
Faster!Faster!
Vidhyashankar VenkataramanVidhyashankar Venkataraman
CS614 PresentationCS614 Presentation

U-Net : A User-Level Network U-Net : A User-Level Network Interface for Parallel and Interface for Parallel and Distributed ComputingDistributed Computing

Background – Fast ComputingBackground – Fast Computing
Emergence of MPP – Massively Parallel Processors in Emergence of MPP – Massively Parallel Processors in the early 90’sthe early 90’s
Repackage hardware components to form a dense configuration Repackage hardware components to form a dense configuration of very large parallel computing systemsof very large parallel computing systems
But require custom software But require custom software
Alternative : Alternative : NOWNOW (Berkeley) – Network Of Workstations (Berkeley) – Network Of Workstations Formed by inexpensive, low latency, high bandwidth, scalable, Formed by inexpensive, low latency, high bandwidth, scalable,
interconnect networks of workstationsinterconnect networks of workstations Interconnected through fast switchesInterconnected through fast switches Challenge: To build a scalable system that is able to use the Challenge: To build a scalable system that is able to use the
aggregate resources in the network to execute parallel programs aggregate resources in the network to execute parallel programs efficientlyefficiently

IssuesIssues
Problem with traditional networking architecturesProblem with traditional networking architectures Software path through kernel involves several copies Software path through kernel involves several copies
- processing overhead- processing overhead In faster networks, may not get application speed-up In faster networks, may not get application speed-up
commensurate with network performancecommensurate with network performance
Observations:Observations: Small messages : Processing overhead is more Small messages : Processing overhead is more
dominant than network latencydominant than network latency Most applications use small messagesMost applications use small messages
Eg.. UCB NFS Trace : 50% of bits sent were messages of Eg.. UCB NFS Trace : 50% of bits sent were messages of size 200 bytes or lesssize 200 bytes or less

Issues (contd.)Issues (contd.)
Flexibility concerns:Flexibility concerns: Protocol processing in kernelProtocol processing in kernel Greater flexibility if application specific Greater flexibility if application specific
information is integrated into protocol information is integrated into protocol processingprocessing
Can tune protocol to application’s needsCan tune protocol to application’s needs Eg.. Customized retransmission of video Eg.. Customized retransmission of video
framesframes

U-Net PhilosophyU-Net Philosophy
Achieve flexibility and performance byAchieve flexibility and performance by Removing kernel from the critical path Removing kernel from the critical path Placing entire protocol stack at user levelPlacing entire protocol stack at user level Allowing Allowing protectedprotected user-level access to user-level access to
networknetwork Supplying full bandwidth to small messagesSupplying full bandwidth to small messages Supporting both novel and legacy protocolsSupporting both novel and legacy protocols

Do MPPs do this?Do MPPs do this?
Parallel machines like Meiko CS-2, Thinking Parallel machines like Meiko CS-2, Thinking Machines CM-5Machines CM-5 Have tried to solve the problem of providing user-level Have tried to solve the problem of providing user-level
access to networkaccess to network Use of custom network and network interface – No Use of custom network and network interface – No
flexibilityflexibility
U-Net targets applications on standard U-Net targets applications on standard workstationsworkstations Using off-the-shelf componentsUsing off-the-shelf components

Basic U-Net architectureBasic U-Net architecture
Virtualize N/W device so Virtualize N/W device so that each process has that each process has illusion of owning NIillusion of owning NI
Mux/ Demuxing device Mux/ Demuxing device virtualizes the NIvirtualizes the NI
Offers protection!Offers protection!
Kernel removed from Kernel removed from critical pathcritical path
Kernel involved only in Kernel involved only in setupsetup
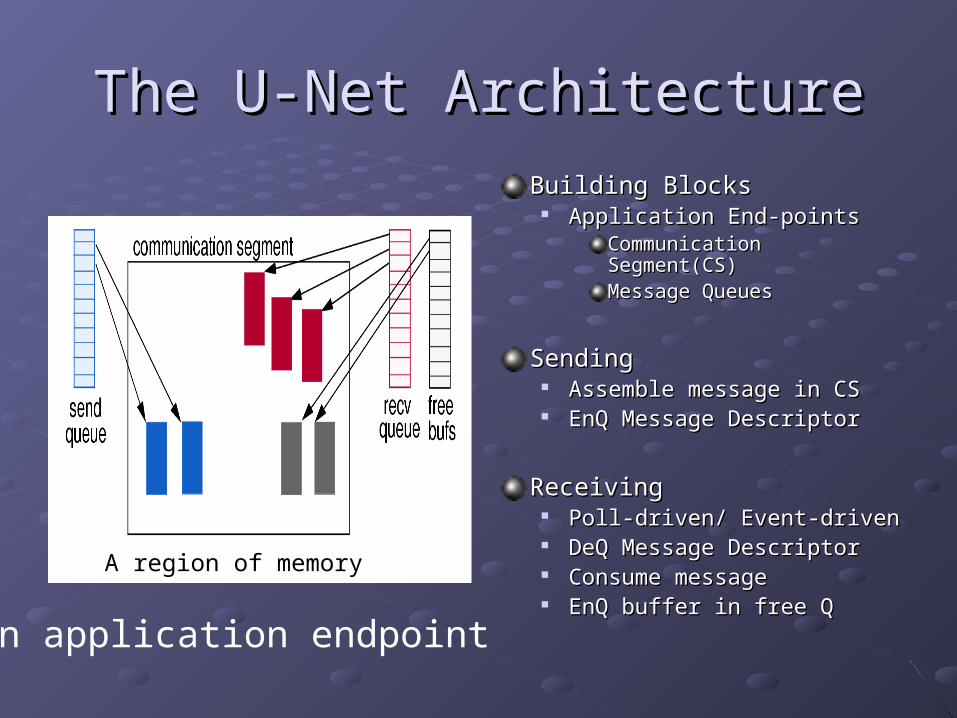
The U-Net ArchitectureThe U-Net Architecture
Building BlocksBuilding Blocks Application End-pointsApplication End-points
Communication Segment(CS)Communication Segment(CS)Message QueuesMessage Queues
SendingSending Assemble message in CSAssemble message in CS EnQ Message DescriptorEnQ Message Descriptor
ReceivingReceiving Poll-driven/ Event-drivenPoll-driven/ Event-driven DeQ Message DescriptorDeQ Message Descriptor Consume messageConsume message EnQ buffer in free QEnQ buffer in free Q
An application endpoint
A region of memory

