
Federico Carminati, Peter HristovNEC’2011 Varna
September 12-19, 2011
Federico Carminati, Peter HristovNEC’2011 Varna
September 12-19, 2011
An Update about ALICE Computing
An Update about ALICE Computing

ALICE@NEC
• NEC’2001 AliRoot for simulation
• NEC’2003 Reconstruction with AliRoot
• NEC’2005 AliRoot for analysis
• NEC’2007 Still no LHC data => Status and plans of the ALICE offline software. Calibration & Alignment
• NEC’2009 In preparation for the first LHC data, no presentation
• NEC’2011 Almost 2 years of stable data taking, a lot of published physics results => An update about the ALICE computing
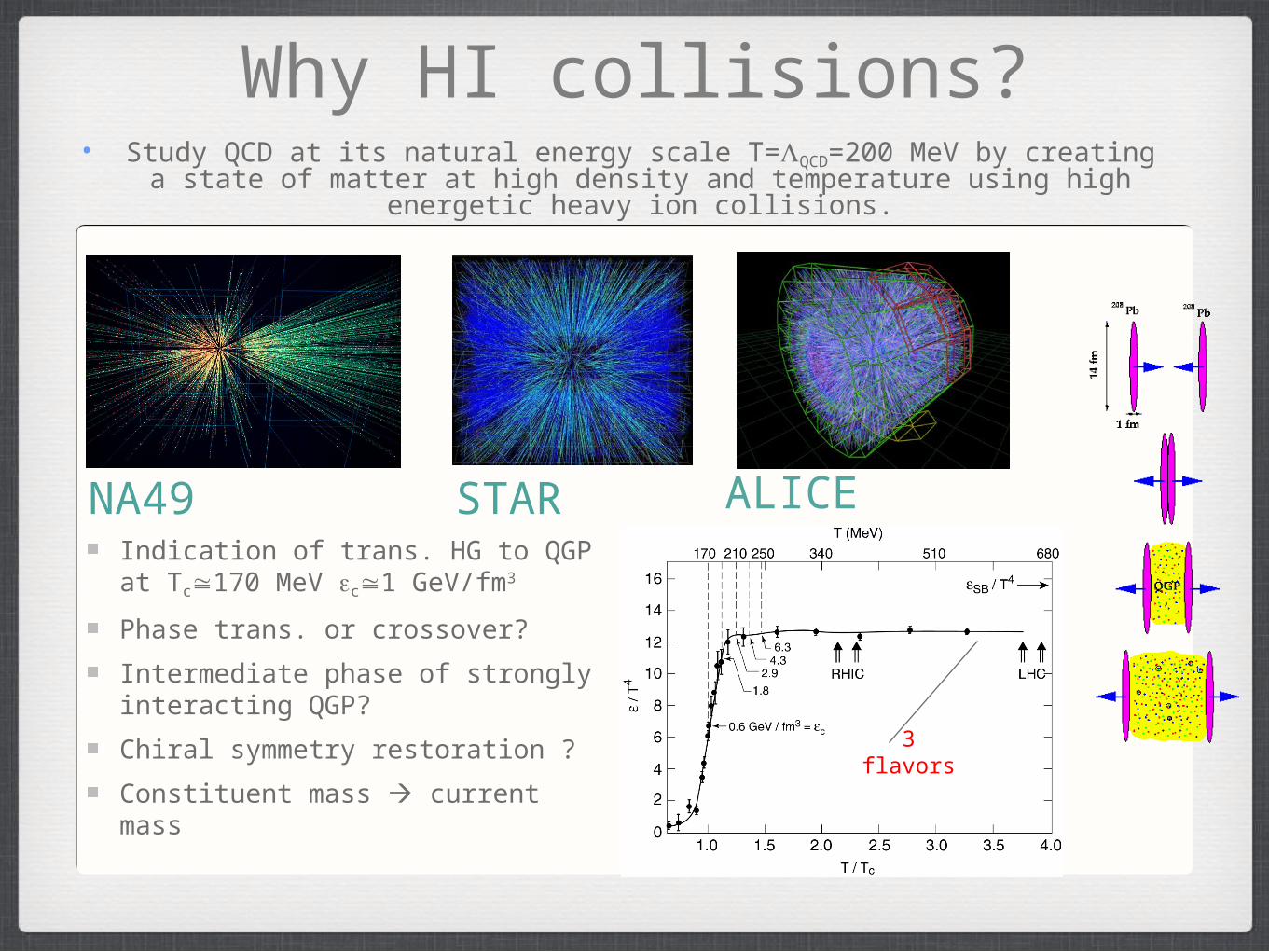
Why HI collisions?
STARIndication of trans. HG to QGP at Tc≅170 MeV εc≅1 GeV/fm3
Phase trans. or crossover?
Intermediate phase of strongly interacting QGP?
Chiral symmetry restoration ?
Constituent mass current mass
NA49
3 flavors
• Study QCD at its natural energy scale T=ΛQCD=200 MeV by creating a state of matter at high density and temperature using high energetic heavy ion
collisions.
ALICE

4
History of High-Energy A+B Beams
