Embed Size (px)
Citation preview

Cluster Schedulers
Pietro Michiardi
Eurecom
Pietro Michiardi (Eurecom) Cluster Schedulers 1 / 129

Introduction
Introduction andPreliminaries
Pietro Michiardi (Eurecom) Cluster Schedulers 2 / 129

Introduction
Overview of the Lecture
General overview of cluster scheduling principlesI General objectivesI A taxonomyI Current architectures
In depth presentation of three representative examplesI YarnI MesosI Borg (Kubernetes)
Pietro Michiardi (Eurecom) Cluster Schedulers 3 / 129

Introduction Cluster Scheduling Principles
Cluster Scheduling Principles
Pietro Michiardi (Eurecom) Cluster Schedulers 4 / 129

Introduction Cluster Scheduling Principles
Objectives
Large-scale clusters are expensive, so it is important to usethem well
I Cluster utilization and efficiency are key indicators for goodresource management and scheduling decisions
I Translates directly to cost arguments: better scheduling → smallerclusters
Multiplexing to the rescueI Multiple, heterogeneous mixes of application run concurrently→ The scheduling problem is a challenge
Scalability bottlenecksI Cluster and workload sizes keep growingI Scheduling complexity roughly proportional to cluster size→ Schedulers must be scalable
Pietro Michiardi (Eurecom) Cluster Schedulers 5 / 129

Introduction Cluster Scheduling Principles
Current Scheduler Architectures
Monolitic: use a centralized scheduling and resourcemanagement algorithm for all jobs
I Difficult to add new scheduling policiesI Do not scale well to large cluster sizes
Two-level: single resource manager that grants resources toindependent “framework schedulers”
I Flexibility in accommodating multiple application frameworksI Resource management and locking are conservative, which can
hurt cluster utilization and performancePietro Michiardi (Eurecom) Cluster Schedulers 6 / 129

Introduction Cluster Scheduling Principles
Typical workloads to support
Cluster scheduler must support heterogeneous workloadsand clusters
I Clusters are made of several generations of machinesI Workloads evolve in time, and can be made of a variety of
applications
Rough categorization of job typesI Batch jobs: e.g., MapReduce computationsI Service jobs: e.g., end-user facing web service
Knowing your workload is fundamental!I Next, some examples from real cluster tracesI The rationale: measurements can inform scheduling design
Pietro Michiardi (Eurecom) Cluster Schedulers 7 / 129

Introduction Cluster Scheduling Principles
Real cluster trace: workload characteristics
Solid lines: batch jobs, dashed lines: service jobs
Pietro Michiardi (Eurecom) Cluster Schedulers 8 / 129

Introduction Cluster Scheduling Principles
Real cluster trace: workload characteristics
Solid lines: batch jobs, dashed lines: service jobs
Pietro Michiardi (Eurecom) Cluster Schedulers 9 / 129

Introduction Cluster Scheduling Principles
Short Taxonomy of Scheduling Design Issues
Scheduling Work Partitioning: how to distribute work acrossframeworks
I Workload-oblivious load-balancingI Workload partitioning and specialized schedulersI Hybrid
Resource choice: which cluster resources are available toconcurrent frameworks
I All resources availableI A subset of cluster resources is granted (or offered)I NOTE: preemption primitives help scheduling flexibility at the cost
of potentially wasting work
Pietro Michiardi (Eurecom) Cluster Schedulers 10 / 129

Introduction Cluster Scheduling Principles
Short Taxonomy of Scheduling Design Issues
Interference: what to do when multiple frameworks attempt atusing the same resources
I Pessimistic concurrency control: make sure to avoid conflicts, bypartitioning resources across frameworks
I Optimistic concurrency control: hope for the best, otherwise detectand undo conflicting claims
Allocation Granularity: task “scheduling” policiesI Atomic, all-or-nothing gang scheduling: e.g. MPII Incremental placement, hoarding: e.g. MapReduce
Cluster-wide behavior: some requirements need global viewI Fairness across frameworksI Global notion of priority
Pietro Michiardi (Eurecom) Cluster Schedulers 11 / 129
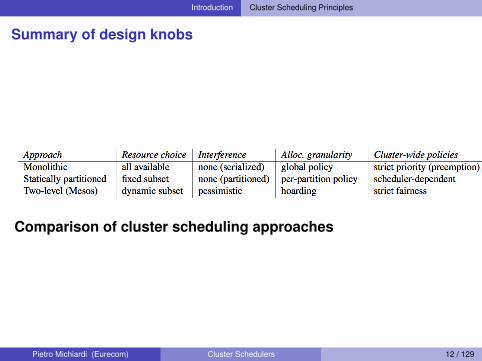
Introduction Cluster Scheduling Principles
Summary of design knobs
Comparison of cluster scheduling approaches
Pietro Michiardi (Eurecom) Cluster Schedulers 12 / 129

Introduction Cluster Scheduling Principles
Architecture Details
High-level summary of scheduling objectivesI Minimize the job queueing time, or more generally, the system
response time (queueing + service times)I Subject to
F Priorities among jobsF Per-job constraintsF Failure toleranceF Scalability
Scheduling architecturesI Monolithic schedulersI Statically partitioned schedulersI Two-level schedulersI Shared-state schedulers (cf. Omega paper)
Pietro Michiardi (Eurecom) Cluster Schedulers 13 / 129

Introduction Cluster Scheduling Principles
Monolithic Schedulers
Single centralized instanceI Typical of HPC settingI Implements all policies in a single code baseI Applies the same scheduling algorithm to all incoming jobs
Alternative designsI Support multiple code paths for different jobsI Each path implements a different scheduling logic→ Difficult to implement and maintain
Pietro Michiardi (Eurecom) Cluster Schedulers 14 / 129

Introduction Cluster Scheduling Principles
Statically Partitioned Schedulers
Standard “Cloud-computing” approachI Underlying assumption: each framework has complete control over
a set of resourcesI Depend on statically partitioned, dedicated resourcesI Examples: Hadoop 1.0, Quincy scheduler
Problems with static partitioningI Fragmentation of resourcesI Sub-optimal cluster utilization
Pietro Michiardi (Eurecom) Cluster Schedulers 15 / 129

