
?
INFERENZA STATISTICA Bruno Chiandotto
Dipartimento di Statistica, Informatica, Applicazioni “G. Parenti”(DISIA)
Firenze, agosto 2017
It is easy to lie with statistics
It is hard to tell the truth without it Andrejs Dunkels
Queste Note didattiche sono state predisposte (in edizione provvisoria) per facilitare la preparazione
dell'esame di Inferenza statistica previsto nel Corso di laurea Magistrale in Statistica, Scienze attuariali
e finanziarie dell’Università degli Studi di Firenze. Lo studente troverà nelle note soltanto alcuni degli
elementi di base del calcolo delle probabilità e dell’inferenza statistica. Si tratta di un’ introduzione alla
conoscenza dei metodi moderni di analisi statistica dei fenomeni collettivi da approfondire mediante la
lettura di altri testi.
.


B. Chiandotto Versione 2017
INFERENZA STATISTICA
Indice
i
INDICE
0. Premessa
Introduzione 1
0.1 Inferenza statistica classica 3
0.2 Inferenza statistica bayesiana 7
0.3 Teoria statistica delle decisioni 8
0.4 Digressione: scale di misura 12
Conclusioni 15
1. Calcolo delle probabilità
Introduzione 17
1.1 Alcuni concetti di base 17
1.2 Algebra degli eventi 20
1.3 Probabilità 24
1.4 Formula di Bayes 33
1.5 Variabili casuali semplici 37
1.6 Valore atteso di funzioni di variabili casuali semplici 40
1.7 Variabili casuali discrete 50
1.7.1 Binomiale 50
1.7.2 Teorema di Markov 56
1.7.3 Ipergeometrica 60
1.7.4 di Poisson 66
1.7.5 Binomiale negativa 70
1.7.6 Geometrica (di Pascal) 75
1.7.7 Variabili casuali discrete: riepilogo 75
1.8 Variabili casuali continue 79
1.8.1 Normale (di Gauss-Laplace 79
1.8.2 Teorema del limite centrale 87
1.8.3 Log-normale 89
1.8.4 Cauchy 90
1.8.5 Gamma 91
1.8.6 Pareto (I° tipo) 92
1.8.7 Weibull 92
1.8.8 Esponenziale negativa 93
1.8.9 2
di Pizzetti-Pearson 95
1.8.10 Beta 97
1.8.11 Uniforme 101
1.8.12 t di Student 101
1.8.13 F di Fisher-Snedecor 102
1.8.14 Variabili casuali continue riepilogo 103
1.9 Variabili casuali multidimensionali 108
1.10 Valore atteso di funzioni di variabili casuali multidimensionali 113
1.11 Variabili casuali discrete e continue a k dimensioni 119
1.11.1 Trinomiale (binomiale doppia) 119
1.11.2 Multinomiale e Ipergeometrica a k dimensioni 122
1.11.3 Normale doppia 123
1.11.4 Normale a k dimensioni 131
1.11.5 di Dirichlet 133
1.12 La famiglia esponenziale 133

B. Chiandotto Versione 2017
INFERENZA STATISTICA
Indice
ii
1.13 Distribuzioni multiple multivariate 136
1.14 Distribuzioni a priori coniugate 139
2. Campionamento e distribuzioni campionarie
Introduzione 143
2.1 Campioni casuali 143
2.2 Sufficienza 150
2.3 Distribuzioni campionarie 155
2.4 Campionamento da popolazioni normali 163
2.5 Campionamento da popolazioni non normali 166
2.6 Campionamento da due popolazioni indipendenti 172
3. Teoria della stima
Introduzione 175
3.1 Stima puntuale 175
3.1.1 Proprietà degli stimatori 177
3.1.2 Sufficienza 178
3.1.3 Concentrazione e prossimità 178
3.1.4 Efficienza 179
3.1.5 Proprietà asintotiche 184
3.2 Metodi di stima puntuale 185
3.2.1 Minimizzazione dell’errore quadratico medio 186
3.2.2 Massima verosimiglianza 188
3.2.3 Proprietà degli stimatori di massima verosimiglianza 197
3.2.4 Altri metodi di stima 198
3.3 Stima statistica di intervallo (intervalli di confidenza) 200
3.3.1 Intervallo di confidenza per la media di una v.c. normale con varianza nota 203
3.3.2 Intervallo di confidenza per la media di una v.c. normale con var. incognita 204
3.3.3 Intervallo di confidenza per la var. di una v.c. normale con media incognita 206
3.3.4 Intervallo di confidenza per la media di una v.c. con distribuz. arbitraria 206
3.3.5 Intervalli simultanei di conf. per la media e la varianza di una v.c. normale 208
3.3.6 Intervallo di confidenza per la differenza tra medie e tra proporzioni 210
3.3.7 Intervallo di confidenza per la differenza tra medie per dati appaiati 212
3.3.8 Intervallo di confidenza per il rapporto tra varianze 213
3.4 Determinazione della numerosità campionaria 214
4. Teoria del test delle ipotesi
Introduzione 217
4.1 Verifica di ipotesi statistiche 217
4.1.1 Ipotesi semplici 221
4.1.2 Ipotesi composite 226
4.2 Test sulla media 227
4.2.1 p-value 234
4.2.2 Potenza del test 236
4.3 Test sulla varianza 246
4.4 Test sulla probabilità 249
4.5 Determinazione della dimensione campionaria 253
4.6 Confronto tra campioni 255
4.6.1 Confronto tra medie 256
4.6.2 Confronto tra proporzioni 262
4.6.3 Confronto tra varianze 265
4.6.4 Confronto per dati appaiati 268

B. Chiandotto Versione 2017
INFERENZA STATISTICA
Indice
iii
4.7 Determinazione della dimensione campionaria 271
5. Modello statistico lineare
Introduzione 275
5.1 Modello di regressione lineare semplice 277
5.1.1 Ipotesi di specificazione (caso A) 280
5.1.2 Stima dei minimi quadrati 281
5.1.3 Ipotesi di specificazione (caso B) 289
5.1.4 Stima di massima verosimiglianza 290
5.1.5 Stima di intervallo 291
5.1.6 Test delle ipotesi 295
5.1.7 Trasformazione di modelli non lineari 296
5.2 Coefficiente di correlazione lineare 296
5.3 Modello di regressione lineare multipla 300
5.3.1 Ipotesi di specificazione (caso A) 300
5.3.2 Stima dei minimi quadrati 301
5.3.3 Ipotesi di specificazione (caso B) 306
5.3.4 Stima di massima verosimiglianza 306
5.3.5 Stima di intervallo e test delle ipotesi 307
5.4 Modello di analisi della Varianza (ANOVA) 316
5.4.1 Analisi a un criterio di classificazione 317
5.4.2 Analisi a due criterio di classificazione 320
5.5 Analisi della Varianza e modello di regressione 326
5.6 Analisi della covarianza (ANCOVA) 330
6. Inferenza statistica bayesiana
Introduzione 333
6.1 Formula di Bayes 336
6.2 Distribuzioni a priori coniugate 342
6.3 Distribuzioni a priori non informative 355
6.4 Stima e teoria del test delle ipotesi in ottica bayesiana 359
6.5 Regressione bayesiana 365
6.5.1 Regressione bayesiana con distribuzioni a priori non infor. e coniugate 367
7. Teoria statistica delle decisioni
Introduzione 373
7.1 Teoria delle decisioni 373
7.2 Decisioni basate sulle sole informazioni a priori 377
7.2.1 Assiomi di comportamento razionale (Ia parte) 378
7.2.2 Assiomi di comportamento razionale (2a parte) 379
7.2.3 Assiomi di comportamento razionale (3a parte) 382
7.3 Decisioni in situazioni di estrema incertezza 384
7.4 Struttura del processo decisionale 387
7.5 Decisioni basate sulle sole informazioni campionarie 392
7.6 Decisioni basate su informazioni a priori e informazioni campionarie 399
7.7 Valore dell’informazione 408
7.8 Teoria causale delle decisioni 415
Riferimenti bibliografici 419


