
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 1/383
Cours de mathématiquesPSI
Aurélien Monteillet

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 2/383
ii

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 3/383
Ce document contient les notes d’un cours de mathématiques pour la classe de PSI.
Les démonstrations non exigibles ou hors programme sont explicitement repérées commetelles dans les notes.
Bonne lecture !
Ce document est mis à disposition selon les termes de la Licence Creative Commons
(Attribution – Pas d’Utilisation Commerciale – Partage dans les Mêmes Conditions 3.0 France)
http://creativecommons.org/licenses/by-nc-sa/3.0/fr/
iii

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 4/383
iv

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 5/383
Sommaire
1 Suites numériques 1I. Définitions et résultats fondamentaux . . . . . . . . . . . . . . . . . . . . . . . . . 1II. Suites définies par récurrence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4III. Suites récurrentes linéaires d’ordre 2 . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Séries numériques 11I. Définition et convergence d’une série . . . . . . . . . . . . . . . . . . . . . . . . . 11II. Séries de réels positifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16III. Convergence absolue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23IV. La formule de Stirling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25V. Le théorème des séries alternées . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26VI. Produit de deux séries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3 Espaces vectoriels et applications linéaires 31I. Espaces vectoriels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31II. Somme et somme directe de sous-espaces vectoriels . . . . . . . . . . . . . . . . . 40III. Applications linéaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45IV. Isomorphismes et automorphismes . . . . . . . . . . . . . . . . . . . . . . . . . . 53V. Rang et théorème du rang . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57VI. Formes linéaires et hyperplans . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4 Matrices 63I. Calcul matriciel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63II. Matrices, vecteurs et applications linéaires . . . . . . . . . . . . . . . . . . . . . . 65III. Image, noyau et rang d’une matrice . . . . . . . . . . . . . . . . . . . . . . . . . . 71IV. La méthode de Gauss-Jordan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73V. Trace d’une matrice et d’un endomorphisme . . . . . . . . . . . . . . . . . . . . . 89VI. Sous-espaces stables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91VII. Déterminant . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
5 Espaces vectoriels normés. Convergence et continuité 107I. Espaces vectoriels normés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107II. Suites d’un espace vectoriel normé de dimension finie . . . . . . . . . . . . . . . . 113III. Vocabulaire de topologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115IV. Fonctions entre espaces vectoriels normés :
limite et continuité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119V. Propriétés des fonctions continues à valeurs réelles . . . . . . . . . . . . . . . . . 125VI. Le cas des applications linéaires et multilinéaires . . . . . . . . . . . . . . . . . . 126
6 Suites et séries de fonctions 129I. Différents modes de convergence . . . . . . . . . . . . . . . . . . . . . . . . . . . 130II. Limite et continuité des suites et séries de fonctions . . . . . . . . . . . . . . . . . 138III. Intégration des suites et séries de fonctions . . . . . . . . . . . . . . . . . . . . . . 140IV. Dérivation des suites et séries de fonctions . . . . . . . . . . . . . . . . . . . . . . 142
v

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 6/383
7 Dérivation et intégration des fonctions de R dans K 145I. Théorème de Rolle et accroissements finis . . . . . . . . . . . . . . . . . . . . . . 145II. Dérivées d’une bijection réciproque . . . . . . . . . . . . . . . . . . . . . . . . . . 148III. Intégration sur un segment des fonctions continues : quelques rappels . . . . . . . 150IV. Intégrale sur un segment des fonctions continues par morceaux . . . . . . . . . . 153V. Méthodes de calculs d’intégrales . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156VI. Formules de Taylor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
8 Réduction des endomorphismes et des matrices carrées 161I. Éléments propres d’un endomorphisme et d’une matrice carrée . . . . . . . . . . 161II. Recherche des éléments propres, polynôme caractéristique . . . . . . . . . . . . . 165III. Diagonalisabilité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169IV. Réduction et polynômes annulateurs . . . . . . . . . . . . . . . . . . . . . . . . . 173V. Endomorphismes et matrices trigonalisables . . . . . . . . . . . . . . . . . . . . . 177
9 Espaces probabilisés 183I. Ensembles dénombrables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183II. Espaces probabilisés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185III. Probabilités conditionnelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193IV. Événements indépendants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
10 Intégrales généralisées 199I. Convergence des intégrales généralisées . . . . . . . . . . . . . . . . . . . . . . . . 199II. Intégrales absolument convergentes, fonctions intégrables . . . . . . . . . . . . . . 204III. Méthodes de calcul des intégrales généralisées . . . . . . . . . . . . . . . . . . . . 207IV. Comparaison entre une série et une intégrale . . . . . . . . . . . . . . . . . . . . . 210V. Espaces fonctionnels et fonctions intégrables . . . . . . . . . . . . . . . . . . . . . 212
11 Interversions pour les intégrales généralisées. Intégrales à paramètre 215I. Les théorèmes d’interversion pour les intégrales généralisées . . . . . . . . . . . . 215
II. Intégrales à paramètre . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 219
12 Espaces préhilbertiens, espaces euclidiens 225I. Produit scalaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225II. Orthogonalité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 229III. Distance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 238IV. Formes linéaires sur un espace euclidien . . . . . . . . . . . . . . . . . . . . . . . 240
13 Séries entières 243I. Définition et convergence des séries entières . . . . . . . . . . . . . . . . . . . . . 243II. Opérations sur les séries entières . . . . . . . . . . . . . . . . . . . . . . . . . . . 248
III. Régularité de la somme d’une série entière . . . . . . . . . . . . . . . . . . . . . . 249IV. Développements en séries entières . . . . . . . . . . . . . . . . . . . . . . . . . . . 252
14 Variables aléatoires 257I. Définitions, premières propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . 257II. Loi d’une variable aléatoire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 258III. Familles de variables aléatoires . . . . . . . . . . . . . . . . . . . . . . . . . . . . 266IV. Espérance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 270V. Séries génératrices des variables aléatoires à valeurs dans N . . . . . . . . . . . . 275VI. Variance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 278
15 Endomorphismes remarquables des espaces euclidiens 289I. Isométries vectorielles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 289II. Endomorphismes symétriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294III. Espaces euclidiens orientés de dimension 2 et 3 . . . . . . . . . . . . . . . . . . . 297
vi

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 7/383
16 Fonctions vectorielles. Arcs paramétrés 307I. Dérivation des fonctions à valeurs vectorielles . . . . . . . . . . . . . . . . . . . . 307II. Dérivées d’ordre supérieur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 311III. Arcs paramétrés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313
17 Équations différentielles 323I. Résultats théoriques sur les systèmes différentiels . . . . . . . . . . . . . . . . . . 323
II. Systèmes à coefficients constants sans second membre . . . . . . . . . . . . . . . . 326III. Équations scalaires d’ordre 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 329IV. Équations scalaires d’ordre 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 331
18 Fonctions de plusieurs variables. Calcul et géométrie différentiels 341I. Fonctions de classe C1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 341II. Problèmes d’extrema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 351III. Dérivées partielles d’ordre 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353IV. Résolution d’équations aux dérivées partielles . . . . . . . . . . . . . . . . . . . . 353V. Courbes et surfaces . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 358
Annexe 1 : Relations de comparaison 367
I. Le cas des suites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 367II. Le cas des fonctions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 371
Annexe 2 : Intégrales de Wallis 373
vii

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 8/383
viii

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 9/383
Chapitre 1
Suites numériques
I. Définitions et résultats fondamentaux
Dans cette partie, on considère une suite (un)n∈N d’éléments de K = R ou C, i.e., uneapplication de N dans K. Toutes les définitions et tous les théorèmes que nous allons donnerpeuvent être adaptés au cas d’une suite (un)n p définie à partir d’un certain rang p.
1. Convergence d’une suite
• Soit ℓ ∈ K. On dit que (un) converge vers ℓ (ou que un tend vers ℓ) si
∀ ε > 0, ∃n0 ∈ N; ∀ n n0, |un − ℓ| ε.
On note ceci un → ℓ.
• On dit que (un) est convergente s’il existe ℓ ∈ K tel que un → ℓ. Dans ce cas, ℓ est
unique, il est appelé limite de (un) et noté lim un.• Lorsque K = R, on dit que (un) a pour limite +∞ (ou diverge vers +∞, ou queun tend vers +∞) si :
∀ A > 0, ∃n0 ∈ N; ∀ n n0, un A.
On définit de façon analogue le fait que (un) a pour limite −∞.On note ceci un → +∞ (ou un → −∞).
• Sinon, on dit que (un) diverge.
Définition
Démonstration de l’unicité de la limiteOn suppose qu’il existe ℓ et ℓ ′ dans K qui sont tous deux limites de (un). Soit ε > 0 fixé; il
existe n1 et n2 dans N tels que
∀ n n1, |un − ℓ| ε et ∀ n n2, |un − ℓ′| ε.
Alors, pour tout n n0 = maxn1,n2,
|ℓ − ℓ′| = |ℓ − un + un − ℓ′| |un − ℓ| + |un − ℓ′| 2ε.
Le nombre positif
|ℓ
−ℓ′
| est plus petit que toute constante strictement positive, il est donc nul,
ce qui prouve que ℓ = ℓ′.
Remarque – En adaptant cet argument, on montre bien sûr l’unicité de la limite y compris dansle cas des limites infinies.
1

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 10/383
• Soit (un) une suite croissante majorée de nombres réels. Alors (un) converge etlim un = sup un; n ∈ N.
• Toute suite croissante non majorée de nombres réels a pour limite +∞.
Théorème de la limite monotone
Démonstration
• Soit (un)n∈N une suite croissante majorée et soit M = sup un; n ∈ N. Soit ε > 0 fixé. Pardéfinition de la borne supérieure, il existe n0 ∈ N tel que un0 M − ε (en effet, M − ε < M ,donc M − ε n’est pas un majorant de un; n ∈N). Par croissance de (un), on a alors, pour toutn n0,
un un0 M − ε.
Sachant de plus que pour tout n, un M M + ε, on a finalement, pour tout n n0,|un − M | ε, donc un → M.
• Soit (un)n∈N une suite croissante non majorée et soit A > 0 fixé. Il existe n0 ∈ N tel queun0 A, et par croissance de un, on a pour tout n n0, un un0 A, ce qui montre queun → +∞.
Remarques
• On a un résultat analogue pour une suite décroissante, selon qu’elle est minorée ou non (avecune limite finie ou égale à −∞).
• Bien entendu, ce n’est pas la seule possibilité qu’a une suite pour converger : par exemple, lasuite ((−1)n/n)n1 converge vers 0 mais n’est ni croissante, ni décroissante.
Soient (un) et (vn) deux suites de réels. On dit que (un) et (vn) sont adjacentes si
• (un) est croissante et (vn) décroissante (ou le contraire),
• un − vn → 0.
Définition
Deux suites adjacentes sont convergentes et ont la même limite.
Théorème
Démonstration – Quitte à échanger les rôles de (un) et (vn), on peut supposer que (un) estcroissante et (vn) décroissante. Soit ε > 0 fixé et n0 ∈ N tel que |un − vn| ε.
Pour tout n n0, on a en particulier un vn + ε v0 + ε par décroissance de (vn). Donc(un) est majorée. Sachant de plus qu’elle est croissante, elle converge d’après le théorème de la
limite monotone. Soit ℓ sa limite.On montre de même que (vn) converge et on note ℓ′ sa limite. Alors en passant à la limite
dans l’inégalité |un − vn| ε valable pour n n0, on obtient |ℓ − ℓ′| ε. Ceci étant vrai pourtout ε > 0, on a ℓ = ℓ′, ce qui termine la démonstration.
2

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 11/383
2. Suites extraites
On appelle suite extraite de la suite (un) (ou sous-suite de (un)) toute suite de laforme (vn) = (uϕ(n)) où ϕ : N → N est une application strictement croissante.
Définition
Remarque – Une suite extraite de (un) est une suite constituée de certains des termes de (un) ;les valeurs prises par ϕ représentent les indices choisis (qui apparaissent par ordre strictementcroissant). Les propriétés de ϕ entraînent immédiatement (par récurrence) que ϕ(n) n pourtout n ∈ N.
Exemple – Les suites (u2n), (u2n+1), (un2) sont extraites de (un).
Si (un) converge, alors toute suite extraite de (un) converge, et admet la même limite.On a un résultat analogue si (un) a pour limite +∞ ou −∞.
Propriété
Démonstration – On démontre le résultat dans le cas d’une limite ℓ ∈ K, les autres cas sontsimilaires. Soit ε > 0 fixé ; il existe n0 ∈ N tel que pour tout n n0, |un− ℓ| ε. Soit (uϕ(n)) unesuite extraite de (un). Alors d’après la remarque précédente, pour tout n n0, ϕ(n) n n0,et donc |uϕ(n) − ℓ| ε, ce qui prouve le résultat.
Remarque – On emploie très souvent la contraposée de cette propriété : pour montrer qu’unesuite n’a pas pour limite ℓ, on en construit une suite extraite qui n’a pas pour limite ℓ; pourprouver qu’une suite diverge, on construit deux suites extraites qui ont des limites différentes.Ainsi les suites ((−1)n), (cos(nπ/2)) et (2n(−1)n) divergent.
Inversement, on a le résultat suivant :
Si les suites (u2n), (u2n+1) convergent vers la même limite ℓ, alors (un) converge versℓ. On a un résultat analogue si (u2n), (u2n+1) tendent vers +∞, ou vers −∞.
Propriété
Démonstration – À nouveau, on fait la preuve dans le cas d’une limite ℓ ∈ K. Soit ε > 0 fixé;il existe n0 ∈ N et n1 ∈ N tels que pour tout n n0, |u2n − ℓ| ε et pour tout n n1,|u2n+1 − ℓ| ε. Alors, pour tout p max2n0, 2n1 + 1, |u p− ℓ| ε ; en effet, soit p est pair, dela forme 2n avec n n0, soit il est impair, de la forme 2n + 1 avec n n1. On a donc montréque un → ℓ.
Exemple – On pose, pour n ∈ N∗, S n =
nk=1
(
−1)k
k .
Les suites (S 2n) et (S 2n+1) sont adjacentes car
∀ n ∈ N∗, S 2n+2 − S 2n = (−1)2n+2
2n + 2 +
(−1)2n+1
2n + 1 =
1
2n + 2 − 1
2n + 1 < 0,
∀ n ∈ N, S 2n+3 − S 2n+1 = (−1)2n+3
2n + 3 +
(−1)2n+2
2n + 2 =
1
2n + 2 − 1
2n + 3 > 0,
∀ n ∈ N∗, S 2n+1 − S 2n = (−1)2n+1
2n + 1 et donc S 2n+1 − S 2n → 0.
On en déduit que (S 2n) et (S 2n+1) convergent vers la même limite ℓ ∈ R, et donc, que (S n)
converge vers ℓ. Ceci montre que la série harmonique alternéek1
(−1)k−1
k est convergente.
3

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 12/383
II. Suites définies par récurrence
Soit D un sous-ensemble de K, f : D →K, a ∈ D et n0 ∈ N. On définit la suite (un)nn0 par
un0 = a et pour tout entier n n0, un+1 = f (un).
Définition de la suite : pour que l’existence de un entraîne l’existence de un+1, il suffit queun
∈ D. En général, il suffira de vérifier que D est stable par f , c’est-à-dire que
f (D) ⊂ D.
Si a ∈ D, on admettra que cela entraîne que (un)nn0 est bien définie, de façon unique, et àtermes dans D (l’unicité se montre facilement par récurrence, mais l’existence est plus délicate,elle est liée à la théorie des ensembles).
On supposera dans la suite que (un)nn0 est bien définie avec un ∈ D pour tout n n0.
Convergence : le plus souvent, la fonction f est continue sur D. Donc, si (un) converge versℓ et si ℓ ∈ D, alors en passant à la limite dans la relation un+1 = f (un), on obtient f (ℓ) = ℓ.
Les solutions de cette équation sont appelés les points fixes de f .
Si l’équation f (ℓ) = ℓ n’a pas de solution dans D, alors, soit la suite (un) est divergente, soitun tend vers un point du « bord » de D (y compris, éventuellement, ±∞).On est donc amené à chercher les solutions de cette équation dans D et à vérifier si la suite (un)converge ou non vers un tel nombre ℓ.
Une fois les points fixes de f déterminés, la vérification de la convergence est facilitée dansles cas suivants :
• La fonction f est contractante sur D, c’est-à-dire
∃ k ∈ [0,1[, ∀ (a,b) ∈ D2, |f (b) − f (a)| k |b − a|. (∗)
Lorsque K = R et D est un intervalle, le théorème des accroissements finis peut permettre detrouver une valeur de k s’il en existe : si f est dérivable sur D et si |f ′| k sur D, alors f estk-contractante.
Tout d’abord, l’inégalité (∗) assure l’unicité d’un éventuel point fixe de f dans D : si a et bsont deux points fixes de f dans D, alors d’après (∗), on a |b − a| = |f (b) − f (a)| k |b − a|.Sachant que k ∈ [0,1[, cela entraîne que a = b.
Supposons que ℓ soit un point fixe de f dans D . En remplaçant b par un ∈ D et a par ℓ ∈ Ddans (∗), on en déduit que
∀ n n0, |un+1 − ℓ| k |un − ℓ|.
Par récurrence sur n, on montre alors que
∀ n n0, |un − ℓ| kn−n0 |un0 − ℓ|.
Pour n = n0, la propriété est vraie car |un0 − ℓ| k0 |un0 − ℓ|.Supposons la propriété vraie pour un certain entier naturel n. Alors d’après l’inégalité (∗),
|un+1 − ℓ| k |un − ℓ| k × kn−n0 |un0 − ℓ| = kn+1−n0 |un0 − ℓ|.
La propriété est donc vraie au rang n + 1, et par principe de récurrence, elle est vraie pour toutn n0.
On conclut que (un) converge vers ℓ car kn tend vers 0. De plus, pour ǫ > 0 fixé, on peuttrouver n tel que |un− ℓ| < ǫ : il suffit que kn−n0 |un0 − ℓ| < ǫ (pour être exploitable, cela suposede connaître au moins une majoration de |un0 − ℓ|).
4

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 13/383
• K = R et f (x) − x est de signe constant sur D ; dans ce cas la suite (un) est monotone.
– Si f (x) x sur D , la suite (un) est croissante.– Si f (x) x sur D , la suite (un) est décroissante.
En effet, si f (x) x sur D, alors pour tout n n0, un+1 = f (un) un, donc (un) estcroissante. On procède de même si f (x) x sur D .
• K = R et la fonction f est croissante sur D ; dans ce cas la suite (un) est monotone.
– Si f (un0) = un0+1 un0 , on montre par récurrence que la suite (un) est croissante. Eneffet la propriété « un+1 un » est vraie au rang n0 et héréditaire car un+1 un entraîne,par croissance de f , que f (un+1) f (un), c’est-à-dire un+2 un+1.
– Si f (un0) = un0+1 un0 , on montre de même que la suite (un) est décroissante.
Dans les cas évoqués dans les deux derniers points, le problème est donc ramené à trouverun majorant ou un minorant (qui pourra être la limite ℓ supposée) afin d’appliquer le théorèmede la limite monotone.
• K = R et la fonction f est décroissante sur D ; dans ce cas la fonction f f est croissante.
On étudie alors les suites extraites (vn) = (u2n) et (wn) = (u2n+1). Ce sont des suitesrécurrentes associées à la fonction croissante f
f . Elles sont donc monotones d’après le point
précédent, et en fait, elles sont de monotonie contraire : par exemple si (u2n) est croissante, pourtout n tel que 2n n0, u2n+2 u2n, donc par décroissance de f , u2n+3 u2n+1. Ainsi (u2n+1)est décroissante.
Pour que (un) converge, il faut et il suffit que (vn) et (wn) convergent vers la même limite, ceque l’on peut essayer de montrer en utilisant le théorème de la limite monotone et en étudiantles points fixes de f f dans D. Si (vn) et (wn) convergent vers la même limite ℓ, alors (un)converge vers ℓ.
Remarques
• Dans la pratique, pour que certaines des propriétés ci-dessus soient vraies (stabilité de D par f ,comportement de f ), on est souvent amené à choisir D en restreignant l’ensemble de définition
de f , quitte à étudier plusieurs cas, chacun correspondant à un choix différent de D .• Pour guider ce choix et bien visualiser la situation, il est souvent judicieux de commencer parun graphique, sur lequel on représente les courbes d’équation y = x et y = f (x). Mais bien sûr,un dessin ne constitue pas une démonstration.
Cas particuliers :
• Suite arithmétique de raison b : ∀ n n0, un+1 = un + b. On a alors, pour tout n n0,un = un0 + (n − n0)b.
Si b = 0, la suite est constante, si b = 0, la suite ne converge pas (|un| tend vers +∞).
• Suite géométrique de raison a : ∀ n n0, un+1 = a un et un0 = 0. On a alors, pour toutn n0, un = an−n0 un0 .
– si |a| < 1, la suite converge vers 0.– si |a| > 1, la suite ne converge pas (|un| tend vers +∞).– si a = −1, la suite diverge (un = un0 si n − n0 est pair, un = −un0 sinon).– si a = 1, la suite est constante.
• Suite arithmético-géométrique : ∀ n n0, un+1 = a un + b avec a = 1.
L’unique point fixe de f : x → a x + b est ℓ = b
1 − a. On se ramène à l’étude d’une suite
géométrique définie par vn = un − ℓ. En effet, pour tout n n0,
vn+1 = un+1 − ℓ = (a un + b) − (a ℓ + b) = a(un − ℓ) = a vn.
On a donc, pour tout n n0, vn = an−n0 vn0
= an−n0 (un0 −
ℓ), puis
un = ℓ + an−n0(un0 − ℓ) = b
1 − a + an−n0
un0 −
b
1 − a
.
5
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 14/383
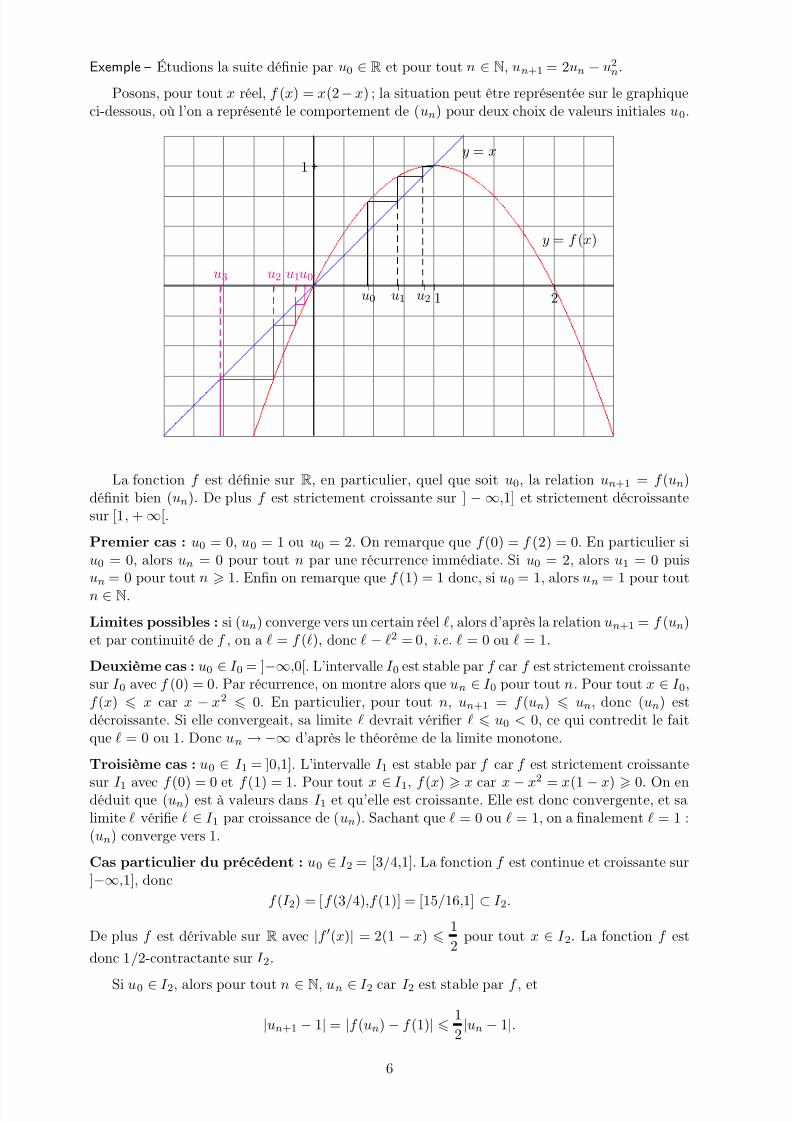
Exemple – Étudions la suite définie par u0 ∈ R et pour tout n ∈ N, un+1 = 2un − u2n.
Posons, pour tout x réel, f (x) = x(2 − x) ; la situation peut être représentée sur le graphiqueci-dessous, où l’on a représenté le comportement de (un) pour deux choix de valeurs initiales u0.
1
1|
+
|
u0|
u1|
u2|
2|
u0|
u1|
u2|
u3
y = x
y = f (x)
La fonction f est définie sur R, en particulier, quel que soit u0, la relation un+1 = f (un)
définit bien (un). De plus f est strictement croissante sur ] − ∞,1] et strictement décroissantesur [1, + ∞[.
Premier cas : u0 = 0, u0 = 1 ou u0 = 2. On remarque que f (0) = f (2) = 0. En particulier siu0 = 0, alors un = 0 pour tout n par une récurrence immédiate. Si u0 = 2, alors u1 = 0 puisun = 0 pour tout n 1. Enfin on remarque que f (1) = 1 donc, si u0 = 1, alors un = 1 pour toutn ∈ N.
Limites possibles : si (un) converge vers un certain réel ℓ, alors d’après la relation un+1 = f (un)
et par continuité de f , on a ℓ = f (ℓ), donc ℓ − ℓ2 = 0, i.e. ℓ = 0 ou ℓ = 1.
Deuxième cas : u0 ∈ I 0 = ]−∞,0[. L’intervalle I 0 est stable par f car f est strictement croissantesur I 0 avec f (0) = 0. Par récurrence, on montre alors que un ∈ I 0 pour tout n. Pour tout x ∈ I 0,f (x) x car x − x2 0. En particulier, pour tout n, un+1 = f (un) un, donc (un) estdécroissante. Si elle convergeait, sa limite ℓ devrait vérifier ℓ u0 < 0, ce qui contredit le faitque ℓ = 0 ou 1. Donc un → −∞ d’après le théorème de la limite monotone.
Troisième cas : u0 ∈ I 1 = ]0,1]. L’intervalle I 1 est stable par f car f est strictement croissante
sur I 1 avec f (0) = 0 et f (1) = 1. Pour tout x ∈ I 1, f (x) x car x − x2
= x(1 − x) 0. On endéduit que (un) est à valeurs dans I 1 et qu’elle est croissante. Elle est donc convergente, et salimite ℓ vérifie ℓ ∈ I 1 par croissance de (un). Sachant que ℓ = 0 ou ℓ = 1, on a finalement ℓ = 1 :(un) converge vers 1.
Cas particulier du précédent : u0 ∈ I 2 = [3/4,1]. La fonction f est continue et croissante sur]−∞,1], donc
f (I 2) = [f (3/4),f (1)] = [15/16,1] ⊂ I 2.
De plus f est dérivable sur R avec |f ′(x)| = 2(1 − x) 1
2 pour tout x ∈ I 2. La fonction f est
donc 1/2-contractante sur I 2.
Si u0 ∈ I 2, alors pour tout n ∈ N, un ∈ I 2 car I 2 est stable par f , et
|un+1 − 1| = |f (un) − f (1)| 1
2|un − 1|.
6

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 15/383
On montre alors par récurrence sur n que |un − 1| 1
2n|u0 − 1| pour tout n ∈ N.
On retrouve, par encadrement, le fait que dans ce cas, un → 1, car 1/2n → 0. Mais on a deplus une estimation de la vitesse de convergence. D’ailleurs, dans le cas où u0 ∈ I 0 = ]0,1], ona montré que (un) converge vers 1 en croissant. Il existe donc n0 ∈ N tel que un0 ∈ [3/4,1].L’estimation de la vitesse de convergence s’applique à partir de n0.
Autres cas : si u0
∈ [1,2[, alors u1
∈]0,1] = I 1 et, à un décalage d’indice près, on est dans la
situation du troisième cas, donc un → 1. Si u0 > 2, alors u1 ∈ ]−∞,0[ = I 0 et, à un décalaged’indice près, on est dans la situation du deuxième cas, donc un → −∞.
III. Suites récurrentes linéaires d’ordre 2
Les raisonnements de cette partie utilisent des notions d’algèbre linéaire, vues en premièreannée et qui seront rappelées en détails dans le chapitre Espaces vectoriels et applicationslinéaires.
Soit (a,b) ∈ K2. On cherche à déterminer l’ensemble noté S a,b des suites d’éléments de K,vérifiant la relation de récurrence linéaire d’ordre 2 suivante :
∀ n ∈ N, un+2 + aun+1 + bun = 0.
Première formulation : soit F : (un)n∈N → (un+2 +aun+1 +bun)n∈N. On vérifie très facilementque F ∈ L (KN), et on cherche à déterminer l’ensemble des solutions de l’équation linéaireF (u) = 0
KN , i.e. S a,b = Ker(F ). En particulier, S a,b est un sous-espace vectoriel de KN.
Deuxième formulation : soit φ :
S a,b → K2
u = (un) → (u0,u1)
En imposant les conditions initiales u0 = x et u1 = y, le problème revient à déterminer l’ensembledes éléments u de S a,b tels que φ(u) = (x,y).
L’application φ est un isomorphisme de S a,b sur K2. En particulier, dim(S a,b) = 2.
Théorème
Démonstration – Tout d’abord, φ est linéaire : soient u = (un) et v = (vn) deux suites et λ unscalaire. Alors
φ(λu + v) = (λu0 + v0,λu1 + v1)
= λ(u0,u1) + (v0,v1)
= λφ(u) + φ(v).
La bijectivité de φ se traduit ainsi : pour tout (x,y) ∈ K2, il existe une unique suite vérifiant larelation de récurrence d’ordre 2, et dont les deux premiers termes sont respectivement x et y.
Or, les relations un+2 + aun+1 + bun = 0 ∀ n ∈ Nu0 = x, u1 = y
définissent entièrement et de façon unique la suite (un) : φ est donc un isomorphisme.
Reste à savoir comment déterminer explicitement une suite (un) de S a,b en fonction de sesdeux premiers termes.
Pour r ∈ K, la suite géométrique (rn)n∈N appartient à S a,b si et seulement si r est unesolution de l’équation caractéristique associée :
x2 + ax + b = 0. (E )
Propriété
7

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 16/383
Démonstration
⇒ Si (rn)n∈N appartient à S a,b, alors pour tout n ∈ N, rn+2 + arn+1 + brn = 0. Avec n = 0, onobtient r 2 + ar + b = 0.
⇐ Si r2 + ar + b = 0, en multipliant cette égalité par rn, on obtient rn+2 + arn+1 + brn = 0
pour tout n ∈ N, donc (rn)n∈N appartient à S a,b.
On suppose (a,b) = (0,0).
• Si (E ) admet deux racines distinctes r1 et r2 dans K, alors les suites ((r1)n) et ((r2)n)forment une base de S a,b.Pour tout (un) ∈ S a,b, il existe un unique couple (λ,µ) ∈K2 tel que, pour tout n ∈N,
un = λ(r1)n + µ(r2)n.
• Si (E ) admet une racine double r dans K, alors les suites (rn) et (nrn) forment unebase de S a,b.Pour tout (un) ∈ S a,b, il existe un unique couple (λ,µ) ∈K2 tel que, pour tout n ∈N,
un = λrn + µ nrn = (λ + µn)rn.
• Si K = R et si (E ) admet deux racines complexes conjuguées distinctes z = ρeiθ et z,alors les suites (ρn cos(nθ)) et (ρn sin(nθ)) forment une base de S a,b.Pour tout (un) ∈ S a,b, il existe un unique couple (λ,µ) ∈R2 tel que, pour tout n ∈ N,
un = λ ρn cos(nθ) + µ ρn sin(nθ) = ρn(λ cos(nθ) + µ sin(nθ)).
Théorème
Démonstration
• On sait que ((r1)n) et ((r2)n) appartiennent à S a,b d’après la propriété précédente. De plus,
S a,b est de dimension 2. Il suffit donc de montrer que ((r1)n) et ((r2)n) sont indépendantes.Supposons qu’il existe deux scalaires λ et µ tels que λ(r1)n + µ(r2)n = 0 pour tout n. On endéduit en particulier, pour n = 0 et n = 1, que (λ,µ) est solution du système linéaire
λ + µ = 0λ r1 + µ r2 = 0
Or, r1 et r2 étant distinctes, ce système est de rang 2, et son unique solution est (0,0). Doncλ = µ = 0.
• On procède de la même façon lorsque (E ) possède une racine double r. Il suffit de remarquerque la suite (nrn) appartient à S a,b car, pour tout n 0,
(n + 2)rn+2 = (n + 2)rn × [−(ar + b)] = −a(n + 2)rn+1 − b(n + 2)rn
= −a(n + 1)rn+1 − b nrn − (ar + 2b)rn.
Or, r étant racine double du polynôme X 2 + aX + b, on a
X 2 + aX + b = (X − r)2 = X 2 − 2rX + r2.
On en déduit que a = −2r et b = r2, d’où ar +2b = 0. Ainsi (nrn) vérifie la relation de récurrenced’ordre 2. La liberté de la famille se prouve comme dans le point précédent (elle est même plussimple, il suffit de remarquer que r = 0 car (a,b) = (0,0)).
• Enfin, lorsque K = R et (E ) admet deux racines complexes conjuguées distinctes z = ρeiθ etz = ρe−iθ, on sait d’après le premier point que (zn) et (z n) forment une base de
S a,b vu comme
C-espace vectoriel. Il suffit de remarquer que
ρn cos(nθ) = Re(zn) = 1
2(zn + z n),
8

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 17/383
et donc (ρn cos(nθ)) appartient à S a,b comme combinaison linéaire de (zn) et (z n). De même,
ρn sin(nθ) = I m(zn) = 1
2i(zn − z n),
et donc (ρn sin(nθ)) appartient à S a,b comme combinaison linéaire (dans C, même si cette suiteest réelle) de (zn) et (z n). La liberté de la famille se prouve à nouveau comme dans le premierpoint, en remarquant que ρ
= 0 et sin(θ)
= 0 car z est complexe non réel.
Méthode – Pour déterminer explicitement λ et µ, qui sont les coordonnées de (un) sur la baseque l’on vient d’expliciter (selon les cas), on procède en considérant les deux premiers termes.
Par exemple, dans le premier cas, pour trouver λ et µ tels que un = λ(r1)n + µ(r2)n pourtout n ∈ N, on résout le système
λ + µ = u0
λ r1 + µ r2 = u1
correspondant à n = 0 et n = 1.
Dans le second cas, on résout le système λ = u0
λ r + µ r = u1
et dans le troisième, λ = u0
λ ρ cos(θ) + µ ρ sin(θ) = u1.
Dans tous les cas, le système à résoudre est de rang 2.
Exemple – Déterminons explicitement la suite (un) définie par u0 = 0, u1 = 1 et pour tout n ∈N,
un+2 = un+1 + un.
L’équation caractéristique associée à cette suite suite récurrente linéaire d’ordre 2 est
X 2 = X + 1
qui possède deux racines distinctes,
r1 = 1 +
√ 5
2 et r2 =
1 − √ 5
2 .
On sait donc qu’il existe (λ,µ) ∈R2 tel que pour tout n ∈ N,
un = λ(r1)n + µ(r2)n.
Les conditions initiales donnent
λ + µ = 0
λr1 + µr2 = 1 ⇔
λ + µ = 0
λr1 − λr2 = 1 ⇔
λ + µ = 0
λ = 1
r1 − r2
⇔
λ = 1√
5
µ = − 1√ 5
Finalement, pour tout n ∈ N,
un = 1√
5 1 +
√ 5
2 n
− 1√ 5
1 − √ 5
2 n
.
La suite (un) est appelée suite de Fibonacci. Le réel r1 = 1 +
√ 5
2 est le nombre d’or.
9

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 18/383
10

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 19/383
Chapitre 2
Séries numériques
Dans ce chapitre, K désigne R ou C et (un) une suite d’éléments de K.
I. Définition et convergence d’une série
1. Notion de série
Soit (un) une suite d’éléments de K. Notons, pour tout entier naturel p,
S p =
pn=0
un.
On appelle série de terme général un la suite (S p) p∈N.
Elle est notée
un,n0
un oun∈N
un.
Le scalaire S p est appelée somme partielle d’ordre p de cette série.
Définition
Remarques
• Bien sûr, on s’autorise aussi à considérer des suites (un) définies à partir d’un certain rang n0.Dans ce cas, on note
nn0
un la série correspondante. On peut aussi poser un = 0 pour n < n0
afin de définirn0 un. Pour simplifier les notations, on écrira la plupart des résultats pour une
série
n0 un.
• Pour toute suite (S p), il existe une unique suite (un) telle que (S p) soit la série de terme généralun : c’est la suite définie par u0 = S 0 et pour tout n ∈ N∗, un = S n − S n−1 (voir plus loin leprincipe des séries télescopiques).
• On parle de séries numériques pour les distinguer des séries de fonctions, des séries entières,
que nous étudierons également.
La sérien0 un est convergente (i.e., la suite (S p) possède une limite dans K) si et
seulement s’il existe S ∈ K tel que
pn=0
un −→ p→+∞ S.
Dans ce cas, cette limite S est notée+∞
n=0
un. Elle est appelée somme de la série.
Dans le cas contraire, la série est dite divergente.
Définition – Somme d’une série convergente
11

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 20/383
Remarque – On notera bien la distinction entre les objetsn0
un et+∞n=0
un.
Le premier existe toujours et désigne une suite, le second existe si et seulement si la série converge,et désigne alors un élément de K.
Remarques – Par définition, étudier une série
n0 un revient à étudier la suite (S p) de sessommes partielles.
• On pourrait donc croire que le travail est déjà fait. Pourtant, sauf cas très favorables, on nepeut pas simplifier l’expression des sommes partielles S p. Nous allons voir qu’en fait, on passetrès rarement par l’étude directe de la suite des sommes partielles pour étudier une série. On vaplutôt développer des critères portant sur le terme général un.
• Inversement, on a vu que pour n 1, un = S n − S n−1; on peut parfois étudier une suite (un)
en passant par la série de terme général un.
Soit
n0 un une série et m un entier naturel. Alors la série
nm+1 un est de même
nature (convergente ou divergente) que n0 un.
Si elle converge, sa somme
Rm =+∞
n=m+1
un
est appelé reste d’ordre m de la série.
Propriété/Définition
Démonstration – Pour tout p m + 1,
p
n=0
un
−
p
n=m+1
un =m
n=0
un
ne dépend pas de p. La suite associée est donc stationnaire. En particulier, les séries
n0 un etnm+1 un sont de même nature.
Si la série
n0 un converge, la suite (Rm)m∈N converge vers 0.
Propriété
Démonstration – En notant S p les sommes partielles de la série, on a en passant à la limite lorsque
p → +∞ dans l’égalité de la démonstration précédente,
+∞n=0
un = S m + Rm,
et ce pour tout m ∈ N. Or, par définition,
S m −→m→+∞
+∞n=0
un.
Le résultat suit par différence.
La propriété suivante montre que si nécessaire, l’étude des séries de nombres complexes seramène à l’étude des séries de réels :
12

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 21/383
Une série
n0 un de nombres complexes converge si et seulement si les sériesn0
Re(un) etn0
I m(un)
(séries des parties réelles et imaginaires de un) convergent. Dans ce cas,
+∞n=0
un =+∞n=0
Re(un) + i+∞n=0
I m(un).
Propriété
Démonstration – Pour tout p ∈ N, pn=0
un =
pn=0
(Re(un) + i I m(un)) =
pn=0
Re(un) + i
pn=0
I m(un).
Or, d’après une propriété connue sur les suites, (
pn=0 un) a une limite dans K si et seulement si sa
partie réelle et sa partie imaginaire ont une limite finie (dans R), ce qui équivaut d’après l’égalité
ci-dessus à la convergence des séries n0 Re(un) et n0 I m(un). En cas de convergence, ona l’égalité souhaitée en passant à la limite dans l’égalité ci-dessus.
2. Premiers exemples
Série géométrique
Soit z un nombre complexe. On appelle série géométrique de raison z la sérien0
zn.
On sait que pour tout entier naturel p,
S p =
pn=0
zn = 1 − z p+1
1 − z si z
= 1
p + 1 si z = 1.
Ainsi, (S p) est convergente si et seulement si : z = 1 et (z p) converge. Ceci équivaut à : |z| < 1. Eneffet, si |z| < 1, alors z = 1 et (z p) converge. Réciproquement, si z = 1 et si (z p) converge, alors|z| 1 (car (z p) diverge si |z| > 1). Supposons que |z| = 1 ; sachant de plus que (z p) converge,sa limite ℓ vérifie ℓ = 0 ; en remarquant que z p+1/z p = z pour tout p ∈ N, et en passant à lalimite dans cette relation, on obtient z = 1, ce qui est exclu. Donc |z| < 1.
En cas de convergence, on a+∞
n=0
zn = 1
1 − z.
Si z est un nombre complexe tel que |z| < 1, alors le reste d’ordre m de la série géométrique deraison z est
Rm =+∞
n=m+1
zn = zm+1
1 − z.
Série harmonique
On appelle série harmonique la sériek1
1
k.
La série harmonique est divergente : en notant H n =n
k=1
1
k pour tout n 1, on a
H 2n − H n =2nk=1
1
k −
nk=1
1
k =
2nk=n+1
1
k
1
2n
2nk=n+1
1 = 1
2.
13

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 22/383
Si la série harmonique convergeait, on aurait H 2n − H n → 0, ce que contredit l’inégalité précé-dente.
Série harmonique alternée
On appelle série harmonique alternée la sériek1
(−1)k−1
k .
La série harmonique alternée converge et sa somme est ln(2). En effet, on remarque que pour
tout n 1,nk=1
(−1)k−1
k =
nk=1
1
0(−1)k−1tk−1 dt =
1
0
nk=1
(−t)k−1
dt.
On reconnaît la somme des premiers termes d’une série géométrique de raison −t = 1 :
1
0
nk=1
(−1)k−1tk−1
dt =
1
0
1 − (−t)n
1 + t dt =
1
0
1
1 + t dt −
1
0
(−t)n
1 + t dt.
Or, 1
0
1
1 + t dt = ln(2) et
1
0
(−t)n
1 + t dt
1
0tn dt =
1
n + 1 → 0.
Séries téléscopiques
On appelle série télescopique une série de la formen0
(αn+1 − αn).
L’expression des sommes partielles de cette série est très simple, car pour tout entier naturel p,
pn=0
(αn+1 − αn) =
pn=0
αn+1 − pn=0
αn =
p+1n=1
αn − pn=0
αn = α p+1 − α0.
On en déduit le résultat suivant :
La série télescopiquen0
(αn+1 − αn) converge si et seulement si la suite (αn) converge.
Propriété
Exemple – Pour p 1,
pn=1
1
n(n + 1) =
pn=1
1
n − 1
n + 1
= 1 − 1
p + 1.
La sérien1
1
n(n + 1) est donc convergente, et sa somme est 1.
3. Une condition nécessaire mais non suffisante de convergence
Soit n0
un une série convergente. Alors un tend vers 0 lorsque n → +∞.
Propriété
14

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 23/383
Démonstration – En notant S n =nk=0
uk, on a, pour tout entier n 1,
un = S n − S n−1.
Par hypothèse, (S n) converge, et donc (S n−1) converge également, vers la même limite. Pardifférence, un
→ 0.
Attention ! Il ne faut surtout pas confondre cette proposition avec sa réciproque qui est fausse :ce n’est pas parce que le terme général d’une série tend vers 0 que cette série converge : l’exemplede la série harmonique le montre bien.
Remarque – On utilise souvent la contraposée de ce résultat : si un ne tend pas vers 0, alors lasérie
n0 un est divergente. On parle alors de divergence grossière.
4. Opérations sur les séries
Soient
n0 un et
n0 vn deux séries convergentes, et λ ∈ K. Alors la sérien0
(λun + vn)
converge et+∞n=0
(λun + vn) = λ+∞n=0
un ++∞n=0
vn.
Propriété
Démonstration – Pour p ∈ N, on a
pn=0
(λun + vn) = λ
pn=0
un +
pn=0
vn −→ p→+∞ λ
+∞n=0
un ++∞n=0
vn
par définition de la convergence des deux sériesn0 un et
n0 vn et par combinaison linéaire
de limites. Ceci signifie exactement que la série
n0(λun + vn) converge ainsi que la formuleannoncée.
L’ensemble des séries convergentes d’éléments de K est un K-espace vectoriel.
Corollaire
Très souvent, les hypothèses des théorèmes sur les séries seront vérifiées à partir d’un certainrang. Cela n’empêchera pas leur application, grâce à la propriété suivante :
Soit (un) et (vn) deux suites dont seulement un nombre fini de termes diffèrent.Alors les deux séries n0 un et n0 vn sont de même nature.
Propriété
Attention ! En revanche, elles n’ont pas nécessairement même somme.
15

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 24/383
II. Séries de réels positifs
1. Critère de convergence, théorèmes de comparaison
Soit
n0 un une série à termes réels positifs. Alors, pour que cette série converge, ilfaut et il suffit que la suite de ses sommes partielles soit majorée. Dans ce cas, on a
+∞n=0
un = sup p0
pn=0
un.
Propriété
Démonstration – La suite des sommes partielles (S p) est croissante. Le résultat vient donc duthéorème de la limite monotone : si (S p) est majorée, alors la série converge vers sa bornesupérieure, sinon elle diverge vers +∞.
Soient n0 un et n0 vn deux séries à termes réels positifs, et soit n0 ∈N
.• Si pour tout n n0, un vn et sin0
vn converge, alorsn0
un converge et
0 +∞n=n0
un +∞n=n0
vn.
• Si pour tout n n0, un vn et sin0
un diverge, alorsn0
vn diverge.
• Si un ∼ vn, alors les séries
n0 un et
n0 vn sont de même nature.
Théorème
Rappel – Pour des suites (un) et (vn) à termes positifs telles que vn = 0 à partir d’un certainrang N , la condition un ∼ vn signifie que
unvn
→ 1, i.e., ∀ ε > 0, ∃ n1 ∈ N, n1 N ; ∀ n n1, (1 − ε) vn un (1 + ε) vn.
Démonstration du théorème
• De l’hypothèse, on déduit que pour tout p n0,
0
p
n=n0
un
p
n=n0
vn.
Si
n0 vn converge,
nn0 vn converge, donc la suite de ses sommes partielles est majorée
d’après la propriété précédente. Il en est donc de même pour
nn0 un. D’après la propriété
précédente,
nn0 un converge, et donc
n0 un converge. De plus, en passant à la limite dans
l’inégalité précédente, on obtient
0
+∞n=n0
un
+∞n=n0
vn.
• Le deuxième point est tout simplement la contraposée du premier.
• Si un ∼ vn, alors il existe n1 ∈ N tel que pour tout n n1, 12 vn un
32 vn. Les deux premiers
points, et le fait que l’on ne modifie pas la nature d’une série par multiplication par un scalairenon nul, permettent de conclure.
16

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 25/383
Exemples
• Montrons que la sérien1
1
n2 converge. Pour tout n 2,
0 1
n2
1
n(n − 1).
Or, nous avons prouvé plus haut (à un décalage d’indices près), que la série n2
1
n(n − 1) converge.
On en déduit le résultat par comparaison de séries à termes positifs.
• De même, la sérien1
1√ n
diverge par comparaison avec la série harmonique : pour tout n 1,
0 1
n
1√ n
.
Or on a montré plus haut que la série harmonique diverge. On en déduit le résultat par compa-raison de séries à termes positifs.
• La série n1
n sin 1n2 diverge : en effet
n sin
1
n2
∼ 1
n > 0.
Par comparaison avec la série harmonique, divergente et à termes positifs, on en déduit le résul-tat.
Remarques
• On peut bien sûr remplacer l’hypothèse « à termes positifs » par l’hypothèse « à termes néga-tifs » (si on le fait, ce doit être pour les deux séries).
• En revanche, l’hypothèse de même signe constant est essentielle. Par exemple, pour n 1,
− 1
n
1
n2,
et la sérien1
1
n2 converge. Bien sûr, pourtant, la série
n1
− 1
n diverge.
Le théorème précédent montre bien l’utilité de connaître la nature de quelques séries deréférence auxquelles on pourra essayer de comparer les séries que l’on étudiera. Nous connaissonsdéjà la nature de la série géométrique, des séries de termes généraux 1/n, 1/n2, 1/
√ n. En fait,
ces trois derniers exemples se généralisent :
Une série de Riemann est une série de la formen1
1
nα où α ∈ R.
On a le critère suivant de convergence des séries de Riemann :n1
1
nα converge si et seulement si α > 1.
Théorème/Définition : Séries de Riemann
Démonstration – Si α 1, alors pour tout n 1,
0 1
n
1
nα,
17

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 26/383
donc la sérien1 1/nα diverge par comparaison avec la série harmonique.
Si α > 1, on remarque que pour tout n 2, et pour tout t ∈ [n − 1,n],
1
nα
1
tα,
et donc, après intégration sur [n − 1,n], intervalle de longueur 1, on a
1
nα nn−1
1
tα dt.
En sommant ces inégalités pour n entre 2 et p 2, et en ajoutant le terme manquant correspon-dant à n = 1, on obtient, d’après la relation de Chasles,
pn=1
1
nα 1 +
p1
1
tα dt = 1 +
1
(1 − α)tα−1
p1
= 1 + 1
α − 1
1 − 1
pα−1
1 +
1
α − 1
car α − 1 > 0. La suite des sommes partielles de la série
n1 1/nα, qui est à termes positifs,est majorée. On en déduit que la série
n1 1/nα converge lorsque α > 1.
Exemple – La série n0 n8e−n converge : la suite de terme général n2
×n8e−n = n10e−n tend
vers 0 par croissances comparées puissance/exponentielle. Donc pour n assez grand,
0 n8e−n 1
n2.
Par comparaison de séries à termes positifs, on en déduit le résultat, car la série de Riemannn1
1
n2, d’exposant 2 > 1, converge.
On peut souvent montrer par cet argument la convergence de séries dont le terme généralconverge assez vite vers 0.
L’idée de la démonstration du théorème précédent (dans le cas où α > 1) est généralisable :
considérons une fonction f : [0, + ∞[→ R+ continue et décroissante. Si n ∈ N∗, on a pour toutt ∈ [n − 1,n], f (n) f (t), et donc, après intégration sur [n − 1,n],
f (n)
nn−1
f (t) dt.
De la même façon, pour tout n ∈ N, n+1
nf (t) dt f (n).
Ceci est illustré sur le graphique suivant, l’aire sous la courbe de f entre les points d’abscissesn
−1 et n étant minorée par l’aire du rectangle de base 1 et de hauteur f (n), et l’aire sous la
courbe de f entre les points d’abscisses n et n + 1 étant majorée par l’aire de ce même rectangle.
Cf
n − 1 n n + 1
f (n)
18

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 27/383
En additionnant la première inégalité pour n entre 1 et p 1 puis en ajoutant f (0), et enadditionnant la seconde pour n entre 0 et p, on obtient p+1
0f (t) dt
pn=0
f (n) f (0) +
p0
f (t) dt.
On peut donc, grâce à la méthode des rectangles, encadrer les sommes partielles de la série
n0f (n).
Si l’on sait calculer les intégrales de f
, ou au moins décrire leur comportement,ceci peut permettre de décrire le comportement asymptotique des sommes partielles p
n=0 f (n)
lorsque p → +∞.
Remarque – On adapte facilement cet encadrement :
• Lorsque f est définie sur [n0, + ∞[, comme dans la démonstration du critère de convergencedes séries de Riemann avec n0 = 1.
• Lorsque f est croissante.
Exemples
• La série harmonique correspond au choix de la fonction inverse qui est continue, décroissante etpositive sur [1, + ∞[ ; en mettant en oeuvre la méthode précédente, on obtient, pour tout p 1, p+1
1
1
t dt
pn=1
1
n f (1) +
p1
1
t dt,
c’est-à-dire,
ln( p + 1)
pn=1
1
n 1 + ln( p).
On retrouve la divergence de la série harmonique, mais bien plus précisément, car par encadre-ment, on obtient que
p
n=1
1
n ∼ p→
+∞
ln( p).
En effet,
1 + ln( p) ∼ p→+∞ ln( p) et ln( p + 1) = ln( p) + ln
1 +
1
p
= p→+∞ ln( p) + o(1) ∼
p→+∞ ln( p).
• En sommant différemment les inégalités obtenues par la méthode des rectangles, on peut obtenird’autres résultats intéressants. Par exemple, dans le cas des séries de Riemann convergentes, c’est-à-dire lorsque f : t → 1/tα avec α > 1 (f est continue, décroissante et positive sur [1, + ∞[), ona pour tout n 2,
n+1
n
f (t) dt f (n) n
n−1
f (t) dt.
En sommant ces inégalités entre m + 1 avec m 1 et p m + 1, on obtient donc p+1
m+1f (t) dt
pn=m+1
f (n)
pm
f (t) dt,
c’est-à-dire
1
α − 1
1
(m + 1)α−1 − 1
( p + 1)α−1
pn=m+1
1
nα
1
α − 1
1
mα−1 − 1
pα−1
.
Lorsque p tend vers +∞
, tous les termes ont une limite finie et on obtient
1
α − 1
1
(m + 1)α−1
+∞n=m+1
1
nα
1
α − 1
1
mα−1,
19

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 28/383
ce qui entraîne que+∞
n=m+1
1
nα ∼m→+∞
1
α − 1
1
mα−1.
On obtient donc un équivalent des restes d’ordre m de la sérien1
1
nα lorsque m → +∞.
2. La règle de d’Alembert
Soitn0
un une série à termes réels strictement positifs. On suppose que
un+1
un
possède une limite ℓ 0 (éventuellement infinie).
• Si ℓ ∈ [0,1[, alorsn0
un converge.
• Si ℓ > 1 ou si ℓ = +∞, alors n0
un diverge grossièrement.
• Si ℓ = 1, on ne peut pas conclure.
Théorème – Règle (ou critère) de d’Alembert
Démonstration
• On suppose que
un+1
un
a une limite ℓ ∈ [0,1[. En appliquant la définition de la limite avec
ε = 1 − ℓ
2 , on en déduit qu’il existe n0 ∈ N tel que pour tout n n0,
0 un+1
un ℓ + ε =
1 + ℓ
2 < 1.
En notant k = 1 + ℓ
2 , on a k ∈ [0,1[ et pour n n0,
0 un+1
un k. (1)
Montrons alors par récurrence que pour tout n n0,
0 un un0kn0
kn.
Pour n = n0, le résultat est vrai car il se lit 0 un0 un0. Si le résultat est vrai au rang n, alorsd’après (1),
0 un+1 kun k un0kn0
kn = un0kn0
kn+1;
le résultat est donc vrai au rang n + 1 et d’après le principe de récurrence, il est vrai pour toutn n0.
La série de terme général kn converge car c’est la série géométrique de raison k ∈ [0,1[,
donc la sérienn0
un0kn0
kn converge. Par comparaison de séries à termes positifs, la sérien0 un
converge.
• On procède de la même façon dans le cas où ℓ > 1. On obtient l’existence de k > 1 tel quepour tout n assez grand,
un+1
un k.
On en déduit que kn = O(un). Or, sachant que k > 1, kn → +∞ lorsque n → +∞ et il en estdonc de même pour un. En particulier,
n0 un diverge grossièrement.
20

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 29/383
Remarques
• Lorsqu’elle s’applique, la règle de d’Alembert permet de conclure à des convergences, ou desdivergences grossières, c’est-à-dire, des comportements particuliers. Souvent, la limite du quo-tient, si elle existe, est égale à 1, et on ne peut pas conclure par cet argument. Par exemple, ilne s’applique pas aux séries
n,
1/n2. Souvent aussi, cette limite n’existe pas et la règle nes’applique pas. En revanche, la règle de d’Alembert est très efficace pour traiter des séries qui« ressemblent » à des séries géométriques.
• Il n’existe pas de réciproque à la règle de d’Alembert : si une série n0 un à termes positifsconverge, on ne peut pas en déduire quoi que ce soit sur le comportement du quotient un+1/un,qui peut même ne pas être défini!
• Il est indispensable de passer à la limite dans la règle de d’Alembert : si un > 0 pour tout n, lefait que le quotient un+1/un appartienne à [0,1[, ou à ]1, + ∞], pour tout n, ne permet aucuneconclusion quant à la convergence ou divergence de la série
n0 un.
Exemple – Soit x un réel positif. Montrons que la sérien0
nxn converge si et seulement si x ∈ [0,1[.
Si x = 0 le résultat est évident. Sinon, pour tout n,
(n + 1)xn+1
nxn = n + 1
n x −→
n→+∞ x.
Par conséquent, d’après la règle de d’Alembert, si x < 1, la série converge, si x > 1, elle diverge.Si x = 1, on ne peut pas conclure par la règle de d’Alembert mais on obtient la série
n qui
diverge grossièrement.
3. Développement décimal d’un nombre réel
On a l’habitude, au point de ne plus y penser, d’écrire nos nombres en base 10. Pourtant,notre système de numération est le fruit de plusieurs millénaires de maturation depuis l’appari-tion des premiers systèmes de numérations additifs (égyptien, romain et grec par exemple), quiconsistaient à représenter un nombre entier par juxtaposition de symboles représentant chacunune quantité fixée (1, 10, 50,...), la valeur du nombre représenté étant la somme des valeurs desdifférents symboles. Sont ensuite apparus des systèmes de numération dans lesquels la valeur d’unsymbole dépend de sa place dans l’écriture : ils sont dits systèmes de numération de position.Les sytèmes chinois, babylonien et bien sûr les systèmes de base b en sont des exemples. Et cen’est qu’autour du 4e siècle de notre ère que le zéro, venu d’Inde, efface les ambiguïtés dues auxespaces dans l’écriture d’un nombre, pour prendre, peu à peu, un véritable caractère opératoire.
D’ailleurs, la base 10 n’est pas plus naturelle que d’autres qui ont été et sont encore largementutilisées dans de nombreuses civilisations : la base 12 et la base 60 ont l’avantage d’offrir de plusnombreux diviseurs que la base 10; on se sert encore de la première pour compter les oeufs
par exemple, de la seconde pour l’heure. La base 2 enfin a pris toute son importance avec ledéveloppement de l’informatique, évidemment (c’est Leibniz qui en avait entrevu l’importance).La notion de série permet de définir l’écriture en base b des nombres réels ; donnons l’exemple
de l’écriture décimale des réels de [0,1[.
Soit (an)n1 une suite d’entiers naturels compris entre 0 et 9. Alors la sérien1
an10n
converge. En notant x sa somme, on a x ∈ [0,1], et on dit que cette série est undéveloppement décimal (ou en base 10) de x.
Propriété/Définition
21

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 30/383
Démonstration – Les an étant compris entre 0 et 9 pour tout n 1, on a l’encadrement
0 an10n
9
10n.
Par comparaison avec une série géométrique de raison 0,1 et de premier terme 9 (dont la sommeest 1, voir la remarque suivante), on en déduit la convergence de la série et le fait que x ∈ [0,1].
Remarque – Contrairement à ce qu’on pourrait croire, un tel développement n’est pas unique :posons
x =+∞n=1
9
10n = 0,9999 . . .
Alors
x = 9+∞n=1
1
10n = 9
1
10
1
1 − 110
= 1 = 1,00000 . . .
Pour éviter ce phénomène, on définit les développements décimaux propres :
Avec les notations précédentes, on dit que n1 an/10n est un développement décimalpropre de x si la suite (an) ne devient pas constante égale à 9.
Définition
On a alors le résultat suivant :
Tout réel x ∈ [0,1[ possède un unique développement décimal propre.
Théorème
Démonstration de l’existence d’un développement décimal (démonstration non exigible)
Fixons x ∈ [0,1[. Dans ce qui suit, la notation ⌊a⌋ désigne la partie entière d’un réel a. Pour
tout n ∈ N, on poseAn =
⌊10n x⌋10n
,
en remarquant que A0 = ⌊x⌋ = 0, et pour tout n 1, on pose
an = 10n(An − An−1),
de sorte que An soit la troncature de x à n décimales, et an la n-ième décimale du développementde x. Pour tout n 1, on a 0 an 9. En effet,
10n x − 1 < ⌊10n x⌋ 10n x,
d’oùx
− 1
10n
< An x. (2)
On en déduit que
− 1
10n =
x − 1
10n
− x < An − An−1 < x −
x − 1
10n−1
=
1
10n−1
et finalement l’inégalité 0 an 9 pour tout n 1. D’après la propriété précédente, la sérien1 an/10n converge.
En fait, on remarque que la série
n1 an/10n est télescopique, et pour tout p 1,
pn=1
an10n
=
pn=1
(An − An−1) = A p − A0 = A p.
Or, d’après l’inégalité (2), A p −→ p→+∞ x, d’où le résultat.
Remarque – On peut montrer qu’un réel x ∈ [0,1[ est rationnel si et seulement si son développe-ment décimal propre est périodique à partir d’un certain rang.
22

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 31/383
III. Convergence absolue
1. Définition et lien avec la convergence
La partie précédente montre que les séries à termes positifs jouent un rôle particulier et quel’on dispose pour ces séries de critères de convergence. Il serait donc intéressant de pouvoir s’yramener. Pour cela, la démarche la plus naturelle est de considérer la série
n0 |un|.
On dit que la série
n0 un est absolument convergente si la série
n0 |un|converge.
Définition
Si
n0 un est absolument convergente, alors elle est convergente.
Dans ce cas, on a l’inégalité triangulaire
+∞
n=0 un
+∞
n=0 |un|.
Théorème
Démonstration – Les séries
n0 Re(un) et
n0 I m(un) sont absolument convergentes parcomparaison, car pour tout n 0,
|Re(un)|
Re(un)2 + I m(un)2 = |un| et de même |I m(un)| |un|.Si l’on montre que les séries
n0 Re(un) et
n0 I m(un) convergent, alors d’après une pro-
priété donnée plus haut, on saura que
n0 un converge. Posons αn = Re(un) (ainsin0 |αn|
converge) et
α+n = max0,αn =
1
2 (|αn| + αn), α−n = max0, − αn = 1
2 (|αn| − αn).
Pour tout n ∈N,0 α+
n |αn|, 0 α−n |αn|.Par comparaison de séries à termes positifs,
n0 α+
n et
n0 α−n convergent. On remarqueenfin que l’on a αn = α+
n − α−n , et donc, par différence,n0 αn converge. On procède de même
avec la partie imaginaire.
On a alors, pour tout p ∈ N, pn=0
un
pn=0
|un|,
d’où, en passant à la limite, l’inégalité souhaitée.
Exemples
• La série géométrique
n0 zn est absolument convergente si et seulement sin0 |z|n converge,
ce qui équivaut à : |z| < 1. On remarque que dans ce cas, la convergence équivaut à la convergenceabsolue, mais c’est un cas très particulier.
• La sérien1
(−1)n
n(n + 1) est absolument convergente.
Attention ! La réciproque du théorème ci-dessus est fausse, comme le montrent les exemples desséries harmonique et harmonique alternée :
n1
(−1)n
−1
n converge mais n1
(−1)n
−1
n =
n1
1n diverge.
Si la série ne converge pas absolument, on ne peut pas en déduire qu’elle ne converge pas.
23

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 32/383
2. Théorème de comparaison
Soient
n0 un une série à termes dans K, et
n0 vn une série à termes réelspositifs. On suppose que
un = O(vn)
et que n0 vn est convergente.
Alors
n0 un est absolument convergente, et donc convergente.
Théorème
Rappel – Pour des suites (un) et (vn) telles que vn = 0 à partir d’un certain rang N , la conditionun = O(vn) signifie que la suite (un/vn)nN est bornée.
Démonstration – D’après l’hypothèse, il existe M ∈ R+ et N ∈ N tels que pour tout n N ,on ait |un| M vn. La série
n0 vn converge, donc
n0 M vn converge également, et par
comparaison de séries à termes positifs,
n0 |un| converge, c’est-à-dire que
n0 un convergeabsolument. La convergence absolue entraîne la convergence, d’où le résultat.
Remarques• L’hypothèse un = O(vn) est en particulier vérifiée dans chacun des cas suivants, qui sont descas particuliers fréquents d’utilisation du théorème précédent :
• un = o(vn).• Pour tout n assez grand, |un| vn.
• un ∼ vn.
• Si (un) est à valeurs dans K∗, on peut essayer d’appliquer la règle de d’Alembert à la suite
un+1
un
.
Si cette suite possède une limite ℓ < 1, alors la série n0 |un| converge d’après la règle ded’Alembert, c’est-à-dire quen0 un converge absolument, et donc elle converge. Si elle possède
une limite ℓ > 1 ou une limite infinie, alors la sérien0 |un| diverge grossièrement, donc un ne
tend pas vers 0, et la sérien0 un diverge également grossièrement (l’utilisation de la divergence
grossière est ici cruciale).
Exemple – Pour tout nombre complexe z, la sérien0
zn
n! est absolument convergente.
En effet, si z = 0 (sinon la convergence est évidente), alors pour tout n ∈ N,
zn+1/(n + 1)!
zn/n! =
|z|n + 1
et donc
zn+1/(n + 1)!
zn/n! −→n→+∞ 0.
La règle de d’Alembert s’applique. Nous montrerons dans le chapitre Séries entières que lasomme de cette série est ez. Cette série est appelée série exponentielle.
De la convergence de cette série, on déduit notamment que pour tout nombre complexe z,
zn
n! −→n→+∞
0.
On retrouve ainsi un théorème de croissances comparées : pour tout z ∈ C, zn = o(n!). On peutde même retrouver certaines des autres croissances comparées usuelles : nα = o(an) si (α,a) ∈C2
et |a| > 1, n! = o(nn). Cela n’a rien d’étonnant, en fait, leur démonstration classique reposesur le même principe que celui mis en oeuvre dans la démonstration de la règle de d’Alembert :en notant u
n le quotient dont on veut prouver qu’il tend vers 0 (respectivement, u
n = zn/n!,
nα/an ou n!/nn), on montre que un = O(kn) pour un certain k ∈ [0,1[ en déterminant la limitedu quotient un+1/un. Dans les cas présentés, cette limite existe et vaut respectivement 0, 1/a et1/e, dont le module est élément de [0,1[ dans les trois cas.
24

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 33/383
IV. La formule de Stirling
On a l’équivalent suivant : n! ∼n
e
n√ 2πn.
Théorème
Idée de démonstration (non exigible) – Notons, pour tout entier naturel n 1,
un = n!ne
n√ 2πn
.
Alors un > 0 pour tout n 1 ; le but est de démontrer que un → 1. Pour cela, définissons
vn = ln
un+1
un
.
Première étape : montrons quen1
vn converge.
Par définition, pour tout n 1,
vn = ln
un+1
un
= ln
(n+1)!
(n+1e )
n+1√ 2π(n+1)
n!
(ne )n√
2πn
= ln
(n + 1) e
nn
(n + 1)n+1
n
n + 1
= ln
e
n
n + 1
n n
n + 1
= ln
e
n
n + 1
n+ 12
= 1 + n + 1
2 ln n
n + 1= 1 −
n +
1
2
ln
1 +
1
n
.
Effectuons alors un développement limité de vn à l’ordre 2 :
vn = 1 −
n + 1
2
1
n − 1
2n2 + O
1
n3
= 1 −
1 − 1
2n + O
1
n2
−
1
2n + O
1
n2
= O
1
n2.
La série de terme général 1/n2 est une série de Riemann d’exposant 2 > 1 donc convergente. Parcomparaison,
n1
vn converge absolument, et donc converge.
Deuxième étape : montrons que (un) converge.
Pour tout n 1,
ln
un+1
un
= ln(un+1) − ln(un),
qui est le terme général d’une série télescopique. La série
n1 vn étant convergente, on en déduitque la suite (ln(un)) est convergente, puis que (un) converge vers une limite strictement positive,
car la fonction exponentielle est continue et à valeurs strictement positives. Il existe donc ℓ > 0tel quen!
ne
n√ 2πn
→ ℓ.
25

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 34/383
Troisième étape : montrons que ℓ = 1.
On peut montrer (voir Annexe 2) que les intégrales de Wallis
I n =
π/2
0sinn(x) dx
vérifient, pour tout entier naturel n,
I 2n = (2n)!
22n+1(n!)2 π, et que I 2n ∼
π4n
.
Ainsi(2n)!
22n(n!)2 ∼ 1√
πn.
Sachant que
n! ∼ ℓn
e
n√ 2πn,
on a doncℓ 2n
e 2n √
4πn
ℓ2 ne2n 2πn ∼ 2
2n 1
√ πn .
Après simplifications, on obtient22n
ℓ√
πn ∼ 22n 1√
πn,
et donc ℓ = 1.
V. Le théorème des séries alternées
On appelle série alternée une série de la forme n0(−1)n
un où (un) est une suitede nombres réels de signe constant.
Définition
Exemples – La série harmonique alternée, les sériesn0
(−1)n n2,n0
(−1)n
1 +√
n, sont alternées.
Soit
n0(−1)n un une série alternée dont la valeur absolue du terme général (|un|)n∈Nest décroissante et converge vers 0. Alors :
• La série n0
(−1)n
un converge.
• Pour tout m ∈ N,+∞n=m
(−1)n un est du signe de (−1)m um, et
+∞n=m
(−1)n un
|um|.
Théorème spécial des séries alternées
Démonstration – Nous allons faire la démonstration dans le cas où un 0 pour tout n, l’autrecas étant similaire (avec des inversions de signes). Notons (S
n) la suite des sommes partielles de
la série. Nous allons montrer que les suites (S 2n) et (S 2n+1) sont adjacentes. On sait que celaimplique qu’elles convergent vers la même limite, ce qui à son tour entraîne que (S n) converge(vers cette même limite). Cela démontrera le premier point.
26

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 35/383
La suite (S 2n+1) est croissante ; en effet, pour tout n ∈ N,
S 2n+3 − S 2n+1 = u2n+2 − u2n+3 0,
car (un) est décroissante. De même, pour tout n ∈ N,
S 2n+2 − S 2n = −u2n+1 + u2n+2 0,
et donc (S 2n) est décroissante. Enfin, S 2n+1 − S 2n = −u2n+1 → 0. D’où le résultat.
Démontrons maintenant l’estimation de la somme et des restes. On sait d’après ce qui précèdeque pour tout p ∈ N,
S 2 p+1
+∞n=0
(−1)n un S 2 p.
En particulier, pour p = 0,
u0 − u1
+∞
n=0
(−1)n un u0.
Par décroissance de (un), on a u0 − u1 0. On en déduit que+∞n=0(−1)n un est du signe de u0
(ici, positif) et
+∞n=0
(−1)n un
|u0|. Pour l’estimation de+∞n=m
(−1)n un on remarque que la série
nm
(−1)n un =n0
(−1)n+m un+m = (−1)mn0
(−1)n un+m
est, au facteur (−1)m près, une série alternée de réels dont la valeur absolue du terme généraldécroît vers 0. En lui appliquant ce qui précède, on obtient que
+∞n=m(−1)n un est du signe de
(−1)
m
um, et sa valeur absolue est majorée par |um|.
Exemple – La sérien1
(−1)n√ n
est alternée, et
1√
n
n1
décroît vers 0. Cette série est donc
convergente et pour tout m 1, la somme
+∞n=m
(−1)n√ n
est du signe de (−1)m, et est majorée en valeur absolue par 1√
m. Par exemple,
+∞n=1
(−1)n√ n 0 et −
+∞n=1
(−1)n√ n 1, d’où − 1
+∞n=1
(−1)n√ n 0,
+∞n=2
(−1)n√ n 0 et
+∞n=2
(−1)n√ n
1√ 2
, d’où 0 +∞n=2
(−1)n√ n
1√ 2
.
Remarques
• Lorsqu’une série converge, son reste d’ordre m tend vers 0 lorsque m → +∞. Dans le casd’une série alternée qui vérifie les hypothèses du théorème spécial, on peut affiner ce résultat endonnant le signe de ce reste et en précisant la vitesse avec laquelle il tend vers 0.
• Parfois, les hypothèses du théorème ne sont vérifiées qu’à partir d’un rang n0 1. Dans cecas, la conclusion sur la convergence de la série reste vraie, mais le résultat sur le signe et lamajoration des restes ne peut être appliqué que pour m n0.
27

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 36/383
VI. Produit de deux séries
Soient
n0 un et
n0 vn deux séries d’éléments de K. Si ces deux séries convergent, onsait que l’on peut faire une combinaison linéaire de leur somme. On peut aussi se demander si onpeut les multiplier, et si oui, si l’on peut exprimer le produit obtenu comme somme d’une série.
On appelle produit de Cauchy des séries nn0 un et nm0 vn la sérienn0+m0
p+q=n
u p vq.
Lorsque n0 = m0 = 0, cette série s’écrit de trois façons :
n0
p+q=n
u p vq =n0
nk=0
uk vn−k =n0
nk=0
un−k vk.
Définition
Soientn0
un etn0
vn deux séries absolument convergentes d’éléments de K.
Alors le produit de Cauchy den0 un et
n0 vn est absolument convergent et
+∞n=0
un
+∞n=0
vn
=
+∞n=0
nk=0
uk vn−k =+∞n=0
nk=0
un−k vk.
Théorème (admis : démonstration non exigible)
Exemple – Pour x
∈ ]
−1,1[ , la série n0 xn converge absolument. Calculons le carré de sa
somme ; d’après le théorème précédent,+∞n=0
xn
2
=+∞n=0
nk=0
xk xn−k =+∞n=0
nk=0
xn =+∞n=0
(n + 1) xn.
D’après la formule donnant la somme d’une série géométrique,+∞n=0
xn
2
=
1
1 − x
2
,
de sorte que l’on a montré que pour tout x ∈ ]−1,1[ ,
+∞n=0
(n + 1) xn = 1
(1 − x)2.
Nous verrons dans le chapitre Séries entières que cela n’a rien d’étonnant : il s’agit d’uneopération de dérivation!
Remarque – Dans le cas du produit de Cauchy de deux sériesnn0
un et
nm0 vn avec n0 1
et/ou m0 1, pour ne pas se tromper, il ne faut pas hésiter à se ramener au cas général en posantun = 0 pour 0 n < n0 et vn = 0 pour 0 n < m0. On simplifie ensuite l’expression obtenue.On pourra aussi faire des changements d’indices : par exemple,
nn0
un =
n0 un+n0 .
Contre-exemple – L’hypothèse d’absolue convergence est importante, comme le montre le contre-exemple suivant : considérons la série
n1
(−1)n√ n
,
28

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 37/383
qui est convergente d’après le théorème des séries alternées, mais pas absolument convergented’après la caractérisation des séries de Riemann convergentes. Calculons son produit de Cauchypar elle-même : il s’agit de la série
n2
n−1k=1
(−1)k√ k
(−1)n−k√ n − k
=n2
(−1)nn−1k=1
1 k(n − k)
.
Une étude de fonction montre facilement que pour tout k ∈ [[1,n − 1]], k(n − k) n2
4 , et donc
1 k(n − k)
2
n.
Ainsi, en valeur absolue, le terme général de la série produit vérifie
n−1k=1
1 k(n − k)
2(n − 1)
n → 2,
et donc le produit de Cauchy diverge grossièrement.
Remarque – En revanche, la convergence absolue des deux séries n’est pas nécessaire à la conver-gence de leur produit de Cauchy : on peut montrer que si les deux séries convergent, dont uneabsolument, alors la série produit de Cauchy converge.
Application – Pour tout (z,z ′) ∈C2, la sérien0
zn
n! est absolument convergente, de même pour
z′, donc d’après le théorème précédent,+∞n=0
zn
n!
+∞n=0
(z′)n
n!
=
+∞n=0
nk=0
zk
k!
(z′)n−k
(n − k)!.
Or,nk=0
zk
k!
(z′)n−k
(n − k)! =
nk=0
1
n!
nk
zk(z′)n−k =
1
n!(z + z′)n,
d’après la formule du binôme de Newton. Finalement,+∞n=0
zn
n!
+∞n=0
(z′)n
n!
=
+∞n=0
(z + z′)n
n! .
En admettant le résultat mentionné plus haut (i.e., le fait que
+∞n=0 zn/n! = ez pour tout z ∈ C),
ceci est aussi une conséquence de la formule ez+z′ = ez ez′.
29

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 38/383
30

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 39/383
Chapitre 3
Espaces vectoriels et applicationslinéaires
Dans ce chapitre K désigne R ou C. Ses éléments sont appelés scalaires.
I. Espaces vectoriels
1. Généralités
Soit E un ensemble non vide, muni de deux lois :
• Une loi interne notée +, de E × E à valeurs dans E ,
• Une loi externe notée ·, de K× E à valeurs dans E .
On dit que (E, + ,·) est un K-espace vectoriel si :
• Il existe un élément de E , noté 0E , tel que pour tout x ∈ E , x + 0E = x,
• Pour tout x ∈ E , il existe y ∈ E tel que x + y = 0E (le vecteur y est alors appelé
opposé de x et noté −x),pour tout (x,y,z) ∈ E 3, (λ,µ) ∈ K2,
• x + y = y + x (commutativité de +),
• (x + y) + z = x + (y + z) (associativité de +),
• 1 · x = x,
• λ · (x + y) = λ · x + λ · y (distributivité à gauche de · sur +),
• (λ + µ) · x = λ · x + µ · x (distributivité à droite de · sur l’addition de K),• (λ µ) · x = λ · (µ · x) (propriété d’associativité).
On dit aussi que (E, + ,·) est un espace vectoriel sur K. S’il n’y a aucune ambiguïtésur les lois, on mentionne simplement E au lieu de (E, + ,
·). Les éléments de E sont
appelés vecteurs.
Définition – Espace vectoriel
Remarques
• On note très souvent λ x au lieu de λ ·x. Il est d’usage de noter le scalaire à gauche et le vecteurà droite.
• Si un vecteur x ∈ E apparaît des deux côtés d’une égalité de la forme x + y = x + z, alors parajout de −x à gauche et à droite, par commutativité et associativité de +, on peut simplifierl’égalité en « enlevant » x des deux côtés.
• L’élément 0E est unique : si e ∈ E vérifie la même propriété que 0E , on a e = e + 0E = 0E .
• De même, l’opposé d’un vecteur x
∈ E est unique : si y
∈ E vérifie x + y = 0E , alors par
simplification, on a y = −x.
• D’après les propriétés ci-dessus, pour tout x ∈ E , 0 · x = (0 + 0) · x = 0 · x + 0 · x, et donc parsimplification, on a 0 · x = 0E .
31

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 40/383
Alors, 0E = 0 · x = (1 + (−1)) · x = 1 · x + (−1) · x = x + (−1) · x, et donc −x = (−1) · x.
De même, on montre que pour tout λ ∈ K, λ · 0E = 0E .
Espaces vectoriels de référence
Soient n, p et k trois entiers naturels non nuls.
• L’ensemble Kn est un K-espace vectoriel.
• L’ensemble K[X ] des polynômes à coefficients dans K est un K-espace vectoriel.
• L’ensemble Kn[X ] des polynômes à coefficients dans K de degré inférieur ou égal à n est unK-espace vectoriel.
• L’ensemble M n,p(K) des matrices à n lignes et p colonnes à coefficients dans K est un K-espacevectoriel.
• L’ensemble E X = F (X,E ) des fonctions de X dans E , où X est un ensemble et E un K-espacevectoriel, est un K-espace vectoriel, avec les opérations usuelles.
• L’ensemble C0(I,K) des fonctions continues sur I , intervalle de R, à valeurs dans K, est unK-espace vectoriel.
• L’ensemble Ck(I,K) des fonctions de classe Ck sur I , intervalle de R, à valeurs dans K, est unK-espace vectoriel.
• L’ensemble KN des suites à valeurs dans K est un K-espace vectoriel.
Soient E un K-espace vectoriel et (e1, . . . , e p) une famille de vecteurs de E . Pour tout(λ1, . . . , λ p) ∈ K p, on définit un vecteur x de E en posant
x =
pi=1
λiei = λ1e1 + · · · + λ pe p.
Les vecteurs de cette forme sont appelés combinaisons linéaires de e1, . . . , e p.
Propriété/Définition – Combinaison linéaire
Remarque – Dans l’expression précédente, il est inutile de parenthéser car l’addition est associa-tive. De même, l’ordre des termes est sans importance par commutativité.
Soit E un K-espace vectoriel. On dit qu’un ensemble F est un sous-espace vectorielde E , si F ⊂ E et si F est un K-espace vectoriel.
Définition – Sous-espace vectoriel
Pour montrer qu’un ensemble est un espace vectoriel, il suffit souvent de montrer que c’est
un sous-espace vectoriel d’un espace vectoriel de référence. Pour cela, on utilise la propriétésuivante :
Soit E un K-espace vectoriel. Alors F est un sous-espace vectoriel de E si et seulementsi :
• F ⊂ E ,• 0E ∈ F ,
• ∀ λ ∈ K, ∀ (x,y) ∈ F 2, λx + y ∈ F .
Propriété – Caractérisation des sous-espaces vectoriels
Remarque – Pour prouver que F n’est pas un sous-espace vectoriel de E , il suffit souvent deprouver que 0E /∈ F . Par exemple, A ∈M n(R); A2 = I n n’est pas un sous-espace vectoriel deM n(R).
32

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 41/383
Exemple – Rn[X ] est un sous-espace vectoriel de R[X ] et C1(R,R) est un sous-espace vectoriel deC0(R,R).
Exercice – Quels sont parmi les ensembles suivants ceux qui sont des espaces vectoriels ?
• L’ensemble des suites réelles (un)n0 vérifiant : ∀ n ∈ N, un+2 = 2un+1 + un.
• L’ensemble des solutions de y ′′ + ay = 0 où a est une fonction continue.
• L’ensemble des solutions de y ′′ + ay = b où, de plus, b est une fonction continue non nulle.
• L’ensemble des polynômes P ∈ C[X ] tels que P (1) = 0, puis tels que P (0) = 1.• L’ensemble K[X ]P des multiples d’un polynôme P .
Soient E un K-espace vectoriel, I un ensemble d’indices et (E i)i∈I une famille de sous-espaces vectoriels de E . Alors
i∈I E i est un sous-espace vectoriel de E .
Propriété – Intersection de sous-espaces vectoriels
Démonstration – Bien sûr,i∈I E i est inclus dans E , et contient 0E comme chacun des E i. Soient
x et y deux éléments de
i∈I E i et λ un scalaire. Alors, pour tout i ∈ I , x et y appartiennentau sous-espace vectoriel E i, et donc λx + y ∈ E i. Ainsi λx + y ∈
i∈I E i.
Soit F = (e1, . . . , e p) une famille de vecteurs d’un K-espace vectoriel E .
L’intersection de tous les sous-espaces vectoriels de E auxquels appartiennent e1, . . . , e pest un sous-espace vectoriel de E ; c’est le plus petit (au sens de l’inclusion) sous-espacevectoriel de E auquel appartiennent e1, . . . , e p.
Il est appelé espace vectoriel engendré par F , et noté Vect(F ) ou Vect(e1, . . . , e p).
Propriété/Définition – Espace vectoriel engendré par une famille
Remarque – Vect(F ) existe toujours car E est un sous-espace vectoriel de E auquel appartiennente1, . . . , e p.
L’intersection porte donc sur un ensemble d’indices non vide.Démonstration – L’intersection de tous les sous-espaces vectoriels de E auxquels appartiennente1, . . . , e p est un sous-espace vectoriel de E d’après la propriété précédente. De plus, si F estun sous-espace vectoriel de E auquel appartiennent e1, . . . , e p, alors F figure parmi l’ensembledes sous-espaces vectoriels de E dont on fait l’intersection pour définir Vect(F ). En particulier,Vect(F ) ⊂ F , ce qui montre que Vect(F ) est le plus petit sous-espace vectoriel de E auquelappartiennent e1, . . . , e p.
Soit F = (e1, . . . , e p) une famille de vecteurs d’un K-espace vectoriel E .
Alors Vect(F
) est l’ensemble des combinaisons linéaires de e1, . . . , e p.
Propriété
Démonstration – Soit F l’ensemble des combinaisons linéaires de e1, . . . , e p. Il est immédiat devérifier que F est un sous-espace vectoriel de E . De plus, e1, . . . , e p appartiennent à F . On a doncVect(F ) ⊂ F. Réciproquement, Vect(F ) étant un sous-espace vectoriel de E avec ei ∈ Vect(F )pour tout i ∈ [[1,p]], toutes les combinaisons linéaires de e1, . . . , e p appartiennent à Vect(F ), d’oùF ⊂ Vect(F ).
Exemple – Soit M =
0 1 1
0 0 10 0 0
∈M 3(R). Alors
Vect(I 3,M ) =a b b0 a b
0 0 a
; (a,b) ∈ R2 .
33

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 42/383
Dans toute la suite, E désigne un K-espace vectoriel.
2. Familles libres, génératrices, bases et dimension
Soit F = (e1, . . . , e p) une famille d’éléments de E .
• On dit que
F est libre si pour toute famille de scalaires (λ
1, . . . , λ
p), on a
pi=1
λiei = 0E ⇒ ∀ i ∈ [[1,p]], λi = 0.
On dit aussi que les vecteurs e1, . . . , e p sont linéairement indépendants.
Si elle n’est pas libre, on dit que la famille est liée, ou que les vecteurs e1, . . . , e p sontlinéairement dépendants. Ceci équivaut à l’existence d’une famille (λ1, . . . , λ p) descalaires non tous nuls telle que
pi=1 λiei = 0E .
• On dit que F est génératrice de E si pour tout x ∈ E , il existe une famille descalaires (λ1, . . . , λ p) telle que
x =
pi=1
λiei.
Ceci équivaut à : E = Vect(e1, . . . , e p). On dit également que (e1, . . . , e p) engendre E .
• On dit que F est une base de E si elle est à la fois libre et génératrice de E .
Définition – Familles libres, génératrices, bases
Remarques
• Une famille où figure le vecteur nul est nécessairement liée.
• Une famille constituée d’un vecteur est liée si et seulement si ce vecteur est nul.
• Si (e1, . . . , e p) est une famille liée, alors l’un des vecteurs e1, . . . , e p est combinaison linéaire des
autres : en effet, il existe (λ1, . . . , λ p) ∈ K p et i ∈ [[1,p]] tels que λi = 0 et λ1e1 + · · · + λ pe p = 0E ,et alors
ei = − 1
λi
j=i
λ je j.
En revanche, on ne peut pas affirmer que n’importe lequel des vecteurs e1, . . . , e p est combinaisonlinéaire des autres.
Soit (P 0, . . . , P n) une famille de polynômes tous non nuls et à degrés échelonnés, c’est-
à-dire telle que pour tout i ∈ [[0,n − 1]], deg(P i) < deg(P i+1). Alors (P 0, . . . , P n) estlibre.
Propriété – Famille de polynômes à degrés échelonnés (ou étagés)
Démonstration – Soit (λ0, . . . , λn) ∈ Kn tel que λ0P 0 + · · · + λnP n = 0. Tous les coefficients dupolynôme λ0P 0 + · · · + λnP n sont donc nuls. La famille (P 0, . . . , P n) étant à degrés échelonnés, lecoefficient dominant de ce polynôme est λnan, où an est le coefficient dominant de P n, non nulcar P n est non nul. Donc λn = 0. En réitérant ce raisonnement, on obtient que λ0 = · · · = λn = 0,d’où le résultat.
On peut aussi rédiger ce raisonnement sans l’étape d’itération : on raisonne par l’absurde, ensupposant que tous les λi ne sont pas nuls ; on peut donc définir i0 = maxi ∈ [[0,n]]; λi = 0(maximum d’une partie non vide majorée de N). On raisonne alors comme ci-dessus : le coefficientdominant de λ0P 0 + · · · + λnP n est λi0ai0 , où ai0 est le coefficient dominant de P i0 , non nul carP i0 est non nul. On en déduit que λi0 = 0, ce qui contredit la définition de i0. Donc tous les λisont nuls.
34

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 43/383
La famille (e1, . . . , e p) est une base de E si et seulement si tout élément de E s’écrit demanière unique comme combinaison linéaire de e1, . . . , e p.
Dans ce cas, si x = p
i=1 xiei, on dit que x1, . . . , x p sont les coordonnées de x dansla base (e1, . . . , e p).
Propriété/Définition
Démonstration laissée en exercice (elle est très semblable à une démonstration donnée ci-dessous,voir le paragraphe sur les sommes directes).
On dit que E est de dimension finie si E admet une famille génératrice (finie). Dansle cas contraire, on dit que E est de dimension infinie.
Définition – Espace de dimension finie
Si E = 0E , alors de toute famille génératrice de E , on peut extraire une base de E :si (e1, . . . , e p) est une famille génératrice de E , il existe une partie I de [[1,p]] telle que(ei)i∈I soit une base de E .
Théorème de la base extraite
Démonstration – Soit (e1, . . . , e p) une famille génératrice de E . Si (e1, . . . , e p) n’est pas libre, ondoit avoir p 2 : en effet, si l’on avait p = 1, on aurait e1 = 0E (car la famille (e1) est liée), et doncE = Vect(e1) = 0E , ce qui est exclu. Alors l’un des vecteurs de la famille (e1, . . . , e p) est com-binaison linéaire des autres, d’après une remarque précédente. Quitte à renommer les éléments,on peut supposer que e p ∈ Vect(e1, . . . , e p−1), et alors E = Vect(e1, . . . , e p) = Vect(e1, . . . , e p−1).
On a donc construit une famille génératrice de E à p
−1 éléments et on peut recommencer
cette procédure. La procédure s’arrête nécessairement, car le nombre d’éléments de la familleconstruite décroît strictement à chaque étape. Lorsque la procédure s’arrête, la famille obtenueest libre ; c’est finalement une famille libre et génératrice de E , donc une base de E .
Remarque – Dans la démonstration précédente apparaît une idée très souvent utilisée en algo-rithmique pour prouver qu’un algorithme se termine : on a utilisé un « variant de boucle », icile nombre d’éléments de la famille.
Du théorème précédent, on déduit immédiatement le résultat suivant :
Si E =
0E
et si E est de dimension finie, alors E possède des bases.
Corollaire
Si E est de dimension finie, alors toute famille libre d’éléments de E peut être complétéeen une base de E . De plus, pour compléter une telle famille, on peut choisir les vecteursparmi ceux d’une famille génératrice donnée à l’avance.
Théorème de la base incomplète
Démonstration – Soient (e1, . . . , e p) une famille libre d’éléments de E et (u1, . . . , um) une famille gé-nératrice de E (une telle famille existe car E est de dimension finie). Posons F 0 = Vect(e1, . . . , e p).
• Si u1 n’appartient pas à Vect(e1, . . . , e p), alors on pose e p+1 = u1 et F 1 = Vect(e1, . . . , e p+1).La famille (e1, . . . , e p+1) ainsi construite est libre : en effet, soit (λ1, . . . , λ p+1) ∈ K p+1 tel que p+1
i=1 λiei = 0E . Si l’on avait λ p+1 = 0, on aurait e p+1 ∈ Vect(e1, . . . , e p), ce qui est absurde. Ainsi
35

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 44/383
λ p+1 = 0, puis pi=1 λiei = 0E , ce qui par liberté de (e1, . . . , e p) entraîne que λ1 = · · · = λ p = 0 ;
tous les λi sont donc nuls.
• Si u1 ∈ Vect(e1, . . . , e p), on ne complète pas la famille (e1, . . . , e p), on pose F 1 = F 0.
On poursuit alors la procédure avec u2, dont on teste l’appartenance à F 1, ce qui permet dedéfinir F 2. On procède ainsi jusqu’à um.
À l’issue de l’étape m, on dispose donc d’une famille (e1, . . . , ek) avec k p, qui est libre, ettelle que u
1, . . . , u
m sont des éléments de F
m = Vect(e
1, . . . , e
k). Alors
E = Vect(u1, . . . , um) ⊂ Vect(e1, . . . , ek) ⊂ E.
La famille (e1, . . . , ek) est donc génératrice de E , et étant libre, c’est une base de E ; de plus, ellea été construite en complétant la famille (e1, . . . , e p) avec certains des vecteurs u1, . . . , um.
Soit (e1, . . . , e p) une famille de vecteurs de E et (u1, . . . , u p+1) une famille de vecteursde Vect(e1, . . . , e p). Alors la famille (u1, . . . , u p+1) est liée.
Théorème
Remarque – En particulier, si E admet une famille génératrice finie (e1, . . . , e p), alors une famillelibre d’éléments de E est composée d’au plus p vecteurs.
Démonstration – On procède par récurrence sur p. Pour p = 1, le résultat est vrai car deuxvecteurs colinéaires à un même vecteur e1 sont linéairement dépendants. Supposons le résultatvrai pour un certain entier p 1. Soient p + 2 vecteurs u1, . . . , u p+2 engendrés par p + 1 vecteurse1, . . . , e p+1. On peut donc écrire
u1 = λ1,1 e1 + · · · + λ1,p+1 e p+1,
u2 = λ2,1 e1 +
· · ·+ λ2,p+1 e p+1,
...
u p+2 = λ p+2,1 e1 + · · · + λ p+2,p+1 e p+1,
où les λi,j sont des scalaires. Si λi,1 = 0 pour tout i, alors (u1, . . . , u p+2) est une famille de vecteursde Vect(e2, . . . , e p+1), donc est liée par hypothèse de récurrence. Sinon, on peut supposer sansperte de généralité que λ1,1 = 0. Alors, grâce à λ1,1, on élimine e1 dans l’expression des vecteursu2, . . . , u p+2 :
u2 − λ2,1
λ1,1u1 ∈ Vect(e2, . . . , e p+1),
...
u p+2 − λ p+2,1
λ1,1u1 ∈ Vect(e2, . . . , e p+1).
On en déduit que les p + 1 vecteurs
u2 − λ2,1
λ1,1u1, . . . , u p+2 − λ p+2,1
λ1,1u1
sont combinaisons linéaires des p vecteurs e2, . . . , e p+1. Par hypothèse de récurrence, ils formentdonc une famille liée. En écrivant une combinaison linéaire nulle de ces vecteurs avec des coeffi-
cients non tous nuls, on voit alors que la famille (u1, . . . , u p+2) est liée.
Remarque – Cette idée est à la base de l’algorithme de Gauss-Jordan, dont on rappelera le principeen détails dans le chapitre Matrices.
36

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 45/383
• Si E = 0E et si E est de dimension finie, alors il existe n ∈ N∗ tel que toutes lesbases de E sont constituées de n vecteurs.
L’entier n est appelé dimension de E , noté dim(E ).
• Si E = 0E , on pose dim(E ) = 0 (mais dans ce cas, E n’admet aucune base).
Théorème/Définition – Dimension
Démonstration – Soient B et B′ deux bases de E constituées respectivement de p et m vecteurs. Lafamille B est libre et B′ engendre E , donc d’après le théorème précédent, p m. En échangeantles roles de B et B′, on obtient m p et finalement p = m. Toutes les bases de E sont doncconstituées du même nombre de vecteurs.
Remarques
• Si E est de dimension n 1, il est engendré par une famille de n vecteurs, donc toute famillede n + 1 vecteurs de E est liée.
• Si E = 0E , la convention dim(E ) = 0 assure que cette dernière propriété est encore valable.
• Ainsi, en dimension n, une famille libre est composée d’au plus n vecteurs. De même, unefamille génératrice est composée d’au moins n vecteurs, car d’une telle famille, si E
=
0E
(sinon le résultat est évident), on peut extraire une base de E , qui comporte n vecteurs.
Exemple – Les espaces de référence sont-ils de dimension finie ? Si oui, donner leur dimension.
On suppose E de dimension finie n 1. Soit F une famille de n vecteurs de E .
Alors on a les équivalences :
F est une base de E ⇔ F est libre ⇔ F est une famille génératrice de E .
Théorème – Caractérisation des bases
Démonstration – Si F
est libre, on peut la compléter en base de E , et cette base comporte nvecteurs, qui est déjà le nombre de vecteurs de F . Il n’y a donc pas eu de complétion à faire,c’est-à-dire que F est une base de E . De même, si F est génératrice de E , on peut en extraireune base de E (car E = 0E ), mais il n’y a en fait pas d’extraction à faire, donc F est une basede E . Les implications réciproques sont évidentes.
Application – Soit (P 0, . . . , P n) une famille d’éléments de K[X ] telle que deg(P i) = i pour touti ∈ [[0,n]]. Alors (P 0, . . . , P n) est une base de Kn[X ].
En effet, la famille (P 0, . . . , P n) d’éléments de Kn[X ] est à degrés échelonnés et tous seséléments sont non nuls (le degré du polynôme nul est −∞), donc elle est libre. De plus, ellecomporte n + 1 = dim(Kn[X ]) éléments, donc d’après le théorème ci-dessus, c’est une base deKn[X ].
On suppose E de dimension finie n. Soit F un sous-espace vectoriel de E . Alors :
• F est de dimension finie et dim(F ) dim(E ).
• Si dim(F ) = n, alors E = F .
Théorème
Démonstration – On commence par remarquer que pour les deux points, si F = 0E , le résultatest évident. On suppose donc dans la suite que F = 0E .
• Si F était de dimension infinie, on pourrait construire, par une procédure proche de la démons-tration du théorème de la base incomplète, une famille libre constituée d’un nombre arbitraire-ment grand d’éléments de F , et en particulier une famille libre de n + 1 vecteurs de E , ce qui estimpossible car E est de dimension n ; F est donc de dimension finie. Soit (e1, . . . , e p) une basede F . C’est une famille libre d’éléments de E , on a donc p n, c’est-à-dire dim(F ) dim(E ).
37

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 46/383
• De plus, si dim(F ) = dim(E ) (i.e. p = n), alors (e1, . . . , e p) est une famille libre de n vecteursde E , c’en est donc une base ; on en déduit que E = Vect(e1, . . . , e p) = F.
Attention ! Il est essentiel que F soit un sous-espace vectoriel de E pour appliquer ce théorème.Si F et G sont deux sous-espaces vectoriels de E de même dimension, on ne peut évidemmentpas affirmer que F = G.
On suppose E dimension finie. Soit F un sous-espace vectoriel de E .
Une base de E est dite adaptée à F si on peut en extraire une base de F .
Définition – Base adaptée
Soit (x1, . . . , x p) une famille de vecteurs de E , espace de dimension finie ou non.
On appelle rang de cette famille, noté rg(x1
, . . . , x p
), la dimension du sous-espacevectoriel Vect(x1, . . . , x p).
Définition – Rang
Remarque – La famille finie (x1, . . . , x p) est génératrice de Vect(x1, . . . , x p), qui est donc dedimension finie inférieure ou égale à p. On en déduit que rg(x1, . . . , x p) est bien défini, et inférieurou égal à p.
• Si E est de dimension finie n, une famille (x1, . . . , x p) de vecteurs de E est génératrice
de E si et seulement si rg(x1, . . . , x p) = n.• Une famille (x1, . . . , x p) de vecteurs de E (de dimension finie ou non) est libre si etseulement si rg(x1, . . . , x p) = p.
• Si E est de dimension finie n, une famille (x1, . . . , x p) de vecteurs de E est une basede E si et seulement si p = n et rg(x1, . . . , xn) = n.
Propriété – Caractérisation des familles libres, génératrices par le rang
Démonstration
• La famille (x1, . . . , x p) est génératrice de E si et seulement si Vect(x1, . . . , x p) = E , cequi équivaut d’après le théorème précédent à dim(Vect(x1, . . . , x p)) = dim(E ), i.e., à l’égalité
rg(x1, . . . , x p) = n.
• Pour le second point :
⇒ La famille (x1, . . . , x p) engendre Vect(x1, . . . , x p) donc, si elle est libre, c’est une base deVect(x1, . . . , x p) et on a
dim(Vect(x1, . . . , x p)) = p, i.e. rg(x1, . . . , x p) = p.
⇐ La famille (x1, . . . , x p) engendre Vect(x1, . . . , x p) ; si de plus rg(x1, . . . , x p) = p, alors lenombre de vecteurs de cette famille est dim(Vect(x1, . . . , x p)), c’est donc une famille libre d’aprèsle théorème de caractérisation des bases.
• Si (x1, . . . , x p) est une base de E , on a p = n, et d’après le premier point, rg(x1, . . . , xn) = n. Si p = n et rg(x1, . . . , xn) = n, la famille (x1, . . . , xn) est une base de E d’après les deux premierspoints.
38

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 47/383
3. Produit de sous-espaces vectoriels
Soient E 1, . . . , E p des K-espaces vectoriels. Le produit cartésien
p
i=1
E i = E 1 × · · · × E p
est l’ensemble(x1, . . . , x p); ∀ i ∈ [[1,p]], xi ∈ E i.
Si (x1, . . . , x p) et (y1, . . . , y p) sont deux éléments de E 1 × · · · × E p, et si λ ∈K, on pose
(x1, . . . , x p) + (y1, . . . , y p) = (x1 + y1, . . . , x p + y p),
λ(x1, . . . , x p) = (λx1, . . . , λ x p)
(toutes les additions et multiplications par un scalaire sont notées avec le même sym-bole, mais à droite du signe d’égalité, ce sont celles de chaque espace vectoriel E i).
Définition – Produit cartésien
Attention ! Dans un produit cartésien, l’ordre des termes est important. La notation p
i=1 E idoit être comprise en gardant cela à l’esprit. Par exemple, le produit E 1 ×E 2 n’est pas le produitE 2 × E 1.
Soient E 1, . . . , E p des K-espaces vectoriels. Alors E 1×· · ·×E p est un K-espace vectoriel.
Propriété – Produit de sous-espaces vectoriels
Démonstration – C’est une vérification immédiate, en utilisant le fait que chaque E i est un K-espace vectoriel, le vecteur nul de E 1 × · · · × E p étant (0E 1 , . . . ,0E p), et l’opposé d’un vecteur
(x1, . . . , x p) étant (−x1, . . . , − x p).
Exemples
• Le produit cartésien R ×R2 est l’ensemble des éléments de la forme (x,(y,z)) où x, y et z sontdes réels. Il peut être identifié (mais n’est pas égal ) à R3.
• Le produit cartésien M n(K) × K[X ] est l’ensemble des éléments de la forme (A,P ) oùA ∈ M n(K) et P ∈ K[X ]. Si A et B sont deux éléments de M n(K), P et Q deux élémentsde K[X ] et λ ∈ K, on a, par définition,
λ(A,P ) + (B,Q) = (λA + B,λP + Q).
On voit bien sur cet exemple que les opérations, bien que notées avec le même symbole, ne sont
pas les mêmes opérations (elles ne portent pas sur le même espace vectoriel).
Soient E 1, . . . , E p des K-espaces vectoriels de dimension finie. Alors E 1 × · · · × E p estde dimension finie et
dim(E 1 × · · · × E p) =
pi=1
dim E i.
Propriété
Démonstration – Pour tout i ∈ [[1,p]], on note ni = dim(E i), et l’on choisit une base
Bi = (ei,1, . . . , ei,ni) de E i. Alors on vérifie facilement que la famille((e1,1,0E 2 , . . . ,0E p), . . . ,(e1,n1 ,0E 2 , . . . ,0E p),(0E 1 ,e2,1, . . . ,0E p), . . . ,(0E 1 ,e2,n2 , . . . ,0E p), . . .
. . .(0E 1 , . . . ,0E p−1 ,e p,1), . . . ,(0E 1 , . . . ,0E p−1 ,e p,np))
39

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 48/383
d’éléments de E 1 × · · · × E p est une base de E 1 × · · · × E p. En particulier, E 1 × · · · × E p est dedimension finie et
dim(E 1 × · · · × E p) =
pi=1
ni =
pi=1
dim(E i).
Les détails de cette démonstration sont très semblables à ceux d’une démonstration donnée ci-dessous pour les sommes directes (voir le théorème sur les bases adaptées à une somme directe).
II. Somme et somme directe de sous-espaces vectoriels
1. Définitions et caractérisations
Soit (E 1, . . . , E p) une famille de sous-espaces vectoriels de E . La somme
pi=1
E i = E 1 + · · · + E p
est l’ensemble des vecteurs x de E de la forme
x =
pi=1
xi = x1 + · · · + x p où, pour tout i ∈ [[1,p]], xi ∈ E i.
Définition – Somme de sous-espaces vectoriels
Remarque – On vérifie facilement que l’opération de sommation de sous-espaces vectoriels de E
est associative (il est inutile de parenthéser, même lorsque p 3) et commutative (l’ordre destermes n’a pas d’importance, contrairement aux produits cartésiens), car l’addition de vecteursde E possède ces propriétés.
Avec les notations précédentes, pi=1
E i est un sous-espace vectoriel de E .
Propriété
Démonstration – On a bien sûr E 1 + · · · + E p ⊂ E et 0E ∈ E 1 + · · · + E p (car 0E = 0E + · · · + 0E ).Soient x = x1 + · · · + x p et y = y1 + · · · + y p deux éléments de E 1 + · · · + E p, et λ ∈ K. Alors
λx + y = λ(x1 + · · · + x p) + (y1 + · · · + y p) = (λx1 + y1) + · · · + (λx p + y p) ∈ E 1 + · · · + E p
car chaque E i est un sous-espace vectoriel de E . Ainsi E 1 + · · · + E p est un sous-espace vectoriel
de E .
Exemple – On a R2 = Vect(1,0) + Vect(1,1) + Vect(0,1).
On dit que la somme pi=1
E i est directe si : pour tout (x1, . . . , x p) ∈ E 1 × · · · × E p, on
a l’implication pi=1
xi = 0E ⇒ ∀ i ∈ [[1,p]], xi = 0E .
Dans ce cas la somme
pi=1
E i se note
pi=1
E i = E 1 ⊕ · · · ⊕ E p.
Définition – Somme directe
40

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 49/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 50/383
2. Sommes directes, bases et dimensions
• Soit (x1, . . . , x p) une famille libre d’éléments de E ( p 2). Pour tout i ∈ [[1, p − 1]],Vect(x1, . . . , xi) et Vect(xi+1, . . . , x p) sont en somme directe et
Vect(x1, . . . , x p) = Vect(x1, . . . , xi) ⊕ Vect(xi+1, . . . , x p).
• Si (E 1, . . . , E p) est une famille de sous-espaces vectoriels de E dont la somme estdirecte et si (x1, . . . , x p) ∈ E 1 ×· · ·× E p est une famille de vecteurs tous non nuls, alorscette famille est libre.
Propriété – Sommes directes et familles libres
Démonstration
• Soit x = λ1x1 + · · ·+ λixi = λi+1xi+1 + · · ·+ λ px p ∈ Vect(x1, . . . , xi)∩Vect(xi+1, . . . , x p). Alors
λ1x1 + · · · + λixi − λi+1xi+1 + · · · − λ px p = 0E .
La famille (x1, . . . , x p) étant libre, on en déduit que λi = 0 pour tout i, et donc x = 0E . Ainsi
Vect(x1, . . . , xi)∩Vect(xi+1, . . . , x p) = 0E , donc la somme de ces deux sous-espaces est directe.Il est de plus immédiat que Vect(x1, . . . , x p) = Vect(x1, . . . , xi) + Vect(xi+1, . . . , x p).
• Si une combinaison linéaire λ1x1 + · · · + λ px p est nulle, alors, sachant que λixi ∈ E i pour touti, l’aspect direct de la somme des E i entraîne que λixi = 0E pour tout i, avec xi = 0E , et doncλi = 0, d’où le résultat.
Notation – Si F 1, . . . ,F p sont des familles d’éléments de E , on appellera juxtaposition (ouconcaténation) de ces familles la famille F obtenue en plaçant dans une même famille tous lesvecteurs de F 1, . . . ,F p, en gardant les répétitions éventuelles et en respectant l’ordre d’apparitiondes termes. On pourra représenter ceci par la notation F = F 1 ⊔ · · · ⊔ F p, mais cette notationn’est pas universelle.
Par exemple, (e1,e2) ⊔ (f 1,f 2,f 3) = (e1,e2,f 1,f 2,f 3). En appliquant plusieurs fois le premier point de la propriété précédente, on obtient immédia-
tement :
On suppose que E est de dimension finie n 2 ; soit B = F 1 ⊔ · · · ⊔ F p une base de E .
Alors
E =
pi=1
Vect(F i).
Corollaire – Fractionnement d’une base
Si E est de dimension finie et si F est un sous-espace vectoriel de E , alors F possèdedes supplémentaires.
Propriété
Démonstration – Si F = 0E , le résultat est évident : E est un supplémentaire de F . De même,si F = E , 0E est un supplémentaire de F . Sinon, soit F une base de F . En complétant F enbase de E , et en appliquant le corollaire précédent avec p = 2, on obtient un supplémentaire deF (et la base de E ainsi construite est adaptée à F ).
42

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 51/383
Inversement, on peut construire des bases de E à partir d’une décomposition de E en sommedirecte :
Soit (E 1, . . . , E p) une famille de sous-espaces vectoriels de E , tous de dimension finienon nulle, telle que E =
pi=1 E i. Pour tout i, on se donne une base Bi de E i.
Alors la juxtaposition B =
B1⊔···⊔B p de ces bases est une base de E
(qui en particulierest de dimension finie).
On appelle base de E adaptée à la décomposition en somme directe E = p
i=1 E i unebase de E de la forme de B.
Propriété/Définition – Base adaptée à une somme directe
Démonstration – Pour tout i, on note ni = dim(E i), Bi = (ei,1, . . . , ei,ni) et on pose n = pi=1 ni.
• Caractère générateur : tout d’abord, chaque vecteur ek,j appartient à E k et donc à la sommedes E i. Soit x ∈ E . Il existe (xi)1i p ∈ E 1 × · · · × E p tel que x =
pi=1 xi. De plus pour tout
i ∈ [[1,p]], il existe (λi,j)1≤ j≤ni ∈ Kni tel que
xi =
ni j=1
λi,jei,j.
Alors
x =
pi=1
ni j=1
λi,jei,j
∈ Vect(B).
Ceci étant valable pour tout x appartenant à E , on en déduit que E = Vect(B).
• Liberté : soit (λi,j) ∈ Kn un n-uplet de scalaires (avec 1 ≤ i ≤ p et pour tout i, 1 ≤ j ≤ ni)tel que
n
i=1
ni
j=1 λi,jei,j = 0E .
Pour tout i ∈ [[1,n]], le vecteur vi = ni
j=1 λi,jei,j appartient à E i, et la somme des E i étantdirecte, l’égalité
ni=1 vi = 0E entraîne que vi = 0E pour tout i ∈ [[1,p]]. Mais alors, pour tout
i ∈ [[1,p]], on ani j=1
λi,jei,j = 0E ,
or Bi est une base de E i donc est une famille libre. On en déduit que λi,j = 0 pour tout j ∈ [[1,ni]].Finalement, pour tout 1 ≤ i ≤ p, 1 ≤ j ≤ ni, on a λi,j = 0, donc B est libre.
Soit (E 1, . . . , E p) une famille de sous-espaces vectoriels de dimension finie de E . Alors :
• pi=1
E i est de dimension finie et dim
pi=1
E i
pi=1
dim(E i),
• Il y a égalité dans l’inégalité précédente si et seulement si la somme pi=1
E i est directe.
• Si E est de dimension finie et si la somme pi=1
E i est directe, alors pour que E =
pi=1
E i,
il faut et il suffit que
pi=1
dim(E i) = dim(E ).
Propriété – Dimension d’une somme
43

