
17Genome Sequencing, Molecular
Biology, and Medicine

17 Genome Sequencing, Molecular Biology, and Medicine
• 17.1 How Do Defective Proteins Lead to Diseases?
• 17.2 What Kinds of DNA Changes Lead to Diseases?
• 17.3 How Does Genetic Screening Detect Diseases?
• 17.4 What Is Cancer?
• 17.5 How Are Genetic Diseases Treated?
• 17.6 What Have We Learned from the Human Genome Project?

17.1 How Do Defective Proteins Lead to Diseases?
Genetic mutations are often expressed as proteins that differ from wild-type.
Genetic diseases can result from abnormalities in enzymes, receptor proteins, transport proteins, structural proteins, etc.

17.1 How Do Defective Proteins Lead to Diseases?
Phenylketonuria (PKU) was traced to its molecular phenotype in the 1950s.
Results from an abnormal enzyme phenylalanine hydroxylase—normally catalyzes conversion of dietary phenylalanine to tyrosine.
The abnormal enzyme has tryptophan instead of arginine in position 408.
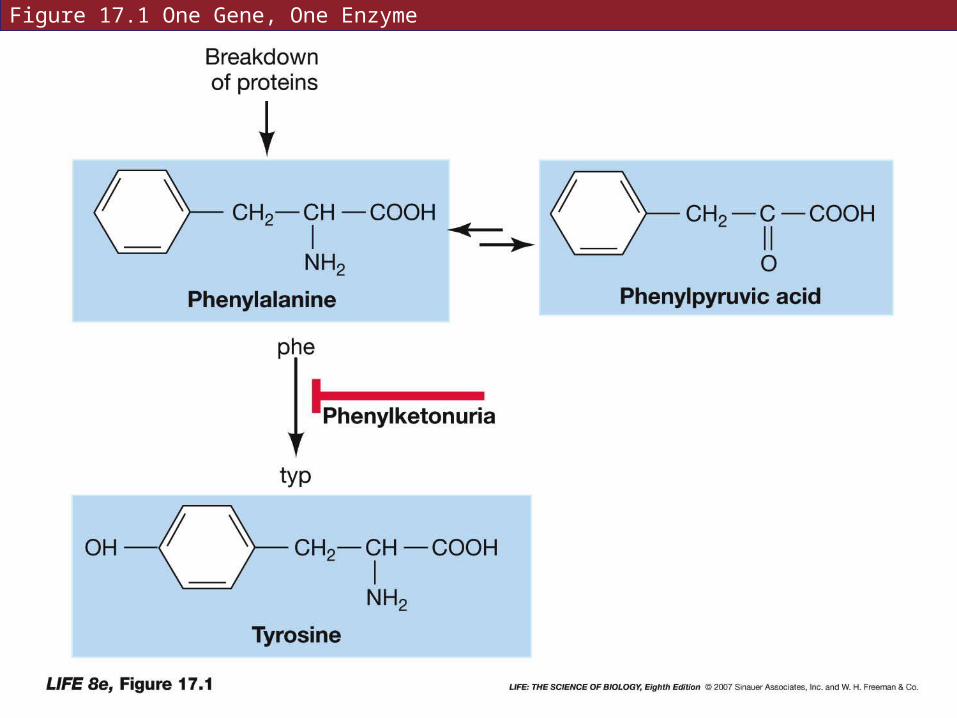
Figure 17.1 One Gene, One Enzyme

17.1 How Do Defective Proteins Lead to Diseases?
People with PKU have light skin and hair color.
Melanin—pigment in dark skin and hair, is made from tyrosine, which people with PKU can not synthesize.

17.1 How Do Defective Proteins Lead to Diseases?
Polymorphism in proteins does not always mean disease.
There can be numerous normal alleles of a gene which produce normally functioning proteins.

17.1 How Do Defective Proteins Lead to Diseases?
The first human disease known to be caused by an abnormal protein was sickle-cell disease.
The abnormal allele produces abnormal hemoglobin that results in sickle-shaped blood cells.
The sickle-shaped cells block blood flow in capillaries.

17.1 How Do Defective Proteins Lead to Diseases?
Hemoglobin—protein with quaternary structure; 2 α and 2 β chains.
In sickle-cell disease, one of 146 amino acids in the β-globin chain is different: glutamic acid (negatively charged) is replaced by valine (neutral).
Changes shape of the hemoglobin and causes anemia.

17.1How Do Defective Proteins Lead to Diseases?
Variation in hemoglobin has been well documented.
There are many amino acid substitutions; many have no effect on the protein function.

Figure 17.2 Hemoglobin Polymorphism

17.1 How Do Defective Proteins Lead to Diseases?
Some diseases result from altered membrane receptors or transport proteins.
Familial hypercholesterolemia (FH)—excess cholesterol can accumulate on artery walls and block them, causing heart attacks and strokes.

17.1 How Do Defective Proteins Lead to Diseases?
People with FH are unable to transport cholesterol to the liver and other cells that use it.
Cholesterol travels as a lipoprotein (LDL). LDL binds to a receptor on a liver cell, and is taken up by endocytosis.
In FH, the receptor protein is nonfunctional.
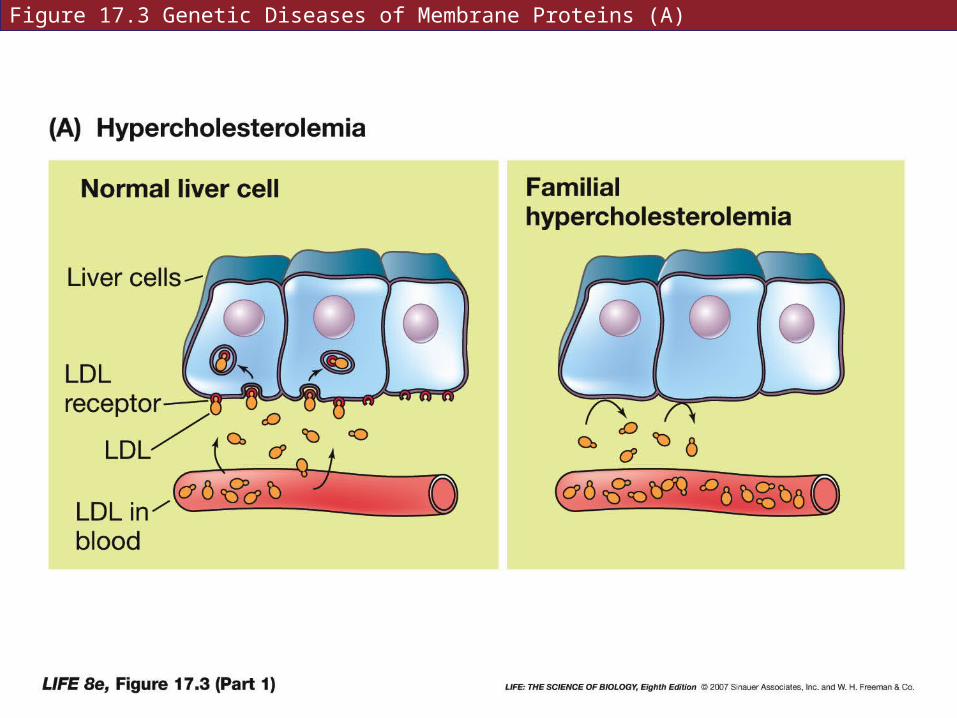
Figure 17.3 Genetic Diseases of Membrane Proteins (A)

17.1How Do Defective Proteins Lead to Diseases?
In cystic fibrosis, thick dry mucous lines surfaces such as the respiratory tract and prevents passage of air, and prevents cilia from functioning.
This is caused by a nonfunctional chloride transporter protein. Normally, this ion channel releases Cl– outside the cell. Water leaves cell by osmosis, providing moist surfaces.
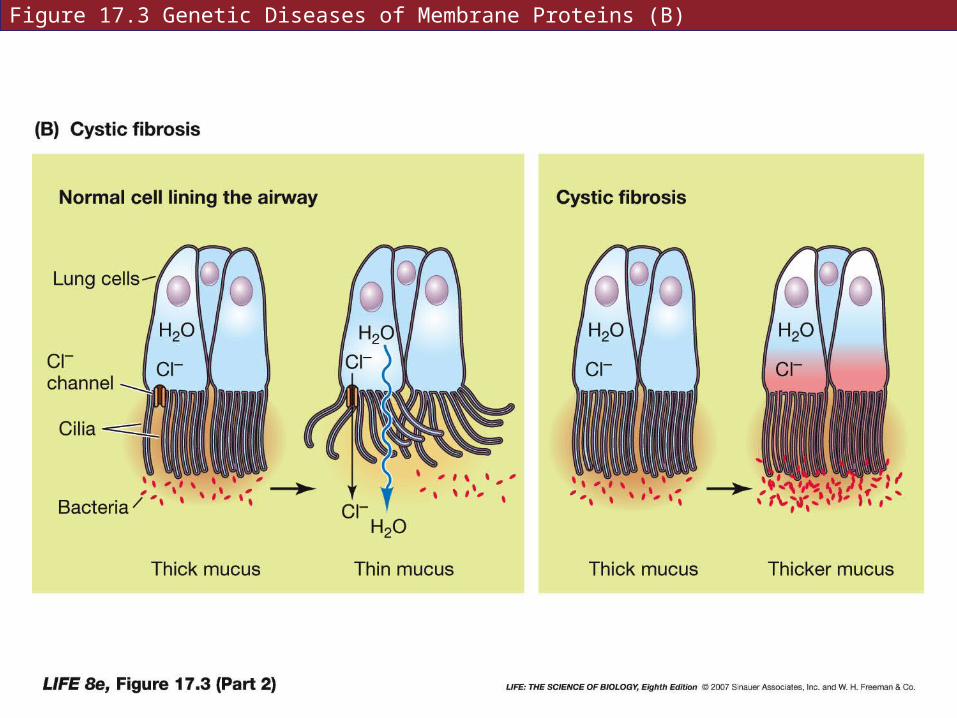
Figure 17.3 Genetic Diseases of Membrane Proteins (B)

17.1 How Do Defective Proteins Lead to Diseases?
Duchenne muscular dystrophy and hemophilia are diseases caused by altered structural proteins.
In Duchenne muscular dystrophy, there is no functional dystrophin, which normally connects actin fibers of muscle cells to the extracellular matrix. Without it, muscle cells are structurally disorganized, and stop working.

