Embed Size (px)
Citation preview

Artificial Intelligence in Medicine 15 (1999) 235–254
Using Boolean reasoning to anonymize databases
Aleksander Øhrn a,*, Lucila Ohno-Machado b,1
a Knowledge Systems Group, Department of Computer and Information Science,Norwegian Uni6ersity of Science and Technology, Gløshaugen, N-7034, Trondheim, Norway
b Decision Systems Group, Department of Radiology, Brigham and Women’s Hospital,Har6ard Medical School, 75 Francis Street, Boston, MA 02215, USA
Received 22 April 1998; received in revised form 7 July 1998; accepted 18 August 1998
Abstract
This paper investigates how Boolean reasoning can be used to make the records in adatabase anonymous. In a medical setting, this is of particular interest due to privacy issuesand to prevent the possible misuse of confidential information. As electronic medical recordsand medical data repositories get more common and widespread, the issue of makingsensitive data anonymous becomes increasingly important. A theoretically well-foundedalgorithm is proposed that via cell suppression can be used to make a database anonymousbefore releasing or sharing it to the outside world. The degree of anonymity can be tailoredaccording to the specific needs of the recipient, and according to the amount of trust weplace in the recipient. Furthermore, the required measure of anonymity can be specified asfar down as to the individual objects in the database. The algorithm can also be used foranonymization relative to a particular piece of information, effectively blocking deterministicinferences about sensitive database fields. © 1999 Elsevier Science B.V. All rights reserved.
Keywords: Boolean reasoning; Cell suppression; Disclosure control; Confidentiality
* Corresponding author. Tel.: +47-73-594480; Fax: +47-73-594466; e-mail: [email protected] E-mail: [email protected]
0933-3657/99/$ - see front matter © 1999 Elsevier Science B.V. All rights reserved.
PII: S0933 -3657 (98 )00056 -6

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254236
1. Introduction
Broadly speaking, the field of medical informatics can be said to concern itselfwith the capture of medically related data in a structured way and with ways todistribute and analyze these data to ultimately increase efficiency and the quality ofhealthcare. But as time progresses and more data becomes electronically availableand shared, the challenge of protecting patient confidentiality becomes greater andmore difficult. Woodward [10] and Clayton et al. [2] list several issues that thisimportant problem complex raises, and provide several examples of how electronicmedical records can be misused and have been misused in the past.
It is a common misconception that sensitive information is kept confidentialsimply because some directly identifying fields in the database, such as name orsocial security number, have been removed or obfuscated. Such databases may havebeen de-identified, but they are not likely to be anonymous. For example, acombination of attributes such as ethnicity, date of birth, gender and zip code mayvery well enable one to almost uniquely identify a patient by linking this informa-tion up to an external source of information, such as publicly available census data.Sweeney [9] defines the distinction between de-identification and anonymity asfollows:
In de-identified data, all explicit identifiers, such as social security number,name, address and phone number are removed, generalized or replaced with amade-up alternative; anonymous, however, implies that the data cannot bemanipulated or linked to identify any individual.
Since any external information source may be used for linking, the only way tobe certain that data is truly anonymous is therefore to make sure that the data isanonymous within the database itself. By that we mean that for each patient in thedatabase there has to be at least one other patient from which the first patientcannot be discerned, at least with respect to the database fields that are most likelyto be used for linking.
The fields of data mining and knowledge discovery are concerned with automat-ing the detection and discovery of patterns in large volumes of data. Many suchtechniques are based on extracting identifying patterns that are then typically usedfor constructing association rules or for prediction or classification purposes.However, if identifying patterns can be found, they can also be employed in reverseto make the database they were extracted from anonymous. If we suppress some orall of the information described by the patterns, they become invalidated. Thispaper investigates how an approach based on Boolean reasoning can be used tofind and subsequently mask away combinations of field values that can be used toidentify individual patients in a medical database.
Section 2 of this paper outlines the mathematical foundation of the proposedalgorithm. The algorithm itself is presented in Section 3, while Section 4 discussesrelated work. An example of the operation of the proposed algorithm is presented

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254 237
in Section 5. Lastly, an analysis of different aspects of the algorithm and adiscussion can be found in Section 6.
2. Background concepts
This section introduces the notation and outlines some concepts from Booleanreasoning. Details and formal definitions can be found in [1,6,7].
2.1. Boolean algebra
A Boolean algebra is a quintuple (B, + , · , 0, 1) where the four postulates givenbelow are satisfied. The set B is called the carrier set, and + and are · binaryoperations on B. The elements 0 and 1 are distinct members of B. A Booleanalgebra is often denoted in shorthand by its carrier set alone.1. Commutati6e laws : For all a, b in B, a+b=b+a and a ·b=b ·a.2. Distributi6e laws : For all a, b, c in B, a+ (b ·c)= (a+b)·(a+c) and a ·(b+c)=
(a ·b)+ (a ·c)3. Identities : For all a in B, 0+a=a and 1·a=a.4. Complements : To any element a in B there corresponds an element a % in B such
that a+a %=1 and a ·a %=0.All Boolean algebras with a finite carrier set are isomorphic (by Stone’s represen-
tation theorem) to the Boolean algebra of subsets (2A, , � , Ø, A) of some finiteset A. We define the relation 5 on a Boolean algebra so that a5b if and only ifa·b %=0. The relation 5 is a partial order. Because the relation 5 in a Booleanalgebra B corresponds to the relation ¤ in the subset-algebra isomorphic to B, 5is called the inclusion relation.
2.2. Implicants
An m-variable function f : Bm�B is called a Boolean function if and only if itcan be expressed by a Boolean formula. An implicant of a Boolean function f is aterm p such that p5 f. Any term of a sum-of-products (SOP) formula for f is clearlyan implicant of f. A prime implicant is an implicant of f that ceases to be so if anyof its literals are removed. An implicant p of f is a prime implicant of f in case, forany term q, the implication below holds.
p5q5 f [p=q (1)
The disjunction of all prime implicants of f is called Blake’s canonical form and isdenoted BCF( f ).
2.3. Databases
A database is in this context assumed to be a single flat table, either physically orlogically in form of a view across several underlying tables. We can thus define a

