Embed Size (px)
Citation preview

!
La semantica per automatizzare una redazione web:!
l’esperienza di Innolabsplus.eu Bologna 4 dicembre 2015
Luca De Santis – Massimiliano Pardini Net7 Srl - Pisa

!
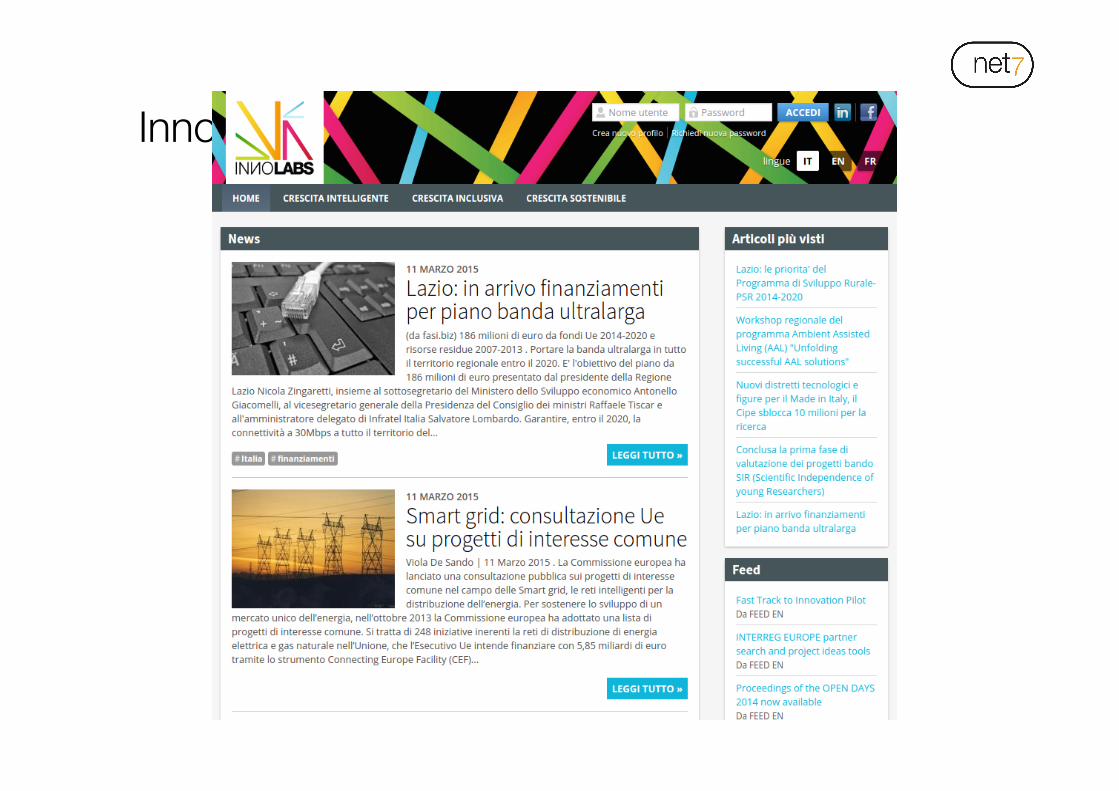
Innolabsplus.eu: cos’è
http://innolabsplus.eu/!
• Innolabs+: portale informativo multilingua per professionisti e imprese sulle politiche comunitarie in materia di innovazione.!
• Realizzato nell’ambito di un progetto del Dipartimento di Scienze Politiche dell’Università di Pisa!
!
Innolabsplus.eu: cos’è
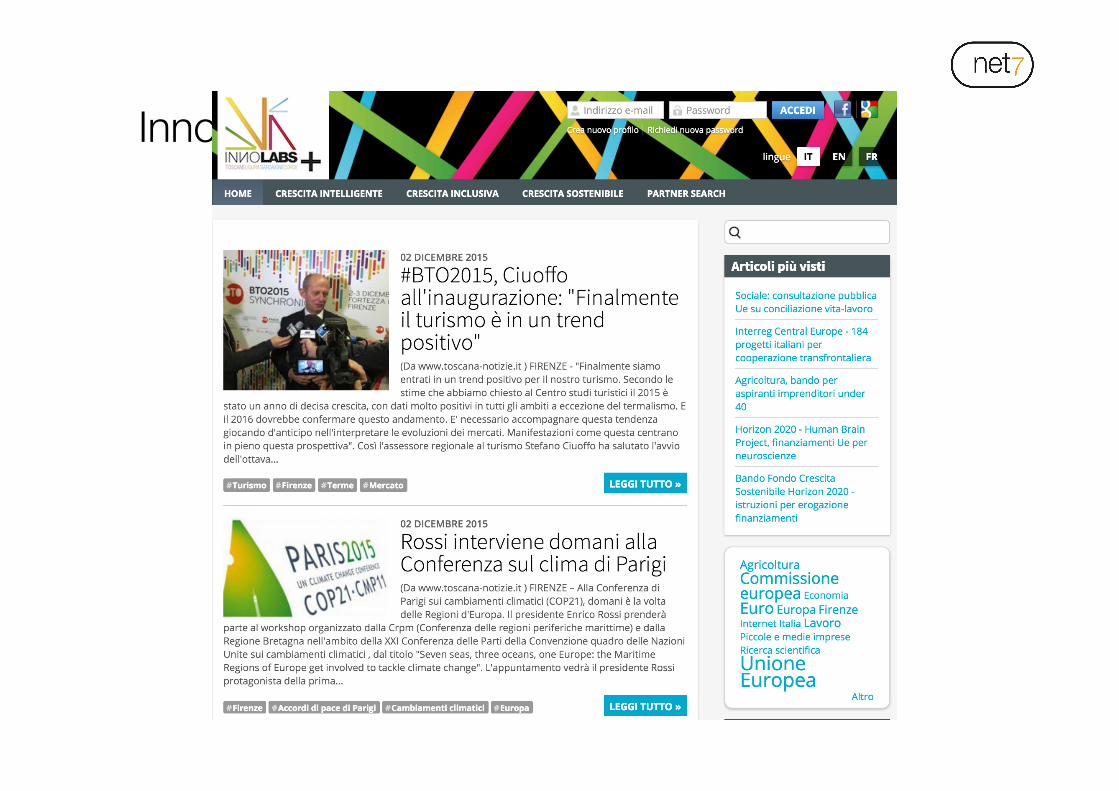
!
Innolabsplus.eu: cos’è

!
• Obiettivo: fornire informazioni aggiornate, selezionate e classificate secondo 3 obiettivi principali e 11 categorie!– Crescita Intelligente, Crescita Inclusiva, Crescita Sostenibile!
• Fonti: oltre 40 siti italiani, francesi e comunitari in lingua inglese!• Il lavoro di cernita è facile se hai a disposizione una redazione
numerosa ed esperta di politiche comunitarie…!
Innolabsplus.eu: cosa fa

!
• Obiettivo: fornire informazioni aggiornate, selezionate e classificate secondo 3 obiettivi principali e 11 categorie!– Crescita Intelligente, Crescita Inclusiva, Crescita Sostenibile!
• Fonti: oltre 40 siti italiani, francesi e comunitari in lingua inglese!• Il lavoro di cernita è facile se hai a disposizione una redazione
numerosa ed esperta di politiche comunitarie…!
Innolabsplus.eu: cosa fa
• …ma come fare quando il tuo team è decisamente più ristretto (e per di più pesantemente sovraccarico di lavoro???)!

!
Innolabsplus.eu: come fa
• Perché non farsi aiutare… dalle macchine? • Un sistema che completamente in
automatico – analizzi gli articoli prelevati da molteplici
fonti – decida di pubblicarli o meno se il loro testo
è pertinente con le tematiche del portale

!
Innolabsplus.eu: come fa
• Perché non farsi aiutare… dalle macchine? • Un sistema che completamente in
automatico – analizzi gli articoli prelevati da molteplici
fonti – decida di pubblicarli o meno se il loro testo
è pertinente con le tematiche del portale
• Da un lavoro puramente manuale…

!
Innolabsplus.eu: come fa
• Perché non farsi aiutare… dalle macchine? • Un sistema che completamente in
automatico – analizzi gli articoli prelevati da molteplici
fonti – decida di pubblicarli o meno se il loro testo
è pertinente con le tematiche del portale
• Da un lavoro puramente manuale… • ... allo sfruttamento dell’intelligenza della
macchina

