Embed Size (px)
Citation preview

Best practices for highly available SolrCloudAnshum Gupta
Apache Lucene/Solr committer, PMC memberSearch Guy @ IBM Watson

• Anshum Gupta, Apache Lucene/Solr committer and PMC member, IBM Watson Search team.
• Interested in search and related stuff.
• Apache Lucene since 2006 and Solr since 2010.
• Organizations I am or have been a part of:
About me

Apache Solr is the most widely-used search solution on the planet.
Solr has tens of thousands of applications in production.
You use everyday.
8,000,000+Total downloads
Solr is both established and growing.
250,000+Monthly downloads
2,500+Open Solr jobs and the largest
community of developers.
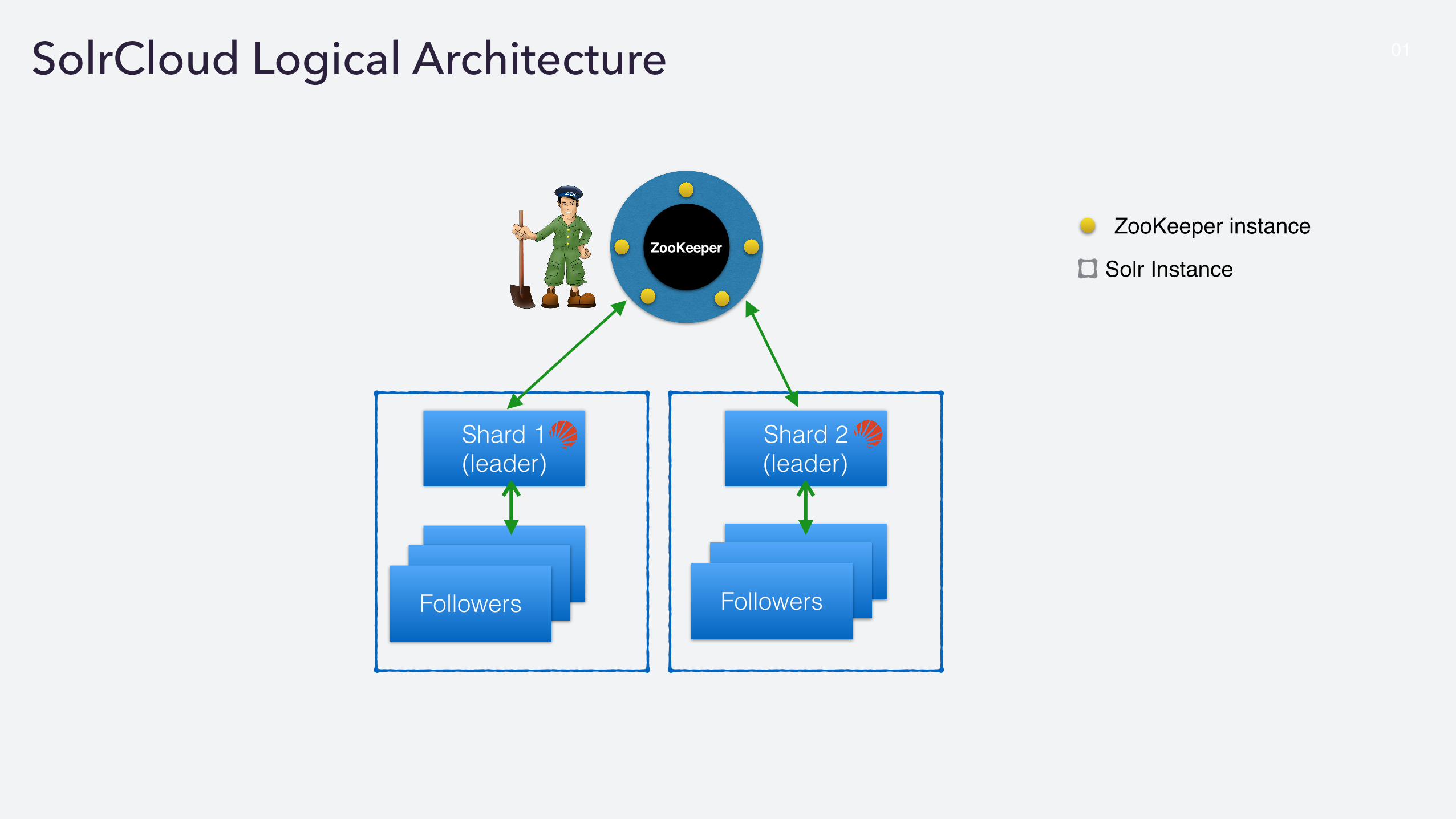
01SolrCloud Logical Architecture
Shard 1 (leader)
Followers
Shard 2 (leader)
Followers
ZooKeeperZooKeeper instance
Solr Instance
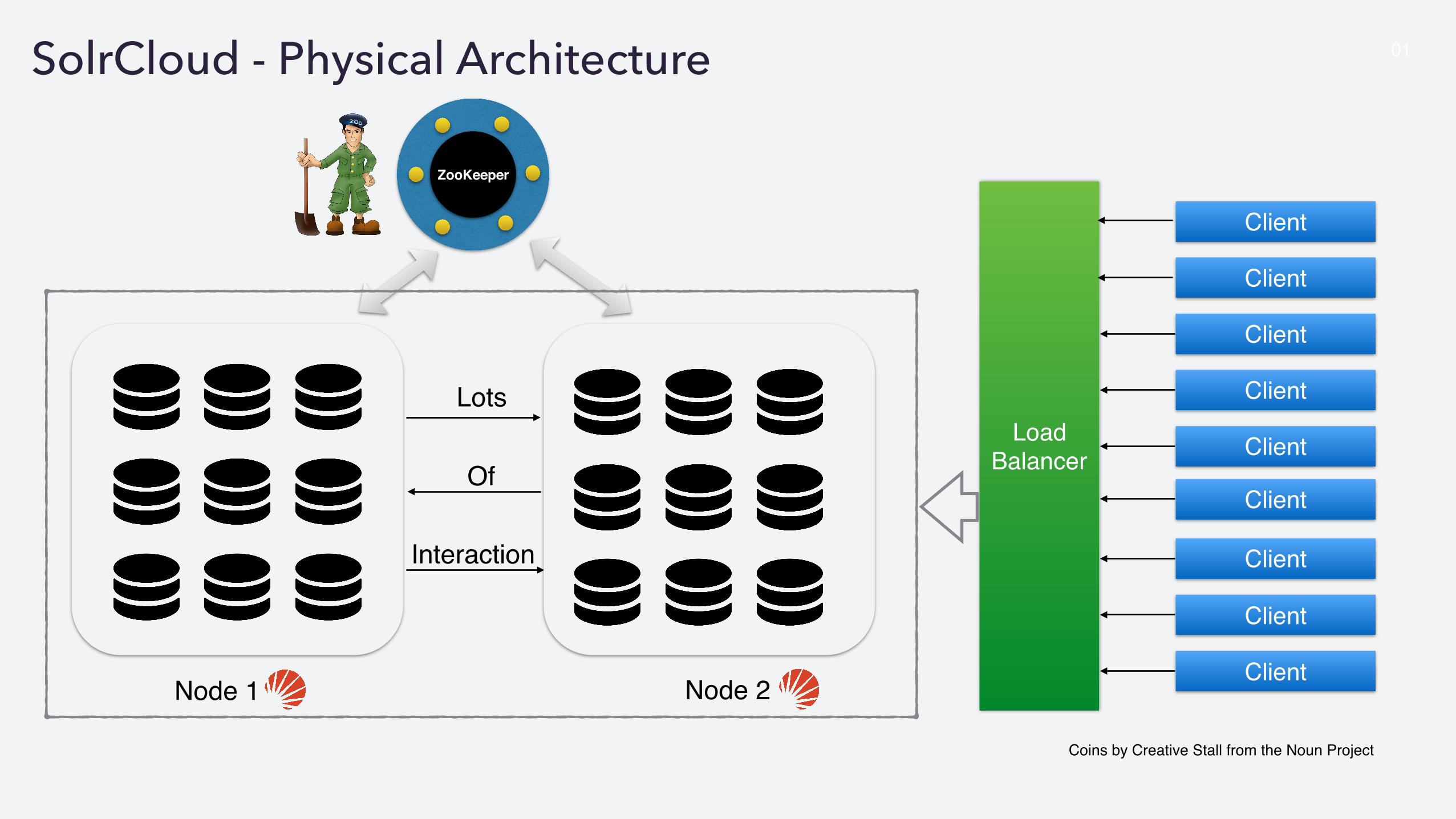
01SolrCloud - Physical Architecture
ZooKeeper
Node 1 Node 2
LoadBalancer
Client
Client
Client
Client
Client
Client
Client
Client
Client
Lots
Of
Interaction
Coins by Creative Stall from the Noun Project

