Embed Size (px)
Citation preview

SVEUČILIŠTE U ZAGREBU
FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA
ZAVRŠNI RAD br. 3308
Višedretvena paralelizacija evolucijskih
algoritama
Branimir Gregov
Mentor: Prof. dr. sc. Domagoj Jakobović
Zagreb, lipanj 2013.


Sadržaj
1. Uvod ................................................................................................ 1
2. ECF ................................................................................................. 2
3. OpenMP .......................................................................................... 4
3.1. Kratka povijest OpenMP-a ........................................................ 4
3.2. Što je uopće OpenMP ............................................................... 4
3.3 Osnovne pretprocesorske naredbe standarda OpenMP ............ 6
3.3.1. Naredba PARALLEL ........................................................... 6
3.3.2. Naredba SINGLE ................................................................ 7
3.3.3. Naredba FOR ..................................................................... 7
3.3.4. Naredba CRITICAL ............................................................ 7
4. Paralelizirani algoritmi...................................................................... 8
4.1. Differential Evolution ................................................................. 9
4.2. Elimination ................................................................................ 9
4.3. Genetic Annealing ................................................................... 11
4.4. Hooke-Jeeves ......................................................................... 14
4.5. Particle Swarm Optimization ................................................... 15
4.6. Roulette Wheel........................................................................ 16
4.7. Steady State Tournament ....................................................... 19

5. Zaključak ....................................................................................... 20
6. Literatura ....................................................................................... 21
7. Sažetak .......................................................................................... 22

1
1. Uvod
Tema ovog završnog rada je višedretvena paralelizacija evolucijskih
algoritama iz okruženja Evolutionary Computational Framework (ECF) uporabom
tehnologije OpenMP (Open Multi-Processing).
OpenMP se koristi za jednostavnu paralelizaciju programa na računalima
sa dijeljenim memorijskim prostorom.
Evolucijsko računanje (engl. evolutionary computation) je grana umjetne
inteligencije koja vuče inspiraciju iz prirode. Ono je rezultat ljudskog promatranja
procesa u prirodi te pokušaja oponašanja tih procesa u svrhu rješavanja određenih
optimizacijskih problema, tj. problema koji zahtijevaju pronalazak što boljeg (ne
nužno i najboljeg) rješenja, pritom se koristeći metodama stohastičke optimizacije
te raznim metaheuristikama.
Evolucijski algoritam je grana evolucijskog računanja. On obuhvaća niz
koraka koji oponašaju biološku evoluciju, tj. razvoj određene populacije (populacija
je skup jedinki od kojih svaka pojedina jedinka predstavlja jedno moguće rješenje
zadanog problema zapisano na kompaktni i računalu shvatljivi način) kroz neki
broj iteracija, tj. generacija. Razvoj pojedine generacije koristi mehanizme koje
možemo pronaći u prirodi, kao što su razmnožavanje, prirodna selekcija, mutacija,
opstanak najjačih, i sl.

2
2. ECF
Evolutionary Computational Framework (ECF) je radno okruženje napisano
u programskom jeziku C++ koje se koristi za evolucijsko računanje. Napisan je sa
namjerom da se omogući što lakše dodavanje novih algoritama te raznih
operatora (križanja, mutacije, selekcije i sl.) kao i jednostavnu konfiguraciju
parametara potrebnih za rad pojedinog algoritma. Pod konfiguracijom parametara
se misli na zadavanje vrijednosti poput veličine populacije, maksimalnog broja
generacija, vjerojatnosti križanja i mutacije, broj subpopulacija, učestalost
migracije među subpopulacijama i mnoge druge.
3
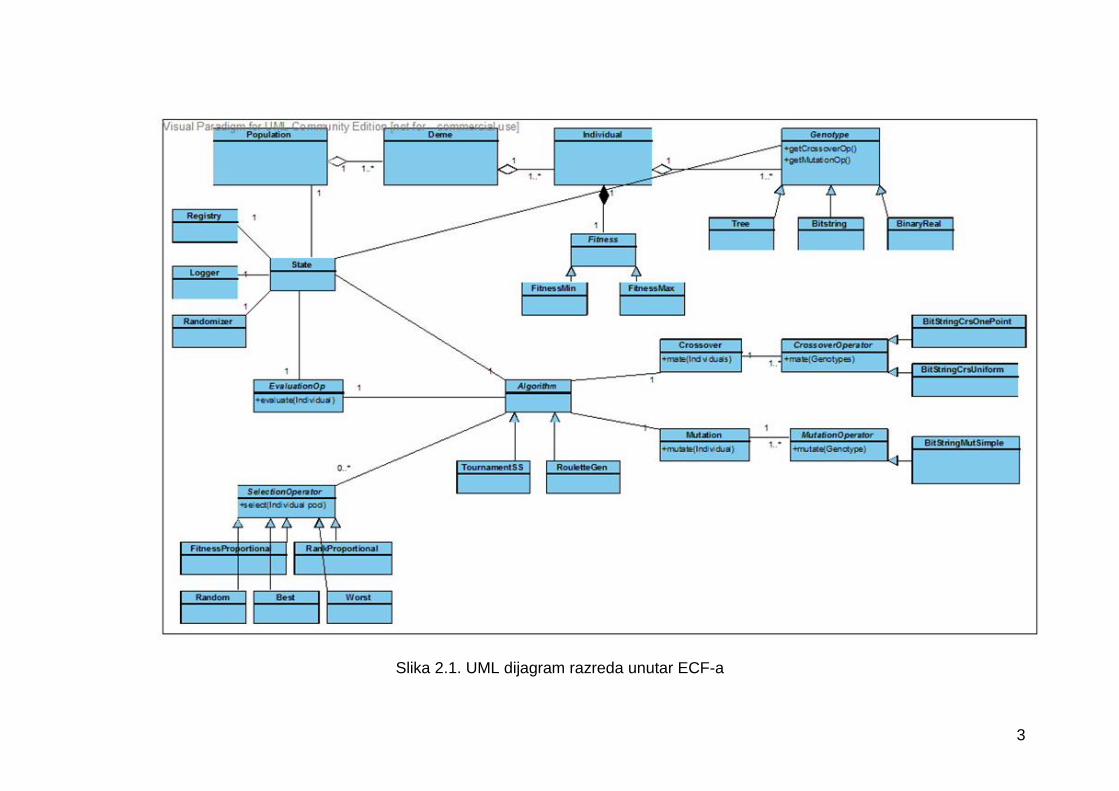
Slika 2.1. UML dijagram razreda unutar ECF-a

