mesh Architecture
Out-of-Order Cores
On-Package Memory Over 5x STREAM vs. DDR43
Up to 16 GB at launch
Platform Memory
Up to 384 GB DDR4 (6 ch)
Omni-Path(optional)
1st Intel processor to integrate
I/O Up to 36 PCIe 3.0 lanes
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.
Performance tests are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other
information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.
For more complete information visit http://www.intel.com/performance.
Knights LandingHolistic Approach to Real Application breakthroughs

INTEGRATIONIntel® Omni Scale™ fabric integration
High-performance
on-package memory
(MCDRAM)
Over 5x STREAM vs. DDR41 Over 400 GB/s
Up to 16GB at launch
NUMA support
Over 5x Energy Efficiency vs. GDDR52
Over 3x Density vs. GDDR52
In partnership with Micron Technology
Flexible memory modes including cache and flat
AVAILABILITYFirst commercial HPC systems in 2H’15
Knights Corner to Knights Landing upgrade program available today
Intel Adams Pass board (1U half-width) is custom designed for Knights Landing (KNL) and will
be available to system integrators for KNL launch; the board is OCP Open Rack 1.0 compliant,
features 6 ch native DDR4 (1866/2133/2400MHz) and 36 lanes of integrated PCIe* Gen 3 I/O
MICROARCHITECTUREOver 8 billion transistors per die based on Intel’s 14 nanometer manufacturing technology
Binary compatible with Intel® Xeon® Processors with support for Intel® Advanced Vector
Extensions 512 (Intel® AVX-512) 6
3x Single-Thread Performance compared to Knights Corner7
60+ cores in a 2D Mesh architecture
2 cores per tile with 2 vector processing units (VPU) per core)
1MB L2 cache shared between 2 cores in a tile (cache-coherent)
“Based on Intel® Atom™ core (based
on Silvermont microarchitecture) with
many HPC enhancements”
4 Threads / Core
2X Out-of-Order Buffer Depth8
Gather/scatter in hardware
Advanced Branch Prediction
High cache bandwidth
32KB Icache, Dcache
2 x 64B Load ports in Dcache
46/48 Physical/virtual address bits
Most of today’s parallel optimizations carry forward to KNL
Multiple NUMA domain support per socket
SERVER PROCESSORStandalone bootable processor (running host OS) and a PCIe coprocessor (PCIe end-point
device)
Platform memory: up to 384GB DDR4 using 6 channels
Reliability (“Intel server-class reliability”)
Power Efficiency (Over 25% better than discrete coprocessor)4 Over 10 GF/W
Density (3+ KNL with fabric in 1U)5
Up to 36 lanes PCIe* Gen 3.0
All products, computer systems, dates and figures specified are preliminary based on current expectations, and are subject to change without notice.All projections are provided for informational purposes only. Any difference in system hardware or software design or configuration may affect actual performance.0 Over 3 Teraflops of peak theoretical double-precision performance is preliminary and based on current expecations of cores, clock frequency and floatingpoint operations per cycle. 1 Projected result based on internal Intel analysis of STREAM benchmark using a Knights Landing processor with 16GB of ultra h igh-bandwidth versus DDR4 memory with all channels populated.2 Projected result based on internal Intel analysis comparison of 16GB of ultra high-bandwidth memory to 16GB of GDDR5 memory used in the Intel® Xeon Phi™ coprocessor 7120P.3 Compared to 1st Generation Intel® Xeon Phi™ 7120P Coprocessor (formerly codenamed Knights Corner)4 Projected result based on internal Intel analysis using estimated performance and power consumption of a rack sized deployment of Intel® Xeon® processors and Knights Landing coprocessors as compared to a rack with KNL processors only5 Projected result based on internal Intel analysis comparing a discrete Knights Landing processor with integrated fabric to a discrete Intel fabric component card.6 Binary compatible with Intel® Xeon® Processors v3 (Haswell) with the exception of Intel® TSX (Transactionaly Synchronization Extensions)7 Projected peak theoretical single-thread performance relative to 1st Generation Intel® Xeon Phi™ Coprocessor 7120P8 Compared to the Intel® Atom™ core (base on Silvermont microarchitecture)
PERFORMANCE3+ TeraFLOPS of double-precision peak theoretical performance per single socket node0
FUTUREKnights Hill is the codename for
the 3rd generation of the Intel®
Xeon Phi™ product family
Based on Intel’s 10 nanometer manufacturing technology
Integrated 2nd generation Intel® Omni-Path Fabric
Continuedon next page
Knights Landing Details

All products, computer systems, dates and figures specified are preliminary based on current expectations, and are subject to change without notice.All projections are provided for informational purposes only. Any difference in system hardware or software design or configuration may affect actual performance.
Knights Landing DetailsMOMENTUM More info
• Aurora is currently the largest planned system at 180-450 petaFLOP/s, to be delivered in 2018. Intel
is teaming with Cray on both projects.
• Aurora: 50,000 nodes:
• Future generation Intel Xeon Phi processors (Knights Hill);
• 2nd generation Intel Omni-Path fabric;
• New memory hierarchy composed of Intel Lustre, Burst Buffer Storage, and persistent
memory through high bandwidth on-package memory;
• Cray’s Shasta platform.
The path to Aurora
HPC Scalable System
Framework
Coral Program Overview
• Cori Supercomputer at NERSC (National Energy Research Scientific Computing Center at
LBNL/DOE) became the first publically announced Knights Landing based system, with over 9,300
nodes slated to be deployed in mid-2016
“Trinity” Supercomputer at NNSA (National Nuclear Security Administration) is a $174 million deal
awarded to Cray that will feature Haswell and Knights Landing, with acceptance phases in both late-
2015 and 2016.
Expecting over 50 system providers for the KNL host processor, in addition to many more PCIe-card
based solutions.
>100 Petaflops of committed customer deals to date

