Embed Size (px)
DESCRIPTION
Векторизация кода (Code vectorization: SSE, AVX)
Citation preview

Лекция 3Векторизация кода (Code vectorization: SSE/AVX)
Курносов Михаил Георгиевич
E-mail: [email protected]: www.mkurnosov.net
Курс “Высокопроизводительные вычислительные системы”Сибирский государственный университет телекоммуникаций и информатики (Новосибирск)Осенний семестр, 2014

Instruction Level Parallelism
22
Архитектурные решения для обеспечения параллельного выполнения коротких последовательностей инструкций
Вычислительный конвейер (Pipeline) – совмещение (overlap) во времени выполнения инструкций
Суперскалярное выполнение (Superscalar) – выдача и выполнение нескольких инструкций за такт (CPI < 1)
Внеочередное выполнение (Out-of-order execution) –динамическая выдача инструкций на выполнение по готовности их данных

Instruction Level Parallelism
33
Архитектурные решения для обеспечения параллельного выполнения коротких последовательностей инструкций
Вычислительный конвейер (Pipeline) – совмещение (overlap) во времени выполнения инструкций
Суперскалярное выполнение (Superscalar) – выдача и выполнение нескольких инструкций за такт (CPI < 1)
Внеочередное выполнение (Out-of-order execution) –динамическая выдача инструкций на выполнение по готовности их данных
Каждый подход имеет свои плюсы и минусы
Существует ли альтернатива этим подходам?

Векторные процессоры (SIMD)
44
Векторный процессор (Vector processor) –это процессор, поддерживающий на уровне системы команд операции для работы с одномерными массивами – векторами (vector)
X Y
X + Y
+
Скалярный процессор(Scalar processor)
X0 X1 … Xn-1
+
Y0 Y1 … Yn-1
X0 + Y0 X1 + Y1 … Xn-1 + Yn-1
Векторный процессор(Vector processor)
add Z, X, Y add.v Z[0:n-1], X[0:n-1], Y[0:n-1]

Vector CPU vs. Scalar CPU
55
Поэлементное суммирование двух массивов из 10 чисел
for i = 1 to 10 do // cmp, jle, incIF – Instruction Fetch (next) ID – Instruction DecodeLoad Operand1Load Operand2Add Operand1 Operand2Store Result
end for
IF – Instruction Fetch ID – Instruction DecodeLoad Operand1[0:9]Load Operand2[0:9]Add Operand1[0:9] Operand2[0:9]Store Result
Скалярный процессор (Scalar processor)
Векторный процессор (Vector processor)

Vector CPU vs. Scalar CPU
66
Поэлементное суммирование двух массивов из 10 чисел
for i = 1 to 10 doIF – Instruction Fetch (next) ID – Instruction DecodeLoad Operand1Load Operand2Add Operand1 Operand2Store Result
end for
IF – Instruction Fetch ID – Instruction DecodeLoad Operand1[0:9]Load Operand2[0:9]Add Operand1[0:9] Operand2[0:9]Store Result
Скалярный процессор (Scalar processor)
Векторный процессор (Vector processor)
Меньше преобразований адресов
Меньше IF, ID
Меньше конфликтов конвейера, ошибок предсказания переходов
Эффективнее доступ к памяти (2 выборки vs. 20)
Операция над операндами выполняется параллельно
Уменьшился размер кода

Производительность векторного процессора
77
Факторы влияющие на производительность векторного процессора
Доля кода, который может быть выражен в векторной форме (с использованием векторных инструкций)
Длина вектора (векторного регистра)
Латентность векторной инструкции (Vector startup latency) –начальная задержка конвейера при обработке векторной инструкции
Количество векторных регистров
Количество векторных модулей доступа к памяти (load-store)
…

Виды векторных процессоров
88
Векторные процессоры память-память (Memory-memory vector processor) – векторы размещены в оперативной памяти, все векторные операции память-память
Примеры:
CDC STAR-100 (1972, вектор 65535 элементов)
Texas Instruments ASC (1973)
Векторные процессоры регистр-регистр (Register-vector vector processor) – векторы размещены в векторных регистрах, все векторные операции выполняются между векторными регистрами
Примеры: практически все векторные системы начиная с конца 1980-х – Cray, Convex, Fujitsu, Hitachi, NEC, …
SIMD – Single Instruction Stream, Multiple Data Stream

Векторные вычислительные системы
99
Cray 1 (1976) 80 MHz, 8 regs, 64 elems
Cray XMP (1983) 120 MHz 8 regs, 64 elems
Cray YMP (1988) 166 MHz 8 regs, 64 elems
Cray C-90 (1991) 240 MHz 8 regs, 128 elems
Cray T-90 (1996) 455 MHz 8 regs, 128 elems
Conv. C-1 (1984) 10 MHz 8 regs, 128 elems
Conv. C-4 (1994) 133 MHz 16 regs, 128 elems
Fuj. VP200 (1982 133 MHz 8-256 regs, 32-1024 elems
Fuj. VP300 (1996) 100 MHz 8-256 regs, 32-1024 elems
NEC SX/2 (1984) 160 MHz 8+8K regs, 256+var elems
NEC SX/3 (1995) 400 MHz 8+8K regs, 256+var elems

Модули векторного процессора
1010
Векторные функциональные устройства (Vector Functional Units): полностью конвейеризированы, FP add, FP mul, FP reciprocal (1/x), Int. add, Int. mul, …
Векторные модули доступа к памяти (Vector Load-Store Units)
Векторные регистры (Vector Registers): регистры фиксированной длины (как правило, 64-512 бит)

