Embed Size (px)
Citation preview

Vladimir Litvin, Harvey Newman,
Sergei Shevchenko
Caltech CMS
Long-Term Massive Production Runs on Alliance resources: Experience

Introduction
• Caltech Higgs diphoton decay channel study is in the second stage. 10M background events with full detector simulation are being simulated, reconstructed and analyzed.
• 4.5M events has been done since April 2003
• Physics results have been presented at the Les Houches conference and reported on atCMS weeks and in CMS notes.
• In 2004-2005 a 50-100M run on TeraGrid Alliance facilities is planned.
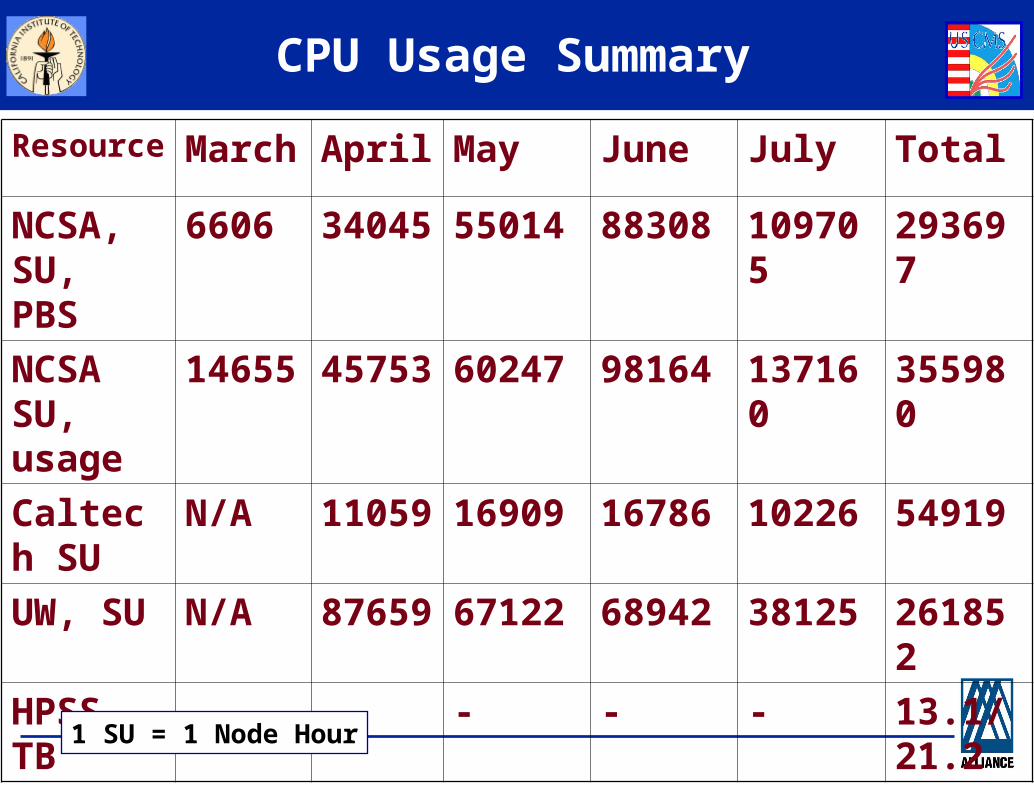
CPU Usage Summary
Resource March April May June July Total
NCSA, SU, PBS
6606 34045 55014 88308 109705 293697
NCSA SU, usage
14655 45753 60247 98164 137160 355980
Caltech SU
N/A 11059 16909 16786 10226 54919
UW, SU N/A 87659 67122 68942 38125 261852
HPSS, TB
- - - - - 13.1/ 21.2
1 SU = 1 Node Hour
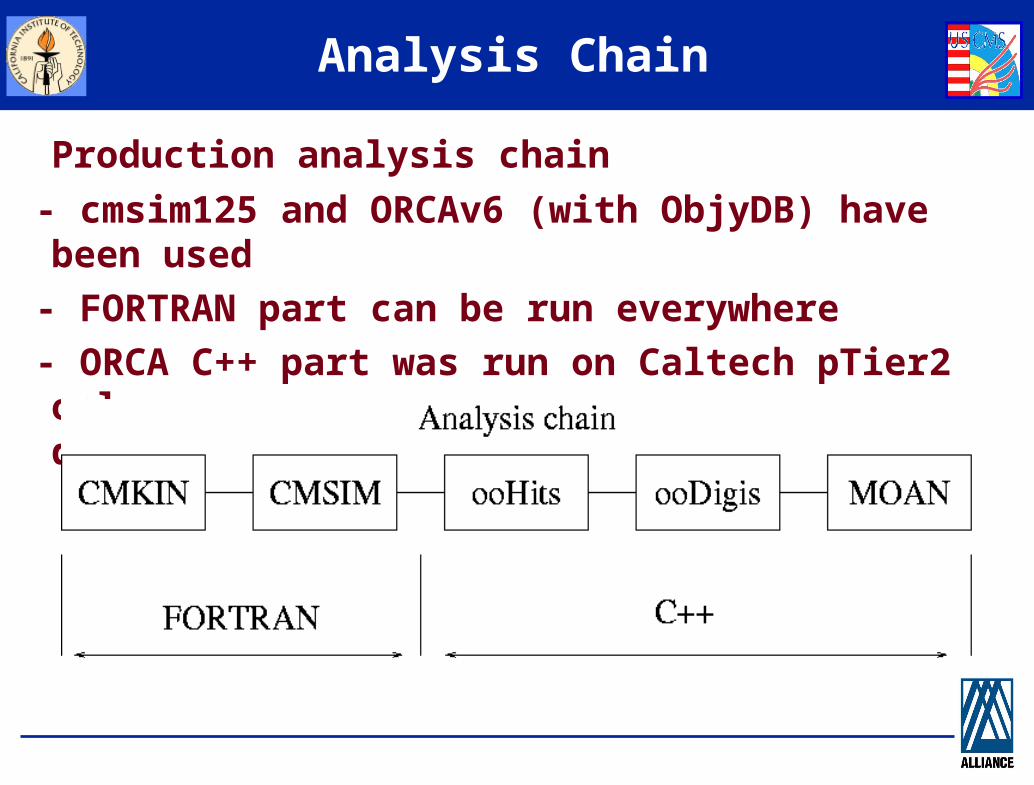
Analysis Chain
Production analysis chain
- cmsim125 and ORCAv6 (with ObjyDB) have been used
- FORTRAN part can be run everywhere
- ORCA C++ part was run on Caltech pTier2 only, due to ObjyDB RH6x restrictions