10
Modernização de código em processadores Xeon®
Identificando oportunidades de otimização - Vetorização

Legal Disclaimers
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are
measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other
information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.
Relative performance is calculated by assigning a baseline value of 1.0 to one benchmark result, and then dividing the actual benchmark result for the baseline platform into each of the
specific benchmark results of each of the other platforms, and assigning them a relative performance number that correlates with the performance improvements reported.
Intel does not control or audit the design or implementation of third party benchmarks or Web sites referenced in this document. Intel encourages all of its customers to visit the referenced
Web sites or others where similar performance benchmarks are reported and confirm whether the referenced benchmarks are accurate and reflect performance of systems available for
purchase.
Intel® Hyper-Threading Technology Available on select Intel® Xeon® processors. Requires an Intel® HT Technology-enabled system. Consult your PC manufacturer. Performance will
vary depending on the specific hardware and software used. For more information including details on which processors support HT Technology, visit
http://www.intel.com/info/hyperthreading.
Intel® Turbo Boost Technology requires a Platform with a processor with Intel Turbo Boost Technology capability. Intel Turbo Boost Technology performance varies depending on
hardware, software and overall system configuration. Check with your platform manufacturer on whether your system delivers Intel Turbo Boost Technology. For more information, see
http://www.intel.com/technology/turboboost
Intel processor numbers are not a measure of performance. Processor numbers differentiate features within each processor series, not across different processor sequences. See
http://www.intel.com/products/processor_number for details. Intel products are not intended for use in medical, life saving, life sustaining, critical control or safety systems, or in nuclear
facility applications. All dates and products specified are for planning purposes only and are subject to change without notice
Intel product plans in this presentation do not constitute Intel plan of record product roadmaps. Please contact your Intel representative to obtain Intel’s current plan of record product
roadmaps. Product plans, dates, and specifications are preliminary and subject to change without notice
Copyright © 2012-15 Intel Corporation. All rights reserved. Intel, the Intel logo, Xeon and Xeon logo , Xeon Phi and Xeon Phi logo are trademarks or registered trademarks of Intel
Corporation or its subsidiaries in the United States and other countries. All dates and products specified are for planning purposes only and are subject to change without notice.
*Other names and brands may be claimed as the property of others.
11

Identificando oportunidades de otimizaçãoFoco deste seminário: Modernização de código
12
Composer Edition
Threading design
& prototyping
Parallel performance
tuning
Memory & thread
correctness
Professional Edition
Intel® C++ and
Fortran compilers
Parallel models
(e.g., OpenMP*)Optimized libraries
Multi-fabric MPI
library
MPI error checking
and tuning
Cluster EditionHPC Cluster
MPI Messages
Vectorized
& Threaded
Node
Otimização em um único “nó” de processamento
Vetorização & Paralelismo

13
Código
C/C++ ou
Fortran
Thread 0
/ Core 0
Thread 1/
Core1
Thread 2
/ Core 2
Thread
12 /
Core12
...
Thread
0/Core0
Thread
1/Core1
Thread
2/Core2
Thread
244
/Core61
.
.
.
128 Bits 256 Bits
Vector Processor Unit por Core Vector Processor Unit por Core
Paralelismo (Multithreading)
Vetorização
512 Bits
Identificando oportunidades de otimizaçãoFoco deste seminário: Modernização do código

Identificando oportunidades de otimizaçãoVetorização dentro do “core”
Código de exemplo - Black-Scholes Pricing Code “a mathematical model of a financial market containing certain derivative investment
instruments. “
Exemplo retirado do livro “High Performance Parallelism Pearls”
Código fonte: http://lotsofcores.com/pearls.code
Artigo sobre otimização deste método
https://software.intel.com/en-us/articles/case-study-computing-black-scholes-with-intel-
advanced-vector-extensions
14

Identificando oportunidades de otimizaçãoRecapitulando o que é vetorização / SIMD
15
for (i=0;i<=MAX;i++)
c[i]=a[i]+b[i];
+
c[i+7] c[i+6] c[i+5] c[i+4] c[i+3] c[i+2] c[i+1] c[i]
b[i+7] b[i+6] b[i+5] b[i+4] b[i+3] b[i+2] b[i+1] b[i]
a[i+7] a[i+6] a[i+5] a[i+4] a[i+3] a[i+2] a[i+1] a[i]Vector
- Uma instrução
- Oito operações
+
C
B
A
Scalar
- Uma instrução
- Uma operação
• O que é e ? • Capacidade de realizar uma
operação matemática em dois ou
mais elementos ao mesmo tempo.
• Por que Vetorizar ?• Ganho substancial em performance !