!
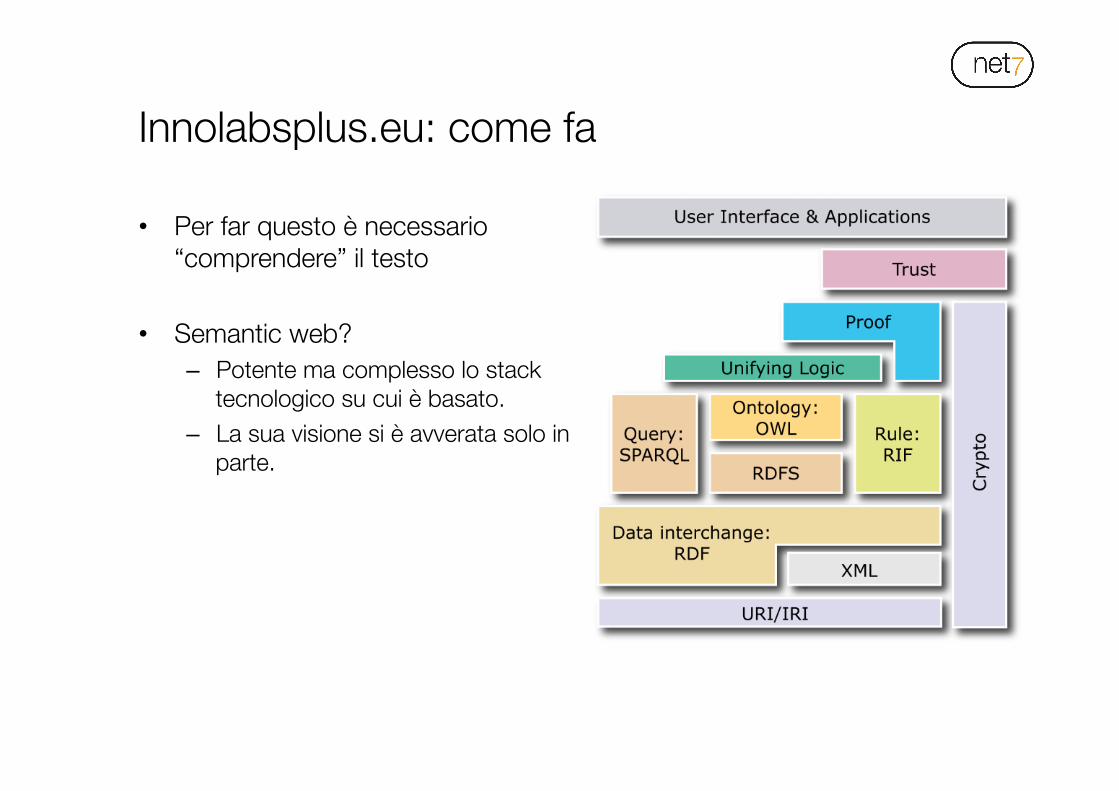
Innolabsplus.eu: come fa
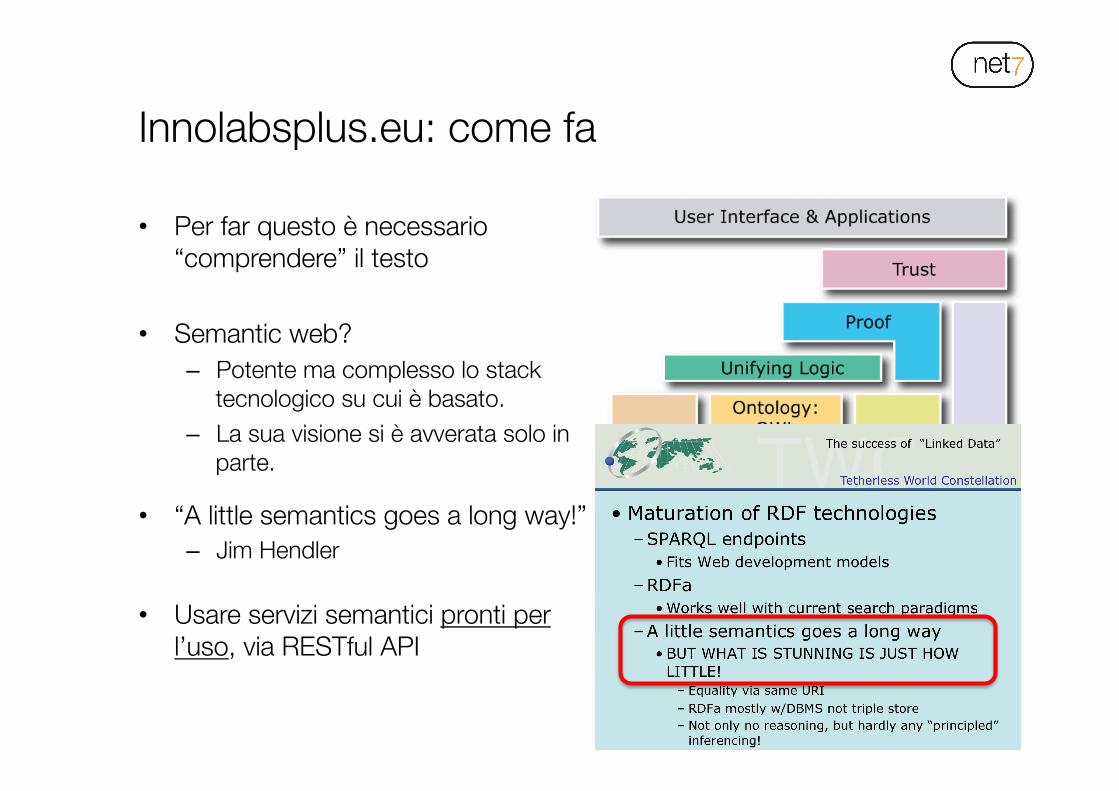
• Per far questo è necessario “comprendere” il testo
• Semantic web?
!
Innolabsplus.eu: come fa
• Per far questo è necessario “comprendere” il testo
• Semantic web? – Potente ma complesso lo stack
tecnologico su cui è basato. – La sua visione si è avverata solo in
parte.
!
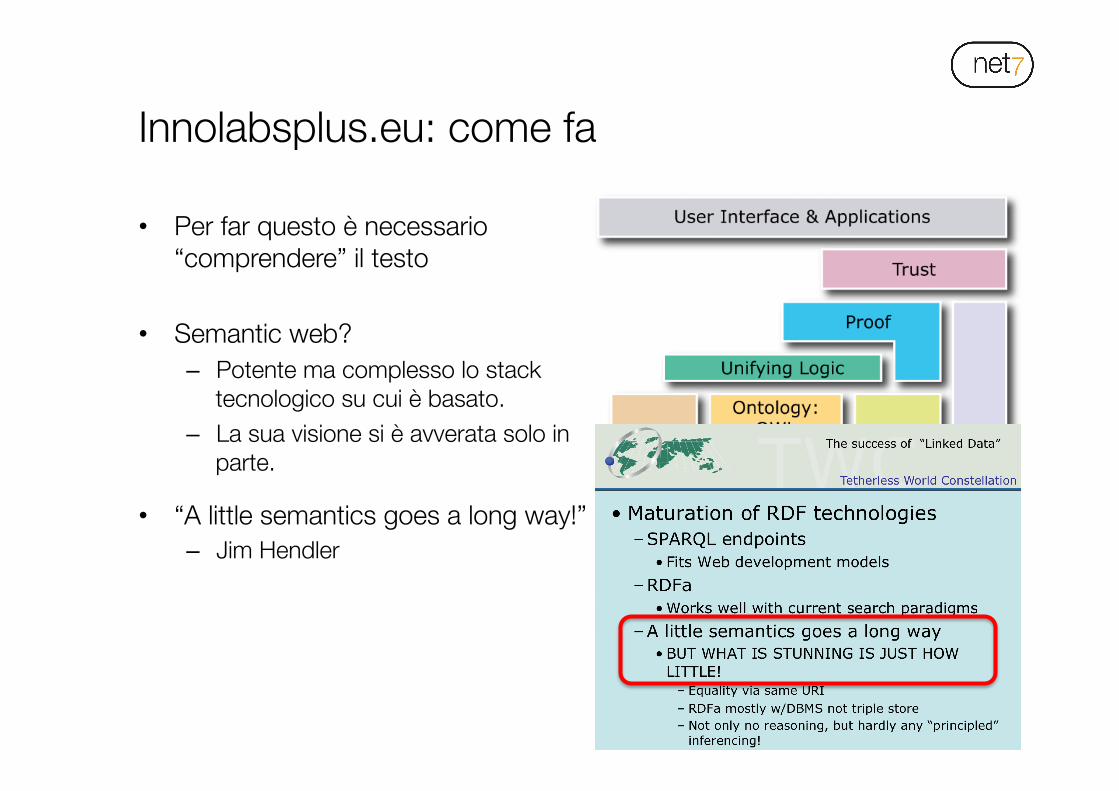
Innolabsplus.eu: come fa
• Per far questo è necessario “comprendere” il testo
• Semantic web? – Potente ma complesso lo stack
tecnologico su cui è basato. – La sua visione si è avverata solo in
parte. • “A little semantics goes a long way!”
– Jim Hendler
!
Innolabsplus.eu: come fa
• Per far questo è necessario “comprendere” il testo
• Semantic web? – Potente ma complesso lo stack
tecnologico su cui è basato. – La sua visione si è avverata solo in
parte.
• Usare servizi semantici pronti per l’uso, via RESTful API
• “A little semantics goes a long way!” – Jim Hendler
!
Dandelion API
• Servizio commerciale dell’azienda Spazio Dati Srl: https://dandelion.eu/