• •
Operational Issues
• There is a hierarchy of operational issues
• We will concentrate mainly on the lowest, infrastructure, level including clusters, network, mass storage system, social issues
• Even at this level there are a lot of open issues
• “3-tier architecture”

NCSA(I)
NCSA Platinum Cluster Technical Summary• IBM eServer x330 thin server (dual-processor)• ECC SDRAM: 1.5GB (compute nodes)• Access nodes – 4 (8 CPU)• Compute nodes – 484 (968 CPU)• Storage nodes – 32 (64 CPU)• Intel PIII 1GHz, 256kB full-speed L2 cache (peak
performance 1 Gflop)• Network Interconnect:
– Access node – Gigabit Ethernet– Compute node – Myrinet 2000
• Disks: local 10GB per node and 4 NFS mounted FSs 650GB each
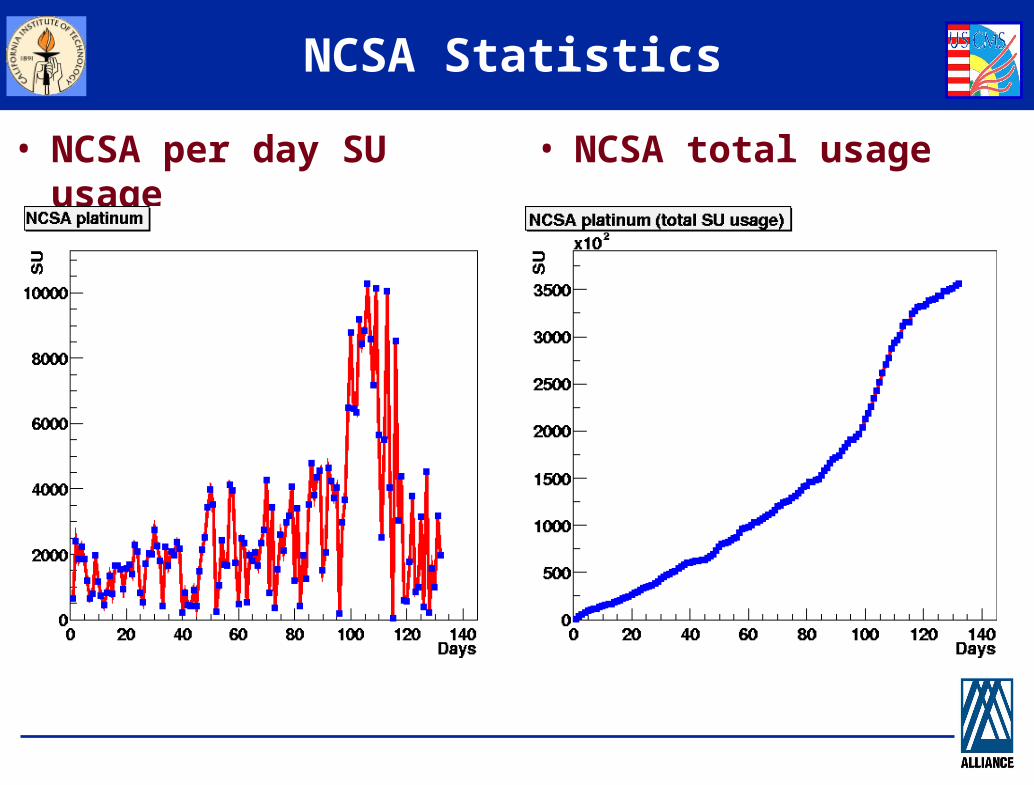
NCSA Statistics
• NCSA per day SU usage • NCSA total usage
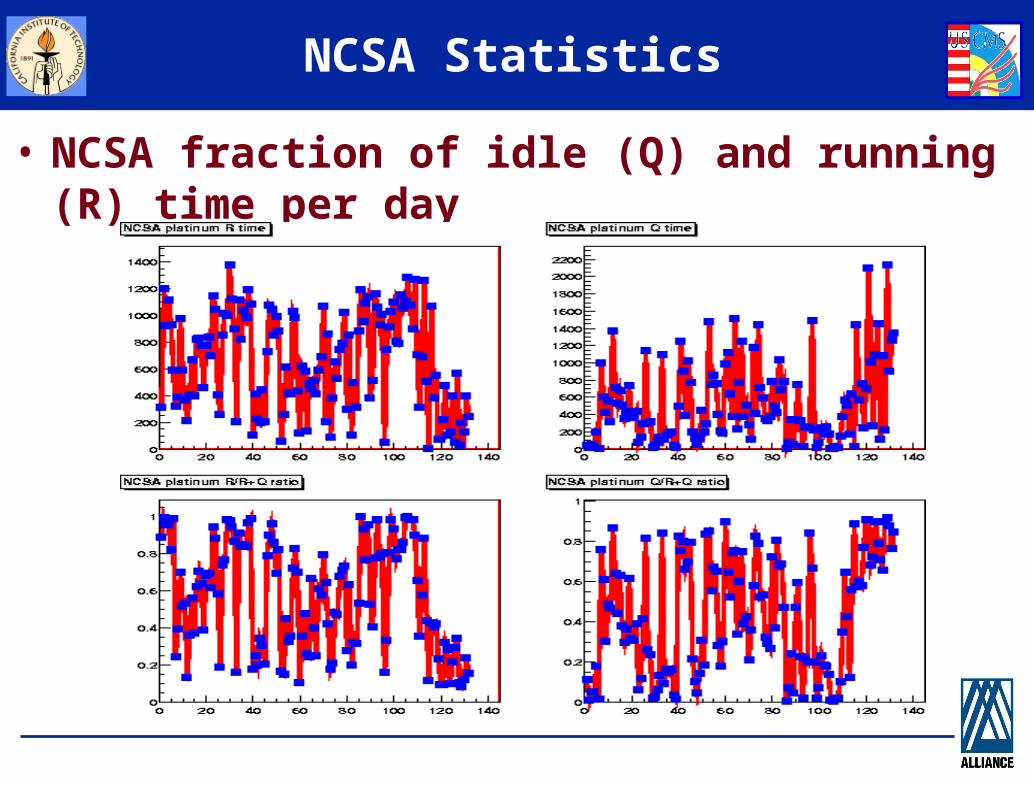
NCSA Statistics
• NCSA fraction of idle (Q) and running (R) time per day
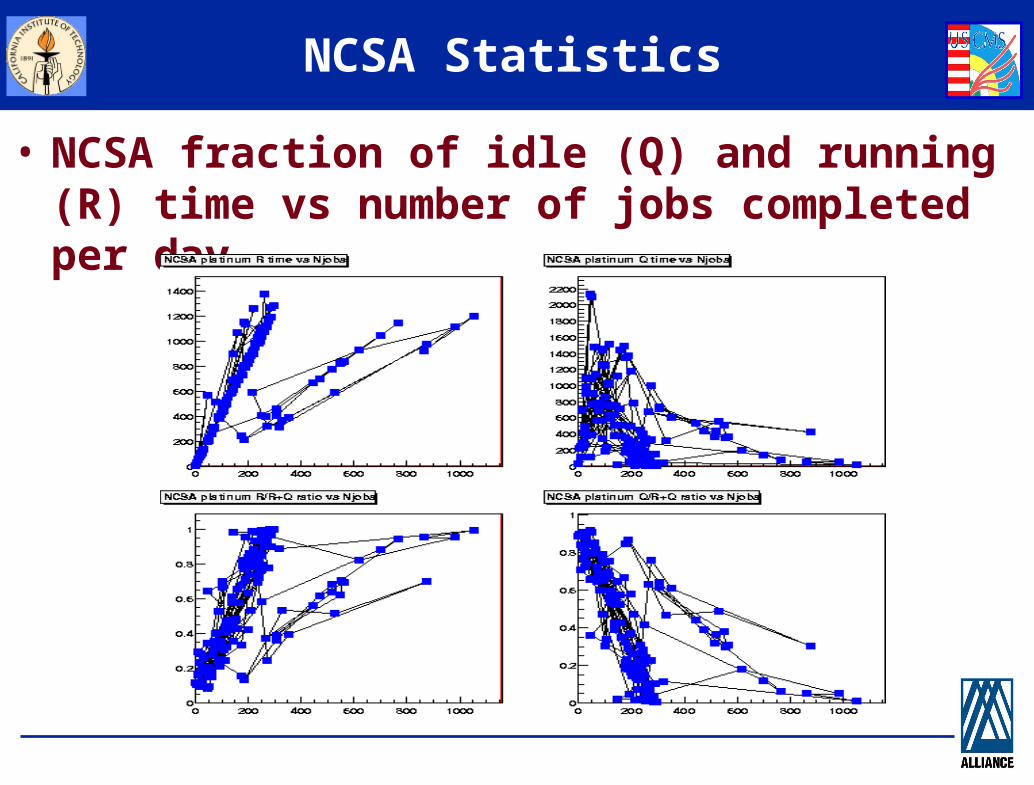
NCSA Statistics
• NCSA fraction of idle (Q) and running (R) time vs number of jobs completed per day

