Embed Size (px)
Citation preview

VLSI Placement and Area Optimization Using a Genetic
Algorithm to Breed Normalized Postfix Expressions
Christine L. Valenzuela (Mumford)∗and Pearl Y. Wang†
Published in 2002
Abstract
We present a genetic algorithm (GA) that uses aslicing tree construction process for the placementand area optimization of soft modules in very largescale integration floorplan design. We have over-come the serious representational problems usu-ally associated with encoding slicing floorplans intoGAs, and have obtained excellent (often optimal)results for module sets with up to 100 rectangles.The slicing tree construction process used by ourGA to generate the floorplans has a run-time scal-ing of O(n lg n). This compares very favourablywith other recent approaches based on non-slicingfloorplans that require much longer run times. Wedemonstrate that our GA outperforms a simulatedannealing implementation with the same represen-tation and mutation operators as the GA.
Keywords: Floorplanning, genetic algorithm,normalized postfix expression, simulated annealing,slicing tree.
1 Introduction
Simulated annealing (SA) and tabu search (TS)tend to be more popular than genetic algorithms(GAs) with crossover for solving large combinato-rial problems. One reason for this is the difficultyinvolved in devising representations for GAs thatfacilitate effective crossover operators. The verylarge scale integration (VLSI) floorplanning prob-lem provides a particularly challenging application.The candidate floorplan solutions are frequentlyrepresented either as binary trees or as postfix ex-pressions, both of which encode specific instructionsfor combining the rectangles in pairs using a mix ofsymbols to represent the basic rectangles and bi-nary operators. Naive GA crossover operators eas-
∗Christine Valenzuela (Mumford) is with the School ofComputer Science & Informatics, Cardiff University, CF243AA, UK.†Pearl Y. Wang is with the Department of Computer
Science, George Mason University, Fairfax, VA 22030-4444USA.
ily produce duplications and deletions of the basicrectangles when applied to the binary tree represen-tation and may create illegal expressions if appliedto postfix representations.
These difficulties can be overcome. This paperdescribes a solution approach that incorporates anovel encoding system with a simple and effectiveGA. It utilizes an order-based representation thatencodes the rectangles and the binary operationsinto a simple permutation of structures, and a de-coder that converts the permutation of structuresinto a normalized postfix expression. The normal-ized postfix expression is a non-redundant represen-tation because it produces a unique postfix repre-sentation for every distinct slicing floorplan. If thepostfix expressions are not constrained by normal-ization, a single layout can be expressed by verymany equivalent postfix expressions. (Details ofnormalized postfix expressions are given in section2 of this paper.)
VLSI floorplanning is an important stage in chipdesign. It involves the placement of a set of rect-angular circuit modules (macro cells) on a chip soas to minimize the total area and the total inter-connecting wire length. When placing macro cells,many of the circuit modules are themselves not yetfully designed and frequently have some flexibilityin their shape. For example, a circuit module madeup from 12 identical components may have themplaced in one row of 12 components, 2 rows of 6components, 3 rows of 4 components, etc., offeringthe floorplan designer a range of possible shapesfor that module. Circuit modules having flexibilityin their shape are often referred to as soft mod-ules, and those with no flexibility in their shape arecalled hard modules. Using a technique based ona slicing floorplan, which can be obtained by re-cursively dividing a rectangle into two parts witheither a vertical or a horizontal cut, it is possible tofully exploit the available flexibility of soft modulesand efficiently combine module placement and areaoptimization into a single algorithm.
An alternative to the slicing floorplan is thenon-slicing floorplan, in which there is no require-
1

ment for recursive construction, and tighter pack-ings may be possible using this approach. Stock-meyer [14] examined cases where each subcircuitmay have different layout alternatives in a floorplanand showed that there is an efficient polynomial-time area optimization algorithm for slicing floor-plans, whereas the area optimization problem fornon-slicing floorplans is NP-Hard.
The main disadvantage of the slicing floorplanapproach is that for a particular set of circuit mod-ules, the majority of the feasible layouts will benon-slicing [9]. In other words, the slicing floor-plan approach severely reduces the size of the searchspace and may eliminate the very best circuit lay-outs. On the other hand, reduction in the size ofthe search space is advantageous as long as the so-lutions are good enough. According to [20] this isindeed the case for problems where modules haveflexibility in their shape. Another feature of theslicing floorplan that makes it an attractive propo-sition is the simple way that solutions can be rep-resented as normalized postfix expressions [19]. Itis interesting to note that techniques involving softmodules and slicing floorplans are equally applica-ble to facility layout problems [4, 5] as they are toVLSI floorplanning.
Non-slicing floorplan design for VLSI is oftendealt with by separating the two stages of place-ment and area optimization, and many researchersin recent years have concentrated extensively on thearea optimization stage [11, 12, 18]. A recent non-slicing placement technique called the sequence-pair method [8] has been extended to handle softmodules and area optimization [7]. However, thesequence-pair method has to solve expensive con-vex programming problems in order to determinethe exact shape of each module and this results ina very long run time. Another relatively new tech-nique called the bounded sliceline grid (BSG) pack-ing algorithm [9] has proved successful in the place-ment of hard rectangles, i.e., rectangles that haveno flexibility in their shape. The BSG approach isvery adaptable and is able to accommodate mod-ules that are not rectangular and modules whichare allowed to partially overlap. On the downside,though, a single application of the BSG packing al-gorithm scales at T (n) = O(n2) for hard modulesgiven the n x n grid size suggested by the authors.This compares with T(n) = O(n) for hard modulesusing a slicing floorplan approach. The average caserun time scaling of the combined placement andarea optimization algorithm of slicing floorplans forsoft modules is T (n) = O(n lg n).
