Embed Size (px)
Citation preview

Univerzita Karlova v Praze – Pedagogická fakulta Katedra pedagogické a školní psychologie
Paměť na věty ve francouzštině
Radovan Slavík Psychologie - speciální pedagogika
3. ročník - 2005/2006

2
1. ÚVOD Zatímco předškolákům paměť slouží především na nevědomé, implicitní úrovni a na-
pomáhá jim zvládat nároky a požadavky, jež na ně klade jejich sociální okolí, začíná se ve škole náhle po dětech vyžadovat záměrné zapamatování si nějaké látky, určitého postupu či v případě učení se cizím jazykům slovní zásoby potažmo gramatických struktur, a vybavovat si tyto vědomosti „na povel“, tj. oproštěně od spojení s určitým kontextem, který byl v minulosti většinou přítomen.
Při nástupu do školy děti zjišťují, že pro to, aby si něco tímto způsobem zapamatovaly, musí dané informaci věnovat dostatečnou pozornost a vyvíjet určitou fokální snahu a zjišťují, že se jejich výkony v tomto ohledu velmi liší od výkonů ostatních dětí. Dochází také k vývoji různých paměťových postupů a strategií, od jednoduchého, ale relativně účinného opakování, přes mnemotechnické pomůcky až po komplexní metody založené na logickém myšlení.
Tato práce se soustředí pouze na velmi úzkou výseč toho, co by se dalo obecně nazý-vat „problematika paměti“. Zabývá se totiž takovou pamětí, jež je záměrná, krátkodobá (v rozsahu několika sekund) a orientovaná jen na oblast (velmi) krátkých vět, které jsou navíc v cizím jazyce.
Při praktické výuce cizích jazyků je velmi často využívána dovednost vybavit si právě slyšený podnět. Především ve formě tzv. poslechových cvičení. Při nich si žáci nejen osvojují správnou výslovnost, ale též usnadňují uložení nově probrané slovní zásoby do dlouhodobé paměti jejím pasivním i aktivním zapojením do smysluplných vět. Princip poslechového cvi-čení spočívá v neprodleném, co nejpřesnějším zopakování slyšené věty či slovního spojení předtočeného na některé z forem audio či videozáznamu.
Několikerá pozorování při výuce, během nichž proběhl též terénní předvýzkum nazna-čila, že velkému počtu dětí činí tento typ cvičení obtíže, a to jak objektivně (tj. výsledky v těchto typech úloh byly u dětí horší než jejich stupeň znalosti jazyka naznačený klasifikací a jen zřídka je v nich dosahováno výsledků srovnatelných s výsledky v odlišných typech úkolů - např. čtení či praktická gramatická cvičení) tak subjektivně (děti takovéto úlohy hodnotily jako obtížnější než úlohy jiné).
Vyvstává otázka, zda není možné vysledovat, z jakého důvodu se děti potýkají s výše uvedenými problémy, případně jak jim předcházet a zvýšit tak úspěšnost dětí v úkolech toho-to typu.
Proto jsem formuloval několik základních výzkumných otázek, na které jsem se poku-sil nalézt odpovědi na základě analýzy dat získaných z úkolů, které jsem dětem zadával. Tyto otázky zní:
1) Čím je chybovost v předloženém úkolu ovlivněna? 2) Jakých chyb se děti nečastěji dopouštění? 3) Jaké věty v cizím jazyce jsou si děti schopny zapamatovat? 4) Jaké strategie řešení úkolu je možné identifikovat?
2. VÝZKUM A JEHO KONTEXT
Výzkum jsem prováděl v primě na osmiletém jazykovém gymnáziu v Praze. Na hodi-
ně bylo přítomno 11 dětí (jedná se pouze o polovinu třídy, druhá polovina má němčinu) ve věku od 11 od 12 let, z toho 5 chlapců a 6 dívek. V době mých návštěv se děti učily francouz-štinu 9. měsíc a bez větších problémů dokázaly číst z učebnice věty odpovídající předpoklá-dané úrovni jejich znalostí, ale při poslechovém cvičení nedokázaly často stejné věty, jako

3
předtím četly v učebnici, bez chyby zopakovat přesto, že disponovaly slovní zásobou i grama-tickou úrovní v nich obsaženou.
Ve třídě se nevyskytoval žádný vyloženě podprůměrný resp. nadprůměrný žák, mimo Vojty (viz dále).
Před samotným výzkumem bylo nutné nejprve provést základní terénní předvýzkum v němž mělo ke sběru dat dojít. Tento předvýzkum se skládal ze sběru doplňujících dat, jež se měla stát základem samotného hlavního výzkumu. Tato data, týkající se subjektivního hodno-cení předmětu francouzštiny stran náročnosti a obliby jejích jednotlivých složek (gramatika, poslech etc.). Cílem bylo utvořit si na základě odpovědí žáků představu o tom, jak obtížná jim francouzština přijde a jak si myslí, že jim jde.
Obliba Obecně není možné tvrdit, že by byla francouzština v této třídě předmětem příliš oblí-
beným. Na hodnotící stupnici1 byl aritmetický průměr celé třídy 3,2. Jako nejoblíbenější náplň hodiny bylo označeno čtení (sedm kladných odpovědí) a hrané scénky (čtyři odpovědi). Nao-pak jako zdaleka nejneoblíbenější náplní hodiny je v této třídě poslech (osm odpovědí).
Pro hlavní výzkum se jako velmi cenná informace ukázala být skutečnost, že je to prá-vě poslech, tedy činnost mající totožné nároky jako reprodukce slyšených vět, co je pro větši-nu žáků při hodině tím nejhorším. Pokud nebereme v potaz odpovědi jako „zkoušení“ či „pí-semky“, jsou zdánlivě nenáročná poslechová cvičení ještě méně atraktivní, než například komplikovaná (a často též velmi obávaná) francouzská gramatika (tři odpovědi).
Obtížnost Cílem terénního předvýzkumu bylo m.j. též zjistit, jak si žáci myslí, že jim tento
předmět jde (byla použitá stejná stupnice jako v předchozím případě). Třídní průměr hodno-cení obtížnosti byl 2,7.
Při následném porovnání subjektivního hodnocení žáků, jak si myslí, že jim francouz-ština jde, s jejich skutečnými výsledky bylo zjištěno, že u většiny neodpovídá stupeň sebe-hodnocení hodnocení ze strany vyučujícího. Diskrepance je prakticky vždy o 1 stupeň a větši-nou záporná, tj. žáci se sami hodnotí hůře, než jaké mají známky. Jako nejsnadnější součást francouzštiny žáci označovali čtení (6 odpovědí), jako nejobtížnější se jim jeví poslech (osm odpovědí).
Jak je z výše uvedeného jasně patrné, je klíčovým pojmem jak u obliby tak obtížnosti předmětu právě poslech, resp. poslechová cvičení. Nabízí se psychologicky velmi jednoduché a přímočaré vysvětlení, tj. že obtížnost poslechových cvičení vyvolávají u žáků frustraci, která nevyhnutelně vede k velmi nízké oblibě této činnosti2.
Po analýze všech informací získaných během první fáze bylo potřeba zvolit metodu sběru dat pro vlastní výzkum. Ten byl realizován prostřednictvím 4.revize Stanford-Binetova inteligenčního testu, konkrétně subtestu Paměť na věty (Thorndike, Hagen, Sattler, 1995).
Vzhledem k tomu, že jsem neměl k dispozici francouzskou verzi tohoto testu3, vytvořil jsem na základě české verze ve francouzštině dvě analogické, stejně vzestupně obtížné škály vět.
První škála (typ A) obsahovala pouze takovou slovní zásobu a gramatiku, s níž jsou děti již obeznámeny a dá se tudíž předpokládat vysoká míra porozumění předkládaným vě-tám. Ve škále A byly použity i některé věty vybrané přímo z učebnice. Škála druhá (typ B) byla utvořena tak, aby děti větám (ač de facto stejně obtížným jako v rámci škály A) rozuměly
1 Tato stupnice obsahovala škálu od 1 do 5, kde, analogicky školní klasifikaci, je 1 nejlepší a 5 nejhorší. 2 Není však předmětem tohoto výzkumu pokoušet se o vysvětlení příčiny neoblíbenosti poslechových cvičení, ale o prezentaci skutečnosti, že tato problematika stojí za hlubší prozkoumání. 3 Originální francouzskou verzi by stejně nebylo možné použít vzhledem ke skutečnosti, že bylo třeba škály přizpůsobit úrovni znalostí francouzského jazyka testovaných dětí.