NCSA (II)
• Multiple runs should be submitted in one PBS job.Due to NCSA computing policy, PBS cannot allocate one CPU – it always allocates one NODE. The same will be on future TeraGrid– Two different tasks of two different users can ask large
RAM in both tasks
During one CPU allocation, second CPU is sitting idle anyway.
Smaller number of allocated nodes - lower the priority of this PBS job
Large number of nodes allocated per one PBS job is not good from Caltech HPSS usage point of view
“Fair” maui policy is even more unfair
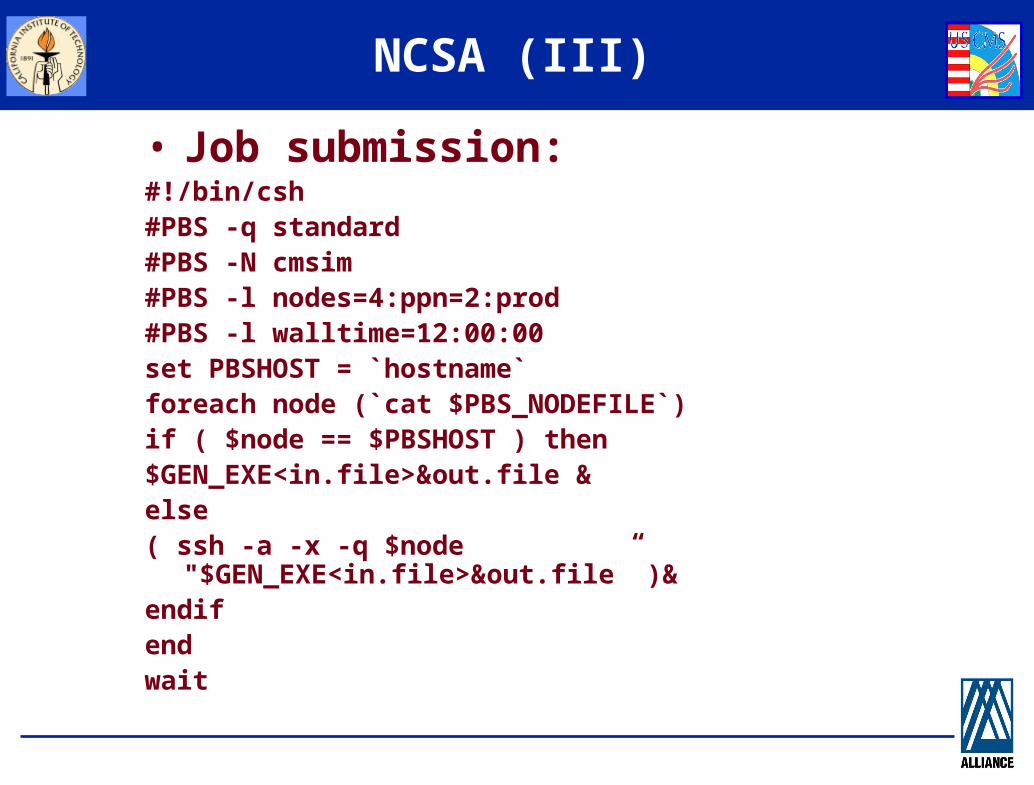
NCSA (III)
• Job submission:#!/bin/csh #PBS -q standard #PBS -N cmsim #PBS -l nodes=4:ppn=2:prod #PBS -l walltime=12:00:00 set PBSHOST = `hostname` foreach node (`cat $PBS_NODEFILE`) if ( $node == $PBSHOST ) then $GEN_EXE<in.file>&out.file &else( ssh -a -x -q $node
"$GEN_EXE<in.file>&out.file” )&endif end wait