It would appear that we are the first to use en-coded normalized postfix expressions in our GA.Although several other examples of GAs applied
to slicing tree structures can be found in the lit-erature, they do not use normalized expressions.Schnecke and Vornberger [13], for example, used aGA to manipulate the slicing tree directly for VLSIfloorplanning problems. However the crossover in-volves complex repair mechanisms simply to ensurethat the final product (or offspring) represents a le-gal slicing floorplan, with no duplications or dele-tions of modules. Cohoon et al. [2], in what isprobably the best known study of its type, used acollection of four different crossovers and appliedthem to postfix expressions that were not normal-ized. In a more recent study Kado et al. [5] com-pared the approach of Cohoon et al. with someother techniques from the literature and also somenew approaches, based on seeding the initial pop-ulation. Kado et al. were able to improve on pub-lished results for several facility layout problemsusing a variety of non-normalized representationsand further improvements have since been made tosome of these results by Garces-Perez et al. [4] us-ing Genetic Programming . Kroger [3], working ontwo-dimensional bin packing problems, also usednon-normalized postfix expressions and devised acrossover that searches the parental expressions forsubtrees that do not have any rectangles in com-mon, and combines subtrees from both parents intothe offspring. Although Kroger’s GA outperformedhis SA algorithm, the processing involved with thecrossover he used was both complex and time con-suming.
We view our main contribution to the field of slic-ing tree optimization as the extension of the ideasof [19] which used a normalized postfix represen-tation for SA. Through the addition of an encod-ing system, we have adapted the approach to pro-duce a simple but effective GA. We test our GA onsoft modules from the benchmark MCNC data sets,ami33, ami49, and playout and also on a larger dataset that we independently generated. The objectiveof our present study is a ‘proof of concept’ and welimit our objective function to the construction ofa floorplan of minimum area. Other elements, suchas the minimization of the total wire length, will beincluded in the cost function at a later date.
To complement our GA, we have written somesupporting software that checks the final floorplanfor correctness and draws a picture of the layout.
Figure 1 shows the roles played by the differ-ent software components. The process by whichthe GA evaluates individual postfix expressions iscomplicated when soft modules are involved. Eachtime a pair of rectangles or subassemblies is com-bined, a range of possibilities is stored for heightsand widths. At the end of the construction processthe best floorplan (i.e., the one with the smallest
2

Figure 1: Schematic showing the relationships between the software and data components of the system.
percent dead space) is chosen from a range of candi-date solutions. The backtrack program receives thepostfix expression from the GA and re-evaluates thefloorplan (i.e postfix string) using the same proce-dure as the original GA, only this time vital inter-mediate stages are saved. Once the postfix expres-sion has been evaluated and the dimensions of theenclosing rectangle established, the backtrack pro-gram traces through the saved intermediate stages,retrieving the exact heights and widths of all thecomponent rectangles. In addition to its vital rolein calculating dimensions for the basic rectangles asinput to the drawing tool, the backtrack programcarries out several verification procedures. First, itchecks that all the modules are present in the finalfloorplan. Second, it checks that the module dimen-sions are correct given their areas and shape flex-ibilities. Finally it verifies the percentage of deadspace produced by the GA. The backtrack programterminates when it has finished all its checking andestablished the precise dimensions of the basic mod-ules and stored all of these in a file. It is this file,now a file of hard modules, that provides the datafor the drawing tool. The drawing tool produces adiagram of a floorplan by re-evaluating the postfixexpression, backtracking this time to establish rel-ative placement positions for all the basic modulesin the floorplan.
Section 2 begins with a review of slicing floor-plans and their postfix representations, and thendescribes our approach to shape-curve addition forthe combination of soft modules. Section 3 de-scribes the representation used to encode our slicingfloorplans and also the decoder, which interpretsthese structures as normalized postfix expressions.
In Section 4 we outline our GA and explain the or-der based genetic operators we have used. Section 5describes our simulated annealing implementationand Section 6 defines the data sets we have used.Section 7 presents our results and, finally, we pro-vide a summary of our achievements and outlineour plans for future work in Section 8. The presentpaper expands the work presented in [16].
2 Slicing Structures and Post-fix Representations
A slicing floorplan is a rectangular floorplan with nbasic rectangles that can be obtained by recursivelycutting a rectangle into smaller rectangles using aseries of vertical and horizontal edge-to-edge (i.e.,guillotine) cuts. A slicing floorplan can be repre-sented in the form of a binary tree, called a slicingtree, in which each internal node of the tree is la-belled either * or +, corresponding to a vertical ora horizontal cut respectively. Each leaf representsa basic rectangle and is labelled between 1 and n,where n is the total number of basic rectangles. Aslicing tree can be represented, alternatively, usinga postfix expression. The postfix expression is de-rived by carrying out a post-order traversal.
There is a one-to-many relationship between slic-ing floorplans and slicing tree representations forslicing floorplans. If we restrict our representationsto skewed slicing trees, however, we obtain uniquedepictions for slicing floorplans [19]. The postfix ex-pression derived from a skewed slicing tree is calleda normalized postfix expression, and provides a lin-ear form of the representation. Figure 2 (a) il-
3

Figure 2: Slicing floorplan (a), skewed slicing tree represen-tation of floorplan (b) and corresponding normalized postfixexpression (c).
lustrates a typical slicing floorplan, (b) shows theskewed slicing tree, and (c) the normalized postfixexpression representing the floorplan in (a).
A skewed slicing tree is a slicing tree in whichno node and its right child have the same label in *, + and it is obtained by making consecutivevertical cuts from right to left, and making consec-utive horizontal cuts from top to bottom. A nor-malized postfix expression is obtained by traversinga skewed slicing tree in post-order and is character-ized by chains of *, + operators in which theoperators alternate. For example, the postfix ex-pression 1 2 3 + * 4 * is normalized, but the ex-pression 1 2 3 + + 4 * is not (because of the twoadjacent + symbols). A slicing floorplan with n-1cuts will produce n basic rectangles. Thus a postfixexpression consists of exactly 2n - 1 entries.
A normalized postfix expression which character-izes a slicing floorplan can be written:
π1c1π2c2π3c3π4 c4,.......,πncnwhere π1π2π3π4.......πn represent a permutation ofthe 1,2,...,n basic rectangles, and the ci’s are chainsof operators, either + * + * + *...., or * + * + * ......(see [19] for more details). If we let l(ci) representthe length of the chain, ci, then
∑i l(ci) = n - 1,
and l( c1) = 0. Also the maximum length of anychain of operators, ci, is constrained by the ballotingproperty as follows: for any position, i : 1 ≤ i ≤ n,l(ci) ≤ i - 1.