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 52/383
Démonstration – Tout d’abord, on se ramène facilement au cas où les E i sont de dimension nonnulle, ce que l’on suppose dans la suite de la démonstration.
• Pour tout i ∈ [[1,p]], soit Bi une base de E i, et ni = dim(E i). En reprenant la démonstrationprécédente, on obtient que la juxtaposition F de ces bases est une famille génératrice de
pi=1 E i.
On a donc
dim
p
i=1
E i
p
i=1
ni =
p
i=1
dim(E i).
• Si la somme p
i=1 E i est directe, la famille F est une base de p
i=1 E i (d’après la démonstrationprécédente), donc l’inégalité précédente est une égalité.
Réciproquement, si l’inégalité précédente est une égalité, alors F est une famille génératricede p
i=1 E i de dim( pi=1 E i) vecteurs, donc F est une base de
pi=1 E i. D’après la propriété
de fractionnement d’une base, on en déduit que p
i=1 E i = p
i=1 Vect(F i) = p
i=1 E i, donc lasomme est directe.
• Dans ce cas, pour que E = p
i=1 E i, il faut et il suffit que dim ( p
i=1 E i) = dim(E ), c’est-à-dire,d’après le deuxième point, que
pi=1 dim(E i) = dim(E ).
Exemple – La somme de deux plans vectoriels de R3 n’est jamais directe, car la somme de leursdimensions est 4.
On suppose E de dimension finie. Soient F et G deux sous-espaces vectoriels de E .
Pour que E = F ⊕ G, il faut et il suffit que
F ∩ G = 0E et dim(E ) = dim(F ) + dim(G).
Corollaire
Démonstration – C’est un cas particulier de la propriété précédente dans le cas de deux sous-espaces vectoriels F et G, puisqu’alors, le fait que la somme F + G soit directe équivaut au faitque F
∩G =
0E
.
Remarque – En particulier, tous les supplémentaires de F ont la même dimension.
Lorsque la somme de deux sous-espaces vectoriels de E n’est pas directe, on a le résultatsuivant :
Si E est de dimension finie et F et G sont deux sous-espaces vectoriels de E , alors
dim(F + G) = dim(F ) + dim(G) − dim(F ∩ G).
Théorème – Formule de Grassmann
Démonstration – Soit F ′ un supplémentaire de F ∩ G dans F et G′ un supplémentaire de F ∩ Gdans G. Montrons que F + G = F ′⊕ G′⊕ (F ∩G). Tout d’abord, si x′+ y′+ z = 0E avec x′ ∈ F ′,y′ ∈ G′ et z ∈ F ∩ G, alors
x′ = −y′ − z ∈ F ′ ∩ G ⊂ F ′ ∩ (F ∩ G) = 0E .
On en déduit que y′ = −z ∈ G′ ∩ (F ∩ G) = 0E et finalement x′ = y′ = z = 0E . Donc lasomme est directe. De plus, on constate que
F + G = [(F ∩ G) + F ′] + [(F ∩ G) + G′] = F ′ + G′ + (F ∩ G).
Alors, d’après la propriété sur la dimension d’une somme,
dim(F + G) = dim(F ′) + dim(G′) + dim(F ∩ G)
= dim(F ) − dim(F ∩ G) + dim(G) − dim(F ∩ G) + dim(F ∩ G)
= dim(F ) + dim(G) − dim(F ∩ G).
44

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 53/383
Exemple – Soit E = M n(R) (n 2), F = S n(R) (ensemble des matrices symétriques de M n(R))et G l’ensemble des matrices triangulaires supérieures de M n(R). Alors F et G sont des sous-espaces vectoriels de E , dont l’intersection est l’ensemble des matrices diagonales de M n(R). Ona, d’après la formule de Grassmann,
dim(F + G) = dim(F ) + dim(G) − dim(F ∩ G) = n(n + 1)
2 +
n(n + 1)
2 − n = n2.
Sachant que dim(M n(R)) = n2, on en déduit que F + G = M n(R).
On peut d’ailleurs prouver ce résultat directement en décomposant toute matrice A deM n(R)sous la forme de la somme d’une matrice symétrique S et d’une matrice triangulaire supérieureT : on choisit pour S la matrice de diagonale nulle dont la partie « strictement inférieure » est lamême que celle de A, et dont la partie « strictement supérieure » est obtenue par symétrie de lapartie strictement inférieure. On pose alors T = A−S ; T est triangulaire supérieure car A et S ontla même partie triangulaire strictement inférieure. On a donc la décomposition souhaitée. Cettedécomposition n’est pas unique car la somme F + G n’est pas directe (F ∩ G = 0E ), l’absenced’unicité provient en fait, lorsque l’on effectue la décomposition, d’un choix des diagonales quin’est pas unique : on peut choisir pour S , au lieu d’une diagonale nulle, une diagonale quelconque.
III. Applications linéaires
Dans toute la suite, E et F désignent deux K-espaces vectoriels.
1. Définition et exemples
On appelle application linéaire de E dans F toute application u de E dans F vérifiantles deux conditions suivantes :
• ∀ (x,y) ∈ E 2 , u(x + y) = u(x) + u(y),
• ∀ λ ∈ K , ∀ x ∈ E , u(λx) = λu(x).
L’ensemble des applications linéaires de E dans F est noté L (E,F ).
Si u est une application linéaire de E dans E , on dit que u est un endomorphismede E. L’ensemble des endomorphismes de E est noté L (E ).
Définition – Application linéaire
Remarque – Si u est linéaire, on a nécessairement u(0E ) = 0F . En effet,
u(0E ) = u(0E + 0E ) = u(0E ) + u(0E ),
d’où le résultat par soustraction de u(0E ). En particulier, si u(0E ) = 0F , alors u n’est pas linéaire.
Par exemple, u :
R3 → R2
(x,y,z) → (2x + y,1) n’est pas linéaire.
L’application u de E dans F est linéaire si et seulement si
∀ (x,y) ∈ E 2, ∀ λ ∈ K, u(λx + y) = λu(x) + u(y).
Propriété
45

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 54/383
Exemples
• L’application nulle de E dans F , u :
E → F
x → 0F est une application linéaire. On la
notera 0L (E,F ) ou 0L (E ) si E = F .
• L’application identité de E dans E , IdE :
E → E
x → x est une application linéaire.
• Plus généralement, si λ ∈ K, l’application de E dans E , f : E
→ E
x → λx est une applicationlinéaire. Elle est appelée homothétie de rapport λ.
• L’application f :
R3 → R2
(x,y,z) → (2x + y − z,x − y + z) est linéaire.
• L’application φ :
C1(R,R) → C0(R,R)f → f ′ est linéaire.
Soit M ∈ M n,p(K). On définit une application uM par
uM : M p,1(K) → M n,1(K)
X → M X
L’application uM est linéaire , elle est appelée application linéaire canoniquementassociée à la matrice M .
Définition – Application linéaire canoniquement associée à une matrice
2. Opérations sur les applications linéaires
Soient u et v deux éléments de L (E,F ) et λ ∈ K. Sachant que F est un K-espacevectoriel, on définit des applications u + v et λ · u (ou simplement λu) en posant, pourtout x ∈ E ,
(u + v)(x) = u(x) + v(x) et (λu)(x) = λ · u(x).
Définition
L’espace (L(E,F ), + ,·) est un K-espace vectoriel. En particulier,
∀(u,v)
∈L (E,F )2,
∀λ
∈K, u + v
∈L (E,F ) et λu
∈L (E,F ).
Propriété
Soient E , F et G trois K-espaces vectoriels. Si u ∈ L (E,F ) et v ∈ L (F,G) alorsv u ∈ L (E,G).
Propriété – Composition d’applications linéaires
La démonstration de ces deux propriétés est laissée en exercice.
Cas particuliers des endomorphismes
Les deux propriétés ci-dessus montrent que L (E ) est un ensemble dont les éléments peuventêtre additionnés, multipliés par un scalaire, et composés. En général, la loi de composition n’estpas commutative : il existe des endomorphismes u et v de E tels que u v = v u.
46

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 55/383
Soit u un endomorphisme de E . Pour tout k ∈ N, on note uk l’endomorphisme obtenuen effectuant la composition u · · · u (k fois). Par convention, u0 = IdE .
Définition
Soient u et v deux endomorphismes de E qui commutent (c’est-à-dire tels que uv =v u). Alors
∀ n ∈ N, (u + v)n =nk=0
nk
uk vn−k =
nk=0
nk
un−k vk.
Propriété – Formule du binôme de Newton
Démonstration – Il suffit de démontrer la première des deux formules, l’autre en étant une réécri-ture obtenue par changement d’indice. On remarque tout d’abord que pour tout k ∈ N, uk etv commutent (cela se prouve par récurrence immédiate sur k). On prouve alors la formule par
récurrence sur n. Pour n = 0, le résultat est évident car (u + v)0 = IdE par convention, et
0k=0
0k
uk v0−k = u0 v0 = IdE IdE = IdE .
Supposons le résultat vrai au rang n. Alors
(u + v)n+1 = (u + v) (u + n)n = (u + v) nk=0
nk
uk vn−k
par hypothèse de récurrence. Par linéarité de u et v et le fait que v commute avec toutes lespuissances de u, on a donc
(u + v)n+1 =nk=0
nk
uk+1 vn−k +
nk=0
nk
uk vn−k+1.
Par le changement d’indice m = k + 1 dans la première somme, on obtient
(u + v)n+1 =n+1m=1
n
m − 1
um vn−m+1 +
nk=0
nk
uk vn−k+1.
En regroupant les termes communs dans ces deux sommes (on rappelle que k et m sont desindices muets), on a
(u + v)n+1 = un+1 +nk=1
n
k − 1
+
nk
uk vn−k+1 + vn+1
= un+1 +nk=1
n + 1
k
uk vn+1−k + vn+1
d’après la formule de Pascal. On remarque alors que les termes un+1 et vn+1 correspondent auterme général de la somme, pour k = n + 1 et k = 0 respectivement. On a donc la formule au
rang n + 1 et finalement pour tout n par principe de récurrence.
Remarque – On utilise souvent cette formule dans le cas où l’un des deux endomorphismes estl’identité, ou une homothétie, qui commute avec tous les endomorphismes.
47

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 56/383
Polynômes d’endomorphismes
Soit u ∈ L (E ) et P (X ) = d
k=0 akX k ∈ K[X ]. On peut alors définir P (u), nouvelélément de L (E ) par
P (u) =
dk=0
akuk = adud + · · · + a1u + a0 IdE .
On dit que P (u) est un polynôme de u. L’ensemble des polynômes de u est noté K[u].
Définition – Polynômes d’un endomorphisme
Attention ! Ne pas se tromper dans le terme a0 IdE correspondant au terme constant de P ! Parexemple, lorsque P (X ) = X 2 + 2X + 3, on a P (u) = u2 + 2u + 3IdE , c’est-à-dire, pour toutx ∈ E ,
P (u)(x) = u2(x) + 2u(x) + 3x.
Soit u ∈ L (E ). Soient P et Q deux éléments de K[X ] et λ ∈ K. Alors :
• 1(u) = IdE
• (λP + Q)(u) = λP (u) + Q(u).• (P Q)(u) = P (u) Q(u). En particulier, P (u) et Q(u) commutent.
Propriété
Soit u ∈ L (E ). On dit qu’un polynôme P ∈ K[X ] est annulateur de u (ou que que uannule P ) si P (u) = 0L (E ).
Définition
3. Applications linéaires et sommes directes
Soit (E i)1i p une famille de sous-espaces vectoriels de E telle que E =
pi=1 E i.
Pour tout i
∈ [[1,p]], soit ui une application linéaire de E i dans F .
Alors il existe une unique application linéaire u de E dans F dont la restriction à E isoit ui pour tout i ∈ [[1,p]].
Théorème
Démonstration
Analyse : si u vérifie les conditions ci-dessus et si x = x1 + · · · + x p ∈ E avec xi ∈ E i pour touti, on a nécessairement
u(x) = u(x1 + · · · + x p) = u(x1) + · · · + u(x p) = u1(x1) + · · · + u p(x p).
L’application u est donc entièrement déterminée, et ceci prouve en particulier son unicité.
Synthèse : pour tout x = x1 + · · · + x p avec xi ∈ E i pour tout i, on pose
u(x) = u1(x1) + · · · + u p(x p).
48

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 57/383
L’application u est bien définie car la décomposition de x existe et est unique, la somme étantdirecte et égale à E . Elle est linéaire : si x = x1 + · · · + x p et y = y1 + · · · + y p sont deux élémentsde E décomposés sur la somme E 1 ⊕ · · · ⊕ E p, et si λ ∈ K, alors
λx + y =
pi=1
(λxi + yi),
avec λxi + yi ∈
E i pour tout i
∈ [[1,p]], donc par définition,
u(λx + y) =
pi=1
ui(λxi + yi) =
pi=1
(λui(xi) + ui(yi))
par linéarité des ui. Finalement
u(λx + y) = λ
pi=1
ui(xi) +
pi=1
ui(yi) = λu(x) + u(y).
Enfin, u coïncide avec ui sur E i, car pour tout x ∈ E i, u(x) = ui(x), les autres composantes dex dans la décomposition étant nulles. Ceci prouve l’existence de u.
On suppose E de dimension finie. Soient B = (e1, . . . , en) une base de E et (f 1, . . . , f n)une famille de vecteurs de F .
Alors il existe une unique application linéaire u ∈ L (E,F ) telle que pour tout i ∈ [[1,n]],u(ei) = f i.
Corollaire
Démonstration – On a E = n
i=1 Vect(ei) ; il suffit d’appliquer le résultat précédent avec, pourtout i,
ui : Vect(ei) → F
λ ei
→ λ f i
4. Image et noyau d’une application linéaire
Image et surjectivité
L’image par une application linéaire u ∈ L (E,F ) d’un sous-espace vectoriel de E estun sous-espace vectoriel de F .
Propriété
Démonstration – Soit G un sous-espace vectoriel de E . Tout d’abord, on a évidemment u(G)
⊂ F .
De plus, 0F ∈ u(G) car 0F = u(0E ) et 0E ∈ E. Enfin, soient u(x) et u(y) deux éléments de u(G)
avec x ∈ G et y ∈ G, et soit λ ∈ K. Alors, par linéarité de u, λu(x) + u(y) = u(λx + y). OrG est un sous-espace vectoriel de E et x et y sont deux éléments de G, donc λx + y ∈ G, etainsi u(λx + y) ∈ u(G). On a donc montré que u(G) est stable par combinaison linéaire, d’où lerésultat.
L’image de u, notée Im(u), est l’image de E par u, i.e. l’ensemble des images deséléments de E par u :
Im(u) = u(E ) =
y
∈ F ;
∃x
∈ E, u(x) = y
.
L’ensemble Im(u) est un sous-espace vectoriel de F d’après la propriété précédente.
Propriété/Définition – Image d’une application linéaire
49

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 58/383
Soit u ∈ L (E,F ) et (e1, . . . , en) une famille génératrice de E (par exemple, une base).Alors Im(u) est le sous-espace vectoriel de F engendré par les vecteurs u(e1), . . . , u(en) :
Im(u) = Vect (u(e1), . . . , u(en)) .
Propriété – Détermination de Im(u)
Démonstration – Si y = u(x) ∈ Im(u) avec x ∈ E , on peut décomposer x sur la famille génératrice(e1, . . . , en) de E : il existe (λ1, . . . , λn) ∈ Kn tel que x = λ1e1 + · · · + λnen. Par linéarité de u,on a donc
y = u(x) = λ1u(e1) + · · · + λnu(en) ∈ Vect (u(e1), . . . , u(en)) .
Ainsi Im(u) ⊂ Vect (u(e1), . . . , u(en)) . Réciproquement, Im(u) est un sous-espace vectoriel de F auquel appartiennent u(e1), . . . , u(en), donc
Vect (u(e1), . . . , u(en)) ⊂ Im(u).
On a donc l’égalité souhaitée.
Remarque – Soit u
∈L (E,F ) ; u est surjective si et seulement si pour tout y
∈ F , il existe x
∈ E
tel que u(x) = y, c’est-à-dire si et seulement si Im(u) = F .
Exemple – Soit φ :
C1(R,R) → C0(R,R)f → f ′
L’application linéaire φ est surjective, car toute fonction continue sur R possède des primitives,qui sont de classe C1.
Noyau et injectivité
Soit u ∈ L (E,F ). Le noyau de u est l’ensemble des vecteurs de E qui ont pour image
le vecteur nul de F . On le note Ker(u). On a donc :Ker(u) = x ∈ E ; u(x) = 0F = u−1(0F ).
Ker(u) est un sous-espace vectoriel de E .
Propriété/Définition – Noyau d’une application linéaire
Démonstration – Tout d’abord, Ker(u) ⊂ E par définition. De plus, 0E ∈ Ker(u) car u(0E ) = 0F .Enfin, soient x et y deux éléments de E , et λ ∈ K. Alors par linéarité de u,
u(λx + y) = λu(x) + u(y) = λ · 0F + 0F = 0F ,
et donc λx + y ∈
Ker(u). Ceci montre que Ker(u) est un sous-espace vectoriel de E .
Exemple – Soit u :
R3 → R3
(x,y,z) → (x − 2y,x + 2z,x − y + z)
Pour déterminer Ker(u), on résout l’équation u(x,y,z) = 0, ce qui nous conduit à la résolutiondu système :
x −2y = 0x +2z = 0x −y +z = 0
qui équivaut à
x = −2zy = −z
D’où Ker(u) = (−2z, − z,z), z ∈ R = Vect(−2, − 1,1).
Soit u ∈ L (E,F ). Pour que u soit injective, il faut et il suffit que Ker(u) = 0E .Propriété
50

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 59/383
Démonstration
⇒ Soit x ∈ Ker(u). Alors u(x) = 0F = u(0E ), donc par injectivité de u, x = 0E , ce qui montreque Ker(u) ⊂ 0E , l’inclusion réciproque étant toujours vraie.
⇐ Soient x et y deux éléments de E tels que u(x) = u(y). Par linéarité de u, on a u(x−y) = 0F ,et donc x − y ∈ Ker(u) = 0E . Ainsi x = y, ce qui prouve que u est injective.
Exemple – Soit φ : C1(R,R) → C0(R,R)
f → f ′L’application linéaire φ n’est pas injective, car toute fonction constante appartient à sonnoyau (et il existe des fonctions constantes non nulles). En fait, Ker(φ) est égal à l’ensemble desfonctions constantes sur R.
Équations linéaires
Une équation linéaire est une équation de la forme u(x) = b où u ∈ L (E,F ) etb ∈ F , d’inconnue x ∈ E.
Définition
Bien sûr, l’équation u(x) = b possède des solutions si et seulement si b ∈ Im(u). Si l’équationest sans second membre, c’est-à-dire si b = 0, alors elle s’écrit u(x) = 0, équation dont l’ensembledes solutions est Ker(u). En particulier, l’ensemble des solutions d’une équation linéaire sanssecond membre est un K-espace vectoriel.
Dans le cas général (b quelconque), on peut décrire la forme de l’ensemble des solutions :
Avec les notations précédentes, si x0 ∈ E est une solution particulière de u(x) = b,alors l’ensemble
S des solutions de cette équation est
S = x0 + y; y ∈ Ker(u).
Propriété – Structure de l’ensemble des solutions
Démonstration – On a u(x0) = b et donc pour x ∈ E , on a les équivalences :
u(x) = b ⇔ u(x) = u(x0) ⇔ u(x − x0) = 0F ⇔ x − x0 ∈ Ker(u),
d’où le résultat.
Exemples
• On considère le système linéaire de n équations à p inconnues suivant :
(S ) :
a1,1x1+ · · · + a1,px p = b1
a2,1x1+ · · · + a2,px p = b2
...
an,1x1+ · · · + an,px p = bn
En notant A = (ai,j)1in,1 j p ∈ M n,p(K), X ∈ M p,1(K) la matrice colonne de coefficientsx1, . . . , x p et B ∈M n,1(K) la matrice colonne de coefficients b1, . . . , bn, ce système se met sous laforme matricielle (E ) : AX = B , c’est-à-dire que (x1, . . . , x p) est solution de (S ) si et seulementsi X est solution de (E ). Le système (S ) et l’équation (E ) sont des équations linéaires. Dans le
cas de l’équation (E ) : AX = B , on a u = uA, application linéaire canoniquement associée à A.On dit que A est la matrice du système linéaire (S ). On reviendra en détails sur l’étude
des systèmes linéaires dans le chapitre suivant.
51

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 60/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 61/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 62/383
Exemples
• Soient
u :
Rn[X ] → Rn[X ]
P (X ) → P (X + 2) et v :
Rn[X ] → Rn[X ]
Q(X ) → Q(X − 2)
Alors u est un isomorphisme de Rn[X ] sur Rn[X ], de bijection réciproque v .
• Soit u ∈ L (E ) et soit P (X ) = adX d + · · · + a0 ∈ K[X ] (d 1) tel que P (u) = 0L (E ),c’est-à-dire
0L (E ) = adud + · · · + a0 IdE .
Si le coefficient constant a0 de P est différent de 0, alors on peut écrire
−ada0
ud − · · · − a1
a0u = IdE ,
et donc
u
−ada0
ud−1 + · · · − a1
a0IdE
=
−ad
a0ud−1 + · · · − a1
a0IdE
u = IdE .
Ainsi, u est un isomorphisme de E sur E , de bijection réciproque
−ada0
ud−1 − · · · − a1
a0IdE .
Cette expression de u−1 est d’autant plus simple que P est de bas degré. On voit donc quel’obtention de polynômes annulateurs de u peut donner des informations importantes sur u. Ondéveloppera largement ce thème dans le chapitre Réduction des endomorphismes et desmatrices carrées.
Par exemple, soit u ∈L (E ) tel que u3 + 2u − Id = 0. Alors
u (u2 + 2 Id) = (u2 + 2 Id) u = Id .
On sait donc que u est un isomorphisme de E sur E avec u−1 = u2 + 2Id .
Si u est un isomorphisme de E sur E (c’est-à-dire si u : E → E est linéaire et bijective)on dit que u est un automorphisme de E .
L’ensemble des automorphismes de E est noté Gℓ(E ).
Définition – Automorphismes
L’ensemble Gℓ(E ), muni de l’opération de composition des applications, est appelégroupe linéaire de E . On a notamment :
• Si u ∈ Gℓ(E ), alors u−1 ∈ Gℓ(E ).
• Si u ∈ Gℓ(E ) et v ∈ Gℓ(E ) alors uv ∈ Gℓ(E ). En fait, on a : (uv)−1 = v−1u−1.
Si u ∈ Gℓ(E ), on dit également que u est inversible, et u−1 est appelé inverse de u.
Propriété/Définition
Démonstration – Le premier point a été démontré plus haut. Quant au second, soient u et v deuxéléments de Gℓ(E ), alors on sait déjà que u v est linéaire ; de plus,
(u v) (v−1
u−1
) = u (v v−1
) u−1
= u IdE u−1
= u u−1
= IdE
et de même, (v−1 u−1)(uv) = IdE . Ceci prouve que u v ∈ Gℓ(E ) avec (uv)−1 = v−1 u−1.
54

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 63/383
2. Isomorphismes en dimension finie
Caractérisation
On suppose que E est de dimension finie n 1. Soit B = (e1, . . . , en) une base de E etu
∈L (E,F ).
L’application u est un isomorphisme si et seulement si u(B) = (u(e1), . . . , u(en)) estune base de F .
Théorème – Caractérisation des isomorphismes par les bases
Démonstration
⇒ Supposons que u est un isomorphisme, et montrons que u(B) est une famille libre et géné-ratrice de F .
Liberté : si λ1u(e1) + · · · + λnu(en) = 0F pour des scalaires λ1, . . . , λn, alors par linéarité de u,
u(λ1e1 + · · · + λnen) = 0F .
L’application u étant injective, on a donc λ1e1 + · · · + λnen = 0E . La famille B étant libre, onen déduit que λi = 0 pour tout i.
Aspect générateur : soit y ∈ F et x ∈ E tel que u(x) = y (un tel x existe car u est surjective).On peut alors écrire x = λ1e1 + · · · + λnen pour des scalaires λ1, . . . , λn, car B est une famillegénératrice de E . Finalement
y = u(x) = u(λ1e1 + · · · + λnen) = λ1u(e1) + · · · + λnu(en).
On a donc montré que y ∈ Vect(u(e1), . . . , u(en)), et ce pour tout y ∈ F , d’où le résultat.
⇐ Si u(
B) = (u(e1), . . . , u(en)) est une base de F , montrons que u est bijective.
Injectivité : soit x = λ1e1 + · · · + λnen ∈ E tel que u(x) = 0F . Alors
0F = u(λ1e1 + · · · + λnen) = λ1u(e1) + · · · + λnu(en).
La famille (u(e1), . . . , u(en)) étant libre, on a λi = 0 pour tout i, et donc x = 0E : u est injective.
Surjectivité : (u(e1), . . . , u(en)) engendre F , donc pour tout y ∈ F , il existe des scalairesλ1, . . . , λn tels que y = λ1u(e1) + · · · + λnu(en), et ainsi
y = u(λ1e1 + · · · + λnen)
avec λ1e1 + · · · + λnen ∈ E . Finalement, y ∈ Im(u), pour tout y ∈ F : u est surjective.
Remarque – Pour le sens direct, on a en fait montré les résultats suivants :
• Si u est injective, alors l’image par u d’une famille libre d’éléments de E est une famille libred’éléments de F .
• Si E est de dimension finie, et si u est surjective, alors l’image par u d’une famille génératricede E est une famille génératrice de F .
Soient E et F deux K-espaces vectoriels de même dimension finie n et u uneapplication linéaire de E dans F . On a les équivalences :
u est injective ⇔ u est surjective ⇔ u est bijective.
Théorème – Caractérisation des isomorphismes en dimension finie
55

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 64/383
Démonstration – Le résultat est évident si n = 0 (les trois propriétés sont vraies). Sinon, soitB une base de E . Si u est injective, u(B) est une famille libre d’éléments de F de n = dim(F )
vecteurs; c’est donc une base de F . Donc u est bijective d’après le théorème précédent. Si u estsurjective, u(B) est une famille génératrice de F de n vecteurs; c’est donc une base de F . Dansce cas aussi, u est bijective. Les implications réciproques sont évidentes.
Bilan – Sous les hypothèses précédentes, les propriétés suivantes sont équivalentes :
• u est bijective,• u est injective,• u est surjective,
• u est un isomorphisme de E sur F,
• Ker(u) = 0E ,
• Im(u) = F,
• u transforme toute base de E en une base de F .
Attention ! L’hypothèse dim(E ) = dim(F ) est cruciale. En effet :
• f : x → (x,x), de R dans R2, est injective mais non surjective.
• g : (x,y) → x, de R2 dans R, est surjective mais non injective.
De même, l’hypothèse de dimension finie est essentielle même si E = F , comme le montrel’exemple suivant : soit φ : C0([0,1],R) → C0([0,1],R) l’application linéaire définie par :
∀ f ∈ C0([0,1],R), φ(f ) : x → x0
f (t)dt.
Alors φ est un endomorphisme, φ est injective mais non surjective.
Autre contre-exemple : si D : K[X ] →K[X ] désigne l’opérateur de dérivation P → P ′, alorsD est un endomorphisme, D est surjective mais non injective.
Espaces isomorphes
Soit u ∈ L (E,F ) un isomorphisme. Alors E est de dimension finie si et seulement si
F est de dimension finie, et dans ce cas dim(E ) = dim(F ). On mentionne souvent cerésultat en disant : « les isomorphismes préservent la dimension ».
Propriété
Démonstration – Supposons E de dimension finie n. Si n = 0, le résultat est évident car alorsF = 0F . Si n 1, l’image d’une base de E par u est une base de F , qui par conséquentest de dimension finie. De plus, ces deux bases ont le même nombre de vecteurs, donc on adim(E ) = dim(F ). Si F est de dimension finie, on raisonne de la même façon avec la bijectionréciproque u−1 : F → E.
Soit E un K-espace vectoriel de dimension finie n. Un K-espace vectoriel F est iso-morphe à E si et seulement si F est de dimension finie avec dim(F ) = n.
Propriété – Caractérisation des espaces isomorphes par la dimension
Démonstration – Si E et F sont isomorphes, la propriété précédente montre que F est de dimensionfinie n. Réciproquement, supposons que F est de dimension finie n. Si n = 0, le résultat estévident, l’application nulle étant un isomorphisme de E sur F . Si n 1, soit (e1, . . . , en) unebase de E et (f 1, . . . , f n) une base de F . L’unique application linéaire de E dans F vérifiantu(ei) = f i pour tout i est un isomorphisme de E sur F , car elle transforme une base de E enune base de F . Les espaces E et F sont donc isomorphes.
Exemple – Si dim(E ) = n 1 et si (e1, . . . , en) est une base de E , alors l’application linéaire
φ :
L (E,F ) → F n
u → (u(e1), . . . , u(en))
56

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 65/383
est un isomorphisme : en effet, pour toute famille (f 1, . . . , f n) d’éléments de F , il existe uneunique application linéaire u ∈ L (E,F ) telle que u(ei) = f i pour tout i ∈ [[1,n]], c’est-à-dire,telle que φ(u) = (f 1, . . . , f n). Ainsi, si F est de dimension finie, L(E,F ) est un espace vectoriel dedimension finie et de même dimension que F n, i.e. de dimension n×dim(F ) = dim(E )×dim(F ).
Tout K-espace vectoriel E de dimension n 1 est isomorphe à Kn.
Corollaire
Remarque – Dans ce cas, pour faire le lien avec la démonstration de la propriéte précédente,on choisit F = Kn, (f 1, . . . , f n) la base canonique de Kn, et u : E → Kn l’application qui àtout vecteur de E associe le n-uplet de ses coordonnées dans une base fixée (e1, . . . , en) de E .L’application u est parfois appelée isomorphisme des coordonnées.
Le corollaire précédent montre que Kn est le « modèle » du K-espace vectoriel de dimension n.
V. Rang et théorème du rang
1. Rang d’une application linéaire
Soit u une application linéaire de E dans F . Si Im(u) est de dimension finie, on dit queu est de rang fini et on appelle rang de u la dimension de Im(u), notée rg(u).
Définition – Rang d’une application linéaire
Remarques
• Si F est de dimension finie, alors sachant que Im(u) ⊂ F , on en déduit que u est de rang finiavec
rg(u) dim(F ).
On a égalité si et seulement si Im(u) = F , i.e., si et seulement si u est surjectif.
• Si E est dimension finie n et si (e1, . . . , en) est une famille génératrice de E , on sait queIm(u) = Vect(u(e1), . . . , u(en)), donc u est de rang fini avec
rg(u) = rg(u(e1), . . . , u(en)) n = dim(E ).
En particulier, si, de plus, u est surjective, alors F est de dimension finie et dim(F ) dim(E ).
Soient E , F et G trois K-espaces vectoriels et u : E → F , v : F → G deux applicationslinéaires. Si u ou v est de rang fini, alors v u est de rang fini; dans le premier cas ona rg(v u) rg(u), dans le second, rg(v u) rg(v).
En particulier, si u et v sont tous deux de rang fini,
rg(v u) minrg(u), rg(v).
Propriété – Rang et composition
Démonstration – Tout d’abord, Im(v u) ⊂ Im(v), donc si v est de rang fini, v u est de rang finiavec
rg(v u) = dim(Im(v u)) dim(Im(v)) = rg(v).
Cela prouve l’inégalité dans le second cas évoqué ci-dessus.Dans le premier cas, notons r le rang de u. Si r = 0, u et v u sont nulles, donc le résultat est
vrai. Si r 1, il existe une base (u(e1), . . . , u(er)) de Im(u) où e1, . . . , er sont des vecteurs de E .
57

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 66/383
Montrons alors que ((v u)(e1), . . . ,(v u)(er)) engendre Im(v u) : soit z = (v u)(x) ∈ Im(v u)
avec x ∈ E . Alors u(x) ∈ Im(u), on peut donc le décomposer sous la forme
u(x) = λ1u(e1) + · · · + λru(er)
où (λ1, . . . , λr) ∈ Kr. Par linéarité de v , on a alors
z = λ1(v
u)(e1) +
· · ·+ λr(v
u)(er),
ce qui prouve que ((v u)(e1), . . . ,(v u)(er)) engendre Im(v u). On en déduit que v u est derang fini avec
rg(v u) r = rg(u),
d’où le résultat dans ce cas.
Soit f ∈ Gℓ(E ) et g ∈ Gℓ(F ) deux automorphismes et u ∈ L(E,F ). Si u est de rangfini, alors g u f est de rang fini et
rg(u) = rg(g
u
f ).
Propriété – Invariance du rang par composition par des isomorphismes
Démonstration – D’après l’inégalité de la propriété précédente, on sait que g u est de rang finiavec rg(g u) rg(u). On en déduit de la même façon que g u f est de rang fini avec
rg(g u f ) rg(g u) rg(u).
En remarquant queu = g−1 (g u f ) f −1
et en raisonnant de même, on obtient l’inégalité opposée
rg(u) rg(g u f )
et finalement le résultat.
2. Théorème du rang
Si E est de dimension finie et u ∈L (E,F ), alors u est de rang fini et
dim(E ) = dim(Ker(u)) + rg(u).
Théorème du rang
Démonstration – L’espace E est de dimension finie, on sait déjà d’après une remarque précédenteque u est de rang fini; de plus, Ker(u) admet un supplémentaire V (dans E ) : E = Ker(u) ⊕ V .Soit
u :
V → Im(u)
x → u(x)
Alors u est injective : soit x ∈ V tel que u(x) = 0Im(u) = 0F . Alors x ∈ V ∩ Ker(u) = 0E , doncx = 0E = 0V . De plus, u est surjective : fixons y ∈ Im(u) et soit x ∈ E tel que u(x) = y. Onécrit x = x1 + x2 avec x1 ∈ V et x2 ∈ Ker(u). On a donc
y = u(x1 + x2) = u(x1) + u(x2) = u(x1) = u(x1),
et donc y ∈ u(V ). Finalement, u est un isomorphisme de V sur Im(u) avec E = Ker(u) ⊕ V ,donc
dim(E ) = dim(Ker(u)) + dim(V ) = dim(Ker(u)) + dim(Im(u)),
58

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 67/383
car les isomorphismes préservent la dimension. On a donc le résultat car dim(Im(u)) = rg(u).
Remarque – On retrouve la caractérisation des isomorphismes en dimension finie : si E et F sontde même dimension finie n, on sait que u est injective si et seulement si dim(Ker(u)) = 0, ce quiéquivaut d’après le théorème du rang à rg(u) = dim(E ) = dim(F ), c’est-à-dire à la surjectivitéde u. En particulier, u est un isomorphisme si et seulement si rg(u) = n.
VI. Formes linéaires et hyperplansNous allons maintenant expliciter un lien particulier entre un certain type de sous-espaces
vectoriels de E et un certain type d’applications linéaires. Dans cette partie, E est de dimensionfinie n 1.
1. Formes linéaires
On appelle forme linéaire sur E toute application linéaire de E dans K, i.e., toutélément de L (E,K).
Définition – Forme linéaire
Remarques
• Il s’agit d’un cas particulier d’application linéaire avec F = K ; en particulier, les scalaires sontégalement les vecteurs de l’espace d’arrivée.
• L’espace vectoriel K est un K-espace vectoriel de dimension 1, et donc L (E,K) est de dimensionn, comme E .
Exemples
• Pour tout i ∈ [[1,n]], l’application
φi : Kn
→ K(x1, . . . , xn) → xi
est une forme linéaire sur Kn, appelée i-ième forme coordonnée (associée à la base canoniquede Kn). Elle est aussi notée dxi.
• L’application
ψ :
Kn[X ] → K
f → 1
0f (x) dx
est une forme linéaire sur Kn[X ].
• Pour tout α
∈K, l’application
ϕ :
Kn[X ] → K
P → P (α)
est une forme linéaire sur Kn[X ].
Remarque – Soit ϕ ∈ L (E,K). Si ϕ est non nulle, alors ϕ est surjective.
En effet Im(ϕ) est un sous-espace vectoriel de K, c’est donc 0 ou K. Sachant que ϕ = 0, on aIm(ϕ) = K, ce qui prouve que ϕ est surjective.
On peut aussi donner une démonstration plus constructive : il existe x ∈ E tel que ϕ(x) = 0.Soit λ
∈K ; alors
ϕ
λ xϕ(x)
= λ ϕ(x)
ϕ(x) = λ.
On a donc construit, pour tout λ ∈ K, un vecteur y de E tel que ϕ(y) = λ : ϕ est surjective.
59

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 68/383
2. Hyperplans
Soit H un sous-espace vectoriel de E . Les propriétés suivantes sont équivalentes :
1. dim(H ) = dim(E ) − 1.
2. Il existe x0 ∈ E non nul tel que E = H ⊕Kx0.
3. Il existe une forme linéaire ϕ sur E , non nulle, telle que H = Ker(ϕ).
Si H vérifie l’une de ces propriétés équivalentes, on dit que H est un hyperplan de E .
Théorème/Définition
Démonstration
2 ⇒ 1 : Si E = H ⊕Kx0 pour un certain vecteur x0 non nul de E , alors
dim(E ) = dim(H ) + dim(Kx0) = dim(H ) + 1,
d’où le résultat.
1 ⇒ 3 : Si n = 1, H = 0E , et toute forme linéaire non nulle convient. Sinon, soit (e1, . . . , en−1)une base de H , que l’on complète en base B = (e1, . . . , en) de E . On définit alors entièrement
une forme linéaire ϕ sur E en posantϕ(e1) = 0, . . . , ϕ(en−1) = 0 , ϕ(en) = 1.
Alors ϕ est non nulle (car ϕ(en) = 1) et, si x = x1e1 + · · · + xnen est un vecteur de E décomposésur la base B, on a x ∈ Ker(ϕ) si et seulement si
x1ϕ(e1) + · · · + xnϕ(en) = 0
ce qui équivaut à xn = 0, et donc au fait que x ∈ Vect(e1, . . . , en−1) = H. On a donc H = Ker(ϕ).
3 ⇒ 2 : Soit x0 ∈ E tel que ϕ(x0) = 0 ; en particulier x0 = 0E . Il suffit de montrer queE = Ker(ϕ) ⊕Kx0. Pour tout x ∈ E , on a
x = x − ϕ(x)ϕ(x0)
x0 + ϕ(x)ϕ(x0)
x0.
De plus,
ϕ
x − ϕ(x)
ϕ(x0) x0
= ϕ(x) − ϕ(x)
ϕ(x0) ϕ(x0) = 0,
donc x − ϕ(x)
ϕ(x0) x0 ∈ Ker(ϕ), et bien sûr
ϕ(x)
ϕ(x0) x0 ∈ Kx0. On a donc E = Ker(ϕ) + Kx0.
Enfin, si x ∈ Ker(ϕ) ∩ Kx0, alors il existe λ ∈ K tel que x = λx0, et 0 = ϕ(x) = λϕ(x0).
Sachant que ϕ(x0) = 0, on a nécessairement λ = 0, d’où x = 0E . Ainsi Ker ϕ ∩ Kx0 = 0E , cequi achève de prouver que E = Ker(ϕ)
⊕Kx
0.
Remarque – Les raisonnements précédents montrent même que si H = Ker(ϕ) est un hyperplande E et x0 ∈ E , alors E = H ⊕Kx0 si et seulement si x0 /∈ H , ce qui équivaut à : ϕ(x0) = 0.
Si H est un hyperplan de E et ϕ ∈L (E,K) une forme linéaire telle que H = Ker(ϕ),on dit que l’équation ϕ(x) = 0 est une équation de H.
Définition – Équation d’un hyperplan
Soient ϕ et ψ deux formes linéaires sur E . Alors Ker(ϕ) = Ker(ψ) si et seulement si ilexiste λ ∈ K∗ tel que ψ = λϕ.
Propriété
60

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 69/383
Démonstration
⇐ C’est évident : sachant que λ = 0, pour x ∈ E , on a ϕ(x) = 0 si et seulement si ψ(x) = 0.
⇒ Si ϕ = 0, alors ψ = 0 (car dans ce cas Ker(ϕ) = Ker(ψ) = E ) et on a ψ = ϕ. Sinon, soitH = Ker(ϕ), c’est un hyperplan de E en tant que noyau d’une forme linéaire non nulle. Si n 2,soit (e1, . . . , en−1) une base de H , que l’on complète en base B = (e1, . . . , en) de E . Alors
ϕ(e1) = 0 = ψ(e1), . . . , ϕ(en−1) = 0 = ψ(en−1),
et ϕ(en) = 0, ψ(en) = 0. En posant λ = ψ(en)
ϕ(en) ∈ K∗, on a ψ = λϕ, car ces deux applications
linéaires coïncident sur la base B. Si n = 1, on reprend le raisonnement avec uniquement en.
Remarque – On sait que tout hyperplan possède une équation. D’après la propriété précédente,une telle équation est unique à multiplication par un scalaire non nul près.
Soient B = (e1, . . . , en) une base de E et H un hyperplan de E , noyau d’une forme linéairenon nulle ϕ. Alors, un vecteur x = x1e1 + · · · + xnen appartient à H si et seulement si ϕ(x) = 0,ce qui équivaut par linéarité de ϕ à
x1ϕ(e1) +
· · ·+ xnϕ(en) = 0.
En notant, pour tout i ∈ [[1,n]], ai = ϕ(ei) (qui est un élément de K), on a finalement l’équiva-lence :
x ∈ H ⇔ a1x1 + · · · + anxn = 0.
Avec les notations précédentes, on dit que l’équation
a1x1 + · · · + anxn = 0
est une équation de H dans la base
B.
Définition – Équation d’un hyperplan dans une base
On retrouve les équations « classiques » des hyperplans, par exemple en dimension 2 (droitesvectorielles) et 3 (plans vectoriels).
Les formes linéaires sur E définissant l’hyperplan H sont exactement celles dont l’expressionen coordonnées dans la base B est de la forme
x → λ(a1x1 + · · · + anxn)
où λ ∈ K∗. Autrement dit, deux équations d’hyperplans dans une même base définissent le mêmehyperplan si et seulement si elles sont proportionnelles.
Exemples
• L’équation x + 2y + 3z = 0 définit un hyperplan de R3, c’est-à-dire un plan vectoriel de R3.C’est le noyau de la forme linéaire non nulle (x,y,z) → x + 2y + 3z.
• Soit H = P ∈ Kn[X ]; P (1) = 0. Alors H est un hyperplan de Kn[X ], c’est le noyau de laforme linéaire non nulle
ϕ :
Kn[X ] → K
P → P (1)
Il a pour équation P (1) = 0. Dans la base (X n, . . . ,1) de Kn[X ] (et en notant P =nk=0 xkX k),
H a pour équationxn +
· · ·+ x0 = 0.
61

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 70/383
62

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 71/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 72/383
• Si A =
L1
...Ln
∈ M n,p(K) et B =
C 1 · · · C q
∈ M p,q(K), alors :
– La j -ième colonne de AB est le produit AC j de A par la j-ième colonne de B .– La i-ième ligne de AB est le produit LiB de la i-ième ligne de A par B .
Attention !
• Le produit matriciel est associatif, mais non commutatif en général : si A et B sont deuxéléments de M n(K), on a en général AB = BA.
• Si n 2, il existe des éléments tous deux non nuls A et B de M n(K) tels que AB = 0.
Le résultat suivant est immédiat :
• (M n,p(K), + ,·) est un K-espace vectoriel.
• Pour tout (i,j) ∈ [[1,n]]× [[1,p]], on note E i,j la matrice de M n,p(K) dont tous les coeffi-cients sont nuls sauf celui en position (i,j) qui vaut 1. Alors la famille (E i,j)1in,1 j p
est une base de M n,p(K), appelée base canonique de M n,p(K).
• (M n,p(K), + ,·) est de dimension finie égale à n × p.
Propriété
On montre également que la formule du binôme de Newton est valable pour deux matricescarrées de même taille qui commutent.
2. Polynômes de matrices
Si A ∈M n(K) est une matrice carrée, on définit, de même qu’on l’a fait pour les endomor-phismes, les polynômes de A, et les polynômes annulateurs de A.
Présentons une méthode très utile pour calculer les puissances d’une matrice A
∈ M n(K).
Soit P un polynôme annulateur non nul de A. Pour k ∈ N, effectuons la division euclidienne deX k par P : il existe Qk ∈ K[X ] et Rk ∈ K[X ] vérifiant deg(Rk) < deg(P ), tels que
X k = P (X )Qk(X ) + Rk(X ).
En évaluant cette relation en A, on obtient
Ak = P (A)Qk(A) + Rk(A) = Rk(A),
car P (A) = 0 par définition. Le calcul de Ak se ramène donc à celui de Rk : il est d’autant plussimple que le degré de P est petit.
Par exemple, soit
A =0 1 1
1 0 11 1 0
∈M 3(R).
On vérifie facilement que A2 = A + 2I 3, de sorte que le polynôme
P (X ) = X 2 − X − 2 = (X + 1)(X − 2)
est annulateur de A. Pour k ∈ N, la division euclidienne de X k par P peut s’écrire sous la forme
X k = (X + 1)(X − 2)Qk(X ) + akX + bk,
le reste Rk étant de degré au plus 1. On détermine ak et bk en évaluant la relation précédente en
−1 et 2 (racines de P ) : (−1)k = −ak + bk
2k = 2ak + bk,
64

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 73/383
ce qui donne immédiatement
ak = 2k + (−1)k+1
3 , bk =
2k + 2(−1)k
3 .
Finalement, on a montré que pour tout k ∈ N,
Ak = 2k + (−1)k+1
3 A +
2k + 2(−1)k
3 I 3.
3. Matrices inversibles
• Soit A ∈ M n(K). On dit que A est inversible s’il existe une matrice B ∈ M n(K)
telle que AB = BA = I n.Une telle matrice est alors unique, elle est notée A−1 et appelée inverse de A.
• L’ensemble des matrices inversibles de M n(K) est noté Gℓn(K), il est appelé groupelinéaire d’ordre n.
Propriété/Définition
Démonstration de l’unicitéSi B et C vérifient les propriétés de la définition, alors
B = BI n = B(AC ) = (BA)C = I nC = C.
Si A et B sont deux éléments de Gℓn(K), alors AB ∈ Gℓn(K) et
(AB)−1 = B−1A−1
Propriété
Démonstration – On a
(AB)(B−1A−1) = A(BB−1)A−1 = AI nA−1 = AA−1 = I n,
et de même pour le produit (B−1A−1)(AB). D’où le résultat.
Remarque – Dans le chapitre précédent, on a donné, pour un endomorphisme u, une méthodepour prouver l’existence de u−1 à partir d’un polynôme annulateur de u de coefficient constantnon nul. Cette méthode peut bien sûr être adaptée pour les matrices carrées.
II. Matrices, vecteurs et applications linéaires
Dans cette partie, sauf indication contraire, E et F désignent deux K-espaces vectoriels dedimension finie non nulle. On note p = dim(E ), n = dim(F ), B = (e1, . . . , e p) une base deE et C = (f 1, . . . , f n) une base de F . Enfin, u désigne une application linéaire entre E et F :u ∈ L (E,F ).
1. Matrices d’une famille de vecteurs
Si x est un vecteur de F par exemple (ce qui suit s’adapte pour tout espace vectoriel dedimension finie), on peut décomposer x dans la base C de F : on peut écrire x =
ni=1 ai f i, où
les ai, éléments de K, sont les coordonnées de x dans la base C. Le vecteur
a1...
an
65

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 74/383
est appelé vecteur (ou matrice) colonne des coordonnées de x dans la base C.
Plus généralement, si (x1, . . . , xk) est une famille de vecteurs de F , pour tout j ∈ [[1,k]], onpeut écrire
x j =ni=1
ai,j f i,
où les ai,j sont des éléments de K. Soit A la matrice
a1,1 . . . a1,j . . . a1,k...
......
ai,1 . . . ai,j . . . ai,k...
......
an,1 . . . an,j . . . an,k
∈M n,k(K)
dont la j -ième colonne est, pour tout j ∈ [[1,k]], le vecteur des coordonnées de x j dans la base C.La matrice A est appelée matrice de la famille (x1, . . . , xk) dans la base C, notée MatC(x1, . . . , xk).
Exemple – Si C = (1,X,X 2) est la base canonique de R2[X ], la matrice de la famille
(2X 2
−X + 1,3X 2
−1)
dans la base C est 1 −1
−1 02 3
.
2. Matrices d’une application linéaire
On sait que l’application linéaire u est entièrement déterminée par les p vecteurs u(e1), . . . , u(e p),et donc, par leurs coordonnées dans la base C. L’information concernant u est donc entièrementcontenue dans la donnée de n × p scalaires.
La matrice de la famille u(B) = (u(e1), . . . , u(e p)) dans la base C, i.e.
MatC(u(e1), . . . , u(e p)) ∈M n,p(K)
est appelée matrice de u dans les bases B et C, et notée MatCB(u).
Si E = F et B = C, on note simplement MatB(u).
Définition
On retiendra notamment que pour tout j ∈ [[1,p]], la j-ième colonne de MatCB(u) est le vecteurdes coordonnées de u(e j) dans la base C : le fait que
MatCB(u) = (ai,j)1in1 j p
est équivalent au fait que pour tout j ∈ [[1,p]],
u(e j) =ni=1
ai,jf i.
Exemple – Soit
φ :
R3[X ] → R2[X ]
P → P ′
La matrice de φ dans les bases canoniques de R3[X ] et R2[X ] est
0 1 0 00 0 2 00 0 0 3
.
66

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 75/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 76/383
4. Calcul de l’image d’un vecteur
Soit x ∈ E et y = u(x). On note
X =
x1...
x p
et Y =
y1...
yn
les vecteurs colonne des coordonnées de x et y dans les bases B et C, respectivement.Soit A = MatCB(u). Alors Y = AX .
Propriété
Démonstration – Notons A = (ai,j)1in1 j p
. On a x =
p j=1
x je j et donc, par linéarité de u,
u(x) =
p j=1
x ju(e j) =
p j=1
x j ni=1
ai,jf i =
ni=1
p j=1
ai,jx j f i.
Par unicité des coordonnées dans la base C, on en déduit
∀ i ∈ [[1,n]], yi =
p j=1
ai,jx j.
Par définition du produit matriciel, ces égalités signifient exactement que Y = AX .
Remarque – Le produit matriciel a été défini pour que la propriété précédente soit vraie.
5. Lien entre produit de matrices et composition d’applications
Soient E , E ′, E ′′ trois K-espaces vectoriels de dimension finie. Soit B une base de E ,B′ une base de E ′ et B′′ une base de E ′′. Soit u ∈ L(E,E ′) et v ∈ L(E ′,E ′′). On saitque
v u :
E
u→ E ′ v→ E ′′
x → u(x) → v(u(x))
appartient à L (E,E ′′). Alors
MatB′′
B (v u) = MatB′′
B′ (v)MatB′
B (u).
Propriété
Démonstration – Notons M = MatB′′
B (v u), A = MatB′
B (u) et B = MatB′′
B′ (v). Soit x ∈ E et X le vecteur colonne des coordonnées de x dans la base B. On sait que M X est le vecteur colonnedes coordonnées de (v u)(x) dans la base B′′. Or le vecteur colonne des coordonnées de u(x)dans la base B′ est Y = AX et le vecteur colonne des coordonnées de v(u(x)) dans la base B′′est B Y = BAX . Donc
∀ X ∈M p,1(K), M X = BAX,
où p = dim(E ). On en déduit que M = BA en choisissant pour X les vecteurs de la basecanonique de M p,1(K).
68

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 77/383
Soient E et F deux K-espaces vectoriels de dimension n. Soit B une base de E et Cune base de F . Soit u ∈ L (E,F ). Alors on a l’équivalence :
u est un isomorphisme ⇔ MatCB(u) ∈ Gℓn(K).
Dans ce cas,
(MatCB(u))−1
= MatBC (u−1
).Cas particulier : si E = F et u ∈ L (E ), on a l’équivalence
u est un automorphisme ⇔ MatB(u) ∈ Gℓn(K).
Dans ce cas,(MatB(u))−1 = MatB(u−1).
Corollaire
Démonstration
⇒ Si u est un isomorphisme, alors il existe une application linéaire v = u−1 telle que uv = IdF
et v u = IdE . Alors d’après la propriété précédente, MatCB(u)MatBC (v) = MatBC (v)MatCB(u) = I n,donc MatCB(u) est inversible, d’inverse MatBC (v).
⇐ Soit A = MatCB(u). Si A est inversible, alors il existe une matrice B = A−1 telle queAB = BA = I n. Soit v l’unique application linéaire de F dans E telle que MatBC (v) = B . Alorsd’après la propriété précédente, MatC(uv) = MatB(v u) = I n, donc u v = IdF et v u = IdE .
6. Changements de bases
Soient
B = (e1, . . . , e p) et
B′ = (e′1, . . . , e′ p) deux bases de E . Pour tout j
∈ [[1,p]], on
peut écrire e ′ j = pi=1 pi,jei, c’est-à-dire exprimer e′ j dans la base B.La matrice P = ( pi,j) ∈ M p(K) est appelée matrice de passage de la base B à labase B′.Les colonnes de P sont les coordonnées des vecteurs de la « nouvelle » base dans « l’an-cienne ».
Définition – Matrice de passage
Remarque – On a P = MatB(e′1, . . . , e′ p) = MatBB′(Id). En particulier, P est inversible et P −1 estla matrice de passage de B′ à B.
Exemple – Les familles B = (1,X,X 2) et B′ = (1 − X + X 2,X + 2X 2,2 − X + 2X 2) sont des basesde R2[X ] : la première est la base canonique, la seconde comporte 3 = dim(R2[X ]) vecteurs eton vérifie très facilement qu’elle est libre. La matrice de passage de B à B′ est
P =
1 0 2
−1 1 −11 2 2
.
Soient x un vecteur de E , X la matrice colonne des coordonnées de x dans la base B,X ′ la matrice colonne des coordonnées de x dans la base B′ et P la matrice de passagede
B à
B′.
Alors on a la relation X = P X ′, c’est-à-dire que l’on obtient les anciennes coordonnées en fonction des nouvelles .
Propriété – Formule de changement de bases pour les vecteurs
69

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 78/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 79/383
Si (A,B) ∈ (M n(K))2, on dit que A et B sont semblables si
∃ P ∈ Gℓn(K); B = P −1AP.
Définition – Matrices semblables
Deux matrices de M n(K) sont semblables si et seulement si elles représentent le mêmeendomorphisme d’un espace de dimension n, quitte à faire le même changement debase au départ et à l’arrivée.
Propriété
Remarque – La relation de similitude entre matrices définit une relation d’équivalence sur M n(K).
III. Image, noyau et rang d’une matrice
1. Définitions, propriétés du rang
Toutes les définitions et propriétés des applications linéaires se transposent aux matricesA ∈M n,p(K) par l’intermédiaire de l’application linéaire canoniquement associée
uA :
M p,1(K) → M n,1(K)
X → AX
En particulier, pour A ∈M n,p(K), on définit :
• le noyau de A comme le noyau de uA, i.e.
Ker(A) = X ∈ M p,1(K); AX = 0.
• l’image de A comme l’image de uA, i.e.
Im(A) = Y ∈M n,1(K); ∃ X ∈M p,1(K); Y = AX .
• le rang de A comme le rang de uA.
Remarques
• Déterminer Ker(A) revient à résoudre le système linéaire sans second membre de matrice A.
• Si A = (C 1 · · · C p) et X = t
x1 · · · x p
, alors AX = x1C 1 + · · · + x pC p. En particulier, lescolonnes de A forment une famille liée si et seulement s’il existe un vecteur non nul dans Ker(A),et un tel vecteur donne explicitement une relation de dépendance linéaire entre les colonnes de
A.• Im(A) est engendré par les images par l’application uA des vecteurs de la base canonique deM p,1(K), c’est-à-dire par les colonnes de A.
• En particulier, rg(A) est le rang de la famille des vecteurs colonnes de A.
On sait que le rang d’une application linéaire n’est pas modifié par composition (à droite ouà gauche) par un isomorphisme. Matriciellement, ce résultat se traduit ainsi :
Le rang d’une matrice A ∈ M n,p(K) n’est pas modifié par multiplication (à droite ouà gauche) par une matrice inversible : si P
∈ Gℓn(K) et Q
∈ Gℓ p(K), alors
rg(P A Q) = rg(A).
Propriété
71

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 80/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 81/383
Soient (x1, . . . , x p) une famille de vecteurs de E (on rappelle que p = dim(E )) et
A = MatB(x1, . . . , x p).
Alors, pour que (x1, . . . , x p) soit une base de E , il faut et il suffit que A soit inversible.
Corollaire
Démonstration – La famille (x1, . . . , x p) est une famille de p vecteurs de E avec p = dim(E ), doncc’est une base de E si et seulement si elle est génératrice de E , ce qui équivaut à rg(x1, . . . , x p) = p,i.e., à rg(A) = p. D’après le théorème précédent, ceci équivaut à l’inversibilité de A.
En appliquant le théorème du rang à uA avec A ∈ M n,p(K) (l’espace de départ étant alorsde dimension p), on obtient :
Soit A
∈M n,p(K). Alors
dim(Ker(A)) + rg(A) = p.
Théorème du rang pour les matrices
Soient A et B deux matrices de M n(K).
Si AB = I n alors A et B sont inversibles et inverses l’une de l’autre.
Propriété
Démonstration – Si AB = I n alors uA uB = Id donc uA est surjective et uB est injective.D’après la caractérisation des isomorphismes en dimension finie, on en déduit que uA et uB sontdes isomorphismes, donc A et B sont inversibles. De plus, (uA)−1 = uB et donc A−1 = B.
Remarque – Lorsque AB = I n pour deux matrices A et B de M n(K), il est donc inutile devérifier que BA = I n, on peut directement conclure que A et B sont inversibles et inverses l’unede l’autre.
IV. La méthode de Gauss-Jordan
1. Opérations élémentaires
Soit A ∈ M n,p(K). On appelle opérations élémentaires les manipulations suivantes (où λdésigne un scalaire) :
Opérations élémentaires sur les colonnes de A :
• Multiplier la i-ième colonne de A par un scalaire λ non nul : C i ← λC i.
• Permuter les colonnes i et j de A : C i ↔ C j,
• Ajouter à la i-ième colonne de A, λ fois la j -ième ( j = i) : C i ← C i + λC j,
Opérations élémentaires sur les lignes de A :
• Multiplier la i-ième ligne de A par un scalaire λ non nul : Li ← λLi.• Permuter les lignes i et j de A : Li ↔ L j,
• Ajouter à la i-ième ligne de A, λ fois la j -ième ( j = i) : Li ← Li + λL j,
73

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 82/383
Dans les matrices qui suivent, les coefficients non précisés sont égaux à 0. Soit m ∈ N∗.
• Pour tout i ∈ [[1,m]] et λ ∈ K∗, on définit la matrice de dilatation
Dmi (λ) = λE i,i +
k∈[[1,m]]k=i
E k,k =
C i
1.. .
1λ Li
1. . .
. . .
1
∈M m(K)
• Pour tout (i,j) ∈ [[1,m]]2 tel que i = j, on définit la matrice de transposition
τ mi,j = E i,j + E j,i+
k∈[[1,m]]k=i,k= j
E k,k =
C i C j
1. . .
0 · · · 1 Li...
. . . ...
1 · · · 0 L j. . .
. . .
1
∈M m(K)
Dans la matrice précédente, on a choisi i < j, ce qui n’est pas restrictif car pour tout(i,j) ∈ [[1,m]]2 tel que i = j, τ mi,j = τ m j,i.
• Pour tout (i,j) ∈ [[1,m]]2 tel que i = j, pour tout λ ∈ K, on définit la matrice detransvection
T mi,j(λ) = I m + λE i,j =
C j C i
1. . .
1 L j... . . .
λ · · · 1 Li. . .
. . .
1
∈M m(K)
Dans la matrice précédente, on a choisi i > j , ce qui est restrictif : il est bien sûr possiblede choisir i < j , auquel cas le coefficient λ sera placé au-dessus de la diagonale.
Définition – Matrices élémentaires
74

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 83/383
Soit A ∈M n,p(K). Alors :
1. Opérations élémentaires sur les colonnes de A :
• La matrice obtenue à partir de A par l’opération C i ← λC i est A D pi (λ).
• La matrice obtenue à partir de A par l’opération C i ↔ C j est A τ pi,j.
• La matrice obtenue à partir de A par l’opération C i
← C i + λC j est A T p j,i(λ).
2. Opérations élémentaires sur les lignes de A :
• La matrice obtenue à partir de A par l’opération Li ← λLi est Dni (λ) A.
• La matrice obtenue à partir de A par l’opération Li ↔ L j est τ ni,j A.• La matrice obtenue à partir de A par l’opération Li ← Li + λL j est T ni,j(λ) A.
Propriété – Traduction matricielle des opérations élémentaires
Démonstration
1. On rappelle qu’en général, la k-ième colonne d’un produit AB est le produit de A par lak-ième colonne de B. On notera C 1, . . . , C p les colonnes de A.
• En notant T 1, . . . , T p les colonnes de D
p
i (λ), on a AT i = λC i et AT k = C k si k = i. D’où lerésultat du premier point.
• De même, en notant T 1, . . . , T p les colonnes de τ pi,j, on a AT i = C j, AT j = C i et AT k = C k sik = i et k = j. D’où le résultat du deuxième point.
• Enfin, en notant T 1, . . . , T p les colonnes de T p j,i(λ), on a AT i = C i + λC j et AT k = C k si k = i.D’où le résultat du troisième point.
2. De même, la k-ième ligne d’un produit BA est le produit de la k-ième ligne de B par A. Onnotera L1, . . . , Ln les lignes de A.
• En notant T 1, . . . , T n les lignes de Dni (λ), on a T iA = λLi et T kA = Lk si k = i. D’où le résultat
du premier point.
• De même, en notant T 1, . . . , T n les lignes de τ n
i,j, on a T iA = L j , T jA = Li et T kA = Lk si k = iet k = j. D’où le résultat du deuxième point.
• Enfin, en notant T 1, . . . , T n les lignes de T ni,j(λ), on a T iA = Li + λL j et T kA = Lk si k = i.
D’où le résultat du troisième point.
Toutes les matrices élémentaires sont inversibles ; plus précisément : pour tout m ∈ N∗,pour tout i ∈ [[1,m]], tout j ∈ [[1,m]] tel que i = j, pour tout λ ∈ K,
(Dmi (λ))−1 = Dm
i (1/λ) si λ = 0,
τ mi,j
−1= τ mi,j,
T mi,j(λ)
−1
= T mi,j(−λ).
Propriété
Démonstration – On raisonne à l’aide d’opérations sur les lignes : si λ = 0, Dmi (1/λ)Dm
i (λ) est,d’après la propriété précédente, la matrice obtenue à partir de Dm
i (λ) par l’opération Li ← Li/λ,c’est-à-dire la matrice identité I m. Donc Dm
i (λ) est inversible d’inverse Dmi (1/λ).
De même, τ mi,j τ mi,j est la matrice obtenue à partir de τ mi,j par l’opération Li ↔ L j , c’est-à-dire,la matrice I m. Donc τ mi,j est inversible et égale à sa propre matrice inverse.
Enfin, T mi,j(−λ)T mi,j(λ) est la matrice obtenue à partir de T mi,j(λ) par l’opérationLi ← Li − λL j, c’est-à-dire, ici encore, la matrice I m. Donc T mi,j(λ) est inversible d’inverseT mi,j(−λ).
Remarque – On comprend bien cette propriété et sa démonstration en voyant les choses ainsi :les opérations élémentaires sont « reversibles », l’opération Li ← λLi pour λ = 0 est compenséepar l’opération Li ← Li/λ, l’opération Li ↔ L j est compensée par elle-même, et l’opérationLi ← Li + λL j est compensée par l’opération Li ← Li − λL j (de même pour les colonnes).
75

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 84/383
Deux matrices A et A′ de M n,p(K) sont dites équivalentes par lignes (resp., par co-lonnes) si elles se déduisent l’une de l’autre par une suite finie d’opérations élémentairessur les lignes (resp., les colonnes). Ceci se note : A ∼
LA′ (resp. A ∼
C A′).
Définition – Matrices équivalentes par lignes ou par colonnes
Les opérations élémentaires étant réversibles, il est équivalent d’écrire A ∼L
A′ et A′ ∼L
A (de
même pour les colonnes).
De plus, grâce aux résultats précédents, A ∼L
A′ si et seulement s’il existe une matrice
E ∈ Gℓn(K), qui est un produit de matrices élémentaires, telle que A = EA′. De même, A ∼C
A′
si et seulement s’il existe une matrice E ∈ Gℓ p(K) produit de matrices élémentaires, telle queA = A′E.
2. Algorithme du pivot de Gauss-Jordan
On a montré plus haut que le rang n’est pas modifié par multiplication à gauche ou à droitepar une matrice inversible. En fait, il y a d’autres invariants de ce type : soit A ∈ M n,p(K).
• Si P ∈ Gℓn(K), alors pour tout vecteur X ∈M p,1(K), on a l’équivalence :
AX = 0 ⇔ P AX = 0,
car P est inversible. Ceci montre que Ker(A) = Ker(P A) : le noyau d’une matrice n’est donc pasmodifié par multiplication à gauche par une matrice inversible.
• Si P ∈ Gℓ p(K), alors pour tout vecteur Y ∈M n,1(K), on a l’équivalence
∃ X ∈M p,1(K); Y = AX ⇔ ∃ X ∈M p,1(K); Y = (AP )(P −1X ).
Sachant que P −1X décrit M p,1(K) lorsque X décrit M p,1(K) (car P est inversible), on en déduitque Im(A) = Im(AP ) : l’image d’une matrice n’est donc pas modifiée par multiplication à droite
par une matrice inversible.
Reprenons ces considérations dans le cas où P est une matrice élémentaire : le rang d’unematrice A n’est pas modifié par les opérations élémentaires, son noyau n’est pas modifié par lesopérations élémentaires sur ses lignes , son image n’est pas modifiée par les opérations élémentairessur ses colonnes . En d’autres termes :
• Deux matrices équivalentes par lignes ou par colonnes ont le même rang.
• Deux matrices équivalentes par lignes ont le même noyau.
• Deux matrices équivalentes par colonnes ont la même image.
Propriété
Il est donc naturel d’essayer, au moyen d’opérations élémentaires bien choisies, d’obtenir àpartir de A une matrice A′ sur laquelle il sera plus facile de lire les informations telles que son
rang, son noyau ou son image, qui seront les mêmes que ceux de A. C’est l’objectif de l’algorithmede Gauss-Jordan.
Commençons par décrire la forme équivalente la plus simple à laquelle on souhaite aboutir :
76

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 85/383
Soit B ∈M n,p(K).
• On dit que B est échelonnée par lignes si elle vérifie les propriétés suivantes :
(i) Si une ligne de B est nulle, alors toutes les lignes suivantes de B sont nulles.
(ii) Le cas échéant, dans chaque ligne non nulle à partir de la deuxième ligne, le premiercoefficient non nul (à partir de la gauche) et situé strictement à droite du premier
coefficient non nul de la ligne précédente.Le premier coefficient non nul d’une ligne non nulle est appelé pivot.
• On dit que B est échelonnée réduite par lignes si elle est échelonnée par ligneset si tous ses pivots sont égaux à 1 et sont les seuls éléments non nuls de leur colonne.
• On dit que B est échelonnée par colonnes (resp. échelonnée réduite par co-lonnes) si tB est échelonnée par lignes (resp. échelonnée réduite par lignes).
Définition – Matrices échelonnées, échelonnées réduites
Remarque – Une matrice échelonnée réduite par lignes non nulle a la forme suivante (les pivotssont notés en gras, le symbole ∗ désigne un coefficient éventuellement non nul. ) :
0 · · · 1 ∗ · · · ∗ 0 ∗ · · · ∗ 0 ∗ · · · ∗0 · · · 0 0 · · · 0 1 ∗ · · · ∗ 0 ∗ · · · ∗0 · · · 0 0 · · · 0 0 ∗ · · · ∗ 0 ∗ · · · ∗...
......
......
... . . .
......
......
0 · · · 0 0 · · · 0 0 0 · · · ∗ 0 ∗ · · · ∗0 · · · 0 0 · · · 0 0 0 · · · 0 1 ∗ · · · ∗0 · · · 0 0 · · · 0 0 0 · · · 0 0 0 · · · 0...
......
......
......
......
...0 · · · 0 0 · · · 0 0 0 · · · 0 0 0 · · · 0
Le trait de séparation représenté en partie dans la matrice ci-dessus permet de mettre envaleur sa structure de matrice échelonnée et ses pivots. On parle de schéma en escalier.
Chaque ligne et chaque colonne possédant au plus un pivot, le nombre r de pivots d’unematrice échelonnée B ∈M n,p(K) vérifie r n et r p.
Exemple – La matrice 1 0 3 5 7
0 2 4 6 80 0 0 1 9
est échelonnée par lignes, mais pas échelonnée réduite par lignes. La matrice
1 0 3 0 7
0 1 4 0 80 0 0 1 9
est échelonnée réduite par lignes. Une telle matrice peut donc tout à fait posséder, en dehors despivots, des coefficients non nuls.
La matrice précédente n’est pas échelonnée par colonnes. La matrice
1 0 02 0 00 1 0
est échelonnée réduite par colonnes.
77

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 86/383
Soit A ∈M n,p(K). Alors :
• A est équivalente par lignes à une unique matrice échelonnée réduite par lignes.
De façon équivalente : il existe une matrice E ∈ Gℓn(K), qui est un produit de matricesélémentaires, et une unique matrice R ∈M n,p(K) échelonnée réduite par lignes, tellesque A = ER.
• A est équivalente par colonnes à une unique matrice échelonnée réduite par colonnes.De façon équivalente : il existe une matrice E ′ ∈ Gℓ p(K), qui est un produit de matricesélémentaires, et une unique matrice R′ ∈ M n,p(K) échelonnée réduite par colonnes,telles que A = R′E ′.
Théorème – Algorithme de Gauss-Jordan et traduction matricielle
Démonstration de l’existence (la démonstration de l’unicité, non exigible, est admise)
Montrons tout d’abord que le premier point entraîne le second; pour cela on applique lerésultat du premier point à tA : il existe E , produit de matrices élémentaires, et R échelonnéeréduite par lignes, telles que tA = ER. Alors A = tR tE . Par définition, R′ = tR est échelonnée par
colonnes ; la transposée de toute matrice élémentaire étant une matrice élémentaire, E ′ = tE estun produit de matrices élémentaires. D’où l’existence dans le cas des opérations sur les colonnes.
Dans le cas des opérations sur les lignes, on procède par récurrence sur le nombre p de colonnesde A = (ai,j).
Initialisation : si p = 1, A est une matrice colonne. Si A = 0, le résultat est vrai, sinon, ilexiste i0 ∈ [[1,n]] tel que ai0,1 = 0. L’opération Li0 ↔ L1 (ce qui revient à multiplier A à gauchepar τ n1,i0) fournit une matrice A′ équivalente par lignes à A dont le coefficient en position (1,1)vaut ai0,1 (et dont le coefficient en position (i0,1) vaut a1,1). Après l’opération L1 ↔ L1/ai0,1(multiplication de A′ à gauche par Dn
1 (1/ai0,1)) le coefficient en position (1,1) vaut 1. On faitalors, si n 2, les n
−1 opérations suivantes : Li
← Li
−ai,1L1, pour i
∈ [[2,n]] (multiplication
à gauche par T ni,1(−ai,1)), ce qui prouve que A est équivalente par lignes à
R =
10...0
et prouve le résultat dans ce cas, car R est évidemment échelonnée réduite par lignes.
Hérédité : supposons le résultat vrai au rang p, et soit A
∈M n,p+1(K).
Premier cas : la première colonne de A est nulle. On applique alors l’hypothèse de récurrenceà la matrice B obtenue en extrayant les p dernières colonnes de A. Les opérations faites sur Bpeuvent alors être faites sur A ; elles ne modifient pas la première colonne de A car cette colonneest nulle. La matrice obtenue à partir de B est échelonnée réduite par lignes, il en est de mêmepour celle obtenue à partir de A.
Deuxième cas : la première colonne de A est non nulle. On fait tout d’abord, pour cettepremière colonne, exactement le même raisonnement que pour l’initialisation. On note A1 lamatrice équivalente par lignes à A à laquelle on aboutit alors, puis on applique, si n 2,l’hypothèse de récurrence à la matrice B1 obtenue en extrayant les n − 1 dernières lignes etles p dernières colonnes de A
1. Les opérations faites sur B
1 peuvent alors être traduites en des
opérations sur les n − 1 dernières lignes de A1 ; on obtient ainsi une matrice notée A2. Cesopérations ne modifient pas la première colonne de A1 car les coefficients de A1 en position (i,1)avec i 2 sont nuls.
78

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 87/383
Pour résumer les notations, on a donc l’enchaînement suivant dans ce cas :
A =
a1,1 · · · · · · · · · · · ·...
. . . ...
ai0,1. . .
......
. . . ...
an,1 · · · · · · · · · · · ·
traitement de la première colonne−→ A1 =
1 · · · · · · · · · · · ·0... B1...
0
échelonnement de B1−→ A2 =
1 · · · · · · · · · · · ·0... B2...0
,
la matrice B2 étant échelonnée réduite par lignes.
En particulier, il est clair que A2 est échelonnée par lignes. En revanche, elle peut ne pas être
échelonnée réduite car un pivot de B2 peut ne pas être le seul coefficient non nul de sa colonnedans la matrice A2. Ceci n’est possible que si B2 = 0. Dans ce cas, notons (i1,j1), . . . ,(ir,jr) lespositions dans la matrice A2 des pivots de B2, avec i1 < · · · < ir. Pour k de r à 1, on effectuesur A2 l’opération L1 ← L1 − a1,jkLik . Pour chacune de ces opérations, la première colonne deA2 n’est pas modifiée, les coefficients a1,jm tels que m > k ne sont pas modifiés ; à l’issue de cesopérations, les pivots de la matrice obtenue, notée R, sont donc les seuls coefficients non nuls deleur colonne. La matrice R est échelonnée réduite par lignes, ce qui prouve le résultat du pointde vue « opérations élémentaires ».
Du point de vue matriciel, chaque opération revient à multiplier à gauche par une matriceélémentaire (comme indiqué dans l’étape d’initialisation). On en déduit qu’il existe une matrice
D, produit de matrices élémentaires, telle que DA = R. Une matrice élémentaire étant inversibleet son inverse étant une matrice élémentaire, D est inversible et D−1 est un produit de matricesélémentaires. En posant E = D−1, on a bien A = ER avec la forme voulue.
Remarques
• La démonstration ci-dessus décrit entièrement une méthode effective d’échelonnement par lignesou colonnes. Elle est en particulier programmable pour un traitement par ordinateur.
• Dans le cas d’opérations sur les lignes, la première étape de l’algorithme est dite étape dedescente, elle aboutit à une forme échelonnée par lignes. La deuxième étape, qui aboutit à laforme échelonnée réduite par lignes, est dite étape de remontée.
• Le théorème affirme l’unicité de R mais pas celle de E . Cela est lié au fait qu’il n’y a pas une
unique suite d’opérations élémentaires qui permet de passer de A à R. En revanche, quelle quesoit la suite d’opérations convenable, on aboutira à la même matrice échelonnée réduite R. Toutesuite d’opérations élémentaires sur les lignes qui permet de déduire de A une matrice échelonnéeréduite par lignes est donc acceptée (de même pour les colonnes).
• Notamment, même si la démonstration précédente présente l’annulation des coefficients situésau-dessus d’un pivot seulement en fin de procédure, de la droite vers la gauche, on vérifie faci-lement qu’il est possible de le faire au fur et à mesure, c’est-à-dire de traiter entièrement unecolonne avant de passer à la suivante. On remarquera cependant que cela entraîne des calculsmoins simples (report de coefficients non nuls) lors des opérations du type Li ← Li + λL j.
• Il faut être vigilant lorsque l’on fait plusieurs opérations à la suite, par exemple sur les lignes :si après la première opération, la ligne i est modifiée, et si l’opération suivante utilise L
i, il s’agit
de la ligne modifiée . C’est ce qui se passe par exemple lors de la suite d’opérations L2 ← L2 −L1,L3 ← L3 − L2 : la ligne L2 utilisée pour la deuxième opération est celle qui est issue de lapremière opération !
79

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 88/383
Exemples
• Échelonnons par lignes la matrice M suivante. À gauche, on indique les différentes matriceséquivalentes par lignes obtenues, jusqu’à la forme échelonnée réduite par lignes, et à droite, onindique l’opération qui permet de passer à l’étape suivante, et sa traduction matricielle (m. à g.signifie « multiplication à gauche »).
M =0 0 −1 22 4 6 −2
3 6 5 3
L1 ↔ L2, m. à g. par0 1 01 0 0
0 0 1
∼L
2 4 6 −2
0 0 −1 23 6 5 3
L1 ← L1/2, m. à g. par
1/2 0 0
0 1 00 0 1
∼L
1 2 3 −1
0 0 −1 23 6 5 3
L3 ← L3 − 3L1, m. à g. par
1 0 0
0 1 0−3 0 1
∼L
1 2 3 −10 0 −1 2
0 0 −4 6
.
On a alors traité la première colonne, on poursuit l’algorithme en raisonnant sur la matriceextraite d’ordre 2 × 3 en bas à droite. La première colonne de cette matrice étant nulle, onpoursuit en raisonnant sur la matrice extraite d’ordre 2 × 2 en bas à droite :
1 2 3 −1
0 0 −1 20 0 −4 6
L2 ← −L2, m. à g. par
1 0 0
0 −1 00 0 1
∼L 1 2 3 −1
0 0 1 −20 0 −4 6
L3 ← L3 + 4L2, m. à g. par1 0 0
0 1 00 4 1
∼L
1 2 3 −1
0 0 1 −20 0 0 −2
L3 ← L3/(−2), m. à g. par
1 0 0
0 1 00 0 −1/2
∼L
1 2 3 −1
0 0 1 −20 0 0 1
.
À ce stade, on a une matrice échelonnée par lignes mais pas échelonnée réduite. On annule donc,en partant de la droite, les coefficients situés au-dessus des pivots :
1 2 3 −1
0 0 1 −20 0 0 1
L2 ← L2 + 2L3
L1 ← L1 + L3, m. à g. par
1 0 0
0 1 20 0 1
, puis
1 0 1
0 1 00 0 1
∼L
1 2 3 0
0 0 1 00 0 0 1
L1 ← L1 − 3L2, m. à g. par
1 −3 0
0 1 00 0 1
∼L
1 2 0 00 0 1 00 0 0 1
.
La matrice ci-dessus, notée R, est la matrice échelonnée réduite par lignes associée à M . On peutdonner directement à partir des calculs précédents, une décomposition E R pour la matrice M .
80

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 89/383
• L’exemple suivant illustre, sur une même matrice A, les deux méthodes. On remarquera quel’échelonnement en ligne ou en colonne n’aboutit pas à la même matrice.
Échelonnement par lignes :
A =
1 2 8
−1 0 −21 1 5
L3 ← L3 + L2
L2 ← L2 + L1
∼L
1 2 80 2 60 1 3
L2 ↔ L3
∼L
1 2 8
0 1 30 2 6
L3 ← L3 − 2L2
∼L
1 2 8
0 1 30 0 0
L1 ← L1 − 2L2
∼L1 0 2
0 1 30 0 0
Échelonnement par colonnes :
A =
1 2 8
−1 0 −21 1 5
C 2 ← C 2 − 2C 1C 3 ← C 3 − 8C 1
∼C
1 0 0−1 2 61 −1 −3
C 3 ← C 3 − 3C 2
∼C
1 0 0
−1 2 01 −1 0
C 2 ← C 2/2
∼C
1 0 0
−1 1 01 −1/2 0
C 1 ← C 1 + C 2
∼C 1 0 0
0 1 01/2 −1/2 0
Rappelons que l’image de A n’est pas modifiée par l’algorithme de Gauss-Jordan sur les
colonnes. On en déduit que
Im(A) = Vect
1
01/2
,
0
1−1/2
,
et en particulier rg(A) = 2. Plus généralement, cette méthode permet de déterminer l’espacevectoriel engendré par une famille finie de vecteurs d’un espace de dimension finie.
De même, le noyau n’est pas modifié par l’algorithme de Gauss-Jordan sur les lignes, et donc :x
yz
∈ Ker(A) ⇔
x
yz
∈ Ker
1 0 2
0 1 30 0 0
, ⇔
x + 2z = 0
y + 3z = 0
On en déduit que
Ker(A) =
−2z
−3zz
; z ∈ K
= Vect
−2
−31
,
de dimension 1, en accord avec le théorème du rang.
3. Échelonnement, rang et matrices inversibles
Soit A ∈ M n,p(K). Alors le rang de A est égal au nombre de pivots de sa matriceéchelonnée réduite par lignes, et égal au nombre de pivots de sa matrice échelonnéeréduite par colonnes.
Propriété
Démonstration – Soit R la matrice échelonnée réduite par lignes associée à A. La matrice R peutavoir des coefficients non nuls : en position de pivot, à droite dans la ligne de chaque pivot (maispas au-dessus d’autres pivots), et seulement à ces positions.
À l’aide d’opérations sur les colonnes de R, on obtient une matrice équivalente par colonnesà R, où les coefficients autres que les pivots ont été remplacés par des 0. Cette matrice est encore
81

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 90/383
échelonnée réduite par lignes et a les mêmes pivots que R (attention cependant, elle n’est engénéral pas équivalente par lignes à A).
Finalement, il existe une suite finie d’opérations élémentaires sur les lignes et les colonnes,qui permet de déduire de A une matrice échelonnée réduite par ligne, dont les seuls coefficientsnon nuls sont les pivots de R, un tel pivot étant le seul coefficient non nul de sa ligne et de sacolonne. Le rang d’une telle matrice est égal au nombre r des pivots, car la famille de ses colonnesnon nulles est clairement libre, et constituée de r vecteurs.
Les opérations élémentaires ne modifient pas le rang, donc le rang de A est égal au nombrede pivots de sa matrice échelonnée réduite par lignes. En raisonnant de la même façon, mais enéchelonnant d’abord par colonnes, on obtient que le rang de A est égal au nombre de pivots desa matrice échelonnée réduite par colonnes.
Remarques
• Dans le cas des exemples ci-dessus, les transformations du raisonnement précédent sont lessuivantes :
M ∼L
1 2 0 00 0 1 00 0 0 1
∼C
1 0 0 00 0 1 00 0 0 1
, A ∼
L
1 0 20 1 30 0 0
∼C
1 0 00 1 00 0 0
• Lorsque l’on passe, par opérations élémentaires, d’une matrice échelonnée à une matrice éche-lonnée réduite (par lignes ou colonnes), le nombre et la position des pivots ne sont pas modifiés.On en déduit que le rang d’une matrice échelonnée (même si elle n’est pas échelonnée réduite)est égal au nombre de ses pivots. En particulier, le rang de A ∈M n,p(K) est égal au nombre depivots de toute matrice échelonnée équivalente par lignes ou par colonnes à A.
Soit A ∈M n,p(K). Alors rg(tA) = rg(A).
En particulier, le rang de A (qui est le rang de la famille des colonnes de A) est aussiégal au rang de la famille de ses lignes.
Propriété – Rang de la transposée
Démonstration – Le rang de tA est égal au nombre de pivots de sa matrice échelonnée réduitepar lignes. Or, échelonner tA par lignes revient à échelonner A par colonnes, et à transposer lerésultat obtenu. Le nombre de pivots de la matrice échelonnée réduite par lignes de tA est doncégal au nombre de pivots de la matrice échelonnée réduite par colonnes de A, qui est le rangde A. On a donc rg(tA) = rg(A). On en déduit que le rang de A est le rang de la famille descolonnes de tA, c’est-à-dire le rang de la famille des lignes de A.
Soit A ∈M
n(K). La matrice A est inversible si et seulement si elle est équivalente (par
lignes ou par colonnes) à la matrice I n.
Propriété
Démonstration – On raisonne dans le cas des lignes, celui des colonnes est analogue. Notons R lamatrice échelonnée réduite par lignes de A. La matrice A est carrée, on sait qu’elle est inversiblesi et seulement si rg(A) = n, c’est-à-dire, si et seulement si R possède n pivots. D’après ladéfinition d’une matrice échelonnée réduite, c’est le cas si et seulement si R = I n.
Or, on remarque que la matrice I n est échelonnée réduite par lignes, donc si A ∼L
I n, alors
par unicité, R = I n. La réciproque est évidente car A ∼L
R par définition de R. Finalement, A
est inversible si et seulement si A ∼L
I n.
Or, on sait exactement comment déterminer la matrice échelonnée réduite par lignes de A :c’est l’algorithme de Gauss-Jordan. Il en découle un moyen effectif de déterminer A−1 lorsque Aest inversible :
82

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 91/383
Soit A ∈ Gℓn(K). On note (L) une suite finie d’opérations élémentaires sur les lignesde A à partir de laquelle on obtient sa matrice échelonnée réduite par lignes, I n.
Alors la matrice déduite de I n par la suite d’opérations (L) est A−1. On peut donnerle même résultat sur les colonnes.
Propriété – Calcul de l’inverse par l’algorithme de Gauss-Jordan
Démonstration – La suite (L) correspond à une matrice E ∈ Gℓn(K), produit de matrices élémen-taires, telle que EA = I n. On en déduit que E = A−1, c’est-à-dire, EI n = A−1. En effectuantsur I n la suite (L) d’opérations élémentaires, on obtient donc A−1.
Remarque – L’algorithme de Gauss-Jordan permet aussi de prouver que A est inversible : l’algo-rithme aboutit à I n si et seulement si A est inversible.
Exemple – Soit C =
1 0 1
2 1 3−1 2 2
. On fait en parallèle les mêmes opérations sur les lignes de C
et de I 3 :
1 0 12 1 3
−1 2 2
L2 ← L2 − 2L1
L3 ← L3 + L1
1 0 00 1 00 0 1
1 0 1
0 1 10 2 3
L3 ← L3 − 2L2
1 0 0
−2 1 01 0 1
1 0 1
0 1 10 0 1
L1 ← L1 − L3
L2 ← L2 − L3
1 0 0
−2 1 05 −2 1
1 0 00 1 00 0 1
−4 2 −1−7 3 −15
−2 1
.
On en déduit que C est inversible et que C −1 =
−4 2 −1
−7 3 −15 −2 1
.
Soit (x1, . . . , x p) une famille d’un K-espace vectoriel E de dimension n. On rappelle que :
• (x1, . . . , x p) est libre si et seulement si rg(x1, . . . , x p) = p.
• (x1, . . . , x p) engendre E si et seulement si rg(x1, . . . , x p) = n.
• (x1, . . . , x p) est une base de E si et seulement si p = n et rg(x1, . . . , x p) = n.
Soit A ∈ M n,p(K) la matrice de (x1, . . . , x p) dans une base quelconque de E . Le rang de
(x1, . . . , x p) est égal au rang de la matrice A, qui lui-même, est égal au nombre r de pivotsde toute matrice échelonnée équivalente par lignes ou colonnes à la matrice A. On en déduitque :
• (x1, . . . , x p) est libre si et seulement si r = p.
• (x1, . . . , x p) engendre E si et seulement si r = n.
• (x1, . . . , x p) est une base de E si et seulement si r = p = n.
Exemples
• Avec la matrice A des exemples précédents, montrons que M 3,1(R) = Ker(A) ⊕ Im(A) : pourcela on montre que la famille
−2
−31
,
1
01/2
,
0
1−1/2
83

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 92/383
est une base de M 3,1(R) grâce à l’algorithme de Gauss-Jordan sur sa matrice D dans la basecanonique :
D =
−2 1 0
−3 0 11 1/2 −1/2
C 1 ↔ C 2
∼C 1 −2 00
−3 1
1/2 1 −1/2 C 2
← C 2 + 2C 1
∼C
1 0 0
0 −3 11/2 2 −1/2
C 2 ↔ C 3
∼C
1 0 0
0 1 −31/2 −1/2 2
C 3 ← C 3 + 3C 2
∼C
1 0 00 1 0
1/2
−1/2 1/2
La matrice précédente est échelonnée par colonnes. Avec les notations précédentes, on a dans cecas r = p = n = 3, d’où le résultat. D’après un résultat du chapitre précédent (fractionnementd’une base), on a donc
M 3,1(R) = Vect
−2
−31
⊕ Vect
1
01/2
,
0
1−1/2
= Ker(A) ⊕ Im(A).
• Dans E = R1[X ], on considère la famille
F = (X + 1,X + 2,X + 3).
On sait que cette famille est liée car elle est constituée de 3 vecteurs en dimension 2 ; on chercheune relation de dépendance linéaire entre ses éléments. On met en oeuvre l’algorithme de Gauss-Jordan sur les lignes de N , matrice de la famille F dans la base (X,1) de R1[X ] :
N =
1 1 11 2 3
L2 ↔ L2 − L1
∼L
1 1 10 1 2
L1 ← L1 − L2
∼L 1 0
−1
0 1 2 On a r = n = 2 et p = 3. On retrouve le fait que la famille F est liée, mais on sait aussi qu’elleengendre R1[X ]. De plus, déterminer les relations de dépendance linéaire entre les éléments deF revient à déterminer les éléments non nuls de Ker(N ), qui d’après le calcul précédent, estcaractérisé par le système
x − z = 0
y + 2z = 0
On en déduit que Ker(N ) = Vect(t
1 −2 1
) et notamment,
(X + 1) − 2(X + 2) + (X + 3) = 0.
84

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 93/383
4. Résolution de systèmes linéaires
On s’intéresse dans ce paragraphe à la résolution des systèmes linéaires par l’algorithme deGauss-Jordan. On rappelle que la forme générale d’un tel système est
(S ) :
a1,1x1+ · · · + a1,px p = b1
a2,1x1+ · · · + a2,px p = b2
.
..an,1x1+ · · · + an,px p = bn
et qu’en notant A = (ai,j)1in,1 j p ∈M n,p(K), X ∈M p,1(K) la matrice colonne de coefficientsx1, . . . , x p et B ∈M n,1(K) la matrice colonne de coefficients b1, . . . , bn, ce système se met sous laforme matricielle (E ) : AX = B , c’est-à-dire que (x1, . . . , x p) est solution de (S ) si et seulementsi X est solution de (E ).
Avec les notations précédentes :
• On dit que A est la matrice du système linéaire (S ).• On appelle seconds membres du système (S ) les scalaires b1, . . . , bn ; on appellecolonne des seconds membres de (S ) la matrice colonne B.
• On appelle système homogène (ou sans second membre) associé à (S ) le systèmeobtenu à partir de (S ) en remplaçant tous les bi par 0. Ce système s’écrit matriciellementAX = 0.
• On appelle matrice augmentée associée à (S ) la matrice (A|B) obtenue en mettantcôte à côte A et B (dans cet ordre) dans une même matrice, i.e.
∀ (i,j) ∈ [[1,n]] × [[1,p + 1]], (A|B)i,j =
ai,j si j p
bi si j = p + 1.
Définition
Comme on l’a expliqué dans le chapitre précédent, le système (S ) possède au moins unesolution si et seulement si l’équation AX = B possède au moins une solution, ce qui équivaut aufait que B ∈ Im(A).
Dans ce cas, l’ensemble des solutions de l’équation AX = B est X 0 + Y ; Y ∈ Ker(A), oùX 0 désigne une solution particulière de l’équation. En d’autres termes, l’ensemble des solutionsde (S ) est x0 + y; y ∈ S h, où x0 est une solution particulière de (S ) et S h désigne l’ensembledes solutions du système homogène (S h) associé à (S ).
• On dit que le système (S ) est compatible s’il possède au moins une solution (c’est-à-dire, avec les notations précédentes, si B ∈ Im(A)).
• On dit que (S ) est incompatible dans le cas contraire.
Définition – Système compatible/incompatible
Remarque – Un vecteur (x1, . . . , x p) ∈ K p est solution de (S ) si et seulement si
a1,1x1+ · · · + a1,px p − b1 = 0
a2,1x1+ · · · + a2,px p − b2 = 0
...
an,1x1+ · · · + an,px p − bn = 0,
, ce qui équivaut à :
x1...
x p−1
∈ Ker((A|B)).
Nous allons maintenant expliquer comment résoudre en pratique les systèmes linéaires.
85

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 94/383
• On définit les mêmes opérations élémentaires sur les lignes d’un système linéaire quesur les matrices (en tenant compte des seconds membres).
• On dit que deux systèmes linéaires sont équivalents si on peut passer de l’un àl’autre par une suite finie d’opérations élémentaires sur les lignes.
Définition – Opérations sur les lignes d’un système linéaire
Remarques
• Les opérations élémentaires étant réversibles, il n’est pas ambigu de dire que deux systèmessont équivalents.
• Soient (S ) et (S ′) deux systèmes linéaires de matrices respectives A et A′ de même taille, et decolonnes des seconds membres respectives B et B ′. Alors, pour que (S ) et (S ′) soient équivalents,il faut et il suffit que (A|B) et (A′|B′) soient équivalentes par lignes. Plus précisément, si (L)désigne une suite finie d’opérations sur les lignes, alors on peut passer de (S ) à (S ′) par la suite(L) si et seulement si on peut passer de (A|B) à (A′|B′) par la suite (L).
Ceci justifie la présentation matricielle des systèmes linéaires : pour passer d’un systèmelinéaire (S ) à un système (S ′) qui lui soit équivalent, on peut former la matrice augmentée (A|B)
associée à (S ), effectuer des opérations élémentaires sur les lignes de (A|B), ce qui fournit unematrice de la forme (A′|B′) à partir de laquelle on obtient (S ′).
L’intérêt des opérations élémentaires sur les lignes d’un système linéaire vient notamment dela propriété suivante :
Deux systèmes linéaires équivalents ont le même ensemble de solutions.
Propriété
Démonstration – Avec les notations précédentes, si (S ) et (S ′) sont équivalents, (A|B) et (A′|B′)
sont équivalentes par lignes. Comme on l’a déjà montré, elles ont donc le même noyau. Ainsi,pour (x1, . . . , x p) ∈ K p, on a l’équivalence
x1...
x p−1
∈ Ker((A|B)) ⇔
x1...
x p−1
∈ Ker((A′|B′)),
et donc, d’après une remarque faite plus haut, (x1, . . . , x p) est solution de (S ) si et seulement si(x1, . . . , x p) est solution de (S ′).
Résolution pratique d’un système linéaire
Un système linéaire (S ) de forme matricielle AX = B, dont la matrice A est échelonnéeréduite par lignes, est particulièrement facile à résoudre : en gardant à l’esprit la forme généraled’une matrice échelonnée réduite par lignes donnée page 77, notons (i1,j1), . . . ,(ir,jr) les positionsdes pivots de A (on suppose A non nulle) ; en particulier, on a :
• j1 < · · · < jr,
• les r premières lignes de A sont non nulles et, le cas échéant, les n − r dernières sont nulles,
• pour tout k ∈ [[1,r]], aik,jk = 1, et aik ,j = 0 si j < jk, ai,jk = 0 si i = ik.
Commençons par examiner, le cas échéant, les n − r dernières lignes de A. Elles correspondentaux équations 0 = bi, pour i ∈ [[r + 1,n]]. Si l’un des bi, pour i ∈ [[r + 1,n]], est non nul, alors (S )ne possède aucune solution : il est incompatible.
Sinon, la r-ième équation s’écrit
x jr + ar,jr+1 x jr+1 + · · · + ar,p x p = br,
86

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 95/383
elle donne directement x jr en fonction de br et x jr+1, . . . , x p. On remonte alors dans le système, jusqu’à la première équation,
x j1 + a1,j1+1 x j1+1 + · · · + a1,p x p = b1,
ce qui donne directement x j1 en fonction de b1 et x j1+1, . . . , x p, mais l’expression ne fait pasintervenir x j2 , . . . , x jr car la matrice A est échelonnée réduite . Finalement, dans ce cas, (S ) possèdedes solutions, et tout choix de valeurs pour les x j tels que j /∈ j1, . . . , jr donne explicitement
une solution de (S ).Dans le cas général, (A quelconque), il existe une matrice E , produit de matrices élémentaires,
et R, échelonnée réduite par lignes, telles que EA = R. L’équation AX = B équivaut à l’équationRX = EB : on retrouve la situation précédente. On remarque que EB est la matrice colonneobtenue en effectuant sur B les opérations faites pour passer de A à sa forme échelonnée réduitepar lignes R.
En pratique, pour résoudre l’équation AX = B , on forme la matrice augmentée (A|B), surlaquelle on met en oeuvre l’algorithme de Gauss-Jordan sur les lignes :
• À l’issue de la phase de descente, on peut déjà déterminer si le système est compatible ouincompatible : il est compatible si et seulement si la dernière colonne (correspondant au second
membre) ne contient aucun pivot. Les opérations élémentaires que l’on aurait faites en traitantuniquement A suffisent à faire cette vérification.
• Si le système est compatible, la phase de remontée fera intervenir les mêmes opérations élémen-taires que si l’on échelonnait uniquement A, car le dernier pivot ne se situe pas dans la dernièrecolonne correspondant au second membre. On obtient donc bien la forme équivalente RX = EB.
Exemple – Résolvons le système linéaire
x +2y +8z = 7−x −2z = −3x +y +5z = 5
La matrice de ce système est la matrice A d’un exemple traité page 81. La colonne des secondsmembres est B = t
7 −3 5
. On met en oeuvre l’algorithme de Gauss-Jordan sur les lignesde la matrice augmentée (A|B) :
(A|B) =
1 2 8 7
−1 0 −2 −31 1 5 5
L3 ← L3 + L2
L2 ← L2 + L1
∼L
1 2 8 7
0 2 6 40 1 3 2
L2 ↔ L3
∼L 1 2 8 7
0 1 3 20 2 6 4
L3 ← L3 − 2L2
∼L
1 2 8 7
0 1 3 20 0 0 0
Le système est compatible. L’opération L1 ← L1 − 2L2 montre finalement que
(A|B) ∼L
1 0 2 3
0 1 3 20 0 0 0
Le système (S ) est donc équivalent àx + 2z = 3
y + 3z = 2i.e., à
x = 3 − 2z
y = 2 − 3z
87

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 96/383
L’inconnue z n’est liée par aucune équation, on la choisit comme paramètre, que l’on peutrenommer λ, c’est-à-dire que l’ensemble des solutions de (S ) est
(3 − 2λ, 2 − 3λ, λ); λ ∈ K = (3,2,0) + λ (−2, − 3,1); λ ∈ K.
On obtient une représentation paramétrique de l’ensemble des solutions, et on retrouve bien,pour les solutions, la forme générale x0 + y où x0 = (3,2,0) est une solution particulière (obtenue
pour λ = 0), et y ∈ Vect(−2, − 3,1) avec
Vect
−2
−31
= Ker(A).
Soit (S ) un système linéaire de matrice A non nulle.
• Les inconnues x j1 , . . . , x jr dont les indices sont ceux des colonnes des pivots de la ma-trice échelonnée réduite par lignes associée à A, sont appelées inconnues principalesde (S ).
• Les autres inconnues sont appelées inconnues secondaires, ou paramètres.
• On appelle rang du système (S ) le nombre r, c’est-à-dire le nombre de pivots de lamatrice échelonnée réduite par lignes associée à A.
• Le nombre de paramètres est donc égal à p −r, c’est-à-dire, à la différence du nombred’inconnues et du rang de (S ).
Définition
Remarques
• Comme on l’a montré dans le paragraphe 3, r est aussi le rang de la matrice A, ce qui montrela cohérence de l’appellation.
• Un système sans second membre est toujours compatible, car le p-uplet (0, . . . ,0) en est solution.• Dans l’exemple traité ci-dessus, les inconnues principales sont x et y, le paramètre est z. Lerang du système est 2.
De l’étude précédente, on déduit que trois cas se présentent quant à l’ensemble S des solutionsd’un système linéaire (S ) de rang r et de matrice A ∈M n,p(K) :
• Si le système est incompatible, alors S = ∅.
• Si le système est compatible et si r = p, alors le système n’a que des inconnues principales,et donc, possède une unique solution : S est réduit à un point.
• Si le système est compatible et si r < p, alors le système a p − r paramètres et S est infini.
Le théorème du rang montre aussi que
p = dim(Ker(A)) + rg(A), c’est-à-dire que p − r = dim(Ker(A)).
Le nombre de paramètres d’un système compatible de matrice A est donc égal à dim(Ker(A)).Ceci est bien sûr cohérent avec la description de l’ensemble des solutions de (S ).
De plus, on rappelle que le système est compatible si et seulement si B ∈ Im(A). Par exemple,si r = n, alors rg(A) = dim(M n,1(R)), et donc Im(A) = M n,1(R) : le système est donc compatiblequel que soit le choix de B. Si r < n, il existe des choix de B pour lesquels le système estincompatible. C’est par exemple le cas si p < n, car dans ce cas r p < n.
La situation suivante est également intéressante : si r = n = p, alors quel que soit le choixde B , le système (S ) est compatible et possède une unique solution (on dit dans ce cas que (S )est un système de Cramer). On retrouve ce résultat en remarquant que dans ce cas, A est unematrice carrée inversible; pour tout B , on a l’équivalence AX = B ⇔ X = A−1B.
88

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 97/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 98/383
Soient A et B deux matrices carrées d’ordre n. Alors Tr(AB) = Tr(BA).
Propriété
Démonstration – Notons ai,j et bi,j les coefficients de A et B . Alors pour tout (i,j) ∈ [[1,n]]2,
(AB)i,j =n
k=1
ai,k
bk,j
,
de sorte que Tr(AB) =ni=1
(AB)i,i =ni=1
nk=1
ai,k bk,i. En changeant d’indice, on peut écrire
Tr(AB) =n
i,j=1
ai,j b j,i.
En échangeant les rôles de A et B , on a de même
Tr(BA) =
ni,j=1
bi,j a j,i.
Le changement d’indice i ↔ j montre alors que Tr(BA) = Tr(AB).
Deux matrices semblables ont la même trace.
Propriété
Démonstration – Si A et B sont semblables, il existe P ∈ Gℓn(K) tel que B = P −1AP. Alorsd’après la propriété précédente,
Tr(B) = Tr(P −1AP ) = Tr(AP P −1) = Tr(A).
2. Trace d’un endomorphisme
Soient E un K-espace vectoriel de dimension finie et u ∈ L (E ). Toutes les matricesreprésentant l’endomorphisme u ont la même trace : si B et B′ sont deux bases de E ,si A = MatB(u) et B = MatB′(u), alors Tr(A) = Tr(B).
Propriété
Démonstration – Si A = MatB
(u) et B = MatB′(u), alors A et B sont semblables d’après les
formules de changement de bases. Le résultat provient alors de la propriété précédente.
Soient E un K-espace vectoriel de dimension finie et u ∈L (E ). On définit la trace deu comme la trace d’une quelconque de ses matrices.
Définition – Trace d’un endomorphisme
Exemple – Soit
u :
M 2(R) → M 2(R)
M → tM + 2M
Pour calculer Tr(u), écrivons la matrice de u dans la base de M 2(R)
B = (e1,e2,e3,e4) =
1 00 0
,
0 01 0
,
0 10 0
,
0 00 1
;
90

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 99/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 100/383
2. Sous-espaces stables
Dans ce paragraphe uniquement, E est un K-espace vectoriel qui n’est pas supposé de di-mension finie.
Si E = V ⊕ W , un endomorphisme u ∈ L (E ) est entièrement défini par ses restrictions à V et W , qui peuvent être plus simples si V et W sont bien choisis.
Soit V un sous-espace vectoriel de E , et u ∈ L (E ).
On dit que V est stable par u si u(V ) ⊂ V , c’est-à-dire : ∀ x ∈ V , u(x) ∈ V .
Définition – Sous-espace stable par un endomorphisme
Exemple – Soit E = K[X ], V = P ∈ E ; P (1) = 0 et u l’application linéaire qui à P ∈ E
associe le polynôme X P (X ). Alors V est stable par u : si P (1) = 0, on a aussi (u(P ))(1) = 0.
Si V est un sous-espace vectoriel de E stable par u, alors l’application
u|V :
V → V
x → u(x)
est un endomorphisme de V , appelé endomorphisme de V induit par u.
Propriété/Définition – Endomorphisme induit
Attention ! Il ne s’agit pas d’une simple restriction de u : l’espace d’arrivée est aussi restreint.
Soient u et v deux endomorphismes de E qui commutent (i.e. u
v = v
u).
Alors Ker(u) et Im(u) sont stables par v.
Propriété
Démonstration – Soit x ∈ Ker(u). Montrons que v(x) ∈ Ker(u) : sachant que u et v commutent,on a u(v(x)) = v(u(x)) = v(0) = 0, i.e. v(x) ∈ Ker(u), d’où le résultat.
De même si y = u(x) ∈ Im(u), avec x ∈ E, alors v(y) = v(u(x)) = u(v(x)) ∈ Im(u), doncIm(u) est stable par v .
Remarque – En particulier, si u ∈ L (E ), Ker(u) et Im(u) sont stables par u (en effet, u commuteavec lui-même).
3. Traduction matricielleDans ce paragraphe, E est un K-espace vectoriel de dimension finie n 2.
Soit V un sous-espace vectoriel de E de dimension r ∈ [[1,n − 1]]. Soit B = BV ⊔ F unebase de E adaptée à V (avec BV une base de V ) et soit u ∈ L (E ).
Alors V est stable par u si et seulement si MatB(u) est de la forme
A B0 C
où A est d’ordre r et 0 désigne un bloc nul. Dans ce cas, A = MatBV (u|V ).
Propriété
92

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 101/383
Démonstration – Notons B = (e1, . . . , en), de sorte que BV = (e1, . . . , er). Le sous-espace V eststable par u si et seulement si pour tout vecteur x de V , u(x) ∈ Vect(e1, . . . , er). En raison-nant avec des combinaisons linéaires, il est immédiat que ceci équivaut à : pour tout i ∈ [[1,r]],u(ei) ∈ Vect(e1, . . . , er).
Ainsi, V est stable par u si et seulement si les coordonnées de u(e1), . . . , u(er) selon er+1, . . . , ensont nulles. Or les r premières colonnes de MatB(u) sont les matrices colonnes des coordonnéesde u(e1), . . . , u(er) dans la base B. On a donc l’équivalence souhaitée.
Lorsque V est stable par u, les colonnes de la matrice A sont les matrices colonnes descoordonnées de u(e1), . . . , u(er) dans la base (e1, . . . , er) de V , donc A = MatBV (u|V ).
En raisonnant de façon analogue, on obtient :
Soient m 2, u ∈ L (E ) et B = B1 ⊔ · · · ⊔ Bm une base de E , où, pour tout i ∈ [[1,m]],Bi est composée de ni vecteurs.
Les propriétés suivantes sont équivalentes :
• MatB(u) est de la forme
A1 0
· · · 0
0 . . .
. . . ...
... . . .
. . . 00 · · · 0 Am
avec, pour tout i ∈ [[1,m]], Ai d’ordre ni.
• Pour tout i ∈ [[1,m]], E i = Vect(Bi) est stable par u.
Dans ce cas, on a Ai = MatBi(u|E i) pour tout i ∈ [[1,m]].
On a alors une décomposition E = E 1 ⊕ · · · ⊕ E m en somme directe de sous-espacesstables par u.
Propriété
On appelle matrice diagonale par blocs une matrice carrée de la forme précédente.
Définition
Cas particulier – Une matrice diagonale est une matrice diagonale par blocs telle que, avec lesnotations précédentes, pour tout i ∈ [[1,m]], Ai n’a qu’un coefficient (on a alors m = n).
D’après la propriété précédente, si B = (e1, . . . , en), ceci équivaut au fait que pour touti ∈ [[1,n]],
u(ei)
∈ Vect(ei).
c’est-à-dire, au fait que u(ei) soit un multiple de ei.
On appelle matrice triangulaire supérieure par blocs une matrice carrée, définiepar blocs, de la forme
A1,1 A1,2 · · · A1,m
0 . . .
. . . ...
... . . .
. . . Am−1,m
0
· · · 0 Am,m
,
où m 2 et pour tout i ∈ [[1,m]], Ai,i est une matrice carrée.
Définition
93

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 102/383
Soient m 2, u ∈ L (E ) et B = B1 ⊔ · · · ⊔ Bm une base de E , où, pour tout i ∈ [[1,m]],Bi est composée de ni vecteurs. On note, pour tout i ∈ [[1,m]], E i = Vect(Bi).
Les propriétés suivantes sont équivalentes :
• MatB(u) est de la forme précédente avec, pour tout i ∈ [[1,m]], Ai,i d’ordre ni,• Pour tout i ∈ [[1,m]], u(E i) ⊂ E 1 ⊕ · · · ⊕ E i.
Propriété
Remarque – Dans ce cas, E 1 est stable par u, mais en général, pas E 2, . . . , E m.
Cas particulier – Une matrice triangulaire supérieure est une matrice triangulaire par blocstelle que, avec les notations précédentes, pour tout i ∈ [[1,m]], Ai,i n’a qu’un coefficient (on aalors m = n).
D’après la propriété précédente, si B = (e1, . . . , en), ceci équivaut au fait que pour touti ∈ [[1,n]],
u(ei) ∈ Vect(e1, . . . , ei).
Exemple – Les matrices
A =
1 2 5 3 13 4 3 2 40 0 2 3 00 0 0 5 10 0 0 3 2
et B =
1 2 0 0 03 4 0 0 00 0 2 0 00 0 0 5 10 0 0 3 2
sont respectivement triangulaire par blocs et diagonale par blocs. Si A et B sont les matricesrespectives de deux endomorphismes u et v de E dans une base (e1,e2,e3,e4,e5), alors en notantE 1 = Vect(e1,e2), E 2 = Vect(e3), E 3 = Vect(e4,e5), on a E = E 1 ⊕ E 2 ⊕ E 3, avec E 1 stable paru et v , E 2 et E 3 stables par v, et u(E 2) ⊂ E 1 ⊕ E 2.
Remarque – Un objectif fondamental de l’algèbre linéaire consiste à construire des sous-espacesstables par u ou à en prouver l’existence, voire à construire des décompositions de l’espace ensomme directe de sous-espaces stables par u. Dans le cas idéal, l’endomorphisme induit par u surchacun de ces sous-espaces est une homothétie ; la matrice de u dans une base adaptée est alorsdiagonale, ce qui simplifie tous les calculs. C’est l’objectif de la réduction des endomorphismes,voir les chapitres Réduction et Endomorphismes remarquables des espaces euclidiens.
Exemple – Le cas particulier des projecteurs et des symétries
Si p est un projecteur (c’est-à-dire, si p p = p), alors
E = Ker( p − Id) ⊕ Ker( p)
avec Ker( p − Id) = Im( p). De plus Ker( p − Id) et Ker( p) sont stables par p (car p commute avec
lui-même) et p|Ker( p−Id) = Id, p|Ker p = 0. On a donc, dans une base adaptée B :
MatB( p) =
I r 00 0
où r = dim(Im( p)) = rg( p). On remarque en particulier que Tr( p) = rg( p) : le rang d’unprojecteur est égal à sa trace.
De même, si s est une symétrie (c’est-à-dire, si s s = Id), alors
E = Ker(s − Id) ⊕ Ker(s + Id).
De plus Ker(s − Id) et Ker(s + Id) sont stables par s, avec s|Ker(s−Id) = Id et s|Ker(s+Id) = − Id.On a donc dans une base adaptée B :
MatB(s) =I m 0
0 −I q
avec m = dim(Ker(s − Id)) et q = dim(Ker(s + Id)).
94

