
Dept. for Speech, Music and Hearing
Quarterly Progress andStatus Report
Grapheme-to-phoneme rules:A reviewHunnicutt, S.
journal: STL-QPSRvolume: 21number: 2-3year: 1980pages: 038-060
http://www.speech.kth.se/qpsr


111. SPEECH SYNTHESIS
A . GRAPHEME-TO-PHONEME RULES: A REVIEW
S. Hunnicut'k*
Abstract
A set of mgl ish rules has been written for the speech synthesis sys- tem developed a t the Royal Ins t i tu te of Technology (KTH) i n Stockholm. The rules were written in the formalism provided by this system, an important feature of which is a higher-level progranming language which greatly f ac i l i t a t e s the extension of the system t o other lan- guages. A categorization of grapheme-to-phoneme rules i n terms of special contexts is presented here, and som3 aspects of the u t i l i t y of the formalism are discussed. The resul t s of a preliminary evalua- t ion of the grapheme-to-phoneme and lexical stress rules are also in- cluded.
Introduction
The value of a ccanprehensive set of grapheme-to-phoneme rules in
a text-to-speech system is well appreciated. Such rules allow the ,
processing of unrestricted text i n a ccanprehensive and ef f ic ient man-
ner. It is also recognized that sane form of "exceptions lexicon" is . ,
important since correctness of high-frequency m r d s in synthetic speech
is thus ensured. As text-to-speech m r k developed (see Cooper et al,
1 972) , it became clear that lexicons and grapheme-to-phoneme algorithms
muld be a natural, and eventually, necessary adjunct to phoneme-to-
speech processing. In order t o develop camplete systems, a n&r of
groups mrking w i t h synthetic speech inst i tuted research to construct
lexicons of various s izes and grapheme-to-phoneme and lexical stress
algorithms. Because grapheme-to-phoneme algorithms in English could ?
be quite ccanplex due to the lack of one-to-one grapheme-to-phone
correspondences, these researchers drew on studies previously done by
a number of l inguists such a s Chamsky and Halle (1968) and Venezb ,
(1 970) . Scarre early m r k on graphe-to-phoneme correspondences was done
a t Haskins Laboratories. An algorithm for the conversion of graphemes
t o phonemes i n English was written by Ainsmrth a t the University of
Keele in 1973. In 1974, algorithms were presented by both McIlroy of
Bell Laboratories and Hunnicutt of MIT. An Ehglish rule system was
* Employed a s a research assis tant a t the Dept. of Speech ccmmmica- t ion, KTH during the period February 15 - August 15, 1980.