Intel MMX: 1997, Intel Pentium MMX, IA-32
AMD 3DNow!: 1998, AMD K6-2, IA-32
Apple, IBM, Motorola AltiVec: 1998, PowerPC G4, G5, IBM Cell
Intel SSE (Streaming SIMD Extensions): 1999, Intel Pentium III
Intel SSE2: 2001, Intel Pentium 4, IA-32
Intel SSE3: 2004, Intel Pentium 4 Prescott, IA-32
Intel SSE4: 2006, Intel Core, AMD K10, x86-64
AMD SSE5 (XOP, FMA4, CVT16): 2007, 2009, AMD Buldozzer
Intel AVX: 2008, Intel Sandy Bridge
ARM Advanced SIMD (NEON): ARMv7, ARM Cortex A
MIPS SIMD Architecture (MSA): 2012, MIPS R5
Intel AVX2: 2013, Intel Haswell
Intel AVX-512: Intel Xeon Phi
…
SIMD-инструкции современных процессоров
1111

CPUID (CPU Identification): Microsoft Windows
1212
Windows CPU-Z
MMX SSE AVX AES …

Файл /proc/cpuinfo: в поле flags хранится информация о процессоре
Файл /sys/devices/system/cpu/cpuX/microcode/processor_flags
Устройство /dev/cpu/CPUNUM/cpuid: чтение выполняется через lseekи pread (требуется загрузка модуля ядра cpuid)
CPUID (CPU Identification): GNU/Linux
1313
$ cat /proc/cpuinfo
processor : 0vendor_id : GenuineIntelcpu family : 6model name : Intel(R) Core(TM) i5-2520M CPU @ 2.50GHz...flags : fpu vme de pse tsc msr pae mce cx8 apic sepmtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp lm constant_tsc arch_perfmonpebs bts nopl xtopology nonstop_tsc aperfmperf pni pclmulqdqdtes64 ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer xsave avx lahf_lm idaarat epb xsaveopt pln pts dtherm tpr_shadow vnmi flexpriorityept vpid

#include <intrin.h>
int isAVXSupported(){
bool AVXSupported = false;
int cpuInfo[4];__cpuid(cpuInfo, 1);
bool osUsesXSAVE_XRSTORE = cpuInfo[2] & (1 << 27) || false;bool cpuAVXSuport = cpuInfo[2] & (1 << 28) || false;
if (osUsesXSAVE_XRSTORE && cpuAVXSuport) {// Check if the OS will save the YMM registersunsigned long long xcrFeatureMask =
_xgetbv(_XCR_XFEATURE_ENABLED_MASK);AVXSupported = (xcrFeatureMask & 0x6) || false;
}return AVXSupported;
}
CPUID (CPU Identification): Microsoft Windows
1414

inline void cpuid(int fn, unsigned int *eax, unsigned int *ebx, unsigned int *ecx, unsigned int *edx)
{asm volatile("cpuid"
: "=a" (*eax), "=b" (*ebx), "=c" (*ecx), "=d" (*edx) : "a" (fn));
}
int is_avx_supported(){
unsigned int eax, ebx, ecx, edx;
cpuid(1, &eax, &ebx, &ecx, &edx);return (ecx & (1 << 28)) ? 1 : 0;
}
int main(){
printf("AVX supported: %d\n", is_avx_supported());
return 0;}
CPUID (CPU Identification): GNU/Linux
1515
Intel 64 and IA-32 Architectures Software Developer’s Manual
(Vol. 2A)

Intel MMX
1616
1997, Intel Pentium MMX
MMX – набор SIMD-инструкции обработки целочисленных векторов длиной 64 бит
8 виртуальных регистров mm0, mm1, …, mm7 –ссылки на физические регистры x87 FPU (ОС не требуется сохранять/восстанавливать регистрыmm0, …, mm7 при переключении контекста)
Типы векторов: 8 x 1 char, 4 x short int, 2 x int
MMX-инструкции разделяли x87 FPU с FP-инструкциями – требовалось оптимизировать поток инструкций (отдавать предпочтение инструкциям одного типа)

Intel SSE
1717
1999, Pentium III
8 векторных регистров шириной 128 бит:%xmm0, %xmm1, …, %xmm7
Типы данных: float (4 элемента на вектор)
70 инструкций: команды пересылки, арифметические команды, команды сравнения, преобразования типов, побитовые операции
Инструкции явной предвыборки данных, контроля кэширования данных и контроля порядка операций сохранения
float float float floatXMM0
float float float floatXMM1
mulps %xmm1, %xmm0 // xmm0 = xmm0 * xmm1

Intel SSE
1818
1999, Pentium III
8 векторных регистров шириной 128 бит:%xmm0, %xmm1, …, %xmm7
Типы данных: float (4 элемента на вектор)
70 инструкций: команды пересылки, арифметические команды, команды сравнения, преобразования типов, побитовые операции
Инструкции явной предвыборки данных, контроля кэширования данных и контроля порядка операций сохранения
float float float floatXMM0
float float float floatXMM1
mulps %xmm1, %xmm0 // xmm0 = xmm0 * xmm1
Один из разработчиков расширения SSE –В.М. Пентковский (1946 – 2012 г.)
До переход в Intel являлся сотрудником Новосибирского филиала ИТМиВТ (программное обеспечение многопроцессорных комплексов Эльбрус 1 и 2, язык Эль-76, процессор Эль-90, …)
Jagannath Keshava and Vladimir Pentkovski: Pentium III Processor Implementation Tradeoffs. // Intel Technology Journal. — 1999. — Т. 3. — № 2.
Srinivas K. Raman, Vladimir M. Pentkovski, Jagannath Keshava: Implementing Streaming SIMD Extensions on the Pentium III Processor. // IEEE Micro, Volume 20, Number 1, January/February 2000: 47-57 (2000)