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254238
database in terms of a pair A= (U, A), where U={x1,…, xn} is a non-empty finiteset of objects and A={a1, … , am} is a non-empty finite set of attributes. Eachattribute ai�A can be viewed as a function that maps elements of U into the setVai {Þ}. The set Vai
is called the value set of attribute ai, while the value Þsignifies a missing 6alue (an unrecorded database entry).
2.4. Discernibility
A discernibility matrix of a database A is a symmetric n×n matrix2 where eachentry mij consists of the set of attributes upon which objects xi and xj differ. We canadditionally require that an attribute cannot be used to discern between two objectsunless it has been recorded for both objects.
mij={a�A �a(xi)"a(xj), a(xi)"Þ, a(xj)"Þ} (2)
The discernibility matrix can be used to define a relation R¤U×U as definedbelow. If we had not required that an attribute must be observed for both objectsin order for it to be used to discern between them (or if missing values do not occurat all), the relation R would be an equivalence relation. However, as formulated, Ris not transitive but only reflexive and symmetric. Such relations are sometimescalled similarity relations or tolerance relations.
xiRxjUmij=® (3)
The indiscernibility set of an object xk�U is denoted Ck and consists of those objectsfrom which xk cannot be discerned. Had R been an equivalence relation, then Ck
had simply been the equivalence classes of R and the indiscernibility sets would allbe disjoint. In the more general formulation, however, the indiscernibility sets forma covering of U where the clusters may overlap.
Ck={xi�U �xiRxk} (4)
The discernibility function relative to an object xk�U and a subset X¤U is aBoolean product-of-sums (POS) function fk
X Of m Boolean variables a1*,…, am*(corresponding to the attributes a1, … , am) defined as below. Each conjunction offk
X stems from an object xi�X from which xk can be discerned, and each term withinthat conjunction represents an attribute that discerns between those objects. Theprime implicants of fk
X reveal the minimal attribute subsets needed to discern xk (orthe objects identical to xk) from all objects in X.
fkX= 5
xi�X
!% a* �a�mik, mik"®"
(5)
A descriptor is an expression (ai, 6) where ai�A and 6�Vai. A pattern is in this
context defined as a conjunction of descriptors. A set of patterns that identifyobject xk can hence be constructed by conceptually overlaying each prime implicantof fk
U on top of object xk in the database and reading off the attribute values.
2 Conceptually, at least. More pragmatically, we only need to consider the number of distinct objects.This will be explored in Section 6.3.

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254 239
3. Methodology
Based on the theoretical foundations in Section 2, this section presents thefundamental building blocks needed to assemble an algorithm for making adatabase anonymous.
3.1. Basic algorithm
In order to make an object xk anonymous, we can execute the anonymizeprocedure outlined in Fig. 1. First, we compute the set Pk of prime implicants of thediscernibility function fk
U. The set Pk thus summarizes all the ways in which xk canbe identified. Now, in order to make xk anonymous we have to disable each patternp�Pk from being applicable. A pattern p can be rendered inapplicable if at least oneof the attribute values it contains is suppressed. The in7alidate procedure imple-ments a simple greedy algorithm for suppressing attribute values for all p�Pk, witha bias towards suppressing as few attribute values for object xk as possible. First,the attribute a that occurs the most often in the set Pk is determined by the selectfunction. The value of attribute a is then suppressed, and the set of remaining validpatterns updated. This process is repeated until all the patterns are invalidated orsome specified stopping condition is met. Although not listed, a post-processingstep might be desirable to add after the in7alidate procedure to hamper the
Fig. 1. Pseudo-code for making object xk anonymous.