STL-QPSR 2-3/1980
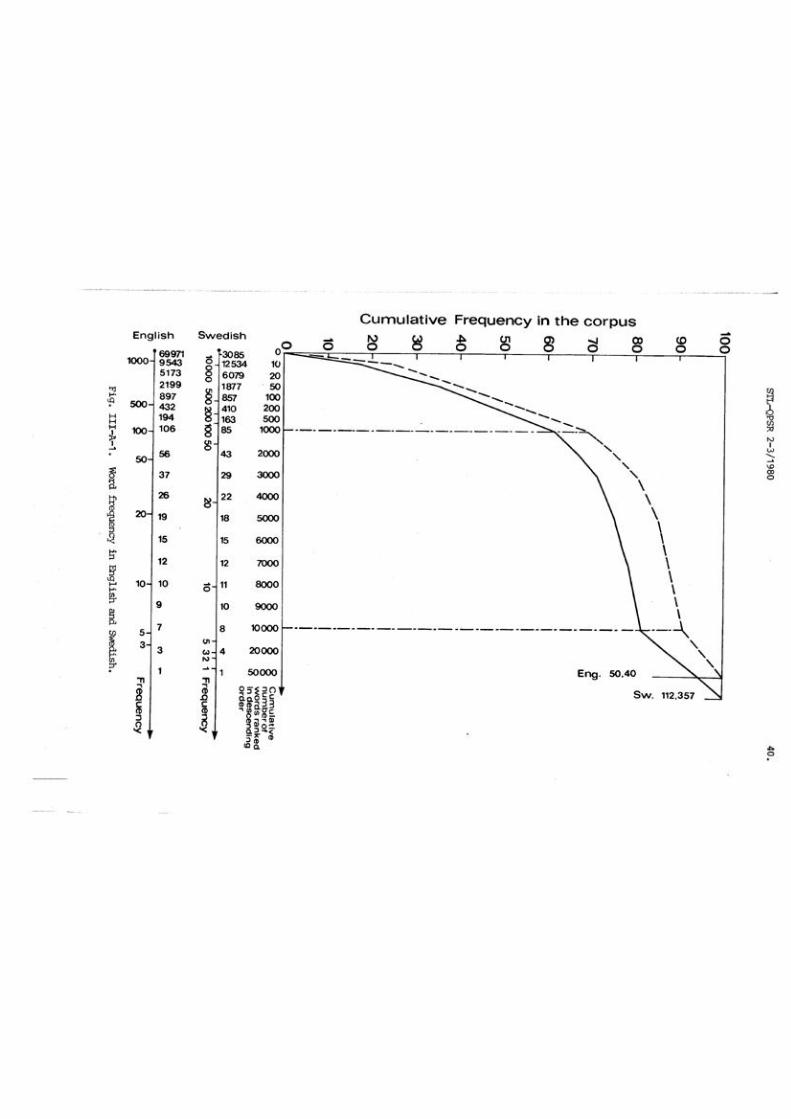
("Brown Corpus", Kucera & Francis, 1967) produces the correct pho-
nemic output for over f i f t y percent (53.6%) of the mrds i n running
text. The mst frequent 1,000 m r d s -- f ive times a s many -- cover
68.9% of the w r d s i n running text, an additional coverage of only
15.3% for 800 m r e mrds . This trend is mre and mre exaggerated
as w consider lower frequency mrds . Once again, increasing our
vocabulary by a factor of nine (considering the mst frequent
20,000 mrds) adds another 23.7% coverage. And the 40,000 lowest
frequency m r d s add a mre 7.4%. It is quite clear, then, that al-
though a small lexicon is remrkably productive, increasing its s ize
w i l l yield quickly dimishing returns. This realization has led t o
a much mre eff ic ient solution -- a modest set of grapheme-to-pho-
nem rules.
It should be noted, however, tha t t h i s solution precludes the
use of a lexicon for parts-of-speech and semantic information which
are necessary t o completely characterize an utterance. The exten-
sive mrph lexicon developed a t MIT (Allen e t a l , 1979) was construct-
ed with such considerations in mind.
Note: A comparison of the graphs for Swedish ( A l l & , 1970) and
English indicates that f e m r m r d s i n English cover a greater percent-
age of running text . It may also be observed tha t aver twice as many
different m r d s =re found i n the %dish texts a s in the English.
These phenomens indicate the greater incidence of inflectional
forms in Swedish and the greater freedom to compound; encouraging
new compound forms rather than s tr ings of descriptive adjectives
and nouns.
The KTH text-to-speech system
A diagram of the KTH text-to-speech system (Carlson & Granstrh,
1976) is shown i n Fig.111-A-2. The system accepts unrestricted input
text, and its f i r s t operation is t o convert t h i s text t o phonemes.
This conversion is accomplished e i ther by a small lexicon o r by tm
paral lel sets of rules: a set of grapheme-to-phoneme and lexical
stress rules, and a s e t of number-to-phoneme rules. The next set of
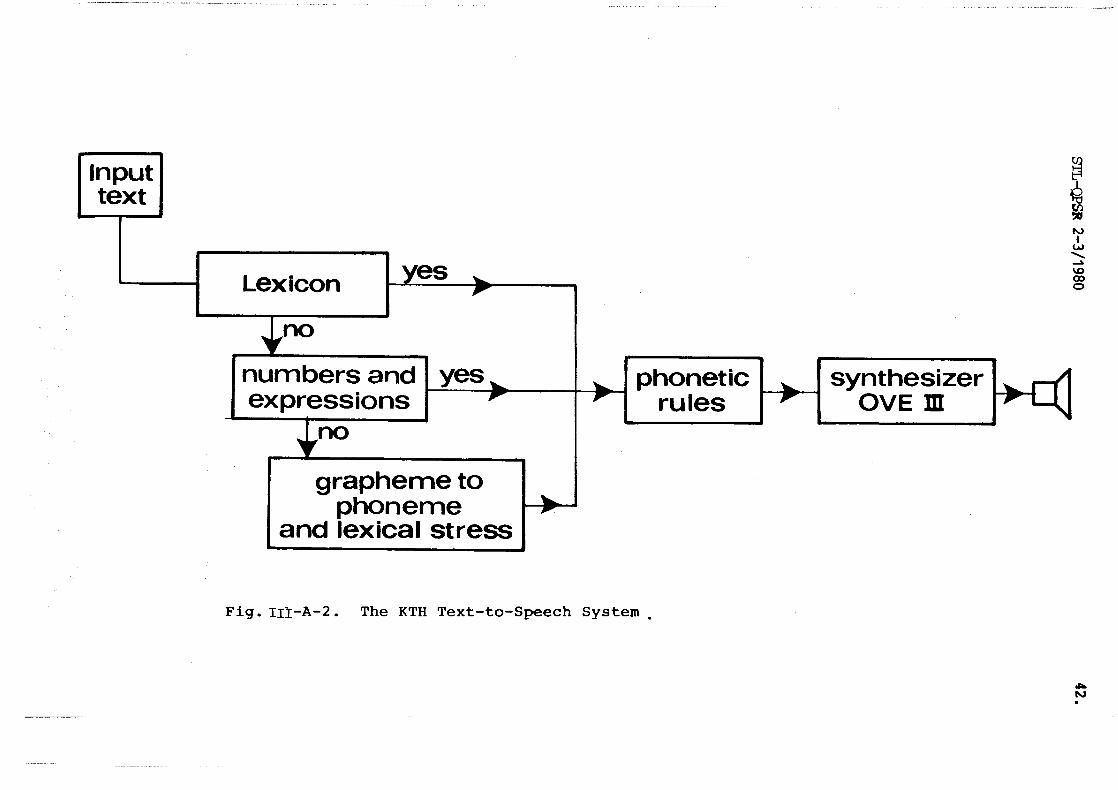
1-1 Lexicon 1 4 ,
grapheme to phoneme
and lexical stress
I
Fig. 111-A-2. The KTH Text-to-Speech System.
numbers and yes, expressions F
P a
phonetic synthesizer rules OVE m
no