Evolução do processamento vetorial dos processadores Intel®
16
X4
Y4
X4opY4
X3
Y3
X3opY3
X2
Y2
X2opY2
X1
Y1
X1opY1
064
X4
Y4
X4opY4
X3
Y3
X3opY3
X2
Y2
X2opY2
X1
Y1
X1opY1
0128
MMX™
Vector size: 64bit
Data types: 8, 16 and 32 bit integers
VL: 2,4,8
For sample on the left: Xi, Yi 16 bit
integers
Intel® SSE
Vector size: 128bit
Data types:
8,16,32,64 bit integers
32 and 64bit floats
VL: 2,4,8,16
Sample: Xi, Yi bit 32 int / float

Evolução do processamento vetorial dos processadores Intel®
17
Intel® AVX / AVX2
Vector size: 256bit
Data types: 32 and 64 bit floats
VL: 4, 8, 16
Sample: Xi, Yi 32 bit int or float
Intel® MIC / AVX-512
Vector size: 512bit
Data types:
32 and 64 bit integers
32 and 64bit floats
(some support for
16 bits floats)
VL: 8,16
Sample: 32 bit float
X4
Y4
X4opY4
X3
Y3
X3opY3
X2
Y2
X2opY2
X1
Y1
X1opY1
0127
X8
Y8
X8opY8
X7
Y7
X7opY7
X6
Y6
X6opY6
X5
Y5
X5opY5
128255
X4
Y4
…
X3
Y3
…
X2
Y2
…
X1
Y1
X1opY1
0
X8
Y8
X7
Y7
X6
Y6
...
X5
Y5
…
255
…
…
…
…
…
…
…
…
…
X9
Y9
X16
Y16
X16opY16
…
…
…
...
…
…
…
…
…
511
X9opY9 X8opY8 …

*Other logos, brands and names are the property of their respective owners.
All products, computer systems, dates and figures specified are preliminary based on current expectations, and are subject to change without notice.
Intel® Xeon® Processor generations from left to right in each chart: 64-bit, 5100 series, 5500 series, 5600 series, E5-2600, E5-2600 v2
Intel® Xeon Phi™ Product Family from left to right in each chart: Intel® Xeon Phi™ x100 Product Family (formerly codenamed Knights Corner), Knights Landing (next-generation Intel® Xeon Phi™
Product Family)
WorkTime =
WorkInstruction
InstructionCyclex
CycleTimex
FrequencyIPC
Não podemos mais contar somente com aumento da frequência
Algoritmo eficiente mesma carga de trabalho com menos
instruções
Compilador reduz as instruções e melhora IPC (Instructions per cyle)
Uso eficiente da Cache: melhora IPC
Vetorização: mesmo trabalho com menos instruções
Paralelização: mais instruções por ciclo
Path LengthPerformance
Princípios do desempenho obtidoVários caminhos, uma única arquitetura

19
Facilidade de Uso
Ajuste Fino
Vectors
Intel® Math Kernel Library
Array Notation: Intel® Cilk™ Plus
Auto vectorization
Semi-auto vectorization:
#pragma (vector, ivdep, simd)
C/C++ Vector Classes
(F32vec16, F64vec8)
Devemos avaliar três fatores:
Necessidade de performance
Disponibilidade de recursos
para otimizar o código
Portabilidade do código
Identificando oportunidades de otimizaçãoManeiras de vetorizar o código

Identificando oportunidades de otimizaçãoVetorização dentro do “core”
• Compilar o código com parâmetro “-qopt-report[=n]” no Linux ou “/Qopt-report[:n]” no
Windows .
• /Qopt-report-file:vecReport.txt
Analisar relatório, encontrar dicas sobre loops não vetorizados e principal causa
20
LOOP BEGIN at ...Black-scholes-ch19\02_ReferenceVersion.cpp(93,3)
remark #15344: loop was not vectorized: vector dependence prevents vectorization. First dependence is shown below.
Use level 5 report for details
remark #15346: vector dependence: assumed OUTPUT dependence between pT line 95 and pK line 97
remark #25439: unrolled with remainder by 2
LOOP END
LOOP BEGIN at ...Black-scholes-ch19\02_ReferenceVersion.cpp(56,3)
remark #15344: loop was not vectorized: vector dependence prevents vectorization. First
dependence is shown below. Use level 5 report for details
remark #15346: vector dependence: assumed ANTI dependence between pS0 line 58 and pC line 62
LOOP END
Loop de inicialização de variáveis
Loop dentro da função “GetOptionPrices”
O código está otimizado para rodar em uma única thread ?

Identificando oportunidades de otimizaçãoVetorização dentro do “core”
• Rodar Intel® VTune – “General Exploration” marcar opção “Analyze memory
bandwidth”
• Identificar “hotspot” = função que gasta mais tempo na execução
• Identificar se as funções estão vetorizadas
21

Identificando oportunidades de otimizaçãoVetorização dentro do “core”
Parâmetros de compilação utilizados:
/GS /W3 /Gy /Zc:wchar_t /Zi /O2 /Fd"x64\Release\vc110.pdb" /D "WIN32" /D "NDEBUG"
/D "_CONSOLE" /D "_UNICODE" /D "UNICODE" /Qipo /Zc:forScope /Oi /MD
/Fa"x64\Release\" /EHsc /nologo /Fo"x64\Release\" /Qprof-dir "x64\Release\"
/Fp"x64\Release\Reference.pch“
Parâmetros de execução
<número de elementos> <número de threads>
“60000000 1”
22

Identificando oportunidades de otimizaçãoVetorização dentro do “core”
23
Instruções escalares como “movsd” ou “cvtsd2ss” (“s” de scalar) estão sendo
utilizadas ao invés de “vmovapd” ; “v” de AVX , “p” de packed , “d” de double
SSE utiliza 128 bits ; e não 256 bits igual instruções AVX

Identificando oportunidades de otimizaçãoVetorização dentro do “core”
24
O que identificamos ?
• Código não está vetorizado, não utiliza instruções AVX/AVX2 de 256 bits
• Compilador apontou dependência de dados
• Oportunidades apontadas pelo VTune
• “Back-end bound”: baixo desempenho na execução das instruções
• Memory bound: aplicação dependente da troca de mensagens entre Cache –
RAM
• Instruções load (ram -> cache) e store ( cache -> ram )
• L1 bound: dados não são encontrados neste nível de cache
• Port utilization: baixa utilização do “core” , “non-memory issues”
• Funções “cdfnormf” e “GetOptionPrices” são hotspots