17.1 How Do Defective Proteins Lead to Diseases?
Hemophilia is caused by the absence of a blood clotting protein.
Normally, clotting proteins are always present in the blood.

17.1 How Do Defective Proteins Lead to Diseases?
Transmissible spongiform encephalopathies (TSEs) are degenerative diseases in which holes develop in the brain—includes mad cow disease.
Results from errors in conformation of proteins.
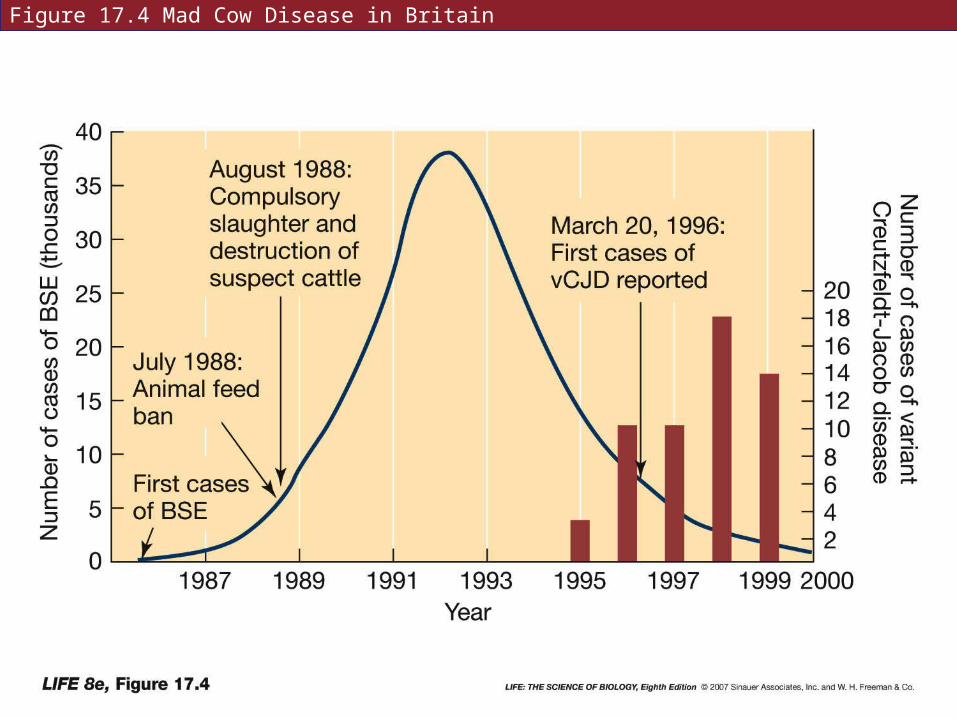
Figure 17.4 Mad Cow Disease in Britain

17.1How Do Defective Proteins Lead to Diseases?
TSEs can be transferred by eating animals that had the disease.
Kuru—a TSE is found in a tribe in New Guinea that practiced ritual cannibalism.
The infectious agent is a prion—proteinaceous infective particle.

17.1 How Do Defective Proteins Lead to Diseases?
Normal brain cell membranes have a protein called PrPc.
In TSE infected tissue, the protein has a different shape, called PrPsc. This protein piles up as fibers and causes cell death.
The abnormal PrPsc causes the normal protein to change conformation.
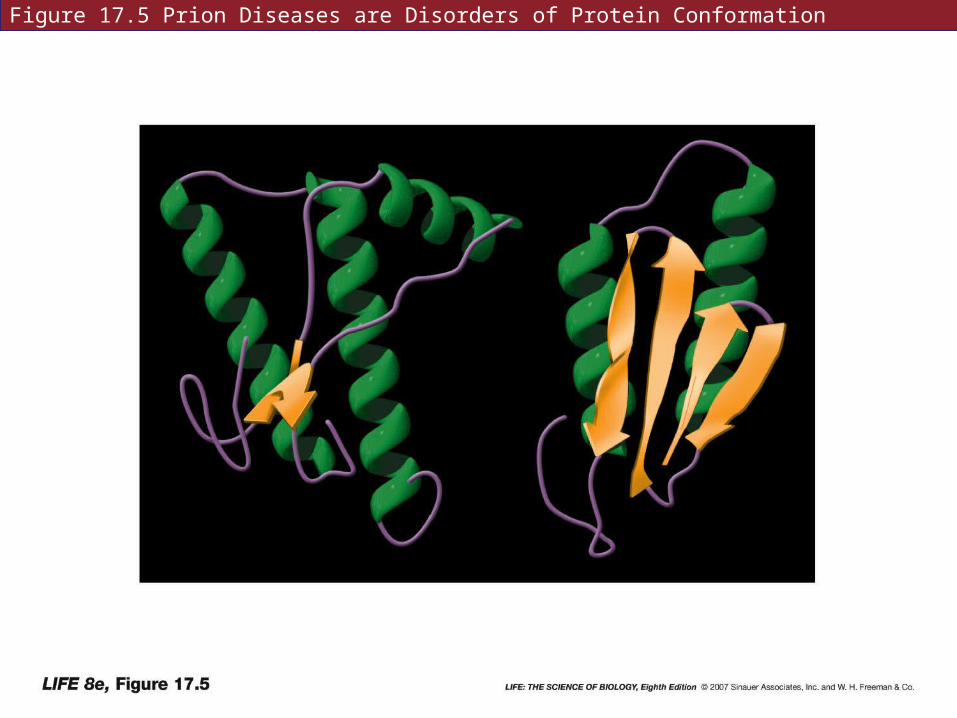
Figure 17.5 Prion Diseases are Disorders of Protein Conformation

17.1 How Do Defective Proteins Lead to Diseases?
Most human diseases are multifactorial—caused by interactions of many genes and proteins and the environment.
Alleles that cause genetic diseases may be inherited in a dominant or recessive pattern, and may be carried on autosomes or sex chromosomes.
Some diseases result from extensive chromosomal abnormalities.

17.1 How Do Defective Proteins Lead to Diseases?
PKU, sickle-cell disease, and cystic fibrosis are autosomal recessive.
If both parents are carriers (heterozygotes with normal phenotypes), every time a child is conceived there is a one in four chance that it will have the disease.

17.1 How Do Defective Proteins Lead to Diseases?
Familial hypercholesterolemia is caused by an autosomal dominant allele.
Presence of only one mutant allele is enough to cause the disease.

17.1 How Do Defective Proteins Lead to Diseases?
Hemophilia is X-linked recessive.
A son that inherits the allele from the mother will have the disease, because there is no allele on the Y chromosome.
All rare X-linked diseases are much more common in men than women.

17.1 How Do Defective Proteins Lead to Diseases?
Chromosomal abnormalities include the gain or loss of chromosomes (aneuploidy), deletions, and translocations.
Some are inherited, some result from meiotic events.
Fragile-X syndrome is a constriction at the tip of the X chromosome. Causes mental retardation in some people.
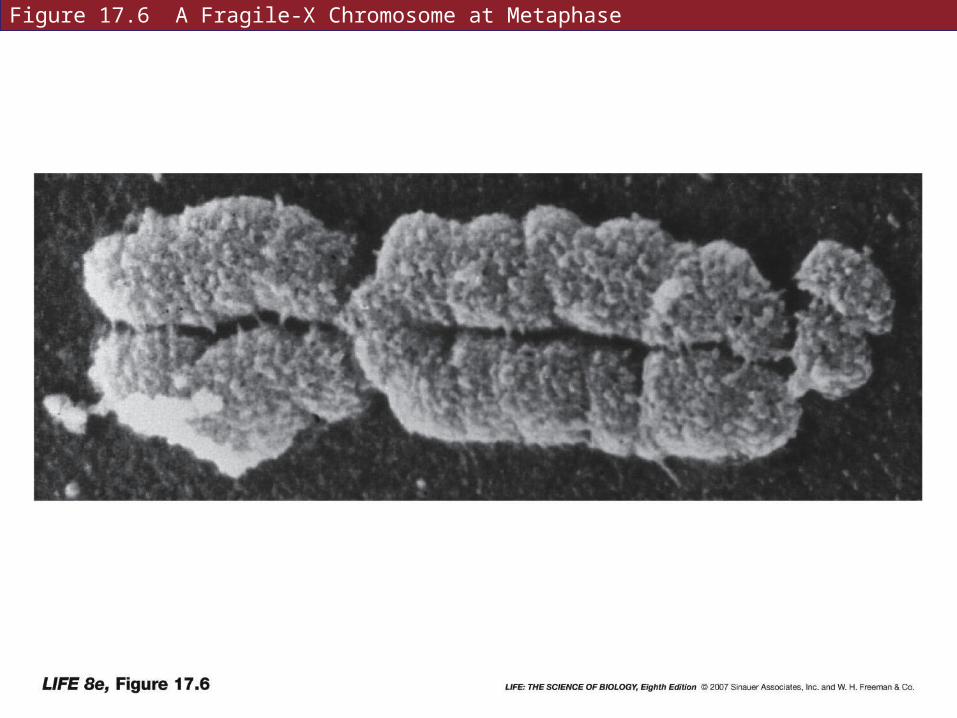
Figure 17.6 A Fragile-X Chromosome at Metaphase

17.2 What Kinds of DNA Changes Lead to Diseases?
Some disease-causing mutations are determined when the abnormal protein phenotype is known, the gene can be cloned.
In other cases, the defective protein is unknown until the gene is isolated.

17.2 What Kinds of DNA Changes Lead to Diseases?
For sickle-cell disease, mRNA was isolated from immature red blood cells, a cDNA copy was made and used to probe a human gene library.
Then gene sequencing was used to compare normal and sickle-cell genes.