• Not just config repo but a lot more!
• No Zk = Stale clusterstate, and other things + No writes
• Watches & GC!
Solr <> ZK interaction

• NEVER use embedded zk in production
• ZK ensemble - (2n + 1) nodes
• ZK chroot, especially if sharing
• Use an OOM hook - shipped with Solr
ZooKeeper best practices

• Be frugal with watches - For every watch on the ZK server, there’s a 300 bytes memory footprint
• ZK - not built for 1000’s of watchers on a single node. Break it down! e.g. Clusterstate
Also remember - for custom code

Data and Indexing

• Shard your data - It generally helps
• Sharding is almost = Splitting into different collections
• Use different nodes for replicas - Replica placement strategy
• Use a composite key or a custom router
• Distributed IDF - Sharding > Different collections
Sharding and Routing

• Batching
• Reuse the http and solr client
• CloudSolrClient
• Atomic updates - It’s wrapped and expensive
• Omit norms, term freq, and positions if you don’t need them
Indexing best practices

• Replication Bandwidth limiting
• Think about what you want indexed vs stored
Other things to look at

• Soft commits = visibility
• delay as much as you can
• Hard commits = durability
• Durability
• autoCommit
• openSearcher
• initiate background merges if needed
• Only in times of desperation : updateLog config - syncLevel=fsync
Commits and transaction log
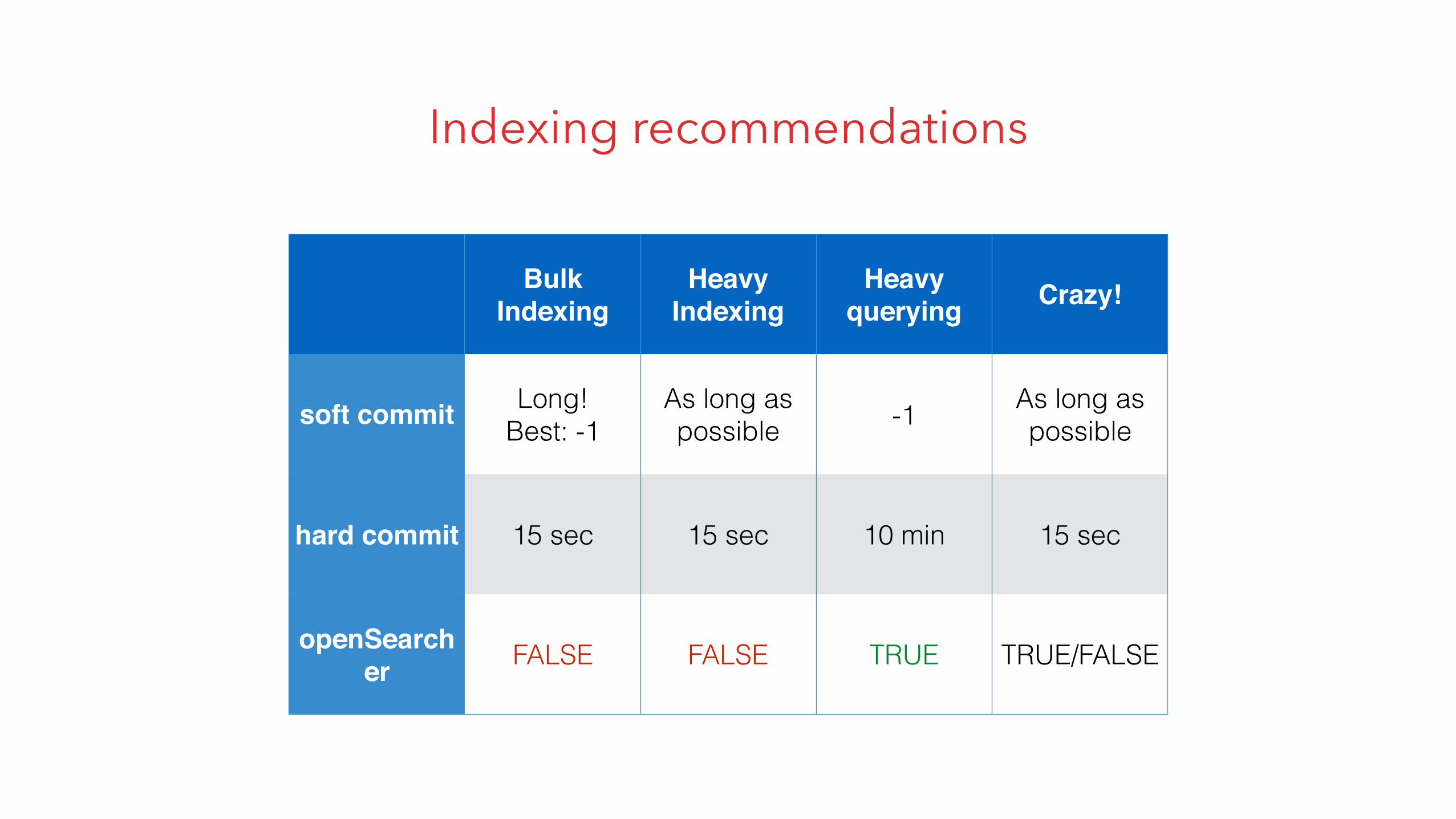
Indexing recommendations
Bulk Indexing
Heavy Indexing
Heavy querying Crazy!
soft commit Long! Best: -1
As long as possible -1 As long as
possible
hard commit 15 sec 15 sec 10 min 15 sec