BNL-AGS: mid 80’s, early 90’s
• O+A, Si+A 15 AGeV/c √sNN ~ 6 GeV
• Au+Au 11 AGeV/c √sNN ~ 5 GeV
CERN-SPS: mid 80’s, 90’s
• O+A, S+A 200 AGeV/c √sNN ~ 20 GeV
• Pb+A 160 AGeV/c √sNN ~ 17 GeV
BNL-RHIC: early 00’s
• Au+Au √sNN ~ 130 GeV
• p+p, d+Au √sNN ~ 200 GeV
• LHC: 2010 (!)
• Pb+Pb √sNN ~ 5,500 (2,760 in ’10-’12) GeV
• p+p √sNN ~ 14,000 (7000 in ’10-’12) GeV

2
level 0 - special hardware
level 0 - special hardware8 kHz (160 GB/sec)
level 1 - embedded processors
level 1 - embedded processors
level 2 - PCslevel 2 - PCs
200 Hz (4 GB/sec)
30 Hz (2.5 GB/sec)
30 Hz
(1.25 GB/sec)
data recording &
offline processing
Total weight 10,000t
Overall diameter 16.00mOverall length 25mMagnetic Field 0.5Tesla
ALICE Collaboration~ 1/2 ATLAS, CMS, ~ 2x LHCb~1000 people, 30 countries, ~ 80 Institutes
•A full pp programme•Data rate for pp is 100Hz@1MB
Organization
Core Offline is CERN responsibility
Framework development
Coordination activities
Documentation
Integration
Testing & release
Resource planning
Each sub detector is responsible for its own offline system
It must comply with the general ALICE Computing Policy as defined by the Computing Board