4
3. OpenMP
3.1. Kratka povijest OpenMP-a
Ranih devedesetih godina pojavila se potreba za paralelizacijom programa
pisanih u programskom jeziku Fortran koji su se izvršavali na sustavima sa
dijeljenom memorijom. Ideja je bila napraviti nešto jednostavno za korištenje što bi
automatski paraleliziralo petlje, tj. raspodijelilo posao koji se mogao izvršavati
paralelno na više procesorskih jezgri istovremeno. Nastale su mnoge razne
implementacije u obliku ekstenzija za Fortran te se nedugo nakon toga, sasvim
prirodno, pojavila potreba za standardizacijom. Prvi pokušaj standardizacije je
standard ANSI X3H5 iz 1994. godine koji međutim nije dobro primljen u
programerskoj zajednici jer se u to vrijeme počelo obraćati više pažnje na sustave
sa raspodijeljenom memorijom koji su tada postajali popularni.
Tri godine kasnije je započeo rad na standardu OpenMP koji je preuzeo
stari ANSI X3H5 standard.
3.2. Što je uopće OpenMP
OpenMP je sučelje za programiranje aplikacija (engl. Application
Programming Interface) koje se koristi za pisanje aplikacija koje dio programa (a
može i cijeli) izvršavaju paralelno. OpenMP podržava višedretveni paralelizam
isključivo na sustavima sa dijeljenom memorijom. Sustav može imati jednu ili više
procesorskih jezgri, ali je bitno da je memorija koju procesori koriste dostupna
svakome od njih (slika 3.1. i slika 3.2.). Napravljen je za lako paraleliziranje
uglavnom kratkih odsječaka teksta programa (slika 3.3.), koristeći pretprocesorske
naredbe, biblioteke te varijable okružja. Iako se lako koristi, sve je prepušteno
programeru koji mora sam paziti na moguće probleme pri paralelizaciji te zadati
parametre potrebne za rad OpenMP-a. Osnovna ideja OpenMP-a je bila da se
paralelizacija postigne sa tri do četiri naredbe, ali sa svakom sljedećom
specifikacijom ta je ideja sve manje i manje izražena. Kroz šesnaest godina,
OpenMP je došao do verzije broj 4.0. Radi sa većinom operacijskih sustava i
procesorskih arhitektura. U ovom završnom radu koristi se nešto starija verzija 2.0
što je posljedica korištenja programskog okruženja Microsoft Visual Studio 2010.
5
U sljedećem poglavlju ćemo obraditi samo najosnovnije pretprocesorske naredbe
potrebne za razumijevanje ovog završnog rada.
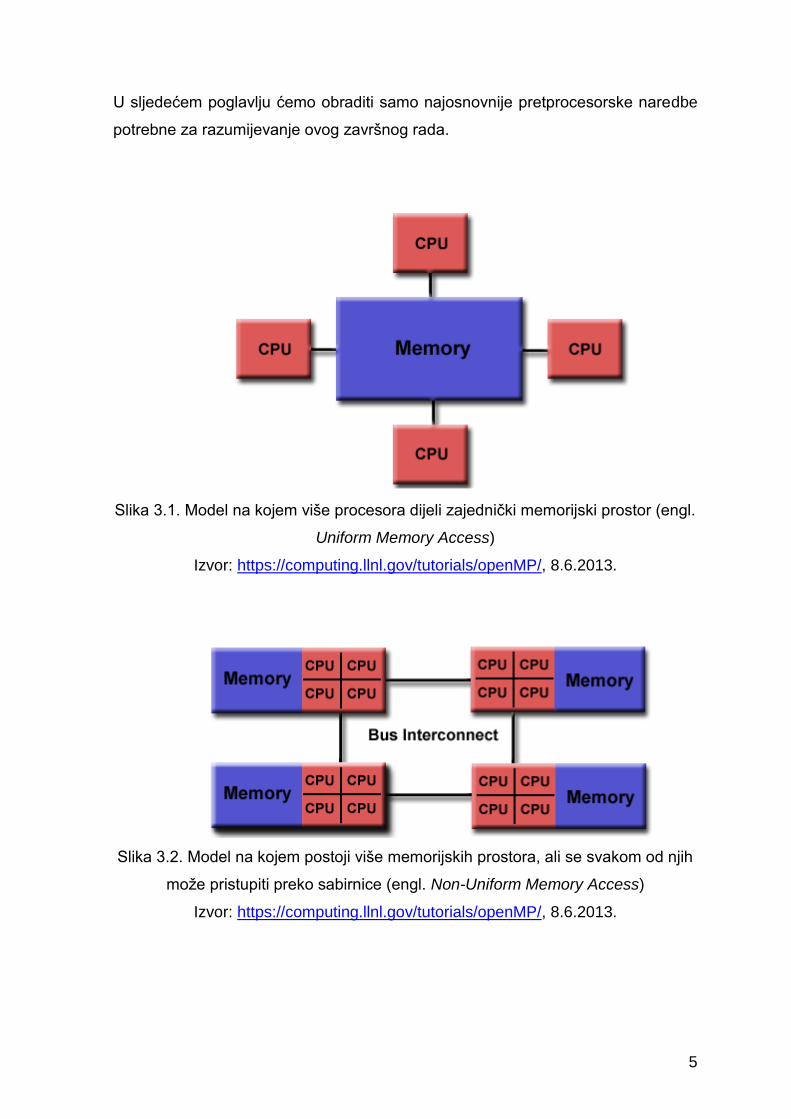
Slika 3.1. Model na kojem više procesora dijeli zajednički memorijski prostor (engl.
Uniform Memory Access)
Izvor: https://computing.llnl.gov/tutorials/openMP/, 8.6.2013.
Slika 3.2. Model na kojem postoji više memorijskih prostora, ali se svakom od njih
može pristupiti preko sabirnice (engl. Non-Uniform Memory Access)
Izvor: https://computing.llnl.gov/tutorials/openMP/, 8.6.2013.