U-Net Architecture (contd.)U-Net Architecture (contd.)
More on event-handling (upcalls)More on event-handling (upcalls) Can be UNIX signal handler or user-level interrupt handlerCan be UNIX signal handler or user-level interrupt handler Amortize cost of upcalls by batching receptionsAmortize cost of upcalls by batching receptions
Mux/ Demux :Mux/ Demux : Each endpoint uniquely identified by a tag (eg.. VCI in ATM)Each endpoint uniquely identified by a tag (eg.. VCI in ATM) OS performs initial route setup and security tests and registers a OS performs initial route setup and security tests and registers a
tag in U-Net for that applicationtag in U-Net for that application The message tag mapped to a communication channel The message tag mapped to a communication channel

ObservationsObservations
Have to preallocate buffers – memory overhead!Have to preallocate buffers – memory overhead!
Protected User-level access to NI : Ensured by Protected User-level access to NI : Ensured by demarcating into protection boundariesdemarcating into protection boundaries Defined by endpoints and communication channelsDefined by endpoints and communication channels
Applications cannot interfere with each other because Applications cannot interfere with each other because Endpoints, CS and message queues user-ownedEndpoints, CS and message queues user-ownedOutgoing messages tagged with originating endpoint Outgoing messages tagged with originating endpoint address address Incoming messages demuxed by U-Net and sent to correct Incoming messages demuxed by U-Net and sent to correct endpointendpoint

Zero-copy and True zero-copyZero-copy and True zero-copy
Two levels of sophistication depending on whether copy Two levels of sophistication depending on whether copy is made at CSis made at CS
Base-Level ArchitectureBase-Level ArchitectureZero-copy : Copied in an intermediate buffer in the CS Zero-copy : Copied in an intermediate buffer in the CS CS’es are allocated, aligned, pinned to physical memoryCS’es are allocated, aligned, pinned to physical memoryOptimization for small messagesOptimization for small messages
Direct-access ArchitectureDirect-access ArchitectureTrue zero copy : Data sent directly out of data structureTrue zero copy : Data sent directly out of data structureAlso specify offset where data has to be depositedAlso specify offset where data has to be depositedCS spans the entire process address spaceCS spans the entire process address space
Limitations in I/O Addressing force one to resort to Zero-Limitations in I/O Addressing force one to resort to Zero-copycopy
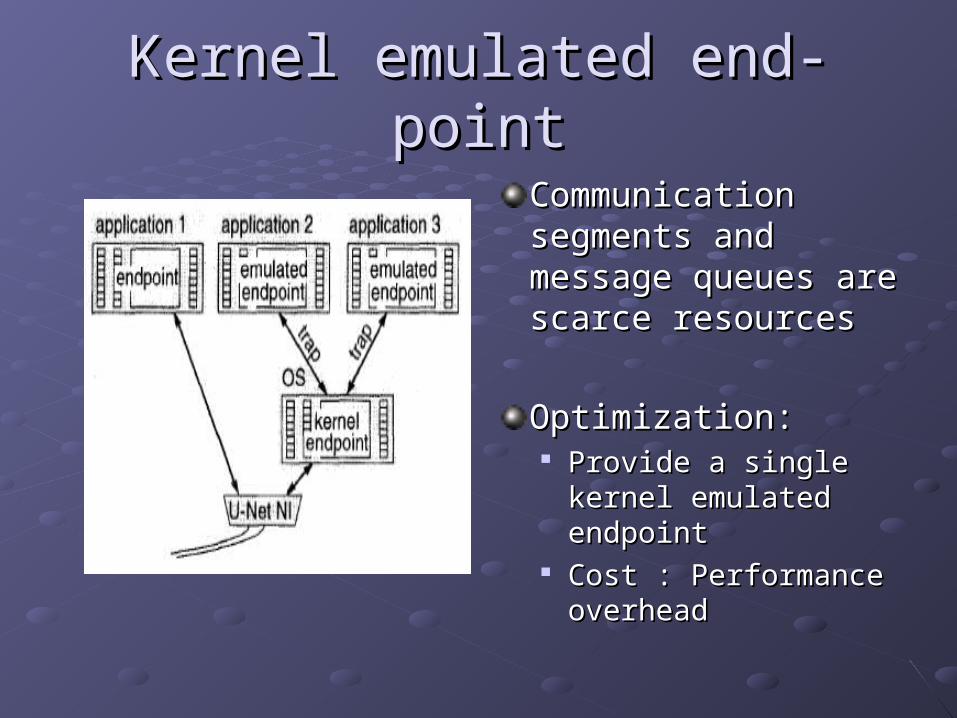
Kernel emulated end-pointKernel emulated end-point
Communication Communication segments and segments and message queues are message queues are scarce resourcesscarce resources
Optimization: Optimization: Provide a single kernel Provide a single kernel
emulated endpointemulated endpoint Cost : Performance Cost : Performance
overheadoverhead

