Embed Size (px)
Citation preview

Biol Cybern (2014) 108:103–119DOI 10.1007/s00422-014-0586-6
ORIGINAL PAPER
Visually guided gait modifications for stepping overan obstacle: a bio-inspired approach
Pedro Silva · Vitor Matos · Cristina P. Santos
Received: 30 May 2013 / Accepted: 13 January 2014 / Published online: 28 January 2014© Springer-Verlag Berlin Heidelberg 2014
Abstract There is an increasing interest in conceivingrobotic systems that are able to move and act in an unstruc-tured and not predefined environment, for which autonomyand adaptability are crucial features. In nature, animals areautonomous biological systems, which often serve as bio-inspiration models, not only for their physical and mechan-ical properties, but also their control structures that enableadaptability and autonomy—for which learning is (at least)partially responsible. This work proposes a system whichseeks to enable a quadruped robot to online learn to detect andto avoid stumbling on an obstacle in its path. The detectionrelies in a forward internal model that estimates the robot’sperceptive information by exploring the locomotion repet-itive nature. The system adapts the locomotion in order toplace the robot optimally before attempting to step over theobstacle, avoiding any stumbling. Locomotion adaptation isachieved by changing control parameters of a central patterngenerator (CPG)-based locomotion controller. The mecha-nism learns the necessary alterations to the stride length inorder to adapt the locomotion by changing the required CPGparameter. Both learning tasks occur online and togetherdefine a sensorimotor map, which enables the robot to learnto step over the obstacle in its path. Simulation results showthe feasibility of the proposed approach.
Electronic supplementary material The online version of thisarticle (doi:10.1007/s00422-014-0586-6) contains supplementarymaterial, which is available to authorized users.
P. Silva · V. Matos · C. P. Santos (B)Centro Algoritmi, University of Minho, Braga, Portugale-mail: [email protected]
P. Silvae-mail: [email protected]
V. Matose-mail: [email protected]
Keywords Adaptive robot controller · Autonomy inrobotics · Biological inspiration · Sensorimotor map ·Forward internal model · Real-time learning
1 Introduction
Robotic legged locomotion constitutes nowadays an inten-sive field of investigation. It provides for a considerable levelof flexibility and enables mobility in a wide range of terrainsand environments (e.g., rough terrain, uneven terrain or over-come obstacles). Legged robots should autonomously moveand act in the environment, in a way that enables them todetect and adapt to unexpected situations or alterations in theenvironment, rather than by reconfiguring the environment orthe robotic platform. Therefore, autonomy and adaptabilityare crucial features to the development of robotic systems.
The ability to adapt legged locomotion to the environ-ment’s conditions poses an increased complexity to the loco-motion generation. On the one hand, the perception of therelevant environmental features. On the other hand, the ade-quate responses to these features. Both the changes in therobot state and the generation of motor responses, define ahighly nonlinear relationship that ideally, would be automat-ically built upon the necessities of the robot’s characteris-tics and goals. Furthermore, the reactions should be definedgenerically, w.r.t. the robot’s goals, thus enabling the actua-tion in any environment.
Biological systems exhibit a remarkable ability to dealwith unknown and unexpected situations and to adapt tothese situations as required. Thus, a man–machine analogywith clearly cross-fertilized ideas in the fields of robotics andneurophysiology has been emerging. This analogy demandsto identify properties that are common to many sensorimotorcontrol systems, whether artificial or biological, as well as
123

104 Biol Cybern (2014) 108:103–119
new features such as hybrid control. Robotic systems haveusually taken inspiration in nature to achieve some auton-omy and adaptability, both in the morphology and mechani-cal structures (e.g., biped, quadruped, hexapod robot), as wellas in the control structures, such as central pattern generators(CPGs) or neural networks.
Visually goal-directed locomotion has been the subject ofmuch research, especially in the field of behavioral and neuralstudies. However, the complexity of goal-directed locomo-tion is huge, and one has to further tackle the problem in smallsubtasks. In this work, we specifically consider the ability tolearn to step over an obstacle in visually guided locomotion.By learning, we mean not only to learn the required gait mod-ifications, both in specifying limb trajectory and where thepaw will be placed in the steps previous to obstacle step over,but also to learn to identify the presence of the obstacle in itspath.
There is a big complexity in the planning and executionof the step over of obstacles in our path while we locomote,despite the ease with which we are able to modify as requiredour gait to successfully perform this task. Further, recentstudies in intact cats have shown that with respect to theneural mechanisms involved in the control of visually guidedgait modifications, important insights can be provided intohow goal-directed locomotion is regulated and produced.
It is commonly accepted that in biological systems, repet-itive movements, such as locomotion, are generated by CPGsneural networks (see Ijspeert 2008 for a review). The initialfinding of locomotor CPGs came from the first studies byBrown (1911), suggesting that locomotor behaviors are theresult of central rhythmogenic mechanisms in the cat, fol-lowed by research in both invertebrate (Marder et al. 2005)and vertebrate animals (Orlovskii et al. 1999; Kiehn 2006).Recent research (Büschges and Borgmann 2013) extendedthe concept of a modular neural network organization forlocomotion from invertebrates and lower vertebrates to mam-mals.
Locomotion generation is also largely dependent onreflexes: animals react to specific stimulus by generatingparticular movements. In fact, one idea by Burke (2007),defended that rhythms could be the result of a chain ofreflexes triggered and governed by external sensorial events,producing the final rhythmic locomotor activity. Even thoughlocomotion is a centrally generated process, the importantrole that sensory feedback plays in the adaptation and cor-rection of legged locomotion is unarguable (see Pearson 2004for an important review).
It has been shown that the CPG and locomotion generationis highly integrated and dependent on feedback pathways. Forinstance, it has been demonstrated (Rossignol et al. 2006) thatstimulation of sensory afferents can elicit locomotion, sen-sory events can adjust the duration of the rhythmic activityand sensory removal deteriorates locomotor abilities, such as
precise foot placement. Additionally, the generation of loco-motion takes into account sensory information to enable itsadaptation, and this occurs at different levels. For instance, inorder to overcome an obstacle, a reflexive response is issuedin case a cat stumbles on an obstacle (Forssberg 1979), or atan higher level, when it visually sees an obstacle and lateron steps over it without looking at it (Wilkinson and Sherk2005).
The biological concept of efference copy (Holst and Mit-telstaedt 1950) defines a copy of the motor commands usedto create expectations about the sensory consequences ofsuch acts (called a reafference signal). The external stim-ulations yield exafference signals, which together with thereafference compose the afference signals: the full perceptioninput. In Held (1961), efference signals and sensory inputswere proven not to be directly comparable due to their differ-ent state space configurations. Later in Wolpert and Kawato(1998), was revealed that a forward internal model (FIM)could make the “translation” between the two configura-tion spaces, allowing the differentiation of the exafferenceand reafference signals; meaning the differentiation betweeninternally and externally caused sensory alterations.
The FIM concept is believed to be integrated in the centralnervous system and to be generally relevant in sensorimotorcoordination. See Miall and Wolpert (1996) for a review.Discerning the externally caused disturbances from the self-generated ones, provides for useful information about theenvironment that can then be used for adaptation purposes.
There are also animal learning mechanisms that providefor adaptation of animals and survival. For instance in McVeaand Pearson (2007a), the authors report the ability of a catto learn to adapt its locomotion according to the surroundingenvironment and context, and in McVea and Pearson (2007b),long-lasting alterations to the locomotion were observed, asa consequence of repeatedly triggering cutaneous receptorsof a cat.
In Drew et al. (2008), it was shown that in order to step overan obstacle, the central nervous system produces sequentialchanges in the duration, the magnitude and the timing ofactivity in a large number of muscles acting around multiplejoints. This results in the modification of the base locomotoractivity required to control paw placement and limb trajec-tory in the step over of the obstacle, in which there is visualregulation of the base rhythm. Specifically, it was identifiedthe posterior parietal cortex (PPC) contribution to control theprecise position of the limbs prior to the gait modification,thus assuring to clear the advancing obstacle. It was alsosuggested that PPC might have a preferential role in coordi-nating fore and hindlimbs and that gait modifications can bespecified in a limb-independent manner.
Online neural control of limb movement suggests requir-ing complex integration of predictive central feedforward andperipheral sensory feedback signals (Gritsenko et al. 2009).
123

Biol Cybern (2014) 108:103–119 105
The mechanism of trajectory correction suggests to involve apredictive efferent copy-based state estimation process suchas an internal forward model of future limb states.
This idea of encompassing both feedforward motor com-mands and sensory feedback components has been aroundfor long (Burke 2007). But the manner by which these com-ponents integrate is still answered. It is clear, however, that acontrol architecture should thus integrate these two compo-nents (Gritsenko et al. 2009).
In summary, recent neurophysiological developments,surveyed in Prochazka et al. (2002), Prochazka (2002),Yakovenko et al. (2004), Gritsenko et al. (2009), have drewimportant conclusions in the control of locomotion, which arerelevant to the present study, as follows. (1) The noisy, multi-variate and complex nature of sensory input. (2) The adjust-ment of locomotor movements to terrain two or three stepsin advance, in visually guided locomotion. Moreover, thesepredictive changes are correlated with the firing of motorcortical neurons. (3) The existence of an “internal model”that processes multimodal sensory input to produce musclecommands based on internal predictions of the biomechan-ical consequence of these commands. (4) The role of thecerebellum as a state analyzer.
However, a still remaining question is how are these var-ious mechanisms of rhythm generation and sensorimotorreactions or reflexes to be reconciled into a single smoothlyoperating control system?
In this paper, we take advantage of this know-how andinclude these advancements into our model, in order to pro-vide for improvements in flexibility of level overground loco-motion able to step over obstacles. We propose an architec-ture inspired in Drew et al. (2008), that joins CPGs, reflexesand forward models to achieve stepping over an obstacle ina quadruped robot. The applied solution is partly inspired inLewis and Simó (1999, 2001) and extends the authors currentwork (Matos and Santos 2011).
A forward model/novelty detector modulates the steplength in the CPG. Biological evidence comes, for instance,from the work of Prochazka et al. (2002) in which flexorand extensor burst durations (which could be considered asoutputs from a forward model) can be modulated by descend-ing signals. Other options would be a simple scaling of theflexion phase of a normal locomotor step cycle, e.g., by thehypothesized pattern formation layer of the CPG. Further,adapting the locomotion based on visual or past informationis supported by the fact that cats do not look at obstacleswhen stepping over them and that its stride length is changedduring the approach (Wilkinson and Sherk 2005); and longjump athletes module their step length prior to the liftoff andits standard deviation decreases over the last three steps (Leeet al. 1982).
In this work, when considering autonomy, we seek tobe able to learn to deal with specific situations with mini-
mal external configuration. Thus: (1) these situations shouldbe self-perceived through stimulus; and (2) the solution hasto autonomously build a map between the detected situa-tions, through the sensory inputs, and the necessary motorresponses. These abilities will enable the robot to adequatelydetect and respond to certain environmental changes. Thisway, the motor reactions take into account the physical andmechanical properties of both the platform and the environ-ment.