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254240
suppressed values from being reconstructed. This issue will be discussed in Section3.4.
What the procedure anonymize actually does is to enlarge the indiscernibility setCk. This ensures us that, after execution of the procedure, object xk is lessidentifiable than before, but still does not allow us to control and check if an objectis ‘anonymous enough’. In fact, anonymize may not even be necessary to execute ifthis is the case to start with. A prerequisite for resolving this issue is to be able tonumerically quantify the degree of anonymity of xk in the context of the databaseA.
3.1.1. Quantifying anonymityLetting �fk
U� denote the number of conjunctions of the discernibility function fkU,
we can define the degree of anonymity for object xk with respect to a database A
as shown below. Since no object is discernible from itself, �fkU� can be no larger than
n−1. Furthermore, Ck always includes xk, so the total number of objects n mustequal the number of objects �Ck � that are indiscernible from xk plus the number ofobjects �fk
U� that are discernible from xk.
a(xk)=�Ck �−1
n−1=1−
�fkU�
n−1(6)
The quantity a(xk) thus gives us a way to measure how anonymous xk really isin the context of A. If a(xk)=0, then xk is uniquely identifiable by attributes A andhence completely non-anonymous. Conversely, if a(xk)=1, then xk cannot bediscerned from any other object and is hence completely anonymous.
The formula for a(xk) is a very simple one, and an issue it does not take intoaccount is how difficult it would be to identify xk. For instance, two objects that areuniquely identifiable would both have an anonymity measure of 0, regardless ofhow the complexity of the identifying patterns of the two objects differ. Intuitively,a uniquely identifiable object that can only be identified through a very complexpattern would be said to be more anonymous than a uniquely identifiable objectthat has several very simple identifying patterns. In order to cover this notion, arefinement of the formula for a(xk) should also incorporate the size of the set Pk ofprime implicants of fk
U as well as the lengths (and possibly nature) of the primeimplicants p�Pk.
Having a way to quantify the degree of anonymity for a single object xk enablesus to express the overall level of anonymity a(A) of a full database A in a varietyof ways. For example, we can simply compute the average value of a(xk) for allobjects in the database.
a(A)=1n
%xk�U
a(xk) (7)
A chain is only as strong as its weakest link, so another possibility would be todefine the overall anonymity level as the smallest a(xk) for any object xk.
a(A)=minxk�U a(xk) (8)

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254 241
Fig. 2. Pseudo-code for one possible way of making a database A ‘anonymous enough’.
3.2. Anonymizing a database
Now that the fundamental building blocks have been outlined, they can becombined in a multitude of ways in order to assemble an algorithm where thedegree of anonymity can be controlled. One possible example is shown in Fig. 2.More elaborate implementations could also include individual anonymity levels txk
.Additionally, if a more refined definition of a(xk) was developed, a function thatrelated this to txk
could be passed (by name) to the in7alidate procedure as anargument instead of true, possibly aborting the loop before the set Pk was fullyemptied.
It should be pointed out that making an object anonymous may alter thediscernibility functions for other objects. Hence, different orderings in the for loopin Fig. 2 may yield different anonymizations of A. Alternative implementationscould either fix a ‘good’ ordering, or compute the identifying patterns for all objectsand then invalidate them in two separate for loops that are executed sequentially.This would make the result order-independent, and is outlined in Fig. 3.
3.3. Relati6e anonymization
It might be the case that even though a(xk) is substantially larger than zero, allmembers of Ck have the same value for some attribute d. Thus, we may still be ableto infer the value of d(xk), even though we cannot ascertain exactly which recordin A that corresponds to object xk. This leads us to consider the concept ofd-relative anonymity, i.e., anonymity with respect to attribute d.
Relative anonymity has definite practical importance. For example, attribute dcould denote the result of a HIV test, xk could refer to a Hollywood celebrity, andwe want to ensure that the celebrity’s HIV status is kept confidential even if atabloid journalist gains access to the database. Obviously, our ability to block

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254242
Fig. 3. Pseudo-code for another possible way of making a database A ‘anonymous enough’. In this case,the order the objects are processed in does not matter.
inferences about the value of d(xk) is determined by the spread of values d takes forall objects in Ck. In the following, for sake of simplicity, d will be assumed to notbe a member of A and to not have any missing values.
In order to ensure d-relative anonymity for object xk, we must be able to answerthe following: Which patterns that match xk enable us to infer the 6alue of d(xk)? Asit happens, this pertinent question can be answered within the Boolean reasoningframework by a slight twist of the previously proposed anonymization procedure.Our focus hence turns from identifying patterns to patterns that constitute an-tecedents of propositional rules.
For rule generation, the key observation to make is that we do not need todiscern xk from objects that have the same value for attribute d as xk has. Or, moreprecisely, we do not need to discern between objects that have the same value fora generalized version Gd of d, defined below. The generalized attribute Gd whenapplied to xk simply summarizes the set of values that the objects in the indiscerni-bility set Ck take on for attribute d.
Gd(xk)={6�Vd �×xi�Ck such that d(xi)=6} (9)
A variation of the basic anonymize algorithm with focus on d-relative anonymityis given in Fig. 4. The only difference between Fig. 1 and Fig. 4 is that we computethe prime implicants from fk
X instead of from fkU, where Gd functions as a filter for
defining the discerning subset X¤U. Each element of Pk determines a pattern p
Fig. 4. Pseudo-code for making object xk anonymous relative to attribute d.