U-Net ImplementationU-Net Implementation
U-Net architectures implemented in two systems U-Net architectures implemented in two systems Using Fore Systems SBA 100 and 200 ATM network interfacesUsing Fore Systems SBA 100 and 200 ATM network interfaces But why ATM?But why ATM? Setup : SPARCStations 10 and 20 on SunOS 4.1.3 with ASX-Setup : SPARCStations 10 and 20 on SunOS 4.1.3 with ASX-
200 ATM switch with 140 Mbps fiber links200 ATM switch with 140 Mbps fiber links
SBA-200 firmwareSBA-200 firmware 25 MHz On-board i960 processor, 256 KB RAM, DMA 25 MHz On-board i960 processor, 256 KB RAM, DMA
capabilitiescapabilities Complete redesign of firmwareComplete redesign of firmware
Device DriverDevice Driver Protection offered through VM system (CS’es)Protection offered through VM system (CS’es) Also through <VCI, communication channel> mappingsAlso through <VCI, communication channel> mappings
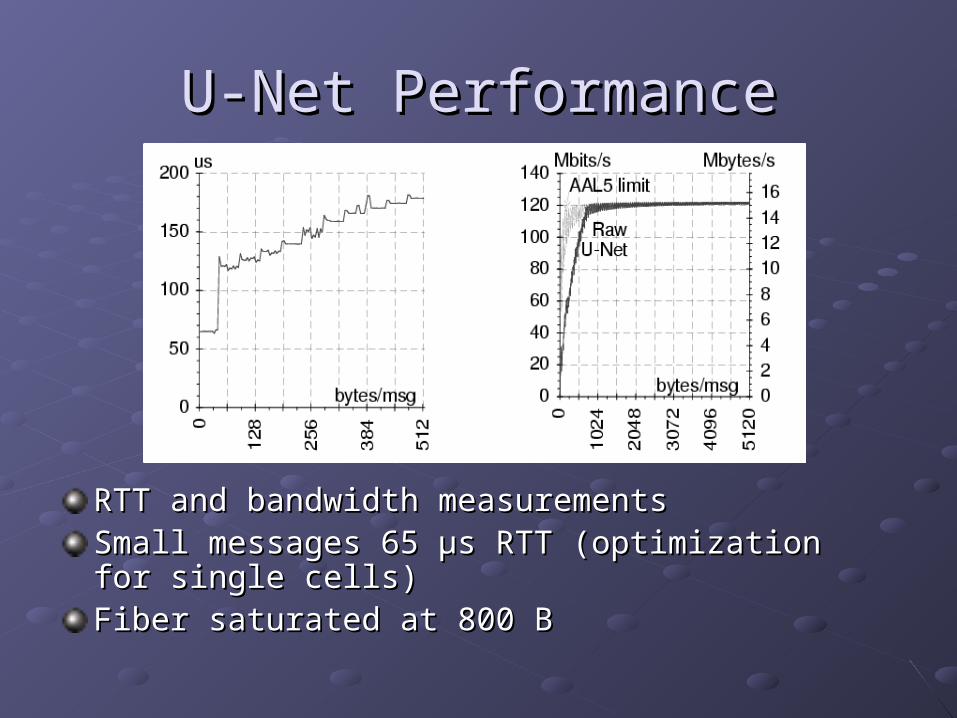
U-Net PerformanceU-Net Performance
RTT and bandwidth measurementsRTT and bandwidth measurementsSmall messages 65 Small messages 65 μμs RTT (optimization for single s RTT (optimization for single cells)cells)Fiber saturated at 800 BFiber saturated at 800 B