6
Slika 3.3. Ilustracija višedretvenosti gdje se glavna dretva grana na više dretvi
kako bi se izvršio neki paralelni zadatak
Slika preuzeta sa http://en.wikipedia.org/wiki/OpenMP, 8.6.2013. i modificirana za
potrebe završnog rada
3.3 Osnovne pretprocesorske naredbe standarda OpenMP
Kao što smo već rekli, u ovom radu koristimo programsko okruženje
Microsoft Visual Studio 2010 koji dolazi sa predinstaliranim OpenMP-jem verzije
2.0. Ovdje nećemo obrađivati funkcije iz biblioteke omp.h niti varijable okruženja
(engl. environment variables) jer nisu potrebni za ovaj rad.
3.3.1. Naredba PARALLEL
Pomoću naredbe #pragma omp parallel prevoditelju govorimo da želimo
paralelizirati prvi sljedeći blok naredbi. Tu se mogu navesti parametri poput broja
dretvi koje će biti stvorene, koje varijable su dijeljene, a koje privatne i sl. Ukoliko
nije drugačije navedeno, svaka dretva će izvršiti blok programa koji se nalazi
nakon zadane naredbe.

7
3.3.2. Naredba SINGLE
Naredba #pragma omp single se mora nalaziti unutar bloka definiranog
naredbom #pragma omp parallel. Označava dio programa koji će izvršiti samo
jedna dretva dok će ostale čekati na njegovo izvršenje.
3.3.3. Naredba FOR
Naredba #pragma omp for se također mora nalaziti unutar bloka programa
definiranog naredbom #pragma omp parallel. Nakon njega mora slijediti for petlja
koja će se paralelizirati. Tu možemo zadati iste parametre kao i kod naredbe
parallel, ali i neke dodatne kao što su schedule (određuje koliko će iteracija petlje
preuzeti pojedina dretva odjednom), da li će se svaka iteracija izvršavati
redoslijedom kojim je zadana, i još neke naredbe koja nisu bitne za ovaj rad.
Moguće je kombinirati naredbu omp parallel sa naredbom omp for u naredbu
#pragma omp parallel for.
3.3.4. Naredba CRITICAL
Naredba #pragma omp critical označava kritični odsječak koji će biti
zaključan sa mutex ključem, tj. samo jedna dretva će moći izvršavati taj dio. Druge
dretve moraju čekati dok ta jedna dretva ne završi, a potom ulazi ponovno samo
jedna dretva.

8
4. Paralelizirani algoritmi
U ovom poglavlju ćemo pogledati sve algoritme koji su trenutno napisani za
ECF, tj. njihove metode advanceGeneration koja predstavlja „glavni“ dio
evolucijskog algoritma. Neki od algoritama su uspješno paralelizirani, a neke se
jednostavno nije moglo paralelizirati zbog ograničenja OpenMP-a i konkretne
implementacije ECF-a. Glavni razlog za to je nemogućnost pisanja jedne OpenMP
naredbe koja bi se protezala kroz više blokova programa istovremeno. To povlači
za sobom ne samo nemogućnost paraleliziranja nekih algoritama nego i daleko
lošiju efikasnost. Konkretno, kod svakog poziva metode advanceGeneration, tj.
kod svake sljedeće generacije, potrebno je stvarati novi skup dretvi što je
vremenski vrlo zahtjevna operacija. Zbog toga neki algoritmi koji su uspješno
paralelizirani daju lošije rezultate od slijednih varijanti.
Sva mjerenja pokazana u sljedećim potpoglavljima provedena su nad
problemom minimizacije Rosenbrockove funkcije sa sljedećim parametrima:
dimenzija problema: 1000
veličina populacije: 1000
vjerojatnost mutacije pojedine jedinke: 0.3
uvjet zaustavljanja: izvršeno 1,000,000 evaluacija jedinki
broj ponavljanja pojedinog algoritma: 5
Rosenbrockova funkcija definirana je za dvodimenzijski vektor kao
sa globalnim minimum u točki
(x,y) = (1,1). Taj minimum je po iznosu jednak nuli. Za višedimenzijske vektore
formula je definirana kao
U tom slučaju, minimum je postignut za N-dimenzijski vektor u točki za koju vrijedi
da su svi elementi vektora jednaki jedan.