Intel SSE2
2001, Pentium 4, IA32, x86-64 (Intel 64, 2004)
16 векторных регистров шириной 128 бит:%xmm0, %xmm1, …, %xmm7; %xmm8, …, %xmm15
Добавлено 144 инструкции к 70 инструкциям SSE
По сравнению с SSE сопроцессор FPU (x87) обеспечивает более точный результат при работе с вещественными числами
char char char char char … char16 x char
1 x 128-bit int
8 x short int
4 x float | int
2 x double
short int short int … short int
float float float float
double double
128-bit integer

Intel SSE3 & SSE4
2020
Intel SSE3: 2003, Pentium 4 Prescott, IA32, x86-64 (Intel 64, 2004)
Добавлено 13 новых инструкции к инструкциям SSE2
Возможность горизонтальной работы с регистрами – команды сложения и вычитания нескольких значений, хранящихся в одном регистре
a3 a2 a1 a0XMM0
b3 b2 b1 b0XMM1
haddps %xmm1, %xmm0
b3+b2 b1+b0 a3+a2 a1+a0XMM1
Intel SSE4: 2006, Intel Core, AMD Bulldozer
Добавлено 54 новых инструкции:
o SSE 4.1: 47 инструкций,Intel Penryn
o SSE 4.2: 7 инструкций, Intel Nehalem
Horizontal instruction

Intel AVX
2121
2008, Intel Sandy Bridge (2011), AMD Bulldozer (2011)
Размер векторов увеличен до 256 бит
Векторные регистры переименованы: ymm0, ymm1, …, ymm15
Регистры xmm# – это младшие 128 бит регистров ymm#
Трехоперандный синтаксис AVX-инструкций: С = A + B
Использование ymm регистров требует поддержки со стороны операционной системы (для сохранения регистров)
o Linux ядра >= 2.6.30o Apple OS X 10.6.8o Windows 7 SP 1
Поддержка компиляторами:
o GCC >= 4.6o Intel C++ Compiler >= 11.1o Clang (LLVM) >= 3.1o Microsoft Visual Studio >= 2010o Open64 >= 4.5.1

Тип элементов вектора/скаляраS – single precision (float, 32-бита)D – double precision (double, 64-бита)
ADDPS
Название инструкции
Формат SSE-инструкций
2222
Тип инструкцииS – над скаляром (scalar)P – над упакованным вектором (packed)
ADDPS – add 4 packed single-precision values (float)
ADDSD – add 1 scalar double-precision value (double)

Скалярные SSE-инструкции
2323
Скалярные SSE-инструкции (scalar instruction) –в операции участвуют только младшие элементы данных (скаляры) в векторных регистрах/памяти
ADDSS, SUBSS, MULSS, DIVSS, ADDSD, SUBSD, MULSD, DIVSD, SQRTSS, RSQRTSS, RCPSS, MAXSS, MINSS, …
4.0 3.0 2.0 1.0XMM0
7.0 7.0 7.0 7.0XMM1
addss %xmm0, %xmm1
4.0 3.0 2.0 8.0XMM1
8.0 6.0XMM0
7.0 7.0XMM1
addsd %xmm0, %xmm1
8.0 13.0XMM1
Результат помещается в младшее двойное слово (32-bit) операнда-назначения (xmm1)
Три старших двойных слова из операнда-источника (xmm0) копируются в операнд-назначение (xmm1)
Scalar Single-precision (float) Scalar Double-precision (double)
Результат помещается в младшие 64 бита операнда-назначения (xmm1)
Старшие 64 бита из операнда-источника (xmm0)копируются в операнд-назначение (xmm1)

Инструкции над упакованными векторами
2424
SSE-инструкция над упакованными векторами (packed instruction) –в операции участвуют все элементы данных векторных регистров/памяти
ADDPS, SUBPS, MULPS, DIVPS, ADDPD, SUBPD, MULPD, DIVPD, SQRTPS, RSQRTPS, RCPPS, MAXPS, MINPS, …
4.0 3.0 2.0 1.0XMM0
7.0 7.0 7.0 7.0XMM1
addps %xmm0, %xmm1
11.0 10.0 9.0 8.0XMM1
8.0 6.0XMM0
7.0 7.0XMM1
addpd %xmm0, %xmm1
15.0 13.0XMM1
Packed Single-precision (float) Packed Double-precision (double)

Инструкций SSE
2525
Операции копирования данных (mem-reg/reg-mem/reg-reg)
o Scalar: MOVSS
o Packed: MOVAPS, MOVUPS, MOVLPS, MOVHPS, MOVLHPS, MOVHLPS
Арифметические операции
o Scalar: ADDSS, SUBSS, MULSS, DIVSS, RCPSS, SQRTSS, MAXSS, MINSS, RSQRTSS
o Packed: ADDPS, SUBPS, MULPS, DIVPS, RCPPS, SQRTPS, MAXPS, MINPS, RSQRTPS
Операции сравнения
o Scalar: CMPSS, COMISS, UCOMISS
o Packed: CMPPS
Поразрядные логические операции
o Packed: ANDPS, ORPS, XORPS, ANDNPS
…

SSE-инструкции копирования данных
2626
MOVSS: Copy a single floating-point data
MOVLPS: Сopy 2 floating-point data (low packed)
MOVHPS: Сopy 2 floating-point data (high packed)
MOVAPS: Сopy aligned 4 floating-point data (fast)
MOVUPS: Сopy unaligned 4 floating-point data (slow)
MOVHLPS: Сopy 2 high elements to low position
MOVLHPS: Сopy 2 low elements to high position
При копировании данных из памяти в векторный регистр (и наоборот) рекомендуется чтобы адрес
был выровнен на границу в 16 байт