!
Dandelion API
• Servizio commerciale dell’azienda Spazio Dati Srl: https://dandelion.eu/
• Parte da una ricerca dell’Università di Pisa – TagMe

!
Dandelion API
• Servizio commerciale dell’azienda Spazio Dati Srl: https://dandelion.eu/
• Parte da una ricerca dell’Università di Pisa – TagMe
• Potenziato anche nell’ambito del progetto di ricerca SenTaClAus – Net7 come azienda coordinatrice – Info: http://sentaclaus.netseven.it

!
Dandelion API
• Servizio commerciale dell’azienda Spazio Dati Srl: https://dandelion.eu/
• Parte da una ricerca dell’Università di Pisa – TagMe
• Potenziato anche nell’ambito del progetto di ricerca SenTaClAus – Net7 come azienda coordinatrice – Info: http://sentaclaus.netseven.it
• I servizi usati in Innolabsplus.eu – Named Entity Recognition (NER) – Classificazione automatica

!
Named Entity Recognition/Extraction
• È il servizio base delle Dandelion API • Permette di identificate i concetti nel testo • Concetti non parole chiave!
– Ciò di cui parla l’articolo
• Riconoscere concetti vuol dire: – Risolvere eventuali omonimie
• Serra: Gas Serra? Richard Serra? Monte Serra? O la Serra in Agricoltura?
– Identificare i termini anche se sono scritti in forma alternativa o parziale – In breve…. Riconoscere il contesto
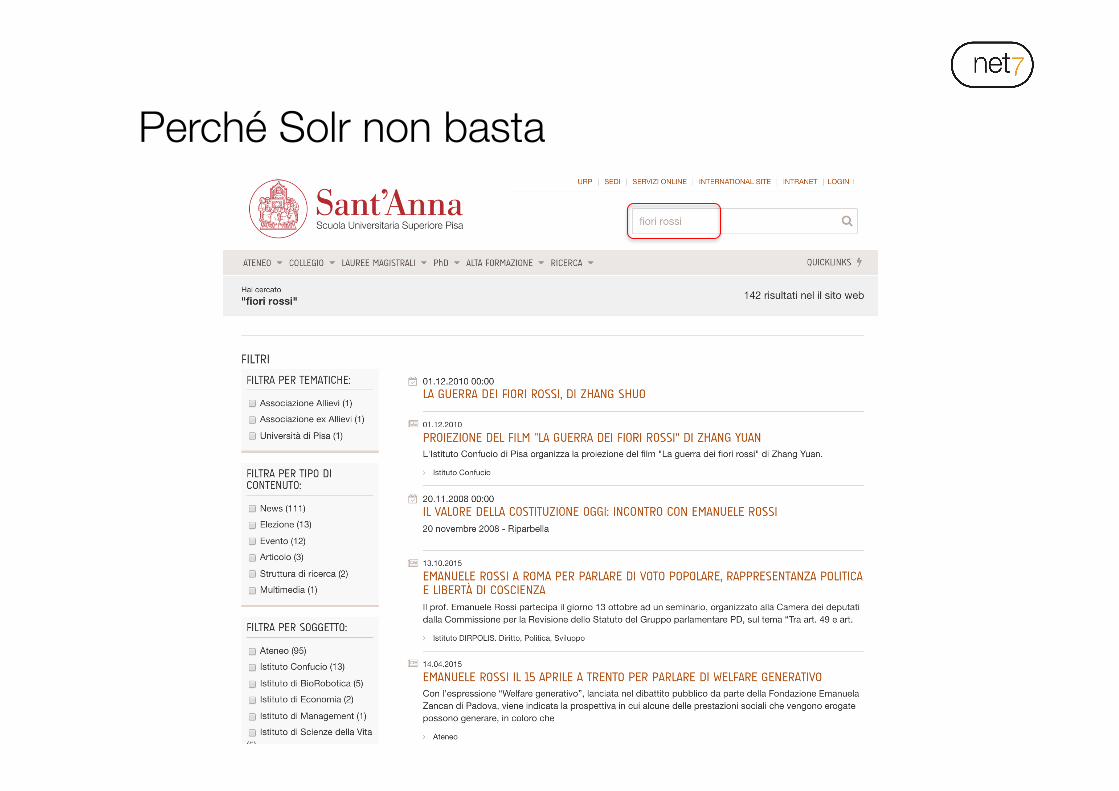
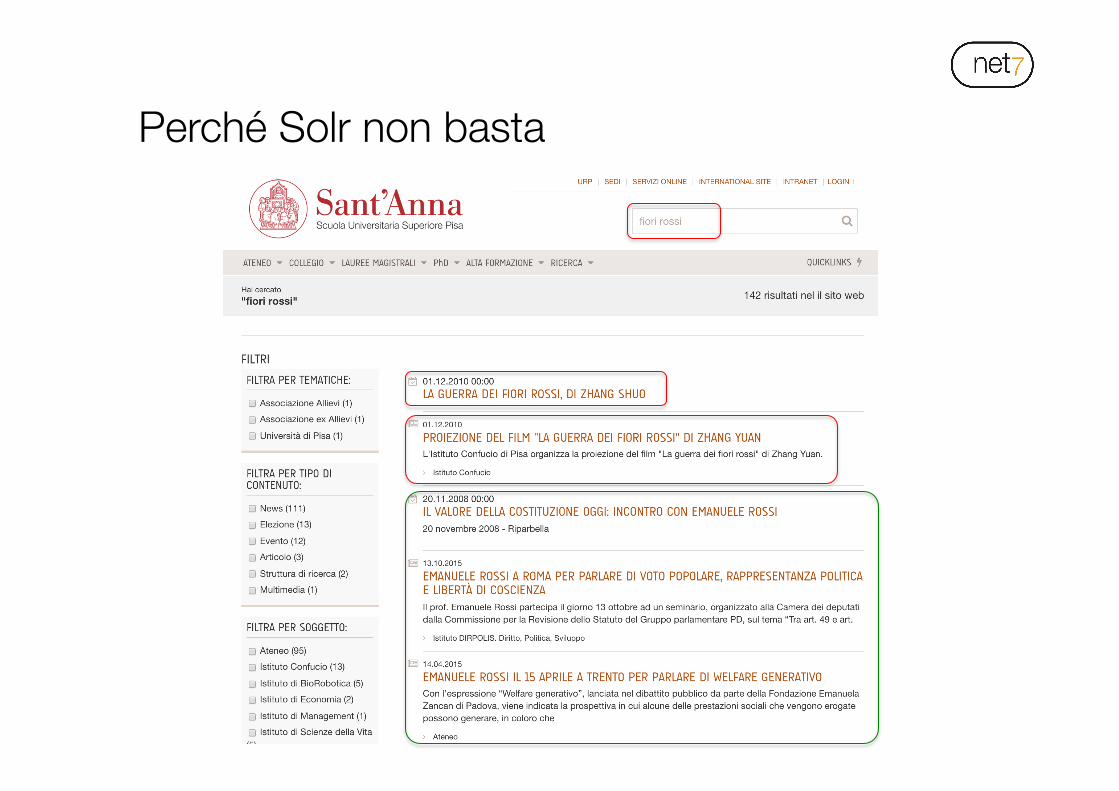
• Un motore di ricerca full-text (es. Solr) può indicizzare le stringhe senza discernere il loro significato (approccio bag of words)
!
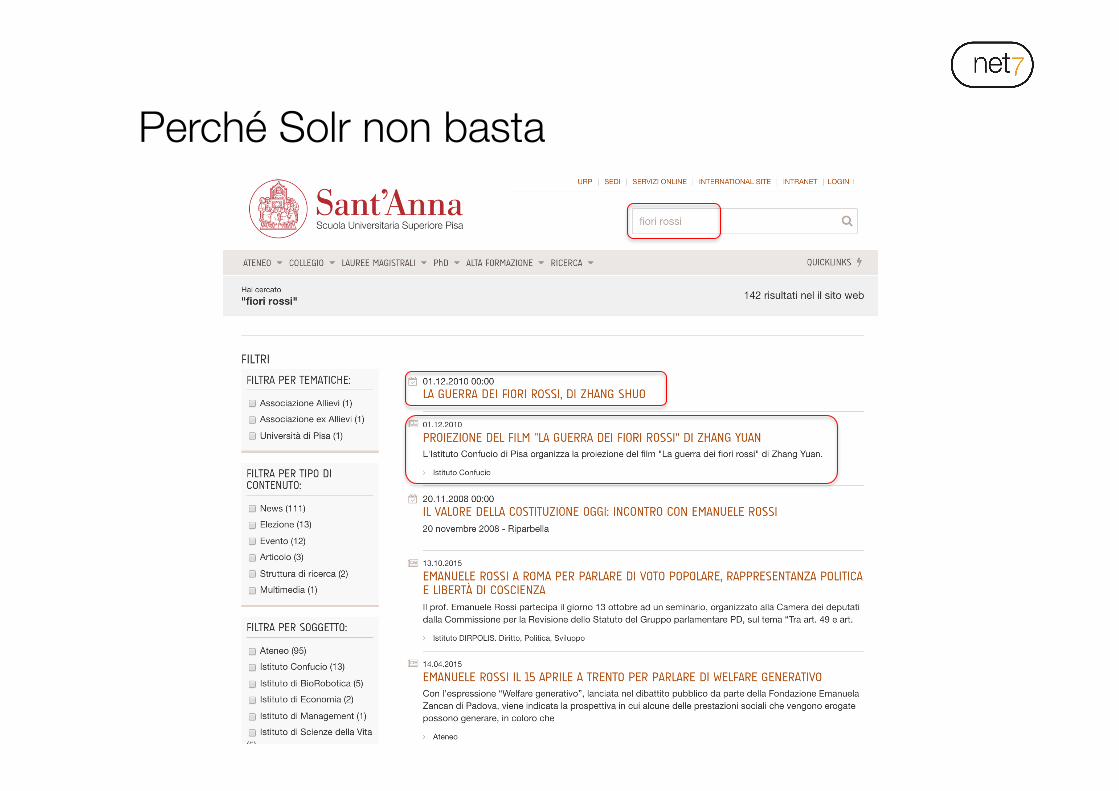
Perché Solr non basta
!
Perché Solr non basta
!
Perché Solr non basta