NCSA (IV)
• Walltime limit exceeding problem – Huge LAN traffic from another computing nodes
in the same segment
– Job was started incorrectly
• Random order of running jobs– If 100 same jobs were started, the first running job
might be any job – hard to predict the chunk of already ready events
• PBS MAXJOB limit was set to 50; jobs are killed by PBS when number of jobs exceeds this limit

NCSA (V)
• Blocked Jobs– maui can start a job and if it fails, job will be
blocked and sitting in a queue without any notification. Unblock must be done by hand asking support team to do so. There isn't any way to be notified by maui/PBS.
• Accounting Problem– PBS accounting cannot calculate correctly CPU
used time when ssh was used to start runs on another allocated nodes
– NCSA own Sybase based accounting system is wrong as well (overestimate the CPU usage)
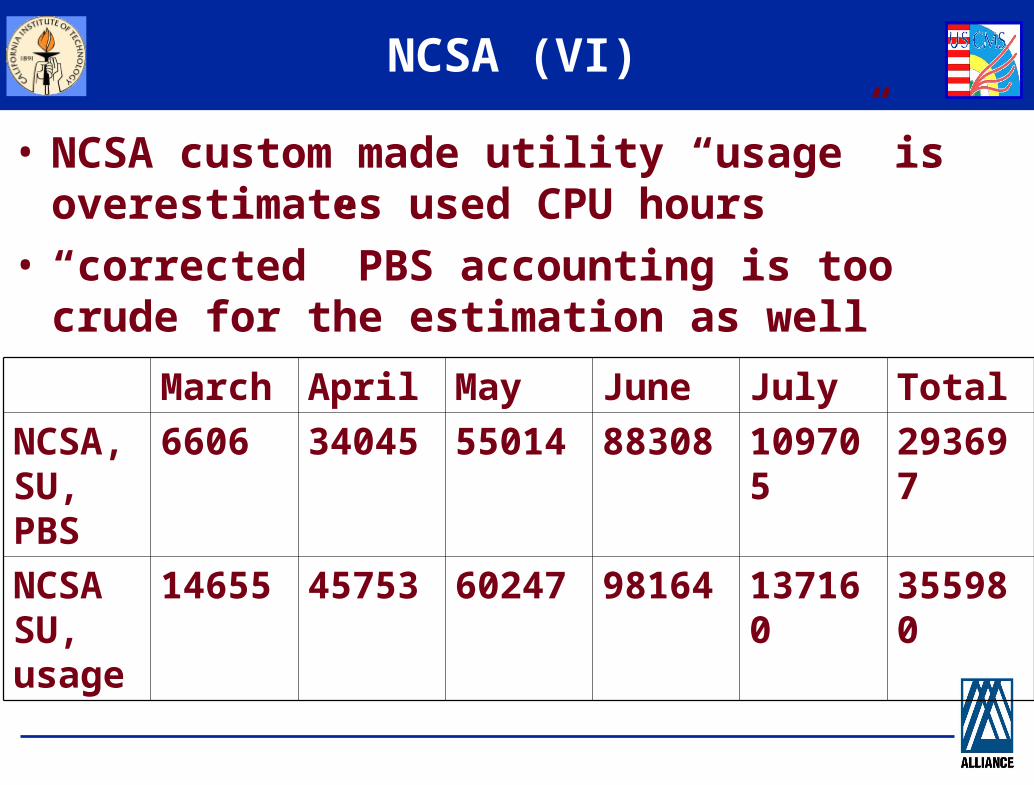
NCSA (VI)
• NCSA custom made utility “usage” is overestimates used CPU hours
• “corrected” PBS accounting is too crude for the estimation as well
March April May June July Total
NCSA, SU, PBS
6606 34045 55014 88308 109705 293697
NCSA SU, usage
14655 45753 60247 98164 137160 355980

