Embed Size (px)
Citation preview

Università degli Studi di Ferrara
Facoltà di Scienze Matematiche, Fisiche e Naturali
Simulazioni Monte Carlo
per problemi di colorazione di
gra random
Tesi di Laurea in Fisica
Anno Accademico 2006-2007
Relatore Laureando
prof. Raaele Tripiccione Marco Guidetti




Indice
1 Introduzione 1
2 Introduzione Teorica 3
2.1 Teoria dei Gra . . . . . . . . . . . . . . . . . . . . . . . . . 32.1.1 Gra random di Erdös-Rényi . . . . . . . . . . . . . . 62.1.2 Colorazione dei gra . . . . . . . . . . . . . . . . . . . 14
2.2 k-soddisfacibilità, k-SAT . . . . . . . . . . . . . . . . . . . . . 192.3 Il modello di Potts . . . . . . . . . . . . . . . . . . . . . . . . 222.4 Tecniche Monte Carlo . . . . . . . . . . . . . . . . . . . . . . 25
2.4.1 L'algoritmo di Metropolis . . . . . . . . . . . . . . . . 312.4.2 Simulated Annealing . . . . . . . . . . . . . . . . . . . 342.4.3 Parallel Tempering . . . . . . . . . . . . . . . . . . . . 34
3 Connessioni tra i modelli teorici 37
3.1 Il modello di Potts e la colorazione dei nodi di un grafo . . . . 373.1.1 Esempi di polinomio cromatico . . . . . . . . . . . . . 39
4 Rassegna dei principali risultati conosciuti 49
4.1 Transizioni di fase . . . . . . . . . . . . . . . . . . . . . . . . . 494.2 k-core . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 624.3 Transizioni di Fase nel problema k-SAT . . . . . . . . . . . . . 65
5 Algoritmi Monte Carlo e risultati numerici 67
5.1 La struttura dati . . . . . . . . . . . . . . . . . . . . . . . . . 675.2 Generatore . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 685.3 Analisi della distribuzione del grado dei nodi . . . . . . . . . . 685.4 La simulazione Monte Carlo . . . . . . . . . . . . . . . . . . . 695.5 La libreria libgra.h . . . . . . . . . . . . . . . . . . . . . . . . 725.6 Distanza tra le soluzioni . . . . . . . . . . . . . . . . . . . . . 74
5.6.1 La matrice delle distanze . . . . . . . . . . . . . . . . . 755.7 L'emergenza del k-Core . . . . . . . . . . . . . . . . . . . . . . 765.8 Distribuzione del grado dei nodi all'interno del k-Core . . . . . 77
v

vi INDICE
5.9 Misura del diametro e del coeciente di clustering . . . . . . . 785.10 Divisore . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
6 Conclusioni 83
Bibliograa 85

1Introduzione
I gra, e la teoria dei gra in generale, sono rilevanti in natura, come proble-ma di sica statistica ed in ambito tecnologico: ogni informazione che coin-volge entitá, e in cui sono particolarmente rilevanti le interconnessioni traloro, é rappresentabile come un grafo. Si pensi per esempio ai network disimilitudine genetica, alle conformazioni delle proteine nel cammino di pro-tein folding, al World-Wide Web, ad Internet, alle linee telefoniche, alle retineurali, alle reti che quanticano le interazioni tra diverse specie in un eco-sistema, ed altri sistemi.In questa tesi ci si é concentrati sulla probabilitá di colorare un grafo random.Il problema della colorazione é il prototipo dei problemi di ottimizzazione, edha varie applicazioni. Per studiare la probabilitá di colorazione si é svilup-pato un algoritmo numerico basato su tecniche di Monte Carlo, che é statoutilizzato per riprodurre, su gra di dimensione relativamente limitata, alcu-ni risultati noti disponibili a vario livello di dettaglio in letteratura.Questa attivitá va pensata come punto di partenza per sviluppi futuri in cui,utilizzando sistemi di calcolo dedicato ad altissime prestazioni, si studierá ingrande dettaglio la struttura asintotica di gra vicino alla soglia di colorabil-itá.La tesi é costituita dai seguenti capitoli:
- il primo capitolo introduce alcuni dei concetti: la teoria dei gra ran-dom, i problemi di k-soddisfacibilitá, un modello di spin (il modello diPotts) e una breve trattazione delle tecniche Monte Carlo

2 1. Introduzione
- il secondo capitolo evidenzia le connessioni tra i problemi introdotti nelprimo capitolo
- il terzo capitolo riassume alcuni dei principali risultati noti in letter-atura
- il quarto capitolo presenta gli algoritmi Monte Carlo e i risultati nu-merici ottenuti. Questo capitolo descrive il lavoro eettivamente svolto.
Un breve capitolo di conclusioni completa il testo.

Entia non sunt multiplicanda praeter necessitatem.
Gugliemo d'Occam
2Introduzione Teorica
In questo capitolo si introdurrano i problemi trattati in questa tesi, e sicercherá di denirli in modo esauriente. Si esamineranno in sequenza la teoriadei gra random, il problema della logic-satisability, alcuni modelli di spine si concluderá con una breve trattazione delle tecniche Monte Carlo. Nelcapitolo successivo si vedrá che questi argomenti, apparentemente disgiunti,hanno in realtá forti legami tra loro.
2.1 Teoria dei Gra
Un grafo è una coppia ordinata di insiemi disgiunti, (V,E) tale che E è unsottoinsieme di V (2), insieme delle coppie non ordinate di V . L'insieme V èdetto l'insieme dei vertici, o nodi, ed E l'insieme degli archi. Se, dunque, Gè un grafo, V (G) è l'insieme dei vertici (o nodi) di G e E(G) l'insieme degliarchi di G.Si dice che un arco x, y collega i vertici x ed y, e lo si denota con xy.Pertando x ed y sono i vertici estremi dell'arco xy. In particolare se xy ∈E(G) allora i vertici x ed y sono vertici adiacenti in G, e i vertici x ed y sonoincidenti con l'arco xy.Due archi sono adiacenti se hanno in comune esattamente un vertice estremo.Diciamo che G′ = (V ′, E ′) è un sottografo di G = (V,E) se V ′ ⊂ V eE ′ ⊂ E. In tal caso scriveremo G′ ⊂ G. Se G′ contiene tutti gli archi di Gche collegano due vertici in V ′ allora G′ è riconosciuto come un sottografo
3

4 2. Introduzione Teorica
indotto (spanned) da V ′ ed è notato con G [V ′]. Quindi un sottografo G′ diG è un sottografo indotto se G′ = G [V (G′)]. Se V ′ = V , allora G′ è dettoun sottografo inducibile (spanning subgraph) di G. Se x è un vertice di ungrafo G, occasionalmente scriveremo x ∈ G anziché x ∈ V (G).
L'ordine di G è il numero di vertici di G; è notato con |G|: la stessanotazione è usata per la cardinalitá di un insieme. La dimensione di G è ilnumero di archi di G: la si nota con e(G). Scriviamo Gn per un grafo arbi-trario di ordine n. Similmente, G(n,m) denota un grafo arbitrario d'ordinen e dimensione m.
Un grafo non dipende dalla sua rappresentazione: ogni grafo è completa-mente specicato dai suoi vertici e dagli archi che li collegano.
La dimensione di un grafo di ordine m è almeno 0, ed al piú (n2 ) = n!2(n−2)!
.Chiaramente, per ognim compreso tra 0 e (n2 ), c'è un grafo G(n,m). Un grafodi ordine n e dimensione (n2 ) è detto un n-grafo completo ed è notato con Kn;un n-grafo vuoto Enè un grafo di ordine n e senza archi. In Kn ogni coppiadi vertici è adiacente, mentre in En nessuna coppia di vertici è adiacente. Ilgrafo E1 = K1 è detto banale. Siccome En é una notazione molto vicina aquella di E(V ), l'insieme degli archi del grafo, si usa alle volte la notazioneKn per il grafo vuoto di ordine n, intendendo con questo il complementodel corrispondente grafo completo. Il complemento di un grafo G(V,E), ingenerale, è denito come G = (V, V (2)−E): quindi due vertici sono adiacentiin G se e solo se non sono adiacenti in G.
L'insieme dei vertici adiacenti ad un vertice x ∈ G, i vicini di x, è notatocon Γ(x). Alle volte si usa la notazione x ∼ y per dire che x ed y sonoadiacenti: quindi x ∈ Γ(y) e y ∈ Γ(x), x ∼ y e y ∼ x, sono tutti equivalenti.Tutti infatti signicano che xy è un arco.
Il grado di x è d(x) = |Γ(x)|.Il grado minimale dei vertici di un grafo G è notato con δ(G) e il gra-
do massimale con ∆(G). Un vertice di grado zero è detto isolato. Seδ(G) = ∆(G) = k, cioé se tutti i vertici di G hanno lo stesso grado k, ilgrafo è detto k -regolare, oppure regolare di grado k. Un grafo è regolare se èk-regolare per qualche k.
Un percorso è un grafo P nella forma
V (P ) = x0, x1, . . . , xl E(P ) = x0x1, x1x2, . . . , xl−1xl.
Il percorso P è di solito identicato con x0x1x2 · · ·xl. I vertici x0 ed xl sonodetti vertici estremi di P ed l = e(P ) è detta la lunghezza di P : diciamo che

2.1. Teoria dei Gra 5
P è un percorso da x0 a xl, o percorso x0 − xl. Chiaramente P è anche unpercorso da xl a x0. Alle volte, se vogliamo enfatizzare il fatto che il percorsolo consideriamo andare da x0 a xl, chiamiamo x0 il vertice iniziale e xl ilvertice nale. Un percorso con vertice iniziale x è un x -percorso.
Il termine indipendente puó essere usato in connessione a vertici, archi epercorsi di un grafo. Un insieme di vertici o archi è indipendente se nessunacoppia di suoi elementi è adiacente; ancora, W ⊂ V (G) consiste di verticiindipendenti se e solo se G [W ] è un grafo vuoto.
Un insieme di percorsi è indipendente se, per qualsiasi coppia di percorsi,ogni vertice che appartiene ad entrambi è vertice estremo di entrambi. QuindiP1, P2, . . . , Pk sono percorsi x− y indipendenti se e solo se V (Pi) ∩ V (Pj) =x, y ogni qualvolta che i 6= j. I percorsi Pi sono anche detti essere interna-mente disgiunti.
Ci sono diverse nozioni interessanti collegate strettamente a quella di per-corso in un grafo. Un cammino W in un grafo è una sequenza alternata divertici e archi: x0, e1, x1, e2, . . . , el, xl dove ei = xi−1xi, 0 < i ≤ l. In accordocon la terminologia precedente, W è un cammino x0 − xl ed è notato conx0x1x2 · · · xl; la lunghezza di un cammino W è l. Un cammino è chiamatotraccia se tutti i suoi archi sono distinti. Da notare che un percorso è un cam-mino con tutti i vertici distinti. Una traccia i cui vertici estremi coincidono(una traccia chiusa) è detta un circuito. Per essere precisi, un circuito è unatraccia chiusa senza vertici estremi e direzione, cosí che, per esempio, duetriangoli che condividono esattamente un vertice danno luogo a due circuiticon 6 archi. Se un cammino W = x0x1 · · ·xl è tale che l ≥ 3, x0 = xl, e ivertici xi,0 < i ≤ l, sono distinti uno dall'altro e da x0, allora W è dettoun ciclo. Per semplicitá un ciclo è notato con x1x2x3 · · ·xl. La notazione èdiversa da quella di un percorso, perché x1xl è un arco del ciclo. Un ciclo nonha nè un vertice iniziale, nè una direzione, così che x1x2 · · · xl, xl−1xl · · ·x1,x2x3 · · ·xlx1, e xixi−1 · · ·x1xlxl−1 · · ·xi+1 tutti denotano lo stesso ciclo.
Si usa spesso il simbolo Pl per notare un arbitrario percorso di lunghezzal e Cl per indicare un ciclo di lunghezza l. Chiamiamo C3 un triangolo, C4
un quadrilatero, C5 un pentagono, e cosí via; Cl è anche chiamato un l -ciclo.Un ciclo é pari (o dispari) a seconda che la sua lunghezza sia pari (o dispari).
Dati due vertici x ed y, la loro distanza d(x, y) è la minima lunghezza diun percorso x − y. Se tale percorso x − y non esiste, allora la loro distanzad(x, y) = ∞. Un grafo è connesso se, per qualsiasi coppia x, y di verticidistinti c'è un cammino da x a y.

6 2. Introduzione Teorica
Un grafo senza cicli è detto una foresta, o grafo aciclico; un albero è unaforesta connessa. La relazione tra albero e foresta risulta meno assurda se sinota che una foresta è l'unione digiunta di alberi; in altre parole, una forestaè un grafo in cui ogni componente è un albero.
Un grafo G è bipartito con classi di vertici V1 e V2 se V (G) = V1 ∪ V2,V1 ∩ V2 = ∅ e ogni arco unisce un vertice in V1 con un vertice in V2. Sidice anche, allora, che G ha una bipartizione (V1, V2). Similmente G è r-partito con classi di vertici V1, V2, . . . , Vr (o ha una r -partizione (V1, . . . , Vr)se V (G) = V1 ∪ V2 ∪ · · · ∪ Vr, Vi ∩ Vj = ∅ ogni qual volta che 1 ≤ i ≤ j ≤ r,e non ci sono archi che uniscono vertici nella stessa classe.
Vale la pena di ricordare qui alcuni risultati: un grafo è bipartito se e solose non contiente un ciclo dispari; un grafo è una foresta se e solo se per ognicoppia x, y di vertici distinti contiene al piú un percorso x − y. Di questirisultati non si darà qui dimostrazione.
2.1.1 Gra random di Erdös-Rényi
L'importanza teorica dei gra casuali di Erdös-Rényi risiede nel fatto di poterastrarre dalla struttura topologica di un particolare grafo, di fatto interes-sandosi alle proprietá statistiche di una famiglia di gra. Introdotti alla nedegli anni '50, appunto da Erdös e Rényi, sono gra deniti da G(N, p), Nessendo il numero nodi del grafo e p la probabilità di esistenza di un arco. Perogni coppia (i, j) di vertici un arco è disegnato, casualmente e ogni volta in-dipendentemente, con probabilitá p = c/(N−1), e quindi la coppia di verticirimane sconnessa con probabilitá 1−p. Si è qui principalmente interessati allimite termodinamico N →∞, cioé si descrivono grandi gra con c nito. Ilgrado medio di ogni vertice è facilmente calcolato come (N−1)(c/(N−1)) = cche rimane nito nel limite di N grande. Ci sono, comunque, uttuazioni delgrado dei vertici e del grado medio del grafo per ogni c nito. Infatti laprobabilitá che un certo vertice abbia grado m è data dalla distribuzionepoissoniana:
pm = e−ccm
m!(2.1.1)
Un altro punto focale dell'analisi è che, per c niti, il numero di triangoli ealtri piccoli cicli nel grafo rimane nito nel limite di N -grande. Questo diceche il grafo è quasi ovunque, localmente, un albero. Per c > 1 esiste un grannumero di cicli chiusi, questi hanno, comunque, lunghezza proporzionale aO(lnN), e diventano innitamente lunghi per N →∞.

2.1. Teoria dei Gra 7
Il modello di Erdös-Rényi denisce uno spazio di probabilitá in cui la realiz-zazione di ciascun grafo è equiprobabile. La teoria dei gra random studiale proprietá dello spazio di probabilitá associato ai gra quando N → ∞:molte proprietá di tali gra possono essere determinate con metodi proba-bilistici. Riguardo questo Erdös e Rényi denirono che un quasi ogni grafoha la proprietá Q se la probabilitá di avere la proprietá Q si avvicina ad 1quando N →∞.La costruzione di un grafo random è spesso chiamata evoluzione nella let-teratura: si parte con un insieme di N vertici isolati ed il grafo cresce poicon l'aggiunta successiva di archi random: quindi a gra ottenuti a diversistadi di questa evoluzione, corrisponde una sempre piú grande probabilitá pdi connessione, arrivando al grafo totalmente connesso (cioé che ha il massi-mo numero di archi (n2 )) per p→ 1)E` interessante ricercare per quale particolare probabilitá p (di esistenza diciascun arco) una certa proprietá appare. La piú grande scoperta di Erdöse Rényi fu che molte proprietá interessanti dei gra random appaiono piut-tosto improvvisamente: cioé, ad una certa probabilitá p o quasi ogni grafoha la proprietá Q o il contrario, cioé quasi nessun grafo ha la proprietá Q.La transizione tra la situazione in cui la proprietá é molto probabile e quellain cui la proprietá é poco probabile é di solito piuttosto veloce. Per molteproprietá c'é una probabilitá critica pc(N). Se la probabilitá p(N) cresce piúlentamente di pc(N) quando N →∞ allora quasi ogni grafo con probabilitádi connessione p(N) manca della proprietá Q; al contrario, se p(N) cresce,in qualche modo, piú velocemente di pc(N), allora quasi ogni grafo presentala proprietá Q. Quindi la probabilitá che un grafo con N nodi e probabilitádi connessione p = p(N) presenti la proprietá Q soddisfa
limx→∞
PN,p(Q) =
1 se p(N)
pc(N)→ 0
0 se p(N)pc(N)
→ 1
La probabilitá p rappresenta, da un altro punto di vista, la frazione diarchi che sono presenti tra i possibili N(N − 1). Gra più grandi, a paritádi p, avranno più archi e quindi alcune proprietá, come l'apparizione di cicli,possono anche a p più piccoli per gra grandi. Questo signica che peralcune proprietá Q, su gra random, non esiste una denita ed unica sogliaindipendente da N , ma che si deve denire una funzione di soglia che dipendadalla dimensione del sistema, e pc(N → ∞) → 0. D'altra parte, si vede cheil grado medio di un grafo
〈k〉 = 2n/N = p(N − 1) ' pN
ha un valore critico che é indipendente dalla dimensione del sistema.

8 2. Introduzione Teorica
Altro insieme di gra casuali interessanti sono i gra c-regolari con Nvertici, dove c è un intero positivo, sono notati con Gc(N). Un grafo, comesi è visto nel paragrafo precedente, è c-regolare se e solo se tutti i suoi verticihanno grado c. In questo caso la probabilitá di trovare un vertice di gradom è:
pm = δ(c,m)
Un grafo casuale regolare è un elemento di questo insieme di gra. Questadenizione garantisce, di nuovo, che il grafo sia quasi ovunque localmente adalbero. Da notare che a causa della costanza del grado dei vertici, questi grasembrano localmente omogenei, su scala nita non mostrano alcun disordine.La loro caratteristica casuale si mostra solamente attraverso i lunghi ciclichiusi, che, di nuovo, hanno lunghezza proporzionale a O(lnN).In un contesto più generale, si possono includere entrambi gli insieme di gracasuali deniti sopra nell'insieme dei gra casuali con denita distribuzionedei gradi dei vertici. Per tali gra solo pd è denita, ed ogni grafo con la datadistribuzione di grado è considerato equiprobabile.
Sottogra
Si consideri il processo di evoluzione di un grafo random descritto in prece-denza: si parte da un insieme di N nodi isolati e poi si collega ogni coppia conprobabilitá p. Per piccole probabilitá di connessione gli archi sono isolati, mamentre p, e con essa il numero di archi, cresce, due archi si possono collegaread un nodo comune, formando un albero di ordine 3. Un problema inter-essante sarebbe determinare la probabilitá critica pc(N) a cui quasi ciascungrafo G contiene un albero di ordine 3. Piú generalmente si puó chiedere seesista una probabilitá critica che segnala l'apparizione di sottogra arbitrariformati da k nodi ed l archi. Nella teoria dei gra random c'é una rispostarigorosa a questa domanda, data da Bollobás.Si consideri un grafo random G(N, p) e un piccolo grafo fdi k nodi ed larchi: in linea di principio il grafo G puó contenere diversi piccoli gra F .Il primo passo é determinare quanti di questi piccoli sottogra esitono. Ik nodi possono essere scelti dagli N nodi in Ck
N modi e gli l archi esistonocon probabilitá pl. Inoltre, si possono permutare i k nodi e potenzialmenteottenere k! nuovi gra (il numero corretto sarebbe k!/a dove a é il numerodi gra che sono tra loro isomor). Quindi il numero atteso di sottogra Fcontenuti in G é
E(X) = CkN
k!
apl ' Nkpl
a(2.1.2)
La notazione usata suggerisce che il numero reale di sottogra, X possa es-sere diverso da E(X), ma nella maggioranza dei casi sará piuttosto vicino.