9
Važno je još za napomenuti da je unutar ECF-a promijenjena metoda
evaluate tako da ne sprema u kontekst pokazivač na jedinku koja se trenutno
evaluira jer se taj pokazivač ne može deklarirati kao privatna varijabla svake
dretve što efektivno onemogućava paralelizaciju.
Sličan problem pojavio se pri pokušaju višedretvene paralelizacije petlje
koja prolazi po svim subpopulacijama. Ona, naime, koristi pokazivač na
subpopulaciju koja trenutno izvršava metodu advanceGeneration. Taj problem se
nažalost ne može riješiti tehnikama koje smo upotrijebili kod metode evaluate.
4.1. Differential Evolution
Ovaj algoritam se nažalost nije mogao paralelizirati iz sljedećeg razloga:
jedini dio koji bi se mogao paralelizirati je evaluacija jedinki, ali problem je u tome
što se unutar iste for petlje nalazi i zamjena jedinki unutar subpopulacije (slika
4.1.), a ta naredba koristi varijablu zapisanu u datoteci State.h (pokazivač na
subpopulaciju koja se trenutno obrađuje) te zbog ograničenja OpenMP-a nije
moguće deklarirati tu varijablu privatnom za svaku dretvu.
Slika 4.1. Dio teksta programa iz algoritma Differential Evolution napisanog za
ECF
4.2. Elimination
Kratak pseudokod:
jedna generacija {
eliminiraj (učitani_faktor * veličina_subpopulacije) najgorih jedinki;
stvori jednako toliko novih jedinki križanjem preostalih;

10
mutiraj novu generaciju;
}
Ono što je napravljeno kod ovog programa je paralelizacija evaluacije svih
jedinki koja se odvija pred kraj svake generacije (slika 4.2.).
Slika 4.2. Dio teksta programa iz algoritma Elimination napisanog za ECF
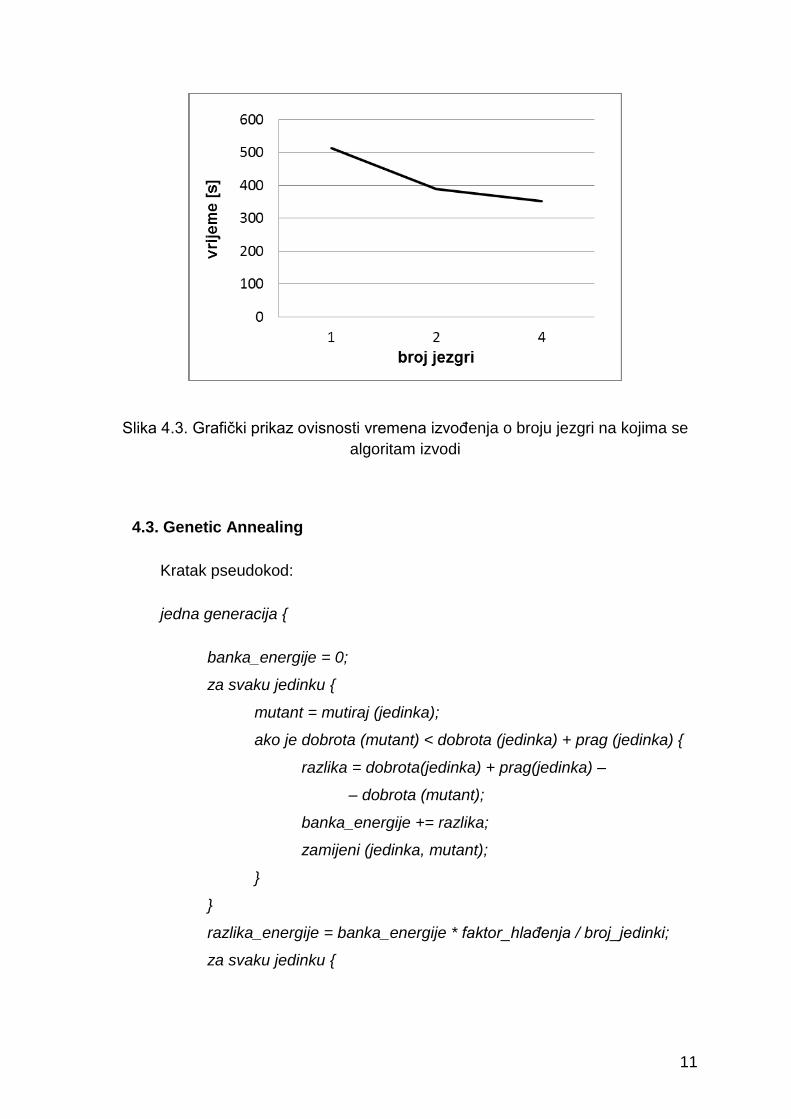
Ubrzanje postignuto paralelizacijom prikazano je u tablici 4.1. te na slici 4.3.
U tablici su navedene prosječne vrijednosti dobivene iz pet uzastopnih pokretanja
algoritma. Razmatrano je izvođenje na jednoj, dvije te četiri procesorske jezgre.
Tablica 4.1. Rezultati mjerenja kod izvršavanja algoritma Elimination
Broj
jezgri fit_min fit_max fit_avg fit_std time [s] ubrzanje
1 1,02*1014 1,39*1016 1,11*1016 1,67*1015 514,2 1
2 1,32*1014 8,98*1015 7,11*1015 1,66*1015 389,8 1,32
4 1,21*1014 1,41*1016 1,10*1016 1,36*1015 353,0 1,46
11
Slika 4.3. Grafički prikaz ovisnosti vremena izvođenja o broju jezgri na kojima se
algoritam izvodi
4.3. Genetic Annealing
Kratak pseudokod:
jedna generacija {
banka_energije = 0;
za svaku jedinku {
mutant = mutiraj (jedinka);
ako je dobrota (mutant) < dobrota (jedinka) + prag (jedinka) {
razlika = dobrota(jedinka) + prag(jedinka) –
– dobrota (mutant);
banka_energije += razlika;
zamijeni (jedinka, mutant);
}
}
razlika_energije = banka_energije * faktor_hlađenja / broj_jedinki;
za svaku jedinku {