It must integrate into the AliRoot framework
http://aliweb.cern.ch/Offline/
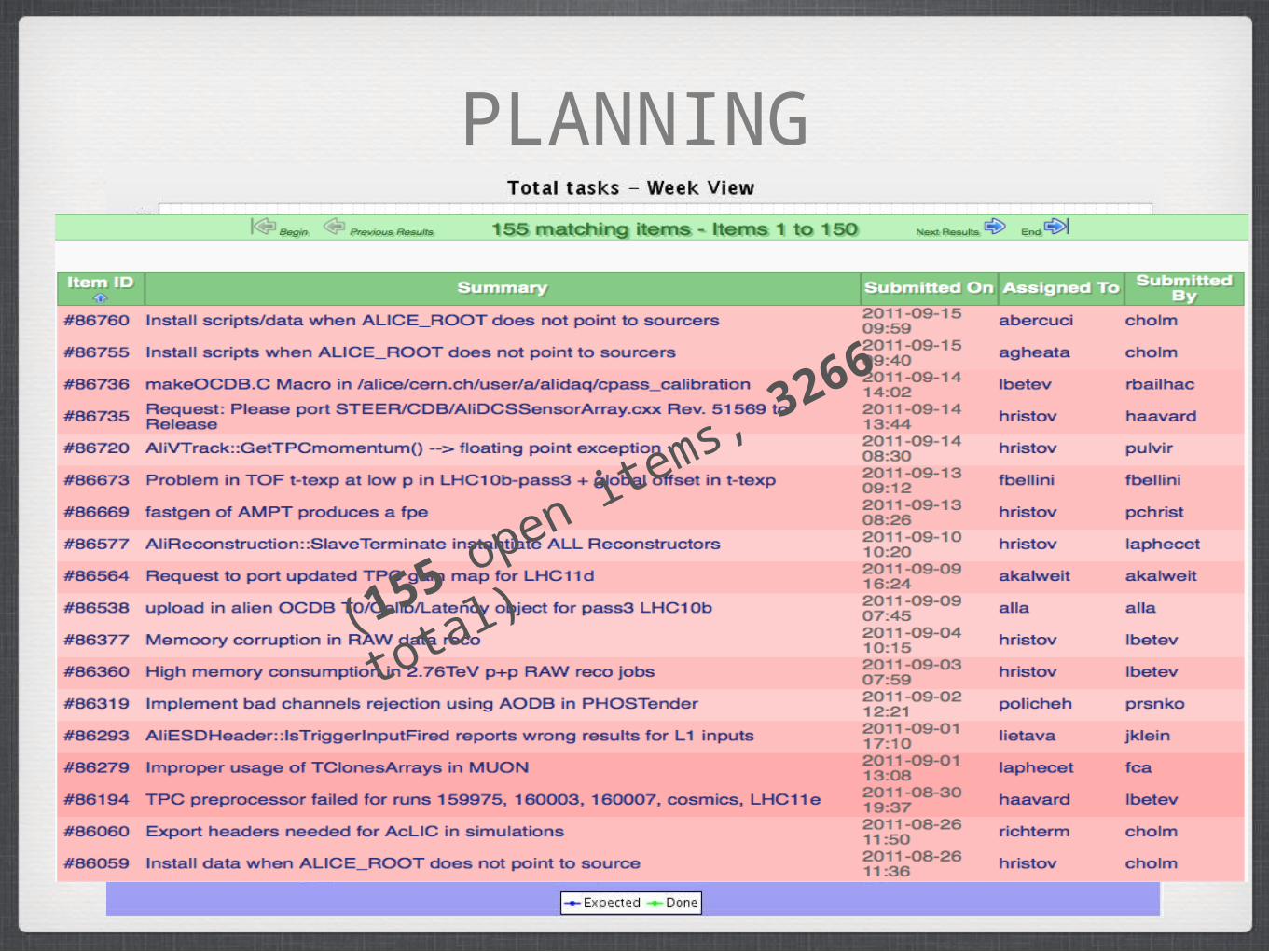
PLANNING
IN PREPARING FOR BATTLE I ALWAYS FOUND PLANS
USELESS BUT PLANNING ESSENTIAL
GEN D.EISENHAUER(155 o
pen items, 32
66 total)
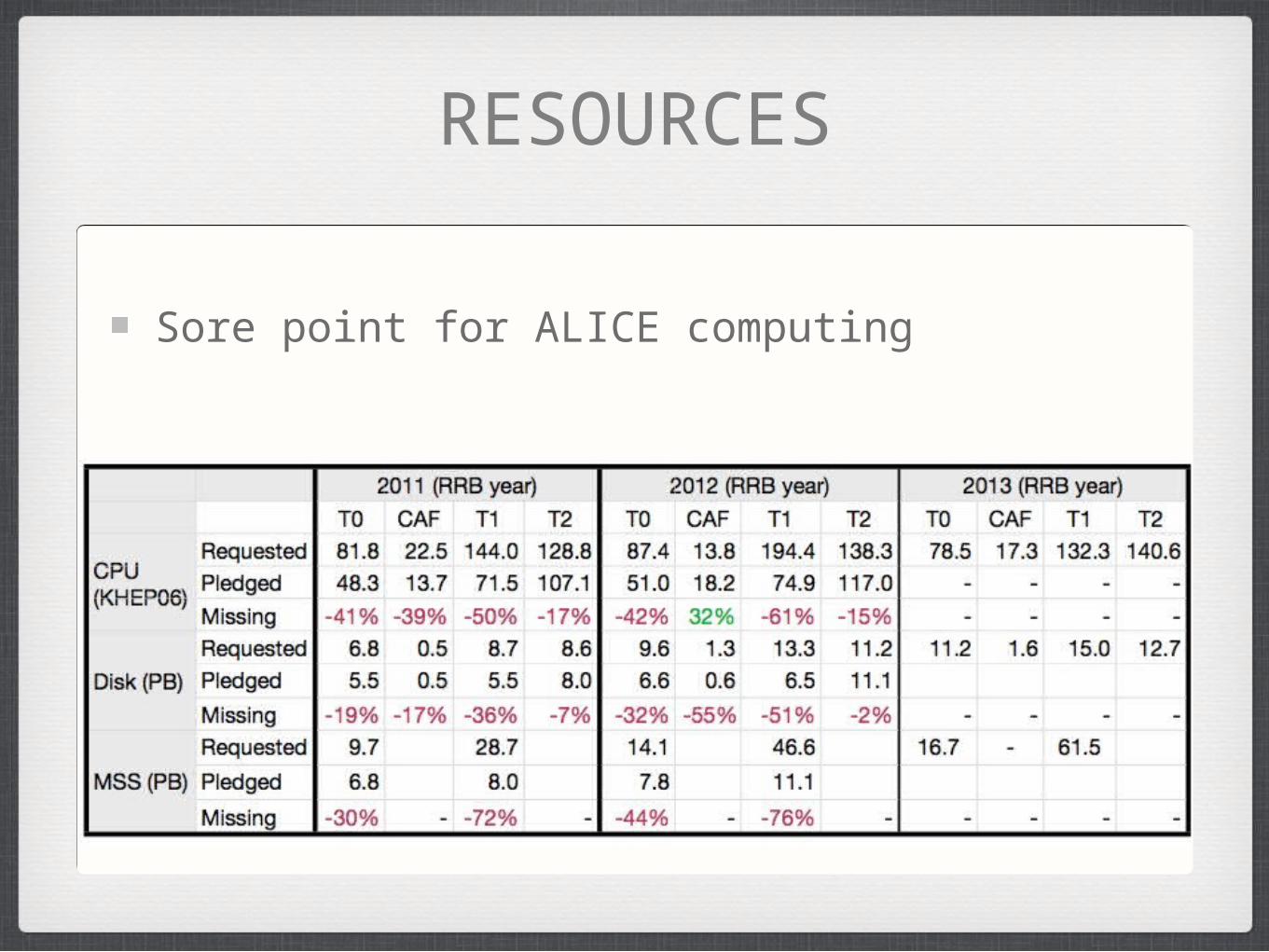
RESOURCES
Sore point for ALICE computing
9
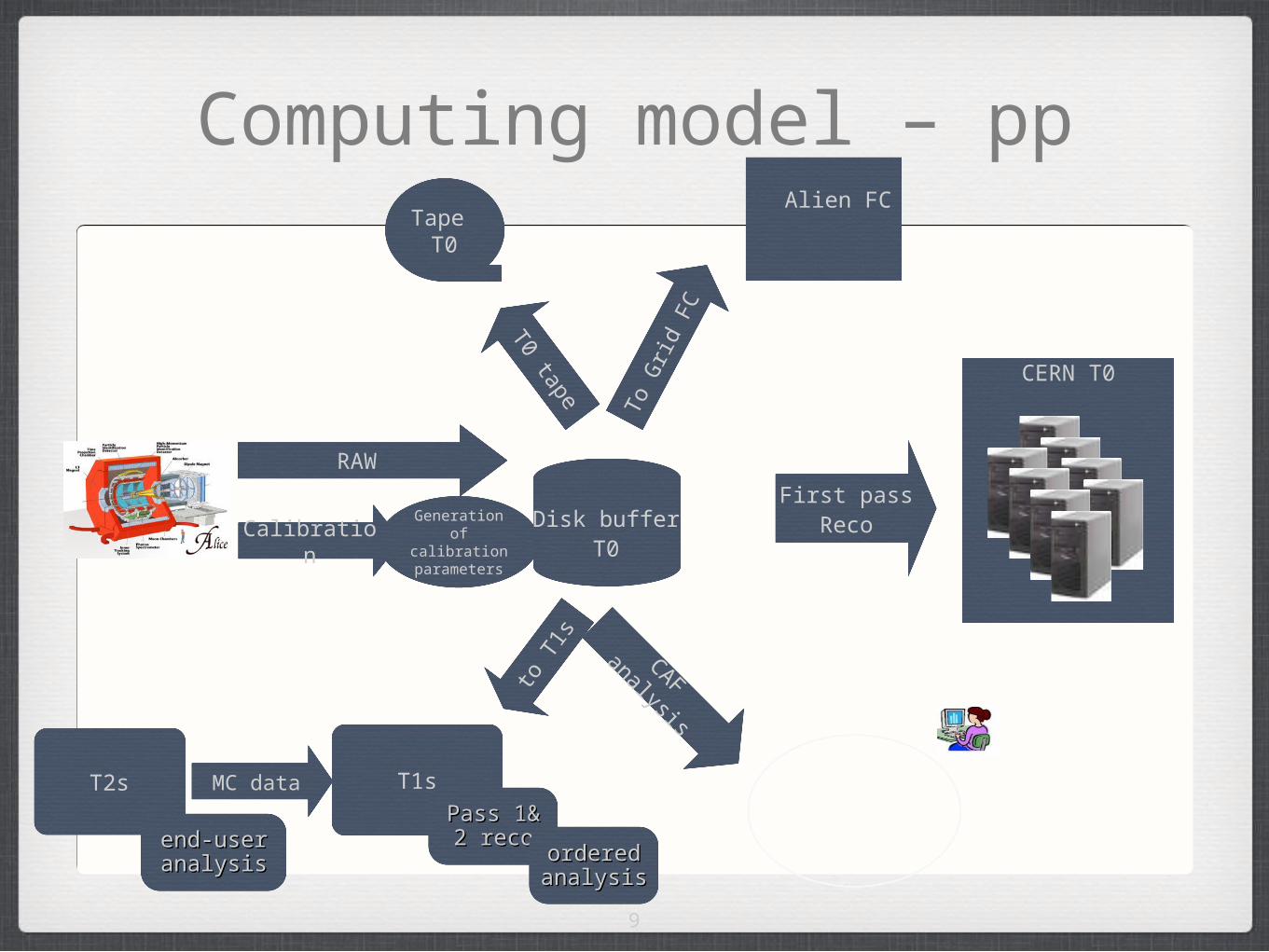
Computing model – pp
Generationof calibrationparameters
RAW
CalibrationDisk buffer
T0
CERN T0
First passReco
Tape T0
T0 tape To G
rid
FC
Alien FC
CAF analysis
to T
1s
T1sMC dataT2sPass 1& 2 Pass 1& 2
recorecoordered ordered analysisanalysis
end-user end-user analysisanalysis
10
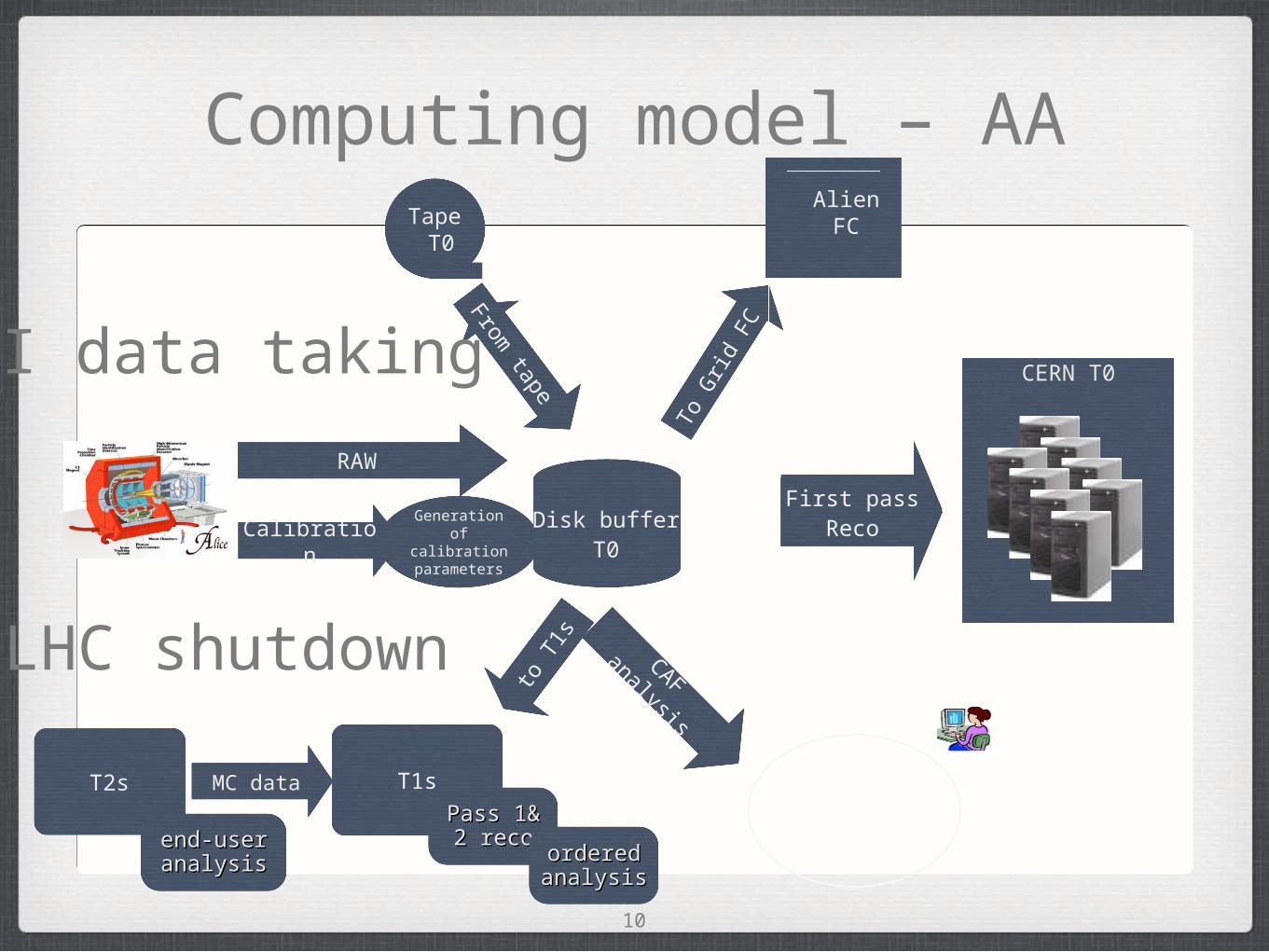
Computing model – AA
Generationof calibrationparameters
RAW
CalibrationDisk buffer
T0
Tape T0
To tape
To G
rid
FC
Alien FC
CAF analysis
to T
1s
T1s
CERN T0
PilotReco
First passReco
HI data taking
LHC shutdown
From tape
MC dataT2sPass 1& 2 Pass 1& 2
recorecoordered ordered analysisanalysis
end-user end-user analysisanalysis

Prompt reconstruction
Based on PROOF (TSelector)