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 103/383
VII. Déterminant
Notation – Si f est une application de M n(K) dans K, si A = (C 1 · · · C n) ∈ M n(K) etU ∈ M n,1(K), on sera amené à utiliser la notation
f (C 1 · · · C i−1 U C i+1 · · · C n) ou simplement f (C 1 · · · U · · · C n)
pour i ∈ [[1,n]]. Bien sûr, cette notation n’a pas toujours de sens, par exemple pour i = 1, ou
i = n. Dans ces cas, on sous-entend respectivement
f (U · · · C n) et f (C 1 · · · U )
c’est-à-dire que dans tous les cas, on remplace la colonne C i par U dans l’expression f (C 1 · · · C n).
De plus, pour favoriser la lisibilité dans certains cas, on utilisera un trait de séparation verticalentre les colonnes, c’est-à-dire que la matrice (C 1 · · · C n) sera parfois notée (C 1 | · · · |C n).
1. Déterminant d’une matrice carrée
Il existe une unique application f : M n(K) → K vérifiant les propriétés suivantes :(i) f est linéaire par rapport à chacune des colonnes de sa variable :
∀ i ∈ [[1,n]], ∀ (C 1 · · · C n) ∈M n(K), ∀ (U,V ) ∈ (M n,1(K))2, ∀ λ ∈ K :
f (C 1 | · · · | C i−1 | λU + V | C i+1 | · · · |C n)
= λ f (C 1 | · · · | C i−1 | U |C i+1 | · · · |C n) + f (C 1 | · · · |C i−1 | V | C i+1 | · · · | C n).
(ii) f est antisymétrique par rapport aux colonnes de sa variable :
∀ (i,j) ∈ [[1,n]]2; i = j, ∀ (C 1 · · · C n) ∈M n(K),
f (C 1 · · · C i position i
· · · C j position j
· · · C n) = −f (C 1 · · · C j position i
· · · C i position j
· · · C n).
(iii) f (I n) = 1.
Cette application est appelée déterminant et notée det.
Théorème/Définition : Déterminant d’une matrice carrée
Une application f : M n(K) → K qui vérifie la propriété (ii) vérifie aussi la propriétésuivante : si A
∈M n(K) a deux colonnes égales, alors f (A) = 0.
Propriété
Démonstration – En effet, si les colonnes d’indices i et j de A sont égales, avec i = j , on a parantisymétrie
f (A) = f (C 1 · · · C i · · · C i · · · C n) = −f (C 1 · · · C i · · · C i · · · C n) = −f (A)
et donc f (A) = 0.
Démonstration de l’existence et de l’unicité du déterminant
Démontrons cette propriété dans le cas où n = 3 ; la démonstration est plus facile dans lescas n = 1 et n = 2, elle est hors programme pour n 4.
Unicité : Soit f une application vérifiant les trois propriétés ci-dessus et A = (ai,j) ∈ M 3(K).En notant (e1,e2,e3) la base canonique de M 3,1(K), on a donc
f (A) = f (a1,1e1 + a2,1e2 + a3,1e3|a1,2e1 + a2,2e2 + a3,2e3|a1,3e1 + a2,3e2 + a3,3e3) .
95

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 104/383
Par linéarité de f par rapport à chacune des colonnes de sa variable, on peut développer l’ex-pression ci-dessus. De plus, d’après la propriété précédente, tous les termes correspondant à desmatrices ayant deux colonnes égales sont nuls. Ainsi
f (A) = a1,1a2,2a3,3 f (e1|e2|e3) + a1,1a3,2a2,3 f (e1|e3|e2)
+ a2,1a1,2a3,3 f (e2|e1|e3) + a2,1a3,2a1,3 f (e2|e3|e1)
+ a3,1a1,2a2,3 f (e3|e1|e2) + a3,1a2,2a1,3 f (e3|e2|e1)
De plus, d’après la propriété (iii), f (I 3) = 1, et par antisymétrie,
f (e1|e3|e2) = f (e3|e2|e1) = f (e2|e1|e3) = −f (e1|e2|e3) = −1
f (e2|e3|e1) = −f (e1|e3|e2) = f (e1|e2|e3) = 1
f (e3|e1|e2) = −f (e1|e3|e2) = f (e1|e2|e3) = 1.
Finalement,
f (A) = a1,1a2,2a3,3 + a2,1a3,2a1,3 + a3,1a1,2a2,3
−a3,1a2,2a1,3 − a2,1a1,2a3,3 − a1,1a3,2a2,3.
Pour tout A ∈ M n(K), le scalaire f (A) est donc entièrement déterminé par une même formulesur les coefficients de A. En particulier, il existe au plus une application f vérifiant les troispropriétés du théorème.
Existence : On définit f par la formule obtenue ci-dessus. Il est alors immédiat que f (I 3) = 1 cardans ce cas, seul le terme a1,1a2,2a3,3 est non nul, et il vaut 1. Donc f vérifie la propriété (iii). De
plus, échanger deux colonnes de A a pour effet d’échanger les indices de colonnes correspondantssur les ai,j, à l’intérieur de chacun des termes de la somme. On remarque alors que chaque termeaffecté d’un signe positif est échangé avec un terme affecté d’un signe négatif. L’image par f de lamatrice obtenue est donc −f (A), ce qui prouve que f vérifie la propriété (ii). Enfin, si la colonne
j de la matrice A est de la forme λU + V avec (U,V ) ∈M 3,1(K)2 (de coefficients respectifs notésu1, u2, u3 et v1, v2, v3), alors pour tout i ∈ [[1,3]], ai,j = λui + vi. En reportant cette expressiondans la somme donnant f (A), en développant le résultat et en regroupant les termes, on obtientla linéarité de f par rapport à la j-ième colonne de sa variable, et ce pour tout j ∈ [[1,n]].
Remarques
• Pour n = 1, si A = (a) avec a
∈ K, on a det(A) = a. Pour n = 2, on obtient, pour tout
(a,b,c,d) ∈K4,
det
a cb d
= ad − bc.
Pour n = 2 et n = 3, les formules démontrées sont appelées règle de Sarrus. Elle n’ont pasd’équivalent lorsque n 4.
• On remarquera que pour chacun des termes de la somme donnant det(A), on choisit un coef-ficient dans la première colonne, puis un dans la seconde, jusqu’à la n-ième, en choisissant desindices de lignes deux à deux distincts. On fait ensuite la somme pour toutes les façons possiblesde faire un tel choix, en affectant à chaque terme un signe (dépendant en fait de l’ordre dans le-quel on a choisi les lignes). Cette structure apparaît nettement dans la démonstration d’existenceci-dessus.
96

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 105/383
Soit A = (C 1 · · · C n) ∈ M n(K).
• Si B est obtenue à partir de A par l’opération C i ↔ C j (i = j), alors
det(B) = − det(A).
• Si B est obtenue à partir de A par l’opération C i
← C i + λC j (i
= j), alors on a :
det(B) = det(A).
• Si B est obtenue à partir de A par l’opération C i ← λC i (λ ∈K), alors on a :
det(B) = λ det(A).
• Pour tout λ ∈K, det(λA) = λn det(A).
Propriété – Effet des opérations élémentaires
Démonstration
• C’est une réécriture de la propriété d’antisymétrie par rapport aux colonnes.
• Par linéarité du déterminant par rapport à la i-ième colonne de sa variable,
det(B) = det(C 1 · · · C i−1 C i C i+1 · · · C n) + λf (C 1 · · · C i−1 C j C i+1 · · · C n).
Dans le dernier terme, la colonne C j apparaît deux fois, car i = j. Ce terme est donc nul d’aprèsune propriété du déterminant. On en déduit que
det(B) = det(C 1 · · · C i−1 C i C i+1 · · · C n) = det(A).
• Il suffit d’utiliser la linéarité du déterminant par rapport à la i-ème colonne de sa variable.
• On applique successivement le point précédent à chacune des n colonnes de A.
Remarques
• En particulier, on remarquera que les opérations élémentaires sur les colonnes conservent ledéterminant ou le multiplient par un scalaire non nul .
• D’après le troisième point, le déterminant d’une matrice de dilatation Dni (λ) vérifie
det(Dni (λ)) = λ det(I n) = λ.
Une matrice de transposition τ ni,j est obtenue à partir de I n par l’opération C i ↔ C j, donc parantisymétrie,
det(τ ni,j) = −1.
Une matrice de transvection T ni,j(λ) est obtenue à partir de I n par l’opération C j ← C j + λC iqui ne modifie pas le déterminant, donc
det(T ni,j) = 1.
Soit A ∈M n(K). Pour que A soit inversible, il faut et il suffit que det(A) = 0.
Corollaire – Matrices inversibles et déterminant
Démonstration
⇒ Si A est inversible, alors A ∼C
I n, donc on peut passer de I n à A par une suite finied’opérations élémentaires sur les colonnes ; d’après ce qui précède, il existe α ∈ K∗ tel quedet(A) = α det(I n) = α. En particulier, det(A) = 0.
97

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 106/383
⇐ On raisonne par contraposition : si A n’est pas inversible, l’une de ses colonnes, disons C i,est combinaison linéaire des autres : on peut écrire
C i = j=i
λ jC j
où les λ j sont des scalaires. Alors, par linéarité du déterminant par rapport à la i-ième colonnede sa variable,
det(A) = j=i
det(C 1 · · · C j position i
· · · C n) = 0
car dans chacun des termes de cette somme, deux des colonnes sont égales.
Soient A et B deux éléments de M n(K). Alors det(AB) = det(A)det(B).
Propriété
Démonstration – Si AB est inversible, B l’est également : en effet, si X ∈ M n,1(K) vérifieBX = 0, alors ABX = 0 et, AB étant inversible, X = 0, ce qui prouve que B est inver-
sible. Par contraposition, si B n’est pas inversible, AB ne l’est pas non plus. Dans ce cas, laformule est vraie car det(B) = det(AB) = 0.
Si B est inversible, elle est équivalente par colonnes à I n et en particulier, B est un produitde matrices élémentaires. Notons m le nombre de matrices de transpositions, et p le nombre dematrices de dilatations, figurant dans ce produit. Notons enfin λ1, . . . , λ p les coefficients de cesmatrices de dilatations (on peut toujours supposer que p 1, quitte à ajouter la dilatation I ndans le produit). D’après la propriété sur l’effet des opérations élémentaires sur le déterminant,
det(AB) = det(A) × (−1)m × pi=1
λi.
Mais on a également B = I nB, et donc
det(B) = det(I n) × (−1)m × pi=1
λi = (−1)m × pi=1
λi.
On en déduit que det(AB) = det(A)det(B).
Attention ! Il n’y a pas de propriété analogue pour la somme si n 2 : det(I n + I n) = 2n 4tandis que det(I n) + det(I n) = 2.
Si A est inversible, det(A−1
) =
1
det(A) .
Propriété
Démonstration – En effet, det(A)det(A−1) = det(AA−1) = det(I n) = 1.
Deux matrices semblables ont le même déterminant.
Propriété
Démonstration – Si A et B sont semblables, il existe P ∈ Gℓn(K) tel que B = P −1AP. Alorsd’après ce qui précède,
det(B) = det(P −1AP ) = det(P −1)det(AP ) = det(AP )det(P −1) = det(AP P −1) = det(A).
98

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 107/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 108/383
Remarque – Si A ∈ M n(K), l’application linéaire uA canoniquement associée à A a pour matriceA dans la base canonique de M n,1(K), donc det(uA) = det(A).
Soient u et v deux endomorphismes de E .
• Pour tout λ ∈K, det(λu) = λn det(u).
• det(u
v) = det(u)
×det(v).
• u est un isomorphisme si et seulement si det(u) = 0. Dans ce cas
det(u−1) = 1
det(u).
Propriété
Démonstration – C’est une conséquence immédiate de la définition et des propriétés analoguessur les matrices.
4. Matrices triangulaires
Soit (ai,j)1i jn une famille de scalaires. Alors
a1,1 · · · · · · a1,n
0 . . .
......
. . . . . .
...0 · · · 0 an,n
=
ni=1
ai,i
(de même pour une matrice triangulaire inférieure).
Propriété – Déterminant d’une matrice triangulaire
Démonstration – Notons A la matrice dont on cherche à calculer le déterminant. Si a1,1 = 0, lerésultat est vrai car A a une colonne nulle, elle n’est donc pas inversible, et det(A) = 0 =
ni=1 ai,i.
Sinon, on effectue successivement les opérations
C 2 ← C 2 − a1,2
a1,1C 1 , . . . , C n ← C n − a1,n
a1,1C 1
ce qui ne modifie pas la valeur de det(A). On a donc
det(A) =
a1,1 0 · · · · · · 00 a2,2 · · · · · · a2,n... 0
. . . ...
... ... . . . . . . ...0 0 · · · 0 an,n
On reproduit le raisonnement jusqu’à aboutir à
det(A) =
a1,1 0 · · · 0
0 . . .
. . . ...
... . . .
. . . 00 · · · 0 an,n
.
Par linéarité du déterminant par rapport à chaque colonne, on a donc
det(A) = ni=1
ai,i
det(I n) =ni=1
ai,i.
100

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 109/383
5. Calculs de déterminants par blocs
On suppose n 2. Soit B ∈ M n−1(K), L ∈ M 1,n−1(K) et C ∈ M n−1,1(K). Alors lesmatrices définies par blocs
A = 1 L
0 B et A′ = B C
0 1ont pour déterminant det(B).
Lemme
Démonstration – On fait la démonstration dans le cas de A, l’autre cas est similaire. Si B n’estpas inversible, ses lignes forment une famille liée, donc celles de A également, et A n’est pasinversible. La formule est donc vraie dans ce cas. Sinon, lorsque l’on effectue l’algorithme deGauss-Jordan sur les colonnes de A, il est évident que l’on aboutit à la matrice
1 00 R
où R est la matrice échelonnée réduite par colonnes associée à B. De plus, les opérations effectuéessur A pour aboutir à ce résultat sont du type C i ← C i− λC 1 pour i 2 (remplacement de L parune ligne de 0), elles ne changent pas le déterminant, puis ce sont les mêmes que celles effectuéessur B. Le déterminant étant entièrement calculable à partir du nombre d’échanges de colonnes,et des coefficients des dilatations effectuées, on en déduit que det(A) = det(B). On procède demême pour A′.
Soit A une matrice carrée de la forme A =
B C 0 D
, avec B et D des matrices carrées.
Alors det(A) = det(B) × det(D).
Propriété
Démonstration – Soit r l’ordre de la matrice B. On remarque que
B C 0 D = I r C 0 D
B 00 I n−r .
De plus, en utilisant plusieurs fois le lemme précédent, on a
det
I r C 0 D
= det(D)
et
detB 0
0 I n−r = det(B).
Le résultat suit car le déterminant d’un produit de matrices est le produit des déterminants.
101

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 110/383
• Soit
A =
A1 A1,2 · · · A1,m
0 . . .
. . . ...
... . . .
. . . Am−1,m
0 · · · 0 Am
ou A =
A1 0 · · · 0
0 . . .
. . . ...
... . . .
. . . 0
0 · · · 0 Am
une matrice triangulaire par blocs ou diagonale par blocs. Alors
det(A) = det(A1) × · · · × det(Am) =mi=1
det(Ai).
• Soient E un K-espace vectoriel de dimension finie, u ∈ L (E ) et E 1, . . . , E m dessous-espaces vectoriels de E stables par u tels que E = E 1 ⊕ · · · ⊕ E m. Alors
det(u) = det(u|E 1)
× · · · ×det(u|E m) =
m
i=1
det(u|E i).
Propriété – Matrice triangulaire par blocs ou diagonale par blocs
Démonstration
• Elle se fait par une récurrence immédiate à partir de la propriété précédente.
• Soit B = B1 ⊔ · · · ⊔ Bm une base de E adaptée à cette décomposition en somme directe. Onsait que MatB(u) est de la forme
A =
A1 0 · · · 0
0 . . .
. . . ...
..
.
. ..
. .. 0
0 · · · 0 Am
où, pour tout i ∈ [[1,m]], Ai est d’ordre dim(E i), et Ai = MatBi(u|E i). Le résultat vient alors dupoint précédent, et du fait que det(u) = det(A) et det(u|E i) = det(Ai) pour tout i.
6. Développement d’un déterminant par rapport aux lignes et colonnes
Soit A ∈ M n(K). Pour tout (i,j) ∈ [[1,n]]2, soit Ai,j ∈ M n−1(K) la matrice obtenue ensupprimant la i-ème ligne et la j -ème colonne de A. Alors :
• Développement par rapport à la j -ième colonne :
det(A) =ni=1
ai,j (−1)i+ j det(Ai,j).
• Développement par rapport à la i-ième ligne :
det(A) =n
j=1
ai,j (−1)i+ j det(Ai,j).
Théorème – Développement par rapport à une ligne ou une colonne
Démonstration (non exigible)
On fait la démonstration de la formule de développement par rapport aux colonnes, cellesur les lignes est analogue. Pour i ∈ [[1,n]], on note E i le i-ème vecteur de la base canonique
102

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 111/383
de M n,1(K). Notons A = (ai,j)1i,jn = (C 1 · · · C n). On a donc, pour tout j ∈ [[1,n]],C j =
ni=1 ai,j E i. Alors, par linéarité du déterminant par rapport à la j-ième colonne de sa
variable,
det(A) = det
C 1 | · · · |C j−1 |
ni=1
ai,jE i | C j+1 | · · · |C n
=n
i=1
ai,j det(C 1
· · · C j
−1 E i C j+1
· · · C n).
Notons M i,j = (C 1 · · · C j−1 E i C j+1 · · · C n). En échangeant la ligne i − 1 et la ligne i, puis laligne i − 2 et la ligne i − 1, jusqu’à échanger la ligne 1 et la ligne 2, on se ramène à une matriceobtenue en plaçant la i-ème ligne de M i,j à la place de la première ligne. Au cours de chacunede ces i − 1 opérations, le déterminant de A est multiplié par −1. On procède de même avec lescolonnes, ce qui amène à multiplier le déterminant par −1, pour chacune des j − 1 opérations.On obtient ainsi une matrice
B =
1 ∗0 Ai,j
avec det(M i,j) = (−1)i+ j−2 det(B) = (−1)i+ j det(B). Or, le lemme ci-dessus montre que l’on a
det(B) = det(Ai,j). On en déduit quedet(C 1 · · · C j−1 E i C j+1 · · · C n) = (−1)i+ j det(Ai,j)
et le résultat.
Remarques
• Ces formules sont très utiles, par exemple :
• Lorsqu’une ligne ou colonne de A a un nombre important de coefficients nuls.
• Pour calculer des déterminants par récurrence, lorsque la structure du déterminant s’yprête (par exemple, les déterminants tridiagonaux).
• En dimension 3, on retrouve des formules déjà connues, par exemplea1,1 a1,2 a1,3
a2,1 a2,2 a2,3
a3,1 a3,2 a3,3
= a1,1(a2,2a3,3 − a3,2a2,3) − a2,1(a1,2a3,3 − a3,2a1,3) + a3,1(a1,2a2,3 − a2,2a1,3).
En développant le membre de gauche, on retrouve bien sûr la formule du déterminant et la règlede Sarrus.
7. Déterminant de Vandermonde
Soit (a1, . . . , an) ∈ Kn. On pose
M n(a1, . . . , an) =
1 a1 a21 . . . an−1
1
1 a2 a22 . . . an−1
2
1 a3 a23 . . . an−1
3...
......
......
1 an a2n . . . an−1
n
= (a j−1
i )1i,jn ∈M n(K)
et V n(a1, . . . , an) = det(M n(a1, . . . , an)).
Ce déterminant (ou celui de sa transposée) est appelé déterminant de Vandermondeassocié aux scalaires a1, . . . , an.
Définition
103

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 112/383
Il est non nul si et seulement si les ai sont deux à deux distincts, ce que l’on peut prouversans calculer le déterminant : si deux des ai sont égaux, alors M n(a1, . . . , an) a deux lignes égales,donc son déterminant est nul. Si les ai sont deux à deux distincts, et si t
λ0 · · · λn−1
∈ Knappartient au noyau de M n(a1, . . . , an), alors pour tout i ∈ [[1,n]],
n−1
j=0
λ ja ji = 0.
Le polynôme P (X ) =n−1 j=0 λ jX j , de degré au plus n−1, a donc n racines deux à deux distinctes,
ce qui montre qu’il est nul, et donc que tous les λ j sont nuls. Donc la matrice carrée M n(a1, . . . , an)est inversible et son déterminant est non nul.
Ce déterminant et la matrice associée ont d’importantes applications. Par exemple, soient(a0, . . . , an) et (b0, . . . , bn) dans Kn+1. On cherche une fonction polyomiale P telle que
P (a0) = b0, . . . , P (an) = bn;
autrement dit, connaissant les valeurs prises par une fonction polynomiale en certains points, onrecherche les coefficients du polynôme associé.
Cherchons P sous la forme x0 + x1X + · · · + xnX n
. Les conditions ci-dessus s’écrivent
1 a0 a20 . . . an0
1 a1 a21 . . . an1
......
......
...
1 an a2n . . . ann
x0......
xn
=
b0......
bn
c’est-à-dire comme un système linéaire dont la matrice est la matrice de VandermondeM n+1(a0, . . . , an). Si les ai sont deux à deux distincts, cette matrice est inversible, et il existeun unique polynôme de Kn[X ] qui est solution du problème. Ces problématiques interviennentnotamment en théorie du signal.
On peut en fait calculer explicitement V n(a1, . . . , an) :
Avec les notations précédentes,
V n(a1, . . . , an) =i<j
(a j − ai).
Propriété – Déterminant de Van der Monde
Démonstration
Première méthode : si n 2, alors, pour tout j de n à 2, on fait l’opération élémentaireC j ← C j − a1 C j−1, ce qui ne change pas la valeur du déterminant. On obtient
V n(a1, . . . , an) =
1 0 0 . . . 0
1 a2 − a1 a22 − a1a2 . . . an−1
2 − a1an−22
1 a3 − a1 a23 − a1a3 . . . an−1
3 − a1an−23
......
... . . .
...1 an − a1 a2
n − a1an . . . an−1n − a1an−2
n
c’est-à-dire
V n(a1, . . . , an) =
1 0 0 . . . 01 a2
−a1 (a2
−a1)a2 . . . (a2
−a1)an−2
2
1 a3 − a1 (a3 − a1)a3 . . . (a3 − a1)an−23...
......
. . . ...
1 an − a1 (an − a1)an . . . (an − a1)an−2n
104

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 113/383
En développant par rapport à la première ligne, on a donc
V n(a1, . . . , an) =
a2 − a1 (a2 − a1)a2 . . . (a2 − a1)an−22
a3 − a1 (a3 − a1)a3 . . . (a3 − a1)an−23
......
. . . ...
an − a1 (an − a1)an . . . (an − a1)an−2n
(déterminant d’ordre n − 1). Chaque ligne Li étant multiple de ai+1 − a1, on obtient
V n(a1, . . . , an) = (a2 − a1)(a3 − a1) · · · (an − a1)
1 a2 a2
2 . . . an−22
1 a3 a22 . . . an−2
3...
......
. . . ...
1 an a2n . . . an−2
n
= (a2 − a1)(a3 − a1) · · · (an − a1) V n−1(a2, . . . , an).
Une récurrence immédiate, avec le fait que V 1(an) = 1, montre alors le résultat.
Deuxième méthode : si n 2, soit P (X ) =n−1i=1
(X − ai) = X n−1 +n−2k=0
λkX k où les λk sont
des scalaires.
L’opération C n ← C n +n−2k=0
λkC k+1 montre que
V n(a1, . . . , an) =
1 a1 a21 . . . P (a1)
1 a2 a22 . . . P (a2)
......
... . . .
...1 a
n−1 a2
n−1 . . . P (a
n−1)
1 an a2n . . . P (an)
=
1 a1 a21 . . . 0
1 a2 a22 . . . 0
......
... . . .
...1 a
n−1 a2
n−1 . . . 0
1 an a2n . . . P (an)
,
et donc, en développant par rapport à la dernière colonne,
V n(a1, . . . , an) = P (an) V n−1(a1, . . . , an−1) =n−1i=1
(an − ai) V n−1(a1, . . . , an−1),
ce qui permet de conclure par récurrence comme ci-dessus (on a V 1(a1) = 1).
105

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 114/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 115/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 116/383
est une norme sur E , appelée norme euclidienne. L’inégalité triangulaire est une conséquence del’inégalité de Cauchy-Schwarz
| (x | y) | x y.
En effet, pour tout (x,y) ∈ E 2,
x + y2 = (x + y | x + y) = x2 + 2 (x | y) + y2
x2
+ 2xy + y2
= (x + y)2.
• Sur Kn
Pour tout x = (x1, . . . , xn) ∈ Kn, on définit
N 1(x) = x1 =ni=1
|xi|,
N 2(x) = x2 =
n
i=1
|xi|2
N ∞(x) = x∞ = supi∈[[1,n]]
|xi| = maxi∈[[1,n]]
|xi|.
Elles sont appelées respectivement « norme 1 », « norme 2 », et « norme infini ».
Toutes les propriétés sont évidentes sauf l’inégalité triangulaire : si x = (x1, . . . , xn) ∈ Kn ety = (y1, . . . , yn) ∈Kn, alors
x + y1 =ni=1
|xi + yi| ni=1
(|xi| + |yi|) ni=1
|xi| +ni=1
|yi| = x1 + y1.
Cela prouve l’inégalité triangulaire pour la norme 1. La norme 2 sur Rn est la norme euclidienneassociée au produit scalaire défini par
(x | y) =ni=1
xi yi.
Pour la norme 2 sur Cn, on remarque que
x + y2 =
ni=1
|xi + yi|21/2
ni=1
(|xi| + |yi|)2
1/2
= X + Y 2
où X et Y désignent les vecteurs (|x1|, . . . ,|xn|) et (|y1|, . . . ,|yn|). Ces vecteurs étant à coefficientsréels, on a
X + Y 2 X 2 + Y 2 = x2 + y2.
On a donc aussi l’inégalité triangulaire dans ce cas.
Quant à la norme infini, pour tout i ∈ [[1,n]], on a
|xi + yi| |xi| + |yi| max j∈[[1,n]]
|x j | + max j∈[[1,n]]
|y j| = x∞ + y∞.
Le majorant étant indépendant de i, en passant au maximum gauche, on en déduit
x + y∞ = maxi∈[[1,n]]
|xi + yi| x∞ + y∞.
108

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 117/383
• Sur B (I,K)
Soit I un intervalle (non vide) de R. L’ensemble B (I,K) des fonctions bornées de I dans K,muni de l’addition des fonctions et du produit d’une fonction par un scalaire, est un K-espacevectoriel. Pour f ∈ B (I,K), on définit
N ∞(f ) = f ∞ = supx∈I
|f (x)|.
L’application N ∞ est appelée « norme infini » ou norme de la convergence uniforme (cette dernièreappellation sera expliquée dans le chapitre Suites et séries de fonctions). Elle est bien définie,car si f ∈ B (I,K), l’ensemble |f (x)|; x ∈ I est une partie non vide majorée de R, elle a doncune borne supérieure.
Prouvons simplement l’inégalité triangulaire, les autres propriétés étant évidentes. Soient f
et g deux éléments de B (I,K). Par définition, pour tout x ∈ I ,
|f (x) + g(x)| |f (x)| + |g(x)| supy∈I
|f (y)| + supy∈I
|g(y)|.
Le majorant étant indépendant de x, en passant à la borne supérieure à gauche, on en déduit
supx∈I
|f (x) + g(x)| supy∈I
|f (y)| + supy∈I
|g(y)|,
c’est-à-dire
f + g∞ f ∞ + g∞.
Remarque – Si [a,b] est un segment de R, on a C0([a,b],K) ⊂ B ([a,b],K) car la fonction |f | estcontinue sur un segment, à valeurs réelles, donc elle est bornée et atteint ses bornes. Ceci montreaussi que pour f ∈ C0([a,b],K),
f ∞ = maxx∈[a,b] |f (x)|.
Soit (E, · ) un espace vectoriel normé. Alors, pour tout (x,y) ∈ E 2, x − y x − y.
Propriété
Démonstration – On remarque que x = (x − y) + y et donc, d’après l’inégalité triangulaire,
x x − y + y,
ce qui implique que
x − y x − y.
De même, en écrivant y = (y − x) + x, on montre que
y − x x − y.
De ces deux inégalités, on déduit le résultat.
Remarque – Cette deuxième forme de l’inégalité triangulaire est très utile pour obtenir des infor-mations sur la norme d’un vecteur, à partir d’informations sur sa distance à d’autres vecteurs.
109

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 118/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 119/383
Exemple – Soit A ∈M p(K). Alors (An)n∈N est une suite d’éléments de M p(K) : c’est la suite despuissances de A.
On définit alors les suites extraites d’une suite d’éléments de E de la même façon que cela aété fait pour les suites réelles ou complexes.
4. Parties, suites et fonctions bornées
Soit (E, · ) un espace vectoriel normé.
• Soit A une partie de E . On dit que A est bornée s’il existe M 0 tel queA ⊂ Bf (0,M ), c’est-à-dire, s’il existe M 0 tel que pour tout x ∈ A, x M.
• Soit (un) une suite d’éléments de E . On dit que (un) est bornée s’il existe M 0
tel que pour tout n ∈ N, un M.
• Soit (F,N ) un espace vectoriel normé, A une partie de E et f : A → F une fonction.On dit que f est bornée si f (A) est une partie bornée de F , c’est-à-dire, s’il existeM 0 tel que pour tout x ∈ A, N (f (x)) M.
Définition
Exemples
• Une boule fermée Bf (a,r) de E est une partie bornée. En effet, pour tout x ∈ Bf (a,r),
x = (x − a) + a x − a + a r + a.
La définition est donc vérifiée avec M = r + a. On raisonne de même avec les boules ouvertes,ou les sphères.
• On munit C0([0,1],R) de la norme infini. Soit, pour tout n ∈ N, f n : x → √ n xn. La suite
(f n)n∈N n’est pas bornée car pour tout n ∈N,
f n
∞ =
√ n, donc
f n
∞ → +
∞;
la définition ne peut être vérifiée pour aucune valeur de M .
• On munit R3 et R2 de la norme infini. La fonction
f :
[0,1]3 → R2
(x,y,z) → (x − y + 2z, x2 + y2 + z2)
est bornée car pour tout (x,y,z) ∈ [0,1]3,
f (x,y,z)∞ = max|x − y + 2z|,|x2 + y2 + z2| max|x| + |y| + 2|z|,x2 + y2 + z2 4.
5. Parties convexes
Soit A une partie de E . On dit que A est convexe si
∀ (a,b) ∈ A2, ∀λ ∈ [0,1], λa + (1 − λ)b ∈ A.
Autrement dit, A est convexe si A contient tout segment dont il contient les deuxextrémités.
Définition – Partie convexe
Une boule (ouverte ou fermée) est convexe.Propriété
111

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 120/383
Démonstration – Soit Bf (c,r) une boule fermée (on raisonne de même avec une boule ouverte).Soient a et b deux éléments de Bf (c,r) et λ ∈ [0,1] ; alors
λa + (1 − λ)b − c = (λa + (1 − λ)b) − (λc + (1 − λ)c) = λ(a − c) + (1 − λ)(b − c).
D’après l’inégalité triangulaire et la propriété d’homogénéité, sachant que λ 0 et 1 − λ 0, ona
λa + (1
−λ)b
−c λ
a
−c
+ (1−
λ)
b−
c λr + (1
−λ)r = r.
Donc λa + (1 − λ)b ∈ Bf (c,r).
Remarque – En revanche, une sphère de E de rayon non nul, R2 \(x,0); x 0 ou une couronnede R2 ne sont pas convexes.
6. Effet d’un changement de norme
Certaines des notions que nous avons définies jusqu’à présent dépendent de la norme considé-rée. Pour illustrer ceci, posons, pour tout n ∈ N, f n : x → √
n xn et considérons la suite (f n)n∈Nd’éléments de E = C0([0,1],R). On sait que l’on peut munir E de la norme infini, on peut aussile munir de la norme
· 2 associée au produit scalaire usuel sur E . La suite (f n) est bornée dans
(E, · 2), car pour tout n ∈N,
f n2 =
1
0(√
n xn)2 dx
1/2
=
n
2n + 1
1/2
1.
Elle n’est pourtant pas bornée dans (E, · ∞) comme on l’a montré dans un exemple précédent.
Nous admettrons que lorsque E est de dimension finie, toutes les notions que nous allonsdéfinir dans la suite sont indépendantes du choix de norme. C’est aussi le cas des notions pré-cédentes de partie, suite ou fonction bornée, de partie convexe (la définition de cette dernièrenotion ne fait en fait pas intervenir de norme) mais ce n’est pas le cas des notions de distanceassociée à une norme, de boules et de sphère.
À partir de maintenant, E désigne un K-espace vectoriel de dimension finie.
Soit · une norme sur Kn et B = (e1, . . . , en) une base de E . Pour tout x de E de coordonnées(x1, . . . , xn) dans la base B, on peut définir xE = (x1, . . . , xn). Alors · E est une norme surE (vérification immédiate).
Un choix très utile est souvent celui donné par
∀ x ∈ E, x∞ = maxi∈[[1,n]]
|xi|,
correspondant à la norme infini sur Kn. On fera parfois référence à cette norme sur E comme
norme infini associée à la base B.Un espace vectoriel E de dimension finie peut donc toujours être muni d’une norme, et par
le moyen précédent, l’étude « topologique » de E se ramène à celle de Kn muni d’une normequelconque.
112

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 121/383
II. Suites d’un espace vectoriel normé de dimension finie
Soit (E, · ) un espace vectoriel normé et (un) une suite d’éléments de E .
• Soit ℓ ∈ E . On dit que (un) converge vers ℓ (ou que un tend vers ℓ) si
∀ε > 0,
∃n0
∈N;
∀n n0,
un
−ℓ
ε.
On note ceci un → ℓ.
• On dit que (un) est convergente s’il existe ℓ ∈ E tel que (un) converge vers ℓ. Levecteur ℓ est alors unique; il est appelé limite de la suite (un), noté lim un.
• Dans le cas contraire, on dit que (un) est divergente.
Définition – Convergence d’une suite
Remarque – En d’autres termes, (un) converge vers ℓ si pour toute boule fermée B centrée en ℓde rayon strictement positif, tous les termes de la suite sauf un nombre fini appartiennent à B .
Démonstration de l’unicité de ℓ – Supposons l’existence de deux vecteurs ℓ et ℓ′ vérifiant la dé-finition. Soient ε > 0 et deux entiers n0 et n1 vérifiant la condition ci-dessus pour ℓ et ℓ′
respectivement. Alors pour tout n max(n0,n1),
ℓ − ℓ′ ℓ − un + un − ℓ′ un − ℓ + un − ℓ′ 2ε.
Ceci étant valable pour tout ε, on a ℓ − ℓ′ = 0, donc ℓ = ℓ′.
Remarques
• Une suite (un) d’éléments d’un espace vectoriel normé (E, · ) converge vers ℓ si et seulementsi la suite réelle (un − ℓ) converge vers 0. Cette caractérisation est très utile pour prouver uneconvergence (lorsque l’on a l’intuition de la limite), par des majorations de un − ℓ.
• Comme nous l’avons indiqué ci-dessus, la convergence ou divergence d’une suite, et en cas de
convergence, la valeur de sa limite, ne dépendent pas de la norme choisie, du fait de la dimensionfinie.
Exemples
• Illustrons la remarque précédente dans Kn muni des normes 1 et infini. On remarque que pourtout x ∈ Kn, x∞ x1 et x1 n x∞. Si (uk) converge vers ℓ dans (Kn, · 1), alors pourtout k ∈ N,
uk − ℓ∞ uk − ℓ1 avec uk − ℓ1 → 0,
et donc (uk) converge vers ℓ dans (Kn, · ∞). De même, si (uk) converge vers ℓ dans (Kn, · ∞),alors pour tout k ∈ N,
uk
−ℓ
1 n
uk
−ℓ
∞ avec
uk
−ℓ
∞ → 0,
et donc (uk) converge vers ℓ dans (Kn, · 1).
• La suite
e1/n 2/n3/n 4/n
n1
d’éléments de M 2(R) converge vers
1 00 0
.
En effet, en notant · ∞ la norme sur M 2(R) associée à la norme · ∞ sur R4 (maximumdes valeurs absolues des coefficients de la matrice), on a
e1/n 2/n3/n 4/n
−
1 00 0
∞
=
e1/n − 1 2/n3/n 4/n
∞
→ 0
car chacun des termes apparaissant dans le maximum tend vers 0.
Même si la convergence d’une suite ne dépend pas de la norme, il semble quand même qu’ilfaille considérer une norme pour vérifier la définition. En fait, ce n’est pas le cas, car l’étude dela convergence d’une suite se ramène à celle de ses coordonnées dans une base :
113

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 122/383
Soit (uk)k∈N une suite d’éléments de E muni d’une base B = (e1, . . . , en). Notons, pourtout k,
uk =ni=1
uk,i ei
la décomposition de uk dans la base
B.
Alors, pour que la suite (uk)k∈N soit convergente, il faut et il suffit que pour touti ∈ [[1,n]], (uk,i)k∈N soit convergente. Dans ce cas, on a
limk→+∞
uk =ni=1
limk→+∞
uk,i
ei,
c’est-à-dire que les coordonnées de la limite sont les limites des suites-coordonnées.
Théorème – Convergence composante par composante
Démonstration – Notons · ∞ la norme infini sur E associée à la base B.
⇒ Fixons un entier i
∈ [[1,n]]. Supposons que (u
k) converge vers ℓ =
n
i=1
ℓi
ei. Alors pour tout
k ∈ N,|uk,i − ℓi| uk − ℓ∞ avec uk − ℓ∞ → 0.
On en déduit que (uk,i)k∈N converge vers ℓi.
⇐ Soit ε > 0 fixé. Si uk,i −→k→+∞
ℓi pour tout i ∈ [[1,n]], alors il existe des entiers k1, . . . , kn tels
que pour tout i ∈ [[1,n]] et pour tout k ki,
|uk,i − ℓi| ε.
Alors pour tout k max(k1, . . . , kn),
uk − ℓ∞ = maxi∈[[1,n]]
|uk,i − ℓi| ε.
Ainsi (uk) converge vers ℓ =ni=1
ℓi ei.
Remarques
• Une démonstration semblable montre qu’une suite d’éléments de E est bornée si et seulementsi chacune de ses suites-coordonnées dans la base B est bornée.
• De même, si C est une base d’un espace vectoriel de dimension finie F , alors une fonctionf : A
⊂ E
→ F est bornée si et seulement si chacune de ses fonctions-coordonnées dans la base
C est bornée.• On parle de convergence (ou de suite ou fonction bornée) « composante par composante ».L’intérêt principal de ces résultats est de pouvoir se ramener à des suites ou à des fonctions àvaleurs dans K (les coordonnées). Par exemple, une suite de matrices converge si et seulementsi chacune de ses suites-coefficients converge. De même pour une suite de polynômes de Kn[X ].En revanche, cela n’a pas de sens pour nous dans K[X ], qui n’est pas de dimension finie.
• En application de ceci, on obtient le résultat suivant : soient E et F deux espaces vectoriels dedimension finie. Alors une suite (xk,yk) d’éléments de E × F converge vers (x,y) si et seulementsi (xk) converge vers x et (yk) converge vers y .
En effet, si (e1, . . . , e p) est une base de E , et (f 1, . . . , f n) une base de F , alors
((e1,0) . . . (e p,0),(0,f 1) . . . (0,f n))
est une base de E × F. Il suffit alors d’appliquer le résultat précédent.
114

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 123/383
Toute suite convergente d’éléments d’un espace vectoriel normé est bornée.
La réciproque est fausse.
Propriété
Démonstration – On utilise les notations précédentes. Appliquons la définition de la limite avecε = 1 : il existe n0
∈ N∗ tel que pour tout n n0,
un
−ℓ
1. D’après la seconde forme de
l’inégalité triangulaire, on en déduit un − ℓ 1, et donc, un ℓ + 1 pour tout n n0.Alors, pour tout n ∈ N,
un max(u0, . . . ,un0−1,ℓ + 1).
L’exemple de ((−1)n)n∈N montre que la réciproque est fausse.
Soient (un) et (vn) deux suites convergentes d’éléments de E , et (αn) une suite conver-gente d’éléments de K. Soit n0 ∈ N. Alors :
• La suite (un + vn) est convergente et lim(un + vn) = lim un + lim vn.
• La suite (αnun) est convergente et lim(αnun) = lim αn · lim un.
• Si αn = 0 pour tout n n0 et si lim αn = 0, alors la suite
unαn
nn0
est convergente
et
lim
unαn
=
lim unlim αn
.
Propriété – Opérations sur les limites
Démonstration – Il suffit de raisonner composante par composante, et d’appliquer les résultatscorrespondants pour les suites à valeurs scalaires.
De la même façon, on obtient le résultat suivant :
Soit (un) une suite d’éléments de E qui converge vers ℓ ∈ E .
Alors toute suite extraite de (un) converge vers ℓ.
Propriété
III. Vocabulaire de topologie
Soient A une partie de E , et a un point de A. On dit que a est un point intérieur àA si :
∃ r > 0 ; B(a,r) ⊂ A.
En d’autres termes, a est intérieur à A si on peut trouver une boule ouverte centrée ena, de rayon strictement positif, et incluse dans A.
Définition – Points intérieurs à une partie
Exemple – 2 est intérieur à [0,3] car 2 ∈ ]1.5,2.5[⊂ [0,3]. En revanche, 0 et 3 ne sont pas intérieursà [0,3].
Remarque – Soit A une partie de E . Soit (xn) une suite d’éléments de E qui converge vers unpoint a intérieur à A. Alors, pour n assez grand, xn ∈ A.
En effet, soit r > 0 tel que B(a,r) ⊂ A. En appliquant la définition de la limite avec ε = r/2,on obtient l’existence de n0 ∈ N tel que pour tout n n0, xn−a < r, et donc, xn ∈ B(a,r) ⊂ A.
115

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 124/383
Soit A une partie de E . On appelle intérieur de A l’ensemble, noté A, des pointsintérieurs à A.
Définition – Intérieur d’une partie
Remarque – On a toujours A ⊂ A.
Une partie A de E est dite ouverte (on dit aussi que A est un ouvert de E ) si chacunde ses points est un point intérieur à A :
∀ a ∈ A, ∃ r > 0 ; B(a,r) ⊂ A.
Ceci équivaut à chacune des propriétés suivantes :
• A = A.• Pour chaque point a de A, on peut trouver une boule ouverte centrée en a, de
rayon strictement positif, et incluse dans A.
Définition – Partie ouverte
Exemple – E et ∅ sont des ouverts.
Une boule ouverte est un ouvert.
Propriété
Démonstration – Le cas d’une boule ouverte de rayon 0 est trivial. Soient x ∈ E et R > 0.Montrons que B (x,R) est un ouvert de E . On fixe donc a ∈ B(x,R), et on définit
d = d(a,x) = x − a.
Alors d < R car a ∈ B(x,R), et pour tout y appartenant à B (a,R − d), on a
x − y ≤ x − a + a − y = d + y − a < d + R − d = R,
donc y ∈ B(x,R). Ainsi, en posant r = R − d > 0, on a : B(a,r) ⊂ B (x,R). Cette constructionétant possible pour tout a ∈ B (x,R) (avec r dépendant de a, ce qui est tout à fait possible auvu de la définition précédente), on a le résultat.
x
a
R
d
r = R − d
116

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 125/383
Exemples
• Les intervalles ouverts de R sont des ouverts.
• Le demi-planP = (x,y) ∈R2, y > 0
est un ouvert de R2. On vérifie la définition avec la norme euclidienne usuelle · 2.
Soit a = (x,y)
∈ P . Notons r = y > 0. Pour tout p = (u,v) dans B(a,r), on a
|y − v| ≤
(x − u)2 + (y − v)2 = p − a2 < r = y,
doncy − v ≤ |y − v| < y.
On en déduit que v > 0, donc p ∈ P . Ainsi, B (a,r) ⊂ P .
De même que l’on a défini les points situés « à l’intérieur » de A, on peut définir les points« qui touchent » A (sans nécessairement appartenir à A) : il s’agit, intuitivement, des pointssitués arbitrairement près de points de A :
Soient A une partie de E et a ∈ E . On dit que a est un point adhérent à A si
∀ r > 0, B(a,r) ∩ A = ∅.
Définition – Points adhérents à une partie
Exemples
• Tout point de A est adhérent à A.
• 4 est adhérent à [−2,4[.
Soient A une partie de E et a ∈ E . Le point a est adhérent à A si et seulement si ilexiste une suite d’éléments de A qui converge vers a.
Propriété – Caractérisation séquentielle des points adhérents
Démonstration
⇒ Si a est adhérent à A, pour tout entier n 1, il existe xn ∈ B(a,1/n) ∩ A. Alors xn → a carpour tout n 1,
xn − a < 1
n.
De plus (xn) est une suite d’éléments de A.⇐ Soient r > 0 et (xn) une suite d’éléments de A qui converge vers a. Comme xn → a, pour n
assez grand, xn ∈ B(a,r) et même xn ∈ B(a,r) ∩ A. Cet ensemble est donc non vide, et ce pourtout r > 0, donc a est adhérent à A.
Exemple – La matrice 1 00 0
est adhérente à l’ensemble des matrices inversibles, car elle est limite de la suite des matrices
1 0
0 1/nlorsque n tend vers +∞.
117

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 126/383
Soit A une partie de E . On appelle adhérence de A l’ensemble, noté A, des pointsadhérents à A.
Définition – Adhérence d’une partie
Remarque – On a toujours A ⊂ A.
Une partie A de E est dite fermée (on dit aussi que A est un fermé de E ) si tous lespoints adhérents à A appartiennent à A (ce qui équivaut au fait que A = A).
Définition – Partie fermée
Exemples
• E et ∅ sont des fermés.
• ]−∞, − 1] ∪ [1, + ∞[ est un fermé de R.
• Toute boule fermée est un fermé. Toute sphère est un fermé.
On déduit en particulier de la propriété précédente une caractérisation des parties fermés :
Soit A une partie de E . Les propriétés suivantes sont équivalentes :
• A est une partie fermée.
• Pour toute suite convergente (xn) d’éléments de A, on a lim xn ∈ A.
Propriété – Caractérisation séquentielle des fermés
Exemple – Le cercle unité de R2 est l’ensemble
U = (x,y) ∈ R2; x2 + y2 = 1.
Soit (xn,yn) une suite d’éléments de U convergeant vers (x,y) ∈ R2
. On a, pour tout n ∈ N,x2n + y2
n = 1,
de sorte qu’à la limite, on obtient x2 + y2 = 1. Le point (x,y) appartient donc à U. On a doncmontré que U est fermé.
Attention ! Les notions d’ouverts et de fermés ne sont pas contraires l’une de l’autre : E etl’ensemble vide sont par exemple à la fois ouverts et fermés.
Le lien est en fait le suivant :
Une partie A de E est fermée si et seulement si son complémentaire dans E est ouvert.On rappelle que le complémentaire de A est défini par ∁A = E \ A = x ∈ E ; x /∈ A.
Propriété
Démonstration
⇒ Si A est fermé, soit a ∈ ∁A. On veut montrer qu’il existe r > 0 tel que B (a,r) ⊂ ∁A. Si teln’était pas le cas, pour tout n ∈ N∗, il existerait xn ∈ B(a,1/n) tel que xn ∈ A. Le point a seraitdonc limite d’une suite d’éléments de A, et A étant fermé, on devrait avoir a ∈ A, ce qui n’estpas le cas. On en déduit l’existence de r , et on a donc montré que ∁A est ouvert.
⇐ Si ∁A est ouvert, soit a un point de E qui est limite d’une suite (xn) d’éléments de A. Sia /
∈ A, alors a appartient au complémentaire de A qui est ouvert. Il existe donc r > 0 tel que
B(a,r) ⊂ ∁A. Sachant que xn → a, on en déduit que pour n assez grand, xn ∈ B(a,r) ⊂ ∁A, cequi est absurde car (xn) est une suite d’éléments de A. Donc a ∈ A, ce qui montre que A estfermé.
118

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 127/383
• Une réunion d’ouverts est un ouvert.
• Une intersection d’un nombre fini d’ouverts est un ouvert.
• Une intersection de fermés est un fermé.
• Une réunion d’un nombre fini de fermés est un fermé.
Propriété
Démonstration• Soit U =
i∈I U i une réunion d’ouverts, I désignant un ensemble d’indices. Soit a ∈ U . Il
existe i ∈ I tel que a ∈ U i. Comme U i est un ouvert, il existe r > 0 tel que B (a,r) ⊂ U i.Alors B (a,r) ⊂
j∈I U j = U .
• Soient p ∈ N∗, et U = pi=1 U i une intersection finie d’ouverts. Soit a ∈ U . Pour tout i ∈ [[1,p]],
il existe ri > 0 tel que B(a,ri) ⊂ U i. Posons r = minri; i ∈ [[1,p]]. On a alors r > 0 etB(a,r) ⊂ B(a,ri) pour tout i, donc
B(a,r) ⊂ pi=1
U i = U.
• Pour les deux points concernant les fermés, il suffit de passer au complémentaire et d’utiliserles deux premiers points ; en effet, si les F i sont des fermés,
∁
i∈I
F i
=i∈I
∁F i
et ∁
pi=1
F i
=
pi=1
∁F i
.
Soit A une partie de E . On appelle frontière de A l’ensemble F r(A) = A\A, constituédes points de E qui sont adhérents à A mais pas intérieurs à A.
Définition – Frontière d’une partie
Bien sûr, cette notion coincide avec l’intuition que suggère son nom : la frontière correspondau « bord » de l’ensemble. Par exemple, la frontière d’une boule Bf (a,r) ou B(a,r) de rayon nonnul est la sphère S (a,r).
IV. Fonctions entre espaces vectoriels normés :limite et continuité
Dans toute la suite, E et F désignent deux espaces vectoriels normés de dimension finie, A
une partie de E et f une fonction définie sur A et à valeurs dans F . On peut munir E d’unenorme
· E et F d’une norme
· F .
1. Définitions
• Soit a un point adhérent à A (a ∈ A) et b ∈ F .
On dit que f a pour limite b en a (ou que f (x) tend vers b lorsque x tend vers a) si
∀ ε > 0, ∃ η > 0; ∀ x ∈ A, [x − aE η] ⇒ [f (x) − bF ε].
On note ceci f (x) −→x→a b.
• On dit que f a une limite en a s’il existe b ∈ F tel que f (x) −→x→a b. Le vecteur b estalors unique ; il est appelé limite de f en a et noté limx→a f (x) ou lima f.
Définition – Limite en un point
119

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 128/383
Démonstration de l’unicité de b
Soient b et b′ deux vecteurs de F vérifiant la définition; soient ε > 0 et deux réels η > 0 etη′ > 0 vérifiant la condition ci-dessus pour b et b′ respectivement. Alors pour tout x ∈ A tel quex − aE min(η,η′),
b − b′F = b − f (x) + f (x) − b′F f (x) − bF + f (x) − b′F 2ε.
Ceci étant vrai pour tout ε > 0, on en déduit b = b′.
Remarque – Pourquoi définir la limite de f en un point a adhérent à A ? Dans la définition depoint adhérent, on peut clairement remplacer B (a,r) par Bf (a,r) : les points adhérents à A sontexactement les points de E pour lesquels, pour tout η > 0, Bf (a,η) ∩ A n’est pas vide, et doncceux pour lesquels l’éventualité « x ∈ A et x − aE η » se présente.
• Soient m ∈ R, f une fonction définie sur ]m, + ∞[ à valeurs dans F et b ∈ F .On dit que f a pour limite b en +∞ si
∀ ε > 0, ∃ M > 0 ; ∀ x M, f (x) − bF ε.
• Soient m ∈ R, f une fonction définie sur ]−∞,m[ à valeurs dans F et b ∈ F .On dit que f a pour limite b en −∞ si
∀ ε > 0, ∃ M > 0 ; ∀ x −M, f (x) − bF ε.
Définition – Limite en ±∞
• Soient f une fonction définie sur A à valeurs réelles et a un point adhérent à A.On dit que f a pour limite +∞ en a si
∀K > 0,
∃η > 0 ;
∀x
∈ A, [
x
−a
E η]
⇒ [f (x) K ].
• Soient f une fonction définie sur A à valeurs réelles et a un point adhérent à A.On dit que f a pour limite −∞ en a si
∀ K > 0, ∃η > 0 ; ∀ x ∈ A, [x − aE η] ⇒ [f (x) −K ].
Définition – Limite infinie
On vérifie aisément que l’unicité de la limite est toujours vérifiée.
Lorsque a ∈ A et f admet une limite en a, on a nécessairement limx→af (x) = f (a).
Dans ce cas, on dit que f est continue en a.
Propriété/Définition – Continuité en un point
Démonstration – Soit ε > 0 fixé et b = lima f . Il existe η > 0 tel que pour tout x de A vérifiantx − aE η, on ait f (x) − bF ε. En appliquant ceci à x = a (ce qui est possible car a ∈ A),on a donc f (a) − bF ε, et ce pour tout ε > 0. Ainsi b = f (a), c’est-à-dire
limx→af (x) = f (a).
On dit que f est continue sur A si f est continue en tout point de A. Ceci équivaut à :
∀ a ∈ A, ∀ ε > 0, ∃ η > 0; ∀x ∈ A, [x − aE η] ⇒ [f (x) − f (a)F ε].
Définition – Continuité sur une partie
120

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 129/383
2. Caractérisation séquentielle de la limite
Soit a un point adhérent à A ; les propriétés suivantes sont équivalentes :
• La fonction f possède une limite en a.
• Pour toute suite (an) d’éléments de A qui converge vers a, la suite (f (an))n∈N a
une limite.Dans ce cas, pour toute suite (an) d’éléments de A qui converge vers a,
limx→af (x) = lim
n→+∞f (an).
Propriété – Caractérisation séquentielle de la limite
Démonstration
⇒ Notons b = limx→af (x). Soit (an) une suite d’éléments de A convergeant vers a. Soit ε > 0
fixé. Il existe η > 0 tel que pour tout x de A vérifiant x − aE η, on ait f (x) − bF ε. Oran
→ a, donc il existe n0
∈N tel que pour tout n n0,
an
−aE η. Alors, pour un tel n,
f (an) − bF ε,
d’où le résultat.
⇐ Commençons par montrer que, avec les notations de l’énoncé, la limite de (f (an)) ne dépendpas de la suite (an). Soient donc (an) et (αn) deux suites d’éléments de A qui convergent versa. On construit une suite (cn) en posant, pour tout p ∈ N, c2 p = a p et c2 p+1 = α p : (cn) estconstruite en écrivant alternativement les termes de (an) et (αn). En particulier, la suite (cn)converge vers a, et donc la suite (f (cn)) est convergente. Or les suites (f (an)) et (f (αn)) sontextraites de (f (cn)), donc
lim f (an) = lim f (cn) = lim f (αn),
qui est le résultat annoncé.
Notons alors b la valeur commune de la limite de toutes les suites (f (an)) où (an) est unesuite d’éléments de A qui converge vers a. Pour montrer que f a une limite en a égale à b, onraisonne par l’absurde : supposons au contraire qu’il existe ε > 0 tel que pour tout η > 0, ilexiste x ∈ A tel que x − aE η mais f (x) − bF > ε. En appliquant cela avec η = 1/n(n ∈ N∗) on construit une suite (an) d’éléments de A telle que pour tout n 1,
an − aE 1
n et f (an) − bF > ε.
Alors an → a mais (f (an)) ne converge pas vers b ; c’est absurde, et on en déduit le résultat.
Remarques
• L’implication directe est très souvent employée sous la forme suivante :
an → a
f est continue en a⇒ f (an) → f (a).
• Cette caractérisation permet de ramener de nombreuses questions de limites de fonctions à desquestions de limites de suites, pour lesquelles on a déjà de nombreuses propriétés.
• On a une propriété analogue pour les limites en ±∞ lorsque E = R.
121

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 130/383
3. Limite et continuité composante par composante, opérations
Soient C = (ε1, . . . , εn) une base de F et f : A → F une fonction. Notons
f =n
i=1
f i εi
la décomposition de f dans la base C, c’est-à-dire que les fonctions f i : A →K sont lesfonctions-coordonnées de f dans la base C.
Alors :
1. Soit a un point adhérent à A. Pour que f ait une limite en a, il faut et il suffit quepour tout i ∈ [[1,n]], f i ait une limite en a. Dans ce cas, on a
lima f =ni=1
(lima f i) εi,
c’est-à-dire que les coordonnées de la limite sont les limites des fonctions-coordonnées.2. Soit a ∈ A. Pour que f soit continue en a, il faut et il suffit que pour tout i ∈ [[1,n]],f i soit continue en a.
3. Pour que f soit continue sur A, il faut et il suffit que pour tout i ∈ [[1,n]], f i soitcontinue sur A.
Propriété – Limite ou continuité composante par composante
Démonstration – Il suffit d’utiliser la caractérisation séquentielle de la limite et la propriété deconvergence composante par composante pour les suites.
Soient f et g deux fonctions définies sur A à valeurs dans F , et α une fonction définiesur A à valeurs dans K.
1. Soit a un point adhérent à A. On suppose que f , g et α ont une limite en a.
Alors :
• La fonction f + g a une limite en a et lima(f + g) = lima f + lima g.
• La fonction αf a une limite en a et lima(αf ) = (lima α)(lima f ).
• Si α(x) = 0 pour tout x ∈ A et si lima α = 0, alors la fonction f
α a une limite en
a et
lima
f α
= lima f
lima α.
Toutes ces propriétés sont vraies si E = R et a = ±∞, ainsi que les cas déjà connuspour des limites infinies ; attention cependant aux formes indéterminées.
2. Lorsque a appartient à A, on peut traduire ces propriétés en termes de continuitéen a.
3. On peut traduire ces propriétés en termes de continuité sur A.
En particulier, l’ensemble C0(A,F ) des fonctions continues sur A à valeurs dans F estun K-espace vectoriel (pour les lois usuelles).
Propriété – Opérations algébriques
Démonstration – Il suffit de démontrer le point 1. On se ramène aux propriétés analogues sur lessuites grâce à la caractérisation séquentielle de la limite.
122

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 131/383
Soient E , F et G trois espaces vectoriels normés de dimension finie, A une partie de E et B une partie de F . Soient f : A → F et g : B → G deux fonctions. On suppose quef (A) ⊂ B, de sorte que la fonction g f : A → G est bien définie.
1. Soit a un point adhérent à A. On suppose que f a une limite b en a. Alors :
• b est adhérent à B .
Si de plus g a une limite c en b, on a :• g f a une limite en a et (g f )(x) −→
x→a c.
2. Soit a ∈ A. Si f est continue en a et si g est continue en f (a), alors g f est continueen a.
3. Si f est continue sur A et si g est continue sur B , alors g f est continue sur A.
Propriété – Composition
Démonstration – Il suffit de démontrer le point 1.
• Le point a est adhérent à A, donc il existe une suite (an) d’éléments de A qui converge vers a.Sachant que f a pour limite b en a, on a donc f (an) → b. Or, pour tout n ∈ N, f (an) ∈ f (A) ⊂ B .
On a donc construit une suite d’éléments de B qui converge vers b : b est adhérent à B .• Soit (an) une suite d’éléments de A qui converge vers a. Alors sachant que f a pour limite ben a et que g a pour limite c en b, on a f (an) → b et g(f (an)) → c. D’après la caractérisationséquentielle de la limite (sens réciproque, appliqué à g f ), on obtient que g f a pour limite cen a.
Toute application polynomiale f définie sur Kn est continue (par application poly-nomiale, on entend que chaque fonction-coordonnée de f dans une base de l’espaced’arrivée est un polynôme en les composantes x1, . . . , xn de la variable x).
Propriété – Continuité des applications polynomiales
Démonstration – D’après les deux premières propriétés de ce paragraphe, il suffit de prouver quepour tout i ∈ [[1,n]], l’application x = (x1, . . . , xn) → xi est continue, ce qui est immédiat.
Exemple – L’application (x,y,z) → (x2 + 3xy + 4xz2,xz − y3) est continue de R3 dans R2.
Remarque – On montre de la même façon que toute application f définie sur E , polynomiale enles coordonnées (x1, . . . , xn) de sa variable x dans une base de E , est continue.
4. Fonctions Lipschitziennes
Soit k ∈ R+. On dit que f est k-Lipschitzienne si
∀ (x,y) ∈ A2, f (x) − f (y)F k x − yE .
On dit que f est Lipschitzienne s’il existe k tel que f est k-Lipschitzienne.
Définition – Fonction Lipschitzienne
Remarque – Le fait pour une fonction d’être Lipschitzienne ne dépend pas des normes choisies,mais le fait d’être k-Lipschitzienne en dépend!
Exemples
• La fonction racine carrée f : x
→
√ x est Lipschitzienne sur [1, +
∞[ : en effet, f est dérivable
sur [1, + ∞[ avec, pour tout x 1,
f ′(x) = 1
2√
x
1
2.
123

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 132/383
D’après le théorème des accroissements finis, on a donc, pour tout (x,y) ∈ [1, + ∞[ 2,
|f (x) − f (y)| 1
2|x − y|.
Le théorème des accroissements finis est un outil très utile pour prouver qu’une fonction estLipschitzienne.
• Si
· est une norme sur E , l’application x
→ x
de E dans R est 1-Lipschitzienne : en effet,
d’après la seconde forme de l’inégalité triangulaire, pour tout (x,y) ∈ E 2, on a x − y x − y.
Remarques
• Il est très facile de prouver que l’ensemble des fonctions Lipschitziennes de A ⊂ E dans F estun K-espace vectoriel.
• On a également une propriété de stabilité vis-à-vis de la composition : soient (E,·E ), (F,·F )et (G, · G) trois espaces vectoriels normés, A une partie de E et B une partie de F . Soientf : A
→ F et g : B
→ G deux fonctions. On suppose que f (A)
⊂ B, de sorte que la fonction
g f est bien définie.Si f est k1-Lipschitzienne et g est k2-Lipschitzienne, alors g f est k1k2-Lipschitzienne.
En effet, pour tout (x,y) ∈ A2,
(g f )(x) − (g f )(y)G k2f (x) − f (y)F k2 k1 x − yE .
Toute fonction Lipschitzienne est continue. La réciproque est fausse.
Propriété
Démonstration – Avec les notations précédentes, soit f une fonction k-Lipschitzienne. Si k = 0,f est constante et le résultat est évident. Sinon, soient a ∈ A et ε > 0. Pour tout (x,y) ∈ A2,
f (x) − f (y)F k x − yE .
En particulier, si x − aE ε/k, alors
f (x) − f (a)F k ε
k = ε.
Donc f est continue en a, et ce pour tout a ∈ A. On voit même que le nombre η = ε/k permettant
de vérifier la définition de la continuité est indépendant de x : le caractère Lipschitzien est doncbeaucoup plus fort que la continuité en chaque point.
Pour montrer que la réciproque est fausse : la fonction x → x2 définie sur R n’est pasLipschitzienne, bien qu’elle soit continue. En effet, supposons au contraire qu’il existe k tel quepour tout (x,y) ∈ R2, |x2 − y2| k|x − y|. Alors, pour tout x et y distincts, on a
|x + y| |x − y| k|x − y| d’où |x + y| k,
ce qui est absurde lorsque par exemple y = 0 et x tend vers +∞.
124

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 133/383
V. Propriétés des fonctions continues à valeurs réelles
1. Ensembles de niveaux d’une fonction continue
Soit f une application continue sur E à valeurs dans R. Alors :
• L’ensemble x ∈ E ; f (x) > 0 est une partie ouverte de E .
• L’ensemble x ∈ E ; f (x) 0 est une partie fermée de E .• L’ensemble x ∈ E ; f (x) = 0 est une partie fermée de E .
Propriété
Démonstration
• Soit a ∈ E tel que f (a) > 0 ; par continuité de f , il existe η > 0 tel que pour tout x de E vérifiant x − aE η, on ait |f (x) − f (a)| f (a)/2, et donc
f (x) f (a) − f (a)
2 =
f (a)
2 > 0.
En particulier, B(a,η) ⊂ x ∈ E ; f (x) > 0. Il en résulte que x ∈ E ; f (x) > 0 est ouvert.• On utilise la caractérisation séquentielle des fermés : soit (an) une suite d’éléments dex ∈ E ; f (x) 0 qui converge vers a ∈ E . Pour tout n, f (an) 0, et f étant continue,on sait que f (an) → f (a). On en déduit que f (a) 0, c’est-à-dire, a ∈ x ∈ E ; f (x) 0. Cetensemble est donc fermé.
• On raisonne de même en passant à la limite dans la relation f (an) = 0.
Remarque – Bien sûr, en changeant f en −f , on prouve des résultats analogues pour f (x) < 0 etf (x) 0.
Cette dernière propriété est très utile pour prouver que des parties de E sont ouvertes, oufermées : on peut parfois voir ces parties comme ensembles de niveau f (x) > 0, f (x) 0 ou
f (x) = 0 d’une application continue à valeurs réelles f bien choisie.Exemples
• L’exemple du cercle unité U traité plus haut entre dans ce cadre : on a
U = (x,y) ∈R2; x2 + y2 − 1 = 0,
la fonction f : (x,y) → x2 + y2 − 1 étant continue car polynomiale.
• Revenons sur l’exemple du demi-plan
P = (x,y) ∈R2, y > 0
Montrons par cette méthode qu’il s’agit d’un ouvert de R2 : l’application
f :
R2 → R
(x,y) → y
est continue sur R2. De plus, P = (x,y) ∈ R2; f (x,y) > 0. D’après la propriété précédente, P est donc un ouvert.
• L’ensemble Gℓn(R) des matrices inversibles d’ordre n est un ouvert de M n(R) : en effet, unematrice carrée A est inversible si et seulement si det(A) = 0. On en déduit donc que
Gℓn(R
) = A ∈M
n(R
); det(A) < 0 ∪ A ∈M
n(R
); det(A) > 0.
Nous montrerons bientôt que la fonction déterminant est continue sur M n(R). On en déduit queGℓn(R) est la réunion de deux ouverts de M n(R), c’est donc une partie ouverte.
125

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 134/383
• L’ensemble O des trinômes à coefficients réels qui ont deux racines réelles distinctes est unepartie ouverte de R2[X ]. Soit en effet l’application discriminant
φ :
R2[X ] → R
aX 2 + bX + c → b2 − 4ac
et ψ : aX 2 + bX + c → a. Alors
O = (P ∈ R2[X ]; ψ(P ) < 0 ∪ P ∈ R2[X ]; ψ(P ) > 0) ∩ P ∈ R2[X ]; φ(P ) > 0.
Or, φ et ψ sont continues sur R2[X ] (c’est immédiat pour ψ, et φ est polynomiale en les coor-données de sa variable). Donc O est une partie ouverte comme intersection de deux ouverts, lepremier étant lui-même la réunion de deux ouverts. De la même façon, on montre que l’ensembledes polynômes de R2[X ] ayant deux racines complexes conjuguées distinctes est un ouvert, etque l’ensemble des polynômes de R2[X ] ayant au plus une racine (éventuellement double) est unfermé.
2. Extrema de fonctions continues
Si K est une partie fermée, bornée et non vide de E et f : K → R est continue, alorsf est bornée et atteint ses bornes.
Théorème des bornes atteintes (admis : démonstration non exigible)
Remarque – Ce théorème est bien sûr une généralisation du théorème selon lequel une fonctioncontinue sur un segment, à valeurs dans R, est bornée et atteint ses bornes.
Exemple – La boule unité B de M n(R) pour la norme infini est fermée, bornée et non vide. Lafonction déterminant, qui est continue sur B , est donc bornée sur B et atteint ses bornes. Ainsi,parmi les matrices de M n(R) dont tous les coefficients sont compris entre −1 et 1, il en existeau moins une dont le déterminant est maximal.
VI. Le cas des applications linéaires et multilinéaires
Soient E et F deux espaces vectoriels de dimension finie et u ∈L (E,F ).
Alors u est Lipschitzienne.
Théorème – Caractère Lipschitzien des applications linéaires
Démonstration – Munissons E d’une base B = (e1, . . . , en) et de la norme infini · ∞ associéeà cette base, et F d’une norme · F . Soit x ∈ E dont la décomposition dans la base B estx = x1e1 +
· · ·+ xnen. Alors par linéarité de u,
u(x)F = x1u(e1) + · · · + xnu(en)F |x1|u(e1)F + · · · + |xn|u(en)F ,d’après l’inégalité triangulaire. Alors
u(x)F [u(e1)F + · · · + u(en)F ] x∞.
Posons k = u(e1)F + · · · + u(en)F . Soit (x,y) ∈ E 2 ; alors par linéarité de u et d’aprèsl’inégalité précédente,
u(x) − u(y)F = u(x − y)F k x − y∞,
d’où le résultat, car la notion de fonction Lipschitzienne ne dépend pas des normes choisies sur
E et F .
Attention ! La linéarité de u est essentielle pour que l’inégalité u(x)F k x∞, valable pourx ∈ E , entraîne que u est Lipschitzienne.
126

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 135/383
On sait que le caractère Lipschitzien entraîne la continuité, on a donc le résultat suivant :
Une application linéaire entre espaces vectoriels de dimension finie est continue.
Corollaire
Exemple – L’application Trace, de M n(K) dans K, est linéaire entre deux espaces de dimension
finie, donc Tr est Lipschitzienne. Si M n(K) est muni de la norme infini (et K de la valeur absolueou du module), elle est en fait n-Lipschitzienne car pour tout M = (mi,j)1i,jn ∈M n(K),
| Tr(M )| =ni=1
mi,i
ni=1
|mi,i| n maxi,j
|mi,j| = n M ∞.
Si M n(K) est muni de la norme 1, définie par M 1 =ni,j=1 |mi,j|, elle est 1-Lipschitzienne car
| Tr(M )| ni=1
|mi,i| n
i,j=1
|mi,j| = M 1.
Soit p un entier avec p 2 et f : (Kn) p → F une application multilinéaire, c’est-à-dire,linéaire par rapport à chacune de ses p variables.
Alors f est continue.
Propriété – Continuité des applications multilinéaires
Démonstration – On notera (e1, . . . , en) la base canonique de Kn. Pour j ∈ [[1,p]], soitx j = (x j1, . . . , x jn) = x j1e1 + · · · + x jnen ∈ Kn. Par multilinéarité de f , on a
f (x1, . . . , x p) = (i1,...,ip)∈[[1,n]]p
x1i1 · · · x pip f (ei1 , . . . , eip).
En décomposant tous les vecteurs f (ei1 , . . . , eip) dans une base de F , on voit que chaque coordon-
née de f (x1, . . . , x p) dans cette base définit une fonction polynomiale en les x ji pour(i,j) ∈ [[1,n]] × [[1,p]], et donc, définit une fonction continue. On en déduit que f est continue.
Remarque – Si E et F sont de dimension finie, on généralisera sans difficulté la propriété précé-dente pour montrer qu’une application f : E p → F multilinéaire est continue.
Exemples
• L’application déterminant, de M n(K) dans K, est continue car multilinéaire par rapport auxcolonnes de sa variable.
• Si (E, (· | ·)) est un espace euclidien, alors le produit scalaire (· | ·) est une application continue.Si de plus E est orienté de dimension 3, alors le produit vectoriel ∧ est une application continue.En effet, dans ces deux cas, l’application considérée est bilinéaire.
• Le produit matriciel M n(K) ×M n(K) → M n(K)
(A,B) → AB
est continu car bilinéaire.
On peut donc passer à la limite dans un déterminant, un produit scalaire en dimension finie,un produit vectoriel, un produit de matrices.
127

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 136/383
128
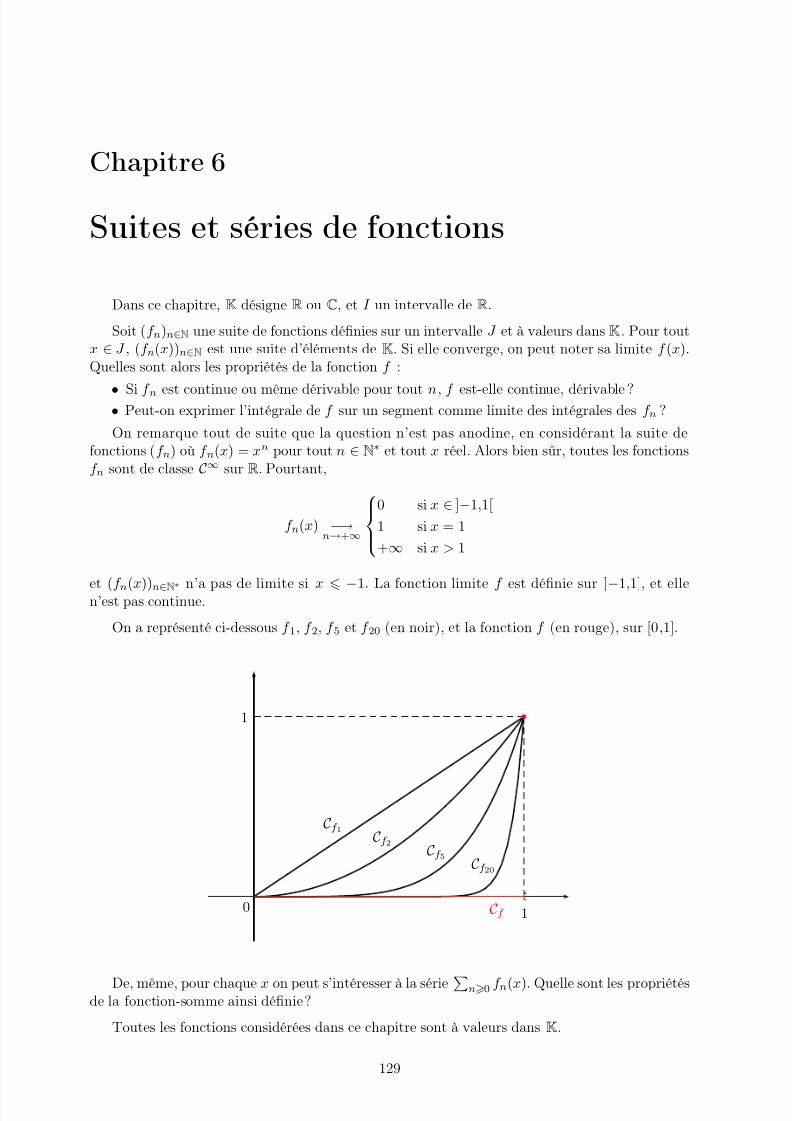
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 137/383
Chapitre 6
Suites et séries de fonctions
Dans ce chapitre, K désigne R ou C, et I un intervalle de R.
Soit (f n)n∈N une suite de fonctions définies sur un intervalle J et à valeurs dans K. Pour toutx ∈ J , (f n(x))n∈N est une suite d’éléments de K. Si elle converge, on peut noter sa limite f (x).Quelles sont alors les propriétés de la fonction f :
• Si f n est continue ou même dérivable pour tout n, f est-elle continue, dérivable ?• Peut-on exprimer l’intégrale de f sur un segment comme limite des intégrales des f n ?
On remarque tout de suite que la question n’est pas anodine, en considérant la suite defonctions (f n) où f n(x) = xn pour tout n ∈ N∗ et tout x réel. Alors bien sûr, toutes les fonctionsf n sont de classe C∞ sur R. Pourtant,
f n(x) −→n→+∞
0 si x ∈ ]−1,1[
1 si x = 1
+∞ si x > 1
et (f n(x))n∈N∗
n’a pas de limite si x −1. La fonction limite f est définie sur ]−1,1], et ellen’est pas continue.
On a représenté ci-dessous f 1, f 2, f 5 et f 20 (en noir), et la fonction f (en rouge), sur [0,1].
1
10
Cf 1 Cf 2 Cf 5 Cf 20
Cf
De, même, pour chaque x on peut s’intéresser à la série n0 f n(x). Quelle sont les propriétésde la fonction-somme ainsi définie?
Toutes les fonctions considérées dans ce chapitre sont à valeurs dans K.
129

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 138/383
I. Différents modes de convergence
1. Convergence simple, convergence uniforme
Commençons par définir la convergence envisagée dans l’introduction :
Pour tout n ∈ N (ou n n0 avec n0 ∈ N∗), on se donne une fonction f n : I → K.On se donne également une fonction f : I → K.
On dit que la suite de fonctions (f n)n∈N converge simplement vers f sur I si :
∀ x ∈ I , f n(x) −→n→+∞ f (x).
Définition – Convergence simple
Exemple – Comme nous l’avons montré dans l’introduction, la suite (f n)n∈N∗ des fonctionsf n : x → xn converge vers la fonction
f : x
→ 0 si x ∈ ]−1,1[
1 si x = 1
sur ]−1,1].
La convergence simple est donc une notion qui s’applique « x par x ». Pour la montrer, oncommence par fixer x et on étudie la suite (f n(x))n∈N d’éléments de K. Or, le comportement decette suite pour un certain x peut être indépendant du comportement pour un autre x, mêmeproche. C’est ce qui arrive dans notre exemple entre x ∈ ]−1,1[ et x = 1.
Pour pallier cette difficulté, on va définir un autre mode de convergence en imposant unecertaine uniformité entre les différentes valeurs de x :
Avec les notations ci-dessus, on dit que (f n) converge uniformément vers f sur I si
• pour n ∈ N assez grand, f n − f est bornée sur I ;
• supx∈I
|f n(x) − f (x)| −→n→+∞ 0.
Définition – Convergence uniforme
Regardons de plus près cette définition, et traduisons-la avec des quantificateurs ; elle signifie :
∀ ε > 0, ∃n0 ∈ N; ∀ n n0, ∀ x ∈ I , |f n(x) − f (x)| ε.
Comparons-la à la convergence simple ; cette dernière signifie :
∀ ε > 0, ∀x ∈ I , ∃n0 ∈ N; ∀ n n0, |f n(x) − f (x)| ε.
Toute la différence réside dans cet échange de quantificateurs : dans la convergence simple, lerang n0 dépend de x ; dans la convergence uniforme, le même n0 doit convenir pour tout x ∈ I .La convergence uniforme est donc beaucoup plus exigeante que la convergence simple.
Si K = R, l’inégalité |f n(x) − f (x)| ε est équivalente à f (x) − ε f n(x) f (x) + ε. Ainsi,pour que la suite de fonctions (f n) converge uniformément vers f sur I , il faut et il suffit quepour tout ε > 0, il existe un entier n0 tel que pour tout n n0, pour tout x ∈ I ,
f (x) − ε f n(x) f (x) + ε,
ce qui signifie que pour n n0, le graphe de f n est inclus dans le « tube » d’épaisseur 2 ε autourdu graphe de f .
130
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 139/383
Ce phénomène est illustré sur le graphique suivant :
y = f (x)
y = f (x) + ε
y = f (x) − ε
y = f n(x) avec n n0
ε
ε
x
y
Soit (f n) une suite de fonctions définies sur I , à valeurs dans K, et f : I →
K unefonction.Pour que (f n) converge uniformément vers f sur I , il faut et il suffit qu’il existe unesuite (an) de réels positifs telle que
• pour n assez grand, pour tout x ∈ I , |f n(x) − f (x)| an ;
• an −→n→+∞ 0.
Propriété
Démonstration
⇒ Il suffit de choisir an = supx∈I |f n(x) − f (x)| si f n − f est bornée (ce qui est le cas pour n
assez grand), an
= 0 sinon.
⇐ Si une telle suite (an) existe, alors pour n ∈ N assez grand, f n − f est bornée et
supx∈I
|f n(x) − f (x)| an avec an −→n→+∞ 0,
donc (f n) converge uniformément vers f sur I .
L’intérêt de cette propriété est de montrer que pour prouver la convergence uniforme de (f n)
vers f sur I , il n’est pas nécessaire de calculer supx∈I |f n(x) − f (x)|, mais il suffit de le majorer
par un terme an convenable.
En revanche, si les majorations ne sont pas assez fines, il se peut que l’on ne puisse pas
conclure. Il faut alors améliorer les majorations, sachant que la majoration la plus fine possiblesera toujours celle donnée par le calcul de supx∈I |f n(x) − f (x)|, qui peut se faire par des étudesde fonctions.
Pour prouver que (f n) ne converge pas uniformément vers f sur I , on peut essayer de calculersupx∈I |f n(x) − f (x)|, ou le minorer par une quantité positive qui ne tend pas vers 0 lorsquen → +∞.
Remarque – Supposons que toutes les fonctions avec lesquelles on travaille soient bornées, c’est-à-dire, appartiennent à B (I,K). Sur cet espace, on a défini dans le chapitre Espaces vectorielsnormés la norme · ∞. Alors, par définition même, (f n) converge uniformément vers f sur I si et seulement si
f n − f ∞ −→n→+∞ 0.
C’est pourquoi la norme infini sur B (I,K) est appelée norme de la convergence uniforme.
131

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 140/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 141/383
sur R vers la fonction f définie par f (0) = 0, f (x) = −π/2 si x < 0 et f (x) = π/2 si x > 0.Cette convergence n’est pas uniforme sur tout segment de R car, par exemple,
supx∈[−1,1]
|f n(x) − f (x)| = π
2,
comme le montre une étude de fonctions sans difficulté. Cet exemple montre aussi que la seconderéciproque est fausse.
Remarque – Dans certains cas, prouver la convergence uniforme de (f n) vers f sur tout segmentde I revient à la prouver pour des segments d’une forme particulière, plus simple :
• Si I est de la forme [α, β [, on peut se limiter aux segments de la forme [α,b] où b ∈ I (de mêmesi I = ]α,β ] avec les segments de la forme [a,β ] où a ∈ I ).
• Si I est symétrique par rapport à 0, de la forme ]−α, α[, on peut se limiter aux segments de laforme [−a,a] où a ∈ [0,α[.
En effet, dans chaque cas, tout segment de I est inclus dans un segment de la forme particulièreindiquée.
Méthode – Pour étudier la convergence d’une suite de fonctions (f n)n∈N, on procède souventcomme suit :
• On fixe x et on étudie la convergence de la suite de scalaires (f n(x))n∈N. On note f (x) sa limite,où x appartient à un certain intervalle I (qui n’est pas nécessairement l’ensemble de définitiondes f n) : la suite de fonctions (f n) converge simplement vers f sur I .
• On se demande alors si la convergence est meilleure. Si elle est uniforme, ou au moins uniformesur tout segment de I , on sait que la limite ne peut être que f . On essaie donc de majorer|f n(x) − f (x)|, et plus précisément, de prouver, pour x ∈ I et n assez grand, une inégalité dutype
|f n(x) − f (x)| an
où an est indépendant de x, et an −→n→+∞ 0.
– Si l’on y parvient sur I tout entier, alors la convergence est uniforme sur I .– Sinon, on essaie de le faire sur tout segment inclus dans I . Si l’on y parvient, la convergenceest uniforme sur tout segment de I .
Exemples
• Étudions la suite des fonctions f n : x →
x2 + 1
n, pour n 1, sur R. Il est évident que (f n)
converge simplement vers la fonction valeur absolue (notée f ) sur R, car pour tout réel x, x2 +
1
n −→n→+∞
√ x2 = |x|.
On se demande si cette convergence est uniforme. Or, pour tout n 1 et x ∈R,
0 f n(x) − f (x) =
x2 +
1
n −
√ x2 =
1/n x2 + 1
n + |x|
1/n
1/√
n =
1√ n
avec 1√
n −→n→+∞ 0,
et l’encadrement est indépendant de x. La convergence est donc uniforme sur R. Ce résultatmontre au passage que l’on peut approcher la valeur absolue (non dérivable en 0) par des fonctionsde classe C∞, de façon uniforme sur R et arbitrairement précise.
• Étudions la suite des fonctions f n : x → nxn(1 − x), pour n 1, sur [0,1]. Par croissancescomparées, (f n) converge simplement vers la fonction nulle f sur [0,1[, et f n(1) = 0 pour toutn ∈ N∗. Il y a donc convergence simple vers f sur [0,1]. Pour savoir si cette convergence est
uniforme, étudions la fonction f n − f = f n sur [0,1]. Pour tout n ∈ N∗, f n est dérivable sur [0,1]et pour tout x ∈ [0,1],
f ′n(x) = n2xn−1(1 − x) − nxn = nxn−1(n(1 − x) − x) = nxn−1(n − (n + 1)x).
133

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 142/383
On en déduit immédiatement que f n, qui est positive, admet un maximum global sur [0,1] enn
n + 1. Or
f n
n
n + 1
= n
n
n + 1
n 1
n + 1 =
n
n + 1
1
1 + 1n
n∼
1
1 + 1n
n.
Un développement limité classique montre que
11 + 1
n
n −→n→+∞
1e
.
Finalement, f et toutes les fonctions f n sont bornées sur [0,1], et
f n − f ∞ = f n
n
n + 1
−→n→+∞
1
e.
La convergence n’est donc pas uniforme sur [0,1]. Elle est cependant uniforme sur tout segmentde la forme [0,a] avec 0 a < 1 (et donc sur tout segment de [0,1[). En effet, pour tout n tel
que a < n
n + 1 ( ce qui est le cas pour n assez grand car
n
n + 1 −→n→+∞ 1), on a
supx∈[0,a] |
f n
(x)−
f (x)| = f
n(a) = nan(1
−a)
−→n→+∞0.
Le cas des séries de fonctions
Bien sûr, on définit la convergence (simple ou uniforme) d’une série de fonctions
n0 f ncomme la convergence de la suite des sommes partielles
(S p) p∈N =
pn=0
f n
p∈N
On se ramène ainsi à une suite de fonctions.
Exemples de convergence simple
• Posons, pour n ∈ N∗ et x ∈ R, f n(x) = 1nx
. La série de Riemann
n1 f n(x) converge si et
seulement si x > 1. La fonction +∞
n=1 f n est appelée fonction ζ de Riemann, elle est définie sur]1, + ∞[.
• Posons, pour n ∈ N et x ∈ R, f n(x) = xn. La série géométrique
n0 xn converge si et
seulement si x ∈ ]−1,1[. La fonction S =+∞n=0 f n est définie sur ]−1,1[ et pour tout x ∈ ]−1,1[,
S (x) = 1
1 − x.
Traduisons plus particulièrement la convergence uniforme d’une série de fonctions n0 f n.
Supposons que la fonction somme S soit définie sur I . Pour tout x ∈ I et p ∈ N,
S (x) − S p(x) =+∞n=0
f n(x) − pn=0
f n(x) =+∞
n= p+1
f n(x) = R p(x);
R p est le reste d’ordre p de cette série de fonctions.
Ainsi, les propriétés suivantes sont équivalentes :
• La série de fonctions
n0 f n converge uniformément sur I .• La suite (R p) p∈N de ses restes converge uniformément vers la fonction nulle sur I .• Pour p assez grand, R p est borné sur I et
supx∈I
|R p(x)| −→ p→+∞ 0, i.e. sup
x∈I
+∞n= p+1
f n(x) −→ p→+∞ 0.
134

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 143/383
2. Convergence normale des séries de fonctions
Nous allons chercher une condition suffisante simple pour que toutes ces propriétés soientsatisfaites. Supposons que f n soit bornée sur I pour tout n. Pour tout x ∈ I ,
|f n(x)| f n∞.
Supposons que la série
n0
f n∞
converge (la norme infini étant calculée sur I ). Alors, par comparaison des séries à termes positifs,la série
n0 f n(x) converge absolument, et donc converge, pour tout x ∈ I . La série de fonctions
n0 f n converge donc simplement sur I . Pour tout x ∈ I , pour tout ( p,q ) ∈ N2 tel que q > p,on a de plus
qn= p+1
f n(x)
q
n= p+1
|f n(x)| q
n= p+1
f n∞.
Lorsque q tend vers +∞, on obtient en particulier, pour tout x ∈ I , et tout p ∈ N,
|R p(x)| =
+∞n= p+1
f n(x)
+∞n= p+1
|f n(x)| +∞n= p+1
f n∞ avec+∞
n= p+1
f n∞ −→ p→+∞ 0.
Nous avons majoré le reste d’ordre p de la série par une quantité qui tend vers 0, indépendantede x : la convergence est donc uniforme sur I .
On définit ainsi un nouveau mode de convergence spécifique aux séries de fonctions :
On dit que la série de fonctions
n0 f n (où f n est définie sur I pour tout n) converge
normalement sur I si :
• f n est bornée sur I pour tout n ∈ N,
• la série numérique
n0 f n∞ converge.
On définit de façon similaire la convergence normale sur tout segment de I .
Définition – Convergence normale
Si
n0 f n converge normalement sur I , alors elle converge uniformément sur I .
Elle converge aussi normalement sur tout segment de I .
Propriété
Démonstration – La première implication a été démontrée ci-dessus. La seconde vient du fait quela norme infini de f n sur un segment de I est inférieure ou égale à sa norme infini sur I. Lethéorème de comparaison de séries à termes positifs donne alors le résultat.
En pratique, la convergence normale se montre souvent de la façon suivante :
Pour quen0 f n converge normalement sur I , il faut et il suffit qu’il existe une suite
(αn) de réels positifs telle que
• Pour tout x ∈ I , pour tout n ∈ N, |f n(x)| αn,
• n0
αn converge.
Propriété
135

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 144/383
Démonstration
⇒ Il suffit de choisir αn = f n∞ pour tout n ∈N.
⇐ Si une telle suite (αn) existe, alors pour tout n ∈ N, f n∞ αn. Par comparaison de sériesà termes positifs, la convergence de la série
n0 αn entraîne la convergence normale de la série
n0 f n.
Remarque – Ainsi, pour prouver la convergence normale de
n0 f n, il n’est pas nécessaire decalculer
f n∞
, mais il suffit de majorer
f n∞
par un terme αn
convenable.Pour prouver l’absence de convergence normale, on peut calculer f n∞ ou le minorer par le
terme général positif d’une série divergente.
Exemples
• Posons, pour n ∈ N∗ et x ∈ R,
f n(x) = sin(nx)
n2 ;
la série de fonctionsn1 f n converge normalement sur R, car pour tout n 1, pour tout x ∈ R,
sin(nx)
n2
1
n2
et la sérien1
1
n2 converge.
• Posons, pour n ∈ N∗ et x > 1, f n(x) = 1
nx ;n1 f n ne converge pas normalement sur ]1, +∞[
car
supx>1
1
nx =
1
n,
or la série harmonique diverge. En revanche,
n1 f n converge normalement sur tout intervallede la forme [a, + ∞[ où a > 1. En effet, dans ce cas,
supxa
1nx
= 1na
,
et la sérien1 1/na converge car a > 1. Ceci montre d’ailleurs que la convergence normale sur
tout segment de I n’entraîne pas la convergence normale sur I .
• On montre de même que la série géométrique,
n0 f n où f n : x → xn, ne converge pasnormalement sur ]−1,1[, mais converge normalement sur tout segment de ]−1,1[.
Donnons un autre exemple, qui montre d’ailleurs que la convergence uniforme sur I n’entraînepas la convergence normale sur I , ni même la convergence normale sur tout segment de I :
Exemple – Posons, pour n ∈ N et x > 0,
f n(x) = (−1)n
x + n;
la série de fonctions
n0 f n ne converge pas normalement sur tout segment de ]0, + ∞[, carpar exemple, pour tout n ∈ N,
supx∈[1,2]
(−1)n
x + n
= 1
1 + n,
or la sérien1
1
1 + n diverge (série harmonique).
Pourtant, n
0
f n converge uniformément sur ]0, +∞
[ : on remarque en effet que pour toutx > 0, la série
n0
(−1)n
x + n
136

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 145/383
est une série alternée de réels, dont la valeur absolue du terme général décroît vers 0. Elle estdonc convergente et, pour tout x > 0 et p ∈ N, on a la majoration suivante de la somme et desrestes :
+∞n= p+1
(−1)n
x + n
1
x + p + 1
1
p + 1.
Ce majorant tend vers 0 lorsque p tend vers +∞, et est indépendant de x, d’où la conclusion.Méthode – Pour étudier la convergence d’une série de fonctions
n0 f n, on procède souvent
comme suit :
• On fixe x et on étudie la convergence de la série numérique
n0 f n(x).
On note S (x) sa somme, où x appartient à un certain intervalle I : la série de fonctions
n0 f nconverge simplement sur I (vers S ).
On se demande alors si la convergence est meilleure.
• On essaie de majorer, pour x ∈ I , le module du reste d’ordre p,
|S (x) − S p(x)| = +∞n= p+1
f n(x)
par une quantité indépendante de x, qui converge vers 0 lorsque p → +∞.
– Si l’on y parvient sur I tout entier, alors la convergence de
n0 f n est uniforme sur I .
– Sinon, on essaie de le faire sur tout segment inclus dans I . Si l’on y parvient, la convergenceest uniforme sur tout segment de I .
• On essaie de majorer, pour x ∈ I et n ∈ N, |f n(x)| par un terme αn indépendant de x, et telque n0 αn converge.
– Si l’on y parvient sur I tout entier, alors la convergence de
n0 f n est normale sur I .
– Sinon, on essaie de le faire sur tout segment inclus dans I . Si l’on y parvient, la convergenceest normale sur tout segment de I .
Si l’une de ces deux situations a lieu, la convergence est en particulier uniforme (sur I ou surtout segment de I selon le cas) et donc simple sur I . On peut donc directement commencer parla convergence normale si on a l’intuition que cela va aboutir, et si c’est le cas, cela remplace lesdeux premiers points. Sinon, on essaie de vérifier le premier voire les deux premiers points.
Nous sommes maintenant prêts à examiner la question de la régularité, de la dérivation etde l’intégration des suites et séries de fonctions. Si (f n) est une suite de fonctions définies sur I ,qui converge (en un certain sens) sur I vers une fonction f , à quelles conditions peut-on écrire :
• limx→a lim
n→+∞f n(x) = limn→+∞ lim
x→af n(x),
• ba
f n(x) dx −→n→+∞
ba
f (x) dx, i.e. limn→+∞
ba
f n(x) dx =
ba
limn→+∞f n(x)
dx,
• (f n)′ −→n→+∞ f ′, i.e. lim
n→+∞f ′n =
limn→+∞f n
′?
On imagine désormais facilement que la validité de ces égalités dépend notamment du mode deconvergence de la suite (f
n) vers sa limite. On remarque aussi que chacune de ces égalités revient
à intervertir une limite selon n avec, soit une limite selon x, soit une intégrale, soit l’opérateurde dérivation. On fait donc souvent référence à ces théorèmes que nous allons étudier, commethéorèmes d’interversion.
137

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 146/383
II. Limite et continuité des suites et séries de fonctions
1. Théorèmes de continuité
Soit (f n)n∈N une suite de fonctions définies sur I . On suppose que :
• Pour tout n ∈ N, f n est continue sur I ,
• (f n) converge uniformément sur I , ou uniformément sur tout segment deI , vers une fonction f .
Alors f est continue sur I .
Théorème – Continuité pour les suites de fonctions
Démonstration – Il suffit de faire la démonstration sous l’hypothèse de convergence uniforme surtout segment de I . Soit ε > 0 fixé et a ∈ I . Pour η > 0 assez petit, J = I ∩ [a − η,a + η] est unsegment de I . Pour tout x ∈ J , on a
|f (x) − f (a)| |f (x) − f n(x)| + |f n(x) − f n(a)| + |f n(a) − f (a)|.Par convergence uniforme de (f n) vers f sur J , il existe n0
∈N tel que pour tout n n0,
supx∈J
|f n(x) − f (x)| ε.
Alors, pour tout x ∈ J ,
|f (x) − f (a)| |f (x) − f n0(x)| + |f n0(x) − f n0(a)| + |f n0(a) − f (a)| ε + |f n0(x) − f n0(a)| + ε.
La fonction f n0 étant continue en a, il existe δ > 0 tel que pour tout x ∈ I vérifiant |x − a| δ ,on ait x ∈ J et |f n0(x) − f n0(a)| ε. Dans ces conditions, on a |f (x) − f (a)| 3ε, d’où lacontinuité de f en a, et ce pour tout a ∈ I . Donc f est continue sur I .
Remarque – Ce théorème donne aussi un moyen efficace pour montrer qu’une suite de fonctionsne converge pas uniformément : par contraposition, on en déduit en effet que, si la limite simplede la suite (f n) n’est pas continue en un point a de I alors que chacune des fonctions f n estcontinue sur I , alors la convergence de (f n) vers f n’est pas uniforme sur I , ni uniforme sur toutsegment de I . Cet argument s’applique par exemple à la suite des fonctions f n : x → xn sur [0,1],avec a = 1.
Pour les séries de fonctions, ce théorème prend la forme suivante :
Soit n0 f n une série de fonctions définies sur I . On suppose que :
• Pour tout n ∈ N, f n est continue sur I ,•n0
f n converge uniformément sur I , ou uniformément sur tout segment
de I .
Alors+∞n=0
f n est continue sur I .
Théorème – Continuité pour les séries de fonctions
Exemple – La fonction ζ de Riemann x →+∞
n=1
1
nx est continue sur ]1, + ∞[.
En effet, la série de fonctions associée converge normalement sur tout segment (et donc unifor-mément sur tout segment) de ]1, + ∞[ et pour tout n, la fonction x → 1
nx est continue sur
]1, + ∞[.
138

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 147/383
2. Passages à la limite
Soit (f n) une suite de fonctions définies sur I , et a une extrémité de I , éventuellementinfinie. On suppose que :
• Pour tout n ∈ N, f n possède une limite finie ℓn en a,
• (f n) converge uniformément sur I vers une fonction f .
Alors :
• La suite (ℓn) converge,
• La fonction f possède une limite en a, et limx→af (x) = lim
n→+∞ℓn, i.e.
limx→a lim
n→+∞f n(x) = limn→+∞ lim
x→af n(x).
Théorème de la double limite (admis : démonstration hors programme)
Pour les séries de fonctions, ce théorème prend la forme suivante :
Soit
n0 f n une série de fonctions définies sur I et a une extrémité de I , éventuelle-ment infinie. On suppose que :
• Pour tout n ∈ N, f n possède une limite finie ℓn en a.• n0 f n converge uniformément sur I .
Alors :
• La série
n0 ℓn converge,
• La fonction
+∞
n=0
f n possède une limite en a, et limx→a
+∞
n=0
f n(x) =+∞
n=0
ℓn, i.e.
limx→a
+∞n=0
f n(x) =+∞n=0
limx→a f n(x).
Théorème – Interversion limite/somme (admis : démonstration hors programme)
Exemple – Dans le cas de la fonction ζ de Riemann,+∞n=1
1
nx −→x→+∞ 1.
En effet, la série de fonctions associée converge normalement sur tout intervalle de la forme[a, +
∞[ avec a > 1, donc par exemple sur [2, +
∞[ dont +
∞ est une extrémité, et pour tout
n 2, la fonction x → 1nx
converge vers 0 lorsque x → +∞, la limite étant égale à 1 pour n = 1.
Attention !
• Dans l’exemple précédent, il est essentiel de vérifier une convergence au moins uniforme sur unintervalle de la forme [a, + ∞[. On ne peut se contenter de citer une convergence uniforme ounormale sur tout segment de ]1, + ∞[.
• D’une manière générale, une convergence uniforme sur tout segment de I ne permet pas d’ap-pliquer ce théorème aux extrémités de I . Pour illustrer ceci, donnons l’exemple de la série géo-métrique. La série de fonctions associée converge normalement (et donc uniformément) sur tout
segment de ]−1,1[ et pour tout n ∈N
, x
n
−→x→1− 1. Pourtant, la série n0 1 diverge.• Ce résultat ne porte que sur des limites finies. Par exemple, il ne s’applique donc pas lorsquef n(x) −→
x→a +∞ pour tout n.
139
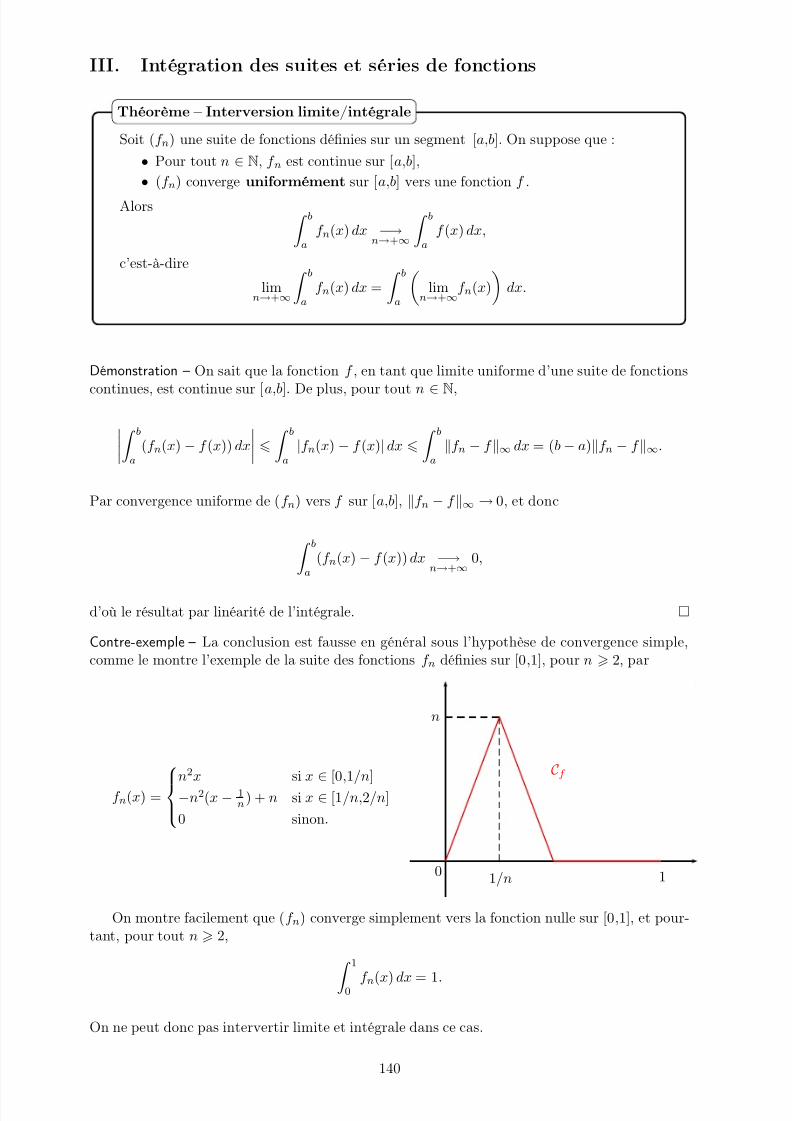
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 148/383
III. Intégration des suites et séries de fonctions
Soit (f n) une suite de fonctions définies sur un segment [a,b]. On suppose que :
• Pour tout n ∈ N, f n est continue sur [a,b],
• (f n) converge uniformément sur [a,b] vers une fonction f .
Alors ba
f n(x) dx −→n→+∞
ba
f (x) dx,
c’est-à-dire
limn→+∞
ba
f n(x) dx =
ba
limn→+∞f n(x)
dx.
Théorème – Interversion limite/intégrale
Démonstration – On sait que la fonction f , en tant que limite uniforme d’une suite de fonctions
continues, est continue sur [a,b]. De plus, pour tout n ∈ N,
ba
(f n(x) − f (x)) dx
ba
|f n(x) − f (x)| dx
ba
f n − f ∞ dx = (b − a)f n − f ∞.
Par convergence uniforme de (f n) vers f sur [a,b], f n − f ∞ → 0, et donc
ba
(f n(x) − f (x)) dx −→n→+∞ 0,
d’où le résultat par linéarité de l’intégrale.
Contre-exemple – La conclusion est fausse en général sous l’hypothèse de convergence simple,comme le montre l’exemple de la suite des fonctions f n définies sur [0,1], pour n 2, par
f n(x) =
n2x si x ∈
[0,1/n]
−n2(x − 1n) + n si x ∈ [1/n,2/n]
0 sinon.
n
1/n 10
Cf
On montre facilement que (f n) converge simplement vers la fonction nulle sur [0,1], et pour-tant, pour tout n 2,
1
0 f n(x) dx = 1.
On ne peut donc pas intervertir limite et intégrale dans ce cas.
140

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 149/383
Pour les séries de fonctions, on obtient :
Soit
n0 f n une série de fonctions définies sur un segment [a,b]. On suppose que :
• Pour tout n ∈ N, f n est continue sur [a,b],
• n0 f n converge uniformément sur [a,b].
Alors la sérien0
ba
f n(x) dx converge et
+∞n=0
ba
f n(x) dx =
ba
+∞n=0
f n(x)
dx.
Théorème – Intégration terme à terme des séries de fonctions
Exemple – On veut prouver la convergence et calculer la somme de la série
n1
1
n(e−n − e−2n).
On remarque que, pour tout n ∈ N∗,
1
n(e−n − e−2n) =
2
1e−nx dx.
On définit donc, pour tout n ∈ N∗, la fonction f n : x → e−nx.
Pour tout n ∈ N∗, f n est continue sur [1,2]. De plus, la série
n1 f n converge normalement (eten particulier uniformément) sur [1,2] car pour tout n ∈ N∗ et x ∈ [1,2],
0 e−nx e−n,
la série n1 e−n, indépendante de x, étant convergente (série géométrique de raison 1/e avec
|1/e| < 1). D’après le théorème d’intégration terme à terme, la série n1 21 e−nx dx converge
et+∞n=1
2
1e−nx dx =
2
1
+∞n=1
e−nx
dx.
Or, pour tout x ∈ [1,2], on a+∞n=1
e−nx = e−x
1 − e−x
(somme d’une série géométrique de raison e−x avec |e−x| < 1). On vient donc de montrer laconvergence de la série étudiée, avec
+∞n=1
1n
(e−n − e−2n) = 2
1
e−x1 − e−x
dx =
ln(1 − e−x)2
1 = ln(1 + e) − 1
après simplifications. Finalement :
+∞n=1
1
n(e−n − e−2n) = ln(1 + e) − 1.
Le théorème d’intégration terme à terme permet de calculer des sommes de séries non triviales.
Remarque – On peut montrer (également par intégration terme à terme par exemple) que pourtout x ∈ ]−1,1[,
+
∞n=1
xn
n = − ln(1 − x).
Cela permet de retrouver le résultat ci-dessus (en utilisant cette égalité avec x = 1/e et x = 1/e2).
141

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 150/383
IV. Dérivation des suites et séries de fonctions
1. Théorèmes sur la classe C1
La convergence uniforme semble un mode de convergence efficace qui permet de conserverles propriétés des fonctions f n. Pourtant, elle ne suffit pas dès lors que l’on souhaite dériver une
limite de suite ou série de fonctions. En effet, la suite des fonctions f n : x →
x2 + 1n , toutes de
classe C∞, converge uniformément vers la fonction valeur absolue sur R, qui n’est pas dérivable
en 0.
Soit (f n) une suite de fonctions définies sur I . On suppose que :
• Pour tout n ∈ N, f n est de classe C1 sur I ,
• (f n) converge simplement vers une fonction f sur I ,• (f ′n) converge uniformément sur I , ou uniformément sur tout segment de
I , vers une fonction g.
Alors f est de classe C1 sur I et f ′ = g.
Théorème – Classe C1 pour les suites de fonctions
Démonstration – Fixons a ∈ I . Pour tout x ∈ I et n ∈ N, on a
f n(x) = f n(a) +
xa
f ′n(t) dt,
car f n est de classe C1. Or, (f n) converge simplement vers f sur I , donc
f n(x) −→n→+∞
f (x) et f n(a) −→n→+∞
f (a).
De plus, g étant limite uniforme sur tout segment de la suite de fonctions continues (f ′n), d’aprèsle théorème d’interversion limite/intégrale, on a, pour tout x ∈ I ,
xa f ′n(t) dt −→n→+∞ x
a g(t) dt.
Finalement, lorsque n tend vers +∞, on obtient, pour tout x ∈ I ,
f (x) = f (a) +
xa
g(t) dt.
Ceci entraîne que f est de classe C1 sur I avec f ′ = g.
Remarque – L’hypothèse forte du théorème porte sur les dérivées des f n, et pas sur les fonctionselles-mêmes. Il est indispensable de prouver la convergence uniforme sur tout segment pour (f ′n),mais il est inutile de prouver la convergence uniforme de (f n) : une convergence simple suffit.
Pour les séries, on a le résultat suivant :
Soit
n0 f n une série de fonctions définies sur I . On suppose que :
• Pour tout n ∈ N, f n est de classe C1 sur I ,
•n0
f n converge simplement sur I .
•n0
f ′n converge uniformément sur I , ou uniformément sur tout segment
de I .
Alors la fonction+
∞n=0
f n est de classe C1 sur I et +
∞n=0
f n′ =
+
∞n=0
f ′n.
Théorème – Dérivation terme à terme des séries de fonctions
142

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 151/383
Exemples
• Complétons l’étude de la fonction ζ de Riemann : la convergence simple de la série a été établieplus haut (on a même montré une convergence normale sur tout intervalle [a, + ∞[ avec a > 1).Pour tout n 1, la fonction
f n : x → 1
nx = exp(−x ln(n))
est de classe C1 sur ]1, + ∞[ et pour tout x > 1,
f ′n(x) = − ln(n) exp(−x ln(n)) = − ln(n)
nx .
Montrons que la série des dérivées converge normalement sur tout intervalle [a, + ∞[ avec a > 1.Pour tout x a, pour tout n 1, − ln(n)
nx
ln(n)
na .
Il suffit donc d’établir la convergence de la sérien1
ln(n)
na . Or, en fixant δ ∈ ]1,a[, on a
nδ ln(n)na
= ln(n)na−δ
−→n→+∞
0
par croissances comparées, car a − δ > 0. Ainsi
ln(n)
na = o
1
nδ
.
Or, la sérien1
1
nδ converge car δ > 1. Par comparaison de séries à termes positifs, on obtient le
résultat.
Finalement, on a montré que la fonction ζ de Riemann est de classe C
1 sur ]1, + ∞
[ avec,pour tout x > 1,
ζ ′(x) = −+∞n=1
ln(n)
nx .
En particulier, ζ est strictement décroissante sur ]1, + ∞[.
• Considérons la série n0
(−1)n x2n+1
2n + 1
pour x ∈ ]−1,1[. Pour tout n ∈ N, la fonction
f n : x → (−1)n x2n+1
2n + 1
est de classe C1 sur ]−1,1[. Pour x = 0, tous les termes de la série sont nuls. Pour tout x ∈ ]−1,1[différent de 0, pour tout n ∈ N,x2n+3/(2n + 3)
x2n+1/(2n + 1)
= |x|2 2n + 1
2n + 3 −→n→+∞ |x|2 < 1.
D’après le critère de d’Alembert, la série converge simplement (et absolument) sur ]−1,1[. Deplus, pour tout n ∈ N et x ∈ ]−1,1[, f ′n(x) = (−1)nx2n. La série
n0 f ′n converge uniformément
(et même normalement) sur tout segment de ]−1,1[, car il s’agit de la série géométrique de raison
−x
2
. D’après le théorème de dérivation terme à terme, on sait donc que la fonction somme
S : x →+∞n=0
(−1)n x2n+1
2n + 1
143