The concepts of CPGs and reflexes to generate locomo-tion have been explored in robotics (Taga et al. 1991; Taga1995a,b, 1998; Matos and Santos 2011; Righetti and Ijspeert2008; Schröder-Schetelig et al. 2010; Kimura et al. 2007a;Ilg et al. 1999; Takemura et al. 2002, 2005; Shimada et al.2002; Ishii et al. 2004; Endo et al. 2004, 2005; Komatsuand Usui 2005; Matsubara et al. 2005; Aoi and Tsuchiya2005; Aoi et al. 2010a,b, 2011; Ogino et al. 2004; Mori-moto et al. 2008a,b; Sugimoto and Morimoto 2011; Aoi andTsuchiya 2007; Maufroy et al. 2010a,b). Furthermore, loco-motion has also been achieved by the application of sim-ple sensory driven reflexes rules, both in simulations and inrobotic platforms (Geng et al. 2006; Geyer and Herr 2010;Cruse et al. 1998). FIMs have also been applied in robotics(Schenck and Möller 2007; Schröder-Schetelig et al. 2010;Hoffmann 2007).
The proposed solution is innovative since it enablesautonomous detection and continuous adaptation to the envi-ronment conditions, both in the perception as well as in theactuation side. Based on sensor feedback, the approach learnsa predictive model of the task outcome. It predicts the out-come of a task based on previous experience, instead of apriori knowledge. It does so by predicting the sensory eventsassociated with a skill, and temporal sequence learning isused to teach the system to act accordingly when irregulari-ties are detected. This results in motor actions that enable toadapt previous learnt skills and learn new ones. For instance,the system is never explicitly told of what is an obstacle butrather appears as an irregularity in the repetitive and stereo-typical self-induced periodic movement patterns. This abilityenables the robot to self-adapt its perception and actuationso that a given task is performed even if the conditions arechanged in real time.
In this work, a quadruped robot needs to learn a map ofadaptations to its locomotion when approaching an obstacle,so as to be adequately positioned when it attempts to stepover it.
The obstacle detection is based on estimations about theacquired sensory information, which are computed by a FIM.This provides for a predictive mechanism that explores therepetitive nature of locomotion and the associated sensoryvariables to form a representation of the locomotion and pre-dict future failures. Similar ideas are explored in Pastor et al.(2011a,b).
123

106 Biol Cybern (2014) 108:103–119
When the robot stumbles on the obstacle, simple signalsare used to trigger learning according to the way the colli-sion occurred. A map of alterations to the CPG parameterswith the corresponding change in the stride length is iter-atively built every time the robot stumbles in the obstacle.The learning is kept active through time, enabling continu-ous adaptation both to different obstacles and different gaitconditions.
Results are demonstrated in simulations. A bioloid bench-mark quadruped robot equipped with range and touch sensorsis shown to effectively learn to detect and step over unknownobstacles in its path after a few failed attempts. Robustness ofthe approach is shown by using obstacles placed at differentdistances from the robot, online changing the gait and thetype of obstacles. Results show that the robot is able to learnto step over these obstacles, and it memorizes the requiredadaptations along different experiments.
This paper extends preliminary work of the team (Silva etal. 2012). Herein, we have detailed the architecture presenta-tion, extended previous results, verified the approach robust-ness and detailed explanations. We have included an analysison the number of learning iterations necessary to learn dif-ferent skills; we verified how the robot responds to differentconditions; we verified the approach robustness over longerperiods and real-time changing conditions.
The remainder of this work is organized as follows. NextSect. presents the related work. Section 3 briefly overviewsthe whole system. Then, the architecture for the proposedmechanism is presented in Sect. 4. Follows the results inSect. 5. Lastly, conclusions and future work are discussed inSect. 6.
2 Related work
There are several different approaches to the problemof adaptively control a legged robot, so that it becomesautonomous. Some approaches apply geometrical represen-tations or alike models that simplify the robot’s perceptionand/or action space, through a-priori information about theenvironment. In other approaches, the main concern is toachieve adaptability through the building of sensorimotormaps.
Some approaches resort to the construction and mainte-nance of geometrical representations of the environment—or similarly, environmental features—to enable the detec-tion and adaptation to environmental features. An exampleis presented in Doshi et al. (2007) in which the little dog isable to detect and select the best possible foot positions on arough terrain and cross it. It uses a support vector machine(SVM) and AdaBoost to the classification process (modelswere trained offline). In Kalakrishnan et al. (2010), a con-troller enabled the little dog to traverse a patch of terrain
with a high level of roughness. They divided the complexityof the task in different, simpler tasks and addressed each at atime; thus, enabling the robot to move in such harsh condi-tions. However, the adaptability to the environment requiredpreprocessed information from the best foothold positions ofa particular terrain, as well as an approximation to the bestpath on that terrain. Therefore, despite the great quality ofthe achieved results, autonomy was not completely achieved.
One approach that seeks adaptation by building a mapbetween the detected situations and the correspondingrequired responses is to apply reflexes, joined or not withCPGs.
Taga et al. (1991) presented a seminal work where walk-ing and running were generated for a simplified biped model,resorting to a half-center approach to the CPG, using neuraloscillators for producing torques to be applied at the joints.The work was progressively improved (Taga 1995a,b, 1998).These works were so significant that many CPG-based solu-tions have followed similar implementations.
Different approaches addressed the Titan robots (Take-mura et al. 2002, 2005; Shimada et al. 2002; Ishii et al. 2004),the quadruped walking machine BISAM (Berns et al. 2008)and other quadruped robots (Aoi and Tsuchiya 2007; Aoi etal. 2010b; Maufroy et al. 2010a,b), bipedal robots (Endo et al.2004, 2005; Komatsu and Usui 2005; Matsubara et al. 2005;Aoi and Tsuchiya 2005; Aoi et al. 2010a, 2011; Ogino etal. 2004; Morimoto et al. 2008a,b; Sugimoto and Morimoto2011) and multi-legged robots (Aoi et al. 2007).
Fukuoka et al. (2003) proposed a quadruped locomotionmodel based on CPGs and a set of reflexes that enabled loco-motion in rough terrain, while granting the required stabilityand energy consumption optimization. In addition, a pas-sive ankle was designed for the purpose. The work was laterextended (Kimura and Fukuoka 2004; Kimura et al. 2007b)to enable locomotion in natural ground through the use ofextra reflexes that granted the required stability in a widerrange of unexpected situations.
Another approach that relies in reflexes to generate adap-tive locomotion is proposed in Ilg et al. (1999) and Albiezet al. (2001). In Ilg et al. (1999), locomotion is generatedthrough the interaction of different abstraction and controllayers of the walking machine BISAM. Reflexes are trig-gered by a mechanism trained by reinforcement learning(RL), which captures the required sensorimotor interactions,in order to generate adaptive locomotion. This grants the sys-tem its stability and correct posture when walking in uneventerrain. However, the learning tasks were performed in asingle leg. In Albiez et al. (2001), the adaptive locomotionrelies on the center of gravity trajectories and inverse kine-matics, together with the previous posture control (Ilg et al.1999), which was implemented resorting to fuzzy rules andRL. This controller enables the robot to trigger the reflexeswhen necessary, in order to guarantee its posture and stabil-
123

Biol Cybern (2014) 108:103–119 107
ity, generating adaptive locomotion and surpassing unknownobstacles.
Reflexes provide for an interesting and effective wayof achieving adaptable locomotion. However, they usuallyrequire careful design of motor responses to particular sit-uations. They do not incorporate onto a solution the abil-ity to predict similar situations and change the control suchthat adaptation may be achieved, i.e., the ability to learn.Through learning, the system should be able to incorporatethe required changes to the movement generation once thecorresponding sensory events are detected. Further, the adap-tation should be extended to the perception such that differ-ent conditions do not disrupt the detection of the necessarystimulus. Both this detection and adaptation should occurautonomously.
The concept of behavior was also explored to the creationof the state action pair. Maes and Brooks (1990) proposeda behavior-based learning controller for a hexapod robot. Aset of behaviors for each actuator is executed upon the verifi-cation of certain prerequisites. These are shaped by the pos-itive reinforcement signals obtained through the performedlocomotion, hence enabling the learning process toward thedesirable locomotion generation.
Sensory information provides a direct way to perceiveboth the surrounding environment and the robot’s inter-nal state. Therefore, the entrainment of sensory feedbackin the actual locomotion generation poses an interestingapproach to define the state action relation. An exampleis presented in Heliot and Espiau (2008), in which a mas-ter oscillation signal is used to drive the different jointsaccording to the cyclic pattern of the sensory inputs. Thus,movement generation is driven by online sensory links. Arelated approach proposed in Buchli and Ijspeert (2008)tracks the resonant frequencies of a quadruped robot withcompliant knees in order to generate adaptive locomo-tion.
Relevant implementations of forward models (FIM) inrobots have been pursued. These are able to detect exter-nal disturbances and apply that information to adapt to thechanging conditions.
In Schröder-Schetelig et al. (2010), a FIM is used to detectthe ground’s slope by expecting flat ground: A biped robotuses the detected changes to adapt itself by shifting its centerof mass through an upper body component. The FIM relieson an offline trained artificial neural network that learns theexpected activations in flat ground which brings adaptation.
In previous works (Manoonpong et al. 2007; Manoonpongand Wörgötter 2009), the robot learns in real time to adapt thelocomotion such that it is able to climb a slope. These workshold some similarities with our own, despite the differenttask and platform. A failure detection steers the learning andcauses the robot to iteratively improve its performance towardthe desired task.
Recently, the same group presented a control architecturefor an hexapod robot that also holds some similarities withour own, but applied to different goals (Manoonpong et al.2013). The robot learned to predict ground contact with thelegs for a particular gait using a FIM and to model jointtrajectories when such activation patterns were not respected.Very interesting results were achieved in terms of adaptabilityof the locomotion.
However, in Manoonpong et al. (2013), different gaitsrequired retraining the FIM. Also, locomotion is adapted todifferent terrains through a previously trained visual systemand predetermined mapping of type of terrain and gait. Fur-ther, in these works (Schröder-Schetelig et al. 2010; Manoon-pong et al. 2007, 2013; Manoonpong and Wörgötter 2009),perception relies in predetermined conditions, e.g., IR sen-sors detect particular ground colors that represent differenttypes of ground. Despite obvious differences, such as theplatform and/or the task, it is our believe that the biologicalplausibility of the proposed solution provides for improve-ments in flexibility of locomotion able to step over obstacles.The solution provides the ability to predict the outcome of atask based on previous experience, instead of a priori knowl-edge. It does so by predicting the sensory events associatedwith a skill and acting accordingly when irregularities aredetected. This results in motor actions that enable to adaptprevious learnt skills and learn new ones.