The KTH rule notation
In order t o separate the l inguist ic and phonetic knowledge base
of a text-ot-speech system from the programning necessary t o imple-
ment t h i s knowledge, a special higher-level programning language was
developed a t KTH (Carlson & GranstrGm, 1975a). This language was
written t o conform as closely as possible t o phonetic and linguistic
terminology, so tha t the knowledge represented by the rule sets in
the system wuld be clear t o those mrking i n language and speech re-
search.
The basic structure of the rules is:
where & marks the occurrence of the s tructural description X in the
context A B. The structural change is denoted by Y; other symbols
are delimiters. Either A or B may be empty; both A and B empty de-
fines a context-free rule. An insertion may be defined by X unspeci-
fied, and a deletion by unspecified Y. Recursive rule application is
made possible by a special rule label.
The symbols A, B, X , and Y are s t r ing elements which are defined
by the user. Such a definition is composed of up t o 32 dis t inct ive
features such as "voiced" or "vocalic," and variables such as formant
frequency and bandwidth. Basic features can be grouped into natural
classes, and both one- and tw-dimensional variables can be defined.
There is also a f ac i l i ty for specifying optional elements. Any of
the s tr ing elements i n a rule, then, might be a symbol o r a list of
specified features and values for variables (including arithmetic ex-
pressions) . Consider, for example, the grapheme-to-phoneme rule for conver-
sion of the past-tense/past part icipial mrd-final suff ix ED i n Eng-
l i s h a f t e r a voiced segment
The phoneme /D/ and the features "voiced," "segmental," "formative
boundary" and "mrd boundary" are defined by the user. Note the pos-
s i b l i t y of a ternary (+, - or unspecified) specification for each
feature.