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 152/383
est de classe C1 sur ]−1,1[, et pour tout x ∈ ]−1,1[,
S ′(x) =+∞n=0
(−1)nx2n = 1
1 − (−x2) =
1
1 + x2.
On reconnaît la dérivée de la fonction arctan. Sachant que l’on travaille sur un intervalle, on endéduit qu’il existe une constante k telle que pour tout x ∈ ]−1,1[,
+∞n=0
(−1)n x2n+1
2n + 1 = arctan(x) + k.
En évaluant cette relation en x = 0, on obtient k = 0. On a donc montré que pour tout x ∈ ]−1,1[,
arctan(x) =+∞n=0
(−1)n x2n+1
2n + 1.
On remarque que les premiers termes de la somme forment les développements limités de arctanen 0. L’égalité précédente s’appelle un développement en série entière de la fonction arctan sur
]−1,1[ (voir le chapitre Séries entières).
2. Théorèmes sur la classe CkPour la classe Ck (k 2), on peut bien sûr raisonner par récurrence à partir des théorèmes
de la classe C1. On admettra que cela conduit aux théorèmes suivants, que l’on pourra appliquerdirectement :
Soit (f n) une suite de fonctions définies sur I . On suppose que :
• Pour tout n ∈N
, f n est de classe Ck
sur I ,• (f n)n∈N converge simplement vers une fonction f sur I ,
• Pour 1 j k − 1, (f ( j)n )n∈N converge simplement vers une fonction g j sur I ,
• (f (k)n )n∈N converge uniformément sur tout segment de I vers une fonction
gk.
Alors f est de classe Ck sur I et pour tout j ∈ [[1,k]], f ( j) = g j .
Théorème – Classe Ck pour les suites de fonctions
Soit n0 f n une série de fonctions définies sur I . On suppose que :• Pour tout n ∈ N, f n est de classe Ck sur I ,• n0 f n converge simplement sur I ,
• Pour 1 j k − 1,
n0 f ( j)n converge simplement sur I .
• n0 f (k)n converge uniformément sur tout segment de I .
Alors la fonction+∞n=0
f n est de classe Ck sur I et pour tout j ∈ [[1,k]],
+∞n=0
f n( j)
=
+∞n=0
f ( j)n .
Théorème – Classe Ck pour les séries de fonctions
144

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 153/383
Chapitre 7
Dérivation et intégration des fonctionsde R dans K
Dans ce chapitre, sauf indication contraire, [a,b] désigne un segment de R (avec a < b), et I
un intervalle de R. Sauf précision, les fonctions considérées sont à valeurs dans K = R ou C.
Les parties I, II, III et VI rassemblent des rappels de certains résultats fondamentaux de déri-vation et d’intégration du cours de première année. La partie IV étend à une classe plus généralede fonctions l’intégration des fonctions continues sur un segment, étudiée en première année. Lapartie V rappelle et/ou généralise un certain nombre de méthodes de calculs d’intégrales.
I. Théorème de Rolle et accroissements finis
Soit f : [a,b] → R une fonction continue sur [a,b], dérivable sur ]a,b[, telle quef (a) = f (b).
Alors il existe c ∈ ]a,b[ tel que f ′(c) = 0.
Théorème de Rolle
Démonstration – Si f est constante, le résultat est vrai et tout élément c de ]a,b[ convient. Lafonction f est continue sur le segment [a,b], elle est donc bornée et atteint ses bornes. Si f n’estpas constante, et si par exemple elle prend une valeur strictement supérieure à f (a), alors elleatteint un maximum en un point noté c ∈ ]a,b[. Alors, pour tout t ∈ [a,b], f (t) f (c) et donc,pour t ∈ [a,c[,
f (t) − f (c)
t − c 0.
Lorsque t → c−, on en déduit que f ′(c)
0. De même, pour t ∈ ]c,b],f (t) − f (c)
t − c 0.
Lorsque t → c+, on en déduit que f ′(c) 0, d’où finalement f ′(c) = 0. On procède de même sif prend une valeur strictement inférieure à f (a), en considérant le minimum de f .
Soit f : [a,b] → R une fonction continue sur [a,b], dérivable sur ]a,b[.
Alors il existe c
∈]a,b[ tel que
f (b) − f (a) = f ′(c)(b − a).
Théorème – Égalité des accroissements finis
145

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 154/383
Démonstration – Soit
g : x → f (x) − f (a) − f (b) − f (a)
b − a (x − a).
Alors g est continue sur [a,b], dérivable sur ]a,b[ de même que f , et g(a) = g(b) = 0. D’après lethéorème de Rolle, il existe c ∈ ]a,b[ tel que g ′(c) = 0, i.e.,
f ′(c)
−
f (b) − f (a)
b − a
= 0.
On en déduit le résultat.
Contre-exemple – Le résultat du théorème de Rolle et l’égalité des accroissements finis sont fauxen général si f est à valeurs dans C, ou à valeurs vectorielles : par exemple, la fonction
f :
[0,2π] → C
t → eit
est continue et dérivable sur [0,2π], et f ( 0 ) = 1 = f (2π). Pourtant, pour tout t ∈ [0,2π],f ′(t) = ieit = 0.
Soit f : I → R une fonction dérivable sur I . On suppose qu’il existe une constanteM 0 telle que pour tout t ∈ I ,
|f ′(t)| M.
Alors f est M -Lipschitzienne sur I : pour tout (x,y) ∈ I 2,
|f (x) − f (y)| M |x − y|.
Théorème – Inégalité des accroissements finis, cas réel
Démonstration – Soit (x,y) ∈ I 2 tel que x < y. La fonction f est continue sur [x,y], dérivable sur]x,y[, donc d’après l’égalité des accroissements finis, il existe c ∈ ]x,y[ tel que
f (y) − f (x) = f ′(c)(y − x).
Alors|f (x) − f (y)| = |f ′(c)| |x − y| M |x − y|
d’après l’hypothèse sur f ′. On procède de même si x > y en raisonnant sur [y,x], et le résultatest évident si x = y.
Soit f : I → K une fonction dérivable. On rappelle que I est un intervalle.
Pour que f soit constante sur I , il faut et il suffit que f ′ = 0.
Corollaire – Dérivation et fonctions constantes
Démonstration – Il est évident que pour que f soit constante, il faut et il suffit que les partiesréelle et imaginaire de f (qui sont à valeurs réelles) soient constantes. Or, ces deux fonctions sontdérivables sur I , et on a f ′ = Re(f )′ + i I m(f )′. Il suffit donc de prouver le résultat pour unefonction g : I → R dérivable. Or, pour une telle fonction, si g′ est nulle, alors d’après l’inégalitédes accroissements finis, pour tout (x,y) ∈ I 2,
|g(x) − g(y)| 0 (x − y) = 0,
et donc g(x) = g(y). Ceci est vrai pour tout (x,y) ∈ I 2, donc g est constante. La réciproque estévidente : une fonction constante a une dérivée nulle.
146

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 155/383
Soit f : I → R une fonction dérivable. Alors :
• f est croissante si et seulement si f ′ 0 sur I .
• Si f ′ 0 sur I et si les zéros de f ′ sont en nombre fini, ou forment une suite, alors f est strictement croissante sur I .
Théorème – Dérivation et monotonie
Démonstration• Si f est croissante, alors pour tout a ∈ I et x ∈ I distinct de a,
f (x) − f (a)
x − a 0.
Lorsque x → a, on obtient f ′(a) 0.
Réciproquement, si f ′ 0, alors pour tout (x,y) ∈ I 2 tel que x < y, d’après l’égalité desaccroissements finis, il existe c ∈ ]x,y[ tel que f (x) − f (y) = f ′(c)(x − y). On en déduit que x − yet f (x) − f (y) sont de même signe : f est croissante.
• On sait d’après le premier point que f est croissante. Si elle n’était pas strictement croissante,
il existerait a et b dans I tels que a < b et f (a) = f (b). Alors f est nécessairement constantesur [a,b], et donc pour tout x ∈ [a,b], f ′(x) = 0. Ceci est impossible car les zéros de f ′ sont ennombre fini ou forment une suite.
Soit f : I → K une fonction continue sur I et dérivable sur I \ a, telle que f ′ admetune limite ℓ en a (éventuellement infinie lorsque K = R). Alors
f (x) − f (a)
x − a −→x→ax=a
ℓ.
En particulier, si ℓ ∈ K, alors f est dérivable en a et f ′(a) = ℓ.
Théorème – Limite de la dérivée
Démonstration
• Premier cas : ℓ ∈ K. D’après la caractérisation de la limite et de la dérivabilité à l’aide desparties réelle et imaginaire, on se ramène en fait à K = R. Définissons sur I la fonction
g : x → f (x) − f (a) − ℓ(x − a).
La fonction g est continue sur I , dérivable sur I \ a avec, pour tout x ∈ I \ a,
g′(x) = f ′(x)−
ℓ.
Par hypothèse, g′ a donc pour limite 0 en a. Fixons ε > 0 ; il existe η > 0 tel que pour toutt ∈ (I \ a) ∩ [a − η,a + η], |g′(t)| ε. Soit x ∈ (I \ a) ∩ [a − η,a + η]. D’après l’égalité desaccroissements finis, il existe c strictement compris entre a et x, tel que g(x)−g(a) = g′(c)(x−a),et alors on a |g′(c)| ε, d’où
|g(x) − g(a)| ε(x − a),
puis f (x) − f (a)
x − a − ℓ
=
f (x) − f (a) − ℓ(x − a)
x − a
=
g(x) − g(a)
x − a
ε.
On a donc montré que
f (x) − f (a)x − a
−→x→ax=a
ℓ,
f est donc dérivable en a avec f ′(a) = ℓ.
147

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 156/383
• Deuxième cas : K = R et ℓ = ±∞. On adapte la démonstration précédente avec g = f
et en traduisant les limites infinies (il est indispensable alors de raisonner avec l’égalité desaccroissements finis, afin de pouvoir minorer la valeur absolue du taux d’accroissement, et nonpas avec l’inégalité).
Remarques
• Ce théorème ne permet pas de prolonger par continuité la fonction f ′ sur I : une fois la fonctionf définie sur I , si a
∈ I , l’éventuelle dérivabilité de f en a est fixée. Si f est dérivable en a, ce
théorème est l’un des moyens de le prouver, mais ce que l’on prouve est que f ′(a) est défini .
• Une fonction f peut être dérivable sur I sans que f ′ ait pour limite f ′(a) en tout point a ∈ I .Par exemple, la fonction
f :
]0,1] → R
x → x2 sin
1
x
prolongée par continuité en 0 avec f (0) = 0, est dérivable à droite en 0 car
f (x) − f (0)
x = x sin
1
x
−→x→0+
0.
La fonction f est également dérivable sur ]0,1] (par produit et composition) et pour tout x ∈ ]0,1],
f ′(x) = 2x sin
1
x
− cos
1
x
.
Le premier terme tend vers 0, mais le second n’a pas de limite lorsque x → 0+, donc f ′ n’a pasde limite en 0.
Il y a donc une différence importante entre la dérivabilité et la classe C1.
II. Dérivées d’une bijection réciproque
Dans cette partie, les fonctions sont à valeurs réelles. Rappelons, sans démonstration, lerésultat suivant de première année :
Soit f : I → R une fonction continue et strictement monotone sur I .
Alors f réalise une bijection de I sur l’intervalle f (I ), et sa réciproque f −1 est continueet strictement monotone sur f (I ), de même monotonie que f .
Théorème
Concernant la dérivabilité, on a le résultat suivant :
Soit f : I → R une fonction dérivable et strictement monotone sur I .
Soit a ∈ I tel que f ′(a) = 0.
Alors f −1 est dérivable en f (a) et
(f −1)′(f (a)) = 1
f ′(a).
Théorème
Démonstration – Notons b = f (a). Pour y dans f (I ) avec y = b, on a
f −1(y) − f −1(b)
y − b =
f −1(y) − f −1(b)
f (f −1(y)) − f (f −1(b)),
148

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 157/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 158/383
III. Intégration sur un segment des fonctions continues :quelques rappels
1. Primitives, intégrale fonction de ses bornes
Soient f : I
→K une fonction continue et g : I
→K une fonction.
On dit que g est une primitive de f sur I si g est de classe C1 sur I et g ′ = f .
Définition
Soient g et h deux primitives d’une fonction f continue sur un intervalle I , à valeursdans K. Alors il existe k ∈ K tel que pour tout x ∈ I , g(x) = h(x) + k.
Propriété
Démonstration – La fonction g − h est de classe C1 sur I et vérifie (g − h)′ = 0, donc g − h estconstante sur l’intervalle I.
On sait donc qu’il existe au plus une primitive de f sur I prenant en un point donné unevaleur donnée. On se pose maintenant la question de l’existence. Soit f : I → K une fonctioncontinue et a ∈ I . On peut alors définir la fonction
F a :
I → K
x → xa
f (t) dt
Soit f : I → K une fonction continue.
• Soit a ∈ I . La fonction F a est de classe C1 sur I . C’est l’unique primitive de f sur I qui s’annule en a.
• Soit a ∈ I et b ∈K. Il existe une unique primitive de f sur I qui prend la valeur b ena. Il s’agit de la fonction x → F a(x) + b.
• Si g est une primitive de f sur I , alors pour tout segment [a,b] de I , on a ba
f (t) dt = g(b) − g(a), noté [g(t)]ba .
Théorème
Démonstration
• Soit c ∈ I et ε > 0 fixé. Par continuité de f en c, il existe η > 0 tel que pour toutt ∈ I ∩ [c − η,c + η], |f (t) − f (c)| ε. Soit x ∈ I ∩ [c − η,c + η]. Alors, pour tout t com-pris entre c et x, |f (t) − f (c)| ε. On évalue alors
|F a(x) − F a(c) − (x − c)f (c)| = xc
[f (t) − f (c)] dt
xc
|f (t) − f (c)| dt
ε |x − c|.
Si de plus x = c, on a donc
F a(x) − F a(c)
x − c − f (c)
ε.
On en déduit que F a est dérivable en c avec F ′a(c) = f (c), et ce pour tout c
∈ I . De plus, la
fonction f étant continue, F a est de classe C1 : F a est donc une primitive de f sur I . Elle s’annuleen a, et on a déjà prouvé qu’il y a unicité d’une telle fonction.
• C’est maintenant immédiat : cette fonction convient, et on sait qu’il y a unicité.
150

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 159/383
• Soit g une primitive de f sur I et [a,b] un segment de I . D’après le point précédent, g = F a+g(a)
et donc ba
f (t) dt = F a(b) = g(b) − g(a).
Si f : I →
K est de classe C
1, alors pour tout (a,b) ∈
I 2, ba
f ′(t) dt = f (b) − f (a).
Corollaire
Démonstration – La fonction f est une primitive de la fonction continue f ′. Le résultat vient doncdu troisième point du théorème précédent (y compris si b a, car dans ce cas on se ramène aucas précédent quitte à considérer −f ).
En application de ce résultat, on montre facilement l’inégalité des accroissements finis pourles fonctions à valeurs complexes :
Soit f : I → C une fonction de classe C1 sur I . On suppose qu’il existe une constanteM 0 telle que pour tout t ∈ I ,
|f ′(t)| M.
Alors f est M -Lipschitzienne sur I : pour tout (x,y) ∈ I 2,
|f (x) − f (y)| M |x − y|.
Théorème – Inégalité des accroissements finis, cas complexe
Démonstration – Soient x et y dans I tels que x < y ; f est de classe
C1 sur [x,y], donc on peut
écrire, d’après le corollaire précédent,
|f (y) − f (x)| = yx
f ′(t) dt
.
Sachant que |f ′(t)| M pour tout t ∈ [x,y], on a aussi yx
f ′(t) dt
yx
|f ′(t)| dt M (y − x).
On en déduit le résultat. On procède de même si x > y en raisonnant sur [y,x], et le résultat estévident si x = y.
Remarques
• Bien sûr, ce théorème s’applique aussi au cas réel : ses hypothèses sont plus fortes que l’inégalitédonnée dans le cas réel.
• En revanche, la démonstration du théorème dans le cas réel ne peut pas être adaptée au cascomplexe : elle repose sur l’égalité des accroissements finis, et donc sur le théorème de Rolle,dont le résultat est faux en général pour les fonctions à valeurs complexes. Cela explique leshypothèses plus fortes données dans le théorème ci-dessus.
2. Sommes de Riemann
Soit f : [a,b] →K une fonction. On définit, pour tout entier n 1,
S n = b − an
n
−1
k=0
f a + k b − an
.
Ces quantités sont appelées sommes de Riemann associées à f sur [a,b]. On a alors :
151

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 160/383
Soit f : [a,b] → R une fonction continue. Alors
S n −→n→+∞
ba
f (x) dx.
Théorème
Démonstration dans le cas où f est de classe C1
On notera, pour tout k ∈ N,
ak = a + k b − a
n ;
ainsi (a0, . . . , an) est la subdivision régulière de [a,b] à n + 1 points (i.e., ak+1 − ak est constantégal à (b − a)/n).
La fonction f ′ est continue sur le segment [a,b], elle est donc bornée par une certaine constanteM 0. D’après l’inégalité des accroissements finis, f est M -Lipschitzienne sur [a,b]. Alors pourtout n 1, d’après la relation de Chasles notamment, on a
ba f (x) dx − S n =
n−1k=0
ak+1
ak f (x) dx − b
−a
n
n−1k=0
f (ak)=
n−1k=0
ak+1
ak
(f (x) − f (ak)) dx
n−1k=0
ak+1
ak
|f (x) − f (ak)| dx.
Or f est M -Lipschitzienne sur [a,b], donc pour tout k ∈ [[0,n − 1]], pour tout x ∈ [ak,ak+1],
|f (x) − f (ak)| M |x − ak| = M (x − ak).
Ainsi ba
f (x) dx − S n
M n−1k=0
ak+1
ak
(x − ak) dx
= M n−1k=0
(x − ak)2
2
ak+1
ak
= M n−1k=0
(ak+1 − ak)2
2 = M n
(b − a)2
2n2 = M
(b − a)2
2n −→n→+∞ 0.
Remarque – Les sommes de Riemann correspondent à un cas particulier de l’approximationnumérique de ba f (x) dx par la méthode des rectangles.
Exemple – Soit, pour tout n 1, xn =n−1k=0
1
n + k. En réécrivant
xn = 1
n
n−1k=0
1
1 + kn
,
on voit que les xn sont les sommes de Riemann associées à la fonction f : x → 1
1 + x sur [0,1].
La fonction f étant continue sur [0,1], on sait donc que
xn −→n→+∞
1
0
1
1 + x dx = ln(2).
152
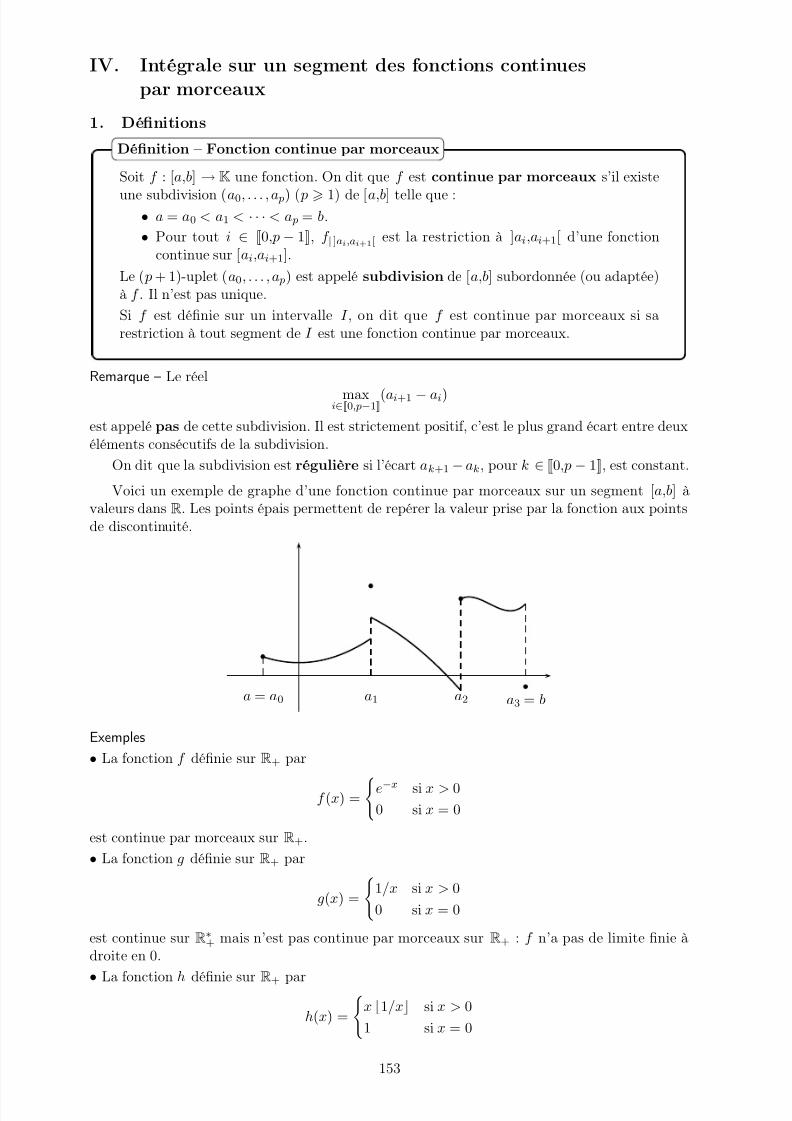
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 161/383
IV. Intégrale sur un segment des fonctions continuespar morceaux
1. Définitions
Soit f : [a,b] → K une fonction. On dit que f est continue par morceaux s’il existe
une subdivision (a0, . . . , a p) ( p 1) de [a,b] telle que :• a = a0 < a1 < · · · < a p = b.• Pour tout i ∈ [[0,p − 1]], f | ]ai,ai+1[ est la restriction à ]ai,ai+1[ d’une fonction
continue sur [ai,ai+1].
Le ( p + 1)-uplet (a0, . . . , a p) est appelé subdivision de [a,b] subordonnée (ou adaptée)à f . Il n’est pas unique.
Si f est définie sur un intervalle I , on dit que f est continue par morceaux si sarestriction à tout segment de I est une fonction continue par morceaux.
Définition – Fonction continue par morceaux
Remarque – Le réel
maxi∈[[0,p−1]]
(ai+1 − ai)
est appelé pas de cette subdivision. Il est strictement positif, c’est le plus grand écart entre deuxéléments consécutifs de la subdivision.
On dit que la subdivision est régulière si l’écart ak+1 − ak, pour k ∈ [[0,p − 1]], est constant.
Voici un exemple de graphe d’une fonction continue par morceaux sur un segment [a,b] àvaleurs dans R. Les points épais permettent de repérer la valeur prise par la fonction aux pointsde discontinuité.
a = a0 a1 a2 a3 = b
Exemples
• La fonction f définie sur R+ par
f (x) =e−x si x > 0
0 si x = 0
est continue par morceaux sur R+.
• La fonction g définie sur R+ par
g(x) =
1/x si x > 0
0 si x = 0
est continue sur R∗+ mais n’est pas continue par morceaux sur R+ : f n’a pas de limite finie àdroite en 0.
• La fonction h définie sur R+ par
h(x) =
x ⌊1/x⌋ si x > 0
1 si x = 0
153

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 162/383
n’est pas continue par morceaux sur R+ : elle a une infinité de points de discontinuité dans ]0,1].En revanche, elle est continue par morceaux sur R∗+.
Remarques
• La deuxième condition de la définition équivaut à chacune des propriétés suivantes :
— Pour tout i ∈ [[0,p − 1]], f |]ai,ai+1[ est prolongeable par continuité sur le segment [ai,ai+1].
— Pour tout i
∈ [[0,p
−1]], f est continue sur ]ai,ai+1[, f possède une limite finie à droite en
ai, et une limite finie à gauche en ai+1.
• Une fonction continue par morceaux sur un segment est bornée.
• Les limites de f en ai ne sont pas nécessairement égales à f (ai) ; f peut être discontinue enchaque point ai.
• Avec les notations précédentes, si f est continue en un certain ai0 ∈ ]a,b[, alors on peut enleverai0 de la subdivision (a0, . . . , a p) pour obtenir une subdivision de [a,b] encore adaptée à f . Enfaisant cela pour tous les points de la subdivision qui appartiennent à ]a,b[ et qui sont des pointsde continuité de f , on construit une subdivision de [a,b] adaptée à f dont les points sont a, b, etles points de discontinuité de f dans ]a,b[. Une telle subdivision est unique, elle est, en un certainsens, minimale.
L’ensemble des fonctions continues par morceaux sur I à valeurs dans K est un K-espacevectoriel.
Propriété
Démonstration – La fonction nulle est évidemment continue par morceaux. Si f est continue parmorceaux sur I , et si λ ∈ K, alors toute subdivision adaptée à f d’un segment de I est aussi
adaptée à λf , qui est ainsi continue par morceaux sur I . Enfin, soient f et g deux fonctions conti-nues par morceaux sur I , et soit [a,b] un segment de I . On se donne une subdivision (a0, . . . , a p)de [a,b] adaptée à f , une subdivision (b0, . . . , bm) de [a,b] adaptée à g. On construit alors unesubdivision adaptée à la fois à f et g en plaçant les nombres a0, . . . , a p, b0, . . . , bm par ordre crois-sant, et en enlevant les répétitions. On en déduit que f + g est continue par morceaux sur [a,b],cette nouvelle subdivision de [a,b] étant adaptée à f + g. Ceci est valable pour tout segment de I ,donc f + g est continue par morceaux sur I . Finalement, l’ensemble des fonctions continues parmorceaux sur I à valeurs dans K est un sous-espace vectoriel de l’espace vectoriel des fonctionsde I dans K.
On admettra que l’on peut adapter la construction de l’intégrale sur un segment, faite enpremière année pour les fonctions continues, au cadre des fonctions continues par morceaux. Sif : [a,b] →K est une fonction continue par morceaux, son intégrale est toujours notée
ba
f (x) dx,
[a,b]
f ou ba
f.
Si f est continue par morceaux sur I , elle est continue par morceaux sur tout segment de I , etdonc on peut définir son intégrale sur tout segment de I .
2. Propriétés de l’intégraleLes propriétés de l’intégrale des fonctions continues sur un segment se généralisent aux fonc-
tions continues par morceaux. Nous donnons ici, souvent sans démonstration, ces propriétés.
154

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 163/383
Soient f et g deux fonctions continues par morceaux sur [a,b] à valeurs dans K, etλ ∈ K.
Alors ba
(λf + g) = λ
ba
f +
ba
g.
Propriété – Linéarité de l’intégration
Soit f : [a,b] → K une fonction continue par morceaux et c ∈ [a,b].
Alors, les restrictions de f à [a,c] et [c,b] sont continues par morceaux et ba
f =
ca
f +
bc
f.
Propriété – Relation de Chasles
• Soit f : [a,b] → R+ une fonction continue par morceaux à valeurs réelles positives.
Alors ba
f 0.
• Soient f et g deux fonctions continues par morceaux sur [a,b] à valeurs réelles, telles
que f g sur [a,b]. Alors ba
f
ba
g.
Propriété – Positivité et croissance de l’intégrale
Soit f : [a,b] → K une fonction continue par morceaux.
Alors la fonction |f | : x → |f (x)| est continue par morceaux et ba
f
ba
|f |.
Propriété
Remarque – Soit f : [a,b] → K une fonction continue par morceaux. Alors
b
a
f (x) dx b
a
|f (x)| dx b
a
f ∞ dx = (b − a)f ∞.
Le vecteur 1
b − a
ba
f (x) dx est appelé valeur moyenne de f sur [a,b]. L’inégalité précédente,
qu’il faut absolument savoir redémontrer pour majorer des intégrales, est appelée inégalité de lamoyenne.
Soient f et g deux fonctions continues par morceaux sur [a,b] à valeurs dans K, qui
coïncident sauf en un nombre fini de points. Alors ba
f =
ba
g.
Propriété
En particulier, l’intégrale d’une fonction continue par morceaux f n’est pas modifiée si l’onchange les valeurs de f en un nombre fini de points.
155

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 164/383
Soit f : [a,b] → R+ une fonction continue à valeurs réelles positives.
Alors pour que f soit nulle, il faut et il suffit que ba
f (x) dx = 0.
Théorème
Démonstration – Bien sûr, si f est nulle, son intégrale est nulle. Réciproquement, raisonnons par
contraposée : si f n’est pas identiquement nulle, alors par continuité de f , il existe c ∈ ]a,b[ telque f (c) > 0, et il existe η > 0 tel que [c − η,c + η] ⊂ [a,b] et pour tout x ∈ [c − η,c + η],|f (x) − f (c)| 1
2 f (c), et en particulier f (x) 12 f (c). Alors, d’après la relation de Chasles, la
positivité et la croissance de l’intégrale, ba
f =
c−ηa
f +
c+η
c−ηf +
bc+η
f
c+η
c−ηf 2η
1
2f (c) = ηf (c) > 0,
d’où le résultat.
Remarque – Si f est continue par morceaux sur [a,b], positive, on en déduit en raisonnant surchaque morceau que, pour que
ba f soit nulle, il faut et il suffit que f soit nulle sauf éventuellement
en un nombre fini de points.
3. Le cas des fonctions continues par morceaux sur un intervalle
Lorsque f est continue par morceaux sur I , si (a, b) ∈ I 2 avec a = b ou a > b, on donneégalement un sens à
ba f (x) dx en posant respectivement aa
f (x) dx = 0 et ba
f (x) dx = − ab
f (x) dx.
La relation de Chasles reste valide, ainsi que la propriété de linéarité de l’intégrale. En revanche,dès que des inégalités entrent en jeu, il faut être vigilant sur l’ordre des bornes. Par exemple, la
majoration du module de l’intégrale prend la forme ba
f (x) dx
ba
|f (x)| dx
.
Pour toute constante k telle que |f (x)| k pour tout x compris entre a et b, on a ba
f (x) dx
k |b − a| .
V. Méthodes de calculs d’intégrales
1. Intégration par parties
Soient f et g deux fonctions de classe C1 sur I à valeurs dans K, et soit (a,b) ∈ I 2.Alors b
af ′(t)g(t) dt = [f (t)g(t)]ba −
ba
f (t)g′(t) dt.
Théorème – Intégration par parties
Démonstration – La fonction f g est de classe C1 sur I donc
[f (t)g(t)]ba = ba
[f g]′(t) dt = ba
[f ′(t)g(t) + f (t)g′(t)] dt = ba
f ′(t)g(t) dt + ba
f (t)g′(t) dt,
par linéarité de l’intégrale.
156

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 165/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 166/383
Remarque – Dans la démonstration, on voit l’utilité de l’hypothèse de stricte monotonie de φ.Pour faire la simplification ai+1
ai
f i(φ(t)) φ′(t) dt =
ai+1
ai
f (φ(t)) φ′(t) dt,
on utilise le fait que les fonctions f i φ et f φ coïncident sur [ai,ai+1], sauf peut-être auxpoints t de [a
i,ai+1
] tels que φ(t) est l’un des b j
, car dans ce cas φ(t) est un point d’éventuellediscontinuité de f . Or, les seuls points vérifiant cette condition sont ai et ai+1, d’après notrehypothèse sur φ. Sans cette hypothèse, la fonction f φ pourrait même ne pas être continue parmorceaux.
VI. Formules de Taylor
Soit f : I → K une fonction de classe Cn+1 (n ∈ N). Alors pour tout (a,x) ∈ I 2,
f (x) =
nk=0
f (k)
(a)k!
(x − a)k + xa
(x − t)n
n! f (n+1)(t) dt.
Théorème – Formule de Taylor avec reste intégral
Démonstration – On procède par récurrence sur n. Pour n = 0, le résultat à montrer s’écrit
f (x) = f (a) +
xa
f ′(t) dt,
ce qui est vrai d’après un théorème donné plus haut, f étant de classe C1.
Supposons le résultat vrai pour les fonctions de classe Cn+1, et soit f : I
→ K une fonction
de classe Cn+2. On raisonne dans le cas où a < x, les autres cas étant similaires. L’hypothèse derécurrence pour la fonction f s’écrit
f (x) =nk=0
f (k)(a)
k! (x − a)k +
xa
(x − t)n
n! f (n+1)(t) dt.
Or t → −(x − t)n+1
(n + 1)! et f (n+1) sont de classe C1 sur [a,x], donc par intégration par parties,
x
a
(x − t)n
n!
f (n+1)(t) dt = −(x − t)n+1
(n + 1)!
f (n+1)(t)x
a
+ x
a
(x − t)n+1
(n + 1)!
f (n+2)(t) dt
= (x − a)n+1
(n + 1)! f (n+1)(a) +
xa
(x − t)n+1
(n + 1)! f (n+2)(t) dt,
d’où le résultat au rang n + 1. Par principe de récurrence, la formule est vraie pour tout n ∈N.
Remarque – Pour exploiter cette formule, il est souvent utile de savoir majorer le reste intégral.Sous les hypothèses précédentes, on a pour tout (a,x) ∈ I 2,
f (x) =n
k=0
f (k)(a)
k! (x − a)k +
x
a
(x − t)n
n! f (n+1)(t) dt.
Or, f étant de classe Cn+1, f (n+1) est continue sur le segment [a,x] (ou [x,a]), elle est donc bornéesur ce segment (car ses parties réelle et imaginaire le sont), par une certaine constante M . On
158

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 167/383
en déduit que f (x) −nk=0
f (k)(a)
k! (x − a)k
xa
|x − t|nn!
|f (n+1)(t)| dt
M
xa
|x − t|nn!
dt
M |
x
−a
|n+1
(n + 1)! .
L’avantage de la formule de Taylor avec reste intégral est d’être explicite et globale : elle donneune information pour tout x de I . Lorsque x est proche de a, on peut donner une estimation def (x) sous forme de développement limité. Commençons par rappeler le résultat suivant :
Soit f : I → K une fonction continue. On suppose que f possède un développementlimité à l’ordre n en a ∈ I , c’est-à-dire que l’on peut écrire
f (x) =x→a
nk=0
αk(x − a)k + o((x − a)n)
avec αk ∈ K pour tout k ∈ [[0,n]].
Alors toute primitive g de f sur I possède un développement limité à l’ordre n + 1 ena, avec
g(x) =x→a g(a) +
nk=0
αkk + 1
(x − a)k+1 + o((x − a)n+1).
Théorème – Primitivation d’un développement limité
Démonstration – Il suffit de prouver cette formule pour la fonction F a : x → xa f (t) dt vérifiant
F a(a) = 0, toutes les autres primitives de f s’en déduisant par ajout de la valeur en a. Fixonsε > 0. Par définition d’un petit « o », il existe η > 0 tel que pour tout x ∈ I ∩ [a − η,a + η],f (x) −nk=0
αk(x − a)k
ε|x − a|n.
Alors pour un tel x, xa
f (t) dt −nk=0
αkk + 1
(x − a)k+1
xa
f (t) −nk=0
αk(t − a)k
dt
ε
x
a |t
−a
|n dt
ε |x − a|n+1
n + 1 .
On a donc montré que xa
f (t) dt −nk=0
αkk + 1
(x − a)k+1 =x→a o((x − a)n+1),
qui est le résultat voulu.
Remarque – Ce résultat est très utile pour obtenir des développements limités. Par exemple, onobtient par cette méthode un développement à tout ordre en 0 de la fonction tangente, basé surla formule tan′ = 1 + tan2 ; on obtient des développements de x → ln(1 + x) en 0 à tout ordreen intégrant ceux de la fonction x → 1
1+x , très faciles à obtenir à partir de la série géométriquede raison −x.
159

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 168/383
Soit f : I → K une fonction de classe Cn (n ∈ N). Alors pour tout a ∈ I ,
f (x) =x→a
nk=0
f (k)(a)
k! (x − a)k + o((x − a)n).
Théorème – Formule de Taylor-Young
Démonstration – On procède par récurrence sur n. Pour n = 0 on reconnaît la définition de lacontinuité de f en a. Supposons le résultat vrai pour toute fonction de classe Cn. Soit f unefonction de classe Cn+1 sur I ; on peut appliquer l’hypothèse de récurrence à f ′, ce qui montreque pour tout a ∈ I ,
f ′(x) =x→a
nk=0
(f ′)(k)(a)
k! (x − a)k + o((x − a)n) =
x→a
nk=0
f (k+1)(a)
k! (x − a)k + o((x − a)n).
D’après le théorème d’intégration des développements limités (f ′ étant continue), on obtient
f (x) =x→a f (a) +
nk=0
f (k+1)(a)
(k + 1)! (x − a)k+1
+ o((x − a)n+1
)
=x→a
n+1k=0
f (k)(a)
k! (x − a)k + o((x − a)n+1),
d’où le résultat à l’ordre n + 1, ce qui achève la démonstration.
Pour terminer, donnons les développements limités de référence : pour tout n ∈ N (ou n ∈ N∗si la somme commence à k = 1),
• 1
1
−x
=x
→0
n
k=0
xk + o(xn) = 1 + x + x2 + · · · + xn + o(xn),
• ex =x→0
nk=0
xk
k! + o(xn) = 1 + x +
x2
2! + · · · +
xn
n! + o(xn),
• cos(x) =x→0
nk=0
(−1)k x2k
(2k)! + o(x2n) = 1 − x2
2! + · · · + (−1)n
x2n
(2n)! + o(x2n),
• sin(x) =x→0
nk=0
(−1)k x2k+1
(2k + 1)! + o(x2n+1) = x − x3
3! + · · · + (−1)n
x2n+1
(2n + 1)! + o(x2n+1),
• (1 + x)α =x→0
1 +nk=1
α(α − 1) · · · (α − k + 1)
k! xk + o(xn)
= 1 + αx + α(α − 1)
2! x2 + · · · +
α(α − 1) · · · (α − n + 1)
n! xn + o(xn) (α ∈R),
• ln(1 + x) =x→0
nk=1
(−1)k−1 xk
k + o(xn) = x − x2
2 +
x3
3 + · · · + (−1)n−1 xn
n + o(xn),
• arctan(x) =x
→0
n
k=0
(−1)k x2k+1
2k + 1 + o(xn) = x − x3
3 + · · · + (−1)n
x2n+1
2n + 1 + o(x2n+1),
• tan(x) =x→0
x + x3
3 + o(x3).
160

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 169/383
Chapitre 8
Réduction des endomorphismes et desmatrices carrées
De nombreux problèmes se ramènent à l’étude d’une matrice ou d’un endomorphisme, commecertaines équations différentielles linéaires ou suites récurrentes linéaires. On est alors amené àfaire notamment des calculs de puissances, d’inverse... Dans ce cas, le choix d’une base dans
laquelle travailler influence grandement la simplicité des calculs, et donc de l’étude du problème.Un des objectifs de ce chapitre est de ramener l’étude des matrices à celle de matrices sem-
blables dont la manipulation est plus simple. En particulier, il est très pratique de travailler avecdes matrices diagonales, ou avec des matrices triangulaires supérieures. En effet, par exemple,si A = P DP −1 avec P inversible et D diagonale, on montre très facilement par récurrence quepour tout k ∈ N, Ak = P DkP −1, le calcul de Dk étant immédiat : il suffit d’élever chaquecoefficient diagonal de D à la puissance k. De plus, A est inversible si et seulement si D estinversible, c’est-à-dire, si et seulement si aucun coefficient diagonal de D n’est nul. Dans ce cas,A−1 = P D−1P −1, le calcul de D−1 se faisant en inversant chaque coefficient diagonal de D .
En termes d’endomorphismes, notre objectif est (en dimension finie) de construire des bases
adaptées dans lesquelles écrire la matrice de l’endomorphisme considéré.Sauf mention contraire, dans tout ce chapitre E désigne un K-espace vectoriel (non réduit au
vecteur nul) avec K = R ou C, et u un endomorphisme de E .
I. Éléments propres d’un endomorphisme et d’une matrice carrée
Comme on l’a déjà remarqué dans le chapitre Matrices, en dimension finie, « simplifier »l’écriture matricielle de u, c’est par exemple chercher une décomposition de E en somme directede sous-espaces stables par u. Si cela est possible, la matrice obtenue est diagonale par blocs,elle est d’autant plus « simple » que la dimension de ces sous-espaces est petite (mais non nulle,
évidemment). On s’intéresse donc très naturellement aux droites stables par u (ce qui est possiblemême en dimension infinie, nous ne supposons donc pas ici que E soit de dimension finie).
Soient D une droite vectorielle de E et x ∈ D non nul. Les propriétés suivantes sontéquivalentes :
• La droite D est stable par u.
• Il existe λ ∈ K tel que u(x) = λx.
Propriété
Démonstration
⇒ D est stable par u, donc u(x) ∈ D. Or D = Vect(x), donc il existe λ ∈ K tel que u(x) = λx.⇐ On a u(D) = Vect(u(x)), donc s’il existe λ ∈ K tel que u(x) = λx, alors u(D) = Vect(λx).
Or, quel que soit λ, Vect(λx) ⊂ Vect(x) = D. Donc D est stable par u.
161

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 170/383
1. Éléments propres d’un endomorphisme
• Un scalaire λ ∈ K est appelé valeur propre de u s’il existe x ∈ E non nul tel queu(x) = λx.
• Un vecteur x ∈ E est appelé vecteur propre de u si x est non nul et s’il existeλ
∈K tel que u(x) = λx.
Définition – Valeur propre, vecteur propre
Remarques
• Dans cette définition, la condition x = 0E est essentielle, sinon tout scalaire serait valeur proprede u. En effet pour tout λ ∈ K, on a u(0E ) = 0E = λ · 0E .
• Un vecteur propre x vérifie la relation u(x) = λx pour une unique valeur propre λ. En effet, siu(x) = λx = λ′x, alors x étant non nul, on a nécessairement λ = λ′. On peut donc dire que λest la valeur propre associée au vecteur propre x de u.
• En revanche, si λ est valeur propre de u, et si x non nul vérifie u(x) = λx, alors par exemple,pour tout α ∈ K∗, le vecteur y = αx est non nul et vérifie
u(y) = u(αx) = αu(x) = α(λx) = λ(αx) = λy.
Un vecteur x = 0E tel que u(x) = λx est un vecteur propre associé à la valeur propre λ de u. Ily a une infinité de vecteurs propres associés à une même valeur propre.
• Pour faire le lien avec la propriété précédente, on remarquera qu’un vecteur x est vecteur proprede u si et seulement si Vect(x) est une droite vectorielle stable par u.
Exemples
• Une rotation vectorielle de R2 d’angle θ = 0 [π] n’a pas de valeur propre.
• Soit u : P → P ′, défini sur E = R[X ]. Soit P un vecteur propre de u et λ la valeur propreassociée. Alors P ′(X ) = λP (X ). En considérant les degrés de ces deux polynômes, on a néces-
sairement λ = 0, et P est un polynôme constant non nul. La réciproque est immédiate. On endéduit que l’unique valeur propre de u est 0, et l’ensemble des vecteurs propres de u associés àcette valeur propre est R0[X ] \ 0.
Remarquons que, pour λ ∈ K et x ∈ E , l’égalité u(x) = λx équivaut à (u − λ IdE )(x) = 0E ,i.e., au fait que x ∈ Ker(u − λ IdE ). On en déduit immédiatement le résultat suivant :
Soit λ ∈ K. Alors λ est une valeur propre de u si et seulement si Ker(u−λ IdE ) = 0E ,c’est-à-dire, si et seulement si u − λ IdE n’est pas injectif.
Propriété
Si λ est une valeur propre de u, l’ensemble E λ(u) = Ker(u − λ IdE ) est appelé sous-espace propre de u associé à la valeur propre λ.
Définition – Sous-espace propre
Soit λ une valeur propre de u. Alors :
• E λ(u) est un sous-espace vectoriel de E , non réduit à
0E
.
• Les vecteurs propres de u associés à la valeur propre λ sont les éléments non nuls deE λ(u).
Propriété
162

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 171/383
Démonstration – L’ensemble E λ(u) est le noyau de l’application linéaire u − λ IdE , c’est donc unsous-espace vectoriel de E . Le reste des propriétés résulte directement des définitions.
Cas particulier – Le scalaire 0 est une valeur propre de u si et seulement si u n’est pas injectif.Les vecteurs propres de u associés à la valeur propre 0 sont alors les éléments de Ker(u) \ 0E .
Exemple – Homothéties, projecteurs et symétries
• Une homothétie u de E de rapport α ∈ K a pour unique valeur propre α, et tout vecteur non
nul de E est vecteur propre de u associé à la valeur propre α.• Soit E = F ⊕ G une décomposition de E en somme de deux sous-espaces avec F = 0E etG = 0E , et soit p la projection sur F parallèlement à G. Alors les valeurs propres de p sont 1et 0. On a de plus E 1( p) = F , E 0( p) = G.
• Avec les même notations, soit s la symétrie par rapport à F parallèlement à G. Alors les valeurspropres de s sont 1 et −1. On a de plus E 1( p) = F , E −1( p) = G.
Faisons la démonstration dans le cas d’un projecteur, les autres cas sont laissés en exercice.Déterminons les éléments propres de p : soit x un vecteur propre de p et λ la valeur propre associée.Écrivons x = y + z où y ∈ F et z ∈ G. On a p(x) = λx, donc y = λx = λ(y + z) = λy + λz. Lasomme F + G étant directe, on en déduit que (1 − λ)y = 0E et λz = 0E . Or x est non nul, donc
y ou z est non nul. Dans le premier cas, on a nécessairement λ = 1, z = 0E et donc x = y ∈ F ;dans le second, on a λ = 0, y = 0E et donc x = z ∈ G. La réciproque est immédiate.
Remarque – Soit λ une valeur propre de u, et x un vecteur propre associé à la valeur propre λ.Alors, pour tout entier k 1, x est vecteur propre de uk associé à la valeur propre λk.
Pour démontrer ce résultat, on procède par récurrence sur k. Pour k = 1, le résultat est vraipar hypothèse. Si le résultat est vrai pour un certain entier k , alors
uk(x) = λkx.
En appliquant u, on obtient
uk+1(x) = u(λkx) = λku(x) = λk λx = λk+1x.
Comme x = 0E , le résultat est donc vrai au rang k + 1 et finalement pour tout k 1 par principede récurrence.
2. Stabilité et somme de sous-espaces propres
• Tout sous-espace propre de u est stable par u. Si λ est valeur propre de u, l’endo-morphisme de E λ(u) induit par u est l’homothétie de rapport λ.
• Soient u et v deux endomorphismes de E qui commutent (i.e. u v = v u).Alors tout sous-espace propre de u est stable par v.
Propriété
Démonstration – Le premier point est immédiat car pour tout x ∈ E λ(u), u(x) = λx par défini-tion. Le second point vient d’une propriété du chapitre Espaces vectoriels et applicationslinéaires : pour toute valeur propre λ de u, u − λ IdE et v commutent de même que u et v, doncE λ(u) = Ker(u − λ IdE ) est stable par v .
D’après le premier point, les sous-espaces E λ(u) sont donc de bons candidats à former unedécomposition de E pour laquelle l’expression de u soit particulièrement simple. De plus, on ala propriété suivante :
La somme d’une famille finie de sous-espaces propres associés à des valeurs propres deu deux à deux distinctes est directe.
Propriété
163

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 172/383
Démonstration – Soient E λ1 , . . . , E λp des sous-espaces propres de u associés aux valeurs propresdeux à deux distinctes λ1, . . . , λ p. Soit (x1, . . . , x p) ∈ E λ1 × · · · × E λp tel que x1 + · · · + x p = 0E .
En appliquant uk pour k ∈ N, on obtient, d’après la remarque ci-dessus,
λk1x1 + · · · + λk px p = 0E .
On en déduit que pour tout P ∈ K[X ],
P (λ1)x1 + · · · + P (λ p)x p = 0E .
Soit i ∈ [[1,p]] fixé. En choisissant
P (X ) = j=i
(X − λ j),
qui vérifie P (λi) = 0 et P (λ j) = 0 pour tout j = i, on obtient alors xi = 0E , ce qui prouve lerésultat.
Remarque – On en déduit que toute famille finie de vecteurs propres de u associés à des valeurspropres deux à deux distinctes est libre. C’est une conséquence de la propriété précédente et d’unrésultat du chapitre Espaces vectoriels et applications linéaires, des vecteurs propres étantnon nuls par définition.
Par exemple, la famille (exp0
, . . . , exp p
) d’éléments de C∞(R) est libre pour tout entier naturel p. En effet, pour tout k ∈ N, l’application expk : x → ekx est vecteur propre de l’opérateurdérivation sur C∞(R), associé à la valeur propre k.
3. Éléments propres d’une matrice
Dans ce paragraphe, A désigne une matrice de M n(K). Toutes les définitions des élémentspropres se traduisent en termes de matrices.
Les éléments propres de la matrice A sont les éléments propres de l’endomorphisme
uA : M n,1(K) → M n,1(K)
X → AX
canoniquement associé à A. En d’autres termes :
• Un scalaire λ ∈ K est appelé valeur propre de A s’il existe X ∈ M n,1(K) non nultel que AX = λX .
• Un vecteur X ∈ M n,1(K) est appelé vecteur propre de A si X est non nul et s’ilexiste λ ∈ K tel que AX = λX .
• Si λ est valeur propre de A, le sous-espace propre de A associé à la valeur propreλ est
E λ(A) = Ker(A
−λI n).
Définition
Remarque – Soit u ∈ L (E ). Soit B une base de E , et A la matrice de u dans cette base. Pour xvecteur quelconque de E , on note X la matrice colonne de ses coordonnées dans la base B. Ona alors :
• Pour tout λ ∈K, (u(x) = λx) ⇔ (AX = λX ).
• En particulier, u et A ont les mêmes valeurs propres et pour toute valeur propre λ de u et A,x est un vecteur propre de u si et seulement si X est un vecteur propre de A.
• Deux matrices semblables ont les mêmes valeurs propres, car elles représentent le même endo-morphisme dans des bases différentes.
Remarque – Bien sûr, toute matrice A ∈ M
n(R) peut être vue comme élément de M
n(C). La
relation AX = λX , pour X ∈ M n,1(R) et λ ∈ R, est également valable dans C. On en déduitque l’ensemble des valeurs propres de A vue comme matrice réelle est inclus dans l’ensemble desvaleurs propres de A vue comme matrice complexe.
164

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 173/383
II. Recherche des éléments propres, polynôme caractéristique
Dans toute la suite, E est supposé de dimension finie n.
1. Polynôme caractéristique
Pour l’instant, nous n’avons aucun moyen pratique autre que la définition pour déterminerl’ensemble des valeurs propres d’un endomorphisme u ou d’une matrice carrée A.
La caractérisation des isomorphismes en dimension finie donne immédiatement la propriétésuivante :
Soient u ∈ L (E ) et λ ∈K. Les propriétés suivantes sont équivalentes :
• Le scalaire λ est valeur propre de u.
• L’endomorphisme u − λ IdE n’est pas inversible.
• det(u − λ IdE ) = 0.
On a les équivalences analogues pour une matrice carrée.
Propriété
Ainsi λ ∈K est valeur propre de u si et seulement si λ est un zéro de la fonction
x → det(u − x IdE ).
Fixons une base B de E et soit A = (ai,j)1i,jn = MatB(u). Alors pour tout x ∈ K, u − x IdE a pour matrice A − xI n dans cette base, donc
det(u − x IdE ) = det(A − xI n) =
a1,1 − x . . . a1,n...
. . . ...
an,1 . . . an,n − x
.
En imaginant le développement de ce déterminant (obtenu par linéarité du déterminant parrapport à chaque colonne de sa variable, ou par développements successifs par rapport à lapremière colonne), on voit que la fonction x → det(u − x IdE ) est polynomiale.
• Le polynôme χu(X ) = (−1)n det(u − X IdE ) = det(X IdE −u) est appelé polynômecaractéristique de u.
• L’ensemble des valeurs propres de u est égal à l’ensemble des racines dans K de χu.Il est appelé spectre de u, et noté Sp(u).
• Si A ∈M n(K), on définit le polynôme caractéristique
χA(X ) = (−1)n det(A − XI n) = det(XI n − A)
de A, et son spectre Sp(A), comme étant ceux de l’endomorphisme canoniquementassocié à A.
Propriété/Définition
Exemple – Soit A =
2 5 0
−2 −1 1−2 2 3
. Alors
χA(X ) = X − 2 −5 0
2 X + 1
−1
2 −2 X − 3 = (X
−2)(X + 1)(X
−3) + 10
−2(X
−2) + 10(X
−3)
= (X − 2)(X 2 − 2X + 5)
= (X − 2)(X − 1 − 2i)(X − 1 + 2i).
165

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 174/383
La matrice réelle A a donc une seule valeur propre, 2, mais la matrice complexe A a trois valeurspropres, 2, 1 + 2i et 1 − 2i.
Remarques
• Comme on l’a expliqué plus haut, si u a pour matrice A dans une certaine base, alors pourtout x ∈K, det(x IdE −u) = det(xI n− A), et donc det(X IdE −u) = det(XI n− A) (égalité entrepolynômes) : u et A ont le même polynôme caractéristique.
• Deux matrices semblables ont le même polynôme caractéristique car elles représentent le mêmeendomorphisme dans des bases différentes. On peut aussi le montrer ainsi : si deux matrices A
et B de M n(K) sont semblables, il existe P ∈ Gℓn(K) telle que A = P BP −1. Alors
χA(X ) = det(XI n−A) = det(XI n−P BP −1) = det(P (XI n−B)P −1) = det(XI n−B) = χB(X ).
D’après ce qui précède, la recherche des valeurs propres d’un endomorphisme ou d’une ma-trice se ramène à la recherche des racines dans K d’un certain polynôme (dépendant de cetendomorphisme ou matrice). Explicitons en partie ce polynôme :
Soit u ∈ L (E ). Alors χu a pour terme de plus haut degré X n et pour coefficientconstant (−1)n det(u).
Propriété
Démonstration – Notons (E 1, . . . , E n) la base canonique de M n,1(K). Si M = (mi,j)1i,jn, parlinéarité du déterminant par rapport à chaque colonne de sa variable, det(M ) est la somme detous les termes de la forme
mi1,1 . . . min,n det E i1
· · · E in
où (i1, . . . , in) ∈ [[1,n]]n. Si A = (ai,j) est la matrice de u dans une base fixée et M celle deX IdE −u, on a, pour tout (i,j) ∈ [[1,n]]2, mi,j = −ai,j si i = j et mi,i = X − ai,i. Le terme deplus haut degré de χu provient donc uniquement du produit
(X − a1,1) · · · (X − an,n),
il est égal à X n.
De plus, le coefficient constant de χu est égal à χu(0) = (−1)n det(u) par définition de χu.
Remarques
• On a bien sûr un résultat analogue sur les matrices.
• Le polynôme caractéristique de u ∈ L (E ) (ou A ∈ M n(K)) est défini comme det(X IdE −u)
(ou det(XI n−A)) pour qu’il soit unitaire. Cela dit, dans les calculs, afin de ne pas avoir à changerles signes de tous les coefficients de A, on pourra calculer det(u − X IdE ) (ou det(A − XI n)) puismultiplier le résultat obtenu par (−1)n, c’est-à-dire, changer le signe lorsque n est impair.
Exemple – Si A =
a bc d
est une matrice de M 2(K), alors
χA(X ) = X − a −b
−c X
−d = (X −a)(X −d)−bc = X 2−(a+d)X +ad−bc = X 2−Tr(A)X +det(A).
Le fait que la trace de A apparaisse n’est pas un hasard, on retrouvera ce phénomène plus tarddans le chapitre.
166

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 175/383
Soit u ∈ L (E ). Alors :
• L’endomorphisme u admet au plus n valeurs propres.
• Si K = C, u admet au moins une valeur propre.
Corollaire
Démonstration
• Les valeurs propres de u sont les racines de χu. Or, le polynôme χu est de degré n (et enparticulier non nul), il a donc au plus n racines.
• Le polynôme χu possède au moins une racine dans C, d’après le théorème de d’Alembert-Gauss.
Remarque – Si K = R et n est impair, u possède au moins une valeur propre. En effet, dans ce cas,n = deg(χu) est impair ; χu étant de plus unitaire, on a lim
x→−∞χu(x) = −∞ et limx→+∞χu(x) = +∞.
Enfin χu définit une fonction continue. Le théorème des valeurs intermédiaires montre que χupossède au moins une racine réelle, et donc u possède au moins une valeur propre.
Soit u ∈ L (E ). On suppose que χu est scindé sur K, c’est-à-dire qu’il possède n racinesdans K, notées λ1, . . . , λn (non nécessairement distinctes, et qu’il faut donc compteravec leur ordre de multiplicité). Autrement dit, on suppose que u possède n valeurspropres dans K.
Alors
det(u) =ni=1
λi.
On a un résultat analogue pour une matrice carrée.
Propriété
Démonstration – On peut écrireχu(X ) =
ni=1
(X − λi).
Ainsi, le coefficient constant de χu est (−1)nni=1 λi. Or, on sait qu’il vaut aussi (−1)n det(u).
Remarque – Tout polynôme de C[X ] est scindé dans C (d’après le théorème de d’Alembert-Gauss) ; cette formule est donc toujours vraie si K = C. Elle peut être fausse dans R comme lemontre l’exemple de la matrice réelle
A = 0 −1
1 0 dont le polynôme caractéristique est X 2 +1, qui n’est pas scindé dans R : le spectre de A est doncvide. En revanche, si l’on passe dans C, A possède deux valeurs propres, i et −i, et la formuleest alors vérifiée.
Remarque – Déterminer les éléments propres de u ∈ L (E ) (en dimension finie) ou de A ∈ M n(K)
se fait donc généralement en deux étapes (formulées ici avec A) :
• On détermine les valeurs propres de A, ce qui correspond à la résolution d’une équation poly-nomiale, l’équation χA(λ) = 0.
• On recherche ses vecteurs propres en déterminant, pour λ ∈ Sp(A), le noyau de A − λI n,ce qui revient à résoudre l’équation linéaire (A
−λI n
)X = 0, par exemple par l’algorithme deGauss-Jordan.On sait notamment que dim(E λ(A)) = n − rg(A − λI n) est le nombre de paramètres de cesystème.
167

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 176/383
2. Sous-espaces stables et polynôme caractéristique
Soit M ∈ M n(K) une matrice carrée définie par blocs, de la forme
M =
A B0 C
avec A et C deux matrices carrées.
AlorsχM (X ) = χA(X ) χC (X ).
Propriété
Démonstration – Soit r l’ordre de la matrice A. Alors, d’après l’expression du déterminant d’unematrice triangulaire par blocs,
χM (X ) =
XI r − A −B
0 XI n−r − C
= det(XI r − A)det(XI n−r − C ) = χA(X ) χC (X ).
Soit u ∈ L (E ). Soit F un sous-espace vectoriel de E stable par u, avec F = 0E .
Alors χu|F , le polynôme caractéristique de u|F , divise χu, le polynôme caractéristiquede u.
Corollaire
Démonstration – Il suffit d’écrire la matrice de u dans une base adaptée à F et d’appliquer lapropriété précédente.
Soit u ∈L (E ). Soit λ une valeur propre de u. L’ordre de multiplicité de λ en tant queracine de χu est appelé multiplicité de la valeur propre λ, noté m(λ).
On a1 dim(E λ(u)) m(λ).
Propriété/Définition
Démonstration – Soit r la dimension de E λ(u). Un sous-espace propre est par définition non réduitau vecteur nul, donc 1 r. De plus, E λ(u) est stable par u et l’endomorphisme de E λ(u) induitpar u est l’homothétie de rapport λ. Sa matrice dans une base quelconque est λI r, d’où
χu|Eλ(u)(X ) = (X − λ)r
.
Or, d’après la propriété précédente, χu|Eλ(u) divise χu, donc r m(λ).
On dit qu’une valeur propre λ de u est simple si m(λ) = 1.
De l’inégalité précédente, on déduit que dans ce cas, dim(E λ(u)) = 1.
Ainsi, l’espace propre associé à une valeur propre simple est une droite vectorielle.
Propriété/Définition
Attention ! Il n’y a pas de propriété analogue pour une valeur propre λ de multiplicité m(λ) 2 :la dimension de E λ(u) peut être a priori n’importe quel entier compris entre 1 et m(λ).Par exemple, le sous-espace propre associé à une valeur propre double (i.e. de multiplicité 2)peut être une droite ou un plan.
168

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 177/383
III. Diagonalisabilité
1. Définition et premier critère
Soit u ∈ L (E ). On dit que u est diagonalisable s’il existe une base de E dans laquellela matrice de u est diagonale.
Définition – Endomorphisme diagonalisable
Cette définition s’interprète bien sûr en termes de vecteurs propres :
Soit u ∈ L (E ). Les propriétés suivantes sont équivalentes :
• u est diagonalisable.• Il existe une base de E formée de vecteurs propres pour u.
Dans ce cas, si D est une matrice diagonale représentant u dans une base de E , lescoefficients diagonaux de D sont les valeurs propres de u.
Propriété
Démonstration – On remarque que, si B = (e1, . . . , en) est une base de E , alors MatB(u) estdiagonale si et seulement si pour tout i ∈ [[1,n]], ei est un vecteur propre de u associé au coefficientdiagonal de la colonne i de MatB(u), ce qui prouve l’équivalence souhaitée.
Si u est diagonalisable, et si D est une matrice diagonale représentant u dans une base de E ,notons d1, . . . , dn les coefficients diagonaux de D. Alors
χu(X ) = det(X IdE −u) = det(XI n − D) =ni=1
(X − di).
Les coefficients di sont donc exactement les valeurs propres de u.
Donnons deux premiers critères de diagonalisabilité.
Soit u ∈ L (E ). Pour que u soit diagonalisable, il faut et il suffit que la dimension deE soit égale à la somme des dimensions des sous-espaces propres de u, c’est-à-dire, que
dim(E ) =
λ∈Sp(u)
dim(E λ(u)).
Théorème
Démonstration – On sait que la somme λ∈
Sp(u) E λ(u) est directe. Ainsi, d’après un résultat du
chapitre Espaces vectoriels et applications linéaires, le fait que
dim(E ) =
λ∈Sp(u)
dim(E λ(u))
équivaut au fait queE =
λ∈Sp(u)
E λ(u).
⇐ Si tel est le cas, en juxtaposant des bases des E λ(u) dont E est somme directe, on obtient unebase de E (d’après un théorème du chapitre Espaces vectoriels et applications linéaires).Une telle base de E est formée de vecteurs propres de u, car tout élément non nul d’un espace
propre de u est vecteur propre de u. Donc u est diagonalisable.⇒ Si u est diagonalisable, il nous suffit de prouver que E ⊂
λ∈Sp(u) E λ(u), l’aspect direct dela somme étant acquis. Soit donc (e1, . . . , en) une base de E formée de vecteurs propres pour u,
169

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 178/383
et soit x ∈ E ; il existe (α1, . . . , αn) ∈ Kn tel que x = α1e1 + · · · + αnen. Pour tout i ∈ [[1,n]],αiei ∈ E λ(u) pour un certain λ ∈ Sp(u). On a donc une décomposition de x comme somme devecteurs appartenant tous à un sous-espace propre de u, d’où le résultat.
Soit u ∈L (E ). Pour que u soit diagonalisable, il faut et il suffit que les deux propriétéssuivantes soient vérifiées :
• Le polynôme caractéristique χu de u est scindé sur K.• Pour toute valeur propre λ de u, la dimension du sous-espace propre associé est égaleà la multiplicité de λ en tant que valeur propre de u, c’est-à-dire,
∀ λ ∈ Sp(u), dim(E λ(u)) = m(λ).
Théorème
Démonstration – Si Sp(u) = ∅, u n’est pas diagonalisable car elle n’a pas de valeur propre,et χu n’est pas scindé sur K pour la même raison. Sinon, notons λ1, . . . , λ p les valeurs propresdeux à deux distinctes de u, de sorte que Sp(u) = λ1, . . . , λ p. Alors on a, pour tout i ∈ [[1,p]],dim(E λi(u)) m(λi). On en déduit que
pi=1
dim(E λi(u))
pi=1
m(λi) deg(χu) = dim(E ).
Or, d’après le théorème précédent, u est diagonalisable si et seulement si
dim(E ) =
pi=1
dim(E λi(u)).
D’après les inégalités précédentes, ceci est équivalent au fait que
pi=1
m(λi) = deg(χu)
et que, pour tout i ∈ [[1,p]], dim(E λi(u)) = m(λi). En remarquant que χu est scindé sur K si etseulement si
pi=1 m(λi) = deg(χu), on obtient le résultat.
Si u ∈ L (E ) admet n valeurs propres deux à deux distinctes, alors u est diagonalisable.De plus, chaque espace propre de u est une droite vectorielle.
Corollaire
Démonstration – Nous avons vu plus haut que le sous-espace propre associé à une valeur propresimple est une droite vectorielle. Ici, on a donc
dim(E ) = n =
λ∈Sp(u)
dim(E λ(u)).
Le premier critère ci-dessus montre que u est diagonalisable.
Attention ! Bien évidemment, la réciproque est fausse : l’identité de E est diagonalisable, maispossède 1 comme unique valeur propre.
Remarque – Le cas du corollaire précédent est en quelque sorte le cas « idéal ». Lorsque l’on n’estpas dans ce cas, on détermine par le calcul les sous-espaces propres (par la méthode de Gauss-Jordan notamment), pour vérifier l’un des critères ci-dessus. Il s’agit souvent d’une vérificationfastidieuse, d’où l’intérêt de nouveaux critères de diagonalisabilité, que nous donnerons dans lapartie IV.
170

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 179/383
2. Matrices diagonalisables
Soit A ∈M n(K). On dit que la matrice A est diagonalisable si A est semblable à unematrice diagonale, c’est-à-dire, s’il existe P ∈ Gℓn(K) et D ∈ M n(K) diagonale tellesque A = P DP −1.
Définition – Matrice diagonalisable
Soit A ∈M n(K) une matrice carrée. Les propriétés suivantes sont équivalentes :
1. A est diagonalisable.2. Il existe une base de M n,1(K) formée de vecteurs propres pour A.
3. Tout endomorphisme d’un K-espace vectoriel de dimension n, de matrice A dansune certaine base, est diagonalisable.
Si A est diagonalisable et s’écrit P DP −1 avec P inversible et D diagonale, alors les co-efficients diagonaux de D sont les valeurs propres de A, et les colonnes de P constituent
une base deM
n,1(K) de vecteurs propres de A.
Théorème – Lien entre matrices et endomorphismes diagonalisables
Démonstration – Ces équivalences viennent des formules de changement de base. Si A = P DP −1
avec P inversible et D diagonale, alors les colonnes de P constituent une base de M n,1(K) danslaquelle la matrice de uA est D ; les coefficients diagonaux de D sont donc les valeurs propres deA, et les colonnes de P constituent une base de M n,1(K) de vecteurs propres de A, apparaissantdans l’ordre correspondant à l’ordre des valeurs propres dans la matrice D. Il n’y a donc d’ailleurspas qu’un choix possible de P et D .
Remarque – Tous les résultats concernant la diagonalisabilité des endomorphismes se traduisentdonc sur les matrices carrées, via les endomorphismes canoniquement associés, et grâce au théo-
rème précédent. Dans le premier critère de diagonalisabilité, il convient de remplacer dim(E ) parl’ordre de la matrice considérée (n si A ∈ M n(K)).
Exemple – Considérons la matrice réelle A =
1 4 2
0 −3 −20 4 3
. Son polynôme caractéristique est
X − 1 −4 −2
0 X + 3 20 −4 X − 3
= (X − 1)
X + 3 2−4 X − 3
= (X − 1)[(X + 3)(X − 3) − (−4) × 2]
= (X − 1)(X 2
− 1)= (X − 1)2(X + 1).
La matrice A possède donc une valeur propre double, 1, et une valeur propre simple, −1. On saitsans calcul que E −1(A) est de dimension 1. Pour en déterminer une base, on résout l’équationAX = −X correspondant au système
x +4y +2z = −x
−3y −2z = −y4y +3z = −z
⇔
2x +4y +2z = 0−2y −2z = 0
4y +4z = 0
⇔ x +2y +z = 0
y +z = 0
⇔
y = −z
x = −2y − z = z
171

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 180/383
On a donc E −1(A) = Vect
1
−11
. Notons e3 =
1
−11
.
De même, déterminons E 1(A) en résolvant l’équation AX = X correspondant au système
x +4y +2z = x
−3y
−2z = y
4y +3z = z ⇔ 4y +2z = 0
−4y
−2z = 0
4y +2z = 0 ⇔ 2y + z = 0.
Donc E 1(A) est un plan vectoriel ; une base de E 1(A) est
(e1,e2) =
1
00
,
0
1−2
.
En particulier, dim(E 1(A)) = 2 et finalement, dim(E −1(A)) + dim(E 1(A)) = 1 + 2 = 3 qui estl’ordre de la matrice A. On sait donc que A est diagonalisable. En fait, en posant
P = 1 0 1
0 1 −10 −2 1
,
alors P est la matrice de passage de la base canonique de M 3,1(R) à la base (e1,e2,e3) de vecteurspropres que l’on vient de déterminer, et
A = P
1 0 0
0 1 00 0 −1
P −1.
Remarque – La matrice A est la matrice d’une symétrie de R3 (identifié à M 3,1(R)) car A2 = I 2.Les calculs précédents permettent de décrire entièrement cette symétrie : il s’agit de la symétrie
par rapport au plan E 1(A), parallèlement à la droite E −1(A).
Soit A ∈M n(K) une matrice diagonalisable. On peut écrire
A = P
λ1 · · · 0...
. . . ...
0 · · · λn
P −1
avec λ1, . . . , λn les valeurs propres de A et P
∈ Gℓn(K).
Alors, pour tout k ∈ N,
Ak = P
(λ1)k · · · 0
... . . .
...0 · · · (λn)k
P −1.
Propriété
Démonstration – Elle se fait par récurrence immédiate, en utilisant le fait que P −1P = I n.
Dans l’exemple précédent, pour tout entier k ∈ N (et même pour tout k ∈ Z dans ce cas),
Ak = P 1 0 0
0 1 00 0 (−1)k
P −1.
172

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 181/383
Application – Récurrences linéaires
Considérons la relation de récurrence linéaire d’ordre 1
∀ k ∈ N,
x1k+1 = a1,1x1
k + · · · + a1,nxnk...
xnk+1 = an,1x1k + · · · + an,nxnk
(1)
dont les inconnues sont les n suites (x1k)k∈N, . . . ,(xnk )k∈N (l’exposant n’indique pas une puissance,
mais permet de repérer la j -ième suite inconnue, avec j ∈ [[1,n]]).
En notant U k le vecteur-colonne de coefficients x1k, . . . , xnk et A = (ai,j)1i,jn, la relation (1)
est équivalente à la relation de récurrence matricielle
∀ k ∈ N, U k+1 = AU k. (2)
Par récurrence immédiate, (U k) est solution de (2) si et seulement si pour tout k ∈ N, U k = AkU 0.
Si A est diagonalisable, la propriété précédente permet d’exprimer explicitement toute solu-tion de (1), en fonction des valeurs propres de A et des conditions initiales.
IV. Réduction et polynômes annulateurs
1. Polynômes annulateurs et valeurs propres
Soit u ∈ L (E ) et P ∈ K[X ] un polynôme annulateur de u.
Alors toute valeur propre de u est une racine de P .
Propriété
Démonstration – Nous avons montré plus haut que lorsque x est un vecteur propre de u associéà la valeur propre λ, alors pour tout entier naturel k, uk(x) = λkx. En écrivant P sous formedéveloppée, on en déduit que P (u)(x) = P (λ) · x = 0E car P (u) = 0L (E ). Or x étant vecteurpropre, il est non nul ; on a donc nécessairement P (λ) = 0.
Remarques
• Cette propriété est très intéressante, car elle montre que les valeurs propres de u, bien qu’ellessoient les racines du polynôme caractéristique de u, qui est de degré n, sont à chercher parmi lesracines de tout polynôme annulateur de u. Or, on peut parfois trouver un polynôme annulateurtrès simple : par exemple, X 2 − X est un polynôme annulateur de toute projection ; X − λ estun polynôme annulateur de toute homothétie de rapport λ. De même, X 2 − 1 est annulateur detoute symétrie.
• On avait déjà remarqué l’intérêt des polynômes annulateurs d’un endomorphisme ou d’unematrice pour les calculs de puissances ou d’inverse éventuel. La propriété précédente en donneune nouvelle application.
• La propriété précédente est vraie même en dimension infinie.
Exemple – Soit u ∈ L (E ) tel que u2 − 2u − 3 IdE = 0. Alors (u − 3 IdE ) (u + IdE ) = 0, donc(X − 3)(X + 1) est annulateur de u. Les valeurs propres de u sont donc éléments de −1; 3.
Attention ! Ne pas confondre cette propriété avec sa réciproque qui est fausse : si P est annulateurde u et si P (λ) = 0, alors rien ne dit que λ est valeur propre de u. En reprenant l’exempleprécédent avec u = 3 IdE , on a bien (u − 3 IdE ) (u + IdE ) = 0, mais −1 n’est pas valeur proprede u.
Dans tout polynôme annulateur de u, il peut y avoir des facteurs « inutiles » : soit
P (X ) = (X − α1) · · · (X − α p)
173

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 182/383
un polynôme annulateur scindé de u ∈ L (E ). Si un certain αi n’est pas valeur propre de u,alors u − αi IdE est injective et donc inversible d’après la caractérisation des isomorphismes endimension finie. En composant la relation (que l’on peut écrire dans un ordre arbitraire)
(u − α1 IdE ) · · · (u − α p IdE ) = 0
par (u−αi IdE )−1, on voit que l’on peut « enlever » u −αi IdE de cette relation. On obtient donc
un polynôme annulateur avec un facteur en moins. C’est le cas du facteur X + 1 dans l’exemple
ci-dessus lorsque u = 3 IdE .
Remarque – Tout élément u ∈ L (E ) (E étant de dimension finie n) admet un polynôme annu-lateur non nul. En effet, la famille (IdE ,u, . . . , un
2) est composée de n2 + 1 vecteurs de L (E )
qui est de dimension n2, elle est donc liée. Soitn2
k=0 akuk une combinaison linéaire nulle de ces
éléments, les ak étant non tous nuls. Alors le polynômen2
k=0 akX k est annulateur de u, et il estnon nul.
2. Le théorème de Cayley-Hamilton
Le résultat de la remarque précédente possède les inconvénients suivants : il ne donne pasexplicitement un polynôme annulateur de u, il garantit seulement l’existence de polynômes an-nulateurs de u de degré au plus n2, qui est un degré plutôt « élevé ». Le théorème suivant yremédie en partie :
Soit u ∈ L (E ). Alors χu(u) = 0L (E ) : le polynôme caractéristique de u est un polynômeannulateur de u.
On a un résultat analogue pour les matrices carrées.
Théorème de Cayley-Hamilton (admis : démonstration non exigible)
Exemple – Considérons la matrice A = 2 0 00 2 00 0 1 . Alors
χA(X ) =
X − 2 0 0
0 X − 2 00 0 X − 1
= (X − 2)2(X − 1).
Il est immédiat que (X −2)2(X −1) est annulateur de A (conformément au théorème de Cayley-Hamilton). En fait, (X − 2)(X − 1) est aussi annulateur de A.
Considérons maintenant la matrice B =
2 0 43 −4 121
−2 5
. Son polynôme caractéristique est
χB(X ) =
X − 2 0 −4−3 X + 4 −12−1 2 X − 5
C 2 ← C 2 + 2C 1
=
X − 2 2(X − 2) −4−3 X − 2 −12−1 0 X − 5
L1 ← L1 − 2L2
=
X + 4 0 20−3 X − 2 −12−1 0 X − 5
= X (X − 1)(X − 2).
En particulier, on sait sans calcul supplémentaire que B est diagonalisable, car B est d’ordre3 et possède trois valeurs propres distinctes. On vérifie que B(B − I 3)(B − 2I 3) = 0, mais ni
174

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 183/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 184/383
le symbole k= j
désignant la composition de tous les facteurs d’indice k = j.
Soit i ∈ [[1,n]], et λ j la valeur propre associée au vecteur ei ; ainsi (u − λ j IdE )(ei) = 0E . Enévaluant P (u) en ei, on a alors
P (u)(ei) =
k= j
(u − λk IdE )
((u − λ j IdE )(ei)) =
k= j
(u − λk IdE )
(0E ) = 0E .
Ceci étant valable pour tous les vecteurs de la base (e1, . . . , en), on a bien P (u) = 0.
2 ⇒ 1 : On procède par récurrence : montrons que pour tout entier p 1, tout endomorphismed’un espace de dimension finie admettant un polynôme scindé avec p racines simples, est dia-gonalisable. On pourra toujours, quitte à diviser par le coefficient dominant, supposer que lespolynômes annulateurs non nuls sont unitaires.
Initialisation : si p = 1 et si u ∈ L (E ) annule un polynôme de la forme X − α1, alorsu = α1 IdE . Ainsi, u est diagonalisable.
Hérédité : supposons le résultat vrai pour un nombre p de racines simples. Soit u un endo-morphisme annulant un polynôme P scindé et ayant p + 1 racines simples, que l’on écrit sous laforme
P (X ) = (X − α1) · · · (X − α p)(X − α p+1).
Notons Q(X ) = (X − α1) · · · (X − α p).
Étape 1 : montrons que E = Ker(Q(u)) ⊕ Ker(u − α p+1 IdE ) : tout d’abord, si un vecteur x
appartient à Ker(Q(u)) ∩ Ker(u − α p+1 IdE ), alors u(x) = α p+1x et donc
0E = Q(u)(x) = Q(α p+1) · x.
Le scalaire Q(α p+1) est non nul car les αi sont deux à deux distincts : on en déduit que x = 0E .On a donc montré que Ker(Q(u)) ∩ Ker(u − α p+1 IdE ) = 0E . De plus, effectuons la divisioneuclidienne de Q par (X −α p+1) : il existe un polynôme A et un polynôme B de degré strictementinférieur à deg(X
−α p+1) = 1, c’est-à-dire que B est un polynôme constant que l’on notera b
∈K,
tels queQ(X ) = A(X )(X − α p+1) + b.
En évaluant cette relation en α p+1, on obtient
Q(α p+1) = b
et en particulier b = 0 car α p+1 n’est pas racine de Q. On a alors
Q(u) = A(u) (u − α p+1 IdE ) + b IdE ,
c’est-à-dire1
b Q(u) − 1
b A(u) (u − α p+1 IdE ) = IdE .
Soit alors x ∈ E. On a d’après la relation précédente,
x = 1
bQ(u)(x) − 1
b (A(u) (u − α p+1 IdE )) (x).
De plus, le vecteur
y = 1
bQ(u)(x)
appartient à Ker(u − α p+1 IdE ) car
((u
−α p+1 IdE )
Q(u))(x) = P (u)(x) = 0E .
De même,
z = −1
b(A(u) (u − α p+1 IdE ))(x)
176

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 185/383
appartient à Ker(Q(u)). On a donc décomposé x sur la somme Ker(Q(u)) + Ker(u − α p+1 IdE ),ce qui achève de prouver que E = Ker(Q(u)) ⊕ Ker(u − α p+1 IdE ).
Étape 2 : Les endomorphismes u et Q(u) commutent, donc Ker(Q(u)) est stable par u. Soitv l’endomorphisme de Ker(Q(u)) induit par u. Alors Q est un polynôme annulateur de v pardéfinition, et Q est scindé et possède p racines simples. D’après l’hypothèse de récurrence, v estdiagonalisable et il existe une base de Ker(Q(u)) constituée de vecteurs propres pour v , et doncpour u.
Si Ker(u − α p+1 IdE ) = 0E , on a alors construit une base de E de vecteurs propres pour u.Sinon, on juxtapose à la base de Ker(Q(u)) que l’on a construite, une base de Ker(u−α p+1 IdE ),qui par définition est constituée de vecteurs propres pour u (associés à la valeur propre α p+1).Comme Ker(u −α p+1 IdE ) est supplémentaire de Ker(Q(u)) dans E , on a obtient finalement unebase de E constituée de vecteurs propres pour u, qui est donc diagonalisable, et l’hérédité estdémontrée.
Exemple – Revenons sur l’exemple d’un endomorphisme u ∈ L (E ) (E étant de dimension finie)tel que u2 − 2u − 3 IdE = 0. Alors le polynôme
X 2 − 2X − 3 = (X + 1)(X − 3)
est annulateur de u, et il est scindé dans R, à racines simples, donc u est diagonalisable. Ilexiste une base de E dans laquelle la matrice de u est diagonale, ses coefficients diagonaux étantéléments de −1; 3 (mais, sans information supplémentaire, on ne peut pas savoir si −1 et 3sont tous les deux valeurs propres de u, il se peut que seul l’un de ces deux nombres le soit).
Soient u ∈L (E ) diagonalisable et F un sous espace vectoriel de E stable par u, avecF = 0E .
Alors u|F est diagonalisable.
Corollaire
Démonstration – En effet, u est diagonalisable donc admet un polynôme annulateur scindé àracines simples. Ce même polynôme est aussi annulateur de u|F , qui par conséquent est diago-nalisable.
V. Endomorphismes et matrices trigonalisables
Bien sûr, parvenir à diagonaliser un endomorphisme u est la situation la plus favorable. Iln’est pas toujours possible d’y arriver, mais on peut dans ce cas essayer de trouver une matricede u non pas diagonale, mais au moins triangulaire supérieure.
• On dit qu’un endomorphisme u ∈ L (E ) est trigonalisable s’il existe une base deE dans laquelle la matrice de u est triangulaire supérieure.
• On dit qu’une matrice A ∈ M n(K) est trigonalisable si elle est semblable à unematrice triangulaire supérieure.
Définition – Trigonalisabilité
Remarques
• Si B = (e1, . . . , en) est une base de E , alors MatB(u) est triangulaire supérieure si et seulementsi pour tout i
∈ [[1,n]],
u(ei) ∈ Vect(e1, . . . , ei).
Dans ce cas, e1 est vecteur propre de u, mais pas nécessairement les autres vecteurs de la baseB.
177

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 186/383
• En revanche, les coefficients diagonaux d’une matrice triangulaire supérieure T = (ti,j) repré-sentant u sont nécessairement les valeurs propres de u : en effet,
χu(X ) = det(X IdE −u) = det(XI n − T ).
Or, la matrice XI n − T est triangulaire supérieure, donc son déterminant est le produit de seséléments diagonaux, ici
ni=1(X − ti,i). On en déduit que les coefficients diagonaux de T sont
exactement les valeurs propres de u.
Soit A ∈M n(K) une matrice carrée. Les propriétés suivantes sont équivalentes :
• A est trigonalisable.
• Tout endomorphisme d’un K-espace vectoriel de dimension n, de matrice A dansune certaine base, est trigonalisable.
Si A est trigonalisable et s’écrit A = P T P −1 avec P inversible et T triangulaire supé-rieure, alors les coefficients diagonaux de T sont les valeurs propres de A.
Théorème – Lien entre matrices et endomorphismes trigonalisables
Démonstration – L’équivalence vient des formules de changement de base. Si A = P T P −1 avec P
inversible et T triangulaire supérieure, alors les colonnes de P constituent une base de M n,1(K)dans laquelle la matrice de uA est T . Ainsi les coefficients diagonaux de T sont les valeurs propresde A d’après la remarque précédente. Il n’y a pas qu’un choix possible de P et T .
De la remarque précédente, on déduit que, si u ∈ L (E ) est trigonalisable, alors son po-lynôme caractéristique est scindé sur K. Cette condition n’était pas suffisante pour que u soitdiagonalisable, elle l’est pour que u soit trigonalisable :
Soit u ∈ L (E ).Pour que u soit trigonalisable, il faut et il suffit que χu soit scindé sur K.
On a un résultat analogue pour les matrices carrées.
Théorème
Démonstration (non exigible)
⇒ C’est ce que nous avons montré dans la remarque précédente.
⇐ On va prouver le résultat pour une matrice A ∈M n(K), celui sur les endomorphismes s’endéduisant, grâce au théorème précédent. On procède par récurrence sur n. Si n = 1, le résultatest vrai car A est trigonalisable et χA scindé sur K. Supposons le résultat vrai pour toute matricede M n(K) et soit A
∈ M n+1(K) telle que χA soit scindé sur K. Il existe donc λ
∈ Sp(A), et
X ∈ E λ(A) non nul. En choisissant une matrice P 1 ∈ Gℓn+1(K) dont la première colonne soit X ,la matrice (P 1)−1A P 1 est (d’après les formules de changement de bases) de la forme
λ L0 B
où L ∈M 1,n(K) et B ∈M n(K). Alors, on a
χA(X ) = (X − λ)χB(X )
et donc χB est scindé sur K. Par hypothèse de récurrence, il existe une matrice Q ∈ Gℓn(K) telle
que Q−1
BQ soit triangulaire supérieure. En effectuant les calculs par blocs, il est immédiat que1 00 Q
est inversible, d’inverse
1 00 Q−1
,
178

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 187/383
et on a 1 00 Q−1
λ L0 B
1 00 Q
=
λ LQ0 Q−1BQ
,
qui est triangulaire supérieure. Finalement, en posant P = P 1
1 00 Q
, on a P ∈ Gℓn+1(K) et
P −1AP est triangulaire supérieure, d’où le résultat.
Toute matrice de M n(C) est trigonalisable.
Corollaire
Démonstration – Le polynôme caractéristique d’une matrice complexe est scindé sur C, commetout polynôme à coefficients dans C (théorème de d’Alembert-Gauss). Le résultat vient donc duthéorème précédent.
Soit u ∈ L (E ). On suppose que χu est scindé sur K et on note λ1, . . . , λn les valeurs
propres de u, comptées avec multiplicité.Alors
det(u) =ni=1
λi et Tr(u) =ni=1
λi.
On a un résultat analogue pour une matrice carrée.
Propriété
Démonstration – D’après le théorème précédent, u est trigonalisable. Il existe donc une base deE dans laquelle la matrice de u est de la forme
T =
λ1
∗ · · · ∗0 . . . . . . ......
. . . ∗0 · · · 0 λn
,
Alors
det(u) = det(T ) =ni=1
λi et Tr(u) = Tr(T ) =ni=1
λi.
Rappel – Le résultat concernant le déterminant avait déjà été démontré plus haut en calculantde deux façons le coefficient constant de χu.
Remarque – Une méthode numérique de calcul d’une valeur propre
Soit A ∈ M n(C) (n 2). On note λ1, . . . , λn les valeurs propres de A, classées par modulecroissant, et on suppose que λn est l’unique valeur propre de plus grand module (en particulier,on a λn = 0). En raisonnant comme ci-dessus, on a, pour tout k ∈ N,
Tr(Ak) = (λ1)k + · · · + (λn)k, donc Tr(Ak) ∼ (λn)k
etTr(Ak+1)
Tr(Ak) ∼ (λn)k+1
(λn)k = λn.
Ainsi le quotient des traces de deux puissances itérées successives de A permet une approximationnumérique, programmable sur ordinateur, de λn, valeur propre de plus grand module de A.L’intérêt d’une telle méthode est qu’elle ne nécessite pas le calcul de χA puis la résolution del’équation polynomiale χA(λ) = 0. En revanche, elle ne donne pas toutes les valeurs propres.
179

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 188/383
Testons cette méthode numériquement avec le module numpy de Python :
>>> import numpy as np
>>> import numpy.linalg as npl
>>> B = np.array([[2,0,4],[3,-4,12],[1,-2,5]])
>>> np.trace(npl.matrix_power(B,10))/np.trace(npl.matrix_power(B,9))
1.9980506822612085
>>> np.trace(npl.matrix_power(B,20))/np.trace(npl.matrix_power(B,19))
1.9999980926550052
>>> npl.eigvals(B)
array([ 2.00000000e+00, 5.09314813e-15, 1.00000000e+00])
On a fait appel à la fonction eigvals, qui donne un tableau des valeurs propres (approchées)d’une matrice, afin de comparer les résultats. On rappelle que l’on avait obtenu, par le calcul deχB , que les valeurs propres de B sont 0, 1 et 2 (voir page 174).
Exemple – Suites récurrentes linéaires d’ordre n 2
Dans le chapitre Espaces vectoriels et applications linéaires, on s’est intéressé aux suitesd’éléments de K vérifiant la relation de récurrence :
∀k
∈N, uk+2 + auk+1 + buk = 0,
et la condition initiale u0 = x, u1 = y. Nous avons entièrement décrit ces suites. La réductiondonne un nouvel éclairage à ce problème : notons, pour tout entier naturel k ,
X k =
ukuk+1
.
Alors, pour tout k ∈ N, la relation uk+2 + auk+1 + buk = 0 équivaut à :
X k+1 =
uk+1
uk+2
=
0 1−b −a
ukuk+1
= AX k,
oùA =
0 1−b −a
.
L’avantage principal de cette présentation est d’avoir transformé une relation d’ordre 2 en unerelation d’ordre 1 : on se ramène à une suite géométrique dont la « raison » est la matrice A. Enparticulier, pour tout entier naturel k ,
X k = AkX 0, i.e.
ukuk+1
= Ak
u0
u1
.
On en déduira immédiatement uk. L’inconvénient est que cette relation n’a plus lieu dans Kmais dans M
2,1(K) : l’étude du problème n’est pas évidente car il nous faudrait déterminer les
puissances de la matrice A.
Essayons donc de trouver une forme réduite intéressante pour cette matrice. Son polynômecaractéristique est
χA(X ) =
X −1b X + a
= X (X + a) + b = X 2 + aX + b.
Il s’agit du polynôme définissant l’équation caractéristique.
En particulier, si l’équation caractéristique a deux solutions distinctes r1 et r2 dans K, alorsA est diagonalisable et, en notant P la matrice de passage de la base canonique de M 2,1(K) à
une base de vecteurs propres de A, on a
A = P
r1 00 r2
P −1,
180

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 189/383
et donc pour tout entier naturel k ,
Ak = P
(r1)k 0
0 (r2)k
P −1.
Après avoir fait le produit par P , P −1 et X 0, on retrouve bien le fait qu’il existe (λ,µ) ∈ K2 telque, pour tout k ∈ N,
uk = λ(r1)k + µ(r2)k,
où λ et µ dépendent de u0, u1, r1 et r2.
Si l’équation caractéristique a une solution double r dans K, alors A n’est pas diagonalisable :en effet, si A était diagonalisable, elle serait semblable à la matrice rI 2 qui commute avec toutematrice; A serait donc égale à rI 2, ce qui n’est pas le cas. En revanche, A est trigonalisable carχA est scindé sur K ; montrons qu’il existe une matrice inversible P telle que
A = P
r 10 r
P −1.
Ceci équivaut à l’existence d’une base (e1,e2) de M 2,1(K) telle que
Ae1 = re1
Ae2 = e1 + re2ce qui équivaut à
(A − rI 2)e1 = 0
(A − rI 2)e2 = e1i.e. à
(A − rI 2)2e2 = 0
(A − rI 2)e2 = e1
Le polynôme caractéristique de A étant (X − r)2, le théorème de Cayley-Hamilton montre que(A − rI 2)2 = 0, la première relation du système précédent est donc toujours vraie.Soit donc e2 ∈ M 2,1(K) et e1 = (A − rI 2)e2. Pour que e1 soit non nul, on impose de plus quee2 /∈ Ker(A − rI 2). Ceci est possible car Ker(A − rI 2) n’est pas égal à M 2,1(K), la matrice A
n’étant pas égale à rI 2.
Il reste seulement à montrer que (e1,e2) est une base de M 2,1(K), et par raison de dimension,qu’elle est libre. Soit donc (λ,µ) ∈ K2 tel que λe1 + µe2 = 0. En multipliant à gauche par A −rI 2,
on obtient λ(A − rI 2)e1 + µ(A − rI 2)e2 = 0 i.e. µe1 = 0.
Comme e1 = 0, on en déduit µ = 0. La relation initiale donne alors λe1 = 0, d’où λ = 0 et lerésultat.
Par construction, la matrice de uA dans cette base est
r 10 r
, donc A est semblable à
r 10 r
.
Or, une récurrence immédiate montre que pour tout entier naturel k 1,r 10 r
k=
rk krk−1
0 rk
.
On retrouve le fait qu’il existe (λ,µ) ∈ K2 tel que, pour tout k ∈ N,
uk = λrk + µ krk = (λ + µk)rk,
où λ et µ dépendent de u0, u1 et r .
Cette méthode se généralise aux relations de récurrence linéaires scalaires d’ordre n 2quelconque : si (a0, . . . , an−1) ∈Kn, une suite (uk)k∈N vérifie la relation de récurrence
∀ k ∈ N, uk+n + an−1uk+n−1 + · · · + a0uk = 0
si et seulement si la suite vectorielle (X k)k∈N définie par
X k =
uk...
uk+n−1
181

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 190/383
vérifie la relation d’ordre 1∀ k ∈ N, X k+1 = AX k,
où
A =
0 1 0 · · · · · · 0...
. . . 1 . . .
......
. . . . . .
. . . ...
... . . . . . . 00 · · · · · · · · · 0 1
−a0 −a1 · · · · · · · · · −an−1
∈
M n(K).
Dans le cas où A est diagonalisable, on sait en déduire X k, et donc uk, pour tout k .
Remarque – Calcul des puissances d’une matrice
Le calcul de puissances ci-dessus (cas d’une racine double) est un cas particulier d’une méthodeplus générale pour calculer les puissances d’une matrice triangulaire supérieure A de la formeα I n+ N , où α I n est la partie diagonale de A, et N (comme « nilpotente ») sa partie triangulaire« strictement supérieure ». Dans ce cas, α I n et N commutent, donc d’après la formule du binôme
de Newton, pour tout k ∈ N,Ak =
k j=0
k j
αk− j N j.
L’avantage de cette décomposition est que N j = 0 pour tout j n. Le nombre de termes dansla somme est donc au plus n, quelle que soit la valeur de k. Par exemple, pour tout k ∈ N,
2 30 2
k=
2 00 2
+
0 30 0
k=
k j=0
k j
2k− j
0 30 0
j.
On a donc, pour tout k 1,2 30 2
k= 2k
1 00 1
+ k 2k−1
0 30 0
=
2k 3k2k−1
0 2k
et cette formule est d’ailleurs aussi valable pour k = 0.
Comme nous l’avions expliqué dans le chapitre Matrices, on peut aussi effectuer le calculdes puissances k-ièmes d’une matrice carrée A à partir d’un polynôme annulateur P de A (parexemple son polynôme caractéristique), en déterminant le reste de la division euclidienne de X k
par P . Ce calcul est d’autant plus simple que le degré de P est petit.
182

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 191/383
Chapitre 9
Espaces probabilisés
Dans de nombreuses situations, une expérience, reproduite plusieurs fois dans des conditionsapparemment identiques, peut fournir des résultats différents et imprévisibles. Lorsque l’on lanceune pièce en l’air, si l’on avait une parfaite connaissance de toutes les données (sur la pièce,la façon dont elle est lancée, la constitution et le mouvement de l’air ambiant, les équationsdes différents mouvements, le moment où la personne rattrape la pièce,...) on serait peut-être en
mesure de prévoir si le résultat obtenu est « pile » ou « face ». En pratique, une telle connaissanceest sans doute impossible, et la moindre variation dans les conditions de l’expérience peut avoirsur le résultat une influence qui le rend impossible à prévoir.
On considère que de tels phénomènes relèvent de l’aléatoire, du hasard (parmi ces phéno-mènes, on peut aussi citer le comportement de particules physiques, l’évolution du cours de labourse, la démographie, les jeux de hasard). Pour les étudier, on ne cherche pas à prévoir leurrésultat mais on s’attache à mesurer les « chances » ou le « risque » qu’un événement se réalise.La théorie des probabilités donne un cadre mathématique à ce que l’on entend par « expériencealéatoire » et développe des outils permettant l’étude des phénomènes associés.
Dans tout le chapitre, Ω est un ensemble ; P (Ω) désigne la collection de toutes les parties de Ω.
I. Ensembles dénombrables
En première année ont été étudiées des expériences aléatoires ayant un nombre fini de résultatspossibles. De nombreuses expériences aléatoires ont un nombre infini de résultats possibles. Maisil convient de distinguer plusieurs types d’infinis, ce qui mène à définir la notion d’ensembledénombrable.
Intuitivement, un ensemble est dénombrable si l’on peut « étiqueter » ses éléments, c’est-à-dire en dresser une liste exhaustive où chaque élément est repéré par un nombre, l’ensemble deces nombres parcourant N. Mathématiquement, cela s’écrit ainsi :
Soit E un ensemble. On dit que E est dénombrable si E est en bijection avec N,c’est-à-dire s’il existe une bijection ϕ de N sur E .
Dans ce cas, on peut noter, pour tout n ∈ N, xn = ϕ(n), et on a donc E = xn; n ∈ N.C’est ce que l’on appelle décrire E en extension.
Définition – Ensemble dénombrable
Exemples
• L’ensemble N est bien sûr dénombrable (choisir ϕ = Id), c’est en quelque sorte le modèle
d’ensemble dénombrable.• L’ensemble 2N des entiers naturels pairs est dénombrable : ϕ : n → 2n est une bijection de Nsur 2N.
183
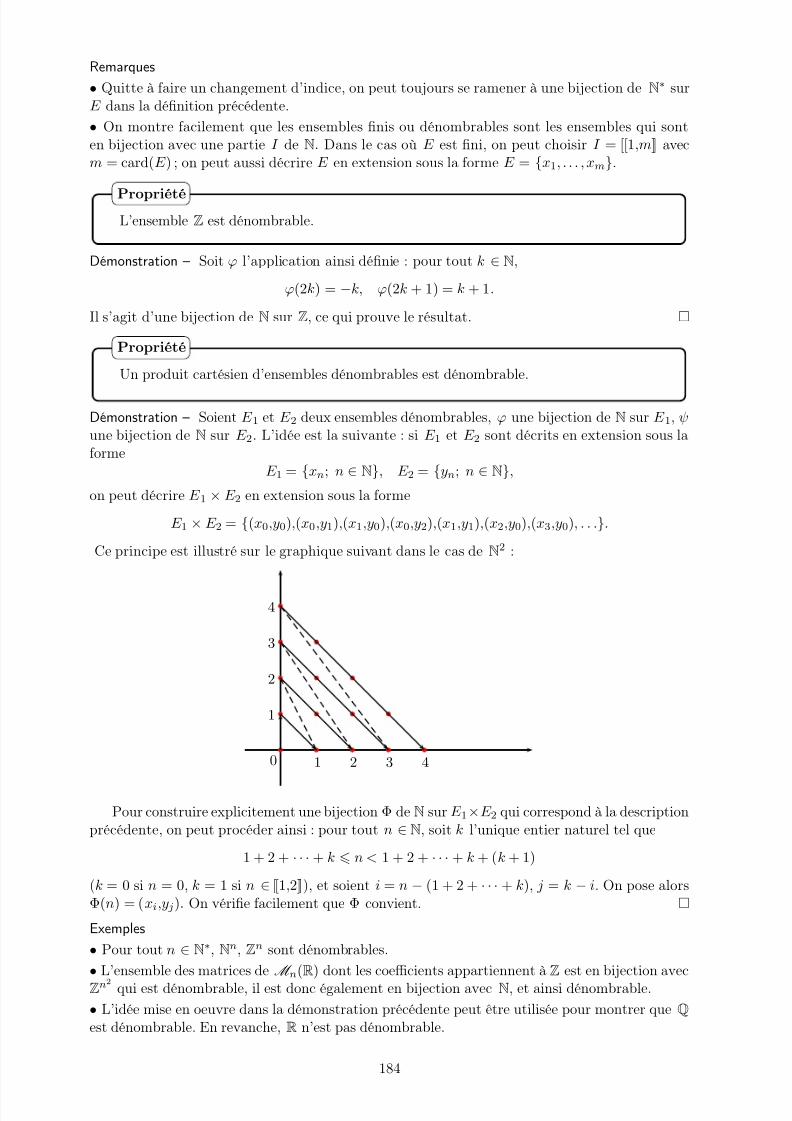
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 192/383
Remarques
• Quitte à faire un changement d’indice, on peut toujours se ramener à une bijection de N∗ surE dans la définition précédente.
• On montre facilement que les ensembles finis ou dénombrables sont les ensembles qui sonten bijection avec une partie I de N. Dans le cas où E est fini, on peut choisir I = [[1,m]] avecm = card(E ) ; on peut aussi décrire E en extension sous la forme E = x1, . . . , xm.
L’ensemble Z est dénombrable.Propriété
Démonstration – Soit ϕ l’application ainsi définie : pour tout k ∈ N,
ϕ(2k) = −k, ϕ(2k + 1) = k + 1.
Il s’agit d’une bijection de N sur Z, ce qui prouve le résultat.
Un produit cartésien d’ensembles dénombrables est dénombrable.
Propriété
Démonstration – Soient E 1 et E 2 deux ensembles dénombrables, ϕ une bijection de N sur E 1, ψune bijection de N sur E 2. L’idée est la suivante : si E 1 et E 2 sont décrits en extension sous laforme
E 1 = xn; n ∈ N, E 2 = yn; n ∈ N,
on peut décrire E 1 × E 2 en extension sous la forme
E 1 × E 2 = (x0,y0),(x0,y1),(x1,y0),(x0,y2),(x1,y1),(x2,y0),(x3,y0), . . ..
Ce principe est illustré sur le graphique suivant dans le cas de N2 :
0
1
2
3
4
1 2 3 4
Pour construire explicitement une bijection Φ de N sur E 1×E 2 qui correspond à la descriptionprécédente, on peut procéder ainsi : pour tout n ∈N, soit k l’unique entier naturel tel que
1 + 2 + · · · + k n < 1 + 2 + · · · + k + (k + 1)
(k = 0 si n = 0, k = 1 si n ∈ [[1,2]]), et soient i = n − (1 + 2 + · · · + k), j = k − i. On pose alorsΦ(n) = (xi,y j). On vérifie facilement que Φ convient.
Exemples
• Pour tout n ∈ N∗, Nn, Zn sont dénombrables.
• L’ensemble des matrices de M n(R) dont les coefficients appartiennent à Z est en bijection avecZn2 qui est dénombrable, il est donc également en bijection avec N, et ainsi dénombrable.• L’idée mise en oeuvre dans la démonstration précédente peut être utilisée pour montrer que Qest dénombrable. En revanche, R n’est pas dénombrable.
184

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 193/383
II. Espaces probabilisés
1. Tribu, probabilité
Modéliser une expérience aléatoire (afin de pouvoir l’étudier), c’est choisir :
• un ensemble Ω qui permet de représenter toutes les issues de l’expérience, c’est-à-diretous les résultats possibles de l’expérience. L’ensemble Ω est appelé univers.
• une probabilité sur Ω, qui est une fonction ayant certaines propriétés qui font que cettefonction peut être choisie pour mesurer les chances ou le risque qu’un résultat ou ensemblede résultats possibles de l’expérience (ce que l’on appelle sous certaines conditions unévénement), se réalise.
Exemples
• Une expérience aléatoire ayant deux issues, l’une (interprétée comme succès) de probabilité p,et l’autre (échec) de probabilité q = 1− p, est appelée épreuve de Bernoulli de paramètre p. C’estle cas de l’expérience consistant à lancer une fois une pièce non nécessairement équilibrée (avecpar exemple, p la probabilité d’obtenir « pile », q celle d’obtenir « face »).
• L’expérience aléatoire consistant à lancer une fois un dé équilibré et à noter le résultat obtenupeut être modélisée de la façon suivante : l’ensemble des issues est Ω =
1,2,3,4,5,6
, le fait
que le dé soit équilibré se traduit par le choix de la probabilité uniforme sur Ω, c’est-à-dire quechacun des résultats possibles a la probabilité 1/6 de se réaliser. Le sous-ensemble 2,4,6 de Ω
est l’événement que l’on peut décrire en français comme « le résultat est un nombre pair ».
• Une personne se lève de façon aléatoire à 7h00 ou 7h05 ou 7h10 ou 7h15. Pour son petitdéjeuner, elle choisit au hasard soit des tartines, soit des céréales. En numérotant 1, 2, 3 et 4les horaires possibles de lever, et en notant T et C les deux petits déjeuners possibles, on peutmodéliser l’expérience aléatoire consistant à observer, un jour, l’heure de réveil et le choix depetit déjeuner de cette personne, par le choix de
Ω = (1,C ),(1,T ),(2,C ),(2,T ),(3,C ),(3,T ),(4,C ),(4,T ),
chaque élément ayant par exemple une probabilité 1/8 de se produire. Selon la connaissance quel’on a de la situation, on peut bien sûr être amené à choisir des valeurs de probabilités différentes.
On peut bien sûr imaginer des expériences aléatoires plus complexes, par exemple des lancerssuccessifs de pièces jusqu’à obtenir « pile » trois fois de suite, l’observation du déplacementd’un insecte sur une surface plane, la trajectoire d’une balle de tennis. Dans ce cas, déterminerl’ensemble des issues peut être très complexe, cet ensemble peut notamment être infini . Pourcette raison, on est amené à préciser ce que l’on entend par événement :
Soit Ω un ensemble. On appelle tribu sur Ω une partie A de P (Ω) telle que :
• Ω ∈ A ,• Pour tout A ∈ A , le complémentaire de A, i.e. A = Ω \ A, appartient à A .
• Pour toute suite (An)n∈N d’éléments de A , la réunion+∞n=0
An appartient à A .
Lorsque A est une tribu sur Ω, l’ensemble Ω est appelé univers, et les éléments de A (qui sont des parties de Ω) sont appelés les événements.
Définition – Tribu
Remarques
• Les opérations ensemblistes correspondent bien sûr à des opérations logiques : le passage au
complémentaire traduit la négation, la réunion correspond à « ou ». Une tribu rassemble tousles événements observables lors de l’expérience aléatoire considérée, et la définition précédentefixe les règles fondamentales de logique permettant de combiner ces événements.
185

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 194/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 195/383
On voit donc qu’une tribu est également stable par réunion et intersection finie.
Le tableau suivant définit un certain nombre de termes du vocabulaire des probabilités, enparallèle avec le vocabulaire ensembliste :
Vocabulaire ensembliste Vocabulaire des probabilitésEnsemble Ω Univers, événement certainÉlément ω de Ω Issue (ou résultat possible, ou réalisation)
A ∈A (A ∈ P (Ω) si Ω est fini) Événement Aω ∈ A L’issue ω réalise l’événement A
Si Ω est fini par exemple : singleton ω Événement élémentaireEnsemble vide ∅ Événement impossible (jamais réalisé)Réunion A ∪ B Événement « A ou B »Réunion
+∞n=0 An Événement « l’un au moins des An est réalisé »
Intersection A ∩ B Événement « A et B »Intersection
+∞n=0 An Événement « tous les An sont réalisés »
Complémentaire A = Ω \ A Événement contraireParties disjointes : A ∩ B = ∅ Événements incompatibles
On appelle système complet (dénombrable) d’événements toute suite (An)n∈Nd’événements telle que :
• Les événements An sont deux à deux incompatibles,
•+∞n=0
An = Ω.
Définition – Système complet d’événements
Remarques
• On définit comme en première année les systèmes complets (finis) d’événements, les An étanten nombre fini.
• Un système complet d’événement permet de partitionner l’univers en plusieurs événements, cequi permet de faire des disjonctions de cas dans les raisonnements.
Exemples
• Si A est un événement, (A,A) est un système complet d’événements.
• On lance un dé à six faces. Pour n ∈ [[1,6]], on note An l’événement « le numéro obtenu est n ».La famille (Ai)1i6 est un système complet d’événements.
Soient Ω un ensemble et A une tribu sur Ω. On appelle probabilité sur (Ω,A ) uneapplication P : A → [0,1] telle que :
• P (Ω) = 1,
• Pour toute suite (An)n∈N d’éléments de A deux à deux incompatibles, la sérien0 P (An) converge et
P
+∞n=0
An
=
+∞n=0
P (An).
Lorsque P est une probabilité sur (Ω,A ), on dit que le triplet (Ω,A , P ) est un espace
probabilisé.Deux événements A et B tels que P (A) = P (B) sont dits équiprobables.
Définition – Probabilité
187

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 196/383
Remarques
• La probabilité d’un événement A s’interprète comme la « mesure » de l’ensemble des issuesconstituant A relativement à l’ensemble des issues. C’est, de façon imagée, le « poids relatif », laproportion de A dans l’univers Ω.
• Si (An)n∈N est un système complet d’événements,
n0 P (An) converge et a pour somme 1.
Cas des univers finis
Si Ω est un ensemble fini de cardinal N , la définition précédente est équivalente à la définitiondonnée en première année, dans laquelle le deuxième point était remplacé par la propriété :
si A et B sont deux événements incompatibles, P (A ∪ B) = P (A) + P (B).
Dans ce cas, on choisit toujours A = P (Ω). On dit alors simplement que le couple (Ω,P ) est unespace probabilisé fini. Avec la règle de calcul ci-dessus, la fonction P est entièrement déterminéepar la donnée des probabilités des événements élémentaires : pour tout A ∈P (Ω),
P (A) =ω∈A
P (ω).
On définit la probabilité uniforme sur Ω en posant, pour tout ω ∈ Ω, P (ω) = 1/N , c’est-à-dire que tous les événements élémentaires sont équiprobables. C’est le cas dans le deuxièmeexemple décrit plus haut (lancer de dé). On a alors, pour tout événement A,
P (A) =ω∈A
P (ω) = card(A) 1
N =
card(A)
card(Ω),
ce que l’on résume souvent ainsi :
P (A) = nombre de cas favorables
nombre de cas possibles .
Le fait de choisir la probabilité uniforme est souvent signalé par des expressions comme « la pièceest équilibrée », « le dé est équilibré », « les billes sont indiscernables au toucher et le contenude l’urne est soigneusement mélangé », etc...
On remarque immédiatement que la situation est plus complexe lorsque l’univers est infini :il n’est pas possible de généraliser la notion précédente de probabilité uniforme.
Cas des univers dénombrables
Soit Ω un ensemble dénombrable, avec Ω = ωn; n ∈ N, et soit ( pn)n∈N une suite de nombrespositifs telle que la série
n0 pn soit convergente et de somme 1. Si A ∈ P (Ω), on pose
P (A) = ωn∈A pn. Alors on pourra vérifier que (Ω,P (Ω), P ) est un espace probabilisé, pn étant
pour tout n ∈ N la probabilité de l’événement élémentaire ωn.
Dans ce qui précède, la notation
ωn∈A pn est intuitive, mais lorsque Ω est dénombrable, ilconvient de l’expliquer. Dans ce cas, A est lui-même fini ou dénombrable, et peut-être décrit enextension sous la forme (ωϕ(1), . . . , ωϕ(m)) (où m = card(A)) ou ωϕ(k); k ∈ N (où ϕ est unebijection de N sur N). Alors
ωn∈A pn s’exprime comme une somme finie ou une somme de série
convergente : ωn∈A
pn =mk=1
pϕ(k) ouωn∈A
pn =+∞k=0
pϕ(k).
Par exemple, si Ω = N et A = 2N = 2k; k ∈ N, alors P (A) = +∞k=0 P (2k).
Exemples
• Une personne participe à un jeu dans lequel elle remporte une somme d’argent (un nombreentier naturel d’euros) déterminée de façon aléatoire. On modélise ce jeu de la façon suivante :
188