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254 243
that defines a decision rule p� (d, Gd(xk)). The set of decision rules generatedthis way are both complete and minimal with respect to descriptors in A [7].The comment made in Section 3.1 about an additional anti-reconstruction stepto be executed after the in7alidate procedure, also applies here. This issue will befurther discussed in Section 3.4.
After executing the anonymize procedure in Fig. 4, �Gd(xk)�\1. However, westill lack a way of numerically quantifying how well an inference about the valueof d(xk) is blocked. Having such a measure would enable the procedure in Fig. 4to be employed in a wider database setting, similar to Fig. 2 or Fig. 3.
It should be pointed out that the discerning subset X as defined in Fig. 4 istypically suitable for one anonymization cycle only, if the algorithm in Fig. 4 isto be used as a component of the procedures in Fig. 2 or Fig. 3. The reason forthis is that after one cycle for each object, all objects may then have the samegeneralized decision value. If �Vd �=2 this is definitely the case. Then, X=® andthe function fk
X will have no product terms. Hence, if d-relative anonymization isto be repeated until some anonymity criterion is met, then X should be defineddifferently, for instance by using d as a filter instead of Gd.
3.3.1. Quantifying relati6e anonymityThe relative degree of anonymity a(xk, d) for an object xk with respect to an
attribute d gives a measure of how well the value of d(xk) is ‘disguised’ in Ck.As noted, our ability to block inferences about the value of d(xk) is determinedby the spread of values d takes for all objects in Ck.
a(xk, d)=�Gd(xk)�−1
�Vd �−1(10)
A naive way of defining a(xk, d) is given above. If a(xk, d)=0, then allobjects in Ck have the same value for attribute d. Conversely, if a(xk, d)=1,then all possible values for d are represented in Ck. However, the definitionabove says nothing about the internal distribution of values within Ck, andhence yields little information about the certainty with which one can make aninference about d(xk).
The difficulty of determining d(xk) increases with the degree of heterogeneityof Ck with respect to d. A natural way of incorporating this notion is by lettinga(xk, d) vary proportionally to the entropy or disorder of Ck with respect to d,as defined below.
Pr(6 �Ck)=�{xi�Ck �d(xi)=6}�
�Ck � (11)
a(xk,d)8 %6�Vd
−Pr(6 �Ck)log2Pr(6 �Ck) (12)
An extended definition of a(xk, d) should also take into account �Ck � similarlyto how a(xk) was defined in Section 3.1.1.
A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254244
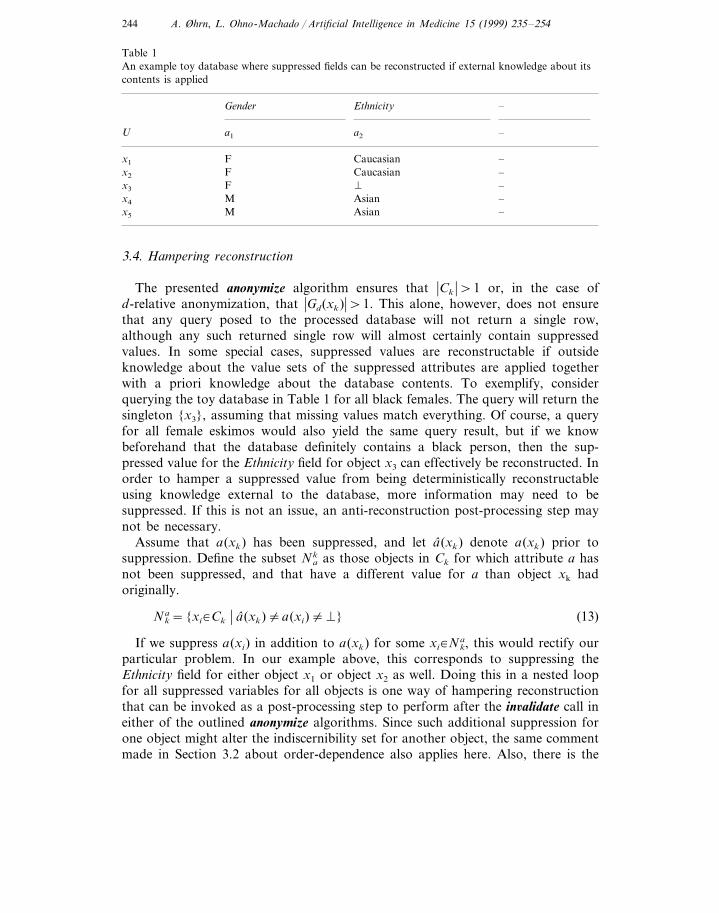
Table 1An example toy database where suppressed fields can be reconstructed if external knowledge about itscontents is applied
–EthnicityGender
–a1U a2
Caucasianx1 –FCaucasianx2 F –Þ –Fx3
M Asian –x4
–AsianMx5
3.4. Hampering reconstruction
The presented anonymize algorithm ensures that �Ck �\1 or, in the case ofd-relative anonymization, that �Gd(xk)�\1. This alone, however, does not ensurethat any query posed to the processed database will not return a single row,although any such returned single row will almost certainly contain suppressedvalues. In some special cases, suppressed values are reconstructable if outsideknowledge about the value sets of the suppressed attributes are applied togetherwith a priori knowledge about the database contents. To exemplify, considerquerying the toy database in Table 1 for all black females. The query will return thesingleton {x3}, assuming that missing values match everything. Of course, a queryfor all female eskimos would also yield the same query result, but if we knowbeforehand that the database definitely contains a black person, then the sup-pressed value for the Ethnicity field for object x3 can effectively be reconstructed. Inorder to hamper a suppressed value from being deterministically reconstructableusing knowledge external to the database, more information may need to besuppressed. If this is not an issue, an anti-reconstruction post-processing step maynot be necessary.
Assume that a(xk) has been suppressed, and let a(xk) denote a(xk) prior tosuppression. Define the subset Nk
a as those objects in Ck for which attribute a hasnot been suppressed, and that have a different value for a than object xk hadoriginally.
Nka={xi�Ck � a(xk)"a(xi)"Þ} (13)
If we suppress a(xi) in addition to a(xk) for some xi�Nka, this would rectify our
particular problem. In our example above, this corresponds to suppressing theEthnicity field for either object x1 or object x2 as well. Doing this in a nested loopfor all suppressed variables for all objects is one way of hampering reconstructionthat can be invoked as a post-processing step to perform after the in7alidate call ineither of the outlined anonymize algorithms. Since such additional suppression forone object might alter the indiscernibility set for another object, the same commentmade in Section 3.2 about order-dependence also applies here. Also, there is the

