
7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 1/22
ALGORITMA YANG AKAN DIGUNAKAN
A. Adaptive Neuro Fuzzy Inferrence System (ANFIS)
Adaptive Network-Based-Fuzzy Inferences System (ANFIS) merupakan
perpaduan dua konsep, neural network dan fuzzy logic. Neuralnetwork untuk mengenali
pola dan menyesuaikan pola terhadap perubahan lingkungan, sedangkan fuzzy logic
menggabungkan pengetahuan manusia dan mencari kesimpulan untuk membuat suatu
keputusan. Arsitektur ANFIS terdiri dari 5 layer: fuzzification layer , proses inferences,
defuzzification layer , dan summation sebagai output layer .
Jaringan neural adalah struktur jaringan dimana keseluruhan tingkah laku
masukan-keluaran ditentukan oleh sekumpulan parameter-parameter yang dimodifikasi.
Salah satu struktur jaringan neural adalah multilayer perceptrons (MLP). Jenis jaringan
ini khusus bertipe umpan maju. MLP telah diterapkan dengan sukses untuk
menyelesaikan masalah-masalah yang sulit dan beragam dengan melatihnya
menggunakan algoritma propagasi balik dari kesalahan atau error backpropagation
(EBP)
Selanjutnya, sistem fuzzy dapat melukiskan suatu sistem dengan pengetahuan
linguistik yang mudah dimengerti. Sistem infererensi fuzzy dapat ditala dengan
algoritma propagasi balik berdasarkan pasangan data masukan-keluaran menggunakan
arsitektur jaringan neural. Dengan cara ini memungkinkan sistem fuzzy dapat belajar .

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 2/22
Dibawah ini adalah gambar struktur dasar dari model ANFIS
Gambar xxx. Struktur ANFIS
(Sumber: Bhuwana & Sayama: Rainfall Runoff Modelling by Using
Adaptive-Network-Based Fuzzy Inference System (ANFIS)
Masing-masing lapisan di atas dapat dijelaskan sebagai berikut :
Lapisan 1:
Setiap simpul i pada lapisan ini adalah simpul adaptif dengan fungsi simpul [2]:
untuk i=1,2, atau
dimana x (atau y ) adalah masukan bagi simpul i , dan Ai (atau Bi-2 ) adalah label bahasa
(linguistic label) seperti misalnya “kecil” atau “luas”, dan lain-lain. Dengan kata lain, O1,i
adalah tingkatan keanggotaan dari himpunan fuzzy A (= A1, A2, B1 atau B2 ) dan
menentukan derajad keanggotaan dari masukan x (atau y ) yang diberikan. Fungsi
keanggotaan parameter dari A dapat didekati dengan fungsi bell [2]:

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 3/22
Di mana {ai, bi, ci} adalah himpunan parameter. Parameter pada lapisan ini disebut
parameter premis.
Lapisan 2:
Setiap simpul pada lapisan ini diberi label Π ,bersifat non-adaptif (parameter tetap) yang
mempunyai keluaran berupa perkalian dari semua sinyal yang masuk
(y), i = 1,2
Masing-masing keluaran simpul menyatakan derajat pengaktifan dari aturan fuzzy.
Secara umum beberapa operator T-norm yang dapat mengungkapkan logika fuzzy
AND dapat digunakan sebagai fungsi simpul pada lapisan ini.
Lapisan 3:
Setiap simpul pada lapisan ini diberi label N , juga bersifat non-adaptif. Masing-masing
simpul menampilkan derajat pengaktifan ternormalisasi dengan bentuk [2].