2.1. Teoria dei Gra 9
Da notare che ciascun sottografo non deve essere isolato: per esempio pos-sono esistere archi con un nodo estremo dentro il sottografo e l'altro no.L'equazione (2.1.2) fa notare che se p(N) é tale che p(N)Nk/l → 0 quandoN → 0, il numero atteso di sottogra E(X) → 0, cioé quasi nessun graforandom contiene un sottografo F . D'altro canto, se p(N) = cN−k/l il nu-mero di sottogra é un numero nito, notato con λ = cl/a, il che indica chequesta funzione potrebbe essere la probabilitá critica. La validitá di ques-ta supposizione puó essere testata calcolando la distribuzione del numero disottogra, Pp(X = r), ottenendo:
limN→∞
Pp(X = r) = e−λλr
r!(2.1.3)
E quindi la probabilitá che G contenga almeno un sottografo F é
Pp(G ⊃ F ) =∞∑r=1
Pp(X = r) = 1− e−λ (2.1.4)
che converge a 1 con il crescere di c. Per i valori di p che soddisfano pNk/l →∞ la probabilitá Pp(G ⊃ F ) converge a 1, quindi, la probabilitá critica a cuiquasi ogni grafo contiene un sottografo con k nodi ed l archi é pc(N) = cN−k/l.Alcuni casi importanti seguono direttamente dall'equazione (2.1.4):
- la probabilitá critica di avere un albero di ordine k é pc(N) = cN−k/(k−1)
- la probabilitá critica di avere un ciclo di ordine k é pc(N) = cN−1
- la probabilitá critica di avere un sottografo completo di ordine k épc(N) = cN−2/(k−1).
Evoluzione dei gra random
E' istruttivo rivedere i risultati discussi poco sopra da un diverso punto divista. Si consideri un grafo random con N nodi e si assuma che la probabil-itá di connessione p(N) scali come N z, dove z é un parametro aggiustabileche puó prendere qualsivoglia valore nell'intervallo da −∞ a 0(gura 2.1).Per z piú piccolo di −3/2 quasi tutti i gra contengono solo archi e nodiisolati. Quando z supera −3/2 improvvisamente appaiono alberi di ordine 3.Quando z raggiunge il valore −4/3 appaiono alberi di ordine 4, e mentre zapproccia −1, il grafo contiene alberi di ordine sempre piú grande. Ad ognimodo, ntanto che z < −1, tale che il grado medio del grafo 〈k〉 = pN → 0per N →∞, il grafo é l'unione di alberi disgiunti e i cicli sono assenti. Esat-tamente quando z sorpassa −1, corrispondente a 〈k〉 = cost, anche se z sta

10 2. Introduzione Teorica
cambiando lentamente, la probabilitá asintotica di cicli di ogni ordine saltada 0 a 1. Cicli di ordine 3 possono essere visti come gra completi di ordine3. Sottogra completi di ordine 4 appaiono per z = −2/3, e al crescere di zsottogra completi di sempre crescente ordine continuano ad emergere. In-ne, mentre z approccia 0, quasi ogni grafo random é un grafo completo diN nodi. Si possono ricavare altri risultati per z = −1: per esempio quando
Figura 2.1: Apparizione di strutture diverse al variare del parametro z
si ha p ∝ N−1 e il grado medio dei nodi 〈k〉 = cost. Per p ∝ N−1 un graforandom contiene alberi e cicli di ogni ordine, ma per ora non si é ancoradiscusso della dimensione e della struttura del componente tipico del grafo.Un tal componente é per denizione un sottografo connesso ed isolato, anchedetto cluster. Come é stato mostrato da Erdös e Rényi c'é un cambiamentobrusco nella struttura del cluster per un grafo random quando 〈k〉 si avvicinaad 1.Se 0 < 〈k〉 < 1, quasi tutti i clusters sono alberi oppure contengono esat-tamente un ciclo. Anche se i cicli sono presenti, la maggior parte dei nodiappartiene ad alberi. Il numero medio di clusters é dell'ordine di N − m,dove m é il numero di archi: aggiungere un nuovo arco fa diminuire il nu-mero di cluster di 1. Il cluster piú grande é un albero, e la sua dimensione éproporzionale a ln N .Quando 〈k〉 passail valore di soglia 〈k〉c = 1, la struttura del grafo cambiaimprovvisamente. Mentre il cluster piú grande per 〈k〉 < 1 é un albero,per 〈k〉c = 1 ha approssimativamente N2/3 nodi ed una struttura piuttostocomplessa. Inoltre per 〈k〉 > 1 il cluster piú grande1 ha[1 − f(〈k〉)]N nodi,dove f(x) é una funzione che decresce esponenzialmente da 1 a 0 per x→ 0.Quindi una frazione nita S = 1 − f(〈k〉) di nodi appartiene al cluster piúgrande. Eccetto che per questo cluster gigante, gli altri clusters sono rela-tivamente piccoli, la maggior parte sono alberi ed il numero totale di nodiche appartengono a questi alberi é Nf(〈k〉). Facendo ancora crescere 〈k〉 ipiccoli clusters si uniscono al cluster gigante, pur avendo i clusters piú piccoli
1ci si riferisce in questi casi a componenti giganti, se tal componente é il piú grande delgrafo ed é l'unico

2.1. Teoria dei Gra 11
maggiore probabilitá di sopravvivenza.Quindi a pc ' 1/N la topologia del grafo random cambia improvvisamenteda un insieme di piccoli clusters ad un grande cluster gigante. La dimensionedi tale cluster gigante, S, cresce proporzionalmente alla separazione dallaprobabilitá critica
S ∝ (p− pc).
Distribuzione del grado dei vertici
Erdös e Rényi furono i primi a studiare la distribuzione del grado massimo eminimo di un grafo random, mentre Bolloás, in un secondo momento, ha rica-vato la distribuzione completa del grado. In un grafo random con probabilitádi connessione p il grado ki di un nodo i segue una distribuzione binomialecon parametri N − 1 e p
P (ki = k) = CkN−1p
k(1− p)N−1−k (2.1.5)
Questa probabilitá rappresenta il numero di modi in cui k archi posso esserecollegati ad un certo nodo: la probabilitá dei k archi é pk, la probabilitá diassenza di archi aggiuntivi é (1 − p)N−1−k, e ci sono Ck
N−1 modi equivalentiin cui si possono selezionare i k nodi estremi dei k archi. Ancora, se i e jsono nodi dierenti, P (ki = k) e P (kj = k) sono, sostanzialmente, variabilicasuali indipendenti. Per trovare la distribuzione del grado nel grafo, si devestudiare il numero di nodi con grado k, Xk. Lo scopo principale é stabilirela probabilitá che Xk abbia un dato valore: P (Xk = r).In accordo con (2.1.5) il valore di aspettazione del numero di nodi con gradok é
E(Xk) = NP (ki = k) = λk, (2.1.6)
doveλk = NCk
N−1pk(1− p)N−1−k. (2.1.7)
La distribuzione del grado dei nodi, P (Xk = r) approccia la distribuzionePoissoniana
P (Xk = r) = e−λkλrkr!
(2.1.8)
Quindi il numero di nodi con grado k segue una distribuzione di Poisson convalor medio λk. Da notare che la distribuzione (2.1.8) ha come valore d'aspet-tazione la funzione λk data da (2.1.7) e non una costante. La distribuzionedi Poisson decade velocemente per valori grandi di r, dal momento che ladeviazione standard della distribuzione é σk =
√λk. Con forse un po' di
semplicazione si potrebbe dire che (2.1.8) implica che Xk non diverge trop-po dal risultato approssimato Xk = NP (ki = k), valido peró solo se i nodi

12 2. Introduzione Teorica
sono indipendenti. Quindi. in prima approssimazione, la distribuzione delgrado di un grafo casuale e` una distribuzione binomiale
P (k) = CkN−1p
k(1− p)N−1−k
che per N grande puó essere rimpiazzata da una da una distribuzione Pois-soniana
P (k) ' epN(pN)k
k!= e〈k〉
〈k〉k
k!(2.1.9)
Diametro
Il diametro di un grafo é la distanza massimale tra una coppia qualsiasi disuoi vertici. In dettaglio, il diametro di un grafo disconnesso (cioé costi-tuito da diversi clusters isolati) é innito, ma puó essere ridenito come ildiametro massimo dei suoi clusters. I gra random hanno la tendenza adavere piccoli diametri, ammesso che p non sia troppo piccola. La ragione percui si ha questo comportamento é che un grafo random ha la tendenza adallargarsi: con grande probabilitá il numero di nodi a distanza l da un datonodo non é molto piú piccola di 〈k〉l. Uguagliando 〈k〉l con N si trova che ildiametro é proporzionale a ln(N)/ln(〈k〉), e quindi dipende solo logaritmica-mente dal numero dei nodi. E' una conclusione generalmente accettata cheper la maggior parte dei valori di p, quasi tutti i gra hanno precisamente lostesso diametro. Questo signica che considerando tutti i gra con N nodie probabilitá di connessione p, la gamma di valori in cui il diametro di taligra puó variare é molto piccolo, e di solito é concentrato intorno a
d =ln(N)
ln(pN)=
ln(N)
ln(〈k〉)(2.1.10)
Si puó dare la seguente caratterizzazione di importanti risultati:
- se 〈k〉 = pN < 1 il grafo é composto da alberi isolati ed il suo diametroé uguale al diametro di un albero.
- se 〈k〉 > 1 appare il cluster gigante. Il diametro del grafo è uguale aldiametro del cluster se 〈k〉 > 3.5 ed é proporzionale a ln(N)/ln(〈k〉)
- se 〈k〉 ≥ ln(N) il grafo é totalmente connesso. Il suo diametro éconcentrato attorno al valore ln(N)/ln(〈k〉)
Un altro modo per caratterizzare la diusione di un grafo random é cal-colare la distanza media tra ogni coppia di nodi, o la lunghezza media di un

2.1. Teoria dei Gra 13
Figura 2.2: in alto a sinistra: grafo random con 〈k〉 < 1: si possono notare gli
alberi isolati; in alto a destra: 〈k〉 ≈ 2.5: si nota l'emergenza del componente
connesso centrale; in basso: 〈k〉 ≈ ln(N): il grafo é quasi totalmente connesso.
cammino. Ci si puó aspettare che la lunghezza media di un cammino scalicon il numero dei nodi nello stesso modo del diametro:
`rand ∼ln(N)
ln(〈k〉)(2.1.11)
Clustering
Il coeciente di clustering di un grafo G = (V,E) é la media dei coecientidi clustering dei singoli nodi del grafo. Il coeciente di clustering di unnodo é denito come il rapporto tra il numero di archi che esistono tra ivicini (gli adiacenti) del nodo e il numero di archi che potrebbero esistere,complessivamente, tra i vicini. Se quindi il vertice i ha ki adiacenti, allora traquesti adiacenti potrebbero, complessivamente, esistere ki(ki− 1)/2 archi. Equindi il coeciente di clustering del nodo i sarebbe:
Ci =2|ij|ki(ki − 1)
i, j ∈ V (G), ij ∈ E(G)

14 2. Introduzione Teorica
Se si considera un nodo in un grafo random e i nodi a lui adiacenti, laprobabilitá che due di questi vicini siano connessi é pari alla probabilitáche due nodi selezionati a caso nel grafo siano connessi. Di conseguenza ilcoeciente di clustering di un grafo random é denito come
Crand = p =〈k〉N
(2.1.12)
L'emergenza del k-Core
Il k-Core é denito, in un grafo, come il sottografo massimale i cui verticihanno grado minimo k. Per un grafo di Erdös e Rényi G(n,m) di n nodied m archi é stato dimostrato, in letteratura, che un 2-Core gigante cresceparallelamente ad un componente grande e compatto del grafo, il clustergigante. Per k ≥ 3 si puó dimostrare che con grande probabilitá un k-Coregigante appare improvvisamente non appena m (il numero degli archi delgrado random) raggiunge e soprassa un valore critico.
2.1.2 Colorazione dei gra
La colorazione dei gra é un problema ben conosciuto e fondamentale. Esi-ste un famoso teorema che aerma che é sempre possibile colorare un grafoplanare usando solo quattro colori. Per gra generici (non solo random) ilproblema puó essere molto dicile da risolvere ed é riconosciuto (giá dal1972) come problema NP-completo: ovvero é convinzione diusa che sia unproblema per cui nessun algoritmo puó decidere se un grafo arbitrario é co-lorabile o meno in tempo polinomiale, rispetto alla dimensione del grafo. Ilproblema della colorazione ha importanti applicazioni tecnologiche. Tra lealtre: scheduling, allocazione dei registri nel processori e assegnamento dellefrequenze nelle comunicazioni radio.
Si supponga, per esempio, di voler organizzare i talks di un congressoin modo che nessun partecipante sia obbligato a scegliere tra due talks con-temporanei a cui vorrebbe partecipare. Assumendo che ci siano abbastanzastanze, quanto durerá il programma? Qual è il numero più piccolo, k, diunità temporali necessarie? E' possibile riformulare queste domande intermini di gra: sia G un grafo i cui vertici siano i talks, e in modo che duevertici siano collegati da un arco se e solo se c'è un partecipante che vogliapartecipare ad entrambi. Qual è allora il minimo valore, k, per cui V (G) puóessere partizionato in k classi, V1, V2, . . . , Vk, in modo che nessun arco uniscadue vertici della stessa classe?Questo minimo si chiama numero cromatico (di vertice), χ(G).La denizione usuale di χ(G): una colorazione corretta, o semplicemente

2.1. Teoria dei Gra 15
una colorazione, di G è l'assegnazione di colori ai vertici del grafo, in modoche vertici adiacenti abbiano colori distinti; χ(G) è allora il numero min-imo di colori in una colorazione (sui vertici) di G. Quindi, per esempio:χ(Kk) = k, χ(Kk) = 1, χ(C2k) = 2, χ(C2k+1) = 3. E' in generale diciledeterminare il numero cromatico di un grafo. Comunque si puó notare chese Kk ⊂ G allora χ(G) ≥ χ(Kk) = k.
Quindi una k-colorazione dei vertici di G è una funzione c : V (G) →1, 2, . . . , k tale che ogni insieme c−1(j) è indipendente. Gli insiemi c−1(j)sono le classi di colore della colorazione.
Colorazione dei vertici
Si è giá visto che un grafo è bipartito se e solo se non contiene un ciclo dispari.Quindi χ(G) ≥ 2 se e solo se G contiene un arco e χ(G) ≥ 3 se e solo se Gcontiene un ciclo dispari. Per k ≥ 4 non si ha una simile caratterizzazionedei gra con numero cromatico almeno k. Anzichè richiedere una caratte-rizzazione è piú conveniente abbassare il tiro considerevolmente, e chiedersiqual è la ragione piú ovvia per cui un grafo dovrebbe avere numero cromati-co grande. Uno di tali motivi è evidente: l'esistenza di un grafo completogrande. Questo dá la disuguaglianza
χ(G) ≥ ω(G) (2.1.13)
dove ω(G) è il numero di gruppo2 di G, ovvero l'ordine massimale di unsottografo completo di G. Un'altra ragione viene alla mente, dopo un attimo:l'assenza di un grande insieme indipendente. Infatti, se G non contiene h+ 1vertici indipendenti, allora in ogni colorazione di G al piú h vertici hanno lostesso colore, poichè ogni classe di colore ha al piú h vertici. Quindi:
χ(G) ≥ maxω(G), |G|/α(G) (2.1.14)
dove α(G) è il numero di indipendenza di G, ovvero la dimensione massimadi un insieme indipendente. Anche se quest'ultima disuguaglianza è debole,è comunque un miglioramento rispetto alla prima. Comunque non è facilevedere che ω(G) puó essere molto piú piccolo di χ(G). Infatti, non è facilemostrare che si puó avere ω(G) = 2 e χ(G) grande, ovvero che ci sono grasenza triangoli che hanno numero cromatico grande.Come si puó provare a colorare i vertici di un grafo con i colori 1, 2, . . .,
2anche detto numero di clique

16 2. Introduzione Teorica
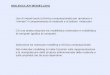
usando meno colori possibile? Un approccio molto semplice è il seguente:si ordinino i vertici del grafo, x1, x2, . . . , xn e poi li si colorino uno per uno:dando a x1 il colore 1, poi a x2 il colore 1 se x1x2 /∈ E(G) o altrimenti ilcolore 2. E avanti così: si colora ogni vertice con il colore piú piccolo che puóavere a quel punto. Questo algoritmo, chiamato algoritmo ingordo (greedyalgorithm), produce una colorazione, ma tale colorazione puó (e spesso ècosí) usare piú colori del necessario. La gura 1.1 mostra un grafo bipartito(e quindi 2-colorabile) per il quale l'algoritmo ingordo spreca due colori.
Figura 2.3: Un grafo bipartito: l'algoritmo ingordo ha bisogno di 4 colori
Comunque è facile vedere che per ogni grafo i vertici possono essere or-dinati in modo tale che l'algoritmo ingordo usi meno colori possibile. Nonè pertanto soprendente che paghi l'investigare il numero di colori di cui habisogno l'algoritmo ingordo in diversi ordini dei vertici. Si noti che, qualsiasiordine seguiamo l'algoritmo ingordo usa al piú ∆(G) + 1 colori per colorarei vertici di un grafo G. Infatti quando si arriva a colorare un vertice x digrado d(x), almeno uno dei primi d(x)+1 colori non è ancora stato usato perun vicino di x, quindi almeno uno di quei colori è ancora disponibile per x.Questa semplice osservazione mostra che ció che importa non è nemmeno ilgrado massimale, ma il numero massimale di vicini di un vertice che abbiamocolorato prima di colorare il vertice stesso. Da qui è facile vedere il prossimorisultato.
Teorema Sia k = maxHδ(H), dove il massimo è preso su tutti i sottograindotti di G. Allora χ(G) ≤ k + 1.
Dimostrazione Il grafo G ha un vertice di ordine al piú k; sia xn talevertice, e si ponga Hn−1 = G−xn. Per assunto Hn−1 ha un nodo di gradoal piú k. Sia xn−1 uno di tali vertici si ponga Hn−2 = Hn−1 − xn−2 =

2.1. Teoria dei Gra 17
G− xn, xn−1. Continuando in questo modo enumeriamo tutti i vertici delgrafo.Ora, la sequenza x1, x2, . . . , xn è tale che ogni xj è collegato al piú con kvertici che lo precedono. Quindi l'algoritmo ingordo non avrá mai bisognodel colore k + 2 per colorare un vertice.
In alcuni casi il problema della colorazione di un grafo puó essere ridottoal problema della colorazione di alcuni sottogra. Questo succede se il grafonon è connesso, oppure se contiene un sottografo completo il cui insieme divertici disconnette il grafo stesso. Dopodiché possiamo colorare ogni partedel grafo separatamente perchè, al piú con un cambio di notazione, possiamoricongiungere le colorazioni per produrre una colorazione del grafo originario.
Un altro algoritmo di colorazione puó essere ottenuto riducendo il prob-lema alla colorazione di due gra diversi derivati da G. Questa riduzionepermette anche di ottenere qualche informazione sul numero di modi di col-orare un grafo con un dato insieme di colori. Siano a e b vertici non adiacentidi un grafo G. Sia G′ ottenuto da G unendo a e b con un arco, e sia G′′ ot-tenuto daG identicando ab (gura 2.4), come la fusione dei vertici a e b in ab.
Figura 2.4: Esempio di contrazione e fusione dei vertici di un grafo
Quindi in G′′ c'è un nuovo vertice (ab), anzichè a e b, che è unito aivertici che erano adiacenti ad almeno uno tra a e b. Queste operazioni sonoancora piú naturali se si parte da G′: G è allora ottenuto da G′ tagliando ocancellando l'arco ab, e G′′ si ottiene da G′ fondendo, o contraendo, ab. Lecolorazioni di G in cui a e b ricevono colori distinti sono in corrispondenza 1-1con le colorazioni di G′. Infatti c : V (G) → 1, 2, . . . , k è una colorazionedi G con c(a) 6= c(b) se e solo se c è una colorazione di G′. Similmente lecolorazioni di G in cui a e b ottengono lo stesso colore sono in corrispondenza1-1 con le colorazioni di G′′. In particolare se, presi un numero naturale x edun grafo H, scriviamo pH(x) per il numero di colorazioni di un grafo H con

