Embed Size (px)
Citation preview

Proteomics repositories
Dr. Juan Antonio Vizcaíno
PRIDE Group CoordinatorProteomics Services TeamEMBL-EBIHinxton, Cambridge, UK

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• Why sharing MS proteomics data?
• Types of information stored in MS proteomics repositories.
• Main existing repositories and their main characteristics• No data reprocessing• Data reprocessing• Recently developed resources• Other resources
Overview

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Genomics
Transcriptomics
Proteomics
From the genome to the proteome

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Corresponding public repositories
Genomics
Transcript-omics
Proteomics
DNA sequence databases (GenBank, EMBL, DDJB)
ArrayExpress (EBI), GEO (NCBI)
MS proteomics resources (ProteomeXchange)

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Data sharing in Proteomics
• Proteomics data can be very complex and its interpretation is often troublesome and/or controversial.
• In other ‘omics’ fields, data sharing ‘culture’ is well established. Generally, it is considered to be a good scientific practise.
• In proteomics, the ‘culture’ is definitely evolving in that direction. A big shift is happening in the last few years.
• Scientific journals and funding agencies are two of the main drivers.

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• 1) Data producers are not always the best data analystsSharing of data allows analysts access to real data, and in turn
allowsbetter analysis tools to be developed
• 2) Meta-analysis of data can recycle previous findings for new tasks
Putting findings in the context of other findings increases their scope
• 3) Sharing data allows independent review of the findingsWhen actual replication of an experiment is often impossible, a re-analysis or spot checks on the obtained data become vitally important
• 4) Direct benefit for the field Development of fragmentation models, spectral libraries, SRM
assays, ...
Data sharing. Why?

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
What is a proteomics publication in 2015?• Proteomics studies generate potentially large amounts of
data and results.
• Ideally, a proteomics publication needs to:• Summarize the results of the study• Provide supporting information for reliability of any
results reported
• Information in a publication:• Manuscript• Supplementary material• Associated data submitted to a public repository

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• Why sharing MS proteomics data?
• Types of information stored in MS proteomics repositories
• Main existing repositories and their main characteristics• No data reprocessing• Data reprocessing• Recently developed resources• Other resources
Overview

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Main types of information stored
• 1) Original experimental data recorded by the mass spectrometer (primary data) -. Raw data and peak lists.
• 2) Identification results inferred from the original primary data
• 3) Quantification information
• 4) Experimental and technical metadata
• 5) Any other type of information (e.g. scripts)

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Data types/ PSI standard formats
• mzTabFinal Results
• TraMLSRM
• mzQuantMLQuantitation
• mzIdentMLIdentification
• mzMLMS data

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• Why sharing MS proteomics data?
• Types of information stored in MS proteomics repositories.
• Main existing repositories and their main characteristics• No data reprocessing• Data reprocessing• Recently developed resources• Other resources
Overview

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• Main public MS-based proteomics repositories:- PROteomics IDEntifications database (PRIDE Archive, EBI)- Global Proteome Machine (GPMDB)- PeptideAtlas (ISB, Seattle)
• Many others, more specialized:Among others: Human Proteinpedia, Genome Annotation Proteomics Pipeline (GAPP),…
• Recently developed ones: ProteomicsDB, CHORUS, MassIVE, iProx.
• Very diverse: different aims, functionalities,… but also complementary.
• Main focus is MS/MS data.
Proteomics repositories

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Proteomics repositories (2)• Many different workflows need to be supported. They provide
complementary ‘views’.
• No data reprocessing. Data is stored as ‘published’ or originally analysed:• PRIDE Archive (MS/MS data)• MassIVE (MS/MS data)• PASSEL (SRM data)
• Data reprocessing (MS/MS data):• PeptideAtlas• GPMDB

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• Why sharing MS proteomics data?
• Types of information stored in MS proteomics repositories.
• Main existing repositories and their main characteristics• No data reprocessing• Data reprocessing• Recently developed resources• Other resources
Overview

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Resources that don’t reprocess data1) Resources that try to represent the authors’ analysis
view on the data.
• Various workflows are allowed and they can provide complementary results.
• Data are not ‘updated’ in time. However, meta-analysis on top is possible.
• Accumulation of FDRs when datasets are combined.
• Main representatives: PRIDE Archive and MassIVE (MS/MS data) and PeptideAtlas/PASSEL (SRM data).
• Data standards are essential.