4
co nejméně, tzn. byla v nich použita pouze dětem dosud pravděpodobně neznámá slovíčka a gramatika. Jako příklad možno uvést první větu obou škál (Plné znění testu je v příloze 2):
Škála A: „Un cheval grand.“ – „Velký kůň.“ Škála B: „Une affirmation incertaine.“ – „Nejisté tvrzení.“ Na počátku každého testování jsem dítěti přečetl následující instrukce: Budu ti teď číst nějaké věty ve francouzštině a byl bych rád, kdybys je po mně mohl(a)
hned zopakovat tak, jak si je zapamatuješ. Nevadí, pokud jim nebudeš rozumět a ani se nemu-síš bát, že uděláš chybu, na tom vůbec nezáleží. Pokud si pamatuješ jen část věty, klidně to, co si nepamatuješ vynechej a zopakuj, jen tu část, kterou si pamatuješ.
Během samotného testování jsem zohlednil doporučení uvedená v manuálu pro 4. re-vizi Stanford-Binetova inteligenčního testu. Odpovědi jsem pak nahrával na diktafon a sou-
časně zapisoval do záznamového archu. Mimo uvedený test byl jako výzkumná metoda použit též nestrukturovaný rozhovor s
každým dítětem, který proběhl vždy neprodleně po ukončení testu. V rámci tohoto rozhovoru děti odpovídaly m.j. na otázku, jakým způsobem úlohu řešily.
2.1 Vývojové hledisko Původním záměrem této práce bylo m.j. porovnat chybovost dětí v předkládaném úko-
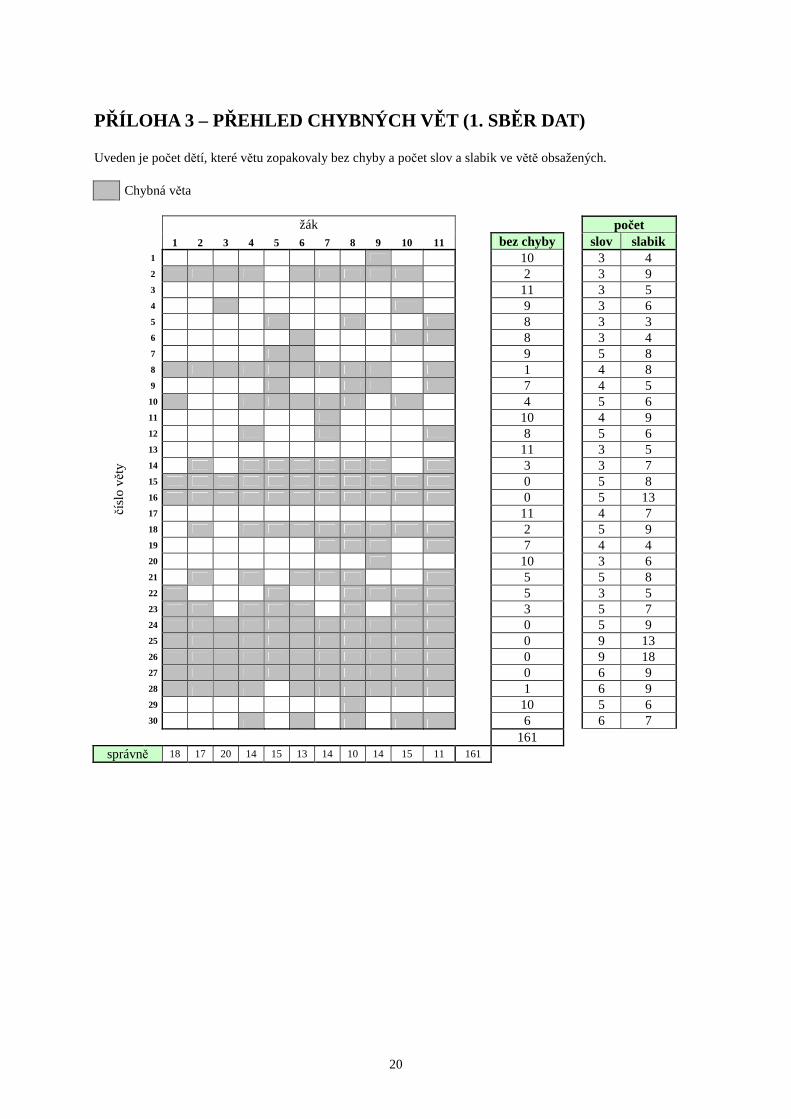
lu v rozmezí několikaměsíčního časového odstupu. První testování proběhlo během druhého pololetí primy (konec května), druhé pak v prvním pololetí sekundy (začátek října). Rozestup tedy činil 5 měsíců. Oboje dětmi dosažené výsledky (viz přílohy 3 a 4) se však lišily jen mi-nimálně. Celkově sice děti při druhém sběru měly o 9 vět bez chyby více, ale toto zlepšení jednak není nikterak výrazné, vzhledem k tomu že celkově bylo při prvním testování chybně 170 vět. Vše je patrné z uvedené tabulky:
Průměrně došlo ke zlepšení o 1 větu na žáka (přesněji 0,82 věty), což je velmi málo. O
neexistenci statistické významnosti svědčí též provedený Wilcoxonův test (viz příloha 5). Vyskytly se pouze dvě výjimky, a to Anička (zlepšení o 4 věty) a Petra (zlepšení o 5
vět). U Aničky se nepodařilo nalézt žádnou příčinu, která by mohla její nadprůměrné zlepšení způsobit, zatímco u Petry je možné jednoznačně přičíst její výsledek skutečnosti, že strávila téměř celé letní prázdniny s rodiči ve Francii u příbuzných. Je obecně známo, že největší po-kroky v cizím jazyce jsou zaznamenány právě při pobytu v daným jazykem hovořící zemi. Petra tento předpoklad svým výkone potvrdila. Díky pořízeným audionahrávkám bylo možné též konstatovat, že se oproti ostatním dětem značně zlepšila i její výslovnost. Mimo uvedené dívky však k výraznějším změnám nedošlo.
Předpokládám, že získané výsledky byly značně ovlivněny faktem, že se oba sběry dat uskutečnily mezi letní prázdninami. Jak mi bylo potvrzeno učitelkou, která děti má na fran-couzštinu, začínají se na konci května psát závěrečné písemky a děti se snaží „dotáhnout“ své známky. Proto je vlivem domácí přípravy jejich výkon ve francouzštině na relativně vysoké úrovni. Naopak během letních prázdnin si děti jazyk neopakují ani neprocvičují a začátek
1 2 3 4 5 6 7 8 9 10 11 celkem18 17 20 14 15 13 14 10 14 15 11 16116 17 21 14 13 14 17 14 13 20 11 170
-2 0 1 0 -2 1 3 4 -1 5 0 9
testovaný žák
počet vět bez chyby
1.sběr2.sběr
rozdíl

5
školního roku tak bývá často ve znamení poklesu výkonu. Výsledek je tedy takový, že i když děti ve svých jazykových znalostech prodělaly mezi oběma sběry pokrok, není tento z výsledků v použitém testu příliš patrný.
Z tohoto důvodu jsem se tedy věnoval především analýze chyb získaných při prvním sběru dat, tj. po 5 měsících učení se jazyku. 3. PŘEDPOKLADY SPRÁVNÉHO ŘEŠENÍ
Již bylo uvedeno, že úkol dětem zadávaný přímo vychází ze Subtestu Paměť na věty, který je 4. subtestem Stanfordského Binetova inteligenčního testu a patří do oblasti krátkodo-bé paměti. Subtest je založen na velmi jednoduchém principu – testované osobě jsou adminis-trátorem postupně slovně prezentovány věty, které má ihned co nejpřesněji zopakovat, tzn. pokud možno bez jakýchkoliv obměn. Pokud se testovaný dopustí jakékoliv chyby, je celá věta automaticky považovaná za neúspěšnou. Chybou je každá odchylka od originálního zně-ní věty, tedy jakákoliv změna slova, slovosledu, vynechání části potažmo celé věty etc.
V tomto místě se otevírá možnost pro porovnání úspěšnosti v takovémto typu úlohy s reálným životem. Zatímco v rámci testování v podstatě nezáleží na smyslu věty tak, jak je re-prezentovaná žákem a každá sebemenší odchylka se počítá jako chybná odpověď, je nao-pak ve většině „netestových“ situací, do nichž se děti dostávají mnohem důležitější sémantic-ká úroveň jazyka, tj. jde především o porozumění sdělené informaci, přičemž bohatost jazyka umožňuje při případné následující re-prezentaci vyjádřit prakticky identický význam několika různými způsoby. Takové odpovědi (byť sémanticky správné) však budou při testování pova-žovány za chybné.
V rámci rozličných modelů paměti je možné se opřít o tvrzení Craika a Lockharta (1972, in Sternberg, 2002), kteří mimo jiné představují paměť jako mechanismus kódující informace na několika úrovních. Ty nadále určují míru úspěšnosti reprodukce dané informace. Čím hlouběji je tedy informace zakódovaná, tím snazší bude si ji v budoucnosti vybavit. Nej-hlubší a nejkomplexnější je úroveň sémantická (sémiotická), založená na významu slov. Nad ní se nachází úroveň akustická, pracující se zvukovými kombinacemi asociovanými s písmeny. Nejvýše se nachází úroveň fyzikální, stojící na konkrétních vlastnostech dané věci. Ukázalo se však, že toto pořadí neplatí absolutně, ale že je úspěšnost vybavení ovlivněna cí-lem, k němuž vybavení užíváme, tedy že existuje korelace mezi druhem kódování a druhem úlohy. Zajímavá je zde spojitost s testem, který byl dětem zadáván. V něm je totiž úkolem pouze zopakovat větu, avšak k tomu není nezbytně nutné zakódovat si ji na nejhlubší, séman-tické úrovni, ani plně pochopit její význam. Stačí použít kódování akustické, tj. soustředit se především na fonetickou podobu věty a nikoliv na její sémantický význam. Avšak je pravdě-podobné, že různé děti k tomuto úkolu přistupovaly s různou strategií, tedy že některé kódo-valy větu hlouběji než jiné. Pro akustický způsob kódování by však hovořil zvýšený výskyt chyb založených na fonetické podobnosti (viz 4.4.1).
Je možné si položit otázku, jak by se s identickým úkolem vypořádaly francouzské dě-ti. Pro ně by byl prezentovaný test (a nezáleželo by na skutečnosti, zda jde o originální fran-couzskou verzi, či českou verzi do francouzštiny přeloženou) nepoměrně snazší než pro děti české. Vzhledem k nemožnosti přímého porovnání je možné pouze spekulovat na téma, zda by české děti v tomto věku nedosáhly stejných výsledků, jako děti francouzské ve věku (mno-hem) nižším. Domnívám se však, že skladba chyb by byla zcela odlišná, a to s ohledem na skutečnost, že pro rodilé mluvčí nečiní překážku „obtížná“ výslovnost či neznámá slovní zá-soba. Ze zpracování dostupných dat získaných na základě výzkumu PSŠE (2005) je u českých dětí v oficiální české verzi subtestu Paměť na věty minimum chyb ve výslovnosti (pouze 2% všech chyb) a nevyskytl se jediný případ zkomolení slova, potažmo části věty do smyslupros-

