Embed Size (px)
Citation preview


Definition: an inverted file is a word-oriented mechanism for indexing a text collection in order to speed up the searching task.
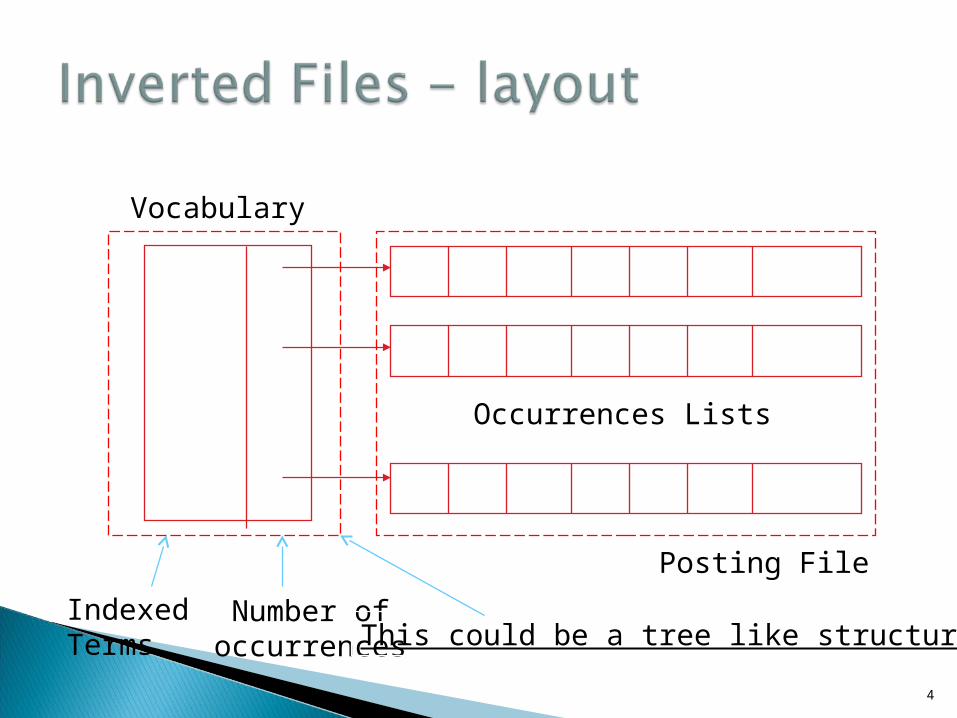
Structure of inverted file:◦ Vocabulary: is the set of all distinct words in
the text◦ Occurrences: lists containing all information
necessary for each word of the vocabulary (text position, frequency, documents where the word appears, etc.)

Inverted file index is list of terms that appear in the document collection (called a lexicon or vocabulary) and for each term in the lexicon, stores a list of pointers to all occurrences of that term in the document collection. This list is called an inverted list.
Granularity of an index determines the accuracy of representation of the location of the word◦ Coarse-grained index requires less storage and
more query processing to eliminate false matches
◦ Word-level index enables queries involving adjacency and proximity, but has higher space requirements
4
IndexedTerms
Number of occurrences
Occurrences Lists
Vocabulary
Posting File
This could be a tree like structure !

5
Text:
Inverted file
1 6 12 16 18 25 29 36 40 45 54 58 66 70
That house has a garden. The garden has many flowers. The flowers are beautiful
beautiful
flowers
garden
house
70
45, 58
18, 29
6
Vocabulary Occurrences

Prior example allows for boolean queries.
Need the document frequency and term frequency.
Vocabulary entry Posting file entry
k dk doc1 f1k doc2 f2k …
dk : document frequency of term k
doci : i-th document that contains term k
fik : term frequency of term k in document i

The space required for the vocabulary is rather small. According to Heaps’ law the vocabulary grows as O(n), where is a constant between 0.4 and 0.6 in practice◦ TREC-2: 1 GB text, 5 MB lexicon
On the other hand, the occurrences demand much more space. Since each word appearing in the text is referenced once in that structure, the extra space is O(n)
To reduce space requirements, a technique called block addressing is used

The text is divided in blocks The occurrences point to the blocks where
the word appears Advantages:
◦the number of pointers is smaller than positions
◦all the occurrences of a word inside a single block are collapsed to one reference
Disadvantages:◦online search over the qualifying blocks if
exact positions are required

Text:
Inverted file
beautiful
flowers
garden
house
4
3
2
1
Vocabulary Occurrences
Block 1 Block 2 Block 3 Block 4
That house has a garden. The garden has many flowers. The flowers are beautiful

How big are inverted files?◦ In relation to original collection size
right column indexes stopwords while left removes stopwords
Blocks require text to be available for location of terms within blocks.
45%
27%
18%
73%
41%
25%
36%
18%
1.7%
64%
32%
2.4%
35%
5%
0.5%
63%
9%
0.7%
Addressing words
Addressing 256 blocks
Addressing 64K blocks
Index Small collection
(1Mb)
Medium collection
(200Mb)
Large collection
(2Gb)