18 2. Introduzione Teorica
i colori 1, 2, . . . , x, allora:
pG(x) = pG′(x) + pG′′(x).
Per denizione χ(G) è il numero naturale piú piccolo, k, per cui pG(k) ≥ 1.Quindi queste riessioni insieme a alla condizione (2.1.14) ci portano a:
χ(G) = minχ(G′), χ(G′′).
Transizioni di fase nella colorazione dei gra random
Presa una istanza tipica dall'insieme dei gra random con una connettivitámedia tipica, 〈k〉 = c si assiste ad un fenomeno di soglia: al di sotto di unvalore critico cq una colorazione corretta per il grafo esiste, con probabilitáche va a 1 nel limite di N → ∞, mentre al di sopra del valore critico, talecolorazione non esiste. Tale fenome di soglia esiste anche in altri problemidi soddisfazione di vincoli (CSP, Constrains Satisfaction Problems), comela soddisfacibilitá di formule booleane (k-SAT). L'esistenza di questa tran-sizione colorabile/non-colorabile (COL/UNCOL) é stata provata nel 1999 daAchliopatas e Friedgut ed il calcolo rigoroso della sua posizione é uno deiproblemi aperti nella teoria dei gra. Diverse stime di limiti superiori edinferiori sono state fatte, sia per gra di Erdös e Rényi che per gra randomregolari (cioé gra random in cui ogni nodo ha lo stesso grado). E' statoanche empiricamente osservato che decidere della colorabilitá di un grafo di-venta man a mano piú dicile avvicinandosi al valore di soglia cq, piuttostoche lontano dallo stesso.Oltre questa transizione COL/UNCOL un risultato forse piú interessante cheviene dall'analisi, con gli strumenti della meccanica statistica, dei CSP é l'i-denticazione di una nuova transizione che riguarda la struttura dell'insiemedelle soluzioni, che appare prima della soglia di non colorazione: mentre abasse connettivitá tutte le soluzioni sono in un singolo stato puro, l'insiemedelle soluzioni si divide in un numero esponenziale di stati puri diversi (clus-ters) per connettivitá crescenti oltre un valore di soglia cd, ma comunque aldi sotto del valore di soglia cq, dal momento che per cd < c < cq esisonocomunque soluzioni. Recentemente l'esistenza di questa transizione é statadimostrata rigorosamente in alcuni problemi di soddisfacibilitá.Al crescere della connettivitá l'insieme delle soluzioni, subisce una serie ditransizioni di fase, dunque: lo spazio delle soluzioni prima si decomponein un numero esponenziale di clusters (che sono entropicamente trascurabilirispetto ad un cluster grande), poi al valore di soglia cd anche questo clustergrande si decompone in un numero esponenziale di stati piú piccoli. Succes-sivamente, al valore di condensazione cg, la maggior parte delle soluzioni si

2.2. k-soddisfacibilità, k-SAT 19
Figura 2.5: Transizioni dello spazio delle fasi delle soluzioni di colorazione diun grafo, in funzione della connettivitá
trova in un numero nito di stati grandi. Oltre questo punto si raggiungeil valore di soglia cq oltre il quale il grafo non é piú colorabile.Altra importante transizione, cui ci si riferisce con il nome di rigiditá haluogo ad un altro valore di soglia cr, allorché una frazione nita di variabilicongelate (cioé che non cambiano tra le soluzioni appartenenti allo stessocluster) appare all'interno degli stati puri dominanti (quelli che contengonoquasi tutte le soluzioni).
2.2 k-soddisfacibilità, k-SAT
Il problema della k-soddisfacibilità è un problema fondamentale nella teoriadella ottimizzazione combinatoriale, e spesso serve come banco di prova perdiversi algoritmi di ricerca nel campo dell'intelligenza articiale e in generalein informatica. Un algoritmo in grado di risolvere ecentemente k-SAT perk ≥ 3 porterebbe immediatamente alla soluzione di altri problemi combina-toriali deniti hard.La classe di problemi combinatoriali che condividono tali caratteristiche cru-ciali è denita NP-completa ed è una congettura della moderna computerscience che un tale algoritmo, eciente, non esista. In particolare il prob-lema di k-SAT è stato il primo problema NP -completo conosciuto, come hadimostrato Stephen Cook nel 1971. Fino ad allora il concetto di problemaNP -completo non esisteva nemmeno. Gli algoritmi che sono usati per risol-vere questo tipo di problemi mostrano una grande variabilitá in termini ditempo di completamento, da lineare ad esponenziale.Mentre i problemi di 1-sat e 2-sat sono ecacemente completati da algoritmicon run time polinomiali, per k > 2 il problema puó diventare incredibil-mente complicato. E' stato osservato, numericamente, che istanze casualicomputazionalmente hard sono generate quando i problemi sono vincolatiin modo critico: quando s'è vicini alla transizione di fase SAT-UNSAT. Lostudio di tali istanze critiche rappresenta una sda teorica che porta versouna piú profonda conoscenza della complessitá computazionale e dell'analisi

20 2. Introduzione Teorica
degli algoritmi. Ancora, tali istanze sono un campo di test comune per glialgoritmi di ricerca.
Dato un insieme di N variabili booleane xi = 0, 1i=1,...,N si scelgonoprima di tutto K tra gli N possibili indici i e poi, per ciascuno di essi, sisceglie un letterale zi corrispondente a xi o la sua negazione xi. Nel casoin cui si stia generando un problema k-SAT in modo casuale, la probabilitádi scegliere la variabile o la sua negazione, è uguale. Una clausola C é l'orlogico dei K letterali scelti precedentemente. Quindi la clausola C è vera se esolo se almeno uno dei letterali é vero. Si ripete il processo di creazione delleclausole no ad ottenere M clausole scelte indipendentemnte Cll=1,...,M . Sichiede inne che tutte le clausole siano vere insieme, ovvero si prende l'andlogico delleM clausole, ottenendo cosí una espressione booleana in quella cheè chiamata la forma congiuntiva normale (CNF, Conjuctive Normal Form).La risultante formula K-CNF, F , puó essere scritta come:
F =M∧l=1
Cl =M∧l=1
(K∨i=1
z(l)i ), (2.2.1)
dove ∧ e ∨ stanno rispettivamente per le operazioni di and e or logico.Un assegnamento delle xi che soddisfa tutte le clausole, ovvero in cui Frisulta vera, è detta una soluzione del problema della k-soddisfacibilitá. Seun tale assegnamento delle variabili booleane non esiste, F è detta non sod-disfabile.Quando il numero di clausole diventa dello stesso ordine del numero dellevariabili (M = αN) e nel limite di N grande, il problema k-SAT mostraun fenomeno di soglia evidente. Esperimenti numerici infatti mostrano chela probabilitá di trovare un assegnamento booleano corretto va da 1 a 0improvvisamente quando α = M/N cresce oltre un valore critico αc(K) diclausole per variabile. Sopra αc(K), non possono essere piú soddisfatte tuttele clausole e diviene interessante cercare di minimizzare il numero di clau-sole non soddisfatte, che è la versione di ottimizzazione del problema k-SAT,anche chiamata MAX-k-SAT. Inoltre, per α vicino αc(K), algoritmi euristi-ci di ricerca si bloccano in soluzioni non ottimali e si osserva un eetto dirallentamento (concentrazione di intrattabilitá3). Al contrario, lontano dallacriticitá i processi euristici sono generalmente piuttosto ecienti.Molto schematicamente, i risultati conosciuti sulla k-SAT che sono stati ot-tenuti nell'ambito della teoria della complessitá possono essere riassunti come
3la spiegazione di questo fenomeno, come si vedrá piú avanti é una transizione simile aquelal di clustering per il problema del graph coloring

2.2. k-soddisfacibilità, k-SAT 21
segue:
1. Per k = 2, 2-SAT appartiene alla classe P di problemi polinomiali.P è denito come l'insieme dei problemi computazionali i cui algo-ritmi di soluzione migliori hanno tempi che crescono polinomialmentecon il numero delle variabili rilevanti, nel trovare una soluzione. Perα > αc, MAX-2-SAT è NP-completo; i problemi NP-completi sonoi problemi polinomiali non deterministici piú dicili, le cui soluzionipossono essere trovate con l'ispezione completa di un albero decision-ale la cui profonditá cresce in modo polinomiale con il numero dellevariabili rilevanti; si pensa, generalmente, che i tempi di soluzione cres-cano esponenzialmente con il numero di variabili rilevanti. Il mappingdel problema 2-SAT sulla teoria dei gra diretti (cioè in cui si assegnauna direzione agli archi) permette di derivare rigorosamente il valoredi soglia αc = 1 e un algoritmo polinomiale 2-SAT che funziona perα < αc è stato sviluppato.
2. Per k ≥ 3 sia il problema k-SAT che quello MAX-k-SAT appartengonoalla classe NP-completo. Solo limiti superiori ed inferiori per αc(K)sono conosciuti da un punto di vista rigoroso. Tecniche di riscalamentoa dimensione nita (nite size scaling techniques) hanno, recentemente,permesso di trovare valori numerici per αc nei casi di k = 3, 4, 5, 6.
3. per k 1 le clausole diventano disaccoppiate e si puó trovare l'espres-sione asintotica αc ' 2k ln 2 per αc. Non si sa ancora se questa legge diriscalamento è corretta o meno da un punto di vista rigoroso.
3-SAT, come visto, è un caso particolare della k-SAT, in cui ciascunaclausola contiene al piuú k = 3 letterali. Un esempio di 3-SAT puó esserescritto come:
F = (x1 ∨ x2 ∨ x3) ∧ (x1 ∨ x2 ∨ x4)
F ha quattro letterali, due clausole e 3 letterali per clausola, quindi k = 3.Per risolvere questa istanza del problema si deve assegnare ad ogni letteraleun valore booleano, cosí che F risulti vera. In questa particolare istanzatale assegnamento esiste (x1 = Vero, x2 = Vero, x3 = Vero, x4 = Vero) equindi la risposta al problema di soddisfacibilità è positiva. Questo è solouno dei possibili assegnamenti; per esempio, ogni assegnamento che includax1 = Vero è suciente per la soluzione. Non ci fosse stato un assegnamen-to possibile, la risposta al problema di soddisfacibilitá sarebbe stata negativa.

22 2. Introduzione Teorica
E` possibile collegare un problema di graph coloring ad una istanza diun problema k-SAT, avendo cura di denire clausole di due tipi: dapprimaci saranno clausole che assicureranno che ciascuno dei colori assegnato adun vertice é un colore corretto, cioé un valore che ha senso nella lista deicolori disponbili, poi le clausole che garantiscono la colorazione corretta delgrafo: ovvero quelle clausole che impediscono la colorazione uguale di duenodi adiacenti.
2.3 Il modello di Potts
In meccanica statistica il modello di Potts è una generalizzazione del mo-dello di Ising di spin interangenti su di un reticolo cristallino. Il reticologeneralmente è considerato essere un reticolo bidimensionale rettangolare edeuclideo, ma spesso si puó generalizzarlo a piú dimensioni e a reticoli di for-ma diversa. Il modello di Potts si puó trovare applicato in piú campi, anchemolto diversi: protein folding, reti neurali, membrane biologiche, comporta-mento sociale, separazione di fase nelle leghe binarie, vetri di spin, cellulecardiache.
Il modello di Ising prevede che gli spin sui siti reticolari possano averedue congurazioni: spin su e spin giú. Una generalizzazione, proposta daDomb e poi realizzata da Potts, prevede invece che gli spin possano, sui sitireticolari, puntare in una delle q direzioni denite dagli angoli
θn =2π
q, n = 0, 1, . . . , q − 1
L'Hamiltoniana di tale sistema è:
H = −∑〈i,j〉
J(θij)
dove la funzione J(θij) è periodica di periodo 2π e θij = θni − θnj è l'angolotra due spin nei siti vicini i e j: l'interazione tra gli spin piú vicini (nearest-neighbor) dipende solo dall'angolo relativo tra i due vettori.Il modello suggerito da Domb prevedeva la scelta di
J(θ) = −ε1cos(θ) (2.3.1)
Potts ricavó i punti critici di questo modello per q = 2, 3, 4, ma non fu in

2.3. Il modello di Potts 23
grado di estendere questo risultato per q > 4. Peró per il modello denitoda:
J(θij) = ε2δ(n1, n2) (2.3.2)
fu in grado di denire il punto critico per ogni q. Qui per δ si considera ladelta di Kronecker, che è 1 se n1 = n2 e 0 altrimenti.Seguendo il suggerimento di Domb, si usa chiamare (2.3.1) modello di Pottsplanare, anche detto modello di Potts vettoriale o modello ad orologio, e(2.3.2) modello di Potts standard. E' infatti quest'ultimo che ha attratto piúattenzione.Il modello di Potts (standard) è ferromagnetico se ε2 > 0 ed antiferromagneti-co se ε2 < 0. L'interazione (2.3.2) puó essere formulata in modo alternativoper riettere la sua completa simmetria in uno spazio q − 1 dimensionale.Questo puó essere fatto scrivendo in (2.3.2)
δ(α, β) =1
q
[1 + (q − 1)eα · eβ
]dove eα, α = 0, 1, . . . , q − 1 sono q versori che puntano nelle q direzionisimmetriche di un ipertetraedro in q − 1 dimesioni.Il modello planare e quello standard sono identici per q = 2 e q = 3 con,rispettivamente, ε2 = 2ε1 ed ε2 = 3ε1/2. Per q = 2 si riottiene il modellodi Ising. Insieme all'interazione tra due siti, si puó considerare l'interazionemultisito e l'interazione con un campo esterno. Per un modello di Potts suun reticolo G di N siti, l'Hamiltoniana H puó, cosí, prendere la forma
−βH = L∑i
δ(σi, 0) +K∑(i,j)
δ(σi, σj) +K3
∑(i,j,k)
δ(σi, σj, σk) + · · ·
dove β = 1/kT , e σi specica lo stato dello spin all'i-imo sito. Ovviamente
δ(σi, . . . , σk) =
1 se σi = . . . = σk
0 altrimenti.
Qui K = βε2,Kn, n ≥ 3, è la forza delle interazioni ad n siti, ed L è il campoesterno applicato allo stato di spin 0. La funzione di partizione Z
ZG(q;L,K,Kn) =
q−1∑σi=0
e−βH.
Le proprietá siche del sistema sono derivate prendendo il limite termodi-namico. Quantitá interessanti per la termodinamica del sistema includono:l'energia libera per sito:
f(q;L,K,Kn) = limN→∞
1
Nln ZG(q;L,K,Kn),

24 2. Introduzione Teorica
l'energia per sito
E(q;L,K,Kn) = − ∂
∂βf(q;L,K,Kn)
e la magnetizzazione per sito:
M(q;L,K,Kn) = − ∂
∂Lf(q;L,K,Kn).
Il parametro d'ordinem, che prende i valori 0 ed 1 rispettivamente per sistemidisordinati ed ordinati è denito essere
m(q;L,K,Kn) =qM − 1
q − 1.
Una transizione ferromagnetica è quindi accompagnata dall'apparizione diun ordine spontaneo:
m0 = m(q; 0+, K,Kn).
La funzione di correlazione a due punti Γαα(r1, r2) del modello di Potts azero-campo è
Γαα(r1, r2) = Pαα(r1, r2)− q−2
dove Pαα(r1, r2) é la probabilitá che i siti in r1 ed r2 siano nello stesso statodi spin α. Chiaramente Γαα prende i valori 0 e (q − 1)/q2 rispettivamenteper sistemi completamente disordinati e completamente ordinati. Questoallora suggerisce la seguente relazione tra la correlazione a grande distanza el'ordine spontaneo:
lim|r1−r2|→∞
Γαα(r1, r2) = (q − 1)(m0
q)2. (2.3.3)
Di fatto la relazione (2.3.3) puó essere stabilita decomponendo la funzione dicorrelazione in quelle degli stati estremi. E' stato dimostrato rigorosamenteche Γαα decade esponenzialmente per T al di sopra di una temperatura crit-ica Tc.
Il modello di Potts è analizzabile usando la descrizione di campo medio:tale descrizion è ben conosciuta e dá risultati qualitativamente corretti peril modello di Ising. Nell'assenza, quindi, di soluzioni generiche esatte, è nat-urale esaminare il modello di Potts a q-componenti con l'approssimazione dicampo medio. Tale studio, eettuato usando l'approssimazione di Braggs-Williams, porta a concludere che esiste una transizione di fase di primo ordineper tutti i q > 2. Tale risultato è poi stato confermato essere esatto nell'es-pansione di grandi q in d = 2 dimensioni: di fatto il risultato esatto in d = 2

2.4. Tecniche Monte Carlo 25
Figura 2.6: Plot schematico di qc(d), il valore critico oltre il quale la tran-sizione è simile a quella di campo medio.(di primo ordine per q > 2 e continuaper q ≤ 2). I punti noti sono qc(2) = d, qc(4) = 2 e qc(6) = 1 in cerchiettivuoti. Il cerchietto nero invece indica la supposta transizione di primo ordineper d = 3, q = 3.
dimensioni mostra una transizione di primo ordine per q > 4. Ci si aspettaquindi, piú genericamente, l'esistenza di un valore critico qc(d) tale che, in ddimensioni, la teoria di campo medio sia valida per q > qc(d). Guardando qe d come variabili continue l'esistenza di un valore critico qc(d) implica l'e-sistenza di una dimensione critica dc(q) tale che il comportamento di campomedio prevalga per d > dc(q). I punti conosciuti sono dc(2) = 4 e qc(4) = 2.
2.4 Tecniche Monte Carlo
Studiando un sistema costituito da un numero elevato di particelle diventaimmediatamente chiaro che il numero di possibili congurazioni cresce espo-nenzialmente con il numero di costituenti. Nel modello di Potts, infatti, ogniparticella puó esistere in un numero q di stati, pertanto sono possibili qN con-gurazioni. In un modello bidimensionale di, per esempio, 32 siti reticolari,si hanno 32× 32 = 1024 = 210 spin da considerare. Per ognuno di questi, sihanno q possibili congurazioni e, prendendo come esempio il caso q=2 delmodello di Ising,
Ω = 2210 ≈ 10308
il numero delle congurazioni è grande.La funzione di partizione di un sistema é denita come
Z =∑i
e−βEi (2.4.1)
dove i indica uno stato del sistema: é quindi impensabile di calcolare 2.4.1 inmodo esatto per un sistema cosí grande, nei casi in cui, in qualche modo, non