17.2 What Kinds of DNA Changes Lead to Diseases?
Duchenne muscular dystrophy was thought to be X-linked, but the abnormal protein nor the gene could be identified.
A small chromosome deletion was discovered in the X chromosome.
Comparing with normal chromosomes allowed the gene to be isolated.
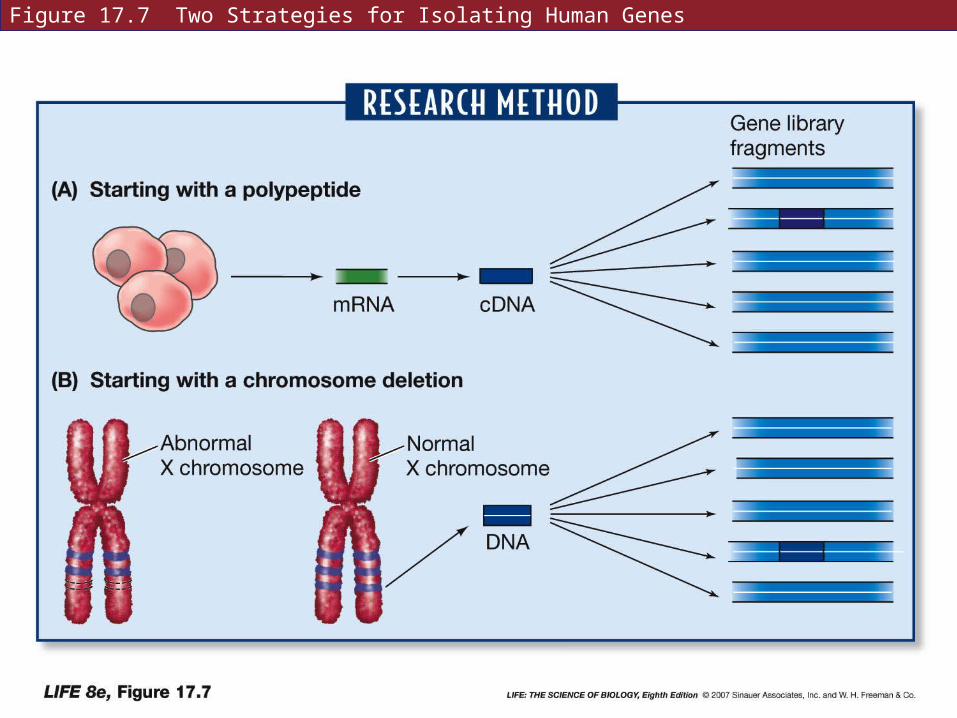
Figure 17.7 Two Strategies for Isolating Human Genes

17.2 What Kinds of DNA Changes Lead to Diseases?
When no abnormal protein or chromosome deletion can be identified, positional cloning is used.
Genetic markers can be positioned anywhere on the DNA. They must be polymorphic (more than one allele).

17.2 What Kinds of DNA Changes Lead to Diseases?
RFLPs (Restriction Fragment Length Polymorphisms)
If there is a mutation in a restriction site, it will not be cut by a restriction enzyme, resulting in a larger fragment. These can be seen in gel electrophoresis.
An RFLP band pattern is inherited in Mendelian fashion.

Figure 17.8 RFLP Mapping (Part 1)
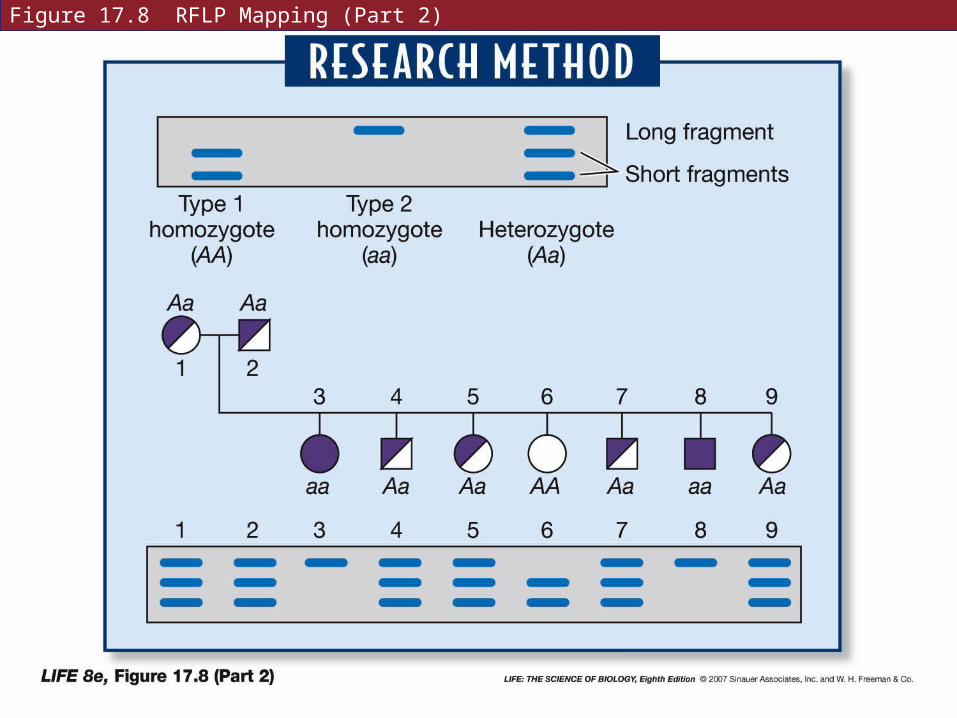
Figure 17.8 RFLP Mapping (Part 2)

17.2 What Kinds of DNA Changes Lead to Diseases?
SNPs (single nucleotide polymorphisms) are widespread in eukaryotic genomes.
SNPs can be detected by direct sequence comparisons or chemical methods such as mass spectrometry.

17.2 What Kinds of DNA Changes Lead to Diseases?
Genetic markers such as RFLPs and SNPs can be used to find genes if the genes are polymorphic too.
The gene and the marker must always be inherited together—pedigrees are constructed to determine this.

17.2 What Kinds of DNA Changes Lead to Diseases?
To isolate a gene, the neighborhood around an RFLP might be screened with other restriction enzymes.
When a relatively short sequence of DNA is identified as a candidate for the gene, it can be cut in fragments and tested with probes made from mRNA from affected cells.

17.2 What Kinds of DNA Changes Lead to Diseases?
DNA sequencing has shown that mutations occur most often in certain base pairs—“hot spots” for mutation.
Often where cytosine has been methylated to 5-methylcytosine
Unmethylated cytosine can lose its amino group to form uracil—this error is detected and repaired.

17.2 What Kinds of DNA Changes Lead to Diseases?
When 5-methylcytosine loses its amino group, it forms thymine, which is ignored by DNA repair mechanism.
Mismatch repair recognizes the mistake, GT instead of GC, but cannot tell which member of the pair was incorrect.
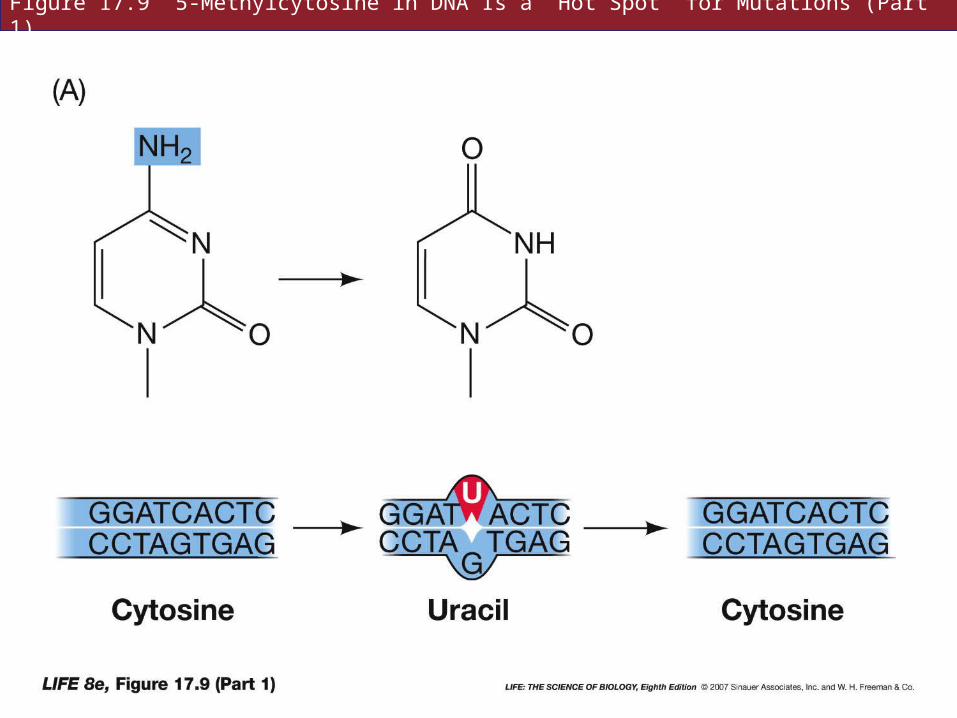
Figure 17.9 5-Methylcytosine in DNA Is a “Hot Spot” for Mutations (Part 1)
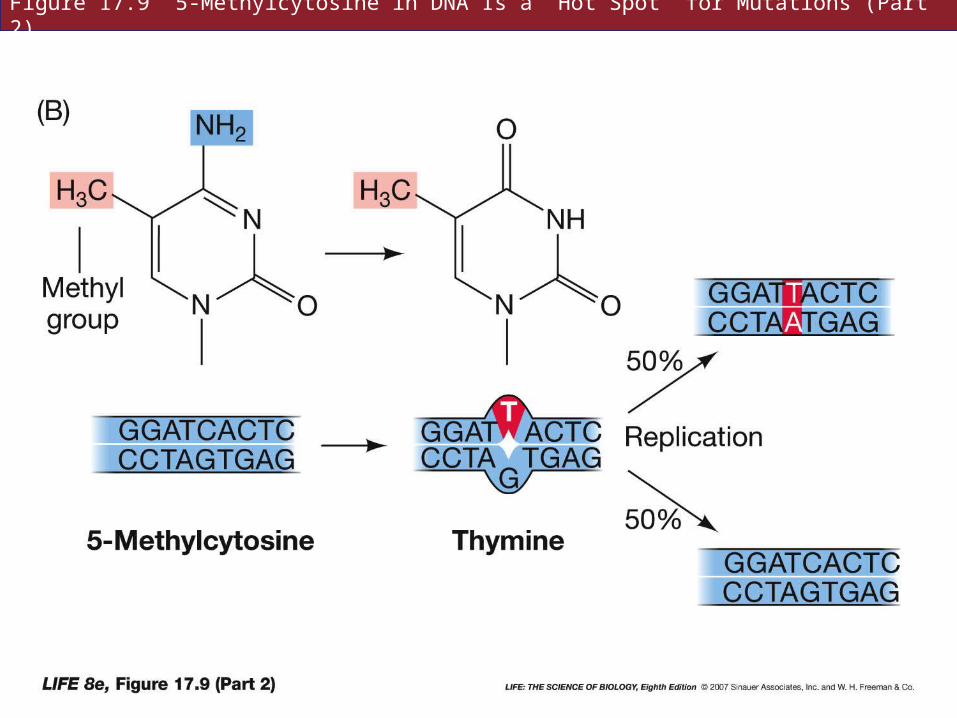
Figure 17.9 5-Methylcytosine in DNA Is a “Hot Spot” for Mutations (Part 2)

17.2 What Kinds of DNA Changes Lead to Diseases?
Larger mutations can involve many base pairs.
In Duchenne muscular dystrophy, the deletion may be small, covering only part of the gene for dystrophin, or the entire gene may be deleted.
Other mutations involve millions of base pairs.