openSearcher FALSE FALSE TRUE TRUE/FALSE

Querying

• DocValues - Don’t forget there are 3 of those:
• default
• memory
• direct
• Large heaps - Bad idea generally, unless you know what you're doing
• OS Cache - It’s important
Memory usage

• Only retrieve what you want!
• Fields (fl=*)
• Rows (rows=0, when all you want is hit count)
• timeAllowed
• Partial results
• ReRankQueryParser - Only recent releases
Tuning Queries

• Warm up caches
• UI ! UI ! UI ! - It’s got almost everything you need!
• Efficiently use caches - Hit/eviction stats
• Non-cached - specify cost
• Postfilters can be your friend
Caches

• Don’t run a regular query if all you need is to export the data!
• Cursormark
• /export handler - not distributed, sans ranking
Deep paging

• Have more than 1 replicas
• HDFS - High availability, but at a cost!
• Great work
• Way more redundancy, on its way to being fixed
• Use sharding
• Hostname - More reliable than IP addresses at times.
• Jepsen tests came back fine!
More things to note…

• Overestimating heap size? ~ index-size + delta for new generation
• Watch out for increasing major GCs - Red flag!
• Turn off swapping
• Consider explicit GC if it comes to that
• The OS needs memory, as much as the JVM…
JVM tuning

• Rolling restarts to upgrade
• Watch out back-compat issues
• Don’t kill the leader unless need be. Ditto with the Overseer
• Outsource it all to solr-scale-toolkit
Upgrading and restarts

• Protect your cluster
• Kerberos, BasicAuth
• Role based
• Protect your ZooKeeper
Security

Connect @
http://www.twitter.com/anshumgupta
http://www.linkedin.com/in/anshumgupta/





