Adaptive locomotion was achieved in Lewis and Simó(1999, 2001) applied to a tethered biped robot. The first pro-posed a method to avoid stepping on an obstacle by changingthe locomotion—increasing or decreasing the stride lengthof the last steps prior to the obstacle—and enabling the robotto place itself optimally before attempting to step over theobstacle. In Lewis and Simó (2001), the authors present themethod for the detection of the obstacles ahead, using a FIMthat discerns novelty in visual disparity information. A sim-ilar work was presented in Lewis (2002) that enables thedetection of an obstacle in the robot’s path, but using opticflow instead. Also, the robot was only able to detect the obsta-cle and stop before it, not to step over it.
In Lewis and Bekey (2002), a set of unit CPGs (uCPGs)was proposed that together with a set of reflexes, enabled aquadruped robot to quickly acquire a stable gait. FIMs wereused to detect changes in the expected sensory inputs andproduced the necessary alterations to the uCPGs.
These works present a way to explore, and some to developthe state action relationship, which enables the autonomousadaptation to the environment.
Many of these works achieve interesting results in dif-ferent tasks, and in many cases, the proposed methods arerelevant for most legged locomotion controllers. However,up to some point, they still rely on offline methods that sim-plify the perception and/or action tasks (Schröder-Scheteliget al. 2010; Doshi et al. 2007; Kalakrishnan et al. 2010). Our
123

108 Biol Cybern (2014) 108:103–119
approach aims to full autonomy. It requires minimal indica-tion or predetermination of the desired interaction betweenthe robot and its environment. We focus on continuous adapt-ability of the robot’s perception of the environment, as wellas the adapted motor action to provide a clear step over anobstacle. The robot autonomously learns to deal with suchsituation, without any specific indication, other than analysisof the self-induced periodic movement patterns and built-inreflexes.
3 Overall setup
Consider a robot that locomotes according to a CPG-basedcontroller. The robot interacts with the environment as itwalks. Robot locomotion makes the overall system to oscil-late in each time step. This generates oscillation patterns inthe robot’s state which can be assessed through the robot pro-prioceptive and exteroceptive information. In this paper, thisinformation is collected through different built-in sensors:the joint angles (proprioceptive); the foot touch sensors todetect ground contact and collisions with obstacles and; anarray of infrared sensors (exteroceptive) built-in the robot’schest which scan the ground ahead of the robot. This mul-timodal sensory information is exploited by the proposedlearning mechanism both to learn to detect and to step overthe obstacle.
In case an obstacle appears in the robot’s path, the usuallysensed pattern through the range sensors changes. Properevaluation of these patterns against noise and disturbancesyields possible the detection of obstacles.
Step over the obstacle is achieved by changing the robotlocomotion, increasing or decreasing the robot stride length,through changes in the CPGs parameters. When the robot isat a certain distance from the obstacle a reflex rises the pawto a pre-specified value, the one required to normally stepover an obstacle. This value was set by trial and error for acertain stride length.
Every time an obstacle is detected, a time delayed reg-ister is created, similarly to an eligibility trace (Sutton andBarto 1998). Further, if the robot fails and stumbles on theobstacle, a signal is triggered indicating this occurrence. Ifthe time delayed signal is still active, it is possible to relatethese two events that occurred at different moments in time.Herein, this relation is employed as a means to build a map ofalterations to the stride length. Therefore, robot locomotionis adequately changed while approaching the obstacle. Basi-cally, the robot learns to place itself optimally before steppingover the obstacle—similarly to the way we, humans, avoida puddle of water on our path. This enables the robot, in thelong run, to step over the detected obstacle.
In summary, the learning mechanism changes the robotlocomotion so as to avoid certain events that unexpectedly
Fig. 1 Interaction between the robot, the CPG, the environment andthe proposed learning mechanism
occur in the environment and which are perceived throughstimulus that generate learning signals. The final result is tomake the robot to continuously attempt to step over a real-time detected obstacle at an ideal distance from it, such thatno collision occurs.
The interaction between the proposed learning mecha-nism, the robot and the environment is depicted in Fig. 1.
4 Learning architecture
The developed model addresses the two main tasks: obstacledetection and obstacle step over. Figure 2 shows the elementsthat compose the architecture, divided into two mechanisms:the attention and the adaptation mechanisms. The attentionmechanism is responsible for the detection task. The adapta-tion mechanism carries out the stepping over task.
4.1 Attention mechanism
The main role of the attention mechanism is to detect theobstacles in the robot’s path. It comprises three layers asfollows.
4.1.1 Raw data layer
The raw data layer receives inputs from the ns range sensorsand the n f joint angles and foot sensors. This data were fil-tered with a moving average of 9 samples each stride. Thisdata are collected every n p stride phases in each stride n.The data are organized onto two matrices which hold the sys-tem information during each stride. Rns×n p holds distancesscanned by each range sensor i = 1, . . . , ns at each phasej = 1, . . . , n p of the stride. Pn f ×n p holds the locomotionstate information of each sensor (joint angles and touch sen-sors) i = 1, . . . , n f at each phase j = 1, . . . , n p of thestride. We want to stress the concept of a cell (e.g., ri j ∈ R)
123

Biol Cybern (2014) 108:103–119 109
as an explicit relationship between a distance sensed by one ofthe robot’s sensors (i), during a stride phase ( j). This conceptappears along different elements of the proposed mechanism,always as an element of a matrix of dimensions ns × n p.
At each stride phase j , the raw layer outputs vectors of allrange sensors values r j and the locomotion state informationp j .
4.1.2 Prevision layer
In the prevision layer, an estimation hi j ∈ Hns × n p is cre-ated for each ri j ∈ Rns × n p, generating a difference value,di j ∈ Dns × n p, for each stride n, as follows:
di j (n) = ri j (n) − hi j(p j (n)
). (1)
If di j is high, this means the difference between anobserved distance (ri j ) and the estimated value (hi j ) isalso high. Thus, something changed in the environment thatcaused such difference in the usually observed pattern.
Each hi j is calculated by least mean square (LMS) thatexplores the periodic nature of the locomotion to estimatethe robot’s perception values, ri j , based on p j . Therefore,each hi j is an expected value for ri j . This provides for aforward internal model (FIM), in the sense that exploits theexpected robot’s perception to discernt self-generated fromexternally triggered sensory alterations.
The FIM calculation is kept active through time, thusenabling adaptability of the perception task in case the per-ception values suffer any alteration (e.g., caused by a changein the locomotion gait).
The prevision layer outputs the difference for all sensors,d j , at each stride phase j .
Figure 6 depicts the value of cell i = 9, j = 11 through-out the different layers of the proposed architecture, alongseveral trials (separated by shaded areas). Note how the rawdata, r9,11, indicated by a dashed blue line has its valuechanged when an obstacle is detected. However, the predictedvalue, h9,11, indicated by a solid red line has its value keptunchanged. There difference is sent to the Novelty layer andtreated as follows.
4.1.3 Novelty layer
The novelty layer evaluates each difference value di j ∈Dns×n p according to the reliability of the estimations (hi j )and generates the obstacle detection signals oi j ∈ Ons×n p
for each stride phase j , as follows:
oi j (n) = (gi j (n)di j (n)
)∣∣th , (2)
where gi j ∈ Gns×n p is a reliability variable and th stands fora threshold value set by trial and error.
The output of this layer is o j . An obstacle is detectedby a sensor i during the stride phase j if oi j �= 0. Each
reliability variable, gi j , enhances the difference value if thecorresponding cell, di j , usually produces good estimations(di j is close to zero) or reduces it otherwise. It is updatedaccording to the difference value of its correspondent cell,di j , by a feedback mechanism,
gi j (n) = gi j (n − 1) + F(di j (n))gi j (n − 1)αg, (3)
where αg is the rate at which gi j cells are updated.In this work, F was implemented as a Gaussian function.
It increases the reliability of a given cell (gi j ) if di j is closeto zero, or decreases it otherwise, according to the followingexpression:
F(di j (n)) = −1
2+ exp− di j (n)2
20.042 . (4)
The range defined for gi j controls the reduction in enhance-ment of the difference values di j . According to the chosenparameterization gi j ∈ [1, 1.2]. The numerical values weredetermined by trial and error.
The novelty layer works as a filter for data coming form theprediction layer. If a cell usually produces low error values,its output is amplified; if otherwise that cell is noisy its outputis dampened. This way cells that are usually noisy will notbe taken into account until their performance improves—theprediction layer continuously learns to approximate the rangesensor values.
In summary, the FIM creates predictions of the range sen-sors in normal locomotion conditions that correspond to situ-ations in which there were no disturbances such as obstacles.In case an obstacle is detected, there are changes in the read-ings of the range sensors. These changes cause a novelty sig-nal indicating that something other than expected occurred.The FIM is active through time, enabling continuous adap-tation between the changes in the locomotion and the sensorreadings.
4.2 Adaptation mechanism
The adaptation mechanism shown in Fig. 2 performs the step-ping over task, and it is composed by the following blocks.
4.2.1 Short-term memory
The short-term memory cells, xi j ∈ XSTMns×n p
, are activatedtaking into account the obstacle detection signals, oi j ∈Ons×n p , i.e., if oi j is activated, so will be xSTM
i j accordingto the following dynamics:
τSTMi j (n)
dxSTMi j (n)
dt= −xSTM
i j (n) + oi j (n). (5)
123

110 Biol Cybern (2014) 108:103–119
Fig. 2 Proposed architecture divided into two main mechanisms that address each of the main tasks: the attention and the adaptation mechanisms
After activation, the value of xSTMi j decreases with time,
according to:
τSTMi j (n) = 1 + 2
1 + exp
(xSTM
i j (n) − oi j (n)) . (6)
Thus, the cell is active for a while. If during this period oftime the robot stumbles on the obstacle, the current strengthof xSTM
i j is used as a measure of the time that has passedsince obstacle detection. This period of time makes it possi-ble to relate obstacle detection with obstacle collision. Thisstrength is taken in consideration when adapting the weightswhich will change the stride length. Objects encounteredshortly after detection affect more the stride length than thoseencountered later. Basically, the robot learns to place itselfoptimally before stepping over the obstacle.
This procedure is described in the following.
4.2.2 Learning signals
When the robot stumbles on the obstacle, this event isdetected by the touch sensors placed in the fore and backsides of the paw (Fig. 5.1, 2, respectively). A learning signalδ is triggered. The value of δ will be used to change the CPGparameter μ that changes the stride length of the generatedlocomotion, such that in the future, there is no stumbling onthe obstacle. Its value depends on the moment of the stride inwhich the signal is triggered. If it is during the paw extensionphase (Fig. 5.1), δ = −1, the stride length must be reduced,such that the paw does not reach so far away. If otherwise ithappens during the paw placement phase (Fig. 5.2), δ = 1,the stride length should be increased so that the paw reachesfurther.
These alterations to the stride length will make the robot,in the long run, to place itself optimally before attempting to
step over an obstacle which the system learnt to detect andavoid.
4.2.3 Weights
When a learning signal, δ, is triggered (δ �= 0) and a registerof a detected obstacle, xSTM
i j , is active, the weights, wi j ∈Wns×n p , are changed by:
�wi j = δxSTMi j (n)
(|wi j (n)| + c)αSTM, (7)
where c is a small constant to start up the learning processand αSTM is the rate of the learning task. wi j ∈ [−1, 1] andits value is normalized so that their sum over all the ns rangesensors is,
∑nsi=1 |wi j | = 1, at each stride phase j .