17.2 What Kinds of DNA Changes Lead to Diseases?
About 1/5 of males and their daughters with fragile X chromosome are phenotypically normal, but their sons are mentally retarded.
Later generations tend to show earlier onset and more severe symptoms.

17.2 What Kinds of DNA Changes Lead to Diseases?
The gene for fragile-X, FMR1, contains a repeated triplet (CGG) in the promoter region.
In normal people it is repeated six to 54 times.
In mentally retarded people with fragile-X, it is repeated 200 to 2,000 times.

17.2 What Kinds of DNA Changes Lead to Diseases?
Males with a moderate number of repeats (55–200) have no symptoms and are said to be premutated.
The repeats become more numerous in successive generations.
With more than 200 repeats, increased methylation of cytosine results in transcriptional inactivation of FMR1.

17.2 What Kinds of DNA Changes Lead to Diseases?
Normal function of protein made by FMR1 is to bind to mRNAs involved in neuron function and regulate translation.
If the mRNAs are not translated in sufficient amounts, the nerve cells die.
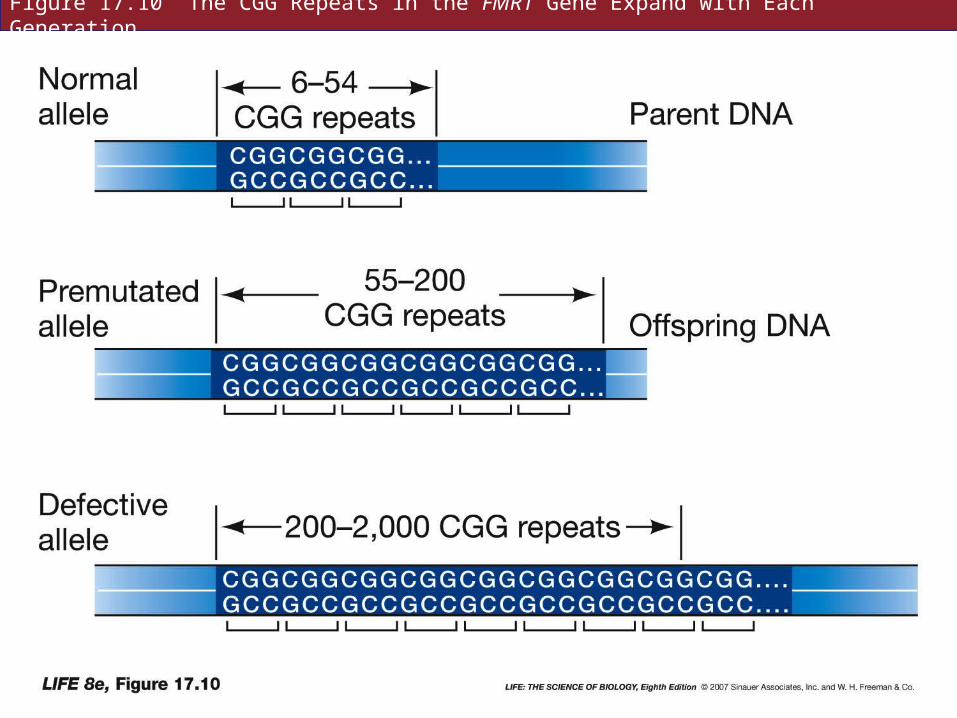
Figure 17.10 The CGG Repeats in the FMR1 Gene Expand with Each Generation

17.2 What Kinds of DNA Changes Lead to Diseases?
Expanding triplet repeats has been found in other diseases—myotonic dystrophy, Huntington’s disease.
How the repeats expand is unknown; possibly DNA polymerase slips after copying the triplet, and copies it again.

17.2 What Kinds of DNA Changes Lead to Diseases?
Groups of genes differ in their phenotypic effect depending on which parent they came from—genomic imprinting.
Raises the possibility that male and female genomes are not functionally equivalent.

17.2 What Kinds of DNA Changes Lead to Diseases?
A small deletion on mother’s chromosome 15 results in Angleman syndrome—thin child with prominent jaw and wide mouth.
Same deletion on father’s chromosome 15 results in a short, obese child with small hands and feet—Prader-Willi syndrome.
Both are heterozygotes—one deleted and one “normal” allele.

17.3 How Does Genetic Screening Detect Diseases?
Genetic screening: using tests to determine if an individual has a genetic disease, or is predisposed to one, or is a carrier.
• Prenatal screening
• Screening of newborns
• Screening asymptomatic people with relatives who have genetic diseases.

17.3 How Does Genetic Screening Detect Diseases?
Enzymes can be checked for low activity—suggests mutation.
Phenylketonuria can be detected in newborns—treatment can begin immediately.
Before birth, excess phenylalanine diffuses across placenta to mother’s blood; she has adequate phenylalanine hydrolase.

17.3 How Does Genetic Screening Detect Diseases?
Screening method uses auxotrophic bacteria that require phenylalanine to grow. If bacteria grow in presence of baby’s blood—there is too much phenylalanine in it.
Now being replaced by direct chemical tests.
Mandatory screening of newborns is now done for 25 diseases.

Figure 17.11 Genetic Screening of Newborns for Phenylketonuria

17.3 How Does Genetic Screening Detect Diseases?
DNA testing is the most direct and accurate way to detect abnormal alleles.
Any cell can be scanned at any time for mutations.
Works best for diseases caused by only one or a few mutations.

17.3 How Does Genetic Screening Detect Diseases?
Fetal cells can be screened preimplantation (rare), or after implantation.
Fetal cells can be analyzed at 10 weeks by chorionic villus sampling, or by amniocentesis during the 13th to 17th weeks.

17.3 How Does Genetic Screening Detect Diseases?
DNA testing of adults is also used to screen for heterozygotes.
For example, a sister of a boy with Duchenne muscular dystrophy can be screened to determine whether she is a carrier.

17.3 How Does Genetic Screening Detect Diseases?
Two main methods for DNA testing:
Allele specific cleavage method: normal and mutant alleles have different restriction recognition sequences.
A restriction enzyme may cut a normal allele, but not the mutant allele, resulting in a larger DNA fragment.

Figure 17.12 DNA Testing by Allele-Specific Cleavage

17.3 How Does Genetic Screening Detect Diseases?
Allele-specific oligonucleotide hybridization uses short artificial DNA strands, or oligonucleotides, that will hybridize with either the normal or mutant allele.
The oligonucleotide probe can be labeled with radioisotopes or florescent dyes.
Easier and faster than allele-specific cleavage.
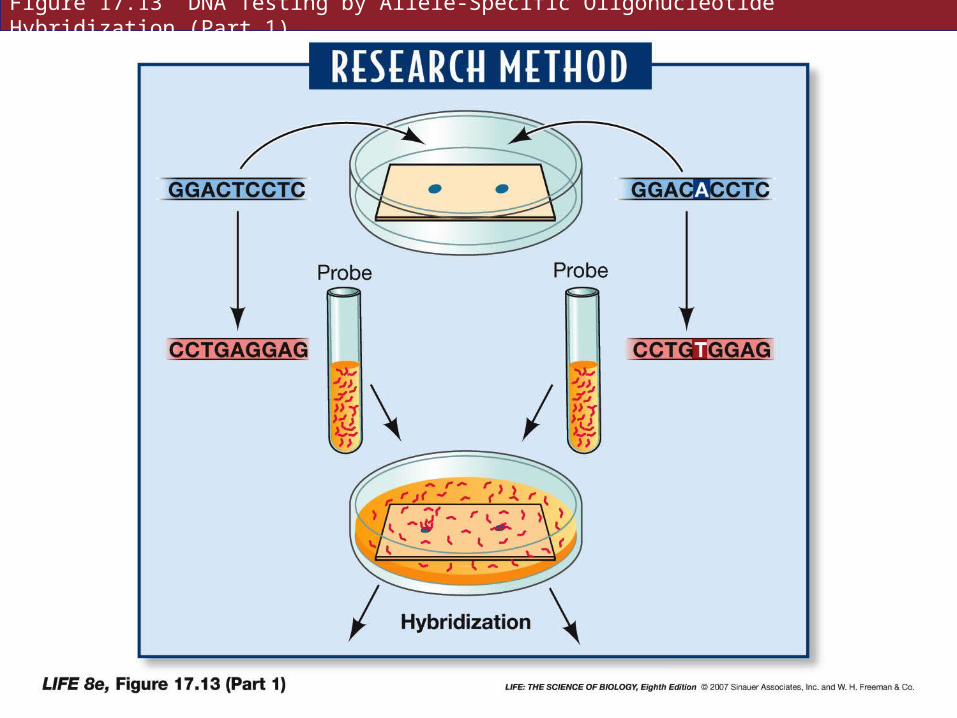
Figure 17.13 DNA Testing by Allele-Specific Oligonucleotide Hybridization (Part 1)
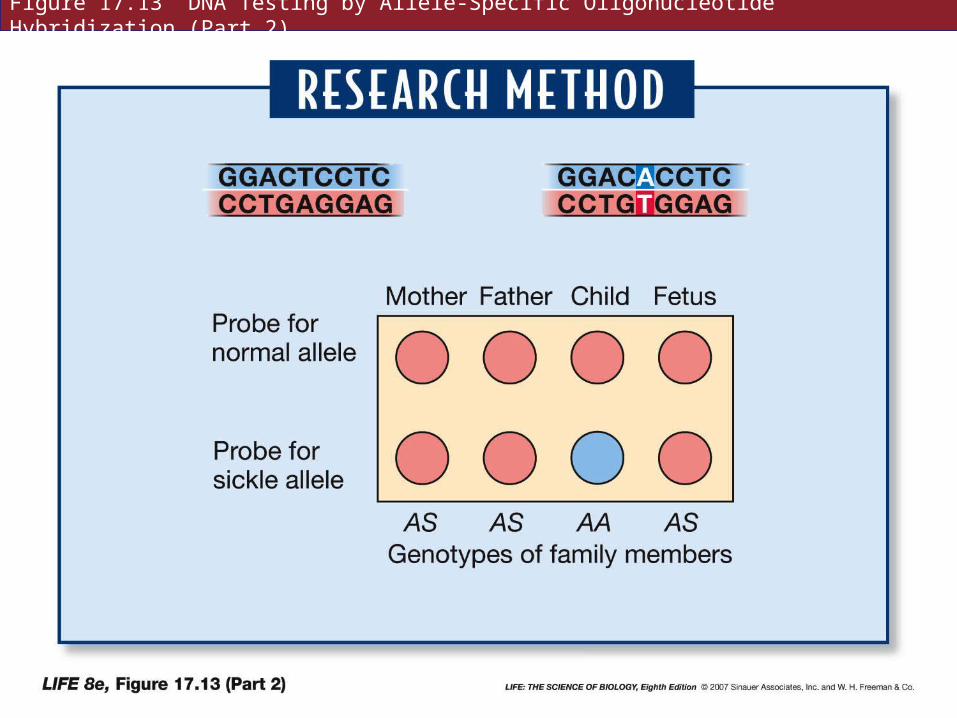
Figure 17.13 DNA Testing by Allele-Specific Oligonucleotide Hybridization (Part 2)