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254 245
question of selecting which object in Nka to additionally suppress. In case of
d-relative anonymity, we would typically select an object xi such that d(xi)"d(xk).Note that if Ck contains more than one suppressed value for attribute a or if
�Nka�B �Ck �−1 then additional suppression may or may not be necessary to hamper
a(xk) from being reconstructed, depending on what external knowledge we expecta reconstructor to have. Suppose for instance that our query for black femalesreturned two objects, both with the Ethnicity field suppressed. If we knew before-hand that the database must contain one black female, we still cannot be surewhich of the two returned records that belong to that individual. But if we knewbeforehand that the database must contain two black females, both suppressedEthnicity fields are reconstructable. There is thus a problem- and recipient-specificlimit on the effort one should put into hampering reconstruction.
4. Related work
The presented approach to anonymization is based on mathematical logic andindiscernibility. Complementary techniques often have statistical roots [3,4]. Fien-berg [3] provides an overview of statistical disclosure control and some of its issues.
4.1. Main approaches
Basically, there are three main approaches to making a database more anony-mous while preserving the ‘truthfulness’ of the data:� Outlier remo6al. Certain rows or columns objects and/or attributes are removed
altogether.� Generalization. The value sets are made smaller.� Cell suppression. Selected database entries are locally suppressed.
An issue that should be considered when selecting a method for making adatabase anonymous is how the recipient of the processed data is going to make useof it. If the recipient is a researcher doing a data analysis project, complete butgeneralized data would probably be preferred to very specific data with missingvalues. This simply because most data analysis tools do not handle missing valuesin databases very well. If, however, the processed data is only going to be used forbrowsing or for simple queries, difficulties associated with the handling of missingdata might not matter.
4.1.1. Remo6ing outliersA database may contain objects that in some sense significantly stray from the
rest of the database contents. Such objects are referred to as outliers. If such anabnormal object can be identified, removing it from the database is a safe butperhaps overly radical way of maintaining anonymity. Conversely, if an outlier islabeled so because of a deviant value of a particular attribute, removing theattribute from the database would aid in maintaining the anonymity of the outlier.Attribute removal is equivalent to joining equivalence classes.

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254246
Removing or dropping outliers from a database is not entirely unproblematic,though. In the medical domain, the outliers often constitute the interesting cases.Moreover, if the dropped outliers belong to some subgroup of the population,removing them may skew the distribution of data as perceived by the recipient ofthe processed database.
4.1.2. GeneralizationThe value set of many attributes can often be ordered or organized in a
hierarchy. For example, diagnose codes can be organized according to the ICD-9classification system and dates and numerical values can be sorted. The generaliza-tion process amounts to defining a coarser view of the world. This is done byreducing the set of possible values an attribute is allowed to take on, and may thusmake two previously discernible objects indiscernible. If the attribute values can besemantically organized in a tree structure, this indiscernibility can be achieved bysubstituting the attribute value for an object with a more general attribute valuesomewhere above it in the tree. If the attribute values can be sorted or orderedalong a line, generalization can be done by grouping the values into intervals.Otherwise, generalization can be done by forming subsets of the value set andassigning the same value to all elements in the subset.
In the machine learning literature, this is also referred to as discretization orgrouping. In the statistical disclosure control community, generalization is alsocalled global recoding.
4.1.3. Cell suppressionCell suppression consists of blanking out selected attribute values for outliers.
Cell suppression thus preserves the number of rows and columns in the originaldatabase, and does not ‘blur’ the perceived values of the non-suppressed entries.The algorithms we present in this article are examples of cell suppression.
4.2. Software systems
Software systems for making confidential databases more anonymous exist.Sweeney [9] reviews how the Datafly [8,9] and m-ARGUS [4] systems operate andperform. Neither Datafly nor m-ARGUS address relative anonymization. TheDatafly system performs generalization and may remove outliers entirely, but doesnot incorporate cell suppression. The m-ARGUS system also performs generaliza-tion, but performs cell suppression instead of removing the outliers.
This paper has focused on presenting a formal mathematical approach fordetecting identifying combinations of fields in a database. In the m-ARGUS system,this problem is addressed in a very limited manner by only considering combina-tions of two or three fields among a certain subset specified by the user. Largercombinations or combinations that involve attributes outside the specified subset goundetected. The Datafly system combats the problem in a better way by requiringthat the cardinality of the equivalence classes of objects with respect to a specifiedsubset of attributes be no less than a certain threshold. If this requirement cannot