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 4/22
= =
Apabila dibentuk lebih dari dua aturan, fungsi dapat diperluas dengan membagi wi
dengan jumlah total w untuk semua aturan.
Lapisan 4:
Tiap simpul pada lapisan ini berupa simpul adaptif dengan fungsi simpul:
dimana wi adalah derajat pengaktifan ternormalisasi dari lapisan 3 dan { pi, qi, ri }
merupakan himpunan parameter dari simpul ini. Parameter di lapisan ini dinamakan
parameterparameter konsekuen.
Lapisan 5:
Simpul tunggal pada lapisan ini diberi label Σ, yang mana menghitung semua keluaran
sebagai penjumlahan dari semua sinyal yang masuk: Keluaran keseluruhan =
Prediksi dengan metode ANFIS terbagi menjadi 3 proses yaitu: proses
Inisialisasi awal, proses pembelajaran (learning ), dan proses peramalan. Penentuan
periode input dan periode training dilakukan saat inisialisasi awal dimana tiap-tiap
periode input memiliki pola atau pattern yang berbeda. Data yang digunakan untuk
proses pembelajaran (traning ) terdiri dari data input, parameter ANFIS, dan data test

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 5/22
yang berada pada priode traning ANFIS. Training dengan ANFIS menggunakan
algoritma belajar hibrida, dimana dilakukan penggabungan metode Least-squares
estimator (LSE) pada alur maju dan error backpropagation (EBP) pada alur mundur.
Pada algoritma belajar ini nilai parameter premis akan tetap saat alur maju, namun
sebaliknya parameter konsekuen akan terupdate saat alur maju. Alur maju Gambar 2.
Blok diagram alur maju ANFIS untuk time series forecasting.
Pada blok diagram Gambar 2 digambarkan mengenai proses alur maju dari sebuah
sistem ANFIS yang terdiri dari beberapa layer. Pada layer pertama data input pada
masing masing periode akan dilakukan proses fuzzyfikasi. Proses ini adalah untuk
memetakan inputan data kedalam himpunan fuzzy sesuai dengan klasifikasi yang dipilih
(pada proyek akhir ini hanya menggunakan dua jenis himpunan fuzzy yaitu: tinggi dan
rendah). Dalam proses ini inputan akan dilakukan perhitungan fungsi keanggotaan
fuzzy untuk mentransformasi masukan himpunan klasik (crisp) ke derajat tertentu.
Fungsi keanggotaan yang digunakan adalah jenis Gaussian dimana pada fungsi
keanggotaan ini terdapat dua parameter yaitu mean dan varian, parameter tersebut
dalam metode ANFIS disebut sebagai parameter premis. Pada layer kedua dan ketiga
dilakuakn proses inference engine (system inferensi fuzzy) ditentukan rule fuzzy untuk
dilakukan proses perhitungan selanjutnya. Pada proses ini digunakan model Takagi
Sugeno.
Pada penelitian ini digunakan dua rule yaitu: jika mx1 bertemu my1 maka akan
dilanjutkan ke W1, dan jika mx2 bertemu my2 maka akan dilanjutkan ke W2 . nilai W1
dan W2 didapat dari hasil pencarian nilai minimum untuk masing – masing input
keanggotaan fuzzy. Pada layer 4 dilakukan proses defuzzyfikasi dilakukan perhitungan