25
Modernização de código com “semi-autovetorização”

Modernização de códigoSemi-autovetorização
26
Uso do #pragma ivdep (por enquanto utilizando apenas 1 thread/core)
• Código não está vetorizado, não utiliza instruções AVX/AVX2 de 256 bits
• Compilador apontou dependência de dados na linha 56
#pragma ivdepfor (i = 0; i < N; i++)
{
d1 = (log(pS0[i] / pK[i]) + (r + sig * sig * 0.5) * pT[i]) / (sig * sqrt(pT[i]));
d2 = (log(pS0[i] / pK[i]) + (r - sig * sig * 0.5) * pT[i]) / (sig * sqrt(pT[i]));
p1 = cdfnormf(d1);
p2 = cdfnormf(d2);
pC[i] = pS0[i] * p1 - pK[i] * exp((-1.0) * r * pT[i]) * p2;
}
Performance – 60.000.000 elementos
#pragma ivdep
time = 1.886624
Código original
time = 22.904422
12.1x de
speedup
Configuração
Intel Core i5-4300 CPU 2.5 GHZ
4GB RAM
Windows 8.1 x64
Intel Compiler C++ 15.0

Modernização de códigoSemi-autovetorização
27
Uso do #pragma ivdep
• Entenda o que mudou rodando novamente o VTune, compare as duas versões !
Menos instruções executadas !
Menos ciclos de clock por execução !
Menos “misses” na cache L1
Melhor uso do “core”

Modernização de códigoSemi-autovetorização
28
Uso do #pragma ivdep
• Entenda o que mudou rodando novamente o VTune, compare as duas versões !
Menos instruções executadas !
Menos ciclos de clock por execução !
Menos “misses” na cache L1
Melhor uso do “core”

Modernização de códigoSemi-autovetorização
Uso do #pragma ivdep
• Entenda o que mudou rodando novamente o VTune, compare as duas versões !
• Relatório do Compilador: análise do loop vetorizado e dicas de como vetorizar
week\pdf-codigos-intel-lncc\paralelismo-dia-02\Black-scholes-ch19\02_ReferenceVersion.cpp(63,5) ]
remark #15300: LOOP WAS VECTORIZEDremark #15442: entire loop may be executed in remainder
remark #15448: unmasked aligned unit stride loads: 1
remark #15450: unmasked unaligned unit stride loads: 2
remark #15451: unmasked unaligned unit stride stores: 1
remark #15475: --- begin vector loop cost summary ---
remark #15476: scalar loop cost: 760
remark #15477: vector loop cost: 290.250
remark #15478: estimated potential speedup: 2.560 remark #15479: lightweight vector operations: 66
remark #15480: medium-overhead vector operations: 2
remark #15482: vectorized math library calls: 5
remark #15487: type converts: 13
remark #15488: --- end vector loop cost summary ---
LOOP END

Modernização de códigoSemi-autovetorização
0
5
10
15
20
BASELINE IVDEP QXAVX + IVDEP
QXAVX + IVDEP +
UNROLL(4)
SP
EE
DU
P
OTIMIZAÇÕES “DENTRO DO CORE” – 1 THREAD
60Mi 120Mi
• IVDEP
• Ignora dependência entre os vetores
• (QxAVX) Instruções AVX – 256 bits
• Unroll ( n )
• Desmembra o loop para instruções
SIMD
• Link sobre unroll
• Requisitos para loop ser vetorizado
• Loop unrolling
Configuração
Intel Core i5-4300 CPU 2.5 GHZ
4GB RAM
Windows 8.1 x64
Intel Compiler C++ 15.0

31
Identificando oportunidades de otimização [2]
Precisão numérica e alinhamento de dados

Identificando oportunidades de otimizaçãoVetorização dentro do “core” – Precisão e dados alinhados
LOOP BEGIN at ... Black-scholes-ch19\02_ReferenceVersion.cpp(58,3)
remark #15389: vectorization support: reference pS0 has unaligned access [
remark #15381: vectorization support: unaligned access used inside loop body
remark #15399: vectorization support: unroll factor set to 2
remark #15417: vectorization support: number of FP up converts: single precision to double precision 1
remark #15389: vectorization support: reference pK has unaligned access [ ... Black-scholes-
ch19\02_ReferenceVersion.cpp(64,5) ]
remark #15381: vectorization support: unaligned access used inside loop body
remark #15399: vectorization support: unroll factor set to 8
remark #15417: vectorization support: number of FP up converts: single precision to double precision 1 [ ... Black-scholes-ch19\02_ReferenceVersion.cpp(60,5) ]
2 oportunidades apontadas pelo Compilador !
• Redução da precisão numérica – Double (64 bits) para Single (32 bits)
• Alinhamento de dados

Otimizando o código para precisão simples
d1 = (logf(pS0[i] / pK[i]) + (r + sig * sig * 0.5f) * pT[i]) / (sig * sqrtf(pT[i]));
d2 = (logf(pS0[i] / pK[i]) + (r - sig * sig * 0.5f) * pT[i]) / (sig * sqrtf(pT[i]));
p1 = cdfnormf (d1);
p2 = cdfnormf (d2);
pC[i] = pS0[i] * p1 - pK[i] * expf((-1.0f) * r * pT[i]) * p2;
d1 = (log(pS0[i] / pK[i]) + (r + sig * sig * 0.5) * pT[i]) / (sig * sqrt(pT[i]));
d2 = (log(pS0[i] / pK[i]) + (r - sig * sig * 0.5) * pT[i]) / (sig * sqrt(pT[i]));
p1 = cdfnormf(d1);
p2 = cdfnormf(d2);
pC[i] = pS0[i] * p1 - pK[i] * exp((-1.0) * r * pT[i]) * p2;
23.6x speedup vs Código original
1.4x speedup vs “AVX + Unrool + IVDEP”
Identificando oportunidades de otimizaçãoVetorização dentro do “core” – Precisão e dados alinhados