!
“Concetti” vs keywords su Innolabsplus.eu
• Analisi semantica del testo di un articolo (recuperato in automatico) per identificare i concetti attraverso i servizi NER

!
“Concetti” vs keywords su Innolabsplus.eu
• Analisi semantica del testo di un articolo (recuperato in automatico) per identificare i concetti attraverso i servizi NER

!
“Concetti” vs keywords su Innolabsplus.eu
• Analisi semantica del testo di un articolo (recuperato in automatico) per identificare i concetti attraverso i servizi NER

!
“Concetti” vs keywords su Innolabsplus.eu
• Analisi semantica del testo di un articolo (recuperato in automatico) per identificare i concetti attraverso i servizi NER

!
“Concetti” vs keywords su Innolabsplus.eu
• Analisi semantica del testo di un articolo (recuperato in automatico) per identificare i concetti attraverso i servizi NER

!
“Concetti” vs keywords su Innolabsplus.eu
• Analisi semantica del testo di un articolo (recuperato in automatico) per identificare i concetti attraverso i servizi NER

!
“Concetti” vs keywords su Innolabsplus.eu
• Analisi semantica del testo di un articolo (recuperato in automatico) per identificare i concetti attraverso i servizi NER

!
• Wikipedia usato come un dizionario controllato • I link tra le pagine di Wikipedia rappresentano i legami logici tra i
concetti: si crea così un grafo di termini • Tanto le pagine (concetti) sono vicine, tanto maggiore è il loro legame
semantico
Come funziona la NER delle Dandelion API

!
• Wikipedia usato come un dizionario controllato • I link tra le pagine di Wikipedia rappresentano i legami logici tra i
concetti: si crea così un grafo di termini • Tanto le pagine (concetti) sono vicine, tanto maggiore è il loro legame
semantico
Come funziona la NER delle Dandelion API

!
• Wikipedia usato come un dizionario controllato • I link tra le pagine di Wikipedia rappresentano i legami logici tra i
concetti: si crea così un grafo di termini • Tanto le pagine (concetti) sono vicine, tanto maggiore è il loro legame
semantico
Come funziona la NER delle Dandelion API

!
• Wikipedia usato come un dizionario controllato • I link tra le pagine di Wikipedia rappresentano i legami logici tra i
concetti: si crea così un grafo di termini • Tanto le pagine (concetti) sono vicine, tanto maggiore è il loro legame
semantico
Come funziona la NER delle Dandelion API

!
NER: il riconoscimento del “contesto”
• Analizzo il testo per riconoscere termini del mio dizionario (concetti potenziali)
• La “vicinanza” dei termini nel grafo mi permette di selezionare solo quelli effettivamente pertinenti (“di cosa parla un testo”)
• Disambiguazione di testi sintatticamente simili

!
NER: il riconoscimento del “contesto”
• Analizzo il testo per riconoscere termini del mio dizionario (concetti potenziali)
• La “vicinanza” dei termini nel grafo mi permette di selezionare solo quelli effettivamente pertinenti (“di cosa parla un testo”)
• Disambiguazione di testi sintatticamente simili “Nuovo record di gas serra nell’atmosfera terrestre”
“Riscaldamento notturno di una serra ad energia solare anziché a gas: è record”

!
NER: il riconoscimento del “contesto”
• Analizzo il testo per riconoscere termini del mio dizionario (concetti potenziali)
• La “vicinanza” dei termini nel grafo mi permette di selezionare solo quelli effettivamente pertinenti (“di cosa parla un testo”)
• Disambiguazione di testi sintatticamente simili “Nuovo record di gas serra nell’atmosfera terrestre”
“Riscaldamento notturno di una serra ad energia solare anziché a gas: è record”

!
NER: il riconoscimento del “contesto”
• Analizzo il testo per riconoscere termini del mio dizionario (concetti potenziali)
• La “vicinanza” dei termini nel grafo mi permette di selezionare solo quelli effettivamente pertinenti (“di cosa parla un testo”)
• Disambiguazione di testi sintatticamente simili “Nuovo record di gas serra nell’atmosfera terrestre”
“Riscaldamento notturno di una serra ad energia solare anziché a gas: è record”