For slicing floorplans, postfix expressions providea convenient mechanism with which to representvarious placements alternatives. The process offloorplan design requires a further stage, however,when soft modules are involved – area optimization.
Figure 3: Binary operations for slicing floorplans.
We deal with the two main components of the floor-planning process separately in the two subsectionsthat follow.
A. The Placement Stage and the Bi-nary ‘+’ and ‘*’ Operations
In the discussion so far, we have viewed a slicingtree as a top-down description of a slicing floor-plan in which the slicing tree specifies how a givenrectangle is cut into smaller rectangles by verticaland horizontal cuts. An alternative is to view aslicing tree as a description of a bottom-up proce-dure. From a bottom up point of view the slicingtree describes how pairs of rectangles can be com-bined recursively to yield larger rectangles. Figure3 shows the actions of the binary operations + and* on the two rectangles A and B: ‘+’ puts B on topof A, and ‘*’ puts B on the right of A. In the exam-ple depicted in Figure 3, the two rectangles A andB combine under + and * to form L-shaped mod-ules. When following a bottom up slicing tree de-scription however, each L-shaped module (and anyother shaped modules which are not rectangular)will be replaced by the smallest possible enclosingrectangle, resulting in the creation of dead space (orwaste) in the floorplan.
Determining exactly where to position each rect-angle is frequently referred to as the placementproblem, and is NP-Hard. A simple lower boundfor a brute-force algorithm that searches the so-lution space of normalized postfix expressions canbe obtained if we make a simplifying assumptionthat places a single operator between each pair ofoperands in the expression, from the second to thenth on the postfix list, (i.e., either a ‘*’ or ‘+’),giving 2n−1 choices for the whole postfix string.Thus, considering the n! orderings of the rectanglesand the choices for the operators, a lower boundon the total number of distinct postfix strings is2nn! giving the following lower bound for therun time complexity of the brute-force algorithm
4

T (n) = Ω(2nn!n), assuming that it takes a time ofΘ(n) to process each individual string.
In order to derive a simple upper bound for asimilar brute-force algorithm, we examine all theindividual possibilities for the operator chains ly-ing between each pair of operands in a normalizedpostfix expression. The length of the operator chainis zero following the first rectangle, but from thesecond rectangle in the list onwards the length ofthe chain following the ith rectangle can take anyintegral value from the set 0, 1, 2,..., (i-1) . Fur-thermore, an operator chain of any given non-zerolength can exist in one of two possible forms: either* + * + * ... or + * + * +.... Following the sec-ond operand in the postfix expression, for example,the possibilities for operator chains are either nooperators (i.e., the empty chain), or a single opera-tor selected from *, + , giving three possibilities.Following the third operand are five possible chains:the empty chain, *, +, * + or + *. Following theith operand are 2*(i-1) + 1 possible operator chains;however the total number of operators for the entirepostfix string is constrained to n - 1.
A simple upper bound can be obtained by con-sidering the n! orderings of rectangles, togetherwith the above mentioned 2*(i-1) + 1 possible op-erator chains following the ith operand. Once againwe assume that it takes Θ(n) time to process eachstring.
T(n) ≤ Cn!*(1 * 3 * 5 *.....*(2*(i-1) + 1)*.....* (2*(n-1) + 1)n< Cn!*(2 * 4 * 6 * * 2i * .... * 2n)n= Cn!2nn!n
where C is a positive constant, giving the simpleupper bound O(n!n!2nn) (Note: our upper boundand lower bound differ by a factor of n!.)
For problems such as these, where very largesearch spaces are involved, meta-heuristics, such asGAs may provide the only viable options.
B. Area Optimization Using SoftModules
Flexible circuit modules or soft modules are charac-terized by their aspect ratios. Let a given rectangle,R, have height h(R), width w(R), and area A(R).The aspect ratio of R is the ratio h(R)/w(R). Asoft rectangle is one that can have different shapesas long as the area remains the same. The shapeflexibility of a soft rectangle specifies the range ofits aspect ratio. A soft rectangle of area A(R) issaid to have a shape flexibility r if and only if Rcan be represented by any rectangle of area A(R)for which:
1r ≤
h(R)w(R) ≤ r
Figure 4: Shape curve for a module with shape flexibility3.
For the purposes of our present study we adopt thedefinition of shape flexibility from [20] as it pro-vides a continuous range of candidate aspect ratiosfor our soft modules. For a soft module with aspectratio, ρ, such that 1/r ≤ρ ≤ r, various vertical (ycoordinate) and horizontal (x coordinate) dimen-sions are possible and these can be modelled by ashape curve, Γ. Γ is a continuous non-increasingcurve lying entirely within the first quadrant, suchthat the x and y coordinates of points lying on orabove the curve define the feasible region. Figure 4illustrates a typical shape curve for a rectangle ofarea 3 and shape flexibility 3. The two points onthe curve mark the limits of flexibility for the rect-angle, which means that the rectangle can only bemade taller or wider than 3 units if dead space isadded. The feasible region depicted in the diagramindicates possible height and width dimensions foran enclosing rectangle and covers all points on andabove the curve.