17.4 What Is Cancer?
Cancer is caused primarily by genetic changes—mostly by mutations of DNA in the somatic cells.
Cancer cells differ from normal cells in two main ways:
• Cancer cells lose control over cell division.
• Cancer cells can invade other tissues.

17.4 What Is Cancer?
Most cells divide only when exposed to external factors such as hormones or growth factors.
Cancer cells divide continuously, forming tumors (large masses of cells).
Benign tumors resemble the tissue they start from, grow slowly, and remain localized (e.g., a lipoma is a tumor of fat cells, but not a cancer).

17.4 What Is Cancer?
Malignant tumors do not resemble parent tissue and often have irregular structures.
Many malignant cells express the gene for telomerase, and do not shorten the ends of chromosomes after each DNA replication.

Figure 17.14 A Cancer Cell with Its Normal Neighbors

17.4 What Is Cancer?
Cancer cells can invade other tissues—called metastasis.
Occurs in stages:
• First extends into surrounding tissue by secreting digestive enzymes.
• Then some cells enter the blood stream or lymphatic system. Only a few cells survive this.

17.4 What Is Cancer?
• If a cancer cell finds new suitable tissue, it expresses cell surface proteins to bind to and invade the new tissue.
• Cancer cells at a new site secrete chemical signals that cause blood vessels to grow to the tumor to supply it with nutrients—angiogenesis.

17.4 What Is Cancer?
Different forms of cancer affect different parts of the body:
• Carcinomas arise in surface tissues, skin and linings of organs. Lung cancer, colon cancer, breast cancer, liver cancer.
• Sarcomas occur in blood, bone, and muscle.
• Leukemias and lymphomas affect cells that give rise to blood cells.

17.4 What Is Cancer?
About 15 percent of human cancers are virally induced.
Hepatitis B virus is associated with liver cancer, but some gene mutations may also be necessary for tumor formation.

Table 17. 1

17.4 What Is Cancer?
Papillomaviruses seem to act on their own, not needing any gene mutations.
Occasionally the circular chromosome is broken and the virus genome inserts itself into a cell in the uterine cervix.
It disrupts a gene that normally blocks cell division, and a tumor results.

17.4 What Is Cancer?
85 percent of cancers are not caused by viruses.
Most cancers develop in older people—one must live long enough for genetic mutations to occur.

17.4 What Is Cancer?
DNA can be damaged in many ways.
Some mutations are spontaneous.
Mutagens called carcinogens can cause mutations that lead to cancer.
Carcinogens include chemicals in tobacco smoke, UV radiation, and radiation from radioisotopes.

17.4 What Is Cancer?
Thousands of chemicals that occur naturally in food are also carcinogens.
Cells that divide often, such as epithelial cells and bone marrow stem cells, are especially susceptible to cancer because there is not as much time for DNA repair in between cell cycles.

17.4 What Is Cancer?
Changes in the control of cell division lie at the heart of cancer.
In the human genome, some genes act to stimulate cell division—oncogenes;
others act to suppress cell division—tumor suppressor genes.

17.4 What Is Cancer?
Oncogenes are normally turned off.
Products of oncogenes are involved in pathways by which growth factors stimulate division.
Some control apoptosis. Activation of these genes by mutation prevents apoptosis.
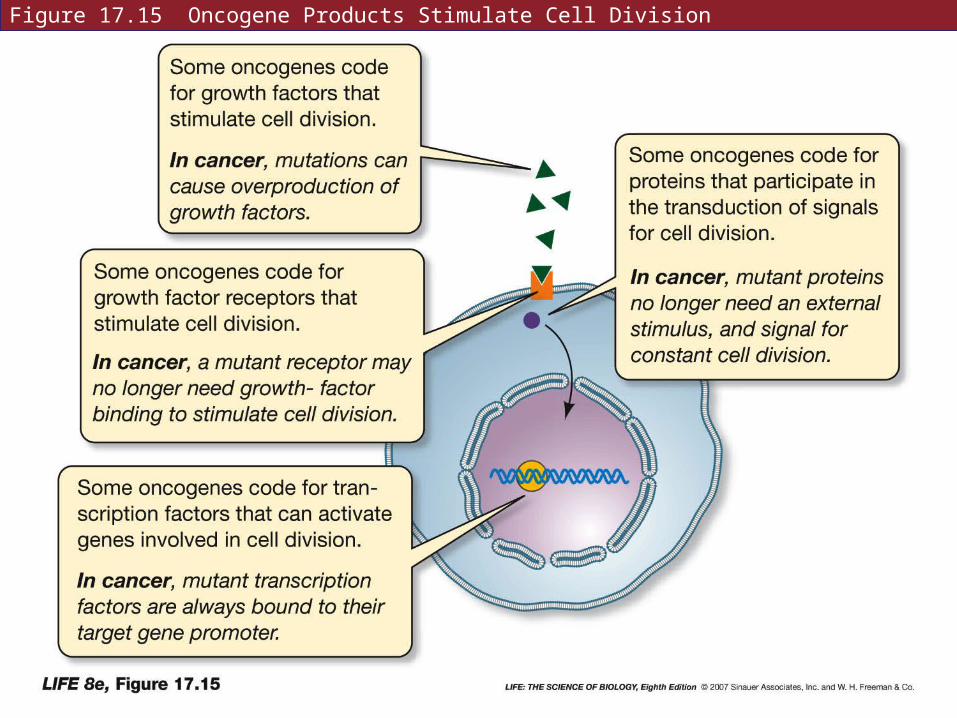
Figure 17.15 Oncogene Products Stimulate Cell Division

17.4 What Is Cancer?
About 10 percent of cancers are inherited.
Noninherited cancers are usually a form that occur later in life—sporadic form.
Inherited cancers show up earlier in life, and as multiple tumors.
A tumor suppressor gene that normally acts as a brake must be inactivated.

17.4 What Is Cancer?
Full inactivation requires two mutations—both alleles must be turned off.
People with inherited cancer are born with one mutant allele, and need only one more mutational event for inactivation of the tumor suppressor gene.
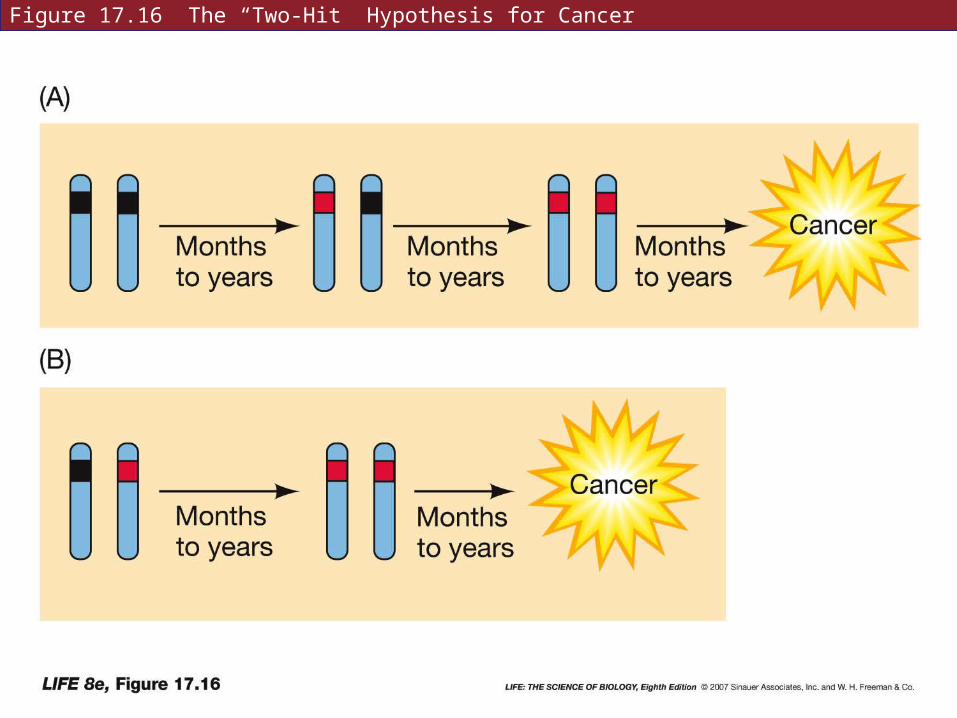
Figure 17.16 The “Two-Hit” Hypothesis for Cancer

17.4 What Is Cancer?
Example: Women who inherit one mutant allele of the gene BRCA1 have a 60 percent chance of developing breast cancer by age 50; and an 82 percent chance by age 70.
Chances for women who have two normal alleles are 2 percent and 7 percent.

17.4 What Is Cancer?
Tumor suppressor genes regulate the cell cycle.
Rb gene and gene for p53 keep the cell in G1 phase.
These genes are mutated in many types of cancer.