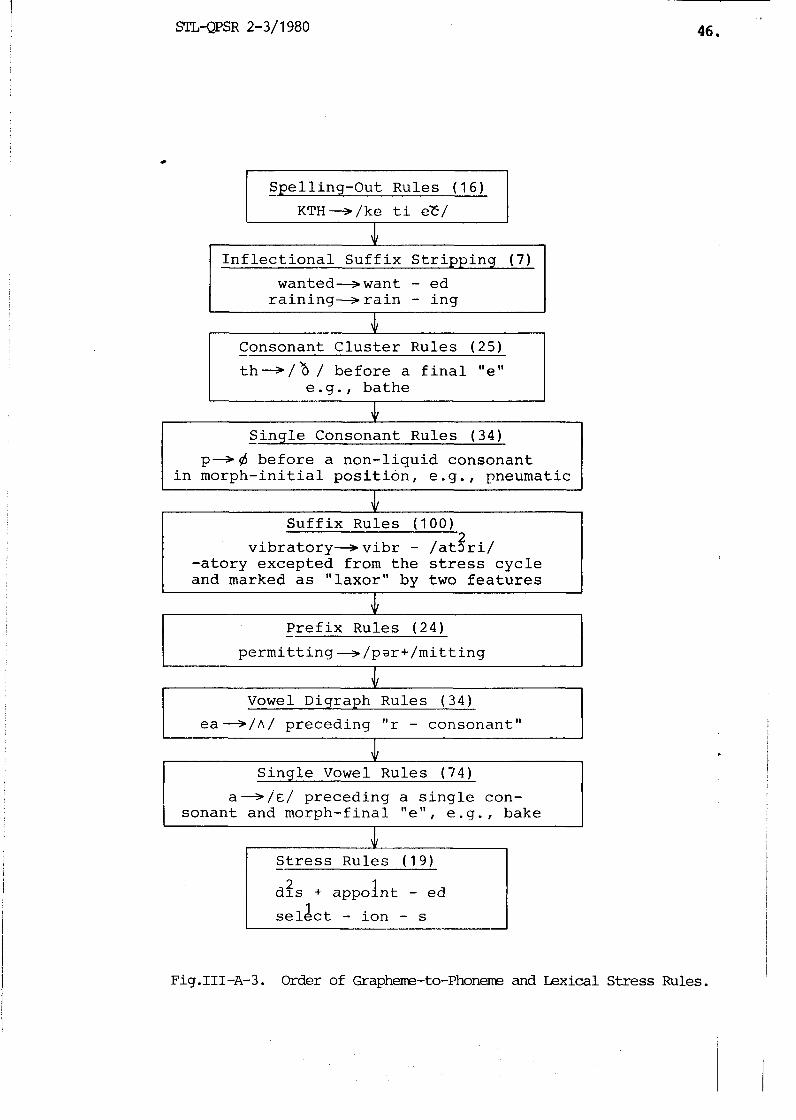
STL-QPSR 2-3/1980
I - Spel l ing-Out Rules (16) 1
I I n f l e c t i o n a l S u f f i x S t r i p p i n g ( 7 ) 1 wanted-want - e d
r a i n i n g - r a i n - i n g I
th--+/ 'a / b e f o r e a f i n a l " e " e . g . , b a t h e
4 S i n g l e Consonant Rules ( 3 4 ) - 1
p-6 b e f o r e a n o n - l i q u i d consonant i n m o r p h - i n i t i a l p o s i t i o n , e . g . , pneumatic
I
S u f f i x Rules (100) 2
v i b r a t o r y - v i b r - / a t 3 r i / - a t o r y e x c e p t e d from t h e stress c y c l e and marked a s " l a x o r " by two f e a t u r e s
P r e f i x Rules ( 2 4 ) - p e r m i t t i n g - - + / p a r + / m i t t i n g
v
Vowel Digraph Rules ( 3 4 )
I ea-+/n/ p r e c e d i n g "r - consonan tn I h
S i n g l e Vowel Rules ( 7 4 )
a + / € / p r e c e d i n g a s i n g l e con- s o n a n t and morph-f ina l " e " , e . g . , bake
I - S t r e s s Rules (19) I 2 1 d l s + a p p o l n t - ed
1 s e l e c t - i o n - s
Fig.111-A-3. Order of Grapheme-to-Phoneme and Lexical Stress Rules.