!
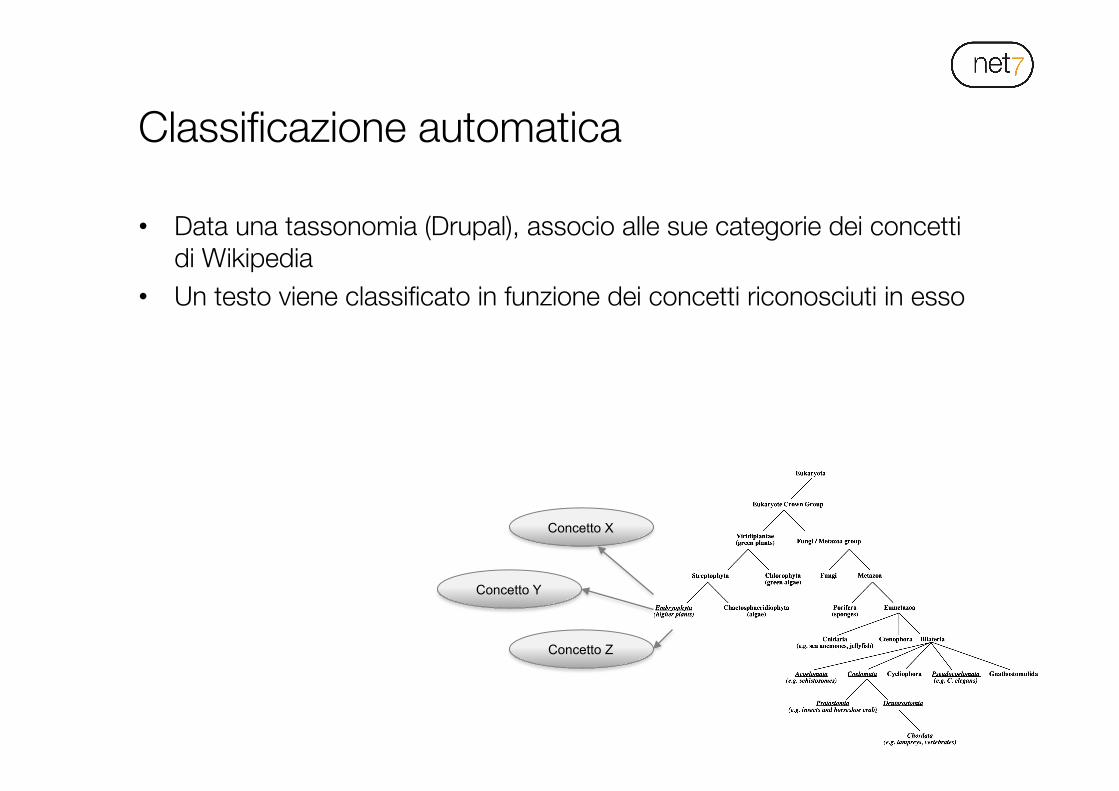
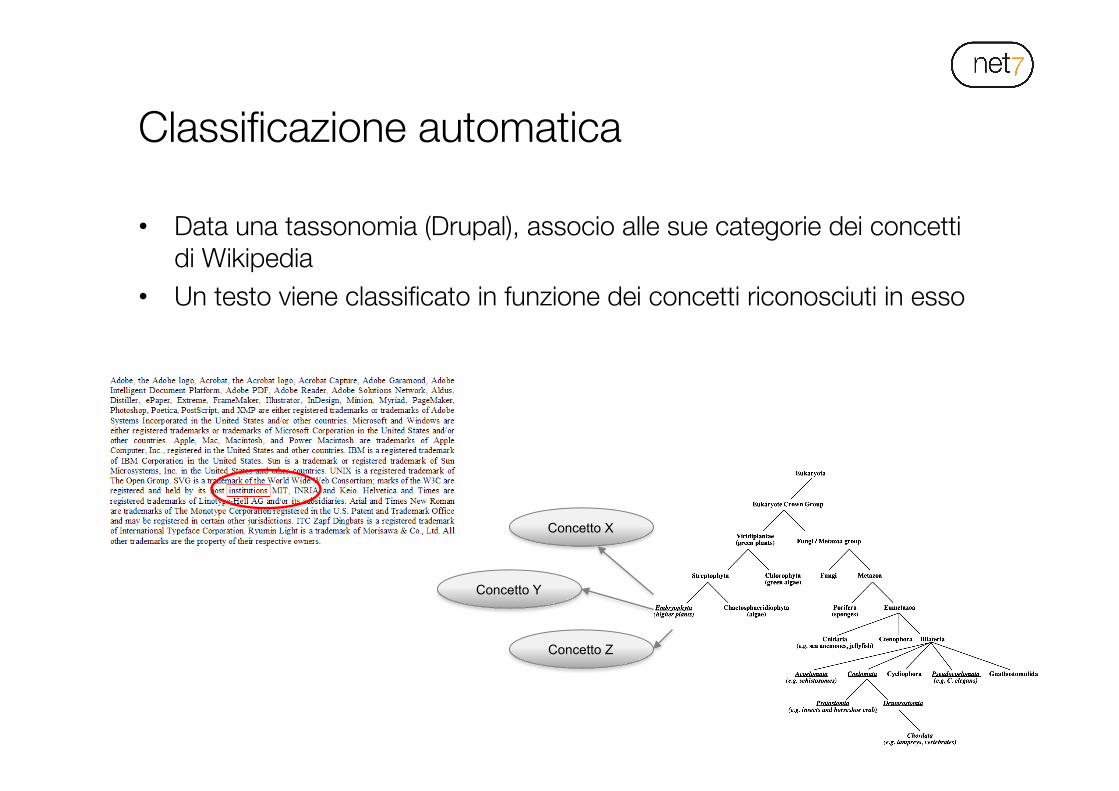
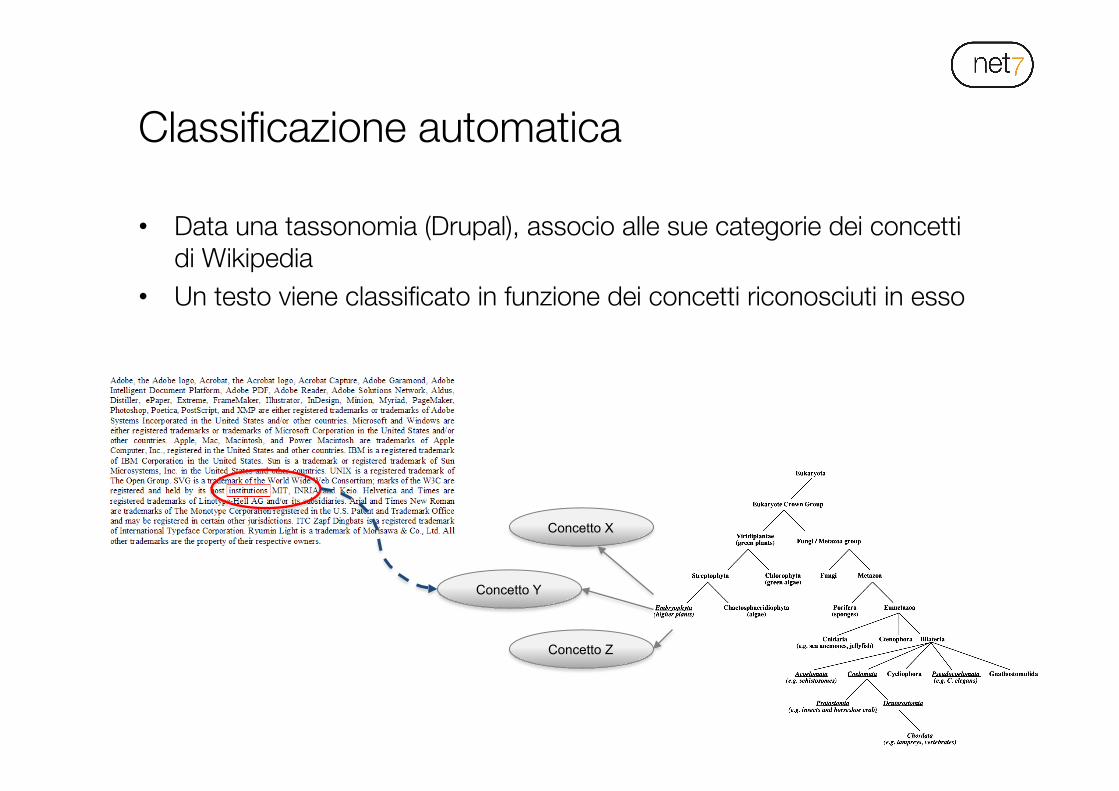
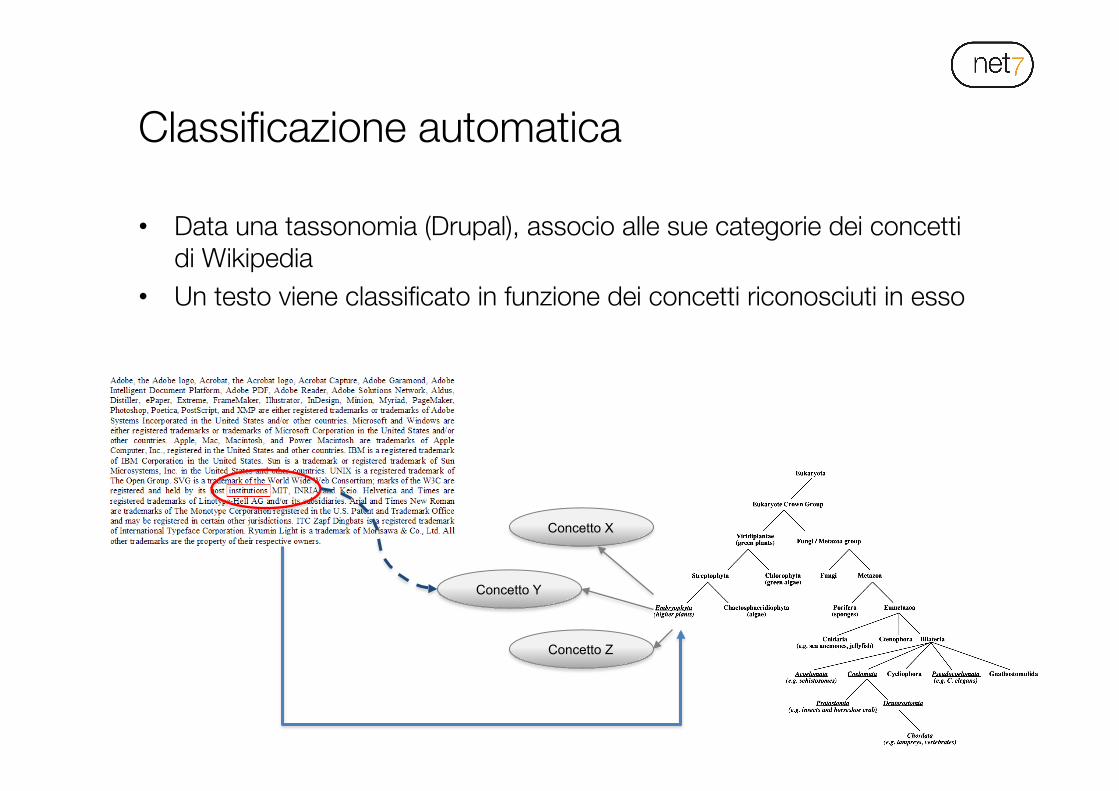
Classificazione automatica
• Data una tassonomia (Drupal), associo alle sue categorie dei concetti di Wikipedia
• Un testo viene classificato in funzione dei concetti riconosciuti in esso
!
Classificazione automatica
• Data una tassonomia (Drupal), associo alle sue categorie dei concetti di Wikipedia
• Un testo viene classificato in funzione dei concetti riconosciuti in esso
Concetto X
Concetto Y
Concetto Z
!
Classificazione automatica
• Data una tassonomia (Drupal), associo alle sue categorie dei concetti di Wikipedia
• Un testo viene classificato in funzione dei concetti riconosciuti in esso
Concetto X
Concetto Y
Concetto Z
!
Classificazione automatica
• Data una tassonomia (Drupal), associo alle sue categorie dei concetti di Wikipedia
• Un testo viene classificato in funzione dei concetti riconosciuti in esso
Concetto X
Concetto Y
Concetto Z
!
Classificazione automatica
• Data una tassonomia (Drupal), associo alle sue categorie dei concetti di Wikipedia
• Un testo viene classificato in funzione dei concetti riconosciuti in esso
Concetto X
Concetto Y
Concetto Z
!
Classificazione automatica
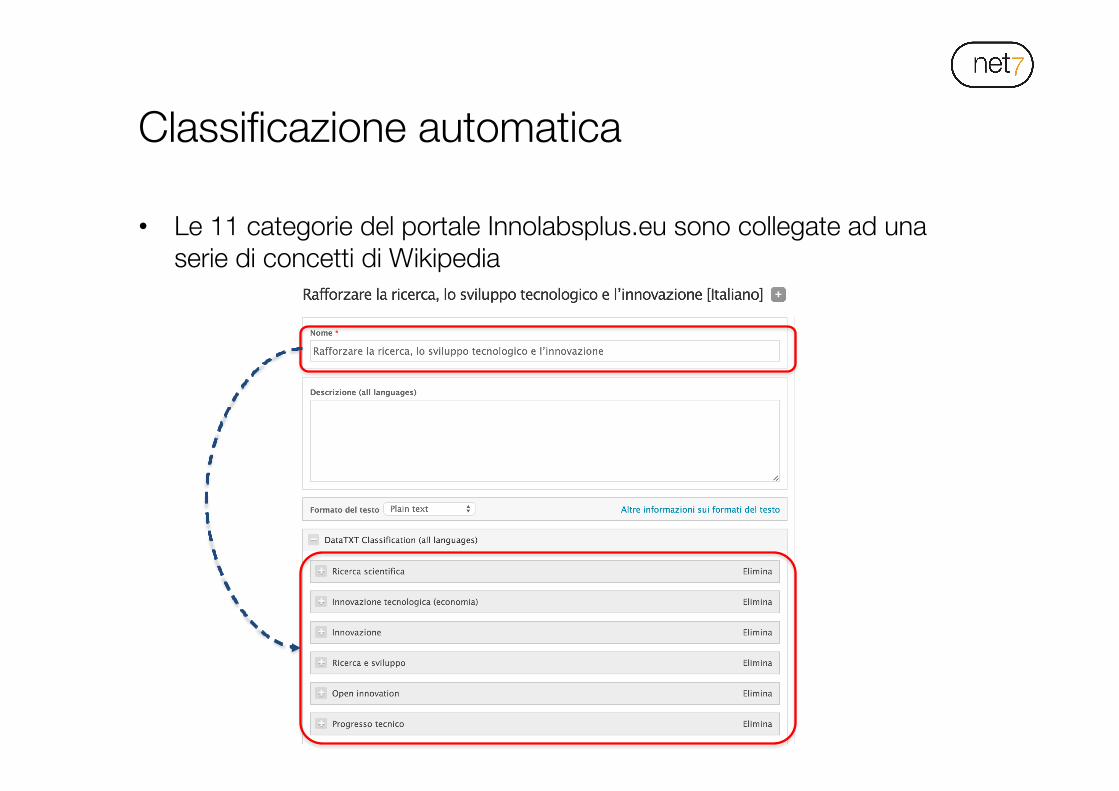
• Le 11 categorie del portale Innolabsplus.eu sono collegate ad una serie di concetti di Wikipedia