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 197/383
Ω = N, l’événement « la personne gagne n euros » est le singleton n. On pose p0 = 0 et, pourtout n ∈ N∗,
pn = P (n) = 1
2n.
La série
n1 pn (série géométrique de raison 1/2 et de premier terme 1/2) converge et
+∞
n=0 pn =
+∞
n=1
1
2n =
1
2
1
1 − 1/2 = 1.
Le triplet (N,P (N),P ) est un espace probabilisé modélisant cette expérience.
Considérons l’événement A suivant : « la personne remporte une somme paire ». On a alors
A = ω ∈ N; ∃ k ∈ N, ω = 2k =+∞k=0
2k.
Les événements 2k sont deux à deux incompatibles, donc par définition d’une probabilité,
P (A) =
+∞k=0
P (2k) = p0 +
+∞k=1
p2k =
+∞k=1
122k = 14 11 − 1/4 = 13 .
Fixons p ∈ N et considérons l’événement S p suivant : « la personne remporte une somme stric-tement supérieure à p euros ». On a alors
S p = ω ∈ N; ∃ n ∈ N; n > p, ω = n =+∞
n= p+1
n.
Les événements n pour n > p sont deux à deux incompatibles, donc
P (S p) =+∞
n= p+1
P (n) =+∞
n= p+1
12n
= 12 p+1
11 − 1/2
= 12 p
.
La personne a autant de chances de remporter exactement p euros que de remporter une sommeau moins égale à p + 1 euros.
• Jeu de pile ou face infini. L’expérience consistant à lancer indéfiniment une pièce peut-êtremodélisée par le choix de Ω = 0,1N∗ des suites à termes dans 0,1 indexées à partir de 1 (0représente « face », 1 représente « pile »). Cet ensemble n’est pas dénombrable, il n’est alors pasévident de définir une tribu A sur Ω et une probabilité sur (Ω,A ). On peut montrer qu’il existeune tribu A sur Ω qui contient toutes les parties de Ω constituées des éléments dont les premierstermes sont imposés, c’est-à-dire les parties
C u1,...,uk = ω = (ωn)n1; ω1 = u1, . . . , ωk = uk
où k ∈ N∗ et (u1, . . . , uk) ∈ 0,1k représente les k premiers termes imposés. Ce sont desévénements naturels. Il existe alors une probabilité P sur (Ω,A ) telle que, avec les notationsprécédentes,
P (C u1,...,uk) = 1
2k.
Par exemple :
– « le résultat du second lancer est pile » est un événement : il s’agit de C 0,1 ∪ C 1,1;– « on n’obtient jamais pile » est un événement : il s’agit de A
0 = +∞
k=1C u1,...,uk
où tous lesun sont nuls;
– pour tout n ∈ N∗, « on obtient pile pour la première fois au n-ième lancer » est un événe-ment : il s’agit de An = C 0,...,0,1 (0 apparaissant n − 1 fois).
189

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 198/383
La famille (An)n∈N est un système complet dénombrable d’événements.
• Il existe une tribu A sur [0,1] qui contient les segments inclus dans [0,1], et une probabilité P sur (Ω,A ) telle que pour tout segment [a,b] inclus dans [0,1], on ait P ([a,b]) = b − a. L’espaceprobabilisé ([0,1],A , P ) peut modéliser par exemple l’expérience consistant à noter le momentoù une particule se désintègre, l’intervalle de temps étant ramené à [0,1] si l’on est sûr que ladésintégration a lieu avant un temps connu.
Remarques
• Un événement peut tout à fait avoir une probabilité nulle sans être impossible. C’est le cas detous les singletons dans l’exemple précédent. En particulier, la définition P (A) =
ω∈A P (ω)
est impossible à généraliser dans ce cadre.
• Lorsque Ω n’est pas dénombrable, P n’est presque jamais définie en donnant la probabilité detous les événements ; on peut par exemple donner (en analysant les conditions de l’expérience) laprobabilité d’événements fondamentaux à partir desquels on peut retrouver toutes les probabilitéssouhaitées, en utilisant les règles de calculs imposées. Dans l’exemple du jeu de pile ou face infini,l’événement A : « le résultat du second lancer est pile » est la réunion des deux événementsincompatibles C 0,1 et C 1,1, chacun de probabilité 1/4 ; on a donc (voir la propriété suivante)P (A) = 1/2.
Ce raisonnement se généralise et montre que pour tout k ∈ N∗, la probabilité d’obtenir krésultats fixés est 1/2k (et en particulier, à chaque lancer, la probabilité d’obtenir « pile » est1/2) : en fait, cette modélisation porte en elle le fait que la pièce est équilibrée et que chaquelancer est indépendant de tous les autres (cette notion sera précisée dans la suite).
2. Propriétés élémentaires
Soit (Ω,A , P ) un espace probabilisé. Alors :
• P (∅) = 0.
• Pour tout événement A, P (A) = 1
−P (A).
• Si n ∈ N et A0, . . . , An sont des événements deux à deux incompatibles, l’événementnk=0 Ak vérifie
P
nk=0
Ak
=
nk=0
P (Ak).
• Si A et B sont des événements avec A ⊂ B , alors P (A) P (B).
• Si A et B sont des événements, l’événement A ∪ B vérifie
P (A ∪ B) = P (A) + P (B) − P (A ∩ B).
• Si n ∈ N et A0, . . . , An sont des événements,
P
nk=0
Ak
nk=0
P (Ak).
Propriété
Démonstration
• Posons Bn = ∅ pour tout n ∈ N. Les événements Bn sont deux à deux incompatibles doncn0 P (Bn) =
n0 P (∅) converge. Cette série étant à termes constant, on a P (∅) = 0.
• Posons B0 = A, B1 = A et Bn = ∅ si n 2. Les Bn sont des événements deux à deuxincompatibles donc la série n0 P (Bn) converge et
P
+∞n=0
Bn
=
+∞n=0
P (Bn), i.e. P (Ω) = P (A) + P (A) d’après le point 1.
190

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 199/383
Sachant que P (Ω) = 1, on obtient le résultat.
• Posons Ak = ∅ pour tout k n + 1. Les Ak sont deux à deux incompatibles, donc
P
nk=0
Ak
= P
+∞k=0
Ak
=
+∞k=0
P (Ak) =nk=0
P (Ak).
• On écrit B = A
∪(B
∩A). Les événements A et B
∩A = B
\A sont incompatibles, donc
P (B) = P (A) + P (B ∩ A) P (A).
• Posons B0 = A ∩ B, B1 = A ∩ B, B2 = A ∩ B. Alors B0, B1 et B2 sont des événements deuxà deux incompatibles et A ∪ B = B0 ∪ B1 ∪ B2, donc d’après le point précédent,
P (A ∪ B) = P (A ∩ B) + P (A ∩ B) + P (A ∩ B).
Mais on a également
P (A) = P (A ∩ B) + P (A ∩ B) et P (B) = P (A ∩ B) + P (A ∩ B).
AinsiP (A ∪ B) = P (A) − P (A ∩ B) + P (B) − P (A ∩ B) + P (A ∩ B)
= P (A) + P (B) − P (A ∩ B).
On remarquera en particulier que P (A ∪ B) P (A) + P (B).
• On prouve cette dernière propriété par récurrence sur n, à partir de l’inégalité ci-dessus.
Soient (Ω,A , P ) un espace probabilisé et (An)n∈N une suite d’événements.
• Continuité croissante : si pour tout n ∈ N, An ⊂ An+1, alors
P (An) −→n→+∞ P
+∞k=0
Ak
.
• Continuité décroissante : si pour tout n ∈ N, An+1 ⊂ An, alors
P (An) −→n→+∞
P
+∞k=0
Ak
.
• Sous-additivité : sin0 P (An) converge, alors
P +
∞n=0
An
+∞
n=0
P (An).
Propriété – Suites monotones d’événements, sous-additivité
Démonstration
• Posons B0 = A0 et pour tout k ∈ N∗, Bk = Ak ∩ Ak−1 = Ak \ Ak−1. Alors
+∞k=0
Ak =+∞k=0
Bk,
les événements Bk étant deux à deux incompatibles : s’il existait (n,m) ∈ N2 tel que n < m etBn ∩ Bm = ∅, on pourrait trouver un élément ω de An n’appartenant pas à Am−1, ce qui estabsurde car An ⊂ Am−1.
191

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 200/383
Mais, d’après la démonstration de la propriété précédente, pour tout k ∈ N∗,
P (Ak ∩ Ak−1) = P (Ak) − P (Ak−1).
Finalement,
P
+∞
k=0
Ak
=
+∞
k=0
P (Bk) = P (B0) ++∞
k=1
P (Ak ∩ Ak−1) = P (A0) ++∞
k=1
(P (Ak) − P (Ak−1)).
On reconnaît une somme de série télescopique, et on conclut en rappelant que pour tout n ∈ N∗,
nk=1
(P (Ak) − P (Ak−1)) = P (An) − P (A0).
• Posons, pour tout k ∈ N, Bk = Ak. Alors, pour tout k ∈ N, Bk est un événement et Bk ⊂ Bk+1.D’après le point précédent,
P (Bn) −→n→+∞ P
+∞k=0
Bk
,
c’est-à-dire1 − P (An) −→
n→+∞1 − P
+∞k=0
Bk
= 1 − P
+∞k=0
Ak
,
d’où le résultat. On remarquera que la suite (P (An))n∈N est décroissante.
• Posons, pour tout n ∈ N, Bn = n
k=0 Ak. Alors pour tout n ∈ N, Bn est un événement etBn ⊂ Bn+1, donc d’après la propriété de continuité croissante,
P (Bn) −→n→+∞ P
+∞k=0
Bk
= P
+∞k=0
Ak
.
Mais d’après le dernier point de la propriété précédente, on obtient, pour tout n ∈ N,
P (Bn) nk=0
P (Ak).
En passant à la limite lorsque n → +∞, on obtient l’inégalité souhaitée.
Exemples
• Dans le jeu de pile ou face infini, soit A l’événement « on obtient pile au moins deux fois », etpour tout n 2, An l’événement « on obtient pile au moins deux fois au cours des n premierslancers ». Réaliser An revient à obtenir pile aucune fois ou une fois exactement au cours des npremiers lancers : An est la réunion des événements deux à deux incompatibles C u1,...,un où lesui sont tous nuls, ou bien tous nuls sauf un. Ces événements sont au nombre de n + 1 et ont touspour probabilité 1/2n, donc
P (An) = 1 − n + 1
2n .
De plus, pour tout n 2, An ⊂ An+1 ; enfin, A =+∞n=2 An. Ainsi,
P (A) = limn→+∞P (An) = 1
par croissances comparées.
• Soit (Ak)k∈N une suite d’événements. Pour tout n ∈ N, notons Bn l’événement
+∞k=n Ak ;
notons également B l’événement +∞n=0 Bn. Ainsi,
B =+∞n=0
+∞k=n
Ak
.
192

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 201/383
Il s’agit de l’événement « une infinité des Ak sont réalisés ». En effet, ω ∈ B si et seulement sipour tout n ∈ N, il existe k n tel que ω ∈ Ak, ce qui équivaut au fait que ω appartient à uneinfinité de Ak.
Supposons que la sériek0 P (Ak) converge. Pour tout n ∈ N, B ⊂ Bn, donc P (B) P (Bn).
Or, d’après la propriété de sous-additivité et le fait que
k0 P (Ak) converge, on a pour toutn ∈ N,
P (Bn)
+∞
k=nP (Ak),
le majorant tendant vers 0 en tant que reste d’une série convergente. Une probabilité étantpositive, on en déduit que P (Bn) → 0, et donc P (B) = 0. Cette propriété s’écrit ainsi : presquesûrement, le nombre des événements An qui sont réalisés est fini.
III. Probabilités conditionnelles
1. Conditionnement
Lors d’une expérience aléatoire, le fait de savoir (ou d’imaginer) qu’un événement est réalisé
revient à ajouter de l’information sur l’expérience, et peut modifier notre façon de calculer laprobabilité de certains événements. C’est ce que l’on appelle les probabilités conditionnelles. Soit(Ω,A , P ) un espace probabilisé. Supposons que A soit un événement tel que P (A) > 0. Calculerla probabilité qu’un événement B soit réalisé en sachant que l’événement A est réalisé revient àconsidérer, parmi les issues qui réalisent A, celles qui réalisent également B . Tout se passe commesi, pour ce calcul, on considérait l’expérience aléatoire à travers le « filtre » de l’événement A,comme si l’on considérait A comme univers.
Soit A un événement tel que P (A) > 0. Pour tout événement B , on appelle probabilitéconditionnelle de B sachant A le réel, noté P A(B) ou P (B
|A), défini par
P A(B) = P (A ∩ B)
P (A) .
On a donc P (A ∩ B) = P (B | A)P (A).
Définition – Probabilité conditionnelle
Remarque – Sachant que A ∩ B ⊂ A, on a P (A ∩ B) P (A), et donc avec le fait que P (A) > 0,on a P A(B) ∈ [0,1].
Exemple – Reprenons l’exemple du petit déjeuner exposé au début de ce chapitre, avec la proba-bilité définie par le tableau suivant :
ω (1,C ) (1,T ) (2,C ) (2,T ) (3,C ) (3,T ) (4,C ) (4,T )
P (ω) 0,2 0,05 0,1 0,15 0,05 0,3 0,05 0,1
Notons A l’événement « la personne se lève à 7h00 » (i.e., l’ensemble des issues ω dont lapremière composante est 1) et B l’événement « la personne choisit des céréales » (i.e., l’ensembledes issues ω dont la deuxième composante est C ). Alors on a
P (A) = 0,2 + 0,05 = 0,25, P (B) = 0,2 + 0,1 + 0,05 + 0,05 = 0,4
P (B | A) = P (A ∩ B)
P (A) =
0,2
0,25 =
4
5, P (A | B) =
P (A ∩ B)
P (B) =
0,2
0,4 =
1
2.
On notera que le calcul d’une probabilité conditionnelle n’est pas à confondre avec un liende cause à effet, on peut calculer P (A | B) même si la personne se lève avant de déjeuner!Simplement, quelqu’un arrivant chez cette personne après son déjeuner, voyant un bol vide sur
193

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 202/383
la table (et disposant du tableau précédent), peut affirmer qu’il y a une chance sur deux quela personne se soit levée à 7h00. Sans cette information, on pouvait donner une probabilitéP (A) = 0,25, deux fois moindre!
Soit A un événement tel que P (A) > 0. L’application
P A : A → [0,1]
B → P A(B)
est une probabilité sur (Ω,A ), appelée probabilité conditionnelle sachant A.
Propriété/Définition – Probabilité conditionnelle
Démonstration – On a remarqué plus haut que P A est à valeurs dans [0,1]. On a
P A(Ω) = P (Ω ∩ A)
P (A) =
P (A)
P (A) = 1.
Enfin, si (Bn)n∈N est une suite d’événements deux à deux incompatibles, on a
P A
+∞n=0
Bn
=
1
P (A)P
A ∩
+∞n=0
Bn
=
1
P (A)P
+∞n=0
(A ∩ Bn)
.
Les événements Bn sont deux à deux incompatibles, donc les événements A ∩ Bn également ; P étant une probabilité, on a alors
P A
+∞n=0
Bn
=
1
P (A)
+∞n=0
P (A ∩ Bn) =+∞n=0
P (A ∩ Bn)
P (A) =
+∞n=0
P A(Bn).
On a vérifié les différentes propriétés qui font de P A une probabilité sur (Ω,A ).
Remarque – Si P (A) = 0, afin que l’égalité P (A ∩ B) = P (B | A)P (A) reste valable, on pose par convention P (B | A)P (A) = 0 (mais le terme P (B | A) seul n’est pas défini dans ce cas).
2. Propriétés et utilisation des probabilités conditionnelles
Soient A1, . . . , A p des événements ( p 2) tels que P (A1 ∩ · · · ∩ A p−1) > 0. Alors
P (A1 ∩ · · · ∩ A p) = P (A1) P (A2 | A1) P (A3 | A1 ∩ A2) · · · P (A p | A1 ∩ · · · ∩ A p−1).
Propriété – Formule des probabilités composées
Démonstration – On procède par récurrence sur le nombre p 2 d’événements :
Initialisation ( p = 2) : cela résulte de la définition de P (A2 | A1) (on a P (A1) > 0 par hypo-thèse).
Hérédité : supposons le résultat vrai pour un nombre p 2 d’événements, et considéronsA1, . . . , A p+1 des événements tels que P (A1 ∩ · · · ∩ A p) > 0. Alors, par définition
P (A1 ∩ · · · ∩ A p+1) = P (A p+1 | A1 ∩ · · · ∩ A p) P (A1 ∩ · · · ∩ A p).
Or on a également P (A1 ∩ · · · ∩ A p−1) > 0, et donc par hypothèse de récurrence,
P (A1 ∩ · · · ∩ A p) = P (A1) P (A2 | A1) P (A3 | A1 ∩ A2) · · · P (A p | A1 ∩ · · · ∩ A p−1).
Des deux égalités précédentes, on déduit le résultat au rang p + 1 et finalement pour tout p 2par principe de récurrence.
194

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 203/383
Remarque – On réalise parfois des arbres pour représenter une expérience aléatoire. La formuledes probabilités composées traduit le fait que la probabilité d’un chemin est le produit desprobabilités des arêtes qui le composent.
Exemple – Une personne qui se rend au restaurant prend uniquement un plat une fois sur trois,un menu sinon (événement M ). Lorsqu’elle prend un menu, elle choisit de la viande (événementV ) une fois sur deux. Dans ce cas, elle prend un café (événement C ) trois fois sur quatre.Les données du problème se traduisent de la manière suivante :
P (M ) = 1 − 1
3 =
2
3, P (V | M ) =
1
2, P (C | M ∩ V ) =
3
4.
La probabilité pour que la personne choisisse un menu avec viande puis café est, d’après laformule des probabilités composées,
P (M ∩ V ∩ C ) = P (M )P (V | M )P (C | M ∩ V ) = 2
3
1
2
3
4 =
1
4.
Soient (An)n∈N un système complet d’événements et B un événement. Alors la sérien0 P (B ∩ An) converge, et on a
P (B) =+∞n=0
P (B ∩ An) =+∞n=0
P (B | An)P (An).
Le résultat précédent reste valable dans le cas plus général suivant :
(An)n∈N est une suite d’événements deux à deux incompatibles tels que+∞n=0
P (An) = 1.
Propriété – Formule des probabilités totales
Démonstration – Il suffit de faire la démonstration sous la deuxième hypothèse, puisqu’elle estplus générale. On se place donc dans ce cadre. Tout d’abord, la série
n0 P (B ∩ An) converge,
car les événements B ∩ An sont deux à deux incompatibles. De plus, notons N l’événementΩ \+∞
n=0 An. Les An étant deux à deux incompatibles,
P
+∞n=0
An
=
+∞n=0
P (An) = 1
et donc P (N ) = 0. En particulier, P (B ∩ N ) = 0. On a alors
B = B ∩ Ω = B ∩
N ∪+∞n=0
An
= (B ∩ N ) ∪
+∞n=0
(B ∩ An).
Les An et N forment une famille d’événements deux à deux incompatibles, donc c’est aussi lecas des B ∩ An et de B ∩ N , et on a finalement
P (B) = P (B ∩ N ) ++∞n=0
P (B ∩ An) =+∞n=0
P (B ∩ An) =+∞n=0
P (B | An)P (An).
Cas particulier – Lorsque A est un événement, (A, A) est un système complet d’événements,donc pour tout événement B,
P (B) = P (B | A)P (A) + P (B | A)P (A).
195

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 204/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 205/383
IV. Événements indépendants
Dans de nombreuses situations, le fait de savoir qu’un événement A est réalisé n’apporte rienpour le calcul de la probabilité d’un événement B. C’est la notion d’événements indépendants :
Soient A et B deux événements. On dit que A et B sont indépendants si
P (A ∩ B) = P (A) P (B).
Si P (A) > 0, ceci équivaut à : P (B | A) = P (B).
Propriété/Définition : Événements indépendants
L’équivalence des deux propriétés lorsque P (A) > 0 est immédiate car
P (B | A) = P (A ∩ B)
P (A) .
On remarquera cependant que la deuxième formulation n’est pas symétrique en A et B, alorsque la première l’est.
Soient A1, . . . , A p des événements. On dit que A1, . . . , A p sont mutuellement indé-pendants si pour tout sous-ensemble J de [[1,p]], on a
P
n∈J
An
=n∈J
P (An).
Définition – Événements mutuellement indépendants
Des événements A1, . . . , A p mutuellement indépendants sont deux à deux indépendants.
La réciproque est fausse en général : si n 3, l’indépendance de n événements deux àdeux n’entraîne pas leur indépendance mutuelle.
Propriété – Indépendance mutuelle / indépendance deux à deux
Démonstration – Si A1, . . . , A p sont mutuellement indépendants, alors pour tout (i,j) ∈ [[1,p]] telsque i = j, en choisissant J = i,j dans la définition, on obtient
P (Ai ∩ A j) = P (Ai)P (A j).
Donc A1
, . . . , A p
sont deux à deux indépendants.
En revanche, considérons l’exemple suivant : on dispose de quatre livres, un livre de mathé-matiques, un livre de physique, un livre de chimie, et un livre mathématiques-physique-chimie.On choisit au hasard, avec la probabilité uniforme, un livre parmi les quatre. Notons M , ϕ et C les événements « le livre choisi traite notamment de mathématiques » (respectivement physique,chimie). On a
P (M ∩ ϕ) = P (M ∩ C ) = P (ϕ ∩ C ) = 1
4
P (M )P (ϕ) = P (M )P (C ) = P (ϕ)P (C ) =
2
4
2
= 1
4
donc les événements M , ϕ et C sont deux à deux indépendants. Pourtant, ils ne sont pas mu-
tuellement indépendants car
P (M ∩ ϕ ∩ C ) = 1
4 et P (M )P (ϕ)P (C ) =
2
4
3
= 1
8.
197

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 206/383
Remarque – Si A et B sont indépendants, alors A et B sont indépendants : en effet,
P (A) = P (A ∩ B) + P (A ∩ B) = P (A)P (B) + P (A ∩ B)
et doncP (A ∩ B) = P (A)(1 − P (B)) = P (A)P (B).
Plus généralement, si A1, . . . , A p sont mutuellement indépendants, et si pour tout i ∈ [[1,p]],Bi = Ai ou Bi = Ai, alors B1, . . . , B p sont mutuellement indépendants.
Exemples
• Lors d’un parcours à vélo, les événements « le trajet est parcouru en moins de n minutes » etl’événement « il y a un vent de face de 40 km/h » ne sont sans doute pas toujours indépendants !
• L’indépendance entre événements relève parfois de la modélisation : on postule que certainsévénements fondamentaux sont indépendants.
Par exemple, dans un jeu de pile ou face, on considère dans la plupart des cas que les lancerssont mutuellement indépendants. Ce type d’expérience sera d’ailleurs plutôt modélisé ainsi, enfaisant l’hypothèse qu’à chaque lancer, « pile » et « face » ont des probabilités d’apparition
respectives p et q = 1 − p, et l’hypothèse d’indépendance mutuelle des lancers.Lorsque p = q = 1/2, le fait que pour tout n ∈ N∗, les événements consistant à fixer les
résultats des n premiers lancers aient pour probabilité 1/2n, est alors une conséquence de cettemodélisation, ce qui est une démarche peut-être plus naturelle que de postuler ces probabilités.
Par exemple, l’événement « pile apparaît pour la première fois au n-ième lancer » a pourprobabilité 1/2n (car il correspond à n−1 premiers résultats « face » suivis d’un résultat « pile »).De plus, l’événement « tous les lancers donnent face » est de probabilité nulle : pour tout n ∈ N∗,cet événement est inclus dans un événement de probabilité 1/2n, celui consistant à fixer n premiersrésultats « face ». Il suffit alors de faire tendre n vers +∞.
198

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 207/383
Chapitre 10
Intégrales généralisées
Le but de ce chapitre est de définir l’intégrale d’une fonction continue par morceaux sur unintervalle quelconque de R ; a et b désignent deux éléments de R ∪±∞ tels que a < b (avecdes conventions évidentes si a et/ou b est infini), et I désigne un intervalle d’extrémités a etb. L’intervalle I peut donc être de l’une des quatre formes suivantes : [a,b] (avec a et b finis),[a,b[ (avec a fini), ]a,b] (avec b fini), ou ]a,b[. On remarquera que le premier cas correspond à
l’intégrale sur un segment, et a donc été étudié dans le chapitre Dérivation et intégrationdes fonctions de R dans K. Enfin, K désigne R ou C.
I. Convergence des intégrales généralisées
1. Définitions
Soit f : I → K une fonction continue par morceaux.
• Si I = [a,b[, on dit que l’intégrale généralisée b
a
f (t) dt est convergente si la fonction
x → xa
f (t) dt possède une limite dans K lorsque x → b−.
• Si I = ]a,b], on dit que l’intégrale généralisée ba
f (t) dt est convergente si la fonction
x → bx
f (t) dt possède une limite dans K lorsque x → a+.
Dans les deux cas précédents, en cas de convergence, la limite est notée ba
f (t) dt.
• Si I = ]a,b[, on dit que l’intégrale généralisée b
af (t) dt est convergente s’il existe
c ∈ ]a,b[ tel que les deux intégrales généralisées ca
f (t) dt et bc
f (t) dt soient conver-
gentes. Dans ce cas, on pose ba
f (t) dt =
ca
f (t) dt +
bc
f (t) dt = limx→a+
cx
f (t) dt + limy→b−
yc
f (t) dt.
• Dans tous les cas, on dit que l’intégrale est divergente si elle n’est pas convergente.
Définition – Convergence d’une intégrale généralisée
Remarques
• On appelle nature d’une intégrale généralisée son caractère convergent ou divergent.
• Par définition, f est continue par morceaux sur I si elle est continue par morceaux sur toutsegment de I . Ainsi, lorsque I = [a,b[ par exemple, alors pour tout x ∈ [a,b[, l’intégrale
xa f (t) dt
apparaissant dans la définition est l’intégrale usuelle de f sur le segment [a,x].
199

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 208/383
• Ces définitions sont très similaires à celles de série et de somme de série convergente.
En revanche, pour les séries, on distinguait les notations
n0 un (la suite des sommespartielles) et, en cas de convergence,
+∞n=0 un (la somme de la série). Ici, la même notation est
utilisée pour désigner l’intégrale généralisée de f « avant de savoir si elle converge ou diverge », etsa valeur en cas de convergence. Il faut donc être particulièrement vigilant sur le sens des objetsutilisés, et notamment, ne pas faire de calculs ou de majorations sur des intégrales généraliséesavant d’avoir prouvé la convergence de tous les termes.
• L’intervalle I n’est pas toujours directement donné : lorsque l’on étudie la convergence d’uneintégrale généralisée
ba f (t) dt, il y a trois formes possibles pour I . En pratique, on identifie le
plus grand intervalle I d’extrémités a et b sur lequel f est continue par morceaux, et on commencetoujours la rédaction par une phrase du type « f est continue par morceaux sur I ».
2. Intégrales de référence
Les intégrales généralisées suivantes sont d’utilisation très fréquente. Leur nature est explici-tement au programme, mais pas la valeur des deux dernières en cas de convergence.
Intégrales de Riemann sur [1, +
∞[ :
+∞
1
dt
tα, où α
∈R.
La fonction t → 1/tα est continue (et donc continue par morceaux) sur [1, + ∞[. Pour x 1,
x1
dt
tα =
t1−α
1 − α
x1
= 1
α − 1
1 − 1
xα−1
si α = 1
ln(x) si α = 1.
On en déduit que l’intégrale est convergente si et seulement si α > 1, et dans ce cas
+∞
1
dt
tα =
1
α
−1
.
Intégrales de Riemann sur ]0,1] : 1
0
dt
tα, où α ∈R.
La fonction t → 1/tα est continue sur ]0,1]. Pour x ∈ ]0,1],
1
x
dt
tα =
t1−α
1 − α
1
x
= 1
1 − α
1 − x1−α si α = 1
− ln(x) si α = 1.
On en déduit que l’intégrale est convergente si et seulement si α < 1, et dans ce cas 1
0
dt
tα =
1
1 − α.
+∞
0e−αt dt où α ∈ R. La fonction t → e−αt est continue sur [0, + ∞[. Pour tout x 0,
x0
e−αt dt =
− 1
αe−αt
x0
= 1
α(1 − e−αx) si α = 0
x si α = 0
On en déduit que l’intégrale converge si et seulement si α > 0, et dans ce cas +∞
0e−αt dt =
1
α.
200

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 209/383
1
0ln(t) dt. La fonction ln est continue sur ]0,1]. Pour tout x ∈ ]0,1], une intégration par parties
(les fonctions t → t et t → ln(t) étant de classe C1 sur [x,1]) montre que 1
xln(t) dt = [t ln(t) − t]1
x = −x ln(x) + x − 1 −→x→0+
−1.
L’intégrale est donc convergente et 1
0 ln(t) dt = −1.
3. Lien avec l’intégrale sur un segment
Lorsque f est continue par morceaux sur le segment [a,b] (a et b finis), la notion d’intégralegénéralisée coïncide avec la notion usuelle définie dans le chapitre Dérivation et intégrationdes fonctions de R dans K.
Soit f : [a,b] → K une application continue par morceaux (a est b sont finis).
Alors les trois intégrales de f sur [a,b[, ]a,b] et ]a,b[ sont convergentes, et leur valeur est
l’intégrale « usuelle » [a,b] f.
Propriété
Démonstration – La fonction f est continue par morceaux sur [a,b], elle est donc bornée, d’où,pour x ∈ [a,b[,
xa
f (t) dt −
[a,b]f
=
− bx
f (t) dt
(b − x)f ∞ −→x→b−
0.
On en déduit le résultat dans le cas de l’intégrale sur [a,b[. On procède de façon similaire pourl’intégrale sur ]a,b], puis, pour l’intégrale sur ]a,b[, on découpe les intégrales sur [x,y]
⊂]a,b[ et
sur [a,b] en deux, grâce à une borne c ∈ ]a,b[ quelconque, et on applique les résultats des deuxautres cas.
On en déduit en particulier le résultat suivant :
Si b est fini, soit f : [a,b[→ K une fonction continue qui admet une limite dans K en
b−. Alors ba
f (t) dt est convergente. On parle de faux problème en b.
Propriété
Démonstration – Dans ce cas, f est prolongeable par continuité en b en une fonction ˜f continuesur [a,b]. Alors, pour x ∈ [a,b[, x
af (t) dt =
xa
f (t) dt −→x→b−
ba
f (t) dt.
L’intégrale est donc convergente.
Exemple – L’intégrale 2π
0
sin(t)
t dt est convergente : t → sin(t)/t est continue sur ]0,1] et
sin(t)
t −→t→0
sin′(0) = 1. Il y a un faux problème en 0.
Attention ! Il n’y a pas de faux problème en +∞
. Par exemple, ce n’est pas parce qu’unefonction f : [a, + ∞[→ K continue par morceaux possède une limite dans K en +∞, même nulle,que l’intégrale
+∞a f (t) dt converge. On l’a bien vu avec l’exemple de la fonction inverse, dont
l’intégrale sur [1, + ∞[ diverge.
201

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 210/383
Il n’y a pas non plus de condition nécessaire de convergence pour les intégrales (et c’est là unedifférence avec les séries) : du fait que
ba f (t) dt converge, on ne peut pas déduire que f possède
des limites dans K aux bornes de I . On a déjà montré que la fonction logarithme népérien,qui possède une limite infinie en 0+, a une intégrale convergente sur ]0,1]. On construit mêmefacilement des fonctions continues non bornées sur [0, + ∞[ qui ont une intégrale convergente :penser à une fonction « en triangles » pour laquelle la somme des aires des triangles est la sommed’une série convergente.
Il ne faut donc pas croire que les problèmes de convergence se traitent uniquement en exa-minant les limites éventuelles de f aux bornes.
4. Propriétés élémentaires
On peut facilement se ramener à des fonctions à valeurs réelles :
Soit f : I → C une fonction continue par morceaux.
L’intégrale b
af (t) dt converge si et seulement si les deux intégrales b
aRe(f (t)) dt et
ba I m(f (t)) dt
convergent. Dans ce cas, ba
f (t) dt =
ba
Re(f (t)) dt + i
ba I m(f (t)) dt.
Propriété
Les propriétés élémentaires de l’intégrale sont également valables pour les intégrales généra-lisées :
Soient f et g deux fonctions continues par morceaux sur I à valeurs dans K, et λ ∈ K.
Si ba
f (t) dt et ba
g(t) dt convergent, alors ba
(λf (t) + g(t)) dt converge et
ba
(λf (t) + g(t)) dt = λ
ba
f (t) dt +
ba
g(t) dt.
Propriété – Linéarité de l’intégration
Soient f et g deux fonctions continues par morceaux sur I à valeurs dans R telles que ba
f (t) dt et ba
g(t) dt convergent. On rappelle que a < b.
Alors :
• Si f 0 sur I , ba
f (t) dt 0.
• Si f g sur I , ba
f (t) dt ba
g(t) dt.
Propriété – Positivité et croissance de l’intégrale
202

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 211/383
Démonstration des trois propriétés précédentes – Il suffit d’écrire la propriété correspondante (don-née dans le chapitre Dérivation et intégration des fonctions de R dans K) sur un segmentinclus dans I ([a,x], [x,b] ou [x,y] selon la forme de I ) puis, en cas de convergence, de passer àla limite. Pour la première propriété, on utilise la caractérisation de la limite à l’aide des partiesréelle et imaginaire, pour la deuxième, une combinaison linéaire de limites, et pour la troisième,un passage à la limite d’inégalités larges.
Soit f : I → K une fonction continue par morceaux, et soit c ∈ I .
• Si I = [a,b[, alors ba
f (t) dt converge si et seulement si bc
f (t) dt converge.
• Si I = ]a,b], alors ba
f (t) dt converge si et seulement si ca
f (t) dt converge.
• Si I = ]a,b[, alors ba
f (t) dt converge si et seulement si ca
f (t) dt et bc
f (t) dt
convergent.
Dans les trois cas, en cas de convergence, on a ba
f (t) dt =
ca
f (t) dt +
bc
f (t) dt.
Propriété – Relation de Chasles
Démonstration
• Les deux premiers points sont similaires, on ne traite que le premier. Soit x ∈ I ; d’après larelation de Chasles pour les segments,
xa
f (t) dt =
ca
f (t) dt +
xc
f (t) dt.
Le terme ca
f (t) dt étant indépendant de x, les deux autres termes sont de même nature, et en
cas de convergence, on a la formule annoncée en faisant tendre x vers b par valeurs inférieures.
• Dans le cas où I = ]a,b[, si les deux intégrales ca
f (t) dt et bc
f (t) dt convergent, alors
b
a
f (t) dt converge et on a la formule annoncée, par définition.
Réciproquement, si ba
f (t) dt converge, il existe d ∈ I tel que da
f (t) dt et bd
f (t) dt
convergent. D’après les deux premiers points, pour tout c ∈ I , ca
f (t) dt et bc
f (t) dt convergent.
Remarques
• Le premier point montre bien que le problème de convergence ne vient que du voisinage de b
(resp. a) dans le cas d’une intégrale généralisée sur [a,b[ (resp ]a,b]).
• Dans le cas I = ]a,b[, on notera bien la différence entre la propriété ci-dessus (énoncée avec un
quantificateur universel : « pour tout c ∈ I , ... »), et la définition (énoncée avec un quantificateurexistentiel : « il existe c ∈ I tel que ... »). La propriété précédente est donc indispensable, pourprouver que
ba f (t) dt ne dépend pas du « découpage » de l’intervalle.
203

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 212/383
Pour les fonctions à valeurs positives, on a un critère de convergence :
Soit f une fonction continue par morceaux sur I à valeurs réelles positives.
• Si I = [a,b[, pour que ba
f (t) dt converge, il faut et il suffit que x → xa
f (t) dt soit
majorée sur [a,b[.
• Si I = ]a,b], pour que ba
f (t) dt converge, il faut et il suffit que x → bx
f (t) dt soit
majorée sur ]a,b].
Propriété
Démonstration – Dans le premier cas, la fonction x → xa
f (t) dt est croissante sur [a,b[, le résultat
vient donc du théorème de la limite monotone. Le deuxième cas est similaire.
II. Intégrales absolument convergentes, fonctions intégrables
On rappelle que I est un intervalle quelconque de R d’extrémités a et b, éventuellementinfinies.
1. Définition, lien avec la convergence
Soit f : I → K une fonction continue par morceaux.
On dit que l’intégrale ba
f (t) dt est absolument convergente si l’intégrale
b
a |f (t)
|dt est convergente.
Définition – Convergence absolue
Remarque – Pour les fonctions de signe constant, les notions d’intégrale convergente et absolumentconvergente coïncident.
Pour une fonction de signe quelconque, l’intérêt majeur de cette notion est que, comme pourles séries, la convergence absolue entraîne la convergence :
Soit f : I → K une fonction continue par morceaux.
Si l’intégrale ba
f (t) dt est absolument convergente, alors elle est convergente.
Dans ce cas, on a ba
f (t) dt
ba
|f (t)| dt.
Théorème
Démonstration – On raisonne dans le cas où I = [a,b[, les autres cas sont similaires. L’idée estexactement la même que pour les séries. Posons g = Re(f ) et
g+ = max0,g = 1
2(|g| + g), g− = max0, − g =
1
2(|g| − g).
Les fonctions g + et g− sont continues par morceaux sur I et vérifient
0 g+ |g|
Re(f )2 + I m(f )2 = |f |, 0 g− |g| |f |.
204

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 213/383
Pour x ∈ [a,b[ par croissance de l’intégrale, on a xa
g+(t) dt
xa
|f (t)| dt.
La fonction x → xa |f (t)| dt est majorée sur [a,b[ car
ba |f (t)| dt converge. Il en est donc de
même pour la fonction x → xa g+(t) et la fonction g+ étant positive, on en déduit que l’intégrale
ba g+
(t) dt converge. On obtient de même la convergence de ba g−(t) dt.On remarque enfin que l’on a g = g+ − g−, et donc, par différence,
ba g(t) dt converge. On
procède de même avec la partie imaginaire I m(f ), d’où la convergence de ba f (t) dt.
En utilisant l’inégalité triangulaire sur les segments, puis en passant à la limite, on obtientl’inégalité souhaitée.
Soit f : I → K une fonction continue par morceaux.
On dit que f est intégrable sur I si
b
af (t) dt est absolument convergente.
La valeur de cette intégrale est bien définie d’après le théorème précédent. Elle pourraêtre notée b
a
f (t) dt (notation déjà définie), mais aussi I
f (t) dt ou I
f.
Définition
2. Théorèmes de comparaison
Soient f : [a,b[→ K et g : [a,b[→ K deux fonctions continues par morceaux.• Si |f | |g| sur [a,b[, et si g est intégrable sur [a,b[, alors f est intégrable sur [a,b[.
• On a la même conclusion si l’inégalité |f | |g| est remplacée par l’une des conditions
f (t) =t→b−
O(g(t)) ou f (t) =t→b−
o(g(t)).
• Si f (t) ∼t→b−
g(t), alors f est intégrable sur [a,b[ si et seulement si g est intégrable sur
[a,b[.
Théorème de comparaison
Remarque – On adaptera facilement ce théorème au cas d’une intégrale généralisée sur ]a,b], eton peut combiner ces résultats pour traiter une intégrale généralisée sur ]a,b[.
Démonstration
• On reprend une idée déjà utilisée ci-dessus. Pour x ∈ [a,b[ par croissance de l’intégrale, on a xa
|f (t)| dt
xa
|g(t)| dt.
La fonction g est intégrable sur [a,b[, donc la fonction x → xa |g(t)| est majorée sur [a,b[. Il en
est donc de même pour la fonction x →
xa |f (t)|, ce qui montre que f est intégrable sur [a,b[.
• Dans ce cas, il existe M > 0 et a
0 ∈ [a,b[ tel que pour tout t
∈ [a
0,b[,
|f (t)
| M
|g(t)
|. On
prouve alors le résultat de la même façon que le premier point, l’intégrale de |f | et |g| sur [a0,b[et l’intégrale sur [a,b[ étant de même nature. Le cas d’un petit « o » s’en déduit car il est contenudans celui d’un grand « O ».
205

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 214/383
• Si f (t) ∼t→b−
g(t), alors on a f (t) =t→b−
O(g(t)) et g(t) =t→b−
O(f (t)). Le résultat vient donc du
point précédent.
Remarque – Ces résultats sont très fréquemment utilisés en association avec les propriétés sui-vantes que nous avons déjà données :
• Pour des fonctions positives, l’intégrabilité de f sur I équivaut à la convergence de ba
f (t) dt.
• L’intégrabilité de f sur I entraîne la convergence de ba
f (t) dt.
Exemples
• La fonction t → sin(t)
t2 est continue sur [1, + ∞[. Pour tout t 1,
sin(t)
t2
1
t2,
et t → 1/t2 est intégrable sur [1, + ∞[ (critère des intégrales de Riemann sur [1, + ∞[, exposant
2 > 1).Par comparaison, la fonction t → sin(t)
t2 est intégrable sur [1, + ∞[.
En particulier, l’intégrale +∞
1
sin(t)
t2 dt converge.
• La fonction t → e−t
t est continue sur [1, + ∞[ et à valeurs positives. Pour tout t 1,
0 e−t
t e−t
et t →
e−t est intégrable sur R+ (intégrale de référence) donc sur [1, + ∞
[. Par comparaison,
t → e−tt
est intégrable sur [1, + ∞[.
• La fonction t → t cos(t)
et − 1 est continue sur ]0, + ∞[. Examinons la convergence éventuelle de +∞
0
t cos(t)
et − 1 dt. Tout d’abord, il y a un faux problème en 0 car
t cos(t)
et − 1 ∼t→0+
t
t = 1.
De plus, pour t > 0t cos(t)
et − 1
t
et − 1 avec
t
et − 1 ∼t→+∞
t e−t =t→+∞
O(e−t/2)
car t e−t/2 −→t→+∞
0.
La fonction t → e−t/2 est intégrable sur [1,+∞[, donc par comparaison, t → t e−t puis t → t
et − 1
et t → t cos(t)
et − 1 sont intégrables sur [1, + ∞[. Finalement,
+∞
0
t cos(t)
et − 1 dt converge absolument,
et donc converge.
• La fonction t
→ 1
1 − t2 est continue sur [0,1[, à valeurs positives. On a
1
1 − t2 =
1
(1 + t)(1 − t) ∼t→1−
1
2(1 − t).
206

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 215/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 216/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 217/383
3. Changement de variable
Soit f : ]a,b[→ K une fonction continue par morceaux, et soit ϕ : ]α,β [ → ]a,b[ unebijection de classe C1 de ]α,β [ sur ]a,b[. Alors les intégrales
b
a
f (t) dt et β
α
f (ϕ(u)) ϕ′(u) du
sont de même nature, et en cas de convergence :
• Si ϕ est strictement croissante, ba
f (t) dt =
β α
f (ϕ(u)) ϕ′(u) du.
• Si ϕ est strictement décroissante,
b
af (t) dt = −
β
αf (ϕ(u)) ϕ′(u) du.
Théorème – Changement de variable dans une intégrale généralisée
Attention ! Ne pas oublier le signe dans la formule, qui prend en compte la monotonie de ϕ. Encas de convergence des deux intégrales, les deux cas ci-dessus peuvent être réunis dans la formule b
af (t) dt =
β α
f (ϕ(u)) |ϕ′(u)| du.
Remarques
• Sous les hypothèses du théorème, la fonction ϕ est continue et bijective de ]α,β [ sur ]a,b[, eton peut montrer qu’elle est soit strictement croissante, soit strictement décroissante. Les deuxcas considérés ci-dessus sont donc les seuls possibles. De plus, la fonction ϕ−1 est strictementmonotone, de même monotonie que ϕ.
• Le théorème précédent est formulé avec des intervalles ouverts, mais on peut avoir à traiter lecas d’intervalles semi-ouverts. C’est bien sûr possible, puisque pour une fonction f : [a,b[→ K
continue par morceaux, les intégrales de f sur [a,b[ et sur ]a,b[ sont de même nature et égale encas de convergence (la situation est analogue pour ]a,b]). Ceci se prouve en adaptant un résultatdonné plus haut sur la cohérence des différentes notions d’intégrale, pour une fonction continuepar morceaux sur un segment.
Démonstration du théorème – Soient r et s deux éléments de ]α,β [, x et y deux éléments de ]a,b[.En utilisant la formule usuelle pour les segments, on a
ϕ(s)
ϕ(r)f (t) dt = s
rf (ϕ(u)) ϕ′(u) du et y
xf (t) dt = ϕ−1(y)
ϕ−1(x)f (ϕ(u)) ϕ′(u) du.
Si ϕ est strictement croissante,
ϕ(r) −→r→α+
a+, ϕ(s) −→s→β −
b−, ϕ−1(x) −→x→a+
α+ et ϕ−1(y) −→y→b−
β −.
On en déduit que ba
f (t) dt converge si et seulement si β α
f (ϕ(u)) ϕ′(u) du converge, ainsi que
la formule annoncée en cas de convergence.
Si ϕ est strictement décroissante, on reprend le raisonnement, les bornes a et b sont échangées
dans les limites de ϕ et ϕ−1, et en cas de convergence, ab
f (t) dt = − ba
f (t) dt.
209
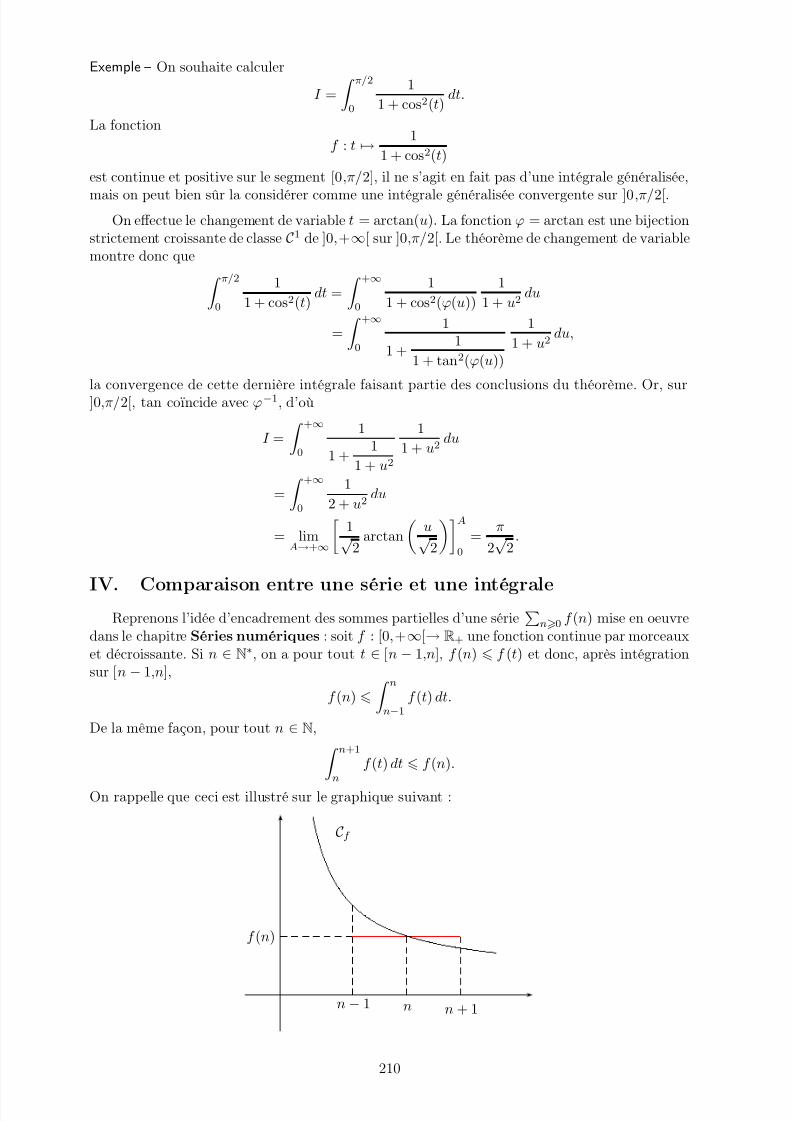
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 218/383
Exemple – On souhaite calculer
I =
π/2
0
1
1 + cos2(t) dt.
La fonctionf : t → 1
1 + cos2(t)
est continue et positive sur le segment [0,π/2], il ne s’agit en fait pas d’une intégrale généralisée,
mais on peut bien sûr la considérer comme une intégrale généralisée convergente sur ]0,π/2[.On effectue le changement de variable t = arctan(u). La fonction ϕ = arctan est une bijection
strictement croissante de classe C1 de ]0,+∞[ sur ]0,π/2[. Le théorème de changement de variablemontre donc que π/2
0
1
1 + cos2(t) dt =
+∞
0
1
1 + cos2(ϕ(u))
1
1 + u2 du
=
+∞
0
1
1 + 1
1 + tan2(ϕ(u))
1
1 + u2 du,
la convergence de cette dernière intégrale faisant partie des conclusions du théorème. Or, sur]0,π/2[, tan coïncide avec ϕ−1, d’où
I =
+∞
0
1
1 + 1
1 + u2
1
1 + u2 du
=
+∞
0
1
2 + u2 du
= limA→+∞
1√
2arctan
u√
2
A0
= π
2√
2.
IV. Comparaison entre une série et une intégraleReprenons l’idée d’encadrement des sommes partielles d’une série
n0 f (n) mise en oeuvre
dans le chapitre Séries numériques : soit f : [0,+∞[→ R+ une fonction continue par morceauxet décroissante. Si n ∈ N∗, on a pour tout t ∈ [n − 1,n], f (n) f (t) et donc, après intégrationsur [n − 1,n],
f (n)
nn−1
f (t) dt.
De la même façon, pour tout n ∈ N,
n+1
nf (t) dt f (n).
On rappelle que ceci est illustré sur le graphique suivant :
Cf
n − 1 n n + 1
f (n)
210

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 219/383
En additionnant la première inégalité pour n entre 1 et p 1 puis en ajoutant f (0), et enadditionnant la seconde pour n entre 0 et p, on obtient p+1
0f (t) dt
pn=0
f (n) f (0) +
p0
f (t) dt.
On en déduit que la suite p0 f (t) dt p∈N est majorée si et seulement si la suite des sommes
partielles de la série n0 f (n) est majorée. Or, la série n0 f (n) est à terme positifs, donc lasuite de ses sommes partielles est majorée si et seulement si elle converge. De plus, la fonctionf étant à valeurs positives, la suite
p0 f (t) dt
p∈N est majorée si et seulement si la fonction
x → x0 f (t) dt (définie sur [0, + ∞[) est majorée : en effet, pour tout x 0, x
0f (t) dt
p0
f (t) dt
avec p = ⌊x⌋ + 1. Pour la même raison (f à valeurs positives), la fonction x → x0 f (t) dt est
majorée si et seulement si f est intégrable sur [0, + ∞[.
Finalement, nous venons de démontrer le résultat suivant :
Soit f : [0, + ∞[→ R+ une fonction continue par morceaux, décroissante, à valeurspositives.
Pour que la sérien0
f (n) converge, il faut et il suffit que f soit intégrable sur [0, + ∞[.
Théorème – Comparaison entre une série et une intégrale
Remarques
• La fonction f étant positive, le fait que f soit intégrable équivaut à la convergence de
+∞
0 f (t) dt.
• Bien sûr, on adapte facilement ce résultat au cas des fonctions définies sur [n0, + ∞[, pourcomparer les natures de +∞n0
f (t) dt et
nn0 f (n).
• Dans le chapitre Séries numériques, on avait montré comment étudier, par encadrement,le comportement asymptotique de sommes partielles, ou de restes de séries convergentes. Laméthode d’encadrement avait été exposée dans le cadre des fonctions continues, mais elle restevalable dans le cadre de l’intégrale des fonctions continues par morceaux.
• On peut donner des encadrements semblables de sommes partielles lorsque f est croissante.
Exemples
• Nous avons déjà mis en oeuvre cette technique pour prouver la convergence des séries de
Riemann n1
1
n
α pour α > 1. En effet, dans ce cas, la fonction f : t
→
1
t
α est continue, positive,
décroissante et intégrable sur [1, + ∞[.
• On peut également obtenir des équivalents de sommes de séries de fonctions par cette méthode :définissons, pour tout n ∈ N∗ et x > 0,
un(x) = 1
n + n2x.
La série de fonctions
n1 un converge normalement sur tout intervalle de la forme [a, + ∞[
avec a > 0, car pour tout x a et n ∈ N∗,
0 un
(x) 1
n2a,
le majorant étant le terme général d’une série convergente. De plus, chaque fonction un estcontinue sur R∗+. En particulier, la somme f de la série de fonctions est définie et continue sur
211

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 220/383
R∗+. On cherche à déterminer un équivalent de f (x) lorsque x tend vers 0+. Pour cela, posons,x > 0 étant fixé,
g : t → 1
t + t2x.
La fonction g est continue et décroissante sur [1, + ∞[. Pour tout n 2, on a donc
n+1
n
g(t) dt g(n) n
n−1
g(t) dt.
En ajoutant ces inégalités pour n entre 2 et p 2, on obtient donc p+1
2g(t) dt
pn=2
1
n + n2x
p1
g(t) dt
puis, en ajoutant le terme correspondant à n = 1,
1
1 + x +
p+1
2g(t) dt
pn=1
1
n + n2x
1
1 + x +
p1
g(t) dt. (10.1)
Or, pour tout (a,b)
∈R2 avec 1 a b, ba
g(t) dt =
ba
1
t − x
1 + tx
dt =
ln
t
1 + tx
ba
Lorsque b → +∞, on a donc, pour tout a 1, la convergence de l’intégrale +∞a g(t) dt avec +∞
ag(t) dt = ln
1
x
− ln
a
1 + ax
.
Finalement, en faisant tendre p vers +∞ dans (10.1), on obtient, pour tout x > 0,
1
1 + x − ln(x) − ln
2
1 + 2x f (x) 1
1 + x − ln(x) − ln
1
1 + x .
Il est alors immédiat, par encadrement, que f (x) ∼ − ln(x) lorsque x → 0+.
V. Espaces fonctionnels et fonctions intégrables
• On note L1(I,K) l’ensemble des fonctions continues par morceaux et intégrables surI , à valeurs dans K.
• Si f est continue par morceaux sur I à valeurs dans K, on dit que f est de carréintégrable sur I si
|f
|2 est intégrable sur I .
On note L2(I,K) l’ensemble des fonctions continues par morceaux sur I , à valeurs dansK, de carré intégrable sur I .
Définition
L’ensemble L1(I,K) est un K-espace vectoriel.
Propriété
Démonstration – On montre que L1(I,K) est un sous-espace vectoriel de l’espace vectoriel desfonctions continues par morceaux sur I à valeurs dans K : la fonction nulle appartient à L1(I,K).De plus, si f et g sont deux éléments de L1(I,K) et λ
∈ K, on a
|λf + g
|
|λ||
f | +
|g|. Les
fonctions |f | et |g| ont une intégrale convergente sur I , il en est donc de même pour |λ||f | + |g|par combinaison linéaire de limites. La fonction positive |λ||f | + |g| est donc intégrable sur I , etpar comparaison, il en est de même pour λf + g.
212

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 221/383
Soit f : I → K une fonction continue et intégrable sur I , telle que I |f (t)| dt = 0.
Alors f = 0.
Propriété
Démonstration – On fait la démonstration dans le cas où I = [a,b[, les autres cas sont similaires.Si J désigne un segment de [a,b[, alors pour x ∈ [a,b[ assez proche de b, on a J ⊂ [a,x] et donc
0
J
|f (t)| dt
xa
|f (t)| dt −→x→b−
ba
|f (t)| dt = 0,
d’où J
|f (t)| dt = 0. Sachant que J est un segment et que |f | est continue et positive, on a
f |J = 0. Ceci étant vrai pour tout segment J ⊂ [a,b[, on a f = 0.
• Le produit de deux éléments de L2(I,K) est un élément de L1(I,K).• L’ensemble L2(I,K) est un K-espace vectoriel.
• Soit H = L2(I,R) ∩ C0(I,R). L’application
(· | ·) :
H × H → R
(f,g) → I
f g
définit un produit scalaire sur H, dont la norme associée est définie par
∀ f ∈ H, f 2 = I f
21/2
.
Propriété
Démonstration
• Si f et g sont deux éléments de L2(I,K), alors d’après la majoration
|f g| |f |2 + |g|22
,
on obtient par comparaison que f g ∈ L1(I,K) car |f |2 et |g|2 sont deux éléments de L1(I,K), quiest un K-espace vectoriel.
• Montrons alors que L2(I,K) est un sous-espace vectoriel de l’espace vectoriel des fonctions
continues par morceaux sur I à valeurs dans K, la seule difficulté étant la stabilité par somme ;or, si f et g sont deux éléments de L2(I,K), alors
|f + g|2 = |f |2 + 2 Re(f g) + |g|2 |f |2 + 2 |f g| + |g|2.
Les fonctions |f |2 et |g|2 sont intégrables, et en particulier il en résulte que f g est intégrable,d’après le premier point. Par comparaison, |f +g|2 est intégrable, c’est-à-dire que f +g ∈ L2(I,K).
• Les propriétés d’un produit scalaire sont immédiates à vérifier, la définie positivité étant uneconséquence de la propriété précédente. Le fait que · 2 soit une norme est alors clair : c’est lanorme associée à ce produit scalaire. On rappelle que dans ce cadre, l’inégalité triangulaire estune conséquence de l’inégalité de Cauchy-Schwarz,
I
f g I
f 2 I
g2,
que nous démontrerons dans le chapitre Espaces préhilbertiens, espaces euclidiens.
213

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 222/383
214

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 223/383
Chapitre 11
Interversions pour les intégralesgénéraliséesIntégrales à paramètre
I. Les théorèmes d’interversion pour les intégrales généraliséesNous allons compléter les résultats du chapitre Suites et séries de fonctions par deux
théorèmes d’interversion dans le cadre des fonctions intégrables. On a tout d’abord :
Soit (f n)n∈N une suite de fonctions définies sur un intervalle I à valeurs dans K. Onsuppose que :
• Pour tout n ∈ N, f n est continue par morceaux sur I .
• (f n)n∈N converge simplement sur I vers une fonction f .
• La fonction f est continue par morceaux sur I .• Il existe une fonction ϕ : I → R+ continue par morceaux, positive et intégrablesur I , telle que
∀ n ∈ N, ∀ t ∈ I , |f n(t)| ϕ(t).
Alors toutes les fonctions f n et f sont intégrables sur I et I
f n −→n→+∞
I
f.
Théorème de convergence dominée (admis : démonstration hors programme)
Remarques
• L’hypothèse « ∀n ∈ N, ∀ t ∈ I, |f n(t)| ϕ(t) » est appelée hypothèse de domination, elledonne son nom au théorème. Sous cette hypothèse, on a en passant à la limite simple, |f (t)| ϕ(t)
pour tout t ∈ I . On sait donc que les fonctions f n et f sont intégrables, par comparaison.
• Vérifier cette hypothèse revient à établir une majoration des fonctions f n par une fonctionintégrable sur I et indépendante de n.
• L’hypothèse « f est continue par morceaux » ne peut pas être enlevée : rien ne garantit que lesmêmes subdivisions sont adaptées à toutes les fonctions f n. À la limite, il se pourrait donc quef ne soit pas continue par morceaux, et donc que son intégrale n’ait pas de sens pour nous. Celadit, cette hypothèse est imposée par le cadre de travail des fonctions continues par morceaux.Elle n’a pas l’importance de l’hypothèse de domination.
Exemple – On pose, pour tout n 2 et t ∈ R+,
f n(t) = 1
1 + ntn.
215

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 224/383
La suite de fonctions (f n)n2 converge simplement sur R+ vers
f = 1[0,1[ : t →
1 si t ∈ [0,1[
0 si t 1
Toutes les fonctions f n, et f , sont continues par morceaux sur R+. Enfin, pour tout n 2 ett ∈ R+,
|f n(t)| ϕ(t) = 1 si t ∈
[0,1[1
1 + 2t2 si t 1,
la fonction ϕ étant continue par morceaux, positive et intégrable sur R+ (par comparaisonimmédiate). D’après le théorème de convergence dominée, toutes les fonctions f n, et f , sontintégrables sur R+ et +∞
0
dt
1 + ntn −→n→+∞
+∞
0f (t) dt = 1.
Pour les séries de fonctions, on a de plus le résultat suivant :
Soit
n0 f n une série de fonctions définies sur un intervalle I à valeurs dans K. Onsuppose que :
• Pour tout n ∈ N, f n est continue par morceaux sur I .
•n0
f n converge simplement sur I .
• La fonction+∞n=0
f n est continue par morceaux sur I .
• Pour tout n ∈ N, f n est intégrable sur I .
• La série n0
I |f n| converge.
Alors+∞n=0
f n est intégrable sur I et
I
+∞n=0
f n =+∞n=0
I
f n.
Théorème – Intégration terme à terme pour les intégrales généralisées
Ce résultat est admis (démonstration hors programme).
Exemples
• Soit, pour tout n 1, f n : t → e−nt
n2 . Les fonctions f n sont continues sur R+ et la série
n1
f n
converge normalement sur R+ car, pour tout n 1 et t 0,e−nt
n2
1
n2
et la sérien1
1
n2 converge. En particulier,
+∞n=1
f n est continue sur R+.
De plus, pour tout n 1, f n est intégrable sur R+ (multiple d’une fonction intégrable deréférence) avec +∞
0|f n(t)| dt =
+∞
0
e−nt
n2 dt =
1
n3,
216

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 225/383
et la sérien1
1
n3 converge.
D’après le théorème précédent, la fonction t →+∞n=1
e−nt
n2 est intégrable sur R+ et
+∞
0 +∞
n=1
e−nt
n2 dt =+∞
n=1
1
n3.
• Ce théorème a l’avantage de s’appliquer dans le cadre des fonctions continues par morceaux, etavec convergence simple. Mais on pourrait avoir l’impression que, pour justifier la régularité de+∞
n=0 f n, on devra recourir au théorème de continuité pour les séries de fonctions, qui s’appliquedans le cadre des fonctions continues , avec convergence au moins uniforme sur tout segment .C’était le cas dans l’exemple précédent, mais ce n’est pas toujours le cas, comme va le montrerl’exemple suivant.
Soit S la fonction définie sur ]0,1[ par
S (x) = ln(1 + x)
x .
On peut montrer (voir le chapitre Séries entières) que pour tout x ∈ ]0,1[,
S (x) =+∞n=0
(−1)n xn
n + 1 =
+∞n=0
f n(x)
où :
∀ n ∈ N, ∀ x ∈ ]0,1[, f n(x) = (−1)n xn
n + 1.
Pour tout n ∈ N, f n est continue, donc continue par morceaux, sur ]0,1[. La série de fonctionsn0 f n converge simplement sur ]0,1[ d’après le développement effectué ci-dessus, et la fonction+∞n=0 f n est continue, donc continue par morceaux, sur ]0,1[, car il s’agit de la fonction S .
Enfin, pour tout n ∈ N, f n est intégrable sur ]0,1[ (fonction polynomiale sur un intervalle borné)et
n0
1
0|f n(x)| dx =
n0
1
(n + 1)2,
série de Riemann d’exposant 2 > 1, donc convergente. D’après le théorème d’intégration termeà terme pour les intégrales généralisées, S est intégrable sur ]0,1[ (ce que l’on aurait pu prouverdirectement) et
1
0
ln(1 + x)
x dx =
+∞
n=0
(−1)n
(n + 1)2.
• Dans le cas d’une série de fonctions, le théorème précédent n’est pas le seul moyen d’intervertirsomme et intégrale généralisée. Par exemple, il ne s’applique pas dans le cas où f n est définie surI = ]0, + ∞[ par f n(x) = (−1)ne−
√ nx, pour tout n 1. Toutes les fonctions f n sont continues
par morceaux et intégrables sur ]0, + ∞[, mais
n1
+∞
0|f n(x)| dx =
n1
+∞
0e−
√ nx dx =
n1
1√ n
,
qui est une série divergente.
Dans ces cas, on pourra parfois utiliser avec profit, notamment :• le théorème de convergence dominée pour la suite des sommes partielles (
pn=0 f n) p∈N.
• des estimations des restes de la série
n0 f n, pour des séries alternées par exemple.
217

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 226/383
Dans l’exemple ci-dessus, pour tout x > 0, la sérien1 f n(x) est une série alternée dont la
valeur absolue du terme général décroît vers 0. On sait donc que
n1 f n(x) converge, et quepour tout m ∈ N,
+∞n=m+1
f n(x)
|f m+1(x)| = e−√ m+1x. (11.1)
En particulier, pour tout a > 0 et x a,
+∞
n=m+1
f n(x) e−√ m+1 x e−√ m+1 a −→
m→+∞ 0,
le majorant étant indépendant de x. La série
n1 f n converge donc uniformément sur toutsegment de I , et comme chaque fonction f n est continue sur I , on en déduit que
+∞n=1 f n est
continue sur I .
Notons, pour tout p ∈ N∗,
S p =
pn=1
f n.
Pour tout p ∈ N∗, S p est continue par morceaux sur I , (S p) p1 converge simplement sur I vers+
∞n=1 f n qui est continue (et donc continue par morceaux) sur I d’après ce qui précède. Enfin,pour tout x > 0 et p ∈ N∗,
|S p(x)| = pn=1
f n(x)
=
+∞n=1
f n(x) −+∞
n= p+1
f n(x)
+∞n=1
f n(x)
+
+∞
n= p+1
f n(x)
e−x + e−
√ p+1x
2 e−x,
ce qui donne l’hypothèse de domination pour la suite des sommes partielles (S p) p∈N∗ car lafonction x → 2 e−x est continue par morceaux et intégrable sur ]0, + ∞[.
D’après le théorème de convergence dominée, S =+∞n=1
f n est intégrable sur ]0, + ∞[ et
+∞
0S p(x) dx −→
p→+∞
+∞
0S (x) dx,
ce qui est le résultat voulu, car pour tout p ∈ N∗,
+∞
0
S p(x) dx = +∞
0 p
n=1
f n(x) dx =
p
n=1 +∞
0
f n(x) dx
par linéarité de l’intégrale : il y a un nombre fini de termes, qui correspondent tous à des intégralesconvergentes (de référence).
Remarque – On peut aussi conclure de la façon suivante : l’inégalité (11.1) prouve, par compa-
raison, que pour tout m ∈ N,+∞
n=m+1
f n est intégrable sur ]0, + ∞[. De plus, pour tout p ∈ N∗,
pn=1
+∞
0f n(x) dx −
+∞
0
+∞n=1
f n(x)
dx
+∞
0
+∞n= p+1
f n(x)
dx
+
∞0
e−√ p+1x dx
= 1√ p + 1
−→ p→+∞
0.
218

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 227/383
On a donc bien +∞
0
+∞n=1
f n(x)
dx =
+∞n=1
+∞
0f n(x) dx.
II. Intégrales à paramètre
Dans la première partie, nous avons donné des résultats de convergence pour des suites définies
par une intégrale de la forme I
f n(t) dt où la suite de fonctions (f n) converge simplement vers
une fonction f .
Écrivons f n(t) = f (n,t) et remplaçons la variable discrète n par une variable continue x : onconsidère alors des intégrales du type
F (x) =
I
f (x,t) dt,
vues comme fonctions du paramètre x. On peut alors très naturellement se demander, commeon l’a fait dans le cas discret, comment se comporte cette intégrale en fonction de x.
En sciences, les intégrales à paramètres sont utilisées notamment pour créer des transforma-tions sur les fonctions : si f est une fonction, on définit (sous certaines conditions) :
• La transformée de Laplace de f , qui est la fonction définie par
L f ( p) =
+∞
0f (t)e− pt dt.
Elle est très utilisée en sciences industrielles.
• La transformée de Fourier de f , qui est la fonction définie par
F f (x) =
+∞
−∞
f (t) e−ixt dt.
Elle joue un rôle fondamental en physique et mathématiques.
Dans cette partie, A et I désignent deux intervalles de R (A pour la variable x, I pour lavariable d’intégration t).
1. Théorème de continuité
Soit f : A × I → K une fonction. On fait les hypothèses suivantes :
• Pour tout x ∈ A, la fonction t → f (x,t) est continue par morceaux sur I .
• Pour tout t ∈ I , la fonction x → f (x,t) est continue sur A.• Il existe une fonction ϕ : I → R+ continue par morceaux et intégrable sur I telleque pour tout (x,t) ∈ A × I,
|f (x,t)| ϕ(t).
Alors la fonction F : x → I
f (x,t) dt est définie et continue sur A.
Théorème – Continuité pour les intégrales à paramètre
Remarques
• On fait souvent référence à ce théorème comme « théorème de continuité sous le signe ».
• La dernière hypothèse est appelée hypothèse de domination, comme dans le cas discret.• Comme dans le cas discret, il est bien entendu essentiel que ϕ ne dépende pas du paramètre,ici x.
219

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 228/383
Démonstration (non exigible) – Tout d’abord, F est bien définie car pour tout x ∈ A, t → f (x,t) estcontinue par morceaux et intégrable sur I , par comparaison et d’après l’hypothèse de domination.D’après la caractérisation séquentielle de la limite, il suffit de montrer que pour tout a ∈ A, ettoute suite (an) d’éléments de A convergeant vers a, on a
I f (an,t) dt −→
n→+∞
I
f (a,t) dt.
Par cette remarque, on est donc ramené au cadre d’application du théorème de convergencedominée. Notons en effet, pour tout n ∈ N, gn : t → f (an,t). Alors gn est continue par morceauxsur I pour tout n, la suite (gn) converge simplement vers la fonction continue par morceauxg : t → f (a,t), par continuité de f par rapport à sa première variable. Enfin, (gn) est dominéepar la fonction ϕ continue par morceaux et intégrable sur I . On en déduit le résultat.
Cette démonstration n’est pas difficile, mais il faut garder à l’esprit qu’elle utilise le théorèmede convergence dominée, que nous avons admis, et qui est un résultat délicat.
Remarque – La continuité étant une notion locale, les hypothèses portant sur la première variablex peuvent être localisées aux segments de A, ce qui peut éviter des problèmes dus aux extrémitésde A. Dans le théorème précédent, on peut ainsi remplacer l’hypothèse de domination par :
• pour tout segment J ⊂ A, il existe une fonction ϕ : I → R+ continue par morceaux etintégrable sur I telle que pour tout (x,t) ∈ J × I,
|f (x,t)| ϕ(t).
La conclusion reste valide.
Exemples
• Pour tout x 0, la fonction t → 1
x + t3 est continue et intégrable sur [1, + ∞[ car
∀ t 1, 0 1x + t3
1t3
,
et t → 1/t3 est continue et intégrable sur [1, +∞[ (critère des intégrales de Riemann sur [1, +∞[,exposant 3 > 1). De plus cette dernière fonction est indépendante de x, ce qui prouve l’hypothèse
de domination. Enfin, pour tout t ∈ [1, + ∞[, x → 1
x + t3 est continue sur [0, + ∞[. On en déduit
que la fonction
F : x → +∞
1
1
x + t3 dt
est continue sur [0, + ∞[.
• Dans le chapitre précédent, nous avons défini la fonction Γ par la relation
Γ(x) =
+∞
0tx−1 e−t dt
pour tout x > 0. Examinons la continuité de Γ. La fonction
f :
]0, + ∞[×]0, + ∞[ → R
(x,t) → tx−1 e−t
est continue par rapport à ses deux variables. Pour tout t > 0,
supx>0
tx−1 e−t =
e−t
t si t ∈ ]0,1]
+∞ si t > 1.
220

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 229/383
Il n’y a donc pas d’hypothèse de domination sur ]0, + ∞[. En revanche, restreignons-nous àx ∈ [a,A] avec 0 < a < A. Alors
supx∈[a,A]
tx−1 e−t =
ta−1 e−t si t ∈ ]0,1]
tA−1 e−t si t > 1.
La fonction ϕ définie sur ]0,+∞[ par la formule précédente est continue par morceaux sur ]0,+∞[
et intégrable (mêmes arguments que pour l’existence de Γ(x) pour x > 0), elle vérifie l’hypothèsede domination sur [a,A]. On en déduit que Γ est continue sur ]0, + ∞[.
2. Classe C1
Soit f : A × I → K une fonction. Si, pour un certain t ∈ I , la fonction x → f (x,t) estde classe C1 sur A, alors pour tout x0 ∈ A, le nombre dérivé de x → f (x,t) en x0 est
noté ∂f
∂x(x0,t). Si cela est vrai quel que soit t ∈ I , on obtient ainsi une fonction
∂f
∂x : (x,t)
→ ∂f
∂x(x,t),
appelée dérivée partielle de f par rapport à x.
On définit de façon analogue la dérivée partielle de f d’ordre k 2 par rapport à x,
notée ∂ kf
∂xk.
Définition
Exemple – Soit f : R2 → R définie par : pour tout (x,t) ∈ R2, f (x,t) = xt
1 + x2. Pour tout t ∈R,
la fonctionx → xt
1 + x2
est de classe C1 sur R comme fraction rationnelle dont le dénominateur ne s’annule pas. Lafonction f admet donc une dérivée partielle par rapport à x ; de plus, pour tout (x,t) ∈R2,
∂f
∂x(x,t) =
t(1 + x2) − xt × 2x
(1 + x2)2 =
t(1 − x2)
(1 + x2)2.
Soit f : A × I → K une fonction. On fait les hypothèses suivantes :
• Pour tout x ∈ A, t → f (x,t) est continue par morceaux et intégrable sur I .
• Pour tout t
∈ I , x
→ f (x,t) est de classe
C1 sur A.
• Pour tout x ∈ A, t → ∂f
∂x(x,t) est continue par morceaux sur I .
• Il existe une fonction ϕ : I → R+ continue par morceaux et intégrable sur I telleque pour tout (x,t) ∈ A × I, ∂f
∂x(x,t)
ϕ(t).
Alors la fonction F : x → I
f (x,t) dt est définie et de classe C1 sur A et pour tout
x
∈ A,
F ′(x) = I
∂f ∂x
(x,t) dt.
Théorème – Classe C1 pour les intégrales à paramètre
221

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 230/383
Remarques
• On fait souvent référence à ce théorème comme « théorème de dérivation sous le signe
».
• On a fait en sorte que les hypothèses fondamentales du théorème précédent soient vérifiées par
la fonction ∂f
∂x.
• À nouveau, on peut remplacer l’hypothèse de domination pour t → ∂f
∂x(x,t) par une version
locale sur tout segment pour la variable x.Démonstration (non exigible) – Tout d’abord, la fonction F est définie sur A car t → f (x,t) estcontinue par morceaux et intégrable sur I pour tout x ∈ A. Soit a ∈ A ; pour montrer que F estdérivable en a avec
F ′(a) =
I
∂f
∂x(a,t) dt,
il suffit de montrer que pour toute suite (an) d’éléments de A distincts de a convergeant vers a,
F (an) − F (a)
an − a −→n→+∞
I
∂f
∂x(a,t) dt,
cette dernière intégrale étant convergente car t → ∂f ∂x
(a,t) est continue par morceaux et intégrable
sur I , par comparaison et d’après l’hypothèse de domination. Par linéarité de l’intégrale, ce tauxde variations est égal à
I
f (an,t) − f (a,t)
an − a dt.
Définissons donc, pour tout n ∈ N,
gn : t → f (an,t) − f (a,t)
an − a .
La suite (gn) de fonctions continues par morceaux sur I converge simplement sur I vers la fonctiont → ∂f
∂x(a,t) par définition d’une dérivée partielle, cette fonction étant continue par morceaux
sur I .
De plus, pour tout n ∈ N et t ∈ I ,
|gn(t)| supx∈J n
∂f
∂x(x,t)
,
d’après l’inégalité des accroissements finis, J n désignant le segment [an,a] ou [a,an]. Ainsi, pourtout n ∈ N et t ∈ I , |gn(t)| ϕ(t), ce qui prouve l’hypothèse de domination du théorème deconvergence dominée. On en déduit finalement que
I
gn(t) dt −→n→+∞
I
∂f
∂x(a,t) dt,
ce qui est le résultat voulu. Enfin, F est de classe C1 sur A d’après le théorème de continuitésous le signe
.
Exemple – Calculons, pour tout x > 0,
I (x) =
+∞
0
sin(t)
t e−xt dt.
Pour cela, définissons pour tout (x,t) ∈ ]0, + ∞[ 2,
f (x,t) = sin(t)
t e−xt.
222

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 231/383
Pour tout x > 0, t → f (x,t) est continue, et intégrable sur ]0, + ∞[ : si t 1,sin(t)
t
e−xt e−xt
l’application t → e−xt étant intégrable sur [1, + ∞[ ; on a de plus un faux problème en 0 car
sin(t)
t
e−xt
−→t→0+
1.
Pour tout t > 0, l’application x → f (x,t) est de classe C1 sur ]0, + ∞[, et pour tout x > 0,
∂f
∂x(x,t) = − sin(t) e−xt.
Fixons a > 0 et restreignons-nous à x a. L’application t → ∂f
∂x(x,t) est continue sur ]0, + ∞[
et pour tout t > 0 et x a,
∂f
∂x(x,t)
|sin(t)| e−at e−at.
Ce majorant définit une fonction intégrable sur ]0, + ∞[ et indépendante de x a, ce quimontre que l’hypothèse de domination locale est satisfaite. Le théorème de dérivation sous lesigne intégral montre alors que I est de classe C1 sur [a,+∞[. Ceci étant valable pour tout a > 0,I est de classe C1 sur ]0, + ∞[. De plus pour tout x > 0,
I ′(x) = − +∞
0sin(t) e−xt dt.
Soit A ∈ R+. On a A0
sin(t) e−xt dt = I m A
0e(i−x)t dt
avec A
0e(i−x)t dt =
e(i−x)t
i − x
A0
= e(i−x)A − 1
i − x −→A→+∞
1
x − i =
x + i
1 + x2.
D’après la caractérisation de la limite à l’aide des parties réelle et imaginaire, on obtient +∞
0sin(t) e−xt dt =
1
1 + x2
(pour le calcul de l’intégrale précédente, on aurait aussi pu effectuer deux intégrations par partiessuccessives).
Finalement, pour tout x de l’intervalle ]0, + ∞[,
I ′(x) = − 11 + x2
.
On en déduit qu’il existe une constante k ∈ R telle que pour tout x > 0,
I (x) = − arctan(x) + k.
On remarque également que I (x) → 0 lorsque x → +∞. En effet, l’application
t → sin(t)
t
est bornée sur ]0, +
∞[, car elle est prolongeable en une fonction continue sur R+ et tend vers 0
en +∞. Soit M un majorant de sa valeur absolue sur ]0, + ∞[. Alors pour tout x > 0,
|I (x)| M
+∞
0e−xt dt =
M
x −→x→+∞ 0.
223

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 232/383
Sachant de plus que− arctan(x) −→
x→+∞−π
2,
on en déduit que k = π
2, d’où, pour tout x > 0,
+∞
0
sin(t)
t e−xt dt =
π
2 − arctan(x).
La fonction I est la transformée de Laplace de la fonction sinus cardinal. Grâce à ce calcul, onpeut montrer, en faisant tendre x vers 0+, que +∞
0
sin(t)
t dt =
π
2.
3. Classe CkOn peut généraliser le résultat du paragraphe précédent aux dérivées d’ordre supérieur, en
raisonnant par récurrence :
Soit f : A × I → K une fonction et k 2 un entier. On fait les hypothèses suivantes :
• Pour tout x ∈ A, t → f (x,t) est continue par morceaux et intégrable sur I .
• Pour tout t ∈ I , x → f (x,t) est de classe Ck sur A.
• Pour tout j ∈ [[1,k − 1]], pour tout x ∈ A, t → ∂ jf
∂x j (x,t) est continue par morceaux
et intégrable sur I .
• Pour tout x
∈ A, t
→
∂ kf
∂x
k(x,t) est continue par morceaux sur I .
• Il existe une fonction ϕ : I → R+ continue par morceaux et intégrable sur I telleque pour tout (x,t) ∈ A × I, ∂ kf
∂xk(x,t)
ϕ(t).
Alors la fonction F : x → I
f (x,t) dt est définie et de classe Ck sur A et pour tout
j ∈ [[1,k]], pour tout x ∈ A,
F ( j)
(x) = I
∂ jf
∂x j (x,t) dt.
On peut remplacer l’hypothèse de domination pour t → ∂ kf
∂xk(x,t) par une version locale
sur tout segment pour la variable x.
Théorème – Classe Ck pour les intégrales à paramètre
224

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 233/383
Chapitre 12
Espaces préhilbertiensEspaces euclidiens
Dans ce chapitre, H désigne un R-espace vectoriel, et E un R-espace vectoriel de dimensionfinie.
I. Produit scalaire
• Un produit scalaire sur H est une forme bilinéaire symétrique définie positive surH, c’est-à-dire, une application f : H× H → R vérifiant les propriétés suivantes :
– Bilinéarité : pour tout (a,b) ∈ H× H, les applications x → f (x,b) et y → f (a,y)
sont linéaires.
– Symétrie : pour tout (x,y) ∈ H × H, f (x,y) = f (y,x).
– Définie positivité pour tout x ∈ H, f (x,x) 0, et on a l’équivalence :f (x,x) = 0 ⇔ x = 0.
Si f est un produit scalaire sur H, on note le plus souvent, pour (x,y) ∈ H2,
f (x,y) = (x | y) , ou x, y, ou x · y.
• Si H est muni d’un produit scalaire (· | ·), on dit que (H, (· | ·)) (ou simplement H s’iln’y a pas d’ambiguité sur le produit scalaire) est un espace préhilbertien (réel).
• Un espace euclidien est un espace préhilbertien de dimension finie.
Définition
Remarques
• Du fait de la symétrie, il suffit en fait d’imposer la linéarité par rapport à une seule des deuxvariables.
• Si (· | ·) est un produit scalaire sur H, alors pour tout (a,b) ∈ H2, (a | 0) = (0 | b) = 0.
• Si E est un sous-espace vectoriel de dimension finie de H, et si (· | ·) est un produit scalaire surH, alors (· | ·) induit par restriction un produit scalaire sur E qui est donc un espace euclidien.
Exemples
• L’application f 1 définie sur R2×R2 par f 1((x1,x2),(y1,y2)) = x1y1+2x2y2 est un produit scalairesur R2, mais pas l’application f 2 définie sur R2 ×R2 par f ((x1,x2),(y1,y2)) = x1y1 − 2x2y2, cettedernière ne vérifiant pas la propriété de définie positivité : en effet, f 2((0,1),(0,1)) = −2 < 0.
225

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 234/383
• L’application (· | ·) définie sur Rn ×Rn par
(x | y) =ni=1
xiyi
(où x = (x1, . . . , xn) et y = (y1, . . . , yn)) est un produit scalaire sur Rn. Il est appelé produitscalaire canonique sur Rn.
• En fait, si E est un R
-espace vectoriel de dimension finie, on peut toujours munir E d’unestructure d’espace euclidien. En effet, soit B = (e1, . . . , en) une base de E ; on définit alors, pourx = x1e1 + · · · + xnen et y = y1e1 + · · · + ynen éléments de E ,
(x | y) =ni=1
xiyi.
Ceci définit un produit scalaire sur E .
• L’application g définie sur M n(R)2 par g(A,B) = Tr(tAB) est un produit scalaire sur M n(R).
Si A = (ai,j) et B = (bi,j), alors, pour tout (i,j) ∈ [[1,n]]2, le coefficient en position (i,j) de lamatrice tAB est
nk=1
ak,i bk,j,
et donc
g(A,B) =ni=1
nk=1
ak,i bk,i =n
i,j=1
ai,j bi,j
après changement d’indices muets. On est donc dans la situation du point précédent, pour lechoix de la base canonique de M n(R).
• Soit ω : [a,b] → R∗+ une application continue. L’application (· | ·) définie sur C0([a,b],R)2 par
(f | g) = b
a
f (x)g(x) ω(x) dx,
est un produit scalaire sur C0([a,b],R) (qui, munit de ce produit scalaire, est un espace préhilber-tien réel, mais pas un espace euclidien).
• Soit I un intervalle de R et H = L2(I,R) ∩ C0(I,R). L’application
(· | ·) :
H × H → R
(f,g) → I
f g
est un produit scalaire sur H.
• L’application (· | ·) définie sur Rn[X ]2 par
(P |Q) =ni=0
P (i)Q(i),
est un produit scalaire sur Rn[X ]. Pour la définie positivité, on remarque qu’un polynôme P deRn[X ] vérifie (P |P ) = 0 si et seulement si P (i) = 0 pour tout i ∈ [[0,n]], ce qui équivaut à P = 0(si P (i) = 0 pour tout i ∈ [[0,n]], P possède au moins n + 1 racines, or P est de degré au plus n).
Soit (· | ·) un produit scalaire sur H. Alors, pour tout (x,y) ∈ H2,
|(x
|y)
| (x
|x) (y
|y),
avec égalité si et seulement si x et y sont colinéaires.
Théorème – Inégalité de Cauchy-Schwarz
226

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 235/383
Démonstration – Fixons x et y dans H et définissons sur R l’application
P : λ → (λx + y | λx + y) .
Pour tout λ ∈ R, par bilinéarité et symétrie,
P (λ) = λ2 (x | x) + λ (x | y) + λ (y | x) + (y | y) = λ2 (x | x) + 2λ (x | y) + (y | y) .
La fonction P ne prend que des valeurs positives d’après la propriété de définie positivité.Si x = 0, (x | x) = 0 pour la même raison, et P est une fonction polynomiale de degré 2 ; on
en déduit que le discriminant du polynôme P est négatif ou nul, c’est-à-dire
(2 (x | y))2 − 4 (x | x) (y | y) 0, d’où (x | y)2 (x | x) (y | y) .
Le résultat suit en composant cette inégalité par la fonction croissante racine carrée.
Si x = 0, P est une fonction affine partout positive, donc le coefficient directeur associé estnul, c’est-à-dire (x | y) = 0. L’inégalité est également vérifiée dans ce cas.
En ce qui concerne le cas d’égalité : si x et y sont colinéaires, il est immédiat que l’égalité est
vérifiée; par exemple s’il existe α ∈R
tel que y = αx, on a(x | y) = (x | αx) = α (x | x) ,
et (x | x)
(y | y) =
(x | x)
(αx | αx) = |α|
(x | x)
(x | x) = |α| (x | x) ,
donc on a égalité dans l’inégalité de Cauchy-Schwarz (on procède de même s’il existe α ∈ Rtel que x = α y). Réciproquement, supposons que x = 0 et que | (x | y) | =
(x | x)
(y | y). En
reprenant la démonstration précédente, on voit que le discriminant de P est nul, donc P possèdeune racine réelle (double) λ, et on a donc P (λ) = (λx + y | λx + y) = 0. Par définie positivité, ils’ensuit que λx + y = 0 et donc x et y sont colinéaires. Si x = 0, x et y sont également colinéaires.
• Si (· | ·) est un produit scalaire sur H, l’application · : x → (x | x) est une norme
sur H, dite norme associée à (· | ·). Une norme associée à un produit scalaire sur Hest appelée norme euclidienne.
• L’application d définie sur H2 par d(x,y) = x − y est appelée distance associéeà (· | ·) .
Propriété/Définition
Démonstration du fait que · est une norme.L’application · est bien définie car (x | x) 0 pour tout x ∈ H.
Homogénéité : pour tout x ∈ H et λ ∈ R,
λx =
(λx | λx) =
λ2 (x | x) = |λ|
(x | x) = |λ| x.
Séparation : pour tout x ∈ H,
x = 0 ⇔ (x | x) = 0 ⇔ x = 0,
car (· | ·) est définie positive.
Inégalité triangulaire : comme on l’a remarqué dans le chapitre Espaces vectoriels normés,elle résulte de l’inégalité de Cauchy-Schwarz, qui se réécrit
∀ (x,y) ∈ H2, | (x | y) | x y.
227

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 236/383
Pour tout (x,y) ∈ H2, on a en effet
x + y2 = (x + y | x + y) = x2 + 2 (x | y) + y2
x2 + 2xy + y2
= (x + y)2.
Le résultat suit en prenant la racine carrée car les deux membres sont positifs.
On peut également caractériser le cas d’égalité dans l’inégalité triangulaire :
Soit (· | ·) un produit scalaire sur H et · la norme associée. Pour tout (x,y) ∈ H2, ona l’équivalence :
x + y = x + y ⇔ il existe α ∈ R+ tel que x = α y ou y = α x.
Propriété – Cas d’égalité dans l’inégalité triangulaire
Démonstration – Si y = α x avec α ∈ R+,
x + y = (1 + α)x = (1 + α)x,
etx + y = x + αx = x + α x = (1 + α)x.
On procède de même si x = α y avec α ∈ R+.
Réciproquement, si x + y = x + y, alors en reprenant l’inégalité de la démonstrationprécédente, on a
(x | y) = xy.
En particulier, il y a égalité dans l’inégalité de Cauchy-Schwarz, donc x et y sont colinéaires. Six est non nul, on peut écrire y = α x avec α ∈R, et on a
(x | y) = α (x | x) = αx2,
etxy = |α| x2.
Sachant que x = 0, x = 0 donc α = |α|, c’est-à-dire que α ∈ R+. Si x = 0, la relation x = α yest vérifiée avec α = 0.
Exemples
• La norme associée au produit scalaire canonique sur Rn est définie par
∀ x ∈ Rn, x =
ni=1
x2i
1/2
Elle est appelée norme euclidienne canonique sur Rn.• La norme associée au produit scalaire défini sur M n(R)2 par (A | B) = Tr(tAB) est donnéepar :
∀ A = (ai,j) ∈M n(R), A =
Tr(tAA1/2
=
ni,j=1
(ai,j)2
1/2
• La norme associée au produit scalaire défini sur C0([a,b],R) par (f | g) = ba f (t) g(t) dt est
donnée par :
∀ f ∈ C0([a,b],R), f = b
af (x)2 dx
1/2
.
Le résultat suivant montre qu’une norme euclidienne provient d’un unique produit scalaire,que l’on peut retrouver à partir d’elle.
228

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 237/383
Soit (· | ·) un produit scalaire sur H et · la norme associée. Alors, pour tout (x,y) ∈ H2,
(x | y) = 1
4(x + y2 − x − y2) =
1
2(x + y2 − x2 − y2).
Propriété – Identité de polarisation
Démonstration – Pour (x,y) ∈ H
2, on a, par bilinéarité et symétrie,
x + y2 = (x + y | x + y) = x2 + 2 (x | y) + y2,
et de mêmex − y2 = (x − y | x − y) = x2 − 2 (x | y) + y2.
On en déduit facilement le premier résultat en retranchant la seconde égalité à la première, et lesecond résultat en utilisant la première égalité.
Remarque – Pour tout (x,y) ∈ H2, on a en additionnant les deux égalités de la démonstrationprécédente,
x + y2 + x − y2 = 2
x2 + y2
.
Cette égalité est appelée identité du parallélogramme. Géométriquement, cette identité signifieque la somme des carrés des longueurs des diagonales d’un parallélogramme est égale à la sommedes carrés de ses côtés.
II. Orthogonalité
Dans cette partie, (H, (· | ·)) désigne un espace préhilbertien réel.
1. Familles orthogonales de vecteurs
• Si x ∈ H, on dit que x est unitaire (ou normé) si x = 1.
• Si x et y appartiennent à H, on dit que x et y sont orthogonaux si (x | y) = 0.
• Si (xi)i∈I est une famille de vecteurs de H (I étant un ensemble d’indices), on ditque cette famille est :– normée si pour tout i ∈ I , xi = 1.– orthogonale si pour tout (i,j) ∈ I tel que i = j, (xi | x j) = 0.– orthonormale (ou orthonormée) si elle est orthogonale et normée.
Ceci équivaut au fait que (xi | x j) = δ i,j pour tout (i,j) ∈ I 2.
Définition
Une famille orthogonale finie de vecteurs tous non nuls de H est libre.
Propriété
Démonstration – Soit (x1, . . . , x p) une famille orthogonale de vecteurs tous non nuls de H et(λ1, . . . , λ p) une famille de scalaires telle que
λ1x1 + · · · + λ px p = 0H.
Alors pour tout i ∈ [[1,p]],
(xi | λ1x1 + · · · + λ px p) = 0i.e. λ1 (xi | x1) + · · · + λ p (xi | x p) = 0,
et donc λi = 0 car la famille est orthogonale et xi = 0, d’où (xi | xi) = 0.
229

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 238/383
Exemple – Définissons sur R, pour tout k ∈ N, la fonction ck : x → cos(kx). Alors, pour toutn ∈ N, la famille (c0, . . . , cn) est libre dans C0([0,2π],R), car est elle composée de vecteurs tousnon nuls, et orthogonale pour le produit scalaire usuel sur C0([0,2π],R). En effet, pour tous p etq distincts dans N, on a p − q = 0 et p + q = 0, donc 2π
0cos( px)cos(qx) dx =
2π
0
1
2(cos(( p + q )x) + cos(( p − q )x)) dx
= 12
sin(( p + q )x) p + q
+ sin(( p − q )x) p − q
2π
0
= 0.
Soit (x1, . . . , x p) une famille orthogonale de vecteurs de H.
Alorsx1 + · · · + x p2 = x12 + · · · + x p2.
Théorème de Pythagore
Démonstration – C’est immédiat puisque les termes 2 (xi
|x j) dans le développement de
x1 + · · · + x p2 sont nuls par orthogonalité de la famille (x1, . . . , x p).
Soit E un espace euclidien et B = (e1, . . . , en) une famille de vecteurs de E .
On dit que B est une base orthonormée de E si B est une base de E et une familleorthonormale.
Définition – Base orthonormée
Soit (E, (· | ·)) un espace euclidien, et B = (e1, . . . , en) une base orthonormée de E.Soient x = x1e1 + · · · + xnen et y = y1e1 + · · · + ynen deux vecteurs de E .
Alors :
(x | y) =ni=1
xi yi et x =
ni=1
|xi|21/2
.
Si X = t
x1 · · · xn
et Y = t
y1 · · · yn
sont les vecteurs-colonnes des coordon-nées de x et y dans la base B, on a (en identifiant une matrice de M 1(R) à son uniquecoefficient)
(x | y) = tX Y et x = (tXX )1/2.
Propriété – Calculs dans une base orthonormée
Démonstration – Il suffit de montrer le premier point. Or, par bilinéarité de (· | ·),
(x | y) = (x1e1 + · · · + xnen | y1e1 + · · · + ynen)
=n
i,j=1
xi y j (ei | e j)
=ni=1
xi yi,
car la base B est orthonormée.
Remarque – Dans M n,1(R), l’expression du produit scalaire canonique entre deux vecteurs X etY s’écrit simplement (X | Y ) = tX Y.
230

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 239/383
Soit (E, (· | ·)) un espace euclidien, u ∈ L (E ) et B = (e1, . . . , en) une base orthonorméede E . Alors
MatB(u) =
(ei | u(e j))
1i,jn
Propriété – Matrice d’une application linéaire dans une base orthonormée
Démonstration – Notons ai,j les coefficients de la matrice Mat
B(u). Pour tout j
∈ [[1,n]], on a
doncu(e j) =
nk=1
ak,jek.
Le produit scalaire (ei | u(e j)) est donc égal àei |
nk=1
ak,jek
=
nk=1
ak,j (ei | ek) = ai,j
car B est une famille orthonormée. D’où le résultat.
Les résultats précédents montrent l’intérêt, pour la simplicité des calculs, de travailler dans
des bases orthonormées. On va donc chercher à construire de telles bases orthonormées.
2. Orthonormalisation
Soit (e1, . . . , e p) une famille libre de vecteurs de H et F = Vect(e1, . . . , e p).
Alors il existe une base orthonormée (ε1, . . . , ε p) de F telle que pour tout i ∈ [[1,p]],
Vect(ε1, . . . , εi) = Vect(e1, . . . , ei).
Théorème – Procédé d’orthonormalisation de Gram-Schmidt
Démonstration – On procède par récurrence sur p.
Initialisation : pour p = 1, on remarque que e1 = 0 car la famille (e1) est libre. Il suffit alorsde poser
ε1 = e1
e1 .
On a évidemment ε1 = 1 et Vect(ε1) = Vect(e1).
Hérédité : supposons la propriété vraie pour un entier p et considérons une famille libre(e1, . . . , e p+1). Par hypothèse de récurrence, on peut supposer ε1, . . . , ε p construits.
Analyse : le vecteur ε p+1 doit vérifier ε p+1 ∈ Vect(e1, . . . , e p+1) = Vect(ε1, . . . , εn,e p+1), donc ildoit exister (λ1, . . . , λ p+1) ∈ R p+1 tel que
ε p+1 = λ1ε1 +
· · ·+ λ pε p + λ p+1e p+1.
Alors pour tout i ∈ [[1,p]],
0 = (εi | ε p+1) =
p j=1
λ j (εi | ε j) + λ p+1 (εi | e p+1) = λi + λ p+1 (εi | e p+1) ,
car la famille (ε1, . . . , ε p+1) doit être orthonormée. On en déduit que
ε p+1 = λ p+1
e p+1 −
pi=1
(εi | e p+1) εi
.
Synthèse : on sait que Vect(ε1, . . . , ε p) = Vect(e1, . . . , e p) ; de plus, la famille e1, . . . , e p+1 étant
libre, le vecteur f p+1 = e p+1 − pi=1 (εi | e p+1) εi est non nul. On peut donc poser
ε p+1 = f p+1
f p+1 .
231

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 240/383
Tout d’abord, la famille (ε1, . . . , ε p+1) est normée. Elle est également orthogonale : en effet, soit( j,k) ∈ [[1,p + 1]]2 avec j = k. Si j p et k p, alors (ε j | εk) = 0 par hypothèse de récurrence.Si j p et k = p + 1, alors
(ε j | ε p+1) = 1
f p+1
ε j
e p+1 − pi=1
(εi | e p+1) εi
= 1
f p+1 (ε j | e p+1) − pi=1
(εi | e p+1) (ε j | εi)=
1
f p+1 ((ε j | e p+1) − (ε j | e p+1)) ,
car seul le terme correspondant à i = j est éventuellement non nul, et (εi | εi) = 1. Donc(ε j | ε p+1) = 0.
Ensuite, montrons que pour tout i ∈ [[1,p + 1]],
Vect(ε1, . . . , εi) = Vect(e1, . . . , ei).
C’est vrai si i p par hypothèse de récurrence. Il suffit donc de le montrer pour i = p + 1. Or
ε p+1 = 1
f p+1e p+1 + y
avec y ∈ Vect(ε1, . . . , ε p) = Vect(e1, . . . , e p). On en déduit le résultat par double inclusion immé-diate.
Illustrons les différentes étapes de ce procédé dans le plan :
e1
ε1(ε1 | e2) ε1
f 2
ε2
e2
Remarques
• On peut aussi montrer que l’on peut imposer que (εi | ei) ∈ R∗+ pour tout i. La famille (ε1, . . . , ε p)est alors unique.
• Cette démonstration est constructive : elle donne un algorithme qui permet de construireexplicitement une famille (ε1, . . . , ε p). En particulier, elle est programmable sur ordinateur. Enpratique, on pourra procéder ainsi : on remarque qu’à chaque étape, si f 1, . . . , f i sont construits,f i+1 est de la forme
f i+1 = ei+1 + λif i + · · · + λ1f 1
où λ1, . . . , λi sont des scalaires. Il suffit alors d’imposer les conditions
(f i+1 | f 1) = · · · = (f i+1 | f i) = 0
pour déterminer ces scalaires. À la fin de la procédure, on pose alors εi = f i/f i et l’on obtientune famille qui répond au problème. Avec cette façon de faire, on peut ainsi ne normer les vecteursqu’à la fin de la procédure, ce qui évite des erreurs de calculs.
On peut procéder de même en cherchant f i+1 sous la forme ei+1 + µiei + · · · + µ1e1, carVect(e1, . . . , ei) = Vect(f 1, . . . , f i).
232

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 241/383
Exemple – Soit B = (e0,e1,e2) la base canonique de R2[X ], muni du produit scalaire défini par
(P |Q) =
1
0P (x) Q(x) dx.
Orthonormalisons la base B.
• On pose f 0 = e0 = 1.
• On choisit f 1 de la forme f 1 = e1 + αf 0 (α réel) de sorte que (f 1 | f 0) = 0, ce qui équivaut à
1
0(t + α) dt = 0 ⇔ α = −1
2.
On pose donc f 1 = X − 1
2.
• On choisit f 2 de la forme f 2 = e2 + βf 1 + γf 0 (β et γ réels) de sorte que (f 2 | f 0) = 0 et(f 2 | f 1) = 0, ce qui équivaut à
1
0
t2 + β
t − 1
2
+ γ
dt = 0 1
0
t2 + β
t − 1
2
+ γ
t − 1
2
dt = 0
i.e. à
1
3 + γ = 0
1
4 − 1
6 + β
1
12 = 0
i.e. à
β = −1
γ = −1
3
On pose donc f 2 = X 2
−f 1
− 1
3
f 0 = X 2
−X +
1
6
.
• On norme enfin les vecteurs f 0, f 1 et f 2 :
f 0 = 1
f 1 =
1
0
t − 1
2
2
dt
1/2
=
1
12 =
1
2√
3
f 2 =
1
0
t2 − t +
1
6
2
dt
1/2
= 1√
180.
On obtient une famille (ε0,ε1,ε2) qui convient.
Soit (E, (· | ·)) un espace euclidien.
Il existe des bases orthonormées de E .
Toute famille orthonormale de E peut être complétée en une base orthonormée de E .
Corollaire
Démonstration – Pour le premier point, il suffit d’appliquer le procédé d’othonormalisation deGram-Schmidt à une base quelconque de E . On obtient alors une famille génératrice de E etlibre (car orthonormale), c’est-à-dire une base de E . Pour le second, on sait que toute familleorthonormale est libre, on peut la compléter en une base de E puis orthonormaliser cette basepar le procédé de Gram-Schmidt, ce qui ne modifie pas la famille initiale.
233

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 242/383
3. Sommes orthogonales
Soient F et G deux sous-espaces vectoriels de H.
On dit que F et G sont orthogonaux si :
∀ (x,y) ∈ F × G, (x | y) = 0.
Ceci se note également : F ⊥ G.
Définition – Sous-espaces orthogonaux
Soient F 1, . . . , F p des sous-espaces vectoriels de H, deux à deux orthogonaux.
Alors la somme F 1 + · · · + F p est directe.
Propriété
Démonstration – Soit (x1, . . . , x p) ∈ F 1 × · · · × F p tel que x1 + · · · + x p = 0. En faisant le produitscalaire de cette expression avec xi pour i ∈ [[1,p]], on obtient
0 = (xi | x1 + · · · + x p) = (xi | x1) + · · · + (xi | x p) .
Les F j étant deux à deux orthogonaux, on en déduit que (xi | xi) = 0 et donc xi = 0, et ce pourtout i. D’où le résultat.
• Soient F 1, . . . , F p des sous-espaces vectoriels de H, deux à deux orthogonaux.
La somme p
i=1 F i est appelée somme directe orthogonale des F i (on dit aussi queles F i sont en somme directe orthogonale).
• Soient F et G deux sous-espaces vectoriels de H.
On dit que F et G sont supplémentaires orthogonaux si F
⊥ G et F
⊕G =
H.
Ceci se note parfois H = F ⊕⊥ G.
Définition
Remarques
• Soient F 1, . . . , F p des sous-espaces vectoriels deux à deux orthogonaux d’un espace euclidienE . Alors leur somme est directe, donc d’après un résultat du chapitre Espaces vectoriels etapplications linéaires, on a
dim(F 1 ⊕ · · · ⊕ F p) = dim(F 1) + · · · + dim(F p)
et pour que E = F 1 ⊕ · · · ⊕ F p, il faut et il suffit que
dim(E ) = dim(F 1) + · · · + dim(F p).• Si F et G sont deux sous-espaces vectoriels de H, pour montrer que F et G sont supplémentairesorthogonaux, il suffit de montrer que F ⊥ G et H ⊂ F + G. En effet, d’après la propriétéprécédente, si F ⊥ G, l’aspect direct de la somme F + G est acquis (notamment, F ∩G = 0E ).
4. Orthogonal d’un sous-espace vectoriel
Soit F un sous-espace vectoriel de H. On appelle orthogonal de F l’ensemble
F ⊥ =
y ∈ H
; ∀
x ∈
F, (x|
y) = 0
.
C’est un sous-espace vectoriel de H, orthogonal à F .
Propriété/Définition
234

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 243/383
Démonstration – On a F ⊥ ⊂ H, et le vecteur nul de H est orthogonal à tout vecteur doncappartient à F ⊥. Si y et z appartiennent à F ⊥ et si λ ∈ R, alors pour tout x ∈ F ,
(x | λy + z) = λ (x | y) + (x | z) = 0
donc λy + z ∈ F ⊥. Ainsi F ⊥ est un sous-espace vectoriel de H. Il est orthogonal à F , car pardéfinition, si x ∈ F et y ∈ F ⊥, (x | y) = 0.
Exemple – Dans Rn (n 1) muni du produit scalaire canonique, soit a = (a1, . . . , an) un vecteurnon nul. Alors Vect(a)⊥ est l’ensemble des vecteurs x = (x1, . . . , xn) tels que
ni=1
ai xi = 0.
Il s’agit du noyau de la forme linéaire ϕ définie sur Rn par
ϕ(x1, . . . , xn) =ni=1
ai xi,
qui est non nulle car a est non nul. En particulier, Vect(a)⊥ est un hyperplan de Rn.
Remarque – Si F et G sont deux sous-espaces vectoriels de H, alors on a les équivalences
F ⊥ G ⇔ F ⊂ G⊥ ⇔ G ⊂ F ⊥.
Par contre, lorsque F ⊥ G on n’a pas toujours les égalités F = G⊥ et G = F ⊥.
On a H⊥ = 0H et 0H⊥ = H.
Propriété
Démonstration – En effet, si y ∈ H vérifie (x | y) = 0 pour tout x ∈ H, alors pour le choix de x = yon obtient (y | y) = 0 et donc y = 0H. L’autre inclusion (et la seconde égalité) vient simplementdu fait que (x | 0H) = 0 pour tout x ∈ H.
Remarque – Soient x et y deux éléments de H tels que pour tout z ∈ H, (x | z) = (y | z). Alorsx = y.
En effet, l’hypothèse entraîne que (x − y | z) = 0 pour tout z ∈ H, et donc x−y ∈ H⊥ = 0H.D’où le résultat.
Soit F un sous-espace vectoriel de dimension finie de H et (e1, . . . e p) une famille géné-ratrice de F .
Pour tout x ∈ H, on a l’équivalence :
x ∈ F ⊥ ⇔ ∀ i ∈ [[1,p]], (ei | x) = 0.
Propriété
Démonstration – Si x ∈ F ⊥, alors pour tout i ∈ [[1,p]], (ei | x) = 0, car ei ∈ F . Réciproquement,si (ei | x) = 0 pour tout i ∈ [[1,p]], alors pour tout (λ1, . . . , λ p) ∈ R p,
pi=1
λi (ei | x) = 0, i.e. ni=1
λiei x = 0,
par linéarité à gauche de (· | ·). Comme F = Vect(e1, . . . , e p), on a bien x ∈ F ⊥.
235

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 244/383
Soit F un sous-espace vectoriel de H. Alors :
• F ⊂ (F ⊥)⊥.
• F et F ⊥ sont en somme directe orthogonale. En particulier, F ∩ F ⊥ = 0H.
• Si G est un supplémentaire orthogonal de F , alors G = F ⊥.
Propriété
Démonstration
• Soit x ∈ F . Alors, pour tout y ∈ F ⊥, (x | y) = 0, donc x ∈ (F ⊥)⊥.
• C’est une conséquence de la propriété du paragraphe précédent, car F ⊥ F ⊥.
• Soit G un supplémentaire orthogonal de F . Montrons que G = F ⊥. Tout d’abord, F ⊥ G doncG ⊂ F ⊥. Réciproquement, soit x ∈ F ⊥. On peut décomposer x sous la forme y + z avec y ∈ F
et z ∈ G. Alors y = x − z ∈ F ⊥ car x ∈ F ⊥ et z ∈ G ⊂ F ⊥. Donc y ∈ F ∩ F ⊥ = 0H etx = z ∈ G. D’où l’égalité G = F ⊥. Ainsi, F a au plus un supplémentaire orthogonal, qui ne peutêtre que F ⊥.
Remarque – Il est important de remarquer que l’inclusion réciproque du premier point est fausseen général. Par exemple, soit
H =
C0([0,1],R) muni du produit scalaire usuel défini par
(f | g) =
1
0
f (t)g(t) dt.
Considérons le sous-espace vectoriel F = f ∈ E ; f (0) = 0 de H. Soit f ∈ F ⊥ ; alors, lafonction g : t → t f (t) étant un élément de F , on a (f |g) = 0, i.e. 1
0t f (t)2 dt = 0.
La fonction t → t f (t)2 étant de plus continue et positive, elle est nulle, donc f (t) = 0 pour toutt
∈]0,1]. Par continuité de f , on a également f (0) = 0, et finalement, f = 0
H. On en déduit que
F ⊥ = 0H. Ainsi, dans ce cas, on a (F ⊥)⊥ = 0H⊥ = H = F .On remarque également que la somme F ⊕ F ⊥ n’est pas toujours égale à H : dans l’exemple
précédent, on a F ⊕F ⊥ = F = H. En général, F et F ⊥ ne sont donc pas toujours supplémentairesorthogonaux.
En revanche, les résultats sont vrais lorsque F est de dimension finie :
Soit F un sous-espace vectoriel de dimension finie de H. Alors :
• H = F ⊕ F ⊥.
• (F ⊥)⊥ = F .
Théorème – Supplémentaire orthogonal d’un sous-espace de dimension finie
Remarque – D’après le premier point, si F est un sous-espace vectoriel de dimension finie de H,F ⊥ est un supplémentaire orthogonal de F , et on sait d’après la propriété précédente que c’estalors l’unique supplémentaire orthogonal de F .
Démonstration
• On sait déjà que la somme est directe, il suffit de montrer que H ⊂ F +F ⊥. Soit B = (ε1, . . . , εn)
une base orthonormée de F (qui existe d’après le procédé de Gram-Schmidt). Pour tout x ∈ H,
on cherche à écrire x = y + z avec y ∈ F et z ∈ F ⊥.
Analyse : supposons qu’une telle décomposition existe, et soit y =
ni=1 λiεi la décomposition
de y dans la base B
. Alors x−
y = z ∈
F ⊥
, donc pour tout j ∈
[[1,n]], (ε j |
x−
y) = 0, c’est-à-dire
(ε j | x) = (ε j | y) =ni=1
λi (ε j | εi) = λ j
236