6
té podoby. Naopak byla v rámci našeho výzkumu chybná výslovnost (s častým výskytem ne-smyslných slov) velmi častou formou chyby.
Vnímáme-li totiž mateřský jazyk, je pro nás snazší mu porozumět spíše, než jazyku ci-zímu (který ovládáme a slyšený text bychom bez problémů přeložili, pokud bychom měli jeho textovou podobu), a to z toho důvodu, že fonémy a jejich kombinace užívané v tom jazyku se patrně odlišují od zvuků, odpovídajících fonémům, na které jsme zvyklí v našem mateřském jazyce.
3.1 Obecné a specifické předpoklady správného řešení úkolů subtestu Test použitý v rámci mého výzkumu má své specifické požadavky na úroveň kogni-
tivních schopností testovaného jedince. Přesto existují některé obecné proměnné, které mohou příznivě resp. nepříznivě ovlivnit úspěšnost v tomto typu úkolu.
Jako klasický obecný předpoklad podání jakéhokoliv výkonu je dostatečná pozornost tomuto výkonu věnovaná. Ta, v tomto kontextu, zlepšuje vjemovou diferenciaci, zostřuje myšlení, usnadňuje pochopení informace, a umožňuje tedy lepší zapamatování vět. V souvislosti s předkládaným výzkumem je důležitá především paměť záměrná doprovázená určitou volní snahou, neboť se předpokládá, že testovaný chce danému úkolu, v tomto případě úzce spojenému s administrátorem, který věty čte, pozornost věnovat.
Abych maximalizoval soustředění dítěte na plnění úkolu, probíhalo testování nikoli ve třídě při hodině, ale v kabinetu, a to v naprostém soukromí. Snažil jsem se, aby docházelo co nejméně k vyrušením způsobeným zvuky jak zvenku (například jedoucí auta, neboť s škola nachází u silnice), tak třeba ze sousední místnosti či chodby. Bohužel ne vždy se to podařilo.
Mimo výše uvedené obecné vlivy na úspěšné plnění tohoto typu úkolů existují samo-zřejmě i vlivy velmi specifické. Ty se váží na komplexní psychické děje, jež není možné po-chopit bez získání hlubší představy o jejich struktuře a funkci. Co se tedy děje v tak nepatrně krátkém časovém intervalu nacházejícím se mezi okamžikem, kdy administrátor pronese větu a testovaná osoba, v tomto případě dítě, tuto větu zopakuje?
Přehled o daných procesech, jejich pořadí a návaznosti jsem se pokusil znázornit v ná-sledujícím schématu:
Produkce informace
Zaznamenání sluchovým analyzátorem
Kódování do vhodné formy mentální repre-
zentace
Symbolické kódování
Přenos pomocí zvukových vln
Uložení do paměti
Vybavení informace
Dekódování a interpretace
Symbolické kódování
Reprodukce informace
Uchování v paměti
1 2
3
9 10
8
7 6
4
5

7
Uvedené zjednodušené schéma je rozdělené na 10 stádií procesu reprodukce právě slyšené věty a vychází ze skutečnosti, že je na paměť možné nahlížet jako na dynamický pro-ces. S nepatrnými rozdíly v pojetí se většina odborníků shoduje, že se tento proces sestává ze tří po sobě (ve specifickém a neměnném pořadí) následujících fází:
Vstup – První fáze paměťového procesu, ve které na jedince působí okolní prostředí prostřednictvím jeho smyslů je označována jako tzv. kódování (encoding). V tuto chvíli do-chází k transformaci získaných dat do podoby mentálních reprezentací. V uvedeném schéma-tu je tato fáze zastoupena stádii 3 – 5. Stádia předcházející, tj. 1 a 2, není sice možné považo-vat za regulérní součást paměťového procesu, ale jsou v daném kontextu pro schéma nezbyt-ná, neboť aby bylo vůbec možné větu si zapamatovat, je třeba aby ji nejprve administrátor přečetl. Informace je tedy v prvním stádiu již produkována - je napsána. Administrátor tuto informaci přečte, jinými slovy jí symbolicky zakóduje do podoby zvukového znakového sys-tému – řeči. Poté nastává samotný paměťový proces. Dítě slyšená slova zaznamená (stádium 3) a poté dekóduje a interpretuje (st. 4), tj. převede zvukové vlny zpět na konkrétní informaci. Dle povahy této informace jsou data transformována do vhodné formy mentální reprezentace (st.5) a jako taková uložena pro další použití (st.6).
Uchování – Jakmile jsou informace správně zakódovány, jsou v paměti uskladněny pro další použití (st.7). Této druhé fázi se proto někdy též říká uskladnění (storage).
Výstup – Poslední fází je ta, během níž jsou uložené informace vybaveny, aby s nimi mohlo být pracováno (st.8). Poté nastávají v opačném pořadí opět stádia 1 a 2, tedy dítě vyba-venou informaci zakóduje do podoby řeči (st.9) a sdělí samotný obsah věty (st.10).
Ovšem toto vybavení (retrieval) není možné jednoznačně považovat za jedinou mož-nost poslední fáze paměťového procesu, neboť ten může také končit ve chvíli, kdy je infor-mace z nějakého důvodu částečně či zcela poškozena, tedy jinak řečeno zapomenuta.
V kontextu řešení úkolu obsažených v tomto výzkumu by předpokládaný paměťový proces probíhal: Dítě pomocí sluchového orgánu zaznamená přednesenou větu, kterou ná-sledně ve své psychice přemění do podoby mentální reprezentace nejvhodnější pro danou informaci, jež si uloží do svých paměťových struktur. Poté si tuto uloženou informaci vědomě vybaví a danou větu zopakuje.
V reprodukovaných větách se však objevují různé chyby. Na tomto místě jen nazna-čím, že paměť jako taková a vybavování z ní nefunguje jako pouhý rekonstruktivní proces tzn., že v ní dochází k pouhému vybavení originálních paměťových stop, ale má naopak po-vahu silně konstruktivní.
4. PREZENTACE A INTERPRETACE VÝSLEDK Ů Všechny odpovědi dětí byly zaznamenávány na diktafon a zároveň značeny do archu
s větami, jež mělo každé jednotlivé dítě přiřazené. Kombinace dvojího záznamu minimalizo-vala možnost případného přehlédnutí chyby a umožnila tak následně velmi podrobně zpraco-vat a analyzovat veškeré získané odpovědi, a to včetně případných nápadných neverbálních projevů.
Při analýze jsem postupoval dle otázek prezentovaných v úvodu (viz 1.). Nejprve jsem vyčlenil chyby dle typu. Z toho pak bylo možné vyvodit, co dětem způsobovalo největší potí-že a určit, jaké věty jsou pro děti snadněji resp. obtížněji zapamatovatelné.