Figure 17.17 Tumor Suppressor Gene Products Inhibit Cell Division

17.4 What Is Cancer?
For a normal cell to become malignant, a complex series of events must occur.
More than two mutations are usually needed for cancer to develop.
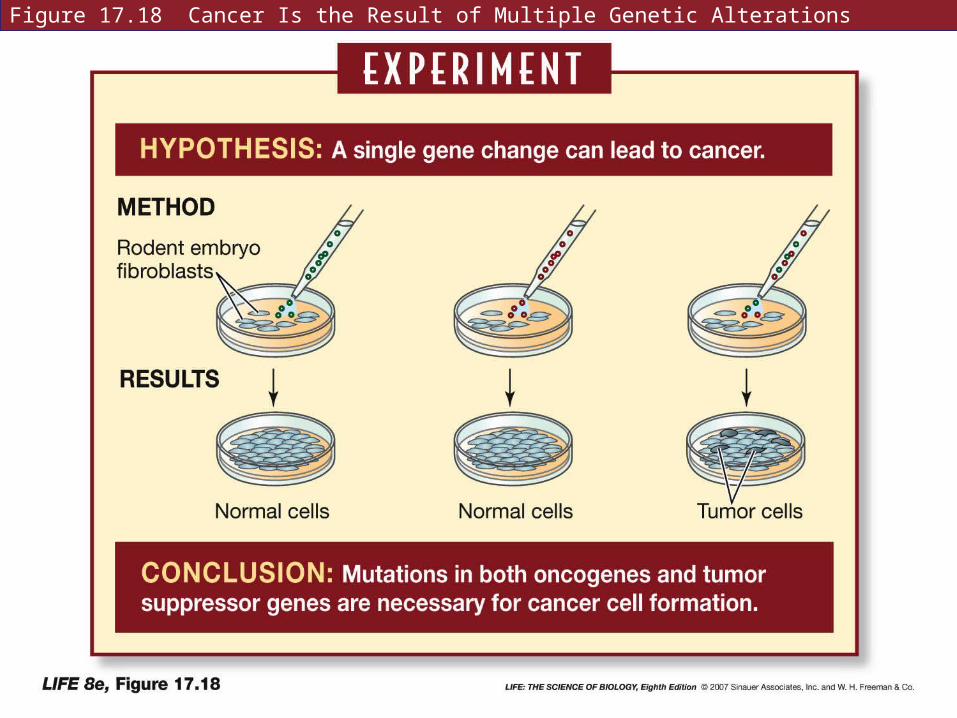
Figure 17.18 Cancer Is the Result of Multiple Genetic Alterations

17.4 What Is Cancer?
Oncogene and tumor suppressor gene mutations involved in colon cancer have been described in detail.
At least four suppressor genes and one oncogene must be mutated in succession.
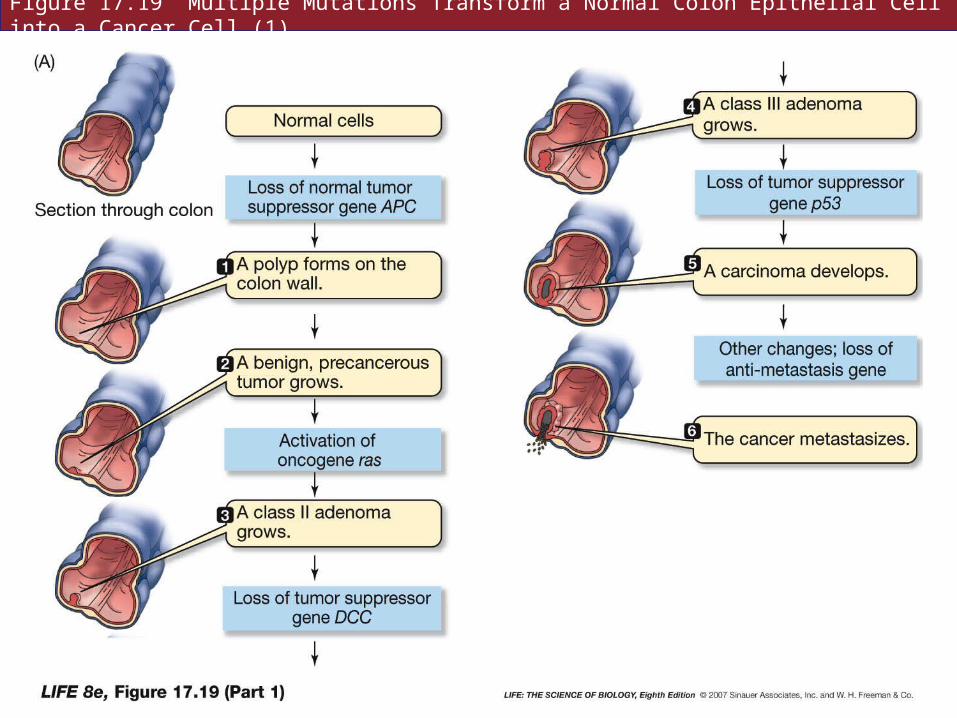
Figure 17.19 Multiple Mutations Transform a Normal Colon Epithelial Cell into a Cancer Cell (1)
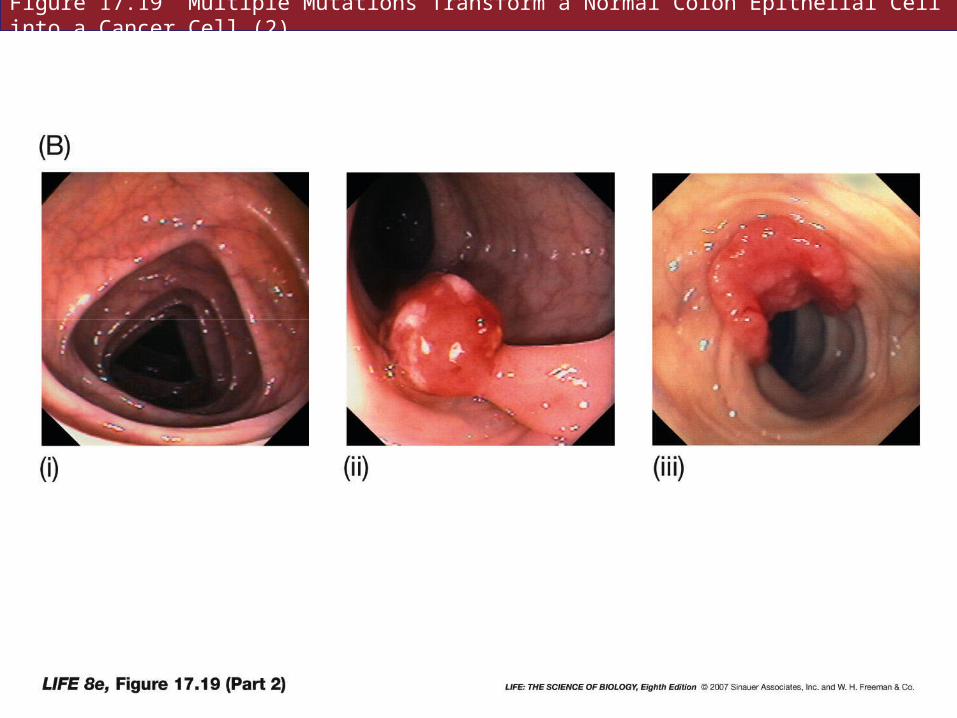
Figure 17.19 Multiple Mutations Transform a Normal Colon Epithelial Cell into a Cancer Cell (2)

17.4 What Is Cancer?
Many cancers are diagnosed using specific oligonucleotide probes.
Mutations can be detected early in life.
New treatments for genetic diseases are also being developed.

17.5 How Are Genetic Diseases Treated?
Two main approaches to treating genetic diseases:
• Modify the disease phenotype
• Replace defective genes

17.5 How Are Genetic Diseases Treated?
Modifying the disease phenotype is done in three ways:
• Restrict substrate of a defective enzyme
• Inhibit a harmful metabolic reaction
• Supply a missing protein product

17.5 How Are Genetic Diseases Treated?
In PKU, the substrate for the enzyme phenylalanine hydroxylase (phenylalanine) is restricted in the diet.
The low phenylalanine diet is crucial during infancy and childhood when the brain is still developing.

17.5 How Are Genetic Diseases Treated?
Statin drugs used to treat familial hypercholesterolemia are examples of metabolic inhibitors.
Statin blocks cholesterol synthesis.

17.5 How Are Genetic Diseases Treated?
Metabolic inhibitors are also used in chemotherapy.
The strategy is to kill rapidly dividing cells in tumors.
Many other cells in the body are also affected—causing the side effects of chemotherapy.
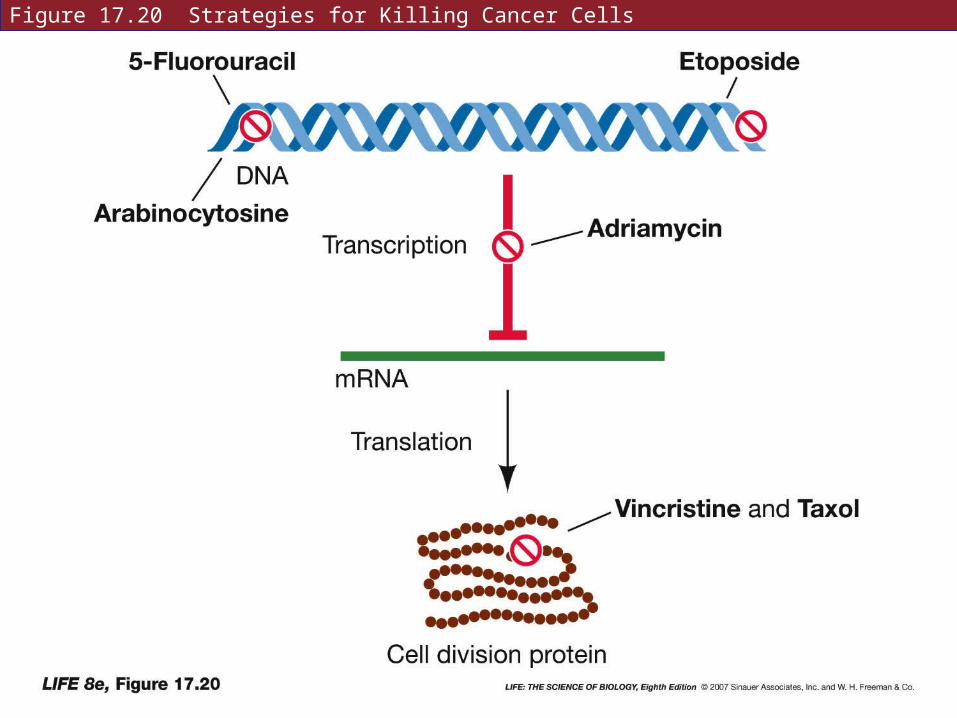
Figure 17.20 Strategies for Killing Cancer Cells

17.5 How Are Genetic Diseases Treated?
To treat hemophilia, the missing blood clotting protein is supplied.
The pure clotting proteins are now made using recombinant DNA technology.