STL-QPSR 2-3/1980 47.
Swcia l contexts
Special contexts, in which less frequent grapheme-to-phoneme
correspondences occur, are seen t o be specified by a s few as ten
categories. Furthemre, these categories frequently define the
contexts for special pronunciations of both consonants and vowels.
These categories are shown i n Fig.111-A-4; the same, o r similar,
contexts for -1s and consonants are found opposite each other.
Examples of graphemes receiving correct pronunciations by rules in
these categories are also shown.
bbst special contexts can be defined in terms of mrpheme
boundaries. Categories (1 ) through (7) are of t h i s type. Cate-
gory (1) expresses the notion of mrph-ini t ial , providing palatal
versions of i n i t i a l /u/ and /v/, labelling i n i t i a l "y" as a con-
sonant and forming the context for special pronunciations i n i n i t i a l
consonant clusters. Category (2) for mrph-ini t ial syllables, Ca-
tegory (4 ) for morph- and mrd-final syllables, and a special case
of both, i.e. Category (3) for single syllables, define contexts i n
which long -1s are found and a few consonants can be singled out.
Long v w l s are also expected in the contexts defined by Categories
(5) and ( 6 ) , but short vowls are found in the context defined by
Category (7) . * Categories (5) and (6) also define contexts for syl-
labic "1" and " r , " and for a few other consonants and consonant clus-
ters.
The mst prol i f ic exception-generating contexts appear to be
those in which a liquid occurs, Category (8) . Twenty-six such rules
are currently included, although f ive are classif ied i n other cate- I
i
gories a s ~ 1 1 . The consonant examples l i s t ed in parenthesis re-
present cases where other rules do not apply due t o the presence - of a l iquid, i.e., "1" is not syllabified a f t e r a liquid and initial
"p" is not s i l en t before a liquid.
Category (9) is a vis ible and active category. This category
defines contexts i n both roots and suffixes (7 suffixes in the pre-
sent set of ru les) . It requires the lengthening of the f i r s t v m l ,
* Another special feature, N O R , is defined for suffixes which define the Category (7) context.

VOWELS
1) MORPH-INITIAL eulogy, u tens i l - -
2) FIRST SYIXABLE thiamine, - iodine, table, wta - -
3) SINGLE-SmLE MORPH pie , - sour, - raced, striate, vocal, rn - - - -
4) WORDFINAL /MoRPHFINAL bonnie, - toe , - potato, bake, ma - - -
5) P-ING C - VOCALIC INFLECTIONAL SUFFIX baking, - miles, - loner, themes - -
6 ) PRECEDING C - Mom-FINAL "en bake, - mile, alone, theme - - -
7 ) PRECEDING C - SPECIAL "LAXING" SUFFIX r a t i f y , - u t i l i t y , - conic, edible - -
8) PRECEDING LIQUID / C - LIQUID a i r , earth, ward, shoulder, do l l , o r ... - - - - - -
9) I N ? H E m v - C - v h i h - v alienate, a m l i o r a t e , uzual , . . . at ion -- -- - - --
10) PRECEDING AN- VOWEL Ptolemaic, - meteor, - q o p i c , experience -
11) OTHERS ru l e , fue l , took, qual i ty , wrong, waste, hind, hi - - - - - - -
Fig. EI-A-4. SPECIAL CONTEXTS
Note : "C" indicates a s ingle consonant, and "V" a s ingle -1.
CONSONANTS
1) MOFPH-INITIAL knee, white, wrote, pneumatic, xears - - -
4) WORD-FINAL / MORPH-FINAL sing, t ic, inch, arguable, pariah_ - - - -
5) PRlTEDrn VOCF;LIC INFLECTIONAL SUFFIX wreathes, a n t i ~ e s , appLes, acKes -
6 ) PRMlEDING MOIiTH-FINAL "e" wreathe, anti%e, apple, acre, o r q e , cheese - - - -
8) PRECEDING / FOLLOWING A LIQUID (quadri l le , o r l e , place) - -
9) I N c m v - c - vhigb - v revision, dispersion, Russian, racial,,,ation - - - - -
10) PFUXEDING ANOTHER CONSONANT picture , clear, r a q , r a ~ b e r r y - -
11) OTHERS came, c i s t e rn , rancor, rancid, qwern, ayrosoope - - - -


rule context is compared. This method appears to be mre efficient,
and does not require the program code needed in the MIT method to
direct the various passes with the appropriate set of rules. In
fact, no new code was written for the English system at all: the
code existent for the Swedish system serves for the English rules
as well.
The major difference between the multi-pass method and this
one-pass procedure is in the manner of processing and ordering af-
fixes. Recognition and removal of all affixes as a first step in
the M T algorithm corresponds to seven rules in the KTH system which
recognize vocalic inflectional suffixes and insert a mrph boundary
marked with the feature "inflectional." Except for the loss of
"transparency" in the spelling of affixes, the effect df not recog-
nizing all affixes before consonant conversion appears to be rather
mall. Initial consonant clusters after unrecognized prefixes have , I
been observed to be mispronounced in a few cases in the KTH system. I
Hmver, the opposite effect may be obsewed in the MIT system:
strings incorrectly recognized as prefixes before application of
the consonant rules also lead to mistaken pronunciations.
There is a significant difference in the ordering of suffix I
i rules in the t m algorithms. Suffixes in the MIT algorithm are re-
cognized first and converted later (in any order). Recognition of
multiple suffixes, however, is contingent upon a verification of
the canpatability of their parts of speech. This verification re-
quires additional code and a table of parts of speech of each suf-
fix and its possible predecessor. In the one-pass system, suffixes
must be listed in the order of their probable occurrence frm the
right-hand side of the mrd so that their mrd-final or mrph-final
position is verified. A short study was undertaken for the purpose
of determining the best order for the suffix rules. Compound af-
fixes found in the mst frequent t~ thousand English mrds accord-
ing to the Brown Corpus (through a frequency of 48 per million) were
inspected. The resulting ordering of suffixes, with a few compound
suffixes added, correctly raves affixes frm this sample of mrds.