Introduction Cluster Scheduling Principles
Two-level Schedulers
Obviates the problems of static partitioningI Dynamic allocation of resources to concurrent frameworksI Use a “logically centralized” coordinator to decide how many
resources to grantA first example: Mesos
I Centralized resource allocator, with dynamic cluster partitioningI Available resources are offered to competing frameworksI Avoids interference by exclusive offersI Frameworks lock resources by accepting offers → pessimistic
concurrency controlI No global cluster state available to frameworks
Another tricky example: YARNI Centralized resource allocator (RM), with per-job framework master
(AM)I AM only provides job management services, not proper scheduling→ YARN is closer to a monolithic architecture
Pietro Michiardi (Eurecom) Cluster Schedulers 16 / 129

Introduction Cluster Scheduling Principles
Representative ClusterSchedulers
Pietro Michiardi (Eurecom) Cluster Schedulers 17 / 129

YARN
YARN
Pietro Michiardi (Eurecom) Cluster Schedulers 18 / 129

YARN Introduction and Motivations
Introduction and Motivations
Pietro Michiardi (Eurecom) Cluster Schedulers 19 / 129
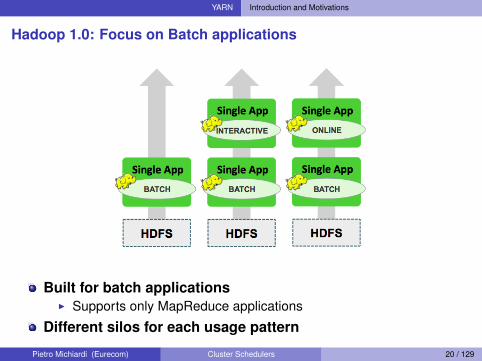
YARN Introduction and Motivations
Hadoop 1.0: Focus on Batch applications
Built for batch applicationsI Supports only MapReduce applications
Different silos for each usage pattern
Pietro Michiardi (Eurecom) Cluster Schedulers 20 / 129

YARN Introduction and Motivations
Hadoop 1.0: Architecture (reloaded)
JobTrackerI Manages cluster resourcesI Performs Job schedulingI Performs Task scheduling
TaskTrackerI Per machine agentI Manages Task execution
Pietro Michiardi (Eurecom) Cluster Schedulers 21 / 129

YARN Introduction and Motivations
Hadoop 1.0: Limitations
Only supports MapReduce, no other paradigmsI Everything needs to be cast to MapReduceI Iterative applications are slow
Scalability issuesI Max cluster size roughy 4,000 nodesI Max concurrent tasks, roughly 40,000 tasks
AvailabilityI System failures destroy running and queued jobs
Resource utilizationI Hard, static partitioning of resources in Map or Reduce slotsI Non-optimal resource utilization
Pietro Michiardi (Eurecom) Cluster Schedulers 22 / 129

YARN Introduction and Motivations
Next Generation Hadoop
Pietro Michiardi (Eurecom) Cluster Schedulers 23 / 129

YARN Introduction and Motivations
The YARN ecosystem
Store all data in one placeI Avoids costly duplication
Interact with data in multiple waysI Not only in batch mode, with the rigid MapReduce model
More predictable performanceI Advanced scheduling mechanisms
Pietro Michiardi (Eurecom) Cluster Schedulers 24 / 129

YARN Introduction and Motivations
Key Improvements in YARN (1)
Support for multiple applicationsI Separate generic resource brokering from application logicI Define protocols/libraries and provide a framework for custom
application developmentI Share same Hadoop Cluster across applications
Improved cluster utilizationI Generic resource container model replaces fixed Map/Reduce slotsI Container allocations based on locality and memoryI Sharing cluster among multiple application
Improved scalabilityI Remove complex app logic from resource managementI State machine, message passing based loosely coupled designI Compact scheduling protocol
Pietro Michiardi (Eurecom) Cluster Schedulers 25 / 129

YARN Introduction and Motivations
Key Improvements in YARN (2)
Application AgilityI Use Protocol Buffers for RPC gives wire compatibilityI Map Reduce becomes an application in user spaceI Multiple versions of an app can co-exist leading to experimentationI Easier upgrade of framework and applications
A data operating system: shared servicesI Common services included in a pluggable frameworkI Distributed file sharing serviceI Remote data read serviceI Log Aggregation Service
Pietro Michiardi (Eurecom) Cluster Schedulers 26 / 129

YARN YARN Architecture Overview
YARN Architecture Overview
Pietro Michiardi (Eurecom) Cluster Schedulers 27 / 129

YARN YARN Architecture Overview
YARN: Architecture Overview
Pietro Michiardi (Eurecom) Cluster Schedulers 28 / 129

YARN YARN Architecture Overview
YARN: Design Decisions
No static resource partitioningI There are no more slotsI Nodes have resources, which are allocated to applications when
requestedSeparate resource management from application logic
I Cluster-wide resource allocation and managementI Per-application master componentI Multiple applications → multiple masters
Pietro Michiardi (Eurecom) Cluster Schedulers 29 / 129

YARN YARN Architecture Overview
YARN Daemons
Resource Manager (RM)I Runs on master nodeI Global resource manager and schedulerI Arbitrates system resources between competing applications
Node Manager (NM)I Run on slave nodesI Communicates with RMI Reports utilization
Resource containersI Created by the RM upon requestI Allocate a certain amount of resources on slave nodesI Applications run in one or more containers
Application Master (AM)I One per application, application specific1
I Requests more containers to execute application tasksI Runs in a container
1Every new application requires a new AM to be designed and implemented!Pietro Michiardi (Eurecom) Cluster Schedulers 30 / 129

YARN YARN Architecture Overview
YARN: Example with 2 Applications
Pietro Michiardi (Eurecom) Cluster Schedulers 31 / 129

YARN YARN Core Components
YARN Core Components
Pietro Michiardi (Eurecom) Cluster Schedulers 32 / 129