Very useful for high-level QA and debugging
Integrated in the AliEVE event display
Full Offline code sampling events directly from DAQ memory
12
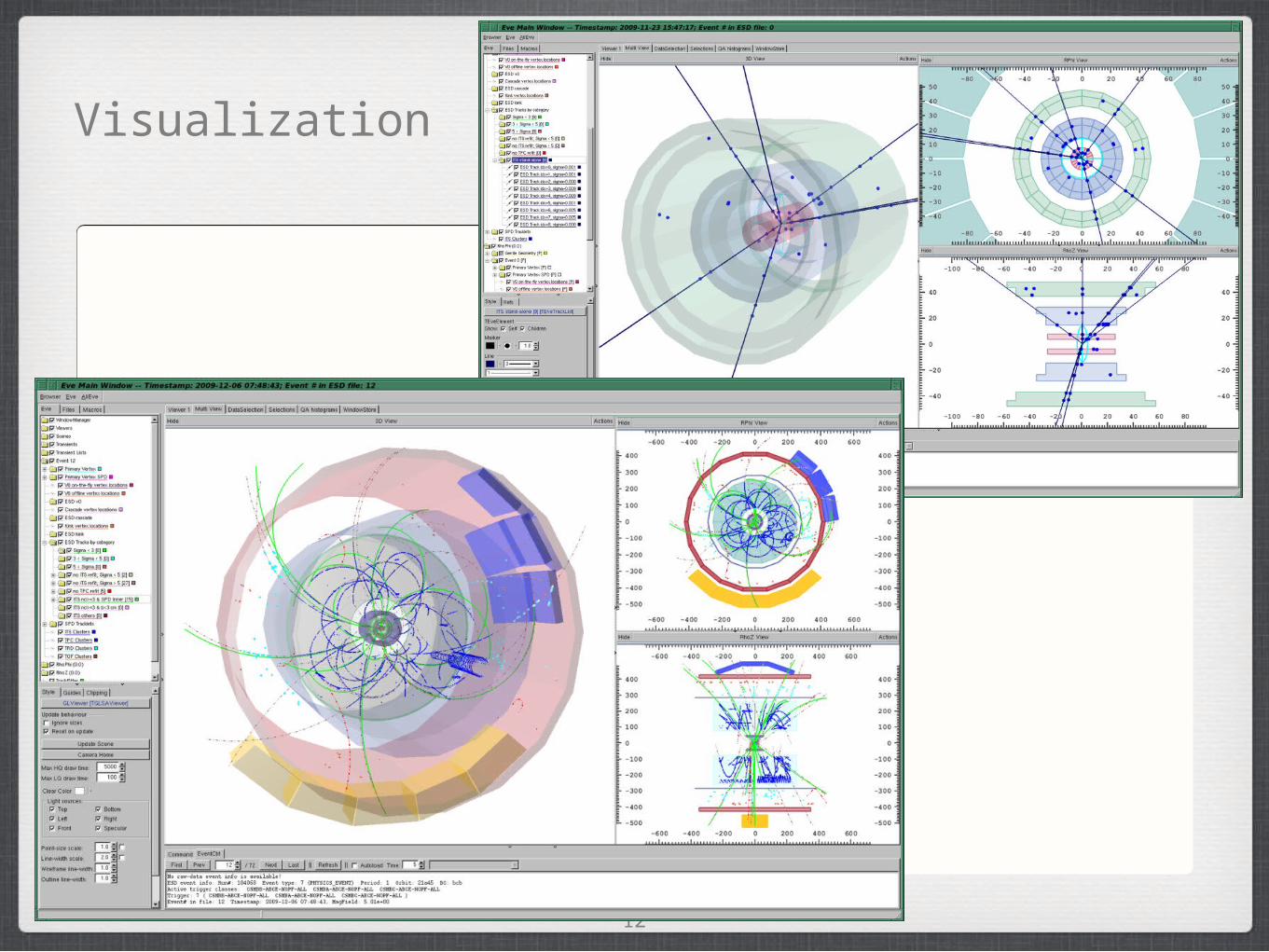
Visualization
V0

13
Ξ→πΛ→pπ
ALICE Analysis Basic Concepts
Analysis Models
Prompt data processing (calib, align, reco, analysis) @CERN with PROOF
Batch Analysis using GRID infrastructure
Local analysis
Interactive analysis PROOF+GRID
User Interface
Access GRID via AliEn or ROOT UIs
PROOF/ROOT
Enabling technology for (C)AF
GRID API class TAliEn
Analysis Object Data contain only data needed for a particular analysis
Extensible with ∆-AODs
Same user code local, on CAF and Grid
Work on the distributed infrastructure has been done by the ARDA project
Ω→Λ→pπ
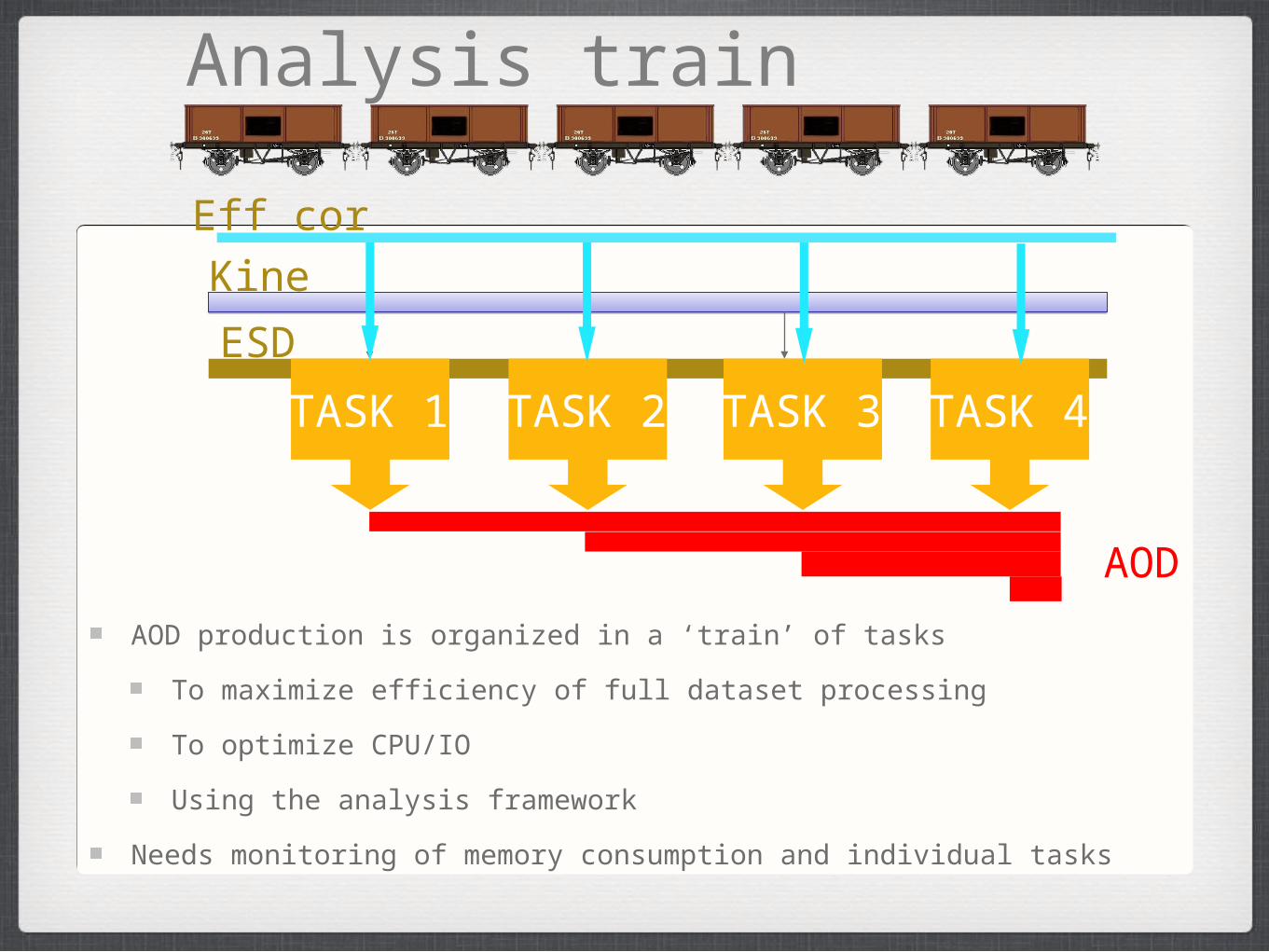
Analysis train
AOD
TASK 1 TASK 2 TASK 3 TASK 4
ESD
KineEff cor
AOD production is organized in a ‘train’ of tasks
To maximize efficiency of full dataset processing
To optimize CPU/IO
Using the analysis framework
Needs monitoring of memory consumption and individual tasks
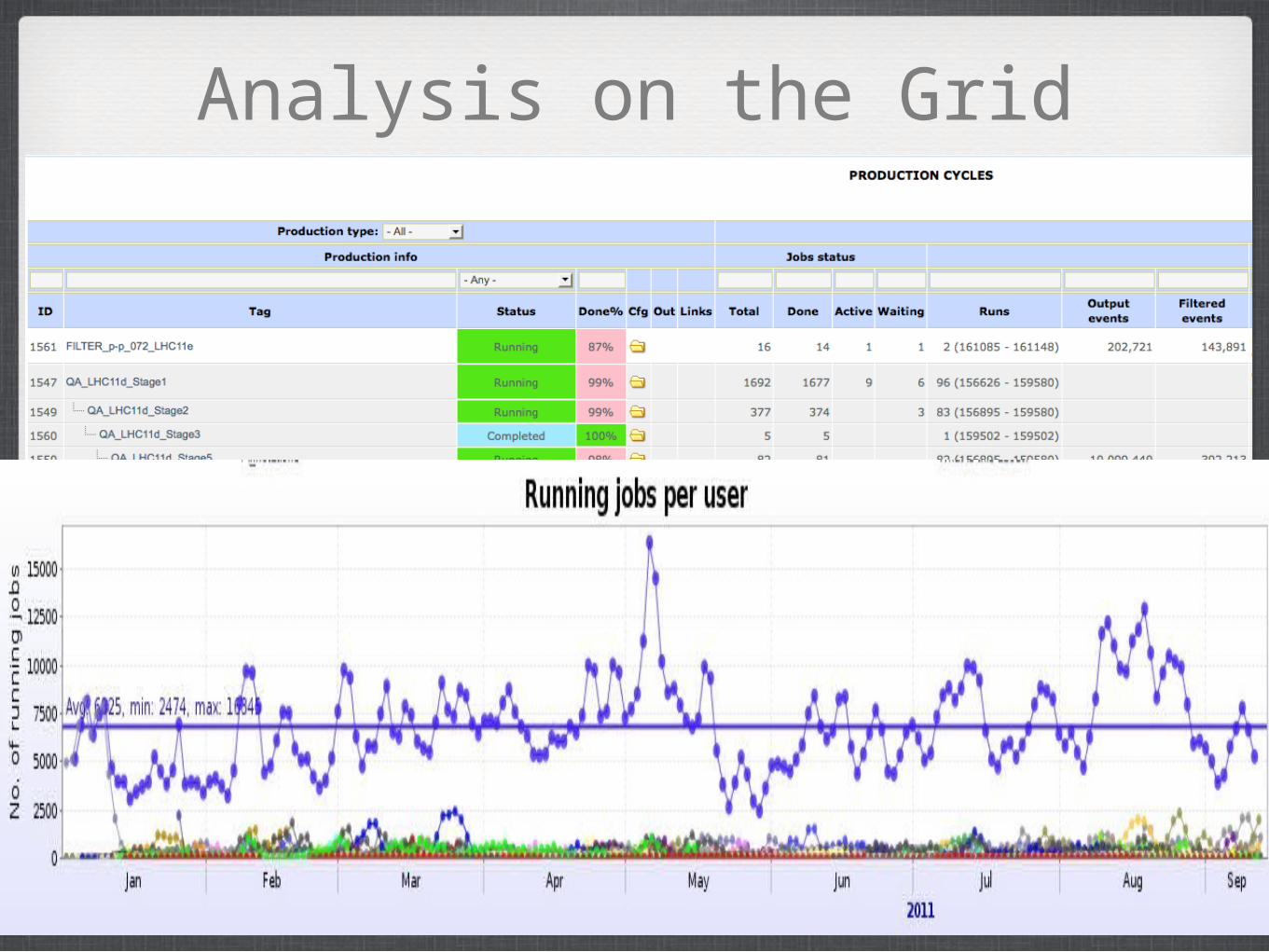