26 2. Introduzione Teorica
si possa gestire la sommatoria, che è fatta su tutte le congurazioni, in modoanalitico. Quando le particelle non interagiscono si riesce a gestire la sommaanaliticamente, ma nel momento in cui, per esempio per via dell'interazionespin-spin, interagiscono, non si riesce piú: non s'ha altra scelta che cercareun'approssimazione, analitica o numerica.All'equilibrio, le congurazioni hanno probabilitá di presentarsi proporzionaleal fattore di Boltzmann
pµ =1
Ze−βEµ . (2.4.2)
Si vuole, quindi, fare un sampling dello spazio delle possibili congurazioniin modo che sia concorde con la probabilitá: P ∝ e−E/T .
Di fatto questo ragionamento é consistente con quello che si nota in natu-ra: un qualsiasi sistema composto da un gran numero di entitá non fa, nellasua esistenza, un sampling degli stati con probabilitá costante quanto, piut-tosto, un sampling basato sulla probabilitá di esistenza di ogni stato: di fattoquindi il sampling avviene, naturalmente, in accordo con la distribuzione diprobabilitá di Boltzmann. Usando lo stesso comportamento, e imitandolo inun algoritmo, saremo dunque in grado di usare questo intervallo, piccolo, dienergie ed altre quantitá, ottenendo misure accurate pur non visitando ognistato del sistema.La strategia dunque é questa: anziché prendere, a caso,M stati per misurareuna certa quantitá 〈Q〉, li si sceglie in modo che la probabilitá che un certostato µ venga scelto sia proporzionale a pµ = Z−1e−βEµ . La nostra stima di〈Q〉 sará dunque
QM =1
M
M∑i=1
Qµi (2.4.3)
dove M é il numero totale di stati visitati.Da notare, come si noterá anche piú avanti, che i fattori di Boltzmann si sonosemplicati, nella stima, lasciando una espressione particolarmente semplice.Questa stima funziona molto meglio di una stima in cui gli stati su cui me-diare sono presi a caso: infatti il sistema spenderá piú tempo negli stati piúprobabili, cioé, per un sistema a bassa temperatura quelli a minore energia,esattamente come farebbe il sistema reale.Rimane peró da chiedersi come esattamente si scelgano gli stati in modo checiascuno appaia con la sua probabilitá di Boltzmann corretta.
Processi di Markov
Quasi ogni schema Monte Carlo utilizza Processi Markoviani come motoreper generare l'insieme degli stati usati. Per quello che lo scopo qui un processo

2.4. Tecniche Monte Carlo 27
Markoviano é un meccanismo che, dato un sistema in uno stato µ, generaun nuovo stato di quel sistema, ν. Questo nuovo stato é generato in modocasuale e non verrá generato lo stesso stato ogni qualvolta lo stato inizialesia µ. La probabilitá di generare lo stato ν dato µ é chiamata la probabilitádi transizione P (µ → ν) per la transizione da µ a ν e perché il processo siaveramente Markoviano tutte le probabilitá di transizione devono soddisfaredue condizioni:
- le probabilitá di transizione non devono variare nel tempo;
- le probabilitá di transizione devono dipendere solamente dagli statiiniziale, µ e nale ν, e non da qualsiasi altro stato in cui il sistema épassato precedentemente;
Queste condizioni dicono che le probabilitá che il processo Markoviano generilo stato ν quando lo stato µ é in ingresso é la stessa ogni qualvolta che iningresso c'é eettivamente lo stato µ, senza riguardo a cosa é successo primaal sistema. Le probabilitá di transizione inoltre devono soddisfare il vincolo∑
ν
P (µ→ ν) = 1 (2.4.4)
dal momento che il processo Markoviano deve generare un qualche stato νogni volta che gli é presentato un sistema nello stato µ. Si noti comunqueche la probabilitá P (µ → µ) che il sistema permanga nello stato µ non perforza deve essere nulla: puó esistere una probabilitá nita che il sistema sem-plicemente rimanga nello stato µ.Nel metodo Monte Carlo si usa un processo Markoviano ripetutamente pergenerare una catena Markoviana di stati. Partendo da uno stato µ si usail processo per generare un nuovo stato ν e poi si usa quest'ultimo sta-to per generare un nuovo stato λ e avanti cosí. Il processo Markovianoé usato in modo che, partendo da uno stato qualsiasi del sistema, si pro-duca una successione di stati che appariranno con probabilitá date dalladistribuzione di Boltzmann (generalmente si chiama questo raggiungimentodella distribuzione di Boltzmann raggiungere l'equilibrio, dal momento cheé esattamente il processo che segue un sistema reale nel raggiungimento del-l'equilibrio con l'ambiente).Per far raggiungere al sistema l'equilibrio bisogna peró mettere altre due con-dizioni a anco della condizione di processo Markoviano: nello specico, lacondizione di ergodicitá e la condizione di bilancio dettagliato.

28 2. Introduzione Teorica
Ergodicitá
La condizione di ergodicitá é la richiesta che, da un qualsiasi stato del sis-tema, sia possibile raggiungere un qualsiasi altro stato del sistema attraversoil processo Markoviano, se questo é lasciato evolvere per un tempo sucien-temente lungo. Questa condizione é necessario per raggiungere l'obiettivodi generare stati con probabilitá correttamente distribuita secondo le prob-abilitá di Boltzmann. Ogni stato ν ha una probabilitá non nulla pν nelladistribuzione di Boltzmann, e se tal stato fosse inacessibile da un altro statoµ allora non si sarebbe in grado di generare, anche facendo andare il pro-cesso Markoviano per un tempo arbitrariamente lungo, una distribuzione diprobabilitá corretta: infatti partendo dalla stato µ la probabilitá di trovarenella catena di Markov lo stato ν sarebbe nulla e non pν , come richiesto.La condizione di ergodicitá dice che é permesso rendere alcune delle prob-abilitá di transizione nulle nel nostro processo Markoviano, ma che deveesistere almeno un cammino di probabilitá non nulle tra due stati qualsiasidel sistema.
Bilancio Dettagliato
L'altra condizione posta sul processo Markoviano é la condizione di bilanciodettagliato. E' questa che garantisce che sia proprio la distribuzione di prob-abilitá di Boltzmann che viene generata una volta che il sistema ha raggiuntol'equilibrio, piuttosto che una qualsiasi altra. All'equilibrio, le frequenze concui il sistema transirá in uno stato µ e con cui uscirá dallo stesso sarannouguali. Questo si puó esprimere matematicamente come∑
ν
pµP (µ→ ν) =∑ν
pνP (ν → µ). (2.4.5)
Facendo uso di (2.4.4), possiamo semplicare quest'ultima in
pµ =∑ν
pνP (ν → µ) (2.4.6)
Questa sola condizione non basta a garantire che la distribuzione di prob-abilitá tenda a pν da qualsiasi stato del sistema si parta facendo andare ilprocesso Markoviano abbastanza a lungo, come si mostrerá ora: si puó pen-sare alle probabilitá di transizione come ad una matrice P, chiamata matricedi Markov, o matrice stocastica. Misurando il tempo in passi lungo la catenaMarkoviana, allora la probabilitá pν(t + 1) di essere nello stato ν al tempot+ 1 é data da
pν(t+ 1) =∑ν
P (µ→ ν)pµ(t). (2.4.7)

2.4. Tecniche Monte Carlo 29
In notazione matriciale quest'ultima diventa
w(t+ 1) = P ·w(t) (2.4.8)
dove il vettore w(t) é formato dalle probabilitá pµ(t). Se il processo Marko-viano raggiunge un stato di equilibrio w(∞) per t → ∞, allora tal statosoddisfa
w(∞) = P ·w(∞). (2.4.9)
E' peró possibile che il processo raggiunga un equilibrio dinamico in cui ladistribuzione di probabilitá w cicli tra un certo numero di valori. Si é dunquein presenza di un ciclo limite. In tal caso w(∞) soddisferebbe
w(∞) = Pn ·w(∞), (2.4.10)
dove n é la lunghezza del ciclo limite. Se si scelgono le probabilitá di tran-sizione (o equivalentemente la matrice di Markov) in modo da soddisfare(2.4.6) si garantisce che la catena Markoviana avrá una distribuzione di prob-abilitá all'equibrio semplice, pµ, ma potrebbe anche avere un qualsiasi numerodi cicli limite nella forma di (2.4.10). Questo signica che non c'é garanziache gli stati generati abbiano la distribuzione di probabilitá che si desidera.Un modo per aggirare questo problema é applicare una ulteriore condizionealle probabilitá di transizione, ovvero:
pµP (µ→ ν) = pνP (ν → µ) (2.4.11)
Questa é la condizione di bilancio dettagliato. E' chiaro che un insieme diprobabilitá di transizione che soddisfa quest'ultima, soddisfa anche (2.4.6)(per provarlo basta sommare entrambi i lati dell'equazione su ν). Inoltrequesta condizione elimina i cicli limite. Per mostrarlo, si consideri il latosinistro dell'equazione, che é la probabilitá di trovarsi in uno stato µ molti-plicato per la probabilitá di transire da tale stato ad uno stato ν. In altreparole questa é una misura di quanto spesso le transizioni da µ a ν avven-gono nel sistema. La parte destra dell'equazione, invece, é misura di quantospesso avviene la transizione inversa. La condizione di bilancio dettagliatodice, quindi, in media, che il sistema dovrebbe transire da µ a ν tanto spessoquanto transisce da ν a µ. In un ciclo limite, in cui la probabilitá di occu-pazione di alcuni o di tutti stati cambia in modo ciclico, si saranno stati percui questa condizione é violata per qualcuno dei passi della catena Marko-viana; perché la probabilitá di occupazione di un certo stato del ciclo cresca,per esempio, ci saranno piú transizioni ad entrare in quello stato che non aduscirci, in media. La condizione di bilancio dettagliato proibisce dinamichedi questo tipo, e quindi proibisce i cicli limite.

30 2. Introduzione Teorica
Il motivo per cui é importante implementare la condizione di bilancio det-tagliato nelle simulazioni Monte Carlo é legato al fatto che i sistemi realiquasi sempre obbediscono a tale condizione. Tali sistemi reali sono basatisulla meccanica classica o quantistica, entrambi simmetriche per inversionitemporali. Se tali sistemi non obbedissero alla condizione di bilancio det-tagliato, allora all'equilibrio potrebbero avere un ciclo limite, che il sistemaattraverserebbe in una particolare direzione. Se su questo sistema venisseinvertito il tempo anche il moto sul ciclo limite verrebbe invertito, e diven-terebbe subito chiaro che la dinamica del sistema in equilibrio non sarebbepiú la stessa se il tempo scorresse in un senso o in senso inverso. Tale viola-zione é proibita nella maggior parte dei sistemi, il che implica che essi devonorispettare la condizione di bilancio dettagliato.
Quindi, si é visto che si possono scegliere le probabilitá di transizione inmodo che la distribuzione di probabilitá di stati generata dal processo Marko-viano tenda ad una distribuzione pµ qualunque, che si sceglie essere, essendoall'equilibrio, quella di Boltzmann. Chiaramente, volendo una distribuzionedi Boltzmann all'equilibrio, si sceglieranno i valori di pµ in modo che essistessi siano fattori di Boltzmann, come descritto in (2.4.2). La condizionedi bilancio dettagliato dice allora che le probabilitá di transizione devonosoddisfare:
P (µ→ ν)
P (ν → µ)=pνpµ
= e−β(Eν−Eµ) (2.4.12)
Questa equzione e l'equazione (2.4.4) sono i vincoli che si devono rispettareenella scelta delle probabilitá di transizione P (µ→ ν). Soddisfatte queste e lacondizione di ergodicitá la distribuzione degli stati all'equilibrio nel processoMarkoviano sará la distribuzione di Boltzmann.
Chiarito questo punto, il piano é di scrivere un programma su un compu-ter che implementi il processo Markoviano corrispondente a queste probabil-itá di transizione tale da generare una catena di stati. Dopo aver aspettatoun tempo adeguato per permettere alla distribuzione degli stati, wµ(t) di ar-rivare sucientemente vicina alla distribuzione di Boltzmann, si media unaosservabile Q, a cui si é interessati, suM stati e si calcola la stima QM , comesi era denito in (2.4.3).
Risulta comodo, molto spesso, dividere la probabilitá di transizione P (µ→ν) in due parti:
P (µ→ ν) = g(µ→ ν)A(µ→ ν). (2.4.13)
La quantitá g(µ → ν) é chiamata probabilitá di selezione. La quantitáA(µ → ν) é invece chiamata probabilitá di accettazione. La prima é una

2.4. Tecniche Monte Carlo 31
misura della probabilitá che lo stato ν, partendo da uno stato µ venga se-lezionato come prossimo stato nella catena Markoviana, mentre la seconda éla probabilitá che questo nuovo stato selezionato venga accettato. La proba-bilitá di accettazione dice, in senso pratico, che se il sistema é nello stato µ eviene proposto di cambiare stato in ν, si deve accettare questo cambiamentouna frazione A(µ→ ν volte. Le altre volte il sistema semplicemente rimarránello stato µ. Si é liberi di scegliere la probabilitá d'accettazione nell'inter-vallo [0, 1]. Questo lascia completamente liberi nel scegliere le probabilitá diselezione g(µ → ν), dal momento che il vincolo (2.4.12) ssa solamente ilrapporto:
P (µ→ ν)
P (ν → µ)=g(µ→ ν)A(µ→ ν)
g(ν → µ)A(ν → µ)(2.4.14)
Il rapporto A(µ → ν)/A(ν → ν) puó prendere qualsiasi valore tra zero edinnito, il che signica che sia g(µ → ν) che g(ν → µ) possono prenderei valori a cui piú si é interessati. L'altro vincolo, l'equazione (2.4.4), é co-munque soddisfatta, dal momento che il sistema, ad ogni passo, deve arrivarein qualche stato, anche se tale stato é quello di cui si era partiti. Quindi, percreare un algoritmo Monte Carlo, si deve pensare ad un algoritmo che generanuovi stati casuali ν partendo da uno stato µ, con una qualche probabilitág(µ→ ν), e poi si accetta un tale stato proposto con probabilitá A(µ→ ν).Questo produrrá una serie di stati che, all'equilibrio, appariranno con la lorocorretta probabilitá, secondo il fattore di Boltzmann, ed inoltre soddisferátutti i vincoli che si sono visti.
2.4.1 L'algoritmo di Metropolis
L'algoritmo di Metropolis é stato il primo algoritmo Monte Carlo proposto,ed é uno dei piú usati e famosi. Fu introdotto da N. Metropolis e dai suoicollaboratori nel 1953. E' usato spesso anche per scopi didattici, per spie-gare i fondamenti delle simulazioni Monte Carlo, incluso il raggiungimentodell'equilibrio, la misura di valori di aspettazione ed il calcolo degli errori.L'algoritmo funziona esattamente come si é visto prima: si sceglie un in-sieme di probabilitá di transizione g(µ→ ν), un altro insieme di probabilitádi accettazione A(µ → ν) tali che (2.4.14) soddis la condizione di bilanciodettagliato. L'algoritmo funziona scegliendo ripetutamente nuovi stati ν, epoi accettandoli o riutandoli secondo la probabilitá d'accettazione scelta.Se il nuovo stato é accettato, allora il sistema si sposta nel nuovo stato, al-trimenti permane nello stato di partenza. Dopodiché il processo é ripetuto,ancora ed ancora. Le probabilitá di selezione g(µ → ν) devono essere sceltein modo che la condizione di ergodicitá sia soddisfatta. Questo processo las-cia ancora, peró, molta libertá sul come scegliere il nuovo stato: nel caso del

32 2. Introduzione Teorica
modello di Ising, per esempio, un nuovo stato puó essere generato semplice-mente cambiando un sottoinsieme degli spin del reticolo. Nei casi reali peróun sistema all'equilibrio passerá la maggior parte del tempo in un insiememolto piccolo di stati, tutti aventi energia simile: le uttuazioni del sistemasono piccole rispetto alla scala delle energie del sistema. Raramente, quindi,un sistema in equilibrio transirá verso una congurazioni che cambiano l'en-ergia in modo drastico. Questo suggerisce che, nelle simulazioni Montecarlo,raramente si vorrá considerare transizioni verso stati la cui energia é moltodiversa rispetto a quella del sistema nello stato corrente. Nell'esempio delmodello di Ising é ragionevole pensare di transire verso stati che dierisconodallo stato corrente per un solo spin.Nell'algoritmo di Metropolis tutte le probabilit± di selezione g(µ → ν) perciascuno degli stati possibili ν sono scelte uguali. Portando avanti l'esempiodel modello di Ising si puó pensare a quali stati sono possibili, partendo dauno stato µ e cambiando un solo spin: avendo un reticolo di N spin, cias-cuno di essi potrebbe essere invertibile, e pertanto, ci sono N possibili statiν accettabili, partendo da µ. Quindi ci sono N probabilitá di transizioneg(µ→ ν) che non sono nulle, e ciascuna di essere ha valore
g(µ→ ν) =1
N(2.4.15)
e tutte le altre probabilitá di transizione (che non vanno a stato accettabili)sono poste a 0. Con queste regole di selezione la condizione di bilanciodettagliato prende la forma
P (µ→ ν)
P (ν → µ)=g(µ→ ν)A(µ→ ν)
g(ν → µ)A(ν → µ)=A(µ→ ν)
A(ν → µ)= e−β(Eν−Eµ) (2.4.16)
A questo punto si devono scegliere le probabilitá di accettazione A(µ→ ν)per soddisfare questa equazione. Una scelta possibile potrebbe essere
A(µ→ ν) = A0e− 1
2β(Eν−Eµ) (2.4.17)
La costante di proporzionalitá si cancellerebbe in (2.4.16), quindi si potrebbescegliere il valore di A0 arbitrariamente, non fosse per il fatto che essendoA(µ → ν) una probabilitá non dovrebbe mai diventare piú grande di uno.Nel modello di Ising la dierenza di energia piú grande possibile tra duestati che dieriscono per uno spin é 2zJ dove J é una costante che entranell'Hamiltoniana e ssa la scala delle energie e z é il numero di coordinazionedel reticolo, ed esprime quanti sono, nel reticolo i primi vicini di uno spin.Questo signica che il valore piú grande possibile per e−
12β(Eν−Eµ) é eβzJ , e,
per essere certi che A(µ→ ν) ≤ 1 sará bene scegliere
A0 ≤ e−βzJ (2.4.18)

2.4. Tecniche Monte Carlo 33
Per rendere l'algoritmo il piú eciente possibile si vuole che A0 sia il piúgrande possibile, e quindi fare in modo che la probabilitá di accettazione ilmaggiore possibile, pur senza violare la condizione A(µ→ ν) ≤ 1, sará
A(µ→ ν) = e−12β(Eν−Eµ+2zJ) (2.4.19)
Usando l'algoritmo con questa probabilitá di accettazione é possibile fareuna simulazione Monte Carlo del modello di Ising (per esempio), ed essofará un sampling corretto della distribuzione di Boltzmann: questa simu-lazione peró sará largamente ineciente, dal momento che la probabilitádi accettazione (2.4.17) é piccola per qualsiasi mossa. Infatti, per una simu-lazione con β = J = 1 ed un reticolo con z = 4 (un reticolo piano), A(µ→ ν)é 1 per ∆E = −8, 0.13 per ∆E = −4, 0.02 per ∆E = 0. Le probabilitádi spostarsi in uno stato che abbia ∆E > 0 sono pressoché nulle: questosignica che l'algoritmo sará incredibilmente lento, di fatto, poiché spenderála maggior parte del tempo nel riutare i cambiamenti agli spin, e, di fatto,non cambiando praticamente lo stato.Esiste una soluzione, ovviamente. Nello scrivere l'equazione (2.4.17) si éfatta l'implicita assunzione di una particolare forma funzionale per la proba-bilitá d'accettazione, ma la condizione di bilancio dettagliato non la richiede.Tale condizione infatti specica solamente il rapporto tra le probabilitá diaccettazione, il che lascia una certa libertá di manovra. In eetti, la cosamigliore da farsi, avendo una condizione come (2.4.16) é mettere la probabil-itá d'accettazione per un nuovo stato a uno (il valore piú grande possibile) inun caso e poi adattare l'altro in modo da rispettare la condizione di bilanciodettagliato. Nel caso in cui, per esempio, si stia passando da uno stato µad uno stato ν in cui il primo avesse energia minore del secondo, Eµ < Eν ,la piú grande tra le probabilitá di accettazione é A(ν → µ), e quindi vieneposta ad 1, poi, per soddisfare l'equazione (2.4.16), si pone A(µ→ ν) pari ae−β(Eν−Eµ). Quindi le probabilitá di accettazione di questo algoritmo sono
A(µ→ ν) =
e−β(Eµ−Eν) se Eµ − Eν > 0
1 altrimenti(2.4.20)
In altre parole se viene selezionato uno stato di destinazione che ha energiaminore o uguale a quella dello stato in cui si é la transizione viene sempreaccettata. Se ha una energia maggiore, allora lo si accetta con una proba-bilitá proporzionale al fattore di Boltzmann della dierenza di energia. E'l'equazione (2.4.20) che fa funzionare l'algoritmo di Metropolis, ed ogni altroalgoritmo che funzioni come questo puó essere detto di Metropolis.