8
4.1 Čím je odpověď v předloženém testu ovlivněna? – Otázka obtížnosti předkládaných vět
Vyvstává otázka, dle jakého kritéria je možné tvrdit, že je některá předložená věta ná-ročnější, než věta jiná. Co tuto náročnost určuje? Je to délka dané věty, v ní použitá slovní zásoba, gramatická stavba nebo snad vše dohromady? A do jaké míry je toto ovlivněno tím, že předkládané věty v tomto výzkumu jsou v cizím jazyce?
Hříbková (2005) rozlišuje několik způsobů, jimiž je dosahováno zvyšování obtížnosti ve výše uvedeném testu: „První způsob je kvantitativní, prodlužováním délky věty a zvyšují-cím se počtem slov ve větě. Další způsob je strukturální, který spočívá v postupném kompli-kování stavby věty. (…) Reprodukci však ztěžují i použité gramatické jevy ve větě nebo pou-žitá neobvyklá slova.“ (s.270).
4.2.1 Délka věty Dá se předpokládat, že samotná délka vět, oproštěná od jakéhokoliv syntakticko-
sémantického kontextu bude jedním ze základních faktorů ovlivňujícího, do jaké míry bude pro děti těžké si větu zapamatovat. Vyvstává však potřeba blíže konkretizovat, jaké faktory ovlivňují to, co zde nazývám „délka věty“, tedy uvést, čím je tato délka definovaná. Opět je možné nahlížet na problém na několika úrovních. Havránek a Jedlička (1981) hovoří o struk-turovanosti jazyka do rozličných úrovní, přičemž je možné toto rozdělení alespoň částečně využít i zde.
O délce věty uvažuji vzestupně na dvou úrovních – a) na úrovni fonetické, kdy je ur-čujícím faktorem počet jednotlivých fonémů, případně slabik, z nichž se věta skládá; b) na úrovni morfologické, kdy mě zajímá počet slov, případně větných členů ve větě obsažených. Na první pohled se může zdát, že by v tomto ohledu měla délka vět korelovat, tj. vyšší počet slov by automaticky znamenal vyšší počet slabik. Není to však pravidlem, jak dokazuje např. věta první u obou škál. Věta 1A „Un cheval grand.“ obsahuje tři slova a čtyři slabiky, zatímco věta 2B „Une affirmation incertaine.“ obsahuje při stejném počtu slov slabik devět (tedy více než dvojnásobek). Z uvedeného důvodu byly věty při analýze rozděleny na dvě již zmíněné úrovně (fonetická, morfologická) a každá tato úroveň pak dle délky vět dále rozčleněna na pět skupin (vzestupně od vět nejkratších po nejdelší).
Fonetická úroveň: Do skupiny I patří věty o délce 3-4 slabik, přičemž se ukázaly být velmi snadnými, neboť je zopakovalo bez chyby v průměru 8 dětí (8,3). Skupina II (5-6 sla-bik) svou obtížností se skupinou první značně korelovala, neboť věty v ní obsažené zopakova-lo bez chyby také v průměru 8 dětí (8,4). Další skupiny jsou však již charakteristické značně sestupným trendem: Věty ze skupiny III (7-8 slabik) zopakovaly v průměru pouze 4 děti (4,8), věty ze skupiny IV (9-10 slabik) pouze 2 děti (2,5) a věty ze skupiny V (11 a více slabik) již nedokázalo zopakovat žádné dítě.
Morfologická úroveň: Jako nejsnadnější je možné označit věty skupiny I a II, tj. věty o 3 a 4 slovech, které dokázalo zopakovat v průměru 7 dětí (7,7 – 3 slova a 7,4 – 4 slova). Skupina III (5 slov) zaznamenala značný pokles na pouhé 4 děti (4,1) a skupina IV (6 slov) byla řešitelná v průměru pouze pro 2 děti (2,3). Stejně jako u fonetické úrovně nebylo skupinu V (7 a více slov) schopno zopakovat bez chyby žádné dítě.
U obou výše uvedených úrovní je tedy možné s rostoucí délkou (a jak je patrné nezá-leží zda jde o délku fonetickou či morfologickou) zaznamenat klesající trend v počtu úspěš-ných odpovědí.
Baddeley, Thompson a Buchanan (1975, in Nakonečný, 1998) tvrdí, že se v pracovní paměti udrží méně slov, pokud je k jejich vyslovení potřeba více času, jinými slovy, jsou-li

9
delší. Předpoklad by tedy mohl být takový, že čím delší budou jednotlivá slova, tím delší bude výsledná věta a tím tedy i nižší míra zapamatování. Stran počtu slov vycházím ze skutečnosti, že každá položka, kterou chceme v paměti udržet musí být do určité míry aktivovaná. Celko-vá míra aktivace však není neomezená, což vede k závěru, že čím více položek je v paměti, tím méně mohou být aktivované, a tím vyšší je pravděpodobnost, že bude některá z nich za-pomenuta.
4.2.2 Porozumění
Výzkum je zaměřen na věty, které jsou prezentovány ve francouzštině, a nejsou tedy v mateřském jazyce žáků. To může mít na míru úspěšnosti značný vliv. Otázku porozumění materiálu určenému k zapamatování se zabývá psychologie již velmi dlouho.
Snad nejznámější raný experiment, jímž se pokusil změřit kapacitu paměti, realizoval Ebbinghouse. Jeho hypotéza vycházela z domněnky, že nejvhodnějším materiálem pro tako-výto pokus bude ten materiál, jež by svou povahou postrádal pro probanda jakýkoliv význam. Základní jednotkou, s jejíž pomocí celý test měřil se tedy nemohlo stát nic jiného než (ne-chvalně) známá „smysluprostá slabika“. Mnozí psychologové, mezi nimi například Ach a Bühler, Ebbinghausův přístup podrobili seriózní kritice v tom smyslu, že asociační spoje uží-vané v testu smysluprostých slabik není možné použít u složitějšího významového materiálu. Paměť byla tehdy nahlížena na rovině vyšší (tzv. duchovní), jež měla za úkol uchovávat si významový materiál a jež vychází z jeho pochopení a nižší (tzv. zvykové), jež odpovídala naopak za materiál beze smyslu a je řízena asociativními zákony. Köhler (in Szewczuk, 1968) o Ebbinghausově práci dokonce prohlásil, že smysluprosté slabiky jsou tím nejhorším mož-ným materiálem pro zkoumání paměti, a to z toho prostého důvodu, že se s nimi nikdo v životě nesetkal. A jak by bylo možné měřit paměť pomocí materiálu, se kterým nebyla ni-kdy určená pracovat, a ani se tedy v tomto směru nijak nevyvíjela. V takovém případě se tudíž logicky nemohou projevit faktory klíčové pro zapamatování.
Spor o význam smyslu paměťového materiálu se táhl dlouhou dobu, aniž by jedna či druhá strana dokázala svůj postoj nevyvratitelně potvrdit. Až Szewcuk ve své práci (1968) přichází s názorem, že nemá smysl dělit materiál na smysluprostý a významový. Vychází z neurofyziologické skutečnosti, že zapamatování probíhá s nejvyšší pravděpodobností v oblasti neokortexu. A pokud veškeré zapamatování probíhá v rámci jedné mozkové struktury, pak je nanejvýše logické předpokládat, že i základní zákony zapamatování budou shodné bez ohledu na povahu materiálu. Szewcuk nepopírá rozdíly v obsahu těchto zákonů, ale tvrdí, že mají naprosto stejné základní podmínky.
Přesto, v rozporu s tímto postojem, zastávají někteří autoři názor, že si děti pamatují více, pokud mohou využít logických souvislostí. To je potvrzováno skutečností, že počet zo-pakovaných slov v větě je vždy vyšší, než počet vzájemně nesouvisejících čísel.
Pro opakování vět v cizím jazyce pak může právě toto být jedním z nejdůležitějších faktorů ovlivňujících úspěšnost. Rozumí-li dítě zadané větě, tj.chápe-li její smysl, zvyšuje se pravděpodobnost, že bude tato věta zapamatovatelná lépe než věta složená z neznámé slovní zásoby. Ta pak (ač ve skutečnosti svůj smysl má) bude spadat do kategorie smysluprostých slabik. Použitá slovní zásoba
Tento aspekt se jeví jako velmi ošidný a také poněkud těžko uchopitelný, a to i v mateřském jazyce žáka. Do hry tu totiž vstupuje jeden velmi problematický faktor, a to slovní zásoba jíž dítě disponuje neboli tzv. slovník jehož rozsah vychází z celkové množiny morfémů daného jazyka, tzv. lexikonu, a jejich kombinací.