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 6/22
mentransformasi hasil fuzzy ke bentuk keluaran yang crisp. Pada layer ini dilakukan
perhitungan LSA untuk mendapatkan nilai parameter konsekuen. Pada layer 5
dilakukan proses summary dari dua output pada layer 4. Pada ANFIS system fuzzy
terletak pada layer 1,2,3 dan 4. dimana system fuzzy ini adalah sebagai penentu hidden
node yang terdapat pada system neural network.
B. ARIMA (Autoregressive Integrated Moving Average)
C.
Model Autoregresif Integrated Moving Average (ARIMA) adalah model yang secara
penuh mengabaikan independen variabel dalam membuat peramalan. ARIMA
menggunakan nilai masa lalu dan sekarang dari variabel dependen untuk
menghasilkan peramalan jangka pendek yang akurat. ARIMA cocok jika observasi dari
deret waktu (time series) secara statistik berhubungan satu sama lain (dependent).
ARIMA sering juga disebut metode runtun waktu Box-Jenkins. ARIMA sangatbaik ketepatannya untuk peramalan jangka pendek, sedangkan untuk peramalan
jangka panjang ketepatan peramalannya kurang baik. Biasanya akan cenderung flat
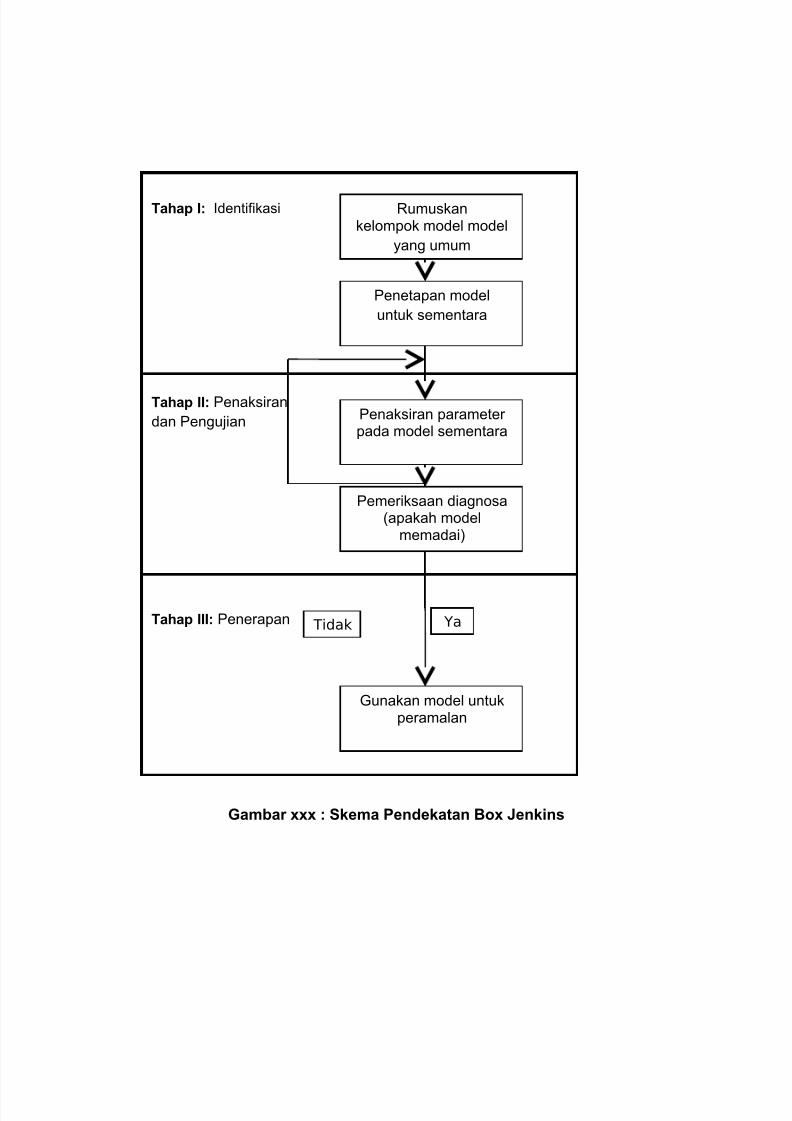
(mendatar/konstan) untuk periode yang cukup panjang. Model ARIMA terdiri dari tiga
langkah dasar, yaitu tahap identifikasi, tahap penaksiran dan pengujian, dan
pemeriksaan diagnostik. Selanjutnya model ARIMA dapat digunakan untuk melakukan
peramalan jika model yang diperoleh memadai.
7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 7/22
Gambar xxx : Skema Pendekatan Box Jenkins
Tahap I: Identifikasi
Tahap II: Penaksirandan Pengujian
Tahap III: Penerapan
Rumuskankelompok model model
yang umum
Penetapan modeluntuk sementara
Penaksiran parameter pada model sementara
Pemeriksaan diagnosa(apakah model
memadai)
Gunakan model untukperamalan
Tidak Ya