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 245/383
car B est orthonormée. Ainsi y est nécessairement donné par : y =ni=1 (εi | x) εi.
Synthèse : définissons donc y par cette formule. Alors y ∈ F et x−y ∈ F ⊥ car pour tout j ∈ [[1,n]],(ε j | x − y) = 0 en reprenant le calcul précédent. On a donc bien la décomposition souhaitée avecz = x − y.
• Le premier point montre que F ⊥ a un supplémentaire orthogonal, à savoir F . Le dernier pointde la propriété précédente (appliqué avec F ⊥ à la place de F et F à la place de G) montre alorsque F = (F ⊥)⊥.
Soit F un sous-espace vectoriel de dimension finie de H.
La projection pF sur F parallèlement à F ⊥ est bien définie car H = F ⊕ F ⊥, elle estappelée projection orthogonale sur F .
Si (ε1, . . . , εn) est une base orthonormée de F , alors pour tout x ∈ H,
pF (x) =ni=1
(εi | x) εi.
Le vecteur pF (x) est appelé le projeté orthogonal de x sur F .
Théorème/Définition – Projection orthogonale
Démonstration – La formule donnant pF (x) a été démontrée dans le théorème précédent.
Remarques
• Pour déterminer le projeté orthogonal de x sur F , il n’est pas nécessaire de disposer d’une baseorthonormée de F . En effet, il suffit de remarquer que pF (x) est entièrement caractérisé par :
pF (x) ∈ F et x − pF (x) ∈ F ⊥. Si l’on dispose d’une famille génératrice quelconque (e1, . . . , e p)
de F , alors d’après une propriété précédente, x − pF (x) ∈ F ⊥ si et seulement si
∀i
∈ [[1,p]], (ei
|x
− pF (x)) = 0,
ce qui peut s’écrire comme un système linéaire dont les inconnues sont les scalaires d’une décom-position de pF (x) sur la famille (e1, . . . , e p).
En revanche, pour que la formule explicite de pF (x) de la propriété précédente soit vraie, ilest essentiel que (ε1, . . . , εn) soit une base orthonormée de F .
• Si F est un sous-espace vectoriel de dimension finie de H, on appelle symétrie orthogonale parrapport à F la symétrie sF par rapport à F , parallèlement à F ⊥. On a la relation IdH +sF = 2 pF .Si E est euclidien et F est un hyperplan de E , on dit que sF est la réflexion par rapport à F .
Soit B
= (ε1, . . . , εn) une base orthonormée d’un espace euclidien (E, (· | ·
)).
Alors, la décomposition d’un vecteur x ∈ E dans la base B est
x =ni=1
(εi | x) εi.
Propriété
Démonstration – C’est une conséquence immédiate de la formule du théorème précédent, avecle choix particulier de F = E ; dans ce cas, bien sûr, le projeté orthogonal de x sur E est xlui-même.
Remarque – En particulier, pour tout (x,y) ∈ E 2,
(x | y) =ni=1
(εi | x) (εi | y) et x =
ni=1
(εi | x)2
1/2
.
237

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 246/383
• Soit F un sous-espace vectoriel d’un espace euclidien E .
Alors E = F ⊕ F ⊥. En particulier,
dim(F ) + dim(F ⊥) = dim(E ).
• Si F et G sont deux sous-espaces vectoriels de E , pour que F et G soient supplémen-
taires orthogonaux, il faut et il suffit que
F ⊥ G et dim(F ) + dim(G) = dim(E ).
Théorème
Démonstration
• On a montré que le résultat E = F ⊕ F ⊥ est toujours vrai si F est de dimension finie, ce quiest le cas dans la situation présente, E étant de dimension finie. La formule des dimensions vientde la première remarque du paragraphe précédent.
• Cela vient aussi de la première remarque du paragraphe précédent.
Remarque – Si F est un sous-espace vectoriel de E , F et F ⊥ sont de dimension finie, les projectionsorthogonales sur F et F ⊥ sont bien définies et on a la relation pF + pF ⊥ = Id, c’est-à-dire quepour tout x ∈ E , x − pF (x) = pF ⊥(x).
III. Distance
Étant donné un vecteur x de H et F un sous-espace vectoriel de H de dimension finie, oncherche un vecteur de F qui soit le plus proche de x au sens de la distance associée au produitscalaire (· | ·) sur H.
Soit x ∈ H et F un sous-espace vectoriel de dimension finie de H.
Alors la fonction F → R+
y → x − ya un minimum sur F , qui est atteint en pF (x) et uniquement en ce point.
Autrement dit, il existe un unique vecteur y0 de F tel que
x − y0 = miny∈F
x − y,
et ce vecteur est pF (x).
Le réel positif x − pF (x) est appelé distance de x à F , noté d(x,F ) :
d(x,F ) = x − pF (x) = miny∈F
x − y.
Théorème/Définition
Démonstration – Comme F est de dimension finie, on sait que H = F ⊕F ⊥. On peut donc écrirex = pF (x) + z avec pF (x) ∈ F et z ∈ F ⊥. Alors pour tout y ∈ F, pF (x) − y ∈ F et doncx − pF (x) = z est orthogonal à pF (x) − y. D’après le théorème de Pythagore, on a donc
x − y2 = (x − pF (x)) + ( pF (x) − y)2 = x − pF (x)2 + pF (x) − y2 x − pF (x)2,
avec égalité si et seulement si pF (x) − y2 = 0 c’est-à-dire y = pF (x).
238

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 247/383
Soit F un sous-espace vectoriel de dimension finie de H et (ε1, . . . , εn) une base ortho-normée de F .
La distance de x à F est donnée par les formules
d(x,F )2 = x2 − pF (x)2 = x2 −n
i=1
(εi | x)2 .
Propriété
Démonstration – La famille (ε1, . . . , εn) est une base orthonormée de F , donc pour tout x ∈ H,on connaît l’expression explicite de pF (x) :
pF (x) =ni=1
(εi | x) εi,
et on a également
pF (x)2
= n
i=1 (εi | x) εi
2
=
n
i=1 (εi | x)
2
.
De plus, les vecteurs pF (x) et x− pF (x) sont orthogonaux, donc d’après le théorème de Pythagore,
x2 = pF (x) + (x − pF (x))2 = pF (x)2 + x − pF (x)2 = pF (x)2 + d(x,F )2.
On en déduit les deux formules.
Soit F un sous-espace vectoriel de dimension finie de H et (ε1, . . . , εn) une base ortho-normée de F .
Pour tout x ∈ H, on a pF (x) x.
Corollaire – Inégalité de Bessel
Démonstration – En effet, la différence x2 − pF (x)2 est égale à d(x,F )2 0.
Exemple – Déterminons le polynôme de degré au plus 2 qui soit le plus proche de X 3 au sens dela norme associée au produit scalaire défini sur R[X ] par
(P |Q) =
1
0P (x) Q(x) dx.
Nous avons déterminé ci-dessus une base orthonormée (ε0,ε1,ε2) de R2[X ] pour ce produit sca-laire. L’unique polynôme qui répond au problème est le projeté orthogonal de X 3 sur R2[X ],c’est-à-dire le polynôme
P (X ) =
ε0 | X 3
ε0 +
ε1 | X 3
ε1 +
ε2 | X 3
ε2
=
1
0t3 dt
+
2√
32 1
0
t − 1
2
t3 dt
X − 1
2
+ 180
1
0
t2 − t +
1
6
t3 dt
X 2 − X +
1
6
=
1
4 + 12 1
5 − 1
2 × 1
4X − 1
2 + 1801
6 − 1
5 +
1
6 × 1
4X
2
− X +
1
6 .
Après simplifications, on obtient P (X ) = 3
2X 2 − 3
5X +
1
20.
239

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 248/383
Comme indiqué dans une remarque de la partie précédente, on peut aussi déterminer P (X )
en résolvant le système
X 3 − aX 2 − bX − c | 1
= 0X 3 − aX 2 − bX − c | X
= 0
X 3 − aX 2 − bX − c | X 2
= 0
ce qui aboutit bien sûr à la même valeur de P (X ), et ne nécessite pas de disposer de la famille
(ε0,ε1,ε2).On peut alors déterminer la distance de X 3 à R2[X ], c’est-à-dire la racine carrée de la quantité
inf (a,b,c)∈R3
1
0
t3 − at2 − bt − c
2dt;
en effet cette borne inférieure est un minimum, qui est atteint pour a = 3
2, b = −3
5 et c =
1
20 et
uniquement pour ces valeurs.
D’après la propriété ci-dessus, on peut également calculer cette valeur en utilisant la formule
inf (a,b,c)∈R3 1
0t
3
− at2
− bt − c2
dt = X 3
2
−2i=0
εi | X 32
.
IV. Formes linéaires sur un espace euclidien
Dans cette partie, (E, (· | ·)) désigne un espace euclidien.
Soit f une forme linéaire sur E . Alors il existe un unique vecteur a ∈ E tel que :
∀ x ∈ E, f (x) = (a | x) .
On dit parfois que le vecteur a représente f via le produit scalaire (· | ·) .
Théorème – Représentation des formes linéaires sur un espace euclidien
Démonstration – Soit B = (e1, . . . , en) une base orthonormée de E , et soit x = x1e1 + · · · + xnenun vecteur de E . Alors
f (x) =ni=1
xif (ei),
qui est le produit scalaire entre x et le vecteur a = f (e1)e1 + · · ·+ f (en)en car B est orthonormée.Ceci prouve l’existence de a.
Quant à l’unicité, supposons que deux vecteurs a et b vérifient, pour tout x ∈ E ,
f (x) = (a | x) = (b | x) .
Alors, pour tout x ∈ E , (a − b | x) = 0 et donc a − b ∈ E ⊥ = 0E . On en déduit que a = b.
Remarque – Réciproquement, si a ∈ E , l’application x → (a | x) est linéaire, par linéarité àdroite du produit scalaire. Le résultat précédent signifie donc que dans un espace euclidien, onsait décrire entièrement les formes linéaires : il s’agit exactement des applications de la formex → (a | x) où a est un vecteur de E , chaque forme linéaire f sur E étant associée à un uniquevecteur a.
Exemples
• Dans le cas de la forme linéaire définie sur R3 (muni du produit scalaire canonique) par
f (x,y,z) = x + 2y + 3z, a est le vecteur (1,2,3).
• Les formes linéaires sur M n(R) sont exactement les applications de la forme M → Tr(AM ) oùA ∈M n(R).
240

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 249/383
Soit H un hyperplan de E et f une forme linéaire non nulle sur E telle que H = Ker(f ).
Il existe a ∈ E non nul tel que f : x → (a | x). Ainsi, pour x ∈ E , on a l’équivalence
x ∈ H ⇔ (a | x) = 0.
On dit que a est un vecteur normal à H .
Avec les notations précédentes, en notant a = a1e1 + · · · + anen la décomposition de adans la base orthonormée B, on a
(a | x) = a1x1 + · · · + anxn.
Ainsi, H a pour équationa1x1 + · · · + anxn = 0
dans la base B.
Propriété/Définition – Vecteur normal à un hyperplan
Remarque – Avec les notations précédentes, l’ensemble des formes linéaires caractérisant H est
Vect(f ) \ 0. De la même façon, l’ensemble des vecteurs normaux à H est Vect(a) \ 0. Il esten effet évident que pour tout λ ∈ R∗, λf est représentée par le vecteur λa. Les équations de H sont donc exactement les équations (λa | x) = 0 où λ ∈ R∗.
Si l’on travaille dans une base orthonormée B = (e1, . . . , en), et si H a pour équation
a1x1 + · · · + anxn = 0
dans la base B, les vecteurs normaux à H sont exactement les vecteurs λ(a1e1 + · · · + anen) oùλ ∈ R∗.
• Soit H un hyperplan de E et a un vecteur normal à H . Alors, pour tout x ∈ E , ladistance de x à H est donnée par
d(x,H ) = | (x | a) |
a .
• Soit D une droite vectorielle de E et a un vecteur non nul de D. Alors, pour toutx ∈ E , la distance de x à D est donnée par
d(x,D) =
x2 − (x | a)2
a2 .
Propriété – Distance d’un vecteur à un hyperplan ou une droite
Démonstration
• La distance de x à H est donnée par d(x,H ) = x− pH (x), le vecteur pH (x) étant entièrementcaractérisé par : pH (x) ∈ H et x − pH (x) ∈ H ⊥ = Vect(a). Ainsi, pH (x) est l’unique vecteur dela forme x − λa, où λ ∈ R, qui appartienne à H , i.e. tel que (x − λa | a) = 0, ce qui équivaut à :(x | a) − λa2 = 0. On a alors
d(x,H ) = x − pH (x) = λa = | (x | a) |
a .
• D’après le théorème de Pythagore, on a d(x,D)2 =
x
2
−d(x,D
⊥)2, la distance d(x,D
⊥) étant
donnée par le premier point, car a est un vecteur normal à l’hyperplan D⊥. On en déduit laformule.
241

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 250/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 251/383
Chapitre 13
Séries entières
Nous avons déjà montré à l’aide du théorème de dérivation terme à terme des séries defonctions, que pour tout x ∈ ]−1,1[,
arctan(x) =+∞
n=0
(−1)n x2n+1
2n + 1.
Nous avons également prouvé dans le chapitre Séries numériques que la sérien0
zn
n! converge
absolument pour tout z ∈ C. L’un des raisonnements que nous avions faits, basé sur la formulede Taylor avec reste intégral, montrait même que pour tout x ∈R,
ex =+∞n=0
xn
n!.
Il semble donc que les séries de la forme
n0 anzn jouent un rôle particulier et que des fonctionsusuelles se représentent comme somme de telles séries ; c’est ce que nous allons étudier dans cechapitre.
I. Définition et convergence des séries entières
1. Définition, rayon de convergence
Une série entière est une série de la forme
n0 anxn où x est une variable réelle,ou de la forme
n0 anzn où z est une variable complexe, les coefficients an étant des
nombres complexes.
On dit que cette série est associée à la suite (an)n∈N, ou qu’elle a pour coefficients les
nombres an.
Définition – Série entière
L’étude de la convergence des séries entières est basée sur le lemme suivant :
Soit
n0 anzn une série entière et z0 ∈ C tel que la suite (anz n0 )n∈N soit bornée.
Alors, pour tout z ∈ C tel que |z| < |z0|, la sérien0
anzn converge absolument.
Lemme d’Abel
Démonstration – Si z0 = 0, il n’y a rien à démontrer. Sinon, soit z ∈ C tel que |z| < |z0|. Alorspour tout n ∈ N,
|anzn| = |anz n0 | z
z0
n .
243

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 252/383
La suite (anz n0 ) étant bornée, on en déduit que
anzn = O
z
z0
n
.
De plus, la série géométrique de raison |z/z0| ∈ [0,1[ est convergente. Par comparaison, la série
n0
anzn converge absolument.
Définissons alors
I = ρ 0; (anρn) est bornée et R = sup I ∈ [0, + ∞].
Ce nombre est bien défini car la suite (anρn) est bornée par exemple pour ρ = 0, donc I est nonvide. La borne supérieure est calculée dans R, et notamment, R peut être infini; c’est le cas siet seulement si la partie I n’est pas majorée.
On remarque de plus que R ne dépend que de (an) et notamment, il est le même, que la sérieentière soit de la variable réelle, ou de la variable complexe.
Enfin, il est tout à fait possible que R /
∈ I , même lorsque R est fini : cela correspond à la
situation où (anRn) n’est pas bornée.
Exemples
• La série géométrique
n0 zn est une série entière. Pour ρ 0, la suite (ρn) est bornée si etseulement si ρ 1. On a donc ici I = [0,1], d’où R = 1.
• Dans le cas de la série
n0 nzn, pour ρ 0, la suite (nρn) est bornée si et seulement si ρ < 1 :on a I = [0,1[ et ici aussi R = 1.
On utilise les notations précédentes. Soit z ∈ C.
• Si |z| < R, alors la série n0
anzn converge absolument.
• Si |z| > R, alors la sérien0
anzn diverge grossièrement.
Propriété
Démonstration
• Si |z| < R, alors par définition de la borne supérieure, il existe ρ ∈ I tel que |z| < ρ. Alors lasuite (anρn) est bornée et d’après le lemme d’Abel,
n0 anzn converge absolument.
• Si |z| > R, alors |z| /∈ I et donc (an|z|n) n’est pas bornée, ce qui entraîne que anzn ne tend
pas vers 0. En particulier, la série n0 anz
n
diverge grossièrement.
• On appelle R le rayon de convergence de la série entièren0
anzn oun0
anxn.
• Dans le cas d’une variable complexe, l’ensemble D(0,R) = z ∈ C; |z| < R estappelé disque ouvert de convergence de la série entière.Si R = +∞, il s’agit de C tout entier.
• Dans le cas d’une variable réelle, l’intervalle ]−R,R[ est appelé intervalle ouvertde convergence de la série entière. Si R = +∞, il s’agit de R tout entier.
Définition – Rayon de convergence, disque/intervalle ouvert de convergence
Remarque – En fait, R est entièrement caractérisé par les deux premiers points de la propriétéprécédente : si R et R′ sont deux réels vérifiant cette propriété, et si par exemple R < R′, alors
244

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 253/383
pour R < r < R′, la série
n0 anrn doit être à la fois convergente et divergente, ce qui estabsurde. On a donc R R′ et de même R R′.
Méthode – On a plusieurs moyens pour minorer et majorer le rayon de convergence R, notamment,pour tout r 0 et z0 ∈ C :
• Si la suite (anρn) est bornée pour tout ρ tel que 0 ρ < r, alors R r.
• Si la suite (anρn) est non bornée pour tout ρ > r, alors R r.
• Si la série n0 anzn
converge pour tout z ∈ C tel que |z| < r, alors R r.• Si la série
n0 anzn diverge pour tout z ∈ C tel que |z| > r, alors R r.
• Si la série
n0 anz n0 converge ou si la suite (anz n0 ) est bornée, alors R |z0|.• Si la série
n0 anz n0 diverge, alors R |z0|.
Ces points proviennent, suivant les cas, de la définition de R, de la propriété précédente, ouse démontrent comme le résultat de la remarque précédente.
La propriété suivante, basée sur le théorème de comparaison, permet de comparer les rayonsde convergence de deux séries entières :
Soient
n0 anzn etn0 bnzn deux séries entières de rayons de convergence respectifs
Ra et Rb.
• Si an = O(bn), alors Ra Rb.
• Si an ∼ bn, alors Ra = Rb.
Propriété – Comparaison de rayons de convergence
Démonstration
• Sachant que an = O(bn), on a, pour tout z ∈ C,
anzn
= O(|bnzn
|).
Si |z| < Rb,n0 bnzn converge absolument, donc par comparaison,
n0 anzn converge abso-
lument, et donc converge. On en déduit que Ra Rb d’après le troisième point de la méthodeprécédente.
• Si an ∼ bn, alors an = O(bn) et bn = O(an), donc d’après le point précédent, Ra Rb etRb Ra, d’où le résultat.
Exemples
• La série géométrique
n0 zn est une série entière de rayon de convergence égal à 1 et pourtout z ∈ C tel que |z| < 1,
+∞
n=0
zn = 11 − z
.
• La sérien1
zn
n est une série entière de rayon de convergence R égal à 1. En effet, on a
1/n = O(1), donc d’après le point précédent et la propriété ci-dessus, R 1. De plus, pourz = 1, la série obtenue est la série harmonique, divergente. On en déduit que R 1.
Remarquons au passage que pour z = −1, de module 1, la série obtenue est la série har-monique alternée, convergente. On retiendra donc de ces exemples qu’aux points du bord dudisque de convergence, on peut avoir convergence comme divergence de la série. En revanche,si n0 |
an|
Rn converge, alors par définition même, la série converge absolument en tout pointdu bord du disque de convergence. En dehors de ce cas particulier, on ne donnera dans ce coursaucun résultat général de convergence au bord du disque de convergence, qui devra donc êtreexaminée au cas par cas.
245

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 254/383
• La sérien1
ln
1 +
1
n
zn a pour rayon de convergence 1 d’après le point précédent et la
propriété ci-dessus, car
ln
1 +
1
n
∼ 1
n.
• La série n0
zn
n! est une série entière de rayon de convergence infini : d’après la règle de d’Alem-
bert, elle converge pour tout z ∈ C.
2. La règle de d’Alembert pour les séries entières
Pour étudier la convergence des séries, nous disposons de la règle de d’Alembert, dont on saitqu’elle permet de conclure à des convergences absolues ou des divergences grossières, ce qui estle cas des séries entières en dehors du bord du disque de convergence. Il paraît donc judicieux detester cette règle dans le cadre des séries entières.
Soit R le rayon de convergence de la série entièren0
anzn. Supposons que an = 0 pour n
assez grand. Pour z = 0
, la série converge toujours. Si z
= 0
, le quotient apparaissant dans larègle de d’Alembert est (pour n assez grand)an+1zn+1
anzn
=
an+1
an
|z|.
Supposons que
an+1
an
possède une limite ℓ (éventuellement infinie). Alors
an+1zn+1
anzn
−→n→+∞ ℓ |z|.
D’après la règle de d’Alembert :
• Si ℓ = 0, la série converge absolument quel que soit z et R = +∞.• Si ℓ = +∞, elle ne converge que pour z = 0 et R = 0.
• Si ℓ ∈ ]0, + ∞[, alors : si ℓ|z| < 1, la série
n0 anzn converge absolument, et si ℓ|z| > 1, ellediverge grossièrement. Ainsi R = 1/ℓ.
On vient donc de démontrer le résultat suivant :
Soit
n0 anzn une série entière. On suppose que an = 0 pour n assez grand, et qu’ilexiste ℓ ∈ R+ ou ℓ = +∞ tel que
an+1
an
→ ℓ.
Alors le rayon de convergence R de la série entière
n0 anzn est donné par :
R =
1
ℓ si ℓ ∈ ]0, + ∞[
+∞ si ℓ = 0
0 si ℓ = +∞
Théorème – Règle de d’Alembert pour les séries entières
Remarque – Comme pour la règle de d’Alembert usuelle, il n’existe pas de réciproque : le quotient|an+1/an| peut ne pas avoir de limite, voire ne pas être défini, alors que le rayon de convergenceexiste toujours. En particulier, lorsque cette règle ne s’applique pas, il faut penser aux autresmoyens que nous avons exposés pour déterminer un rayon de convergence.
246

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 255/383
Exemples
• La série entièren0
nzn a pour rayon de convergence 1 car n + 1
n → 1.
• La série entièren0
n! zn a pour rayon de convergence 0 car (n + 1)!
n! = (n + 1) → +∞. Elle ne
converge que pour z = 0.
• La série entièren0
2n
n!2 zn a pour rayon de convergence +∞ car
2n+1/(n + 1)!2
2n/n!2 =
2
(n + 1)2 → 0.
Elle converge pour tout z ∈ C.
• Attention aux séries dites « lacunaires », dans lesquelles tous les exposants n’apparaissent pas,comme la série
n1
2n ln(n) z2n.
Pour cette série, on a, pour tout p ∈ N, a2 p = 2 p ln( p) si p 1, mais a2 p+1 = 0. Il ne faut pasfaire l’erreur de dire que an = 2n ln(n) pour tout n 1, ce qui donnerait un rayon de convergence(faux) de 1/2. Pour n 2, et z = 0,2n+1 ln(n + 1) z2(n+1)
2n ln(n) z2n
= 2 ln(n + 1)
ln(n) |z|2 −→
n→+∞ 2|z|2.
On en déduit que la série converge absolument si 2|z|2 < 1 et diverge si 2|z|2 > 1. Le rayon deconvergence est donc 1/
√ 2. On retiendra que pour appliquer la règle de d’Alembert à de telles
séries, il faut revenir à la règle de d’Alembert pour les séries numériques.
3. Convergence normale sur tout segment de l’intervalle de convergence
Nous savons déjà que la convergence des séries entières est absolue sur le disque ouvert deconvergence. Qu’en est-il de la convergence uniforme ou normale ?
Soit
n0 anxn une série entière d’une variable réelle, de rayon de convergence R.
Posons, pour tout n ∈ N, f n : x → anxn
.Alors
n0 f n converge normalement sur tout segment inclus dans l’intervalle ouvertde convergence ]−R,R[.
Théorème
Démonstration – Soit [a,b] un segment inclus dans ]−R,R[ et r = max|a|,|b| ∈ [0,R[. Alors,pour tout x ∈ [a,b], pour tout n ∈ N,
|anxn| |an|rn.
La série n0 anrn converge absolument car r
∈ [0,R[, d’où le résultat.
Attention ! Il n’y a pas nécessairement convergence normale sur l’intervalle ouvert de convergencetout entier : par exemple, la série de fonctions associée à
n0 xn ne converge pas normalement
sur ]−1,1[, car la série
n0 1 diverge.
247

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 256/383
II. Opérations sur les séries entières
Soient
n0 anzn etn0 bnzn deux séries entières de rayons de convergence respectifs
Ra et Rb.
Alors le rayon de convergence R de la série entière
n0
(an + bn)zn vérifie
R minRa,Rb,
avec égalité si Ra = Rb.
Pour tout z ∈ C vérifiant |z| < minRa,Rb, on a alors
+∞n=0
(an + bn)zn =+∞n=0
anzn ++∞n=0
bnzn.
Théorème – Somme de séries entières
Démonstration – Si
|z
| < min
Ra,Rb
, alors les deux séries n0 anzn et n0 bnzn convergent,
donc la série n0(an + bn)zn converge, ce qui implique que R minRa,Rb.Si Ra = Rb (par exemple Ra < Rb), alors pour r vérifiant Ra < r < Rb, la série
n0 anrn
diverge tandis que la série
n0 bnrn converge, donc la série
n0(an + bn)rn diverge. On adonc, dans ce cas, R minRa,Rb.
Si |z| < minRa,Rb, la formule sur la somme est une conséquence des résultats sur les séries(linéarité de la somme).
Remarque – On n’a pas toujours R = minRa,Rb si Ra = Rb. Par exemple, les séries
n0 zn
et
n0 −zn ont toutes les deux pour rayon de convergence 1, mais la série somme a un rayonde convergence infini.
Soient
n0 anzn etn0 bnzn deux séries entières de rayons de convergence respectifs
Ra et Rb.
Alors leur produit de Cauchy est la série entière
n0
p+q=n
a pbq
zn,
dont le rayon de convergence R vérifie
R min
Ra,Rb
.
Pour tout z vérifiant |z| < minRa,Rb, on a alors
+∞n=0
p+q=n
a pbq
zn =
+∞ p=0
a pz p
+∞q=0
bqzq
.
Théorème – Produit de Cauchy de séries entières
Démonstration – Le produit de Cauchy des deux séries est la série
n0
p+q=n
(a pz p)(bqzq)
=
n0
p+q=n
a pbq
zn.
Si |z| < minRa,Rb, alors les deux séries
n0 anzn et
n0 bnzn convergent absolument,donc d’après le théorème de convergence du chapitre Séries numériques, on a convergence duproduit de Cauchy, ainsi que la formule annoncée. En particulier R minRa,Rb.
248

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 257/383
Attention ! Il n’y a pas de cas d’égalité pour les rayons de convergence de produits de sériesentières : les séries entières 1 − z et
n0 zn ont pour rayons de convergence respectifs +∞ et
1, qui sont distincts, mais leur produit de Cauchy est la série constante égale à 1, de rayon deconvergence +∞ > min1, + ∞. En effet, avec les notations du théorème, on a ici
p+q=0
a pbq = a0b0 = 1 × 1 = 1,
∀ n 1, p+q=n
a pbq = a0bn + a1bn−1 = 1 × 1 − 1 × 1 = 0.
Exemple – Le produit de Cauchy des séries entièresn0
zn etn1
zn
n est la série entière
n1
H nzn
où, pour tout n 1, H n =nk=1 1/k. Son rayon de convergence R vérifie R 1 (on peut en fait
montrer que R = 1 à partir de l’équivalent H n ∼ ln(n)).
III. Régularité de la somme d’une série entière
Continuité sur le disque ouvert de convergence
• Soit
n0 anxn une série entière d’une variable réelle, de rayon de convergence R.
Alors la fonction somme S : x →+∞n=0
anxn est continue sur ]−R,R[ .
• Soit
n0 anzn une série entière d’une variable complexe, de rayon de convergence
R. Alors la fonction somme S : z →+∞n=0
anzn est continue sur D(0,R).
Théorème
Démonstration
• Pour tout n ∈ N, f n : x → anxn est continue sur ]−R,R[. De plus, la série de fonctions
n0 f nconverge normalement (et donc uniformément) sur tout segment de ]−R,R[. D’après le théorèmede continuité pour les séries de fonctions, S est continue sur ]−R,R[.
• Conformément au programme, ce résultat est admis.
Séries entières de la variable réelle : dérivation et intégration
La série des dérivées d’une série entière
n0 anzn est la série
n1 nanzn−1. À un facteurprès, on obtient la série
n0 nanzn. On s’intéresse donc au rayon de convergence de cette sérieentière.
Soit
n0 anzn une série entière de rayon de convergence R.
Alors la série entière n0
nanzn
a pour rayon de convergence R.
Propriété
Démonstration – Notons R′ le rayon de convergence de la série n0 nanzn. On a tout d’abord
an = O(nan)
donc R R′.
249

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 258/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 259/383
On peut alors réitérer ce raisonnement avec la série des dérivées k-ièmes. On en déduit lerésultat suivant :
Soit
n0 anxn une série entière de rayon de convergence R > 0.
Alors sa fonction somme f est de classe C∞ sur l’intervalle ]−R,R[ et pour tout k ∈ N,pour tout x ∈ ]−R,R[,
f (k)(x) =+∞n=k
n(n − 1) · · · (n − k + 1) anxn−k =+∞n=k
n!
(n − k)! anxn−k.
Théorème
Soit
n0 anxn une série entière de rayon de convergence R > 0.
Alors, pour tout k ∈ N,
ak = f (k)(0)
k! .
Corollaire – Expression des coefficients d’une série entière
Démonstration – Pour tout x ∈ ]−R,R[, on a d’après le théorème précédent,
f (k)(x) =+∞n=k
n!
(n − k)! anxn−k.
En évaluant en x = 0 (ce qui est possible car R > 0), on obtient f (k)(0) = k! ak, car seul le termecorrespondant à n = k fournit un terme éventuellement non nul. D’où le résultat.
On en déduit en particulier que les coefficients an sont entièrement déterminés par la donnéede la somme de la série entière
n0 anxn de rayon de convergence non nul. Par exemple, et
c’est intuitif, si la somme d’une série entière ne prend que des valeurs réelles, alors on sait quetous les coefficients de cette série entière sont réels, même si l’expression de ces coefficients ne lefait pas clairement apparaître.
Du corollaire précédent, on déduit immédiatement :
Soient
n0 anxn et
n0 bnxn deux séries entières de rayons de convergence supé-rieurs ou égaux à un certain r > 0. On suppose que pour tout x ∈ ]−r,r[,
+∞n=0
anxn =+∞n=0
bnxn.
Alors an = bn pour tout n ∈N.
Théorème – Unicité du développement en série entière
Application – Soit
n0 anxn une série entière de rayon de convergence R > 0 et f sa fonctionsomme. Alors :
• f est paire si et seulement si pour tout k ∈ N, a2k+1 = 0.
• f est impaire si et seulement si pour tout k ∈ N, a2k = 0.
Démonstration – Il suffit de traiter le cas où f est paire, l’autre est similaire. Si f est paire, alorspour tout x ∈ ]−R,R[,
+∞
n=0
an
xn =+∞
n=0
an
(−
x)n =+∞
n=0
(−
1)nan
xn.
Par unicité du développement en série entière, on a donc an = (−1)nan pour tout n ∈ N, ce quientraîne le résultat. La réciproque est claire.
251

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 260/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 261/383
Par croissances comparées, f (n)(x) tend vers 0 lorsque x tend vers 0. On obtient alors le résultatpar applications successives du théorème de la limite de la dérivée.
La série de Taylor de f en 0 est la série nulle : elle a évidemment un rayon de convergenceinfini, mais sa somme ne coïncide avec f qu’en 0 puisque f (x) = 0 si x = 0.
2. Lien avec les formules de Taylor
Bien sûr, la série de Taylor d’une fonction f n’est pas sans rapport avec les formules de Taylor
pour la fonction f : on voit bien qu’elles font toutes intervenir les termes f (n)(0)
n! xn.
Tout d’abord, supposons que f est développable en série entière sur ]−r,r[ ; on a donc, pourtout x ∈ ]−r,r[,
f (x) =+∞n=0
f (n)(0)
n! xn.
Soit k ∈ N. Alors, d’après la formule de Taylor-Young à l’ordre k, on a
f (x) =x→0
k
n=0
f (n)(0)
n! xn + o(xk).
Ainsi, le développement limité à l’ordre k de f en 0 est obtenu par troncature à l’ordre k de sondéveloppement en série entière.
Écrivons maintenant la formule de Taylor avec reste intégral à l’ordre k en 0 pour une fonctionf de classe C∞ sur un intervalle I contenant 0 :
∀ x ∈ I , f (x) =k
n=0
f (n)(0)
n! xn +
x0
(x − t)k
k! f (k+1)(t) dt.
Si l’on est capable de prouver que le reste intégral converge vers 0 lorsque k → +∞ pour tout xdans un intervalle de la forme ]−r,r[ ⊂ I , alors on obtiendra un développement en série entièrede f sur ]
−r,r[. En utilisant cette idée, on va prouver le résultat suivant :
Pour tout z ∈ C,
ez =+∞n=0
zn
n!.
Propriété
Démonstration – D’après la formule de Taylor avec reste intégral à l’ordre k pour la fonctionf : t → ezt, de classe C∞ sur [0,1], on a
ez = f (1) =
kn=0
f (n)
(0)n! + 1
0(1 − t)
k
k! f (k+1)(t) dt
=k
n=0
zn
n! +
1
0
(1 − t)k
k! zk+1ezt dt.
Or 1
0
(1 − t)k
k! zk+1ezt dt
1
0
(1 − t)k
k! |zk+1||ezt| dt
=
1
0
(1 − t)k
k! |zk+1| eRe(z)t dt
|z|k+1 e|Re(z)| 1
0
(1−
t)k
k! dt
= |z|k+1 e|Re(z)| 1
(k + 1)!.
253

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 262/383
Ce dernier terme tend vers 0 lorsque k → +∞, par croissances comparées. On en déduit lerésultat par passage à la limite dans la formule de Taylor ci-dessus.
3. Autres développements en série entière de référence
Nous allons donner quelques développements en série entière usuels, en plus de ceux de arctan
et exp. On peut alors en construire beaucoup d’autres par :
• Combinaison linéaire,• Produit de Cauchy,• Intégration et dérivation terme à terme.
Bien sûr, commençons par rappeler le développement en série entière correspondant à la sériegéométrique :
Pour tout z ∈ C tel que |z| < 1,
1
1
−z
=+∞
n=0
zn
Propriété
Remarque – On a en particulier, pour tout x ∈ ]−1,1[,
1
1 − x =
+∞n=0
xn, 1
1 + x =
+∞n=0
(−1)nxn, 1
(1 − x)2 =
+∞n=1
nxn−1,
ce dernier développement étant obtenu par dérivation du premier (on l’avait déjà prouvé parproduit de Cauchy dans le chapitre Séries numériques).
En intégrant terme à terme le deuxième développement de la remarque précédente, on ob-tient :
Pour tout x ∈ ]−1,1[,
ln(1 + x) =+∞n=1
(−1)n−1 xn
n .
Propriété
Remarque – Bien sûr, en changeant x en −x, on a aussi, pour tout x ∈ ]−1,1[ ,
− ln(1 − x) =+∞
n=1
xn
n .
En prenant parties réelle et imaginaire de exp(ix) =+∞n=0
inxn
n! et en utilisant exp(x) =
+∞n=0
xn
n! ,
on a également :
Pour tout x ∈ R,
cos(x) =+∞n=0
(−1)n x2n
(2n)! sin(x) =
+∞n=0
(−1)n x2n+1
(2n + 1)!
ch(x) =
+
∞n=0
x2n
(2n)! sh(x) =
+
∞n=0
x2n+1
(2n + 1)!
Propriété
254

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 263/383
Enfin, donnons le développement en série entière de la fonction x → (1 + x)α :
Pour tout α ∈ R, pour tout x ∈ ]−1,1[,
(1 + x)α = 1 ++∞
n=1
α(α − 1) · · · (α − n + 1)
n! xn.
L’égalité est valable pour tout x ∈ R lorsque α ∈N, auquel cas on reconnaît la formuledu binôme de Newton.
Propriété
Démonstration – Pour α ∈ N, le résultat est connu, il s’agit de la formule du binôme (et c’esten fait une somme finie). Sinon, en posant f (x) = (1 + x)α pour tout x ∈ ]−1,1[, alors f est declasse C∞ sur ]−1,1[ et pour tout n ∈N,
f (n)(0) =
1 si n = 0,
α(α − 1) · · · (α − n + 1) sinon.
La série de Taylor de f en 0,
1 +n1
f (n)(0)
n! xn,
a un rayon de convergence égal à 1 d’après la règle de d’Alembert : en effet, α n’étant pas entiernaturel, α(α − 1) · · · (α − n + 1) = 0 pour tout n 1 etα(α − 1) · · · (α − n)/(n + 1)!
α(α − 1) · · · (α − n + 1)/n!
=
α − n
n + 1
−→n→+∞ 1.
Notons S la fonction somme de cette série. Alors S est de classe C1 sur ]−1,1[ et pour toutx ∈
]−
1,1[,
S ′(x) =+∞n=1
α(α − 1) · · · (α − n + 1)
(n − 1)! xn−1
= α ++∞n=1
α(α − 1) · · · (α − n)
n! xn
= α ++∞n=1
(α − n)α(α − 1) · · · (α − n + 1)
n! xn.
En séparant ce dernier terme en deux, on a pour tout x ∈ ]−1,1[,
S ′(x) = α + α+
∞n=1
α(α − 1) · · · (α − n + 1)n!
xn −+
∞n=1
n α(α − 1) · · · (α − n + 1)n!
xn,
toutes les séries entières dans l’égalité précédente ayant pour rayon de convergence 1. On reconnaîtalors l’égalité
S ′(x) = αS (x) − xS ′(x).
La fonction S est donc solution de l’équation différentielle (1 + x)S ′ = αS sur ]−1,1[.
La fonction x → α ln(1 + x) est une primitive sur ]−1,1[ de la fonction continue x → α
1 + x,
donc il existe λ ∈ R tel que pour tout x ∈ ]−1,1[,
S (x) = λ exp(α ln(1 + x)) = λ (1 + x)α
.
En remarquant de plus que S (0) = 1, on obtient λ = 1, donc f = S sur ]−1,1[, ce qui est lerésultat souhaité.
255

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 264/383
256

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 265/383
Chapitre 14
Variables aléatoires
Très souvent, on peut associer à chaque issue d’une expérience aléatoire un résultat, notam-ment numérique, qui correspond à l’observation d’un des aspects de l’expérience. Par exemple, sion lance deux dés, un rouge et un vert, on peut s’intéresser au résultat du dé rouge, à celui du dévert, à la somme des deux, à la couleur de celui (ou ceux) qui donne(nt) le plus grand résultat.
Si l’on observe le déplacement aléatoire d’une particule dans l’espace, on peut s’intéresser à laposition, à chaque seconde, de la particule, mais aussi à sa vitesse, au temps nécessaire pour quela particule atteigne, éventuellement, une position fixée, etc...
Dans tout le chapitre, (Ω,A ,P ) est un espace probabilisé.
I. Définitions, premières propriétés
Une variable aléatoire discrète sur (Ω,A ) est une application définie sur Ω, etvérifiant les conditions suivantes :
• L’image X (Ω) de X est finie ou dénombrable,• Pour tout x ∈ X (Ω), X −1(x) ∈A .
Pour tout x ∈ X (Ω), l’événement X −1(x) est noté X = x ou (X = x).
Lorsque X est à valeurs dans R, on dit que X est une variable aléatoire réelle.
Définition – Variable aléatoire
Remarques
• On parle aussi souvent de variable aléatoire sur (Ω,A ,P ), mais la définition d’une variablealéatoire n’utilise pas la probabilité P .
• Dans ce cours, toutes les variables aléatoires seront implicitement supposées discrètes.
• On rappelle que X −1(x) = ω ∈ Ω; X (ω) = x. Plus généralement, si U est un sous-ensemble de X (Ω), X −1(U ) = ω ∈ Ω; X (ω) ∈ U . Le fait d’employer cette notation ne signifieabsolument pas que X est bijective!
• Si X est une variable aléatoire sur (Ω,A ), X (Ω) est fini ou dénombrable, donc on peut ledécrire en extension sous la forme X (Ω) = xn; n ∈ I , où I est une partie de N.
Alors la famille ((X = xn))n∈I est un système complet d’événements.
• Lorsque Ω est fini, si X est une application définie sur Ω, X (Ω) est également fini. Sachant
de plus que A = P (Ω), la deuxième condition de la définition ci-dessus est aussi remplie. Unevariable aléatoire est donc tout simplement, dans ce cadre, une application définie sur Ω. Onparle de variable aléatoire sur Ω, au lieu de (Ω,P (Ω)).
257

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 266/383
Soit X une variable aléatoire sur (Ω,A ) et U un sous-ensemble de X (Ω) : U ⊂ X (Ω).
Alors X −1(U ) ∈A . L’événement X −1(U ) est noté X ∈ U ou (X ∈ U ).
Propriété
Démonstration – L’ensemble U est fini ou dénombrable en tant que sous-ensemble de X (Ω), onpeut le décrire en extension sous la forme U =
xn; n
∈ I
, où I est une partie de N. Alors
X −1(U ) =n∈I
X −1(xn);
c’est un élément de A en tant que réunion finie ou dénombrable d’éléments de A .
Notation – Soit X une variable aléatoire réelle sur (Ω,A ) et x ∈ R. Lorsque U = ]−∞,x]∩X (Ω),l’événement (X ∈ U ) est noté plus simplement (X x). On définit de façon analogue lesévénements (X < x), (X x) et (X > x).
Exemple – On modélise le lancer de deux dés, un rouge et un vert, par le choix de Ω = [[1,6]]2,muni de la probabilité uniforme. Pour tout (i,j) ∈ Ω, i est le résultat du dé rouge, j celui du dévert. La fonction X qui à (i,j) associe i + j est une variable aléatoire sur Ω. Elle prend toutesles valeurs de [[2,12]]. Par exemple,
(X = 2) = 1,1 avec P (X = 2) = 1
36,
(X = 4) = (1,3),(2,2),(3,1) avec P (X = 4) = 3
36 =
1
12,
(X = 7) = (1,6),(2,5),(3,4),(4,3),(5,2),(6,1) avec P (X = 7) = 6
36 =
1
6,
Soit X une variable aléatoire sur (Ω,A
) et f une fonction définie sur X (Ω).Alors f X est une variable aléatoire sur (Ω,A ), plus souvent notée f (X ).
Propriété/Définition
Démonstration – L’image de X est finie ou dénombrable, donc celle de f (X ) également. De plus,soit a un élément de f (X (Ω)) (image de f (X )); alors
(f X )−1(a) = (X ∈ f −1(a)).
Or f −1(a) ⊂ X (Ω), donc d’après la propriété précédente, (f X )−1(a) ∈ A , ce qui prouvele résultat.
Exemple – Si X est une variable aléatoire réelle, X 2 est une variable aléatoire. Si X est à valeursstrictement positives, ln(X ) est une variable aléatoire.
II. Loi d’une variable aléatoire
1. Généralités
Soit X une variable aléatoire sur (Ω,A ,P ).
On appelle loi de la variable aléatoire X la fonction définie sur X (Ω) par :
∀ x ∈ X (Ω), P X (x) = P (X = x).
Définition – Loi d’une variable aléatoire
Remarque – La loi de X permet de définir une probabilité sur (X (Ω),P (X (Ω))).
258

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 267/383
Soit X une variable aléatoire sur (Ω,A ,P ). On décrit X (Ω) en extension sous la formeX (Ω) = xn; n ∈ I où I est une partie de N.
Alors, pour tout U ⊂ X (Ω), on a
P (X ∈ U ) =
xn∈U P (X = xn).
Propriété
Rappel – Lorsque X (Ω) est dénombrable et décrit en extension sous la forme xn; n ∈ N, U est fini ou dénombrable, et peut-être décrit en extension sous la forme xϕ(1), . . . , xϕ(m) (oùm = card(U )) ou xϕ(k); k ∈ N (où ϕ est une bijection de N sur N). Alors
xn∈U P (X = xn)
s’exprime comme une somme finie, ou une somme de série convergente :
xn∈U
P (X = xn) =mk=1
P (X = xϕ(k)) ouxn∈U
P (X = xn) =+∞k=0
P (X = xϕ(k)).
Par exemple, si X (Ω) = N et U = 2N =
2k; k
∈N, alors P (X
∈ U ) = +∞
k=0 P (X = 2k).
Démonstration de la propriété – L’événement (X ∈ U ) est la réunion des événements deux àdeux disjoints (X = xn) pour les xn de U , d’où le résultat par définition d’une probabilité (etnotamment, la somme précédente ne dépend pas de la façon de décrire U en extension).
Remarque – Dans le cas dénombrable, la série
n0 P (X = xn) converge et a pour somme 1. Deplus, pour tout événement A ∈ A , on a d’après la formule des probabilités totales,
P (A) =+∞n=0
P (A | X = xn)P (X = xn).
Soit X une variable aléatoire réelle sur (Ω,A ,P ).
On appelle fonction de répartition de X la fonction F X définie sur R par :
∀ x ∈ R, F X (x) = P (X x).
Définition – Fonction de répartition
Soit X une variable aléatoire réelle sur (Ω,A ,P ) et F X sa fonction de répartition. Alors :
• F X est croissante sur R.
• F X (x) −→x→−∞ 0 et F X (x) −→x→+∞ 1.
Propriété
Démonstration
• Soit (x,y) ∈R2 tel que x y ; alors (X x) ⊂ (X y), et donc P (X x) P (X y), i.e.,F X (x) F X (y) : la fonction F X est croissante.
• D’après le premier point, F X a une limite ℓ en +∞, et donc F X (n) −→n→+∞ ℓ. Or on remarque
que +∞
n=0(X n) = Ω, donc par propriété de continuité croissante,
F X (n) = P (X n) −→n→+∞ P (Ω) = 1.
On a donc ℓ = 1.On procède de même pour la limite en −∞ en utilisant la propriété de continuité décroissante
et le fait que +∞
n=0(X −n) = ∅ avec P (∅) = 0.
259
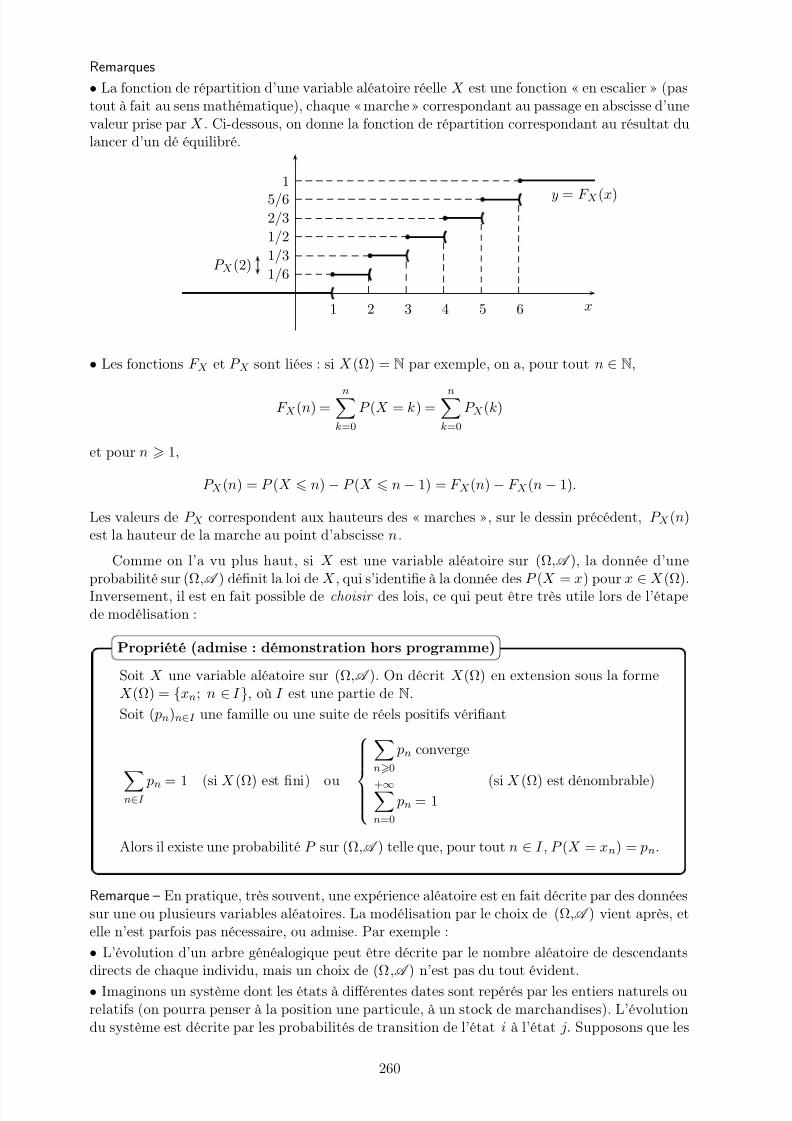
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 268/383
Remarques
• La fonction de répartition d’une variable aléatoire réelle X est une fonction « en escalier » (pastout à fait au sens mathématique), chaque « marche » correspondant au passage en abscisse d’unevaleur prise par X . Ci-dessous, on donne la fonction de répartition correspondant au résultat dulancer d’un dé équilibré.
x
y = F X (x)
1 2 3 4 5 6
1/6
1/3
1/2
2/35/6
1
P X (2)
• Les fonctions F X et P X sont liées : si X (Ω) = N par exemple, on a, pour tout n ∈ N,
F X (n) =nk=0
P (X = k) =nk=0
P X (k)
et pour n 1,
P X (n) = P (X n) − P (X n − 1) = F X (n) − F X (n − 1).
Les valeurs de P X correspondent aux hauteurs des « marches », sur le dessin précédent, P X (n)est la hauteur de la marche au point d’abscisse n.
Comme on l’a vu plus haut, si X est une variable aléatoire sur (Ω,A ), la donnée d’uneprobabilité sur (Ω,A ) définit la loi de X , qui s’identifie à la donnée des P (X = x) pour x
∈ X (Ω).
Inversement, il est en fait possible de choisir des lois, ce qui peut être très utile lors de l’étapede modélisation :
Soit X une variable aléatoire sur (Ω,A ). On décrit X (Ω) en extension sous la formeX (Ω) = xn; n ∈ I , où I est une partie de N.
Soit ( pn)n∈I une famille ou une suite de réels positifs vérifiant
n∈I pn = 1 (si X (Ω) est fini) ou
n0
pn converge
+∞n=0
pn = 1 (si X (Ω) est dénombrable)
Alors il existe une probabilité P sur (Ω,A ) telle que, pour tout n ∈ I , P (X = xn) = pn.
Propriété (admise : démonstration hors programme)
Remarque – En pratique, très souvent, une expérience aléatoire est en fait décrite par des donnéessur une ou plusieurs variables aléatoires. La modélisation par le choix de (Ω,A ) vient après, etelle n’est parfois pas nécessaire, ou admise. Par exemple :
• L’évolution d’un arbre généalogique peut être décrite par le nombre aléatoire de descendantsdirects de chaque individu, mais un choix de (Ω,A ) n’est pas du tout évident.
• Imaginons un système dont les états à différentes dates sont repérés par les entiers naturels ourelatifs (on pourra penser à la position une particule, à un stock de marchandises). L’évolutiondu système est décrite par les probabilités de transition de l’état i à l’état j. Supposons que les
260

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 269/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 270/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 271/383
On peut simuler la variable aléatoire S de la façon suivante :
1 def sim_nb_succes(n,p):
2 S = 0
3 for i in range(n):
4 x = random.random()
5 if x < p :
6 S += 1
7 return S
On peut alors simuler la loi B (n,p) de la façon suivante : on répète N fois la simulation ci-dessus,et on calcule, pour tout k ∈ [[0,n]] la fréquence relative du résultat k lors de ces N exepériences :
1 def loi_binomiale(n,p,N):
2 L = []
3 for i in range(N):
4 S = sim_nb_succes(n,p)
5 L.append(S)
6 return [L.count(k)/float(N) for k in range(n+1)]
d. Loi géométrique
Soit p ∈ ]0,1[. On dit qu’une variable aléatoire X sur (Ω,A ,P ) suit la loi géométriquede paramètre p si X (Ω) ⊃ N∗ et si
∀ k ∈ N∗, P (X = k) = p (1 − p)k−1.
Ceci se note X
→ G ( p).
Définition
Remarques
• C’est le premier exemple que l’on rencontre de variable aléatoire prenant un nombre infini devaleurs.
• On définit bien une loi car la série géométrique de raison (1 − p) ∈ ]0,1[ est à termes positifs,elle converge, et
+∞k=1
p (1 − p)k−1 = p+∞k=0
(1 − p)k = p
1 − (1 − p) = 1.
Exemples
• Considérons le jeu de pile ou face infini, avec p la probabilité d’obtenir « pile ». Pour k ∈ N∗,
l’événement « pile apparaît pour la première fois au rang k » a pour probabilité p (1 − p)k−
1
(k − 1 échecs suivis d’un succès).
• Plus généralement, la loi géométrique peut être interprétée comme loi du rang du premiersuccès dans une suite illimitée d’épreuves de Bernoulli mutuellement indépendantes et de mêmeparamètre p.
Il est parfois utile d’autoriser que X prenne d’autres valeurs que celles de N∗, avec probabiliténulle, notamment, en lien avec l’interprétation précédente, si aucun succès ne survient.
• La loi géométrique est aussi souvent utilisée pour modéliser des durées de fonctionnement decomposants, machines, etc...
Remarque – On peut remplacer X (Ω) = N∗ par X (Ω) = N avec :
∀ k ∈ N, P (X = k) = p (1 − p)k.
Dans ce cas, cette loi s’interprète comme loi du nombre d’échecs avant le premier succès.
263

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 272/383
e. Loi de Poisson
Soit λ ∈ R∗+. On dit qu’une variable aléatoire X sur (Ω,A ,P ) suit la loi de Poissonde paramètre λ si X (Ω) = N et si
∀k ∈N, P (X = k) = e−λ
λk
k!.
Ceci se note X
→P (λ).
Définition
Remarque – On définit bien ainsi une loi, car on reconnaît la série exponentielle de λ, qui est àtermes positifs, convergente, avec
+∞k=0
e−λ λk
k! = e−λ eλ = 1.
Le théorème suivant établit un lien asymptotique entre loi binomiale et loi de Poisson :
Soient ( pn)n∈N une suite d’éléments de [0,1], (X n)n∈N une suite de variables aléatoiressur (Ω,A ,P ) et λ ∈ R∗+. On fait les hypothèses suivantes :
• Pour tout n ∈ N, X n suit la loi binomiale de paramètres n et pn,• n pn −→
n→+∞λ.
Alors, pour tout k ∈ N,
P (X n = k) −→n→+∞
e−λ λk
k!
Théorème – Approximation de la loi binomiale par la loi de Poisson
Démonstration – Soit k ∈ N. Alors, pour n k assez grand, pn ∈ ]0,1[ et on a
P (X n = k) =
nk
pkn (1 − pn)n−k =
n(n − 1) · · · (n − k + 1)
k! pkn (1 − pn)n−k
∼n→+∞
nk
k! pkn (1 − pn)n−k.
Tout d’abord, (npn)k −→n→+∞ λk. De plus, n pn → λ, donc pn → 0+ et, lorsque n → +∞,
(1
− pn)n−k = exp ((n
−k)ln(1
− pn)) = exp ((n
−k)(
− pn + o( pn))) .
Or(n − k)(− pn + o( pn)) = −n pn + o(n pn) ∼
n→+∞ −n pn −→n→+∞ −λ.
Par continuité de l’exponentielle et d’après ce qui précède, on a bien
P (X n = k) −→n→+∞ e−λ
λk
k!
Remarques
• Dans les calculs, on peut donc approcher
nk
pk (1 − p)n−k par e−np
(np)k
k! .
Cela permet d’éviter des calculs de coefficients du binôme, qui font intervenir des quotients degrands nombres.
• On considère que l’approximation est intéressante lorsque p 0,1, n 30 et np < 15.
264

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 273/383
Exemple – On lance 100 fois un dé équilibré à 20 faces et on compte le nombre N de 20 obtenus.Ce nombre suit une loi binomiale B (100,1/20), on a donc, pour tout k ∈ [[0,100]],
P (N = k) =
100
k
1
20k
19
20
100−k
On est dans les conditions de l’approximation avec np = 100/20 = 5, on peut donc approcher
P (N = k) par e−5
5k
/k!. Pour k = 2 par exemple, on a100
2
1
202
19
20
98
≈ 0,081 et e−5 52
2! ≈ 0,084.
Le programme suivant permet d’utiliser cette approximation :
1 from math import exp, factorial
2
3 def approx_poisson(n,p):
4 return [exp(-n*p)*(n*p)**k/factorial(k) for k in range(n+1)]
On peut alors tester par exemple l’approximation de B (30,0.1) par P (3) (listes B et A), ainsiqu’une simulation de cette approximation (liste L); dans ce qui suit, on n’affiche que les 10premières valeurs, en arrondissant à 4 décimales pour B et A :
1 from scipy.special import binom
2
3 # Loi binomiale B(30,0.1)
4 B = [ binom(30,k)*(0.1**k)*(0.9**(30-k)) for k in range(31) ]
5 B = [ float("%.4f" % x) for x in B ]
6
7 # Approximation par P(3)
8 A = approx_poisson(30,0.1)
9 A = [ float("%.4f" % x) for x in A ]
10
11 # Simulation de B(30,0.1)
12 L = loi_binomiale(30,0.1,10000)
13
14 for k in range(10):
15 print "P( X =",k,") :",B[k],",",A[k],",",L[k]
Voici un résultat possible :
P( X = 0 ) : 0.0424 , 0.0498 , 0.0424
P( X = 1 ) : 0.1413 , 0.1494 , 0.139
P( X = 2 ) : 0.2277 , 0.224 , 0.2332
P( X = 3 ) : 0.2361 , 0.224 , 0.2358
P( X = 4 ) : 0.1771 , 0.168 , 0.1743
P( X = 5 ) : 0.1023 , 0.1008 , 0.1014
P( X = 6 ) : 0.0474 , 0.0504 , 0.047
P( X = 7 ) : 0.018 , 0.0216 , 0.0187
P( X = 8 ) : 0.0058 , 0.0081 , 0.006
P( X = 9 ) : 0.0016 , 0.0027 , 0.0019
Remarque – On s’intéresse à la loi du nombre d’occurrences d’un phénomène dans un intervallede temps [0,T ]. On fait les hypothèses suivantes :
• il existe a ∈ R tel que la probabilité que le phénomène se produise une fois dans un intervallede temps de petite longueur h est ah ;
• la probabilité qu’il se produise plus d’une fois est négligeable (en fait, un o(h)) ;• les nombres d’occurrences du phénomène dans des intervalles disjoints sont mutuellement
indépendants.
265

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 274/383
On subdivise [0,T ] en intervalles de longueur T /n. D’après les hypothèses précédentes, onpeut considérer que le nombre d’occurrences du phénomène dans l’intervalle [0,T ] suit la loibinomiale B (n,aT/n). D’après le résultat d’approximation précédent, pour n grand, on peutapprocher cette loi par la loi de Poisson P (aT ) (le paramètre λ s’identifie donc à aT ).
Pour cette raison, la loi de Poisson est dite loi des événements rares ; elle est souventutilisée pour modéliser le nombre d’occurrences d’un phénomène dans un intervalle de tempsfixé, ce phénomène étant « rare » dans un court intervalle de temps, mais observé sur un grand
nombre de tels intervalles. Par exemple, on peut modéliser ainsi le nombre de véhicules passantdevant un point d’observation, de clients entrant dans un magasin, de catastrophes naturelles,de désintégrations de noyaux radioactifs (lorsque la source est éloignée, les mesures faites par uncompteur Geiger font effectivement apparaître une loi de Poisson).
III. Familles de variables aléatoires
1. Couple de variables aléatoires
Soient X et Y deux variables aléatoires sur (Ω,A ).L’application ω → (X (ω),Y (ω)) est une variable aléatoire sur (Ω,A ), appelée couple(X,Y ).
Propriété/Définition
Démonstration – Les ensembles X (Ω) et Y (Ω) sont finis ou dénombrables, donc X (Ω) × Y (Ω) estfini ou dénombrable. L’image de (X,Y ) est contenue dans X (Ω) × Y (Ω), elle est donc aussi finieou dénombrable. Notons Z = (X,Y ). Pour tout (x,y) de Z (Ω),
Z −1((x,y)) = ω ∈ Ω; (X (ω),Y (ω)) = (x,y) = X −1(x) ∩ Y −1(y);
c’est un événement en tant qu’intersection de deux événements.
Notation
• L’événement ((X,Y ) = (x,y)), c’est-à-dire (X = x) ∩ (Y = y) est plus souvent noté(X = x, Y = y).
• Si A ⊂ X (Ω) et B ⊂ Y (Ω), l’événement ((X,Y ) ∈ A × B), c’est-à-dire (X ∈ A) ∩ (Y ∈ B), estplus souvent noté (X ∈ A, Y ∈ B).
L’ensemble des variables aléatoires sur (Ω,A ) à valeurs dans K (K = R ou C) est unK-espace vectoriel (pour les lois d’addition et de multiplication par un scalaire).
Corollaire
Démonstration – C’est un sous-ensemble de l’espace vectoriel des applications de Ω dans K, quiest non vide (la fonction nulle est une variable aléatoire) Enfin, soient X et Y deux variablesaléatoires sur (Ω,A ) à valeurs dans K et soit λ ∈ K. On définit la fonction f : (x,y) → λx + y surK2. Alors λX + Y = f (X,Y ), qui est une variable aléatoire car le couple (X,Y ) est une variablealéatoire.
Soit (X,Y ) un couple de variables aléatoires sur (Ω,A ). On appelle :
• loi conjointe de X et Y la loi du couple (X,Y ).• lois marginales du couple (X,Y ) les lois de X et de Y .
Définition
266

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 275/383
Soit (X,Y ) un couple de variables aléatoires sur (Ω,A ).
La loi du couple (X,Y ) détermine entièrement ses lois marginales par les relations
∀ x ∈ X (Ω), P (X = x) =
y∈Y (Ω)
P (X = x, Y = y),
∀ y ∈ Y (Ω), P (Y = y) = x∈X (Ω)
P (X = x, Y = y).
En revanche, les lois marginales du couple (X,Y ) ne déterminent pas la loi conjointede X et Y .
Propriété
Démonstration – La première égalité est immédiate en remarquant que ((Y = y))y∈Y (Ω) est unsystème complet dénombrable d’événements ; de même pour la seconde, avec ((X = x))x∈X (Ω).
En revanche, considérons l’exemple suivant, où l’on définit les lois de deux couples (X 1,Y 1)
et (X 2,Y 2) :
(x,y) (0,0) (0,1) (1,0) (1,1)P (X 1 = x,Y 1 = y) 0,25 0,25 0,25 0,25
P (X 2 = x,Y 2 = y) 0,3 0,2 0,2 0,3
Dans les deux cas, les lois marginales sont les mêmes, car pour i ∈ 1,2,
P (X i = 0) = P (X i = 1) = P (Y i = 0) = P (Y 1 = 1) = 0,5
mais les lois conjointes ne sont pas les mêmes (car P (X 1 = 0,Y 1 = 0) = P (X 2 = 0,Y 2 = 0) parexemple).
Les lois marginales du couple (X,Y ) ne déterminent donc pas la loi conjointe de X et Y .
2. Conditionnement et indépendance
Soient X et Y deux variables aléatoires sur (Ω,A ,P ) et y ∈ Y (Ω) tel que P (Y = y) > 0.
On appelle loi conditionnelle de X sachant (Y = y) la fonction X (Ω) → [0,1]
x → P (X = x | Y = y)
C’est la loi de X dans l’espace probabilisé (Ω,A
,P (Y =y)).On rappelle que pour tout x ∈ X (Ω),
P (X = x | Y = y) = P (X = x, Y = y)
P (Y = y) .
Définition – Loi conditionnelle
Exemple – Dans l’exemple de la propriété précédente, on a
P (Y 2 = 0) = P (X 2 = 0, Y 2 = 0) + P (X 2 = 1, Y 2 = 0) = 0,3 + 0,2 = 0,5 > 0.
La loi de X 2
sachant (Y 2
= 0) est caractérisée par les deux nombres
P (X 2 = 0 | Y 2 = 0) = 0,3
0,5 = 0,6 et P (X 2 = 1 | Y 2 = 0) =
0,2
0,5 = 0,4.
267

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 276/383
• Soient X et Y deux variables aléatoires sur (Ω,A ,P ).
On dit que X et Y sont indépendantes si pour tout (x,y) ∈ X (Ω) × Y (Ω), lesévénements (X = x) et (Y = y) sont indépendants, i.e.
P (X = x, Y = y) = P (X = x)P (Y = y).
• Soit I un ensemble d’indices. Pour tout i ∈ I , soit X i une variable aléatoire sur(Ω,A ,P ).
On dit que les variables aléatoires X i, pour i ∈ I , sont mutuellement indépendantessi, pour toute famille (xi)i∈I telle que pour tout i ∈ I , xi ∈ X i(Ω), les événements(X i = xi) pour i ∈ I sont mutuellement indépendants, i.e. : pour toute partie finieJ ⊂ I ,
P
j∈J
(X j = x j)
=
j∈J
P (X j = x j).
Définition – Indépendance de variables aléatoires
• Soient X et Y deux variables aléatoires indépendantes sur (Ω,A ,P ), A un sous-ensemble de X (Ω) et B un sous-ensemble de Y (Ω).
Alors les événements (X ∈ A) et (Y ∈ B) sont indépendants, i.e.
P (X ∈ A, Y ∈ B) = P (X ∈ A) P (Y ∈ B).
• Soit (X i)i∈I une famille de variables aléatoires mutuellement indépendantes sur(Ω,A ,P ).
Alors, pour toute famille (Ai)i∈I telle que pour tout i ∈ I , Ai ⊂ X i(Ω), les événements(X i ∈ Ai) pour i ∈ I sont mutuellement indépendants, i.e. : pour toute partie finieJ ⊂ I ,
P
j∈J
(X j ∈ A j)
=
j∈J
P (X j ∈ A j).
Propriété (admise : démonstration hors programme)
Soient X et Y deux variables aléatoires indépendantes sur (Ω,A ,P ).Soient f et g des fonctions définies respectivement sur X (Ω) et Y (Ω).
Alors les variables aléatoires f (X ) et g(Y ) sont indépendantes.
Propriété
Démonstration – Soit a ∈ f (X (Ω)) et b ∈ g(Y (Ω)). Alors
P (f (X ) = a, g(Y ) = b) = P (X ∈ f −1(a), Y ∈ g−1(b)).
Par indépendance de X et Y , et d’après la propriété précédente,
P (f (X ) = a, g(Y ) = b) = P (X ∈ f −1(a)) P (Y ∈ g−1(b)) = P (f (X ) = a) P (g(Y ) = b),
d’où le résultat.
268

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 277/383
3. Quelques propriétés des lois usuelles
Soient X 1, . . . , X n des variables aléatoires mutuellement indépendantes sur (Ω,A ,P ),suivant chacune la loi de Bernoulli B ( p).
Alors la variable aléatoire X 1 + · · · + X n suit la loi binomiale B (n,p).
Propriété – Somme de variables de Bernoulli
Démonstration – La démonstration est identique à celle donnée plus haut en interprétation de laloi B (n,p).
Remarque – Des sommes de variables de Bernoulli, comme dans la propriété précédente, sont trèsutiles pour compter le nombre de succès dans une succession d’épreuves de Bernoulli. On rappellede plus que de telles variables de Bernoulli peuvent être vues comme des fonctions indicatrices.
Soit X une variable aléatoire sur (Ω,A ,P ) telle que X (Ω) = N∗.
Les propriétés suivantes sont équivalentes :
1. Il existe p ∈ ]0,1[ tel que X → G ( p).
2. P (X = 1) > 0, P (X > n) > 0 pour tout n ∈ N et
∀ (n,k) ∈ N2, P (X > n + k | X > n) = P (X > k).
La loi d’une variable aléatoire vérifiant 2 est dite loi sans mémoire (ou sans vieillise-ment).
Ainsi, les lois géométriques sont exactement les lois sans mémoire.
Propriété – Caractérisation des lois géométriques comme lois sans mémoire
Démonstration
1 ⇒ 2 : supposons que X → G ( p) avec p ∈ ]0,1[. Alors P (X = 1) = p > 0 et, pour tout n ∈ N,
P (X > n) =+∞
j=n+1
P (X = j) =+∞
j=n+1
p(1 − p) j−1 = p (1 − p)n
1 − (1 − p) = (1 − p)n.
En particulier, P (X > n) > 0 pour tout n ∈N. Soit (n,k) ∈N2. Alors
P (X > n + k | X > n) = P (X > n + k,X > n)
P (X > n)
= P (X > n + k)
P (X > n)
= (1 − p)n+k
(1 − p)n
= (1
− p)k = P (X > k).
2 ⇒ 1 : posons p = P (X = 1) > 0. On a aussi p = 1 − P (X > 1) < 1. Soit, pour tout n ∈ N,xn = P (X > n). D’après la propriété d’absence de mémoire,
xn+1 = P (X > n + 1) = P (X > n + 1 | X > n) P (X > n) = P (X > 1)P (X > n) = (1 − p) xn.
La suite (xn)n∈N est donc géométrique de raison 1 − p et de premier terme x0 = P (X > 0) = 1,donc pour tout n ∈ N, xn = (1 − p)n. Alors, pour tout n ∈ N∗,
P (X = n) = P (X > n − 1) − P (X > n) = (1 − p)n−1 − (1 − p)n
= (1−
p)n−1(1−
(1−
p))
= p (1 − p)n−1.
Finalement, p ∈ ]0,1[ et X
→ G ( p).
269

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 278/383
Remarque – Comme on l’a dit plus haut, la loi G ( p) modélise souvent une durée de fonctionne-ment, ou plus généralement un temps d’attente avant qu’un phénomène se produise. La propriétéd’absence de mémoire signifie que ce temps d’attente est indépendant de l’étape à laquelle oncommence à attendre.
4. Indépendance et modélisation
Comme nous l’avons déjà vu, la modélisation d’une expérience aléatoire par le choix de(Ω,A ,P ) n’est pas toujours évidente. En fait, elle n’est parfois pas utile, le fait de préciser lesconditions de l’expérience, ce qui est plus intuitif, étant souvent suffisant. C’est ce que permetde faire le résultat suivant :
Soit I un ensemble d’indices fini ou dénombrable. Pour tout i ∈ I , on se donne une loidiscrète L i (ce qui revient à se donner une famille ou une suite de nombres positifs desomme 1).
Alors il existe un espace probabilisé (Ω,A ,P ) et une famille (X i)i∈I de variables aléa-toires sur (Ω,A ,P ), mutuellement indépendantes, tels que pour tout i
∈ I , X i suit la
loi L i.
Théorème (admis : démonstration hors programme)
Il est ainsi possible de modéliser une succession, finie ou infinie, d’expériences aléatoiresmutuellement indépendantes, par le choix des lois de variables aléatoires, sans avoir à préciser(Ω,A ,P ).
Exemples
• Un jeu de pile ou face, fini ou infini, avec indépendance mutuelle des différents lancers, pourraêtre modélisé par le choix d’une suite (X i)i∈I , finie ou infinie, de variables de Bernoulli mutuel-lement indépendantes de même paramètre p. Pour tout i ∈ I , X i représente le résultat du i-ièmelancer (1 pour « pile », de probabilité p, 0 pour « face », par exemple).
• On considère la situation suivante : une urne contient des jetons rouges en proportion p, etblancs en proportion 1 − p ; N personnes tirent successivement, avec remise, n jetons dans l’urne,le gain de chaque personne étant lié au nombre de jetons rouges tirés.
On pourra modéliser cette situation par une famille (X 1, . . . , X N ) de N variables aléatoiresmutuellement indépendantes, suivant chacune la loi binomiale B (n,p). Pour tout i ∈ [[1,N ]], X ireprésente le nombre de jetons rouges tirés par le i-ième participant.
IV. Espérance
Soit X une variable aléatoire réelle sur (Ω,A ,P ), avec X (Ω) dénombrable ; on décritX (Ω) en extension sous la forme xn; n ∈ N.
On dit que X est d’espérance finie si la sérien0
xn P (X = xn)
est absolument convergente.
Dans ce cas, la somme de cette série est appelée espérance de X , et notée E (X ),c’est-à-dire,
E (X ) =
+
∞n=0
xn P (X = xn).
Définition
270

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 279/383
Remarques
• L’espérance de X est à interpréter comme moyenne pondérée des valeurs de X . Par exempleen physique, elle représente l’énergie moyenne de systèmes à spectre discret (comme un atomeconfiné dans une boîte).
• La notion d’espérance de X dépend de X uniquement à travers sa loi.
• La définition précédente semble dépendre du choix des xn (c’est-à-dire de l’ordre d’énumérationdes éléments de X (Ω)). On admettra que lorsque X est d’espérance finie, la somme définissantE (X ) ne dépend pas de l’ordre d’énumération.• Si X (Ω) est fini avec X (Ω) = x1, . . . , xm, alors X est d’espérance finie, et E (X ) est simple-ment définie par :
E (X ) =mn=1
xn P (X = xn).
• S’il existe a ∈ R tel que P (X = a) = 1, alors X est d’espérance finie égale à a.
• Si Ω est fini, on a la relation E (X ) =ω∈Ω
X (ω) P (ω).
Soit X une variable aléatoire sur (Ω,A ,P ).
• Si X suit la loi uniforme avec X (Ω) = x1, . . . , xm, alors X est d’espérance finie avec
E (X ) = 1
m
mn=1
xn.
• Si X
→ B ( p), alors X est d’espérance finie et E (X ) = p.
• Si X
→ B (n,p), alors X est d’espérance finie et E (X ) = np.
• Si X
→G ( p), alors X est d’espérance finie et E (X ) =
1
p.
• Si X
→P (λ), alors X est d’espérance finie et E (X ) = λ.
Propriété – Espérance correspondant aux lois usuelles
Démonstration
• Pour tout n ∈ [[1,m]], P (X = xn) = 1/m, d’où le résultat.
• Si X
→ B ( p), on a E (X ) = 0 × (1 − p) + 1 × p = p.
• Si X
→ B (n,p),
E (X ) =n
k=0
knk pk(1
− p)n−k =
n
k=1
nn − 1k
−1 pk(1
− p)n−k.
Avec le changement d’indice j = k − 1, on obtient
E (X ) = nn−1 j=0
n − 1
j
p j+1(1 − p)(n−1)− j
= npn−1 j=0
n − 1
j
p j(1 − p)(n−1)− j = np ( p + (1 − p))n−1 = np.
• Supposons que X
→ G ( p). La série n1 n p(1− p)n−1 est convergente : on reconnaît la dérivée
de la série géométrique évaluée en 1 − p avec |1 − p| < 1. On a ainsi
E (X ) = p 1
(1 − (1 − p))2 =
1
p.
271

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 280/383
• Supposons que X
→ P (λ). La série
k0
k e−λλk
k! =
k1
e−λ λk
(k − 1)! = λ e−λ
j0
λ j
j!
est convergente (série exponentielle) et
E (X ) = λ e−λ+∞ j=0
λ
j
j! = λ e−λeλ = λ.
Soit X une variable aléatoire sur (Ω,A ,P ) à valeurs dans N.
La variable aléatoire X est d’espérance finie si et seulement si la sérien1 P (X n)
converge, et dans ce cas on a
E (X ) =
+∞
n=1 P (X n).
Propriété
Démonstration – Pour tout n ∈ N, on a
(X n) = (X = n) ∪ (X n + 1),
ces deux événements étant incompatibles, et donc
P (X = n) = P (X n) − P (X n + 1).
Alors, pour tout p
∈N∗,
pn=0
n P (X = n) =
pn=0
n (P (X n) − P (X n + 1))
=
pn=0
n P (X n) − p+1n=1
(n − 1) P (X n)
après séparation des sommes et changement d’indice dans la deuxième somme. Finalement,
p
n=0
n P (X = n) =
p
n=1
P (X n)
− p P (X p + 1). (14.1)
Si X est d’espérance finie, alors on peut écrire
0 p P (X p + 1) = p+∞
n= p+1
P (X = n) +∞
n= p+1
n P (X = n) −→ p→+∞
0
en tant que reste d’une série convergente. On en déduit quen1 P (X n) converge ainsi que
l’égalité souhaitée en faisant tendre p vers +∞.
Par positivité des termes, et d’après (14.1), si
n1 P (X n) converge, alors
n1
n P (X = n)
converge (la suite de ses sommes partielles est majorée) donc X est d’espérance finie. On conclutcomme précédemment.
272

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 281/383
Soit X une variable aléatoire sur (Ω,A ,P ) avec X (Ω) dénombrable ; on décrit X (Ω) enextension sous la forme xn; n ∈ N. Soit f : X (Ω) → R une fonction.
La variable aléatoire f (X ) est d’espérance finie si et seulement si la sérien0 f (xn) P (X = xn) converge absolument, et dans ce cas, on a
E (f (X )) =
+
∞n=0
f (xn) P (X = xn).
Théorème de transfert (admis : démonstration hors-programme)
Remarque – Si l’on appliquait la définition de l’espérance pour f (X ), on devrait déterminer la loide f (X ) : on devrait décrire f (X (Ω)) en extension sous la forme yn; n ∈ I (I fini ou I = N)puis considérer la somme finie ou la série
n∈I yn P (f (X ) = yn).
L’immense avantage du théorème de transfert est de montrer qu’il suffit en fait de considérer laloi de X . On a transféré le calcul de E (f (X )) sur la variable aléatoire X . Ceci est particulièrementintéressant lorsque f n’est pas injective.
Exemple – Soit X une variable aléatoire suivant la loi géométrique de paramètre p. D’après le
théorème de transfert, si la série n1
(−1)n p (1 − p)n−1
converge absolument, alors (−1)X est d’espérance finie et la somme de cette série est E ((−1)X ).On reconnaît (à un facteur − p près) la série géométrique de raison p − 1 avec | p − 1| < 1, doncabsolument convergente. On en déduit que (−1)X est d’espérance finie avec
E ((−1)X ) =+∞n=1
(−1)n p (1 − p)n−1 = − p 1
1 − ( p − 1) =
p
p − 2.
Soient X et Y deux variables aléatoires d’espérance finie sur (Ω,A ,P ) et λ ∈ R. Alors :
• Linéarité : λX + Y est d’espérance finie et E (λX + Y ) = λE (X ) + E (Y ).
• Positivité : si P (X 0) = 1, alors E (X ) 0.
• Croissance : si P (X Y ) = 1, alors E (X ) E (Y ).
Théorème – Quelques propriétés de l’espérance
Démonstration
• La démonstration de la linéarité de l’espérance n’est pas exigible.
Considérons le couple (X,Y ) et lorsque X (Ω) × Y (Ω) est dénombrable, décrivons-le en extension
sous la forme (xn,yn); n ∈ N. Soit f une fonction définie sur X (Ω) × Y (Ω), à valeurs dansR ; d’après le théorème de transfert, la série
n0 f (xn,yn) P (X = xn, Y = yn) est absolumentconvergente si et seulement si f (X,Y ) est d’espérance finie, et dans ce cas
E (f (X,Y )) =+∞n=0
f (xn,yn) P (X = xn, Y = yn).
Nous allons utiliser ce résultat avec f : (x,y) → x, f : (x,y) → y et f : (x,y) → λx + y. Les sériesn0
xn P (X = xn, Y = yn) etn0
yn P (X = xn, Y = yn)
sont absolument convergentes car X et Y sont d’espérance finie. Par combinaison linéaire, lasérie n0
(λxn + yn) P (X = xn, Y = yn)
273

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 282/383
est absolument convergente, donc λX + Y est d’espérance finie ; on a alors
E (λX + Y ) = λ+∞n=0
xn P (X = xn, Y = yn) ++∞n=0
yn P (X = xn, Y = yn) = λE (X ) + E (Y ).
On adapte la démonstration avec des sommes finies si X (Ω) × Y (Ω) est fini.
• On décrit X (Ω) en extension sous la forme xn; n ∈ I . On a P (X < 0) = 0, donc pour tout
n tel que xn < 0, xn P (X = xn) = 0. Donc on peut écrire E (X ) comme somme d’une série (ousomme finie) à termes positifs, d’où E (X ) 0.
• Cela résulte des deux points précédents.
Application – On retrouve facilement l’espérance d’une variable aléatoire suivant la loi B (n,p)
en utilisant la linéarité de l’espérance : soient X 1, . . . , X n des variables aléatoires mutuellementindépendantes suivant la même loi B ( p) (on sait qu’il existe un espace probabilisé portant detelles lois). Alors on sait que S = X 1 + · · · + X n suit la loi B (n,p). Par linéarité de l’espérance,on a donc
E (S ) =nk=1
E (X k) = np
car E (X k) = p pour tout k. L’espérance ne dépendant que de la loi, on obtient ainsi l’espérancede toutes les variables aléatoires suivant la loi B (n,p).
Soient X et Y deux variables aléatoires indépendantes sur (Ω,A ,P ), d’espérance finie.Alors X Y est d’espérance finie et
E (XY ) = E (X )E (Y ).
La réciproque est fausse en général.
Propriété
La démonstration est hors-programme dans le cas général. Dans le cas des univers finis, ellea été donnée en première année.
Exemple – Marche aléatoire
Reprenons un exemple décrit plus haut : une particule peut occuper différentes positions repéréespar les entiers relatifs. À intervalle régulier, la particule peut passer de la position i à la positioni + 1 avec probabilité p ∈ ]0,1[, ou à la position i −1 avec probabilité q = 1− p. On suppose qu’unmouvement ne dépend que de la position à partir de laquelle il est fait. Pour n 1, on noteX n la variable aléatoire représentant la position de la particule après n mouvements; X 0 est lavariable aléatoire nulle (la position initiale est 0). On admet l’existence d’un espace probabilisé
(Ω,A ,P ) modélisant cette expérience.On cherche à étudier différents aspects de cette marche aléatoire.
• Loi de X 1 et X 2 : X 1 prend les valeurs 1 et −1, avec P (X 1 = 1) = p, P (X 1 = −1) = q . Onen déduit que X 2 prend les valeurs −2, 0 et 2. D’après la formule des probabilités totales,
P (X 2 = 2) = P (X 2 = 2 | X 1 = 1)P (X 1 = 1) + P (X 2 = 2 | X 1 = −1)P (X 1 = −1)
= p P (X 1 = 1) + 0 × P (X 1 = −1) = p2,
P (X 2 = 0) = P (X 2 = 0 | X 1 = 1)P (X 1 = 1) + P (X 2 = 0 | X 1 = −1)P (X 1 = −1) = 2 pq,
P (X 2 = −2) = P (X 2 = −2 | X 1 = 1)P (X 1 = 1) + P (X 2 = −2 | X 1 = −1)P (X 1 = −1)
= 0 × P (X 1 = 1) + q P (X 1 = −1) = q 2
.
• La particule ne peut revenir en 0 qu’après un nombre pair de mouvements, ainsi, pour toutn ∈ N, P (X 2n+1 = 0) = 0. Pour n ∈ N, la particule est à l’origine après 2n mouvements si et
274

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 283/383
seulement si elle a effectué n mouvements à droite et n mouvements à gauche. Le nombre demouvements à droite parmi les 2n premiers suit la loi B (2n,p), donc
P (X 2n = 0) =
2nn
pn(1 − p)2n−n =
(2n)!
(n!)2( p(1 − p))n.
D’après la formule de Stirling,
(2n)!
(n!)2 ∼
2n
e
2n √ 4πnn
e
2n2πn
= 4n√
nπ
et finalement,
P (X 2n = 0) ∼ 1√ nπ
(4 p(1 − p))n.
• La variable aléatoire 1(X 2=0) + · · · + 1(X 2n=0) représente le nombre de retours à l’origine aucours des 2n premiers mouvements. Par linéarité de l’espérance (pour tout A ∈ A , la variable
aléatoire 1A est d’espérance finie égale à P (A)),
E (1(X 2=0) + · · · + 1(X 2n=0)) =nk=1
P (X 2k = 0).
Remarquons que l’on a calculé cette espérance sans déterminer la loi du nombre de retours.
– Si p = 1/2, 0 < 4 p(1 − p) < 1, et par comparaison de séries à termes positifs, la série determe général P (X 2n = 0) converge. L’espérance du nombre de retours à l’origine est majoréeindépendamment du nombre de mouvements.
– Si p = 1/2, P (X 2n = 0) ∼ 1√ nπ
et la série de terme général P (X 2n = 0) (à termes positifs)
diverge par comparaison avec une série de Riemann d’exposant 1/2 < 1. Un résultat sur lessommes partielles de séries à termes positifs divergentes, puis une comparaison série/intégrale(que nous ne détaillons pas ici), montrent alors que
nk=1
P (X 2k = 0) ∼nk=1
1√ kπ
∼ 2
n
π.
Cette espérance tend vers +∞ lorsque n → +∞ : en un temps illimité, il y a en moyenne uneinfinité de retours à l’origine !
V. Séries génératrices des variables aléatoires à valeurs dans N
Soit X une variable aléatoire sur (Ω,A ,P ), à valeurs dans N.
Alors, pour tout t ∈ [−1,1], la variable aléatoire tX est d’espérance finie. On pose, pourtout t ∈ [−1,1],
GX (t) = E (tX ), et on a GX (t) =+∞n=0
P (X = n) tn.
La fonction GX est la somme d’une série entière de rayon de convergence au moins égalà 1. Elle est appelée série génératrice (ou fonction génératrice) de X .
Propriété/Définition
275

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 284/383
Démonstration – On peut considérer que X (Ω) = N. Soit t ∈ [−1,1]. D’après le théorème detransfert, tX est d’espérance finie si et seulement si la série
n0
P (X = n) tn
converge absolument. Or, pour tout n ∈ N, |P (X = n) tn| P (X = n), et
n0 P (X = n)
converge (et sa somme vaut 1). Par comparaison, on en déduit l’existence de E (tX ) ; la formule
donnant E (tX
) provient aussi du théorème de transfert.Sachant que la série entière définissant GX converge absolument en tout point de [−1,1], son
rayon de convergence est au moins égal à 1.
Remarques
• On a GX (1) =+∞n=0
P (X = n) = 1.
• Lorsque X (Ω) est fini, GX est un polynôme (et R = +∞).
La loi d’une variable aléatoire à valeurs dans N est caractérisée par sa série génératrice :soient X et Y deux variables aléatoires sur (Ω,A ,P ), à valeurs dans N, telles queX (Ω) = Y (Ω) et GX (t) = GY (t) pour tout t ∈ ] − r,r[ (pour un certain r ∈ ]0,1]).
Alors X et Y ont la même loi.
Propriété
Démonstration – Si GX (t) = GY (t) pour tout t ∈ [−1,1], alors par unicité du développement ensérie entière, P (X = n) = P (Y = n) pour tout n ∈ N.
Remarque – La série génératrice de X contient donc toute l’information sur la loi de X . On a enfait, d’après l’expression des coefficients d’une série entière : pour tout n ∈ N,
P (X = n) = G
(n)X (0)
n!
Soit X une variable aléatoire sur (Ω,A ,P ), à valeurs dans N.
Alors, pour que X soit d’espérance finie, il faut et il suffit que GX soit dérivable àgauche en 1. Dans ce cas, on a
E (X ) = G′X (1).
Propriété
Démonstration (non exigible)
⇒ Posons, pour tout n ∈ N, f n : t → P (X = n) tn
. La série de fonctions n0 f n convergesimplement sur [−1,1] ; pour tout n ∈N, f n est de classe C1 sur [−1,1] avec pour tout n ∈ N∗ ett ∈ [−1,1],
|f ′n(t)| = |n P (X = n) tn−1| n P (X = n).
Le majorant est le terme général d’une série convergente car X est d’espérance finie. D’aprèsle théorème de la classe C1 pour les séries de fonctions, GX est de classe C1 sur [−1,1], et enparticulier dérivable à gauche en 1. On a de plus
G′X (1) =
+∞n=0
f ′n(1) =+∞n=1
n P (X = n) = E (X ).
⇐ Soit p ∈ N∗. Pour tout t ∈ [0,1[,GX (t) − GX (1)
t − 1
pn=0
P (X = n) tn − 1
t − 1 =
pn=1
P (X = n) (1 + t + · · · + tn−1),
276

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 285/383

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 286/383
Démonstration – La variable X + Y est à valeurs dans N de même que X et Y . Les variables X
et Y sont indépendantes, donc pour tout t ∈ [−1,1], tX et tY sont indépendantes. On en déduitque
GX +Y (t) = E (tX +Y ) = E (tX tY ) = E (tX )E (tY ) = GX (t) GY (t).
Remarque – Soit n ∈ N ; on a
(X + Y = n) =nk=0
(X = k, Y = n − k),
ces événements étant deux à deux incompatibles, d’où, par indépendance,
P (X + Y = n) =nk=0
P (X = k, Y = n − k) =nk=0
P (X = k) P (Y = n − k).
On connaît donc la loi de X + Y . Par produit de Cauchy de deux séries entières absolumentconvergentes, on a pour tout t
∈ [
−1,1],
GX (t) GY (t) =+∞n=0
nk=0
P (X = k) P (Y = n − k)
tn =
+∞n=0
P (X + Y = n) tn = GX +Y (t),
ce qui donne une autre démonstration de la propriété précédente.
Soient X et Y deux variables aléatoires indépendantes sur (Ω,A ,P ) et λ, µ deux réelsstrictement positifs. On suppose que X
→P (λ) et Y
→P (µ).
Alors X + Y
→P (λ + µ).
Corollaire
Démonstration – Pour tout n ∈ N, P (X = n, Y = 0) = P (X = n) P (Y = 0) par indépendance,donc P (X + Y = n) > 0. On en déduit que (X + Y )(Ω) = N. De plus, pour tout t ∈ [−1,1] (enfait pour tout t ∈ R),
GX +Y (t) = GX (t) GY (t) = eλ(t−1) eµ(t−1) = e(λ+µ)(t−1).
La série génératrice caractérisant la loi, on en déduit que X + Y
→P (λ + µ).
VI. Variance1. Généralités
L’espérance de X correspond à la moyenne pondérée des valeurs de X , mais ne décrit pascomment sont réparties les valeurs de X autour de cette moyenne. C’est l’intérêt des notions devariance et d’écart-type.
Soit X une variable aléatoire réelle sur (Ω,A ,P ). On suppose que X 2 est d’espérancefinie. Alors :
• X est d’espérance finie.• (X − E (X ))2 est d’espérance finie.
Propriété
278

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 287/383
Démonstration
• Le problème ne se pose que si X (Ω) est dénombrable. On écrit X (Ω) = xn; n ∈N. La variablealéatoire X 2 est d’espérance finie, donc d’après le théorème de transfert,
n0 x2
n P (X = xn)
converge et sa somme est E (X 2). Pour tout p ∈ N, on a d’après l’inégalité de Cauchy-Schwarz,
p
n=0
|xn| P (X = xn) =
p
n=0
|xn|
P (X = xn)
P (X = xn)
pn=0
x2n P (X = xn)
pn=0
P (X = xn)
1/2
+∞n=0
x2n P (X = xn)
+∞n=0
P (X = xn)
1/2
=
E (X 2)
car +∞
n=0 P (X = xn) = 1.
Les sommes partielles de la série à termes positifs
n0 |xn| P (X = xn) sont majorées
indépendamment de p, donc cette série converge, ce qui prouve le résultat. En passant à la limite
dans les inégalités précédentes, on obtient même : E (|X |) E (X 2).• On a (X − E (X ))2 = X 2 − 2E (X )X + E (X )2. Si X 2 est d’espérance finie, X également, etdonc par combinaison linéaire, (X − E (X ))2 est d’espérance finie.
Cette propriété permet de donner la définition suivante :
Soit X une variable aléatoire réelle sur (Ω,A ,P ). On dit que X admet une variance(ou admet un moment d’ordre 2) si X 2 est d’espérance finie. Dans ce cas :
• On appelle variance de X le réel positif
V (X ) = E ((X − E (X ))2).
On a aussi V (X ) = E (X 2) − E (X )2.
• On appelle écart-type de X le réel positif σ(X ) =
V (X ).
Propriété/Définition
Démonstration de la seconde expression de V (X )
D’après la propriété précédente, (X − E (X ))2 = X 2 − 2E (X )X + E (X )2 est d’espérance finie ;par linéarité de l’espérance,
V (X ) = E (X 2) − 2E (X )2 + E (X )2 = E (X 2) − E (X )2.
Remarques• Si X 2 est d’espérance finie, le moment d’ordre 2 de X est le réel positif E (X 2).
• Si X (Ω) = xn; n ∈ N, d’après le théorème de transfert, X a une variance si et seulement sila série à termes positifs
n0 x2
n P (X = xn) converge, et dans ce cas,
V (X ) =+∞n=0
(xn − E (X ))2 P (X = xn).
• Si X admet une variance et m = E (X ), on a V (X ) = 0 si et seulement si P (X = m) = 1.
Exemple – Soit X une variable aléatoire prenant les valeurs 1 et −1 et suivant la loi uniforme, etsoit Y la variable aléatoire nulle. Alors X et Y sont toutes les deux d’espérance nulle. Pourtant,elles se comportent très différemment ; la variance est un moyen de mesurer cette différence : ona
V (X ) = E ((X − 0)2) = E (X 2) = 1 et V (Y ) = 0.
279

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 288/383
Soit X une variable aléatoire réelle sur (Ω,A ,P ) admettant une variance, et (a,b) ∈R2.
Alors aX + b admet une variance et on a : V (aX + b) = a2 V (X ).
Propriété
Démonstration – On a (aX +b)2 = a2X 2+2abX +b2 et X 2 est d’espérance finie donc X également.Par combinaison linéaire, aX + b a une variance et par linéarité de l’espérance,
E ((aX + b)2) = a2E (X 2) + 2abE (X ) + b2
(E (aX + b))2 = (aE (X ) + b)2 = a2E (X )2 + 2abE (X ) + b2.
Par différence, on en déduit que
V (aX + b) = a2(E (X 2) − E (X )2) = a2 V (X ).
Remarque – Cette propriété est cohérente avec l’interprétation de V (X ) et σ(X ) comme indi-cateurs de dispersion des valeurs de X autour de son espérance : ajouter une même valeur b à
toutes les valeurs de X ne modifie pas la variance et l’écart-type, multiplier toutes les valeurs deX par un réel a multiplie l’écart-type par |a|.
Soit X une variable aléatoire sur (Ω,A ,P ), à valeurs dans N.
Pour que X admette une variance, il faut et il suffit que GX soit deux fois dérivable àgauche en 1. Dans ce cas,
V (X ) = G′′X (1) + G′
X (1) − G′X (1)2.
Propriété (démonstration non exigible)
Ce résultat est admis. Il s’agit d’adapter la démonstration faisant le lien entre l’existence deE (X ) et celle de G′
X (1). Expliquons simplement comment retrouver la formule donnant V (X ) :en cas d’existence, on montre que G′
X (t) et G′′X (t) se calculent, pour t ∈ [−1,1], par dérivation
terme à terme avec
G′X (t) =
+∞n=1
n P (X = n) tn−1, G′′X (t) =
+∞n=2
n(n − 1) P (X = n) tn−2
G′X (1) =
+∞n=0
n P (X = n) = E (X ), G′′X (1) =
+∞n=0
n(n − 1) P (X = n) = E (X (X − 1)).
D’après le théorème de transfert, et par linéarité de l’espérance,
V (X ) = E (X 2) − E (X )2 = E (X (X − 1)) + E (X ) − E (X )2 = G′′X (1) + G′
X (1) − G′X (1)2.
Soit X une variable aléatoire sur (Ω,A ,P ).
• Si X
→ B ( p), alors X admet une variance et V (X ) = p(1 − p).
• Si X
→ B (n,p), alors X admet une variance et V (X ) = np(1 − p).
• Si X
→G
( p), alors X admet une variance et V (X ) =
1
− p
p2 .• Si X
→P (λ), alors X admet une variance et V (X ) = λ.
Propriété – Variance correspondant aux lois usuelles
280

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 289/383
Démonstration
• Si X
→ B ( p), on a E (X 2) = 02 × (1 − p) + 12 × p = p. Alors
V (X ) = E (X 2) − E (X )2 = p − p2 = p(1 − p).
• Si X
→ B (n,p), on sait que GX (t) = (1 − p + pt)n pour tout t ∈ R. La fonction GX est deuxfois dérivable en 1, donc X admet une variance, et
V (X ) = G′′X (1) + G′
X (1) − G′X (1)2 = n(n − 1) p2 + np − n2 p2 = np(1 − p).
• Supposons que X
→ G ( p). On sait que GX (t) = pt
1 − (1 − p)t notamment pour tout t ∈ [−1,1].
La fonction GX est deux fois dérivable sur [−1,1], avec
∀ t ∈ [−1,1], G′X (t) =
p
(1 − (1 − p)t)2, G′′
X (t) = 2 p(1 − p)
(1 − (1 − p)t)3.
En particulier, X admet une variance, et
V (X ) = G′′X (1) + G′X (1) − G′X (1)2 = 2 p(1
− p)
p3 + 1
p − 1
p2 = 1
− p
p2 .
• Supposons que X
→ P (λ). On sait que GX (t) = eλ(t−1) pour tout t ∈ R. La fonction GX estdeux fois dérivable en 1, donc X admet une variance, et
V (X ) = G′′X (1) + G′
X (1) − G′X (1)2 = λ2 + λ − λ2 = λ.
Remarque – On peut calculer toutes ces variances directement à partir du théorème de transfert.
2. Covariance et corrélation
Soient X et Y deux variables aléatoires sur (Ω,A ,P ) admettant une variance.
Alors X Y est d’espérance finie et
|E (XY )|
E (X 2)E (Y 2 ).
Propriété – Inégalité de Cauchy-Schwarz
Démonstration – On a |XY | X 2 + Y 2 ; en adaptant la démonstration de la linéarité de l’es-pérance, on en déduit que XY est d’espérance finie. Quant à l’inégalité de Cauchy-Schwarz, onprocède comme pour un produit scalaire, en considérant la fonction polynomiale de degré auplus 2
λ → E ((λX + Y )
2
) = λ
2
E (X
2
) + 2λE (XY ) + E (Y
2
),à valeurs positives.
Soient X et Y deux variables aléatoires sur (Ω,A ,P ) admettant une variance.
• On appelle covariance de X et Y le réel
Cov(X,Y ) = E
[X − E (X )] [Y − E (Y )]
= E (XY ) − E (X )E (Y ).
• Si σ(X ) et σ(Y ) sont non nuls, on appelle coefficient de corrélation de X et Y leréel
ρ(X,Y ) = Cov(X,Y )σ(X ) σ(Y )
.
Définition
281

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 290/383
Démonstration de l’existence de Cov(X,Y ), et de la seconde formule
On a [X − E (X )] [Y − E (Y )] = X Y − E (X )Y − E (Y )X + E (X )E (Y ). Les variables aléatoiresX et Y ont une variance, donc le produit XY est d’espérance finie et par combinaison linéaire,[X − E (X )] [Y − E (Y )] est d’espérance finie. Par linéarité de l’espérance, on a
Cov(X,Y ) = E (XY ) − E (X )E (Y ) − E (Y )E (X ) + E (X )E (Y ) = E (XY ) − E (X )E (Y ).
Remarques• Si X admet une variance, Cov(X,X ) = V (X ).
• Si X et Y admettent une variance, Cov(X,Y ) = Cov(Y,X ).
Soient X et Y deux variables aléatoires indépendantes sur (Ω,A ,P ) admettant unevariance.
Alors Cov(X,Y ) = 0.
Propriété
Démonstration – On a Cov(X,Y ) = E (XY ) − E (X )E (Y ) = 0 par indépendance.
Remarque – La réciproque de la propriété précédente est fausse comme le montre l’exemplesuivant : soit X une variable aléatoire d’image −1,0,1, de loi uniforme, et soit Y = X 2. AlorsE (XY ) = E (X ) = 0 (on a XY = X 3 = X ) donc Cov(X,Y ) = 0, mais X et Y ne sont pasindépendantes car
P (Y = 0 | X = 1) = 0 = 1
3 = P (Y = 0).
Exemple – Soit (X n)n∈N∗ une suite de variables aléatoires mutuellement indépendantes suivantla loi B ( p) avec p ∈ ]0,1[. Posons, pour tout n ∈ N∗, Y n = X nX n+1. Pour tout n, X n est lafonction indicatrice de l’événement (X n = 1), et Y n est la fonction indicatrice de l’événement(X n = 1)
∩(X n+1 = 1), de probabilité p2
∈]0,1[ par indépendance. En particulier, Y n
→B ( p2).
La variable Y n indique deux succès consécutifs aux rangs n et n + 1.De la même façon, pour tout n ∈ N∗, Y nY n+1 = X nX n+1X n+2
→ B ( p3), donc
Cov(Y n,Y n+1) = E (Y nY n+1) − E (Y n)E (Y n+1) = p3 − p4 = p3(1 − p).
Notamment, Y n et Y n+1 ne sont pas indépendantes.
En revanche, si j i + 2, on remarque que Y iY j est la fonction indicatrice de
(Y iY j = 1) = (X i = 1) ∩ (X i+1 = 1) ∩ (X j = 1) ∩ (X j+1 = 1),
de probabilité p4 par indépendance, et donc E (Y iY j) = p4, puis
Cov(Y i,Y j) = E (Y iY j) − E (Y i)E (Y j) = p4 − p2 p2 = 0.
Attention, on ne peut pas en déduire que Y i et Y j sont indépendantes (c’est vrai, mais il faudraitle prouver en revenant par exemple à la définition).
Soient X et Y deux variables aléatoires sur (Ω,A ,P ) admettant une variance.
Alors|Cov(X,Y )| σ(X ) σ(Y ),
En particulier, si σ(X )
= 0 et σ(Y )
= 0,
ρ(X,Y ) ∈ [−1,1].
Propriété
282

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 291/383
Démonstration – D’après l’inégalité de Cauchy-Schwarz,
|Cov(X,Y )| = |E ([X −E (X )][Y −E (Y )])| E ((X − E (X ))2)E ((Y − E (Y ))2)
1/2= σ(X ) σ(Y ).
L’encadrement de ρ(X,Y ) s’ensuit directement.
Remarque – Le coefficient de corrélation mesure en quelque sorte la dépendance entre X et Y .Lorsque
|ρ(X,Y )
|est proche de 1, une information sur X apporte une information sur Y . Lorsque
X et Y sont indépendantes, ρ(X,Y ) = 0, mais la réciproque est fausse.
Soient X 1, . . . , X n des variables aléatoires sur (Ω,A ,P ) admettant une variance.
Alors :
• nk=1 X k admet une variance et
V
nk=1
X k
=
nk=1
V (X k) + 2i<j
Cov(X i,X j).
• Si de plus X 1, . . . , X n sont deux à deux indépendantes, on a
V
nk=1
X k
=
nk=1
V (X k).
Propriété
Démonstration
• On a n
k=1
X k
2
=n
k=1
X 2k + 2
i<jX iX j .
Les X k ont toutes une variance, donc les X iX j sont d’espérance finie, et par combinaison linéaire(nk=1 X k)2 est d’espérance finie (i.e.,
nk=1 X k admet une variance). De plus, par linéarité de
l’espérance,
E
n
k=1
X k
2 =
nk=1
E (X 2k) + 2i<j
E (X iX j).
D’autre part,
E n
k=1
X k2
= n
k=1
E (X k)2
=n
k=1
(E (X k))2 + 2i<j E (X i)E (X j).
On en déduit le résultat par différence.
• Si les X k sont deux à deux indépendantes, on a, pour tout (i,j) ∈ [[1,n]]2 tel que i < j,Cov(X i,X j) = 0, d’où l’égalité souhaitée.
Application – Soient X 1, . . . , X n des variables aléatoires mutuellement indépendantes suivantla même loi B ( p) et soit S = X 1 + · · · + X n. D’après la propriété précédente, S a une variance et
V (S ) =nk=1
V (X k) = np(1 − p).
On sait aussi que S suit la loi B (n,p). La variance ne dépendant que de la loi, on en déduit quepour toute variable aléatoire X qui suit la loi B (n,p), on a V (X ) = np(1 − p). On retrouve doncla valeur de V (X ) déterminée plus tôt par un calcul direct.
283

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 292/383
3. Estimations de la dispersion
La variance s’interprète comme indicateur de dispersion. Dans ce paragraphe, nous allonsmontrer plus précisément comment la variance (ou l’écart-type) permet de mesurer cette disper-sion.
Soit X une variable aléatoire sur (Ω,A
,P ), positive, d’espérance finie.Alors, pour tout ε > 0,
P (X ε) E (X )
ε .
Théorème – Inégalité de Markov
Démonstration – Soit ε > 0 fixé. On décrit X (Ω) en extension sous la forme xn; n ∈ I . SoitU = [ε, + ∞[. Par positivité de X ,
E (X ) xn∈U
xn P (X = xn) εxn∈U
P (X = xn)
car xn ε si xn ∈ U . Alors
E (X ) ε P (X ∈ U ) = ε P (X ε),
d’où le résultat.
Soit X une variable aléatoire sur (Ω,A ,P ) admettant une variance.
Alors, pour tout ε > 0,
P (|X − E (X )| ε) σ(X )2
ε2 .
Théorème – Inégalité de Bienaymé - Tchebychev
Démonstration – Soit ε > 0 fixé. La variable aléatoire X admet une variance donc est d’espérancefinie et, en posant Y = (X −E (X ))2, alors Y est une variable aléatoire positive d’espérance finie.De plus, on remarque que
(|X − E (X )| ε) = (Y ε2).
Alors, d’après l’inégalité de Markov,
P (|X − E (X )| ε) = P (Y ε2) E (Y )
ε2 =
σ(X )2
ε2 .
Remarque – L’inégalité de Bienaymé - Tchebychev permet de majorer la probabilité que X s’écarted’au moins ε de son espérance, i.e., de sa moyenne. On voit que cette majoration fait intervenirl’écart-type de X ; plus précisément, plus σ(X ) est petit, plus la probabilité précédente est faible,c’est-à-dire, plus grande est la probabilité que X soit proche de son espérance. Cela confirmel’interprétation de σ(X ) et V (X ) comme indicateurs de dispersion.
Exemple – Notons m = E (X ) et σ = σ(X ). Pour ε = 2σ, on obtient
P (|X − m| 2σ) 1
4,
ou de façon équivalente,
P (m − 2σ < X < m + 2σ)
3
4 .
La probabilité que X soit au plus à 2 écarts-types de son espérance est donc au moins 3/4. Enrevanche, pour ε = σ, l’inégalité ne donnerait pas de résultat intéressant.
284