The term,(|wi j (n)| + c
), assures that the weights that
contributed more for the triggering of a learning signal arechanged with higher magnitude than the remaining.
Each time the robot stumbles on the obstacle, the value ofwi j is changed in order to generate the necessary change tothe stride length (to increase or decrease it). This yields aniterative process in which the whole map of weights, Wns×n p ,will be shaped such that it adequately adapts the locomotionto the detected obstacles, thus avoiding to stumble on them.
4.2.4 Burst length neuron
When an obstacle is detected by a distance sensor i at amoment of stride j , a synapse s j is established between theo j and w j vectors. s j indicates the necessary change for thelocomotion at each stride phase j and is updated at each stridephase j according to:
s j (n) =ns∑
i=1
wi j (n)|oi j (n)|. (8)
123

Biol Cybern (2014) 108:103–119 111
The synapses, s j , determine the necessary alteration to thestride length, given the current detected obstacle, oi j (for allsensors i = 1, . . . ns), and the knowledge acquired by thelearning process, wi j (for all sensors as well).
s j is used to update the CPG amplitude through bl accord-ing to:
τ bl dbl
dt= −bl + s j (n), (9)
where τ bl is the rate at which bl is changed. bl will be usedto modulate the CPG amplitude, through the μ parameter,changing the resultant stride length in order to prevent therobot to stumble on the detected obstacle. This procedure isdescribed in the following.
4.3 Locomotion generation
Locomotion generation was implemented as described inSantos and Matos (2012). The hip swing joint’s positionsare driven by CPGs implemented as nonlinear dynamicaloscillators, according to:
x = α(μ − r2
)(x − O) − ωz,
z = α(μ − r2
)z + ω(x − O),
(10)
where r = √(x − O)2 + z2 and x, z are state variables.
This nonlinear oscillator contains an Hopf bifurcation suchthat the solution bifurcates to either a stable fixed pointat (x, z) = (O, 0) (for μ < 0) or to a structurally sta-ble harmonic oscillation around (x, z) = (O, 0) (for μ >
0). Speed of convergence is given by 12 αμ
. Amplitude ofthe oscillations (limit cycle radius) is given by
√μ. ω is
the frequency of the oscillation, and O controls the off-set of the x solution. The joint’s position are driven byx .
The output of the adaptation mechanism, bl, is used tochange the CPG parameter, μ, that controls the resultingamplitude of the oscillation as follows:
μ = (ak + (A bl) |a+)2 , (11)
where ak = 10 provides for the default locomotion ampli-tude, without adaptation. bl is amplified by a constant value,A, and the result is threshold by a+. Both these values wereset by trial and error.
The knees are set to fixed values according to the phase ofthe corresponding hip: During the swing phase of the corre-sponding hip swing joint, the knee flexes to θsw; and duringthe stance phase of the corresponding hip swing joint, theknee extends to θst.
Finally, the hip swing joints of each limb have tobe coordinated in order to generate the adequate step-ping sequences. This interlimb coordination is achieved bybilaterally coupling among each other the swing CPGs,
Fig. 3 CPG network schema with imposed phase relations
ensuring a correct coordination between the limbs, as fol-lows:[
xi
zi
]= · · · +
∑
i �= j
R(θj
i )
[(x j −O j)
r jz jr j
]
, (12)
where i and j represent the limb ∈ {LF,RF, LH,RH}. Wenormalize the coupling contributions, minimizing the effectsof the different amplitudes of the other CPGs. The rotationmatrix R(θ
ji ) rotates the linear terms onto each other, where
θj
i is the required relative phase between oscillators i and jto perform a certain gait.
The CPG network schema is depicted in Fig. 3.
5 Simulations
The proposed mechanism was evaluated in a simulatedbenchmark Bioloidquad (Fig. 4), mounted as a quadrupedrobot with 3 DOF in each leg. The robot’s legs height is 16cm. The robot is equipped with an array of 10 infra-red rangesensors, which are used to scan the ground ahead and detectthe obstacles. Also it has touch sensors in the fore and backsides, and under the paws (Fig. 5.1, 2, 3 respectively), thatenables it to detect collisions with the obstacle. The touchsensors under the paws also enable the detection of groundcontact during locomotion.
Fig. 4 The Bioloidquad robot equipped with 10 range sensors. Redlines indicate the sensors measures. The green line projected in thefloor shows the ground area scanned by the set of range sensors (Colorfigure online)
123

112 Biol Cybern (2014) 108:103–119
The robot’s perception of the environment is achievedthrough the range sensors and the built-in touch sensors overthe paw. The locomotion state information is acquired by thehip swing joint values and the paw bottom touch sensors.
The movements in the hip and knee joints are generatedaccording to the CPG architecture described in Sect. 4.3 andin Matos and Santos (2011), Santos and Matos (2012). Theμ CPG parameter may change from [16, 144] resulting ina change in the hip amplitude between [4, 12]◦ and a stridelength of [2.7, 8.8] cm.
In this section are presented the evaluation scenarios andthe achieved results.
5.1 Simulation setup
Results were obtained through a series of simulations thatconsist of several trials. Simulations were performed on thewebots simulator, a simulation software based on ODE, anopen source physics engine for simulating 3D rigid bodydynamics (Michel 2004).
These simulations intend to show that the mechanismlearns both to detect the obstacle and to adjust the locomo-tion accordingly, such that the robot becomes able to stepover the real-time detected obstacle without stumbling. Theused parameters are listed in Table 1. At each sensorial cycle(8 ms), sensory information is acquired. The system is inte-grated considering the Euler method with 1 ms fixed integra-tion step. Both the attention and adaptation mechanisms areupdated each stride phase. The attention mechanism con-siders 9 samples from the joint positions and the sensoryinformation. The adaptation mechanism is updated at eachstride phase, considering the information provided from theattention mechanism.
At each trial, the robot starts walking at a pre-specified dis-tance from the obstacle, located ahead to the right, obstruct-ing the right foreleg. The obstacle is 0.85 cm tall and 0.3 cm
Table 1 Parameters used in the simulations
ns 10
n p 16
n f 8 (4 hip pitch joints and4 touch sensors)
th 0.05
αg 1
αSTM 10
c 0.1
τbl 0.5
a+ 2
ak 10
θsw 10
A 200
wide. As the robot walks, the obstacle is detected by the infra-red range sensors, when within the sensors’ detection range.Before any learning, the robot walks with a stride length of≈7 cm.
When the robot is at 6 cm from the obstacle, it attempts tostep over it with its right foreleg. This movement is elicitedby the step over reflex that increases the amplitude of hipswing CPG amplitude to 2ak and the fixed position of theknee to 2θsw. This results in rising the leg. A new trial thenbegins.
Default walking gait, without any adaptation, has a footsequence LF, RH, RF, LH, a duty factor, β, and a phase rela-tion, φ, of 0.75. The oscillator frequency, ω, is defined as ω =−10.472 rad s−1 during swing, and as ω = −3.491 rad s−1
during stance. This results in a swing and stance durations of0.3 and 0.9 s, respectively.
5.2 Adaptive locomotion evaluation
A typical simulation is depicted in Fig. 5, during which themechanism learns to step over the obstacle after two trials.Initially, the robot starts at ≈2 m away from the obstacle.In Fig. 5.1, the robot fails in its first attempt to step overthe obstacle. There is a collision between the fore side ofthe robot’s paw and the obstacle during the leg extensionphase. The robot tried to step over too close to the obstacle.This collision causes the adaptation mechanism to changethe weights so that the robot decreases the stride length infuture trials, during the approach to the obstacle.
Despite the acquired experience in the first trial, in the sec-ond trial the robot still fails (Fig. 5.2). In this trial, however,while stepping over the obstacle, the robot collides with itsback side of the paw during the placement phase. The stridelength had been decreased but this change made the robotto step over too far away from the obstacle. Therefore, thestride length needs to be increased for future trials.
Finally, in the third trial (Fig. 5.3), it is visible that theexperience acquired in previous attempts was enough, as therobot is able to step over without any collisions. Thus, therobot attempts to step over the obstacle at the ideal distance(which is approximately 6 cm from the obstacle).
A video of such experiment can be found in http://asbg.dei.uminho.pt/node/358.
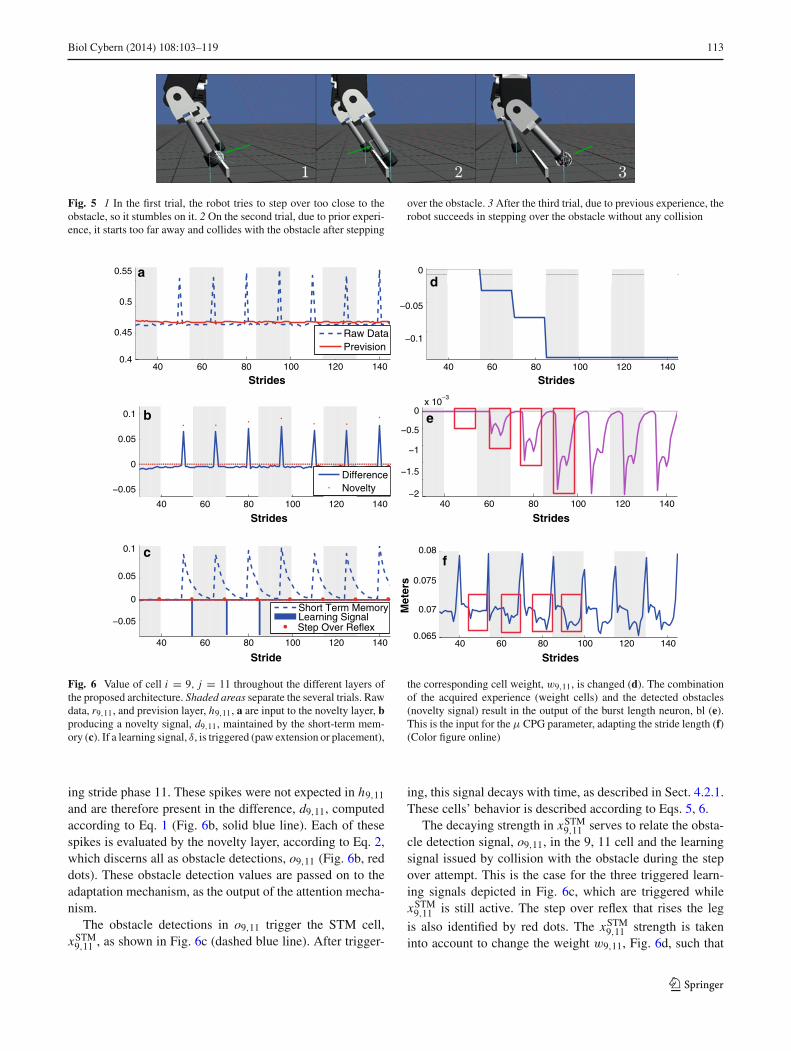
In another simulation, the robot was able to step over anobstacle after three trials. Initially, the robot was placed at≈2 m. In this simulation, we will focus on the study of a singlecell, sensor 9 during stride phase 11, (i = 9, j = 11), alongthe different matrices. Figure 6 displays the time evolutionof this cell. Different trials are denoted by shaded areas.