YARN YARN Core Components
YARN Schedulers (1)
Schedulers are a pluggable component of the RMI In addition to existing ones, advanced scheduling is supported
Current supported schedulersI The Capacity schedulerI The Fair schedulerI Dominant Resource Fairness
What’s different w.r.t. Hadoop 1.0?I Support any YARN application, not just MapReduceI No more slots, tasks are scheduled based on resourcesI Some terminology change
Pietro Michiardi (Eurecom) Cluster Schedulers 33 / 129

YARN YARN Core Components
YARN Schedulers (2)
Hierarchical queuesI Queues can contain
sub-queuesI Sub-queues share
resources assigned toqueues
Pietro Michiardi (Eurecom) Cluster Schedulers 34 / 129

YARN YARN Core Components
YARN Resource Manager: Overview
Pietro Michiardi (Eurecom) Cluster Schedulers 35 / 129

YARN YARN Core Components
YARN Resource Manager: Operations
Node ManagementI Tracks hearbeats from NMs
Container ManagementI Handles AM requests for new containersI De-allocates containers when they expire or application finishes
AM ManagementI Creates a container for every new AM, and tracks its health
Security ManagementI Kerberos integration
Pietro Michiardi (Eurecom) Cluster Schedulers 36 / 129
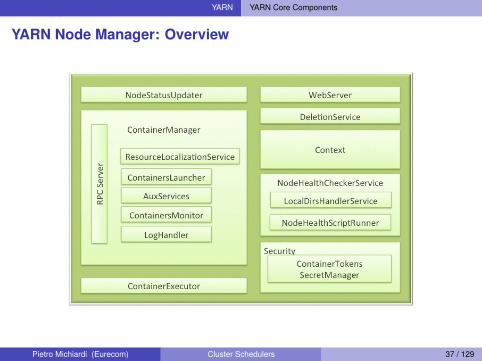
YARN YARN Core Components
YARN Node Manager: Overview
Pietro Michiardi (Eurecom) Cluster Schedulers 37 / 129

YARN YARN Core Components
YARN Node Manager: Operations
Manages communications with the RMI Registers, monitors and communicates node resourcesI Sends heartbeats and container status
Manages processes in containersI Launches AMs on request from the RMI Launches application processes on request from the AMsI Monitors resource usageI Kills processes and containers
Provides logging servicesI Log aggregation and roll over to HDFS
Pietro Michiardi (Eurecom) Cluster Schedulers 38 / 129

YARN YARN Core Components
YARN Resource Request
Resource RequestResource name: hostname, rackname, *Priority: within the same application, not across appsResource requirements: memory, CPU, and more to come...Number of containers
Pietro Michiardi (Eurecom) Cluster Schedulers 39 / 129

YARN YARN Core Components
YARN Containers
Container Launch ContextContainer IDCommands to start application task(s)Environment configurationLocal resources: application/task binary, HDFS files
Pietro Michiardi (Eurecom) Cluster Schedulers 40 / 129

YARN YARN Core Components
YARN Fault Tolerance
Container failureI AM re-attempts containers that complete with exceptions or failI Applications with too many failed containers are considered failed
AM failureI If application or AM fail, the RM will re-attempt the whole applicationI Optional strategy: job recovery
F If false, all containers are re-scheduledF If true, uses state to find which containers succeeded and which
failed, to re-schedule only failed ones
Pietro Michiardi (Eurecom) Cluster Schedulers 41 / 129

YARN YARN Core Components
YARN Fault Tolerance
NM failureI If NM stops sending heartbeats, RM removes it from active node listI Containers on the failed node are re-scheduledI AM on the failed node are re-submitted completely
RM failureI No application can be run if RM is downI Can work in active-passive mode (just like the NN of HDFS)
Pietro Michiardi (Eurecom) Cluster Schedulers 42 / 129

YARN YARN Core Components
YARN Shuffle Service
The Shuffle mechanism is now an auxiliary serviceI Runs in the NM JVM as a persistent service
Pietro Michiardi (Eurecom) Cluster Schedulers 43 / 129

YARN YARN Application Example
YARN Application Example
Pietro Michiardi (Eurecom) Cluster Schedulers 44 / 129

YARN YARN Application Example
YARN WordCount execution
Pietro Michiardi (Eurecom) Cluster Schedulers 45 / 129

YARN YARN Application Example
YARN WordCount execution
Pietro Michiardi (Eurecom) Cluster Schedulers 46 / 129

YARN YARN Application Example
YARN WordCount execution
Pietro Michiardi (Eurecom) Cluster Schedulers 47 / 129

YARN YARN Application Example
YARN WordCount execution
Pietro Michiardi (Eurecom) Cluster Schedulers 48 / 129

YARN YARN Application Example
YARN WordCount execution
Pietro Michiardi (Eurecom) Cluster Schedulers 49 / 129

YARN YARN Application Example
YARN WordCount execution
Pietro Michiardi (Eurecom) Cluster Schedulers 50 / 129

YARN YARN Application Example
YARN WordCount execution
Pietro Michiardi (Eurecom) Cluster Schedulers 51 / 129

YARN YARN Application Example
YARN WordCount execution
Pietro Michiardi (Eurecom) Cluster Schedulers 52 / 129

YARN YARN Application Example
YARN WordCount execution
Pietro Michiardi (Eurecom) Cluster Schedulers 53 / 129

YARN YARN Application Example
YARN WordCount execution
Pietro Michiardi (Eurecom) Cluster Schedulers 54 / 129

MESOS
Mesos
Pietro Michiardi (Eurecom) Cluster Schedulers 55 / 129

MESOS Introduction
Introduction
Pietro Michiardi (Eurecom) Cluster Schedulers 56 / 129

MESOS Introduction
Introduction and Motivations
Clusters of commodity servers major computing platformI Modern Internet ServicesI Data-intensive applications
New frameworks developed to “program the cluster”I Hadoop MapReduce, Apache Spark, Microsoft DryadI Pregel, Storm, ...I and many more
No one-size fit them allI Pick the right frameworks for the applicationI Run multiple frameworks at the same time
→ Multiplexing cluster resources among frameworksI Improves cluster utilizationI Allows sharing of data without the need to replicate it
Pietro Michiardi (Eurecom) Cluster Schedulers 57 / 129