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254 247
be met, generalization of the value set of one of the attributes considered isattempted. Outliers may be dropped in the process, and identifying combinations ofattributes outside the specified subset may still go undetected.
4.3. Anonymity measures
The way we quantified anonymity in Section 3.1.1 is rather traditional. A bin size,in the terminology of Sweeney [8,9], is mathematically nothing more than thecardinality of an equivalence class, and hence, conceptually, overlaps with thedefinition of a(xk). As currently formulated, however, the set Ck is a general clusterand not necessarily an equivalence class. Determining an optimal bin size is outsidethe scope of this paper, but some heuristics and problems regarding this issue aredescribed in [9].
5. Examples
A prototype algorithm for performing the anonymization procedure based onBoolean reasoning has been implemented within the framework of the ROSETTAlibrary [11]. This section provides examples of how the outlined Boolean reasoningalgorithms operate.
5.1. Anonymization
Consider the small example database A in Table 2(a). All objects in the databaseare uniquely identifiable, and most of the records have identifying characteristicseven when the SSN attribute is held aside. After one iteration of the anonymizationalgorithm outlined in Fig. 3, the database has been transformed into the ‘moreanonymous’ database shown in Table 2(b). In this database, each object has at leastone other object from which it cannot be discerned.
As a case study, object x5 will be considered in detail. First, the discernibilityfunction f5
U is constructed as shown below. Each conjunction in the POS formulastems from one of the other objects, and expresses how that particular object canbe discerned from object x5.
f5U= (a1*+a2*+a3*+a4*+a5*) · (a1*+a2*+a4*+a5*) · (a1*+a2*+a3*+a5*)
· (a1*+a2*+a4*+a5*) · (a1*+a2*+a3*+a5*) · (a1*+a2*+a4*+a5*)
· (a1*+a4*+a5*) · (a1*+a2*+a4*+a5*) · (a1*+a2*+a3*+a4*+a5*) (14)
We then proceed to compute BCF(f5U), which represents the same function as f5
U
but rather expressed as a minimal SOP formula. Each term in BCF(f5U) represents
a minimal identifying pattern for object x5, and the set P5 comprises all of these.
BCF(f5U)=a1*+ (a2* · a4*)+ (a3* · a4*)+a5* (15)

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254248
The in7alidate procedure then suppresses the cell entries that would otherwiseidentify object x5. This is done by initially noting that the Ethnicity attribute occursthe most frequently in P5. This field is therefore suppressed for object x5, and thoseelements in P5 that contain this attribute are removed from P5. This leaves only twodisjoint elements in P5 (namely {SSN} and {Zip}), so these are in turn alsosuppressed for object x5.
From Table 2(a) to Table 2(b), the indiscernibility set C5 has grown from thesingleton {x5} to the set {x5, x8}, hence increasing our crude measure of anonymitya(x5) from 0 to 1/9.
5.2. Relati6e anonymization
If we augment the small example database in Table 2(a) with an extra attributeHIV, we obtain the database shown in Table 3(a). We want to anonymize thedatabase relative to the HIV variable, blocking deterministic inferences about theHIV status of each patient. After one iteration of the anonymization algorithmoutlined in Fig. 3, but using fk
X instead of fkU as shown in Fig. 4, the database in
Table 3(a) has been transformed into the database shown in Table 3(b). In theprocessed database, each object will have at least one other object indiscerniblefrom itself that has a different value for the HIV variable.
Table 2Example database A before and after one anonymization cycle
Gender Ethnicity ZipU SSN Birth yeara3a1 a4 a5a2
(a) Before19640 123 456 789 M Caucasian 02116x1
x2 02138CaucasianF19641 234 567 890BlackM 0214419702 345 678 901x3
19683 456 789 012 F Asian 02166x4
4 567 890 123 1969x5 F Black 02156x6 19705 678 901 234 02144BlackMx7 02138CaucasianF6 789 012 345 1964
7 890 123 456x8 1969 F Asian 02116F Asianx9 021668 901 234 567 1968Mx10 Caucasian9 012 345 678 021661964
(b) AfterÞx1 ÞM1964 Caucasian
02138Caucasianx2 Þ 1964 FBlack 02144x3 Þ 1970 M
F Asianx4 02166Þ 1968x5 1969 F Þ ÞÞx6 1970 M Black 02144Þ
02138CaucasianFx7 1964ÞÞ Þ F Asian Þx8
Þ 02166x9 AsianF1968ÞCaucasianM1964Þx10

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254 249
Table 3Example database A before and after one anonymization cycle relative to attribute HIV
HIVZipEthnicitySSN Birth year GenderdU a1 a2 a3 a4 a5
(a) BeforeCaucasian 02116 Positivex1 0 123 456 789 1964 M
Positive02138x2 1 234 567 890 Caucasian1964 FBlack 02144 Negativex3 2 345 678 901 1970 M
02166x4 3 456 789 012 1968 F Asian Negative02156x5 Negative4 567 890 123 Black1969 F02144x6 5 678 901 234 1970 M Black Negative
Negative02138x7 6 789 012 345 Caucasian1964 FAsian 02116x8 Positive7 890 123 456 1969 F
Negativex9 021668 901 234 567 Asian1968 FCaucasian 02166x10 9 012 345 678 Negative1964 M
(b) AfterPositivexl ÞÞ Caucasian1964 M
02138x2 Þ 1964 F PositiveCaucasianNegativeÞx3 Þ ÞÞ M
Asian Þx4 NegativeÞ Þ FNegativeÞx5 Þ Þ1969 F
Þ Þx6 Þ NegativeÞ M02138x7 Þ 1964 F Caucasian NegativeÞx8 PositiveÞ AsianÞ F
Negativex9 Þ Þ F Asian ÞCaucasianx10 Þ Þ1964 NegativeM
Again, object x5 will be considered in detail. To construct the HIV-relativediscernibility function f5
X, we can simply drop those conjunctions from f5U that
discern object x5 from objects with negative HIV values.
f5X= (a1*+a2*+a3*+a4*+a5*) · (a1*+a2*+a4*+a5*) · (a1*+a4*+a5*) (16)
The prime implicants of f5X are then computed and subsequently blocked by the
in7alidate procedure. Each term in BCF(f5X) represents a minimal antecedent for a
rule that could otherwise be used to predict the value of variable HIV for object x5.
BCF(f5X)=a1*+a4*+a5* (17)
From Table 3(a) to (b), the indiscernibility set C5 has grown from the singleton{x5} to the set {x4, x5, x8} As a result, the set of possible HIV values for the objectsin C5 has grown from {Negative} to {Negative, Positive}.
5.3. Remarks
Neither Table 2(b) or 3(b) have been exposed to any kind of anti-reconstructionscheme, as outlined in Section 3.4. As it happens, Table 3(b) is a good example of