For the given cell, the raw data (dashed blue line), r9,11,and the estimated value for each stride (solid red line), h9,11,are depicted in Fig. 6a. The spikes in r9,11 indicate that some-thing disrupted the usually observed pattern in sensor 9 dur-
123
Biol Cybern (2014) 108:103–119 113
Fig. 5 1 In the first trial, the robot tries to step over too close to theobstacle, so it stumbles on it. 2 On the second trial, due to prior experi-ence, it starts too far away and collides with the obstacle after stepping
over the obstacle. 3 After the third trial, due to previous experience, therobot succeeds in stepping over the obstacle without any collision
40 60 80 100 120 1400.4
0.45
0.5
0.55
Strides
Raw DataPrevision
a
40 60 80 100 120 140
−0.1
−0.05
0
Strides
d
40 60 80 100 120 140
−0.05
0
0.05
0.1
Strides
DifferenceNovelty
b
40 60 80 100 120 140−2
−1.5
−1
−0.5
0x 10
−3
Strides
e
40 60 80 100 120 140
−0.05
0
0.05
0.1
Stride
Short Term MemoryLearning Signal
c
Step Over Reflex
40 60 80 100 120 1400.065
0.07
0.075
0.08
Strides
Met
ers
f
Fig. 6 Value of cell i = 9, j = 11 throughout the different layers ofthe proposed architecture. Shaded areas separate the several trials. Rawdata, r9,11, and prevision layer, h9,11, a are input to the novelty layer, bproducing a novelty signal, d9,11, maintained by the short-term mem-ory (c). If a learning signal, δ, is triggered (paw extension or placement),
the corresponding cell weight, w9,11, is changed (d). The combinationof the acquired experience (weight cells) and the detected obstacles(novelty signal) result in the output of the burst length neuron, bl (e).This is the input for the μ CPG parameter, adapting the stride length (f)(Color figure online)
ing stride phase 11. These spikes were not expected in h9,11
and are therefore present in the difference, d9,11, computedaccording to Eq. 1 (Fig. 6b, solid blue line). Each of thesespikes is evaluated by the novelty layer, according to Eq. 2,which discerns all as obstacle detections, o9,11 (Fig. 6b, reddots). These obstacle detection values are passed on to theadaptation mechanism, as the output of the attention mecha-nism.
The obstacle detections in o9,11 trigger the STM cell,xSTM
9,11 , as shown in Fig. 6c (dashed blue line). After trigger-
ing, this signal decays with time, as described in Sect. 4.2.1.These cells’ behavior is described according to Eqs. 5, 6.
The decaying strength in xSTM9,11 serves to relate the obsta-
cle detection signal, o9,11, in the 9, 11 cell and the learningsignal issued by collision with the obstacle during the stepover attempt. This is the case for the three triggered learn-ing signals depicted in Fig. 6c, which are triggered whilexSTM
9,11 is still active. The step over reflex that rises the leg
is also identified by red dots. The xSTM9,11 strength is taken
into account to change the weight w9,11, Fig. 6d, such that
123

114 Biol Cybern (2014) 108:103–119
obstacle detections that occurred closer to the obstacle causegreater changes than those that occurred at higher distances.These changes are computed according to Eq. 7.
The change in w9,11 together with the obstacles detectionsignal o9,11, change the mechanism’s output, bl, as shown inFig. 6e, according to Eqs. 8, 9.
bl is then used to model the CPG’s amplitude throughthe μ parameter, as described in Eq. 11, which will resultin a change in the robot stride length. Figure 6f, shows thestride length evolution through time. In this simulation, noisewas added to sensors and actuators and thus the measuredstride length varies along the different strides. In the peri-ods denoted by red rectangles, the stride length of the robotchanges according to bl, Fig. 6e. This period corresponds tothe robot’s approach to the obstacle, specifically, when theobstacle is within reach of the robot’s range sensors. At theend of each trial, the robot rises the leg according to the stepover reflex. This causes the spikes in the measured stridelength, Fig. 6f. Initially, before any learning signals havebeen triggered, there is no change in bl and thus an approx-imately constant stride length is achieved all over the trial.Then, in the third trial, there are already learning signals, δ,that change the weights and consequently generate differentoutput values, bl. Thus, in the second rectangle of Fig. 6f, theresulting stride length is already quite different.
However, it is relevant to say that the mechanism’s outputis defined by all obstacle detections in oi j and the existingexperience in all weights, wi j . Further, when a learning signalis triggered, all the cells corresponding to the currently activestride phase j are changed as well. Note that according toEq. 7, the weight vector for stride phase 11 is normalized(Sect. 4.2.3). Thus, although the analyzed cell is relevant forthe process, all the range sensors at stride phase 11 influencebl and consequently change the robot’s stride length.
5.3 Reacting to activation patterns by experience
During the approach, the cells that detect the obstacleare activated throughout the different components of themechanism—from the raw layer where the obstacles are firstdetected, to the weights, which register the required changesto the locomotion based on the acquired experience. The cells
are activated according to the stride phases and the distancesat which the obstacle was detected. These activated cells formpatterns in their matrix structures. Thus, spatio-temporal rela-tionships are established such that obstacles placed at differ-ent distances in the beginning of a trial, cause activation ofdifferent cells. We call an activation pattern (AP), the groupof cells activated during an approach.
In this section, we will show different experiments inwhich we vary the distance at which the robot is initiallypositioned relatively to the obstacle. We are particularly inter-ested in studying the generated APs. Distance is set accordingto a base distance of 2 m plus psl sl, where sl is the averagestride length (sl ≈ 7 cm) and psl ∈ [0, 1] is a value used todefine the initial position as part of the average stride length.
The first experiment addresses the simplest case of learn-ing to avoid an obstacle. The robot always starts the trialat the same distance from the obstacle. Thus, a single AP isexpected to be formed to which the robot learns to react. ThisAP may change from trial to trial, but these variations willrepeat for different experiments under the same conditions.
Figure 6 illustrates such a situation for psl = 0.57. Thestride length is successively reduced (Fig. 6f), according to bl(Fig. 6e), as a consequence of the three learning signals (Fig.6c), all triggered during the paw extension phase (δ = −1).
The generated APs corresponding to the depicted four rec-tangles are shown in Fig. 7. They are quite similar.
The second set of simulations addresses situations inwhich the robot is placed at different initial distances fromthe obstacles. This will result in different APs. Specifically,we are interested in verifying how the proposed architecturedeals with different APs.
In order to verify this, we simulate 10 trials of a experi-ment in which the robot always starts at the same distancefrom the obstacle. This distance is changed among differentexperiments. Figure 8 displays the obtained results. The trialsare differentiated by gray shaded areas (as previously), andthe periods that correspond to each experiment are separatedby vertical lines.
Top panel of Fig. 8 illustrates two experiments (a and b) inwhich the robot approaches the obstacle from two differentdistances. The distances for experiment a and b differ by amultiple of the nominal stride length and are set according
Stride Phases
Sen
sors
5 10 15
2
4
6
8
10
Stride Phases
Sen
sors
5 10 15
2
4
6
8
10
Stride Phases
Sen
sors
5 10 15
2
4
6
8
10
Stride Phases
Sen
sors
5 10 15
2
4
6
8
10
Fig. 7 The generated APs corresponding to the depicted four rectangles of Fig. 6e. Left to right, respectively, showing the different learningmoments from no alteration to full adaptation of the stride length. White ares indicate activated cells. Black areas to unactivated cells
123
Biol Cybern (2014) 108:103–119 115
100 200 300 400 500 600 700−1
0
1Learning signals triggering
StridesAP a AP b
No Obstacle
AP a AP b
100 200 300 400 500 600 700−1
0
1Learning signals triggering
StridesAP a AP b
No Obstacle
AP a AP b
100 200 300 400 500 600 700−1
0
1Learning signals triggering
StridesAP a AP b
No Obstacle
AP a AP b
Fig. 8 Learning signals for experiments with equivalent APs (top),with two different APs that do not interfere with each other (middle)and with APs that do interfere with each other (bottom)
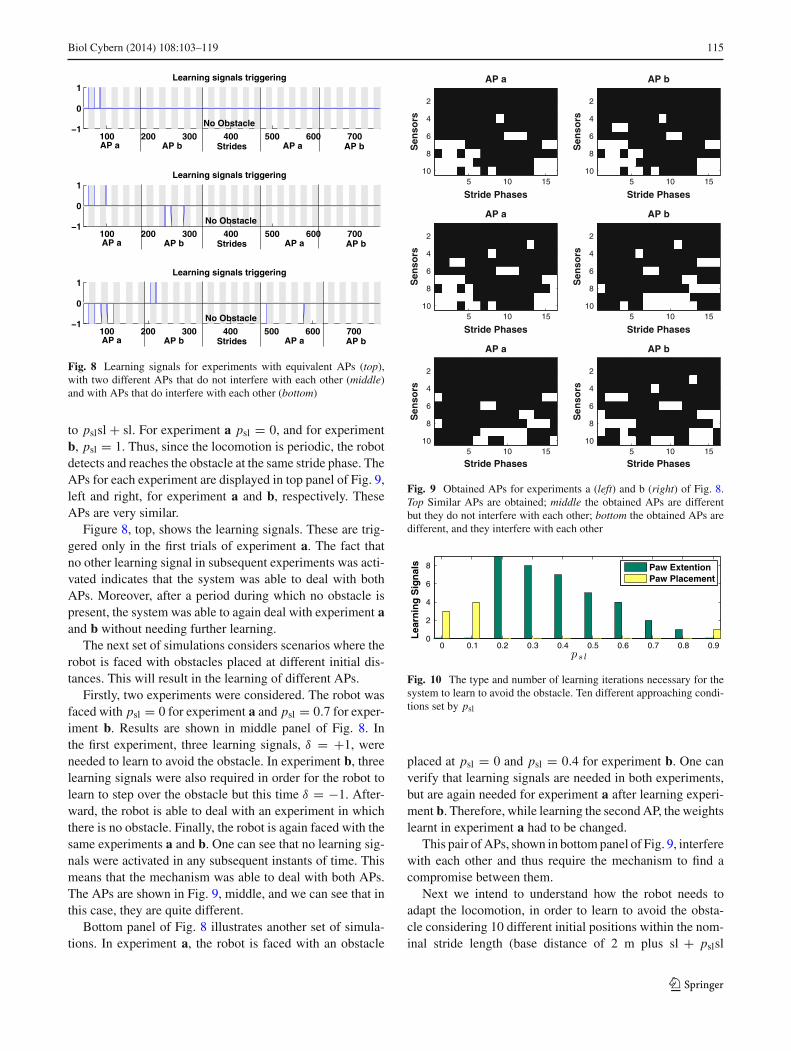
to pslsl + sl. For experiment a psl = 0, and for experimentb, psl = 1. Thus, since the locomotion is periodic, the robotdetects and reaches the obstacle at the same stride phase. TheAPs for each experiment are displayed in top panel of Fig. 9,left and right, for experiment a and b, respectively. TheseAPs are very similar.