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 8/22
Identifikasi
Proses identifikasi dari model musiman tergantung pada alat-alat statistik
berupa autokorelasi dan parsial autokorelasi, serta pengetahuan terhadap sistem
(atau proses) yang dipelajari.
Penaksiran Parameter
Ada dua cara yang mendasar untuk mendapatkan parameter-parameter
tersebut:
a. Dengan cara mencoba-coba (trial and error), menguji beberapa nilai
yang berbeda dan memilih satu nilai tersebut (atau sekumpulan nilai,
apabila terdapat lebih dari satu parameter yang akan ditaksir) yang
meminimumkan jumlah kuadrat nilai sisa (sum of squared residual).
b. Perbaikan secara iteratif, memilih taksiran awal dan kemudian
membiarkan program komputer memperhalus penaksiran tersebut
secara iteratif.
Pengujian Parameter Model
1. Pengujian masing-masing parameter model secara parsial (t-test )
2. Pengujian model secara keseluruhan (Overall F test )
Model dikatakan baik jika nilai error bersifat random, artinya sudah tidak
mempunyai pola tertentu lagi. Dengan kata lain model yang diperoleh dapat
menangkap dengan baik pola data yang ada. Untuk melihat kerandoman nilai
error dilakukan pengujian terhadap nilai koefisien autokorelasi dari error, dengan
menggunakan salah satu dari dua statistik berikut:

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 9/22
1) Uji Q Box dan Pierce:
2) Uji Ljung-Box:
Menyebar secara Khi Kuadrat ( χ 2 ) dengan derajat bebas (db)=(k-p-q-P-
Q) dimana:
n’ = n-(d+SD)
d = ordo pembedaan bukan faktor musiman
D = ordo pembedaan faktor musiman
S = jumlah periode per musim
m = lag waktu maksimum
k r = autokorelasi untuk time lag 1, 2, 3, 4,..., k
Kriteria pengujian:
Jika Q ≤ χ2(α, db) , berarti: nilai error bersifat random (model dapat
diterima).
Jika Q > χ2(α, db) , berarti: nilai error tidak bersifat random (model tidak
dapat diterima).
Pemilihan Model Terbaik
Untuk menentukan model yang terbaik dapat digunakan standard error
estimate berikut:

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 10/22
dimana:
Y t = nilai sebenarnya pada waktu ke-t
Yˆt = nilai dugaan pada waktu ke-t
Model terbaik adalah model yang memiliki nilai standard error estimate (S)
yang paling kecil.
Selain nilai standard error estimate, nilai rata-rata persentase kesalahan
peramalan (MAPE) dapat juga digunakan sebagai bahan pertimbangan dalam
menentukan model yang terbaik yaitu:
dimana:
T = banyaknya periode peramalan/dugaan.
Peramalan Dengan Model ARIMA
Notasi yang digunakan dalam ARIMA adalah notasi yang mudah dan
umum. Misalkan model ARIMA (0,1,1)(0,1,1)12 dijabarkan sebagai berikut:
Tetapi untuk menggunakannya dalam peramalan harus dilakukan suatu
penjabaran dari persamaan tersebut dalam sebuah persamaan regresi yang
lebih umum. untuk model diatas bentuknya adalah:

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 11/22
Untuk meramalkan satu periode ke depan, yaitu X t+1 maka seperti pada
persamaan berikut:
Nilai et+1 tidak akan diketahui, karena nilai yang diharapkan untuk
kesalahan random pada masa yang akan datang harus ditetapkan sama dengan
nol. Akan tetapi dari model yang disesuaikan (fitted model) kita boleh mengganti
nilai et , et-11 dan et-12 dengan nilai nilai mereka yang ditetapkan secara empiris(seperti yang diperoleh setelah iterasi terakhir algoritma Marquardt). Tentu saja
bila kita meramalkan jauh ke depan, tidak akan kita peroleh nilai empiris untuk
“e” sesudah beberapa waktu, dan oleh sebab itu nilai harapan mereka akan
seluruhnya nol.
Untuk nilai X, pada awal proses peramalan, kita akan mengetahui nilai X t ,
Xt-11, Xt-12. Akan tetapi sesudah beberapa saat, nilai X akan berupa nilai ramalan
(forecastedvalue), bukan nilai-nilai masa lalu yang telah diketahui.
1. Stasioneritas dan Nonstasioneritas
Hal yang perlu diperhatikan adalah bahwa kebanyakan deret berkala bersifat
nonstasioner dan bahwa aspek-aspek AR dan MA dari model ARIMA hanya
berkenaan dengan deret berkala yang stasioner. Stasioneritas berarti tidak terdapat
pertumbuhan atau penurunan pada data. Data secara kasarnya harus horizontal
sepanjang sumbu waktu. Dengan kata lain, fluktuasi data berada di sekitar suatu