12
prag (jedinka) += razlika_energije;
}
}
U ovom algoritmu je paralelizirana petlja koja se koristi za mutaciju i
evaluaciju svake zasebne jedinke unutar generacije te njihovu zamjenu u
populaciji ukoliko je ispunjen uvjet zamjene (slika 4.4.). Treba samo pripaziti na
činjenicu da metoda replaceWith stvara probleme ukoliko ju više različitih dretvi
pozove istovremeno pa je stoga stavljena unutar kritičnog odsječka. Isto vrijedi i za
naredbu mutate.
Slika 4.4. Dio teksta programa iz algoritma Genetic Annealing napisanog za ECF
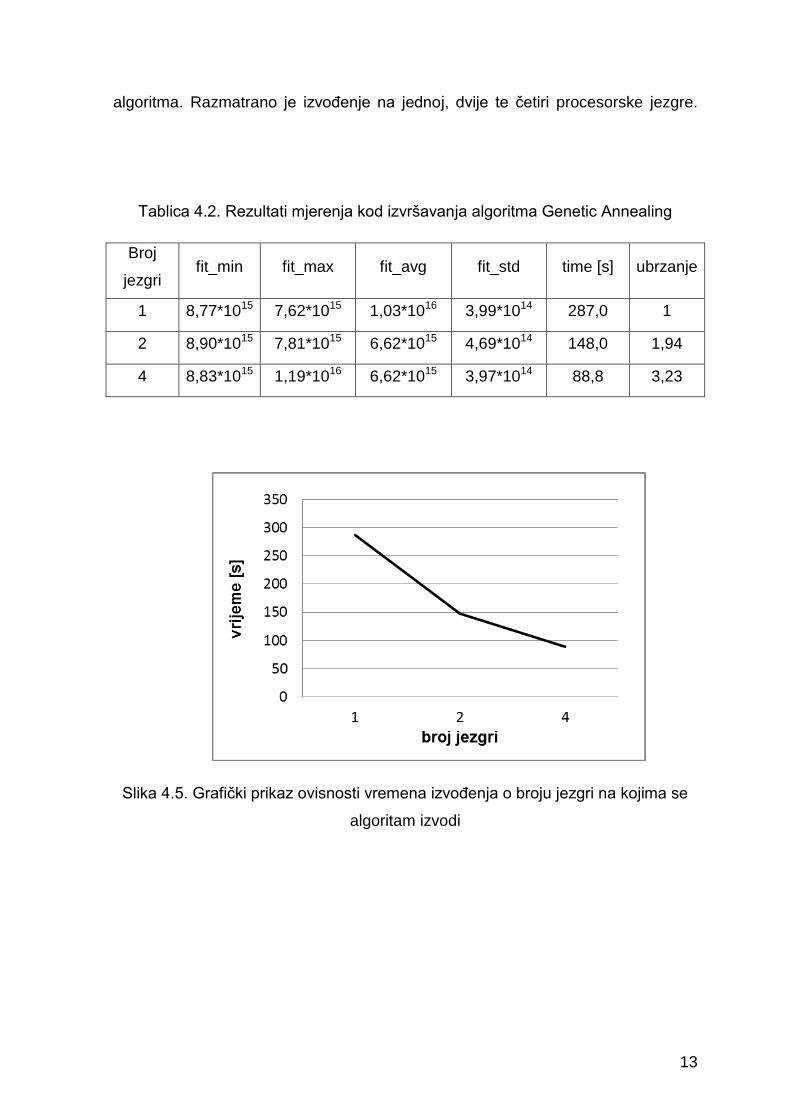
Ubrzanje postignuto paralelizacijom prikazano je u tablici 4.2. te na slici 4.5.
U tablici su navedene prosječne vrijednosti dobivene iz pet uzastopnih pokretanja
13
algoritma. Razmatrano je izvođenje na jednoj, dvije te četiri procesorske jezgre.
Tablica 4.2. Rezultati mjerenja kod izvršavanja algoritma Genetic Annealing
Broj
jezgri fit_min fit_max fit_avg fit_std time [s] ubrzanje
1 8,77*1015 7,62*1015 1,03*1016 3,99*1014 287,0 1
2 8,90*1015 7,81*1015 6,62*1015 4,69*1014 148,0 1,94
4 8,83*1015 1,19*1016 6,62*1015 3,97*1014 88,8 3,23
Slika 4.5. Grafički prikaz ovisnosti vremena izvođenja o broju jezgri na kojima se
algoritam izvodi
14
4.4. Hooke-Jeeves
Kratak pseudokod:
jedna generacija {
za svaku jedinku {
mutant = mutiraj (jedinka);
dijete = križaj (jedinka, mutant)
ako je dobrota (dijete) > dobrota (jedinka) {
zamijeni (jedinka, dijete);
}
}
}
Ukratko, svaka jedinka unutar generacije nezavisno od drugih jedinki
pretražuje prostor mogućih rješenja te je upravo zbog te neovisnosti bilo moguće