Pairs of soft modules, A and B, can be com-bined into super modules by adding their shapecurves: A B +, by adding along the y directionand A B *, by adding along the x direction. Fig-ure 5 and Figure 6 illustrate examples of the verti-cal (+) and horizontal (*) combinations of pairs ofmodules. When a pair of soft modules is combined,the new shape curve can be computed simply byadding the curves at the points which correspondwith the so-called ‘corners’ on the curves of thecomponent modules. The diagrams show clearlythat the shape curves for basic modules of fixedorientation (i.e. no rotation is allowed) are eachcompletely characterized by two ‘corners’. (Note:a hard module of fixed orientation is characterized
5

Figure 5: Adding shape curves for A B +. Shape flexibilityfor A is 2 and for B, 3.
completely by a single point or ‘corner’.)Figure 5 illustrates the addition of two shape
curves for a vertical combination, where module Bis placed on top of module A to produce a newenclosing rectangle, C. The shapes curves for mod-ules A and B each consist of two ‘corners’, A[1] andA[2] for modules A and B[1] and B[2] for module B.A[1] and B[1] define the minimum widths for A andB, and A[2] and B[2] define their maximum widths.The parts of the curves laying between the mini-mum and maximum widths for A and B give all thepossible height and width combinations for area(A)= 2 and area(B) = 3. The minimum width of theenclosing rectangle for the vertical combination ofany two modules X and Y can never be narrowerthan the larger of the two minimum widths,X[1] orY [1], and so if X[1] 6= Y [1] the smaller is discardedin calculating the shape curve for combined mod-ule. In Figure 5, however, A[1] = B[1] , thus nopoints are discarded. The maximum width of thenew enclosing rectangle C is the same as the largerof the two maximum widths (B is this case). Deadspace is added to the narrower module (A) to makeC into the required rectangular shape.
When adding together two shape curves in a ver-tical direction we only add at positions correspond-ing to ‘corners’ on one or other of the componentshape curves. We identify three cases which canoccur when adding such pairs of points at a givenwidth position:
• Case 1: Both component modules have ‘cor-ners’ at this width position,
Figure 6: Adding shape curves for A B *. Shape flexibilityof A is 2 and B, 3.
• Case 2: One module has a ‘corner’ at this po-sition, and the width position lies between twocorners on the curve for the other module.
• Case 3: One module has a ‘corner’ at this po-sition, and the width position lies beyond thelast corner for the other module.
The ‘corners’, C[1], C[2], and C[3], for the com-bined module, C, in Figure 5 illustrate cases 1, 2and 3 respectively, and can be obtained as follows:
Case 1C[1].width = A[1].width (=B[1].width)C[1].height = A[1].height + B[1].heightCase 2C[2].width = A[2].widthC[2].height = A[2].height + Area(B)/A[2].widthCase 3C[3].width = B[2].widthC[3].height = B[2].height + A[2].heightNote that the shape curve addition process shown
in Figure 6 for horizontal combination can be ob-tained in the same way as for Figure 5 by simplyreversing the heights and the widths.
In order to produce a slicing floorplan from a nor-malized postfix expression it is necessary to createa repetitive process that combines modules that re-sult from previous combinations (called super mod-ules) with a mix of basic modules and other supermodules, adding together their shape curves in thebottom-up procedure. Fortunately, the process ofadding shape curves for super modules is essentiallythe same as the procedure for combining two ba-sic modules, only with more ‘corners’ to add. Ourgeneral calculation routines for adding points onpairs of shape curves extend the ideas illustrated
6

in Figure 5. The details are based on the followingobservation:
• For any given shape curve, the area betweentwo consecutive ‘corners’, either along thewidth or along the height axis, varies in a uni-form fashion.
Thus if point Z lies half way between ‘corners’ Xand Y along, say, the width axis, the area at pointZ will lie half way between the areas at X and Y .This simple relationship holds because each ‘corner’on a curve, except for the first, represents the max-imum width (height) possible for one of the basicmodules contained within the curve. Thus betweenany two ‘corners’, dead space is added at a uniformrate This simple observation makes it easy to calcu-late heights and widths exactly for any position ona given shape curve, whether or not that positioncorresponds to a ‘corner’ and no matter how manybasic modules have been included to produce theshape curve.
The pseudocode of the main routine for verti-cal combination is presented in Algorithm 1. De-tails for the three alternative methods of combina-tion, case 1, case 2, and case 3, referred to in thealgorithm, are as described earlier in the presentsection. For each basic module and super modulethe ‘corners’ are stored in a simple list of coordi-nate pairs sorted on increasing value of the x (orwidth) coordinate. In addition to the height andwidth values, a third variable is stored with eachcoordinate pair: the amount of dead space. Thelist of coordinate pairs represents the ‘corners’ ofthe shape curve for a module. The algorithm pro-ceeds by stepping through a pair of lists (one listfor each of the modules to be combined) in ascend-ing sequence of x coordinates value, adding the twocurves together as it proceeds, producing a new listfor the resulting combined module. As explainedthe ‘corner’ selected as a starting point for the ad-dition process is the earliest point on the modulewith the larger of the minimum x values as its first‘corner’. Any ‘corners’ from the other module withx values smaller than this minimum are discarded.The routine for horizontal combination is obtainedby interchanging the x and the y coordinates inthe code and working through simple lists of shapecurve points, this time sorted on ascending y value.
To facilitate both vertical and horizontal combi-nations, we maintain two sorted lists of coordinatesfor each module and super module: one sorted onascending x values, and the other on ascending yvalues. If redundant points (i.e., points that lie inthe feasible region but above the shape curve) areeliminated as soon as they are generated, the two
lists are simple to maintain; the one sorted on xcoordinates is the exact reverse of the list sorted ony coordinates. This has important run-time conse-quences: no sorting algorithm is needed to updateeither of the lists.
As described above, a basic module of fixed orien-tation has a maximum of two ‘corners’. Thus, whentwo basic modules are combined by our methodsthe resulting combined module will have at mostfour ‘corners’ on its shape curve. After combiningn modules following an arbitrary slicing tree, anupper bound on the number of points is 2n.
Currently the run time for our shape curve com-bination routine is rather long because we have notas yet incorporated approximations as suggested in[19] to reduce the number of ‘corners’ accumulatedby our shape curves. The worst case run-time forour routine, assuming that one module is added ata time to a single super module, (e.g., the postfixexpression1 2 + 3 + 4 + 5 + 6 +) is given by:
T (n) = O(n2).
The best and the average case, however, are givenby:
T (n) = O(n lg n) [14]
3 The Representation andDecoder
Our representation for the GA is order based andconsists of an array of records, with one record foreach of the basic rectangles of the data set. Eachrecord contains three fields:• a rectangle ID field : this identifies one of the
rectangles from the set 1, 2, 3,..., n
• an op-type flag : this boolean flag distinguishestwo types of normalized postfix chains, T = +* + * + * +...., and F = * + * + * + *.....