34 2. Introduzione Teorica
Partendo dall'algoritmo di Metropolis é possibile usare metodi piú ra-nati per ottenere risultati migliori sotto il prolo dell'ecienza delle simu-lazioni Monte Carlo.
2.4.2 Simulated Annealing
Il Simulated Annealing (SA) é un meta algoritmo (cioé un algoritmo checontiene al suo interno un altro algoritmo) usato per trovare il minimo omassimo assoluto di una funzione, oppure una sua buona approssimazione.E' stato creato da Kirkpatrick, Gelatt e Vecchi nel 1983 come una genera-lizzazione del metodo Monte Carlo per esaminare le equazioni di stato e glistati congelati in un sistema a n corpi. Il nome e l'ispirazione sono presidalla metallurgia, dove l'annealing (la ricottura, in italiano) é un processoche coinvolge il riscaldamento e il lento rareddamento di un materiale peraumentare le dimensioni dei cristalli e diminuire i loro difetti. Il riscaldamen-to obbliga gli atomi a spostarsi dalle loro posizioni iniziali, un minimo localedell'energia interna, e li fa muovere liberamente e a caso per stati piú ener-getici; il lento rareddamento aumenta le possibilitá che gli atomi possanotrovare congurazioni ad energia minore di quella iniziale (cioé quella primadel riscaldamento). In analogia con questo processo ogni passo dell'algorit-mo di Simulated annealing rimpiazza lo stato corrente con uno stato vicino,nello spazio delle fasi, scelto con una probabilitá che dipende dalla dierenzatra i parametri di stato (per esempio l'energia) e un parametro globale, T(chiamata comunque temperatura), che é, lentamente, fatta diminuire. Ladipendenza é tale che lo stato corrente cambia quasi a caso per T grande, maper T decrescente fa sí che lo stato piú favorito sia sempre quello a minoreenergia. Il fatto che, come nell'algoritmo di Metropolis, ci sia la possibilitáche l'energia dello stato di destinazione sia maggiore di quella dello stato dipartenza salva il metodo dal bloccarsi a minimi locali, cosa che, senza SA,potrebbe succedere. Se il parametro T venisse solo fatto diminuire si avrebbeperó un altro problema: una volta entrato in un minimo locale dell'ener-gia l'algoritmo di Metropolis, con il Simulated Annealing che fa scendere ilparametro T , non ne uscirebbe piú. Ecco allora che si congura la necessitáin certi momenti, di far improvvisamente crescere la temperatura, come nelprocesso reale di annealing.
2.4.3 Parallel Tempering
Anche conosciuto come Replica Exchange, il Parallel Tempering (PT) é unmetodo di simulazione che ha lo scopo di migliorare la dinamica delle simu-lazioni Monte Carlo. Come vedremo piú avanti in certe condizioni si assiste

2.4. Tecniche Monte Carlo 35
ad un rallentamento critico delle performance di una simulazione Monte Car-lo. Il PT consiste nel creare piú repliche dello stesso sistema, per esempiodue. Se queste due repliche fossero sottoposte a simulazioni a temperaturediverse, separate da un ∆T , si troverebbe che, se ∆T fosse abbastanza pic-colo, gli istogrammi dell'energia, ottenuti raccogliendo i valori delle energiesu un insieme di N passi Monte Carlo creerebbero due distribuzioni che,in un qualche modo, si sovrapporrebbero. Tale sovrapposizione puó esseredenita come l'area degli istogrammi che cade sugli stessi intervalli di valoridell'energia, normalizzati rispetto al numero totali di elementi dell'insieme.Per ∆T → 0 tale sovrapposizione tenderebbe a 1. In altro modo si puó in-terpretare questa sovrapposizione dicendo che gli stati (o le congurazioni)del sistema visitati a temperatura T1 hanno una certa probabilitá di apparirealla temperatura T2. In base al fatto che la catena Markoviana degli statinon dovrebbe avere memoria del proprio passato, si puó creare un nuovo ag-giornamento per il sistema contenuto tra i due sistemi a T1 e T2. Ad un certopasso Monte Carlo, si puó aggiornare il sistema globale scambiando le cong-urazioni o, alternativamente, le due temperature. Lo scambio, che é a tuttigli eetti un aggiornamento del sistema, puó essere accettato o riutato conlo stesso criterio dell'algoritmo di Metropolis, con la modica che le due en-ergie saranno le energie delle due repliche. Ovviamente deve essere rispettatala condizione di bilancio dettagliato: deve essere quindi assicurato il fatto chela transizione inversa deve avere pari probabilitá. Questo puó essere fatto inmodo corretto scegliendo aggiornamenti Monte Carlo o PT con probabilitáindipendenti dalle congurazioni dei due sistemi o del passo Monte Carlo.Questo metodo puó essere chiaramente esteso a piú di due repliche. Questometodo puó essere visto come un super-SA che non ha bisogno di rialzaretemperatura, dal momento che una replica ad alta temperatura puó passareottimizzatori locali ad un sistema a bassa temperatura, permettendo di pas-sare attraverso stati metastabili e di fatto migliorando la convergenza ad unminimo globale.

36 2. Introduzione Teorica

3Connessioni tra i modelli teorici
In questo capitolo si cercherá di stabilire collegamenti tra i problemi introdot-ti nel capitolo 1, in modo da poter arontare un problema, guardandone treallo stesso tempo.
3.1 Il modello di Potts e la colorazione dei nodi
di un grafo
È possibile denire il modello di Potts su di un grafo G(V,E) con insieme divertici V ed archi E: assegnato ad ogni nodo del grafo uno stato di spin q, èchiaro che una interazione tra primi vicini (di tipo nearest neighbour, quindi)è presente solo se i nodi del grafo sono adiacenti. In caso contrario, i nodinon interagiscono tra loro. La funzione di partizione, Z, di tale modello diPotts non varia rispetto a quello denito sul reticolo, ed è
Z =∑σi
e−βEσi (3.1.1)
Ora, si supponga di considerare q anzichè uno stato di spin, un colore, concui si intende colorare il grafo G(V,E) su cui abbiamo costruito il modellodi Potts in oggetto. Essendo l'hamiltoniana del modello di Potts
H = −∑(i,j)
δ(σi, σj) (3.1.2)
37

38 3. Connessioni tra i modelli teorici
è evidente che, nel caso in cui i nodi agli estremi dell'arco (e quindi interagentiessendo primi vicini) abbiano lo stesso colore q, il termine nella somma del-l'hamiltoniana é uno, e nel caso invece abbiano colori diversi, è zero. Questoci porta a pensare che, per un grafo correttamente colorato, o piú semplice-mente colorato, la somma che costituisce l'hamiltoniana sia nulla, e pertantol'energia della congurazione sia zero.
Dunque sia G = (V,E) un grafo semplice di dimensione nita e con i ver-tici senza direzione, con insieme dei nodi V e insieme degli archi E. Per ogniintero positivo q, sia PG(q) il numero di modi in cui ai nodi di G si possonoassegnare i colori 1, 2, . . . , q in modo tale che nodi adiacenti abbiano coloridiversi, in modo tale, quindi, da avere una colorazione corretta, o piú sem-plicemente una colorazione. Si puó mostrare che PG(q) è una restrizione aZ+ di un polinomio in q. Questo polinomio è chiamato polinomio cromaticodi G, e si puó prendere quella appena data come denizione di PG(q) pervalori arbitrari di q.Il polinomio cromatico fu introdotto da Birkho in [1] nella speranza che lostudio degli zeri di tal polinomio potesse portare ad una dimostrazione analit-ica della Congettura dei Quattro Colori, che suppone che ogni grafo planaresenza cammini chiusi PG(4) > 0 e che quindi tali gra siano colorabili con 4colori. Fino ad ora tale speranza è stata vana, nonstante altre dimostrazionianalitiche della Congettura siano state trovate.Un polinomio piú generico puó essere denito come segue: si assegni ad ogniarco e ∈ E un peso, complesso o reale, ve. Deniamo allora:
ZG(q, ve) =∑σ(x)
∏e∈E
1 + veδ(σx1(e), σx2(e)), (3.1.3)
dove la somma va su tutte le mappe σ : V → 1, 2, . . . , q, δ è la funzionedi Kronecker e x1(e), x2(e) ∈ V sono gli estremi dell'arco e. Si puó mostrareche ZG(q, ve) è la restrizione a q ∈ Z+ di un polinomio in q e ve. Seprendiamo ve = −1 per ogni e, (3.1.3) si riduce al polinomio cromatico. Perve = v per ogni e, (3.1.3) denisce un polinomio a due variabili ZG(q, v) cheé stato introdotto implicitamente da Whitney [2, 3, 4] ed esplicitamente daTutte [5, 6] ed è conosciuto come polinomio dicromatico oppure polinomiodi Tutte.Ora, riscrivendo l'hamiltoniana (3.1.2) come
H(σx) = −∑e∈E
Jeδ(σx1(e), σx2(e)) (3.1.4)
dove s'é scrittove = eβJe − 1.

3.1. Il modello di Potts e la colorazione dei nodi di un grafo 39
La costante di accoppiamento Je (o ve) è detta ferromagnetica se Je ≥ 0(ve ≥ 0) ed antiferromagnetica se −∞ ≤ Je ≤ 0 (−1 ≤ ve ≤ 0). Il polinomiocromatico corrisponde quindi al limite di temperatura zero del modello diPotts antiferromagnetico.
Per vedere che ZG(q, ve) è eettivamente un polinomio nei suoi argo-menti si procede espandendo il prodotto su e ∈ E in (3.1.3) e prendendo E ′ ⊂E come l'insieme degli archi per cui si calcola il termine veδ(σx1(e), σx2(e)).Si sommi ora sulle congurazioni σx: in ogni componente connesso delsottografo (V,E ′) il valore di σx deve essere costante. Quindi
ZG(q, ve) =∑E′⊂E
qk(E′)∏e∈E′
ve (3.1.5)
dove k(E ′) è il numero di componenti connessi (inclusi vertici isolati) nelsottografo (V,E ′).L'espansione (3.1.5) è stata scoperta da Birkho [1] e Whitney [2] per il casospeciale ve = 1 (ma anche Tutte [5] e [6]); nella sua forma generale è dovutaperó a Fortuin e Kasteleyn ([8] [9]). Si prende (3.1.5) come denizione diZG(q, ve) per q e ve complessi arbitrari. Si noti che una grande quantitádi informazione combinatoriale sul grafo G è contenuta in ZG(q, ve. Casispeciali di ZG(q, ve includono non solo il polinomio cromatico (v = −1), maanche il polinomio di usso (v = q), ed il polinomio di adabilitá 1 (q = 0),altre quantitá (si veda, a questo riguardo, [10]).
Dunque colorare un grafo G = (V,E) puó essere fatto, in senso pratico,trovando tutte le congurazioni ad energia zero del modello di Potts anti-ferromagnetico costruito sul grafo stesso, con i colori al posto degli stati dispin.
3.1.1 Esempi di polinomio cromatico
Per ssare le idee sul calcolo di un polinomio cromatico e quindi sul numerodi colorazioni possibili di un grafo si fará qualche esempio.In un primo esempio si vedrá come, dato un grafo denito, é possibile denireil suo polinomio cromatico, mentre nel secondo si studierá l'insieme dellecolorazioni corrette di un grafo casuale, nell'evoluzione dello stesso.
1Il polinomio di adabilitá denota la probabilitá che un grafo, in cui archi tra 2 verticiesistono con probabilitá p e sono assenti con probabilitá 1− p, sia connesso

40 3. Connessioni tra i modelli teorici
Figura 3.1: Il grafo G ottenuto da H aggiungendo un vertice w adiacente ad ogni
vertice del sotto grafo Kr di H
In un grafo denito
Per il grafo vuoto di ordine N , KN , é chiaro che:
PKN(q) = qN (3.1.6)
e piú generalmente, se⋃ki=1Gi, allora
PG(q) =k∏i=1
PGi(q) (3.1.7)
Per il grafo completo di ordine N , KN , si ha
PKN (q) = q(q − 1) · · · (q −N − 1) (3.1.8)
notando che
PK1(q) = q
PK2(q) = q(q − 1) = q2 − qPK3(q) = q(q − 1)(q − 2) = q3 − 3q2 + 2q
PK4(q) = q(q − 1)(q − 2)(q − 3) = q4 − 6q3 + 11q2 − 6q...
Sia oraH un grafo contenenteKr come sottografo, e siaG il grafo ottenutoda H aggiungendo un nuovo vertice w adiacente ad ogni vertice in Kr (enessun'altro), come nella gura 3.1. Allora si ha
PG(q) = (q − r)PH(q) (3.1.9)
Da questa si ottiene:

3.1. Il modello di Potts e la colorazione dei nodi di un grafo 41
Figura 3.2: un ciclo di 4 nodi, C4
- Se G é un grafo cordale1 (chordal) di ordine N , allora
PG(q) = qr0(q − 1)r1(q − 2)r2 · · · (q − r)rk (3.1.10)
dove k ∈ N e gli ri sono in N tali che∑k
i=0 ri = N . Si noti chek = χ(G)− 1.
- Se G é un k-albero di ordine N , allora
PG(q) = q(q − 1) · · · (q − k + 1)(q − k)N−k (3.1.11)
- Se G é un albero di ordine N , allora
PG(q) = q(q − 1)N−1 (3.1.12)
Si voglia calcolare per esempio il polinomio cromatico di un ciclo di ordine4, come quello in gura 3.2. Sia f una q-colorazione di C4. Si possonodistinguere due casi: se i colori di x ed y sono uguali, allora ci sono q − 1modi di colorare i vertici u e v indipendentemente e quindi il numero di taliq-colorazioni f é q(q − 1)2. Se, al contrario, x ed y hanno colori diversi cisono q − 2 modi per colorare i vertici u e v indipendentemente, e quindi ilnumero di tali q-colorazioni f é q(q − 1)(q − 2)2. Se ne conclude quindi che:
PC4(q) = q(q − 1)2 + q(q − 1)(q − 1)2
= q4 − 4q3 + 6q2 − 3q
= (q − 1)4 + (q − 1)
Si sa che il calcolo di χ(G) é NP -completo, quindi anche il calcolo diPG(q) é almeno dicoltoso come il calcolo di χ(G). Ci sono peró alcunirisultati che sono utili per semplicare il calcolo di PG(q) per alcune classi di
1un grafo é cordale se ciascuno dei suoi cicli di quattro o piú nodi ha una corda, cioéun arco che collega due vertici non adiancenti nel ciclo

42 3. Connessioni tra i modelli teorici
Figura 3.3: Il grafo G dell'esempio
gra.
Il primo di questi:Siano x ed y due vertici non adiancenti in un grafo G. Allora
PG(q) = PG+xy(q) + PG·xy(q). (3.1.13)
Dimostrazione. Sia f una q-colorazione di G. Si hanno due possibilitá:
1. f(x) = f(y) (cioé i colori di x ed y sono uguali)
2. f(x) 6= f(y) (cioé i colori non sono uguali)
Il numero di q-colorazioni nel primo caso é PG+xy(q), cioé` quelle del grafoG con aggiunto l'arco xy, e nel secondo é PG·xy(q), cioé quelle del grafo G incui i vertici x ed y sono fusi insieme. Il risultato quindi evidentemente segue.
Per esempio, sia G il grafo in gura 3.3, applicando ripetutamente questorisultato, come in gura 3.4 otteniamo i due gra G+ xy e G · xy.
Quindi, per il grafo G si avrá:
PG(q) = PK5(q) + 2PK4(q) + PK3(q)
= q(q − q)(q − 2)(q2 − 5q + 7)
= q5 − 8q4 + 24q3 − 31q2 + 14q.
Se si considera in (3.1.13) il grafo G + xy come un grafo dato, H, allorasi puó riscrivere (3.1.13) come:sia H un grafo ed e ∈ E(H) un arco. Allora
PH(q) = PH−e(q)− PH·e(q) (3.1.14)
Questo risultato é conosciuto in letteratura come Teorema Fondamentale diRiduzione (Fundamental Reduction Theorem, FRT). Come si é visto nel-l'esempio l'FRT puó essere usato ripetutamente per esprimere il polinomio

3.1. Il modello di Potts e la colorazione dei nodi di un grafo 43
cromatico come somma dei polinomi cromatici PKr(q). Il modo appena ap-plicato all'esempio di calcolo del polinomio cromatico é particolarmente e-ciente nel caso in cui il grafo sia denso, o quasi completo. Se, al contrario, ilgrafo é sparso, cioé contiene pochi archi, possiamo applicare sempre lo stessoteorema per esprimere il polinomio cromatico come somma dei PKr
(q), deigra vuoti. Comunque sia nulla impedisce, in entrambi i casi, di fermarel'applicazione del teorema FRT non appena i gra H risultanti dalla oper-azione precendente hanno PH(q) noti.
Figura 3.4: Applicazione di (3.1.13) al grafo G di gura 3.3
Siano ora G1 e G2 due gra, e sia r ∈ N0 con r ≤ minω(G1), ω(G2)dove ω(G) é il numero di clique2, o di gruppo, del grafo G. Si scelga un Kr
da ciascuno dei gra G1 e G2 e si formi un nuovo grafo G dall'unione di G1
e G2 identicando i due Kr in modo arbitrario, come mostrato in gura 3.5.Si chiama G Kr-gluing di G1 e G2 e si denota con G[G1 ∪rG2] la famiglia
di tutti i Kr-gluing di G1 e G2. Quando r = 0, G é l'unione disgiunta di G1
e G2; quando r = 1, G é anche chiamato vertex-gluing di G1 e G2; quando
2una clique ún insieme di vertici per cui, dati qualsiasi due vertici dell'insieme, esisteun arco che li collega. Alternativamente una clique é un grafo (o sotto grafo) in cui ognivertice é adiacente ad ogni altro vertice del grafo. Il numero di clique di un grafo é denitocome ω(G) ≥
∑ni=1
1n−di

44 3. Connessioni tra i modelli teorici
Figura 3.5: Un grafo ottenuto per edge-gluing
r = 2, G é chiamato anche edge-gluing di G1 e G2. Il seguente risultato,dovuto a Zykov, permette di calcolare velocemente il polinomio cromatico diun grafo G, se esso é un Kr-gluing di altri gra. Siano G1 e G2 due gra esia G ∈ G[G1 ∪r G2]. Allora
PG(q) =PG1(q)PG2(q)
PKr(q)(3.1.15)
Dimostrazione. Per i = 1, 2, una data q-colorazione di Kr dá luogo aPG1
(q)
PKr (q)
q-colorazioni di Gi. Quindi
PG(q) = PKr(q) ·PG1(q)
PKr(q)· PG2(q)
PKr(q)=PG1(q)PG2(q)
PKr(q)
Inoltre si ha anche questo risultato: se G é un grafo connesso consistente ink blocchi B1 . . . Bk, allora
PG(q) =1
qk−1
k∏i=1
PBk(q).
Questi ultimi due risultati sono direttamente applicabili ad un esempiofatto in precedenza: il grafo in gura 3.1 é il Kr-gluing di H e Kr+1. Quindi,
PG(q) =PH(q)PKr+1(q)
PKr(q)= PH(q)(q − r).
Un altro esempio invece é l'edge-gluing di C3 e C4, come in gura 3.6. Il suopolinomio cromatico é calcolato immediatamente come:
PG(q) =PC3(q)PC4(q)
PK2(q)
=q(q − 1)(q − 2)((q − 1)4 + (q − 1))
q(q − 1)
= q5 − 6q4 + 14q3 − 15q2 + 6q.