paralelizirati cijeli dio programa koji se odnosi na jednu generaciju. Pseudokod
ovog algoritma može se pronaći na stranici
http://www.fer.unizg.hr/_download/repository/hj.html.
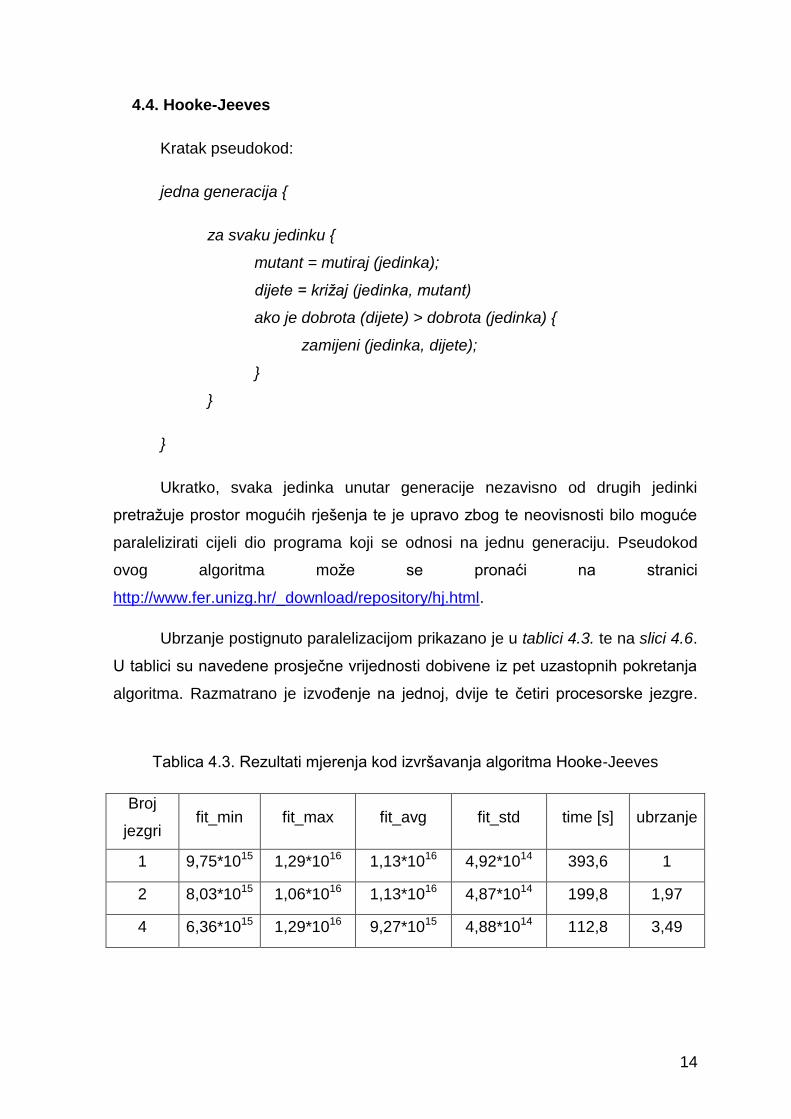
Ubrzanje postignuto paralelizacijom prikazano je u tablici 4.3. te na slici 4.6.
U tablici su navedene prosječne vrijednosti dobivene iz pet uzastopnih pokretanja
algoritma. Razmatrano je izvođenje na jednoj, dvije te četiri procesorske jezgre.
Tablica 4.3. Rezultati mjerenja kod izvršavanja algoritma Hooke-Jeeves
Broj
jezgri fit_min fit_max fit_avg fit_std time [s] ubrzanje
1 9,75*1015 1,29*1016 1,13*1016 4,92*1014 393,6 1
2 8,03*1015 1,06*1016 1,13*1016 4,87*1014 199,8 1,97
4 6,36*1015 1,29*1016 9,27*1015 4,88*1014 112,8 3,49
15
Slika 4.6. Grafički prikaz ovisnosti vremena izvođenja o broju jezgri na kojima se
algoritam izvodi
4.5. Particle Swarm Optimization
Ni ovaj algoritam nećemo objašnjavati zbog njegove složenosti. Ukratko,
čestice (jedinke) se kreću zajedno, pritom imitirajući roj. Budući da se moraju
kretati zajedno i pritom pristupati dijeljenim varijablama, mogao se paralelizirati
samo jedan mali dio algoritma koji i nije baš toliko dobro utjecao na ubrzanje
algoritma. Sporije izvođenje algoritma na više dretvi je posljedica stvaranja skupa
dretvi pri svakoj novoj generaciji.
Ubrzanje postignuto paralelizacijom prikazano je u tablici 4.4. te na slici 4.7.
U tablici su navedene prosječne vrijednosti dobivene iz pet uzastopnih pokretanja
algoritma. Razmatrano je izvođenje na jednoj, dvije te četiri procesorske jezgre.