Caltech pTier2 (I)
• Server node:– Dell PowerEdge 4400, 2GB SDRAM– 3 RAID arrays 3TB in a total
• Computing nodes:– 20 rack mounted dual CPU PIII 800MHz Intel – SDRAM: 512 MB and 133 MHz– 10GB local disk
• Additional (P4) Compute Nodes– Used for official CMS Pre-Challenge Production
(PCP)– Not part of the production discussed today

Caltech Tier2 (II)
• Caltech Tier2 layout (PIII Nodes Only shown)

Caltech Tier2 Statistics
Caltech per day SU usage • Caltech total SU usage
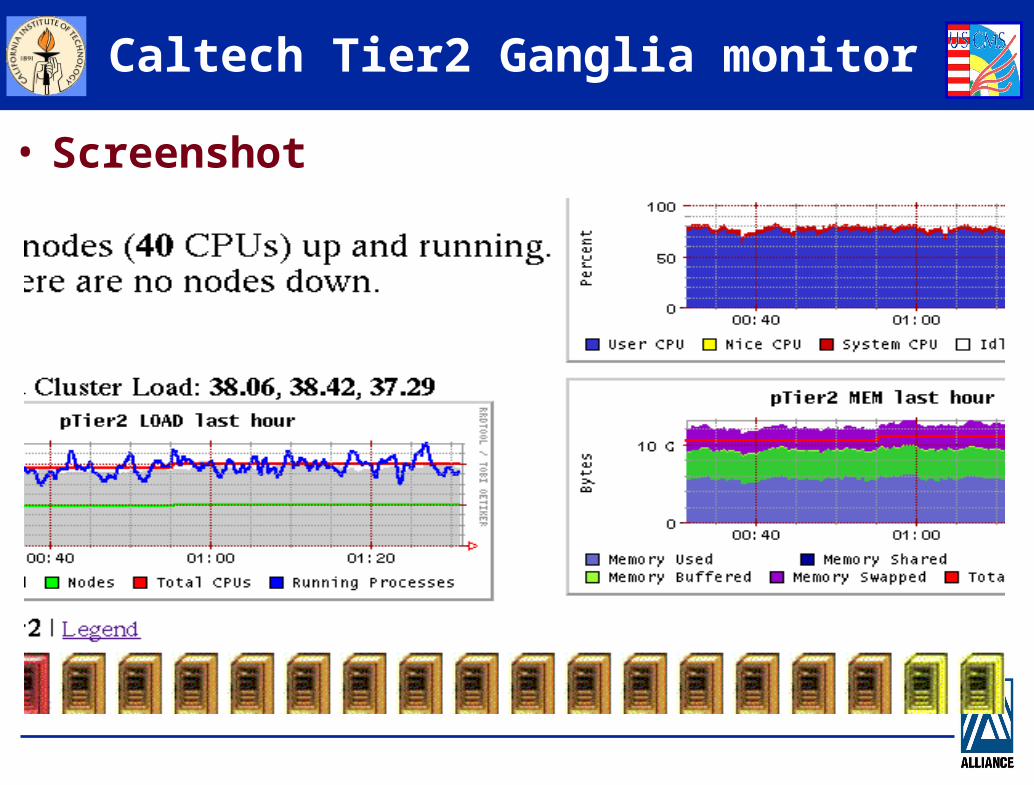
Caltech Tier2 Ganglia monitor
• Screenshot
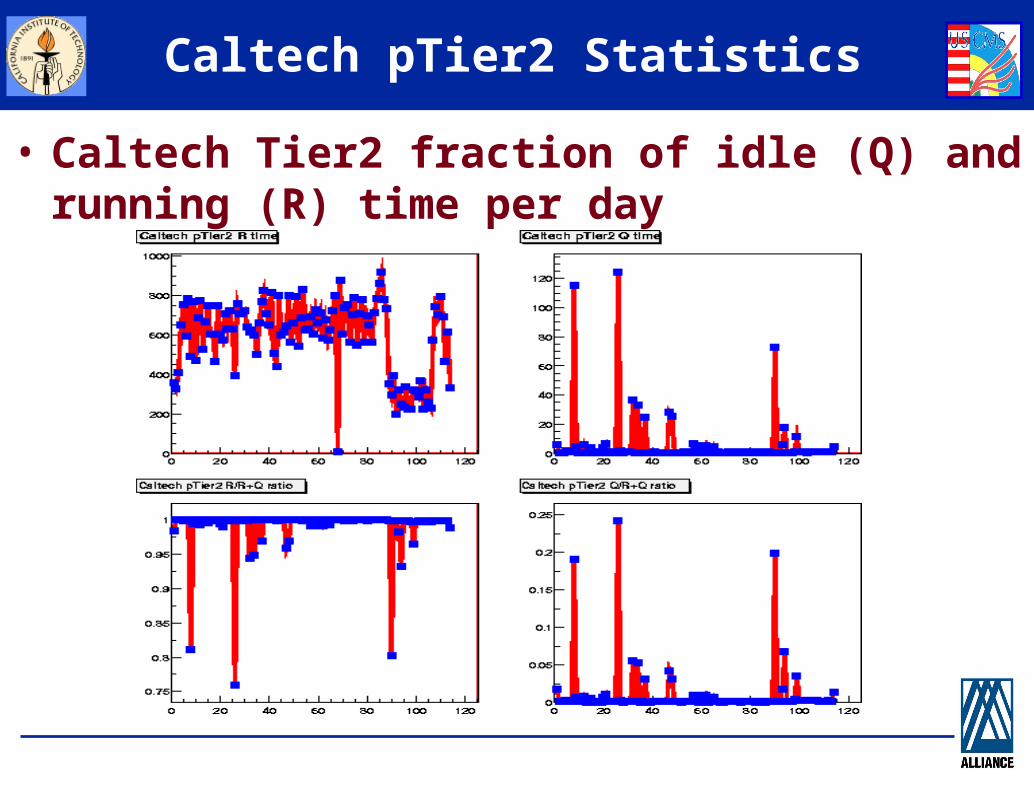
Caltech pTier2 Statistics
• Caltech Tier2 fraction of idle (Q) and running (R) time per day