3.1. Il modello di Potts e la colorazione dei nodi di un grafo 45
Figura 3.6: L'edge-gluing di C3 e C4
Nell'evoluzione di un grafo random
Si prenda per esempio un grafo random composto da 3 nodi, come quello ingura 3.7. All'inizio della sua evoluzione tale grafo sará composto dai trevertici isolati: quindi ogni colorazione dei vertici é una colorazione corretta:ponendo q = 3 (usando, cioé, 3 colori) si hanno qN = 27 congurazioni, tuttecorrette. Ad un certo punto della evoluzione apparirá un primo arco. Aini del conteggio del numero di colorazioni possibili non é importante sapereesattamente quale arco sia, pertanto senza perdere di generalitá si suppor-rá sia quello che connette il primo ed il secondo nodo, a e b. Chiaramentequesto vincolo riduce il numero complessivo di colorazioni corrette possibilisul grafo: infatti i vertici a e b non dovranno, nelle colorazioni corrette, averelo stesso colore. Questo, come si vede in tabella, riduce la cardinalitá dell'in-sieme delle colorazioni.Andando avanti nell'evoluzione, di nuovo, si formerá un altro arco: senza,di nuovo, perdere di generalitá si puó supporre sia l'arco ac. Ancora la car-dinalitá dell'insieme delle soluzioni si riduce. Aggiunto un ultimo arco, nel-l'evoluzione, si arriverá ad avere il grafo completo: tale grafo ha la cardinalitápiú piccola. Si veda, a tal proposito la tabella 3.1
Figura 3.7: Evoluzione di un grafo random composto da 3 nodi
E' chiaro che il grafo completo K3 é colorabile con tre colori, ma non condue. Ció ha senso: nel grafo completo K3 non sarebbe possibile ottenere unacolorazione corretta, con q = 2.

46 3. Connessioni tra i modelli teorici
a b c a b c a b c a b c0 0 0 0 1 0 0 1 1 0 1 20 0 1 0 1 1 0 1 2 0 2 10 0 2 0 1 2 0 2 1 1 0 20 1 0 0 2 0 0 2 2 1 2 00 1 1 0 2 1 1 0 0 2 1 00 1 2 0 2 2 1 0 2 2 0 10 2 0 1 0 0 1 2 00 2 1 1 0 1 1 2 20 2 2 1 0 2 2 0 01 0 0 1 2 0 2 0 11 0 1 1 2 1 2 1 01 0 2 1 2 2 2 1 11 1 0 2 0 01 1 1 2 0 11 1 2 2 0 21 2 0 2 1 01 2 1 2 1 11 2 2 2 1 22 0 02 0 12 0 22 1 02 1 12 1 22 2 02 2 12 2 2
Tabella 3.1: In questa tabella sono elencate le soluzioni, cioé le colorazionicorrette, di un grafo random a 3 nodi: ogni colonna rappresenta un passonell'evoluzione del grafo

3.1. Il modello di Potts e la colorazione dei nodi di un grafo 47
Pur essendo, per un singolo grafo random, possibile calcolare il polinomiocromatico in funzione della evoluzione particolare dello stesso, non é possibilefarlo per una famiglia di gra random. Infatti, anche se é possibile stabilire,una volta ssatoN il numero dei nodi del grafo, l'emergenza di strutture comealberi, sottogra completi e non, cicli ed altro in funzione della connettivitámedia o della probabilitá di esistenza di un arco, non é possibile generalizzarequesto ragionamento in modo da fare previsioni o supposizioni. Solo in casiparticolari é possibile fare previsioni attendibili: quando, nell'evoluzione delgrafo si forma un sottografo completo di ordine q + 1, dove q sono i coloridisponibili, allora il grafo smette di essere colorabile: infatti il polinomiocromatico di quel sottografo é nullo, e rende cosí nullo il polinomio cromaticodi tutto il grafo.

48 3. Connessioni tra i modelli teorici

Sbagliare é possibile in molti modi, ma riuscire é possibile in unmodo solo.
Aristotele
4Rassegna dei principali risultati
conosciuti
In questo capitolo si ricapitoleranno alcuni dei risultati conosciuti in letter-atura riguardo il graph coloring.
4.1 Transizioni di fase
Per descrivere le transizioni di fase nella colorazione dei gra bisogna dis-tinguere, principalmente, due casi: il primo, q > 3, che in questa tesi noné stato considerato e quindi viene riportato solo per completezza, ed il casoq = 3, che interessa strettamente questa tesi. Inoltre, é possibile trovare inletteratura (per esempio in [17]) studi rilevanti sia su gra random nel mo-dello di Erdös-Rényi sia su gra c-regolari, sia su gra bi-regolari (gra cioéin cui i nodi a connettivitá ssa c1 sono tutti connessi a nodi con connettivitác2 e viceversa). Per quel che riguarda questa tesi si é scelto di studiare gradi Erdös-Rényi.(?)I risultati teorici sono stati ottenuti, in [17], usando il formalismo della cav-itá (Cavity Formalism) a livello di repliche simmetriche. Lo si introdurrá orabrevemente.Il problema della colorazione di un grafo é risolto correttamente, su di unalbero, da un metodo iterativo chiamato Belief Propagation Algorithm (po-nendo alcune condizioni sui bordi (sugli estremi) , dal momento che un al-
49

50 4. Rassegna dei principali risultati conosciuti
Figura 4.1: Costruzione iterativa di un albero per aggiunte di spin nel modello di
Potts
bero é sempre colorabile con 2 colori). Tale algoritmo corrisponde al metodochiamato Replica Simmetric Cavity Method. Il metodo della cavitá é unoschema classico della sica statistica che si puó sempre usare su strutture adalbero, la sua storia é tracciabile no alle idee originali di Bethe, Peierls edOnsager. Tale metodo permette di calcolare le probabilitá (marginali) cheun dato nodo ottenga un dato colore (o, volendo, la sua magnetizzazione) e,nel linguaggio della meccanica statistica, osservabili come energia, entropia,magnetizzazione media, etc. L'applicazione di tale metodo é ovviamente nonlimitata a strutture ad albero, ma puó essere utilizzata per gra, come quellidi Erdös-Rényi, che hanno quasi ovunque, localmente, una struttura ad al-bero.
Si noti con ψi→jsila probabilitá che il vertice i abbia colore si quando l'arco
ij non é presente. Si consideri quindi una costruzione iterativa come quelladi gura 4.1. Tale probabilitá quindi segue dalla recursione:
ψi→jsi=
1
Zi→j0
∏k∈i−j
∑sk
eβδsiskψk→isk=
1
Zi→j0
∏k∈i−j
(1− (1− e−β)ψk→isi(4.1.1)
dove Zi→j0 é una costante di normalizzazione (la somma della funzione di
partizione della cavitá) e β l'inverso della temperatura. Con la notazionek ∈ i − j si intende l'insieme dei vicini di i eccetto j. La normalizzazioneZi→j
0 é collegata alla variazione di energia libera dopo l'addizione del nodo ie degli archi ad esso collegati, eccetto ij, come
Zi→j0 = e−β∆F i→j . (4.1.2)
Allo stesso modo, la variazione di energia libera dopo l'aggiunta del nodo i edegli archi ad esso collegati é
e−β∆F i = Zi0 =
∑s
∏k∈i
(1− (1− e−β)ψk→is ) (4.1.3)

4.1. Transizioni di fase 51
La costante Zi0 é, allo stesso tempo, la normalizzazione della probabilitá
totale che il nodo i abbia il colore si, il marginale di i
ψisi =1
Zi0
∏k∈i
(1− (1− e−β)ψk→isi) (4.1.4)
La variazione di energia dopo l'aggiunta dell'arco ij é
e−β∆ij
= Zij0 = 1− (1− e−β)
∑s
ψi→js ψj→is . (4.1.5)
La densitá di energia libera nel limite termodinamico é quindi
f(β) =1
N
(∑i
∆F i −∑ij
∆F ij
). (4.1.6)
Le densitá di energia (che esprime il numero di condizioni di colorazione nonsoddisfatte) e della corrispondente entropia (che é il logaritmo delle soluzioniad una data energia) possono essere calcolate con la trasformata di Legendre:
−βf(β) = −βe+ s(e) (4.1.7)
dove f = F/N , e = E/N ed s = S/N sono tutte variabili intensive.
Per calcolare le medie delle osservabili sugli insiemi di gra random deni-ti dalla distribuzione del grado Q(k) si deve risolvere l'equazione funzionaleautoconsistente di cavitá
P(ψ) =∑k
Q1(k)k−1∏i=1
∫dψi P(ψi) δ(ψ −F(ψi), (4.1.8)
dove Q1(k) é la distribuzione del numero di vicini per nodi che ne hanno giáalmeno uno, e la funzione F(ψi é data nell'equazione (4.1.1). Qui ψ é unvettore a q componenti, anche se si é omesso tale indice nella notazione peralleggerirla nella lettura. Per gra c-regolari la soluzione di questa equazionesi semplica: la soluzione infatti si fattorizza nel senso che il parametro d'or-dine, ψ, é lo stesso per ogni arco. Questo é dovuto al fatto che, localmente,ognuno di tali archi in questi gra vive nello stesso ambiente. Tutti gli archisono quindi equivalenti e quindi la distribuzione P(ψ) deve essere una fun-zione delta.Si osserva che P(ψ) = δ(ψ−1/q) (cioé ciascuna delle q componenti del vettoreψ é pari a 1/q) é sempre una soluzione: per analogia con i sistemi magnetici

52 4. Rassegna dei principali risultati conosciuti
si tende a chiamare questa soluzione paramagnetica. Il numero di colorazionicorrette é quindi calcolabile. Dal momento che P(ψ) = δ(ψ−1/q), la densitádi energia libera é
−βFRS = log q +c
2log
(1− 1− e−β
q
). (4.1.9)
La densitá di entropia a temperatura zero quindi
sRS = log q +c
2log
(1− 1
q
)(4.1.10)
La validitá di quest'ultima va oltre, sorprendentemente, la fase RS: in sostan-za é valida no alla transizione di condensazione. Infatti nello scrivere l'e-quazione (4.1.1) si é assunto che le probabilitá di cavitá ψk→jsi
per i vicini kdi un nodo i fossero sucientemente indipendenti quando il nodo i non erapresente, poiché solo in quel caso la probabilitá si fattorizza. Questo sarebbestato vero se il reticolo fosse stato un albero con condizioni sui bordi noncorrelate. In un grafo generico, peró, loops o correlazioni nelle condizionisui bordi possono creare correlazioni, e le assunzioni fatte smetterebbero diessere valide.Da un punto di vista matematicamente rigoroso la dimostrazione della cor-rettezza delle assunzioni del metodo della RS cavity é un passo cruciale cheancora non é stato fatto nella maggior parte dei casi. L'unico successo nqui raggiunto in letteratura é la dimostrazione di una condizione n troppoforte: l'unicitá della misura di Gibbs1. Rozzamente questo dice che la misuradi Gibbs é unica se il comportamento di uno spin (di un vertice) si é comple-tamente indipendente dalle condizioni sul bordo (per esempio spin (vertici)molto distanti) per qualsiasi condizione sul bordo si possa scegliere.Piú precisamente, si denisca l'insieme sl come l'insieme dei vertici ad unadistanza almeno l da una regione Λ. La misura di Gibbs µ é unica se e solose, per ogni Λ nito, e nel limite N →∞,
E
[supsi,s′i
∑si∈Λ
|µ(si|sl)− µ(si|s′l)|
]→l→∞ 0, (4.1.11)
dove la media é sull'insieme dei gra. E' stato provato il letteratura che lamisura di Gibbs nella colorazione di un grafo regolare é unica se e solo se ilgrado del grafo é c < q. In [17] é stato supposto che per gra di Erdös-Rényi
1per l'Hamiltoniana H(s) =∑
(i,j)∈E(V ) δ(si, sj) la misura di Gibbs é µ(s) =1Z0e−βH(s). Nel limite di temperatura zero, β →∞, questa misura diventa uniforme su
tutte le colorazioni corrette del grafo

4.1. Transizioni di fase 53
sia c < q − 1.In molti casi si osserva che l'approccio RS é corretto al di lá della sogliadi unicitá della misura di Gibbs. E' stato quindi proposto da Mezárd eMontanari che la condizione di estremalitá della misura di Gibbs provvedaun criterio appropriato per le assunzioni sulla RS. Parlando in modo un po'approssimativo, la dierenza tra l'unicitá e l'estremalitá di una misura diGibbs é che, pur potendo esistere condizioni sui bordi che diano al verticesi comportamento diverso da quello che si otterebbe nel caso di un singolostato, tale condizione sui bordi ha misura nulla. Formalmente, la condizionedi estremalitá corrisponde a
E
∑si
µ(si)∑si∈Λ
|µ(si|si)− µ(si)|
→l→∞ 0. (4.1.12)
Matematicamente il termine misura di Gibbs estremale é spesso usato comesinonimo di stato puro. Recentemente gli stessi Mezárd e Montanari hannocalcolato limiti rigorosi per l'estremalitá della misura di Gibbs per il prob-lema della colorazione degli alberi. Nella letteratura sica la condizione didecadimento della correlazione, che giustica gli assunti di cavitá, é spessochiamata proprietá di clustering.Esiste un approccio euristico per controllare la condizione di estremalitá stret-tamente legato la formalismo di cavitá: si verica l'esistenza una soluzionenon banale delle equazioni di 1RSB (One-step Replica Simmetry Breaking)ad m = 1. Prima di passare a questo controllo, peró, si controlla di unacondizione necessaria ma non suciente per la validitá degli assunti dellaReplica Simmetry cavity: la non divergenza della suscettivitá di vetro dispin. Se questa diverge, avviene una transizione di vetro di spin, e quindi lasimmetria della replica (la condizione RS) non vale piú (in altro modo: si éinterrotta la simmetria della replica). L'analisi della stabilitá locale dá quindiun limite superiore alla condizione di estremalitá della misura di Gibbs.La suscettivitá del vetro di spin é denita come:
χSG =1
N
∑i,j
〈sisj〉2c (4.1.13)
Le connettivitá per cui la suscettivitá a temperatura nulla diverge si possonocalcolare all'interno del formalismo della cavitá, infatti si puó riscrivere, pergli ensemble di gra, come
χSG =∞∑d=0
γdE(〈s0sd〉2c , (4.1.14)

54 4. Rassegna dei principali risultati conosciuti
dove si considera la media sui gra, nel limite termodinamico, dove gli spin(i vertici) s0 ed sd sono ad una distanza d. Il fattore γd é il numero mediodi vicini ad una distanza d, quando d log N . Assumento che il termineche si sta sommando, per d grande, esista (posto di fare il limite N → ∞prima), lo si collega al parametro di stabilitá:
λ = limd→∞
γ(E(〈s0sd〉2c
) 1d (4.1.15)
La serie (4.1.13) é essenzialmente geometrica e converge solo per λ < 1. Lacorrelazione 〈s0sd〉c e la variazione di magnetizzazione in s0 causata dallavariazione del campo innitesimo in sd sono collegabili tra loro. Inne, dalmomento che si eettua prima il limite termodinamico di grandi N , tale vari-azione é dominata dall'inuenza diretta attraverso il cammino di lunghezza dtra i due nodi, e questo induce una reazione a catena: se il cammino coinvolgei nodi (d, d− 1, . . . , 0) si ha
E(〈s0sd〉2c) = C ·∑a∈∂db∈∂0
E
[(∂ψa→0
∂ψb→d
)2]
= C ·d∏`=1
E
[(∂ψl→l−1
∂ψl+1→l
)2]
(4.1.16)
Il parametro di stabilitá della soluzione paramagnetica delle equazioni dicavitá rispetto a piccole perturbazioni si puó calcolare dallo jacobiano
T τσ =∂ψ1→0τ
∂ψ2→1σ
∣∣∣∣RS
(4.1.17)
che dá la probabilitá innitesima che un cambio nella probabilitá in ingressoψ2→1σ cambi la probabilitá in uscita ψ1→0
τ . L'indice RS indica che l'espressionedeve essere valutata sulla soluzione paramagnetica trovata in RS . Valutataalla soluzione RS questa matrice ha solamente due risultati in cui tutti glielementi diagonali sono uguali ed anche tutti gli elementi fuori dalla diagonalesono uguali. Come conseguenza immediata, tutti gli jacobiani commutano esono quindi simultaneamente diagonalizzabili, cosicché é possibile calcolarel'eetto dopo una sola interazione del metodo della cavitá (un solo passonella catena di cambio degli stati di magnetizzazione degli spin deniti suivertici). La matrice T ha quindi solo due distinti autovalori
λ1 =
(∂ψ1→0
1
∂ψ2→11
− ∂ψ1→01
∂ψ2→12
)∣∣∣∣RS
,
λ2 =
(∂ψ1→2
1
∂ψ2→11
+ (q − 1)∂ψ1→0
1
∂ψ2→12
)∣∣∣∣RS
.
(4.1.18)

4.1. Transizioni di fase 55
Il secondo autovalore corrisponde all'autovalore omogeneo (1, 1, . . . , 1): questodescrive una uttuazione che cambia tutte le ψ2→1
τ , per τ = 1, . . . , q, dellastessa quantitá, cioé una uttuazione che conserva la simmetria sul colore.Il primo autovalore, invece, é (q − 1) degenere e i suoi autovettori sono
(1,−1, 0, . . . , 0), (0, 1,−1, 0, . . . , 0), . . . , (0, . . . , 1,−1).
Le corrispondenti uttuazioni rompono esplicitamente la simmetria di colore,e sono, di fatto, quelle critiche. Usando la formula ricursiva di cavitá (4.1.1)le due derivate sono
∂ψ1→01
∂ψ2→12
= (1− e−β)(ψ1→0
1 )2
1− (1− e−βψ21
,
∂ψ1→01
∂ψ1→01
= (1− e−β)
((ψ1→0
1 )2
1− (1− e−β)ψ2→11
− ψ1→01
1− (1− e−β)ψ2→11
),
(4.1.19)Cosicché i valori degli autovalori, valutati sulla soluzione RS, dove tutti gliψ sono uguali a 1/q, sono
λ1 =1
1− q1−e−β
, λ2 = 0. (4.1.20)
Il parametro di stabilitá quindi é λ = γλ21 cosí che le temperature critiche al
di sotto delle quali il sistema é localmente instabile sono:
T regc (q, c) =
−1
log(
1− q√c−1+1
) , TERc (q, c) =
−1
log(
1− q√c+1
) (4.1.21)
per, rispettivamente, gra regolari e di Erdös-Rényi. Quindi, per il problemadella colorazione, a temperatura zero, le connettivitá critiche sono:
cregRS stab = q2 − 2q + 2, cERRS stab = q2 − 2q + 1. (4.1.22)
La stabilitá locale di gra bi-regolari con connettivitá c1 e c2 é equivalentea quella di un grafo regolare con connettivitá media c = 1+
√(c1 − 1)(c2 − 1).
Nel caso in cui la condizione di estremalitá della misura di Gibbs non siavalida, la si decompone (la misura di Gibbs) in diverse parti (una per gli statipuri, una per i clusters, etc) in modo che sia ancora estremale in ciascunadi queste parti. Si considera la piú piccola di tali decomposizioni. Questadecomposizione ha molti elementi, non un numero nito, come i q stati di unmodello di Potts ferromagnetico. Di solito si osserva che il numero di stati