10
Pro tento výzkum je nepodstatná informace týkající se slovníku dítěte v jeho mateř-ském jazyce, ale slovníku, jakým disponuje ve francouzštině. Bral jsem na to ohled při vytvá-ření jednotlivých škál. Slova užitá ve větách typu A jsem volil dle kapitoly v učebnici fran-couzštiny, s níž děti pracují, zatímco slovní zásoba použitá ve větách typu B byla zcela (mimo předložek a členů) vybírána tak, aby byla pro děti neznámá, tzn. slovíčka ve větách typu B nepatří mezi základní slovíčka, co se děti učí, když začínají s cizím jazykem. Uvedené tvrzení je možno ověřit v příloze 2.
Gramatická stavba věty
Gramatická stavba věty obecně je jedním z předpokládaných klíéčových faktorů ovlivňujících úspěšnost v tomto typu úkolů, avšak v konkrétním případě uváděného výzkumu ji takovou váhu nepřikládám. Je samozřejmě třeba zohlednit skutečnost, že česká a francouz-ská gramatika jsou dva diametrálně odlišné systémy, avšak testované děti jsou na příliš níz-kém stupni gramatické znalosti francouzštiny, aby mohla mít různá větná stavba nějaký zá-sadní vliv.
Tyto děti dosud mají pouze minimum zažitých pravidel, a pravděpodobně tedy nevidí rozdíly v obtížnosti mezi různě konstruovanými větami ve francouzštině. Proto jediné, co by tak mohlo v tomto smyslu ovlivnit jejich výsledky je fakt, zda se s větou, podobnou větě pre-zentované, již setkali či nikoliv. Vzhledem k této domněnce se věty obou škál v tomto ohledu příliš neodlišovaly - většinou byl použit přítomný čas, případně rozkazovací způsob, v několika případech čas budoucí.
Snaha nalézt vyčerpávající odpověď na položenou otázku (Čím je odpověď v předloženém testu ovlivněna?) by vystačila na samostatnou psychologicko-lingvisticky ori-entovanou práci. Pro účely tohoto výzkumu však postačí zjištění, že nejdůležitějšími faktory, které pravděpodobně mají na obtížnost vět zásadní vliv patří tyto: a) délka věty; b) porozumě-ní větě (vycházející z i) použité slovní zásoby; ii) gramatické stavby věty). 4.2 Jakých chyb se děti nečastěji dopouštějí?
Všechny děti bez výjimky ve větách různou měrou chybovaly, přičemž se všechny
chyby dají rozdělit do několik základních tříd, kterých jsem celkem identifikoval 5:
4.1.1 Chyba ve výslovnosti
Chyba ve výslovnosti znamená, že dítě sice větu/slovo zopakuje, ale přitom částečně nebo zcela zkomolí, tzn. vysloví nepřesně. Chyby tedy mohou být zkomolení části slova, ce-lého slova, části věty či věty celé.
Špatná, nebo nepřesná výslovnost se nepatrně častěji objevuje u chlapců, než u dívek Průměrně chybovali ve výslovnosti chlapci více než dívky (chlapci v průměru chybovali ve výslovnosti ve 4 větách typu B ze 7, dívky ve 2 ze 4). Zvláštním případem je Vojta4, který buď větu zopakoval celou s korektní výslovností, anebo ji nezopakoval vůbec. V jeho případě
4 Vojta se od svých spolužáků velmi odlišuje. Jeho reakce (např. na otázky) se vyznačují vysokou latencí, ver-bální projev je velmi tichý a nevýrazný a téměř všechny odpovědi zakončuje jakoby tázací intonací, což může naznačovat určitou nejistotu. Ve školním prospěchu patří spíše k podprůměru a učitelé se shodují, že je „poma-lejší“. Nabízí se možnost případného mentálního deficitu, proti které však svědčí to, že prošel náročnými přijí-macími zkouškami na školu.

11
je možné si povšimnout, že mu činí potíž především delší věty. Můj názor je však takový, že raději neřekl nic, než aby odpověděl špatně.
Jasně nadpoloviční počet chyb výslovnosti je ve větách s neznámými slovy. To by mohlo naznačovat, že při rekonstrukci věty dítě nespoléhá pouze na fonologickou stopu v pracovní paměti, ale doplňuje si „poškozená“ slova již známou slovní zásobou uloženou v dlouhodobé paměti. Pokud dané slovo nezná, je vyšší pravděpodobnost, že jej zkomolí, za-tímco slova známá „opraví“ a vysloví tedy správně.
Častým jevem je zkomolení celé části věty. Vysvětlení je nasnadě: francouzština je charakteristická svým vázáním jednotlivých slov. Proto mohou po sobě následující neznámá slova splývat do jednoho, takže pokud jim dítě nerozumí a část informace se z paměti ztratí, je výsledkem jeden zkomolený výraz (Honza, 14.B: „Redigez les descriptives.“ [rediže le de-skriptif] – změněno na [režiželedekripis])
Některá obtížně vyslovitelná slova dětem činila potíže (např. většina chybovala ve slově rapidement [rapidmã] - rychle). Obtížnost výslovnosti je tedy dalším z faktorů ovlivňu-jících zapamatování věty.
Zvláštním případ nastává ve chvíli, kdy je poškozeno slovo, které dítě nezná, ale zná nějaké slovo s velmi podobnou výslovností a použije jako vzor opravy právě to. V takových případech se již nedá hovořit o špatné výslovnosti, ale o záměně slova (viz dále).
Pokusím se o bližší vysvětlení, proč k takovýmto chybám může docházet. V úvahu
připadají dva možné přístupy. Tyto přístupy se liší především v místě, kde se hledají příčiny chyby. První z nich, v rámci kterého byla vypracována tzv. teorie fonetického vybrušování patří do oblasti řečové percepce a klade příčinu „ven“, tj. do okolních vlivů. Chybu tedy v tomto případě považuji za retrográdní (nachází se před paměťovým procesem). Naopak pří-stup vycházející z fungování krátkodobé respektive pracovní paměti pracuje s příčinou „vnitř-ní“, tj. takovou, jenž je způsobena v rámci průběhu samotného paměťového procesu. Tako-vouto chybu považuji za chybu anterográdní.
Retrográdní povaha chyby - Pisoni, Nusbaum, Luce a Slowiaczek (1985, in Stern-
berg, 2002) tvrdí, že pokud je slyšené slovo vlivem různých interferencí, tedy například hlu-kem, zkresleno, dochází u jedince k hledání již známé šablony korelující s daným slovem. Podobný postup uvažuje i tzv. model TRACE (McClelland a Elman, 1986, in Sternberg, 2002), jež řečovou percepci uvádí jako tři po sobě jdoucí a vzájemně se ovlivňující úrovně detekce příznaků: úroveň akustických příznaků, úroveň fonémů a úroveň slov. Zde bychom mohli hledat kořeny chyb projevujících se nahrazením slova za slovo foneticky velmi podob-né, avšak přesto významově odlišné.
Anterográdní povaha chyby - Dalším možným úhlem pohledu je hledat zdroj chyby ve špatném zapamatování věty potažmo slova. Z akustického kódu, v němž je slyšená věta v krátkodobé paměti uložena se může část zakódovaného slova z různých důvodů ztratit. Tato chybějící část je pak při vybavování podvědomě nahrazena podobně znějícím zvukem.
Způsob, jakým je chybějící část nahrazena nemusí být vždy náhodný. Ať se přikloní-me k jakékoliv z výše popsaných teorií, zůstává nadále nezodpovězenou otázkou, podle jaké-ho klíče jsou slova doplňována.
Samuel (1981, in Sternberg, 2002), který se vztahuje ke klasickým gestaltickým záko-nům vnímání (například zákon uzavřenosti, kdy máme tendenci doplnit neúplný kruh, aby tak tvořil gestalt), hovoří o tzv. efektu rekonstrukce fonému, jehož závěrem je, že v průběhu ře-čové percepce dochází k integraci toho, co slyšíme s tím, co již máme uloženo v paměti. Při zjišťování, jaké slovo jsme slyšeli tedy podvědomě porovnáváme slyšené s šablonami, popří-padě znaky uloženými v paměti. To, co tedy ve výsledku vnímáme, se může odlišovat od to-ho, co skutečně působí na náš sluch.

12
4.1.2 Záměna slova
� synonymem (sémantická podobnost) � homonymem (akustická podobnost)
Náhrada slova znamená, že dítě zamění slovo za jiné. Tato chyba je velmi obtížně sle-dovatelná, neboť mezi ní a špatnou výslovností je jen velmi slabá hranice vyžadující přesnou znalost kompletní slovní zásoby testovaného dítěte. Z analýzy chyb jsem se pokusil určit míru chybovosti co nejpřesněji. Chlapci nahradili slovo ve 3 větách, z nichž 1 byla typu B; dívky pak nahrazovaly slova pouze ve větách typu B (3 ze 3).
Nahrazování slov synonymy je v tomto stadiu učení se jazyku vysoce nepravděpodob-né, neboť děti nedisponují dostatečnou slovní zásobou, aby mohly zapomenuté slovo nahradit slovem sémanticky podobným, což test dostatečně prokázal (žádné slovo nebylo synonymem nahrazeno). O to vyšší je však výskyt náhrady na základě akustické podobnosti, která zřejmě nevyžaduje tolik úsilí a probíhá víceméně mimovolně (příklad; skoro každý: affirmation [afirmasjõ]- tvrzení změněno na information [ãformasjõ] – informace; Kačka: son echarpe [sõn ešarp]- jeho páska změněno na son chat [sõn ša]- jeho kočka). Nejčastěji bývají nahrazo-vána krátká slova obsahující tzv. nosovku (zvláštní typ výslovnosti ve francouzštině, například slova mon [mõ] – můj, dans [dã] – v, etc.). Vzhledem k tomu, že většina takových slov zní značně podobně, je možné (ba dokonce velmi pravděpodobné), že se jedná o pouhou špatnou výslovnost, která může pouze budit dojem odlišného slova (příklad; Jakub: dans [dã] – v změněno na en [ãn] )
4.1.3 Vynechání
� části slova � celého slova � části věty
Stejně jako u špatné výslovnosti se nepatrně častěji objevuje vynechání slov u vět
s neznámou slovní zásobou (chlapci měli v průměru chybně 8 vět, z toho 4 věty typu B, dívky v průměru 9 vět, z toho 5 typu B). Vynechání, ač by se skutečnost mohla jevit jako opačná, je mnohem komplexnější problém, než chyby ostatního typu. Vzniká tu totiž problém případné klasifikace takovéhoto druhu chyby, neboli jak je možné klasifikovat něco, co „není“ (tj. je vynecháno)? Proč dítě nějaké slovo pouze zkomolí, ale některé přímo vynechá?
Odpověď je možné hledat pomocí lokalizace vynechaného slova (či slov) ve větě. Je totiž zřejmé, že naprostá většina takovýchto chyb je umístěna v druhé polovině věty, přesněji že jsou vynechávána slova od konce věty. Jakub, věta 15.A: „Regarde a un clown ridicule.“, David, 16.B: „Essayez de déchiffrer les indications.“ či Lucka, 18.B: „Jean a poursuivi un chargonard.“ jsou klasickými příklady za všechny (vynecháno bylo podtržené slovo).
Z toho lze předpokládat, že aktivace, nepostradatelná pro zapamatování dané věty je v průběhu percepce věty distribuována nerovnoměrně – nejvyšší míra aktivace je na jejím počátku. V rámci teorie interference, zabývající se příčinou zapomínání, se uvádí tzv. křivka pořadí v sérii. Ta znázorňuje pravděpodobnost, že dojde k vybavení daného slova vzhledem k tomu, v jaké části souboru se nachází. Dle ní se nejsnadněji reprodukují slova ze samého konce souboru (tzv. efekt novosti – recency effect) a počátku souboru (tzv. efekt prvenství – primacy effect). Vysvětlení je prosté - všechna slova v souboru spolu nevyhnutelně vzájemně interferují, a dochází tedy k situaci, že na slova nacházející se na počátku souboru působí re-troaktivně slova následující, na slova na konci naopak proaktivně slova předcházející a na