B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
1
PREMESSA
Introduzione
Nello studio dei fenomeni1 di qualunque natura essi siano (economici, aziendali, fisici,
biologici, ecc.) e qualunque sia la finalità (puramente conoscitiva o operativa) che
s’intende perseguire, sorge sovente la necessità di rappresentare le manifestazioni dei
fenomeni stessi attraverso tabelle e grafici per recepire più immediatamente particolari
caratteristiche del fenomeno oggetto di analisi; altre volte, può interessare cogliere nella
multiforme variabilità o mutabilità2 delle loro manifestazioni quello che in esse c'è di
tipico o di costante, o magari interessa fornire una qualche misura della diversità stessa
e/o di voler evidenziare in qualche modo l’eventuale relazione che lega fenomeni
diversi ma logicamente collegati; infine, si può avere interesse a rappresentare il
fenomeno o la relazione tra fenomeni mediante specifici modelli analitici che,
schematizzando e semplificando la realtà, ne rendono più facile la comprensione.
L’interesse può riguardare quindi:
a. l’esecuzione di rappresentazioni tabellari e grafiche che mettano in evidenza
certi aspetti generali del fenomeno o dei fenomeni oggetto di analisi
(rappresentazioni tabellari e grafiche);
b. il calcolo di indici che mettano in evidenza quello che c'è di tipico nelle
manifestazioni dei fenomeni (rappresentazioni sintetiche: valori medi);
c. il calcolo di indici che mettano in evidenza quello che c'è di mutabile e/o
variabile nelle manifestazioni di fenomeni (rappresentazioni sintetiche: indici
di variabilità e/o mutabilità);
d. la misura della relazione tra fenomeni mediante appropriati indici
(rappresentazioni sintetiche: indici di associazione);
e. l’introduzione di modelli che esprimano analiticamente l'insieme delle
manifestazioni del fenomeno e/o la relazione tra fenomeni (rappresentazioni
analitiche).
In seguito verranno distinti i modelli probabilistici dai modelli statistici. I modelli
probabilistici, quali rappresentazioni, nella generalità dei casi, approssimate della realtà,
1 In questa nota tutte le volte che si usa il termine fenomeno si fa riferimento al così detto fenomeno collettivo, cioè
ad un fenomeno la cui misura e conoscenza richiede l’osservazione di una pluralità di sue manifestazioni. 2 Si dice variabile il fenomeno collettivo le cui manifestazioni si diversificano per grandezze numeriche enumerabili o
misurabili (caratteri quantitativi), si dice mutabile il fenomeno collettivo le cui manifestazioni si diversificano per
attributi non numerici (caratteri qualitativi) che possiedono, o meno, un ordine naturale di successione (cfr.
Digressione sulle scale di misura in questo capitolo) . Come si avrà modo di chiarire nelle pagine seguenti, la natura,
quantitativa o qualitativa, delle modalità classificatorie condiziona interamente il processo di analisi statistica dei dati:
dalla fase della loro raccolta a quella dell’elaborazione finale.

B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
2
consentono una più immediata comprensione degli aspetti più rilevanti relativi ai
fenomeni di interesse. Per contro, i modelli statistici, oltre ad essere rappresentazioni
semplificata della realtà, facilitano anche la formulazione di previsioni e consentono la
ricerca di nessi causali fornendo informazioni utilizzabili a fini decisionali.
In particolare, se si è interessati alla conoscenza di un certo fenomeno (carattere) F si
possono rappresentare le sue possibili manifestazioni (modalità del carattere) come
punti di un insieme P (popolazione). Ovviamente non tutti i punti hanno lo stesso peso,
e cioè può accadere che una determinata manifestazione (specifica modalità del
carattere considerato) si realizzi più frequentemente di una seconda e questa con
maggiore frequenza di una terza e così via, in tal caso, a ciascun punto resta associato
un peso che, a seconda del contesto di riferimento, statistico o probabilistico, assume la
denominazione di frequenza relativa o di probabilità.
All'insieme P può essere associato un secondo insieme R che può essere chiamato
caratteristico, cioè l'insieme di tutti gli indici caratteristici di compattazione dei dati
che possono essere derivati applicando le funzioni (da intendersi in senso lato come
gruppo di operazioni logiche o algebriche di qualunque natura) 1 2, ,......, hg g g ,
all'insieme P in modo tale che ciascun elemento di R, che può essere definito l'insieme
delle rappresentazioni statistiche, consenta una più facile ed immediata comprensione
del fenomeno F.
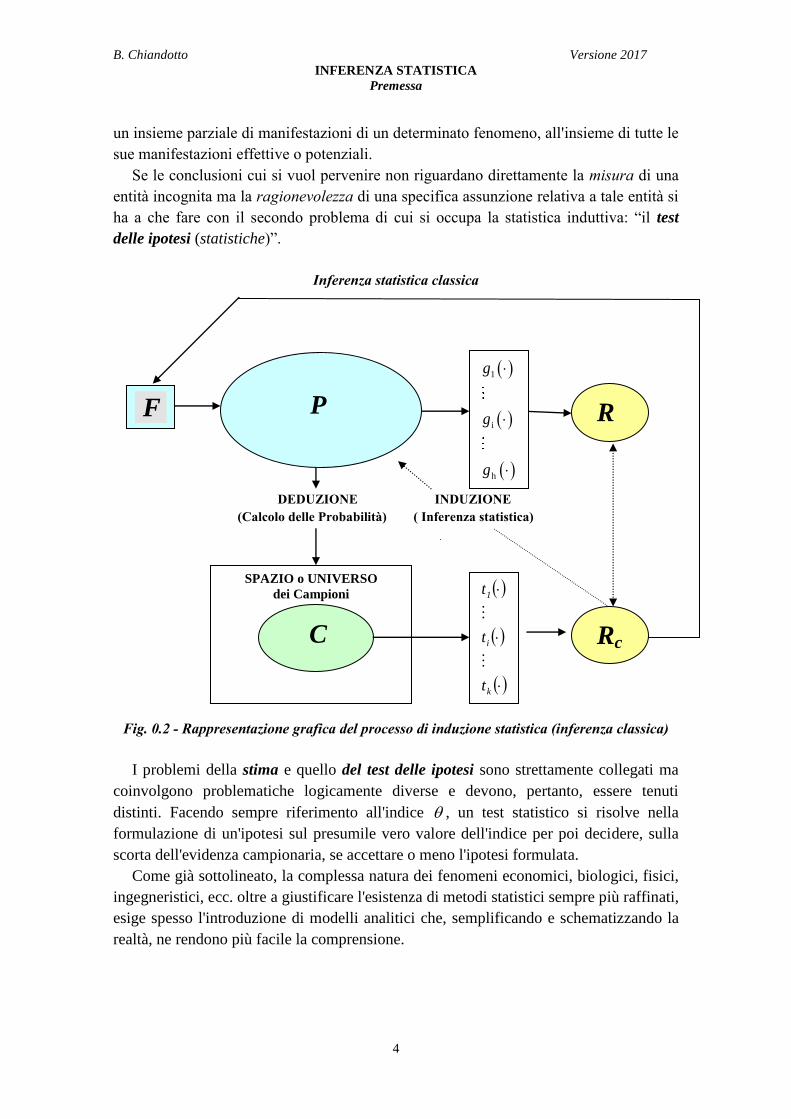
Quella riportata nella Fig.0.1 è una schematizzazione estremamente semplificata dei
problemi propri della cosiddetta statistica descrittiva cui si è riferito ai punti a., b., c., d.
ed e., elencati in precedenza. La figura rettangolare contiene la strumentazione (metodi
di compattazione) capace di trasformare i dati in informazioni.
Statistica descrittiva
Fig. 0.1 - Rappresentazione schematica della struttura logica del metodo statistico
F
P R
h
i
1
g
g
g