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
PRIDE (PRoteomics IDEntifications) Archive
http://www.ebi.ac.uk/pride
• PRIDE stores mass spectrometry based proteomics data:
• Peptide and protein expression data (identification and quantification)
• Post-translational modifications• Mass spectra (raw data and peak
lists)• Technical and biological metadata• Any other related information
• Full support for tandem MS approaches
Martens et al., Proteomics, 2005Vizcaíno et al., NAR, 2013

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
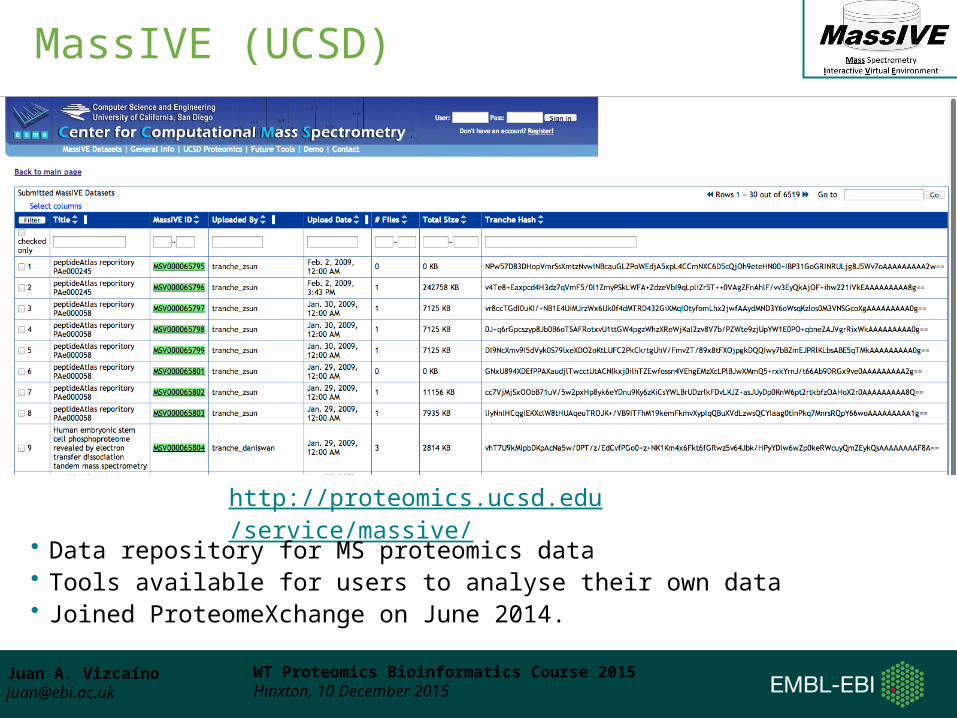
MassIVE (UCSD) • Mass spectrometry Interactive Virtual Environment
• Project led by Nuno Bandeira (Center for Computational Mass Spectrometry, UCSD)
• Dataset storage and data submission
• MassIVE 1.0 – Tranche-like functionality• Imported all data from Tranche• Under development (they want to explore interaction
among users). Not published yet.
http://proteomics.ucsd.edu/ProteoSAFe/datasets.jsp
Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
MassIVE (UCSD)
http://proteomics.ucsd.edu/service/massive/
• Data repository for MS proteomics data• Tools available for users to analyse their own data• Joined ProteomeXchange on June 2014.

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• Suitable for SRM assays
• Use the PSI standard TraML plus the output of the most popular vendor pipelines
• Just started in 2012
• Part of the PX consortium
http://www.peptideatlas.org/passel/Farrah et al., Proteomics, 2012
PASSEL: repository for SRM data

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• Why sharing MS proteomics data?
• Types of information stored in MS proteomics repositories.
• Main existing repositories and their main characteristics• No data reprocessing• Data reprocessing• Recently developed resources• Other resources
Overview

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015 21
Proteomics repositories (2)
09/12/15
• Many different workflows need to be supported. They provide complementary ‘views’.
• No data reprocessing. Data is stored as ‘published’ or originally analysed:• PRIDE (MS/MS data)• MassIVE (MS/MS data)• PASSEL (SRM data)
• Data reprocessing (MS/MS data):• PeptideAtlas• GPMDB

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Reprocessing repositories• These resources collect MS raw data and reprocess it using
one given analysis pipeline, and an up to date protein sequence database.
• Advantage: They provide a ‘standardized’ and updated view on the experimental data available.
• Only one common analysis method is used and there can be information loss.
• Different from the author’s view on the data.
• Main resources: GPMDB and PeptideAtlas (ISB, Seattle).