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 12/22
nilai rata-rata yang konstan, tidak tergantung pada waktu dan varians dari fluktuasi
tersebut pada pokoknya tetap konstan setiap waktu.
Suatu deret waktu yang tidak stasioner harus diubah menjadi data stasioner
dengan melakukan differencing. Yang dimaksud dengan differencing adalah
menghitung perubahan atau selisih nilai observasi. Nilai selisih yang diperoleh dicek
lagi apakah stasioner atau tidak. Jika belum stasioner maka dilakukan differencing
lagi. Jika varians tidak stasioner, maka dilakukan transformasi logaritma.
2. Klasifikasi model ARIMAModel Box-Jenkins (ARIMA) dibagi kedalam 3 kelompok, yaitu: model
autoregressive (AR), moving average (MA), dan model campuran ARIMA
(autoregresivemoving average) yang mempunyai karakteristik dari dua model
pertama.
1) Autoregressive Model (AR)
Bentuk umum model autoregressive dengan ordo p (AR( p)) atau model
ARIMA ( p,0,0) dinyatakan sebagai berikut:
dimana : μ ' = suatu konstanta
p φ = parameter autoregresif ke-p
et = nilai kesalahan pada saat t
2) Moving Average Model (MA)
Bentuk umum model moving average ordo q (MA(q)) atau ARIMA (0,0,q)
dinyatakan sebagai berikut:

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 13/22
dimana: μ ' = suatu konstanta
θ1 sampai θq adalah parameter-parameter moving average
et-k = nilai kesalahan pada saat t – k
3) Model campuran
a. Proses ARMAModel umum untuk campuran proses AR(1) murni dan MA(1) murni, misal
ARIMA (1,0,1) dinyatakan sebagai berikut:
atau
b. Proses ARIMA Apabila nonstasioneritas ditambahkan pada campuran proses ARMA,
maka model umum ARIMA ( p,d,q) terpenuhi. Persamaan untuk kasus sederhana
ARIMA (1,1,1) adalah sebagai berikut:
pembedaan pertama AR(1) MA(1)

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 14/22
3. Musiman dan Model ARIMA
Musiman didefinisikan sebagai suatu pola yang berulang-ulang dalam
selang waktu yang tetap. Untuk data yang stasioner, faktor musiman dapat
ditentukan dengan mengidentifikasi koefisien autokorelasi pada dua atau tiga
time-lag yang berbeda nyata dari nol. Autokorelasi yang secara signifikan
berbeda dari nol menyatakan adanya suatu pola dalam data. Untuk mengenali
adanya faktor musiman, seseorang harus melihat pada autokorelasi yang tinggi.
Untuk menangani musiman, notasi umum yang singkat adalah:
ARIMA ( p,d,q ) (P,D,Q )S
Dimana ( p,d,q) = bagian yang tidak musiman dari model
(P,D,Q) = bagian musiman dari model
S = jumlah periode per musim