U-Net Active Messages LayerU-Net Active Messages Layer
An RPC that can be implemented efficiently on a wide An RPC that can be implemented efficiently on a wide range of hardwarerange of hardware
A basic communication primitive in NOWA basic communication primitive in NOW
Allow overlapping of communication with computationAllow overlapping of communication with computation
Message contains data & ptr to handlerMessage contains data & ptr to handler Reliable Message deliveryReliable Message delivery Handler moves data into data structures for some (ongoing) Handler moves data into data structures for some (ongoing)
operationoperation
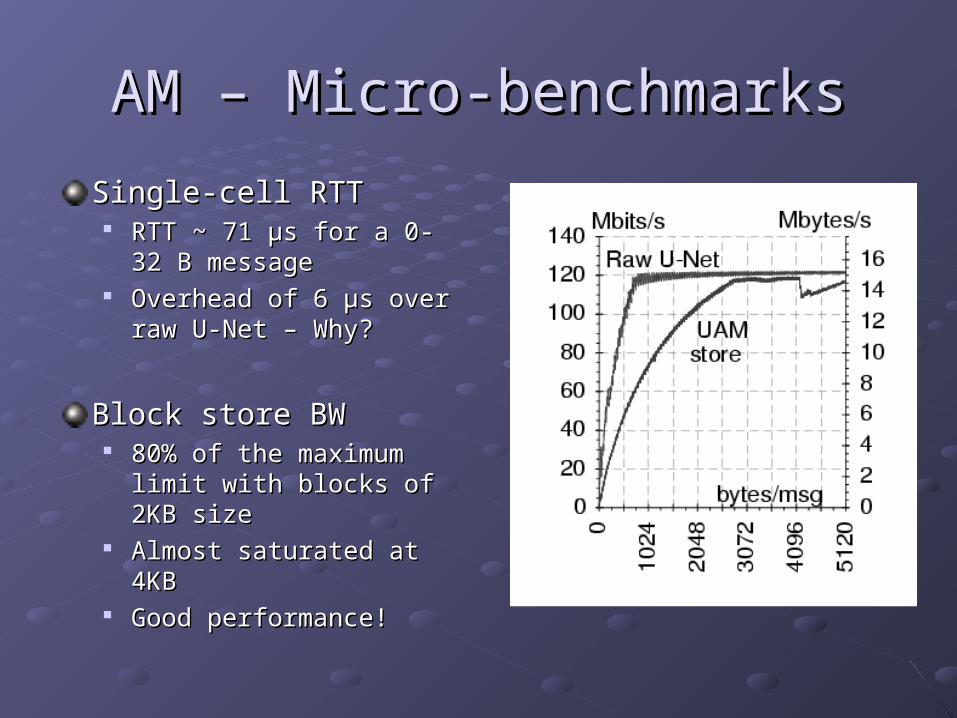
AM – Micro-benchmarksAM – Micro-benchmarks
Single-cell RTTSingle-cell RTT RTT ~ 71 RTT ~ 71 μμs for a 0-32 B s for a 0-32 B
messagemessage Overhead of 6 Overhead of 6 μμs over raw s over raw
U-Net – Why?U-Net – Why?
Block store BWBlock store BW 80% of the maximum limit 80% of the maximum limit
with blocks of 2KB sizewith blocks of 2KB size Almost saturated at 4KBAlmost saturated at 4KB Good performance!Good performance!
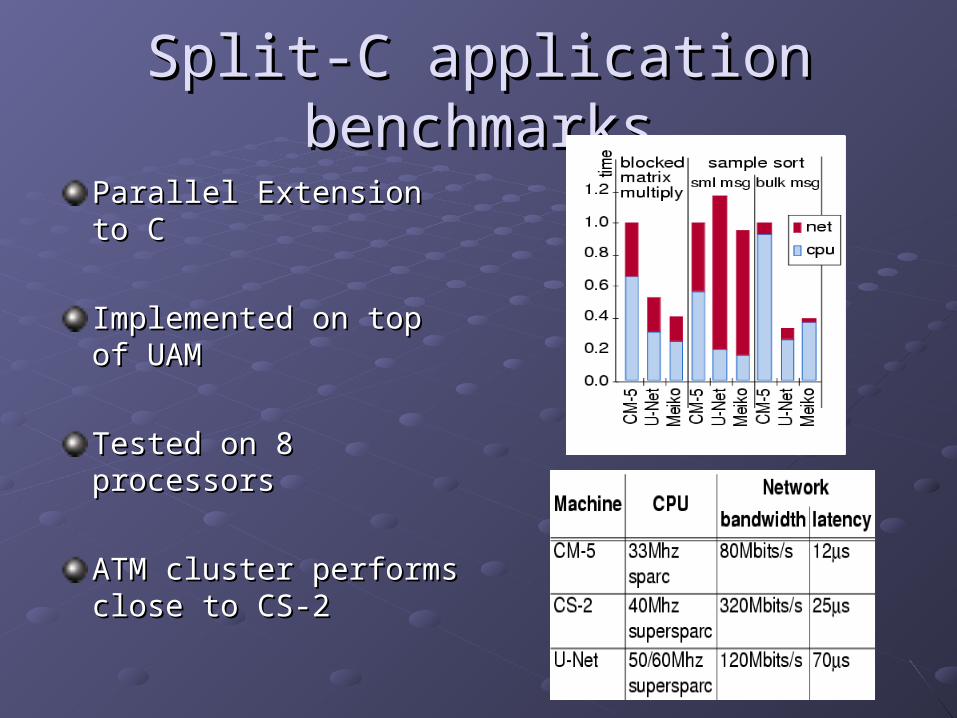
Split-C application benchmarksSplit-C application benchmarks
Parallel Extension to CParallel Extension to C
Implemented on top of Implemented on top of UAMUAM
Tested on 8 processorsTested on 8 processors
ATM cluster performs ATM cluster performs close to CS-2close to CS-2