MESOS Introduction
Common Solutions to Share a Cluster
Common practice to achieve cluster sharingI Static partitioningI Traditional virtualization
Problems of current approachesI Mismatch between allocation granularitiesI No mechanism to allocate resources to short-lived tasks
→ Underlying hypothesis for MesosI Cluster frameworks operate with short tasksI Cluster resources free up quicklyI This allows to achieve data locality
Pietro Michiardi (Eurecom) Cluster Schedulers 58 / 129

MESOS Introduction
Mesos Design Objectives
Mesos: a thin resource sharing layer enabling fine-grained sharingacross diverse frameworks
ChallengesI Each supported framework has different scheduling needsI Scalability is crucial (10,000+ nodes)I Fault-tolerance and high availability
Would a centralized approach work?I Input: framework requirements, instantaneous resource availability,
organization policiesI Output: global schedule for all tasks of all jobs of all frameworks
Pietro Michiardi (Eurecom) Cluster Schedulers 59 / 129

MESOS Introduction
Mesos Key Design Principles
Centralized approach does not workI ComplexityI Scalability and resilienceI Moving framework-specific scheduling to a centralized scheduler
requires expensive refactoring
A decentralized approachI Based on the abstraction of a resource offerI Mesos decides how many resources to offer to a frameworkI The framework decides which resources to accept and which tasks
to run on them
Pietro Michiardi (Eurecom) Cluster Schedulers 60 / 129
MESOS Target Environment
Target Workloads
Pietro Michiardi (Eurecom) Cluster Schedulers 61 / 129

MESOS Target Environment
Target Environment
Typical workloads in “Data Warehouse” systemsI Heterogeneous MapReduce jobs, production and ad-hoc queriesI Large scale machine learningI SQL-like queries
Pietro Michiardi (Eurecom) Cluster Schedulers 62 / 129

MESOS Architecture
Architecture
Pietro Michiardi (Eurecom) Cluster Schedulers 63 / 129

MESOS Architecture
Design Philosophy
Data center operating systemI Scalable and resilient core exposing low-level interfacesI High-level libraries for common functionalities
Minimal interface to support resource sharingI Mesos manages cluster resourcesI Frameworks control task scheduling and execution
Benefits of two-level approachI Frameworks are independent and can support diverse scheduling
requirementsI Mesos is kept simple, minimizing the rate of change to the system
Pietro Michiardi (Eurecom) Cluster Schedulers 64 / 129

MESOS Architecture
Architecture Overview
Pietro Michiardi (Eurecom) Cluster Schedulers 65 / 129

MESOS Architecture
Architecture Overview
The Mesos MasterUses Resource Offers to implement fine-grained sharingCollects resource utilization from slavesResource offer: list of free resources on multiple slaves
First-level SchedulingMaster decides how many resources to offer a frameworkImplements a cluster-wide allocation policy:
I Fair SharingI Priority based
Pietro Michiardi (Eurecom) Cluster Schedulers 66 / 129

MESOS Architecture
Architecture Overview
Mesos FrameworksFramework scheduler
I Registers to the masterI Selects which offer to acceptI Describes the tasks to launch on accepted resources
Framework executorI Launched on Mesos slaves executing on accepted resourcesI Takes care of running the framework’s tasks
Second-level SchedulingOne framework scheduler per applicationFramework decides how to execute a job and its tasksNOTE: The actual task execution is requested by the master
Pietro Michiardi (Eurecom) Cluster Schedulers 67 / 129

MESOS Architecture
Resource Offer Example
Pietro Michiardi (Eurecom) Cluster Schedulers 68 / 129

MESOS Architecture
Consequences of the Mesos Architecture
Mesos makes no assumptions on Framework requirementsI This is unlike other approaches, which requires the cluster
scheduler to understand application constraintsI This does not mean that users are not required to express their
applications’ constraintsRejecting offers
I It is the framework that decides to reject a resource offer that doesnot satisfy application constraints
I Frameworks can wait for offers to satisfy constraints
Arbitrary and complex resource constraintsDelegate logic and control to individual frameworksMesos also implements filters to optimize resource offers
Pietro Michiardi (Eurecom) Cluster Schedulers 69 / 129

MESOS Architecture
Resource Allocation
Pluggable allocation moduleI Max-min FairnessI Strict priority
Fundamental assumptionI Tasks are short→ Mesos only reallocates resources when tasks finish
ExampleI Assume a Framework’s share is 10% of the clusterI It needs to wait 10% of the mean task length to receive its share
Pietro Michiardi (Eurecom) Cluster Schedulers 70 / 129

MESOS Architecture
Resource Revocation
Short vs. long lived tasksI Some jobs (e.g. streaming) may have long tasksI In this case, Mesos can Kill running tasks
Preemption primitivesI Require knowledge about potential resource usage by frameworksI Killing might be wasteful, although not critical (e.g. MapReduce)I Some applications (e.g. MPI) might be harmed
Guaranteed allocationI Minimum set of resources granted to a frameworkI If below guaranteed allocation → never kill tasksI If above guaranteed allocation → kill any tasks
Pietro Michiardi (Eurecom) Cluster Schedulers 71 / 129

MESOS Architecture
Performance Isolation
Isolation between executors on the same slaveI Achieved through low-level OS primitivesI Pluggable isolation modules to support a variety of OS
Currently supported mechanismsI Limit CPU, memory, network and I/O bandwidth of a process treeI Linux Containers and Solaris Cages
Advantages and limitationsI Better isolation than current approach, process-basedI Fine grained isolation is not yet fully functional
Pietro Michiardi (Eurecom) Cluster Schedulers 72 / 129

MESOS Architecture
Mesos Scalability
Filter mechanismI Short-circuit the rejection process, avoids unnecessary
communicationI Filter type 1: restrict which slave machines to useI Filter type 2: check resource availability on slaves
Incentives to speed-up the resource offer mechanismI Mesos counts offers to a framework toward its allocationI Frameworks have to answer and/or filter as quickly as possible
Rescinding offersI Mesos can decide to invalidate an offer to a frameworkI This avoids blocking and misbehavior
Pietro Michiardi (Eurecom) Cluster Schedulers 73 / 129