The search algorithm on an inverted index follows three steps:
1. Vocabulary search: the words present in the query are located in the vocabulary
2. Retrieval occurrences: the lists of the occurrences of all query words found are retrieved
3. Manipulation of occurrences: the occurrences are processed to solve the query

Searching inverted files starts with vocabulary
◦ store the vocabulary in a separate file Structures used to store the vocabulary
include◦ Hashing : O (1) lookup, does not support
range queries◦ Tries : O (c) lookup, c = length (word)◦ B-trees : O (log v) lookup
An alternative is simply storing the words in lexicographical order
◦ cheaper in space and very competitive with O(log v) cost

All the vocabulary is kept in a suitable data structure storing for each word and a list of its occurrences
Each word of each text in the corpus is read and searched for in the vocabulary
If it is not found, it is added to the vocabulary with a empty list of occurrences
The new position is added to the end of its list of occurrences for the word

Once the text is exhausted the vocabulary is written to disk with the list of occurrences.
Two files are created:◦ in the first file, each list of word occurrences
is stored contiguously◦ in the second file, the vocabulary is stored in
lexicographical order and, for each word, a pointer to its list in the first file is also included. This allows the vocabulary to be kept in memory at search time
The overall process is O(n) worst-case time

An option is to use the previous algorithm until the main memory is exhausted. When no more memory is available, the partial index Ii obtained up to now is written to disk and erased the main memory before continuing with the rest of the text
Once the text is exhausted, a number of partial indices Ii exist on disk
The partial indices are merged to obtain the final index
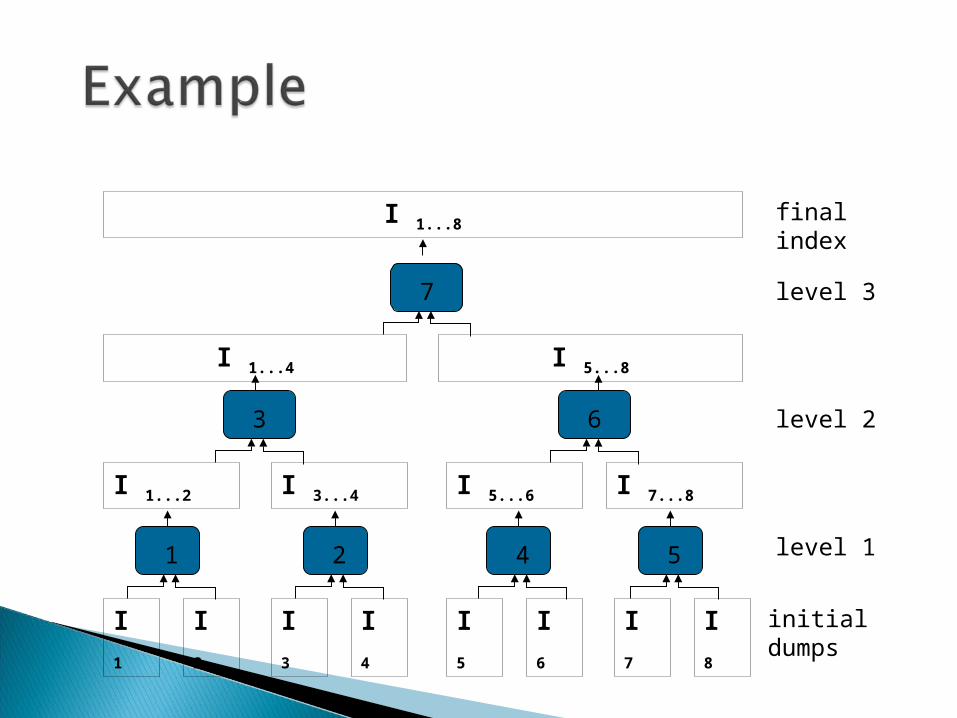
I 1...8
I 1...4 I 5...8
I 1...2 I 3...4 I 5...6 I 7...8
I 1 I 2 I 3 I 4 I 5 I 6 I 7 I 8
1 2 4 5
3 6
7
final index
initial dumps
level 1
level 2
level 3

The total time to generate partial indices is O(n)
The number of partial indices is O(n/M)
To merge the O(n/M) partial indices are necessary log2(n/M) merging levels
The total cost of this algorithm is O(n log(n/M))

Inverted files are used to index text
The indices are appropriate when the text collection is large and semi-static
If the text collection is volatile online searching is the only option
Some techniques combine online and indexed searching

Vocabulary List◦ Text preprocessing modules
lexical analysis, stemming, stopwords
Occurrences of Vocabulary Terms◦ Inverted index creation
term frequency in documents, document frequency
Retrieval and Ranking Algorithm Query and Ranking Interfaces Browsing/Visualization Interface

















![INDEX [assets.cambridge.org]assets.cambridge.org/97805217/92974/index/9780521792974_index.pdf · inverted siphons on , ... INDEX Note:page references to figures are in italic.](https://img.dokumen.tips/doc/110x75/5ac11a627f8b9a1c768c775d/index-siphons-on-index-notepage-references-to-gures-are-in-italic.jpg)