17.5 How Are Genetic Diseases Treated?
In gene therapy, the aim is to supply the missing allele(s) by inserting a new gene that will be expressed in the host.
The challenges: must find appropriate vector, ensure correct insertion into host DNA, ensure appropriate expression, and selection of cells to target.

17.5 How Are Genetic Diseases Treated?
The nonfunctional alleles cannot be replaced in every cell of the body.
Ex vivo techniques—cells are removed from the body, new genes inserted, cells returned to the body.

17.5 How Are Genetic Diseases Treated?
Genes for adenosine deaminase have been inserted (ex vivo) into white blood cells via a viral vector.
The enzyme is required for maturation of white blood cells.
Mature white blood cells were first used; now use of bone marrow stem cells is being investigated.
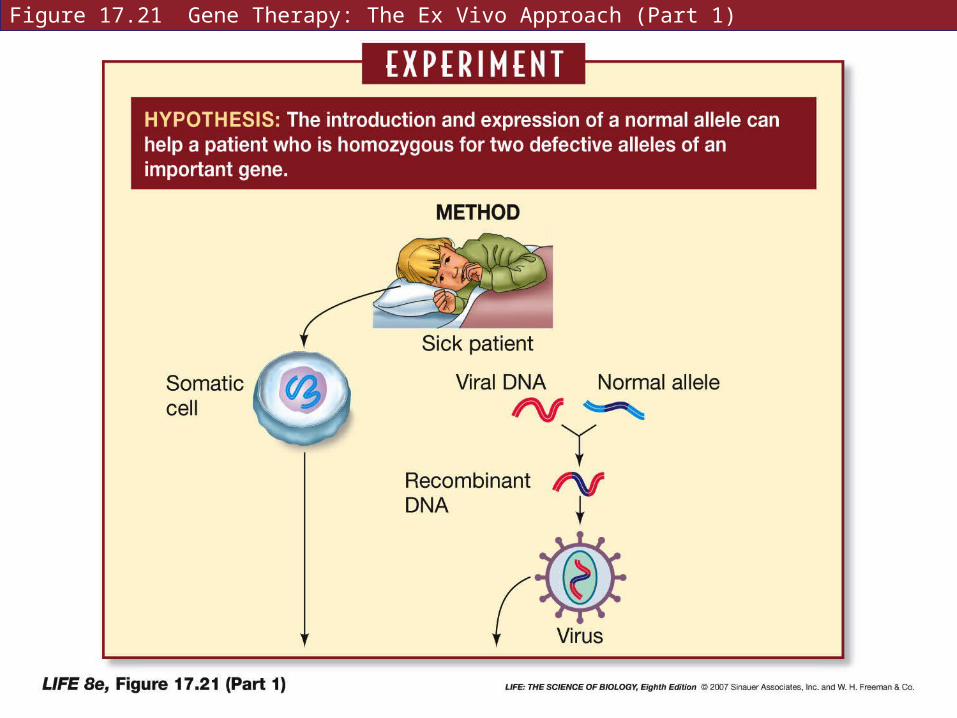
Figure 17.21 Gene Therapy: The Ex Vivo Approach (Part 1)
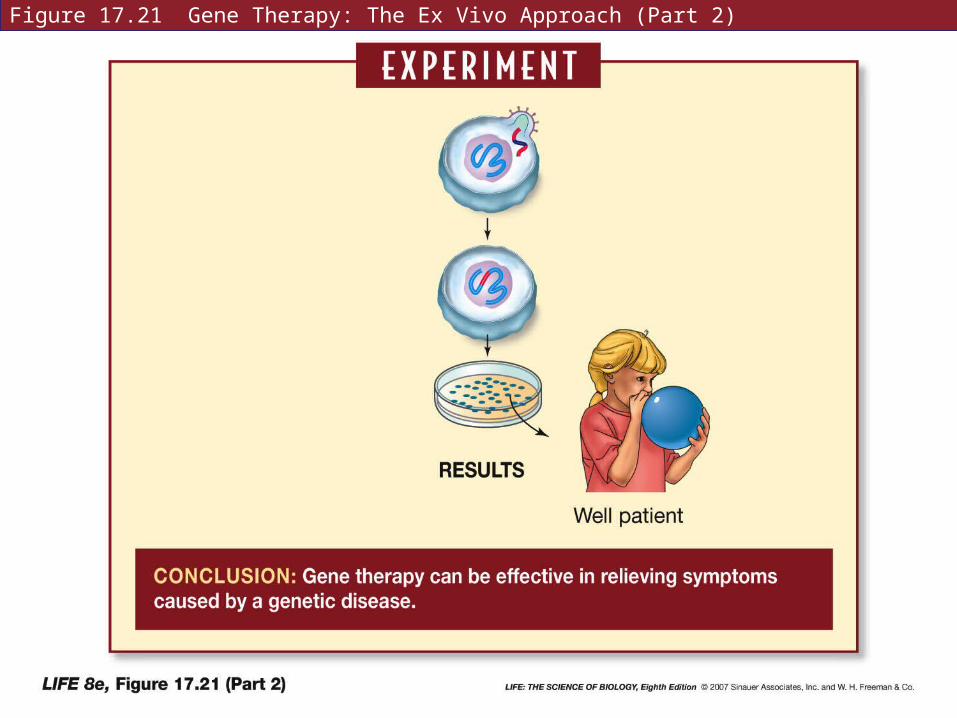
Figure 17.21 Gene Therapy: The Ex Vivo Approach (Part 2)

17.5 How Are Genetic Diseases Treated?
Skin cells have been taken from people with hemophilia, and the gene for blood clotting protein inserted by a plasmid.
Cells were reintroduced into body fat, where they produced enough protein for normal clotting.

17.5 How Are Genetic Diseases Treated?
The second approach to gene therapy is in vivo—insert genes directly into body cells.
Example: DNA or vectors can be introduced to lungs as an aerosol to treat lung cancer.
Vectors carry functional alleles and antisense RNA targeting oncogene mRNAs.

17.6 What Have We Learned from the Human Genome Project?
The Human Genome Project was proposed in 1986—to determine the normal sequence of all human DNA.
Private industries also launched a sequencing effort in the 1990s.
In order to detect mutations, treat cancers, and other applications, the normal sequences must be known.

17.6 What Have We Learned from the Human Genome Project?
The 46 human chromosomes are different sizes—easily separated and identified.
The DNA is first cut into fragments about 500 bp long.
Haploid human genome has about 3.2 billion bp—results in 6 million fragments.

17.6 What Have We Learned from the Human Genome Project?
Smaller fragments of DNA have overlapping sequences and must be aligned.
Two methods are used for this alignment:
• Hierarchical sequencing
• Shotgun sequencing

17.6 What Have We Learned from the Human Genome Project?
In hierarchical sequencing, short marker sequences are identified—ensuring that every DNA fragment would have a marker.
Simplest markers are restriction sites.
Some restriction enzymes recognize a sequence of 8–12 bp—results in larger fragments.

17.6 What Have We Learned from the Human Genome Project?
The large fragments are added to a vector—bacterial artificial chromosome (BAC), and inserted into bacteria to create a gene library.
The fragments are arranged in order along the chromosome map by using marker sequences.
Libraries made with different restriction enzymes are compared and overlaps determined.