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254250
a situation where hampering reconstruction of attribute a4 is a good idea if weexpect a reconstructor to know beforehand that the database contains a blackfemale. In this case, we would also suppress the value of attribute a4 for object x8,since x8�N5
a4 and d(x8)"d(x5).Alternatives to performing such post-processing include more anonymization
cycles, another definition of mij in Section 2.4, or a less conservative implementationof the in6alidate procedure in Fig. 1.
6. Analysis and discussion
This paper has considered the problem of making databases with sensitivecontents anonymous, and framed the problem in the formal mathematical setting ofBoolean reasoning. Furthermore, an algorithm has been presented that can be usedto mask away combinations of values that serve as identifying patterns forindividual records in a database, or for a particular field in the database.
The presented algorithm has several desirable properties:� It is not an ad hoc method, but has a firm, mathematical foundation.� The degree of anonymity can be tailored according to the specific needs of the
recipient, and according to the amount of trust we place in the recipient.Furthermore, the required measure of anonymity can be specified as far down asto the individual objects in the database.
� Outliers are not removed, but are only partially masked in order to make themacceptably anonymous.
� The framework can be used to both preserve object anonymity as well as toblock deterministic inferences about specified database fields.However, the presented algorithm in its most basic form would probably still not
be sufficient for most real-world anonymization applications as a standalonesystem. The most prominent reason for this is that the algorithm does notincorporate any kind of generalization feature. Initial generalization of the data-bases could rather quickly ensure an acceptably large bin size on a per attributebasis, and might even circumvent the problems described in Section 3.4 by makingany equivalence class for any object with respect to the full attribute set A anon-singleton. Additionally, an anonymization approach based on discernibility isbest suited for categorical variables. When dealing with variables over numericaldomains, generalization or discretization thus becomes an important and necessarypre-processing step.
A suitable place for the presented algorithm would therefore be as a subsystemof a larger and more elaborate anonymization system such as Datafly, where itcould be invoked after generalization has taken place. Using the algorithm wepresented would allow us to verify that no further generalization is needed, or tolocally suppress entries for outliers instead of removing them altogether from thedatabase. Also, the procedure may be used to detect identifying combinationsof fields not included in the subset of attributes that have to be specified by the

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254 251
user in both the Datafly and m-ARGUS systems, and to perform relativeanonymization.
6.1. Interpretation and links
Many of the mathematical ideas employed in this paper can be justified andexplained in terms of rough set theory [5]. Skowron [7] discusses tolerance informa-tion systems and applications of Boolean reasoning in conjunction with tolerancerelations and indiscernibility phenomena. It is worth noting the close relationshipbetween how the identifying patterns are detected and how decision rules aregenerated in the rough set approach of rule induction [5–7]. In fact, an identifyingpattern is really a classification rule if we envision our database to be augmentedwith an extra one-to-one attribute d such that, say, d(xk)=k. An identifyingpattern p for object xk is thus equivalent to a decision rule p� (d, k).
In the basic formulation of rough set theory, the relation R described in Section2.4 would have to be an equivalence relation, and the anonymity of an object xk
would consist of it being ‘hidden’ in the upper approximation of the singleton {xk},or equivalently, the singleton {xk} being internally undefinable. However, the upperapproximation is merely a special case of the more general topological notion ofclosure. Hence, the indiscernibility set Ck can be viewed as the closure of thesingleton {xk}.
There is an intimate link between prime implicants of discernibility functionsand the notions of keys and functional dependencies in relational databases. If weconsider the full system’s discernibility function fA given below, a prime implicantp of fA actually defines a minimal functional dependency P�A−P in table A,where P is the set of attributes that occur in p.
fA= 5xk�U
fkU (18)
The cell values that are suppressed for object xk in the in7alidate procedure inFig. 1 actually form an implicant of the Boolean POS function BCF(fk
X)%, where theimplicant is composed of the complemented Boolean variables returned by theselect function. We typically want the implicant to be a prime implicant. Hence, thesuggested definition of the select function seems reasonable.
6.2. Changing biases
As noted, the select function in Fig. 1 makes the in7alidate procedure have a biastowards suppressing as few cells as possible. However, it can easily be redefined toprovide other behaviors. For example, one may instead choose to the return theattribute that minimizes a user-defined cost. That way, user preferences can beincorporated.
Processing data to ensure anonymity necessarily causes a certain degree of loss ofinformation. The challenge of any anonymization process is to preserve as muchinformation as possible, while ensuring a preset level of anonymity. One way of