MESOS Architecture
Mesos Fault Tolerance
Master designed with Soft StateI List of active slavesI List of registered frameworksI List of running tasks
Multiple masters in a hot-standby modeI Leader election through ZookeeperI Upon failure detection new master is electedI Slaves and executors help populating the new master’s state
Helping frameworks to tolerate failureI Master sends “health reports” to framework schedulersI Master allows multiple schedulers for a single framework
Pietro Michiardi (Eurecom) Cluster Schedulers 74 / 129

MESOS Mesos Behavior
System behavior: a very rough Mesos “model”
Pietro Michiardi (Eurecom) Cluster Schedulers 75 / 129

MESOS Mesos Behavior
Overview: Mesos in a nutshell
Ideal workloads for MesosI Elastic frameworks, supporting scaling up and down seamlesslyI Task durations are homogeneous (and short)I No strict preference over cluster nodes
Frameworks with cluster node preferencesI Assume frameworks prefer different (and possibly disjoint) nodesI Mesos can emulate a centralized schedulerI Cluster and Framework wide fair resource sharing
Heterogeneous task durationsI Mesos can handle coexisting short and long lived tasksI Performance degradation is acceptable
Pietro Michiardi (Eurecom) Cluster Schedulers 76 / 129

MESOS Mesos Behavior
Definitions
Workload characterizationI Elasticity: elastic workloads can use resources as soon as they are
acquired, and release them as soon as tasks finish; in contrast,rigid frameworks (e.g. MPI) can only start a job when all resourceshave been acquired, and do not work well with scaling
I Task runtime distribution: both homogeneous and not
Resource characterizationI Mandatory: resource that a framework must acquire to work.
Assumption: mandatory resources < guaranteed shareI Preferred: resources that a framework should acquire to achieve
better performance, but are not necessary for the job to work
Pietro Michiardi (Eurecom) Cluster Schedulers 77 / 129

MESOS Mesos Behavior
Performance Metrics
Performance metricsI Framework ramp-up time: time it takes a new framework to achieve
its fair shareI Job completion time: time it takes a job to complete. Assume one
job per frameworkI System utilization: total cluster resource utilization, with focus on
CPU and memory
Pietro Michiardi (Eurecom) Cluster Schedulers 78 / 129

MESOS Mesos Behavior
Homogeneous Tasks
Cluster with n slots and a framework f entitled with k slotsTask runtime distribution: uniform and exponentialMean task duration TJob duration: βkT
→ If f has k slots, then job duration is βT
Pietro Michiardi (Eurecom) Cluster Schedulers 79 / 129

MESOS Mesos Behavior
Placement preferences
Consider two cases:There exist a configuration satisfying all frameworksconstraints
I The system will eventually converge to the state in which theoptimal allocation is achieved, and this in at most one T interval
No such allocation exists, e.g. demand is larger than supplyI Lottery Scheduling to achieve a weighted fair allocationI Mesos offers a slot to framework i with probability
si∑mi=1 si
I where si is framework’s i intended allocation, and m is the totalnumber of frameworks registered to Mesos
Pietro Michiardi (Eurecom) Cluster Schedulers 80 / 129

MESOS Mesos Behavior
Heterogeneous Tasks
AssumptionsI Workloads with tasks that are either long or shortI Mean duration of long task is longer than short ones
Worst case scenarioI All nodes required by a “short job” are filled with long tasks, which
means it has to wait for a long time
How likely is the worst case?I Assume φ < 1, where φ fraction of long tasksI Assume a cluster with S available slots per node→ Probability for a node to be filled with long tasks is φS
I S = 8 and φ = 0.5 gives a 0.4% chance
Pietro Michiardi (Eurecom) Cluster Schedulers 81 / 129

MESOS Mesos Behavior
Limitations of Distributed Scheduling
FragmentationI Provokes under utilization of system resourcesI Distributed collection of frameworks might not achieve the same
“packing” quality of a centralized scheduler→ This is mitigated by having clusters of “big” nodes (many CPUs,
many cores) running “small” tasks
StarvationI Large jobs may wait indefinitely for slots to become freeI Small tasks from small jobs might monopolize the cluster→ This is mitigated by a minimum offer size mechanism
Pietro Michiardi (Eurecom) Cluster Schedulers 82 / 129

MESOS Mesos Performance
Experimental Mesos Performance Evaluation
Pietro Michiardi (Eurecom) Cluster Schedulers 83 / 129
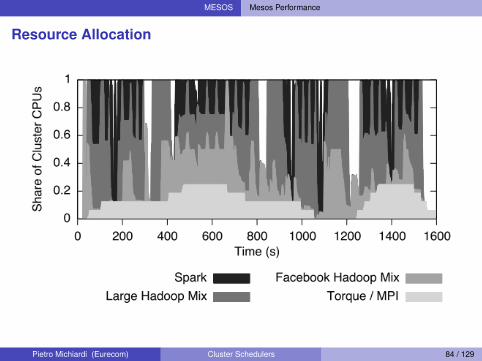
MESOS Mesos Performance
Resource Allocation
Pietro Michiardi (Eurecom) Cluster Schedulers 84 / 129

MESOS Mesos Performance
Resource Utilization
Pietro Michiardi (Eurecom) Cluster Schedulers 85 / 129

MESOS Mesos Performance
Data Locality
Pietro Michiardi (Eurecom) Cluster Schedulers 86 / 129

BORG
Borg
Pietro Michiardi (Eurecom) Cluster Schedulers 87 / 129

BORG Introduction
Introduction
Pietro Michiardi (Eurecom) Cluster Schedulers 88 / 129

BORG Introduction
Introduction and Objectives
Hide the details of resource managementI Let users instead focus on application developlemt
Operate applications with high reliability and availabilityI Tolerate failures within a datacenter and across datacenters
Run heterogeneous workloads and scale across thousandsof machines
Pietro Michiardi (Eurecom) Cluster Schedulers 89 / 129