B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
3
0.1 - Inferenza statistica classica
Nelle argomentazioni svolte, si è implicitamente ipotizzato di avere a disposizione
tutte le manifestazioni del fenomeno o dei fenomeni oggetto di analisi, e di voler in
qualche modo, attraverso tabelle, grafici o calcolo di indici caratteristici, ecc.,
compattare i dati a disposizione, ovvero raccogliere molteplici aspetti in un solo
aspetto, individuare il costante nel variabile, accentuare quella particolarità del
fenomeno che più interessava oscurandone altre ecc.. Quella prospettata non è,
usualmente, la realtà in cui si opera: nella generalità dei casi si deve procedere
nell’analisi di un fenomeno, avendo a disposizione soltanto una parte delle
manifestazioni dello stesso. In altri termini si dispone di un sottoinsieme C (campione)
di manifestazioni del fenomeno F pur restando inalterato il problema di comprensione
del fenomeno stesso attraverso l'utilizzo di tabelle, grafici e appropriati indici di
compattazione.
Si supponga di essere interessati ad un particolare indice caratteristico che
sintetizza specifici aspetti del fenomeno di interesse e che questo possa essere
determinato applicando la funzione g a tutte le manifestazioni del fenomeno di
interesse, ma che sia impossibile effettuare una tale operazione potendo disporre
soltanto di un sottoinsieme di tali manifestazioni.
Il problema da risolvere è quello dell’individuazione di una funzione t , non
necessariamente uguale a g , che applicata ai dati campionari fornisca un punto ̂
che sia il più vicino possibile a (cfr. Fig. 0.2); interessano, cioè, indici che siano
rappresentativi non di particolari aspetti del fenomeno, così come risulta dall'insieme
parziale delle sue manifestazioni, ma come risulterebbe se si disponesse dell'insieme di
tutte le sue manifestazioni.
Con un linguaggio più tecnico si dice che ̂ deve essere una buona stima di ; in
realtà, come si avrà modo di chiarire successivamente, più che di buona stima si parlerà
di buon stimatore, poiché non è possibile misurare la “distanza” di una quantità nota ̂
ad una quantità incognita . Pertanto, è il procedimento che si segue per ottenere la
quantità ̂ che può essere “buono” o “cattivo”, e la “bontà” (proprietà augurabili)
dovrà valere qualunque sia il valore di , bontà che si misura attraverso l'analisi del
suo comportamento nell'insieme di tutti i possibili campioni estraibili dalla popolazione
(universo dei campioni).
La stima, è il primo dei due problemi che costituiscono l'oggetto di studio
dell’inferenza statistica. Un tale problema consiste, come già detto, nel cercare di
estendere le conclusioni relative alla misura di un certo indice caratteristico, derivanti da
B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
4
un insieme parziale di manifestazioni di un determinato fenomeno, all'insieme di tutte le
sue manifestazioni effettive o potenziali.
Se le conclusioni cui si vuol pervenire non riguardano direttamente la misura di una
entità incognita ma la ragionevolezza di una specifica assunzione relativa a tale entità si
ha a che fare con il secondo problema di cui si occupa la statistica induttiva: “il test
delle ipotesi (statistiche)”.
Inferenza statistica classica
DEDUZIONE INDUZIONE
(Calcolo delle Probabilità) ( Inferenza statistica)
Fig. 0.2 - Rappresentazione grafica del processo di induzione statistica (inferenza classica)
I problemi della stima e quello del test delle ipotesi sono strettamente collegati ma
coinvolgono problematiche logicamente diverse e devono, pertanto, essere tenuti
distinti. Facendo sempre riferimento all'indice , un test statistico si risolve nella
formulazione di un'ipotesi sul presumile vero valore dell'indice per poi decidere, sulla
scorta dell'evidenza campionaria, se accettare o meno l'ipotesi formulata.
Come già sottolineato, la complessa natura dei fenomeni economici, biologici, fisici,
ingegneristici, ecc. oltre a giustificare l'esistenza di metodi statistici sempre più raffinati,
esige spesso l'introduzione di modelli analitici che, semplificando e schematizzando la
realtà, ne rendono più facile la comprensione.
F
P
R
SPAZIO o UNIVERSO
dei Campioni
C
1
i
h
g
g
g
k
i
1
t
t
t
Rc

B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
5
Poiché una serie innumerevole di fenomeni nelle varie scienze è governata da leggi
aventi natura aleatoria, ne consegue immediatamente che i modelli probabilistici
risultano essere i più appropriati per descrivere le loro manifestazioni (cfr. Fig. 0.3).
Deduzione
(Probabilità)
Induzione
(Inferenza statistica)
Fig. 0.3 - Relazioni tra probabilità, statistica induttiva, evidenza empirica e modello.
Anche se fra i criteri logici od empirici che possono guidare nella individuazione del
modello rappresentativo più opportuno alcuni hanno validità generale, usualmente essi
sono strettamente connessi alla natura e al tipo del fenomeno che si intende analizzare.
Al riguardo si deve sottolineare che quando si procede all'introduzione di un modello
analitico per esprimere le manifestazioni di un fenomeno di interesse, non ha più senso
parlare di popolazione in quanto la popolazione è rappresentata dal modello stesso,
espressione del processo di generazione dei dati, e le manifestazioni del fenomeno o dei
fenomeni d’interesse osservate hanno, necessariamente, sempre natura di manifestazioni
campionarie essendo la popolazione rappresentata analiticamente attraverso il modello
stesso (superpopolazione)3.
La rappresentazione analitica dei fenomeni si risolve, nel caso in cui si considera, ad
esempio, un solo carattere quantitativo, nella introduzione di un simbolo X al quale è
associata una funzione di massa di probabilità, nel caso discreto, di densità di
probabilità, nel caso continuo, del tipo:
; f x per x S e Θ
dove: S rappresenta lo spazio campionario di definizione di x, cioè lo spazio (supporto)
di tutti i valori assumibili dall'entità variabile x ; il parametro o i parametri
3 Questa affermazione vale, ovviamente, anche quando s’introducono modelli analitici per rappresentare le relazioni
(associazione) tra caratteri.
UNIVERSO
DEI
CAMPIONI
SITUAZIONE
REALE
EVIDENZA
EMPIRICA
(CAMPIONE)
MODELLO