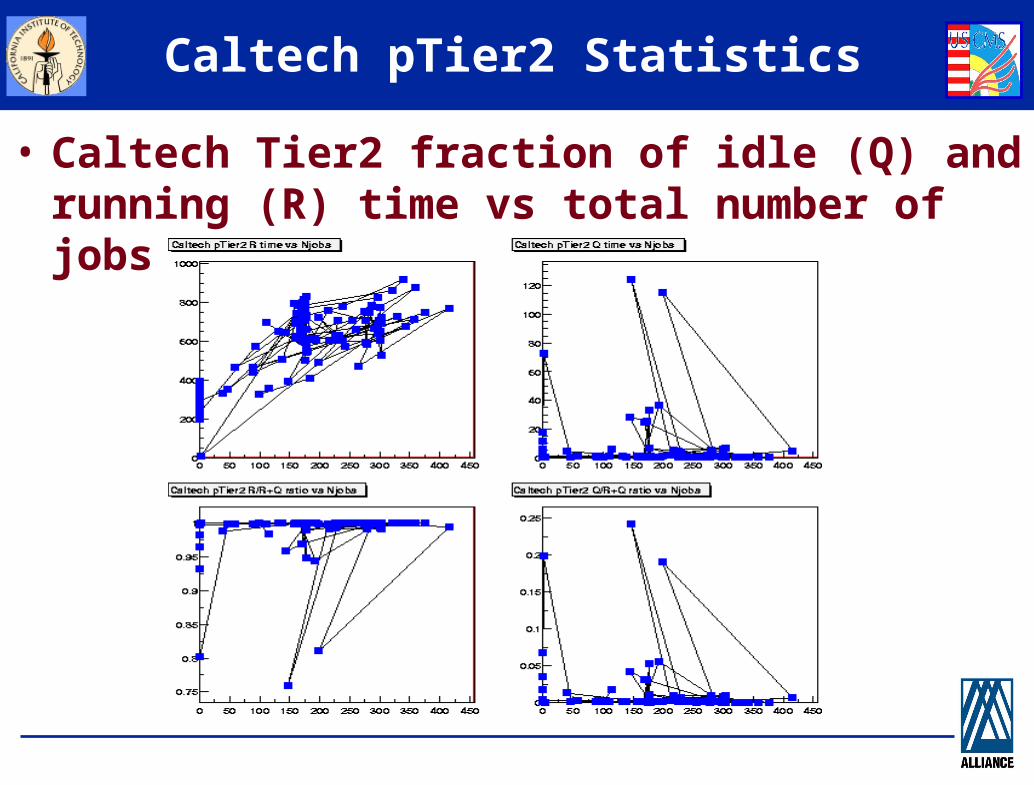
Caltech pTier2 Statistics
• Caltech Tier2 fraction of idle (Q) and running (R) time vs total number of jobs
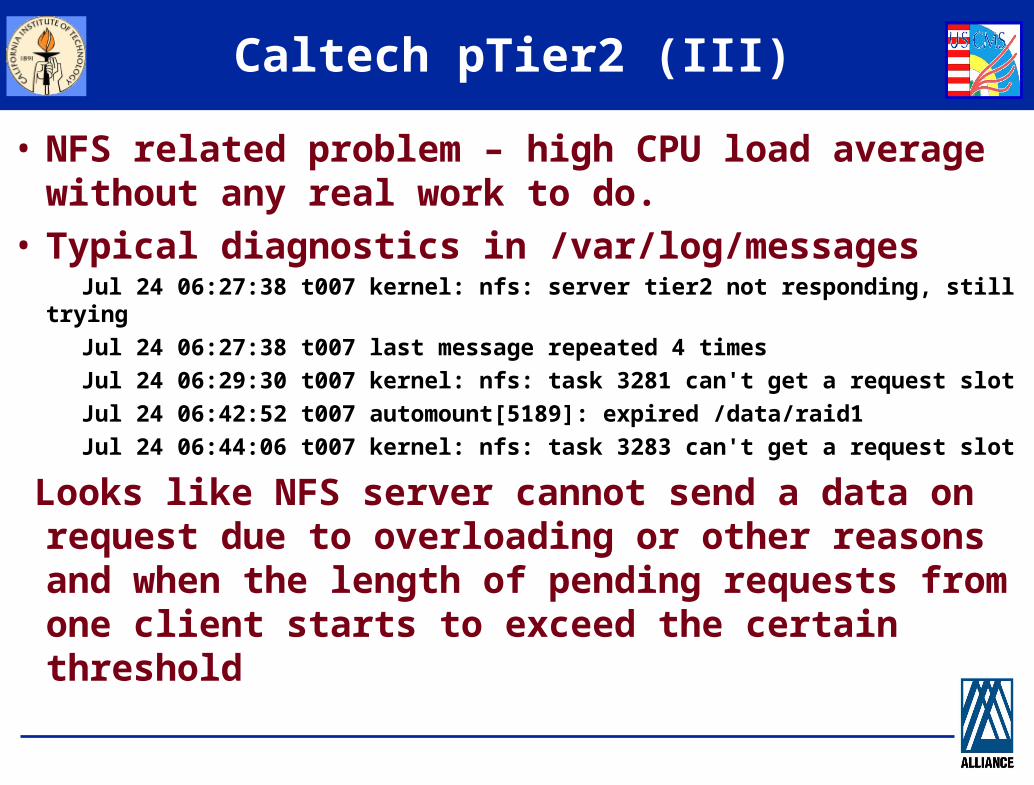
Caltech pTier2 (III)
• NFS related problem – high CPU load average without any real work to do.
• Typical diagnostics in /var/log/messages Jul 24 06:27:38 t007 kernel: nfs: server tier2 not responding, still trying
Jul 24 06:27:38 t007 last message repeated 4 times
Jul 24 06:29:30 t007 kernel: nfs: task 3281 can't get a request slot
Jul 24 06:42:52 t007 automount[5189]: expired /data/raid1
Jul 24 06:44:06 t007 kernel: nfs: task 3283 can't get a request slot