17.6 What Have We Learned from the Human Genome Project?
The shotgun sequencing method cuts DNA in random fragments.
Computers are used to search for overlapping markers.
This approach is much faster. Sophisticated computers and software have refined the alignment process so that it is very accurate.
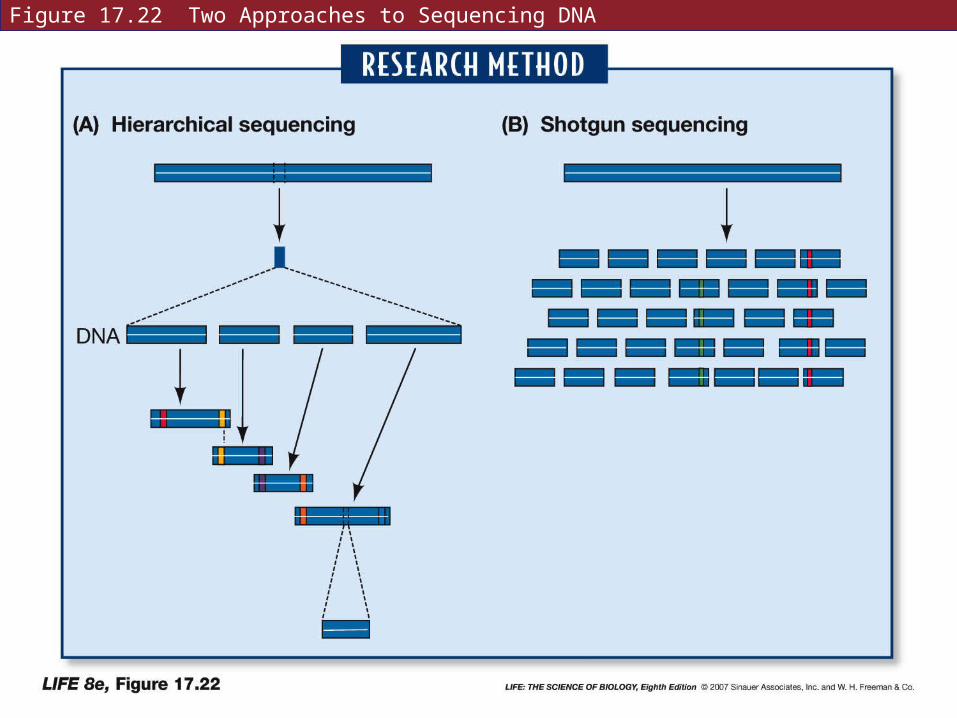
Figure 17.22 Two Approaches to Sequencing DNA
17.6 What Have We Learned from the Human Genome Project?
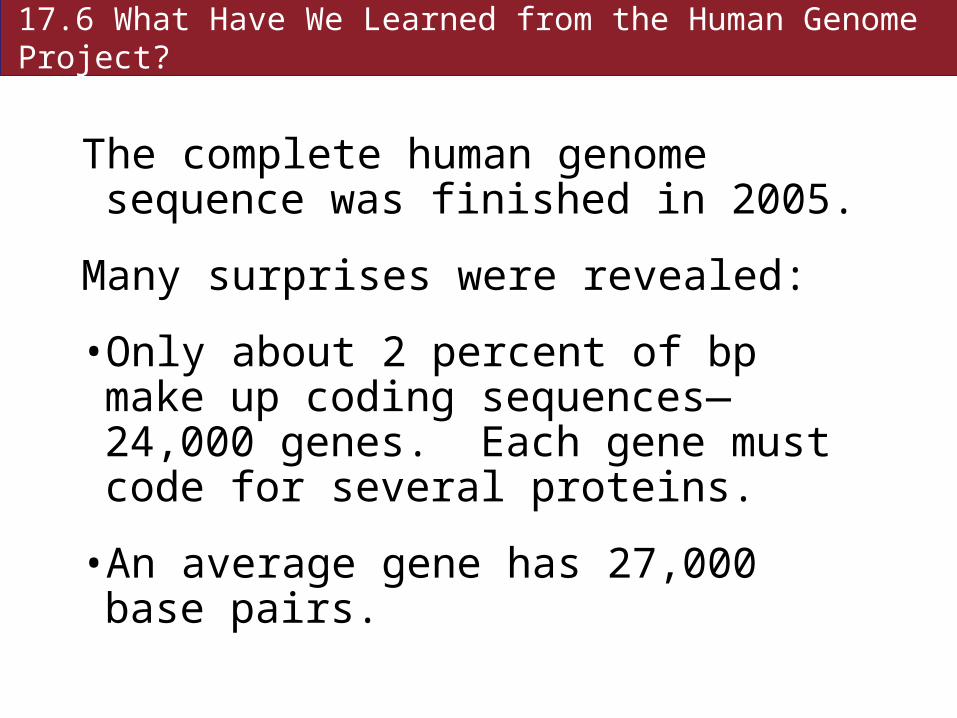
The complete human genome sequence was finished in 2005.
Many surprises were revealed:
• Only about 2 percent of bp make up coding sequences—24,000 genes. Each gene must code for several proteins.
• An average gene has 27,000 base pairs.

17.6 What Have We Learned from the Human Genome Project?
• All human genes have many introns.
• Over 50 percent of the genome is repetitive sequences.
• 99.9 percent of the genome is the same in all people.
• Genes are not evenly distributed over the genome.
• There are many genes with unknown functions.

17.6 What Have We Learned from the Human Genome Project?
ENCODE project (Encyclopedia of DNA Elements) will identify all the functional sequences, not just protein coding sequences.
This project will make use of sequences from closely related species such as the chimpanzee.

17.6 What Have We Learned from the Human Genome Project?
There are many applications of the human genome project:
• Isolation of genes by positional cloning is easier because of genetic markers. Identification of disease-related genes.
• Pharmacogenomics studies variation in drug metabolism.

17.6 What Have We Learned from the Human Genome Project?
• DNA chips are used to analyze gene expression at different times, e.g., during the development of a tumor.
• “Genome prospecting” looks for genes that predispose people to certain conditions.
17.6 What Have We Learned from the Human Genome Project?
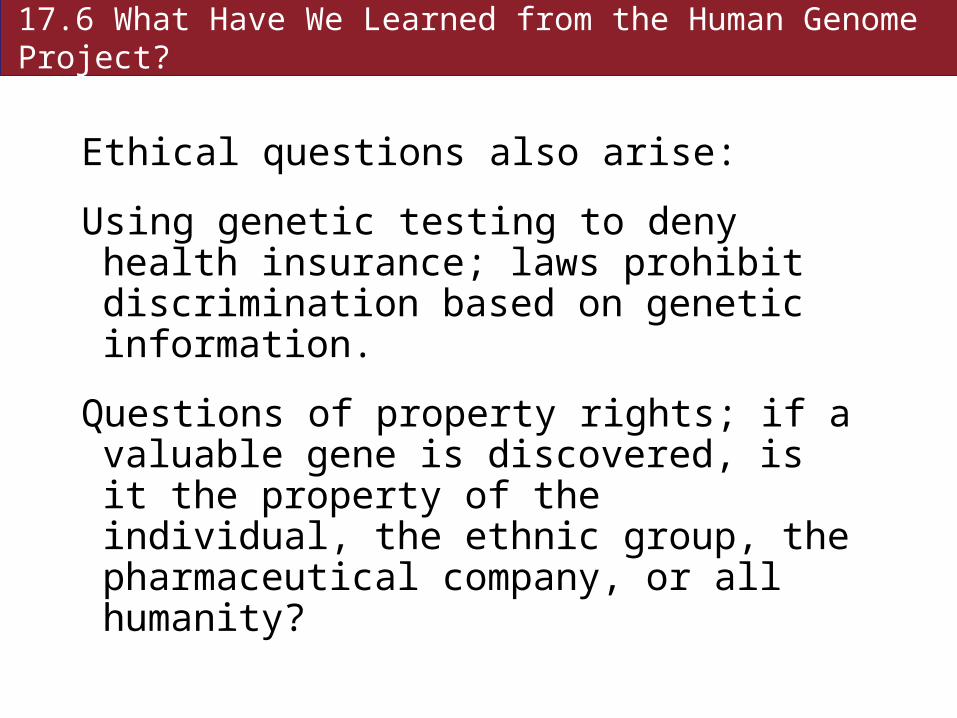
Ethical questions also arise:
Using genetic testing to deny health insurance; laws prohibit discrimination based on genetic information.
Questions of property rights; if a valuable gene is discovered, is it the property of the individual, the ethnic group, the pharmaceutical company, or all humanity?

17.6 What Have We Learned from the Human Genome Project?
Several human populations who have descended from relatively few ancestors are being studied to search for genetic markers, genes that cause or predispose to diseases, and other knowledge.
Examples: French Canadians in Quebec, Costa Ricans, Sardinians, Ashkenazic Jews, Icelanders

17.6 What Have We Learned from the Human Genome Project?
The proteome is the sum total of proteins produced by an organism—more complex than the genome.
Two techniques to analyze the proteome:
• Two-dimensional gel electrophoresis—proteins are separated based on size and electric charges.
• Mass spectrometry identifies proteins by their atomic masses.

Figure 17.23 Proteomics

17.6 What Have We Learned from the Human Genome Project?
Recently, proteomics and DNA chip technology was used to compare brain proteins in humans and chimpanzees.
In 12,000 DNA sequences tested, only 1.4 percent were different in the two species.
But specific proteins expressed differed by 7.4%—probably due to alternative splicing.
Amounts of the proteins differed by 34 percent.

17.6 What Have We Learned from the Human Genome Project?
DNA sequencing and other molecular approaches are reductionist—dissecting biology into ever smaller parts.
Huge quantities of data are produced.
Systems biology aims to integrate molecular biology data.

17.6 What Have We Learned from the Human Genome Project?
A system is a group of parts that interact, forming a whole that is greater than the sum of the parts.
Systems have emergent properties not present in the parts by themselves.
Systems biologists try to discover emergent properties; in order to predict outcomes when physiological conditions change.

17.6 What Have We Learned from the Human Genome Project?
Example: analysis of metabolic pathways of fat metabolism in two strains of mice
Interactions between mRNA transcripts, proteins, and metabolites show that one protein is up-regulated in mutant mice, while another is down-regulated in wild-type.
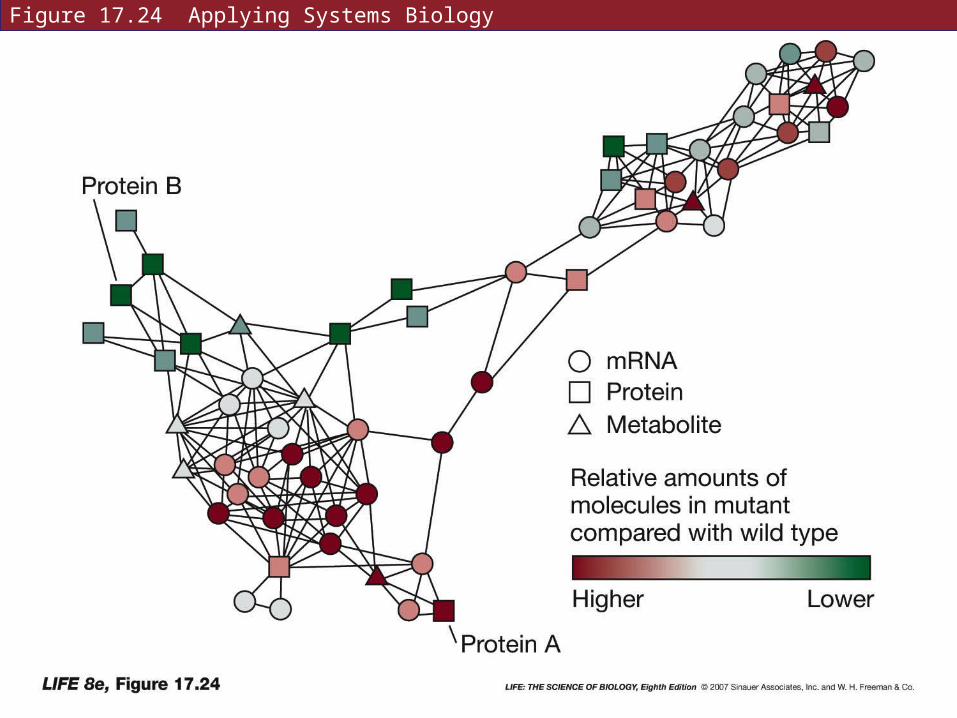
Figure 17.24 Applying Systems Biology

17.6 What Have We Learned from the Human Genome Project?
Systems biology uses information about all the interactions of a protein to predict consequences of a change in that protein.
Requires sophisticated computational techniques.
It will be useful in the study and treatment of complex genetic diseases.
Recommended

