SSE-инструкции копирования данных
2727
v3 v2 v1 v0
XMM0
movaps (%[v]), %xmm0
v0
v1
v2
v3
Memoryv[]
v1 v0
XMM0
movlps %xmm0, (%[v])
v0
v1
Memoryv[]
v1 v0XMM0
movlhps %xmm0, %xmm1
v1 v0XMM1
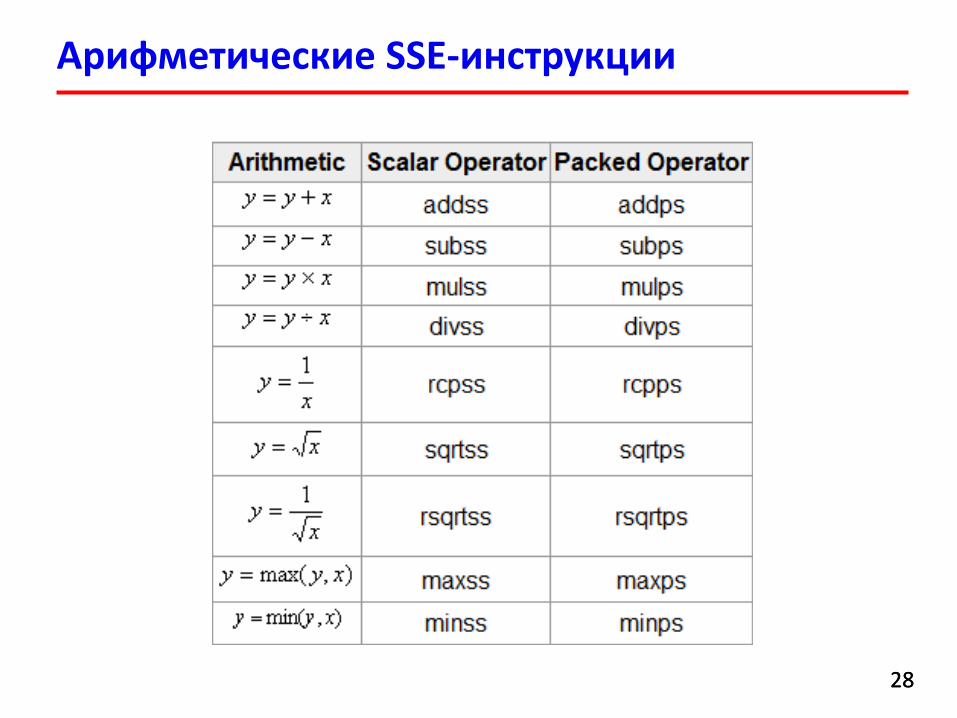
Арифметические SSE-инструкции
2828

Использование инструкций SSE
2929
Простота использования
Лучшая управляемость (полный контроль)
Ассемблерные вставки
Встроенные функции
компилятора (Intrinsic)
C++ классы Автоматическая векторизация компилятора

Автовекторизация компилятором
3030
Сlang (LLVM) – векторизация включена по умолчанию
$ clang -mllvm -force-vector-width=8 ...
$ opt -loop-vectorize -force-vector-width=8 ...
$ clang -fslp-vectorize-aggressive ./prog.c
Visual C++ 2012 – векторизация включена по умолчанию (при использовании опции /O2, подробный отчет формируется опцией /Qvec-report)
Intel C++ Compiler – векторизация включена по умолчанию (при использовании опции /O2, -O2, подробный отчет формируется опцией /Qvec-report, -vec-report)
Oracle Solaris Studio – векторизация включается совместным использованием опций -xvector=simd и –xO3

Автовекторизация компилятором
3131
GNU GCC – векторизация включается при использовании опции
-O3 или -ftree-vectorize
Векторизация для PowerPC (набор инстуркций AltiVec)включается опцией –maltivec
Векторизация для ARM NEON:-mfpu=neon -mfloat-abi=softfp или -mfloat-abi=hard
http://gcc.gnu.org/projects/tree-ssa/vectorization.html

Автовекторизация компилятором
3232
#define N 100
int main(){
int i, a[N];
for (i = 0; i < N; i++) {a[i] = a[i] >> 2;
}return 0;
}

Автовекторизация компилятором GCC
3333
$ gcc –O2 –ftree-vectorize \
–ftree-vectorizer-verbose=2 –msse2
–S ./prog.c
...
.L2:movdqa (%rax), %xmm0psrad $2, %xmm0movdqa %xmm0, (%rax)addq $16, %raxcmpq %rbp, %raxjne .L2movq %rsp, %rbx
...

Автовекторизация компилятором Intel
3434
$ icc –xP –o prog ./prog.c
#if defined (__INTEL_COMPILER)#pragma vector always#endiffor (i = 0; i < 100; i++) {
k = k + 10;a[i] = k;
}

С++ классы SSE (Intel Compiler only)
3535
void add(float *a, float *b, float *c){
int i;
for (i = 0; i < 4; i++) {c[i] = a[i] + b[i];
}}

С++ классы SSE (Intel Compiler only)
3636
#include <fvec.h> /* SSE classes */
void add(float *a, float *b, float *c){
F32vec4 *av = (F32vec4 *)a;F32vec4 *bv = (F32vec4 *)b;F32vec4 *cv = (F32vec4 *)c;
*cv = *av + *bv;}
F32vec4 – класс, представляющий массив из 4 элементов типа float
Intel C++ Class Libraries for SIMD Operations User’s Guide

Вставки на ассемблере
3737
void add_sse_asm(float *a, float *b, float *c){
__asm__ __volatile__(
"movaps (%[a]), %%xmm0 \n\t""movaps (%[b]), %%xmm1 \n\t""addps %%xmm1, %%xmm0 \n\t""movaps %%xmm0, %[c] \n\t": [c] "=m" (*c) /* Output */: [a] "r" (a), [b] "r" (b) /* Input */: "%xmm0", "%xmm1“ /* Clobbered regs */
);}