!
Innolabsplus.eu: come funziona
• Recupera articoli da molteplici siti via feed RSS – …potenziati da un nostro tool (esterno a Drupal) che recupera l’intero
articolo insieme al feed
• Analizza il testo dell’articolo con il servizio NER delle Dandelion API • Misura la “distanza” logica del testo con le categorie principali del sito
(classificazione automatica) – Se “affine” l’articolo viene pubblicato – I concetti estratti sono usati come “tag” liberi: utili per la ricerca, in ottica
SEO, etc. – Se l’articolo non è sufficientemente affine viene ignorato
• In realtà si pubblica il link in un box secondario
• Il tutto integrato in un modulo Drupal (7)

!
Struttura del modulo
Abbiamo cercato di strutturare il modulo utilizzando gli hook ove strettamente necessario, delegando le chiamate API e la gestione del modello a classi opportune.

!
Modello e integrazione con API
Il vocabolario da inviare a Dandelion è salvata in una entità costruita ad hoc, dove troviamo: • Riferimento ID
tassonomia su Dandelion • Riferimento vocabolario
associato Drupal • Lingua • Ultima data di modifica

!
Modello e integrazione con API
Anche il singolo termine tassonomico che arriva dal servizio esterno ha una sua tabella ad hoc. Questa contiene: • Riferimento al vocabolario Dandelion • Riferimento alla relativa voce
tassonomica Drupal • Url Wikipedia che descrive il
concetto • Rilevanza • Lingua • Data di modifica

!
Modello e integrazione con API
Le chiamate implementate verso Dandelion sono: - Classificazione iptc - Classificazione con vocabolario custom - Invio del vocabolario custom - Entity extraction - Wikisearch

!
Modello e integrazione con API
Queste informazioni sono inviate a Dandelion per classificare le tassonomie, come JSON tramite la chiamata API “https://api.dandelion.com/datatxt/cl/models/v1” E’ stata inoltre realizzata un’interfaccia di backend per gestire la creazione di queste tassonomie speciali

!
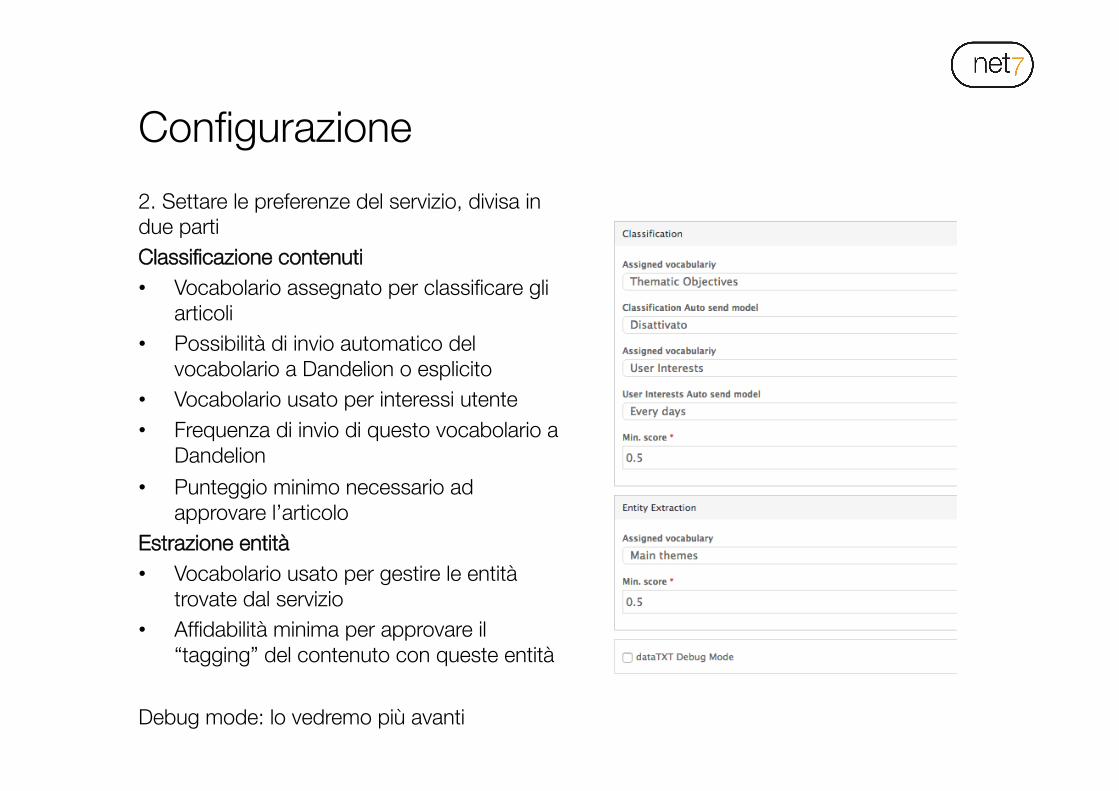
Configurazione
• Come primo step per l’utilizzo del modulo è necessaria un po’ di configurazione…
1. Inserire le credenziali di accesso al web service di entity recognition di Dandelion: endpoint API, app ID e app key
!
Configurazione 2. Settare le preferenze del servizio, divisa in due parti Classificazione contenuti • Vocabolario assegnato per classificare gli
articoli • Possibilità di invio automatico del
vocabolario a Dandelion o esplicito • Vocabolario usato per interessi utente • Frequenza di invio di questo vocabolario a
Dandelion • Punteggio minimo necessario ad
approvare l’articolo Estrazione entità • Vocabolario usato per gestire le entità
trovate dal servizio • Affidabilità minima per approvare il
“tagging” del contenuto con queste entità Debug mode: lo vedremo più avanti
!
Recupero dei FEED Per il recupero dei feed che possono essere convertiti in news vere e proprie abbiamo esteso il modello che arriva dal modulo Feed importer di Drupal, per potersi meglio integrare con il nostro tool di recupero degli articoli (Social Proxy): • E’ stato quindi creato un feed particolare (Feed Proxy)