BORG User perspective
The User Perspective
Pietro Michiardi (Eurecom) Cluster Schedulers 90 / 129

BORG User perspective
Terminology
Users develop applications called jobs
Jobs consists in one or more tasks
All tasks run the same binary
Each job runs in a set of machines managed as a unit, calleda Borg Cell
Pietro Michiardi (Eurecom) Cluster Schedulers 91 / 129

BORG User perspective
WorkloadsTwo main categories supported
I Long-running services: jobs that should “never” go down, andhandle short-lived, latency-sensitive requests
I Batch jobs: delay-tolerant jobs that can take from few seconds tofew days to complete
I Storage services: these are long-running services like above, thatare used to store data
Workload composition in a cell is dynamicI It varies depending on the tenants using the cellI It varies with time: diurnal usage pattern for end-user-facing jobs,
irregular pattern for batch jobsExamples
I High-priority, production jobs → long-running servicesI Low-priority, non-production jobs → batch jobsI In a typical Borg Cell
F Prod Jobs: 70% of CPU allocation, representing 60% of CPU usageF Non-prod Jobs: 55% of CPU allocation, representing 85% of CPU
usage
Pietro Michiardi (Eurecom) Cluster Schedulers 92 / 129

BORG User perspective
Clusters and Cells
Borg Cluster: a set of machines connected by ahigh-performance datacenter-scale network fabric
I The machines in a Borg Cell all belong to a single clusterI A cluster lives inside a datacenter buildingI A collection of building makes up a Site
Borg Machines: physical servers dedicated to execute Borgapplications
I They are generally highly heterogeneous in terms of resourcesI They may expose a public IP addressI They may expose advanced features, like SSD or GPGPU
ExamplesI A typical cluster usually hosts one large cell and a few small-scale
test cellsI The median cell size is about 10k machinesI Borg uses those machines to schedule application tasks, install
their binaries and dependencies, monitor their health and restartingthem if they fail
Pietro Michiardi (Eurecom) Cluster Schedulers 93 / 129

BORG User perspective
Jobs and Tasks
Job DefinitionI Name, owner and number of tasksI Constraints to force tasks run on machines with particular attributesI Constraints can be hard or soft (i.e., preferences)I Each task maps to a set of UNIX processes running in a container
on a Borg machine in a Borg Cell
Task DefinitionI Task index within their parent jobI Resource requirementsI Generally, all tasks have the same definitionI Tasks can run on any resource dimension: there are no fixed-size
slots or buckets
Pietro Michiardi (Eurecom) Cluster Schedulers 94 / 129

BORG User perspective
Jobs and Tasks
The Borg Configuration LanguageI Declarative language to specify jobs and tasksI Lambda functions to allow calculationsI Some application descriptions can be over 1k lines of code
User interacting with live jobsI This is achieved mainly using RPCI Users can update the specification of tasks, while their parent job is
runningI Updates are non-atomic, executed in a rolling-fashion
Task updates “side-effects”I Always require restarts: e.g., pushing a new binaryI Might require migration: e.g., change in specificationI Never require restarts nor migrations: e.g., change in priority
Pietro Michiardi (Eurecom) Cluster Schedulers 95 / 129

BORG User perspective
Jobs State Diagram
Pietro Michiardi (Eurecom) Cluster Schedulers 96 / 129

BORG User perspective
Resource Allocations
The Borg “Alloc”I Reserved set of resources on an individual machineI Can be used to execute one or more tasks, that equally share
resourcesI Resources remain assigned whether or not they are used
Typical use of Borg AllocsI Set resources aside for future tasksI Retain resources between stopping and starting tasksI Consolidate (gather) tasks from different jobs on the same machine
Alloc SetsI Group of allocs on different machinesI Once an alloc set has been created, one or more jobs can be
submitted
Pietro Michiardi (Eurecom) Cluster Schedulers 97 / 129

BORG User perspective
Priority, Quota and Admission Control
Mechanisms to deal with resource demand and offerI What to do when more work shows up than can be accommodated?I Note: this is not scheduling, it is more admission control
Job priorityI Non-overlapping priority bands for different usesI This essentially means users must “manually” cluster their
applications according to such bands→ Tasks from high-priority jobs can preempt low-priority tasksI Cascade preemption is avoided by disabling it for same-band jobs
Job/User quotasI Used to decide which job to admit for schedulingI Expressed as a vector of resource quantities
PricingI Underlying mechanism to regulate user behaviorI Aligns user incentives to better resource utilizationI Discourages over-buying by over-selling quotas at lower priority
Pietro Michiardi (Eurecom) Cluster Schedulers 98 / 129

BORG User perspective
Naming Services
Borg Name ServiceI A mechanism to assign a name to tasksI Task name = Cell name, job name and task number
Uses the Chubby coordination serviceI Writes task names into itI Writes also health information and statusI Used by Borg RPC mechanism to establish communication
endpoints
DNS service inherits from BNSI Example: the 50th task in job “jfoo” owned by user “ubar” in a Borg
Cell called “cc”I 50.jfoo.ubar.cc.borg.google.com
Pietro Michiardi (Eurecom) Cluster Schedulers 99 / 129

BORG User perspective
Monitoring Services
Every task in Borg has a built-in HTTP serverI Provides health informationI Provides performance metrics
Borg SIGMAI Monitoring UI ServiceI State of jobs, of cellsI Drill-down to task levelI Why pending?
F “Debugging” serviceF Helps users with finding job specifications that can be easily
scheduled
Billing servicesI Use monitoring information to compute usage-based chargingI Help users debug their jobsI Used for capacity planning
Pietro Michiardi (Eurecom) Cluster Schedulers 100 / 129

BORG Borg Architecture
Borg Architecture
Pietro Michiardi (Eurecom) Cluster Schedulers 101 / 129

BORG Borg Architecture
Architecture Overview
Pietro Michiardi (Eurecom) Cluster Schedulers 102 / 129

BORG Borg Architecture
Architecture Overview
Architecture componentsI A set of physical machinesI A logically centralized controller, the BorgmasterI An agent process running on all machines, the Borglet
Pietro Michiardi (Eurecom) Cluster Schedulers 103 / 129