13
slova nacházející se ve středu působí interference obojího typu, což vysvětluje, proč jsou prá-vě taty zapamatována nejméně.
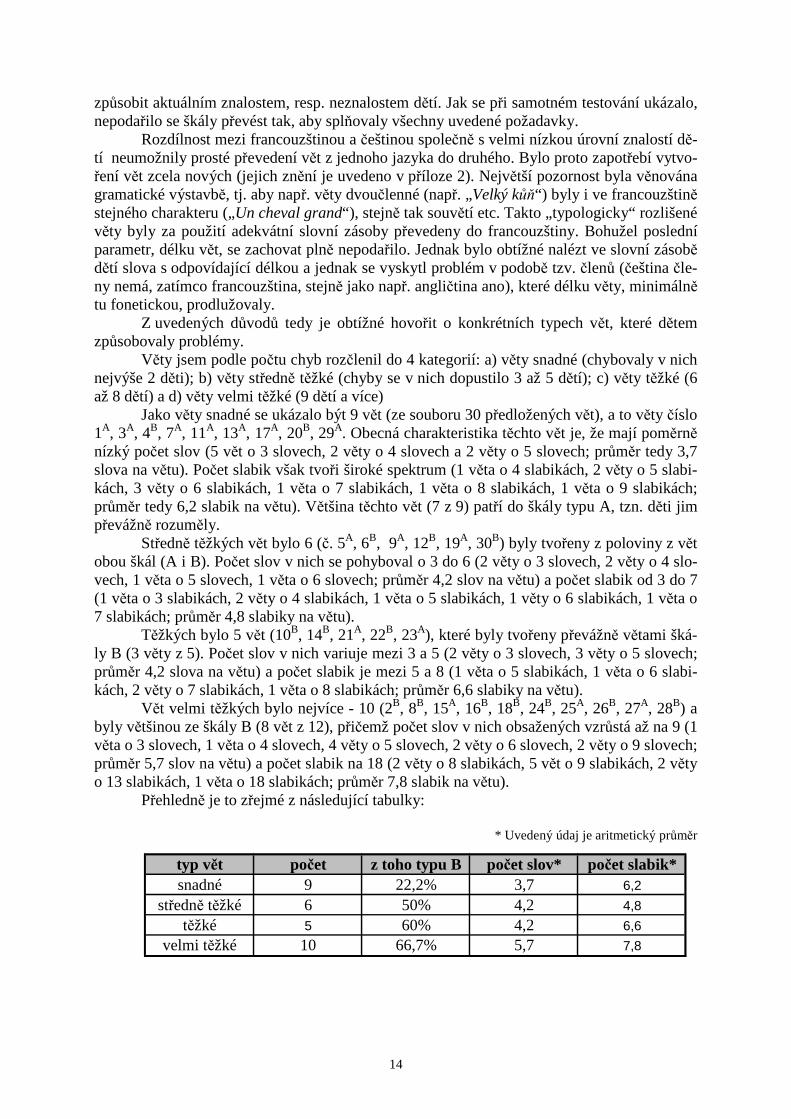
Jak vidno, nebyl v prezentovaném výzkumu uvedený předpoklad (tj. zapamatována by měla být především slova na počátku a na konci věty) naplněn. Jaké je možné vysvětlení? V jiné části této práce (viz 4.4) jsou zmiňovány paměťové strategie, které děti dle vlastních slov používaly. Pakliže by skutečně používaly převážně strategii „opakování v duchu“, mohlo by to způsobit následující efekt: Dítěti je prezentována věta. Samotná prezentace věty trvá v závislosti na délce věty přibližně od 1,5 do 4s. Tento čas dítě od počátku využívá k tomu, aby si v duchu opakovalo již slyšenou část věty. Ale není možné aby si opakovalo tu část, kterou dosud neslyšelo, a tak ve chvíli, kdy dosáhne při opakování doposud známého konce, započne opakovat větu znova do nového konce etc. Na následujícím schématu je patrný před-pokládaný proces5.
V případě, že by byl tento předpoklad pravdivý, mohli bychom jednoduše vysvětlit,
proč si dítě pamatuje především počátek věty, nikoliv již její konec.
4.1.4 Špatný slovosled
Až na jedinou výjimku (David, 8.B: „Les voitures roulent rapidement.“ změněno na „Les rapidement roulent voitures.“ , přičemž však došlo též ke zkomolení slova rapidement) jsem se nesetkal s chybou tohoto typu. Možné vysvětlení je, že děti dosud nemají takové zna-losti jazyka, aby si mohly v případě nepřesného zapamatování věty vyvolat nejprve její vý-znam, z něhož se pak pokusit zpětně zkonstruovat pravděpodobné znění věty.
4.1.5 Nezvládnutí celé věty Děti se často uchylovaly k tomu, že pokud se jim věta zdála příliš dlouhá či kompliko-
vaná, vzdaly se snahy pokusit se ji zopakovat. Bylo to jasně poznat na jejich neverbálních projevech (povzdechnutí, rozhlížení se, etc.); v určitý okamžik úplně přestaly vyvíjet úsilí větu si zapamatovat. V takových případech se pak ani nepokusili o její reprodukci.
4.3 Jaké věty v cizím jazyce jsou si děti schopny zapamatovat?
Převedení škál vět obsažených v subtestu Paměť na věty bylo mnohem komplikova-nější než se na první pohled zdálo. Bylo nutné zohlednit několik, již výše zmíněných faktorů: délku vět, jejich gramatickou stavbu a použitou slovní zásobu. To vše bylo navíc potřeba při- 5 Pokládám za důležité zdůraznit, že uvedené schéma pouze velmi přibližně ilustruje předkládanou hypotézou. K té je však třeba přistupovat velmi opatrně, a to především vzhledem k několika skutečnostem: 1) nebylo prove-deno jakékoliv přesné měření času; 2) není možné přesně určit, jakou rychlostí si dítě větu opakuje; 3) není mož-né vyloučit, že dítě použilo jinou paměťovou strategii. Z těchto důvodů je třeba apelovat, aby byla celá hypotéza pokládána za pouhý náčrt problému, který by si zasloužil samostatné důkladné prozkoumání.
Essayez de dechifrer les informations.
Essayez-Essayez de-Essayez de dechifrer
Administrátor: Testovaný žák:
14
způsobit aktuálním znalostem, resp. neznalostem dětí. Jak se při samotném testování ukázalo, nepodařilo se škály převést tak, aby splňovaly všechny uvedené požadavky.
Rozdílnost mezi francouzštinou a češtinou společně s velmi nízkou úrovní znalostí dě-tí neumožnily prosté převedení vět z jednoho jazyka do druhého. Bylo proto zapotřebí vytvo-ření vět zcela nových (jejich znění je uvedeno v příloze 2). Největší pozornost byla věnována gramatické výstavbě, tj. aby např. věty dvoučlenné (např. „Velký kůň“) byly i ve francouzštině stejného charakteru („Un cheval grand“), stejně tak souvětí etc. Takto „typologicky“ rozlišené věty byly za použití adekvátní slovní zásoby převedeny do francouzštiny. Bohužel poslední parametr, délku vět, se zachovat plně nepodařilo. Jednak bylo obtížné nalézt ve slovní zásobě dětí slova s odpovídající délkou a jednak se vyskytl problém v podobě tzv. členů (čeština čle-ny nemá, zatímco francouzština, stejně jako např. angličtina ano), které délku věty, minimálně tu fonetickou, prodlužovaly.
Z uvedených důvodů tedy je obtížné hovořit o konkrétních typech vět, které dětem způsobovaly problémy.
Věty jsem podle počtu chyb rozčlenil do 4 kategorií: a) věty snadné (chybovaly v nich nejvýše 2 děti); b) věty středně těžké (chyby se v nich dopustilo 3 až 5 dětí); c) věty těžké (6 až 8 dětí) a d) věty velmi těžké (9 dětí a více)
Jako věty snadné se ukázalo být 9 vět (ze souboru 30 předložených vět), a to věty číslo 1A, 3A, 4B, 7A, 11A, 13A, 17A, 20B, 29A. Obecná charakteristika těchto vět je, že mají poměrně nízký počet slov (5 vět o 3 slovech, 2 věty o 4 slovech a 2 věty o 5 slovech; průměr tedy 3,7 slova na větu). Počet slabik však tvoři široké spektrum (1 věta o 4 slabikách, 2 věty o 5 slabi-kách, 3 věty o 6 slabikách, 1 věta o 7 slabikách, 1 věta o 8 slabikách, 1 věta o 9 slabikách; průměr tedy 6,2 slabik na větu). Většina těchto vět (7 z 9) patří do škály typu A, tzn. děti jim převážně rozuměly.
Středně těžkých vět bylo 6 (č. 5A, 6B, 9A, 12B, 19A, 30B) byly tvořeny z poloviny z vět obou škál (A i B). Počet slov v nich se pohyboval o 3 do 6 (2 věty o 3 slovech, 2 věty o 4 slo-vech, 1 věta o 5 slovech, 1 věta o 6 slovech; průměr 4,2 slov na větu) a počet slabik od 3 do 7 (1 věta o 3 slabikách, 2 věty o 4 slabikách, 1 věta o 5 slabikách, 1 věty o 6 slabikách, 1 věta o 7 slabikách; průměr 4,8 slabiky na větu).
Těžkých bylo 5 vět (10B, 14B, 21A, 22B, 23A), které byly tvořeny převážně větami šká-ly B (3 věty z 5). Počet slov v nich variuje mezi 3 a 5 (2 věty o 3 slovech, 3 věty o 5 slovech; průměr 4,2 slova na větu) a počet slabik je mezi 5 a 8 (1 věta o 5 slabikách, 1 věta o 6 slabi-kách, 2 věty o 7 slabikách, 1 věta o 8 slabikách; průměr 6,6 slabiky na větu).
Vět velmi těžkých bylo nejvíce - 10 (2B, 8B, 15A, 16B, 18B, 24B, 25A, 26B, 27A, 28B) a byly většinou ze škály B (8 vět z 12), přičemž počet slov v nich obsažených vzrůstá až na 9 (1 věta o 3 slovech, 1 věta o 4 slovech, 4 věty o 5 slovech, 2 věty o 6 slovech, 2 věty o 9 slovech; průměr 5,7 slov na větu) a počet slabik na 18 (2 věty o 8 slabikách, 5 vět o 9 slabikách, 2 věty o 13 slabikách, 1 věta o 18 slabikách; průměr 7,8 slabik na větu).
Přehledně je to zřejmé z následující tabulky:
* Uvedený údaj je aritmetický průměr
typ vět počet z toho typu B počet slov* počet slabik*snadné 9 22,2% 3,7 6,2
středně těžké 6 50% 4,2 4,8
těžké 5 60% 4,2 6,6
velmi těžké 10 66,7% 5,7 7,8