• a chain length field : this field specifies themaximum length of the operator chain asso-ciated with the rectangle identified in the IDfield.
Our decoder converts a given instantiation ofthe array of records into a legal normalized postfixexpression by writing down the rectangle IDs in theorder given, and inserting the type of normalizedchain of operators (either T = + * +... or F = *+ *...) as indicated by the op-type flag associatedwith that rectangle ID. The length of each chainof operators is given in the chain length field. For
7

Figure 7: Algorithm 1. Add shape curves algorithm. Main routine for the vertical combination of two soft modules.Details for Cases 1, 2, and 3 combinations are given.
8

example, for a length = 5 we would get an operatorchain of either + * + * + or * + * + * , dependingon the value of the op-type flag. However, if achain of operators produced in this way turns outto be too long and violates the balloting property(i.e. if we are currently processing the ith rectanglein the list the total number of operators in thepostfix expression constructed so far must be lessthan or equal to i - 1), the decoder will shorten thechain and maintain legality. If the decoder reachesthe end of the sequence of records and the resultingpostfix string has less than n 1 operators, extraoperators are added on to the end of the stringmaintaining the normalized pattern of ..+ * + *...etc. The decoder algorithm is presented in Algo-rithm 2. Below is an example showing an encodedstring and its normalized postfix interpretation:
rect5 rect2 rect4 rect1 rect3op-type* op-type+ op-type* op-type* op-type+length 2 length 1 length 0 length 2 length 0
Postfix expression generated: 5 2 + 4 1 * + 3 +
4 The Genetic Algorithm
Our GA, presented in Algorithm 3 is an example ofa steady state GA based on the classification givenin [15]. It also uses the weaker parent replacementstrategy first described in [1].
As outlined in Algorithm 3, our GA appliesgenetic operators to permutations of rectanglerecords. The fitness values are based on the amountof dead space produced in each floorplan, F , definedby the individual normalized postfix expressions en-coded in the population. The percentage of deadspace is defined as follows:
A(RF )−∑n
i=1A(Ri)∑n
i=1A(Ri)
× 100
where A(RF ) is the area of the enclosing rectanglefor the floorplan and A(Ri) is the area of the ith
basic rectangle.
In Algorithm 3 the first parent is selected deter-ministically in sequence, but the second parent isselected in a roulette wheel fashion, the selectionprobabilities for each genotype being calculated us-ing the following formula:
selection probability = (Rank)∑Ranks
where the genotypes are ranked according to thevalues of the waste that they have produced, withthe worst ranked 1, the second worst 2, etc., andthe best ranked highest.
The GA breeds permutations of records fromwhich our decoder produces normalized postfix ex-pressions. These expressions are, in turn, processedby adding the shape curves together (as describedin Section 2) for each horizontal or vertical combi-nation, recording the percent of dead space at theend.
The initial population consists of random permu-tations of records with each basic rectangle repre-sented exactly once in each list. The op-type flagfor each record is set to ‘+’ or ‘*’ with equal proba-bility, and the value in the length field is generatedin two stages:
Stage 1: length = 0, with a probability of 0.5Stage 2: if the length is not set to zero, then it
is generated from a Poisson distribution with mean3.
A. Genetic Operators for Permuta-tions
We use three different mutation operators, one foreach of the fields in our encoding structure (rectan-gle ID, op-type, and op length):
• M1 Swap positions of two rectangle IDs.
• M2 Invert op-type flag, + to * or vice versa.
• M3 Mutate length by incrementing or decre-menting (i.e. length = length + 1, length =length - 1) with equal probability. (If length iszero we always increment).
M1 and M2 produce an identical effect to the M1and M2 operators defined in [19]. Our M3 operator,on the other hand, is different from theirs, althoughits effect is similar. But M3 will never produce anillegal postfix string.
In the very early stages of our study wechose some non-problem specific position-based andorder-based crossovers for testing and carried outsome extensive tests to compare the performanceof four permutation crossovers on our data sets.Overall cycle crossover (CX) [10] came out best.Our implementation of CX is efficient and runs inlinear time.
5 Our Simulated AnnealingImplementation
Our simulated annealing implementation is similarto that which is described in [19]. It is based on theroutine developed in [6]. A generic simulated an-nealing procedure is outlined in Algorithm 4. In theouter loop the temperature is reduced gradually. At
9

Figure 8: Algorithm 2. Outline decoder algorithm.
Figure 9: Algorithm 3. Simple steady-state GA.
Figure 10: Algorithm 4. Generic SA.
10

each step of the inner loop a small perturbation, S′,of the configuration, S, is chosen and the resultingchange in the cost function, ∆ = C(S′) − C(S), iscomputed. The new configuration is accepted withprobability 1 if ∆ ≤0, and with probability e−∆/T if∆ > 0. The higher the temperature, the more likelyit is that a poorer solution than S is accepted.
We use the same representation and decoder forour SA as for our GA. The perturbations are se-lected from M1, M2, and M3, the mutations fromthe genetic algorithm in the previous section, withone of the three moves selected at random eachtime. M1 and M3 are each selected with 40% prob-ability, whilst M2 (which is more disruptive) is se-lected with 20% probability, the same proportionas we use in our GA. As we previously mentioned,our M1 and M2 are identical with the M1 and M2operators used in [19], and M3 produces a similareffect to the M3 used in their work.
We use a temperature schedule of the form Tk =r*Tk−1, k = 1, 2, 3, .... and set r = 0.9. Theinitial temperature, T0 is determined by computinga sequence of random moves, using M1, M2, andM3, and computing the quantity ∆avg, the averagevalue of the magnitude of change in cost per move.We should have e∆/T = P '1, for T = T0, so thatthere is a reasonable probability of acceptance athigh temperatures. We start with a temperature of2.5*∆avg, which equates to P '0.7. The startingparameters r and P , were set following extensiveexperimentation.