STL-QPSR 2-3/1980
Special stress effects due to suffixation, which are included
in the operation of the rule cycle in the MIT stress rules, are ac-
camplished in t~ ways in the KTH system. Stress-carrying suffixes
are pre-stressed in the suffix rules by noting primary or secondary
stress as a feature of the appropriate vowel. This stress m y be
adjusted later by the stress rules themselves. In the MIT rules,
special categories of stress-affecting affixes are stipulated as ex-
ceptions to the Main Stress Rule, the first rule in the cycle, and
may be adjusted by later rules, as in the KTH system. Suffixes
which have no effect on the stress cycle are recognized in both sys-
tems, by special categorization for both the Main Stress Iiule and
the Compound Stress Rule in the MIT rules, and by a feature "minus
stress cycle" in the KTH rules. This feature is also assigned to
mrd boundary symbols such as "space" and "period" in the KTH defi-
nitions of these symbols, and becanes part of the right context in
many stress rules.
Unlike the MIT system, the KTH formalism provides no device
with which to retain graphemes after their conversion to phonemes.
The retention of graphemes in the MIT formalism provides for the
specification of either letters of phonemes in both left and right
contexts. As a consequence, a substantial subset of rules differ
in specification of context. Although parallel tests have not been
made, it is believed that this difference gives neither set of
rules an advantage mrthy of note.
In addition, as previously discussed, the KTH programning lan-
guage allaws each phoneme and punctuation mark to be expressed in
terms of distinctive features. This type of specification makes the
rules more "transparent" than those in the MIT listing where variables
are used which, for the mst part, are lists of phonemes with a part-
icular feature. The facility of specifying optional elemnts in this
programning language has also allowed rules to be expressed mre
succinctly in several cases.
A ~reliminarv evaluation
Preliminary tests have been made to evaluate the usage of the
grapheme-to-phoneme and lexical stress rules, the correctness of
their phonemic output, and the speech output of the system with the

STL-QPSR 2-3/1980
complete se t of English rules. A l l t e s t s t o date, have employed
various samples from the Brown Corpus.
Tests for correctness of phonemic output and speech output
have been made on seven sets of t m hundred mrds each having the
following frequency range and correctness score:
TEST n&r Frequency range Score (Occurrence per million)
TEST 1 69,971 - 426 66.5% (100%)
TEST 2 108 - 91 73%
TEST 3 57 - 52 69%
TEST 4 32 - 30 76.5%
TEST 5 15 73%
TEST 6 7 67%
TEST 7 3 66%
Note that these scores are - not frequency weighted.
A l l mrds in TEST 1 are included in the lexicon. Wst of them
are function words, and are l is ted in the lexicon with a "+" follow-
ing their phonemic representation t o allow for their inclusion in
phrases. Their score, i f they had not been i n the lexicon (66.5%)
is rather low, reflecting their exceptional nature as high-frequen-
cy mrds. Words of frequency 7 and 3 also have rather low scores.
This seems t o be, for the most part, a function of carpunding and
a large nuher of non-English proper names. Neglecting the results
of TEST 1 ( a l l lexical entr ies) , an average score of 71% correct is
calculated.
With regard to law-frequency wrds , one might also expect a
rather large variety of new wrds , perhaps technical terms or words
specific t o certain disciplines o r areas of interest. This explana-
tion underlies the a s s q t i o n that users of text-to-speech systems
w i l l probably need the faci l i ty of adding their own special terms
to the lexicon. The performance of graph--to-phoneme rules on