56 4. Rassegna dei principali risultati conosciuti
puri cresce esponenzialmente con la dimensione del sistema.
Sia Σ(f) la funzione di entropia di stato, detta anche complessitá, cheé il logaritmo del numero degli stati ad una certa densitá di energia inter-na f , cioé per esempio N (f) = eNΣ(f). Nel formalismo delle transizioni deivetri di spin ci si riferisce spesso a questa come all'entropia congurazionale.Il fatto d'avere a che fare con un numero esponenzialmente grande di statipuri complica chiaramente molto le cose, soprattutto in un approccio rigo-roso al limite termodinamico: per fortuna il metodo della cavitá sorpassaquesto problema elegantemente. Un'altra intuizione del metodo 1RSB vienedall'identicazione di uno stato α con i punti ssi ψ dell'equazione (4.1.1).L'obiettivo é quello di calcolare le proprietá statistiche di tali punti ssi. Aciascuno di questi stati é collegato un peso, corrispondentemente all'energialibera dell'equazione (4.1.6) elevato alla potenza m, dove m é un parametroanalogo a β, ed é, in letteratura, chiamato parametro di Parisi per la rotturadella simmetria nella replica: alcune volte m é identicato con il numero direpliche del sistema. La misura di probabilitá sugli stati ψ é dunque
µ(ψ) =Z0(ψ)m
Z1
=1
Z1
e−βmN f(ψ), (4.1.23)
dove Z1 é solo la costante di normalizzazione.Per scrivere gli analoghi della equazione di Belief Propagation, equazione(4.1.1) si ha bisogno di denire la distribuzione di probabilitá P i→j(ψi→j) deicampi ψi→j. Questo si puó fare da quelle dei campi entranti come:
P i→j(ψi→j) =1
Zi→j1
∏k∈i−j
∫dψk→isi
P k→i(ψk→isi) δ(ψi→jsi
−F(ψk→isi))(Zi→j
0
)m,
=1
Zi→j1
∫POP
δ(ψ −F)(Zi→j
0
)m.
(4.1.24)la funzione F é data da (4.1.1) e la funzione delta assicura che l'insieme deicampi ψi→j é un punto sso dell'equazione di Belief Propagation. Il termine(Zi→j
0
)mprende in considerazione il cambiamento di energia libera di uno
stato dopo l'addizione del nodi i e degli archi a lui adiacenti, eccezion fattaper (ij), come descritto dall'equazione (4.1.3): questo termine assicura chelo stato α abbia un peso (Zα)m pari a quello di una congurazione µ conil fattore di Boltzmann e(−βH(µ). Inne, Zi→j
1 é una costante di normaliz-zazione. La notazione sull'integrale, POP, oltre che alleggerire la notazione,intende riferirsi alla dinamica della popolazione2 che é il metodo numerico
2in questo metodo si modella la distribuzione di P i→j(ψi→j) con una popolazione di N

4.1. Transizioni di fase 57
che si usa per risolvere l'equazione (4.1.24). La distribuzione di probabilitáP (ψ) é rappresentata da un insieme di campi presi da P (ψ), e quindi lamisura P (ψ)dψ diventa un campionamento uniforme da questo insieme.Si denisce l'energia libera di replica (dal parametro m) in analogia con(4.1.6) come
Φ(β,m) = − 1
βmNlog (Z1) =
1
N
(∑i
∆Φi −∑ij
∆Φij
), (4.1.25)
dove
e−βm∆Φi =
∫POP
e−βmN∆F i , e−βm∆Φij =
∫POP
e−βmN∆F ij . (4.1.26)
Mettendo insieme le equazioni (4.1.23) e (4.1.25) si ha:
Z1 = e−βmNΦ(β,m) =∑ψ
e−βmNf(ψ) =
∫f
df e−N [βmf(β)−Σ(f)], (4.1.27)
dove la somma su ψ si riferisce alla somma su tutti gli stati (i punti s-si dell'equazione di Belief Propagation). La trasformata di Legendre dellacomplessitá Σ, da l'energia libera di replica
−β mΦ(β,m) = −β mf(β) + Σ(f) (4.1.28)
che é corretta solo nel limite termodinamico e per le densitá. Dalle proprietádella trasformata di Legendre si ha
Σ = βm2∂mΦ(β,m), f = ∂m[mΦ(β,m)], βm = ∂fΣ(f). (4.1.29)
Quindi, dall'equazione (4.1.25) l'energia libera diviene:
f(β) =∑i
∫POP
∆F ie−βm∆F i∫POP
e−βm∆F i−∫POP
∆F ije−βm∆F ij∫POP
e−βm∆F ij. (4.1.30)
Quando m = 1 (o, come si trova in letteratura, il numero di repliche delsistema é uno), allora −βΦ(β, 1) = βf(β) + Σ(f) si riduce alla energia liberaconsiderata nell'approssimazione RS
Φ(β, 1) = e− Σ + s
β= e− Tstot, (4.1.31)
vettori ψi→j e per calcolare i P i→j(ψi→j) conoscendo i P k→i(ψk→i) per tutti i k entrantisi calcola la formula ricorsiva (4.1.24) in due passi: nel primo si calcolano i nuovi vettoriψi→j usando la formula ricorsiva (4.1.23) e nel secondo si prendono in considerazione i
pesi(Zi→j0
)m. Per il ricalcolo dei pesi si possono scegliere diversi metodi: si veda [17] per
una discussione sul metodo migliore e per una analisi delle componenti dei vettori.

58 4. Rassegna dei principali risultati conosciuti
dove s é la densitá di entropia interna dei cluster e stot la densitá di entropiatotale del sistema.
A questo punto si é in grado di calcolare la complessitá come una fun-zione dell'energia libera, Σ = Σ(f). Combinando (4.1.25) e (4.1.30) infattisi calcolano Σ ed f per ogni valore di m che dá implicitamente Σ(f). Percalcolare le osservabili termodinamiche si deve minimizzare l'energia liberatotale ftot = f(β)−Σ/β sui valor di f ove la complessitá Σ(f) é non negativa.Il minimo dell'energia libera totale corrisponde ad un valore del parametrom = m∗ e aerma che l'energia libera f ∗ domina la termodinamica. Sonopossibili quindi tre casi:
- Se c'é solo una soluzione banale (nell'RS) a m = 1, allora la misuradi Gibbs é estremante e l'approccio RS é corretto. Se, allo stesso tem-po, esiste una soluzione non banale per qualche m 6= 1, allora i clus-ters corrispondenti a questa soluzione non hanno alcuna inuenza sullatermodinamica.
- Se c'é una soluzione non banale a m = 1 con complessitá positiva,allora m∗ = 1 minimizza l'energia libera totale. Il sistema é allora inuna fase clusterizzata con un numero esponenziale di stati dominanti.
- Se comunque la complessitá é negativa a m = 1, allora gli stati cor-rispondenti sono assenti con probabilitá uno nel limite termodinamico.Invece, l'entropia totale é dominata dai clusters corrispondenti a m∗
tali che Σ(m∗) = 0; il sistema é in una fase condensata. Da notare chela condizione Σ(m∗) = 0 corrisponde al massimo dell'energia libera direplica.
Le transizioni tra questi casi sono ben conosciute nella fenomenologia deivetri di spin e appaiono quando la temperatura é abbassata. La transizionedalla fase paramagnetica a quella clusterizzata é di solito chiamata tran-sizione dinamica, o di clustering. Non é una vera transizione termodinamicapoiché l'energia totale del sistema a m∗ = 1 é ancora uguale a quella dellaRS. Comunque lo spazio delle fasi é diviso in un numero esponenziale di com-ponenti e, come conseguenza, la dinamica si muove al di fuori dell'equilibrioal di lá di questa transizione.La seconda transizione dalla fase clusterizzata alla fase condensata é una veratransizione termodinamica ed é chiamata transizione di rottura della RS. Aquesto punto la misura si condensa in pochi clusters, e di solito la si chiamaanche transizione di condensazione. La dimensione dei clusters nella fasecondensata segue il cosiddetto processo di Poisson-Dirichlet.

4.1. Transizioni di fase 59
La procedura per calcolare l'energia libera di replica le altre osservabiliche si é descritta n'ora coinvolge un solo grande grafo random. Per calcolarele medie sugli ensemble di gra random si deve risolvere l'equazione
P [P (ψ)] =∑k
Q1(k)k−1∏i=1
dP i(ψi)P [P i(ψi)]δ(P (ψ)−F2(P i(ψi))) (4.1.32)
del tutto analoga a (4.1.8) e dove il funzionale F2 é ricavato da (4.1.24).
Il limite di temperatura zero, β →∞, é il limite rilevante per lo studio delcoloring dei gra. In letteratura molto spesso si usa anche il limite di energiazero. Si prende dunque il limite per β → ∞ tenendo costante mβ = y.L'energia libera di replica allora cambia in:
−yΦe(y) = −ye+ Σ(e) (4.1.33)
La connettivitá a cui la funzione di complessitá Σ(e = 0) diventa negativaé la soglia di colorazione. In questo limite per l'equazione (4.1.24) cambiail peso, che diventa e−y∆Ei→j e quando y → ∞ tutte le congurazioni conenergia positiva sono proibite. Volendo studiare la struttura delle soluzioni(cioé delle colorazioni corrette che hanno energia nulla) si ssa l'energia azero. Dopo di che si puó scrivere l'entropia come −βf = s, e si introducel'entropia libera (o entropia di replica), come Φs(m) = −β mΦ(β,m)|β→∞.L'equazione (4.1.28) diventa quindi
Φs(m) = ms+ Σ(s). (4.1.34)
Il Belief Propagation (4.1.1)
ψi→jsi=
1
Zi→j0
∏k∈i−j
(1− ψk→isi
), (4.1.35)
mentre l'equazione (4.1.24) mantiene la stessa espressione. La somma di par-tizione Z0, nella misura di Gibbs, diventa il numero di colorazioni corrette. Iclusters allora possono essere guardati come ad un insieme di soluzioni, e han-no peso proporzionale alla loro dimensione elevata alla potenzam. L'entropialibera Φs(m) é quindi calcolata come
Φs(m) =1
N
(∑i
∆Φis −
∑ij
∆Φijs
)
=1
N
(∑i
log∫POP
(∆Zi
)m −∑ij
log∫POP
(∆Zij
)m),
(4.1.36)

60 4. Rassegna dei principali risultati conosciuti
dove Zi e Zij sono dati dalle equazioni (4.1.3) ed (4.1.2).
Ora, ricordando che ψi→jsisono le probabilitá che il nodo i abbia il colore
si quando il vincolo sull'arco ij non é presente, nel limite di temperaturazero si possono classicarli in due categorie:
- un campo forte (hard eld) corrisponde al caso in cui tutte le compo-nenti di ψi→jsi
sono zero eccetto che per una, s. Allora solo quel coloreé permesso per lo spin i, in assenza dell'arco ij.
- un campo debole (soft) corrisponde al caso in cui piú di una com-ponente di ψi→jsi
é non nulla. La variabile i non é quindi congelata inassenza di ij, e tutti i colori corrispondenti alle componenti non nullesono ammessi.
Questa distinzione é utile anche per le probabilitá ψisi : se c'é un campoforte, allora la variabile i é congelata. Nella trattazione 1RSB é possibileche una frazione nita di variabili siano congelate, all'interno dello stessocluster: in altre parole tutte le soluzioni che appartengono ad un clusterhanno una frazione nita di variabili congelate. Aggiungendo un arco algrafo, la connettivitá cresce di 1/N , e c'é una probabilitá non nulla che uncluster con variabili congelate scompaia.La distribuzione dei campi sugli stati P i→j(ψi→j) puó, in generale, esseredecomposta nelle due componenti dura e morbida:
P i→j(ψi→j) =
q∑s=1
ηi→js δ(ψi→j − rs) + ηi→j0 P i→j(ψi→j), (4.1.37)
dove P i→j é la distribuzione dei campi morbidi e la normalizzazione é
q∑s=0
ηi→js = 1.
E' interessante notare che la presenza di variabili congelate nei clusters chedominano l'entropia é connessa alla divergenza della dimensione della ridis-posizione minimale media (average minimal rearragement), come si vede in[18]. Piú precisamente: si scelga uno nodo i su di un grafo ed una colorazionesi corretta per quel grafo e ci si chieda: qual'é la distanza di Hamming del-la soluzione piú vicina in cui il nodo i ha un colore diverso da si? La mediadi questa distanza su tutti i nodi i del grafo, per tutte le colorazioni validee sugli ensenble di gra é appunto la average minimal rearragement. Vienedunque naturale chiedersi quando sono presenti i campi forti, e quindi le

4.1. Transizioni di fase 61
variabili congelate?. Prima di tutto si noti che, per congelare un dato nodoin un colore, si ha bisogno di q − 1 campi entranti che proibiscano gli altricolori. Ora, partendo dalla condizione in cui ogni colore é equiprobabile conprobabilitá 1/q, si tratta di rimuovere tutti i nodi con connettivitá minoredi q: questo equivale a ricercare il k-core (o, in questo caso il q-core) del grafo.
Trovare la soluzione di (4.1.32) per gra di Erdös-Rényi é complesso, dalmomento che, al contrario di quanto avviene con gra c-regolari, la soluzionenon é piú fattorizzata. Il 3-coloring di gra di tali gra é diverso dai casi incui q > 3, poiché la soluzione RS é localmente instabile nella fase colorabile,e la condizione di estremalitá, condizione per la validitá del metodo dellacavitá RS, smette di essere valida, poiché le lunghezze di correlazione di spinglass divergono (come si era detto per quel che riguardava χSG): la maggiordierenza rispetto ad altri casi, sia q > 3 gra c-regolari, é l'apparizione diuna transizione continua. Ad ogni modo la fenomenologia tra questo e glialtri casi non dierisce molto: semplicemente qui la transizione di clusteringe la transizione di condensazione coincidono e appaiono in modo continuoal punto di instabilitá della RS: cRS = cd = cg = 4 e la fase in cui l'en-tropia é dominata da un numero esponenziale di stati manca (ma comunqueé presente clusterizzazione delle soluzioni). La complessitá corrispondentead m = 1 é sempre negativa. L'entropia é dominata da un numero nito dicluster grandi che non contengono campi forti (nell'intervallo c ∈ [4, 4.42]), ledue soluzioni (per campi forti e deboli) si uniscono per connettivitá intornoa 4.55, ed inne, per c = 4.66 i campi forti arrivano agli stati dominanti (edi conseguenza a tutti gli altri).
Rimane da osservare la struttura di sovrapposizione (overlap structure)per capire intuitivamente i clusters. Prima, si considerino le probabilitámarginali ψi,αα all'interno del cluster α. Si noti che, per via della simmetriapermutazionale esistono altri q!− 1 clusters diversi solo per la permutazionedei colori. Si denisce quindi la sovrapposizione all'interno del cluster di duesoluzioni (mediata sugli stati) come
δ =1
N
∑i
∑si
〈(ψi,αsi )2〉α. (4.1.38)
Nella fase paramagnetica δ = 1/q, altrimenti la si deve calcolare dai puntissi dell'equazione (4.1.24). La sovrapposizione tra due soluzioni che vivonoin due cluster diversi, che dieriscono solo per una permutazione π dei colorié
δj = δj − 1
q − 1+
q − jq(q − 1)
, (4.1.39)

62 4. Rassegna dei principali risultati conosciuti
cd cg cr cqq = 3 4 4 4.660 4.687q = 4 8.353 8.46 8.84 8.901
Tabella 4.1: Valori della connettivitá c alle transizioni: cd di clusterizzazione (o
dinamica), cg di condensazione, cr di rigiditá e cq COL/UNCOL.
dove j é il numero dell posizioni sse nella permutazione π (in particolareδq = δ, e δ1 = 1/q). Nel 3-coloring di gra random di Erdös-Rényi lasovrapposizione cresce in modo continuo da 1/3 a partire dalla transizione diclustering c = 4.
In tabella 4.1 sono riportati i valori di connettivitá per le transizioni infunzione della connettivitá, come riportato in letteratura: si noti come nelcaso q = 3 cd e cg appaiano insieme, e si noti che la transizioni di rigiditá cr,come ha senso che sia, avviene a connettivitá maggiore della transizione diclustering cd.
4.2 k-core
Il k-core, come é stato denito altrove in questa tesi, é il sottografo massimaledi un grafo G i cui vertici abbiano grado minimo k. E' stato inizialmenteintrodotto da Bollobás nel 1984. Per k = 2 si usa chiamare il corek(G)semplicemente core. Il problema di trovare un k-core non vuoto assomiglia,per certi versi, a trovare un sottografo di G che non é k-colorabile, anche sequest'ultimo problema é di gran lunga piú complesso e non é ancora statorisolto. uczak (in [13]) ha studiato dettagliatamente il core (cioé del 2-core)subito dopo la probabilitá critica N/2, calcolando il numero di vertici digrado k nel 2-core di G, chiamato Dk(G), trovando che se t = n/2 + s, cons = o(n) ed s/N2/3 →∞, allora quasi sempre3 Gt é tale cheD2(Gt) ∼ 8s2/N ,D3(Gt) ∼ 32s2/N2 e, per ogni k, Dk(Gt) = O(sk/Nk−1; per Gt si intendel'evoluzione di un grafo random di Erdös-Rényi in cui ad ogni aggiunta ca-suale di un arco la probabilitá p varia. Come parametro per la variazionedi questa probabilitá viene indicato t. Quindi quasi sempre Gt contiene unsottografo casuale cubico indotto, su circa 32s2/n2 vertici. Da un altro teo-rema4, si sa che quasi sempre un grafo cubico ha un ciclo Hamiltoniano, e
3per quasi sempre si intende, come giá visto precedentemente, che una proprietádiventa praticamente certa nel limite termodinamico n → ∞: ovver in tale limite, laprobabilitá che la proprietá appaia tende a 1.
4di Robinsom e Wormald del 1992

4.2. k-core 63
quindi quasi sempre Gt ha un ciclo che passa circa attraverso 32s2/N2 no-di. In questo modo uczak é riuscito a denire la circonferenza (cioé lalunghezza del ciclo piú lungo) di un grafo random, restringendo l'intervallotra (16 + o(1))s2/3N e 15s2/2N .uczak, Pittel e Wierman in [24] hanno mostrato che la transizione in ungrafo tra l'essere planare ed il non esserlo é precisamente in questa nestra.Infatti il piú piccolo sottografo non planare dei primi gra non planari Gt inun processo random G ha alta probabilitá d'avere dimensione cN2/3, il chedice che il problema di non planaritá é ancora una faccenda piuttosto locale.Non é cosí peró per k ≥ 3: giá dalla prima apparizione il 3-core é un sot-tografo gigante, con dimensione proporzionale a N . Si puó infatti denire iltempo di apparizione del k-core per il processo G come:
τk(G) = mint : corek(Gt) 6= ∅ (4.2.1)
Inoltre si denisce γk(G) come l'ordine di grandezza del k-core quando ap-pare:
γk(G) = | corek(Gτk)| (4.2.2)
Pittel, Spencer e Wormald in [12] dimostrano che per ogni k ≥ 3 esistonodelle costanti ck > 1 e pk > 0 tali che τk(G) ∼ ckn/2 e γk(G) ∼ pkn per quasiogni processo di gra G. Inoltre, ck e pk possono essere espressi in terminidi processi di divisione di Poisson. In particolare, ck = minλ>0 λ/πk(λ) =k +√k log k + O(log k), dove πk(λ) = P (Poisson(λ) ≥ k − 1). Numerica-
mente per k = 3, c3 ≈ 3.35 e il neonato core contiente circa il 27% dei nodidel grafo.Altri approcci in questo senso sono quelli di Molloy e Reed, che hanno studi-ato la transizione di fase in un miglioramento dei modelli G(n, p) e G(n,M).Dato un grafo G = (V,E), [12] propone due algoritmi per trovare il k-core.Il primo si propone di, iterativamete, rimuovere nodi con connettivitá k− 1,detti leggeri, no a che ce ne sono. In questo modo i nodi rimasti hannotutti almento grado k: se ne rimangono, quello é il k-core del grafo, se nonne rimangono il k-core del grafo non esiste. Il secondo algoritmo, similmente,si propone di, in primo luogo, formare una lista di tutti i vertici leggeri nonisolati del grafo G, poi, presone uno a caso, i, di eliminare tutti gli archiincidenti su i, rendendolo cosí isolato. Si ripete questo processo no a cherimangono archi da eliminare e no a che l'insieme H dei vertici pesanti (cioécon grado almeno k) é non vuoto. Finito questo processo, o H = ∅ e quindinon c'é k-core, oppure H 6= ∅ e quindi H contiene i vertici appartenenti alk-core del grafo iniziale G. Questo secondo processo puó essere descritto intermini di una catena di Markov, con il vantaggio di poterlo studiare, dalpunto di vista teorico, asintoticamente.