At each temperature we attempt 20n moves (in-ner while loop), following [21, 22]. 20n is also thesize of the population we use for our GA. The an-nealing process is halted when the temperature hasbeen lowered 20 times since the last improvementwas recorded in the best-so-far (outer while loop).Experimentation indicates that the SA is unlikelyto produce any further improvements at this stage.
In our implementation M3, which increments ordecrements the length of a selected normalized op-erator chain, frequently produces perturbed solu-tions that result in floorplans identical to their pre-cursor. This happens because our decoder ‘cor-rects’ information in the operator ‘chain length’field whenever it contradicts the balloting property,by adding or subtracting operators where required.Thus we find that quite a large number of movesinvolving no change in cost are produced through-out the execution of the SA, and all such movesare accepted in our implementation. Nevertheless itwould appear that these ‘sideways’ moves are bene-ficial to the SA process overall, introducing variabil-ity which may lie dormant for a period and yet canbe expressed physically at a later time, followingfurther M3 mutations at different locations in the
postfix expression: if we prevent our SA from ac-cepting moves where no change in cost is involved,our results deteriorate considerably.
We find that it can be beneficial if we refocusthe SA search, from time to time, onto the globalbest floorplan so far discovered. We do this when-ever three consecutive temperature reductions havefailed to produce any improvements to the globalbest.
6 The Data Sets
We use the basic modules of the MCNC bench-marks ami33, ami49, and playout, and model theshape flexibility as continuous curves in a mannersimilar to [21, 22]. An additional problem, f 100,was randomly generated following the guidelines of[19]. The areas of the modules for f 100 were chosenfrom a uniform distribution of floating point num-bers between 1 and 20. Details for the individualdata sets are given in Table 1.
7 Results
In this section we compare the performance our GAand the related SA on a range of problems consist-ing of between 33 and 100 soft modules. It is unfor-tunate that despite using modules taken from thethree larger MCNC benchmark problems, ami33,ami49, and playout, we are unable to make directcomparisons with published results in [21, 22, 23],because of the extra constraints on that have beenimposed by these authors on selected modules ineach data set. For example, in [21] 2 - 4 of the mod-ules are pre-placed in fixed positions, and in [22] 1-5 of the modules are restricted to the chip bound-ary. In [23] the authors mix hard and soft modules,allowing no flexibility in the shapes of 2 - 5 of themodules in each data set. Although at the start of[21] and [22] the authors outline some rather morestraightforward experiments on ami33 and ami49,and report results of less than 1 % dead space, nodetails of shape flexibility are given. Additionally,an estimate of wire length is included in their ob-jective function, although this is not quoted in theirresults, which is stated only in terms of percentagedead space. We will discuss these points further inthe following section, after we have presented ourresults.
As we have mentioned, we choose a populationsize of 20n for our GA where n is the number ofmodules in the problem. The GA is halted when 40generations have passed since the last improvementwas recorded in the best-so-far, as it seems to haveconverged by then.
11

For the GA and SA, we set the limits on the as-pect ratio for the final enclosing rectangle (i.e. thechip aspect ratio) to those used in [19]: 1/2 ≤ chipaspect ratio ≤ 2. Unfortunately, there does not ap-pear to be a way to predict a chip aspect ratio inadvance of a full evaluation of a postfix expression.To ensure that we obtain acceptable solutions, weautomatically reject all moves for the SA and off-spring for the GA in which the best point on thefinal shape curve does not correspond to a legal chipaspect ratio. Following rejection, crossover and mu-tation operators are reapplied at new random posi-tions until an individual with a suitable aspect ratiois produced. In the rare event of 25 consecutive at-tempts failing to produce a suitable individual inthe GA, one of the parents is replaced and the pro-cess attempted again. It is interesting to note thatboth the GA and the SA appear to favour floor-plan solutions with chip aspect ratios close to theboundaries, and the production of neighbourhoodsolutions which lie outside of these boundaries area frequent occurrence, especially for the SA. (Whenwe removed the chip aspect ratio constraint, the re-sults were even more extreme, producing only verylong and skinny layouts.)
The results for our GA and SA are summarizedin Table 2. Where possible we have carried out 100replicate GA or SA runs, each with different ran-dom starts, and averaged the results. The data setsin column 1 are as detailed in Section 6 of this pa-per. The value in brackets in column 1 gives theshape flexibility of the basic rectangles for the ex-periments in the row. Column 2 specifies the num-ber of replicate runs used for averaging the GA andSA results in each row. We used 100 experimentsfor the smaller problems (ami33 and ami49 ), andless for the larger problems. Columns 3 and 6 sum-marize the dead space obtained by the GA., andcolumns 7 and 9 summarize the results for the SA.The average percentage of dead space of the bestfloorplan is recorded for the GA and SA in columns3 and 7 respectively, and the overall best from thereplicate runs is recorded in columns 6 and 9. Thetotal number of postfix expression evaluations (in-cluding those individuals subsequently rejected be-cause of illegal chip aspect ratios) averaged over allthe replicate runs is noted in columns 4 and 8, andthe average run times for the GA appear in columns5. Run times for the GA were recorded on a Pen-tium III computer running at 600 MHz with 128Mbyte RAM. Run times for our SA have not beenincluded, but they are directly proportional to thetotal number of evaluations, and are thus similar tothe run times for the GA. However, we note that,evaluation for evaluation, the SA has the potentialto run very much faster than the GA because it is
better suited to storing and re-using partial floor-plan results. We have, as yet, made no attempt tooptimize our SA code, and our present implemen-tation recomputes each newly generated neighbour-hood floorplan in its entirety, in the same fashionas for the GA.