Вставки на ассемблере
3838
add_sse_asm:.LFB11:
.cfi_startprocmovaps (%rdi), %xmm0 movaps (%rsi), %xmm1 addps %xmm1, %xmm0 movaps %xmm0, (%rdx) ret
.cfi_endproc
$ gcc –O2 –S ./add_sse_asm.c

SSE Intrinsics (builtin functions)
Intrinsaics – набор встроенных функций и типов данных, поддерживаемых компилятором, для предоставления высокоуровневого доступа к SSE-инструкциям
Компилятор самостоятельно распределяет XMM/YMM регистры, принимает решение о способе загрузки данных из памяти (проверяет выравнен адрес или нет) и т.п.
Заголовочные файлы:
#include <mmintrin.h> /* MMX */
#include <xmmintrin.h> /* SSE, нужен также mmintrin.h */
#include <emmintrin.h> /* SSE2, нужен также xmmintrin.h */
#include <pmmintrin.h> /* SSE3, нужен также emmintrin.h */
#include <smmintrin.h> /* SSE4.1 */
#include <nmmintrin.h> /* SSE4.2 */
#include <immintrin.h> /* AVX */

SSE Intrinsics: типы данных
4040
void main()
{
__m128 f; /* float[4] */
__m128d d; /* double[2] */
__m128i i; /* char[16], short int[8], int[4],
uint64_t [2] */
}

SSE Intrinsics
4141
Названия Intrinsic-функций
_mm_<intrinsic_name>_<suffix>
void main()
{
float v[4] = {1.0, 2.0, 3.0, 4.0};
__m128 t1 = _mm_load_ps(v); // v must be 16-byte aligned
__m128 t2 = _mm_set_ps(4.0, 3.0, 2.0, 1.0);}

SSE Intrinsics
4242
void add(float *a, float *b, float *c){
int i;
for (i = 0; i < 4; i++) {c[i] = a[i] + b[i];
}}

SSE Intrinsics
4343
#include <xmmintrin.h> /* SSE */
void add(float *a, float *b, float *c){
__m128 t0, t1;
t0 = _mm_load_ps(a);t1 = _mm_load_ps(b);t0 = _mm_add_ps(t0, t1);_mm_store_ps(c, t0);
}

Выравнивание адресов памяти
4444
Выравнивание адресов памяти
Хранимые в памяти операнды SSE-инструкций должны быть размещены по адресу выровненному на границу в 16 байт
/* Microsoft Visual C/C++ Compiler */
/* Определение статического массива */__declspec(align(16)) float A[N];
/* * Динамическое выделение памяти * с заданным выравниванием адреса */#include <malloc.h>void *_aligned_malloc(size_t size, size_t alignment);void _aligned_free(void *memblock);

Выравнивание адресов памяти
4545
Выравнивание адресов памяти
Хранимые в памяти операнды SSE-инструкций должны быть размещены по адресу выровненному на границу в 16 байт
/* GNU GCC */
/* Определение статического массива */float A[N] __attribute__((aligned(16)));
/* Динамическое выделение памяти с заданным выравниванием */#include <malloc.h>void *_mm_malloc(size_t size, size_t align)void _mm_free(void *p)
#include <stdlib.h>int posix_memalign(void **memptr, size_t alignment,
size_t size);

Intrinsic Name OperationCorresponding
Intel® SSE Instruction
__m128 _mm_load_ss(float * p)Load the low value and clear the three
high valuesMOVSS
__m128 _mm_load1_ps(float * p)Load one value into
all four wordsMOVSS + Shuffling
__m128 _mm_load_ps(float * p)Load four values, address aligned
MOVAPS
__m128 _mm_loadu_ps(float * p)Load four values,
address unalignedMOVUPS
__m128 _mm_loadr_ps(float * p)Load four values
in reverseMOVAPS + Shuffling
Функции копирования данных
4646
#include <xmmintrin.h> /* SSE */
Intel® C++ Compiler XE 13.1 User and Reference Guides

Intrinsic Name OperationCorresponding
Intel® SSE Instruction
__m128d _mm_load_pd(double const *dp)
Loads two DP FP values
MOVAPD
__m128d _mm_load1_pd(double const *dp)
Loads a single DP FP value, copying to both elements
MOVSD + shuffling
__m128d _mm_loadr_pd(double const *dp)
Loads two DP FP values in reverse
order
MOVAPD + shuffling
__m128d _mm_loadu_pd(double const *dp)
Loads two DP FP values
MOVUPD
__m128d _mm_load_sd(double const *dp)
Loads a DP FP value, sets upper
DP FP to zero
MOVSD
Функции копирования данных
4747
#include <emmintrin.h> /* SSE2 */
Intel® C++ Compiler XE 13.1 User and Reference Guides

Функции копирования данных
4848Intel® C++ Compiler XE 13.1 User and Reference Guides
4.0 3.0 2.0 1.0t t = _mm_set_ps(4.0, 3.0, 2.0, 1.0);
1.0 1.0 1.0 1.0t t = _mm_set1_ps(1.0);
0.0 0.0 0.0 1.0t t = _mm_set_ss(1.0);
0.0 0.0 0.0 0.0t t = _mm_setzero_ps();

Intrinsic Name Operation Corresponding SSE Instruction
__m128 _mm_add_ss(__m128 a, __m128 b) Addition ADDSS
_mm_add_ps Addition ADDPS
_mm_sub_ss Subtraction SUBSS
_mm_sub_ps Subtraction SUBPS
_mm_mul_ss Multiplication MULSS
_mm_mul_ps Multiplication MULPS
_mm_div_ss Division DIVSS
_mm_div_ps Division DIVPS
_mm_sqrt_ss Squared Root SQRTSS
_mm_sqrt_ps Squared Root SQRTPS
_mm_rcp_ss Reciprocal RCPSS
_mm_rcp_ps Reciprocal RCPPS
_mm_rsqrt_ss Reciprocal Squared Root RSQRTSS
_mm_rsqrt_ps Reciprocal Squared Root RSQRTPS
_mm_min_ss Computes Minimum MINSS
_mm_min_ps Computes Minimum MINPS
_mm_max_ss Computes Maximum MAXSS
_mm_max_ps Computes Maximum MAXPS
Арифметические операции
4949
#include <xmmintrin.h> /* SSE */
Intel® C++ Compiler XE 13.1 User and Reference Guides