Looks like NFS server cannot send a data on request due to overloading or other reasons and when the length of pending requests from one client starts to exceed the certain threshold
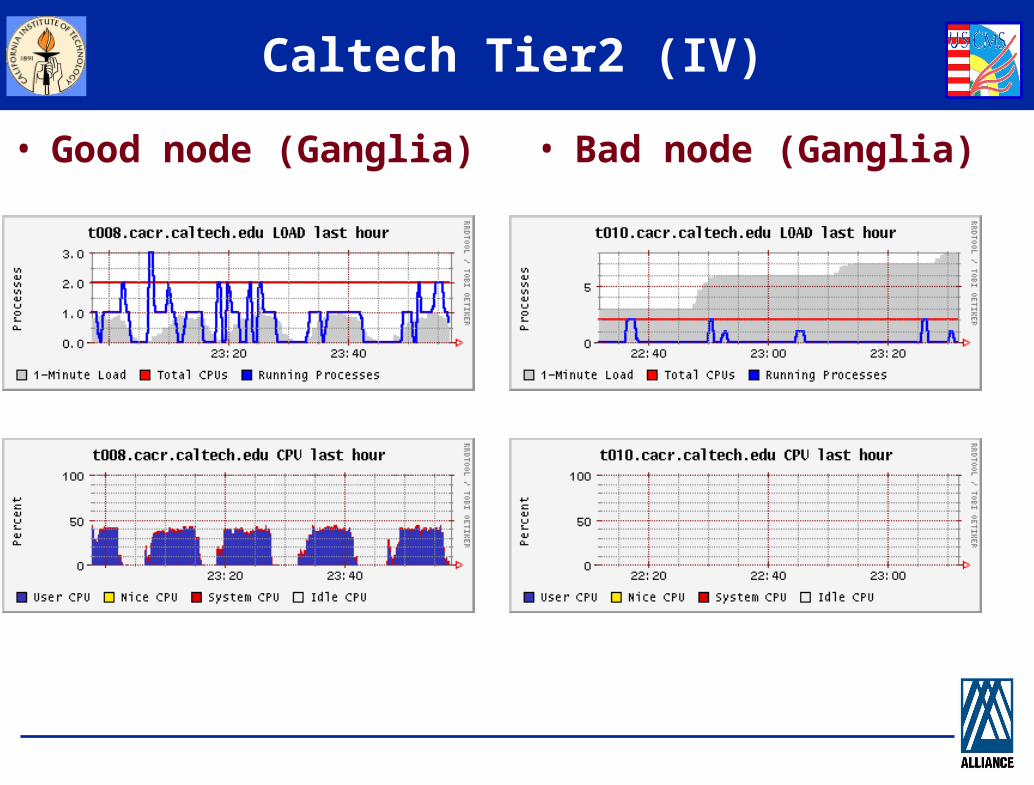
Caltech Tier2 (IV)
• Good node (Ganglia) • Bad node (Ganglia)
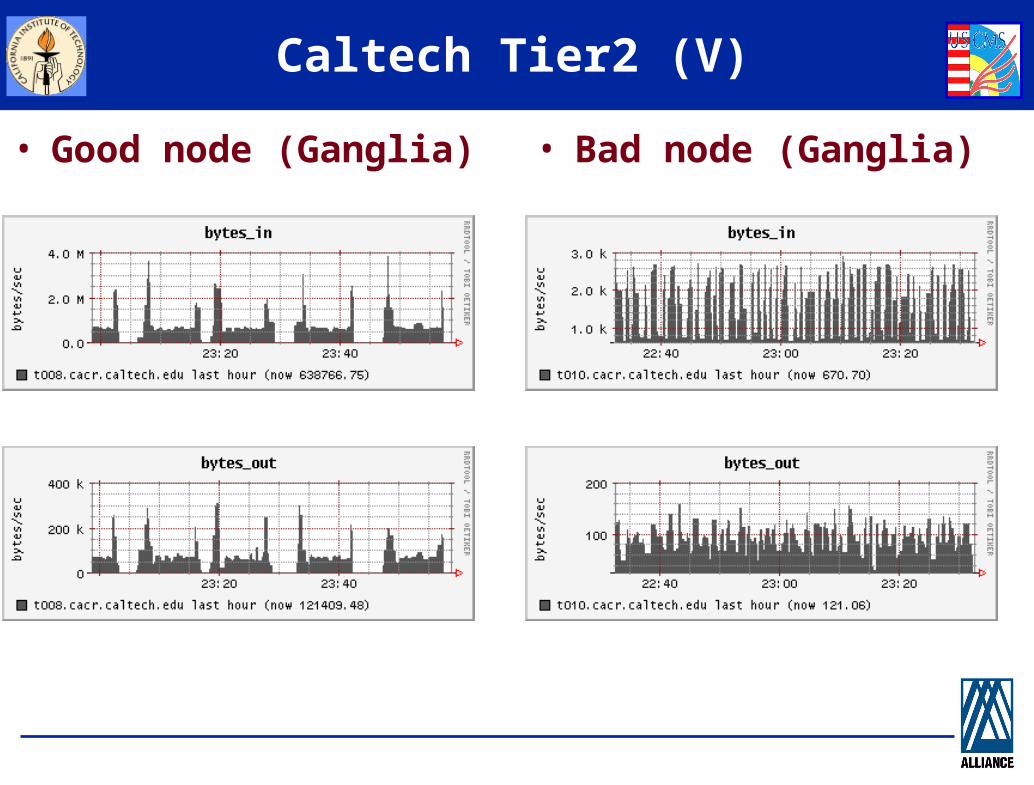
Caltech Tier2 (V)
• Good node (Ganglia) • Bad node (Ganglia)
Condor (UW-Madison)
• Condor flock of chaotically distributed nodes:– Intel/Linux – 614 nodes
– Intel/WinNT50 – 113
– SUN4u/Solaris28 – 105
– SUN4x/Solaris28 – 6
• We are using it for FORTRAN part only
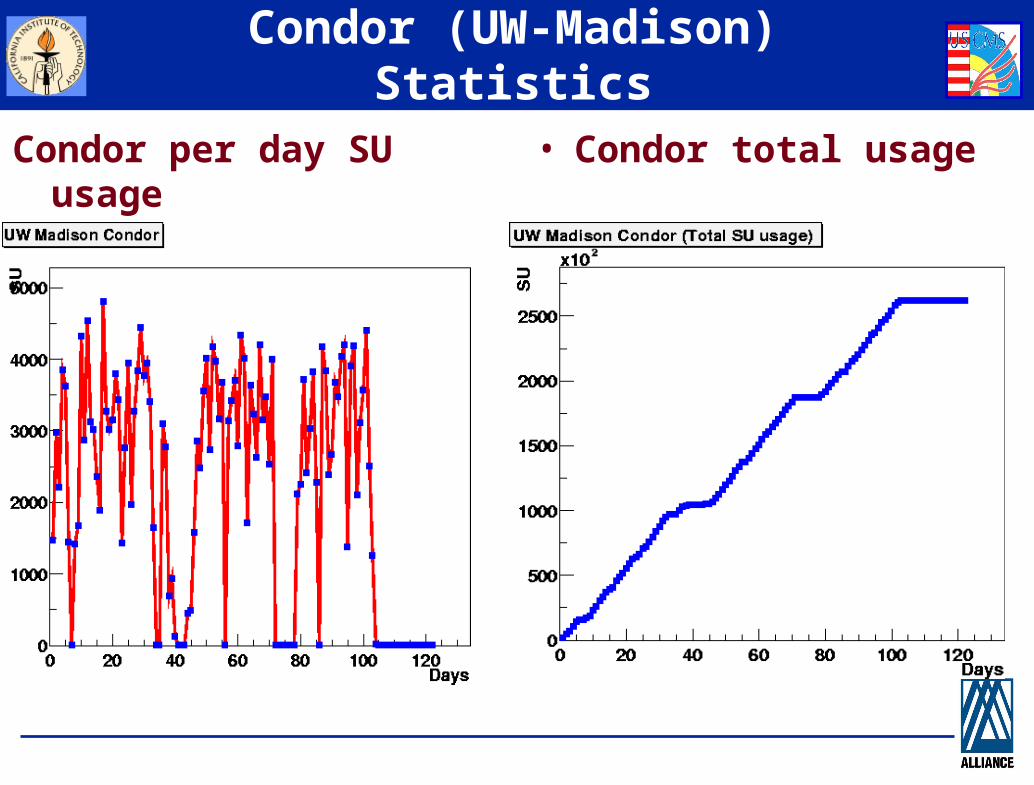
Condor (UW-Madison) Statistics
Condor per day SU usage • Condor total usage