Figure 8, top, shows the learning signals. These are trig-gered only in the first trials of experiment a. The fact thatno other learning signal in subsequent experiments was acti-vated indicates that the system was able to deal with bothAPs. Moreover, after a period during which no obstacle ispresent, the system was able to again deal with experiment aand b without needing further learning.
The next set of simulations considers scenarios where therobot is faced with obstacles placed at different initial dis-tances. This will result in the learning of different APs.
Firstly, two experiments were considered. The robot wasfaced with psl = 0 for experiment a and psl = 0.7 for exper-iment b. Results are shown in middle panel of Fig. 8. Inthe first experiment, three learning signals, δ = +1, wereneeded to learn to avoid the obstacle. In experiment b, threelearning signals were also required in order for the robot tolearn to step over the obstacle but this time δ = −1. After-ward, the robot is able to deal with an experiment in whichthere is no obstacle. Finally, the robot is again faced with thesame experiments a and b. One can see that no learning sig-nals were activated in any subsequent instants of time. Thismeans that the mechanism was able to deal with both APs.The APs are shown in Fig. 9, middle, and we can see that inthis case, they are quite different.
Bottom panel of Fig. 8 illustrates another set of simula-tions. In experiment a, the robot is faced with an obstacle
AP a
Stride Phases
Sen
sors
5 10 15
2
4
6
8
10
AP b
Stride Phases
Sen
sors
5 10 15
2
4
6
8
10
AP a
Stride Phases
Sen
sors
5 10 15
2
4
6
8
10
AP b
Stride Phases
Sen
sors
5 10 15
2
4
6
8
10
AP a
Stride Phases
Sen
sors
5 10 15
2
4
6
8
10
AP b
Stride Phases
Sen
sors
5 10 15
2
4
6
8
10
Fig. 9 Obtained APs for experiments a (left) and b (right) of Fig. 8.Top Similar APs are obtained; middle the obtained APs are differentbut they do not interfere with each other; bottom the obtained APs aredifferent, and they interfere with each other
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.90
2
4
6
8
Lea
rnin
g S
ign
als Paw Extention
Paw Placement
Fig. 10 The type and number of learning iterations necessary for thesystem to learn to avoid the obstacle. Ten different approaching condi-tions set by psl
placed at psl = 0 and psl = 0.4 for experiment b. One canverify that learning signals are needed in both experiments,but are again needed for experiment a after learning experi-ment b. Therefore, while learning the second AP, the weightslearnt in experiment a had to be changed.
This pair of APs, shown in bottom panel of Fig. 9, interferewith each other and thus require the mechanism to find acompromise between them.
Next we intend to understand how the robot needs toadapt the locomotion, in order to learn to avoid the obsta-cle considering 10 different initial positions within the nom-inal stride length (base distance of 2 m plus sl + pslsl
123
116 Biol Cybern (2014) 108:103–119
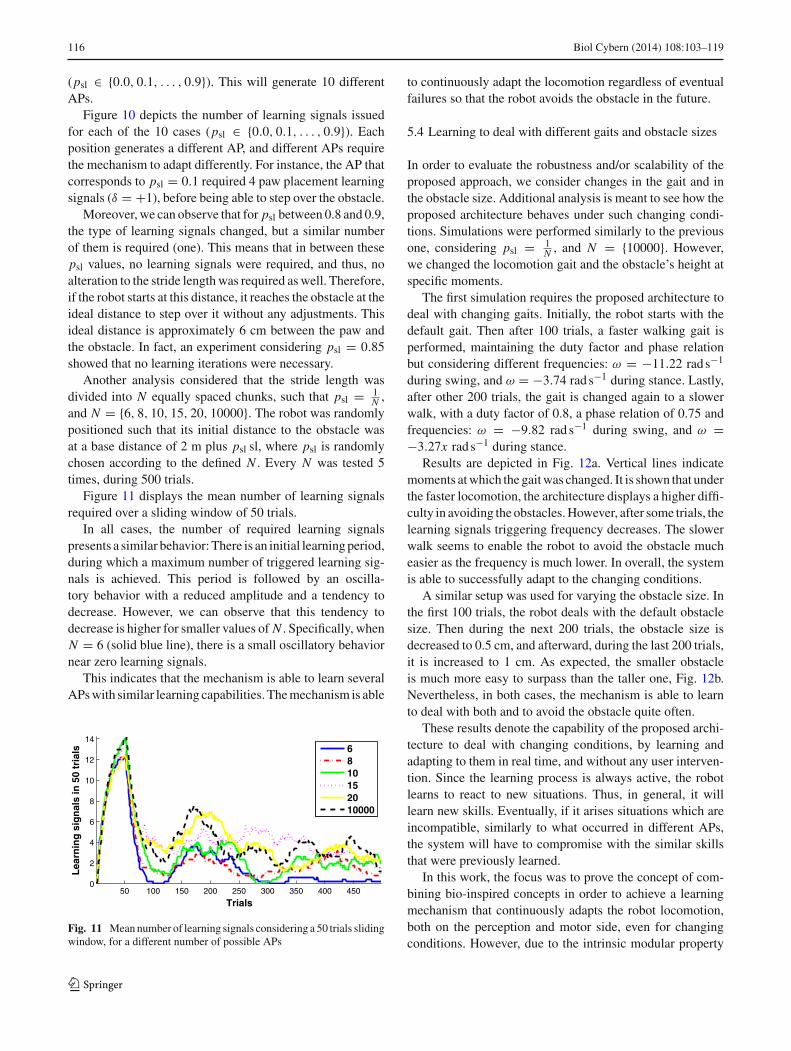
(psl ∈ {0.0, 0.1, . . . , 0.9}). This will generate 10 differentAPs.
Figure 10 depicts the number of learning signals issuedfor each of the 10 cases (psl ∈ {0.0, 0.1, . . . , 0.9}). Eachposition generates a different AP, and different APs requirethe mechanism to adapt differently. For instance, the AP thatcorresponds to psl = 0.1 required 4 paw placement learningsignals (δ = +1), before being able to step over the obstacle.
Moreover, we can observe that for psl between 0.8 and 0.9,the type of learning signals changed, but a similar numberof them is required (one). This means that in between thesepsl values, no learning signals were required, and thus, noalteration to the stride length was required as well. Therefore,if the robot starts at this distance, it reaches the obstacle at theideal distance to step over it without any adjustments. Thisideal distance is approximately 6 cm between the paw andthe obstacle. In fact, an experiment considering psl = 0.85showed that no learning iterations were necessary.
Another analysis considered that the stride length wasdivided into N equally spaced chunks, such that psl = 1
N ,and N = {6, 8, 10, 15, 20, 10000}. The robot was randomlypositioned such that its initial distance to the obstacle wasat a base distance of 2 m plus psl sl, where psl is randomlychosen according to the defined N . Every N was tested 5times, during 500 trials.
Figure 11 displays the mean number of learning signalsrequired over a sliding window of 50 trials.
In all cases, the number of required learning signalspresents a similar behavior: There is an initial learning period,during which a maximum number of triggered learning sig-nals is achieved. This period is followed by an oscilla-tory behavior with a reduced amplitude and a tendency todecrease. However, we can observe that this tendency todecrease is higher for smaller values of N . Specifically, whenN = 6 (solid blue line), there is a small oscillatory behaviornear zero learning signals.
This indicates that the mechanism is able to learn severalAPs with similar learning capabilities. The mechanism is able
50 100 150 200 250 300 350 400 4500
2
4
6
8
10
12
14
Trials
Lea
rnin
g s
ign
als
in 5
0 tr
ials 6
810152010000
Fig. 11 Mean number of learning signals considering a 50 trials slidingwindow, for a different number of possible APs
to continuously adapt the locomotion regardless of eventualfailures so that the robot avoids the obstacle in the future.
5.4 Learning to deal with different gaits and obstacle sizes
In order to evaluate the robustness and/or scalability of theproposed approach, we consider changes in the gait and inthe obstacle size. Additional analysis is meant to see how theproposed architecture behaves under such changing condi-tions. Simulations were performed similarly to the previousone, considering psl = 1
N , and N = {10000}. However,we changed the locomotion gait and the obstacle’s height atspecific moments.
The first simulation requires the proposed architecture todeal with changing gaits. Initially, the robot starts with thedefault gait. Then after 100 trials, a faster walking gait isperformed, maintaining the duty factor and phase relationbut considering different frequencies: ω = −11.22 rad s−1
during swing, and ω = −3.74 rad s−1 during stance. Lastly,after other 200 trials, the gait is changed again to a slowerwalk, with a duty factor of 0.8, a phase relation of 0.75 andfrequencies: ω = −9.82 rad s−1 during swing, and ω =−3.27x rad s−1 during stance.
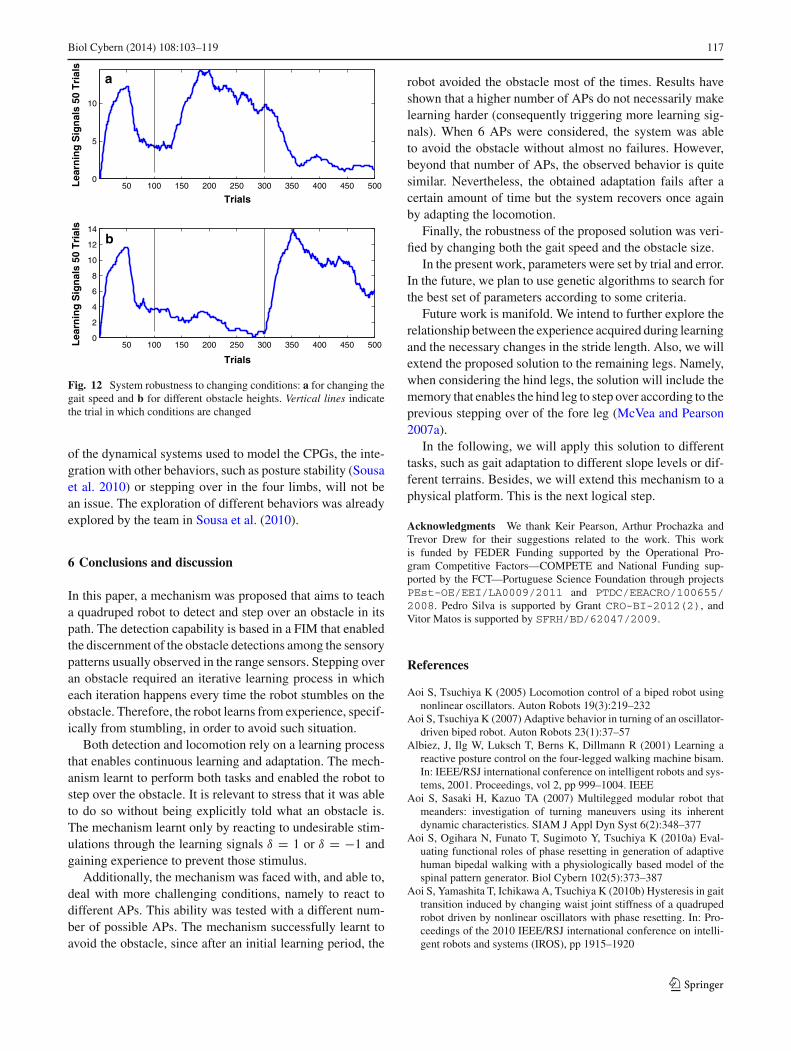
Results are depicted in Fig. 12a. Vertical lines indicatemoments at which the gait was changed. It is shown that underthe faster locomotion, the architecture displays a higher diffi-culty in avoiding the obstacles. However, after some trials, thelearning signals triggering frequency decreases. The slowerwalk seems to enable the robot to avoid the obstacle mucheasier as the frequency is much lower. In overall, the systemis able to successfully adapt to the changing conditions.