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 293/383
Soit (X n)n∈N∗ une famille de variables aléatoires sur (Ω,A ,P ). On suppose que lesvariables aléatoires X n
• sont deux à deux indépendantes,• ont la même loi et admettent une variance.
On note m = E (X 1), σ = σ(X 1) et pour tout n ∈ N∗, S n = X 1 + · · · + X n.
Alors, pour tout ε > 0,P
1
nS n − m
ε
σ2
n ε2,
et en particulier,
P
1
nS n − m
ε
−→n→+∞ 0.
Théorème – Loi faible des grands nombres
Démonstration – Les variables aléatoires X n admettent une variance donc également une espé-rance. Sachant qu’elles ont la même loi, elles ont la même espérance et la même variance (parexemple celles de X 1, m et σ2). De plus, par linéarité de l’espérance, on a pour tout n
∈N∗,
E
1
nS n
=
1
n n E (X 1) = m,
et d’après les propriétés de la variance,
V
1
nS n
=
1
n2 V (S n) =
1
n V (X 1)
par indépendance deux à deux des X k. Ainsi, σ
S nn
2
= σ2
n .
Soit ε > 0 fixé. D’après l’inégalité de Bienaymé-Tchebychev appliquée à S n/n, on a
P
1
nS n − m
ε
σ(S n/n)2
ε2 =
σ2
n ε2 −→n→+∞ 0.
Remarques
• Imaginons que l’on répète indéfiniment une même expérience aléatoire en observant, à chaqueétape, un certain résultat; cette situation est modélisée par une suite (X n)n∈N∗ de variablesaléatoires mutuellement indépendantes et de même loi, X n représentant le résultat observé à lan-ième étape. Alors S n/n représente la moyenne empirique des résultats au cours des n premièresexpériences.
Notons m l’espérance commune à toutes les variables X n. La loi faible des grands nombres affirmeque pour tout ε > 0, la probabilité que S n/n s’écarte de m d’au moins ε tend vers 0 lorsquele nombre d’expériences tend vers +∞. De façon équivalente, la probabilité que cette moyennevérifie m − ε < S n/n < m + ε tend vers 1.
• Par exemple, considérons un jeu de pile ou face infini (ou toute autre expérience de Bernoullireproduite indéfiniment) et notons X n l’indicatrice de l’événement « le n-ième lancer donnepile ». Pour tout n ∈ N∗, X n
→ B ( p), E (X n) = p et V (X n) = p(1 − p). Si les X n sont deux àdeux indépendantes, le théorème précédent affirme que la moyenne S n/n du nombre de « piles »au cours des n premiers tirages sera « proche » de p (à ε près) avec une probabilité tendantvers 1 lorsque n → +∞. En un certain sens, la moyenne se stabilise vers p lorsque le nombred’expériences augmente.
Ci-dessous, on a représenté les fréquences relatives d’apparition de « pile » au cours des npremiers lancers, pour n ∈ [[1,200]] puis pour n ∈ [[1,1000]]. Dans chaque cas, on a effectué troissimulations (courbes des différentes couleurs).
285
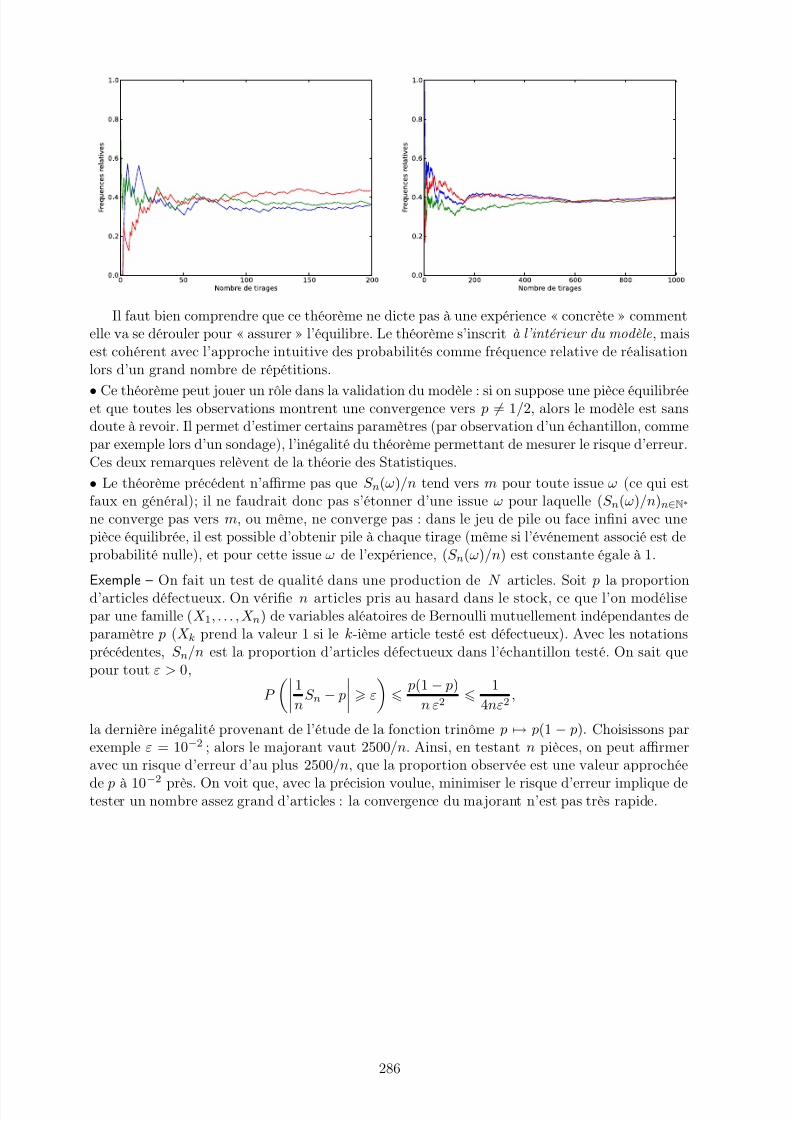
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 294/383
0 5 0 1 0 0 1 5 0 2 0 0
N o m b r e d e t i r a g e s
0 . 0
0 . 2
0 . 4
0 . 6
0 . 8
1 . 0
F
r
e
q
u
e
n
c
e
s
r
e
l
a
t
i
v
e
s
0 2 0 0 4 0 0 6 0 0 8 0 0 1 0 0 0
N o m b r e d e t i r a g e s
0 . 0
0 . 2
0 . 4
0 . 6
0 . 8
1 . 0
F
r
e
q
u
e
n
c
e
s
r
e
l
a
t
i
v
e
s
Il faut bien comprendre que ce théorème ne dicte pas à une expérience « concrète » commentelle va se dérouler pour « assurer » l’équilibre. Le théorème s’inscrit à l’intérieur du modèle , maisest cohérent avec l’approche intuitive des probabilités comme fréquence relative de réalisationlors d’un grand nombre de répétitions.
• Ce théorème peut jouer un rôle dans la validation du modèle : si on suppose une pièce équilibréeet que toutes les observations montrent une convergence vers p = 1/2, alors le modèle est sansdoute à revoir. Il permet d’estimer certains paramètres (par observation d’un échantillon, commepar exemple lors d’un sondage), l’inégalité du théorème permettant de mesurer le risque d’erreur.Ces deux remarques relèvent de la théorie des Statistiques.
• Le théorème précédent n’affirme pas que S n(ω)/n tend vers m pour toute issue ω (ce qui estfaux en général); il ne faudrait donc pas s’étonner d’une issue ω pour laquelle (S n(ω)/n)n∈N∗ne converge pas vers m, ou même, ne converge pas : dans le jeu de pile ou face infini avec unepièce équilibrée, il est possible d’obtenir pile à chaque tirage (même si l’événement associé est deprobabilité nulle), et pour cette issue ω de l’expérience, (S n(ω)/n) est constante égale à 1.
Exemple – On fait un test de qualité dans une production de N articles. Soit p la proportiond’articles défectueux. On vérifie n articles pris au hasard dans le stock, ce que l’on modélisepar une famille (X 1, . . . , X n) de variables aléatoires de Bernoulli mutuellement indépendantes deparamètre p (X k prend la valeur 1 si le k-ième article testé est défectueux). Avec les notationsprécédentes, S n/n est la proportion d’articles défectueux dans l’échantillon testé. On sait quepour tout ε > 0,
P
1
nS n − p
ε
p(1 − p)
n ε2
1
4nε2,
la dernière inégalité provenant de l’étude de la fonction trinôme p → p(1 − p). Choisissons parexemple ε = 10−2 ; alors le majorant vaut 2500/n. Ainsi, en testant n pièces, on peut affirmeravec un risque d’erreur d’au plus 2500/n, que la proportion observée est une valeur approchée
de p à 10−2
près. On voit que, avec la précision voulue, minimiser le risque d’erreur implique detester un nombre assez grand d’articles : la convergence du majorant n’est pas très rapide.
286
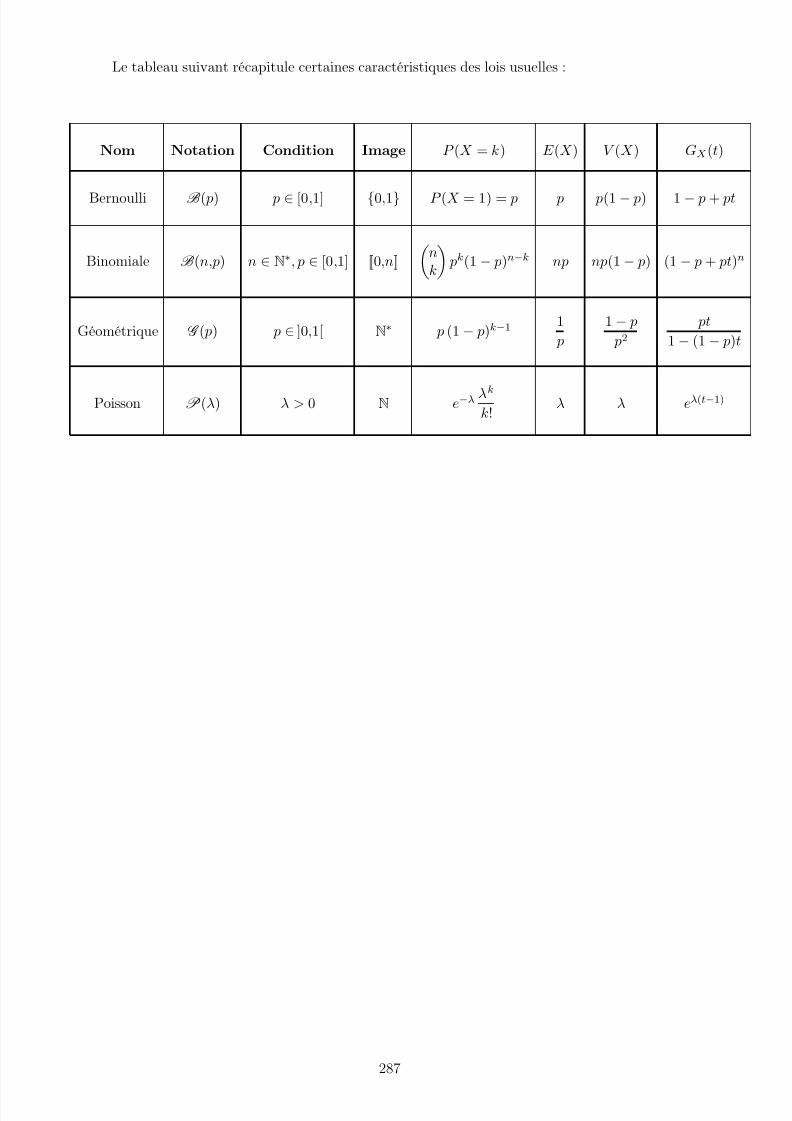
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 295/383
Le tableau suivant récapitule certaines caractéristiques des lois usuelles :
Nom Notation Condition Image P (X = k) E (X ) V (X ) GX (t)
Bernoulli B ( p) p ∈ [0,1] 0,1 P (X = 1) = p p p(1 − p) 1 − p + pt
Binomiale B (n,p) n ∈ N∗, p ∈ [0,1] [[0,n]]
nk
pk(1 − p)n−k np np(1 − p) (1 − p + pt)n
Géométrique G ( p) p ∈ ]0,1[ N∗ p (1 − p)k−1 1
p
1 − p
p2
pt
1 − (1 − p)t
Poisson P (λ) λ > 0 N e−λ λkk!
λ λ eλ(t−1)
287

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 296/383
288

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 297/383
Chapitre 15
Endomorphismes remarquables desespaces euclidiens
Dans ce chapitre, sauf indication contraire, (E, (· | ·)) désigne un espace euclidien de dimensionn et · la norme associée.
I. Isométries vectorielles
1. Définition, propriétés, caractérisations
Soit u ∈ L (E ). On dit que u est une isométrie vectorielle si u conserve la norme,c’est-à-dire si
∀ x ∈ E, u(x) = x.
Définition
Exemple – Dans R2[X ] muni du produit scalaire défini par :aX 2 + bX + c | αX 2 + βX + γ
= aα + bβ + cγ,
soit u l’endomorphisme défini par :
u(aX 2 + bX + c) = b + c√
2X 2 + aX +
b − c√ 2
.
Alors u est une isométrie vectorielle car, pour tout P = aX 2 + bX + c ∈ R2[X ],
u(P )2 = 1
2(b2 + 2bc + c2) + a2 +
1
2(b2 − 2bc + c2) = a2 + b2 + c2 = P 2,
donc en prenant la racine carrée, on obtient que u conserve la norme.
Une isométrie vectorielle est un automorphisme.
Propriété
Démonstration – L’espace E étant de dimension finie, il suffit de montrer que u est injectif. Or,si u(x) = 0E , alors par conservation de la norme, x = u(x) = 0 et donc x = 0E , d’où lerésultat.
Remarque – Les isométries vectorielles sont également appelées automorphismes orthogo-
naux.Attention ! En général, une projection orthogonale n’est pas un automorphisme orthogonal : ellene conserve pas la norme et n’est pas bijective.
289

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 298/383
L’ensemble des isométries vectorielles de E est appelé groupe orthogonal de E , etnoté O(E ).
On a notamment :
• Si u et v sont deux éléments de O(E ), alors u v ∈ O(E ).
• Si u ∈ O(E ), u−1 ∈ O(E ).
Propriété/Définition
Démonstration
• Pour tout x ∈ E , x = v(x) = (u v)(x) car u et v sont des isométries vectoriellesdonc conservent la norme. On en déduit que u v conserve la norme, c’est donc une isométrievectorielle.
• Pour tout x ∈ E , x = (u u−1)(x) = u−1(x) car u conserve la norme. On en déduit queu−1 conserve la norme, c’est donc une isométrie vectorielle.
Soit u ∈ L (E ). Pour que u soit une isométrie vectorielle, il faut et il suffit que u
conserve le produit scalaire, c’est-à-dire, que
∀ (x,y) ∈ E 2, (u(x) | u(y)) = (x | y) .
Propriété
Démonstration
⇐ Si u conserve le produit scalaire, pour tout x ∈ E ,
u(x)2 = (u(x) | u(x)) = (x | x) = x2 et donc u(x) = x.
On en déduit que u est une isométrie vectorielle.
⇒ Si u conserve la norme, on montre que u conserve le produit scalaire à l’aide de l’identité depolarisation : pour tout (x,y) ∈ E 2,
(u(x) | u(y)) = 1
4
u(x) + u(y)2 − u(x) − u(y)2
= 1
4
u(x + y)2 − u(x − y)2
,
par linéarité de u. Comme u conserve la norme, on a donc
(u(x) | u(y)) = 1
4
x + y2 − x − y2
= (x | y) .
D’où la conservation du produit scalaire.
Soit u ∈ L (E ) et B une base orthonormée de E .
Les propriétés suivantes sont équivalentes :
• u est une isométrie vectorielle.
• L’image par u de la base orthonormée B de E est une base orthonormée de E .
Propriété
Démonstration – On note B = (e1, . . . , en).
⇒ Si u est une isométrie vectorielle, alors u conserve le produit scalaire, et donc pour tout(i,j)
∈ [[1,n]]2,
(u(ei) | u(e j)) = (ei | e j) = δ i,j.
La famille u(B) est donc une base orthonormée de E : elle est orthonormée, donc libre, et estcomposée de n vecteurs en dimension n.
290

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 299/383
⇐ On suppose que u(B) = (u(e1), . . . , u(en)) est une base orthonormée de E . Si
x = x1e1 + · · · + xnen et y = y1e1 + · · · + ynen
sont deux vecteurs de E , alors
u(x) = x1u(e1) + · · · + xnu(en) et u(y) = y1u(e1) + · · · + ynu(en),
donc les coordonnées de u(x) et u(y) dans la base u(B) sont les mêmes que celles de x et ydans la base B. L’expression du produit scalaire dans une base orthonormée montre donc que(u(x) | u(y)) = (x | y) . Donc u est une isométrie vectorielle.
Soit u une isométrie vectorielle de E et F un sous-espace vectoriel de E stable par u.
Alors F ⊥ est stable par u.
Propriété
Démonstration – L’application u est un isomorphisme, donc dim(u(F )) = dim(F ). Sachant deplus que u(F )
⊂ F car F est stable par u, on a u(F ) = F .
Soit x ∈ F ⊥ ; on veut montrer que u(x) ∈ F ⊥. Soit donc y ∈ F ; d’après ce qui précède, il existez ∈ F tel que y = u(z). Alors, par conservation du produit scalaire,
(u(x) | y) = (u(x) | u(z)) = (x | z) = 0
car x ∈ F ⊥ et z ∈ F. Donc u(x) est orthogonal à tout vecteur de F : u(x) ∈ F ⊥. Ceci étant vraipour tout x ∈ F ⊥, on a le résultat voulu.
2. Matrices orthogonales
Soit M ∈ M n(R) une matrice carrée réelle.
On dit que M est orthogonale si l’endomorphisme uM canoniquement associé à M
est une isométrie vectorielle pour la norme associée au produit scalaire canonique surM n,1(R).
Définition
Soit M ∈ M n(R). Les propriétés suivantes sont équivalentes :
1. M est une matrice orthogonale.
2. tM M = I n.3. M tM = I n.
4. M est inversible et M −1 = tM.
5. Les colonnes de M forment une famille orthonormée de M n,1(R) muni du produitscalaire canonique. Dans ce cas, elles en forment une base orthonormée.
6. Les lignes de M forment une famille orthonormée de M 1,n(R) muni du produitscalaire canonique. Dans ce cas, elles en forment une base orthonormée.
Propriété
Démonstration – Soit (· | ·) le produit scalaire canonique sur M n,1(R).
1 ⇔ 2 : La matrice M est orthogonale si et seulement si uM conserve le produit scalaire, ce quiéquivaut au fait que pour tout (X,Y ) ∈ M n,1(R)2,
(uM (X ) | uM (Y )) = (X | Y ) .
291

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 300/383
Or, pour tout (X,Y ) ∈M n,1(R)2,
(uM (X ) | uM (Y )) = t(M X )(M Y ) = tX (tM M )Y et (X | Y ) = tXY .
Si tM M = I n, M est donc orthogonale ; réciproquement, si M est orthogonale, en choisissantpour X et Y les vecteurs de la base canonique de M n,1(R), on obtient tM M = I n.
2 ⇔ 3 ⇔ 4 : C’est un résultat du chapitre Matrices.
2
⇔ 5 : Notons C 1, . . . , C n les colonnes de M . Le coefficient en position (i,j) dans la matrice
tM M est tC iC j, c’est-à-dire (C i | C j). On en déduit que tM M = I n si et seulement si pour tout(i,j), (C i | C j) = δ i,j, c’est-à-dire, si et seulement si (C 1, . . . , C n) est une famille orthonormée deM n,1(R). Dans ce cas, sachant de plus que cette famille est composée de n = dim(E ) vecteurs,c’est une base orthonormée de M n,1(R).
3 ⇔ 6 : On raisonne de la même façon, le coefficient en position (i,j) dans la matrice M tM étant(Li | L j), où L1, . . . , Ln sont les lignes de M .
Exemple – La matrice
M = 1√
2
1 −1 01 1 0
0 0√
2
est orthogonale, car la famille (C 1,C 2,C 3) de ses colonnes vérifie les relations (C i | C j) = δ i,j pourtout (i,j) ∈ [[1,3]]2.
Soit u ∈ L (E ) et B une base orthonormée de E .
Les propriétés suivantes sont équivalentes :
• u est une isométrie vectorielle.
• La matrice M de u dans la base orthonormée B est orthogonale.
Propriété – Lien entre isométries vectorielles de E et matrices orthogonales
Démonstration – L’endomorphisme u est une isométrie vectorielle si et seulement si pour tout(x,y) ∈ E 2,(u(x) | u(y)) = (x | y) .
Si X et Y sont les vecteurs-colonnes des coordonnées de x et y dans la base orthonormée B, alors
(u(x) | u(y)) = t(M X )(M Y ) = tX (tM M )Y et (x | y) = tXY.
Or, lorsque x et y parcourent E , X et Y parcourent M n,1(R), et réciproquement. Ainsi, u estune isométrie vectorielle si et seulement si pour tout (X,Y ) ∈M n,1(R)2,
tX (tM M )Y = tXY,
c’est-à-dire, si et seulement si M est orthogonale (voir la démonstration précédente).
Les matrices orthogonales sont exactement les matrices de changement de base ortho-normée : si B est une base orthonormée de E et P ∈ M n(R) est la matrice d’une familleF de vecteurs de E dans la base B, alors P est une matrice orthogonale si et seulementsi F est une base orthonormée de E .
Propriété
Démonstration – Avec les notations de la propriété, soit u l’endomorphisme de E ayant P pourmatrice dans la base B. La matrice P est orthogonale si et seulement si u est une isométrievectorielle, ce qui équivaut au fait que u(B), i.e. F , soit une base orthonormée de E .
Remarque – En particulier, si B et B ′ sont deux bases orthonormées de E , et si P désigne lamatrice de passage de B vers B′, alors pour tout u ∈ L (E ),
MatB′(u) = tP MatB(u) P.
292

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 301/383
L’ensemble des matrices orthogonales d’ordre n est appelé groupe orthogonal d’ordren, et noté O(n) ou On(R) :
O(n) = M ∈ M n(R); tM M = I n.
L’ensemble
O(n) est stable par produit et passage à l’inverse.
Propriété/Définition
Démonstration – Si M ∈ O(n) et N ∈ O(n),
t(M N )(M N ) = tN tM M N = tN N = I n,
donc M N ∈ O(n). De plus,
t(M −1)M −1 = (tM )−1M −1 = (M tM )−1 = I n,
donc M −1 ∈ O(n).
Si M ∈ O(n), alors det(M ) = ±1.
De même, si u ∈ O(E ), alors det(u) = ±1.
Propriété
Démonstration – Une matrice orthogonale M vérifie tM M = I n donc det(tM )det(M ) = 1. Ordet(tM ) = det(M ), donc det(M )2 = 1 et det(M ) = ±1.
Si u ∈ O(E ), on raisonne matriciellement dans une base orthonormée.
Remarque – Bien sûr, la réciproque est fausse, comme le montre l’exemple de la matrice1 10 1
;
elle a pour déterminant 1 mais n’est pas orthogonale : ses deux colonnes ne sont pas orthogonalespour le produit scalaire canonique.
L’ensemble des matrices orthogonales de M n(R) de déterminant 1, est appelé groupespécial orthogonal d’ordre n, noté SO(n) ou SOn(R).
Il est stable par produit et passage à l’inverse.
Propriété/Définition
Démonstration – On sait déjà que On(R) est stable par produit et passage à l’inverse. De plus, siM ∈ SOn(R) et N ∈ SOn(R), on a
det(M N ) = det(M )det(N ) = 1 et det(M −1) = (det(M ))−1 = 1,
d’où le résultat.
Si E est de dimension 2 ou 3, un élément de O(E ) de déterminant 1 est appelé rotationde E .
Définition
293

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 302/383
II. Endomorphismes symétriques
Soit u ∈ L (E ). On dit que u est symétrique si
∀ (x,y) ∈ E 2, (u(x) | y) = (x | u(y)) .
Définition
Soit u ∈ L (E ) et B une base orthonormée de E .
Les propriétés suivantes sont équivalentes :
• u est symétrique.
• La matrice M de u dans la base orthonormée B est symétrique, c’est-à-dire vérifietM = M .
Propriété – Lien entre endomorphismes symétriques et matrices symétriques
Démonstration – L’endomorphisme u est symétrique si et seulement si pour tout (x,y) ∈ E 2
,
(u(x) | y) = (x | u(y)) .
Si X et Y sont les vecteurs-colonnes des coordonnées de x et y dans la base orthonormée B, alors
(u(x) | y) = t(M X )Y = tX tM Y et (x | u(y)) = tX (M Y ) = tXMY.
Or, lorsque x et y parcourent E , X et Y parcourent M n,1(R), et réciproquement. Ainsi, u estsymétrique si et seulement si pour tout (X,Y ) ∈M n,1(R)2,
tX tM Y = tXMY,
c’est-à-dire, si et seulement si tM = M .
Exemple – La projection orthogonale p sur un sous-espace vectoriel F de E est symétrique. Eneffet, dans une base orthonormée de E adaptée à la décomposition
E = Im( p) ⊕ Ker( p) = Im( p) ⊕ Im( p)⊥,
la matrice de p est (en notant r = rg( p))
I r 0r,n−r
0n−r,r
0n−r,n−r ;
elle est symétrique.
Attention ! Pour utiliser ce résultat, il est essentiel que B soit orthonormée, de même que dansla propriété sur le lien entre isométries vectorielles et matrices orthogonales.
Les endomorphismes symétriques ont des propriétés remarquables vis-à-vis de la réductiondes endomorphismes :
Soit u
∈L (E ) un endomorphisme symétrique.
Alors u est diagonalisable dans une base orthonormée : il existe une base orthonorméede E constituée de vecteurs propres pour u.
Théorème spectral
294

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 303/383
Démonstration (non exigible)
On procède par récurrence sur n = dim(E ). Le résultat est vrai pour n = 1 car tout vecteurde E de norme 1 est vecteur propre de u. Si le résultat est vrai en dimension n, soit u unendomorphisme symétrique de E , espace euclidien de dimension n + 1.
• Soit M la matrice de u dans une base orthonormée quelconque. Sachant que u est symétriqueet que M est sa matrice dans une base orthonormée, M est symétrique. La matrice M est réelle,mais on peut la considérer comme matrice complexe et à ce titre, M possède une valeur propre
λ ∈ C. Soit X ∈M n,1(C) un vecteur propre associé; on va calculer tXM X de deux façons : toutd’abord, M étant réelle,
tXM X = tXM X = tXλX = λ tXX.
De plus, M étant symétrique,
tXM X = tX tM X = t(M X )X = t(λX )X = λ tXX .
Mais, en notant x1, . . . , xn les coefficients de X , on a
tXX =n
i=1
xi xi =n
i=1 |xi
|2
= 0
car X = 0. On en déduit que λ = λ, i.e., λ ∈ R. Ainsi, u possède une valeur propre réelle λ.
• Soit e1 un vecteur propre associé. Quitte à diviser e1 par sa norme (qui est non nulle), on peutsupposer e1 unitaire.
Notons F = Vect(e1)⊥ ; il s’agit d’un sous-espace vectoriel de E de dimension n. De plus, F
est stable par u : en effet, si x ∈ F , alors
(u(x) | e1) = (x | u(e1))
car u est symétrique. Or u(e1) = λe1, donc
(u(x) | e1) = λ (x | e1) = 0
car x ∈ F = Vect(e1)⊥. On a finalement (u(x) | e1) = 0, et donc u(x) ∈ Vect(e1)⊥ = F.
On peut donc considérer l’endomorphisme u|F de F induit par u ; F est bien sûr un espaceeuclidien par restriction du produit scalaire de E , et u|F est symétrique de même que u. Parhypothèse de récurrence, il existe une base orthonormée (e2, . . . , en+1) de F constituée de vecteurspropres pour u|F , et donc pour u. Alors, sachant que E = Vect(e1) ⊕ F (cette somme étantorthogonale), on obtient que (e1, . . . , en+1) est une base orthonormée de E de vecteurs proprespour u, ce qui prouve l’hérédité.
Remarques
• En particulier, si u ∈L (E ) est symétrique, u possède n valeurs propres réelles (χu est scindédans R). Ces valeurs propres ne sont pas nécessairement distinctes.
• Si u ∈ L (E ) est un endomorphisme symétrique, les sous-espaces propres de u sont deux àdeux orthogonaux.
En effet, soient λ et µ deux valeurs propres distinctes de u, x et y deux vecteurs propresassociés respectivement à ces valeurs propres. Alors
(u(x) | y) = (λx | y) = λ (x | y) .
Mais u étant symétrique, on a aussi
(u(x) | y) = (x | u(y)) = (x | µy) = µ (x | y) .
Sachant que λ = µ, on en déduit que (x | y) = 0, et donc E λ(u) ⊥ E µ(u).
295

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 304/383
Matriciellement, le théorème spectral s’interprète de la façon suivante :
Soit M ∈ M n(R) une matrice symétrique réelle.
Alors M est diagonalisable au moyen d’une matrice orthogonale, c’est-à-dire qu’ilexiste :
• une matrice diagonale D ∈M
n(R
) dont les coefficients diagonaux sont les valeurspropres de M ,
• une matrice orthogonale P ∈ O(n) dont les colonnes constituent une base ortho-normée de M n,1(R) (pour le produit scalaire canonique) de vecteurs propres pourM ,
telles queM = P D tP.
Théorème spectral (matriciel)
Démonstration – On applique le théorème spectral à l’endomorphisme uM canoniquement associéà M : il existe une base orthonormée B de M n,1(R) constituée de vecteurs propres pour M .Soit P la matrice de passage de la base canonique de M n,1(R) à la base
B; P est une matrice
orthogonale car c’est une matrice de changement de bases orthonormées, donc P −1 = tP . Laformule M = P D tP est alors une conséquence des formules de changement de base.
Attention ! Une matrice symétrique complexe n’est pas toujours diagonalisable, comme le montrel’exemple de la matrice
1 ii −1
de polynôme caractéristique X 2 ; si elle était diagonalisable, elle serait nulle.
Exemple – La matrice
A =
1 1 11 1 11 1 1
est symétrique réelle, elle est donc diagonalisable au moyen d’une matrice orthogonale. Commede plus elle est de rang 1, on sait que 0 est valeur propre double de A. Une base orthonormée deE 0(A), qui est le plan d’équation x + y + z = 0, est
1√ 6
1
−21
,
1√ 2
1
0−1
.
Dans ce cas particulier, on sait alors que le second espace propre est E 0(A)⊥, c’est une droitevectorielle dirigée par le vecteur normal t1 1 1 à E 0(A), dont on constate qu’il est vecteurpropre pour A associé à la valeur propre 3 (ce que l’on pouvait remarquer directement car lasomme des coefficients de chaque ligne de A est 3). En posant
P =
1√ 6
1√ 2
1√ 3
− 2√ 6
0 1√ 3
1√ 6
− 1√ 2
1√ 3
,
on obtient une matrice orthogonale telle que
A = P
0 0 00 0 0
0 0 3
tP.
On remarquera que dans ce cas, on n’a pas à calculer P −1, il suffit de transposer P . Attentioncependant, pour pouvoir affirmer ceci, il faut bien prendre soin de vérifier que P est effectivement
296

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 305/383
orthogonale. Dans cet exemple, il était indispensable de choisir une base de E 0(A) qui soitorthonormée.
Application : en Sciences Industrielles, la matrice d’inertie d’un solide dans un repère ortho-normé est une matrice symétrique réelle, elle est donc diagonalisable au moyen d’une matriceorthogonale. Les droites propres pour cette matrice sont appelées axes principaux d’inertie dusolide.
III. Espaces euclidiens orientés de dimension 2 et 3
1. Orientation
Soient B et B′ deux bases orthonormées de E , et P la matrice de passage de B à B′. On saitque P ∈ On(R), et donc det(P ) = ±1, c’est-à-dire, detB(B′) = ±1. De plus,
detB′(B) = det(P −1) = det(P ) = detB(B′).
Ceci permet de donner la définition suivante :
• On dit que B et B′ ont la même orientation si detB(B′) = 1.
On dit que B et B′ ont des orientations opposées si detB(B′) = −1.
• Orienter E , c’est choisir l’ensemble des bases orthonormées qui ont la même orien-tation qu’une base orthonormée fixée, de référence. Ces bases sont alors dites basesorthonormées directes.
Les autres bases orthonormées sont dites bases orthonormées indirectes.
Définition – Orientation, bases orthonormées directes
Remarques• Les matrices de passage entre bases orthonormées directes de E sont exactement les matricesorthogonales de déterminant 1, i.e., les éléments de SO(n) : si B est une base orthonorméedirecte de E et P ∈ M n(R) est la matrice d’une famille F de vecteurs de E dans la base B, alorsP ∈ SO(n) si et seulement si F est une base orthonormée directe de E .
• Échanger deux vecteurs d’une base orthonormée, ou changer le sens d’un de ses vecteurs,change son orientation (c’est-à-dire son caractère direct ou indirect), d’après les propriétés dudéterminant.
• On définit une relation ∼ entre bases orthonormées de E de la façon suivante : si B et B′ sontdeux bases orthonormées de E , on a B ∼ B′ si, par définition, B et B′ ont la même orientation. Lefait que
SOn(R) contienne I n et soit stable par produit et passage à l’inverse permet de montrer
que ∼ est une relation d’équivalence. Il y a exactement deux classes d’équivalence ; orienter E revient à choisir l’une de ces deux classes, ses éléments sont les bases orthonormées directes deE .
Soit E un espace euclidien orienté de dimension 3.
• Si F est une droite vectorielle ou un plan vectoriel de E , on peut orienter F commetout espace euclidien, par le choix d’une base orthonormée de F .
• Si P est un plan vectoriel, on peut aussi orienter P par le choix d’un vecteur unitaire
a normal à P : une base orthonormée (i,j) de P est dite directe si (i,j,a) est une baseorthonormée directe de E , sinon, elle est dite indirecte.
Définition – Orientation d’une droite ou d’un plan
297

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 306/383
2. Produit mixte, produit vectoriel
Soient B et B ′ deux bases orthonormées directes d’un espace euclidien orienté E dedimension n = 2 ou n = 3.
Alors, pour toute famille (x1, . . . , xn) de vecteurs de E , on a
detB(x1, . . . , xn) = detB′(x1, . . . , xn).
Autrement dit, le déterminant de (x1, . . . , xn) ne dépend pas de la base orthonorméedirecte choisie pour le calculer.
Ce déterminant est appelé produit mixte de la famille (x1, . . . , xn), et noté [x1, . . . , xn].
Propriété/Définition – Produit mixte
Démonstration – Soit M la matrice de (x1, . . . , xn) dans la base B, M ′ sa matrice dans la baseB′ et P la matrice de passage de B à B ′. Alors, d’après les formules de changement de bases,M = P M ′, d’où
det(M ) = det(P )det(M ′) = det(M ′)
car P est une matrice de passage entre bases orthonormées directes, donc P ∈ SOn(R). On endéduit le résultat car
detB(x1, . . . , xn) = det(M ) et detB′(x1, . . . , xn) = det(M ′).
Interprétation géométrique
• Si u et v sont deux vecteurs de R2,[u,v]
est l’aire du parallélogramme formé sur u et v .
• De même, si u, v et w sont trois vecteurs de R3,
[u,v,w]
est le volume du parallélépipède
rectangle formé sur u, v et w.
On a immédiatement :
Soit E un espace euclidien orienté de dimension 3. Alors :
• Échanger deux vecteurs dans un produit mixte change le signe du produit mixte.
• Le produit mixte [u,v,w] est nul si et seulement si la famille (u,v,w) est liée.
• Une base orthonormée (e1,e2,e3) de E est directe si et seulement si [e1,e2,e3] = 1.
On a les propriétés analogues en dimension 2.
Propriété
Soit E un espace euclidien orienté de dimension 3.
Pour tout (u,v) ∈ E 2, il existe un unique vecteur de E , noté u ∧ v, tel que
∀ x ∈ E, [u,v,x] = (u ∧ v | x) . (1)
Le vecteur u ∧ v est appelé produit vectoriel de u et v .
Propriété/Définition – Produit vectoriel
Démonstration – Par linéarité du déterminant par rapport à sa troisième variable, l’applicationx → [u,v,x] est une forme linéaire sur E . Le théorème de représentation des formes linéaires surun espace euclidien entraîne l’existence et l’unicité du vecteur vérifiant (1).
298

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 307/383
Soit E un espace euclidien orienté de dimension 3 et B = (e1,e2,e3) une base orthonor-mée directe de E . Soient u = u1e1 + u2e2 + u3e3 ∈ E et v = v1e1 + v2e2 + v3e3 ∈ E .
Alorsu ∧ v = (u2v3 − u3v2)e1 + (u3v1 − u1v3)e2 + (u1v2 − u2v1)e3.
En particulier, dans E = M 3,1(R),u1
u2
u3
∧
v1
v2
v3
=
u2v3 − u3v2
u3v1 − u1v3
u1v2 − u2v1
.
On peut toujours se ramener à ce cas en raisonnant en coordonnées dans une baseorthonormée directe de E .
Propriété
Démonstration – Pour tout x = x1e1 + x2e2 + x3e3 ∈ E ,
[u,v,x] = detB(u,v,x) = u1 v1 x1
u2 v2 x2u3 v3 x3
.
En développant ce déterminant par rapport à la dernière colonne, on a
[u,v,x] = (u2v3 − u3v2)x1 − (u1v3 − u3v1)x2 + (u1v2 − u2v1)x3.
La base B étant orthonormée, on reconnaît le produit scalaire entre
(u2v3 − u3v2)e1 + (u3v1 − u1v3)e2 + (u1v2 − u2v1)e3
et x. Cette égalité étant vraie pour tout x, et u ∧ v étant l’unique vecteur à la vérifier pour tout
x, on a le résultat.
Soit E un espace euclidien orienté de dimension 3 et (u,v) ∈ E 2.
Alors :
1. u ∧ v = − v ∧ u.
2. Les applications x → u ∧ x et x → x ∧ v sont des endomorphismes de E .
3. La famille (u,v) est libre si et seulement si u ∧ v = 0E .
4. Le vecteur u ∧ v est orthogonal à u et v .
Si u et v sont indépendants, u
∧v est un vecteur normal au plan vectoriel Vect(u,v).
5. Si (e1,e2,e3) est une base orthonormée directe de E , on a
e1 ∧ e2 = e3, e2 ∧ e3 = e1, e3 ∧ e1 = e2.
Si (e1,e2) est une famille orthonormée de E , alors (e1,e2,e1 ∧ e2) est une base orthonor-mée directe de E .
6. Pour tout w ∈ E , on a la formule : u ∧ (v ∧ w) = (u | w) v − (u | v) w.
Propriété
Démonstration
1. Pour tout x
∈ E , par antisymétrie du déterminant,
[u,v,x] = −[v,u,x] = − (v ∧ u | x) = (− v ∧ u | x) .
Ceci étant vrai pour tout x ∈ E , on a u ∧ v = − v ∧ u.
299

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 308/383
2, 6 et première partie de 5. C’est immédiat en revenant aux coordonnées dans une base ortho-normée directe.
Quant à la deuxième partie du point 5, complétons (e1,e2) en base orthonormée directe (e1,e2,e3)de E (ce qui est possible en complétant d’abord en base orthonormée de E puis éventuellementen changeant le sens du troisième vecteur choisi). D’après ce qui précède, on a e1 ∧ e2 = e3, d’oùle résultat.
3. Si (u,v) est liée, alors pour tout x
∈ E , [u,v,x] = 0, et donc (u
∧v
|x) = 0. On en déduit que
u ∧ v = 0E .Si (u,v) est libre, on peut la compléter en une base (u,v,w) de E , et donc [u,v,w] = 0, c’est-à-dire,(u ∧ v | w) = 0, ce qui entraîne que u ∧ v = 0E .
4. On a(u ∧ v | u) = [u,v,u] = 0
car la famille (u,v,u) contient deux fois le même vecteur. Donc u ∧ v est orthogonal à u. Onprocède de même pour v .
Si (u,v) est libre, u ∧ v est un vecteur non nul orthogonal à u et v , donc orthogonal au planVect(u,v). C’est donc un vecteur normal à Vect(u,v).
3. Classification des isométries vectorielles en dimension 2
On a
O2(R) =
cos(θ) − sin(θ)sin(θ) cos(θ)
; θ ∈ R
=SO2(R)
∪
cos(θ) sin(θ)sin(θ) − cos(θ)
; θ ∈ R
=M ∈O2(R); det(M )=−1
.
Théorème – Détermination des éléments de O2(R) et SO2(R)
Démonstration – Il est immédiat que les matrices ci-dessus sont éléments de O2(R), car leurs
colonnes forment une famille orthonormée de M 2,1(R) pour le produit scalaire canonique, d’aprèsla formule cos2 +sin2 = 1. De plus, pour tout θ ∈ R,
det
cos(θ) − sin(θ)sin(θ) cos(θ)
= 1 et det
cos(θ) sin(θ)sin(θ) − cos(θ)
= −1.
Réciproquement, soit
M =
a cb d
∈ O2(R).
Sa première colonne est de norme 1, donc a2 + b2 = 1. En particulier, a2 1, donc a ∈ [−1,1],et il existe θ ∈ R tel que a = cos(θ). Alors b = ±√
1 − a2 = ± sin(θ), mais quitte à changer θ en
−θ, ce qui ne modifie pas la valeur de cos(θ), on peut supposer que b = sin(θ).La deuxième colonne de M est orthogonale à la première. Or, (a,b) = (cos(θ), sin(θ)) = (0,0),donc
Vect
cos(θ)sin(θ)
⊥
est une droite vectorielle ; or elle contient le vecteur non nul
− sin(θ)cos(θ)
, et ainsi
Vect
cos(θ)sin(θ)
⊥= Vect
− sin(θ)cos(θ)
.
En particulier, il existe λ ∈ R tel quecd
= λ
− sin(θ)cos(θ)
.
300

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 309/383
Enfin,
det(M ) = det
cos(θ) −λ sin(θ)sin(θ) λ cos(θ)
= λ.
Or det(M ) = ±1 ; on obtient les formes indiquées dans chaque cas.
Soit θ ∈ R. La matrice
R(θ) = cos(θ) − sin(θ)sin(θ) cos(θ)
est appelée matrice de rotation d’angle de mesure θ .
Définition
On remarquera que, pour (θ,θ ′) ∈ R2, R(θ) = R(θ′) si et seulement si θ − θ′ ∈ 2πZ. Ainsi,
SO2(R) = R(θ); θ ∈ R = R(θ); θ ∈ ]−π,π] .
• Pour tout (θ,θ′) ∈ R2, R(θ)R(θ′) = R(θ + θ′).
• SO2(R) est commutatif pour le produit matriciel : pour tout (A,B)
∈ (
SO2(R))2, on
a AB = BA.
Propriété
Démonstration
• On a
R(θ)R(θ′) =
cos(θ) − sin(θ)sin(θ) cos(θ)
cos(θ′) − sin(θ′)sin(θ′) cos(θ′)
=
cos(θ)cos(θ′) − sin(θ)sin(θ′) − cos(θ)sin(θ′) − sin(θ)cos(θ′)sin(θ)cos(θ′) + cos(θ)sin(θ′) − sin(θ) sin(θ′) + cos(θ)cos(θ′)
= cos(θ + θ′) − sin(θ + θ′)sin(θ + θ′) cos(θ + θ′) = R(θ + θ′).
• Soit (A,B) ∈ (SO2(R))2. D’après le théorème précédent, il existe (θ,θ′) ∈ R2 tel que A = R(θ)
et B = R(θ′). Alors d’après le premier point,
AB = R(θ)R(θ′) = R(θ + θ′) = R(θ′ + θ) = R(θ′)R(θ) = BA.
Soit E un plan euclidien orienté.
1. Soit u ∈ O(E ) vérifiant det(u) = 1 (i.e., une rotation de E ).
Alors, il existe θ ∈ R tel que la matrice de u dans toute base orthonormée directe deE soit R(θ). Le réel θ n’est pas unique, mais unique modulo 2π.
On dit que θ est une mesure de l’angle de la rotation u.On retrouve facilement les mesures θ de l’angle d’une rotation u de E à l’aide desformules suivantes, valables pour tout vecteur unitaire x0 ∈ E :
cos(θ) = 1
2 Tr(u) = (x0 | u(x0)) et sin(θ) = [x0,u(x0)].
2. Soit u ∈ O(E ) vérifiant det(u) = −1.
Alors u est la symétrie par rapport à Ker(u − Id) parallèlement à Ker(u − Id)⊥ (i.e.,la réflexion par rapport à Ker(u − Id)).
Dans toute base adaptée à la décomposition E = Ker(u−Id)⊕Ker(u−Id)⊥, la matricede u est 1 0
0 −1
.
Théorème – Classification des isométries vectorielles en dimension 2
301

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 310/383
Démonstration
1. Si u ∈ O(E ) vérifie det(u) = 1, sa matrice dans une base orthonormée directe B = (e1,e2) estun élément de SO2(R), donc il existe θ ∈ R tel que MatB(u) = R(θ). Si B′ = (ε1,ε2) est uneautre base orthonormée directe de E , alors la matrice de passage P de B à B′ est un élément deSO2(R), donc d’après les formules de changement de base et la commutativité de SO2(R),
MatB′(u) = P −1 MatB(u)P = P −1P MatB(u) = MatB(u) = R(θ).
La matrice de u dans toute base orthonormée directe de E est donc R(θ). Le réel θ est uniquemodulo 2π car R(θ) = R(θ′) si et seulement si θ − θ′ ∈ 2πZ.
On a alors
Tr(u) = Tr(R(θ)) = 2 cos(θ), d’où cos(θ) = 1
2 Tr(u).
Soit x0 = αe1 + βe2 un vecteur unitaire de E . Alors la matrice colonne des coordonnées de u(x0)dans la base B est
R(θ)
αβ
=
α cos(θ) − β sin(θ)α sin(θ) + β cos(θ)
.
La base B étant orthonormée,
(x0 | u(x0)) = α(α cos(θ) − β sin(θ)) + β (α sin(θ) + β cos(θ)) = (α2 + β 2) cos(θ) = cos(θ)
car x0 est unitaire et B orthonormée. De plus,
[x0,u(x0)] =
α α cos(θ) − β sin(θ)β α sin(θ) + β cos(θ)
= α(α sin(θ) + β cos(θ)) − β (α cos(θ) − β sin(θ)) = sin(θ).
2. Si u ∈ O(E ) vérifie det(u) = −1, sa matrice dans la base orthonormée directe B est un élémentde O2(R) de déterminant −1, donc il existe θ ∈ R tel que
MatB(u) =
cos(θ) sin(θ)sin(θ) − cos(θ)
.
Alors
MatB(u)2 =
cos(θ) sin(θ)sin(θ) − cos(θ)
2
= I 2,
donc u est une symétrie. On sait que u est diagonalisable avec Sp(u) ⊂ −1,1, mais sachantque dim(E ) = 2 et que det(u) = −1, on a Sp(u) = −1,1, les valeurs propres 1 et −1 étantsimples. Les espaces propres Ker(u − Id) et Ker(u +Id) sont donc des droites vectorielles. Enfin,ils sont orthogonaux, car si x ∈ Ker(u− Id) et y ∈ Ker(u +Id), alors par conservation du produitscalaire,
(x | y) = (u(x) | u(y)) = (x | − y) = − (x | y) ,
et donc (x | y) = 0. Ainsi, u est la symétrie par rapport à la droite Ker(u − Id) parallèlement
à la droite Ker(u + Id) = Ker(u − Id)⊥. L’écriture matricielle dans toute base adaptée à ladécomposition E = Ker(u − Id) ⊕ Ker(u − Id)⊥ est alors immédiate.
Soit E un plan euclidien orienté et (θ,θ′) ∈ R2. Soit u la rotation d’angle de mesure θet u′ la rotation d’angle de mesure θ ′.Alors u u′ = u′ u est la rotation d’angle de mesure θ + θ′.
Propriété
Démonstration – Il suffit de raisonner matriciellement dans une base orthonormée directe de E .La matrice de u dans cette base est R(θ), celle de u′, R(θ′). Or, d’après une propriété donnée
plus haut,R(θ)R(θ′) = R(θ′)R(θ) = R(θ + θ′),
d’où le résultat.
302

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 311/383
Soit E un plan euclidien orienté et B = (e1,e2) une base orthonormée directe de E . Onidentifie E à C, grâce à l’application bijective
φ :
E → C
αe1 + βe2 → α + iβ
Alors la rotation u d’angle de mesure θ a pour expression complexe
z → eiθz,
c’est-à-dire que pour tout x ∈ E , φ(u(x)) = eiθφ(x).
Propriété – Écriture complexe d’une rotation
Démonstration – Pour tout x = αe1 + βe2 ∈ E , le vecteur-colonne des coordonnées de u(x) dansla base B est
R(θ)
αβ
=
α cos(θ) − β sin(θ)α sin(θ) + β cos(θ)
,
et donc
φ(u(x)) = [α cos(θ) − β sin(θ)] + i[α sin(θ) + β cos(θ)].
De plus,eiθφ(x) = [cos(θ) + i sin(θ)][α + iβ ],
ce qui donne le même résultat après développement.
4. Réduction des isométries vectorielles en dimension 3
Soit E un espace euclidien orienté de dimension 3. Soit u ∈ O(E ) ; on note ε = det(u)
(ε = 1 ou ε =
−1).
• On est dans l’un et un seul des cas suivants :1. u = ε Id.
2. L’ensemble Ker(u − ε Id) est une droite vectorielle. En notant D cette droite, alorsle plan D⊥ est stable par u et l’endomorphisme de D⊥ induit par u est une rotation.
Si a est un vecteur unitaire dirigeant la droite D, alors en orientant D⊥ par le choixdu vecteur normal a, on peut considérer une mesure θ de l’angle de cette rotation. Lamatrice de u dans toute base orthonormée directe de E de la forme (e1,e2,a) est alors
cos(θ) − sin(θ) 0sin(θ) cos(θ) 0
0 0 ε
.
• Pour les rotations (ε = 1) : D est l’ensemble des vecteurs invariants par u ; on ditque u est une rotation d’axe D , et, D⊥ étant orienté par a, que θ est une mesure del’angle de u.
On détermine alors entièrement θ (modulo 2π) par les formules suivantes, dans les-quelles x0 désigne un vecteur unitaire orthogonal à a :
Pour déterminer cos(θ) : Tr(u) = 2cos(θ) + 1, cos(θ) = (x0 | u(x0)) ,
Pour déterminer sin(θ) : x0 ∧ u(x0) = (sin(θ)) a, sin(θ) = [x0,u(x0),a].
Enfin, pour tout x
∈ E , l’image de x par u est donnée explicitement par la formule
u(x) = cos(θ)[x − (a | x) a] + sin(θ) a ∧ x + (a | x) a.
Théorème – Réduction des isométries vectorielles en dimension 3
303

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 312/383
Démonstration – Si u ∈ O(E ), χu est un polynôme unitaire de degré 3, donc définit une fonctioncontinue de limite −∞ en −∞ et +∞ en +∞. D’après le théorème des valeurs intermédiaires,χu possède (au moins) une racine réelle, c’est-à-dire que u possède (au moins) une valeur propreréelle. Soit λ ∈ Sp(u) et x un vecteur propre associé. Par conservation de la norme, u(x) = x,c’est-à-dire, |λ| x = x. Le vecteur x est non nul, donc |λ| = 1, et λ = ±1.
Le polynôme caractéristique de u est scindé sur C, de degré 3 et à coefficients réels, donc, s’ilpossède des racines complexes non réelles, elles sont au nombre de 2 et complexes conjuguées,
on les notera α et α. On a alors αα = |α|2 > 0.Cas ε = 1 : Le déterminant de u, qui vaut 1, est le produit des racines complexes de χu, donc 1doit être valeur propre de u (les différents triplets possibles de racines de χu sont, à l’ordre près,(1,1,1), (1, − 1, − 1), (1,α,α) avec α ∈C \R).
Soit a un vecteur propre unitaire de u associé à a valeur propre 1. On note D = Vect(a)et P = D⊥. Sachant que D est stable par u et que u ∈ O(E ), on sait que P est stable par u.De plus, u conserve le produit scalaire sur E et donc par restriction, sur P . Ainsi, u|P est uneisométrie vectorielle du plan P . De plus, dans toute base B = (e1,e2,a) adaptée à la décompositionE = P ⊕ D,
MatB(u) = Mat(e1,e2)(u|P ) 0
0 1 ,
donc1 = det(u) = det(u|P ) × 1,
ce qui entraîne finalement que u|P est une rotation de P .
On oriente P par le choix du vecteur normal a. D’après le paragraphe précédent, il existeθ ∈ R tel que dans toute base orthonormée directe de P , la matrice de u|P soit R(θ). La matricede u dans toute base orthonormée directe de E de dernier vecteur a est donc
M =
cos(θ) − sin(θ) 0sin(θ) cos(θ) 0
0 0 1
.
Le polynôme caractéristique de u est alors(X − cos(θ))2 + sin(θ)2
(X − 1) = (X 2 − 2cos(θ)X + 1)(X − 1).
Si cos(θ) = 1, M = I 3 et u = Id. Sinon, 1 est valeur propre simple de u et en particulier,Ker(u − Id) est une droite vectorielle. Dans ce cas, on a D = Ker(u − Id) (inclusion et mêmedimension) et la description annoncée.
De plus,Tr(u) = Tr(M ) = 2cos(θ) + 1,
et on démontre les autres formules en raisonnant en coordonnées dans une base orthonorméedirecte (e1,e2,a) de E : soit x0 = αe1 + βe2 un vecteur unitaire orthogonal à a ; les coordonnéesde u(x0) dans la base (e1,e2,a) sont
M
α
β 0
=
cos(θ) − sin(θ) 0
sin(θ) cos(θ) 00 0 1
α
β 0
=
α cos(θ) − β sin(θ)
α sin(θ) + β cos(θ)0
,
donc
(x0 | u(x0)) = α(α cos(θ) − β sin(θ)) + β (α sin(θ) + β cos(θ)) = (α2 + β 2)cos(θ) = cos(θ)
car α2 + β 2 = x02 = 1. De plus, la matrice colonne des coordonnées de x0 ∧ u(x0) dans la base(e1,e2,a) est
αβ 0
∧
α cos(θ) − β sin(θ)
α sin(θ) + β cos(θ)0
= (α2 + β 2)
0
0sin(θ)
=
0
0sin(θ)
,
304

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 313/383
donc x0 ∧ u(x0) = (sin(θ)) a. Par définition, on a alors
[x0,u(x0),a] = (x0 ∧ u(x0) | a) = sin(θ) (a | a) = sin(θ).
Enfin, la formuleu(x) = cos(θ)[x − (a | x) a] + sin(θ) a ∧ x + (a | x) a
est vraie pour x = e1, x = e2 et x = a : par exemple,
u(e1) = cos(θ)e1 + sin(θ)e2
= cos(θ)[e1 − (a | e1) a] + sin(θ) a ∧ e1 + (a | e1) a
car (a | e1) = 0 et a ∧ e1 = e2 ; on procède de même pour u(e2) et u(a). Sachant que (e1,e2,a)est une base de E et que les deux membres de l’égalité à démontrer définissent des applicationslinéaires, l’égalité est vraie pour tout x ∈ E.
Cas ε = −1 : On raisonne de façon analogue en remplaçant la valeur propre 1 par −1 ; avecdes notations semblables, il existe θ ∈ R tel que dans toute base orthonormée directe de E dedernier vecteur a, la matrice de u soit
M = cos(θ) − sin(θ) 0sin(θ) cos(θ) 0
0 0 −1 .
Si cos(θ) = −1, M = −I 3 et u = −Id. Sinon, −1 est valeur propre simple de u, Ker(u + Id) estune droite vectorielle.
Remarques
• Dans le cas d’une rotation, changer l’orientation de l’axe revient à changer θ en −θ.
• Si u ∈ O(E ) vérifie det(u) = −1 avec u = − Id, u est soit la réflexion par rapport à D⊥
(symétrie par rapport à D⊥, parallèlement à D), soit la composée (commutative) d’une rotationd’axe D et d’une réflexion par rapport à D⊥.
Exemple – L’espace R3 étant orienté et muni du produit scalaire canonique, soit
u :
R3 → R3
(x,y,z) → (y,z,x)
La matrice de u dans la base canonique (qui est orthonormée) est
M =
0 1 0
0 0 11 0 0
.
Elle est orthogonale de déterminant 1, donc u est une rotation. Pour déterminer son axe D , onrésout l’équation u(x) = x, ce qui équivaut à
x ∈ Vect(a), où a = 1√ 3
(1,1,1).
On oriente D⊥ par le choix du vecteur normal a. Alors, si θ est une mesure de l’angle de u,
0 = Tr(u) = 2 cos(θ) + 1,
donc cos(θ) = −1/2. Il reste à déterminer le signe de sin(θ). Soit x = (1, − 1,0) ∈ D⊥. Alors lamatrice colonne des coordonnées de x ∧ u(x) dans la base canonique est
1
−1
0
∧
−10
1
,
dont le premier coefficient est −1. Donc x ∧ u(x), dont on sait qu’il est colinéaire à a, est de sensopposé à a. On en déduit que sin(θ) < 0, et donc, on peut choisir θ = 4π/3 (ou −2π/3).
305

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 314/383
306

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 315/383
Chapitre 16
Fonctions vectoriellesArcs paramétrés
Dans ce chapitre, n est un entier strictement positif, I désigne un intervalle de R (non vide etnon réduit à un point), et (sauf indication contraire) f désigne une application définie sur I , àvaleurs dans Rn.
I. Dérivation des fonctions à valeurs vectorielles
1. Définition et premières propriétés
Soit a ∈ I . On dit que f est dérivable en a si la fonction
x → f (x) − f (a)
x − a ,
définie sur I \ a, possède une limite en a.Dans ce cas, cette limite, qui est un vecteur de Rn, est appelée vecteur dérivé de f
en a, noté
f ′(a) ou df
dx(a).
Définition – Dérivabilité en un point
Remarque – La dérivabilité de f en a équivaut au fait que la fonction
h → f (a + h) − f (a)
h ,
définie sur
h
= 0 ; a + h
∈ I
, possède une limite en 0.
Soit a ∈ I . On dit que f est :
• dérivable à gauche en a si a est intérieur à I ou a = sup I , et si x → f (x) − f (a)
x − apossède une limite à gauche en a. Dans ce cas, cette limite est notée f ′(a−).
• dérivable à droite en a si a est intérieur à I ou a = inf I , et si x → f (x) − f (a)
x − apossède une limite à droite en a. Dans ce cas, cette limite est notée f ′(a+).
Définition
Remarque – Si n = 1, on retrouve la définition déjà connue pour les fonctions à valeurs réelles.Le quotient
f (x) − f (a)
x − a
307

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 316/383
est le taux d’accroissement de f entre a et x, et f ′(a) est le coefficient directeur de la tangenteà la courbe représentative de f dans un repère au point d’abscisse a.Cette tangente a pour équation y = f ′(a)(x − a) + f (a).
Exemple – La fonction f : x → (x,x2,x3) est dérivable en tout point de R, et pour tout a ∈ R,
f ′(a) = (1,2a,3a2).
On remarque que pour f : I → Rn, former le quotient
f (x) − f (a)
x − a
revient à former le vecteur contenant les taux d’accroissement de chaque fonction-coordonnée def . Ceci suggère une formule de dérivation composante par composante, dont la démonstrationest immédiate :
Écrivons f = (f 1, . . . , f n) où les f i : I
→R sont les fonctions-coordonnées de f dans la
base canonique.Soit a ∈ I . Pour que f soit dérivable en a, il faut et il suffit que pour tout i ∈ [[1,n]],f i soit dérivable en a. Dans ce cas,
f ′(a) = (f ′1(a), . . . , f ′n(a)).
Propriété – Dérivation composante par composante
La propriété suivante montre le lien entre la dérivabilité en un point a et le fait de posséderun développement limité à l’ordre 1 en a :
Soit a ∈ I et b ∈ Rn. Les propriétés suivantes sont équivalentes :
• f est dérivable en a et f ′(a) = b.
• f admet le développement limité f (x) = f (a) + b(x − a) + o(x − a) en a.
Propriété – Lien avec l’existence d’un développement limité
Notation – La notation o(x − a) représente une fonction x → (x − a) ε(x) où ε : I → Rn a pourlimite (0, . . . ,0) en a.
Démonstration – La fonction f est dérivable en a avec f ′(a) = b si et seulement si
f (x)
−f (a)
x − a −→x→a b,
c’est-à-dire, si et seulement sif (x) − f (a)
x − a =x→a b + o(1).
Ceci équivaut au fait que f (x) = f (a) + b(x − a) + o(x − a) lorsque x → a.
Si f est dérivable en a, elle est continue en a. La réciproque est fausse.
Corollaire
Démonstration – Si f est dérivable en a, elle possède un développement limité à l’ordre 1 en a :f (x) = f (a) + f ′(a)(x−a) + o(x−a). Lorsque x tend vers a, f (x) tend vers f (a), d’où le résultat.L’exemple de la fonction t → (|t|,0, . . . ,0) montre que la réciproque est fausse.
308

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 317/383
2. Opérations sur les fonctions dérivables
Soient f : I → Rn, g : I → Rn et α : I → R trois fonctions dérivables en a ∈ I . Soitλ ∈ R. Alors :
• La fonction λf + g est dérivable en a et (λf + g)′(a) = λf ′(a) + g′(a).
• La fonction αf est dérivable en a et (αf )′(a) = α′(a)f (a) + α(a)f ′(a).
Propriété – Combinaison linéaire et produit
Démonstration
• Le premier point est évident par combinaison linéaire de limites.
• Le cas du produit αf est une conséquence d’une propriété plus générale (voir ci-dessous) surla dérivation des fonctions du type B (f 1,f 2) où B est une application bilinéaire (dans notre cas,le produit), et f 1, f 2 sont deux fonctions dérivables en a ∈ I .
• Soient p ∈ N∗ et L : Rn → R p une application linéaire.
Si f : I
→Rn est dérivable en a
∈ I , alors L
f : I
→R p est dérivable en a et
(L f )′(a) = L(f ′(a)).
• Soient (m,p) ∈ (N∗)2, f : I → Rn et g : I → Rm deux fonctions, et B : Rn×Rm → R p
une application bilinéaire.
Si f et g sont dérivables en a ∈ I , alors B (f, g) : I → R p est dérivable en a et
B(f, g)′(a) = B(f ′(a), g(a)) + B(f (a), g′(a)).
Propriété – Composition par une application linéaire ou bilinéaire
Démonstration
• Pour tout x
∈ I différent de a, par linéarité de L, on a
(L f )(x) − (L f )(a)
x − a = L
f (x) − f (a)
x − a
.
Or, f étant dérivable en a,f (x) − f (a)
x − a −→x→a f ′(a).
De plus, L est une application linéaire sur un espace de dimension finie, elle est donc continue.Il en résulte que
(L f )(x) − (L f )(a)
x − a −→
x→a L(f ′(a)),
d’où le résultat.
• Pour tout x ∈ I différent de a, par bilinéarité de B , on a
B(f, g)(x) − B(f, g)(a)
x − a =
B(f (x), g(x)) − B(f (a), g(x)) + B(f (a), g(x)) − B(f (a), g(a))
x − a
= B
f (x) − f (a)
x − a , g(x)
+ B
f (a),
g(x) − g(a)
x − a
.
Or, f et g étant dérivables (et en particulier continues) en a,
g(x) −→x→a g(a),
f (x) − f (a)
x − a −→x→a f ′(a) et
g(x) − g(a)
x − a −→x→a g′(a).
L’application B est bilinéaire sur Rn ×Rm, elle est donc continue, d’où
B(f, g)(x) − B(f, g)(a)x − a
−→x→a B(f ′(a), g(a)) + B(f (a), g′(a)),
ce qui prouve le résultat.
309

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 318/383
Soit (· | ·) un produit scalaire sur Rn. Soient f : I → Rn et g : I → Rn deux fonctionsdérivables en a ∈ I . Alors :
• La fonction (f | g) est dérivable en a avec
(f | g)′ (a) =
f ′(a) | g(a)
+
f (a) | g′(a)
.
• La fonction f 2 est dérivable en a avec
(f 2)′(a) = 2
f (a) | f ′(a)
.
• Si n = 2 et B est une base de R2, la fonction detB(f,g) est dérivable en a avec
(detB(f,g))′(a) = detB(f ′(a),g(a)) + detB(f (a),g′(a)).
Corollaire – Cas d’un produit scalaire et d’un déterminant
Démonstration – Le premier et le troisième point sont immédiats car un produit scalaire et ledéterminant sont bilinéaires. Pour le second point, il suffit de remarquer que f 2 = (f | f ) etd’appliquer le premier point ainsi que la symétrie du produit scalaire.
Soit ϕ : J → I une fonction où J est un intervalle de R. Soit f : I → Rn une fonction.Si ϕ est dérivable en a ∈ J et si f est dérivable en ϕ(a), alors f ϕ est dérivable en aet
(f ϕ)′(a) = ϕ′(a) (f ′ ϕ)(a).
Propriété – Composition
Démonstration – On raisonne à l’aide d’un développement limité à l’ordre 1 de ϕ en a,
ϕ(x) = ϕ(a) + ϕ′(a)(x−
a) + (x−
a) ε(x),
et de f en ϕ(a),
f (y) = f (ϕ(a)) + f ′(ϕ(a))(y − ϕ(a)) + (y − ϕ(a)) η(y).
En appliquant cette dernière égalité avec y = ϕ(x), on obtient, pour x ∈ J,
f (ϕ(x)) = f (ϕ(a)) + f ′(ϕ(a))
ϕ′(a)(x − a) + (x − a) ε(x)
+
ϕ′(a)(x − a) + (x − a)ε(x)
η
ϕ(a) + ϕ′(a)(x − a) + (x − a) ε(x)
.
Lorsque x tend vers a, ϕ(a) + ϕ′(a)(x − a) + (x − a) ε(x) → ϕ(a) et donc
η
ϕ(a) + ϕ′(a)(x − a) + (x − a) ε(x) → 0.
En rassemblant les termes, on obtient donc une fonction h : J → Rn telle que h(x) −→x→a (0, . . . ,0)
etf (ϕ(x)) = f (ϕ(a)) + f ′(ϕ(a))ϕ′(a) (x − a) + (x − a)h(x).
On en déduit le résultat.
3. Fonction dérivée
Si f est dérivable sur I (c’est-à-dire en tout point de I ), la fonction x → f ′(x) estappelée fonction dérivée de f , notée f ′.
Définition
310

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 319/383
Bien sûr, la propriété de dérivation composante par composante, et les opérations sur lesfonctions dérivables en un point se traduisent pour les fonctions dérivables sur un intervalle.
En raisonnant composante par composante, on obtient :
Soit f : I → Rn une fonction dérivable.
Pour que f soit constante sur I , il faut et il suffit que f ′ = 0.
Propriété – Dérivation et fonctions constantes
II. Dérivées d’ordre supérieur
• Sous réserve d’existence, on définit par récurrence les dérivées successives de f par :f (0) = f et f (k+1) = (f (k))′, pour k ∈ N.
• Pour k ∈ N∗, on dit que f est de classe Ck sur I si f (k) existe et est continue sur I .
• On dit que f est de classe C∞ sur I si f est de classe Ck
sur I pour tout k 1.
La fonction f (k) se note aussi dkf
dxk.
Définition – Classe Ck, dérivées d’ordre k
Écrivons f = (f 1, . . . , f n) où les f i : I → R sont les fonctions-coordonnées de f dans labase canonique. Soit k ∈ N∗.
Alors, pour que f soit de classe Ck (resp. C∞) sur I , il faut et il suffit que pour touti
∈ [[1,n]], f i soit de classe
Ck (resp.
C∞) sur I . Dans ce cas, pour tout j
∈ [[1,k]] (resp.
j ∈ N∗),f ( j) = (f
( j)1 , . . . , f ( j)
n ).
Propriété – Classe Ck composante par composante
Soient f : I → Rn et g : I → Rn deux fonctions de classe Ck (resp. C∞) sur I , et λ ∈ R.
Alors λf + g est de classe Ck (resp. C∞) sur I et pour tout j ∈ [[1,k]] (resp. j ∈ N∗),
(λf + g)( j) = λf ( j) + g( j).
En particulier, l’ensemble Ck(I,Rn) (resp. C∞(I,Rn)) des fonctions de classe Ck (resp.C∞) sur I à valeurs dans Rn, est un R-espace vectoriel.
Propriété – Combinaison linéaire
Soient p ∈ N∗ et L : Rn → R p une application linéaire. Si f : I → Rn est de classe Ck(resp. C∞) sur I , alors L f est de classe Ck (resp. C∞) sur I et pour tout j ∈ [[1,k]](resp. j ∈ N∗),
(L f )( j) = L f ( j).
Propriété – Composition par une application linéaire
Démonstration des trois propriétés précédentes - Elle se fait par récurrences immédiates à partirdes propriétés correspondantes de dérivation première, données plus haut.
311

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 320/383
Soient (m,p) ∈ (N∗)2, f : I → Rn et g : I → Rm deux fonctions, et B : Rn × Rm → R p
une application bilinéaire.
Si f et g sont de classe Ck (resp. C∞) sur I , alors B(f, g) est de classe Ck (resp. C∞)sur I et pour tout j ∈ [[1,k]] (resp. j ∈ N∗),
B(f, g)( j) =
ji=0
jiB(f (i), g( j−i)).
Théorème – Formule de Leibniz
Démonstration – Elle est en tout point semblable à la démonstration de la formule du binômede Newton; elle se fait par récurrence sur k. Tout d’abord, B est bilinéaire sur Rn × Rm, donccontinue. Pour k = 1, le résultat est immédiat d’après la propriété de dérivation de B(f, g), etcar B(f, g)′ = B(f ′, g) + B(f, g′) est continue par composition et somme. De plus, on a bien
B(f, g)′ =1
i=0 1iB(f (i), g(1−i)).
Supposons le résultat vrai pour un certain entier k, et supposons f et g de classe Ck+1. Alors parhypothèse de récurrence,
B(f, g)(k) =ki=0
ki
B(f (i), g(k−i)).
Cette fonction est dérivable sur I par opérations sur les fonctions dérivables. De plus, par linéaritéde la dérivation et d’après la formule donnant la dérivée d’une fonction de la forme B (u,v),
B(f, g)(k+1) =k
i=0
k
i (B((f (i))′, g(k−i)) + B(f (i), (g(k−i))′))
=ki=0
ki
B(f (i+1), g(k−i)) +
ki=0
ki
B(f (i), g(k−i+1))
=k+1 p=1
k
p − 1
B(f ( p), g(k− p+1)) +
ki=0
ki
B(f (i), g(k−i+1))
grâce au changement d’indice p = i + 1 dans la première somme. En rassemblant les termescommuns aux deux sommes, on a donc
B(f, g)(k+1) = B(f (k+1), g) +ki=1
ki − 1
+k
i
B(f (i), g(k−i+1)) + B(f, g(k+1))
= B(f (k+1), g) +ki=1
k + 1
i
B(f (i), g(k−i+1)) + B(f, g(k+1))
=k+1i=0
k + 1
i
B(f (i), g(k+1−i)),
qui est une fonction continue par composition et combinaison linéaire. Ceci prouve le résultat aurang k + 1 et termine la démonstration.
Remarque – En reprenant cette démonstration, il est immédiat que le résultat est vrai pour lesfonctions à valeurs complexes, lorsque B désigne le produit : on retrouve la formule connue duprogramme de première année.
312

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 321/383
Soit ϕ : J → I une fonction avec J intervalle de R. Soit f : I → Rn une fonction.
Si ϕ est de classe Ck (resp. C∞) sur J et si f est de classe Ck (resp. C∞) sur I , alorsf ϕ est de classe Ck (resp. C∞) sur J .
Propriété – Composition
Démonstration – À nouveau, c’est une récurrence immédiate basée sur la formule donnant ladérivée d’une composée. En effet, si ϕ et f sont de classe Ck+1 sur I , alors
(f ϕ)′ = ϕ′ (f ′ ϕ)
est de classe Ck comme produit et composée d’applications de classe Ck, et par hypothèse derécurrence. Donc f ϕ est de classe Ck+1.
Remarque – Les propriétés concernant la combinaison linéaire et la composition d’applications ontleurs équivalents pour des fonctions à valeurs dans C (lorsque cela a un sens, en ce qui concernela composition). On peut également donner une propriété analogue sur le quotient de fonctionsà valeurs dans C dont le dénominateur ne s’annule pas. Pour tous ces résultats, on renvoit au
cours de première année.
III. Arcs paramétrés
1. Définitions
Soit k ∈ N∗.
• On appelle arc paramétré de classe Ck (tracé dans Rn) tout couple Γ = (I,f ) où I
est un intervalle de R et f : I → Rn une fonction de classe Ck.
• L’image C = f (I ) de f est aussi appelée support de l’arc paramétré Γ.
Définition
Dans toute la suite, sauf indication contraire, Γ = (I,f ) désigne un arc paramétré de classe Ck(k ∈ N∗), de support C.
Sans soulever de question théorique, on notera M (t) le point de Rn tel que −−−−→OM (t) = f (t), où O
désigne l’origine du repère canonique de Rn. On identifie vecteur f (t) et point M (t).
Remarque – Si le paramètre décrivant l’intervalle I est le temps, Γ représente le mouvement d’unpoint dans Rn. La courbe C est alors la trajectoire de ce mouvement.
Cas particulier – Lorsque pour tout t ∈
I , f (t) = (t,x(t)) où x : I →
R est une fonction declasse Ck, C est le graphe de la fonction x.
Exemple – Les deux arcs paramétrés par
f :
R → R2
t →
1 − t2
1 + t2,
2t
1 + t2
et g :
]−π,π[ → R2
θ → (cos(θ), sin(θ))
ont pour support le cercle unité de R2 privé du point (−1,0). Deux arcs différents peuvent doncavoir le même support. Il faut bien distinguer un arc et son support.
Un point M deC
peut être associé à plusieurs paramètres : on peut avoir −−→OM = f (t
1) = f (t
2)
avec t1 = t2. Pour cette raison, on distingue les notions de point de paramètre t, indissociablede son paramètre, et de point géométrique , qui désigne l’élément de C correspondant. On parleraplutôt de point de Γ dans le premier cas, et de point de C dans le second.
313

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 322/383
• Un point M (t) de Γ est dit simple s’il existe un unique t ∈ I tel que −−−−→OM (t) = f (t).
Sinon, il est dit multiple. L’arc Γ est dit simple si tous ses points sont simples, ce quiéquivaut au fait que f soit injective.
• L’arc Γ est dit fermé si I est un segment [a,b] et si f (a) = f (b).
Définition
Un point M (t) de Γ est dit régulier si f ′(t) = (0, . . . ,0). Sinon, il est dit stationnaire(ou singulier). Si tous les points de Γ sont réguliers, on dit que Γ est régulier.
Définition – Point régulier
Attention ! Dans le cas d’un point multiple, par exemple f (t1) = f (t2) avec t1 = t2, le pointM (t1) peut être régulier sans que M (t2) le soit.
Exemple – L’arc Γ paramétré par
f : [0,2π] → R2
θ → (cos(θ), sin(θ))
a pour support le cercle unité de R2. Il est fermé et régulier. Tous les points de son supportexcepté (1,0) sont simples.
Il est important de comprendre que cet arc est différent de celui paramétré par
g :
[0,4π] → R2
θ → (cos(θ), sin(θ))
même si ces deux arcs ont le même support (dans le deuxième cas, le cercle est parcouru deuxfois).
Remarque – Un arc (I,f ) de classe C
1 avec f de la forme t →
(t, x(t)) ou t →
(t, x(t), y(t)) esttoujours régulier :
∀ t ∈ I , f ′(t) = (1, x′(t)) = (0,0) (ou f ′(t) = (1, x′(t), y′(t)) = (0,0,0)).
Soit M (a) un point régulier de Γ et · la norme euclidienne usuelle sur Rn. Alors
−−−−−−−→M (a)M (t)
M (a)M (t) −→t→at>a
f ′(a)
f ′(a) et
−−−−−−−→M (a)M (t)
M (a)M (t) −→t→at<a
− f ′(a)
f ′(a) .
La droite passant par M (a) et dirigée par le vecteur f ′(a) (ou par tout vecteur non nulcolinéaire à f ′(a)) est appelée tangente à Γ en M (a).
Propriété/Définition : Tangente en un point régulier
Démonstration – Pour t voisin de a, on peut écrire
f (t) = f (a) + f ′(a) (t − a) + o(t − a)
avec f ′(a) = (0, . . . ,0), et donc
−−−−−−−→M (a)M (t) = f (t) − f (a) = f ′(a) (t − a) + o(t − a) = (t − a)
f ′(a) + o(1)
.
En particulier, pour t > a assez proche de a, M (t) = M (a), et en utilisant l’homogénéité de la
norme, on a −−−−−−−→M (a)M (t)
M (a)M (t) =
t − a
t − a
f ′(a) + o(1)
f ′(a) + o(1) = f ′(a) + o(1)
f ′(a) + o(1) −→t→at>a
f ′(a)
f ′(a) .
314

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 323/383
De même, pour t < a, on a
−−−−−−−→M (a)M (t)
M (a)M (t) =
t − a
a − t
f ′(a) + o(1)
f ′(a) + o(1) = − f ′(a) + o(1)
f ′(a) + o(1) −→t→at<a
− f ′(a)
f ′(a) .
Remarques
• Du point de vue cinématique, f ′(t) est le vecteur vitesse (instantanée) du point mobile M au
temps t. La propriété précédente montre donc qu’à un instant t où la vitesse du point mobile estnon nulle, la trajectoire admet une tangente en M (t) dirigée par le vecteur vitesse en ce point.De même, si Γ est de classe C2, f ′′(t) est le vecteur accélération de M au temps t.
• La démonstration précédente montre que la tangente à Γ en un point régulier M (a) est la« limite » de la droite (M (a)M (t)) lorsque t → a avec t = a.
2. Étude locale des arcs plans
La situation est donc assez simple concernant les points réguliers. On cherche maintenant àdécrire plus précisément l’allure de la courbe au voisinage d’un point. Pour cela il est naturel depousser le développement limité aux ordres suivants.
On suppose que n = 2 (on considère un arc plan). Notons f = (x,y), c’est-à-dire que x ety sont les fonctions-coordonnées de f . Alors x et y sont de classe Ck sur I de même que f . Laformule de Taylor-Young permet d’écrire un développement limité de x et y en a ∈ I à l’ordrek, et donc d’obtenir un développement limité de f de la forme
f (t) =t→a
k j=0
f ( j)(a)
j! (t − a) j + (t − a)k ε(t),
où ε : I → R2 a pour limite (0,0) en a.
Supposons maintenant qu’il existe deux entiers p et q avec 1 p < q k tels que :
• Pour tout j ∈ [[1,p − 1]], f ( j)
(a) = (0,0),• Pour tout j ∈ [[ p + 1,q − 1]], (f ( p)(a),f ( j)(a)) est liée.• (f ( p)(a),f (q)(a)) est libre.
Les entiers p et q sont alors uniques, on dit que p et q sont les entiers caractéristiques de Γ
en a.
On a alors nécéssairement f ( p)(a) = (0,0). D’après la seconde condition, il existe donc (lorsque p + 1 q − 1) des scalaires λ p+1, . . . , λq−1 tels que pour tout j ∈ [[ p + 1,q − 1]],
f ( j)(a) = λ j f ( p)(a).
En tronquant le développement limité précédent à l’ordre q , on obtient un développement limité
de la forme
f (t) =t→a
f (a) + f ( p)(a)(t − a) p
p!
1 +
q−1 j= p+1
λ j(t − a) j− p
j! = o(1)
+ f (q)(a)
(t − a)q
q ! + (t − a)q η(t);
notamment, pour t = a proche de a, on a M (t) = M (a) car f ( p)(a) = (0,0). De plus
−−−−−−−→M (a)M (t)
(t − a) p −→t→at=a
f ( p)(a)
p! ,
M (a)M (t)
|t − a| p −→t→at=a
f ( p)(a)
p!
et donc −−−−−−−→M (a)M (t)
M (a)M (t) −→t→at>a
f ( p)(a)
f ( p)(a) ,
−−−−−−−→M (a)M (t)
M (a)M (t) −→t→at<a
(−1) p f ( p)(a)
f ( p)(a) .
315

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 324/383
La droite passant par M (a) et dirigée par le vecteur f ( p)(a) est ici aussi appelée tangente à Γ
en M (a). Le cas d’un point régulier correspond au cas où p = 1.
De plus, pour tout t ∈ I , le vecteur η(t) peut être décomposé sur la base (f ( p)(a), f (q)(a)) deR2. Finalement, dans le repère (M (a),f ( p)(a),f (q)(a)), et pour t ∈ I proche de a, le point M (t)a pour coordonnées
(t − a) p
p!
+ o((t
−a) p)
(t − a)q
q ! + o((t − a)q)
= (t
−a) p 1
p!
+ o(1)(t − a)q
1
q ! + o(1)
Pour t = a assez proche de a, la première coordonnée est du signe de (t − a) p, la seconde, dusigne de (t − a)q.
Finalement, en déterminant p et q , on peut décrire l’allure de la courbe au voisinage de M (a),selon la parité de p et q :
• Si p est impair, q pair :
On dit que M (a) est un point ordinaire.
f ( p)(a)
f (q)(a)
• Si p est impair, q impair :
On dit que M (a) est un point d’inflexion.
f ( p)(a)
f (q)(a)
• Si p est pair, q impair :
On dit que M (a) est un point de rebrous-sement de première espèce.
f ( p)(a)
f (q)(a)
• Si p est pair, q pair :
On dit que M (a) est un point de rebrous-sement de deuxième espèce.
f ( p)(a)
f (q)(a)
Exemple – Soit Γ l’arc paramétré par
f :
R → R2
t → t2 + cos(t), t − sin(t)
La fonction f est de classe
C∞ sur R. Pour tout t
∈R,
f ′(t) = (2t − sin(t), 1 − cos(t)) .
On en déduit facilement que tous les points sont réguliers, sauf le point (1,0) de paramètre 0.
316

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 325/383
Effectuons un développement limité des fonctions-coordonnées de f en 0 :
f (t) =
t2 + cos(t)
t − sin(t)
=
1 +
1
2t2 + o(t3)
1
6t3 + o(t3)
= 1
0
+1
20
t2 + 0
1
6
t3 + o(t3).
M (0)
Les vecteurs
1
2, 0
et
0,
1
6
sont indépendants, donc p = 2 et q = 3. Il s’agit d’un point de
rebroussement de première espèce.
Remarque – Avec les notations précédentes, supposons que x( p)(a) = 0. Le vecteur −−−−−−−→M (a)M (t) a
pour coordonnées(x(t) − x(a), y(t) − y(a))
avec
x(t) − x(a) ∼t→ax( p)(a)
p! (t − a)
p
y(t) − y(a) =t→a
y( p)(a)
p! (t − a) p + o((t − a) p).
On a notamment x(t) = x(a) pour t = a assez proche de a, et la droite (M (a)M (t)) a pour pente
y(t) − y(a)
x(t) − x(a) −→t→a
y( p)(a)
x( p)(a),
qui est la pente de la tangente à Γ en M (a). De même, d’après la formule de Taylor-Young,
x′(t) ∼t→a
x( p)(a)
( p − 1)!(t
−a) p−1
y′(t) =t→a
y( p)(a)
( p − 1)!(t − a) p−1 + o((t − a) p−1).
On a notamment x′(t) = 0 pour t = a assez proche de a, et la tangente à Γ en M (t) a pour pente
y′(t)
x′(t) −→t→a
y( p)(a)
x( p)(a).
On retiendra que lorsque les entiers caractéristiques existent avec x( p)(a) = 0, la considérationde l’un des quotients
y(t)
−y(a)
x(t) − x(a) ou y′(t)
x′(t)
permet de déterminer la pente de la tangente à Γ en M (a). Si x( p)(a) = 0 alors y( p)(a) = 0 et onpeut raisonner de même avec les quotients inverses pour obtenir l’inverse de la pente.
3. Branches infinies
On suppose que n = 2 ; on note f = (x,y). On s’intéresse aux droites qui donnent la « direc-tion » de la courbe C lorsque le paramètre t tend vers a, point adhérent à I ou ±∞.
On dit que Γ possède une branche infinie en a si f (t) −→t→a +∞.On peut distinguer t → a− et t → a+.
Définition – Branche infinie
317

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 326/383
• Premier cas : x ou y a une limite finie en a.
– Si x(t) −→t→a m ∈ R et y(t) −→
t→a ±∞, on dit que Γ possède une asymptote verticale
d’équation x = m en a.
– Si x(t) −→t→a ±∞ et y(t) −→
t→a m ∈ R, on dit que Γ possède une asymptote horizontale
d’équation y = m en a.
• Deuxième cas : x et y ont une limite infinie en a.
– Si y(t)
x(t) −→t→a
0, on dit que Γ possède une branche parabolique de direction (Ox) en a.
– Si y(t)
x(t) −→t→a ±∞, on dit que Γ possède une branche parabolique de direction (Oy) en a.
– Si y(t)
x(t) −→t→a
m ∈ R∗ :
(i) si y(t)−m x(t) −→t→a
p ∈ R, on dit que Γ possède une asymptote d’équation y = mx+ pen a.
(ii) si y(t)−m x(t) −→t→a ±∞, on dit que Γ possède une direction asymptotique d’équa-tion y = mx en a.
Remarque – La liste de cas ci-dessus n’est pas exhaustive : il se peut par exemple que y n’ait pasde limite en a, comme dans le cas du graphe de la fonction sinus lorsque t → +∞, qui ne rentredans aucun de ces cas.
4. Construction d’arcs plans
On se donne un arc plan Γ = (I,f ) avec f = (x,y).
1. On commence par déterminer l’ensemble de définition de la fonction f et les simplificationséventuelles de l’ensemble d’étude dues par exemple aux symétries de la courbe. Par exemple :
• Si x et y sont T -périodiques, il suffit de restreindre l’étude à un intervalle de longueur T .
Si I est symétrique par rapport à 0, il suffit de restreindre l’étude à I ∩R+, puis de compléter lacourbe par symétrie, dans les cas suivants :
• si x et y sont paires : la courbe C est entièrement obtenue à partir de I ∩R+.
• si x et y sont impaires : la courbe C est symétrique par rapport à l’origine.
• si x est paire et y impaire : la courbe C est symétrique par rapport à l’axe (Ox).
• si x est impaire et y paire : la courbe
C est symétrique par rapport à l’axe (Oy).
• si pour tout t ∈ I , x(−t) = y(t) et y(−t) = x(t) : la courbe C est symétrique par rapport à lapremière bissectrice d’équation y = x.
2. On donne la classe de f , on étudie les variations et les limites aux bornes de x et y .
On en déduit les tangentes horizontales ou verticales.
3. On identifie les points réguliers, les points stationnaires, et on étudie leur nature.
4. On étudie les branches infinies. Pour connaître la position de la courbe par rapport à uneasymptote d’équation y = mx + p, il peut être utile d’étudier le signe de la différencey(t) − mx(t) − p.
5. On peut également rechercher les éventuels points doubles, c’est-à-dire tels qu’il existe t1 = t2
avec x(t1) = x(t2) et y (t1) = y(t2).
6. On effectue le tracé.
318

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 327/383
Exemple – Étudions l’arc Γ paramétré par
x(t) = t
ln(t)
y(t) = t2
2(t − 1)
pour t ∈ D
= R∗+ \
1
(on peut le considérer comme réunion de deux arcs).
Il n’y a pas de symétrie évidente. Les fonctions x et y sont de classe C∞ sur D (y est en faitde classe C∞ sur R \ 1). De plus, pour tout t ∈ D,
x′(t) = ln(t) − 1
ln2(t)
y′(t) = 2t(t − 1) − t2
2(t − 1)2 =
t(t − 2)
2(t − 1)2.
On en déduit le tableau de variations suivant :
t 0 1 2 e +∞x′(t) − − − 0 +
0 +∞ +∞x(t) ց ց 2
ln(2) ց ր
−∞ e
0 +∞ +∞y(t) ց ց ր e2
2(e − 1) ր
−∞ 2y′(t) 0 − − 0 + +
En particulier, Γ est régulier, possède une tangente horizontale au point
2
ln(2), 2
de paramètre
2, et une tangente verticale au point
e,
e2
2(e − 1)
de paramètre e.
L’arc admet trois branches infinies, en 1−, 1+ et +∞, qui ne sont pas des asymptotes hori-zontales ou verticales, car x et y ont des limites infinies. Pour tout t ∈ D,
y(t)
x(t) =
t ln(t)
2(t − 1).
Lorsque t → +∞,y(t)
x(t) ∼ 1
2 ln(t) → +∞,
donc Γ admet une branche parabolique de direction (Oy) en +∞.
Pour t = 1 proche de 1, posons t = 1 + h, avec h non nul voisin de 0. Alors
y(t)
x(t) =
1 + h
2
ln(1 + h)
h −→
h→0
1
2
car ln est dérivable en 1 avec ln′(1) = 1. Alors
y(t) − 1
2x(t) =
(1 + h)2
2h − 1 + h
2 ln(1 + h) =
1
2h + 1 +
h
2 − 1 + h
2
1
h − h2
2 +
h3
3 + o(h3)
.
319
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 328/383
Or1
h − h2
2 +
h3
3 + o(h3)
= 1
h
1
1 − h
2 +
h2
3 + o(h2)
= 1
h
1 +
h
2 − h2
3 +
h2
4 + o(h2)
= 1
h 1 + h
2 − h2
12 + o(h2) ,
d’où
y(t) − 1
2x(t) =
1
2h + 1 +
h
2 − 1 + h
2h
1 +
h
2 − h2
12 + o(h2)
= 1
2h + 1 +
h
2 − 1
2h
1 +
h
2 − h2
12 + h +
h2
2 + o(h2)
=
1
4 +
7
24 h + o(h).
On en déduit notamment que Γ possède une asymptote d’équation y = 1
2x +
1
4 en 1±.
Pour connaître la position de la courbe par rapport à cette asymptote, on étudie le signe dey(t) − 1
2x(t) − 1
4
qui est donné, pour t voisin de 1, par le développement limité précédent. On en déduit que lacourbe est au-dessous de son asymptote pour t < 1 proche de 1, et au-dessus pour t > 1 prochede 1. On remarque l’intérêt d’avoir effectué le développement limité à un ordre suffisant dès ledépart.
Lorsque t → 0, x(t) → 0. On peut prolonger x par continuité en 0 en posant x(0) = 0. Enremarquant que x′(t) → 0 lorsque t → 0+, le théorème de la limite de la dérivée montre que x estde classe C1 en 0 avec x′(0) = 0 ; de plus y(0) = y ′(0) = 0. L’origine n’est pas un point régulier
du prolongement de Γ ; mais, en remarquant quey(t) − y(0)
x(t) − x(0) =
y(t)
x(t) =
t ln(t)
2(t − 1) −→t→0+
0,
on voit que le prolongement de Γ a une tangente horizontale au point (0,0) de paramètre 0.
J
I +
+
320

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 329/383
5. Longueur d’un arc
Dans ce paragraphe, · désigne la norme euclidienne usuelle sur Rn.
Soit Γ = (I,f ) un arc paramétré de classe C1.
• Si I
est un segment [a,b]
, on appelle longueur de Γ
le réel b
a f ′(t)
dt.
• Si I est un intervalle quelconque, on appelle longueur de Γ le réel I f ′(t) dt
lorsque l’intégrale I f ′(t) dt est convergente.
Définition
Remarque – On peut considérer les intégrales écrites dans la définition précédente car la fonction
f ′ est continue sur I .Exemple – On considère la cycloïde paramétrée par
x(t) = t − sin(t)
y(t) = 1 − cos(t)
pour t ∈ R. Il s’agit d’un arc de classe C∞, et on remarque que pour tout t ∈ R,x(t + 2π) = t + 2π − sin(t) = x(t) + 2π
y(t + 2π) = 1 − cos(t) = y(t)
Il suffit donc d’étudier la portion (appelée arche) de l’arc correspondant à t ∈ [0,2π], puis decompléter le tracé par translations horizontales. La longueur de cette arche est donnée par
L =
2π
0
(x′)2(t) + (y′)2(t) dt =
2π
0
(1 − cos(t))2 + (sin(t))2 dt
=
2π
0
2(1 − cos(t)) dt
= 2
2π
0
sin2(t/2) dt
= 2 2π
0
sin(t/2) dt = 8
(on a utilisé que pour tout t ∈ [0,2π], sin(t/2) 0).
Le support de la cycloïde est la courbe décrite par un point fixe sur un cercle qui roule sansglisser sur une droite, par exemple un point d’une roue de vélo. La longueur d’une arche decycloïde est égale à quatre fois le diamètre du cercle correspondant (ci-dessus ce diamètre vaut2 car le périmètre du cercle correspondant est 2π). En revanche, évidemment, l’arc « complet »n’est pas de longueur finie.
321

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 330/383
322

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 331/383
Chapitre 17
Équations différentielles
Dans ce chapitre, I désigne un intervalle de R, non vide et non réduit à un point, K désigneR ou C, et n ∈ N∗.
Les notions de fonction dérivable, de dérivation composante par composante, de classe Ck,définies pour les fonctions de I dans Rn dans le chapitre Fonctions vectorielles – Arcs pa-ramétrés, s’adaptent de façon évidente aux fonctions de I dans M n,1(K).
I. Résultats théoriques sur les systèmes différentiels
Un système différentiel de n équations à n inconnues
x′1(t) = a1,1(t)x1(t) + · · · + a1,n(t)xn(t) + b1(t)
...
x′n(t) = an,1(t)x1(t) + · · · + an,n(t)xn(t) + bn(t)
peut se mettre sous la forme d’une seule équation, X ′(t) = A(t)X (t) + B(t), dans M n,1(K), avec
X (t) =
x1(t)
...xn(t)
, A(t) =
a1,1(t) . . . a1,n(t)
......
an,1(t) . . . an,n(t)
et B(t) =
b1(t)
...bn(t)
.
Une telle équation est appelée équation différentielle linéaire. La fonction inconnue X et lesecond membre B sont définis sur I et à valeurs dans M n,1(K), la fonction A est définie surI à valeurs dans M n(K). Pour n = 1, on retrouve les équations linéaires scalaires d’ordre 1,x′(t) = a(t)x(t) + b(t). Pour n 2, on identifie souvent le système différentiel et l’équationdifférentielle qui lui est associée.
Notation – Une équation différentielle du type précédent est souvent notée X ′ = A(t)X + B(t).On ne note la variable t que pour les coefficients de l’équation, pas pour la fonction inconnue.Ce n’est qu’une notation, qui désigne l’équation que l’on cherche à résoudre.
Soient A : I →M n(K) et B : I →M n,1(K) deux fonctions continues.
Une solution sur I de l’équation différentielle linéaire
X ′ = A(t)X + B(t) (L )
est une fonction X : I
→M n,1(K) dérivable sur I telle que
∀ t ∈ I , X ′(t) = A(t)X (t) + B(t).
Définition
323

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 332/383
Remarques
• Si K = R et X = t
x1 · · · xn
est une solution sur I de (L ), l’arc paramétré (I,(x1, . . . , xn))
(qui est tracé dans Rn) est une courbe intégrale de (L ).
• Une solution sur I de (L ) est nécessairement de classe C1 ; en effet, pour tout t ∈ I , on aX ′(t) = A(t)X (t) + B(t). Or, l’application B est continue, ainsi que l’application t → A(t)X (t),en raisonnant composante par composante et par opérations sur des fonctions continues. Parsomme, X ′ est continue, donc X est de classe
C1, sur I .
Soient A : I →M n(K) et B : I →M n,1(K) deux fonctions continues.
Alors l’équation différentielle linéaire
(L ) : X ′ = A(t)X + B(t)
possède des solutions sur I .
Pour tout t0 ∈ I et X 0 ∈M n,1(K), le problème de Cauchy
X ′(t) = A(t)X (t) + B(t)
∀t
∈ I
X (t0) = X 0
possède une unique solution.
Théorème de Cauchy linéaire (admis : démonstration hors programme)
Conséquence importante – Si B = 0 (on parle d’équation sans second membre), il est immé-diat que la fonction nulle est solution sur I de l’équation différentielle X ′ = A(t)X. L’unicité duthéorème précédent montre alors qu’aucune autre solution de cette équation ne peut s’annulersur I .
Exemple – Soit a ∈ K. L’unique solution sur I de l’équation différentielle x′ = ax qui prend lavaleur x0
∈K en t0
∈ I est la fonction
x : t → x0 ea (t−t0).
Bien sûr, en général, la résolution n’est pas aussi simple et se pose le problème de la recherchedes solutions, ou de la solution du problème de Cauchy (que la démonstration du théorème nedonne pas explicitement).
Supposons que l’on dispose d’une solution particulière X p de (L ). Soit X : I → M n,1(K)une fonction; X est dérivable sur I si et seulement si X − X p est dérivable sur I et dans ce cas,X est solution sur I de (L ) si et seulement si
∀ t ∈ I , X ′(t) = A(t)X (t) + B(t)
ce qui équivaut à ∀ t ∈ I , X ′(t) = A(t)X (t) + [X ′ p(t) − A(t)X p(t)]
ce qui équivaut à ∀ t ∈ I , [X − X p]′(t) = A(t)[X − X p](t).
Ainsi, X est solution sur I de (L ) si et seulement si X − X p est solution sur I de l’équationdifférentielle
Y ′ = A(t) Y. (H)
L’équation (H) est dite équation homogène associée à (L ).
Définition
On obtient toutes les solutions de (L ) sous la forme« Solution particulière de (L ) + solution générale de l’équation homogène (H) »
Propriété – Forme des solutions de (L )
324

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 333/383
Il est donc judicieux de s’intéresser à la fois à la recherche de solutions particulières de (L ),et à l’ensemble des solutions de (H).
En ce qui concerne les solutions particulières, commençons par rappeler le principe de su-perposition, très utile pour simplifier leur recherche lorsque le second membre est somme deplusieurs termes :
Soient B1, . . . , Bk des fonctions continues sur I à valeurs dans M n,1(K), et soitB = B1 + · · · + Bk. Soit, pour tout i ∈ [[1,k]], X i une solution sur I de l’équationdifférentielle linéaire
X ′i = A(t)X i + Bi.
Alors X = X 1 +· · ·+X k est solution de l’équation différentielle linéaire X ′ = A(t)X +Bsur I .
Propriété
Démonstration – La fonction X est dérivable sur I comme somme de fonctions dérivables, et B estcontinue sur I comme somme de fonctions continues. Pour tout t ∈ I , en sommant les relationsX ′i(t) = A(t)X i(t) + Bi(t), on obtient
X ′(t) = A(t)X 1(t) + · · · + A(t)X k(t) + B1(t) + · · · + Bk(t)
= A(t)X (t) + B(t)
par définition de B . D’où le résultat.
Donnons maintenant la structure de l’ensemble des solutions de l’équation homogène (H) :
• L’ensemble S des solutions sur I de l’équation homogène (H) est un K-espace vecto-riel.
• Pour tout t0 ∈ I fixé, l’application
φt0 :
S → M n,1(K)X → X (t0)
est un isomorphisme.
En particulier, S est de dimension finie égale à n.
Théorème
Démonstration
• Nous avons remarqué plus haut que S est un sous-ensemble de l’ensemble des fonctions declasse C1 sur I à valeurs dans M n,1(K), qui est clairement un K-espace vectoriel. De plus, S est
non vide car la fonction nulle est solution de (H). La stabilité de S par combinaison linéaire estun calcul immédiat.
• Soit t0 ∈ I ; il est évident que φt0 est linéaire. De plus, le théorème d’existence et unicité d’unesolution au problème de Cauchy associé à (H) et t0 montre que φt0 est bijective. Donc φt0 est unisomorphisme. Les isomorphismes préservent la dimension, donc S est de dimension finie avecdim(S ) = dim(M n,1(K)) = n.
Exemple – Considérons le système différentiel sans second membrex′ = −y
y′ = x
d’équation différentielle linéaire associée
X ′ =
0 −11 0
X.
325

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 334/383
On vérifie facilement que
X 1 =
cossin
et X 2 =
− sincos
sont deux solutions sur R de cette équation. Elles sont linéairement indépendantes car les fonc-tions cos et sin ne sont pas proportionnelles. Ainsi, (X 1,X 2) est une base de l’espace vectorieldes solutions ; on obtient donc toutes les solutions de l’équation sous la forme
t → λX 1(t) + µX 2(t) =λ cos(t) − µ sin(t)
λ sin(t) + µ cos(t)
où (λ,µ) ∈ K2.
II. Systèmes à coefficients constants sans second membre
Lorsque A : R → M n(K) est une fonction constante, on peut l’identifier à une matriceA ∈M n(K), et on obtient ce que l’on appelle un système différentiel (ou équation différentielle)linéaire à coefficients constants X ′ = AX .
Le théorème de Cauchy, dans ce cas, assure l’existence et l’unicité d’une solution au problèmede Cauchy sur R tout entier.
Commençons par une remarque générale :
Soit A ∈M n(K) et λ ∈ Sp(A) une valeur propre de A.
Alors, pour tout X 0 ∈ E λ(A), la fonction
X : t → eλt X 0
est solution sur R du système différentiel X ′ = AX.
Propriété
Démonstration – La fonction X est dérivable sur R (ses composantes sont des fonctions exponen-tielles). Pour tout t ∈ I ,
X ′(t) = λ eλt X 0 = eλt(λX 0) = eλt AX 0 = A(eλtX 0) = AX (t).
L’étude du système différentiel X ′ = AX est donc liée à la réduction de la matrice A.
Premier cas : A est diagonalisable
Il existe alors une matrice inversible P ∈ Gℓn(K) et une matrice diagonale D dont les coef-
ficients diagonaux sont les valeurs propres de A, notées λ1, . . . , λn, telles que A = P DP −1
. SoitX : R → M n,1(K) une fonction et Y = P −1X ; X est dérivable sur R si et seulement si Y estdérivable sur R et dans ce cas, on a les équivalences suivantes :
X ′ = AX ⇔ X ′ = P DP −1X ⇔ P −1X ′ = DP −1X
⇔ (P −1X )′ = D(P −1X ) ⇔ Y ′ = DY .
Dans ce raisonnement, il est essentiel que P ne dépende pas de t. En notant y1, . . . , yn lesfonctions-coordonnées de Y , la dernière égalité équivaut à
∀ i ∈ [[1,n]], y′i = λi yi,
ce qui équivaut à : ∀ i ∈ [[1,n]], ∃ ki ∈ K; ∀ t ∈ R, yi(t) = ki eλit
.
On retrouve alors très simplement X par la relation X = P Y . On remarquera que l’on a pasbesoin d’expliciter P −1, qui n’intervient que théoriquement.
326

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 335/383
On a donc démontré le résultat suivant :
Avec les notations précédentes, si A est diagonalisable, la solution générale du systèmedifférentiel à coefficients constants X ′ = AX sur R s’écrit
t → P k1 eλ1t
...kn eλnt
où (k1, . . . , kn) ∈ Kn.
Théorème – Résolution de X ′ = AX avec A diagonalisable
Remarque – Le signe de la partie réelle des λi permet d’étudier le comportement asymptotiquedes solutions du système différentiel : pour qu’une solution X ait une limite en +∞ par exemple,il faut et il suffit que pour tout i ∈ [[1,n]], t → ki eλit ait une limite dans K en +∞. En particulier,si Re(λi) < 0 pour tout i, alors
|eλit| = eRe(λi) t −→t
→+
∞
0
et X (t) −→t→+∞
0 dans M n,1(K).
Deuxième cas : A est réelle, diagonalisable dans M n(C)
En appliquant la méthode précédente, on obtient les solutions complexes de l’équation. Pouren retrouver les solutions réelles, on cherche, parmi les solutions complexes, les solutions qui sontégales à leur conjuguée, ce qui donne des conditions sur les constantes ki.
Troisième cas : A est trigonalisable
Il existe alors une matrice inversible P ∈ Gℓn(K) et une matrice triangulaire supérieureT = (ti,j) dont les coefficients diagonaux sont les valeurs propres de A, notées λ1, . . . , λn, telles
que A = P T P −1
. Avec le même changement de fonction inconnue Y = P −1
X, on se ramène ausystème Y ′ = T Y , que l’on peut résoudre en commençant par la dernière équation y′n = λnyn,dont la solution générale sur R s’écrit t → kn eλnt, où kn ∈ K. L’avant-dernière équation est alors
y′n−1 = λn−1 yn−1 + tn−1,n yn(t), i.e. y′n−1 = λn−1 yn−1 + tn−1,n kn eλnt.
On est amené à résoudre une équation du type
y′ − λy = k eαt,
et l’on poursuit la résolution « de bas en haut ».
Exemple – On considère le système différentiel
x′ = x + 2z
y′ = x + y − 5z
z′ = y + 5z
Il est associé à la matrice
A =
1 0 2
1 1 −50 1 5
de polynôme caractéristique (X − 2)2(X − 3). On détermine facilement
E 2(A) = Vect
2
−31
et E 3(A) = Vect
1
−21
.
327

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 336/383
En particulier, dim(E 2(A)) = m(2), donc A n’est pas diagonalisable (ni dans M 3(R) ni dansM 3(C)). Elle est en revanche trigonalisable dans M 3(R) car son polynôme caractéristique estscindé dans R. Cherchons une matrice semblable à A de la forme
T =
2 α 00 2 00 0 3
.
Pour construire une base de M 3,1(R) dans laquelle la matrice de uA soit T , on choisit e1 =
2
−31
et e3 =
1
−21
. Pour le choix de e2, il suffit que (e1,e2,e3) soit libre et que :
∃ α ∈ R; (A − 2I 3)e2 = αe1 i.e. (A − 2I 3)e2 ∈ Vect(e1) = E 2(A) i.e. (A − 2I 3)2e2 = 0.
On montre facilement que e2 = −2
10 convient, avec (A − 2I 3)e2 = e1. En posant
P =
2 −2 1
−3 1 −21 0 1
,
on a donc
A = P
2 1 00 2 00 0 3
P −1.
En posant Y = P −1X =
y1
y2
y3
, le système original équivaut donc à
y′1 = 2y1 + y2
y′2 = 2y2
y′3 = 3y3
Les deux dernières équations équivalent à l’existence de (k2, k3) ∈ K2 tels que pour tout t ∈ R,y2(t) = k2 e2t et y3(t) = k3 e3t. La première équation s’écrit alors y′
1
= 2y1 + k2 e2t ; en posant
y : t → y1(t) e−2t,
cette équation équivaut à : y ′ = k2, donc à l’existence de k1 ∈ K tel que pour tout t ∈ R,
y1(t) = (k2t + k1) e2t.
Les solutions du système différentiel X ′ = AX sont donc données par
∀ t ∈R
, x1(t)
x2(t)x3(t) = P
(k2t + k1) e2t
k2 e
2t
k3 e3t où k1, k2 et k3 sont des scalaires quelconques.
328

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 337/383
III. Équations scalaires d’ordre 1
On s’intéresse au cas d’une équation de la forme
x′ + a(t)x = b(t)
où a et b sont deux fonctions continues sur I à valeurs dans K. C’est bien sûr un cas particulierde la théorie précédente avec n = 1, mais on peut être plus explicite dans ce cas.
Équation homogène
Fixons t0 ∈ I et considérons la fonction x0 : t → exp
− tt0
a(s) ds
.
La fonction a est continue sur I donc x0 est bien définie et dérivable sur I avec, pour tout t ∈ I ,
x′0(t) = −a(t)exp
− tt0
a(s) ds
= −a(t) x0(t),
donc x0 est une solution sur I de l’équation x′ + a(t)x = 0. De plus, x0 ne s’annule pas sur I .Pour qu’une fonction x dérivable sur I soit solution de cette équation, il faut et il suffit que
x′ + ax = 0, i.e. x′x0 + axx0
x20
= 0, i.e.
x
x0
′= 0.
Ceci équivaut à l’existence d’une constante γ ∈ K telle que x = γ x0. L’ensemble des solutionsde l’équation homogène est donc la droite vectorielle engendrée par x0.
Équation complète : la méthode de variation de la constante
On obtient toutes les solutions de (H) sous la forme γ x0 où γ ∈ K. Pour résoudre l’équationcomplète (L ), l’idée est de faire « varier la constante » γ , c’est-à-dire de voir γ comme unefonction de I dans K, et de chercher à quelle condition la fonction γ x0 est solution de (L ).
Tout d’abord, toute fonction x : I
→ K peut s’écrire sous la forme γ x0, car x0 ne s’annule
pas sur I . De plus, sur I , x0 étant dérivable, x est dérivable si et seulement si γ est dérivable.Dans ce cas, on a x′ = γ ′x0 + γx′0, et donc, pour que x soit solution de (L ) sur I , il faut et
il suffit que[γ ′ x0 + γ x′0] + a [γ x0] = b, i.e. γ ′x0 + γ [x′0 + ax0] = b.
Or x0 est solution de (H), donc x′0 + ax0 = 0. Ainsi, x est solution de (L ) si et seulement sipour tout t ∈ I ,
γ ′(t) x0(t) = b(t).
La méthode de variation de la constante se résume donc ainsi : les solutions de l’équation complètex′ + a(t)x = b(t) sur I sont exactement les fonctions γ x0, où γ : I → K est dérivable et vérifieγ ′x
0 = b. Il sufit donc de déterminer une primitive γ de la fonction b/x
0 sur I .
Finalement, on obtient toutes les solutions de l’équation complète sous la forme
x : t → t
t0
b(s)
x0(s) ds + k
exp
− tt0
a(s) ds
,
où k ∈K. Une condition initiale (problème de Cauchy) détermine entièrement k.
Remarque – La solution générale de (L ) se met donc sous la forme
γ x0 + k x0
où γ est une primitive de b/x0 sur I , et k
∈ K. Le premier terme correspond à une solution
particulière de l’équation complète (L ), le second, à la solution générale de l’équation homogène.On retrouve donc la structure de l’ensemble des solutions de (L ) ; la méthode de variation
de la constante permet de trouver des solutions particulières non évidentes.
329

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 338/383
Exemple – Résolvons, sur I = R∗+, l’équation différentielle
x′ = 2
t x +
1
t.
Pour résoudre l’équation homogène, on détermine une primitive sur I de la fonction continuet → 2/t, par exemple t → 2ln(t). La solution générale de l’équation homogène s’écrit donc
x0 : t → γ exp(2ln(t)) = γ t2
où γ ∈ K.
Pour résoudre l’équation complète, on peut remarquer que la fonction constante égale à −1/2
en est solution.
C’est une vérification qu’il faut penser à faire en général : si l’équation ordinaire
∀ t ∈ I , a(t)x + b(t) = 0
possède une solution (indépendante de t), alors la fonction constante y : t → x vérifie l’équationcomplète (L ) car dans ce cas on a y ′(t) = 0 = a(t)y(t) + b(t) pour tout t ∈ I .
Dans notre cas, la solution générale de l’équation complète s’écrit
x : t → −1
2 + kt2
où k ∈K.
Si l’on ne remarque pas qu’il existe une solution constante, on peut bien sûr appliquer laméthode variation de la constante : on obtient toutes les solutions de l’équation complète sousla forme t → γ (t) t2 où γ : R∗+ → K est une fonction dérivable telle que
∀ t > 0, γ ′(t) t2 = 1
t, ce qui équivaut à : ∀ t > 0, γ ′(t) =
1
t3,
et donc à l’existence d’une constante k ∈ K telle que pour tout t > 0, γ (t) = − 1
2t2 + k, et l’on
obtient la solution générale de l’équation complète sous la forme
x : t →
− 12t2
+ k
t2 = −12
+ k t2,
ce qui donne bien sûr le même résultat.
Remarque – Comme nous l’avons remarqué à l’occasion de la résolution des systèmes différentielsà coefficients constants X ′ = AX , on est souvent amené à résoudre des équations scalaires dupremier ordre de la forme
y′ − λy = P (t)eαt
où (λ,α) ∈ K2 et P est une fonction polynomiale. La solution générale de l’équation homogènes’écrit sous la forme t → γ eλt. La méthode de variation de la constante conduit à chercher lesfonctions dérivables γ : I
→K telles que
∀ t ∈ I , γ ′(t)eλt = P (t)eαt,
ce qui équivaut à∀ t ∈ I , γ ′(t) = P (t)e(α−λ)t.
Si α = λ, on peut choisir pour γ la primitive de P qui s’annule en 0; elle se met sous la formet → tQ(t) avec Q de même degré que P . Si α = λ, on peut trouver γ sous la forme
t → Q(t)e(α−λ)t
où Q est une fonction polynomiale de même degré que P .
Finalement, la solution générale de l’équation complète s’écrit
t → keλt + tm(α)Q(t) eαt où k ∈ K,
avec Q une fonction polynomiale de même degré que P , et m(α) = 0 si α = λ, m(α) = 1 siα = λ.
330

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 339/383
IV. Équations scalaires d’ordre 2
On s’intéresse ici au cas d’une équation différentielle linéaire scalaire d’ordre 2, de la forme
x′′ + a(t)x′ + b(t)x = c(t), (L 2)
où a, b et c sont trois fonctions continues sur I à valeurs dans K.
1. Système différentiel d’ordre 1 associéNous allons montrer comment se ramener au cadre d’application de la théorie précédente.
Tout d’abord, on appelle solution sur I de (L 2) toute fonction x : I → K deux fois dérivable surI , telle que pour tout t ∈ I ,
x′′(t) + a(t)x′(t) + b(t)x(t) = c(t).
Une telle solution est alors nécessairement de classe C2 sur I .
Soit x : I → K une solution de (L 2) sur I et
X : t →
x(t)x′(t)
.
Alors X est dérivable sur I , à valeurs dans M 2,1(K), et vérifie : pour tout t ∈ I ,
X ′(t) =
x′(t)x′′(t)
=
x′(t)
−a(t)x′(t) − b(t)x(t) + c(t)
=
0 1
−b(t) −a(t)
x(t)x′(t)
+
0c(t)
.
Posons, pour tout t ∈ I ,
A(t) =
0 1
−b(t) −a(t)
∈ M 2(K) et B(t) =
0c(t)
∈M 2,1(K);
les fonctions A et B sont continues sur I , et X est solution du système différentiel
X ′ = A(t)X + B(t).
Réciproquement, soit X = xy une solution de X ′ = A(t)X + B(t) sur I . Alors on a, pour tout
t ∈ I , x′(t)y′(t)
=
0 1
−b(t) −a(t)
x(t)y(t)
+
0c(t)
=
y(t)
−a(t)y(t) − b(t)x(t) + c(t)
.
D’après la première égalité, on a y = x′ ; en particulier x est deux fois dérivable sur I . De plus,pour tout t ∈ I ,
x′′(t) = −a(t)x′(t) − b(t)x(t) + c(t).
Finalement, x est solution de x ′′ + a(t)x′ + b(t)x = c(t) sur I .
On a donc montré le résultat suivant :
Avec les notations précédentes, les solutions sur I du système différentiel
X ′ = A(t)X + B(t)
sont exactement les fonctions de la formexx′
où x est solution de x′′ + a(t)x′ + b(t)x = c(t) sur I .
En particulier, on obtient exactement les solutions de (L 2) en prenant la premièrefonction-coordonnée des solutions de X ′ = A(t)X + B(t).
Propriété
331