STL-QPSR 2-3/I 980
some such terms may be quite rel iable, but the addition of special
prefixes t o assure proper lexical stress i n special technical areas
is likely. A previous evaluation of the performance of grapheme-
to-phoneme rules on a medical dictionary (Hunnicutt, 1976) shows an
increase i n correctness of 10% by the addition of special prefixes.
The current lexicon contains the 200 mrds of highest frequen-
cy plus another 87 w r d s which guarantee the correct pronunciation
of the f i r s t 580 m r d s according to frequency. These 580 highest-
frequency mrds make up 63% of the original text . The remainder of the
or ig ina l ' tex t (37%, almost 50,000 mrds) can' be estimated a t 71 "arrect using the grapheme-to-phoneme and lexical stress rules. This esti-
mation w i l l resul t in a score of 89% correct for the ent i re text of
over a million mrds. It is of in teres t t o observe that a correct
score of 90% (only 1% higher) could only be achieved by assuring
the correct pronunciation of another 130 mrds , i.e., the 710 mst 1
frequent mrds. An u p a d i n g of the grapheme-to-phoneme and lexical
stress rules by 2% muld ef fec t the same improvement. The figures
for correctness reported here are i n accordance with the highest I
previously reported correctness scores for other schemes, and may
perhaps be judged a b i t bet ter , since lexical stress has been re-
quired t o be correct i n a l l cases.
Other t e s t s have been made t o evaluate the efficiency of the
rules and the frequency of the i r usage. Work is currently in pro-
gress t o improve rule efficiency, and rules which were used ei ther
infrequently o r not a t a l l w i l l receive further evaluation.
Fig.II1-A-5 presents a chart indicating frequency of usage of
the groups discussed in a previous section. The data fo r this
chart and for other studies concerned with rule usage are the f i r s t
3,.D00 m r d s in the Brawn Corpus (by frequenq) and the seven sets
of 200 mrds each i n TEST 1 through TEST 7 (no m r d s are repeated
i n a single test) . Basic (context-free) rules are only 40 in nun-
ber, but t h i s set of rules is used equallyas frequently a s the set
of 112 rules i n the special categories (1) through (10 ) . Each set
has an expectancy of use of .97 times per m r d -- that is, approxi-
mately once i n the average mrd . Affix rules apply with the fre-
quency of -82 P r word, and other rules (Category (1 1 ) ) apply with

Number of Applications per word
I I I
BASIC 40 rules - 1
SPECIAL CONTEXT 112 rules
AFFIXED 124 rules
OTHERS - 15 rules