TCP/IP and UDP/IP over U-NetTCP/IP and UDP/IP over U-Net
Good performance necessary to show flexibilityGood performance necessary to show flexibility
Traditional IP-over-ATM shows very poor performance Traditional IP-over-ATM shows very poor performance eg.. TCP : Only 55% of max BWeg.. TCP : Only 55% of max BW
TCP and UDP over U-Net show improved performanceTCP and UDP over U-Net show improved performance Primarily because of tighter application-network couplingPrimarily because of tighter application-network coupling
IP-over-U-Net:IP-over-U-Net: IP-over-ATM does not exactly correspond to IP-over-UNetIP-over-ATM does not exactly correspond to IP-over-UNet Demultiplexing for the same VCI is not possibleDemultiplexing for the same VCI is not possible
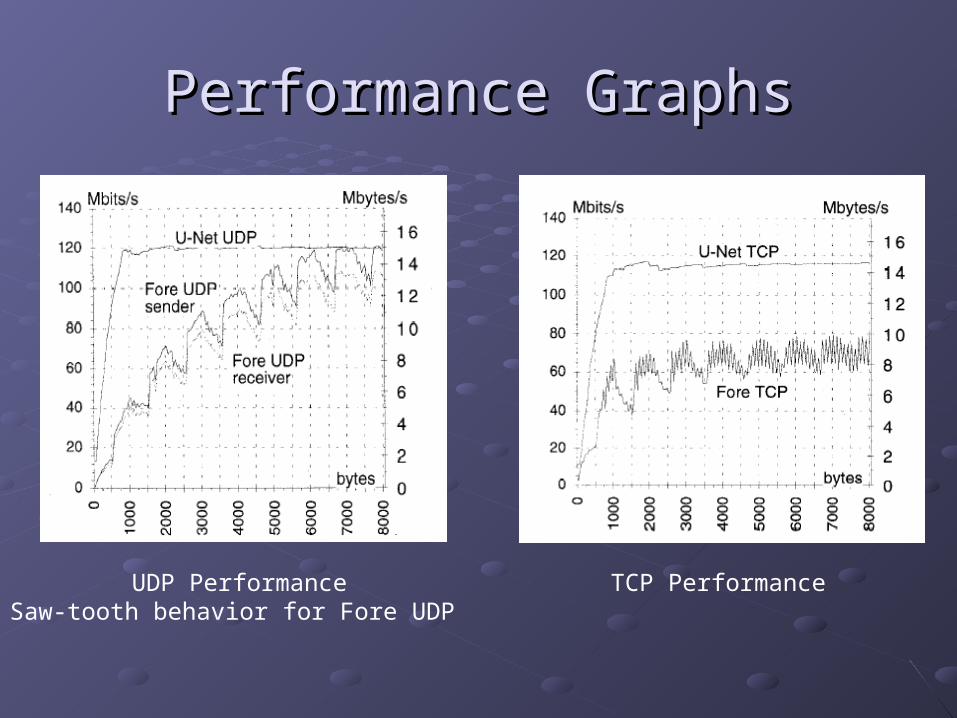
Performance GraphsPerformance Graphs
UDP PerformanceSaw-tooth behavior for Fore UDP
TCP Performance

ConclusionConclusion
U-Net provides virtual view of network interface to enable user-U-Net provides virtual view of network interface to enable user-level access to high-speed communication deviceslevel access to high-speed communication devices
The two main goals were to achieve performance and flexibilityThe two main goals were to achieve performance and flexibility By avoiding kernel in critical pathBy avoiding kernel in critical path Achieved? Look at the table below…Achieved? Look at the table below…

Lightweight Remote Procedure Lightweight Remote Procedure CallsCalls

MotivationMotivation
Small kernel OSes have most services implemented as Small kernel OSes have most services implemented as separate user-level processesseparate user-level processes
Have separate, communicating user processesHave separate, communicating user processes Improve modular structureImprove modular structure More protectionMore protection Ease of system design and maintenanceEase of system design and maintenance
Cross-domain & cross-machine communication treated Cross-domain & cross-machine communication treated equal - Problems?equal - Problems?
Fails to Fails to isolate the common case isolate the common case Performance and Simplicity considerationsPerformance and Simplicity considerations

MeasurementsMeasurements
Measurements show cross-domain predominanceMeasurements show cross-domain predominance V System – 97%V System – 97% Taos Firefly – 94%Taos Firefly – 94% Sun UNIX+NFS Diskless – 99.4%Sun UNIX+NFS Diskless – 99.4%
But how about RPCs these days?But how about RPCs these days?
Taos takes 109 Taos takes 109 μμs for a Null() local call and 464 s for a Null() local call and 464 μμs for s for RPC – 3.5x overheadRPC – 3.5x overhead
Most interactions are simple with small numbers of Most interactions are simple with small numbers of argumentsarguments
This could be used to make optimizationsThis could be used to make optimizations

Overheads in Cross-domain CallsOverheads in Cross-domain Calls
Stub Overhead – Additional execution pathStub Overhead – Additional execution path
Message buffer overhead – Cross-domain calls Message buffer overhead – Cross-domain calls can involve four copy operations for any RPCcan involve four copy operations for any RPC
Context switch – VM context switch from client’s Context switch – VM context switch from client’s domain to the server’s and vice versa on returndomain to the server’s and vice versa on return
Scheduling – Abstract and Concrete threadsScheduling – Abstract and Concrete threads

Available solutions?Available solutions?
Eliminating kernel copies (DASH system)Eliminating kernel copies (DASH system)
Handoff scheduling (Mach and Taos)Handoff scheduling (Mach and Taos)
In SRC RPC : In SRC RPC : Message buffers globally shared!Message buffers globally shared! Trades safety for performanceTrades safety for performance