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 340/383
On se ramène ainsi, quitte à passer dans M 2,1(K), à un système différentiel du premier ordre.
Exemple – L’équation différentielle linéaire scalaire d’ordre 2
x′′ + t x′ + t2 x = t3
se met sous la forme du système différentiel
X ′ = 0 1
−t2 −t
X +
0t3
où X =
xx′
.
La théorie de la première partie (le théorème de Cauchy linéaire et ses conséquences) s’appliqueet donne le résultat suivant :
Soient a, b et c trois fonctions continues sur I à valeurs dans K.
• Alors l’équation différentielle linéaire scalaire d’ordre 2
(L 2) : x′′ + a(t)x′ + b(t)x = c(t)
possède des solutions.
• Pour tout t0 ∈ I , x0 ∈ K et x1 ∈ K, le problème de Cauchy
x′′(t) + a(t)x′(t) + b(t)x(t) = c(t) ∀ t ∈ I
x(t0) = x0
x′(t0) = x1
possède une unique solution.
• L’ensemble
S des solutions de l’équation homogène
x′′ + a(t)x′ + b(t)x = 0 (H2)
est un plan vectoriel de C2(I,K).
• On obtient toutes les solutions de (L 2) sous la forme
« Solution particulière de (L 2) + solution générale de l’équation homogène (H2) ».
Théorème
Démonstration – Avec les notations précédentes, le théorème de Cauchy linéaire s’applique àl’équation X ′ = A(t)X + B(t) posée dans M 2,1(K), car les applications A et B sont continues
sur I . Il existe des solutions de cette équation, et donc des solutions de x′′ + a(t)x′+ b(t)x = c(t).Pour tout t0 ∈ I et (x0,x1) ∈ K2, il existe une solution X de X ′ = A(t)X + B(t) telle que
X (t0) =
x0
x1
; X se met alors sous la forme
xx′
avec x solution de x′′ + a(t)x′ + b(t)x = c(t)
et x(t0)x′(t0)
=
x0
x1
d’où l’existence d’une solution au problème de Cauchy. Si x et y en sont deux solutions, alors
X =
xx′
et Y =
yy′
sont deux solutions du problème de Cauchy matriciel correspondant,
donc par unicité pour ce problème, X = Y , d’où x = y.
L’ensemble S des solutions de l’équation homogène
x′′ + a(t)x′ + b(t)x = 0
332

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 341/383
est un sous-espace vectoriel de C2(I,K) (vérification immédiate), il est de dimension 2 car, d’aprèsl’existence et unicité pour le problème de Cauchy (que l’on vient de prouver), l’application
φt0 :
S → M 2,1(K)
x →
x(t0)x′(t0)
est un isomorphisme, pour tout t0 ∈ I .
Contrairement au premier ordre, il n’existe pas de méthode générale pour déterminer l’en-semble des solutions de l’équation (H2) ou (L 2). Dans la suite, nous allons indiquer un cas quel’on sait traiter, ainsi qu’une méthode d’aide à la recherche de solutions dans le cas général.
2. Cas où l’équation homogène associée est à coefficients constants
On considère le cas particulier des équations de la forme
x′′ + ax′ + bx = c(t)
où (a,b) ∈ K2.
Dans ce cas, le cours de première année permet de déterminer deux solutions indépendantesde l’équation homogène via la résolution de l’équation caractéristique
x2 + ax + b = 0. (E )
• Si (E ) possède deux racines distinctes r1 et r2 dans K, t → er1t et t → er2t constituentune base de l’espace des solutions de (
H2) sur R.
Pour toute solution x de (H2), il existe un unique couple (λ,µ) ∈ K2 tel que, pour toutt ∈ R,
x(t) = λ er1t + µ er2t.
• Si (E ) possède une racine double r dans K, t → ert et t → t ert constituent une basede l’espace des solutions de (H2) sur R.
Pour toute solution x de (H2), il existe un unique couple (λ,µ) ∈ K2 tel que, pour toutt ∈ R,
x(t) = λ ert + µ t ert = (λ + µt)ert.
• Si K = R et (E ) possède deux racines complexes conjuguées z et z dans C, alors
il existe r ∈ R
et ω ∈ R
∗ tels que z = r + iω . Les fonctions t → e
rt
cos(ωt) ett → ert sin(ωt) constituent une base de l’espace des solutions de (H2) sur R.
Pour toute solution x de (H2), il existe un unique couple (λ,µ) ∈R2 tel que, pour toutt ∈ R,
x(t) = λ ert cos(ωt) + µ ert sin(ωt) = ert(λ cos(ωt) + µ sin(ωt)).
Théorème
La forme matricielle de l’équation homogène x′′ + ax′ + bx = 0 est le système différentiel àcoefficients constants X ′ = AX où
A =
0 1−b −a
.
On remarquera que le polynôme X 2 + aX + b apparaissant dans l’équation caractéristique est lepolynôme caractéristique de la matrice A, phénomène semblable à celui que nous avions observélors de l’étude des suites récurrentes linéaires d’ordre 2.
333

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 342/383
Nous avions montré dans le chapitre Réduction des endomorphismes et des matricescarrées que la matrice A est :
• diagonalisable si (E ) possède deux racines distinctes r1 et r2 dans K ; il existe P ∈ Gℓ2(K)tel que
A = P
r1 00 r2
P −1;
• trigonalisable si (
E ) possède une racine double r dans K ; il existe P
∈ Gℓ2(K) tel que
A = P
r 10 r
P −1.
On résout ce système en posant Y = P −1X = t
y1 y2
, ce qui revient à résoudre le système
Y ′ =
r1 00 r2
Y, i.e.
y′1 = r1y1
y′2 = r2y2
dans le premier cas, et le système
Y ′ = r 1
0 rY, i.e. y′1 = ry1 + y2
y′2 = ry2
dans le deuxième cas. Après résolution de ce système, en prenant la première coordonnée deX = P Y , on retrouve bien la forme générale des solutions présentée dans le théorème précédent.
En ce qui concerne l’équation complète :
• Lorsque le second membre est de la forme P (t) eαt avec P ∈ K[X ] et α ∈ K, on pensera àchercher une solution particulière sous la forme t → tm(α)Q(t) eαt où Q ∈ K[X ] est de mêmedegré que P et m(α) est la multiplicité de α comme racine de l’équation caractéristique (E )associée à l’équation homogène (m(α) peut valoir 0, 1 ou 2).On pourra aussi utiliser le changement de fonction inconnue consistant à poser y : t
→ x(t) e−αt.
• En particulier, lorsque b = 0 et le second membre est polynomial, on pourra chercher unesolution particulière polynomiale de même degré. En effet, on est dans la situation précédenteavec α = 0 et m(α) = 0.
• Lorsque K = R et le second membre est de la forme A cos(ωt) ou A sin(ωt) avec (A,ω) ∈ R2
et ω = 0, on pourra chercher une solution particulière sous la forme t → λ cos(ωt) + µ sin(ωt) où(λ,µ) ∈R2 si iω n’est pas racine de (E ), ou sous la forme t → t(λ cos(ωt) + µ sin(ωt)) sinon.En effet, on se ramène au premier point en considérant l’équation
x′′ + ax′ + bx = Aeiωt.
Si x p en est une solution particulière, alors Re(x p) (resp. I m(x p)) est une solution particulière
dex′′ + ax′ + bx = A cos(ωt) (resp. x′′ + ax′ + bx = A sin(ωt)),
car a et b sont réels. Or, ces fonctions sont de la forme indiquée ci-dessus, selon que iω est racineou non de l’équation caractéristique (il ne peut pas en être racine double, car a et b sont réels).
• Enfin, on pourra utiliser le principe de superposition lorsque le second membre est somme deplusieurs termes.
Exemples
• L’évolution d’un oscillateur amorti en régime libre est régie par l’équation différentielle
x′′ + 2λ x′ + ω20 x = 0,
qui regroupe par exemple les systèmes masse-ressort, les pendules de torsion, les circuits RLC.Le coefficient λ 0 est le coefficient d’amortissement du système, ω0 > 0 en est la pulsationpropre.
334

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 343/383
L’équation caractéristique associée à cette équation différentielle linéaire du second ordre àcoefficients constants sans second membre est
r2 + 2λ r + ω20 = 0,
de discriminant réduit λ2 − ω20.
– Si λ = 0 (amortissement nul), on obtient deux solutions indépendantes,
t → cos(ω0t) et t → sin(ω0t).
On écrit la solution générale de l’équation sous la forme t → C cos(ω0t + ϕ), où C est l’ampli-tude des oscillations du système, et ϕ la phase à l’origine. On comprend bien ainsi l’expression« pulsation propre » : c’est la pulsation du système en l’absence d’amortissement et de force ousignal extérieur.
– Si 0 < λ < ω0, les racines de l’équation caractéristique sont −λ ± i
ω20 − λ2 ; on obtient deux
solutions indépendantes,
t
→ e−λt cos(ωt) et t
→ e−λt sin(ωt),
où ω =
ω20 − λ2 (appelée pseudo-pulsation, lorsque l’amortissement est faible). On écrit la
solution générale de l’équation sous la forme t → C e−λt cos(ωt + ϕ), où Ce−λt est l’amplitude,exponentiellement décroissante, des « oscillations » du système.
– Si λ > ω0, les racines de l’équation caractéristique sont r± = −λ ±
λ2 − ω20 ; leur produit
vaut ω20 > 0, leur somme −2λ < 0 : r+ et r− sont donc strictement négatifs. On obtient deux
solutions indépendantes,t → er+t et t → er−t.
Il n’y a pas d’oscillations, on parle de régime apériodique.
– Si λ = ω0, la racine double de l’équation caractéristique est r = −λ. On obtient deux solutionsindépendantes,t → e−λt et t → t e−λt.
On parle de régime critique. C’est celui pour lequel le retour à l’équilibre est le plus rapide.
On peut alors soumettre l’oscillateur à une force ou un signal extérieur (régime forcé), parexemple de la forme F 0 cos(Ωt) où Ω > 0 est la pulsation et F 0 l’amplitude de cette force ou dece signal : l’équation régissant l’évolution du système est alors
x′′ + 2λ x′ + ω20 x = F cos(Ω t),
où F est fonction de F 0 et des caractéristiques du système (inductance ou masse, notamment).On a
(iΩ)2 + 2λ (iΩ) + ω20 = ω2
0 − Ω2 + 2i λ Ω.
Si λ > 0 ou Ω = ω0, iΩ n’est pas racine de l’équation caractéristique, on peut trouver unesolution particulière de l’équation complète sous la forme t → α cos(Ωt + φ).
Si λ = 0 et Ω = ω0, iΩ est racine de l’équation caractéristique, on peut trouver une solutionparticulière de l’équation complète sous la forme t → α t cos(Ωt + φ).
La solution générale de l’équation complète est alors somme de la solution générale de l’équa-tion homogène et de cette solution particulière. La première est amortie, elle correspond au régimetransitoire ; la seconde n’est pas amortie, elle correspond au régime établi ou permanent. Onpeut également rechercher pour quelle pulsation Ω la réponse du système a une amplitude maxi-male ; on montre facilement que pour un amortissement assez faible, cette pulsation existe, onparle de phénomène de résonance (pour λ = 0, on a immédiatement Ω = ω0).
335

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 344/383
• Résolvons sur R l’équation différentielle x′′ + 6x′ + 9x = e−3t
1 + t2.
L’équation caractéristique associée à l’équation homogène est r2 + 6r + 9 = 0, elle admet uneracine double r = −3. La solution générale de l’équation homogène s’écrit donc sous la formet → (at + b) e−3t où (a,b) ∈K2.
On va chercher la solution générale de l’équation complète sous la forme t → b(t) e−3t (ce quirevient en fait à faire varier la constante b). Cela est possible car e−3t
= 0 pour tout t
∈R.
La fonction x : t → b(t) e−3t est deux fois dérivable sur R si et seulement si b l’est, et dans cecas, pour tout t ∈ R,
x′(t) = (b′(t) − 3b(t)) e−3t et x′′(t) = (b′′(t) − 6b′(t) + 9b(t)) e−3t.
Alors, pour tout t ∈ R,
x′′(t) + 6x′(t) + 9x(t) = e−3t
1 + t2
⇔ b′′(t)
−6b′(t) + 9b(t) + 6b′(t)
−3b(t) + 9b(t) =
1
1 + t
2
⇔ b′′(t) = 1
1 + t2.
Ainsi, pour que x soit solution de l’équation complète sur R, il faut et il suffit qu’il existe k1 ∈ Ktel que pour tout t ∈R,
b′(t) = arctan(t) + k1.
On détermine une primitive de arctan sur R par intégration par parties (les fonctions s → s ets → arctan(s) sont de classe C1 sur R) : pour tout t ∈ R,
t
0
arctan(s) ds = [s arctan(s)]t0−
t
0
s
1 + s2
ds = t arctan(t)
− 1
2
ln(1 + t2).
Finalement, pour que x soit solution de l’équation complète sur R, il faut et il suffit qu’il existe(k1,k2) ∈K2 tel que pour tout t ∈ R,
x(t) =
t arctan(t) − 1
2 ln(1 + t2) + k1t + k2
e−3t.
Remarque – La méthode utilisée dans l’exemple précédent est inspirée de la méthode de variationde la constante.
Équations d’Euler
Il s’agit des équations différentielles de la forme at2x′′ + btx′ + cx = 0 sur R∗+, où a, b et c
sont des constantes (a = 0).
Le théorème de Cauchy linéaire s’applique, car l’équation équivaut sur R∗+ à
x′′ + b
atx′ +
c
at2x = 0,
qui est une équation différentielle linéaire scalaire d’ordre 2 à coefficients continus sur R∗+.
Le changement de variable t = eu (pour t ∈ R∗+) permet de résoudre ces équations, car il lestransforme en équations à coefficients constants. En effet, si l’on pose y : u → x(eu) pour u ∈ R,alors pour tout t > 0, x(t) = y (ln(t)). Pour que x soit deux fois dérivable sur R∗+, il faut et il
suffit que y soit deux fois dérivable sur R et dans ce cas, pour tout t > 0,
x′(t) = 1
t y ′(ln(t)), x′′(t) = − 1
t2 y ′(ln(t) +
1
t2 y ′′(ln(t)).
336

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 345/383
La fonction x est solution de l’équation originale si et seulement si pour tout t > 0,
ay′′(ln(t)) − ay′(ln(t)) + by′(ln(t)) + cy(ln(t)) = 0,
L’image de la fonction ln est R, donc ceci équivaut au fait que y soit solution sur R de
ay′′ + (b − a)y′ + cy = 0. (L ′)
L’équation caractéristique associée à cette équation est ar2
+ (b − a)r + c = 0. Soient α1 et α2les racines dans C de cette équation.
Si α1 = α2, la solution générale de (L ′) s’écrit
y : u → λ eα1u + µ eα2u
avec (λ,µ) ∈K2, et donc la solution générale sur R∗+ de l’équation d’origine s’écrit
x : t → λ eα1 ln(t) + µ eα2 ln(t) = λ tα1 + µ tα2.
Si α1 = α2 = α, la solution générale de (L ′) s’écrit
y : u → λ e
αu
+ µ u e
αu
avec (λ,µ) ∈K2, et donc la solution générale sur R∗+ de l’équation d’origine s’écrit
x : t → λ eα ln(t) + µ ln(t) eα ln(t) = λ tα + µ ln(t) tα.
En particulier, il est donc judicieux de chercher des solutions sur R∗+ sous la forme t → tα avecα ∈ C. Soit on trouve de telles solutions pour deux valeurs distinctes de α, soit on en trouvepour une seule valeur de α, et alors t → (ln(t)) tα est une autre solution de l’équation. Dans lesdeux cas, on en déduit la solution générale par combinaison linéaire des deux solutions obtenues.
Enfin, x est solution de l’équation sur R∗+ si et seulement si t → x(−t) en est solution surR∗−
. On en déduit la solution générale de l’équation sur R∗−
.
Exemple – Résolvons l’équation t2x′′ − 4tx′ + 6x = 0 sur R∗+ par la méthode précédente, quiconduit à l’équation
α(α − 1) − 4α + 6 = 0 ⇔ α2 − 5α + 6 = 0 ⇔ α = 2 ou α = 3.
La solution générale de l’équation précédente s’écrit donc
t → λt2 + µt3 où (λ,µ) ∈ K2.
3. Utilisation des séries entières
Pour une équation différentielle linéaire scalaire d’ordre 2 (la méthode peut s’appliquer aussipour l’ordre 1)x′′ + a(t)x′ + b(t)x = c(t)
dont les coefficients a, b, et c sont polynomiaux ou développables en séries entières, il est intéres-sant de chercher les solutions de ces équations qui sont développables en série entière. Donnonsun exemple de telle résolution.
On cherche à résoudre l’équation différentielle (1 + t2)x′′+ 4tx′+ 2x = 0. Cette équation entredans le cadre de ce chapitre, car pour tout t ∈R, 1 + t2 = 0, et donc l’équation équivaut à
x′′ + 4t
1 + t2x′ +
2
1 + t2x = 0,
qui est à coefficients continus (et elle est sans second membre). En particulier, le théorème deCauchy linéaire s’applique et montre que l’ensemble des solutions sur R est un plan vectoriel.Pour le déterminer, on va chercher les solutions développables en série entière.
337

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 346/383
Soitn0 antn une série entière de rayon de convergence R > 0. On pose, pour tout t ∈ ]−R,R[,
f (t) =+∞n=0
antn.
On a les équivalences suivantes :
La fonction f est solution de l’équation (1 + t2
)x′′ + 4tx′ + 2x = 0 sur ]−R,R[
⇔ ∀ t ∈ ]−R,R[ , (1 + t2)+∞n=2
n(n − 1)antn−2 + 4t+∞n=1
nantn−1 + 2+∞n=0
antn = 0
⇔ ∀ t ∈ ]−R,R[ ,+∞n=2
n(n − 1)antn−2 ++∞n=2
n(n − 1)antn ++∞n=1
4nantn + 2+∞n=0
antn = 0
⇔ ∀ t ∈ ]−R,R[ ,+∞n=0
(n + 2)(n + 1)an+2tn ++∞n=0
n(n − 1)antn ++∞n=0
4nantn + 2+∞n=0
antn = 0
⇔ ∀t
∈]
−R,R[ ,
+∞
n=0
[(n + 2)(n + 1)an+2 + (n(n
−1) + 4n + 2)an] tn = 0.
Par unicité du développement en série entière (sachant que R > 0), ceci équivaut à
∀ n ∈ N, (n + 2)(n + 1)an+2 + (n2 + 3n + 2)an = 0
i.e. ∀ n ∈ N, an+2 = −an.
Ceci équivaut au fait que pour tout p ∈ N,
a2 p = (−1) pa0 et a2 p+1 = (−1) pa1.
Définissons la suite (an)n∈N par les relations précédentes, a0 et a1 étant des scalaires quelconques.
Pour tout t ∈ ]−1,1[ et p ∈ N,
|a2 pt2 p| = |a0|(t2) p et |a2 p+1t2 p+1| = |a1t| (t2) p,
la série géométrique de raison t2 ∈ [0,1[ étant convergente. Ainsi, les deux séries entières p0
a2 p t2 p et p0
a2 p+1 t2 p+1
convergent, et par somme,
n0 antn converge. Donc le rayon de convergence R de cette sérieentière vérifie R 1. De plus, pour tout t ∈ ]−1,1[,
+∞n=0
antn =+∞ p=0
a2 pt2 p ++∞ p=0
a2 p+1t2 p+1 = a0
+∞ p=0
(−1) pt2 p + a1 t+∞ p=0
(−1) pt2 p = a0 + a1t
1 + t2 .
D’après la série d’équivalences ci-dessus, les solutions développables en série entière autour de 0de
(1 + t2)x′′ + 4tx′ + 2x = 0
sont exactement les fonctions de la forme
t → at + b
t2 + 1
avec (a,b) ∈K2.On vérifie immédiatement qu’une telle fonction est en fait solution sur R tout entier, même sison développement en série entière n’est pas toujours valable sur R.
338

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 347/383
Les deux fonctionst → t
t2 + 1 et t → 1
t2 + 1
sont clairement linéairement indépendantes; on a donc obtenu un plan vectoriel de solutions, etd’après le théorème de Cauchy linéaire, on a en fait la solution générale de l’équation.
Remarques
• Dans l’exemple précédent, on a pu résoudre entièrement l’équation car toutes ses solutions sont
développables en série entière, mais ce n’est pas toujours le cas.• La démarche précédente fait souvent apparaître des relations de récurrence entre les coefficientsan. On peut parfois en déduire explicitement les coefficients an, voire une forme simple pour f
comme dans l’exemple précédent, mais à nouveau, ce n’est pas toujours le cas. En revanche,la règle de d’Alembert peut permettre de déterminer le rayon de convergence R à partir d’unerelation de récurrence entre les an, même si ces coefficients ne sont pas connus explicitement.Par exemple, en imaginant une équation différentielle qui aboutisse à la relation
a0 = 1 et : ∀ n ∈ N, an+1 = n2 + n + 1
2(n + 1)(n + 2)an,
il n’est pas du tout évident d’obtenir une formule explicite pour an. Pourtant, pour tout n ∈N,an = 0 et an+1
an
= n2 + n + 1
2(n + 1)(n + 2) ∼n→+∞
n2
2n2 =
1
2.
La série entière
n0 antn a donc un rayon de convergence égal à 2 d’après la règle de d’Alem-bert.
339

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 348/383
340
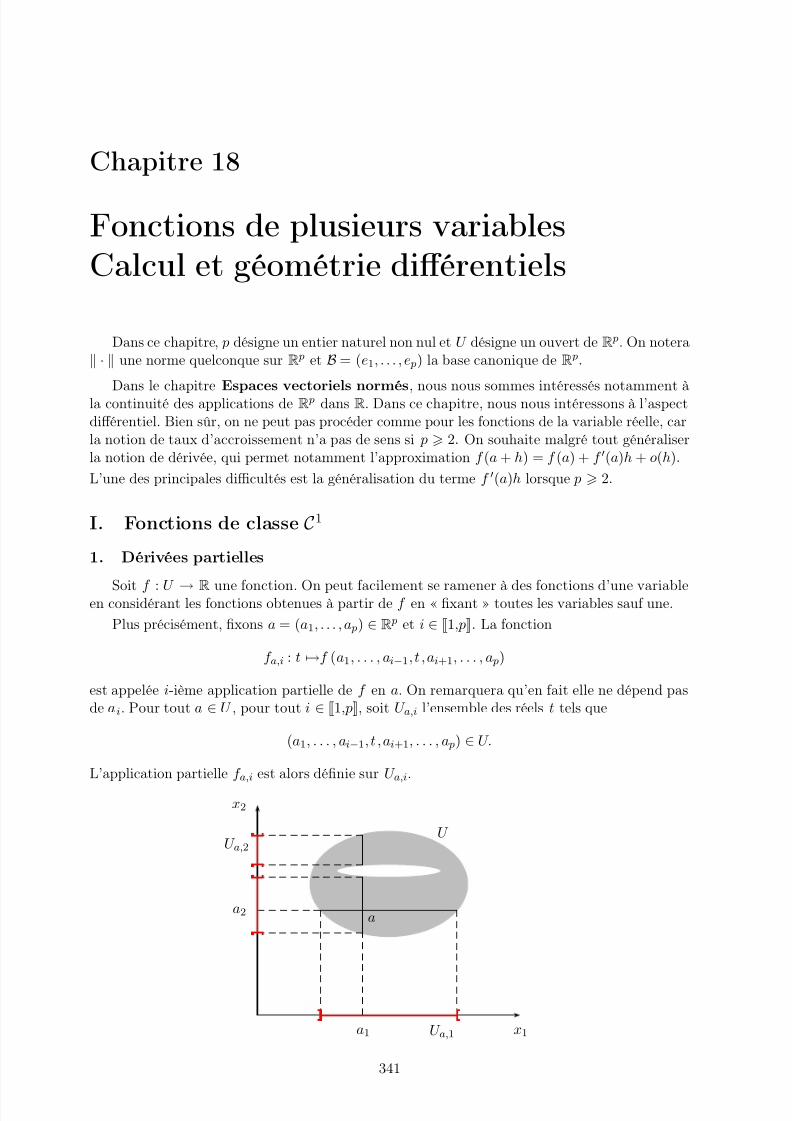
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 349/383
Chapitre 18
Fonctions de plusieurs variablesCalcul et géométrie différentiels
Dans ce chapitre, p désigne un entier naturel non nul et U désigne un ouvert de R p. On notera · une norme quelconque sur R p et B = (e1, . . . , e p) la base canonique de R p.
Dans le chapitre Espaces vectoriels normés, nous nous sommes intéressés notamment àla continuité des applications de R p dans R. Dans ce chapitre, nous nous intéressons à l’aspectdifférentiel. Bien sûr, on ne peut pas procéder comme pour les fonctions de la variable réelle, carla notion de taux d’accroissement n’a pas de sens si p 2. On souhaite malgré tout généraliserla notion de dérivée, qui permet notamment l’approximation f (a + h) = f (a) + f ′(a)h + o(h).
L’une des principales difficultés est la généralisation du terme f ′(a)h lorsque p 2.
I. Fonctions de classe C1
1. Dérivées partielles
Soit f : U → R une fonction. On peut facilement se ramener à des fonctions d’une variableen considérant les fonctions obtenues à partir de f en « fixant » toutes les variables sauf une.
Plus précisément, fixons a = (a1, . . . , a p) ∈ R p et i ∈ [[1,p]]. La fonction
f a,i : t →f (a1, . . . , ai−1, t , ai+1, . . . , a p)
est appelée i-ième application partielle de f en a. On remarquera qu’en fait elle ne dépend pasde ai. Pour tout a ∈ U , pour tout i ∈ [[1,p]], soit U a,i l’ensemble des réels t tels que
(a1, . . . , ai−1, t , ai+1, . . . , a p) ∈ U.
L’application partielle f a,i est alors définie sur U a,i.
x1
x2
a1
a2
U
U a,1
U a,2
a
341

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 350/383
Montrons que U a,i est un ouvert de R : soit t0 ∈ U a,i ; alors
(a1, . . . , ai−1, t0, ai+1, . . . , a p) ∈ U.
Comme U est ouvert, il existe r > 0 tel qu’on ait l’implication
[ |t − t0| < r et ∀ k = i, |xk − ak| < r ] ⇒ (x1, . . . , xi−1, t , xi+1, . . . , x p) ∈ U.
En particulier, en choisissant xk = ak pour tout k = i, on a montré que ]t0 − r,t0 + r[ ⊂ U a,i,d’où le résultat, qui est illustré sur la figure ci-dessus.
Par un raisonnement analogue, on montre facilement le résultat suivant :
Si f est continue sur U , alors pour tout a ∈ U , toutes les applications partielles de f en a sont continues : pour tout i ∈ [[1,p]], f a,i est continue sur U a,i.
Propriété
Attention ! La réciproque est fausse : toutes les applications partielles de f peuvent être continues
sans que f le soit. Ceci tient au fait que la continuité de f signifie que pour tout a ∈ U ,f (x) → f (a) lorsque x tend vers a de façon arbitraire. La continuité de la i-ième applicationpartielle de f en a signifie que f (x) → f (a) lorsque x tend vers a le long de la droite a +R ei, cequi est plus restrictif, même lorsque cela a lieu pour tout i.
Par exemple, soit f : R2 → R définie par
f (x,y) =
xy
x2 + y2 si (x,y) = (0,0)
0 si (x,y) = (0,0)
Les deux applications partielles f a,1 et f a,2 de f sont continues sur R pour tout a ∈ R2. Pourtant,
f n’est pas continue en 0 car pour x = 0,
f (x,x) = x2
2x2 =
1
2,
qui ne tend pas vers f (0,0) lorsque x → 0.
L’étude des applications partielles de f ne suffit donc pas à faire l’étude de f .
Soient a = (a1, . . . , a p) ∈ U et i ∈ [[1,p]]. On dit que f admet une dérivée partielle ena par rapport à la i-ième variable si l’application partielle
f a,i : t → f (a1, . . . , ai−1, t , ai+1, . . . , a p)
est dérivable en ai, c’est-à-dire, si
h → 1
h (f (a1, . . . , ai−1, ai + h, ai+1, . . . , a p) − f (a1, . . . , ai−1, ai, ai+1, . . . , a p))
a une limite finie lorsque h → 0 avec h = 0.
Dans ce cas, cette limite, qui est le nombre dérivé f ′a,i(ai), est notée
∂f
∂xi
(a) ou ∂ if (a).
Elle est appelée dérivée partielle de f en a par rapport à la i-ième variable.
Définition – Dérivées partielles
342

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 351/383
Remarque – Pour p = 2 ou p = 3, les variables sont souvent notées x, y ou x, y, z.
Exemple – Considérons l’application
f :
R3 → R
(x,y,z) → (x2 + y2)sin(z)
Les trois applications
x → f (x,y,z), y → f (x,y,z), z → f (x,y,z)
sont dérivables sur R. La fonction f admet donc des dérivées partielles par rapport à ses troisvariables en tout point de R3 ; pour tout (x,y,z) ∈ R3,
∂f
∂x(x,y,z) = 2x sin(z),
∂f
∂y(x,y,z) = 2y sin(z),
∂f
∂z(x,y,z) = (x2 + y2) cos(z).
Si f admet une dérivée partielle sur U (i.e., en tout point de U ) par rapport à la i-ièmevariable, alors la fonction
a → ∂f
∂xi(a)
(qui est définie sur U , à valeurs dans R) est appelée dérivée partielle de f par rapportà la i-ième variable.
Définition – Fonctions dérivées partielles
2. Classe C1
Soit f : U → R une fonction.
On dit que f est de classe C1 sur U si f admet des dérivées partielles sur U par rapportà toutes ses variables, et si toutes ces dérivées partielles sont continues sur U .
Définition
Attention ! Si f est de classe C1 sur U , alors pour tout a ∈ U , toutes les applications partiellesde f en a sont de classe C1 (chacune sur l’ouvert U a,i de R correspondant) ; la réciproque estfausse, le même contre-exemple que dans le cas de la continuité le prouve.
Soit f : U → R une fonction de classe C1. Alors f admet en tout point a ∈ U ledéveloppement limité à l’ordre 1
f (a + h) = f (a) + ∂f
∂x1(a) h1 + · · · +
∂f
∂x p(a) h p + o(h),
lorsque h = (h1, . . . , h p) → (0, . . . ,0).
Théorème (admis : démonstration non exigible)
Remarque – La notation précédente signifie que l’on peut écrire, pour h tel que a + h ∈ U,
f (a + h) = f (a) + ∂f ∂x1(a) h1 + · · · + ∂f ∂x p
(a) h p + h ε(h),
où ε a pour limite 0 en (0, . . . ,0).
343

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 352/383
Soient f : U → R de classe C1 et a ∈ U . On appelle différentielle de f en a la formelinéaire
df (a) :
R p → R
(h1, . . . , h p) → ∂f
∂x1(a) h1 + · · · +
∂f
∂x p(a) h p
L’image de h ∈R p par l’application df (a) sera notée df (a)
·h.
Définition – Différentielle
Remarque – Le théorème précédent se réinterprète donc ainsi : si f : U → R est de classe C1,alors pour tout a ∈ U ,
f (a + h) =h→0
f (a) + df (a) · h + o(h).
Ceci est bien sûr à mettre en relation avec le développement limité
g(a + h) =h→0
g(a) + g′(a)h + o(h)
pour une fonction g : I ⊂ R → R de classe C1. Ici, le terme
df (a) · h = ∂f ∂x1(a) h1 + · · · + ∂f ∂x p
(a) h p
correspond au terme g′(a)h, mais il prend en compte, du fait de la présence de plusieurs variables,les accroissements de f dans toutes les directions.
Si f est de classe C1 sur U , elle est continue sur U .
Propriété
Démonstration – La fonction f est de classe C1 sur U , donc pour tout point a ∈ U ,
f (a + h) =h→0
f (a) + df (a)·
h + o(
h
) −→h→(0,...,0)
f (a)
car df (a) est continue. D’où le résultat.
• Toute application polynomiale définie sur un ouvert est de classe C1.
• En particulier, toute application linéaire de R p dans R est de classe C1.
• Toute fraction rationnelle dont le dénominateur ne s’annule pas est de classe C1.
Propriété
Démonstration – On considère les applications partielles et on applique les résultats analogues
pour les fonctions d’une variable, d’où l’existence des dérivées partielles ; elles sont elles-mêmessoit polynomiales soit des fractions rationnelles dont le dénominateur ne s’annule pas, donccontinues.
3. Opérations sur les fonctions de classe C1
Soient f : U → R et g : U → R deux fonctions de classe C1, et λ ∈ R.
Alors λf + g est de classe C1 sur U et pour tout a ∈ U,
d(λf + g)(a) = λ df (a) + dg(a),
et : ∀ i ∈ [[1,p]], ∂ (λf + g)∂xi
(a) = λ ∂f ∂xi
(a) + ∂g∂xi
(a).
Propriété – Combinaison linéaire
344

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 353/383
L’ensemble C1(U,R) des fonctions de classe C1 sur U à valeurs dans R est un R-espacevectoriel.
Corollaire
Soient f : U → R et g : U → R deux fonctions de classe C1
.Alors f g est de classe C1 sur U et pour tout a ∈ U,
d(f g)(a) = (df (a))g(a) + f (a)(dg(a)),
et : ∀ i ∈ [[1,p]], ∂ (f g)
∂xi(a) =
∂f
∂xi(a) g(a) + f (a)
∂g
∂xi(a).
Propriété – Produit
Soit f : U → R∗ une fonction de classe C1.
Alors 1/f est de classe C1
sur U et pour tout a ∈ U,
d(1/f )(a) = − 1
f 2(a) df (a),
et : ∀ i ∈ [[1,p]], ∂ (1/f )
∂xi(a) = − 1
f 2(a)
∂f
∂xi(a).
Propriété – Inverse
Démonstration des trois propriétés – C’est immédiat en considérant les applications partielles : lesrésultats sur les fonctions de la variable réelle prouvent l’existence des dérivées partielles ; ellessont continues par opérations sur les fonctions continues.
4. Composition : règle de la chaîne
Soient I un intervalle de R et x1, . . . , x p des fonctions de classe C1 sur I , à valeurs dansR. Soit f : U → R de classe C1. On suppose que pour tout t ∈ I ,
(x1(t), . . . , x p(t)) ∈ U.
Alors la fonctiong : t → f (x1(t), . . . , x p(t))
est définie et de classe C1
sur I , avec, pour tout t ∈ I ,
g′(t) =
pi=1
∂f
∂xi(x1(t), . . . , x p(t)) x′i(t).
Théorème – Règle de la chaîne
Démonstration – La fonction g est bien définie car (x1, . . . , x p) est à valeurs dans U. Soit t ∈ I ;pour tout i ∈ [[1,p]], xi : I → R est de classe C1, donc il existe une fonction ηi qui a pour limite0 en 0, telle que
xi(t + h) = xi(t) + x′i(t)h + h ηi(h)
lorsque t + h ∈ I. De plus, f est de classe C1 sur U , donc en notant a = (x1(t), . . . , x p(t)), il
existe une fonction ε qui a pour limite 0 en (0, . . . ,0), tel que
f (a + k) = f (a) +ni=1
∂f
∂xi(a) ki + k ε(k)
345

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 354/383
pour k = (k1, . . . , k p) tel que a + k ∈ U. On écrit cette égalité avec
k =
x′1(t)h + h η1(h), . . . , x′ p(t)h + h η p(h)
lorsque h → 0 avec t + h ∈ I ; on a alors k → (0, . . . ,0), donc a + k ∈ U pour h assez proche de0, d’où :
g(t + h) = f (x1(t + h), . . . , x p(t + h))
= f (x1(t) + x′1(t)h + h η1(h), . . . , x p(t) + x′ p(t)h + h η p(h))
= f (x1(t), . . . , x p(t)) +ni=1
∂f
∂xi(a)
x′i(t)h + hηi(h)
+ k ε(k)
= g(t) +
ni=1
∂f
∂xi(a) x′i(t)
h +
ni=1
∂f
∂xi(a) h ηi(h) + k ε(k)
Pour conclure, il suffit donc de prouver que le terme dans la dernière parenthèse est un o(h)lorsque h
→ 0. Or, en choisissant la norme 1 (
· =
· 1), on a, pour h
= 0,
1
|h|
ni=1
∂f
∂xi(a) h ηi(h) + k ε(k)
pi=1
∂f
∂xi(a) ηi(h)
+ |x′i(t) + ηi(h)| |ε(k)|
−→h→0
0.
On en déduit que g est dérivable sur I avec la formule annoncée pour g′ ; de plus, cette formulemontre que g ′ est continue sur I , car f et tous les xi sont de classe C1. D’où le résultat.
Remarques
• Si I est semi-ouvert ou fermé, la formule précédente doit être interprétée, aux extrémités de I ,en termes de dérivées de g à gauche ou à droite.
• Dans la formule donnant g′(t), xi apparaît avec deux sens différents qu’il ne faut pas confondre :∂f
∂xiest une notation qui désigne la dérivée partielle de f par rapport à sa i-ième variable ; xi
apparaissant dans xi(t) ou x′i(t) désigne la fonction xi. Il n’y a pas de confusion possible si l’onécrit, de façon équivalente,
g′(t) =
p
i=1
∂ if (x1(t), . . . , x p(t)) x′i(t).
• La formule précédente s’écrit aussi, par définition de la différentielle,
∀ t ∈ I , g′(t) = df (γ (t)) · γ ′(t),
où γ = (x1, . . . , x p).
• Avec les notations précédentes, (I,γ ) est un arc paramétré de classe C1, et g′ représente ladérivée de f le long de cet arc.
Dans la propriété suivante, on s’intéresse au cas de la composition
g :
V ⊂ R2 (x,y)→ U ⊂ R2 f → R
(u,v) → (x(u,v),y(u,v)) → f (x(u,v),y(u,v))
346

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 355/383
Soient V un ouvert de R2, x et y deux fonctions définies sur V , à valeurs dans R, declasse C1 sur V . Soient U un ouvert de R2 et f : U → R de classe C1. On suppose quepour tout (u,v) ∈ V ,
(x(u,v), y(u,v)) ∈ U.
Alors l’application
g : (u,v) → f (x(u,v), y(u,v))
est définie et de classe C1 sur V , avec, pour tout (u,v) ∈ V ,
∂g
∂u(u,v) =
∂f
∂x(x(u,v), y(u,v))
∂x
∂u(u,v) +
∂ f
∂y(x(u,v), y(u,v))
∂ y
∂u(u,v),
∂g
∂v(u,v) =
∂f
∂x(x(u,v), y(u,v))
∂ x
∂v(u,v) +
∂ f
∂y(x(u,v), y(u,v))
∂ y
∂v(u,v).
Propriété – Application aux fonctions de deux variables
Démonstration – Il suffit d’appliquer le théorème précédent en faisant jouer à t le rôle de u àv fixé, puis celui de v à u fixé. La variable t décrit alors un ouvert de R (pas nécessairement
un intervalle) comme on l’a montré au début de ce chapitre. On peut appliquer le théorème auvoisinage de chaque point de cet ouvert.
Exemple – Passage en coordonnées polaires
Pour tout (x,y) ∈ R2, il existe r ∈ R+ et θ ∈ R tels que (x,y) = (r cos(θ), r sin(θ)). On dit quer, θ sont des coordonnées polaires de (x,y). Il n’y a pas unicité de telles coordonnées : parexemple si (x,y) = (0,0), r = 0 et tout θ ∈ R conviennent. De même, si r, θ sont des coordonnéespolaires de (x,y), alors pour tout k ∈ Z, r et θ + 2kπ en sont également.
On définit, pour (r,θ) ∈ R2,
x(r,θ) = r cos(θ) et y(r,θ) = r sin(θ).
Si f : R2 → R est une fonction de classe C1, on pose
g(r,θ) = f (x(r,θ), y(r,θ)) = f (r cos(θ), r sin(θ)).
Par exemple, g(√
2, − π/4) = f (1, − 1). D’après la propriété précédente, g est de classe C1 surR2 et pour tout (r,θ) ∈ R2,
∂g
∂r(r,θ) =
∂f
∂x(r cos(θ), r sin(θ))
∂x
∂r(r,θ) +
∂ f
∂y(r cos(θ), r sin(θ))
∂y
∂r(r,θ)
= ∂f
∂x
(r cos(θ), r sin(θ))cos(θ) + ∂ f
∂y
(r cos(θ), r sin(θ)) sin(θ)
∂g
∂θ(r,θ) =
∂f
∂x(r cos(θ), r sin(θ))
∂x
∂θ(r,θ) +
∂ f
∂y(r cos(θ), r sin(θ))
∂y
∂θ(r,θ)
= ∂f
∂x(r cos(θ), r sin(θ))(−r sin(θ)) +
∂ f
∂y(r cos(θ), r sin(θ)) r cos(θ).
Soit f : U
→R une fonction de classe
C1 sur un ouvert U convexe.
Pour que f soit constante, il faut et il suffit que pour tout i ∈ [[1,p]], ∂f ∂xi
= 0.
Propriété – Caractérisation des fonctions constantes
347
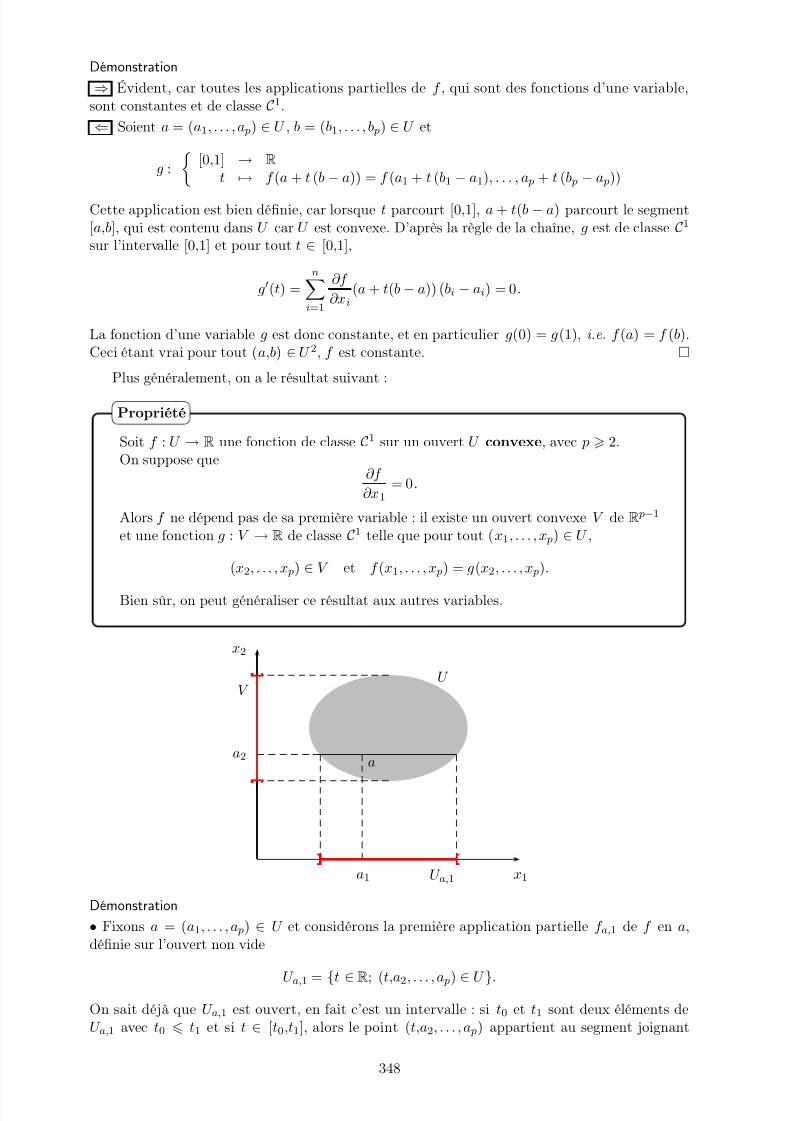
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 356/383
Démonstration
⇒ Évident, car toutes les applications partielles de f , qui sont des fonctions d’une variable,sont constantes et de classe C1.
⇐ Soient a = (a1, . . . , a p) ∈ U , b = (b1, . . . , b p) ∈ U et
g :
[0,1] → R
t → f (a + t (b − a)) = f (a1 + t (b1 − a1), . . . , a p + t (b p − a p))
Cette application est bien définie, car lorsque t parcourt [0,1], a + t(b − a) parcourt le segment[a,b], qui est contenu dans U car U est convexe. D’après la règle de la chaîne, g est de classe C1
sur l’intervalle [0,1] et pour tout t ∈ [0,1],
g′(t) =ni=1
∂f
∂xi(a + t(b − a)) (bi − ai) = 0.
La fonction d’une variable g est donc constante, et en particulier g(0) = g(1), i.e. f (a) = f (b).Ceci étant vrai pour tout (a,b) ∈ U 2, f est constante.
Plus généralement, on a le résultat suivant :
Soit f : U → R une fonction de classe C1 sur un ouvert U convexe, avec p 2.On suppose que
∂f
∂x1= 0.
Alors f ne dépend pas de sa première variable : il existe un ouvert convexe V de R p−1
et une fonction g : V → R de classe C1 telle que pour tout (x1, . . . , x p) ∈ U ,
(x2, . . . , x p) ∈ V et f (x1, . . . , x p) = g(x2, . . . , x p).
Bien sûr, on peut généraliser ce résultat aux autres variables.
Propriété
x1
x2
a1
a2
U
U a,1
V
a
Démonstration
• Fixons a = (a1, . . . , a p) ∈ U et considérons la première application partielle f a,1 de f en a,définie sur l’ouvert non vide
U a,1 = t ∈R; (t,a2, . . . , a p) ∈ U .
On sait déjà que U a,1 est ouvert, en fait c’est un intervalle : si t0 et t1 sont deux éléments deU a,1 avec t0 t1 et si t ∈ [t0,t1], alors le point (t,a2, . . . , a p) appartient au segment joignant
348

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 357/383
(t0,a2, . . . , a p) et (t1,a2, . . . , a p). Comme U est convexe et que ces deux points appartiennent à U ,on a (t,a2, . . . , a p) ∈ U , d’où : t ∈ U a,1. Ceci prouve que U a,1 est un intervalle ouvert. De plus, f
étant de classe C1 sur U , f a,1 est de classe C1 sur U a,1, avec, pour tout t ∈ U a,1,
f ′a,1(t) = ∂f
∂x1(t,a2, . . . , a p) = 0.
On en déduit que f a,1 est constante sur U a,1. Notons g(a2, . . . , a p) l’unique valeur prise par f a,1
sur U a,1. On a doncf (x1,x2, . . . , x p) = g(x2, . . . , x p),
et ce, pour tout (x2, . . . , x p) tel qu’il existe au moins une valeur x1 telle que (x1,x2, . . . , x p) ∈ U .Notons V l’ensemble de ces ( p − 1)-uplets (x2, . . . , x p).
• V est un ouvert de R p−1 : soient (x2, . . . , x p) ∈ V et x1 ∈ R tel que (x1,x2, . . . , x p) ∈ U. CommeU est ouvert, il existe r > 0 tel que pour tout y = (y1, . . . , y p) ∈ R p vérifiant |yi − xi| < r pourtout i, on ait y ∈ U. Alors, pour tout (y2, . . . , y p) ∈ R p−1 vérifiant |yi − xi| < r pour tout i,(x1,y2, . . . , y p) ∈ U et donc (y2, . . . , y p) ∈ V , d’où le résultat.
• V est convexe : soient (x2, . . . , x p) et (y2, . . . , y p) dans V et λ ∈ [0,1]. Il existe x1 ∈ R et y1 ∈ Rtels que (x1, . . . , x p)
∈ U et (y1, . . . , y p)
∈ U . Alors, par convexité de U ,
(λx1 + (1 − λ)y1,λx2 + (1 − λ)y2, . . . , λ x p + (1 − λ)y p) = λ(x1, . . . , x p) + (1 − λ)(y1, . . . , y p) ∈ U,
et donc
λ(x2, . . . , x p) + (1 − λ)(y2, . . . , y p) = (λx2 + (1 − λ)y2, . . . , λ x p + (1 − λ)y p) ∈ V.
• Enfin, comme f est de classe C1 sur U , la formule définissant g montre que g est de classe C1
sur V , ce qui conclut la démonstration.
5. Gradient
Si f : U → R est de classe C1, alors pour tout a ∈ U , on a le développement limité
f (a + h) =h→0
f (a) + df (a) · h + o(h),
avec, pour tout h = (h1, . . . , h p) ∈ R p,
df (a) · h =
pi=1
∂f
∂xi(a) hi.
Dans R p muni du produit scalaire canonique, ce terme se réinterprète comme un produit scalaire :
Soient f : U → R une fonction de classe C1 et a ∈ U . Le vecteur
∇f (a) =
∂f
∂x1(a), . . . ,
∂f
∂x p(a)
est appelé gradient de f en a. L’application ∇f : U → R p est appelée gradient de f .
Pour tout h = (h1, . . . , h p) ∈ R p, on a
df (a)·
h = (∇
f (a)|
h)
pour le produit scalaire canonique sur R p.
Propriété/Définition : Gradient
349

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 358/383
Remarque – La règle de la chaîne se réécrit, en notant γ = (x1, . . . , x p) :
∀ t ∈ I , g′(t) =∇f (γ (t)) | γ ′(t)
.
Exemples
• D’après la loi de Fourier, la densité de flux de chaleur dans un matériau s’écrit −λ ∇T , où T est la température et λ > 0 est la conductivité thermique.
• On note
· la norme euclidienne canonique sur R p. L’application
f :
R p → R
x → x2
est de classe C1 sur R p. En effet, pour tout x = (x1, . . . , x p) ∈ R p,
f (x) = (x | x) = x21 + · · · + x2
p;
l’application f est donc polynomiale. On a de plus, pour tout a = (a1, . . . , a p) ∈ R p,
∇f (a) =
∂f
∂x1(a), . . . ,
∂f
∂x p(a)
= (2a1, . . . ,2a p) = 2a.
• Revenons sur le calcul fait plus haut pour g : (r,θ)
→ f (r cos(θ), r sin(θ)). Le calcul des dérivées
partielles de g peut se mettre sous la forme
∂g
∂r(r,θ)
∂g
∂θ(r,θ)
=
cos(θ) sin(θ)−r sin(θ) r cos(θ)
∂f
∂x(r cos(θ),r sin(θ))
∂f
∂y(r cos(θ),r sin(θ))
.
Or, pour tout (r,θ) ∈ R2,
det
cos(θ) sin(θ)−r sin(θ) r cos(θ)
= r(cos(θ)2 + sin(θ)2) = r
donc, si r > 0, la matrice précédente, notée J (r,θ), est inversible et on vérifie facilement que
J (r,θ)−1 =
cos(θ) −1r
sin(θ)
sin(θ) 1
r cos(θ)
.
On a donc, pour tout (x,y) = (r cos(θ),r sin(θ)) tel que r > 0,
∂f
∂x(r cos(θ),r sin(θ))
∂f
∂y(r cos(θ),r sin(θ))
=
cos(θ) −1
r sin(θ)
sin(θ) 1
r cos(θ)
∂g
∂r(r,θ)
∂g
∂θ(r,θ)
= ∂g
∂r(r,θ)cos(θ) − ∂ g
∂θ(r,θ)
sin(θ)
r∂g
∂r(r,θ)sin(θ) +
∂ g
∂θ(r,θ)
cos(θ)
r
.
Notons alors, pour tout θ ∈ R,
u(θ) = (cos(θ), sin(θ)), v(θ) = (− sin(θ), cos(θ)).
La famille (u(θ),v(θ)) est une base orthonormée de R2 pour tout θ (la famille de fonctions (u,v)
est appelée repère polaire de R2). On remarque que pour tout θ ∈ R,
u ′(θ) = v(θ), v ′(θ) = −u(θ).
Le calcul ci-dessus s’écrit alors : pour tout (r,θ) ∈R∗+ × R et (x,y) = (r cos(θ),r sin(θ)),
∇f (x,y) = ∂g∂r
(r,θ) u(θ) + 1r
∂g∂θ
(r,θ) v(θ).
On parle de formule du gradient en coordonnées polaires.
350

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 359/383
II. Problèmes d’extrema
On recherche les extrema (c’est-à-dire la plus grande et/ou la plus petite valeur) d’une fonctionf : U → R. Pour une fonction d’une variable réelle dérivable sur un intervalle I , on sait qu’enun point a où f atteint un extremum, si a est intérieur à I , on doit avoir f ′(a) = 0. Qu’en est-ilpour les fonctions de plusieurs variables ?
Soit a ∈ U .
• On dit que f admet un minimum local en a s’il existe r > 0 tel que B (a,r) ⊂ U etpour tout x ∈ B(a,r), f (x) f (a).
• On dit que f admet un minimum global en a si pour tout x ∈ U , f (x) f (a).
• On dit que f admet un maximum local en a s’il existe r > 0 tel que B (a,r) ⊂ U etpour tout x ∈ B(a,r), f (x) f (a).
• On dit que f admet un maximum global en a si pour tout x ∈ U , f (x) f (a).
• Enfin, un extremum est, par définition, un minimum ou un maximum.
Définition – Extremum
Remarque – Évidemment, un extremum global est un extremum local du même type, et la réci-proque est fausse.
Supposons que f soit de classe C1 et qu’elle ait par exemple un minimum local en a ∈ U. Soit(e1, . . . , e p) la base canonique de R p ; pour tout i ∈ [[1,p]] et h assez petit, on a donc
f (a + hei) f (a),
et doncf (a + hei) − f (a)
h 0 si h > 0,
f (a + hei) − f (a)
h 0 si h < 0.
Lorsque h tend vers 0, on obtient respectivement ∂f
∂xi (a) 0 et ∂f
∂xi (a) 0. Finalement, pourtout i ∈ [[1,p]],
∂f
∂xi(a) = 0.
On obtiendrait le même résultat avec un maximum local.
Soient f : U → R de classe C1 et a ∈ U .
On dit que a est un point critique de f si ∇f (a) = (0, . . . ,0). Ceci équivaut à
∀ i ∈ [[1,p]], ∂f ∂xi
(a) = 0, ou encore à : df (a) = 0L (Rp,R).
Définition – Point critique
Nous venons donc de montrer le résultat suivant :
Si f : U → R est de classe C1 sur U et admet un extremum local en a ∈ U , alors a estun point critique de f : ∇f (a) = 0.
Théorème – Condition nécessaire d’existence d’un extremum local
Comme pour les fonctions d’une variable, cette condition n’est pas suffisante. Par exemple,
f :
R2 → R
(x,y) → x2 + y2 − 4xy
351

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 360/383
est de classe C1 car polynomiale, et admet (0,0) comme point critique, car
∀ (x,y) ∈R2, ∂f
∂x(x,y) = 2x − 4y et
∂f
∂y(x,y) = 2y − 4x.
Pourtant f n’a pas d’extremum local en (0,0). En effet, pour tout x ∈ R∗,
f (x,0) = x2 > 0 = f (0,0) tandis que f (x,x) = −2x2 < 0.
Remarque – Si K est une partie fermée, bornée et non vide de R p, et si f : K → R est continue,alors on sait que f est bornée et atteint ses bornes : en d’autres termes, f admet un minimumglobal et un maximum global sur K . Mais en général, le théorème des bornes atteintes ne permetpas de savoir en quels points de K ces bornes sont atteintes. La condition nécessaire ci-dessuspermet de savoir, lorsque f est de classe C1 sur K (intérieur de K , qui est un ouvert), en quelspoints de K la fonction f est susceptible d’atteindre ses bornes. Mais il ne faut pas oublierqu’elles peuvent aussi être atteintes sur la frontière F r(K ) de K . Il peut alors suffire de testerla valeur de f sur la frontière de K ainsi qu’aux éventuels points critiques de f dans K , pourdéterminer les points en lesquels f atteint ses bornes.
On pourra garder en tête l’exemple très simple de la fonction f : x → x, continue sur le ferméborné non vide [0,1] de R. Elle atteint ses bornes en 0 et 1, qui ne sont pas des points critiquesde f . Il n’y a pas de contradiction, car [0,1] n’est pas ouvert, 0 et 1 sont sur sa frontière.
Exemple – On souhaite conditionner un produit en cartons d’une contenance de 1 litre. On sedemande quelles sont les dimensions à donner à l’emballage afin d’utiliser le moins de cartonpossible (l’épaisseur du carton étant fixée).
Soient x, y et z les longueurs (exprimées en décimètres) des trois côtés du carton, évidemmentstrictement positives. La contrainte sur le volume de l’emballage s’écrit
xyz = 1.
De plus, la surface utilisée est égale à
2(xy + yz + xz) = 2
xy + 1x
+ 1y
= 2S (x,y).
Le problème revient donc à déterminer l’éventuel minimum de S sur U = (R∗+)2. La fonction S est de classe C1 sur U et pour tout (x,y) ∈ U ,
∂S
∂x(x,y) = y − 1
x2,
∂S
∂y(x,y) = x − 1
y2.
Il s’ensuit immédiatement que S possède un unique point critique sur U , égal à (1,1). On vamontrer que S possède un minimum global sur U en (1,1).
On remarque que S (1,1) = 3 et que l’on a S (x,y) > 3 si x < 1/3 ou y < 1/3 ou xy < 3.
DéfinissonsK = (x,y) ∈ (R∗+)2; x 1/3, y 1/3, xy 3,
de sorte que S (x,y) > 3 si (x,y) /∈ K. De plus, K est non vide, fermé (intersection de trois fermés,par continuité des applications (x,y) → x − 1/3, (x,y) → y − 1/3 et (x,y) → 3 − xy) et K estborné : si (x,y) ∈ K ,
1
3 x
3
y 9
et de même pour y. La fonction S a donc un minimum global sur K ; de plus, si (x,y) /∈ K ,S (x,y) > 3 = S (1,1), donc S admet un minimum global sur U , qui doit être un point critique deS , c’est-à-dire (1,1).
Finalement, la fonction S a un minimum global sur U en (1,1), i.e. pour x = y = z = 1.L’emballage le plus économique répondant aux contraintes données est le cube de côté 10 cm.La surface utilisée correspond à 2S (1,1) = 6 (elle vaut donc 6 dm2).
352

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 361/383
III. Dérivées partielles d’ordre 2
• On dit que f est de classe C2 sur U si f est de classe C1 sur U et si les dérivées
partielles ∂f
∂xi, pour i ∈ [[1,p]], sont de classe C1 sur U .
• Si f est de classe
C2 sur U , alors pour tout (i,j)
∈ [[1,p]]2,
∂
∂xi
∂f
∂x j
est notée
∂ 2f
∂xi∂x jou ∂ 2i,jf.
Lorsque i = j, on écrit simplement
∂ 2f
∂xi2 au lieu de
∂ 2f
∂xi ∂xi.
Ces fonctions sont appelées dérivées partielles d’ordre 2 de f .
Définition
Remarque – On généralisera sans difficulté les résultats concernant les opérations sur les fonctionsde classe C1 (combinaison linéaire, produit, quotient) aux fonctions de classe C2. De plus, lesapplications linéaires, polynomiales, et les fractions rationnelles dont le dénominateur ne s’annulepas, sont de classe C2.
Si f est de classe C2 sur U , alors pour tout (i,j) ∈ [[1,p]]2,
∂ 2f
∂xi ∂x j=
∂ 2f
∂x j ∂xi.
Théorème de Schwarz (admis : démonstration hors programme)
Exemple – Soit
f :
R2 → R
(x,y) → x4 + y3 − 5x2y
La fonction f est de classe C∞ sur R2 car elle est polynomiale. Pour tout (x,y) ∈ R2,
∂f
∂x(x,y) = 4x3 − 10xy,
∂f
∂y(x,y) = 3y2 − 5x2,
et en ce qui concerne les dérivées d’ordre 2 :
∂ 2f
∂x2(x,y) = 12x2 − 10y,
∂ 2f
∂y 2(x,y) = 6y et
∂ 2f
∂x∂y(x,y) =
∂ 2f
∂y ∂x(x,y) = −10x.
IV. Résolution d’équations aux dérivées partielles
De très nombreux phénomènes physiques, chimiques, biologiques, économiques sont modéli-sables par des équations aux dérivées partielles, c’est-à-dire, par une relation entre les différentesdérivées partielles (d’ordre 1 ou 2 très souvent) d’une certaine quantité. Elles sont souvent as-sociées à une condition initiale et/ou une condition « au bord », c’est-à-dire sur la frontière dudomaine d’espace.
Exemples
• L’équation de Poisson∆f (x) = g(x) pour x ∈ U ⊂ R p
353

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 362/383
où ∆f =
pi=1
∂ 2f
∂xi2 est le laplacien de f , intervient par exemple en électrostatique ; g correspond
à la distribution de charges, et f est le potentiel associé.
• L’équation des ondes
∂ 2f
∂t2 (t,x) = c2 ∆f (t,x) pour (t,x) ∈ U ⊂ R×R p,
modélise la propagation d’une onde (par exemple, sonore ou électromagnétique) dans R p (c > 0est la vitesse ou célérité). Ici, ∆f désigne le laplacien de f par rapport aux variables d’espacereprésentées par x. Lorsque p = 1, on obtient l’équation
∂ 2f
∂t2 = c2 ∂ 2f
∂x2,
qui modélise par exemple la vibration unidirectionnelle d’une corde infinie, f (t,x) représentantle déplacement au temps t du point de la corde d’abscisse x.
• L’équation du transfert thermique, ou équation de la chaleur,
∂f
∂t
(t,x) = D ∆f (t,x) pour (t,x)
∈ U
⊂R
×R p,
modélise l’évolution de la température f dans un milieu (D > 0 est le coefficient de diffusivitéthermique). Ici aussi, ∆f désigne le laplacien de f par rapport aux variables d’espace.
• L’équation du transport
∂f
∂t(t,x) + c(t,x)
∂f
∂x(t,x) = 0 pour (t,x) ∈ U ⊂ R× R p,
où c : U → R est continue.
Un principe important de résolution d’équations aux dérivées partielles est d’effectuer unchangement de variable ; si f : U ⊂ R p → R est une fonction de classe C1 (ou C2 pour une équation
d’ordre 2) solution d’une équation aux dérivées partielles, on écrit, pour x = (x1, . . . , x p) ∈ U ,f (x) = g(u1(x), . . . , u p(x))
où u1, . . . , u p sont des fonctions définies sur U , à valeurs dans un ouvert V de R p, et g : V → R.
Pour que cela définisse correctement la fonction g, on choisit les fonctions u1, . . . , u p et l’ouvertV de sorte que
φ :
U → V
x → (u1(x), . . . , u p(x))
soit bijective. Ainsi, la relation f = g φ que l’on veut utiliser équivaut à g = f φ−1. On souhaiteégalement que g et φ soient de classe C1 (resp. C2 pour l’ordre 2), ce qui est le cas si toutes lesfonctions coordonnées de φ et φ−1 sont de classe
C1 (resp.
C2), par application de la règle de la
chaîne.
Le changement de variable est choisi pour que g vérifie une équation aux dérivées partiellesla plus simple possible. Lorsque p = 2, on se ramène par exemple à l’une des équations suivantes(les variables de la fonction g sont notées y1 et y2) :
• ∂g
∂y1= 0 sur V ; si V est convexe, on sait que cela entraîne que g ne dépend pas de sa première
variable, et qu’il existe F de classe C1 sur un intervalle ouvert de R tel que, pour tout (y1,y2) ∈ V ,g(y1,y2) = F (y2). On peut bien sûr adapter avec la deuxième variable.
• ∂ 2g
∂y1 ∂y2= 0 sur V ; de même, si V est convexe, ceci entraîne l’existence de G de classe C1 sur
un intervalle ouvert de R tel que, pour tout (y1,y2) ∈ V ,
∂g
∂y2(y1,y2) = G(y2).
354

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 363/383
En notant G une primitive de G sur cet intervalle, la fonction
g : (y1,y2) → g(y1,y2) − G(y2)
vérifie ∂ g
∂y2= 0 sur V. D’après le premier point, la fonction g ne dépend pas de sa deuxième
variable, et finalement g se met sous la forme
g : (y1,y2) → F (y1) + G(y2)
où F et G sont de classe C2 sur des intervalles ouverts de R.
Dans chaque cas, on en déduit f par la relation f = g φ, puis on vérifie la réciproque.
Voici deux exemples fondamentaux de changements de variables qu’il faut savoir utiliser,avec, dans chaque cas, un exemple détaillé :
Transformation affine
Soit ψ un isomorphisme de R p sur R p. Une transformation affine consiste à choisir
φ : x ∈ U → ψ(x) + a,
où a ∈ R p. Dans ce cas, φ est une bijection, et φ−1 : y → ψ−1(y − a), dont chaque fonctioncoordonnée est de classe C1 (et même C2) sur V = φ(U ), car linéaire. Par exemple, dans R2, unetransformation affine convenable pour effectuer un changement de variable est une applicationde la forme
(x1,x2) → (αx1 + βx2 + a1,γx1 + δx2 + a2)
avec αδ − βγ = 0.
Exemple – On cherche à déterminer toutes les fonctions f de classe C2
sur R2
telles que pour tout(x,y) ∈ R2,
∂ 2f
∂x2(x,y) − 3
∂ 2f
∂x∂y(x,y) + 2
∂ 2f
∂y 2(x,y) = 0. (E )
Soit f une telle fonction et soit
φ :
R2 → R2
(x,y) → (x + y,2x + y)
La fonction φ est linéaire, c’est une bijection de R2 sur R2 car, pour tout (u,v) ∈ R2,
φ(x,y) = (u,v) ⇔
x + y = u
2x + y = v⇔
x = v − u
y = u − x = 2u − v
Ainsi, φ est un isomorphisme de R2 sur R2, et pour tout (u,v) ∈R2, φ−1(u,v) = (−u + v,2u − v).
Définissons alors
g : (u,v) → (f φ−1)(u,v) = f (−u + v,2u − v),
de sorte que pour tout (x,y)
∈R2,
f (x,y) = (g φ)(x,y) = g(x + y,2x + y).
355

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 364/383
D’après la règle de la chaîne pour les fonctions de deux variables, g est de classe C2 sur R2,et pour tout (x,y) ∈ R2,
∂f
∂x(x,y) =
∂g
∂u(x+y,2x+y)+2
∂g
∂v(x+y,2x+y),
∂f
∂y(x,y) =
∂g
∂u(x+y,2x+y)+
∂g
∂v(x+y,2x+y),
et, en tenant compte du théorème de Schwarz,
∂ 2f ∂x2
(x,y) = ∂ 2g∂u2
(x + y,2x + y) + 2 ∂ 2g∂ v ∂ u
(x + y,2x + y) + 2 ∂ 2g∂u∂v
(x + y,2x + y) + 4 ∂ 2g∂v2
(x + y,2x + y)
= ∂ 2g
∂u2(x + y,2x + y) + 4
∂ 2g
∂u∂v(x + y,2x + y) + 4
∂ 2g
∂v2(x + y,2x + y),
∂ 2f
∂x∂y(x,y) =
∂ 2g
∂u2(x + y,2x + y) + 2
∂ 2g
∂v∂u(x + y,2x + y) +
∂ 2g
∂u∂v(x + y,2x + y) + 2
∂ 2g
∂v2(x + y,2x + y)
= ∂ 2g
∂u2(x + y,2x + y) + 3
∂ 2g
∂u∂v(x + y,2x + y) + 2
∂ 2g
∂v2(x + y,2x + y),
∂ 2f
∂y2
(x,y) = ∂ 2g
∂u2
(x + y,2x + y) + ∂ 2g
∂v∂u
(x + y,2x + y) + ∂ 2g
∂u∂v
(x + y,2x + y) + ∂ 2g
∂v2
(x + y,2x + y)
= ∂ 2g
∂u2(x + y,2x + y) + 2
∂ 2g
∂u∂v(x + y,2x + y) +
∂ 2g
∂v2(x + y,2x + y).
Si f est solution de (E ) sur R2, alors après simplifications, pour tout (x,y) ∈ R2,
∂ 2g
∂u∂v(x + y,2x + y) = 0.
L’image de φ étant R2, on a donc ∂ 2g
∂u∂v = 0. Comme R2 est convexe, on en déduit en refaisant
le raisonnement du deuxième point ci-dessus qu’il existe deux fonctions F et G de R dans R declasse
C2 telles que pour tout (u,v)
∈R2,
g(u,v) = F (u) + G(v).
Alors, pour tout (x,y) ∈ R2,
f (x,y) = (g φ)(x,y) = F (x + y) + G(2x + y).
On vérifie la réciproque par un calcul direct. Les solutions de (E ) sur R2 sont donc exactementles fonctions de la forme
(x,y) → F (x + y) + G(2x + y)
où F et G sont de classe C2
sur R à valeurs dans R. Coordonnées polaires
Soit θ0 ∈ [−π,π[. Notons U = R2 \ D, où D est la demi-droite
(x,y) ∈ R2; arg(x + iy) = θ0
(en considérant que 0 ∈ D). Si (x,y) ∈ U , il existe un unique r > 0 et un unique θ ∈ ]θ0,θ0 + 2π[tels que
(x,y) = (r cos(θ), r sin(θ)).
L’application
ψ : ]0, + ∞[ × ]θ0,θ0 + 2π[ → U (r,θ) → (r cos(θ), r sin(θ))
est bijective, de classe C1 sur l’ouvert V = ]0, + ∞[ × ]θ0,θ0 + 2π[.
356

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 365/383
Pour tout (r,θ) ∈ V , l’égalité (x,y) = ψ(r,θ) entraîne que r =
x2 + y2 et donc
cos(θ) = x
r =
x x2 + y2
, sin(θ) = y
r =
y x2 + y2
.
Par exemple, lorsque θ0 = −π, soit (x,y) = ψ(r,θ) ∈ U avec (r,θ) ∈ V . En se restreignant àx > 0, on a
tan(θ) = y
x
avec θ
∈]
−
π
2
,π
2
[,
doncψ−1(x,y) =
x2 + y2, arctan
y
x
,
ce qui montre que chaque fonction-coordonnée de φ = ψ−1 est de classe C1 sur R∗+ ×R. Selon lessituations, on pourra considérer une autre valeur de θ0 et/ou adapter les formules précédentes.
Le passage en coordonnées polaires, c’est-à-dire le changement de variable défini par la fonc-tion φ précédente (ou une forme analogue selon l’ouvert sur lequel on travaille), permet derésoudre un certain nombre d’équations aux dérivées partielles.
Remarque – La formule donnant φ = ψ−1 dépend de l’ouvert sur lequel on travaille. Il est parfoisplus simple de travailler avec la fonction ψ, c’est-à-dire, à partir de la relation
g(r,θ) = (f ψ)(r,θ) = f (r cos(θ), r sin(θ)).
Exemple – Soit U = R∗+ ×R. On recherche toutes les fonctions f : U → R de classe C1 telles que,pour tout (x,y) ∈ U , ∇f (x,y) soit colinéaire à (x,y). Cette condition équivaut au fait que pourtout (x,y) ∈ U ,
∂f
∂x(x,y) x
∂f
∂y(x,y) y
= 0, i.e., y∂f
∂x(x,y) − x
∂f
∂y(x,y) = 0.
On résout cette équation aux dérivées partielles en passant en coordonnées polaires : avec les
notations ci-dessus, on pose, pour f solution du problème,g(r,θ) = f (r cos(θ), r sin(θ))
pour tout (r,θ) ∈ V = ]0, + ∞[ × ]−π2 ,π2 [. D’après la règle de la chaîne, la fonction g est de classe
C1 sur V et pour tout (r,θ) ∈ V ,
∂g
∂θ(r,θ) =
∂f
∂x(r cos(θ),r sin(θ)) (−r sin(θ)) +
∂f
∂y(r cos(θ),r sin(θ)) (r cos(θ)) = 0;
V étant convexe, la fonction g est donc indépendante de θ : il existe F : ]0, + ∞[ → R de classeC1 telle que, pour tout (r,θ) ∈ V , g(r,θ) = F (r). La fonction ψ étant une bijection de V sur U ,pour tout (x,y)
∈ U , il existe (r,θ)
∈ V tel que (x,y) = ψ(r,θ), et alors
f (x,y) = (g φ)(x,y) = F (
x2 + y2) = F (x2 + y2),
où F : r → F (√
r ) est de classe C1 sur ]0, + ∞[ par composition. Réciproquement, soit f unefonction de la forme précédente. Alors f est de classe C1 sur U par composition et, pour tout(x,y) ∈ U ,
y∂f
∂x(x,y) − x
∂f
∂y(x,y) = y × 2x F ′(x2 + y2) − x × 2y F ′(x2 + y2) = 0.
Les solutions du problème sont donc exactement les fonctions de la forme
(x,y) → F (x2
+ y2
)
avec F : ]0, + ∞[ → R de classe C1. Ce sont des fonctions « isotropes », c’est-à-dire, dépendantde (x,y) uniquement via sa norme euclidienne usuelle.
357

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 366/383
V. Courbes et surfaces
Dans le chapitre Fonctions vectorielles – Arcs paramétrés, nous avons étudié les courbesdonnées par une représentation paramétrique, et nous avons notamment décrit l’allure localed’une telle courbe, en lien avec la notion de tangente. Dans cette partie, nous allons étudierle cas d’une courbe ou surface définie par une équation cartésienne de la forme f (x,y) = 0 ouf (x,y,z) = 0.
On travaillera dans R2 ou R3 munis de leur structure euclidienne canonique.
1. Courbes du plan données par une équation cartésienne
Dans ce paragraphe, p = 2. Dans de nombreuses situations, une courbe C du plan n’est pasdonnée par un paramétrage, mais par une équation cartésienne, c’est-à-dire que C est l’ensembledes points (x,y) de U tels que f (x,y) = 0 où f : U → R est de classe C1. Il se peut que cecidéfinisse la courbe de façon implicite, car il faut a priori résoudre une équation pour tracer cettecourbe. On peut citer l’exemple des courbes équipotentielles, isoclines, de même altitude, etc . . .
Exemples
• Si φ : I
→ R est de classe
C1 sur un intervalle ouvert I de R, le graphe de φ est la courbe
Cd’équation y = φ(x), c’est-à-dire f (x,y) = 0 avec f : (x,y) → φ(x) − y, de classe C1 sur l’ouvertU = I ×R. Dans ce cas, la représentation est explicite car y est fonction de x. La courbe C esten fait l’image de l’arc paramétré (I,γ ) où, pour tout x ∈ I , γ (x) = (x,φ(x)).
• Le cercle unité C de R2 a pour équation x2 + y2 = 1. On peut choisir f (x,y) = x2 + y2 − 1 pourtout (x,y) ∈R2.
Dans l’exemple précédent, on remarquera que l’on peut entièrement résoudre l’équation, maisce n’est pas toujours possible. On souhaite trouver un moyen de décrire, malgré cela, la courbeC. On sait notamment le faire pour les arcs paramétrés : si Γ = (I,γ ) est un arc de classe C1, Γpossède, en chaque point régulier M (t0), une tangente dirigée par γ ′(t0) (on rappelle que M (t0)
est un point régulier de Γ si et seulement si γ ′(t0)
= 0). On souhaite se ramener à cette situation.
Soit f : U → R de classe C1 et C la partie de R2 d’équation f (x,y) = 0.
On appelle point régulier de C tout point (x0,y0) ∈ C tel que
∇f (x0,y0) = (0,0),
c’est-à-dire, tel que ∂f
∂x(x0,y0) = 0 ou
∂f
∂y(x0,y0) = 0.
En d’autres termes, il s’agit des points de C qui ne sont pas des points critiques de f .
Définition – Point régulier
Avec les notations précédentes, soit (x0,y0) un point régulier de C.
Alors il existe r > 0, η > 0 et γ : ]−η,η[→ U de classe C1, tels que :
• (x0,y0) = γ (0) ;
• ( ]−η,η[ ,γ ) soit un arc paramétré simple et régulier ;• B((x0,y0),r) ⊂ U et pour tout (x,y) ∈ B((x0,y0),r), on a l’équivalence :
f (x,y) = 0
⇔ ∃t
∈]
−η,η[ ; (x,y) = γ (t).
On dit que ( ]−η,η[ ,γ ) est un paramétrage local de C au voisinage de (x0,y0).
Théorème (admis)
358

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 367/383
Exemple – Soit C le cercle unité d’équation f (x,y) = 0 avec f : (x,y) → x2 + y2 − 1. La fonctionf est de classe C1 sur R2 et pour tout (x,y) ∈R2,
∇f (x,y) = (2x,2y),
qui est non nul sauf à l’origine, qui n’est pas un point de C. Tous les points de C sont donc réguliers.En fait, dans ce cas, on peut construire explicitement un paramétrage de C au voisinage de chaquepoint. Par exemple, au voisinage d’un point (a,b) de
C tel que b > 0, on peut paramétrer
C par
γ 1 :
[−a − 1, − a + 1] → R2
t → (a + t,
1 − (a + t)2)
Au voisinage de (1,0), on peut paramétrer C par
γ 2 :
[−1,1] → R2
t → (
1 − t2, t)
On peut procéder de même dans les autres cas.
Il est important de bien comprendre les différentes notions de point régulier selon le type de
courbe considéré, et les liens entre ces notions :
Bilan
• Si la courbe est donnée par un paramétrage (I,γ ) où γ : I → R2 est de classe C1, un pointM (t) est régulier si et seulement si γ ′(t) = 0.
• Si la courbe est donnée par une équation cartésienne f (x,y) = 0 où f : U → R est de classeC1, un point (x0,y0) de C est régulier si et seulement si ∇f (x0,y0) = (0,0).
Le résultat admis ci-dessus montre que si l’on est dans la situation du deuxième point, on estégalement dans la situation du premier : au voisinage d’un point régulier au sens du deuxièmepoint, une courbe donnée de façon implicite peut être « explicitée », et être vue comme l’imaged’un arc paramétré régulier (on peut écrire x et y comme fonctions d’un paramètre t).
Soit maintenant C une partie de R2 donnée par une équation cartésienne f (x,y) = 0, etsupposons que l’on soit dans le cadre d’application du théorème précédent en un point (x0,y0),c’est-à-dire que f est de classe C1 sur U avec ∇f (x0,y0) = (0,0). Avec les notations du théorème,et en notant γ = (x,y), on a par définition même, pour tout t ∈ ]−η,η[,
f (x(t),y(t)) = 0.
D’après la règle de la chaîne, ceci définit une fonction de classe C1 sur ]−η,η[ et, pour toutt ∈ ]−η,η[,
∂f
∂x(x(t),y(t)) x′(t) +
∂ f
∂y(x(t),y(t)) y′(t) = 0, i.e. ∇f (γ (t))
|γ ′(t) = 0,
et donc, pour t = 0,
∂f
∂x(x0,y0) x′(0) +
∂ f
∂y(x0,y0) y′(0) = 0, i.e.
∇f (x0,y0) | γ ′(0)
= 0.
La tangente à la courbe C au point (x0,y0) (en tant que support d’un arc paramétré simple etrégulier au voisinage de ce point) est la droite passant par (x0,y0) et dirigée par γ ′(0). Or, l’égalitéprécédente montre que le vecteur (non nul) ∇f (x0,y0) est orthogonal à γ ′(0) : ∇f (x0,y0) est unvecteur normal à la tangente.
La tangente à la courbe C au point (x0,y0) est donc l’ensemble des points (x,y) ∈ R2 tels que
(∇f (x0,y0) | (x − x0,y − y0)) = 0.
On a ainsi démontré le résultat suivant :
359

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 368/383
Soit f : U → R de classe C1 et C la partie de R2 d’équation f (x,y) = 0.
Soit (x0,y0) un point régulier de C.
• La courbe C possède une tangente en (x0,y0), d’équation
∂f
∂x(x0,y0) (x
−x0) +
∂ f
∂y(x0,y0) (y
−y0) = 0.
Si ∂f
∂x(x0,y0) = 0, il s’agit d’une tangente horizontale, si
∂f
∂y(x0,y0) = 0, il s’agit d’une
tangente verticale.
• On appelle normale à C au point (x0,y0), la droite passant par (x0,y0) et dirigée parle vecteur
∇f (x0,y0) =
∂f
∂x(x0,y0),
∂f
∂y(x0,y0)
.
On dit que ∇f (x0,y0) est orthogonal à C au point (x0,y0).
Propriété/Définition : Tangente en un point régulier
Exemple – Soit C la partie de R2 d’équation
x3 + 3y2 + 6xy + 4 = 0.
Elle a pour équation cartésienne f (x,y) = 0 où f : (x,y) → x3 + 3y2 + 6xy + 4 est de classe C1
sur R2. Pour tout (x,y) ∈R2,
∂f
∂x(x,y) = 3x2 + 6y et
∂f
∂y(x,y) = 6y + 6x.
On a les équivalences
3x
2
+ 6y = 06y + 6x = 0
⇔ x
2
+ 2y = 0y = −x
⇔ x
2
− 2x = 0y = −x
⇔ (x,y) = (0,0) ou (x,y) = (2,−2).
Les points critiques de f sont donc (0,0) et (2,−2). De ces deux points, seul (2,−2) appartient àC. Tout autre point de C est donc régulier, et l’équation de la tangente à C en l’un de ses pointsréguliers (x0,y0) est
∂f
∂x(x0,y0) (x − x0) +
∂ f
∂y(x0,y0) (y − y0) = 0
i.e. (x20 + 2y0)(x − x0) + 2(x0 + y0)(y − y0) = 0.
Cas particulier – Si φ est une fonction de classe C1 sur un intervalle ouvert I , son graphe Cest la courbe d’équation f (x,y) = 0 avec f : (x,y) → φ(x) − y, de classe C1 sur U = I ×R. Toutpoint de C est régulier car
∇f (x,y) = (φ′(x), − 1) = (0,0)
pour tout (x,y) ∈ C. La tangente à C en un point (x0,y0) a pour équation
∂f
∂x(x0,y0)(x − x0) +
∂ f
∂y(x0,y0)(y − y0) = 0,
i.e. φ′(x0)(x − x0) − (y − y0) = 0.
Sachant que y0 = φ(x0), on retrouve bien sûr l’équation
y = φ′(x0)(x − x0) + φ(x0).
360

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 369/383
Soit f : U → R et λ ∈ R.
On appelle ligne de niveau λ de f la partie de U d’équation f (x,y) = λ.
Définition – Ligne de niveau
Remarque – Bien sûr, l’étude des lignes de niveau de f entre dans le cadre précédent, via l’étudede l’équation f (x,y)
− λ = 0. Les points réguliers de cette ligne de niveau sont ses points en
lesquels ∇f ne s’annule pas, puisque ∇(f − λ) = ∇f.
Soit f : U → R de classe C1 et λ ∈ R. Soit (x0,y0) un point régulier de la ligne deniveau λ de f , c’est-à-dire que f (x0,y0) = λ et ∇f (x0,y0) = (0,0).
Alors ∇f (x0,y0) est orthogonal à la ligne de niveau λ de f , et orienté dans le sens desvaleurs croissantes de f , c’est-à-dire qu’il existe η > 0 tel que la fonction
t → f ((x0,y0) + t ∇f (x0,y0)) = f
x0 + t
∂f
∂x(x0,y0), y0 + t
∂f
∂y(x0,y0)
soit strictement croissante sur ]−η,η[.
Propriété – Gradient et lignes de niveau
Démonstration – La première conclusion est déjà connue, d’après la propriété et la remarqueprécédentes. Pour la seconde conclusion, la fonction f est de classe C1 sur U et les fonctions
x : t → x0 + t ∂f
∂x(x0,y0) et y : t → y0 + t
∂f
∂y(x0,y0)
sont de classe C1 sur R et ont pour limites respectives x0 et y0 en 0, le point (x0,y0) appartenantà l’ouvert U . La fonction
g : t → f ((x0,y0) + t ∇f (x0,y0)) = f (x(t),y(t))
est donc bien définie au voisinage de 0, et d’après la règle de la chaîne, elle est de classe C1 auvoisinage de 0 avec, pour tout t ∈ R assez proche de 0,
g′(t) = ∂f
∂x(x(t),y(t)) x′(t) +
∂ f
∂y(x(t),y(t)) y′(t)
= ∂f
∂x(x(t),y(t))
∂f
∂x(x0,y0) +
∂ f
∂y(x(t),y(t))
∂f
∂y(x0,y0),
et en particulier
g′(0) =∂f
∂x(x0,y0)
2
+∂f
∂y(x0,y0)
2
= ∇f (x0,y0)2.
Sachant que ∇f (x0,y0) = (0,0), on a donc g ′(0) > 0. La fonction g étant de classe C1 au voisinagede 0, il existe η > 0 tel que g ′(t) > 0 pour tout t ∈ ]−η,η[, d’où le résultat.
Exemple – Soit f : (x,y) → x2 + y2. Les lignes de niveau de f sont les sous-ensembles de R2
d’équation x2 + y2 = λ où λ ∈ R. Si λ < 0, cet ensemble est vide, si λ = 0, il est réduit au point(0,0), et si λ > 0, il s’agit du cercle de centre (0,0) et de rayon
√ λ.
La fonction f est de classe C1 sur R2 et pour tout (x,y) ∈ R2,
∇f (x,y) = 2(x,y),
il est donc colinéaire à (x,y) (ce qui est cohérent avec le deuxième exemple d’équation aux dérivéespartielles que nous avons traité). Pour tout (x0,y0) = (0,0), ∇f (x0,y0) est non nul et orthogonal
361

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 370/383
à la ligne de niveau λ = x20 +y2
0 de f , orienté dans le sens des valeurs croissantes de f , c’est-à-dire,« s’éloignant » de l’origine.
Remarque – En électrostatique par exemple :
• Si une fonction V représente un potentiel électrique V , les lignes de niveau de V sont appeléeslignes équipotentielles.
• Si le champ électrostatique −→
E dérive de V , c’est-à-dire vérifie −→
E = −∇V , on appelle ligne
de champ de −→E toute courbe C régulière telle que pour tout (x,y) ∈ C, −→E (x,y) soit un vecteurtangent à C en (x,y).
D’après ce qui précède, les lignes de champ de −→E sont orthogonales aux lignes équipotentielles
de V . De plus, −→
E est dirigé dans le sens des potentiels décroissants.
2. Surfaces données par une équation cartésienne
Dans ce paragraphe, p = 3. On souhaite étudier les surfaces données par une équation carté-sienne de la forme f (x,y,z) = 0, où f : U → R est de classe C1.
Exemples
• La sphère unité de R3 a pour équation cartésienne x2 + y2 + z2 = 1.
• Si g : V → R est une fonction de classe C1 sur un ouvert V de R2, la surface représentativede g a pour équation cartésienne z = g(x,y), ce qui entre dans le cadre précédent, en posantf (x,y,z) = g(x,y) − z pour tout (x,y,z) ∈ R3 tel que (x,y) ∈ V . Dans ce cas, il s’agit d’unereprésentation explicite car z est directement donné en fonction de x et y .
Soit f : U → R de classe C1 et S la partie de R3 d’équation f (x,y,z) = 0.
• On appelle point régulier de
S tout point (x0,y0,z0)
∈ S tel que
∇f (x0,y0,z0) = (0,0,0)
c’est-à-dire, tel que ∂f
∂x(x0,y0,z0) = 0 ou
∂f
∂y(x0,y0,z0) = 0 ou
∂f
∂z(x0,y0,z0) = 0.
• Si (x0,y0,z0) est un point régulier de S , on appelle plan tangent à S en (x0,y0,z0)
le plan orthogonal à ∇f (x0,y0,z0) et passant par (x0,y0,z0), c’est-à-dire, le plan de R3
d’équation
(∇f (x0,y0,z0) | (x − x0, y − y0, z − z0)) = 0,
i.e. ∂f
∂x(x
0,y
0,z
0)(x
−x
0) +
∂ f
∂y(x
0,y
0,z
0)(y
−y
0) +
∂ f
∂z(x
0,y
0,z
0)(z
−z
0) = 0.
Définition – Point régulier, plan tangent
Exemple – Soit g : V → R une fonction de classe C1 sur un ouvert V de R2 et soit S la surfacereprésentative de g , c’est-à-dire, la surface d’équation z = g(x,y).
Comme on l’a expliqué ci-dessus, c’est un cas particulier de surface donnée par une équationcartésienne f (x,y,z) = 0 avec f : (x,y,z) → g(x,y) − z définie sur l’ouvert de R3
U = (x,y,z) ∈ R3; (x,y) ∈ V .
La fonction f est de classe C1
sur U de même que g sur V , et pour tout (x,y,z) ∈ U ,
∇f (x,y,z) =
∂g
∂x(x,y),
∂g
∂y(x,y), − 1
= (0,0,0).
362

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 371/383
En particulier, chaque point de S est régulier. Si (x0,y0,z0) ∈ S , le plan tangent à S en (x0,y0,z0)
a pour équation
∂g
∂x(x0,y0)(x − x0) +
∂ g
∂y(x0,y0)(y − y0) − (z − z0) = 0,
i.e. z = ∂g
∂x(x0,y0)(x − x0) +
∂ g
∂y(x0,y0)(y − y0) + g(x0,y0).
3. Courbes tracées sur une surface
Soit f : U → R de classe C1 et S la partie de R3 d’équation f (x,y,z) = 0.
On appelle courbe tracée sur la surface S tout arc paramétré (I,γ ) où I est unintervalle de R et γ = (x,y,z) : I → R3 vérifie, pour tout t ∈ I , (x(t),y(t),z(t)) ∈ S .
Définition
Par définition même, on a, avec les notations précédentes : pour tout t ∈ I ,
f (x(t), y(t), z(t)) = 0.
Si γ est de classe C1, alors d’après la règle de la chaîne, t → f (x(t), y(t), z(t)) est de classe C1
sur I . Comme cette fonction est nulle, on a, pour tout t ∈ I ,
∂f
∂x(x(t), y(t), z(t)) x′(t) +
∂ f
∂y(x(t), y(t), z(t)) y′(t) +
∂ f
∂z(x(t), y(t), z(t)) z′(t) = 0
i.e.∇f (γ (t)) | γ ′(t)
= 0,
et donc ∇f (γ (t)) est orthogonal à γ ′(t), qui dirige la tangente à la courbe en chacun de ses pointsréguliers.
On en déduit le résultat suivant :
Soit Γ = (I,γ ) une courbe tracée sur la surface S d’équation f (x,y,z) = 0 où f : U → R
est de classe C1. On note C le support de Γ.
Soit (x0,y0,z0) = M (t0) ∈ S un point régulier en tant qu’élément de S et en tant quepoint de Γ.
Alors la tangente à Γ en M (t0) est contenue dans le plan tangent à S en (x0,y0,z0).
Propriété – Tangente à une courbe tracée sur une surface
Cas particulier – Soit S
la surface représentative d’une fonction g : V
→ R de classe
C1,
c’est-à-dire, la surface d’équation z = g(x,y).
Fixons l’une des coordonnées x ou y, ce qui revient à considérer l’intersection de S avec des plansparallèles aux plans de coordonnées (yOz ) ou (xOz). Par exemple, fixons y = y0 et considéronsle sous-ensemble
(x, y0, g(x,y0)); (x,y0) ∈ V .
C’est le support d’une courbe tracée sur S , que l’on peut paramétrer par
x → (x, y0, g(x,y0));
elle est régulière. La situation est analogue si l’on fixe x = x0. Les courbes de cette forme sontappelées courbes coordonnées de
S .
Enfin, si l’on fixe z = z0, on obtient le sous-ensemble
(x,y,z0) ∈ U ; g(x,y) = z0,
363
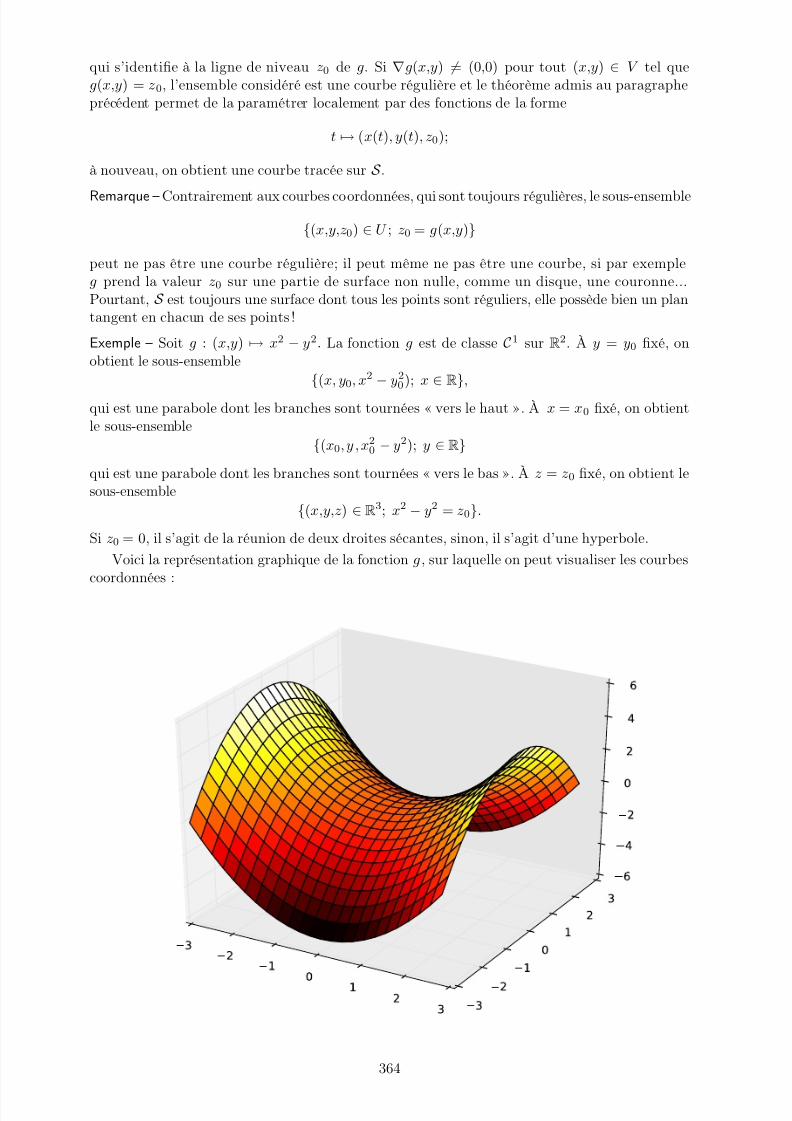
7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 372/383
qui s’identifie à la ligne de niveau z0 de g. Si ∇g(x,y) = (0,0) pour tout (x,y) ∈ V tel queg(x,y) = z0, l’ensemble considéré est une courbe régulière et le théorème admis au paragrapheprécédent permet de la paramétrer localement par des fonctions de la forme
t → (x(t), y(t), z0);
à nouveau, on obtient une courbe tracée sur S .
Remarque – Contrairement aux courbes coordonnées, qui sont toujours régulières, le sous-ensemble
(x,y,z0) ∈ U ; z0 = g(x,y)
peut ne pas être une courbe régulière; il peut même ne pas être une courbe, si par exempleg prend la valeur z0 sur une partie de surface non nulle, comme un disque, une couronne...Pourtant, S est toujours une surface dont tous les points sont réguliers, elle possède bien un plantangent en chacun de ses points !
Exemple – Soit g : (x,y) → x2 − y2. La fonction g est de classe C1 sur R2. À y = y0 fixé, onobtient le sous-ensemble
(x, y0, x2
−y2
0); x
∈R
,
qui est une parabole dont les branches sont tournées « vers le haut ». À x = x0 fixé, on obtientle sous-ensemble
(x0, y , x20 − y2); y ∈ R
qui est une parabole dont les branches sont tournées « vers le bas ». À z = z0 fixé, on obtient lesous-ensemble
(x,y,z) ∈ R3; x2 − y2 = z0.
Si z0 = 0, il s’agit de la réunion de deux droites sécantes, sinon, il s’agit d’une hyperbole.
Voici la représentation graphique de la fonction g , sur laquelle on peut visualiser les courbescoordonnées :
− 3
− 2
− 1
0
1
2
3
− 3
− 2
− 1
0
1
2
3
− 6
− 4
− 2
0
2
4
6
364

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 373/383
Sur la figure suivante, on visualise certaines lignes de niveau de la fonction g :
-
4
.
5
0
0
-
4
.
5
0
0
-
3
.
0
0
0
-
3
.
0
0
0
-
1
.
5
0
0
-
1
.
5
0
0
0
.
0
0
0
0
.
0
0
0
1
.
5
0
0
1
.
5
0
0
3
.
0
0
0
3
.
0
0
0
4
.
5
0
0
4
.
5
0
0
365

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 374/383
366

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 375/383
Annexe 1 : Relations de comparaison
Sauf précision, les suites et fonctions considérées ici sont à valeurs dans K = R ou C.
I. Le cas des suites
Soient (un) et (vn) deux suites d’éléments de K. On suppose qu’il existe N ∈ N tel quepour tout n N , vn
= 0.
• On dit que (un) est négligeable devant (vn) (ou que (vn) est prépondérante devant(un)) si
unvn
→ 0,
ce quotient étant bien défini pour n N.
Ceci équivaut à chacune des propriétés suivantes (que l’on peut prendre comme défini-tion dans le cas plus général où vn peut s’annuler pour des valeurs de n arbitrairementgrandes) :
• Il existe une suite (εn) qui converge vers 0 telle que, pour tout n N,
un = εnvn.
• ∀ ε > 0, ∃ n0 N ; ∀ n n0, |un| ε|vn|.On écrit alors un = o(vn) (se lit « un est un petit o de vn »).
• On dit que (un) est dominée par (vn) (ou que (vn) domine (un)) si la suiteunvn
nN
est bornée.
Ceci équivaut à l’existence d’un réel M 0 tel que, pour tout n N,
|un| M |vn|.
On peut prendre cette propriété comme définition dans le cas plus général où vn peuts’annuler pour des valeurs de n arbitrairement grandes.
On écrit alors un = O(vn) (se lit « un est un grand O de vn »).
Définition – Relations de négligeabilité et de domination
Exemple – Pour tout n ∈N∗, soit un = ein
n2 . Alors un = o
1
n
et un = O
1
n2
.
Remarques• Si (un) est négligeable devant (vn), alors elle est dominée par (vn).
• un = o(1) signifie que (un) converge vers 0, un = O(1) signifie que (un) est bornée.
367

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 376/383
Une suite bornée est négligeable devant une suite (vn) vérifiant |vn| → +∞.
En particulier, une suite convergente est négligeable devant une suite (vn) vérifiant|vn| → +∞.
Propriété
Opérations sur les « o » et les « O »Soient (un), (vn), (wn) et (tn) quatre suites d’éléments de K.
• Transitivité :
un = o(vn)vn = o(wn)
⇒ un = o(wn).
• Produit par un scalaire : Si un = o(vn), alors, pour tout λ ∈ K∗, un = o(λvn).
• Somme :
un = o(wn)vn = o(wn)
⇒ un + vn = o(wn).
• Produit :
un = o(wn)vn = o(tn)
⇒ unvn = o(wntn).
• Puissance : Si k > 0 et si (un) et (vn) sont à termes réels strictement positifs, alors
un = o(vn) ⇒ ukn = o(vkn).
Tous ces résultats sont vrais en remplaçant « o » par « O ».
Croissances comparées classiques
• Si (α,β ) ∈ R2 et α < β, alors nα = o(nβ ).
• Si (a,b) ∈C2 et |a| < |b|, alors an = o(bn).
• Si α > 0 et β ∈ R, (ln n)β = o(nα).
• Si a ∈ C vérifie |a| > 1 et si α ∈C, nα = o(an), an = o(n!).
• Si a ∈ C vérifie |a| < 1 et si α ∈C, an = o
1
nα
.
• n! = o(nn).
Soient (un) et (vn) deux suites d’éléments de K. On suppose qu’il existe N ∈ N tel quepour tout n N , vn
= 0.
On dit que (un) est équivalente à (vn) si
unvn
→ 1,
ce quotient étant bien défini pour n N.
Ceci équivaut à l’existence d’une suite (εn) qui converge vers 0 telle que, pour toutn N,
un = (1 + εn)vn.
On peut prendre cette propriété comme définition dans le cas plus général où vn peuts’annuler pour des valeurs de n arbitrairement grandes.
On écrit alors un ∼ vn (se lit « un est équivalent à vn »).
Définition – Relation d’équivalence
368

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 377/383
Remarques
• un ∼ vn ⇔ un = vn + o(vn) ⇔ un − vn = o(vn).
• Si un ∼ vn, alors pour tout n assez grand, un = 0 et
vnun
→ 1.
On en déduit que un ∼ vn ⇔ vn ∼ un. On peut donc dire que (un) et (vn) sont équivalentes.Exemples
• Tout polynôme en n est équivalent à son terme de plus haut degré.
• Toute fraction rationnelle en n est équivalente au quotient des termes de plus haut degré.
Si (un) et (vn) sont à termes réels, si un ∼ vn et si les termes de l’une des deux suitessont strictement positifs à partir d’un certain rang, alors il en est de même pour l’autre
(de même pour un signe strictement négatif).
Propriété – Signe de deux suites équivalentes
Si ℓ = 0, alors un → ℓ si et seulement si un ∼ ℓ.
Propriété
Si (un) et (vn) sont deux suites équivalentes, alors :
• (un) et (vn) sont de même nature (convergente ou divergente).
• Si un → ℓ ∈ K, alors vn → ℓ.
• Si (un) et (vn) sont à termes réels, et si un → +∞ (resp. −∞) alors vn → +∞ (resp.−∞).
Théorème
Attention ! En revanche, lim un = lim vn un ∼ vn. Par exemple, si pour tout n ∈ N, un = n
et vn = n2, alors un → +∞, vn → +∞ mais un n’est pas équivalent à vn.
Équivalents classiques
• Si un → 0, alors :
ln(1 + un) ∼ un eun − 1 ∼ un
(1 + un)α − 1 ∼ α un (α ∈R) sin(un) ∼ un
cos(un) − 1 ∼ −u2n
2 tan(un) ∼ un.
• Si P (x) = a px p +
· · ·+ aqxq, (avec p q, a p
= 0, aq
= 0), alors :
– si un → 0, P (un) ∼ aquqn;
– si un → +∞ (ou − ∞), P (un) ∼ a pu pn.
369

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 378/383
Opérations sur les équivalents
• Transitivité :
un ∼ vnvn ∼ wn
⇒ un ∼ wn.
• Produit :
un ∼ wn
vn ∼ tn⇒ unvn ∼ wntn.
• Inverse : u
n ∼ vn ⇒
1
un ∼ 1
vn.
• Quotient :
un ∼ wn
vn ∼ tn⇒ un
vn∼ wn
tn.
• Valeur absolue ou module : un ∼ vn ⇒ |un| ∼ |vn|.• Puissance : Si k ∈ R et si (un) et (vn) sont à termes réels strictement positifs, alors
un ∼ vn ⇒ (un)k ∼ (vn)k.
Remarque – La relation ∼ est une relation d’équivalence.
Opérations à ne pas faire en général sur les équivalents• La somme : on peut multiplier et diviser les équivalents, mais pas les sommer.
un ∼ wn
vn ∼ tn⇒ un + vn ∼ wn + tn. Par exemple, on a
n2 + n ∼ n2
−n2 ∼ −n2 , mais n ∼ 0.
• La composition : en général, on ne peut pas composer un équivalent par une fonction.
un ∼ vn ⇒ f (un) ∼ f (vn). Par exemple, on a n2 + n ∼ n2, mais en2+n ∼ en
2.
En dehors du cas de l’élévation à une puissance, il existe toutefois un cas où la composition
est possible, mais à démontrer à chaque usage, car il ne figure pas au programme :
Soient (un) et (vn) deux suites à termes réels strictement positifs telles que un ∼ vn et
un →
ℓ (avec ℓ > 0 et ℓ = 1)ou
+∞
Alors ln(un) ∼ ln(vn).
Propriété (Hors-programme)
Contre-exemple si un → 1 : considérer un = 1 + 1n
et vn = 1 + 12n
.
370

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 379/383
II. Le cas des fonctions
Soit I un intervalle de R et a adhérent à I , avec éventuellement a = ±∞.
Soient f et g deux applications définies sur I \ a à valeurs dans K. On suppose qu’ilexiste η > 0 tel que pour tout x
∈ I
\ a
tel que
|x
−a
| η, on ait g(x)
= 0.
• On dit que f est négligeable devant g (ou que g est prépondérante devant g) ena si
f (x)
g(x) −→x→ax=a
0,
ce quotient étant bien défini pour x ∈ I \ a tel que |x − a| η.
On écrit alors f (x) =x→a o(g(x)) (se lit « f (x) est un petit o de g(x) lorsque x tend vers
a »).
• On dit que f est dominée par g (ou que g domine f ) s’il existe δ ∈ ]0, η] tel que la
fonction f
g soit bornée sur x ∈ I \ a; |x − a| δ .
On écrit alors f (x) =x→a O(g(x)) (se lit « f (x) est un grand O de g(x) lorsque x tend
vers a »).
• On dit que f est équivalente à g en a si
f (x)
g(x) −→x→ax=a
1,
On écrit alors f (x) ∼x→a g(x) (se lit « f (x) est équivalent à g(x) lorsque x tend vers
a »).
Définition – Relations de comparaison pour les fonctions
On établira aisément les propriétés et opérations possibles et impossibles sur les relations decomparaison.
371

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 380/383
372

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 381/383
Annexe 2 : Intégrales de Wallis
On s’intéresse aux intégrales
I n =
π/2
0sinn(x) dx et J n =
π/2
0cosn(x) dx,
où n ∈ N. Ces intégrales sont appelées intégrales de Wallis (John Wallis (1616–1703) était unmathématicien anglais. On lui doit notamment le symbole ∞, mais également des travaux enphonétique et orthophonie).
Le but de cette annexe est de rassembler divers résultats sur ces intégrales, notamment en
rapport avec la démonstration de la formule de Stirling. L’étude des intégrales de Wallis ne figurepas au programme.
1. Montrons que pour tout n ∈ N, I n = J n. Pour cela, on fait dans l’expression de J n lechangement de variable x = π/2 − u pour u ∈ [0,π/2], la fonction cosn étant continue sur [0,π/2]et la fonction u → π/2 − u étant de classe C1 sur [0,π/2]. Alors
J n =
π/2
0cosn(x) dx =
0
π/2− cosn
π
2 − u
du =
0
π/2− sinn(u) du = I n.
Dans la suite, on ne s’intéressera donc qu’à I n.
2. Pour tout n, x → sinn(x) est continue, positive et non identiquement nulle sur [0,π/2]. On endéduit que I n > 0 pour tout n.
3. Pour tout x ∈ [0, π/2], on a 0 sin(x) 1, donc 0 sinn(x) 1 quel que soit n ∈ N. Parcroissance de l’intégrale, on en déduit que
0 I n π
2.
En particulier, la suite (I n) est bornée. De plus, pour tout n ∈ N,
I n+1 − I n =
π/2
0(sinn+1(x) − sinn(x)) dx =
π/2
0sinn(x)(sin(x) − 1) dx.
Or, pour tout x ∈ [0, π/2], sinn(x)(sin(x) − 1) 0, ce qui implique que I n+1 − I n 0. On endéduit que la suite (I n) est décroissante.
4. Limite de (I n) : nous allons montrer que I n −→n→+∞ 0. Pour cela, fixons un réel ε > 0 et soit
δ ∈ ]0,π/2[ à déterminer. On peut supposer sans perte de généralité que ε < π.
a. Pour tout x ∈ [0,π/2] et n ∈ N, sinn(x) 1, et donc π/2
δsinn(x) dx
π/2
δ1 dx =
π
2 − δ.
Si l’on choisit δ =
π
−ε
2 , on obtient donc π/2
δsinn(x) dx
π
2 − δ
ε
2,
373

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 382/383
avec une majoration indépendante de n. On a de plus δ ∈ ]0,π/2[ car ε ∈ ]0,π[.
b. Pour tout x ∈ [0,δ ] et n ∈ N, sinn(x) sinn(δ ), car la fonction sinn est croissante sur[0,π/2]. On en déduit que δ
0sinn(x) dx
δ0
sinn(δ ) dx = δ sinn(δ ).
Or δ
∈]0,π/2[, donc sin(δ )
∈]0,1[. En particulier, δ sinn(δ )
−→n→+∞0 (suite géométrique). Il existe
donc n0 ∈ N tel que pour tout entier n n0, δ sinn(δ ) ε2 .
c. D’après la relation de Chasles et le point 3,
0 I n =
δ0
sinn(x) dx +
π/2
δsinn(x) dx.
En utilisant alors les résultats des points a et b, on obtient, pour tout entier n n0, I n ε.Finalement, pour tout réel ε ∈ ]0,π[, on a montré l’existence d’un entier n0 tel que pour toutentier n n0, 0 I n ε : la suite (I n) tend vers 0 lorsque n tend vers +∞.
Remarque – On peut aussi utiliser le théorème de convergence dominée, puisque sinn est continuepour tout n
∈N, sinn(x)
−→n→+∞0 pour tout x
∈ [0,π/2[ et
|sinn(x)
| 1 pour tout x
∈ [0,π/2[ et
n ∈ N.
5. Relation de récurrence
Pour tout n ∈ N,
I n+2 =
π/2
0sinn+2(x) dx =
π/2
0sin(x)sinn+1(x) dx.
On intègre alors par parties (u = − cos et v = sinn+1 étant de classe C1 sur [0,π/2]) :
I n+2 = − cos(x)sinn+1(x)π/2
0 +
π/2
0
cos(x)(n + 1) cos(x)sinn(x) dx
= (n + 1)
π/2
0cos2(x)sinn(x) dx
= (n + 1)
π/2
0(1 − sin2(x))sinn(x) dx
= (n + 1)
π/2
0(sinn(x) − sinn+2(x)) dx
= (n + 1)(I n − I n+2).
On en déduit que (n + 2)I n+2 = (n + 1)I n, d’où : pour tout n ∈ N, I n+2 = n + 1
n + 2I n.
Sachant que I 0 =
π/2
01 dx =
π
2 et I 1 =
π/2
0sin(x)dx = [− cos(x)]
π/20 = 1, on en déduit
par exemple
I 2 = π
4, I 3 =
2
3, I 4 =
3π
16, I 5 =
8
15.
6. Formule explicite
Montrons par récurrence sur p que pour tout p ∈ N, on a :
I 2 p = (2 p)!
22 p+1( p!)2 π et I 2 p+1 =
22 p( p!)2
(2 p + 1)!.
Initialisation : pour p = 0, on a
I 2×0 = I 0 = π
2 =
(2 × 0)!
22×0+1(0!)2π et I 2×0+1 = I 1 = 1 =
22×0(0!)2
(2 × 0 + 1)!.
374

7/21/2019 maths psi.pdf
http://slidepdf.com/reader/full/maths-psipdf 383/383
Hérédité : supposons la propriété vraie pour un certain p ∈ N. Montrons qu’elle est alors vraiepour p + 1 : on a I 2( p+1) = I 2 p+2, donc, d’après le point 5 (avec n = 2 p),
I 2( p+1) = 2 p + 1
2 p + 2I 2 p.
Avec l’hypothèse de récurrence, on en déduit :
I 2( p+1) = 2 p + 12 p + 2
× (2 p)!22 p+1( p!)2
π
= (2 p + 1)!
(2 p + 2) 22 p+1 ( p!)2π
= (2 p + 2)!
(2 p + 2)2 22 p+1 ( p!)2π
= (2 p + 2)!
4( p + 1)2 22 p+1 ( p!)2π
= (2 p + 2)!
22 p+3 ( p + 1)!2π,
ce qui est bien le résultat souhaité. De même, avec le point 5 (avec n = 2 p + 1),
I 2( p+1)+1 = 2 p + 2
2 p + 3I 2 p+1.
D’où :
I 2( p+1)+1 = 2 p + 2
2 p + 3 × 22 p( p!)2
(2 p + 1)!
= (2 p + 2)2 22 p( p!)2
(2 p + 2)(2 p + 3)(2 p + 1)!
= 4( p + 1)2 22 p ( p!)2
(2 p + 3)!
= 22 p+2( p + 1)!2
(2 p + 3)! ,
ce qui prouve l’hérédité. Les deux égalités sont donc vraies pour tout p ∈ N.
7. Comportement asymptotique
a. Par décroissance de la suite (I n) et d’après le point 5, pour tout n ∈ N, on a
I n+2 I n+1 I n,
c’est-à-diren + 1
n + 2I n I n+1 I n.
En divisant par I n, qui est strictement positif d’après le point 2, on en déduit
n + 1
I n+1 1
Recommended

