Otimizando o código para precisão simples
0
5
10
15
20
25
30
BASELINE IVDEP QXAVX + IVDEP
QXAVX + IVDEP +
UNROLL(4)
ALL + REDUÇÃO DA
PRECISÃO
SP
EE
DU
P
OTIMIZAÇÕES “DENTRO DO CORE” –1 THREAD
60Mi 120Mi
Identificando oportunidades de otimizaçãoVetorização dentro do “core” – Precisão e dados alinhados
Configuração
Intel Core i5-4300 CPU 2.5 GHZ
4GB RAM
Windows 8.1 x64
Intel Compiler C++ 15.0

35
Identificando oportunidades de Paralelismo (multi-threading)
“Do Not Guess – Measure”

Identificando oportunidades de ParalelismoMultithreads – Intel® Advisor XE
36
Apesar de vetorizado (paralelismo em nível de instruções),
o código está rodando em apenas uma única thread/core !
• Antes de começar a otimização no código, podemos analisar se vale a pena paraleliza-
lo em mais threads !
Intel® Advisor XE
• Modela e compara a performance entre vários frameworks para criação de
threads tanto em processadores quanto em co-processadores
• OpenMP, Intel® Cilk ™ Plus, Intel® Threading Bulding Blocks
• C, C++, Fortran (apenas OpenMP) e C# (Microsoft TPL)
• Prevê escalabilidade do código: relação n.º de threads/ganho de performance
• Identifica oportunidades de paralelismo no código
• Checa corretude do código (deadlocks, race condition)

Identificando oportunidades de Paralelismo
Multithreads – Intel® Advisor XE
37
Passos para utilizar o Intel Advisor
1º - Inclua os headers
#include "advisor-annotate.h“
2º - Adicionar referência ao diretório “include” ; linkar lib ao projeto (Windows e Linux)
Windows com Visual Studio 2012 – Geralmente localizado em “C:\Program Files (x86)\Intel\Advisor XE\include”
Linux - Compilando / Link com Advisor
icpc -O2 -openmp 02_ReferenceVersion.cpp
-o 02_ReferenceVersion
-I/opt/intel/advisor_xe/include/
-L/opt/intel/advisor_xe/lib64/

Identificando oportunidades de Paralelismo
Multithreads – Intel® Advisor XE
38
Passos para utilizar o Intel Advisor
3º - Executando o Advisor
Linux
$ advixe-gui &
Crie um novo projeto
- Interface é a mesma para Linux e Windows
- No caso do Visual Studio há a opção de
roda-lo de forma integrada.
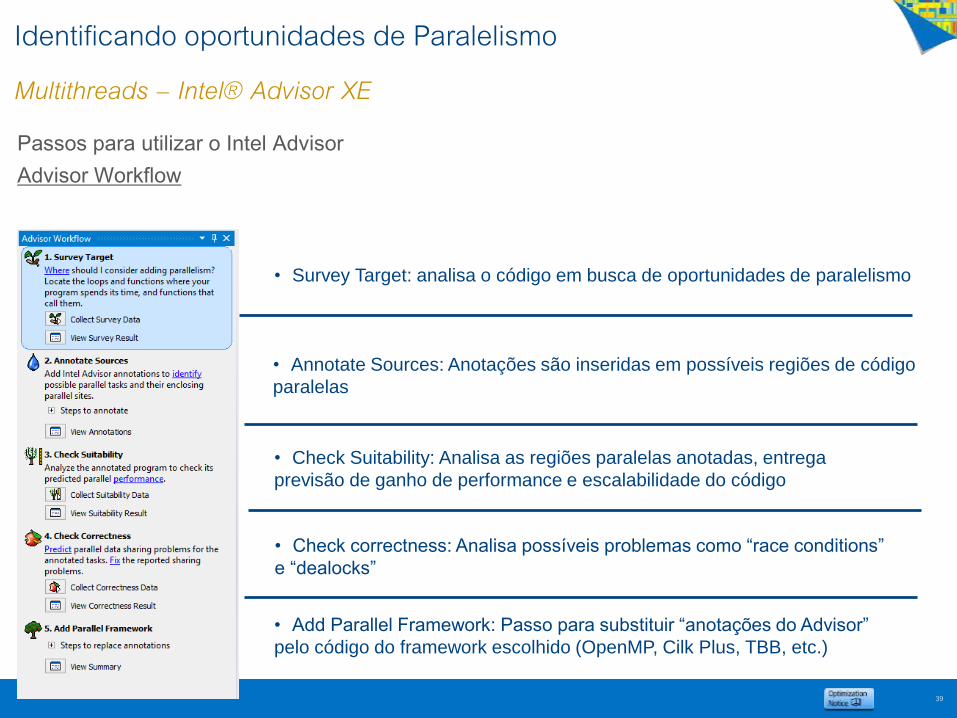
Identificando oportunidades de ParalelismoMultithreads – Intel® Advisor XE
39
Passos para utilizar o Intel Advisor
Advisor Workflow
• Survey Target: analisa o código em busca de oportunidades de paralelismo
• Annotate Sources: Anotações são inseridas em possíveis regiões de código
paralelas
• Check Suitability: Analisa as regiões paralelas anotadas, entrega
previsão de ganho de performance e escalabilidade do código
• Check correctness: Analisa possíveis problemas como “race conditions”
e “dealocks”
• Add Parallel Framework: Passo para substituir “anotações do Advisor”
pelo código do framework escolhido (OpenMP, Cilk Plus, TBB, etc.)