Analysis on the Grid
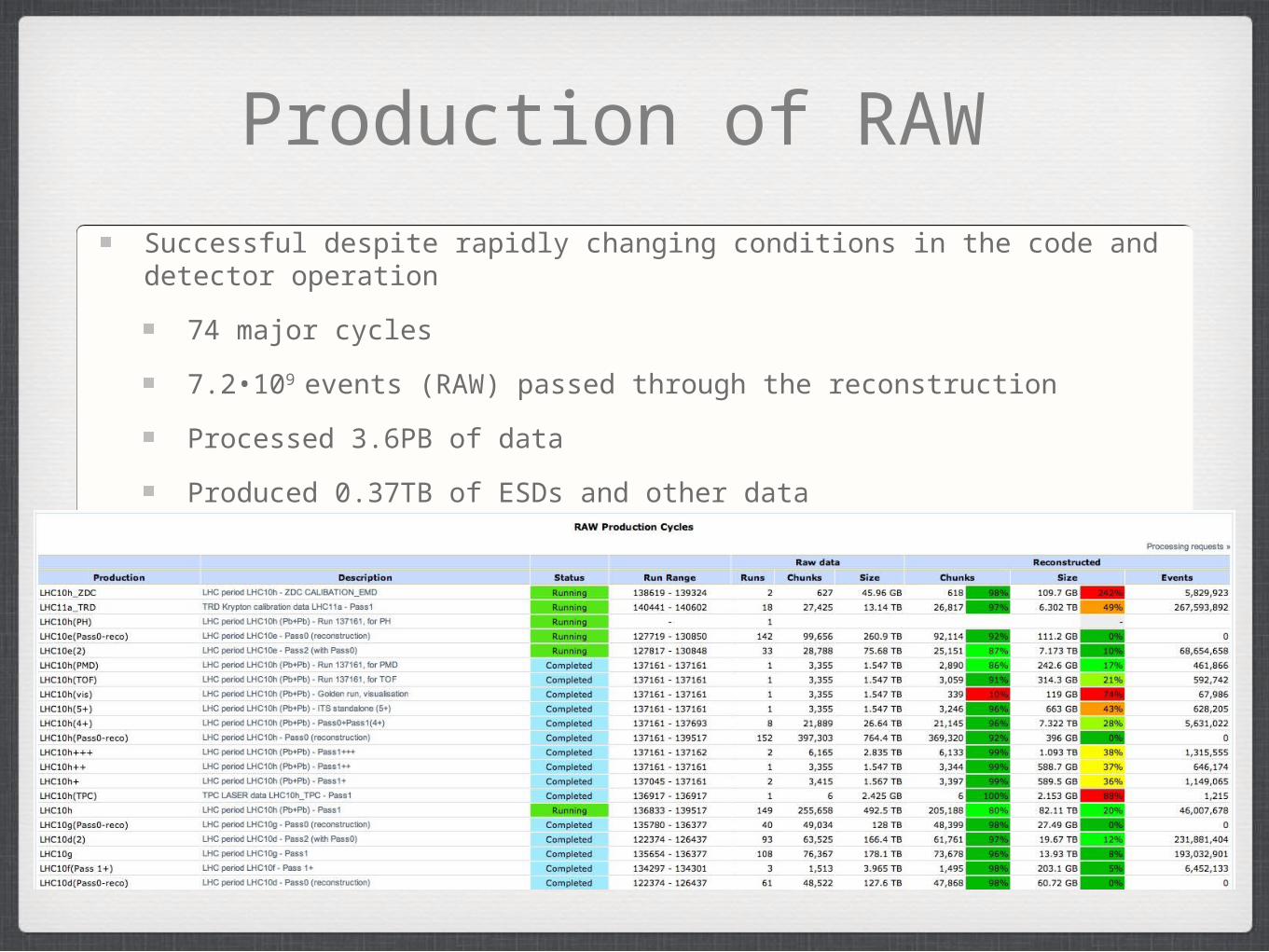
Production of RAW
Successful despite rapidly changing conditions in the code and detector operation
74 major cycles
7.2•109 events (RAW) passed through the reconstruction
Processed 3.6PB of data
Produced 0.37TB of ESDs and other data
17
ALICE central services
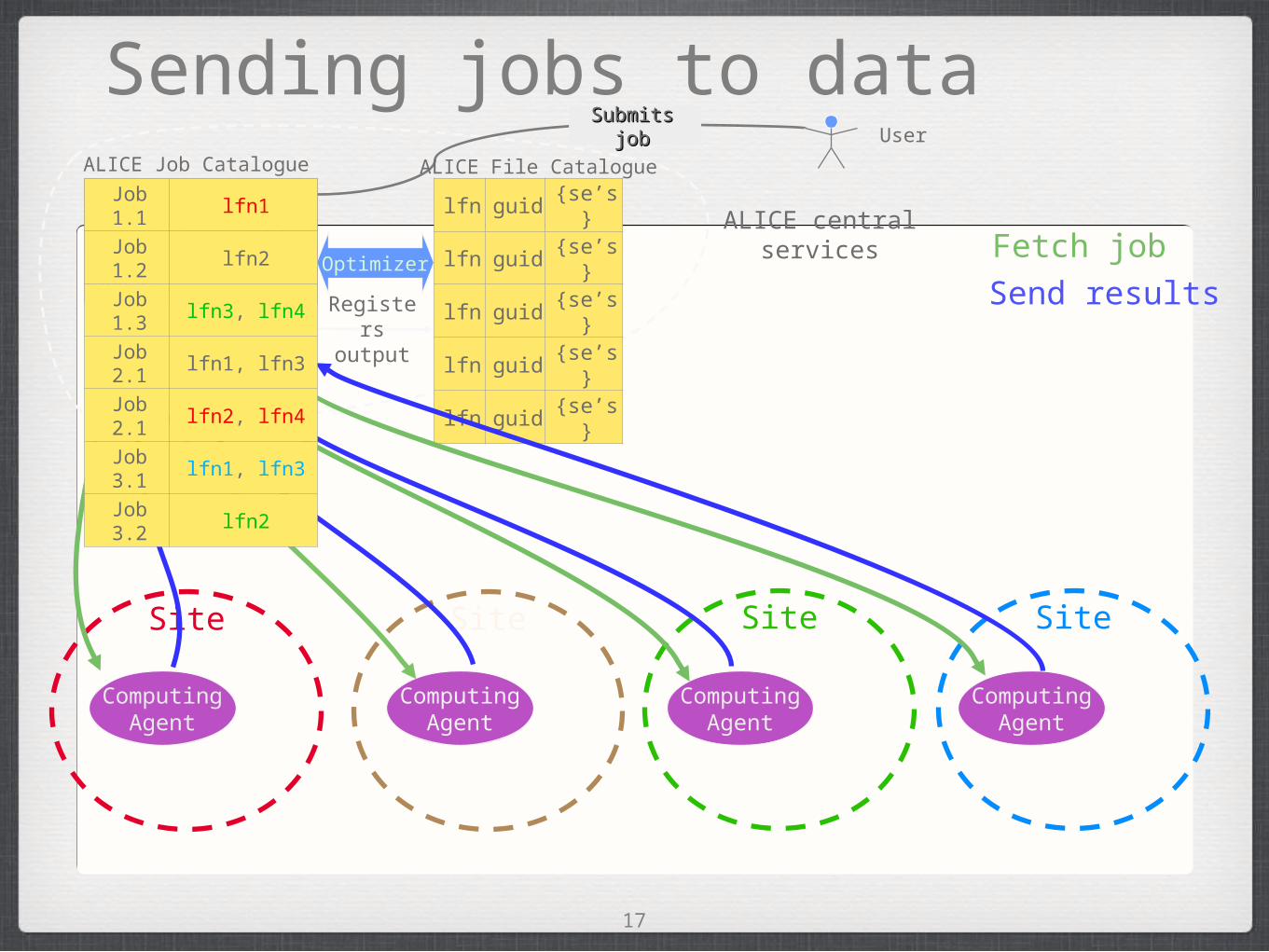
Sending jobs to data
Job 1lfn1, lfn2, lfn3,
lfn4
Job 2lfn1, lfn2, lfn3,
lfn4Job 3 lfn1, lfn2, lfn3 Optimizer
Submits Submits jobjob User
ALICE Job Catalogue
Registers output
lfn guid {se’s}
lfn guid {se’s}
lfn guid {se’s}
lfn guid {se’s}
lfn guid {se’s}
ALICE File Catalogue
ComputingAgent
Site Site
ComputingAgent
Site
ComputingAgent
Site
ComputingAgent
Send results
Fetch job
Job 1.1 lfn1
Job 1.2 lfn2
Job 1.3 lfn3, lfn4
Job 2.1 lfn1, lfn3
Job 2.1 lfn2, lfn4
Job 3.1 lfn1, lfn3
Job 3.2 lfn2
18
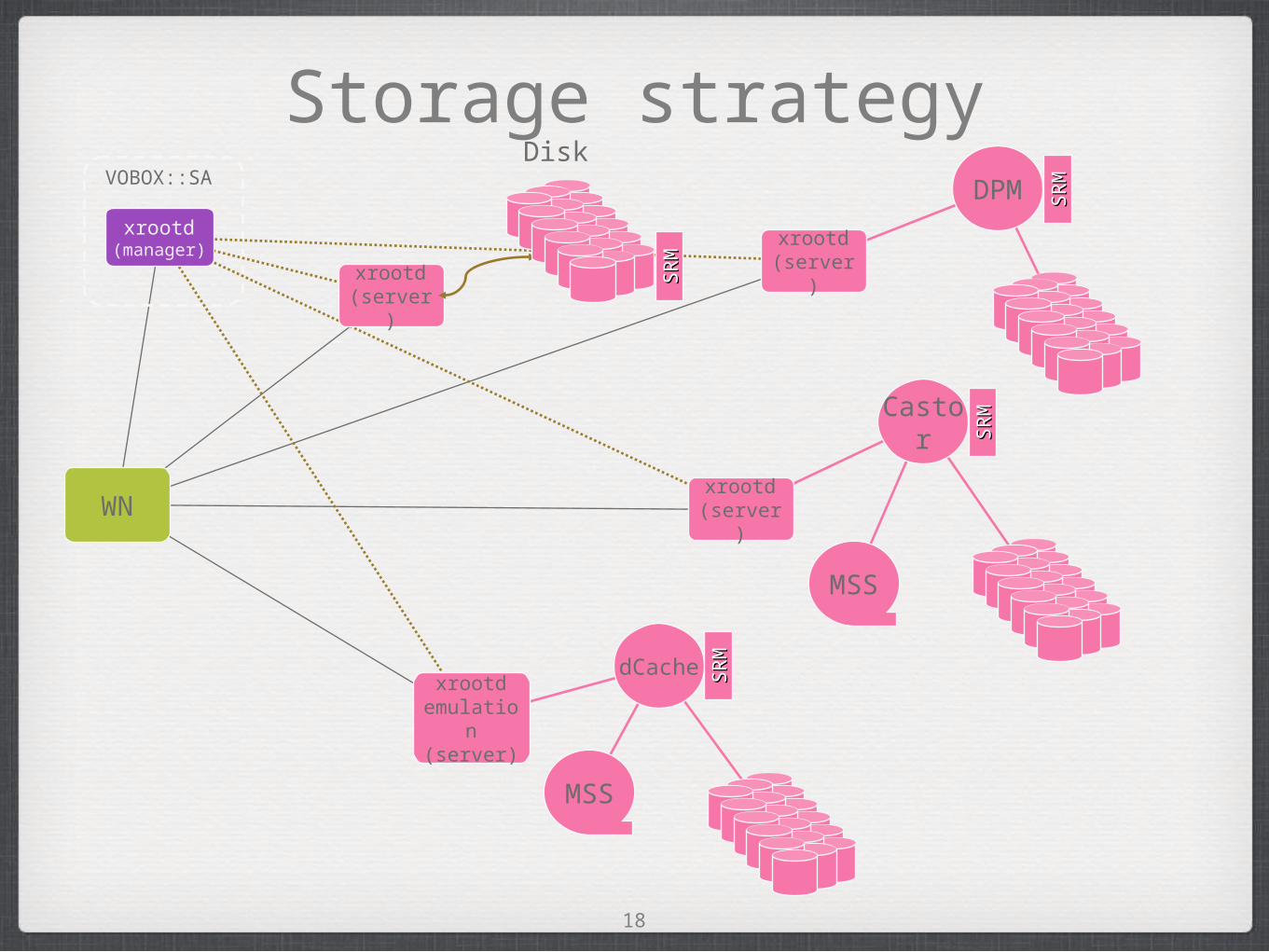
Storage strategy
WN
VOBOX::SA
xrootd (manager)
MSS
xrootd (server)
Disk
SR
MS
RM
xrootd (server)
DPM
xrootd (server)
Castor
SR
MS
RM
SR
MS
RM
MSS
xrootd emulation (server)
dCache
SR
MS
RM