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
http://www.peptideatlas.org
- Developed at the Institute for Systems Biology (ISB, Seattle, USA)
- Peptide identifications from MS/MS approaches
- Data are reprocessed using the popular Trans Proteomic Pipeline (TPP)
- Uses PeptideProphet to derive a probability for the correct identification for all contained peptides
PeptideAtlas

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• All peptides IDs are mapped to Ensembl using ProteinProphet (to handle protein inference)
• Provides proteotypic peptide predictions
• Limited metadata available
• Part of the HPP projectDeutsch et al., Proteomics, 2005Desiere et al., NAR, 2006.Deutsch et al., EMBO Rep, 2008
PeptideAtlas

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Builds are updated in a regular basis (usually once a year)
Examples of builds:
- Human (HPP context)- Human plasma- Human urine- Drosophila- Mouse- Mouse plasma- Cow- Yeast…
PeptideAtlas builds

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
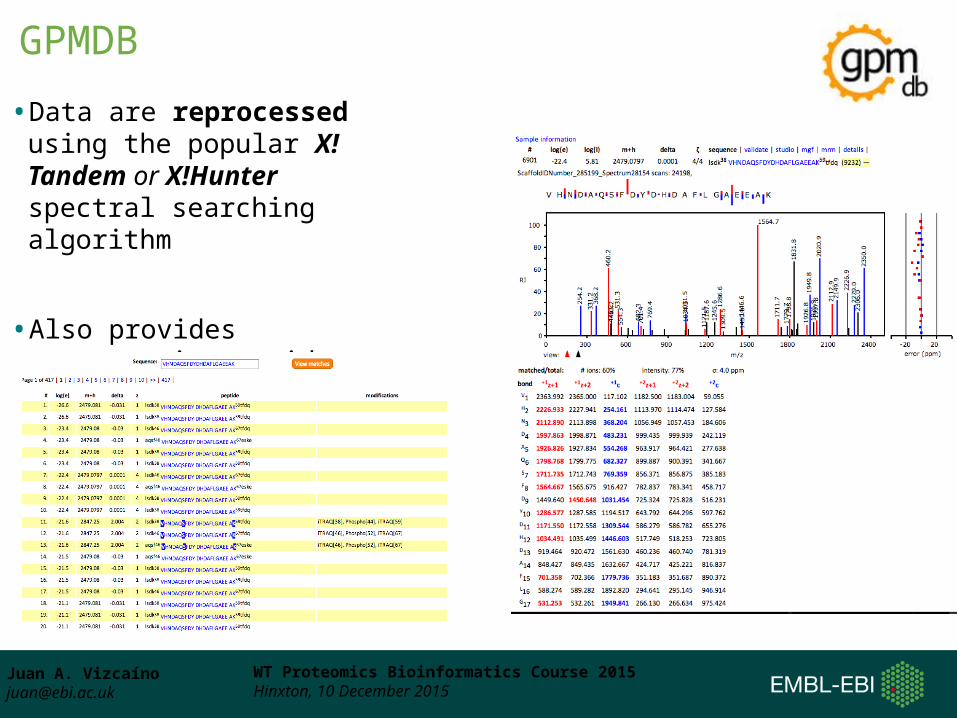
• Originally developed by R. Beavis & R. Craig
• End point of the GPM proteomics pipeline, to aid in the process of validating peptide MS/MS spectra and protein coverage patterns.
http://gpmdb.thegpm.org/Craig et al., J Proteome Res, 2004
GPMDB (Global Proteome Machine DB)
Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• Data are reprocessed using the popular X!Tandem or X!Hunter spectral searching algorithm
• Also provides proteotypic peptides
GPMDB

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• Nice visualization features
• Provides very limited annotation with GO, BTO
• Some support to targeted approaches is available
• Part of the HPP consortium
GPMDB
Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
http://thehpp.org/
The Human Proteome Project (HPP)