Solution proposed : LRPCsSolution proposed : LRPCs
Written for the Firefly system Written for the Firefly system
Mechanism for communication between protection Mechanism for communication between protection domains in the same systemdomains in the same system
Motto : Strive for performance without foregoing safetyMotto : Strive for performance without foregoing safety
Basic Idea : Similar to RPCs but,Basic Idea : Similar to RPCs but, Do not context switch to server threadDo not context switch to server thread
Change the context of the client thread instead, to reduce Change the context of the client thread instead, to reduce overheadoverhead

Overview of LRPCsOverview of LRPCs
DesignDesign Client calls server through kernel trapClient calls server through kernel trap
Kernel validates callerKernel validates caller
Kernel dispatches client thread directly to server’s domainKernel dispatches client thread directly to server’s domain
Client provides server with a shared argument stack and its own Client provides server with a shared argument stack and its own threadthread
Return through the kernel to the callerReturn through the kernel to the caller
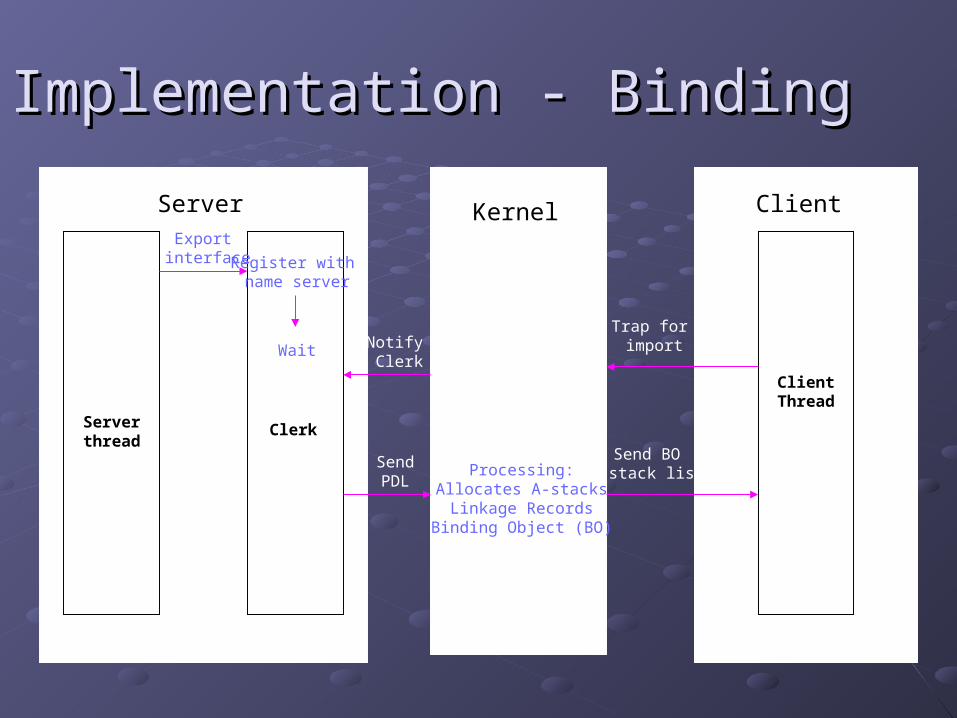
Implementation - BindingImplementation - Binding
Client Thread
Kernel
Server thread
Clerk
Export interface Register with
name server
Wait
Trap for importNotify
Clerk
SendPDL
Processing:Allocates A-stacksLinkage Records
Binding Object (BO)
Send BOA-stack list
ClientServer

Data Structures used and createdData Structures used and created
Kernel receives Kernel receives Procedure Descriptor ListProcedure Descriptor List (PDL) from (PDL) from ClerkClerk
Contains a PD for each procedureContains a PD for each procedureEntry Address apart from other informationEntry Address apart from other information
Kernel allocates Argument stacks (Kernel allocates Argument stacks (A-stacksA-stacks) shared by ) shared by client-server domains for each PDclient-server domains for each PD
Allocates Allocates linkage recordlinkage record for each A-Stack to record for each A-Stack to record caller’s address caller’s address
Allocates Allocates Binding Object -Binding Object - the client’s key to access the the client’s key to access the server’s interfaceserver’s interface

CallingCalling
ClientClient stub traps kernel for call after stub traps kernel for call after Pushing arguments in A-stack Pushing arguments in A-stack Storing BO, procedure identifier, address of A-stack in registersStoring BO, procedure identifier, address of A-stack in registers
KernelKernel Validates client, verifies A-stack and locates PD & linkage Validates client, verifies A-stack and locates PD & linkage Stores Return address in linkage and pushes on stack Stores Return address in linkage and pushes on stack Switches client thread’s context to server by running a new stack Switches client thread’s context to server by running a new stack E-E-
stackstack from server’s domain from server’s domain Calls the server’s stub corresponding to PDCalls the server’s stub corresponding to PD
ServerServer Client thread runs in server’s domain using E-stackClient thread runs in server’s domain using E-stack Can access parameters of A-stackCan access parameters of A-stack Return values in A-stack Return values in A-stack Calls back kernel through stubCalls back kernel through stub

Stub GenerationStub Generation
LRPC stub automatically generated in LRPC stub automatically generated in assembly language for simple execution assembly language for simple execution pathspaths Sacrifices portability for performanceSacrifices portability for performance
Maintains local and remote stubsMaintains local and remote stubs First instruction in local stub is branch stmtFirst instruction in local stub is branch stmt