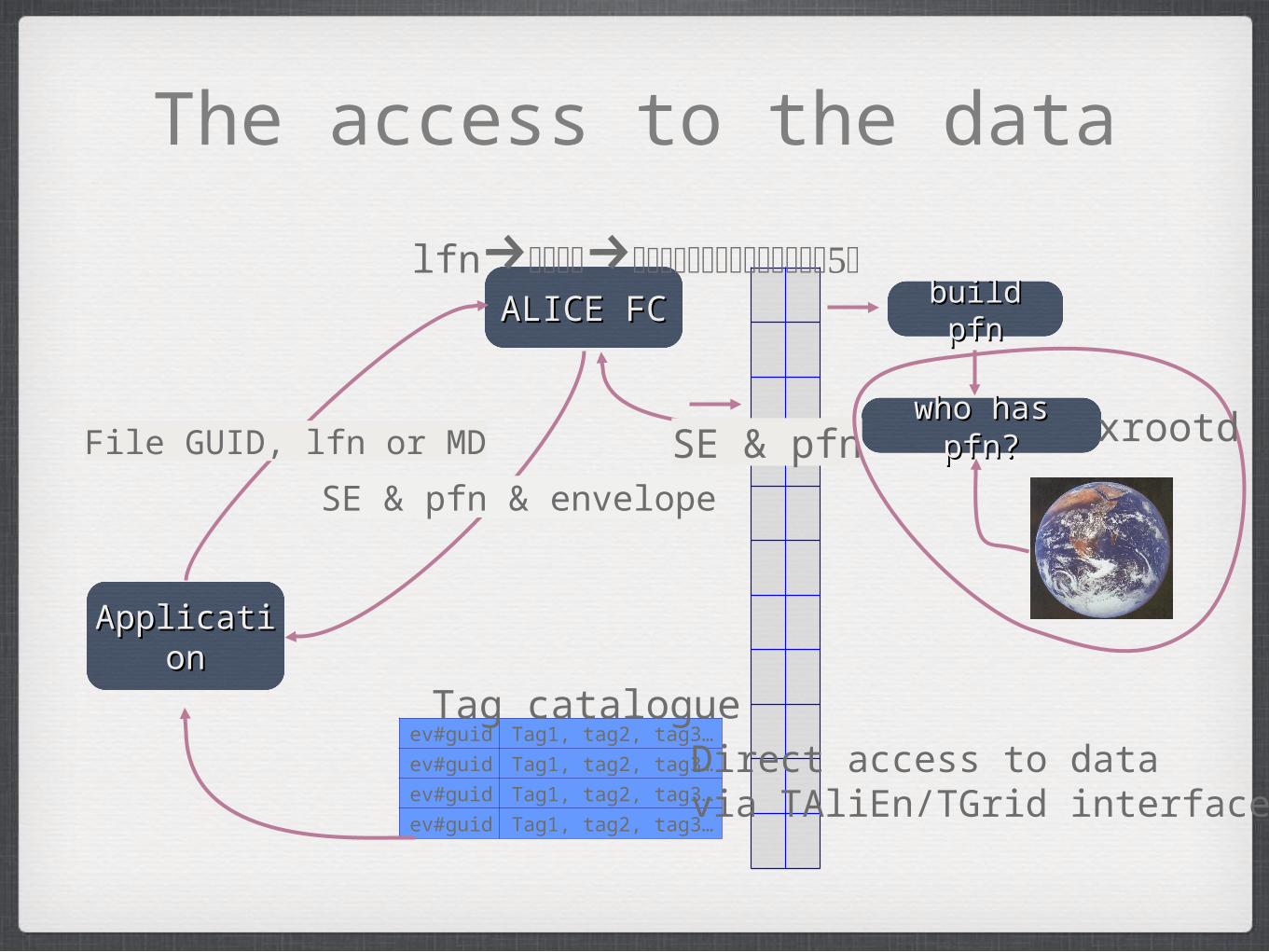
The access to the data
ApplicatioApplicationn
ALICE FCALICE FC
File GUID, lfn or MD
SE & pfn & envelope
lfn→→build pfnbuild pfn
who has pfn?who has pfn?SE & pfn xrootd
ev#guid Tag1, tag2, tag3…
ev#guid Tag1, tag2, tag3…
ev#guid Tag1, tag2, tag3…
ev#guid Tag1, tag2, tag3…
Tag catalogueDirect access to datavia TAliEn/TGrid interface
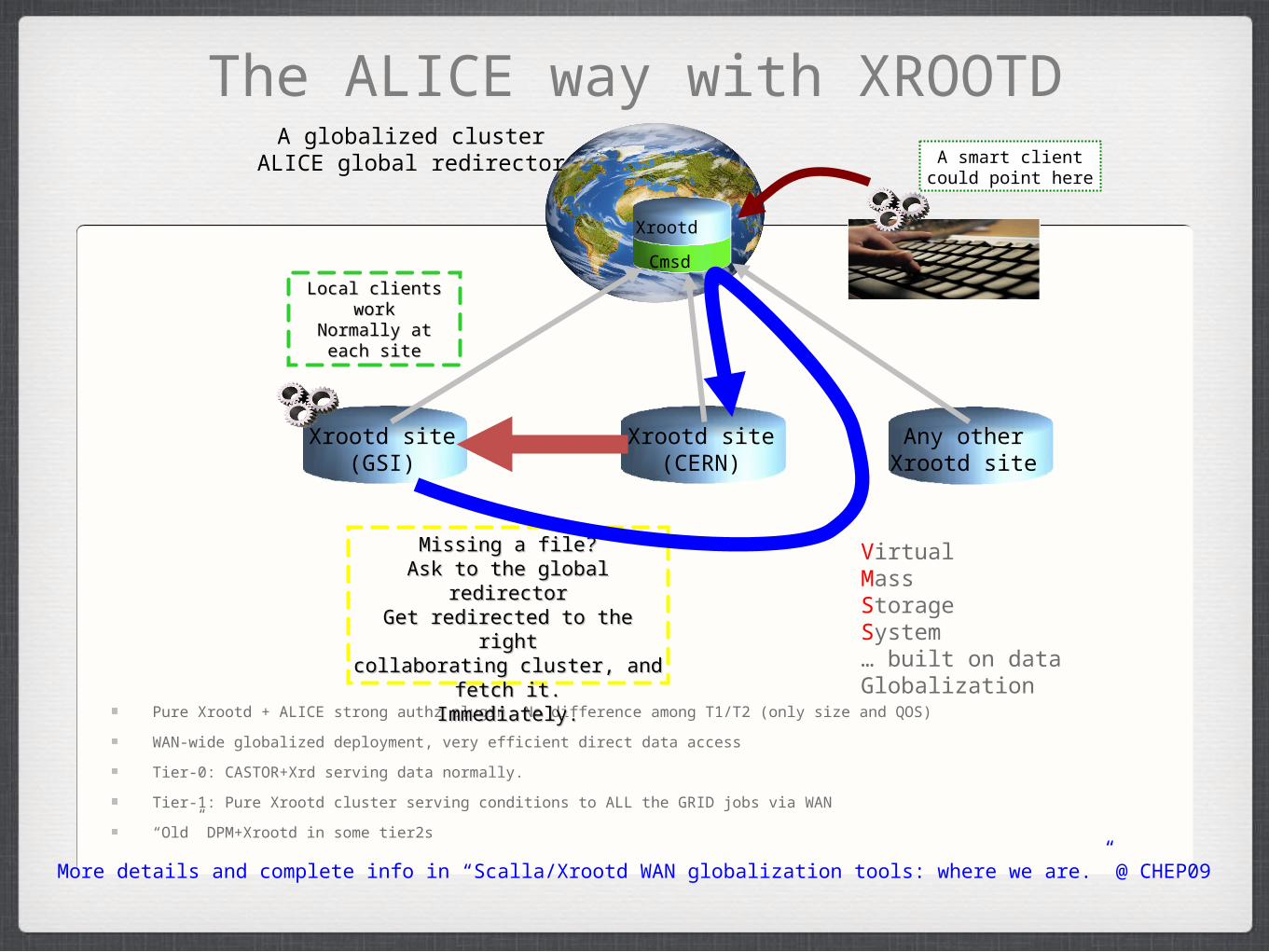
The ALICE way with XROOTD
Pure Xrootd + ALICE strong authz plugin. No difference among T1/T2 (only size and QOS)
WAN-wide globalized deployment, very efficient direct data access
Tier-0: CASTOR+Xrd serving data normally.
Tier-1: Pure Xrootd cluster serving conditions to ALL the GRID jobs via WAN
“Old” DPM+Xrootd in some tier2s
Xrootd site(GSI)
A globalized clusterALICE global redirector
Local clients workLocal clients workNormally at each Normally at each
sitesite
Missing a file?Missing a file?Ask to the global redirectorAsk to the global redirectorGet redirected to the rightGet redirected to the right
collaborating cluster, and fetch it.collaborating cluster, and fetch it.Immediately.Immediately.