15
Chybovost stran rozložení v jednotlivých větách z kvantitativního hlediska je následu-jící: Obtížnost věty vzrůstá spolu se zvyšujícím se počtem slov a s tím do jisté míry souvise-jícím počtem slabik. Zdá se však, že to neplatí absolutně, neboť počet slabik ve snadných vě-tách je vyšší, než ve větách středně těžkých. Tuto výjimku nelze však pokládat za významnou, neboť získaný průměr značně zvedá věta 11 obsahující slovo „television“ (televize), které má samo o sobě 5 slabik, ale jeho obtížnost je vyrovnána tím, že jde o slovo, které každé dítě zná.
Srozumitelnost, resp. porozumění větě má též na míru zapamatování vliv. Podíl nesro-zumitelných vět jednoznačně narůstal spolu s obtížností věty. Jak je zřejmé z výše uvedené tabulky, je nejpatrnější nárůst mezi větami snadnými a středně těžkými (28,2%), zatímco dále již je mnohem nižší (10% a 6,7%). Z toho plyne, že míra porozumění větě je pouze jedním z faktorů ovlivňujících úspěšnost v předkládaném testu a že u vět obtížných vstupují do hry významně i další faktory, především délka.
Při pokusu vysledovat, zda a do jaké míry je chybovost ovlivněna obsahem věty, se bohužel nepodařilo nalézt mezi větami, které byly zopakovány chybně jakoukoliv užší obsa-hovou souvislost. Navíc pokud bychom brali v potaz, že si děti slyšené věty většinou nesnaží překládat a jejich re-produkce tedy vychází převážně na fonetickém základu, je možné jen těžko uvažovat o tom, že by si děti pod slyšenými větami v mysli vytvářely konkrétního men-tální reprezentace, které by mohli významněji ovlivnit míru zapamatování. O tom je tedy možné hypoteticky uvažovat pouze v mateřském jazyce či v jazyce cizím, jímž dítě vládne na vyšší úrovni, než s jakou se setkáváme u zkoumaného vzorku. 4.4 Jaké strategie řešení úkolu je možné identifikovat?
Z analýzy jednotlivých typů chyb a celkového porovnání výsledků v testu je možné
usuzovat, že všechny děti (mimo Vojty, který se v tomto ohledu vymyká, jak je popsáno v části 4.1.1) řeší úkol stejným způsobem, a to opakováním si zadání v duchu a následným zopakováním nahlas. Takovýto postup potvrzují samy děti. Důkazem pro uvedené tvrzení je rovnoměrné rozložení chyb výslovnosti mezi větami typu A a B (u chlapců v průměru 4 chy-by ze 7, u dívek pak 2 chyby ze 4), z něhož plyne, že ztracená část fonetického záznamu věty resp. slova je nahrazena (zřejmě náhodně) zvukem podobným nezávisle na tom, zda je slovu rozuměno či nikoliv.
Na počátku výzkumu jsem si položil otázku, zda ve chvíli, kdy dítě slyší větu, si ji nejprve „v duchu“ přeloží, pak teprve uloží již v mateřském jazyce a při následujícím vyvolá-ní ji přeloží zpět do původního znění, či zda větu vůbec nepřekládá. Pro přítomnost překlado-vé fáze hovoří celkově horší výsledky zaznamenané v testu u nesrozumitelných vět (chlapci 5 vět typu B z celkových 13 bez chyby, dívky pak 6 z 16). Bohužel případná existence takové-hoto nevědomého překládacího mechanismus zapojeného do pracovní paměti se nedala z výsledků výzkumu jasně prokázat (avšak ani vyvrátit).
Když byli žáci požádáni, aby sami určili, v jaké fázi a zda vůbec si slyšenou větu pře-kládají, dali se jejich odpovědi rozčlenit na dvě skupiny: a) nesnaží se překládat (6 dětí ze 14, přičemž to vše byly chlapci); b) snaží se překládat to, čemu rozumí (8 dětí ze 14).
Z těchto výsledků je možné tvrdit pouze tolik, že dívky se více snažily slyšenou větu si přeložit a zapamatovat si ji v češtině, zatímco chlapci ji opakovali pouze foneticky. Existuje však ještě jedna možnost, která se nachází na pomezí obou uvedených případů. Jde o to, že pokud příjemce slyší větu v cizím jazyce, který ovládá, může mu tato věta dávat smysl, aniž by si ji musel nutně explicitně přeložit. Dokonce je i možné, že by pro takovýto explicitní překlad nedokázal najít nejvhodnější slovní či gramatické spojení ve svém mateřském jazyce. Takovouto možnost však nepokládám v případě prezentovaného výzkumu za příliš reálnou