B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
6
caratteristici del modello; Θ 4 lo spazio parametrico, cioè lo spazio di tutti i valori
assumibili dal parametro/i, usualmente incognito/i, . Come si avrà modo di verificare
successivamente, tra gli indici caratteristici (misure di compattazione delle
manifestazioni dei fenomeni di interesse) ed i parametri caratteristici, esiste una stretta
relazione analitica.
Quando si ritiene opportuna l'introduzione di un modello analitico per rappresentare
le manifestazioni di un fenomeno di interesse, si possono distinguere almeno due
situazioni di mancanza di conoscenza: la prima situazione è quella caratterizzata da una
conoscenza parziale della funzione 1 2 ; , ,...., ; kf x f x nel senso che si
conosce la forma analitica della funzione ma non si conosce il valore di tutti o di alcuni
dei parametri che caratterizzano la funzione stessa, in questa circostanza si parla di
inferenza statistica parametrica. La seconda situazione è quella di mancata conoscenza
della forma analitica del modello, in questa circostanza si parla di inferenza statistica
non parametrica. Una terza situazione, intermedia rispetto alle due precedenti, è quella
in cui si specificano certe componenti del modello (ad esempio si suppone che la v.c.
appartenga alla famiglia esponenziale ma non si specifica la sottofamiglia: forma
funzionale della funzione di massa o di densità). Se si opera in tale contesto si parla di
inferenza statistica semi-parametrica, nel senso che la forma analitica del modello è
specificata solo parzialmente.
La dizione inferenza statistica non parametrica non è certamente la più appropriata in
quanto interpretabile come se, in questo ambito, le procedure di statistica induttiva non
riguardassero i parametri. Ovviamente, questa interpretazione è fuorviante, infatti, con
la dizione “non parametrica” si vuole, molto semplicemente, caratterizzare le situazioni
inferenziali nelle quali non si conosce la forma analitica e, ovviamente, il valore dei
parametri caratteristici, elementi questi entrambi coinvolti nelle procedure inferenziali.
La dizione corretta per caratterizzare tali situazioni è quella di inferenza statistica libera
da distribuzione (distribution free).
Ai problemi di stima e di test delle ipotesi, che in questo contesto possono riguardare
i soli parametri caratteristici od anche la forma analitica del modello cui si ritiene
opportuno fare ricorso, si aggiunge la necessità di procedere ad una misura e verifica
della capacità (bontà) rappresentativa (adattamento) del modello stesso.
La stima e il test delle ipotesi sono, in un contesto lievemente differente, gli stessi
due problemi di stima e di verifica delle ipotesi sopra considerati.
Uno degli aspetti più importanti di cui la statistica si occupa, è dunque quello
dell'estensione di conclusioni da un campione di osservazioni alla popolazione o
superpopolazione, nel caso in cui si procede all’impiego di modelli, dal quale il
campione è stato estratto. Se si fa riferimento ai modelli, tale problema si risolverà
nell'utilizzo dei dati campionari per la scelta, la modifica e la misura del grado di
4 In queste note il carattere in grassetto sta ad indicare che il simbolo utilizzato fa riferimento ad un vettore e/o ad una
matrice e non a uno scalare; nel caso specifico i simboli e Θ stanno ad indicare che si sta trattando di uno o più
parametri.
B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
7
rappresentatività dei modelli, od anche, nella verifica di ipotesi statistiche sulla forma
e/o sul valore dei parametri che caratterizzano i modelli stessi.
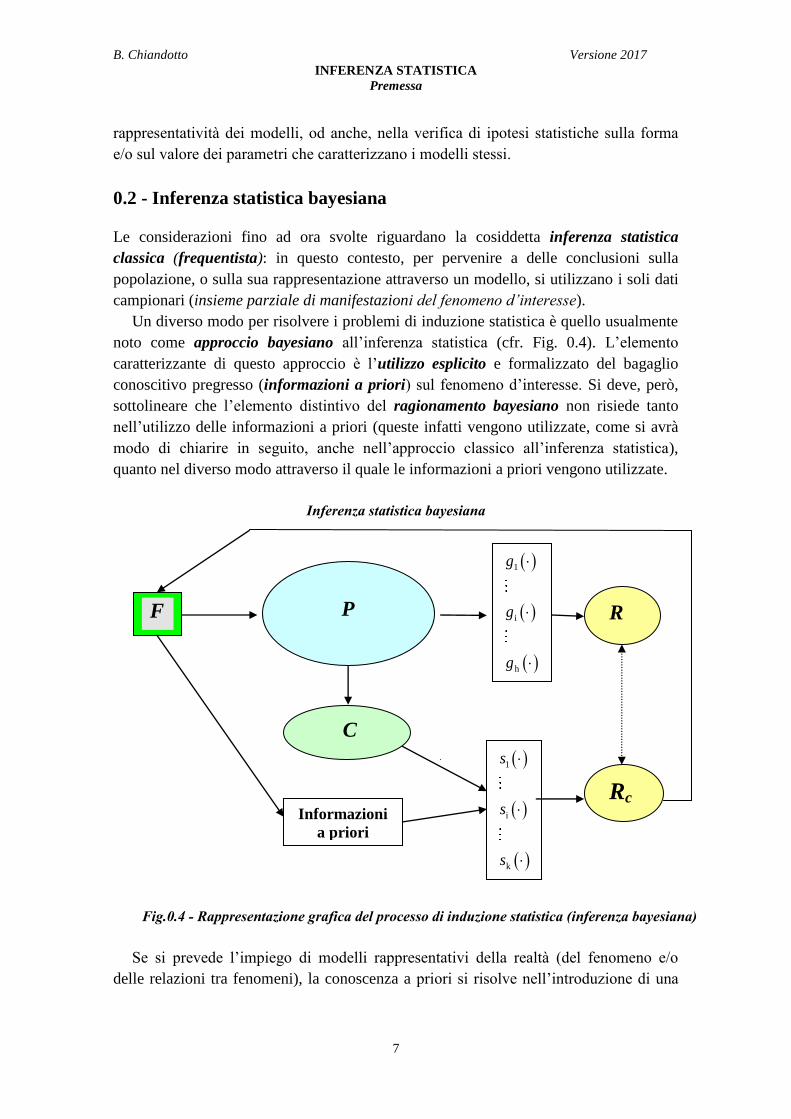
0.2 - Inferenza statistica bayesiana
Le considerazioni fino ad ora svolte riguardano la cosiddetta inferenza statistica
classica (frequentista): in questo contesto, per pervenire a delle conclusioni sulla
popolazione, o sulla sua rappresentazione attraverso un modello, si utilizzano i soli dati
campionari (insieme parziale di manifestazioni del fenomeno d’interesse).
Un diverso modo per risolvere i problemi di induzione statistica è quello usualmente
noto come approccio bayesiano all’inferenza statistica (cfr. Fig. 0.4). L’elemento
caratterizzante di questo approccio è l’utilizzo esplicito e formalizzato del bagaglio
conoscitivo pregresso (informazioni a priori) sul fenomeno d’interesse. Si deve, però,
sottolineare che l’elemento distintivo del ragionamento bayesiano non risiede tanto
nell’utilizzo delle informazioni a priori (queste infatti vengono utilizzate, come si avrà
modo di chiarire in seguito, anche nell’approccio classico all’inferenza statistica),
quanto nel diverso modo attraverso il quale le informazioni a priori vengono utilizzate.
Inferenza statistica bayesiana
Fig.0.4 - Rappresentazione grafica del processo di induzione statistica (inferenza bayesiana)
Se si prevede l’impiego di modelli rappresentativi della realtà (del fenomeno e/o
delle relazioni tra fenomeni), la conoscenza a priori si risolve nell’introduzione di una
F
P
R
Rc
C
1
i
h
g
g
g
1
i
k
s
s
s
Informazioni
a priori