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 15/22
C. Algorima C4.5
Pengertian Algoritma C4.5 merupakan algoritma yang digunakan untuk
membentuk pohon keputusan. Sedang pohon keputusan dapat diartikan suatu
cara untuk memprediksi atau mengklarifikasi yang sangat kuat. Pohon keputusan
dapat membagi kumpulan data yang besar menjadi himpunan-himpunan record
yang lebih kecil dengan menerapkan serangkaian aturan keputusan.
Dalam algoritma C4.5 untuk membangun pohon keputusan hal pertama
yang dilakukan yaitu memilih atribut sebagai akar. Kemudian dibuat cabang
untuk tiap-tiap nilai didalam akar tersebut. Langkah berikutnya yaitu membagi
kasus dalam cabang. Kemudian ulangi proses untuk setiap cabang sampai
semua kasus pada cabang memiliki kelas yang sama.
Untuk memilih atribut dengan akar, didasarkan pada nilai gain tertinggi
dari atribut-tribut yang ada. Untuk menghitung gain digunakan rumus sebagai
berikut:
Keterangan:

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 16/22
S : himpunan kasus
A : Atribut
n : jumlah partisi S
|Si| : jumlah kasus pada partisi ke-i
|S|: jumlah kasus dalam S
Sehingga akan diperoleh nilai gain dari atribut yang paling tertinggi. Gain
adalah salah satu atribute selection measure yang digunakan untuk memilih test
atribute tiap node pada tree. Atribut dengan information gain tertinggi dipilih
sebagai test atribut dari suatu node.
Sementara itu, penghitungan nilai entropi dapat dilihat pada persamaan :
Keterangan :
S : himpunan kasus
A : Atribut
N : jumlah partisi S
pi : proporsi dari terhadap S

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 17/22
D. Wavelet Neural Networks
1. Teori wavelet
Teori wavelet adalah suatu konsep yang relatif baru dikembangkan. Kata
“Wavelet” sendiri diberikan oleh Jean Morlet dan Alex Grossmann pada awal tahun
1980-an, dan berasal dari bahasa Prancis, “ondelette” yang berarti gelombang kecil.
Kata “onde” yang berarti gelombang kemudian diterjemahkan ke bahasa Inggris
menjadi “wave”, lalu digabung dengan kata aslinya sehingga terbentuk kata baru
“wavelet”.
Wavelet merupakan alat analisis yang biasa digunakan untuk menyajikan data
atau fungsi atau operator ke dalam komponen-komponen frekuensi yang berlainan, dan
kemudian mengkaji setiap komponen dengan suatu resolusi yang sesuai dengan
skalanya. (Daubechies, 1995).
Menurut Sydney (1998), Wavelet merupakan gelombang mini (small wave) yang
mempunyai kemampuan mengelompokkan energi citra dan terkonsentrasi pada
sekelompok kecil koefisien, sedangkan kelompok koefisien lainnya hanya mengan-dung
sedikit energi yang dapat dihilangkan tanpa mengurangi nilai informasinya.
Wavelet merupakan keluarga fungsi yang dihasilkan oleh wavelet basis y( x )
disebut mother wavelet . Dua operasi utama yang mendasari wavelet adalah: 1)
penggeseran, misalnya y( x -1), y( x -2), y(x-b), dan 2) penyekalaan, misalnya y(2 x ), y(4 x )
dan y(2 jx ). Kombinasi kedua operasi inilah menghasilkan keluarga wavelet . Secara
umum, keluarga wavelet sering dinyatakan dengan formula:

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 18/22
dengan:
a,b Î R; a _ 0 (R = bilangan nyata),
a adalah paremeter penyekalaan (dilatasi),
b adalah perameter penggeseran posisi (translasi) pada sumbu x, dan
a adalah normalisasi energi yang sama dengan energi induk.
Wavelet induk diskalakan dan digeser melalui pemisahan menurut frekuensi
menjadi sejumlah sub-sub bagian. Untuk mendapatkan sinyal kembali dilakukan prosesrekonstruksi wavelet .
Beberapa contoh keluarga wavelet adalah Haar, Daubechies, Symlets, Coiflets,
BiorSplines, ReverseBior, Meyer, DMeyer, Gaussian, Mexican_hat, Morlet, Complex
Gaussian, Shannon, Frequency B-Spline, Complex Morlet, Riyad , dan lain sebagainya.
2. Neural Network (jaringan saraf tiruan)
Konsep dasar pembuatan struktur jaringan saraf tiruan sebenanya teriilhami oleh
struktur jaringan biologi, khususnya jaringan otak manusia. Terdapat bebeapa istilah
yang secara umum sering digunakan dalam konsep Jaringan Sarat Tiruan. Neuron
adalah satuan unit pemroses terkecil pada otak, bentuk sederhana neuron yang oleh
para ahli dianggap sebagai satuan unit pemroses tersebut di ilustrasikan pada gambar
di bawah
Struktur pada gambar adalah bentuk standar dasar satuan unit jaringan otak
manusia yang telah disederhanakan. Bentuk tersebut bisa jadi suatu saat nanti akan
mengalami perubahan jika ada ilmuan yang dapat menciptakan bentuk standar yang