Intrinsic Name Operation Corresponding Intel® SSE Instruction
__m128d _mm_add_sd(__m128d a, __m128d b)
Addition ADDSD
_mm_add_pd Addition ADDPD
_mm_sub_sd Subtraction SUBSD
_mm_sub_pd Subtraction SUBPD
_mm_mul_sd Multiplication MULSD
_mm_mul_pd Multiplication MULPD
_mm_div_sd Division DIVSD
_mm_div_pd Division DIVPD
_mm_sqrt_sd Computes Square Root SQRTSD
_mm_sqrt_pd Computes Square Root SQRTPD
_mm_min_sd Computes Minimum MINSD
_mm_min_pd Computes Minimum MINPD
_mm_max_sd Computes Maximum MAXSD
_mm_max_pd Computes Maximum MAXPD
Арифметические операции
5050
#include <emmintrin.h> /* SSE2 */
Intel® C++ Compiler XE 13.1 User and Reference Guides

SSE Intrinsics
5151
Intel® C++ Compiler XE 13.1 User and Reference Guide (Intrinsics for SSE{2, 3, 4}), AVX // http://software.intel.com/sites/products/documentation/doclib/iss/2013/compiler/cpp-lin/GUID-712779D8-D085-4464-9662-B630681F16F1.htm
GCC 4.8.1 Manual (X86 Built-in Functions) // http://gcc.gnu.org/onlinedocs/gcc-4.8.1/gcc/X86-Built_002din-Functions.html#X86-Built_002din-Functions
Clang API Documentation // http://clang.llvm.org/doxygen/emmintrin_8h_source.html

Пример 1
5252
void fun(float *a, float *b, float *c, int n){
int i;
for (i = 0; i < n; i++) {c[i] = sqrt(a[i] * a[i] +
b[i] * b[i]) + 0.5f;}
}

void fun_sse(float *a, float *b, float *c, int n){
int i, k;__m128 x, y, z;__m128 *aa = (__m128 *)a;__m128 *bb = (__m128 *)b;__m128 *cc = (__m128 *)c;
/* Предполагаем, что n кратно 4 */k = n / 4;z = _mm_set_ps1(0.5f); /* Заполняем z значением 0.5 */for (i = 0; i < k; i++) {
x = _mm_mul_ps(*aa, *aa); y = _mm_mul_ps(*bb, *bb);x = _mm_add_ps(x, y); x = _mm_sqrt_ps(x); *cc = _mm_add_ps(x, z);aa++;bb++;cc++;
}}
Пример 1 (SSE)

enum { N = 1024 * 1024, NREPS = 10 };
/* Implementation ... */
int main(int argc, char **argv){
int i;float *a, *b, *c;double t;
a = (float *)_mm_malloc(sizeof(float) * N, 16);b = (float *)_mm_malloc(sizeof(float) * N, 16);c = (float *)_mm_malloc(sizeof(float) * N, 16);for (i = 0; i < N; i++) {
a[i] = 1.0; b[i] = 2.0;}
t = hpctimer_getwtime();for (i = 0; i < NREPS; i++)
fun_sse(a, b, c, N); /* fun(a, b, c, N); */t = (hpctimer_getwtime() – t) / NREPS;printf("Elapsed time: %.6f sec.\n", t);
_mm_free(a); _mm_free(b); _mm_free(c);return 0;
}
Пример 1 (Benchmarking)
5454

Пример 1 (Benchmarking)
5555
Функция Время, сек. Ускорение (Speedup)
fun (исходная версия)
0.007828 –
fun_sse(SSE2 Intrinsics)
0.001533 5.1
Intel Core 2 i5 2520M (Sandy Bridge)
GNU/Linux (Fedora 19) x86_64 kernel 3.10.10-200.fc19.x86_64
GCC 4.8.1
Флаги компиляции: gcc -Wall -O2 -msse3 -o vec ./vec.c

AVX Intrinsics
5656
__m256 f; /* float[8] */
__m256d d; /* double[4] */
__m256i i; /* char[32], short int[16], int[8],
uint64_t [4] */

Пример 1 (AVX)
5757
void fun_avx(float *a, float *b, float *c, int n){
int i, k;__m256 x, y;__m256 *aa = (__m256 *)a;__m256 *bb = (__m256 *)b;__m256 *cc = (__m256 *)c;
k = n / 8;for (i = 0; i < k; i++) {
x = _mm256_mul_ps(*aa, *aa);y = _mm256_mul_ps(*bb, *bb);x = _mm256_add_ps(x, y); *cc = _mm256_sqrt_ps(x); aa++;bb++;cc++;
}}

Пример 2
5858
void shift(int *v, int n){
int i;
for (i = 0; i < n; i++) {v[i] = v[i] >> 2;
}}

Пример 2 (SSE)
5959
void shift_sse(int *v, int n){
int i;__m128i *i4 = (__m128i *)v;
/* Полагаем, n – кратно 4 */for (i = 0; i < n / 4; i++) {
i4[i] = _mm_srai_epi32(i4[i], 2);}
}
__m128i _mm_srai_epi32(__m128i a, int count);
Shifts the 4 signed 32-bit integers in a right by count bits
r0 := a0 >> count; r1 := a1 >> count r2 := a2 >> count; r3 := a3 >> count