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254252
measuring the data-quality or information content is to compute the entropy ordisorder in the database, according to standard information–theoretic formulae.Therefore, instead of having the user define the attribute costs, an alternative wouldbe to overload the select function to additionally take into account the informationloss that results by suppressing ai(xk).
6.3. Complexity issues
The biggest drawback of the presented algorithm is its potential complexity. Ingeneral, computing BCF( f ) is an NP-hard problem [7], informally meaning thatthe time it takes to compute BCF( f ) grows exponentially with the number ofattributes contained in f. However, this theoretical drawback does not necessarilyrender the approach useless in practice. An exhaustive computation is still feasibleunless the number of attributes m is very high. (Note that an exhaustive computa-tion does not necessarily imply a full generate-and-test cycle for all 2m subsets). Ifonly the attributes considered likely to be used for linking to external data sourcesare input to the anonymization process (demographic fields, typically), this may initself bring the problem down to a feasible size. And either way, computationallyefficient heuristics exist [11] that can be used to search for individual terms ofBCF( f ). If only some prime implicants are computed, the heuristics can beequipped with a suitable bias so that the short (and thus presumably more ‘easily’detectable) patterns are given priority.
Computing the entries of the discernibility matrix is an O(n2) process, but certainsimplifications can be made. First of all, the matrix is symmetric and has emptydiagonal entries, so less than half the matrix actually needs to be computed.Moreover, since Boolean algebras have the property of multiplicative idempotence(meaning that a ·a=a for all a�B), we need only consider the number of distinctobjects nd, so the complexity can be brought down to O(1/2(nd(nd−1)) If thedatabase is to be anonymized several times or with different recipient profiles, thematrix can be pre-computed and stored so that it only needs to be computed once.
6.4. Record order and multiplicity
An issue that the Boolean reasoning algorithm does not address that couldpotentially be used to identify an object is the object’s order of occurrence in thedatabase. Data is often entered sequentially into the database, and if the order ofoccurrence for an object is known, the record for that individual can always belocated by a fixed look-up call. However, this situation can be easily remedied bysimply permuting or scrambling the objects in the database, either before or afteranonymization.
Another issue not explicitly addressed is that several records in the database maystem from the same patient, for instance if each record denotes a separate patientvisit. If we know that a certain patient has extremely many visits, the databaserecords for that patient may potentially be identified on the basis of such multiplic-ity information alone. This issue also has bearing to the validity of the assumption

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254 253
that the database is a single flat table and not multiple tables. Ways to overcomethese problems are discussed in [9].
6.5. Additional suppression
Additional suppression in order to hamper suppressed database fields from beingreconstructed was discussed in Section 3.4. Another issue to consider when takinga recipient’s a priori knowledge into account is whether some fields that have notbeen suppressed perhaps should be suppressed. For instance, if a recipient somehowknows that the database in Table 3(b) contains exactly one person born in 1969,then it doesn’t matter if a query for all people born in 1969 will return the set {x3,x4, x5, x6, x8, x9}. Since we have one match that is exact for the Birth year field, therecipient has effectively located the row belonging to that particular person, and theset of possible values of the HIV field has been reduced to a singleton. If one hasreason to believe that the recipient of a processed database possesses such back-ground information, a suitable post-processing scheme to counter-effect that infor-mation should be invoked.
Acknowledgements
Special thanks to Latanya Sweeney for reading through an early version of thispaper and for providing valuable and insightful comments. Thanks also to JanKomorowski for reading through a draft version. This work has been supported inpart by grant 74467/410 from the Norwegian Research Council, and by grantLM/OD06538-01 from the National Library of Medicine and National Institutes ofHealth, and was done while the first author was visiting DSG, Harvard MedicalSchool.
References
[1] Brown FM. Boolean Reasoning: The Logic of Boolean Equations. Dordrecht: Kluwer, 1990.[2] Clayton P, et al. For the Record: Protecting Electronic Health Information. Washington DC:
National Academy Press, 1997.[3] Fienberg SE. Confidentiality and disclosure limitation methodology: challenges for national statis-
tics and statistical research, Technical Report 668, Department of Statistics, Carnegie MellonUniversity, 1997.
[4] Hundepool A, Willenborg L. m- and t-ARGUS: software for statistical disclosure control, in: Proc.Third International Seminar on Statistical Confidentiality, Bled, 1996.
[5] Pawlak Z. Rough Sets: Theoretical Aspects of Reasoning about Data. Dordrecht: Kluwer, 1991.[6] Skowron A, Rauszer C. The discernibility matrices and functions in information systems. In:
Slowinski R, editor. Intelligent Decision Support Systems: Handbook of Applications and Ad-vances in Rough Set Theory. Dordrecht: Kluwer, 1991:331–62.
[7] Skowron A. Synthesis of adaptive decision systems from experimental data, in: Aamodt A,Komorowski J, editors, Proc. Fifth Scandinavian Conference on Artificial Intelligence, Frontiers inArtificial Intelligence and Applications 28, IOS Press, 1995:220–238.

A. Øhrn, L. Ohno-Machado / Artificial Intelligence in Medicine 15 (1999) 235–254254
[8] Sweeney L. Guaranteeing anonymity when sharing medical data, the Datafly system. In: Masys DR, editor. Proc. AMIA Annual Fall Symposium (formerly SCAMC). Philadelphia: Hanley andBelfus, 1997:51–5.
[9] Sweeney L. Datafly: a system for providing anonymity in medical data. In: Lin TY, Qian S, editors.Database Security XI: Status and Prospects. New York: Chapman and Hall, 1998.
[10] Woodward B. The computer-based patient record and confidentiality. New Engl J Med1995;333(21):1419–22.
[11] Øhrn A, Komorowski J, Skowron A, Synak P. The design and implementation of a knowledgediscovery toolkit based on rough sets: the ROSETTA system, in: Polkowski L, Skowron A, editors,Rough Sets in Knowledge Discovery, Physica-Verlag, 1998. Software available from http://www.idi.ntnu.no/�aleks/rosetta/.
.





