A similar setup was used for varying the obstacle size. Inthe first 100 trials, the robot deals with the default obstaclesize. Then during the next 200 trials, the obstacle size isdecreased to 0.5 cm, and afterward, during the last 200 trials,it is increased to 1 cm. As expected, the smaller obstacleis much more easy to surpass than the taller one, Fig. 12b.Nevertheless, in both cases, the mechanism is able to learnto deal with both and to avoid the obstacle quite often.
These results denote the capability of the proposed archi-tecture to deal with changing conditions, by learning andadapting to them in real time, and without any user interven-tion. Since the learning process is always active, the robotlearns to react to new situations. Thus, in general, it willlearn new skills. Eventually, if it arises situations which areincompatible, similarly to what occurred in different APs,the system will have to compromise with the similar skillsthat were previously learned.
In this work, the focus was to prove the concept of com-bining bio-inspired concepts in order to achieve a learningmechanism that continuously adapts the robot locomotion,both on the perception and motor side, even for changingconditions. However, due to the intrinsic modular property
123
Biol Cybern (2014) 108:103–119 117
50 100 150 200 250 300 350 400 450 5000
5
10
Trials
Lea
rnin
g S
ign
als
50 T
rial
s a
50 100 150 200 250 300 350 400 450 5000
2
4
6
8
10
12
14
Trials
Lea
rnin
g S
ign
als
50 T
rial
s
b
Fig. 12 System robustness to changing conditions: a for changing thegait speed and b for different obstacle heights. Vertical lines indicatethe trial in which conditions are changed
of the dynamical systems used to model the CPGs, the inte-gration with other behaviors, such as posture stability (Sousaet al. 2010) or stepping over in the four limbs, will not bean issue. The exploration of different behaviors was alreadyexplored by the team in Sousa et al. (2010).
6 Conclusions and discussion
In this paper, a mechanism was proposed that aims to teacha quadruped robot to detect and step over an obstacle in itspath. The detection capability is based in a FIM that enabledthe discernment of the obstacle detections among the sensorypatterns usually observed in the range sensors. Stepping overan obstacle required an iterative learning process in whicheach iteration happens every time the robot stumbles on theobstacle. Therefore, the robot learns from experience, specif-ically from stumbling, in order to avoid such situation.
Both detection and locomotion rely on a learning processthat enables continuous learning and adaptation. The mech-anism learnt to perform both tasks and enabled the robot tostep over the obstacle. It is relevant to stress that it was ableto do so without being explicitly told what an obstacle is.The mechanism learnt only by reacting to undesirable stim-ulations through the learning signals δ = 1 or δ = −1 andgaining experience to prevent those stimulus.
Additionally, the mechanism was faced with, and able to,deal with more challenging conditions, namely to react todifferent APs. This ability was tested with a different num-ber of possible APs. The mechanism successfully learnt toavoid the obstacle, since after an initial learning period, the
robot avoided the obstacle most of the times. Results haveshown that a higher number of APs do not necessarily makelearning harder (consequently triggering more learning sig-nals). When 6 APs were considered, the system was ableto avoid the obstacle without almost no failures. However,beyond that number of APs, the observed behavior is quitesimilar. Nevertheless, the obtained adaptation fails after acertain amount of time but the system recovers once againby adapting the locomotion.
Finally, the robustness of the proposed solution was veri-fied by changing both the gait speed and the obstacle size.
In the present work, parameters were set by trial and error.In the future, we plan to use genetic algorithms to search forthe best set of parameters according to some criteria.
Future work is manifold. We intend to further explore therelationship between the experience acquired during learningand the necessary changes in the stride length. Also, we willextend the proposed solution to the remaining legs. Namely,when considering the hind legs, the solution will include thememory that enables the hind leg to step over according to theprevious stepping over of the fore leg (McVea and Pearson2007a).
In the following, we will apply this solution to differenttasks, such as gait adaptation to different slope levels or dif-ferent terrains. Besides, we will extend this mechanism to aphysical platform. This is the next logical step.
Acknowledgments We thank Keir Pearson, Arthur Prochazka andTrevor Drew for their suggestions related to the work. This workis funded by FEDER Funding supported by the Operational Pro-gram Competitive Factors—COMPETE and National Funding sup-ported by the FCT—Portuguese Science Foundation through projectsPEst-OE/EEI/LA0009/2011 and PTDC/EEACRO/100655/2008. Pedro Silva is supported by Grant CRO-BI-2012(2), andVitor Matos is supported by SFRH/BD/62047/2009.
References
Aoi S, Tsuchiya K (2005) Locomotion control of a biped robot usingnonlinear oscillators. Auton Robots 19(3):219–232
Aoi S, Tsuchiya K (2007) Adaptive behavior in turning of an oscillator-driven biped robot. Auton Robots 23(1):37–57
Albiez, J, Ilg W, Luksch T, Berns K, Dillmann R (2001) Learning areactive posture control on the four-legged walking machine bisam.In: IEEE/RSJ international conference on intelligent robots and sys-tems, 2001. Proceedings, vol 2, pp 999–1004. IEEE
Aoi S, Sasaki H, Kazuo TA (2007) Multilegged modular robot thatmeanders: investigation of turning maneuvers using its inherentdynamic characteristics. SIAM J Appl Dyn Syst 6(2):348–377
Aoi S, Ogihara N, Funato T, Sugimoto Y, Tsuchiya K (2010a) Eval-uating functional roles of phase resetting in generation of adaptivehuman bipedal walking with a physiologically based model of thespinal pattern generator. Biol Cybern 102(5):373–387
Aoi S, Yamashita T, Ichikawa A, Tsuchiya K (2010b) Hysteresis in gaittransition induced by changing waist joint stiffness of a quadrupedrobot driven by nonlinear oscillators with phase resetting. In: Pro-ceedings of the 2010 IEEE/RSJ international conference on intelli-gent robots and systems (IROS), pp 1915–1920
123

118 Biol Cybern (2014) 108:103–119
Aoi S, Fujiki S, Yamashita T, Kohda T, Senda K, Tsuchiya K (2011)Generation of adaptive splitbelt treadmill walking by a biped robotusing nonlinear oscillators with phase resetting. In: Proceedings ofthe 2011 IEEE/RSJ international conference on intelligent robotsand systems (IROS), pp 2274–2279
Berns K, Ilg W, Deck M, Dillmann R (2008) Adaptive control of thefour-legged walking machine BISAM. In: Proceedings of the 1998IEEE international conference on control applications, vol 1, pp 428–432
Brown TG (1911) The intrinsic factors in the act of progression in themammal. In: Proceedings of the Royal Society of London. Series B,containing papers of a biological character, vol 84, pp 308–319
Buchli J, Ijspeert AJ (2008) Self-organized adaptive legged locomotionin a compliant quadruped robot. Auton Robots 25:331–347
Burke RE (2007) Sir Charles Sherrington’s The integrative action of thenervous system: a centenary appreciation. Gait Brian 130(4):887–894
Büschges A, Borgmann A (2013) Network modularity: back to thefuture in motor control. Curr Biol 23(29):R936–R938
Cruse H, Kindermann T, Schumm M, Dean J, Schmitz J (1998)Walknet–a biologically inspired network to control six-legged walk-ing. Neural Netw 11(7):1435–1447
Doshi F, Brunskill E, Shkolnik A, Kollar T, Rohanimanesh K, TedrakeR, Roy N (2007) Collision detection in legged locomotion usingsupervised learning. In: IEEE/RSJ international conference on intel-ligent robots and systems, 2007. IROS 2007, pp 317–322, Oct 2007
Drew T, Andujar J-E, Lajoie K, Yakovenko S (2008) Cortical mecha-nisms involved in visuomotor coordination during precision walking.Brain Res Rev 57:199–211
Endo G, Morimoto J, Nakanishi J, Cheng G (2004) An empirical explo-ration of a neural oscillator for biped locomotion control. In: Pro-ceedings of the 2004 IEEE international conference on robotics andautomation, ICRA 2004, New Orleans, LA, USA, 26 April–1 May,pp 3036–3042
Endo G, Nakanishi J, Morimoto J, Cheng G (2005) Experimental stud-ies of a neural oscillator for biped locomotion with QRIO. In: Pro-ceedings of the 2005 IEEE international conference on robotics andautomation, ICRA 2005, pp 596–602
Forssberg H (1979) Stumbling corrective reaction: a phase-dependent compensatory reaction during locomotion. J Neurophys-iol 42(4):936–953
Fukuoka Y, Kimura H, Cohen A (2003) Adaptive dynamic walking ofa quadruped robot on irregular terrain based on biological concepts.Int J Robot Res 22(3–4):187
Geng T, Porr B, Wörgötter F (2006) Fast biped walking with a sensor-driven neuronal controller and real-time online learning. Int J RobotRes 25(3):243–259
Geyer H, Herr H (2010) A muscle-reflex model that encodes prin-ciples of legged mechanics produces human walking dynamicsand muscle activities. IEEE Trans Neural Syst Rehabil Eng 18(3):263–273
Gritsenko V, Yakovenko S, Kalaska JF (2009) From integration of pre-dictive feedforward and sensory feedback signals for online controlof visually guided movement. J Neurophysiol 102:914–930
Held R (1961) Sensory deprivation: facts in search of a theory.Exposure-history as a factor in maintaining stability of perceptionand coordination. J Nerv Ment Dis 132:26–32
Heliot R, Espiau B (2008) Multisensor input for cpg-based sensory—motor coordination. IEEE Trans Robot 24(1):191–195
Hoffmann H (2007) Perception through visuomotor anticipation in amobile robot. Neural Netw 20(1):22–33
Ijspeert A (2008) special issue: Central pattern generators for locomo-tion control in animals and robots: a review. Neural Netw 21(4):642–653
Ilg W, Albiez J, Jedele H, Berns K, Dillmann R (1999) Adaptive peri-odic movement control for the four legged walking machine bisam.