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
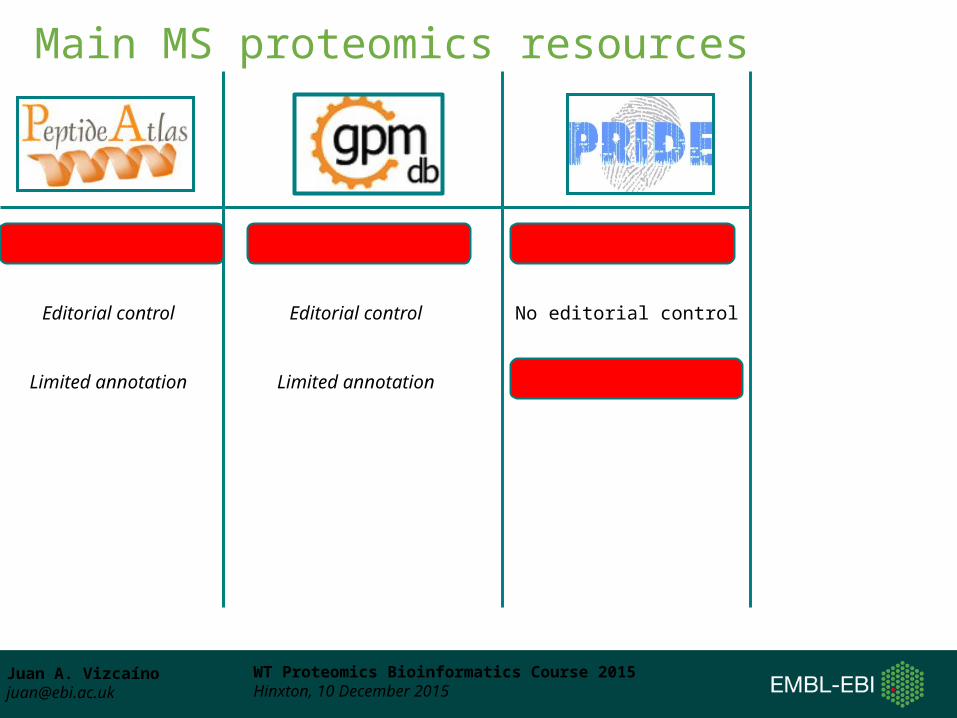
Reprocesses data Reprocesses data No reprocessing
Editorial control Editorial control No editorial control
Limited annotation Limited annotation Detailed annotation
Main MS proteomics resources
Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Reprocesses data Reprocesses data No reprocessing
Editorial control Editorial control No editorial control
Limited annotation Limited annotation Detailed annotation
Main MS proteomics resources

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• Why sharing MS proteomics data?
• Types of information stored in MS proteomics repositories.
• Main existing repositories and their main characteristics• No data reprocessing• Data reprocessing• Recently developed resources• Other resources
Overview

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Draft Human proteome papers published in 2014
Wilhelm et al., Nature, 2014 Kim et al., Nature, 2014
• Two independent groups claimed to have produced the first complete draft of the human proteome by MS.
• Some of their findings are controversial and need further validation… but generated a lot of discussion and put proteomics in the spotlight.
• Two proteomics resources have been developed: proteomicsDB and the Human Proteome Map (HPM).Nature cover 29 May 2014

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
ProteomicsDB https://www.proteomicsdb.org/
• Data analysis using Mascot and MaxQuant
• The way the Protein FDR is calculated is controversial
• Quantification information using label free techniques
• New datasets are added in a regular basis

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
ProteomicsDB (2)

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Human Proteome Map (HPM)
• Developed by the Pandey group.
• Data reanalysis using Mascot.
• Protein FDR is not mentioned at all in the corresponding Nature paper.
http://www.humanproteomemap.org/

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Chorus
https://chorusproject.org/pages/index.html
• Developed by M. MacCoss’ group
• Built on top of Amazon cloud technologies
• Provides data analysis capabilities for the users
• Free for public datasets. A fee needs to be paid for storing private information.