A smart clientcould point here
Any otherXrootd site
Xrootd site(CERN)
Cmsd
Xrootd
VirtualMassStorageSystem… built on data Globalization
More details and complete info in “Scalla/Xrootd WAN globalization tools: where we are.” @ CHEP09
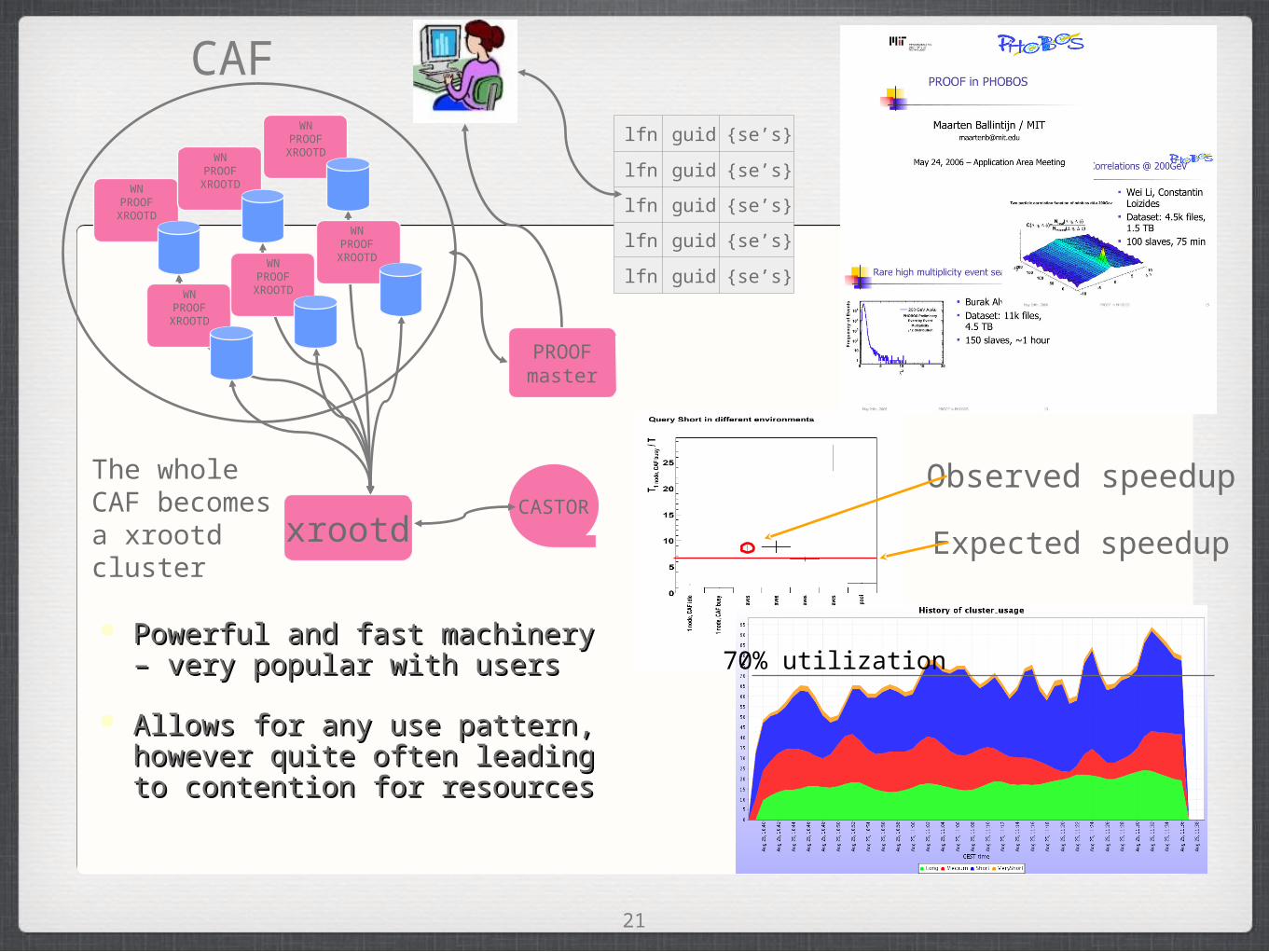
21
CAFlfn guid {se’s}
lfn guid {se’s}
lfn guid {se’s}
lfn guid {se’s}
lfn guid {se’s}
xrootdCASTOR
WNPROOF
XROOTD
WNPROOF
XROOTD
WNPROOF
XROOTD
WNPROOF
XROOTD
WNPROOF
XROOTD
WNPROOF
XROOTD
PROOF master
The whole CAF becomes a xrootd cluster
Powerful and fast machinery – Powerful and fast machinery – very popular with users very popular with users
Allows for any use pattern, Allows for any use pattern, however quite often leading to however quite often leading to contention for resourcescontention for resources
Expected speedup
Observed speedup
70% utilization
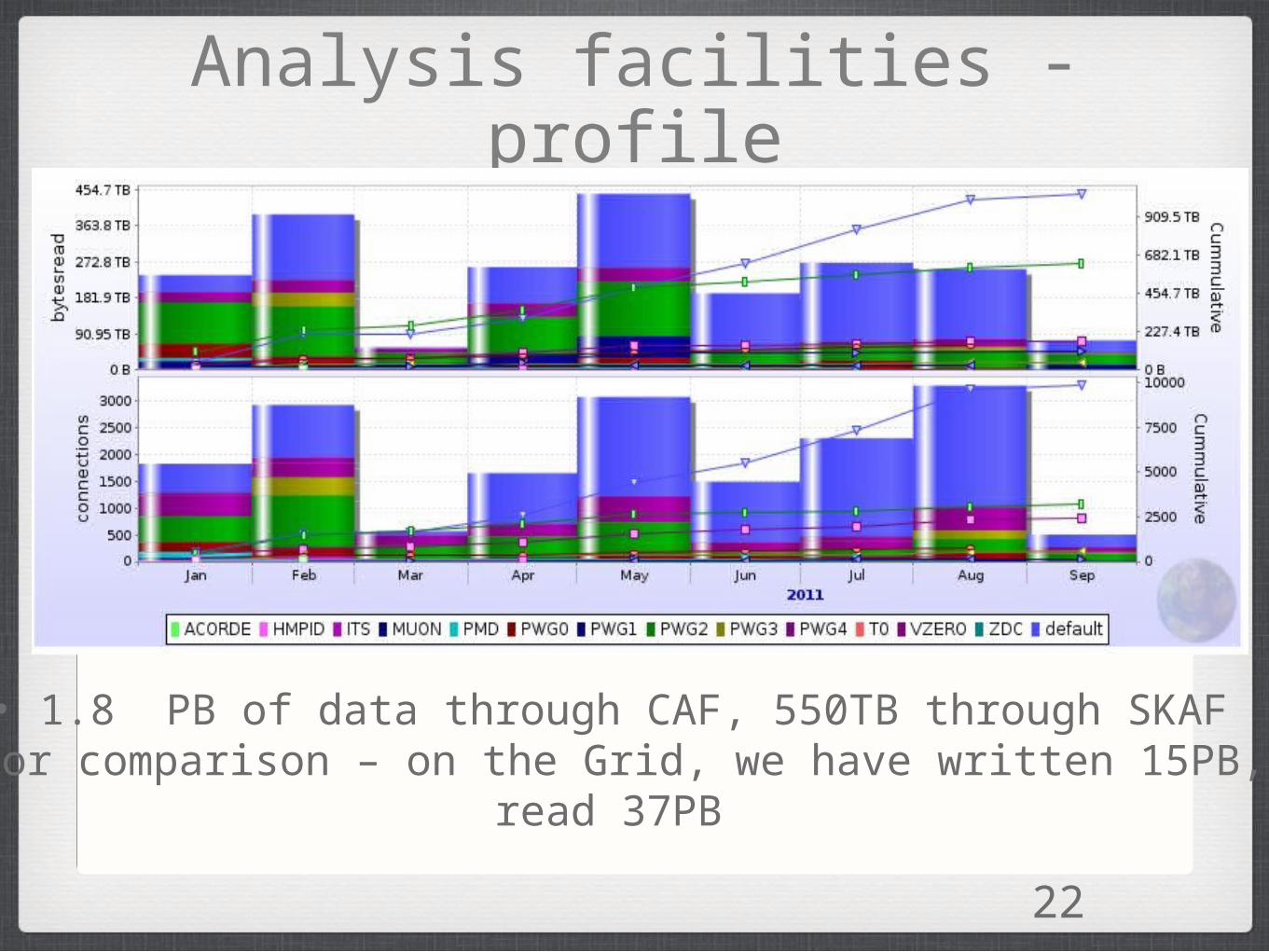
22
Analysis facilities - profile
• 1.8 PB of data through CAF, 550TB through SKAF• For comparison – on the Grid, we have written 15PB,
read 37PB

The ALICE Grid
AliEn working prototype in 2002
Single interface to distributed computing for all ALICE physicists
File catalogue, job submission and control, software management, user analysis
~80 participating sites now
1 T0 (CERN/Switzerland)
6 T1s (France, Germany, Italy, The Netherlands, Nordic DataGrid Facility, UK)
KISTI and UNAM coming (!)