Condor (UW-Madison)
• NFS problem – evicted job cannot open existed file after start on a new node
• Failure rate depends on type of job and varied from <0.01% (cmkin) to 2-5% (cmsim)
• Reason is unknown

Caltech HPSS
• Hardware
• 5SP2 four processor “Silver” nodes
• 1 SP2 eight processor “High” node
• IBM 3494 Robotic tape library with– 6 IBM Magstar 3590 drives (10GB per tape, 9MB/s
– 2300 tape slots (23 TB capacity)
• StorageTek 4410 Robotic tape silo– 4 STK Redwood drives (50GB per tape, 11MB/s)
– 6000 tape slots (300TB capacity)
Caltech HPSS
• Cannot keep more than 200-300 connections at the same time. 400 connections killed the whole system
• Future TeraGrid Caltech Unit will have 100TB of disks under PVFS

Conclusion (I)
• Alliance resources could be a great asset for the future CMS milestones like DC05, Physics and Computing TDRs, etc
• Full use of such resources requires overcoming some operational problems at the outset. But we have been largely successful in dealing with such problems

Conclusion (II)
• In addition to Application and Grid Middleware problems we have a set of infrastructure technical problems, policies and social open issues which can prevent fully utilize future grid capacity– Technical issues are closely connected with
Computing Center policies.
– PBS has a set of limitations – MAXJOB limit, finest granularity is node, not CPU, wrong sequence of running jobs

Conclusion (III)
– Lack of good monitoring and accounting system. This is the basis of any future activity of resource brokers and it is practically impossible to have robust broker without detailed statistical information
– Reliable Mass Storage System is the critical issue for LHC data handling. Current limitation on opened connections at Caltech HPPS is raised questions about MSS reliability. Further investigations with HPSS and PVFS are essential





