What are optimized here?What are optimized here?
Using the same thread in different domains reduces overheadUsing the same thread in different domains reduces overhead Avoids scheduling decisionsAvoids scheduling decisions Saves on cost of saving and restoring thread state Saves on cost of saving and restoring thread state
Pairwise A-stack allocation guarantees protection from third party Pairwise A-stack allocation guarantees protection from third party domaindomain
Within? Asynchronous updates?Within? Asynchronous updates?
Validate client using BO – To provide securityValidate client using BO – To provide security
Elimination of redundant copies through use of A-stack!Elimination of redundant copies through use of A-stack! 1 against 4 in traditional cross-domain RPCs1 against 4 in traditional cross-domain RPCs Sometimes two? Optimizations applySometimes two? Optimizations apply
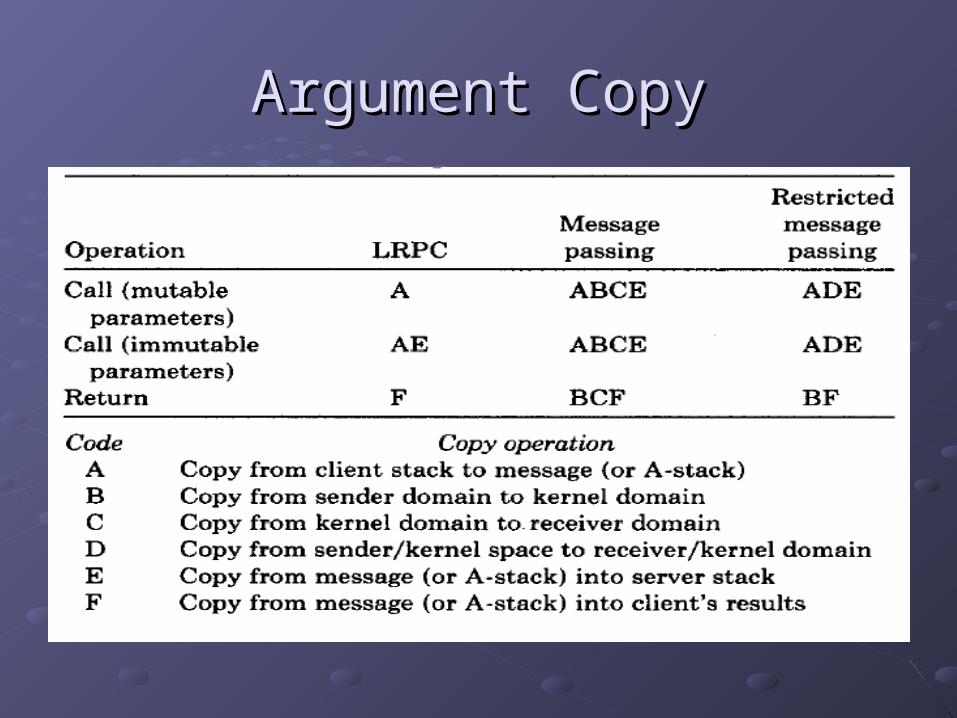
Argument CopyArgument Copy

But… Is it really good enough?But… Is it really good enough?
Trades off memory management costs for Trades off memory management costs for the reduction of overheadthe reduction of overhead A-stacks have to be allocated at bind timeA-stacks have to be allocated at bind time
But size generally smallBut size generally small
Will LRPC work even if a server migrates Will LRPC work even if a server migrates from a remote machine to the local from a remote machine to the local machine?machine?

Other Issues – Domain TerminationOther Issues – Domain Termination
Domain TerminationDomain Termination LRPC from terminated server domain should be returned back to LRPC from terminated server domain should be returned back to
the clientthe client LRPC should not be sent back to the caller if latter has LRPC should not be sent back to the caller if latter has
terminatedterminated
Use binding objectsUse binding objects Revoke binding objects Revoke binding objects For threads running LRPCs in domain restart new threads in For threads running LRPCs in domain restart new threads in
corresponding callercorresponding caller Invalidate active linkage records – thread returned back to first Invalidate active linkage records – thread returned back to first
domain with active linkagedomain with active linkage Otherwise destroyedOtherwise destroyed