Identificando oportunidades de ParalelismoMultithreads – Intel® Advisor XEIdentificando “hotspots” e quais loops podem ser paralelizados

Identificando oportunidades de ParalelismoMultithreads – Intel® Advisor XEInserindo as “anotações” do Advisor para executar a próxima fase: Check Suitability

Identificando oportunidades de ParalelismoMultithreads – Intel® Advisor XEIdentificando “hotspots” e quais loops podem ser paralelizados

Aplicando paralelismo via OpenMP
Análise de concorrência com o Intel® Vtune
Código otimizado “IVDEP + AVX + UNROLL +
FLOAT PRECISION”
Nthreads: 1
time = 0.967425
Nthreads: 2
time = 0.569371
Nthreads: 4
time = 0.387649
Nthreads: 8
time = 0.396282
1
1.2
1.4
1.6
1.8
2
2.2
2.4
2.6
1 2 4 8S
PE
ED
UP
THREADS
OTIMIZAÇÃO MULTI-THREAD
OpenMP - 60mi
Configuração
Intel Core i5-4300 CPU 2.5 GHZ
4GB RAM
Windows 8.1 x64
Intel Compiler C++ 15.0

44
Modernização de código no co-processador Xeon® Phi™

Agenda
45
Black-Scholes Pricing Code
Intensidade computacional - Monte-carlo

Xeon® Multi-Core Centric MIC – Many Core Centric
Multi-Core
Hosted
Aplicações
Seriais e
Paralelas
Offload
Aplicações
com etapas
paralelas
Symmetric
Load
Balance
Many-Core
Hosted - Native
Aplicações
Massivamente
Paralelas
Modelos de programação
Modernização de código no Intel® Xeon® Phi™Recapitulando modelos de programação
46

47
System Level Code
Linux/Windows - Xeon® Host
PCI-e Bus
MPSS
Offload
AplicationSSH
Intel® Xeon Phi™ Coprocessor
System Level Code
PCI-e Bus
Coprocessor
Communication and app-
launching support
Native Aplication
OffloadAplication
SSH Session
MIC Plataform Software Stack
Windows / Linux OS
Linux uOS
Modernização de código no Intel® Xeon® Phi™Recapitulando modelos de programação

Modernização de código no Intel® Xeon® Phi™Black-Scholes Pricing Code
Compilando para Xeon Phi
$ icc -O2 -mmic 02_ReferenceVersion.cpp -o reference.mic –openmp
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/intel/compiler/2015.2.164/composerxe/lib/mic/
$ scp reference.mic mic0:/tmp
$ ssh mic0
$ cd /tmp
$ ./reference.mic
micnativeloadex reference.mic -l
Dependency information for reference.mic
...
Binary was built for Intel(R) Xeon Phi(TM) Coprocessor
(codename: Knights Corner) architecture
SINK_LD_LIBRARY_PATH =
Dependencies Found:
(none found)
Dependencies Not Found Locally (but may exist already on the coprocessor):
libm.so.6
libiomp5.so
libstdc++.so.6
libgcc_s.so.1
libpthread.so.0
libc.so.6
libdl.so.2
Verificando dependências de biblioteca

Testando o código no Intel® Xeon® Phi™Código vetorizado, porém em 1 thread
Código simplesmente portado para Xeon Phi
icc -O2 -openmp -fimf-precision=low -fimf-domain-exclusion=31 -mmic
11_XeonPhi.cpp -o 11_XeonPhi.mic
icc -O2 -openmp -fimf-precision=low -fimf-domain-exclusion=31 -mmic
12_XeonPhiWorkInParallel.cpp -o 12_XeonPhiWorkInParallel.mic
icc -O2 -openmp -fimf-precision=low -fimf-domain-exclusion=31 -mmic
13_XeonPhiStreamingStores.cpp -o 13_XeonPhiStreamingStores.mic
49

Modernização de código no Intel® Xeon® Phi™Código vetorizado, porém em 1 thread#pragma vector aligned#pragma simd
for (i = 0; i < N; i++){
invf = invsqrtf(sig2 * pT[i]);d1 = (logf(pS0[i] / pK[i]) + (r + sig2 * 0.5f) * pT[i]) / invf;d2 = (logf(pS0[i] / pK[i]) + (r - sig2 * 0.5f) * pT[i]) / invf;erf1 = 0.5f + 0.5f * erff(d1 * invsqrt2);erf2 = 0.5f + 0.5f * erff(d2 * invsqrt2);pC[i] = pS0[i] * erf1 - pK[i] * expf((-1.0f) * r * pT[i]) * erf2;
}}
Intel® Xeon® processor Intel® Xeon Phi™ coprocessor
Vetorizado, porém em 1 thread
time = 0.586156time = ~ 0.481689