In: IEEE international conference on robotics and automation. Pro-ceedings, vol 3, pp 2354–2359. IEEE
Ishii T, Masakado S, Ishii K (2004) Locomotion of a quadruped robotusing CPG. In: Proceedings in 2004 IEEE international joint confer-ence on neural networks, vol 4, pp 3179–3184
Kalakrishnan M, Buchli J, Pastor P, Mistry M, Schaal S (2010) Fast,robust quadruped locomotion over challenging terrain. In: IEEEinternational conference on robotics and automation (ICRA), 2010,pp 2665–2670. IEEE
Kiehn O (2006) Locomotor circuits in the mammalian spinal cord. AnnuRev Neurosci 29(1):279–306
Kimura H, Fukuoka Y (2004) Biologically inspired adaptive dynamicwalking in outdoor environment using a self-contained quadrupedrobot: ‘Tekken2’. In: Proceedings. 2004 IEEE/RSJ international con-ference on intelligent robots and systems, 2004. (IROS 2004), vol 1,pp 986–991
Kimura H, Fukuoka Y, Cohen A (2007a) Adaptive dynamic walking ofa quadruped robot on natural ground based on biological concepts.Int J Robot Res 26(5):475
Kimura H, Fukuoka Y, Cohen AH (2007b) Adaptive dynamic walkingof a quadruped robot on natural ground based on biological concepts.Int J Robot Res 26(5):475–490
Komatsu T, Usui M (2005) Dynamic walking and running of a bipedalrobot using hybrid central pattern generator method. In: Proceed-ings of the 2005 IEEE international conference mechatronics andautomation, vol 2, pp 987–992
Lee DN, Lishman JR, Thomson JA (1982) Regulation of gait in longjumping. J Exp Psychol Hum Percept Perform 8(3):448
Lewis M (2002) Detecting surface features during locomotion usingoptic flow. In: IEEE international conference on robotics and automa-tion, 2002. Proceedings. ICRA ’02, vol 1, pp 305–310
Lewis M, Simó L (1999) Elegant stepping: a model of visually triggeredgait adaptation. Connect Sci 11(3):331–344
Lewis MA, Simó LS (2001) Certain principles of biomorphic robots.Auton Robots 11(3):221–226
Lewis M, Bekey G (2002) Gait adaptation in a quadruped robot. AutonRobots 12(3):301–312
Maes P, Brooks R (1990) Learning to coordinate behaviors. In: Pro-ceedings of the eighth national conference on artificial intelligence,pp 796–802
Manoonpong P, Wörgötter F (2009) Efference copies in neural controlof dynamic biped walking. Robot Auton Syst 57(11):1140–1153
Manoonpong P, Geng T, Kulvicius T, Porr B, Wörgötter F (2007) Adap-tive, fast walking in a biped robot under neuronal control and learn-ing. PLoS Comput Biol 3(7):e134
Manoonpong P, Parlitz U, Wörgötter F (2013) Neural control andadaptive neural forward models for insect-like, energy-efficient, andadaptable locomotion of walking machines. Front Neural Circuits7:12 doi 10.3399/fncri.2013.00012
Marder E, Bucher D, Schulz DJ, Taylor AL (2005) Invertebrate centralpattern generation moves along. Curr Biol 15(17):R685–R699
Matos V, Santos C (2011) Omnidirectional locomotion in a quadrupedrobot: a cpg-based approach. In: IEEE/RSJ international conferenceon intelligent robots and systems (IROS), 2010, pp 3392–3397. IEEE
Matsubara T, Morimoto J, Nakanishi J, Sato M, Doya K (2005) LearningCPG-based biped locomotion with a policy gradient method. In:Proceedings of the 2005 5th IEEE-RAS international conference onhumanoid robots, pp 208–213
Maufroy C, Nishikawa T, Kimura H (2010a) Stable dynamic walkingof a quadruped robot Kotetsu; using phase modulations based on legloading/unloading. In: Proceedings of the 2010 IEEE internationalconference on robotics and automation, ICRA 2010, pp 5225–5230
Maufroy C, Kimura H, Takase K (2010b) Integration of posture andrhythmic motion controls in quadrupedal dynamic walking usingphase modulations based on leg loading/unloading. Auton Robots28(3):331–353
123

Biol Cybern (2014) 108:103–119 119
McVea D, Pearson K (2007a) Contextual learning and obstacle memoryin the walking cat. Integr Comp Biol 47(4):457–464
McVea DA, Pearson KG (2007b) Long-lasting, context-dependent mod-ification of stepping in the cat after repeated stumbling-correctiveresponses. J Neurophysiol 97(1):659–669
Miall R, Wolpert DM (1996) Forward models for physiological motorcontrol. Neural Netw 9(8):1265–1279
Michel O (2004) Webots: professional mobile robot simulation. J AdvRobot Syst 1(1):39–42
Morimoto J, Hyon S, Atkeson CG, Cheng G (2008a) Low-dimensionalfeature extraction for humanoid locomotion using kernel dimensionreduction. In: Proceedings of the 2008 IEEE international conferenceon robotics and automation, ICRA 2008, pp 2711–2716
Morimoto J, Endo G, Nakanishi J, Cheng GA (2008b) Biologicallyinspired biped locomotion strategy for humanoid robots: modulationof sinusoidal patterns by a coupled oscillator model. IEEE TransRobot 24(1):185–191
Ogino M, Katoh Y, Aono M, Asada M, Hosoda K (2004) Reinforcementlearning of humanoid rhythmic walking parameters based on visualinformation. Adv Robot 18(7):677–697
Orlovskii GN, Deliagina TG, Grillner S (1999) Neuronal control oflocomotion: from mollusc to man. Oxford University Press, Oxford
Pastor P, Kalakrishnan M, Chitta S, Theodorou E, Schaal S (2011a)Skill learning and task outcome prediction for manipulation. In:IEEE international conference on robotics and automation (ICRA),pp 3828–3834. IEEE
Pastor P, Righetti L, Kalakrishnan M, Schaal S (2011b) Online move-ment adaptation based on previous sensor experiences. In: IEEE/RSJinternational conference on intelligent robots and systems (IROS),pp. 365–371. IEEE
Pearson K (2004) Generating the walking gait: role of sensory feedback.Brain mechanisms for the integration of posture and movement, vol143, Elsevier, Amsterdam, pp 123–129
Prochazka A (2002) The man-machine analogy in robotics and neuro-physiology. J Autom Control 12:4–8
Prochazka A, Gritsenko V, Yakovenko S (2002) Sensory control of loco-motion: reflexes versus higher-level control. Sensori-motor control,vol 57. Kluwer, New York
Righetti L, Ijspeert A (2008) Pattern generators with sensory feedbackfor the control of quadruped locomotion. In: IEEE international con-ference on robotics and automation, 2008. ICRA 2008, pp 819–824,May 2008
Rossignol S, Dubuc R, Gossard J-P (2006) Dynamic sensorimotor inter-actions in locomotion. Physiol Rev 86(1):89–154
Santos CP, Matos V (2012) Cpg modulation for navigation and omnidi-rectional quadruped locomotion. Robot Auton Syst 60(6):912–927
Schenck W, Möller R (2007) Training and application of a visual for-ward model for a robot camera head. In: Butz MV, Sigaud O, PezzuloG, Baldassarre G (eds) Anticipatory behavior in adaptive learningsystems, pp 153–169. Springer, Berlin
Schröder-Schetelig J, Manoonpong P, Wörgötter F (2010), Using effer-ence copy and a forward internal model for adaptive biped walking.Auton Robots 29:1–10
Shimada S, Egami T, Ishimura K, Wada M (2002) Neural control ofquadruped robot for autonomous walking on soft terrain. In: AsamaH, Arai T, Fukuda T, Hasegawa T (eds) Distributed autonomousrobotic systems, vol 5. Springer, Japan, pp 415–423
Silva P, Matos V, Santos CP (2012) Adaptive quadruped locomotion:learning to detect and avoid an obstacle. In: Ziemke T, BalkeniusC, Hallam J (eds) From animals to animats, vol 12. Springer, pp361–370
Sousa J, Matos V, Peixoto dos Santos C (2010) A bio-inspired pos-tural control for a quadruped robot: an attractor-based dynamics. In:IEEE/RSJ international conference on intelligent robots and systems(IROS), pp 5329–5334. IEEE
Sugimoto N, Morimoto J (2011) Phase-dependent trajectory optimiza-tion for CPG-based biped walking using path integral reinforcementlearning. In: Proceedings of the 11th IEEE-RAS international con-ference on humanoid robots, pp 255–260
Sutton R, Barto A (1998) Reinforcement learning: An introduction, vol1. Cambridge University Press, Cambridge
Taga G, Yamaguchi Y, Shimizu H (1991) Self-organized control ofbipedal locomotion by neural oscillators in unpredictable environ-ment. Biol Cybern 65(3):147–159
Taga G (1995a) A model of the neuro-musculo-skeletal systemfor human locomotion–I. Emergence of basic gait. Biol Cybern73(2):97–111
Taga G (1995b) A model of the neuro-musculo-skeletal system forhuman locomotion—II. Real-time adaptability under various con-straints. Biol Cybern 73(2):113–121
Taga G (1998) A model of the neuro-musculo-skeletal system for antic-ipatory adjustment of human locomotion during obstacle avoidance.Biol Cybern 78(1):9–17
Takemura H, Deguchi M, Ueda J, Matsumoto Y, Ogasawara T (2005)Self-organized control of bipedal locomotion by neural oscillators inunpredictable environment. Slip-adaptive walk of quadruped robot.Robot Auton Syst 53:124–141
Takemura H, Ueda J, Matsumoto Y, Ogasawara T (2002) A study ofa gait generation of a quadruped robot based on rhythmic control–optimization of CPG parameters by a fast dynamics simulation envi-ronment. In: Proceedings of 5th international conference on climbingand walking robots (CLAWAR 2002), pp 759–766
von Holst E, Mittelstaedt H (1950) Das Reafferenzprinzip. Naturwis-senschaften 37(20):464–476
Wilkinson EJ, Sherk HA (2005) The use of visual information for plan-ning accurate steps in a cluttered environment. Behav Brain Res164(2):270–274
Wolpert D, Kawato M (1998) Multiple paired forward and inverse mod-els for motor control. Neural Netw 11(7–8):1317–1329
Yakovenko S, Gritsenko V, Prochazka A (2004) Contribution ofstretch reflexes to locomotor control: a modeling study. Biol Cybern90(2):146-155
123
















![Smartphone-Based Obstacle Detection for the Visually Impairedcvg.dsi.unifi.it/colombo_now/CC/Public/smartphone.pdfrecognition (OCR) softwares, such as [17], or by exploiting visual](https://img.dokumen.tips/doc/110x75/603faab2bb89f41cf972f114/smartphone-based-obstacle-detection-for-the-visually-recognition-ocr-softwares.jpg)