BORG Borg Architecture
The Borgmaster: Components
The BorgmasterI One per Borg CellI Orchestrates cell resources
ComponentsI The Borgmaster processI The scheduler process
The Borgmaster processI Handles client RPCs that either mutate state or lookup for stateI Manages the state machines for all Borg “objects” (machines,
tasks, allocs, etc...)I Communicates with all Borglets in the cellI Provides a Web-based UI
Pietro Michiardi (Eurecom) Cluster Schedulers 104 / 129

BORG Borg Architecture
The Borgmaster: Reliability
Borgmaster reliability achieved through replicationI Single logical process, replicated 5 times in a cellI Single master elected using Paxos when starting a cell, or upon
failure of the current masterI Master serves as Paxos leader and cell state mutator
Borgmaster replicasI Maintain an in-memory fresh copy of the cell stateI Persist their state to a distributed Paxos-based storeI Help building the most up-to-date cell state when a new master is
elected
Pietro Michiardi (Eurecom) Cluster Schedulers 105 / 129

BORG Borg Architecture
The Borgmaster: State
Borgmaster checkpoints its stateI Time-based and event-based mechanismI State include everything related to a cell
Checkpoint utilizationI Restore the state to a functional one, e.g. before a failure or a bugI Studying a faulty state and fixing it by handI Build a persistent log of events for future queriesI Use it for offline simulations
Pietro Michiardi (Eurecom) Cluster Schedulers 106 / 129

BORG Borg Architecture
The Fauxmaster
A high-fidelity simulatorI It reads checkpoint filesI Full-fledged Borgmaster codeI Stubbed-out interfaces to Borglets
Fauxmaster operationI Accepts RPCs to make state machine changesI Connects to simulated Borglets that replay real interactions from
checkpoint filesFauxmaster benefits
I Help users debug their applicationI Capacity planning, e.g. “How many new jobs of this type would fit in
the cell?”I Perform sanity checks for cell configurations, e.g. “Will this new
configuration evict any important jobs?”
Pietro Michiardi (Eurecom) Cluster Schedulers 107 / 129

BORG Borg Architecture
Scheduling
Queue based mechanismI New submitted jobs (and their tasks) are stored in the Paxos store
(for reliability) and put in the pending queueThe scheduler process
I Operates at the task level, not the job levelI Scans asynchronously the pending queueI Assigns tasks to machines that satisfy constraints and that have
enough resourcesPending task selection
I Scanning proceeds from high to low priority tasksI Within the same priority class, scheduling uses a round-robin
mechanism→ Ensures fairness→ Avoids head-of-line blocking behind large jobs
Pietro Michiardi (Eurecom) Cluster Schedulers 108 / 129

BORG Borg Architecture
Scheduling Algorithm
The scheduling algorithm has two main processes
I Feasibility checking: find a set of machines thatF Meet tasks’ constraintsF Have enough available resources, including those that are currently
assigned to low-priority tasks that can be evicted
I Scoring: among the set returned by the previous process, ranksuch machines to
F Minimize the number and priority of preempted tasksF Prefer machines with a local copy of tasks binaries and dependenciesF Spread tasks across failure and power domainsF Pack and spread tasks, mixing high and low priority ones on the
same machine to allow high-priority tasks to eventually expand
Pietro Michiardi (Eurecom) Cluster Schedulers 109 / 129

BORG Borg Architecture
More on the scoring mechanism
Worst-fit scoring: spreading tasksI Single cost value across heterogeneous resourcesI Minimize the change in cost when placing a new task→ Leaves headroom for load spikes→ But leads to fragmentation
Best-fit scoring: “waterfilling” algorithmI Tries to fill machines as tightly as possible→ Leaves empty machines that can be used to place large tasks→ But difficult to deal with load spikes as the headroom left in each
machine depends highly on load estimation
HybridI Tries to reduce the amount of stranded resourcesI Performs better than best-fit
Pietro Michiardi (Eurecom) Cluster Schedulers 110 / 129

BORG Borg Architecture
Task startup latency
Task startup latency is a very important metric to optimizeI Time from job submission to a task runningI Highly variableI E.g.: at Google, median was about 25s
Techniques to reduce latencyI The main culprit for high latency is binary and package installationsI Idea: place tasks on machines that already have dependencies
installedI Packages and binaries distributed using a BitTorrent-like protocol
Pietro Michiardi (Eurecom) Cluster Schedulers 111 / 129

BORG Borg Architecture
The Borglet
The BorgletI Borg agent present on every machine in a cellI Starts and stop tasksI Restarts failed tasksI Manages machine resources interacting with the OSI Maintains and rolls over debug logsI Report the state of the machine to the Borgmaster
Interaction with the BorgmasterI Pull-based mechanism: heartbeat-like messages every few
seconds→ Borgmaster perform flow and rate control to avoid message stormsI Borglet continues operation even if communication to Borgmaster is
interruptedI A failed Borglet is blacklisted and all tasks are rescheduled
Pietro Michiardi (Eurecom) Cluster Schedulers 112 / 129

BORG Borg Architecture
Borglet to Borgmaster communication
How to handle control message overhead?I Many Borgmaster replicas receive state updatesI Many Borglets communicate concurrently
The link shard mechanismI Each borgmaster replica communicates with a subset of the cell
BorgletsI Partitioning is computed at each leader electionI Borglets report full state, but the link shard mechanism aggregate
state information→ Differential state update, to reduce the load at the master
Pietro Michiardi (Eurecom) Cluster Schedulers 113 / 129

BORG Borg Architecture
Scalability
A typical Borgmaster resource requirementsI Manages 1000s of machines in a cellI Arrival rates of 10,000 tasks per minuteI 10+ cores, 50+ GB of RAM
Decentralized designI Scheduler process separate from Borgmaster processI One scheduler per Borgmaster replicaI Scheduling is somehow decentralizedI State change communicated from replicas to elected Borgmaster,
that finalizes the state update
Additional techniques to achieve scalabilityI Score cachingI Equivalence classI Relaxed randomization
Pietro Michiardi (Eurecom) Cluster Schedulers 114 / 129