The grey shaded cells in the table indicate sit-uations where floorplans have been found that areknown to be optimal (because they have zero per-cent dead space). The results presented in Table 2indicate that the GA is better than the SA for thedata sets under consideration. Statistical tests bearthis out, showing significant differences between theGA and SA means for the ami33, ami49 and play-out data sets at the 0.02 % level. It is clear, how-ever, that relaxing the shape flexibility of the basicmodules from 2 to 4 makes it easier for the both al-gorithms to find good floorplans. Throughout thestudy we found that the GA was much more robustand easier to tune than the SA: the SA producingmuch more variable and unpredictable results. Theaverage performance of the SA on the three variantsof the 100 module problem was particularly poor,and comparing the total number of evaluations forthe SA with the GA for the 100 module problems,the SA appears to become trapped in a poor sub-optimal region early on. Some caution is needed ininterpreting the results for 100 modules, however,because we carried out only 5 replicate experimentsin each case.
Figure 13 and Figure 14 show typical floorplandesigns found by our GA for ami33 and ami49 re-spectively. These pictures were constructed usingour drawing tool, which is part of our support-ing software described in the introduction to thepresent paper.
8 Conclusions and FurtherWork
This paper describes a GA that uses a novel en-coding and a simple order-based approach to breednormalized postfix expressions for macro cell place-ment and area optimization in VLSI floorplan de-sign. Our experiments confirm that simple order-based genetic operators are effective in guiding thegenetic search for floorplanning.
Results presented for floorplanning problemswith up to 100 modules frequently achieve optimalsolutions: and this is something that we have notobserved in related published work. Comparisonsbetween our GA and a related simulated anneal-ing (SA) implementation clearly demonstrate thesuperiority of the GA for solution quality and ro-bustness.
12
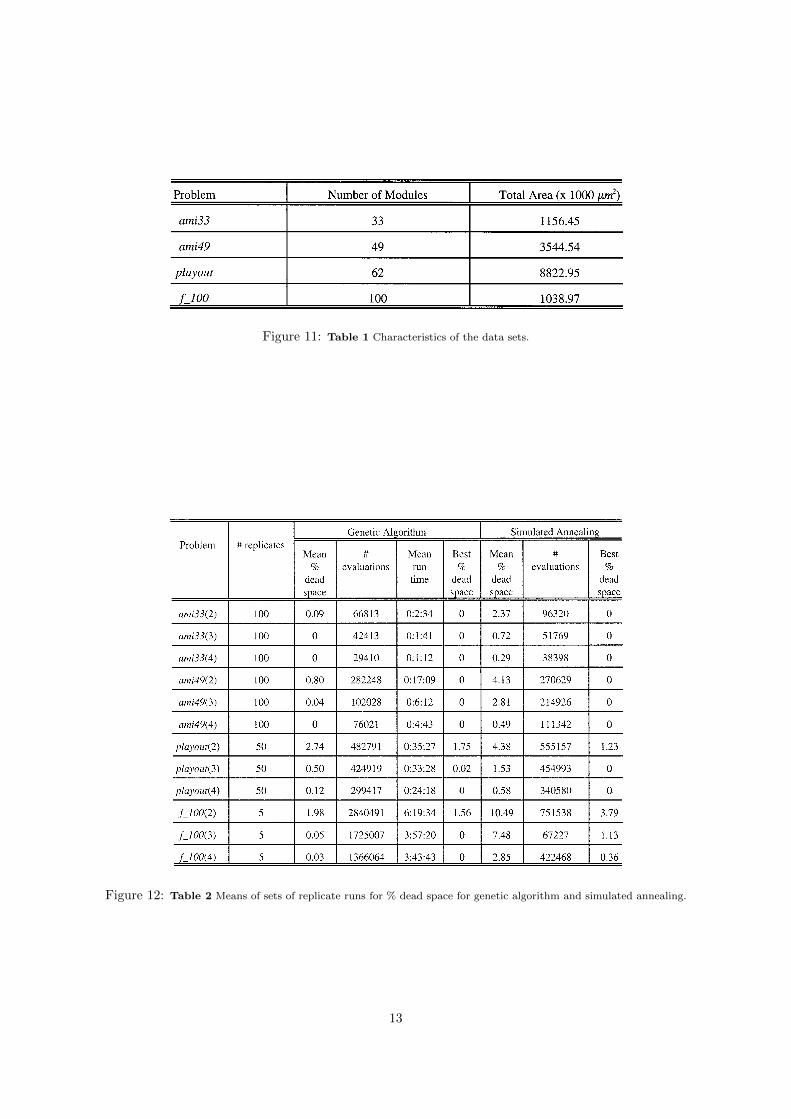
Figure 11: Table 1 Characteristics of the data sets.
Figure 12: Table 2 Means of sets of replicate runs for % dead space for genetic algorithm and simulated annealing.
13

Figure 13: Ami33 floorplan with shape flexibility 2, anddead space 0 %.
Figure 14: Ami49 floorplan with shape flexibility 2, anddead space 0 %.
The only recent related work, of which we areaware, is that reported in [20, 21, 22, 23], whichuses soft modules and normalized postfix expres-sions with a simulated annealing algorithm. In [20]experiments using test problems with 100 modulesare briefly described in the introduction to the pa-per. Each module has a shape flexibility 2, andthe SA yields, on average, 2.2 % dead space. Ourresult of 1.98 % on our 100 module data (shapeflexibility 2) would appear to be very similar, al-though the other authors do not state whether ornot any constraint is imposed upon the final aspectratio for the chip (we constrain our solutions to chipaspect ratios between 1/2 and 2). In the introduc-tion to another paper [22], results are reported ofless than 1 % dead space for several MCNC bench-marks including ami33 and ami49. Once more itwould appear that these results are very similar toours: we mostly achieve zero percent dead spacefor the same problems. However, Young and Wongdo not state the range of aspect ratios which theyallow for the soft modules in their experiments.
Although we are not yet able to match the run-times reported in [20, 21, 22, 23], we expect toachieve a significant speedup when we introducepiecewise linear approximations and reduce thenumber of ‘corners’ we accumulate during the con-struction process. We currently perform exact cal-culations when adding our shape curves. Our plansinclude extensive experimental studies to assess theeffect that reducing the maximum number of ‘cor-ners’ that a shape curve is allowed to have on theaccuracy of the dead space calculation. Our sup-porting software will provide all the verification andcrosscheck tools that we require to carry out thesestudies.