!
Promozione dei feed ad articolo I feed vengono poi processati in automatico allo scattare del cron standard di Drupal, tramite code: • Viene richiesto al Social Proxy il contenuto completo della pagina a cui
riferisce il feed • Viene analizzato con Dandelion rispetto alla tassonomia creata prima • Se l’articolo “parla” di argomenti definiti nella tassonomia con un grado
di affidabilità maggiore a quello impostato, il feed viene salvato come articolo e il feed relativo “spubblicato”
• Nel feed ci sono informazioni necessarie per recuperare informazioni accessorie
• Tramite una chiamata Server2Server verso questa applicazione si recupera non solo il feed, ma anche il testo completo dell’articolo, ripulito degli elementi decorativi della pagina.
!
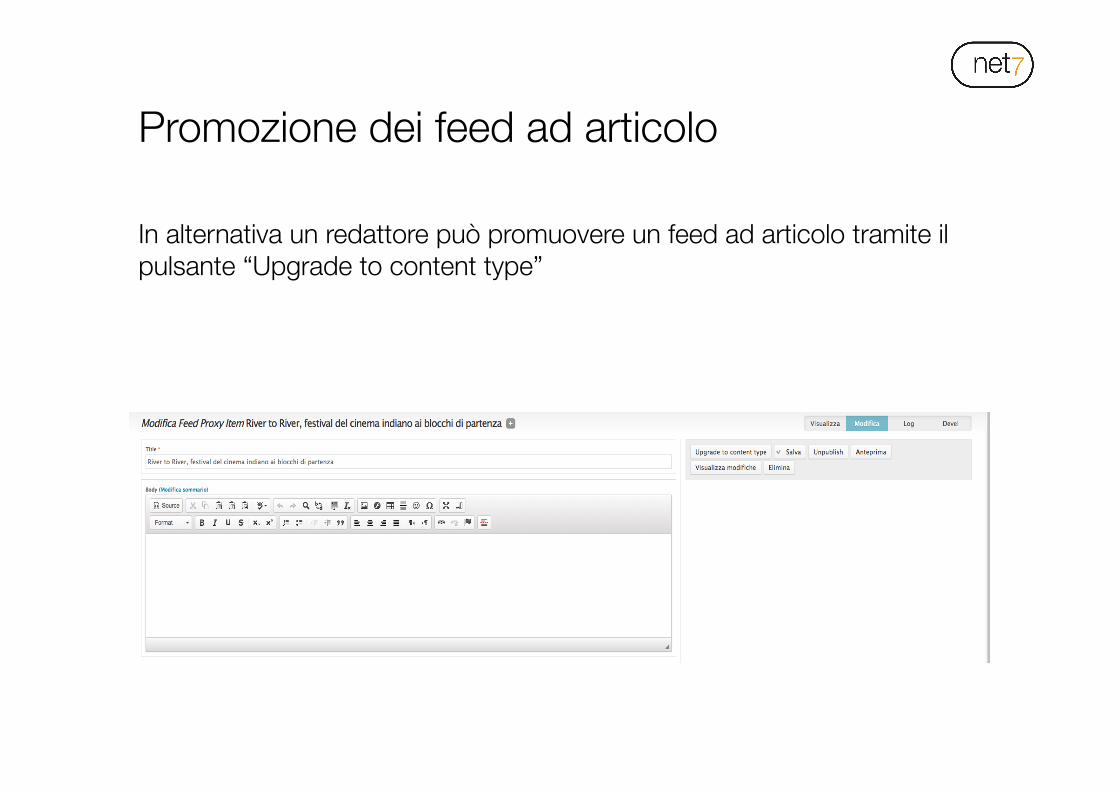
Promozione dei feed ad articolo
In alternativa un redattore può promuovere un feed ad articolo tramite il pulsante “Upgrade to content type”