~73 T2s spread over 4 continents
~30,000 (out of ~150,000 WLCG) cores and 8.5 PB of disk
Resources are “pooled” together
No localization of roles / functions
National resources must integrate seamlessly into the global grid to be accounted for
FAs contribute proportionally to the number of PhDs (M&O-A share)
T3s have the same role than T2s, even if they do not sign the MoU
http://alien.cern.ch
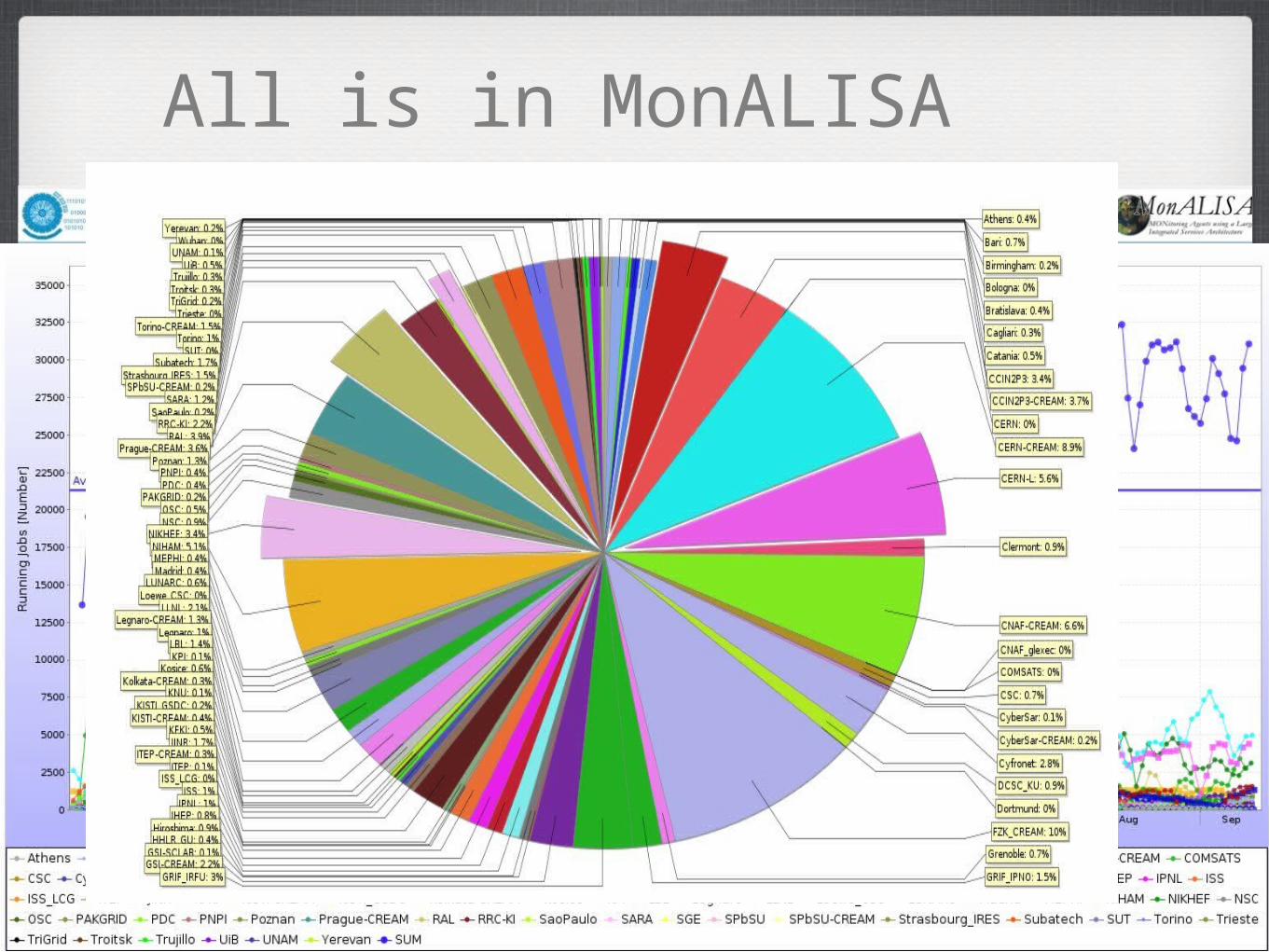
All is in MonALISA
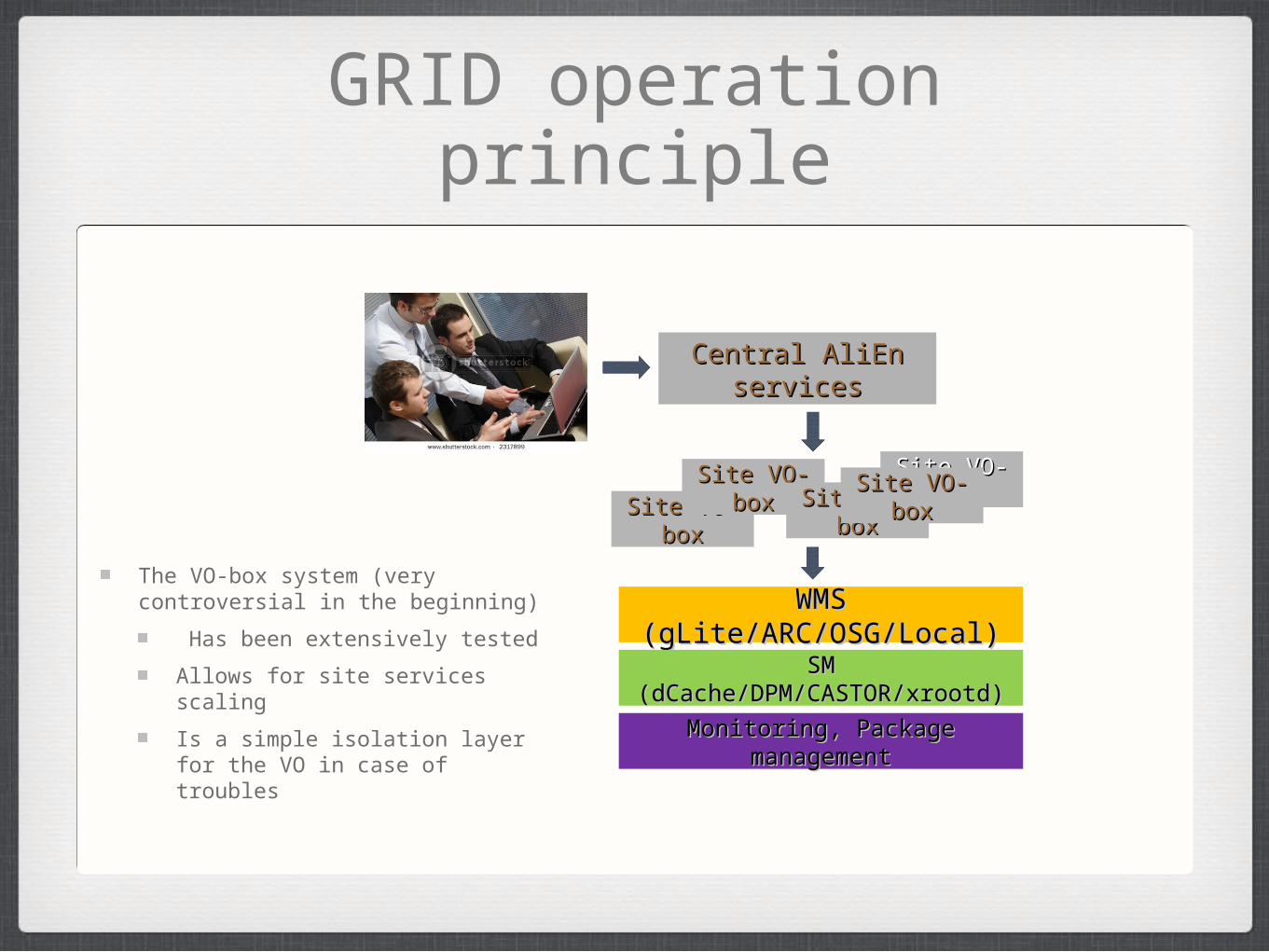
GRID operation principle
Central AliEn Central AliEn servicesservices
Site VO-boxSite VO-boxSite VO-boxSite VO-box Site VO-Site VO-boxbox
Site VO-boxSite VO-boxSite VO-boxSite VO-box
WMS (gLite/ARC/OSG/Local)WMS (gLite/ARC/OSG/Local)
SM (dCache/DPM/CASTOR/xrootd)SM (dCache/DPM/CASTOR/xrootd)
Monitoring, Package Monitoring, Package managementmanagement
The VO-box system (very controversial in the beginning)
Has been extensively tested
Allows for site services scaling
Is a simple isolation layer for the VO in case of troubles

Operation – central/site support
Central services support (2 FTEs equivalent)
There are no experts which do exclusively support – there are 6 highly-qualified experts doing development/support
Site services support - handled by ‘regional experts’ (one per country) in collaboration with local cluster administrators
Extremely important part of the system
In normal operation ~0.2FTEs/site
Regular weekly discussions and active all-activities mailing lists

Summary
• ALICE offline framework (AliRoot) is mature project that covers simulation, reconstruction, calibration, alignment, visualization and analysis
• Successful operation with “real data” since 2009• The results for several major physics
conferences were obtained in time• The Grid and AF resources are adequate to serve the
RAW/MC and user analysis tasks• More resources would be better of course
• The sites operation is very stable• The gLite (EMI now) software is mature and
few changes are necessary
Some PhilosophySome Philosophy

29
The codeThe code• Move to C++ was probably inevitable
• But it made a lot of “collateral damage”• Learning process was long, and it is still going on• Very difficult to judge what would have happened “had root
not been there”
• The most difficult question is now “what next”• A new language? there is none at the horizon• Different languages for different scopes (python, java, C,
CUDA…) just think about debugging• A better discipline in using C++ (in ALICE no STL /
templates)
• Code management tools, build systems, (c)make, autotools
• Still a lot of “glue” has to be provided, no comprehensive system “out of the box”
• Move to C++ was probably inevitable• But it made a lot of “collateral damage”• Learning process was long, and it is still going on• Very difficult to judge what would have happened “had root
not been there”
• The most difficult question is now “what next”• A new language? there is none at the horizon• Different languages for different scopes (python, java, C,
CUDA…) just think about debugging• A better discipline in using C++ (in ALICE no STL /
templates)
• Code management tools, build systems, (c)make, autotools
• Still a lot of “glue” has to be provided, no comprehensive system “out of the box”

30
The GridThe Grid• A half empty glass
• We are still far from the “Vision”• A lot of tinkering and hand-holding to keep it alive• 4+1 solutions for each problem• We are just seeing now some light at the end of the
tunnel of data management
• The half full glass• We are using the Grid as a “distributed heterogeneous
collection of high-end resources”, which was the idea after all
• LHC physics is being produced by the Grid
• A half empty glass• We are still far from the “Vision”• A lot of tinkering and hand-holding to keep it alive• 4+1 solutions for each problem• We are just seeing now some light at the end of the
tunnel of data management
• The half full glass• We are using the Grid as a “distributed heterogeneous
collection of high-end resources”, which was the idea after all
• LHC physics is being produced by the Grid

31
Grid need-to-haveGrid need-to-have• Far more automation and resilience
• Make the Grid less manpower intensive
• More integration between workload management and data placement
• Better control of upgrades (OS, MW)• Or better transparent integration of different OS/MW
• Integration of the network as an active, provisionable resource
• “Close” storage element, file replication / caching vs remote access
• Better monitoring• Or perhaps simply more coherent monitoring...
• Far more automation and resilience• Make the Grid less manpower intensive
• More integration between workload management and data placement
• Better control of upgrades (OS, MW)• Or better transparent integration of different OS/MW
• Integration of the network as an active, provisionable resource
• “Close” storage element, file replication / caching vs remote access
• Better monitoring• Or perhaps simply more coherent monitoring...
Recommended

