16
Tablica 4.4. Rezultati mjerenja kod izvršavanja algoritma Particle Swarm
Optimization
Broj
jezgri fit_min fit_max fit_avg fit_std time [s] ubrzanje
1 3,35*1012 6,67*1013 9,49*1012 7,17*1012 417,0 1
2 3,32*1012 5,53*1013 9,29*1012 5,11*1012 415,2 1,01
4 2,09*1012 7,06*1013 9,37*1012 4,37*1012 421,8 0,99
Slika 4.7. Grafički prikaz ovisnosti vremena izvođenja o broju jezgri na
kojima se algoritam izvodi
4.6. Roulette Wheel
Kratak pseudokod:
jedna generacija {
stvori novu generaciju od starih jedinki;
broj_križanja = veličina_populacije * koeficijent_križanja / 2;
ponavljaj (broj_križanja) {

17
nasumično izaberi dva roditelja;
izvedi križanje i zamijeni roditelje sa djecom;
}
mutiraj novu generaciju;
}
U ovom algoritmu su paralelizirane dvije petlje. Prva obavlja kopiranje
jedinki za novu generaciju (slika 4.8.), a druga obavlja evaluaciju (slika 4.9.).
Naredba pragma omp parallel je pozvana na početku metode advanceGeneration
kako bi se izbjeglo dvostruko stvaranje skupa dretvi unutar te iste metode.
Odsječci programa koje ne želimo paralelizirati su unutar bloka programa prije
kojeg stoji naredba pragma omp single.
Slika 4.8. Dio teksta prorgrama iz algoritma Roulette Wheel napisanog za ECF
Slika 4.9. Dio teksta programa iz algoritma Roulette Wheel napisanog za ECF
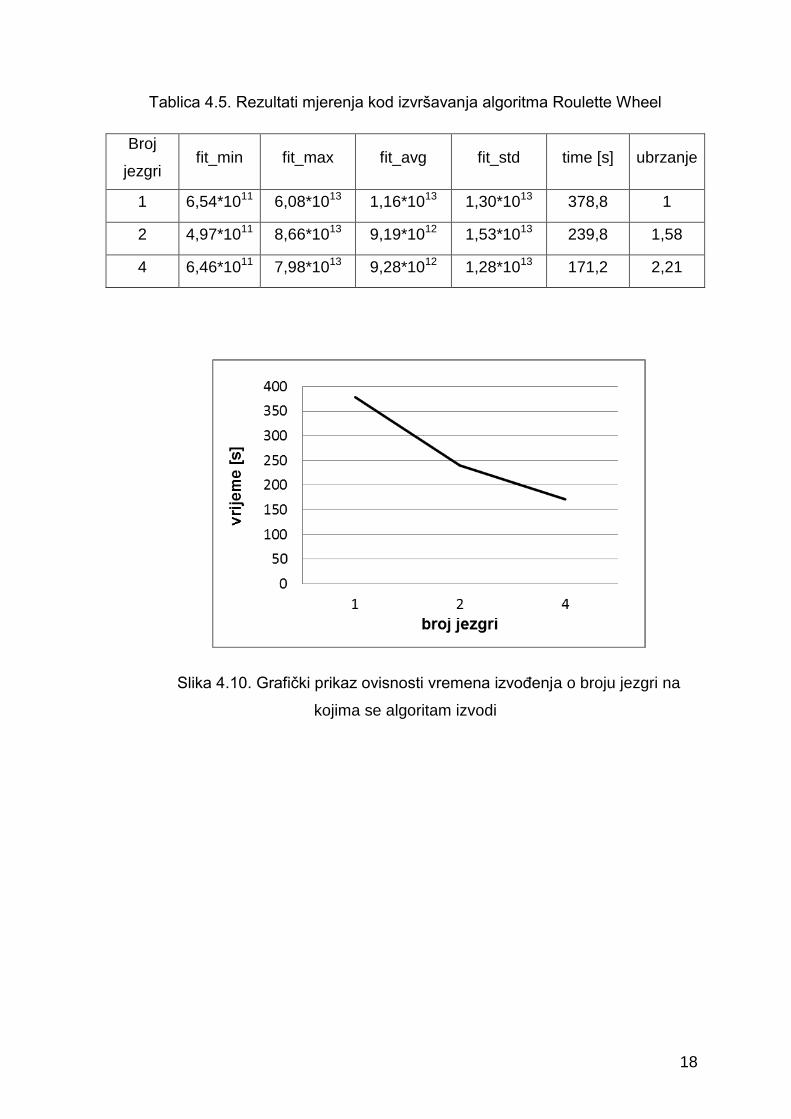
Ubrzanje postignuto paralelizacijom prikazano je u tablici 4.5. te na slici
4.10. U tablici su navedene prosječne vrijednosti dobivene iz pet uzastopnih
pokretanja algoritma. Razmatrano je izvođenje na jednoj, dvije te četiri
procesorske jezgre.
18
Tablica 4.5. Rezultati mjerenja kod izvršavanja algoritma Roulette Wheel
Broj
jezgri fit_min fit_max fit_avg fit_std time [s] ubrzanje
1 6,54*1011 6,08*1013 1,16*1013 1,30*1013 378,8 1
2 4,97*1011 8,66*1013 9,19*1012 1,53*1013 239,8 1,58
4 6,46*1011 7,98*1013 9,28*1012 1,28*1013 171,2 2,21
Slika 4.10. Grafički prikaz ovisnosti vremena izvođenja o broju jezgri na
kojima se algoritam izvodi

19
4.7. Steady State Tournament
Kratak pseudokod:
jedna generacija {
ponavljaj veličina_populacije puta {
nasumično izaberi unaprijed_zadani_broj_puta jedinki;
izaberi najgoru od njih;
nasumično izaberi dva roditelja od preostalih odabranih;
zamijeni najgoru jedinku sa novim djetetom;
mutiraj dijete;
}
}
Program napisan u ECF-u za ovaj algoritam nažalost nije moguće
paralelizirati jer se glavna petlja unutar jedne generacije odvija za jednu po jednu
jedinku koja u svakom trenutku mora znati sve informacije o ostalima. Pošto se
ostale jedinke mijenjaju sa svakim prolazom, sa trenutnom implementacijom
OpenMP-a nije moguće paralelizirati taj program.