!
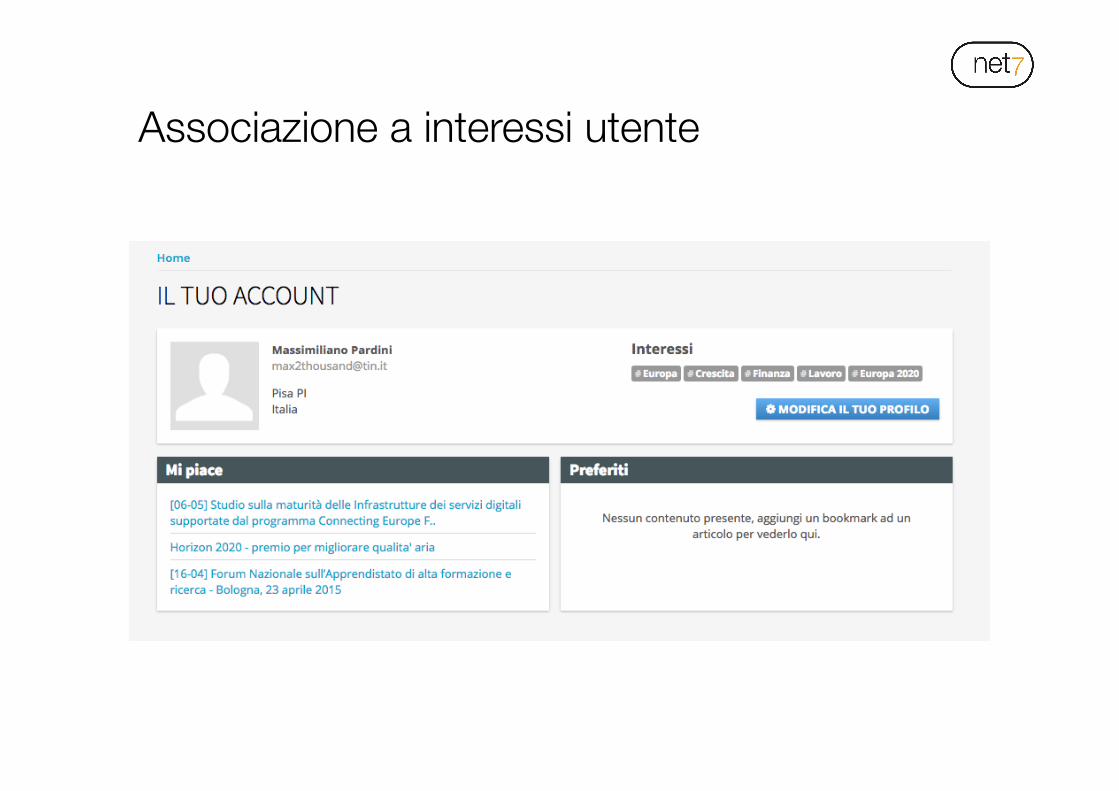
Associazione a interessi utente
Non c’è solo la classificazione e pubblicazione automatica dei feed, ma il sistema riesce anche a suggerire articoli alle persone che si registrano al sito. Questo avviene in due step: 1. L’utente si registra al sito, e come avviene per la definizione
dell’albero di classificazione contenuti, inserisce delle preferenze di argomenti, sempre collegati a concetti Wikipedia
2. I testi dei feed vengono analizzati anche rispetto a questi vocabolari, e se il grado di affidabilità è maggiore di quello soglia impostato, l’articolo viene automaticamente suggerito all’utente
A livello implementativo ciò si traduce nel creare tassonomie collegate agli utenti, che a loro volta sono collegate a concetti Wikipedia.
!
Associazione a interessi utente
!
Associazione a interessi utente
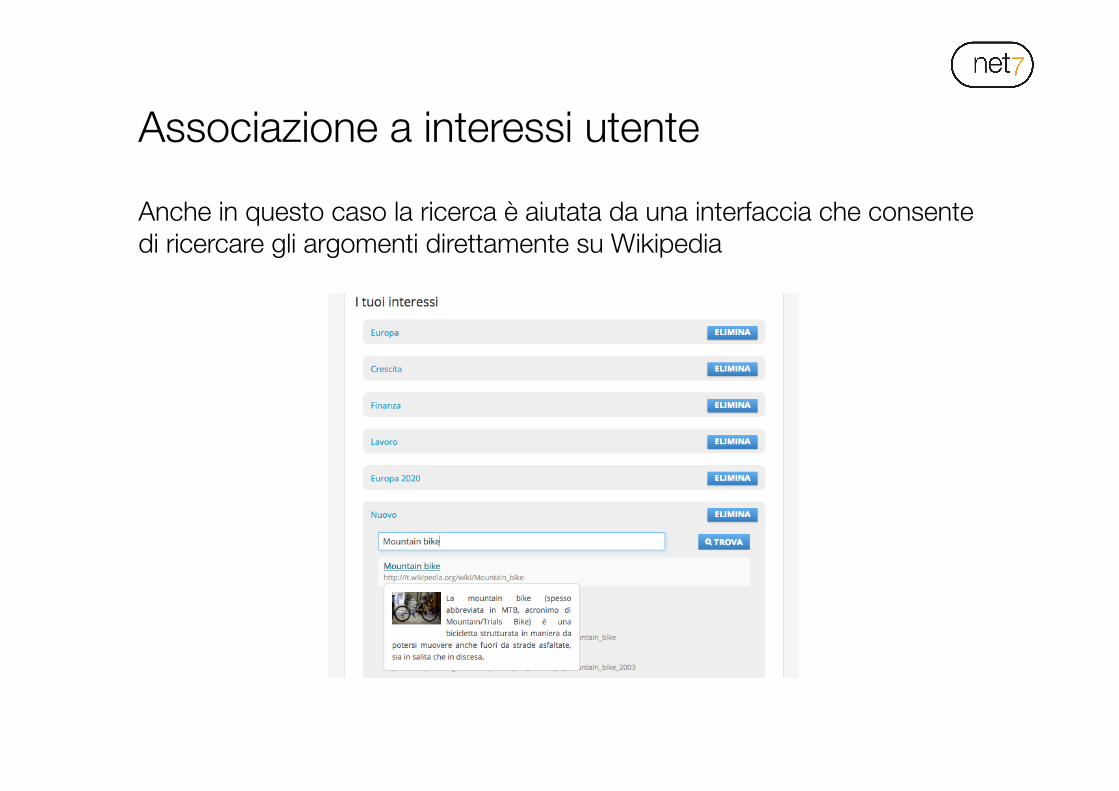
Anche in questo caso la ricerca è aiutata da una interfaccia che consente di ricercare gli argomenti direttamente su Wikipedia
!
Modalità debug
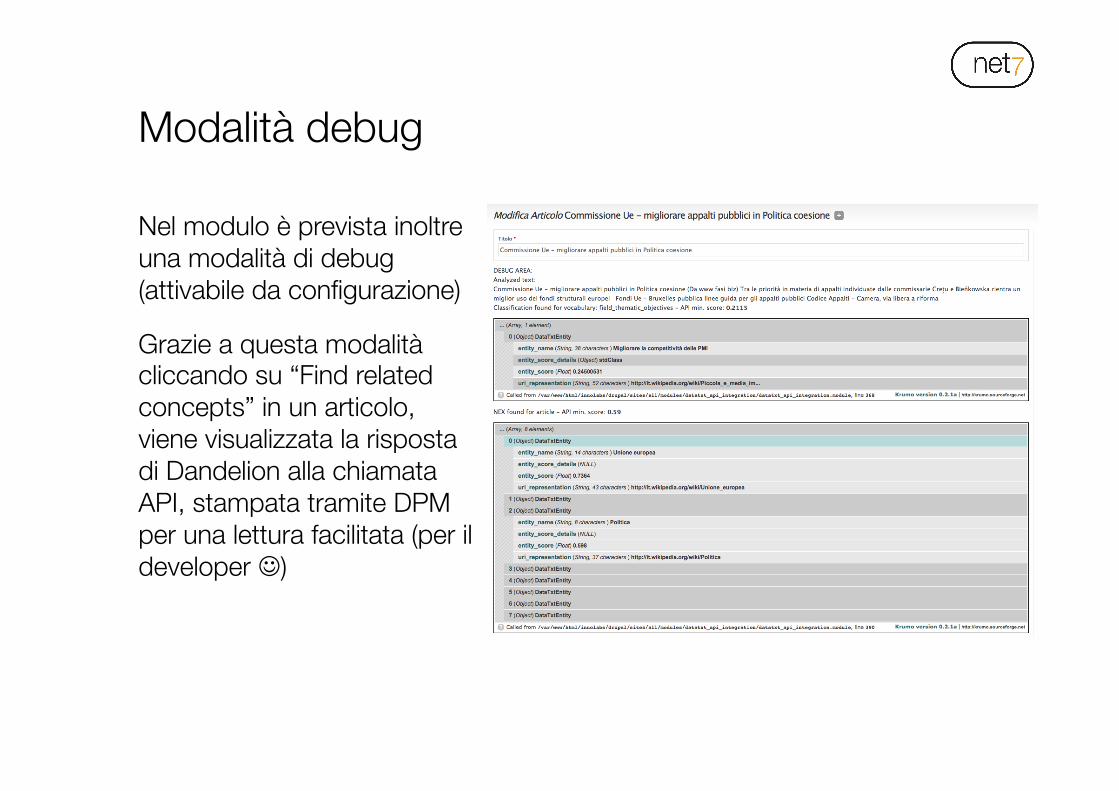
Nel modulo è prevista inoltre una modalità di debug (attivabile da configurazione)
Grazie a questa modalità cliccando su “Find related concepts” in un articolo, viene visualizzata la risposta di Dandelion alla chiamata API, stampata tramite DPM per una lettura facilitata (per il developer J)

!
Migliorie future
• Suite di test per garantire affidabilità modulo • Rifattorizzazione del codice per utilizzo di hook meno generici utilizzati
in alcuni punti del codice (tipo il classico “hook_form_alter”) • Migliorie alle azioni javascript che consentono la definizione del
vocabolario dal backend • Migliorare la gestione degli allarmi (es. Feed fermo da X giorni o
nessun feed item promosso ad articolo da troppo tempo) • Aggiunta di alter nei processi di classificazione dei feed per permettere
a moduli esterni di “agganciarsi” alla procedura.
!
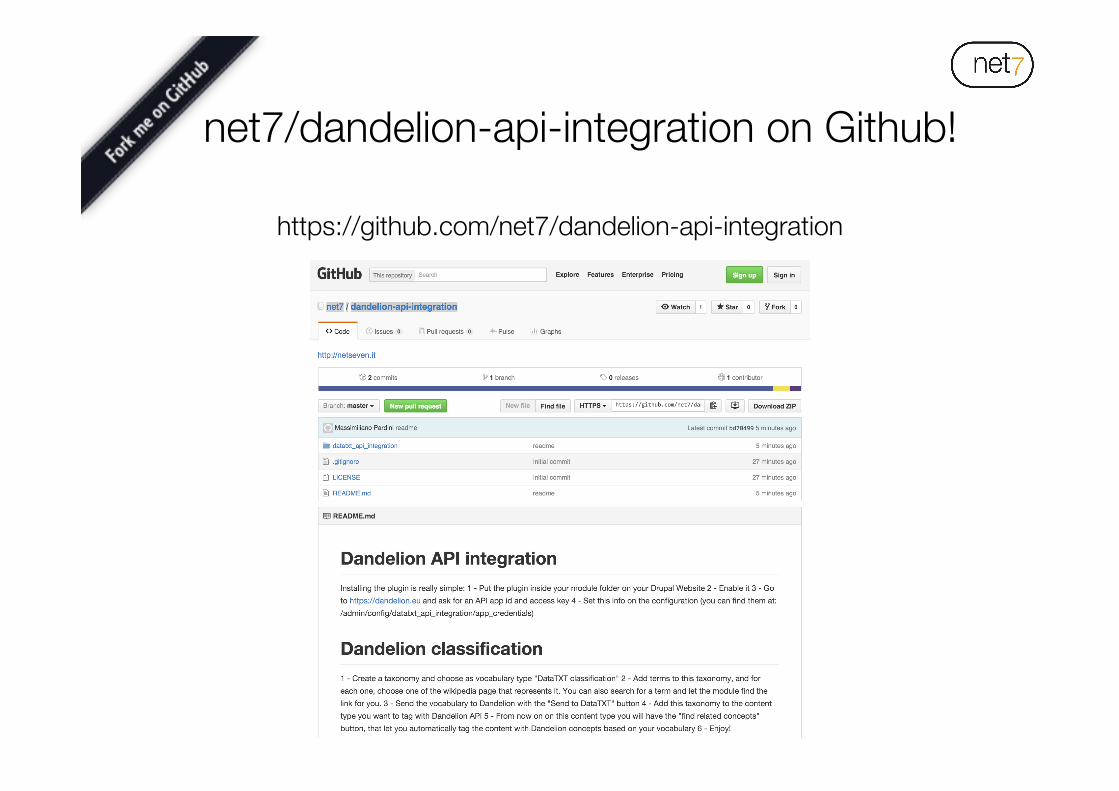
net7/dandelion-api-integration on Github!
https://github.com/net7/dandelion-api-integration

!
Thanks! [email protected] - [email protected]
@lucadex - @naturemaxphoto www.netseven.it
© Immagini • Slide 4: © David All; © Danilo Soscia • Slide 5: http://www.wrlwnd.com/gartners-top-5-over-hyped-
tech-of-2015/ • Slide 6: http://www.scientificamerican.com/article/the-semantic-
web/; © W3C; @ Jim Hendler • Slide 7: © Paolo Ferragina • Slide 9: http://www.santannapisa.it
