Testando o código no Intel® Xeon® Phi™Código vetorizado e paralelizado#pragma vector aligned#pragma simd#pragma omp parallel for private(d1, d2, erf1, erf2, invf)
for (i = 0; i < N; i++){
invf = invsqrtf(sig2 * pT[i]);d1 = (logf(pS0[i] / pK[i]) + (r + sig2 * 0.5f) * pT[i]) / invf;d2 = (logf(pS0[i] / pK[i]) + (r - sig2 * 0.5f) * pT[i]) / invf;erf1 = 0.5f + 0.5f * erff(d1 * invsqrt2);erf2 = 0.5f + 0.5f * erff(d2 * invsqrt2);pC[i] = pS0[i] * erf1 - pK[i] * expf((-1.0f) * r * pT[i]) * erf2;
}}
Intel® Xeon® processor Intel® Xeon Phi™ coprocessor
10 threads
time = 0.174219
4 threads
time = 0.138331
52
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
1 2 4 8 12 16 32 48 60 120 240
TE
MP
O D
E E
XE
CU
ÇÃ
O
THREADS
BLACK SCHOLES
Xeon E5-2697v3 MIC - Simple port MIC - Parallel
MIC-StreamStore MIC - warm-up
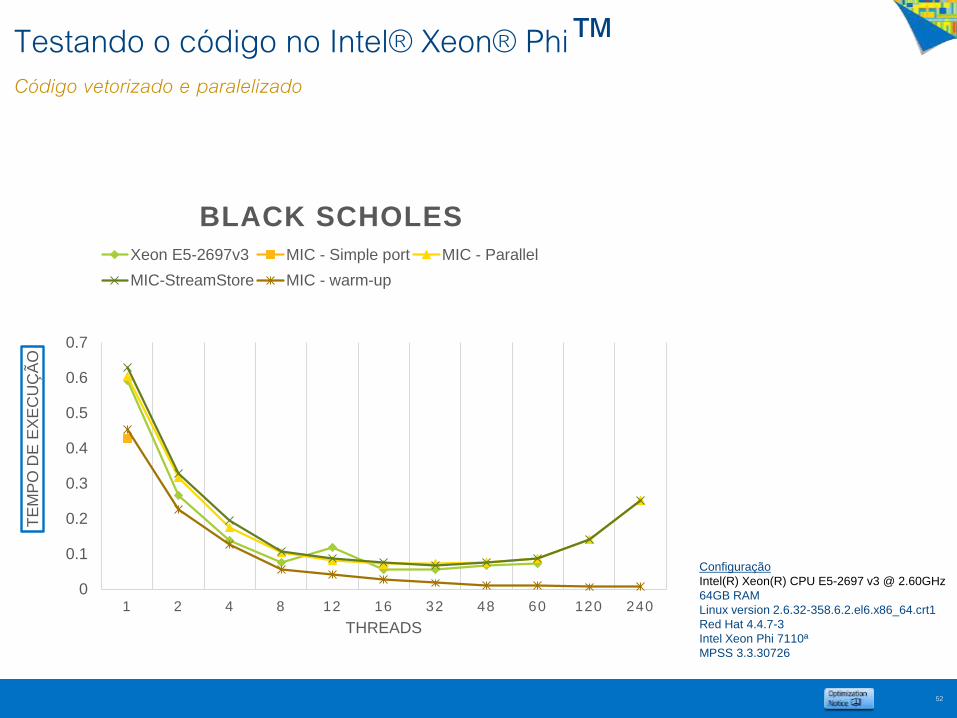
Testando o código no Intel® Xeon® Phi™Código vetorizado e paralelizado
Configuração
Intel(R) Xeon(R) CPU E5-2697 v3 @ 2.60GHz
64GB RAM
Linux version 2.6.32-358.6.2.el6.x86_64.crt1
Red Hat 4.4.7-3
Intel Xeon Phi 7110ª
MPSS 3.3.30726

Testando o código no Intel® Xeon® Phi™Análise de desempenho
53
VTune está indicando que há muita latência, impacto direto na vetorização !

Testando o código no Intel® Xeon® Phi™Análise de desempenho
54
VTune está indicando que há muita latência, impacto direto na vetorização !

Testando o código no Intel® Xeon® Phi™Análise de desempenho - Bandwidth
55
Bandwidth – DRAM << >> CACHE
Versão com instruções StreamStore

Testando o código no Intel® Xeon® Phi™Análise de desempenho - Bandwidth
56
Bandwidth – DRAM << >> CACHE
Comparação StreamStore vs Non-StreamStore

Testando o código no Intel® Xeon® Phi™Algumas conclusões
57
• Aplicação orientada a “memory bandwidth”
• Neste caso, mais threads não trará ganhos
• Streams-stores no Xeon Phi evitou uso de cache nos vetores somente de
escrita, reduzindo consumo de bandwidth
• Latência, devido a “cache misses” impacta vetorização
• Overhead na criação de threads impacta 1ª execução do “loop OpenMP”,
principalmente no Xeon Phi
• Versão final do código computou 2067mi opções/sec no Xeon e 9231mi
opções/sec no Xeon Phi
Computar X options = 3X reads + X writes + X Read-for-ownership = 5X
Streamstore: 3X reads + X writes = 4X

58
Intensidade computacionalMonte Carlo European Option
Xeon® Phi™

Monte Carlo European Option with Pre-generated Random Numbers for Intel® Xeon Phi™
Coprocessor
Artigo 1 – Download do código utilizado
Artigo 2 – Detalhes de otimização
59
Intensidade computacionalMonte Carlo European Option Xeon® Phi™
Compilando para Xeon Phi
icpc MonteCarlo.cpp -mmic -O3 -ipo -fno-alias -opt-threads-per-core=4 -openmp -restrict -vec-report2 -fimf-
precision=low -fimf-domain-exclusion=31 -no-prec-div -no-prec-sqrt -DCOMPILER_VERSION="15"
-ltbbmalloc -DFPFLOAT -o MonteCarloSP.mic
$ ssh mic0
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/intel/compiler/2015.2.164/lib/mic:/opt/intel/compiler/2015.2.164/tbb/lib/mic
$ source /opt/intel/compiler/2015.2.164/composerxe/bin/compilervars.sh intel64
Verificando dependências de biblioteca