the frequency .23. One may therefore expect three (2.99) applica-
t ions of grapheme-to-phoneme rules per mrd. This l o w figure may
be par t ia l ly attributable t o the coverage afforded by a f f ix rules,
and par t ia l ly t o the fac t that only four single consonants, ( H I J,
C, X ) , have pronunciations which require special phonemic corres-
pondence.
The next figure, Fig.111-A-6, shows rule usage for each of the
special categories. The frequent use of rules in Category (11) is
m s t l y accounted for by rules fo r the pronunciation of the conso-
nants "c" and "g," and by palatalization of /u/ and /v'/, as pre-
viously mentioned. Mrph-final contexts are the next mst frequent,
followed by contexts in which a liquid o r a "laxing" suff ix affects
the pronunciation. The lmst-frequency rules are those involving
mrph-ini t ial and f i r s t syllable contexts.
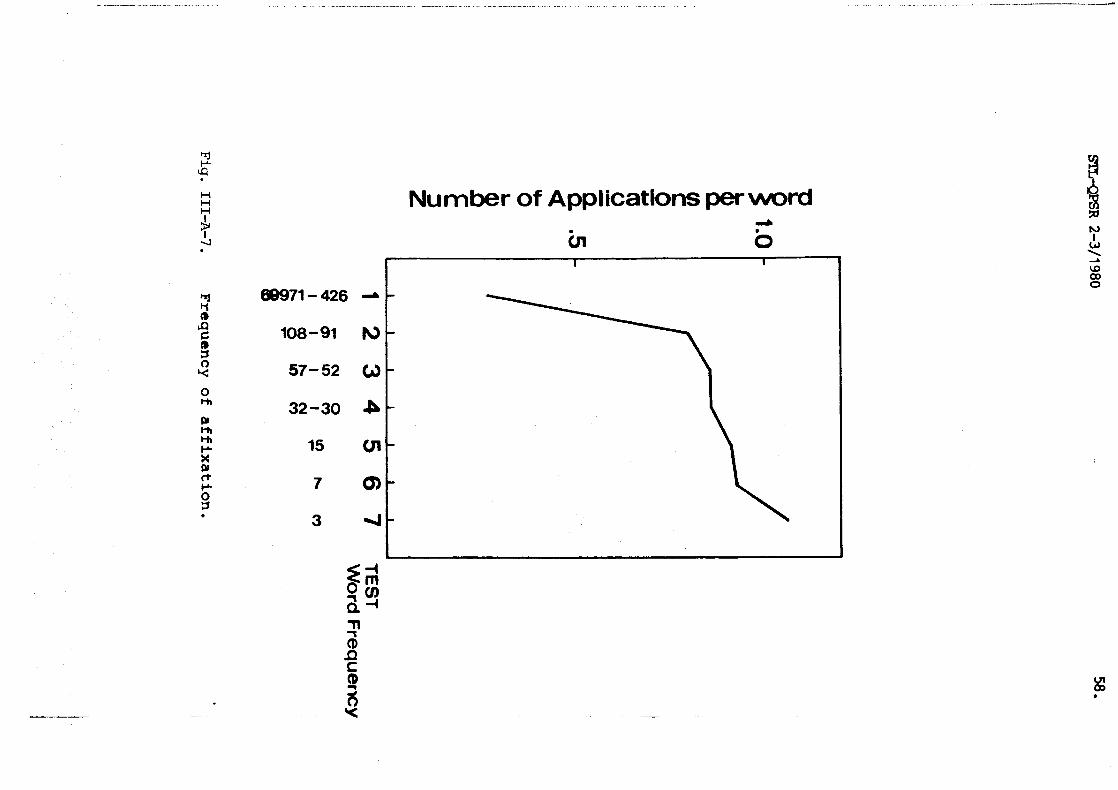
In order to investigate the hypothesis that mre affixation is
found in lower frequency mrds , the seven sets of 200 m r d s each
were tested for frequency of use of a f f ix rules. As can be seen in
Fig.111-A-7, this proved to be the case. Only in the l a s t sample,
however, does the average number of affixes per m r d exceed one (1.06).
Sorrre interesting observations can also be made by examining the
frequency of usage of stress rules. This figure is .54 for the rule
which places a primary stress on a single syllable root which may
be preceded by prefixes and followed by non-stress-affecting suf-
fixes. That is, half the mrds in the samples are of t h i s fonn.
It is also interesting t o note that the tm rules for v a e l reduc-
t ion apply w i t h a frequency of .65 times per mrd. As might be ex-
pected, the number of times vowel reduction rules are applied t o
reduce non-tense unstressed vowls t o "schwa" o r "reduced-i" in-
creases a s the frequency of the m r d s decreases. This shows a ten-
dency for sanewhat longer mrds to be i n a lmer frequency class. I A table of usage appears dn Table 111-A-11.
Examining stress rule usage on the ent i re data base, one may
observe tha t the 19 stress rules are used with a frequency of 2.4
rules per mrd . The previously mentioned rules for single-syllable
roots and vowel reduction account for half of this usage, 1.2 appli-
cations per m d .

Number of Applications per word
Number of Applicatbns perword

STL-QPSR 2-3/ I 980
TableIII-A-11. Frequency of usage of vowel reduction rules.
TEST1 69,971 - 426 TEST 2 108 - 91
TEST 3 57 - 52
TEST 4 32 - 30
TEST 5 15
TEST 6 7
TEST7 3
Use of Vow1 Reduction Rules
.18
.59
.65
.75
.90
.90
1 .oo
1st 1,000 words 69,971 - 105 .44
2nd 1,000 words 105 - 55 .66
3rd 1,000 words 55 - 36 .77
Tuning of the rules will be done with information derived
from the tests discussed above and from samples of text run
through the system.
Concluding remarks
The developnt of rules for other languages has already be-
gun, and shows encouraging potential. The rule notation prmtes
clarity of expression, which, in turn, should facilitate ccanpari-
sons m n g various languages. Such comparisons should be rich
sources in the search for universals, and in the study of language
learning. Cross-language comparisons of phonetic segment defini-
tions and realizations, and prosodic constraints seem particularly
prcanising .
Acknowledgments
I would like to express my appreciation to the staff of Tal-
mrforing (Dept. of Speech Camunication), KTH, for rewarding co-
operation and for making this mrk possible. Productive and en-
joyable work with Rolf Carlson and Bjorn Granstrijm over the past
t m years deserves particular mention. My special thanks plso
goes to Thomas Murray for his assistance in matters of ccsnputing.

Recommended

