Multiprocessor IssuesMultiprocessor Issues
LRPC minimizes use of shared data structures LRPC minimizes use of shared data structures on the critical pathon the critical path Guaranteed by pairwise allocation of A-stacksGuaranteed by pairwise allocation of A-stacks
Cache contexts on idle processorsCache contexts on idle processors Idling threads in server’s context in idle processorsIdling threads in server’s context in idle processors When client thread does RPC to server swap When client thread does RPC to server swap
processorsprocessors Reduces context-switch overhead Reduces context-switch overhead
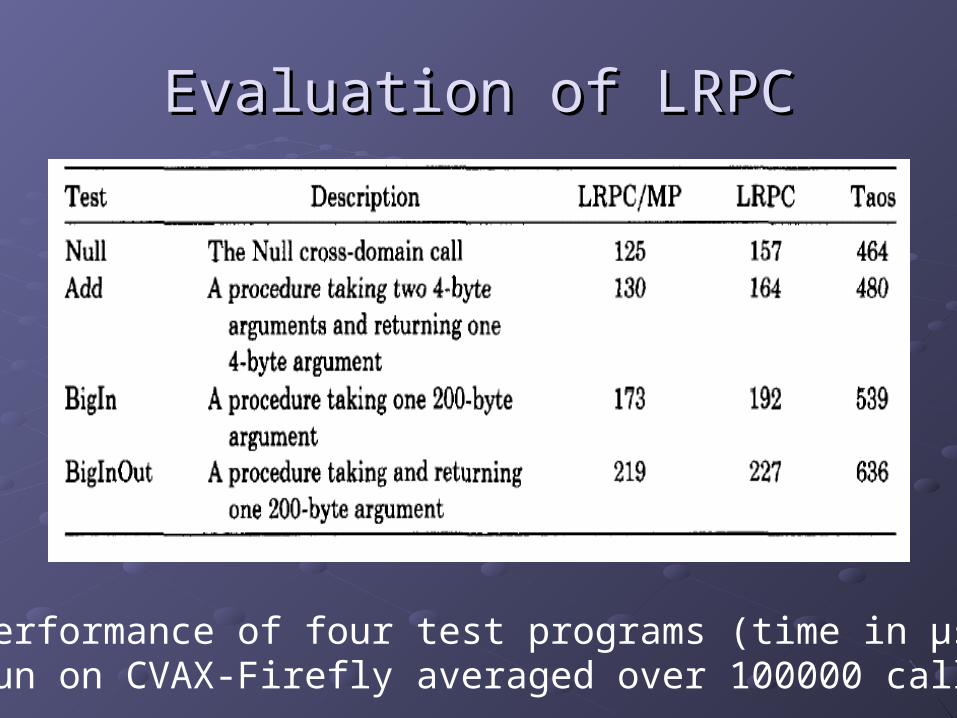
Evaluation of LRPCEvaluation of LRPC
Performance of four test programs (time in μs)(run on CVAX-Firefly averaged over 100000 calls)

Cost Breakdown for the Null LRPCCost Breakdown for the Null LRPC
MinimumMinimum refers to the refers to the inherent minimum inherent minimum overhead overhead
18 18 μμs spent in client s spent in client stub and 3 stub and 3 μμs in the s in the server stubserver stub
25% time spent in 25% time spent in TLB missesTLB misses
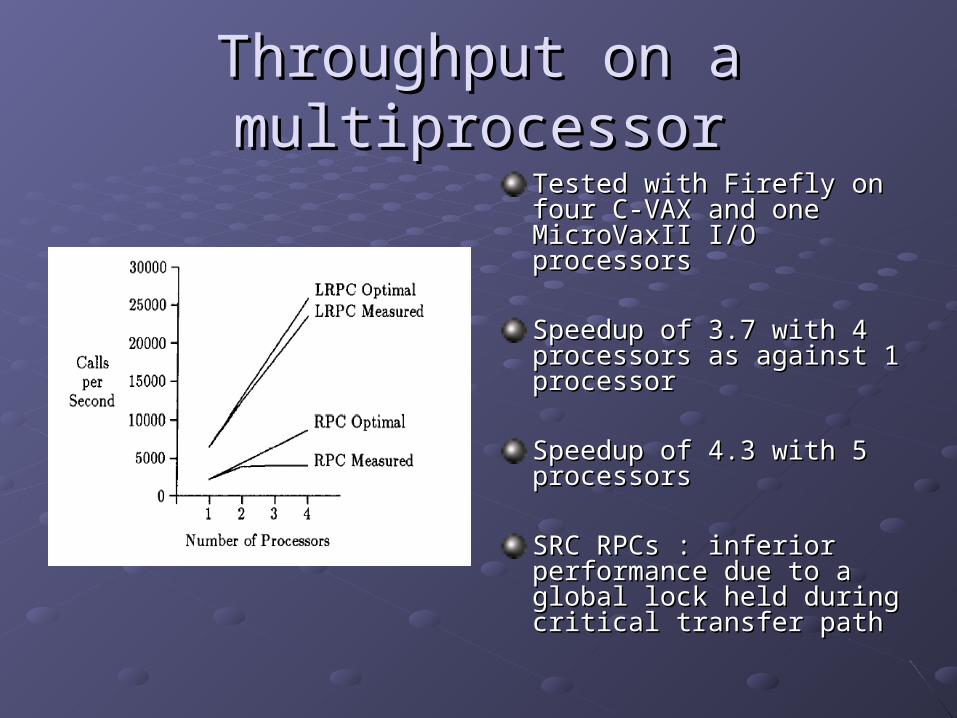
Throughput on a multiprocessorThroughput on a multiprocessor
Tested with Firefly on four C-Tested with Firefly on four C-VAX and one MicroVaxII I/O VAX and one MicroVaxII I/O processorsprocessors
Speedup of 3.7 with 4 Speedup of 3.7 with 4 processors as against 1 processors as against 1 processorprocessor
Speedup of 4.3 with 5 Speedup of 4.3 with 5 processorsprocessors
SRC RPCs : inferior SRC RPCs : inferior performance due to a global performance due to a global lock held during critical transfer lock held during critical transfer pathpath

ConclusionConclusion
LRPC CombinesLRPC Combines Control Transfer and communication model of Control Transfer and communication model of
capability systemscapability systems Programming semantics and large-grained Programming semantics and large-grained
protection model of RPCs protection model of RPCs
Enhances performance by isolating the Enhances performance by isolating the common casecommon case

NOWNOW
We will see ‘NOW’ later in one of the subsequent 614 presentations
Recommended

