B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
8
distribuzione di probabilità sul parametro o sui parametri caratteristici del modello che
assumono, in tale ottica, la natura di variabili casuali e non più, come accade nell’ottica
classica, quella di costanti incognite.
In precedenza, trattando dei modelli rappresentativi dei fenomeni, in funzione del
patrimonio conoscitivo disponibile si è operata la distinzione inferenza statistica
classica parametrica, non parametrica e semiparametrica; analogamente, in funzione
del patrimonio conoscitivo disponibile, si parlerà di inferenza statistica bayesiana
parametrica, inferenza statistica bayesiana non parametrica e inferenza statistica
bayesiana semiparametrica.
In altri termini, nel contesto classico, dato il modello
; f x per x S e Θ
nel caso parametrico l’unica incognita è rappresentata dal parametro (o
parametri) che lo caratterizzano e i dati campionari verranno utilizzati per
trarre conclusioni su tale entità;
nel caso non parametrico sono incognite sia il parametro (o parametri) che lo
caratterizzano, sia la forma analitica , f del modello e i dati campionari
verranno utilizzati per trarre conclusioni sia sulla forma analitiche sui parametri.
Nel contesto bayesiano, dati i modelli5
, f x per x S e Θ
per e Θ
dove , rappresenta la distribuzione a priori del parametro (o parametri) ,
i parametri (detti iperparametri) che caratterizzano la distribuzione a priori. la
dizione di inferenza bayesiana parametrica, non parametrica e semiparametrica,
dipenderà dallo stato di conoscenza sulla forma analitica delle funzioni , f x e
; .
0.3 - Teoria statistica delle decisioni
Per comprendere i fenomeni occorre procedere all’analisi delle loro manifestazioni, se
ci si domanda poi per quale ragione si è interessati ad una tale comprensione, la risposta
è che si può voler soddisfare una mera esigenza conoscitiva fine a se stessa, o che la
conoscenza è finalizzata alla risoluzione di uno specifico problema decisionale.
In un contesto decisionale, la scelta può riguardare gli aspetti più diversificati che
vanno da quelli quotidiani più banali (dovendo raggiungere un luogo di lavoro o di
studio distante dalla propria abitazione ci si può servire di un mezzo pubblico di
5 Si richiama l’attenzione sulla simbologia utilizzata: l’espressione con il punto e virgola come elemento separatore
delle due entità dell’argomento ; f x indica che la prima entità è una variabile mentre la seconda è una
costante, per contro quando l’elemento separatore è una virgola , f x entrambe le entità sono delle variabili.

B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
9
trasporto o utilizzare l’automobile personale o chiamare un taxi; dovendo uscire di casa
con tempo incerto si deve decidere se prendere o meno l’ombrello, ecc.), a quelli
relativamente più complessi riguardanti, ad esempio, il gestore di una piccola attività
commerciale (procedere o meno alla ristrutturazione, e in che modo, dei locali in cui si
svolge l’attività commerciale, effettuare, e in che forma e tramite quale veicolo, o meno
attività promozionali, e fino a che punto, e in che modo, ampliare la gamma di prodotti
offerti, ecc.) fino a quelli più complessi ed articolati quali, ad esempio quelli propri
delle imprese di medie e grandi dimensioni (procedere alla produzione di un nuovo
modello, e quale, di automobile, procedere - come, dove e con quali dimensioni - o
meno all’impianto di un nuovo stabilimento, ecc.).
Qualunque problema decisionale da risolvere, dal più banale al più complesso,
richiede la chiara definizione del problema stesso e l’individuazione delle possibili
relazioni che connettono i vari elementi o aspetti che lo caratterizzano.
Il quadro logico di riferimento e le informazioni sono gli ingredienti basilari di ogni
processo decisionale, la teoria delle decisioni, la teoria statistica ed i metodi e i modelli
sviluppati in questi ambiti disciplinari sono gli strumenti essenziali (e necessari) per lo
svolgimento ottimale di ogni processo decisionale, decisioni che, come già sottolineato
e come si avrà modo di verificare successivamente, devono essere nella generalità dei
casi prese in situazioni di conoscenza parziale della realtà in cui si opera6.
Si è già detto che la disciplina che si occupa della raccolta e del trattamento
scientifico dei dati statistici (manifestazioni dei fenomeni collettivi di interesse) è la
Statistica, se poi le informazioni stesse devono essere utilizzate per risolvere uno
specifico problema decisionale, cioè un problema che si risolve nella scelta ottimale di
una tra diverse alternative a disposizione, allora il contesto di riferimento è la Teoria
delle decisioni. Nella fusione delle due discipline si sostanzia un’altra disciplina
scientifica: “La Teoria statistica delle decisioni” o “Teoria delle decisioni statistiche”
che per certi versi può essere intesa come generalizzazione ed estensione della Statistica
che in questo modo risulta anche meglio caratterizzata nelle sue diverse connotazioni e
meglio precisata nei contenuti. In altri termini si può anche definire la statistica come il
fondamento logico e metodologico per la risoluzione dei problemi decisionali.
La teoria delle decisioni fissa principi razionali di comportamento che consentono la
derivazione di regole di scelta ottimale. Gli sviluppi più recenti di tale teoria consentono
anche di valutare e correggere eventuali incoerenze e contraddizioni nel comportamento
dei decisori.
E’ già stato sottolineato che nel contesto empirico l’elemento fondamentale di
riferimento sono i dati statistici (disponibili e/o acquisibili) e che la statistica può essere
identificata come la disciplina che tratta di metodi attraverso i quali i dati statistici, cioè
6 Come già sottolineato, due sono i motivi principali che determinano una conoscenza parziale della realtà:
l’impossibilità o la non convenienza di acquisire tutte le informazioni relative agli aspetti che interessano pur
essendo, almeno teoricamente, possibile una tale acquisizione, o la non disponibilità, neppure potenziale, delle
informazioni, ed è questo il caso in cui le manifestazioni del fenomeno di interesse riguardano eventi futuri o sono
rappresentate attraverso un modello analitico.

B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
10
le manifestazioni dei fenomeni di interesse, dovrebbero o potrebbero essere impiegati
per ottenere, in funzione delle specificità del problema analizzato, una rappresentazione
semplificata della realtà (i dati vengono trasformati in informazione) facendo emergere
le caratteristiche che interessano in dipendenza degli obiettivi che s’intendono
perseguire (l’informazione diventa conoscenza utilizzabile a fini decisionali).
In tale ottica, assumono rilevanza ulteriori elementi quali l’esatta definizione della
qualità e quantità d’informazione che s’intende acquisire, la decisione sui tempi e sui
modi di acquisizione e la valutazione dei costi connessi.
La statistica, che si occupa della raccolta e del trattamento finalizzato dei dati, entra,
a pieno titolo, in ogni processo decisionale, finalizzato al conseguimento di uno
specifico obiettivo, che prevede l’utilizzo di informazioni. Un processo nel quale:
l’input (materia prima) è costituito da dati statistici riferiti ad una specifica
realtà, della quale rappresentano qualitativamente e/o quantitativamente uno o
più aspetti;
la trasformazione avviene attraverso l’impiego di procedure e metodi analitici;
l’output (prodotto) è la conoscenza del fenomeno indagato la cui natura e
interpretazione dipende dagli input utilizzati e dal meccanismo logico e
metodologico di elaborazione e dalle finalità che s’intendono perseguire.
Da quanto sopra detto, emergono almeno tre insiemi di elementi caratteristici:
un insieme di elementi che vengono introdotti quali input nel processo di
trasformazione;
un insieme di procedure di elaborazione;
un insieme di prodotti costituito da tutte le modalità assumibili dai risultati
conseguenti l’applicazione delle procedure.
Si supponga ora che sia sempre possibile associare ad ogni prodotto la descrizione
delle conseguenze che scaturiscono dalla scelta, le quali assumeranno una fisionomia
particolare a seconda dell’oggetto del problema: se si tratta di operare una
compattazione di dati osservati con l’obiettivo di mettere in risalto una caratteristica
specifica del fenomeno, le conseguenze potranno essere descritte dalla perdita (di
informazione) determinata dal processo, oppure, se il problema è finalizzato alla scelta
di una modalità operativa, le conseguenze potranno essere identificate in perdite
monetarie o di altra natura ed essere, eventualmente, collegate ad errori commessi nel
processo di trasformazione.
Risulta, pertanto, definito un quarto insieme di elementi:
l’insieme delle conseguenze.
Il criterio guida nell’operare la trasformazione dei dati consiste, per quanto possibile,
nell’evitare conseguenze negative. Ne deriva che l’informazione circa le conseguenze
assume una rilevanza esclusiva ed un ruolo condizionante rispetto ad ogni altra tipologia
(disponibile) per la quale si renderà, appunto, necessario un confronto o, meglio,
un’integrazione con i dati di perdita già definiti.