Пример 2 (SSE)
60
void shift_sse(int *v, int n){
int i;__m128i *i4 = (__m128i *)v;
/* Полагаем, n – кратно 4 */for (i = 0; i < n / 4; i++) {
i4[i] = _mm_srai_epi32(i4[i], 2);}
}
__m128i _mm_srai_epi32(__m128i a, int count);
Shifts the 4 signed 32-bit integers in a right by count bits
r0 := a0 >> count; r1 := a1 >> count r2 := a2 >> count; r3 := a3 >> count
Speedup 1.65 (65%) Intel Core i5 2520M (Sandy Bridge) Linux x86_64 (Fedora 19) GCC 4.8.1, opt. flags: -O2 -msse3 n = 16 * 1024 * 1024 60

Пример 3: Reduction (summation)
6161
float reduction(float *v, int n){
int i;float sum = 0.0;
for (i = 0; i < n; i++) {sum += v[i];
}return sum;
}

#include <pmmintrin.h> /* SSE3 */
float reduction_sse(float *v, int n){
int i;float sum;__m128 *v4 = (__m128 *)v;__m128 vsum = _mm_set1_ps(0.0f);
for (i = 0; i < n / 4; i++)vsum = _mm_add_ps(vsum, v4[i]);
/* Horizontal sum: | a3+a2 | a1+a0 | a3+a2 | a1+a0 | */vsum = _mm_hadd_ps(vsum, vsum);/* Horizontal sum: | a3+a2+a1+a0 | -- | -- | -- | */ vsum = _mm_hadd_ps(vsum, vsum);
_mm_store_ss(&sum, vsum);return sum;
}
Пример 3: SSE3 Reduction (summation)

#include <pmmintrin.h> /* SSE3 */
float reduction_sse(float *v, int n){
int i;float sum;__m128 *v4 = (__m128 *)v;__m128 vsum = _mm_set1_ps(0.0f);
for (i = 0; i < n / 4; i++)vsum = _mm_add_ps(vsum, v4[i]);
/* Horizontal sum: | a3+a2 | a1+a0 | a3+a2 | a1+a0 | */vsum = _mm_hadd_ps(vsum, vsum);/* Horizontal sum: | a3+a2+a1+a0 | -- | -- | -- | */ vsum = _mm_hadd_ps(vsum, vsum);_mm_store_ss(&sum, vsum);return sum;
}
Пример 3: SSE3 Reduction (summation)
Speedup 3.2 (220%) Intel Core i5 2520M (Sandy Bridge) Linux x86_64 (Fedora 19) GCC 4.8.1, opt. flags: -O2 -msse3 n = 16 * 1024 * 1024

#include <immintrin.h> /* AVX */
float reduction_avx(float *v, int n){
int i;float vres[8] __attribute__ ((aligned(32)));__m256 *v8 = (__m256 *)v;__m256 vsum = _mm256_setzero_ps();
for (i = 0; i < n / 8; i++)vsum = _mm256_add_ps(vsum, v8[i]);
/* Horizontal summation */vsum = _mm256_hadd_ps(vsum, vsum);vsum = _mm256_hadd_ps(vsum, vsum);vsum = _mm256_hadd_ps(vsum, vsum);
_mm256_store_ps(vres, vsum);return vres[0];
}
Пример 3: AVX Reduction/Summation
6464

#include <immintrin.h> /* AVX */
float reduction_avx(float *v, int n){
int i;float vres[8] __attribute__ ((aligned(32)));__m256 *v8 = (__m256 *)v;__m256 vsum = _mm256_setzero_ps();
for (i = 0; i < n / 8; i++)vsum = _mm256_add_ps(vsum, v8[i]);
/* Horizontal summation */vsum = _mm256_hadd_ps(vsum, vsum);vsum = _mm256_hadd_ps(vsum, vsum);vsum = _mm256_hadd_ps(vsum, vsum);
_mm256_store_ps(vres, vsum);return vres[0];
}
Пример 3: AVX Reduction/Summation
6565
Speedup 3.67 (267%) Intel Core i5 2520M (Sandy Bridge) Linux x86_64 (Fedora 19) GCC 4.8.1, opt. flags: -O2 -mavx n = 16 * 1024 * 1024

Пример 4: Max
6666
float vmax(float *v, int n){
int i;float maxval = 0.0;
for (i = 0; i < n; i++) {if (v[i] > maxval)
maxval = v[i];}return maxval;
}

Пример 4: Max (SSE)
6767
float vmax_sse(float *v, int n){
int i;float res;__m128 *f4 = (__m128 *)v;__m128 maxval = _mm_setzero_ps();
for (i = 0; i < n / 4; i++)maxval = _mm_max_ps(maxval, f4[i]);
/* Horizontal max */maxval = _mm_max_ps(maxval,
_mm_shuffle_ps(maxval, maxval, 0x93));maxval = _mm_max_ps(maxval,
_mm_shuffle_ps(maxval, maxval, 0x93));maxval = _mm_max_ps(maxval,
_mm_shuffle_ps(maxval, maxval, 0x93));_mm_store_ss(&res, maxval);return res;
}

Пример 4: Max (SSE)
float vmax_sse(float *v, int n){
int i;float res;__m128 *f4 = (__m128 *)v;__m128 maxval = _mm_setzero_ps();
for (i = 0; i < n / 4; i++)maxval = _mm_max_ps(maxval, f4[i]);
/* Horizontal max */maxval = _mm_max_ps(maxval,
_mm_shuffle_ps(maxval, maxval, 0x93));maxval = _mm_max_ps(maxval,
_mm_shuffle_ps(maxval, maxval, 0x93));maxval = _mm_max_ps(maxval,
_mm_shuffle_ps(maxval, maxval, 0x93));_mm_store_ss(&res, maxval);return res;
}
v3 v2 v1 v0
v2 v1 v0 v3
v1 v0 v3 v2
v0 v3 v2 v1
shuffle(0x93) & max
shuffle(0x93) & max
shuffle(0x93) & max
max max max max
maxval