16
s tím, že vyžaduje přeci jenom hlubší proniknutí do daného jazyka a jeho jemných sémanticko morfologických nuancí.
Předpokládám tedy, že děti zatím nemají žádný automatický překladový mechanis-mus, který by větu nejprve přeložil do rodného jazyka a poté teprve postoupil dalšímu zpra-cování pracovní pamětí. Říkám zatím, neboť se domnívám, že je to způsobeno pouze dosa-vadní nízkou znalostí jazyka.
Z výsledků testu též bohužel není možné posoudit, zda nejsou u některých dětí zapo-jovány i jiné strategie pro zapamatování (např. shlukování, rytmizace atp.). Jako jediné vý-chodisko je možné použít toliko rozhovor s dětmi, během něhož byly na použité strategie do-tazovány. Všechny děti bez výjimky popsaly užívanou strategii jako „opakování v duchu“. Domnívám se však, že je třeba brát toto určení s rezervou.Vzhledem k omezenému času, který bylo možné využít na testování každého dítěte, byla požadována rychlá a jasná odpověď, a je tedy možné, že děti zkrátka bez hlubší úvahy řekly to, co jim připadá nejpravděpodobnější, bez ohledu na to jakým způsobem skutečně situaci řešily.
5. ZÁVĚR
Z uvedeného textu je patrné, že nejčastější chybou, které se děti při řešení zadaného úkolu dopouštěly je vynechání slova (chlapci vynechali slovo v 8 větách, dívky pak v 9). V případě chlapců je téměř shodný počet chybných vět u špatné výslovnosti (7 vět), zatímco u dívek je míra těchto chyb mnohem nižší (4 věty).
Dívky mají v tomto úkolu ve všech sledovaných aspektech vyšší úspěšnost. Souvislost je možné hledat v rozdílnostech mezi verbálními dispozicemi dívek a chlapců, případně mírou jejich přípravy na vyučování (které vedou k lepšímu zvládání francouzštiny obecně, což dále ovlivní úspěšnost v zadaném úkolu).
Počet vět, které děti zopakovaly bez jediné chyby ukazuje, že jsou o téměř 2/3 úspěš-nější ve větách, kterým rozumí (typ A). Navíc se vyskytl trend růstu počtu chybných vět právě ve větách typu B. Z toho plyne, že srozumitelnost věty ovlivňuje zapamatování v pozitivním slova smyslu – děti si větu spíše zapamatují, pokud rozumí jejímu obsahu a to navzdory tomu, že mírně nadpoloviční většina dětí věty dle vlastního tvrzení nepřekládá.
Výsledky testu též naznačují, že s některými slovíčky měly děti obecně větší problémy než s jinými. To může být způsobeno tím, že je jejich výslovnost pro české děti obtížná. Kaž-dý jazyk má daný tzv. fonetický inventář, obsahující mezi jazyky mnohdy značně variující počet fonémů – některé jazyky mají fonémů více, jiné méně6.
Na rozdíl od slovní zásoby nelze u gramatické stavby předložené věty tvrdit, že by se vzrůstající gramatickou obtížností přímo úměrně rostla i míra chybovosti.
Délka věty se dle mého názoru prokázala jako klíčový faktor při plnění tohoto úkolu, a to přesto, že se vyskytují výjimky - děti někdy chybovaly již ve velmi krátkých větách (např. věta 2) přesto, že některé delší dokázaly zopakovat s lepším výsledkem.
Otázku týkající se strategií použitých při řešení zadaných úkolů se bohužel nepodařilo jednoznačně zodpovědět. Ze získaného materiálu však vyplývá, že děti používají vždy strate-gii „opakování v duchu“ a větě se většinou nesnaží porozumět (v tomto případě tvořily vý-jimku pouze některé dívky, u nichž však mohlo jít toliko o pokus o pozitivní sebe-prezentaci.
6 Český jazyk má 27 souhláskových fonémů a 5 fonému samohláskových, zatímco francouzština má 21 souhlás-kových fonémů, 12 samohláskových a 4 tzv. nosovky.

17
6. POUŽITÁ LITERATURA
NAKONEČNÝ, M.: Encyklopedie obecné psychologie, Praha, Academia, 1998. HAVRÁNEK,B., JEDLIČKA, A.: Česká mluvnice, Praha, SPN, 1981. HŘÍBKOVÁ, L.: In PRAŽSKÁ SKUPINA ŠKOLNÍ ETNOGRAFIE: Psychický vývoj dítěte od 1. do 5. třídy, Praha, Karolinum, 2005. STERNBERG, R. J.: Kognitivní psychologie, Praha, Portál, 2002. SZEWCUK, W.: Psychologie zapomínání, Praha, SPN, 1968. THORNDIKE, R.J., HAGEN, E.P., SATTLER, J.M.: Stanfordský Binetův inteligenční test, Brno, Psychodiagnostika, 1995.

18
PŘÍLOHA 1 - DOTAZNÍK POUŽITÝ V P ŘEDVÝZKUMU 1. Vyznačte na stupnici od 1 do 5, kde 1 je hodně a 5 vůbec.
• Francouzština mě baví: • Francouzština mi jde:
2. Zaškrtněte jednu možnost.
• Ve francouzštině mě nejvíc baví: a. Gramatika b. Čtení c. Psaní d. Poslech e. Něco jiného (napište co) ______________________
• Ve francouzštině mě nejmíň baví:
a. Gramatika b. Čtení c. Psaní d. Poslech e. Něco jiného (napište co) ______________________
• Na francouzštinu se připravuji:
a. denně b. jen před písemkou/zkoušením c. vůbec
3. Odpovězte vlastními slovy
• Ve francouzštině je pro mě nejsnazší:
• Ve francouzštině je pro mě nejtěžší:
1 2 3 4 5
1 2 3 4 5

19
PŘÍLOHA 2 - V ĚTY PŘEDKLÁDANÉ D ĚTEM 1. Původní znění 1. Veliký kůň. 2. Vypij mléko. 3. Podívej se na mě. 4. Auta jedou rychle. 5. Stromy jsou velké. 6. Šel jsem domů. 7. Běž do obchodu. 8. Podívej se na směšného klauna. 9. Do města přijel cirkus. 10. Jana má dva psy. 11. Milan má nového kamaráda . 12. Evě se líbí její nový kočárek. 13. Malé dítě nechce přestat plakat. 14. Přes moje okno svítí slunce. 15. Je už načase jít spát.
2. Francouzské znění 7 1.A Un cheval grand 2.B Une Affirmation incertaine 3.A Chercher une école 4.B Indiquer le chemin 5.A Une fille brune 6.B Regarde a moi 7.A Les garcons habitent a Paris. 8.B Les voitures roulent rapidement 9.A Les arbres sont grands 10.B Les cochons ont triste mine 11.A Je regarde la television 12.B Je m`attende a la baisse 13.A Va au magasin! 14.B Rédigez les descriptives. 15.A Regarde a un clown ridicule 16.B Essayez de déchiffrer les indications. 17.A Daniele regarde un chat 18.B Jean a poursuivi un chargonard 19.A Joan a deux chiens. 20.B Vous devez arroser. 21.A Milan a un nouvel ami 22.B L`equippe vient perdre. 23.A Eva aime son nouveau frére. 24.B Pierre abomine son echarpe noir. 25.A Un petit enfant ne veut pas finir de pleurer. 26.B Un vehicule de cent metres de long sera operationnel. 27.A Un oiseau chante dans le jardin. 28.B Le soleil brille par ma fenetre. 29.A Il est temps de manger 30.B Il est tard pour se coucher.
7 Index za číslem věty označuje škálu.
20
PŘÍLOHA 3 – PŘEHLED CHYBNÝCH V ĚT (1. SBĚR DAT) Uveden je počet dětí, které větu zopakovaly bez chyby a počet slov a slabik ve větě obsažených.
Chybná věta žák počet 1 2 3 4 5 6 7 8 9 10 11 bez chyby slov slabik
1 10 3 4 2 2 3 9 3 11 3 5 4 9 3 6 5 8 3 3 6 8 3 4 7 9 5 8 8 1 4 8 9 7 4 5 10 4 5 6 11 10 4 9 12 8 5 6 13 11 3 5 14 3 3 7 15 0 5 8 16 0 5 13 17 11 4 7 18 2 5 9 19 7 4 4 20 10 3 6 21 5 5 8 22 5 3 5 23 3 5 7 24 0 5 9 25 0 9 13 26 0 9 18 27 0 6 9 28 1 6 9 29 10 5 6
čís
lo věty
30 6 6 7
161 správně 18 17 20 14 15 13 14 10 14 15 11 161

PŘÍLOHA 4 – PŘEHLED CHYBNÝCH V ĚT (2. SBĚR DAT) Uveden je počet dětí, které větu zopakovaly bez chyby a porovnání s 1. sběrem dat.
Chybná věta žák 2. sběr 1 2 3 4 5 6 7 8 9 10 11 bez chyby
1 10 2 5 3 11 4 7 5 7 6 8 7 9 8 1 9 5 10 5 11 9 12 9 13 11 14 3 15 2 16 2 17 10 18 5 19 6 20 11 21 5 22 7 23 6 24 2 25 0 26 1 27 0 28 0 29 8
čís
lo věty
30 5
170
2.sběr 16 17 20 14 15 13 14 10 14 15 11 170

22
PŘÍLOHA 5 – STATISTICKÉ ZPRACOVÁNÍ (WILCOXON ŮV TEST) T0 = T0 = = 18 T1 = 11 σT = σT = = 7,348 U = U = 0,952 U0,975 = 1,96 U < U0,975
Rozdíl výsledků dosažených během prvního a druhého měření není statisticky významný.
1 2 3 4 5 6 7 8 9 10 11 celkem 1.sběr 18 17 20 14 15 13 14 10 14 15 11 161 2.sběr 16 17 20 14 15 13 14 10 14 15 11 159 počet vět
bez chyby rozdíl -2 0 1 0 -2 1 3 4 -1 5 0 9
pořadí 4,5 - 2 - 4,5 2 6 7 2 8 - n(n+1)
4
8(8+1)
4
2(n+1) . T0
6 2(8+1) . 18
6
T1 - T0
σT
