B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
11
La traccia originale viene, quindi, specificata e organizzata secondo lo schema
seguente: avendo definito l’insieme dei risultati possibili (le informazioni finali) e
avendo individuato le perdite corrispondenti, l’elaborazione deve essere effettuata
avendo come obiettivo la minimizzazione della perdita.
Considerando che, con l’impostazione sopra delineata, sulla base di una funzione di
perdita viene selezionato l’elemento ottimo (quello cioè cui corrisponde la perdita
minima), risulta naturale attribuire agli specifici elementi che costituiscono l’insieme
dei prodotti l’identità di decisioni, nel senso che essi rappresentano le alternative
possibili del risultato di un problema del quale è stato specificato l’obiettivo. Si può,
pertanto, accantonare l’espressione processo di trasformazione (compattazione) dei
dati e fare riferimento al problema decisionale quale schematizzazione che prevede la
lista di tutti gli esiti possibili e la scelta di quello ottimo secondo il criterio di
minimizzazione della perdita.
Assumendo come struttura di riferimento quella sopra introdotta è possibile
formulare, senza perdere in generalità e senza condizionamenti, ogni problema statistico
in termini decisionali.
A proposito dell’ultima affermazione fatta, sorge una problematica di estrema
rilevanza riguardo ai vantaggi e alle difficoltà, se non addirittura alla ragionevolezza,
propria di una impostazione quale è quella decisionale. Alcuni autori ritengono
l’impostazione decisionale applicabile ai soli problemi con finalità operative, altri
considerano (come l’autore di queste note) la logica decisionale applicabile, secondo
modalità particolari, a tutte le problematiche descrittive e/o inferenziali anche quando
queste sono caratterizzate da finalità esclusivamente conoscitive, altri ancora ritengono
la logica decisionale semplicistica ed oltremodo riduttiva.
Gli elementi a sostegno dell’impostazione decisionale sono innumerevoli e di varia
natura. Si può, innanzi tutto, osservare che la duplice finalità, conoscitiva ed operativa,
assegnata alla statistica quale disciplina scientifica, con conseguente attribuzione dei
problemi decisionali alla seconda finalità, si risolve, semplicemente, nella
specificazione della duplice tipologia di prodotti che vanno a costituire l’insieme delle
decisioni espresse come:
azioni da intraprendere e da realizzare concretamente;
affermazioni da formulare le quali, a loro volta, possono configurarsi come
asserzioni che specificano la conformità dell’evidenza osservata nei
confronti di una o più ipotesi assunte a priori;
asserzioni che specificano la stima di una quantità incognita e/o
l’adattamento di un modello teorico ad una specifica realtà di interesse,
ecc..
Il problema si risolve sempre in una decisione, che poi questa sia orientata al cosa
dire o al cosa fare è solo una questione di specificità della situazione in cui lo statistico
opera. Se si parla poi di atti o decisioni in termini più generali, nel senso di scelte, la
suddivisione diventa addirittura artificiosa se si pensa che ogni azione può essere

B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
12
considerata come l’effetto dell’affermazione: “ la decisione d ” è la migliore possibile.
Ne scaturisce, allora, una differenza solo verbale, terminologica e, quindi, non
sostenibile dal punto di vista concettuale.
Un altro rilevante aspetto che può consigliare la scelta decisionale, risiede nella
logica interna propria della teoria statistica delle decisioni che induce a formulare ed
interpretare correttamente un problema statistico. Si tratta di una correttezza che può
essere ricondotta a due fatti essenziali: gli obiettivi che s’intendono perseguire e i dati
utilizzabili. L’obiettivo della minimizzazione della perdita evidenzia, infatti, la
parzialità e la particolarità del risultato che scaturisce dall’elaborazione: problemi
analoghi affrontati con specificazioni diverse della funzione di perdita possono
condurre, anzi generalmente conducono, a conclusioni diverse in quanto collegate ad
elementi diversi dell’insieme delle decisioni possibili.
Quale soluzione è quella giusta è quale è quella sbagliata? Nessuna delle due, oppure
entrambe se viste in ottiche diverse; il giudizio non deve essere formulato in termini di
correttezza o errore, si può solo dire che, ritenendo valida (accettabile, verosimile) una
struttura di perdita così come è rappresentata dalla funzione prescelta, la decisione
migliore è quella che risulta dall’imposizione della condizione di perdita minima.
L’ultima riflessione si ricollega alla necessità di attribuire ai dati una specifica forma
per poter ottenere una rappresentazione (compattazione) degli stessi significativa. La
realtà non è né descrivibile né rappresentabile senza ricorrere a schemi concettuali di
riferimento e in corrispondenza di ognuno di essi si ottiene un risultato, evidentemente
parziale e condizionato allo schema specificato. La logica decisionale, i cui risultati
sono condizionati alla particolare funzione di perdita specificata, fa emergere in modo
inequivocabile tale consapevolezza.
Non è infrequente imbattersi in situazioni operative nelle quali la decisione si riflette
sulla situazione reale determinandone in qualche modo i mutamenti, diventa allora
indispensabile procedere ad una ulteriore approfondimento dell’analisi avendo come
obiettivo l’individuazione dei nessi causali presenti nel contesto di interesse. Nessi
causali che, una volta definiti nelle loro specificità, devono essere inseriti nella
procedura di analisi valutandone l’impatto sulle conseguenze relative alle singole
azioni.
A conclusione di questa introduzione si sottolinea che, sempre in funzione del
contesto in cui si opera, si distinguerà la teoria statistica delle decisioni in classica e
bayesiana che potrà essere ulteriormente distinta in causale o non causale7.
0.4 - Digressione: scale di misura
Come sottolineato più volte, uno dei compiti principali della statistica è quello di
descrivere i fenomeni collettivi come primo passo verso la loro spiegazione, cui si può
pervenire anche applicando i metodi induttivi della statistica attraverso la verifica
7 Il lettore interessato ad un approfondimento dell’argomento può utilmente consultare , tra gli altri, Chiandotto
(2012 e 2013). I due contributi sono riportati nella stessa pagina web di queste note.