Пример 4: Max (SSE)
6969
float vmax_sse(float *v, int n){
int i;float res;__m128 *f4 = (__m128 *)v;__m128 maxval = _mm_setzero_ps();
for (i = 0; i < n / 4; i++)maxval = _mm_max_ps(maxval, f4[i]);
/* Horizontal max */maxval = _mm_max_ps(maxval,
_mm_shuffle_ps(maxval, maxval, 0x93));maxval = _mm_max_ps(maxval,
_mm_shuffle_ps(maxval, maxval, 0x93));maxval = _mm_max_ps(maxval,
_mm_shuffle_ps(maxval, maxval, 0x93));_mm_store_ss(&res, maxval);return res;
}
v3 v2 v1 v0
v2 v1 v0 v3
v1 v0 v3 v2
v0 v3 v2 v1
shuffle(0x93) & max
shuffle(0x93) & max
shuffle(0x93) & max
max max max max
maxval
Speedup 4.28 (328%) Intel Core i5 2520M (Sandy Bridge) Linux x86_64 (Fedora 19) GCC 4.8.1, opt. flags: -O2 –msse3 n = 16 * 1024 * 1024

ARM NEON SIMD Engine
7070
Векторные регистры: 64 или 128 бит
Типы данных: signed/unsigned 8-bit, 16-bit, 32-bit, 64-bit, single precision floating point
D1 (64-bit) D0 (64-bit)
Register Q0 (128-bit)
Сложение двух 16-битных целых: D0 = D1 + D2
VADD.I16 D0, D1, D2

#include <arm_neon.h>
int sum_array(int16_t *array, int size){
/* Init the accumulator vector to zero */int16x4_t vec, acc = vdup_n_s16(0);int32x2_t acc1;int64x1_t acc2;
for (; size != 0; size -= 4) {/* Load 4 values in parallel */vec = vld1_s16(array);array += 4;/* Add the vec to the accum vector */acc = vadd_s16(acc, vec);
}acc1 = vpaddl_s16(acc);acc2 = vpaddl_s32(acc1);return (int)vget_lane_s64(acc2, 0);
}
ARM NEON SIMD engine

Анализ SSE/AVX-программ
7272
Intel Software Development Emulator – эмулятор будущих микроархитектур и наборов команд Intel (Intel AVX-512, Intel SHA, Intel MPX, …)
Intel Architecture Code Analyzer – позволяет анализировать распределение инструкций по портам исполнительных устройств ядра процессора

Анализ SSE/AVX-программ
7373
void fun_avx(float *a, float *b, float *c, int n){
int i, k;__m256 x, y;__m256 *aa = (__m256 *)a;__m256 *bb = (__m256 *)b;__m256 *cc = (__m256 *)c;
k = n / 8;for (i = 0; i < k; i++) {
IACA_STARTx = _mm256_mul_ps(aa[i], aa[i]);y = _mm256_mul_ps(bb[i], bb[i]);x = _mm256_add_ps(x, y); cc[i] = _mm256_sqrt_ps(x); IACA_END
}}

void fun_avx(float *a, float *b, float *c, int n){
int i, k;__m256 x, y;__m256 *aa = (__m256 *)a;__m256 *bb = (__m256 *)b;__m256 *cc = (__m256 *)c;
k = n / 8;for (i = 0; i < k; i++) {
IACA_STARTx = _mm256_mul_ps(aa[i], aa[i]);y = _mm256_mul_ps(bb[i], bb[i]);x = _mm256_add_ps(x, y); cc[i] = _mm256_sqrt_ps(x); IACA_END
}}
Анализ SSE/AVX-программ
7474
$ gcc -O2 -mavx -I ~/opt/iaca-lin32/include ./vec.c...
$ iaca.sh -64 -arch SNB -analysis LATENCY \-graph ./mygraph ./vec

Intel IACA Report
7575
Latency Analysis Report---------------------------Latency: 59 Cycles...| Inst | Resource Delay In Cycles | || Num | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | FE | |---------------------------------------------------------------| 0 | | | | | | | | | vmovaps ymm0, y| 1 | | | | | | | | | vmulps ymm2, ym| 2 | | | | | | | | CP | vmovaps ymm0, y| 3 | 1 | | | | | | | CP | vmulps ymm1, ym| 4 | | | | | | | | CP | vaddps ymm0, ym| 5 | | | | | | | | CP | vsqrtps ymm0, y| 6 | | | | | | | 2 | CP | vmovaps ymmword
Resource Conflict on Critical Paths: -------------------------------------------------------| Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 |-------------------------------------------------------| Cycles | 1 0 | 0 | 0 0 | 0 0 | 0 | 0 |-------------------------------------------------------
List Of Delays On Critical Paths-------------------------------1 --> 3 1 Cycles Delay On Port

Intel IACA Graph (data dependency)
7676

Литература
7777
Intel SSE4 Programming Reference // http://software.intel.com/sites/default/files/m/9/4/2/d/5/17971-intel_20sse4_20programming_20reference.pdf
Intel 64 and IA-32 Architectures Software Developer’s Manual (Combined Volumes: 1, 2A, 2B, 2C, 3A, 3B and 3C) // http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-manual-325462.pdf
A Guide to Vectorization with Intel C++ Compilers // http://download-software.intel.com/sites/default/files/m/d/4/1/d/8/CompilerAutovectorizationGuide.pdf
AMD 128-Bit SSE5 Instruction Set // http://developer.amd.com/wordpress/media/2012/10/AMD64_128_Bit_SSE5_Instrs.pdf





