Xeon® and Xeon® Phi™Mesmo código, mesmo modelo de programação
Xeon Phi:
icpc MonteCarlo.cpp -mmic -O3 -ipo -fno-alias -opt-threads-per-core=4 -openmp -restrict -
vec-report2 -fimf-precision=low -fimf-domain-exclusion=31 -no-prec-div -no-prec-sqrt -
DCOMPILER_VERSION="15" -ltbbmalloc –DFPFLOAT -g -o MonteCarloSP.mic
Xeon
icpc MonteCarlo.cpp -O3 -ipo -fno-alias -opt-threads-per-core=2 -openmp -restrict -vec-
report2 -fimf-precision=low -fimf-domain-exclusion=31 -no-prec-div -no-prec-sqrt -
DCOMPILER_VERSION="15" -ltbbmalloc -DFPFLOAT -o MonteCarloSP.xeon
60

...#pragma omp parallel for
for(int opt = 0; opt < OPT_N; opt++) {
...
#pragma vector aligned
#pragma loop count (RAND_N)
#pragma simd reduction(+:v0) reduction(+:v1)
#pragma unroll(UNROLLCOUNT)
for(const FP_TYPE *hrnd = start; hrnd < end; ++hrnd) {
const FP_TYPE result = std::max(TYPED_ZERO, Y*EXP2(VBySqrtT*(*hrnd) + MuByT) - Z);
v0 += result;
v1 += result*result;
}
CallResultList[opt] += v0;
CallConfidenceList[opt] += v1; } }...
Intel® Xeon® processor Intel® Xeon Phi™ coprocessor
240 threads
time = 66.528498 60 threads
time = 480.372514
AVX2
AVX2
AVX2
AVX2
AVX2
Intensidade computacionalMonte Carlo European Option Xeon® Phi™
Baseline: código paralelo e vetorizado !
Intel® IMCI

Monte Carlo European OptionTempo de execução Xeon® and Xeon® Phi™
62
0.00
20.00
40.00
60.00
80.00
100.00
120.00
140.00
4 8 12 16 32 48 60 120 160 240
SP
EE
DU
P
THREADS
Xeon E5-2697v3 Xeon Phi 7110
Configuração
Intel(R) Xeon(R) CPU E5-2697
v3 @ 2.60GHz
64GB RAM
Linux version 2.6.32-358.6.2.
el6.x86_64.crt1
Red Hat 4.4.7-3
Intel Xeon Phi 7110ª
MPSS 3.3.30726

Xeon® and Xeon® Phi™Análise do uso da memória
63
Aplicação é orientada a cálculo dos dados “ compute bound” , e não “memory bandwidth”
Alta utilização da memória cache – boa localidade dos dados

Xeon® and Xeon® Phi™Análise do uso da memória
64
Aplicação é orientada a cálculo dos dados “ compute bound” , e não “memory bandwidth”
• Pode haver espaço para otimizações
• Software prefetching
• Data locality

1 Source: Colfax International and Stanford University. Complete details can be found at: http://research.colfaxinternational.com/?tag=/HEATCODE
• Joint study from Colfax International and Stanford University
• GOAL: building a 3D model of the Mikly Way galaxy using large
volumes of 2D sky survey data
• App ported quickly to Xeon Phi: performance was <1/3 because
we moved from >3 GHz out-of-order modern CPU to a low-
power 1 GHz in-order core
limited threading, no vectorization
• After modernizing the code, it runs up to 125x faster (vs. Xeon)
and 620x faster (vs. Xeon Phi) than baseline!!!
Xeon® and Xeon® Phi™ - Outros CasesMesmo modelo de programação e otimização

620x
1.9x4.4x
125x
CPU
&
Intel
C++ Xeon
Phi
CPU
&
Intel
C++
Xeon
Phi
CPU
+
Xeon
Phi
+
Xeon
Phi
NON-OPTIMIZED OPTIMIZED
104
103
102
101
Pe
rform
ance
(voxels
/second)
HETERO
HEATCODE BENCHMARKS
1 Source: Colfax International and Stanford University. Complete details can be found at: http://research.colfaxinternational.com/?tag=/HEATCODE
Xeon® and Xeon® Phi™ - Outros CasesMesmo modelo de programação e otimização

ConclusõesModernização de código para Xeon® e Xeon® Phi™
67
Vetorização /
SIMD /
Paralelismo em
nível de
instrução /
Multi-threading
Otimização para single-thread
Uso de padrões abertos
Mesma técnica de programação para Xeon® e Xeon® Phi™
Várias maneiras de otimização:Facilidade
ou “Ajuste fino”
1º passo: modernize seu código “serial” para aproveitar ao máximo
o paralelismo em nível de instrução e processamento vetorial
Workflow de otimização: meça, identifique, otimize, teste !
Xeon Phi: Todas otimizações feitas pra Xeon serão preservadas !
Explore Xeon + Xeon Phi

Links úteis
Por favor, dê seu feedback desta palestra - http://bit.ly/IntelPesquisa
• Manual e referência do compilador Intel Compiler 15.0
• Manual e referência - Intel Intrinsics
• Guia para Auto-vetorização
• Xeon Phi™ Home Page
• Xeon Phi™ CODE RECIPES
• Intel Developer Zone
• IPCCs - Centros de Computação Paralela
• Product Overview (IBL)
68

http://software.intel.com/XeonPhiCatalog
A Growing Application CatalogOver 100 apps listed as available today or in flight

©2014, Intel Corporation. All rights reserved. Intel, the Intel logo, Intel Inside, Intel Xeon, and Intel Xeon Phi are trademarks of Intel Corporation in the U.S. and/or other countries. *Other names and brands may be claimed as the
property of others. 70





