B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
13
empirica di ipotesi sviluppate sul piano teorico. Ma il passaggio dal piano teorico a
quello empirico non è per niente immediato; per poter connettere i concetti, sviluppati
nel contesto teorico ed in quello empirico, risulta indispensabile operare delle scelte
preliminari. Una di queste ha carattere fondamentale e riguarda il tipo di misura che si
intende adottare come espressione delle manifestazioni dei fenomeni oggetto di
indagine. La scala di misura non può che avere carattere convenzionale, e sarà tanto più
efficace quanto più riesce a facilitare la spiegazione dei fenomeni.
La classificazione secondo una scala di misura convenzionalmente scelta è
l'operazione che accompagna il processo di osservazione ogni qual volta quest'ultimo si
trasforma da occasionale in volontario e finalistico (osservazione scientifica). La
classificazione pertanto rappresenta il primo stadio di ogni ricerca e consiste nel
raggruppare le manifestazioni dei fenomeni secondo una o più caratteristiche di
interesse, decidendo quali manifestazioni devono considerarsi uguali e quali diverse.
Per ciò che concerne l'operazione di classificazione secondo una scala di misura si
distinguono, generalmente, quattro diversi livelli di misurazione; in questo contesto si
parla di scale nominali, scale ordinali, scale di intervallo e scale razionali o di rapporto.
La scala nominale costituisce il più semplice livello di misurazione. Sotto il profilo
formale le scale nominali possiedono unicamente le proprietà di simmetria e di
transitività; da ciò deriva che relativamente alle manifestazioni di fenomeni classificate
secondo una scala nominale si potrà semplicemente affermare se sono uguali o diverse.
Esempi di caratteri in scala nominale sono: il sesso, il tipo di diploma di scuola media
superiore, il settore merceologico, ecc.
La scala ordinale consente un ordinamento delle manifestazioni dei fenomeni in
funzione dell'entità posseduta di un certo carattere senza che sia possibile, peraltro,
stabilire l'ammontare (intensità) del carattere posseduto; tale fatto pone le scale ordinali
ad un livello inferiore rispetto alle scale di intervallo nelle quali è invece possibile
misurare tale entità. Esempi di caratteri espressi in scala ordinale sono: il titolo di
studio, il grado militare, la qualifica del personale, ecc.
La scala di rapporto rappresenta il più alto livello di misurazione, ha uno zero
assoluto (non arbitrario) e possiede una unità di misura di tipo fisico scelta come
elemento comune di riferimento.
La scala di intervallo, che possiede tutte le proprietà delle scale nominali ed ordinali,
si differenzia dalla scala di rapporto in quanto, pur possedendo una unità di misura di
tipo fisico, lo zero in essa contenuto ha natura arbitraria.
Sia le scale di rapporto che le scale di intervallo sono dunque espresse con una unità
di misura fisica scelta come elemento di riferimento e in questo caso si parla di
fenomeni misurabili, la diversità tra le due scale risiede nello zero scelto, che è assoluto
nelle scale di rapporto (il numero di componenti di un nucleo familiare, l’utile
conseguito da una azienda in un anno, ecc.), relativo nelle scale di intervallo (l’intensità
dei terremoti espressa in scala Mercalli o Richter, la temperatura di un corpo espressa in
gradi Celsius o Fahrenheit, ecc.). Sulle due scale è quindi possibile applicare le usuali