We have shown that our novel genetic representa-tion for normalized postfix expressions can be ap-plied successfully to slicing floorplans. Not onlydo our algorithms produce excellent results but theslicing tree construction process used by our GAto generate the floorplans has a run time scalingof O(n) for hard modules, and O(n lg n) for softmodules. This compares very favourably with thebounded-sliceline grid (BSG), that has been usedin GAs and SA for VLSI placement in recent pa-pers. The BSG packing algorithm scales at O(n2)for hard rectangles, given the n x n grid size sug-gested by the authors.
Work in progress is currently focussed on floor-plan design using soft modules with free orienta-tion (as opposed to fixed orientation), and alsoon adapting some simple bin packing heuristicsfor floorplanning problems. We have recently suc-ceeded in incorporating wire length into the ob-jective function for our GA, and early experi-
14

ments have produced some promising results. Theplanned incorporation of shape curve approxima-tions into our area optimization code has alreadybeen mentioned. In addition we have adapted ourfloorplanning techniques and applied them to somefacility layout problems [17].
Acknowledgements
We should like to thank the editor and the anony-mous referees for their helpful comments and sug-gestions. We believe the paper has been much im-proved due to their insight.
References
[1] D. J. Cavicchio. Adaptive search using simu-lated evolution. Unpublished doctorial disserta-tion, University of Michigan, Ann Arbor, 1970.
[2] J. P. Cohoon, S. U. Hedge, W. N. Martin andD. S. Richards. Distributed Genetic Algorithms forthe Floorplan Design Problem. IEEE Transactionson Computer Aided Design, Vol. 10, No. 4, April1991, pages. 483-492.
[3] Berhold Kroger, Guillotineable bin packing: A ge-netic approach, European Journal of OperationalResearch 84, pp 645-661, 1995.
[4] Jaime Garces-Perez, Dale A. Schoenefeld andRoger L. Wainwright, Solving Facility LayoutProblems Using Genetic Programming. Proc. 1st
Annual Conference in Genetic Programming,pages 182-190, 1996.
[5] Kazuhiro Kado, Peter Ross and David Corne, AStudy of Genetic Algorithm Hybrids for FacilityLayout Problems. Proc. 6th International Confer-ence on Genetic Algorithms, pages 498-505, 1995.
[6] S. Kirkpatrick, C. D. Gelatt Jr. and M. P. Vec-chi, Optimization by simulated annealing. Science(220), pages 671-680, 1983.
[7] H. Murata and Ernest S. Kuh, Sequence-pair basedplacement method for hard/soft /pre-placed mod-ules, International Symposium on Physical De-sign, pages 167-172, 1998.
[8] S. Nakatake, H. Murata, K. Fujiyoushi. and Y.Kajitani. Rectangle-packing-based module place-ment. Proceedings IEEE International Conferenceon Computer-Aided Design, pages 143-145, 1995.
[9] S. Nakatake, K. Fujiyoshi, H. Murata and Y. Ka-jitani. Module Placement on BSG-Structure andIC Layout Applications, Proceedings of ICCAD,pages 484-491, 1996
[10] I. M. Oliver, D. J. Smith, and J. R. C. Holland, Astudy of permutation crossover operators on thetraveling salesman problem. Genetic Algorithmsand their Applications: Proceedings of the SecondInternational Conference on Genetic Algorithms,pages 224-230, 1987.
[11] Peichen Pan and C. L. Liu, Area Minimizationfor Floorplans, IEEE Transactions on ComputerAided Design of Integrated Circuits and Systems,Vol. 14, No 1, January 1995., pages 123-132.
[12] M. Rebaudengo and M. Sonza Reorda, FloorplanArea Optimization Using Genetic Algorithms,Proceedings of Fourth Great Lakes Symposium onVLSI, March 1994, pages 22-25.
[13] V. Schnecke. and O. Vornberger, Genetic Designof VLSI-Layouts, the First International Confer-ence in Genetic ALgorithms in Engineering Sys-tems: Innovations and Applications (GALESIA),IEE 1995, pages 430-435.
[14] L. Stockmeyer, Optimal Orientations of Cells inSlicing floorplan Designs, Information and Con-trol, vol. 59, pages 91-101, 1983.
[15] G. Syswerda, Uniform Crossover in Genetic al-gorithms. Proceedings of the Third InternationalConference on Genetic Algorithms. Hillsdale, NJ:Lawrence Erlbaum Associates, 1989.
[16] Christine L. Valenzuela, and Pearl Y. Wang. AGenetic Algorithm for VLSI Floorplanning. Paral-lel Problem Solving in Nature - PPSN VI. LectureNotes in Computer Science 1917, pages 671-680September 2000.
[17] Christine L. Valenzuela, and Pearl Y. Wang.Breeding Normalized Postfix Expressions for theFacility Layout Problem. Fourth Metaheuristic In-ternational Conference (MIC 2001), Porto, Portu-gal, July 16-20, pages 261- 265, 2001.
[18] Ting-Chi Wang and D. F. Wong, Optimal Floor-plan Area Optimization, IEEE Transactions onComputer Aided Design. Vol. 11, No. 8, pages 992-1002 August 1992.
[19] D. F. Wong, H. W. Leong and C. L. Liu, Sim-ulated Annealing for VLSI Design, Kluwer Aca-demic Press, Boston MA, 1988.
[20] F.Y. Young and D.F. Wong, How Good are Slicingfloorplans, Integration, the VLSI Journal, Vol 23,pages 61-73, 1997.
[21] F. Y. Young and D. F. Wong, Slicing floorplanswith pre-placed modules. Proceedings IEEE Inter-national Conference on Computer-aided Design,pages 252-258, 1998.
[22] F. Y. Young and D. F. Wong, Slicing floorplanswith boundary constraints. IEEE Asia South Pa-cific Design Automation , pages 17-20, 1999.
[23] F. Y. Young and D. F. Wong, Slicing floorplanswith range constraints. International Symposiumon Physical Design, pages 97-102, 1999.
15





