BORG Borg Behavior
Borg Behavior: Experimental PerspectiveAlso, additional details on how Borg works...
Pietro Michiardi (Eurecom) Cluster Schedulers 115 / 129

BORG Borg Behavior
AvailabilityIn large scale systems, failure are the norm not the exception
I Everything can fail, and both Borg and its running applications mustdeal with this
Baseline techniques to achieve high availabilityI ReplicationI Storing persistent state in a distributed file systemI Checkpointing
Additional techniquesI Automatic rescheduling of failed tasksI Mitigating correlated failuresI Rate limitationI Avoid duplicate computationI Admission control to avoid overloadI Minimize external dependencies for task binaries
Pietro Michiardi (Eurecom) Cluster Schedulers 116 / 129

BORG Borg Behavior
System Utilization
The primary goal of a cluster scheduler is to achieve highutilization
I Machines, network fabric, power, cooling ... represent a significantfinancial investment
I Increasing utilization by a few percent can save millions!A sophisticated metric: Cell Compaction
I Replaces the typical “average utilization” metricI Provides a fair, consistent way to compare scheduling policiesI Translates directly into cost/benefit resultI Computed as follows:
F Given a workload in a point in time (so this is not trace drivensimulation)
F Enter a loop of workload packingF At each iteration, remove physical machines from the cellF Exit the loop when the workload can no longer fit the cell size
Use the Fauxmaster to produce experimental results
Pietro Michiardi (Eurecom) Cluster Schedulers 117 / 129

BORG Borg Behavior
System Utilization: Compaction
This graphs shows how much smaller cells would be if we appliedcompaction to them
Pietro Michiardi (Eurecom) Cluster Schedulers 118 / 129

BORG Borg Behavior
System Utilization: Cell Sharing
Fundamental question: to share or not to share?I Many current systems apply static partitioning: one cluster
dedicated only to prod jobs, one cluster for non-prod jobsBenefits from sharing
I Borg can reclaim resources reserved by “anxious” prod jobs
Pietro Michiardi (Eurecom) Cluster Schedulers 119 / 129

BORG Borg Behavior
System Utilization: Cell Sizing
Fundamental question: large or small cells?I Large cells to accommodate large jobsI Large cells also avoid fragmentation
Pietro Michiardi (Eurecom) Cluster Schedulers 120 / 129

BORG Borg Behavior
System Utilization: Fine-grained Resource Requests
Borg users specify Job requirements in terms of resourcesI For CPU: this is done in milli-coreI For RAM and disk: this is done in bytes
Pietro Michiardi (Eurecom) Cluster Schedulers 121 / 129

BORG Borg Behavior
System Utilization: Fine-grained Resource Requests
Would fixed size containers (or slot) be good?I No! It would require more machines in a cell!
Pietro Michiardi (Eurecom) Cluster Schedulers 122 / 129

BORG Borg Behavior
System Utilization: Resource Reclamation
Borg users specify resource limits for their jobsI Used to perform admission controlI Used for feasibility checking (i.e., find sets of suitable machines)
Borg users have the tendency to “over provision” for theirjobs
I Some tasks, occasionally need to use all their resourcesI Most of the tasks never use all resources
Resource reclamationI Borg builds estimates of resource usage: these are called
resource reservationsI Borgmaster receives usage updates from BorgletsI Prod jobs are treated differently: they do not rely on reclaimed
resources, Borgmaster only uses resource limits
Pietro Michiardi (Eurecom) Cluster Schedulers 123 / 129

BORG Borg Behavior
System Utilization: Resource Reclamation
Resource reclamation is quite effective. A CDF of the additionalmachines that would be needed if it was disabled.
Pietro Michiardi (Eurecom) Cluster Schedulers 124 / 129

BORG Borg Behavior
System Utilization: Resource Reclamation
Resource estimation is successful at identifying unusedresources. Most tasks use much less than their limit, although afew use more CPU than requested.
Pietro Michiardi (Eurecom) Cluster Schedulers 125 / 129

BORG Borg Behavior
Isolation
Sharing a multi-tenancy are beneficial, but...I Tasks may interfere one with each otherI Need a good mechanism to prevent interference (both in terms of
security and performance)Performance isolation
I All tasks run in Linux cgroup-based containersI Borglets operate on the OS to control container resourcesI A control-loop assigns resources based on predicted future usage
or on memory pressureAdditional techniques
I Application classes: latency-sensitive, vs. batchI Resource classes: compressible and non-compressibleI Tuning of the underlying OS, especially the OS scheduler
Pietro Michiardi (Eurecom) Cluster Schedulers 126 / 129

BORG Lessons Learned
Lessons learned from building and operating BorgAnd what has been included in Kubernetes, the open source version ofBorg...
Pietro Michiardi (Eurecom) Cluster Schedulers 127 / 129

BORG Lessons Learned
Lessons Learned: the Bad
The “job” abstraction is too simplisticI Multi-job services cannot be easily managed, nor addressedI Kubernetes uses scheduling units called pods (i.e., the Borg allocs)
and labels (key/value pairs describing objects)Addressing services is critical
I One IP address implies managing ports as a resource, whichcomplicates tasks
I Kubernetes uses Linux name-spaces, such that each pod has itsown IP address
Power or casual users?I Borg is geared toward power users: e.g., BCL has about 230
parameters!I Build automation tools, and template settings from historical
executions
Pietro Michiardi (Eurecom) Cluster Schedulers 128 / 129

BORG Lessons Learned
Lessons Learned: the Good
Allocs are usefulI Resource envelope for one or more container co-scheduled on the
same machine and that can share resourcesCluster management is more than task management
I Naming and load balancing are first-class citizensIntrospection is vital
I Clearly true for debuggingI Key for capacity planning and monitoring
The master is the kernel of a distributed systemI Monolithic designs are not working wellI Cooperation of micro-services that use a common low-level API to
process requests and manipulate state
Pietro Michiardi (Eurecom) Cluster Schedulers 129 / 129





