B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
14
operazioni aritmetiche di addizione, sottrazione, moltiplicazione e divisione, ma solo
per i fenomeni le cui manifestazioni sono espresse con una scala di rapporto ha senso
istituire, appunto, un rapporto tra diverse intensità di manifestazione; ad esempio, ha
senso concludere che il salario del dipendente A, che percepisce 3.000 € al mese, è il
doppio di quello del dipendente B, che ne percepisce 1.500, mentre non ha senso
affermare che la temperatura del corpo A è il doppio di quella del corpo B se le due
temperature sono, rispettivamente, pari a 10° e 5° gradi Celsius, mentre è del tutto
sensato dire che la differenza di temperatura tra i due corpi è di 5° gradi Celsius.
L'aver distinto i procedimenti di classificazione secondo una scala di misura è
operazione tutt’altro che oziosa; infatti, è proprio la scala di misura adottata a
condizionare la scelta dei metodi statistici (descrittivi, induttivi o decisionali) d'analisi
più appropriati.
Con riferimento ai problemi di classificazione secondo la scala di misura adottata, va
detto che gli statistici tendono usualmente ad operare una classificazione dicotoma dei
fenomeni a seconda che le loro manifestazioni abbiano natura qualitativa (scale
nominali ed ordinali) o quantitativa (scale di intervallo o di rapporto). Un tale fatto porta
a distinguere, come già evidenziato nelle pagine precedenti, i fenomeni in mutabili8 e
variabili a seconda che essi assumano, nelle loro manifestazioni, modalità qualitative o
modalità quantitative.
Un fenomeno variabile, e cioè un fenomeno classificato secondo le modalità
quantitative di un suo carattere, può avere natura discreta o continua. Essendo il numero
associato a ciascuna modalità misurabile di un certo carattere usualmente detto
variabile, in seguito si parlerà semplicemente di variabili (discrete o continue) senza
stare a specificare ogni volta che si sta trattando di un fenomeno classificato secondo le
modalità quantitative di un suo carattere (discreto o continuo).
Una variabile discreta può assumere soltanto un insieme finito o un’infinità
numerabile di valori, mentre una variabile continua potrà assumere tutti i valori
all'interno di un certo intervallo dell’asse reale. Sono variabili discrete il numero dei
soggetti affetti da cancro polmonare, il numero degli abitanti di una certa regione, ecc.;
sono variabili continue la temperatura di un corpo, l'età di un individuo, la velocità di
un'automobile, ecc. In linea generale tutte le grandezze relative allo spazio (lunghezza,
superficie, ecc.), al tempo (età, durata in vita, ecc.) e alla massa (peso, pressione
arteriosa, ecc.), sono delle variabili continue9.
Si parla di mutabili o variabili semplici, quando un fenomeno risulta classificato
secondo le modalità (qualitative o quantitative) di un solo carattere, si parla invece di
mutabili/variabili multiple o multivariate o multidimensionali (vettori casuali),
8 Si segnala in proposito che la dizione mutabile statistica è poco utilizzata. Quando il carattere di interesse ha natura
qualitativa usualmente si parla di variabili qualitative od anche di dati categorici, espressi con scala nominale o
ordinale. 9 Nel trattare le variabili casuali, cioè entità variabili che possono assumere un’infinità non numerabile di valori
dell’asse reale si farà riferimento ai loro intervalli di definizione (supporto) utilizzando la seguente notazione:
B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
15
quando un fenomeno viene classificato secondo le modalità (qualitative o quantitative)
di più caratteri; nel caso in cui si considerino, relativamente ad un certo fenomeno,
caratteri aventi natura qualitativa e caratteri aventi natura quantitativa, si parla di
variabili miste.
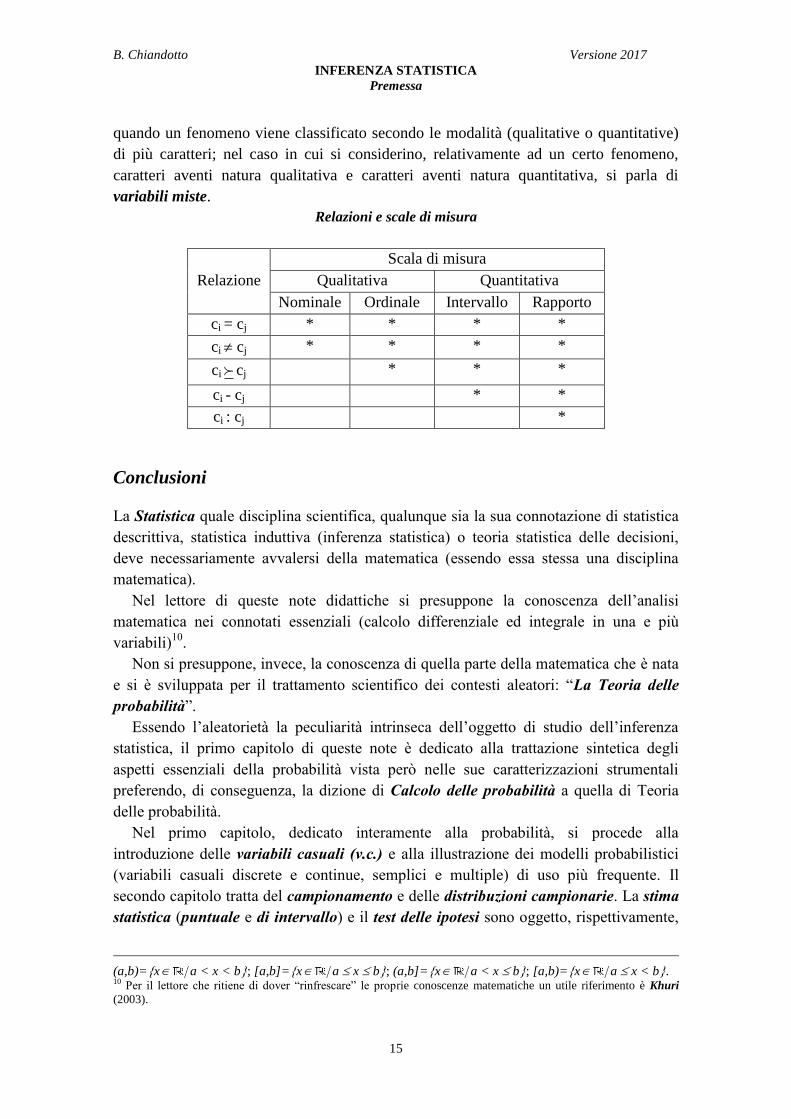
Relazioni e scale di misura
Scala di misura
Relazione Qualitativa Quantitativa
Nominale Ordinale Intervallo Rapporto
ci = cj * * * *
ci cj * * * *
ci cj * * *
ci - cj * *
ci : cj *
Conclusioni
La Statistica quale disciplina scientifica, qualunque sia la sua connotazione di statistica
descrittiva, statistica induttiva (inferenza statistica) o teoria statistica delle decisioni,
deve necessariamente avvalersi della matematica (essendo essa stessa una disciplina
matematica).
Nel lettore di queste note didattiche si presuppone la conoscenza dell’analisi
matematica nei connotati essenziali (calcolo differenziale ed integrale in una e più
variabili)10
.
Non si presuppone, invece, la conoscenza di quella parte della matematica che è nata
e si è sviluppata per il trattamento scientifico dei contesti aleatori: “La Teoria delle
probabilità”.
Essendo l’aleatorietà la peculiarità intrinseca dell’oggetto di studio dell’inferenza
statistica, il primo capitolo di queste note è dedicato alla trattazione sintetica degli
aspetti essenziali della probabilità vista però nelle sue caratterizzazioni strumentali
preferendo, di conseguenza, la dizione di Calcolo delle probabilità a quella di Teoria
delle probabilità.
Nel primo capitolo, dedicato interamente alla probabilità, si procede alla
introduzione delle variabili casuali (v.c.) e alla illustrazione dei modelli probabilistici
(variabili casuali discrete e continue, semplici e multiple) di uso più frequente. Il
secondo capitolo tratta del campionamento e delle distribuzioni campionarie. La stima
statistica (puntuale e di intervallo) e il test delle ipotesi sono oggetto, rispettivamente,
(a,b)=x a < x < b; [a,b]=x a x b; (a,b]=x a < x b; [a,b)=x a x < b. 10 Per il lettore che ritiene di dover “rinfrescare” le proprie conoscenze matematiche un utile riferimento è Khuri
(2003).

B. Chiandotto Versione 2017
INFERENZA STATISTICA
Premessa
16
del terzo e del quarto capitolo. La trattazione rientra nell’ambito della cosidetta
Inferenza statistica classica parametrica mentre l’Inferenza statistica bayesiana
parametrica viene trattata molto sommariamente nel sesto capitolo. Il quinto capitolo è
dedicato alla trattazione di uno dei temi classici e più rilevanti dell’inferenza statistica:
il modello statistico lineare (rappresentazione analitica delle relazioni tra caratteri). La
rappresentazione analitica implica l’introduzione di modelli matematici che sono
logicamente giustificati soltanto se si ritiene che la realtà d’interesse sia rappresentabile
attraverso il modello stesso; se si ritiene, cioè, che il fenomeno o i fenomeni di
riferimento siano governati da leggi esprimibili analiticamente ricordando che:
All models are wrong but some are useful (George E.P. Box, 1979)11
.
Il settimo e conclusivo capitolo è dedicato ad una sommaria esposizione della Teoria
statistica delle decisioni12
.
11
Molti anni prima di Box, Pompilj (1951) in un contributo sulla Logica della conformità, scrive: ”…..
Voglio invece osservare che non solo la conformità è concettualmente diversa dalla plausibilità, ma che
addirittura nel nostro ordine di idee, un problema della plausibilità o significatività non ha senso, perché
non è lecito domandarsi se un modello è vero o falso quando si può sempre rispondere che, a stretto
rigore, ogni modello è falso, in quanto non coincide con la realtà.
Questo, naturalmente, non vuol dire che una teoria della significatività non abbia senso, ma solo che essa
non può servire per discutere se il modello è vero,….”. ….. mentre invece il suo uso, correttamente fatto
nell'ambito del modello, può diventare utilissimo, purché lo schema teorico di per se stesso già affermi
che possono agire più cause e per di più fornisca tutti i dati necessari per una corretta applicazione di
tali teorie, di modo che di volta in volta, e sempre relativamente al modello che sta alla base delle nostre
indagini, si possa inferire, dall'esame dei risultati sperimentali, sulle cause che hanno agito. Ma fuori di
questo modello, che deve essere considerato preesistente e indiscutibile, ogni indagine in tal senso risulta
necessariamente vana!”
Riguardo alle affermazioni di Box e Pompilj, occorre precisare che si tratta di riferimenti ad una
particolare interpretazione del termine modello; in realtà, come si avrà modo di chiarire successivamente,
alcuni modelli (probabilistici) non costituiscono una rappresentazione semplificata della realtà ma
derivano dalla traduzione in termini analitici del processo generatore dei dati. 12
Gli argomenti illustrati in queste note sono trattati in forma più estesa, tra gli altri, in Mood, Graybill,
Boes (1988); Piccolo (1998); Barnett (1999); Robert (2001); Rohatgi e Salek (2001); Gelman e al
(1995); Casella, Berger (2002), Keener (2010) e Olive (2014).
Recommended

















![05 distribuzioni di probabilit [1]](https://img.dokumen.tips/doc/110x75/5875cf8b1a28ab8f438b4fd3/05-distribuzioni-di-probabilit-1.jpg)