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• Why sharing MS proteomics data?
• Types of information stored in MS proteomics repositories.
• Main existing repositories and their main characteristics• No data reprocessing• Data reprocessing• Recently developed resources• Other resources
Overview

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
MaxQB
Human Proteinpedia
Other repositories

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
COPaKBCardiac Organellar Protein Atlas Knowledgebase International collaboration (EMBL-EBI involved)
Windows Client and iPad AppSubmit data for analysis in dta and mzML formatsData submitted to a ProLuCID pipelineNo MS data download

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
CPTAC data portal
Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
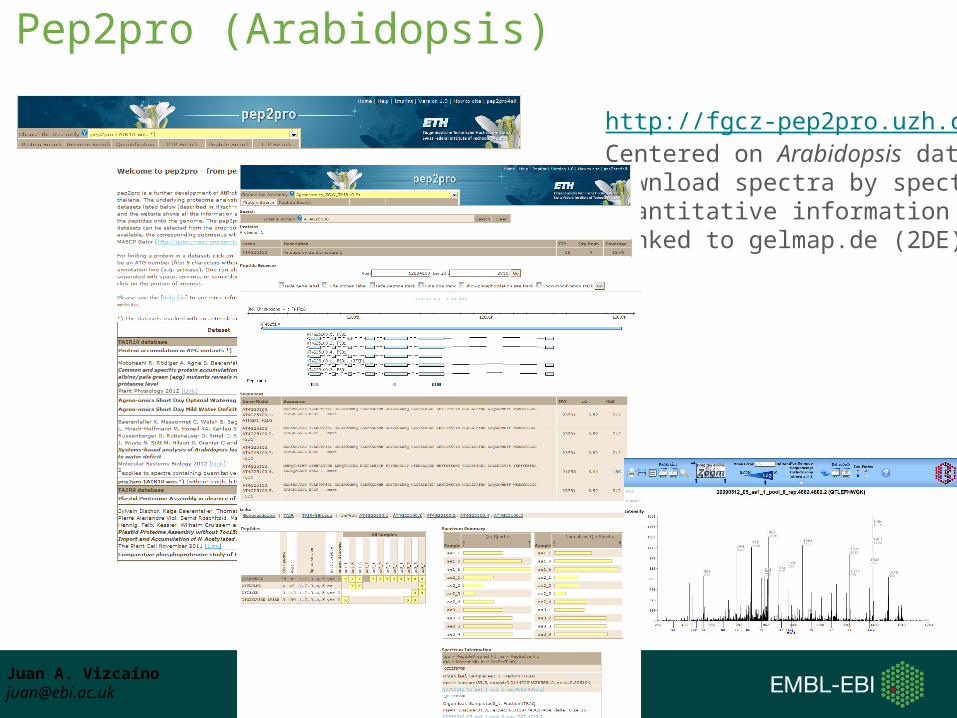
Pep2pro (Arabidopsis)http://fgcz-pep2pro.uzh.ch/Centered on Arabidopsis dataDownload spectra by spectraQuantitative informationLinked to gelmap.de (2DE)

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Example of a repository of supporting data annotation: Steve Gygi’s labSupporting data from publications
Spectra annotation results and PTM evaluation dataQuantitative dataNo data downloads
https://gygi.med.harvard.edu/phosphomouse

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
FINAL THOUGHTS

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Why are repositories not more popular?1. Don’t want to share data
• Researchers don’t like to be shown that they did not analyze the data as well as they could have.• Their FDR may be higher than they reported/think.
• Researchers are worried that they missed something in the data that they could discover if they go back to it at a later date• Don’t want other authors to get a publication from their data.• However, this philosophy is changing gradually…
Slide from R. Chalkley

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Why are repositories not more popular? (2)
2. Submission burden• Getting data into correct format may require some work
• Author is not necessarily computer-savvy
• Having to also supply metadata is seen as a burden, if the information is already present in an associated manuscript
• Associated raw data may be many GB in size; file transfer to repository could take a while
Authors are impatient: want to spend time doing science, not administration!
Slide from R. Chalkley

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• Importance of sharing MS proteomics data
• The main existing proteomics repositories are complementary in focus and functionality
• Main characteristics of:
• PeptideAtlas and GPMDB (Reprocess data)• PASSEL, MassIVE and PRIDE Archive (at
present they do not reprocess data).• New resources: proteomicsDB, HPM, Chorus
Conclusions

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
• Vizcaíno et al., J. Proteomics, 2010. PMID: 20615486
• Perez-Riverol et al., Proteomics, 2015. PMID: 25158685
Recommended reading

Juan A. Vizcaí[email protected]
WT Proteomics Bioinformatics Course 2015Hinxton, 10 December 2015
Questions?





