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 19/22
lebih baik dan kompatibel dengan kebutuhan zaman saat ini. Berdasarkan hasil
penelitian para ahli, bahwa otak manusia tersusun tidak kurang dari 1013 buah neuron
yang masing-masing terhubung oleh sekitar 1015 buah dendrite. Fungsi dendrite adalah
sebagai media penyampai sinyal dari neuron tersebut ke neuron yang terhubung
dengannya. Sebagai keluaran, setiap neuron memiliki axon, sedangkan bagian
penerima sinyal disebut synapse.
Gambar 3: Struktur dasar jaringan saraf tiruan dan struktur sederhana sebuah
neuron
Secara umum jaringan saraf terbentuk dari jutaan bahkan lebih struktur dasar
neuron yang terinterkoneksi dan terintegrasi antara satu dengan yang lain sehingga
dapat melaksanakan aktifitas secara teratur dan terus menerus sesuai dengan
kebutuhan.

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 20/22
Gambar 4 : Model tiruan sebuah neuron
aj = nilai aktivasi dari unit j
wj,i = bobot dari unit j ke unit i
ini = penjumlahan bobot dan masukan ke unit i
g = fungsi aktivasi
ai = nilai aktivasi dari unit i
Jika diumpamakan terdapat n buah sinyal masukan dan n buah penimbang,
maka fungsi keluaran dari neuron adalah seperti persaman berikut ini :

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 21/22
3. Wavelet Neural Network
Struktur jaringan saraf wavelet sangat mirip dengan jaringan saraf (1 + 1/2)
lapisan. Artinya, ke depan pakan jaringan saraf, mengambil satu atau lebih
masukan, dengan satu lapisan tersembunyi dan lapisan output yang terdiri dari satu
atau lebih kombinasi linear atau penjumlahan linear. Lapisan tersembunyi terdiri dari
neuron, yang aktivasi fungsi diambil dari basis wavelet. Neuron wavelet biasanya
disebut sebagai wavelons
Gambar xx: Struktur Wavelet Neural Network
Ada dua pendekatan menciptakan Wavelet Neural Network :
♦ Pada bagian pertama wavelet dan neural network pengolahan dilakukan
secara terpisah. Sinyal input pertama didekomposisi menggunakan
beberapa dasar wavelet oleh neuron pada lapisan tersembunyi. Koefisien
wavelet kemudian output ke satu atau lebih dijumlahkan dengan input bobot
yang telah dimodifikasi sesuai dengan beberapa algoritma pembelajaran.

7/15/2019 Sekilas beberapa ALGORITMA
http://slidepdf.com/reader/full/sekilas-beberapa-algoritma 22/22
♦ Tipe kedua menggabungkan dua teori. Dalam hal ini terjemahan dan
pelebaran dari wavelet bersama dengan bobot dijumlahkan dengan yang
telah dimodifikasi sesuai dengan beberapa algoritma pembelajaran
Secara umum, ketika pendekatan pertama digunakan, hanya dinilai dan
terjemahan sebagai mother wavelet yang membentuk dasar wavelet. Jenis
wavelet Neural Netwok biasanya disebut sebagai sebuah wavenet.
Direkomendasikan merujuk pada jenis kedua yakni jaringan wavelet.
Recommended

