20
5. Zaključak
Iako tehnologija OpenMP još uvijek nije dovoljno zrela za korištenje sa
objektno-orijentiranim jezicima zbog niza nedostataka (poput nemogućnosti
izdvajanja varijabli objekata za svaku dretvu zasebno, nemogućnost kontrole pri
paralelizaciji metoda koje se ne nalaze unutar omp parallel bloka, a pozvane su iz
tog bloka i sl.), dosta uspješno se paraleliziralo većinu algoritama koji trenutno
postoje u ECF-u. Kod nekih doduše nije postignuto nikakvo ubrzanje zbog
relativno „skupe“ operacije stvaranja skupa dretvi pri svakom pozivu metode
advanceGeneration. To se nije moglo drugačije napraviti (kao npr., stvoriti skup
dretvi samo pri inicijalizaciji programa pa da se kasnije tim dretvama proslijedi
posao) jer OpenMP trenutno to ne dozvoljava. Ipak, veći dio se uspješno
paralelizirao i pokazao jako dobre rezultate. Postignuta su velika ubrzanja (kod
nekih je vrijeme izvođenja smanjeno na manje od trideset posto pri paralelnom
izvođenju na četiri dretve).
Mislim da će ovaj završni rad biti od velike koristi za sve koji namjeravaju
koristiti ECF u budućnosti. Omogućit će im ili veliku uštedu vremena ili postizanje
boljih rezultata u jednakom vremenu. Također, neće imati problema sa
instalacijom dodatnih programa kao što je to slučaj sa MPI-jem (Message Passing
Interface) koji je trenutno implementiran za paralelno izvođenje određenih
algoritama u ECF-u. Jednom kada je program preveden zajedno sa OpenMP-jem,
može se pokretati na skoro svim operacijskim sustavima bez potrebe za dodatnim
instalacijama ili podešavanjima ikakvih parametara (iako omogućava podešavanje
parametara preko varijabli okoline, ali ne zamara korisnika s time).

21
6. Literatura
1. Golub, M. (2004.), Skripta „Genetski algoritam“ u dva dijela,
http://www.zemris.fer.hr/~golub/ga/ga_skripta1.pdf,
http://www.zemris.fer.hr/~golub/ga/ga_skripta2.pdf
2. Pseudokod algoritma Hooke-Jeeves,
http://www.fer.unizg.hr/_download/repository/hj.html
3. Predavanja iz kolegija Paralelno programiranje,
http://www.fer.unizg.hr/_download/repository/Paralelno_programiranje_pred
avanja%5B8%5D.pdf
4. OpenMP tutorial, https://computing.llnl.gov/tutorials/openMP/
5. Članak „Reap the Benefits of Multithreading without All the Work“ o
implementaciji OpenMP-a unutar programskog okruženja Visual Studio,
http://msdn.microsoft.com/en-us/magazine/cc163717.aspx
6. Microsoftove službene stranice za Visual C++ i OpenMP,
http://msdn.microsoft.com/en-us/library/tt15eb9t%28v=vs.100%29.aspx
7. Rosenbrockova funkcija, http://www-optima.amp.i.kyoto-
u.ac.jp/member/student/hedar/Hedar_files/TestGO_files/Page2537.htm
Napomena: Za probleme vezane uz programiranje korištena je stranica Stack
Overflow (http://stackoverflow.com) na kojoj se postavljaju pitanja i dobivaju
odgovori od stručnjaka iz područja programskog inženjerstva.

22
7. Sažetak
Višedretvena paralelizacija evolucijskih algoritama
Ovaj rad bavi se paralelizacijom evolucijskih algoritama napisanih za ECF
(Evolutionary Computational Framework) koristeći tehnologiju OpenMP. Neki
algoritmi su uspješno paralelizirani sa znatnim poboljšanjem što se tiče vremena
izvođenja, neki malo manje uspješno, a neke jednostavno nije bilo moguće
paralelizirati zbog ograničenja OpenMP-a.
Značajna vremenska ušteda uz jednostavnost korištenja (nisu potrebne
nikakve dodatne instalacije nakon prevođenja programskog koda) biti će od velike
koristi za sve koji će koristiti ECF u budućnosti.
Ključne riječi: ECF, Evolutionary Computational Framework, OpenMP, Open
Multi Processing, višedretvenost
Multithread parallelization of evolutionary algorithms
This paper deals with parallelization of evolutionary algorithms written for
ECF (Evolutionary Computational Framework) using OpenMP. Some algorithms
were successfully altered to run on more processor cores with significant
improvement in runtime and some weren’t as successful while others were
impossible to alter due to limitations of OpenMP.
Significant improvement in runtime as well as ease of use (no other
installations are required after compiling the source code) will benefit everyone
using ECF.
Keywords: ECF, Evolutionary Computational Framework, OpenMP, Open Multi
Processing, multithreading





