64 4. Rassegna dei principali risultati conosciuti
Si puó quindi considerare il destino di un vertice v ∈ V (E). Se v é un verticepesante, non sará cancellato alla prima iterazione (supponendo di usare ilprimo dei due algoritmi). Chiaramente rimarrá nel grafo anche alla secondaiterazione, ammesso che, nella prima, non sia diventato leggero a causa dellacancellazione di uno dei suoi vicini, e rimarrá ancora dopo diverse iterazioni,di nuovo dipendentemente dal fatto che abbia vertici leggeri non troppo vici-ni.Sia p(n,m) la probabilitá che un vertice ssato v sopravviva a questo proces-so di cancellazione. Chiaramente n p(n,m) é la dimensione totale attesa delk-core. Usando l'algoritmo di cancellazione dei nodi é dicile stimare p(n,m)(diventerebbe piú facile usando l'altro algoritmo, quello che cancella gli archi,come é stato fatto in [12]) ma ci si puó comunque fare un'idea qualitativadel perché il k-core appaia quando il numero degli archi del grafo sorpassail valore γk n/2. Alla luce dell'algoritmo e in analogia con l'apparizione delcomponente gigante del grafo, ci si puó aspettare che p(n,m) sia vicina aφ(c) = limj→∞ φj(c) per c = 2m/n. Qui φj(c) é la probabilitá che il progen-itore dell'albero genealogico per il processo di divisione di Poisson soravvivaalla cancellazione applicato alle prime j generazioni di quell'albero.Al primo round di cancellazione si cancellano tutti gli appartenenti alla j-ima generazione che hanno avuto meno di k − 1 gli (il grado di quelli chevengono cancellati é infatti minore o uguale a k − 1). Al secondo round sicancellano gli appartenenti alla (j−1)-ima generazione che sono sopravvisutial primo round e hanno avuto meno di k − 1 gli. E avanti cosí no a chenon si giunge al progenitore comune, che sopravvive se almeno k dei suoi glisono sopravvissuti a tutti i round del processo di cancellazione.Per calcolare φj(c), si introduce anche ϕj(c), che é la probabilitá che il progen-itore abbia almeno k−1 gli sopravvissuti. Siccome ciascuno dei gli soprav-vive con probabilitá ϕj(c), indipendentemente dagli altri fratelli o sorelle,il numero totale di gli sopravvissuti é distribuito con una Poissoniana dimedia c (ϕj(c)). Quindi, per j ≥ 1
ϕj(c) = PZ(c ϕj−1(c)) ≥ k − 1,φj(c) = PZ(c ϕj−1(c)) ≥ k,
(4.2.3)
dove φ0(c) = 1. Esiste, quindi, il limite limj→∞ φj(c) dal momento che(φj(c))j≥1 é chiaramente decrescente e
ϕ(c) = PZ(c ϕ(c)) ≥ k − 1,φ(c) = PZ(c ϕ(c)) ≥ k.
(4.2.4)

4.3. Transizioni di Fase nel problema k-SAT 65
Seϕ(c) > 0, usando la notazione λ = c ϕ(c), la seconda equazione in (4.2.4)diventa
c =λ
πk(λ)=c ϕ(c)
πk(λ)(4.2.5)
dove si é introdotta la notazione πk(λ) = PZ(λ) ≥ 1. La (4.2.5) é risolubilese e solo se c ≥ γk. Quindi si é portati a credere che
limn→∞
p(n,m) =
0, se c < γk
φ(c), se c > γk(4.2.6)
conφ(c) = PZ(λ) ≥ k = pk(λ) > 0. (4.2.7)
Quindi ogni dato vertice di G appartiene al k-core con probabilitá vicina apλ(k), mentre con alta probabilitá il core ha dimensione prossima ad n pλ(k).Rimane chiaro che, mentre questo ragionamento é rigoroso per il caso al disotto del valore critico c < ck, non c'é modo di renderlo tale nel caso c > ck.
4.3 Transizioni di Fase nel problema k-SAT
Anche il problema della k-SAT presenta una transizione di fase, al variaredel parametro α = M/N , che descrive la densitá di clausole per letterale o divincoli per variabile, sorpassa un valore critico: non epiú possibile, quandoα > αc ∼ 4.256 (per k = 3), trovare un assegnamento corretto delle variabili,e alcuni vincoli rimangono insoddisfatti.Il parallelo con il problema di graph coloring, peró, non si ferma qui: ancheper il problema di k-SAT é presente, prima della transizione SAT/UNSATche avviene ad α = αc, una transizione di clustering (per α = αd ∼ 3.91)in cui lo spazio delle congurazioni si divide in diversi stati, ed esiste unacomplessitá non nulla. Alcuni di questi stati hanno energia nulla, e quindisi é ancora nella fase SAT, cioé esiste soluzione per l'istanza del problema disoddisfacibiltá.Lo studio analitico ed algoritmico (come quello fatto in [23] da Mézard, Parisie Zecchina) di questa transizione é possibile, come nel caso dei gra, con glistrumenti del metodo della cavitá, anche perché il grafo delle clausole, nelproblema di 3-SAT é localmente isomorfo ad un albero.Non stupisce che i valori critici di cd e cq per le transizioni nel graph coloringe i valori di αd ed αc per quelle della k-SAT non corrispondano: infatti, comedetto precedentemente, il numero degli archi di un grafo non corrisponde alnumero dei vincoli in un problema di k-SAT, dal momento che, nel caso dellacolorazione di un grafo, vi sono anche le clausole che devono assicurare lasensatezza della colorazione di un nodo.

66 4. Rassegna dei principali risultati conosciuti

Premature optimization is the root of all evil (or at least most ofit) in programming.
Donald Knuth in Computer Programming as an Art1974 Turing Award lecture
5Algoritmi Monte Carlo e risultati
numerici
In questo capitolo verrà descritto il lavoro che é stato svolto durante il peri-odo di tesi. Verranno descritti i programmi e le routines di libreria scritte, epresentati i risultati ottenuti.
5.1 La struttura dati
La struttura dati é stata pensata e creata per chiarezza, senza particolareattenzione alle performance. Tale struttura ha due componenti principali:una prima struttura che dettaglia le proprietà di un nodo, ed una secondastruttura, più ampia, che guarda a tutto il grafo. Per ogni nodo sono spec-icati: il numero (che é il nome con cui ci si riferisce al nodo), il coloredel nodo, la lista delle adiacenze (adj_list) ed il numero di entries nella listadelle adiancenze (last). Si é preferito usare la lista delle adiacenze, piuttostoche la matrice di adiacenza, perché in generale i gra creati ed usati non sonodensi, e quindi si é risparmiata memoria.
67

68 5. Algoritmi Monte Carlo e risultati numerici
Figura 5.1: Descrizione graca della struttura dati.
5.2 Generatore
Per prima cosa si é scritto un programma, generatore, che crea un grafo,seguendo la denizione del modello di grafo random di Erdös e Rényi, par-tendo dal numero totale di nodi del grafo e dalla connettivitá media richiesta.Come già detto nei capitoli precedenti in tale modello due nodi sono adiacen-ti con probabilità p = c/(N − 1). Pertanto nella generazione viene visitataogni coppia di nodi, estratto un numero casuale e se questo é minore di p,allora viene costruito un arco tra i due nodi, aggiornate le liste di adiacenza(di entrambi i nodi) e aggiornate le variabili last di entrambi i nodi.Essendo il grafo richiesto semplice, si deve fare attenzione ad evitare loop,cioè nodi connessi a sé stessi, e doppi archi tra la stessa coppia di nodi.Nel dettaglio, l'implementazione:
for ( j =0; j<grafo−>nodi_tot ; j++)for ( i=j ; i<grafo−>nodi_tot ; i++)
i f ( i==j ) continue ; i f (rand_max_1()<prob )
grafo−>nodi [ j ] . ne igh [ gra fo−>nodi [ j ] . l a s t ]= i ;gra fo−>nodi [ j ] . l a s t=grafo−>nodi [ j ] . l a s t +1;grafo−>nodi [ i ] . ne igh [ gra fo−>nodi [ i ] . l a s t ]= j ;gra fo−>nodi [ i ] . l a s t=grafo−>nodi [ i ] . l a s t +1;
5.3 Analisi della distribuzione del grado dei no-
di
La prima verica che é stata fatta per valutare la bontà dei gra creati él'analisi della distribuzione dei gradi dei nodi. Infatti, se il generatore fa il suodovere, allora la distribuzione del grado dei nodi del grafo dovrebbe esserePoissoniana. La gura 5.2 presenta la distribuzione del grado per diverse

5.4. La simulazione Monte Carlo 69
Figura 5.2: Distribuzione del grado dei nodi per connettivitá 1,2,3,4 e 5. Nella
gura a sinistra i punti isolati sono la distribuzione di Poisson alla stessa connet-
tivitá media. In quella a destra é mostrato un confronto tra la distribuzione media
di Poisson nella generazione di gra da 512 nodi (in blu) e da 8 nodi (in rosso).
connettivitá: i risultati sperimentali e le distribuzioni di Poisson calcolate,a parte qualche piccolo errore, si sovrappongono molto bene nel caso di Ngrande. Come é possibile notare nella parte destra della gura 5.2 nel limitecontrario, cioè di N piccolo, la condizione di indipendenza delle probabilitàdel grado dei singoli vertici non é più soddisfatta: la distribuzione del gradodel grafo, infatti, oltre che essere troncata alla dimensione del grafo é dimolto discosta dai valori poissoniani ritrovati nel limite di N grande, ed ilsuo andamento é molto più simile a quello di una distribuzione binomiale,che vale per il grado dei singoli nodi.
5.4 La simulazione Monte Carlo
La simulazione Monte Carlo sul grafo come modello di Potts, il cuore delprocesso di colorazione, é stata scritta sia come funzione di libreria che comeprogramma standalone: essa, dato un grafo, cerca di trovare le congurazioniad energia nulla del modello di Potts costruito sul grafo.L'implementazione, semplice e didattica, include anche il Simulated Anneal-ing, con l'intenzione di aiutare la simulazione ad uscire da minimi locali delpotenziale.Nel farlo, ogni volta che completa una visita di tutto grafo, il programmavaluta se sia opportuno diminuire un parametro, che a tutti gli eetti si com-porta come una temperatura, nel modello di Potts: con il suo aumento odiminuzione aumenta o diminuisce la probabilità che lo stato proposto nel-l'algoritmo di Metropolis, se a maggiore energia di quello di partenza, venga

70 5. Algoritmi Monte Carlo e risultati numerici
accettato. Tale probabilità é ovviamente mai nulla, ma pub essere resa pic-cola per favorire la discesa lungo il prolo dell'energia, nella ricerca di unacongurazione ad energia zero. Chiaramente si deve anche rendere possi-bile alla simulazione l'aumento della temperatura: se, infatti, la simulazionedovesse incappare in un minimo locale dell'energia senza tale possibilità ri-marrebbe bloccata nel tentativo, infruttuoso, di diminuire ancora l'energia.In tal caso il programma si occupa di alzare improvvisamente la temperatu-ra, in modo da far uscire la simulazione dalla buca del minimo locale, e poidi ricominciare ad abbassarla lentamente, in un nuovo tentativo di trovare,altrove, una congurazione ad energia nulla.A grandi linee l'algoritmo di Simulated Annealing é stato implementato cosí:
i f ( ( i t e r%grafo−>nodi_tot)==0) i f ( hotrovatounozero !=0)
beta =0.7 ; else
beta=beta ∗1 . 0 5 ;i f ( ene rg i a==energ ia_prec )
contato re++; else
i f ( contatore >0) contatore−−;
energ ia_prec=ene rg i a ;
i f ( contatore>=MAX_CONTATORE) beta=beta / 1 . 2 ;contatore−−;
Ogni volta che l'algoritmo visita tutto il grafo decide cosa fare con lavariabile beta.
- se non sono stati trovati zeri, cioé colorazioni corrette, la temperaturaviene fatta diminuire del 5%; se, invece, sono state trovate colorazionicorrette durante la visita del grafo, la variabile hotrovatounozero énon nulla, e quindi viene aumentata la temperatura in modo da usciredalla valle di potenziale dove si é trovata una soluzione e ritornare adun sistema randomizzato.
- se non sono stati trovati zeri, ma l'energia del sistema non é varia-ta (energia==energia_prec), signica che, molto probabilmente, si é

5.4. La simulazione Monte Carlo 71
fermi in un minimo locale dell'energia: in questa situazione si provaa a diminuire comunque la temperatura un numero MAX_CONTATORE divolte. Se non si trova una soluzione, allora progressivamente si aumen-ta la temperatura, in modo piú veloce rispetto a quando la si diminuiva(infatti la si aumenta del 20% ogni volta). In questo modo il sistemaviene portato di nuovo ad una temperatura alta, con una elevata prob-abilitá di accettare di transire a nuovi stati ad energia maggiore deiprecedenti, uscendo cosí dalla valle di potenziale in cui la ricerca éstata infruttosa.
Un volta trovata una colorazione valida la simulazione la compara contutte le soluzioni che ha trovato precedentemente, e, se trovata uguale, lascarta: in questo modo l'insieme delle soluzioni trovate é formato da soluzioniuniche, senza ripetizioni.
I tempi caratteristici delle simulazioni Monte Carlo eettuate dipendonoin modo netto dalla connettivitá media del grafo. Infatti, il problema dicolorazione subisce, nell'avvicinarsi al punto di transizione COL/UNCOL,un rallentamento critico, dovuto alla complessitá del problema in esame (cisi riferisce a questo rallentamento come critical slowdown, in letteratura).Questo rallentamento é spiegato con l'apparizione di stati metastabili (peresempio minimi locali dell'energia) in cui la simulazione viene, per cosí dire,bloccata. L'algoritmo di Metropolis infatti avrebbe dicoltá ad uscirne, es-sendo possibile ma sfavorita, la transizione a stati ad energia maggiore. IlSimulated Annealing ha proprio il compito, con l'aumento improvviso dellatemperatura, di uscire da questi stati metastabili.In particolare, come detto precedentemente, le simulazioni e le strutture datiscritte non sono state create con le performance in mente: di fatto, la stessasimulazione, a meno del Simulated Annealing, carefully programmed, ottieneperformance migliori di un fattore 10.La simulazione Monte Carlo é stata scritta come studio propedeutico allarealizzazione della stessa su IANUS, una macchina dedicata al calcolo scien-tico basata su FPGA. La tabella 5.4 riassume un confronto tra i tempi diupdate per vertice del grafo, misurati su macchine high-end.
Singola replica 32-64 replicheNon carefully programmed ∼ 300 nsCarefully programmed 27 ns 6 ns
Si stima che con IANUS sia ottenibile un tempo di update per vertice delgrafo di circa 0.25 ns per nodo.

72 5. Algoritmi Monte Carlo e risultati numerici
Figura 5.3: Tempi medi di calcolo, in secondi, per trovare una colorazione di un
grafo random in funzione della connettivitá.
Un'altra misura interessante é il tempo medio complessivo usato dallasimulazione per trovare una colorazione valida: in gura 5.3 é rappresentatol'andamento dei tempi per un grafo da 512 nodi in funzione della connettivitámedia.
Nella gura 5.4 é mostrato l'andamento qualitativo del valore critico dicq della connettivitá oltre la quale non é piú possibile colorare un grafo infunzione della grandezza del grafo stesso. Questo é utile per valutare loscostamento del punto di transizione in funzione della dimensione del grafoe poter cosí in un certo senso stabilire no a dove, diminuendo la dimensionedel grafo, vale l'approssimazione di N → ∞. Ogni punto del grafo é statoottenuto calcolando la probabilitá di colorazione di gra ad N ssato (conN da 8 a 400) in funzione della loro connettivitá media e cercando il puntodi transizione, in cui la probabilitá di colorazione tende a zero.Tale probabilitá é stata calcolata su un campione di dimensione variabile:per gra da 8 nodi, siccome la connettivitá richiesta e quella ottenuta dalgeneratore si discostano anche di molto, il campione é stato ssato in circa500 gra, mentre per N grandi, essendo il generatore piú stabile, é sucienteun campione piú piccolo per poter, comunque, avere una misura signicativa.L'andamento della curva suggerisce, correttamente, la convergenza asintoticadel valore della soglia di colorabilitá cq al valore ricavato in letteratura, 4.69:si vedano in particolare [17] e [20].
5.5 La libreria libgra.h
Sostanzialmente tutti i programmi citati in questo capitolo ed usati per farele simulazioni sono stati, in un secondo momento, riscritti in forma di libre-

5.5. La libreria libgra.h 73
Figura 5.4: Andamento qualitativo del valore di transizione COL/UNCOL in
funzione della grandezza del grafo
ria. In questo modo lo sviluppo di programmi, come quello per la ricerca delk-Core é potuto procedere piú rapidamente.Oltre queste funzioni derivanti dagli altri programmi, si sono scritte al-tre funzioni, principalmente di supporto. Se ne elencheranno ora alcune,descrivendone gli algoritmi:
- graph_remove_nodequesta funzione si occupa di rimuovere un nodo del grafo, avendo curadi restituire un grafo che sia sintatticamente corretto: ovvero che nonabbia buchi nei numeri dei nodi. Per farlo si crea una struttura datiequivalente a quella del grafo di partenza ma vuota e passo passo glisi ricopia dentro l'informazione contenuta nel grafo di partenza. Inparticolare facendo attenzione a:
se i, il nodo che si sta copiando, ha numero inferiore a k, il nodoche si vuole rimuovere, lo si copia tal quale;
se i, il nodo che si sta copiando, ha numero pari a k, il nodo chesi vuole rimuovere, lo si salta;
se i, il nodo che si sta copiando, ha numero superiore a k, il nodoche si vuole rimuovere, lo si copia con il numero i− 1.
Senza scordarsi di correggere anche le liste di adiancenza: infatti rimuoven-do un nodo, bisogna cancellare gli archi incidenti con il nodo rimosso, eriaggiornare la nomenclatura di tutti i nodi rinominati. Per fare questoalgoritmicamente si procede cosí:
se ij nella lista di adiancenza del nodo i, l'arco che si sta copiando,

74 5. Algoritmi Monte Carlo e risultati numerici
contiene j che ha numero inferiore a k, il nodo che si vuole rimuo-vere, allora lo si copia tal quale;
se ij nella lista di adiancenza del nodo i, l'arco che si sta copiando,contiene j che ha numero uguale a k, il nodo che si vuole rimuovere,allora é un arco ad un nodo che non esiste piú e quindi non lo sicopia;
se ij nella lista di adiancenza del nodo i, l'arco che si sta copiando,contiene j che ha numero superiore a k, il nodo che si vuole rimuo-vere, allora, siccome il nodo di destinazione é stato rinominatodiminuendo di uno il suo numero, si diminuirá di uno anche il nu-mero del nodo a cui fa riferimento l'arco, e quindi l'arco diventerái(j − 1).
Inne si aggiorna, nella struttura del grafo, la variabile che identica ilnumero totale dei nodi (nodi_tot), diminuendolo di uno.
- graph_relabellingquesta funzione ha il compito di visitare tutti i nodi del grafo, avendocura di, per ciascuno, modicare il nome in modo che quest'ultimocorrisponda alla posizione che il nodo occupa nella struttura dei dati:in questo modo il grafo é tenuto in ordine. Questa funzione é usatasoprattutto negli algoritmi di divisione del grafo, come si vedrá piúavanti.
Oltre queste sono presenti in libreria funzioni per stampare il grafo, salvar-lo su un le con un formato intellegibile oppure nel formato .dot di GraphViz,funzioni per il calcolo dell'energia ed una pletora di funzioni per i numericasuali, che, come é facile intuire sono largamente usati nella simulazione.
5.6 Distanza tra le soluzioni
Come si é visto nei capitoli precedenti le colorazioni corrette per un datografo sono piú d'una, e il processo di colorazione, a seconda della connet-tivitá media del grafo, trova colorazioni diverse. E' interessante studiare ladistanza tra queste soluzioni per poter vedere e riconoscere le transizioni difase a cui sono sottoposte le soluzioni. In particolare é stata evidenziatala transizione di clusterizzazione delle soluzioni, a cui le soluzioni appaionoclusterizzate e distanti tra di loro. Un esempio di plot in 3 dimensioni dellamatrice é riportato in gura 5.8.

5.6. Distanza tra le soluzioni 75
5.6.1 La matrice delle distanze
La matrice delle distanze é stata calcolata come la distanza di Hammingtra le stringhe delle colorazioni corrette. La distanza di Hamming tra duestringhe di uguale lunghezza n é denita come
dH(s1, s2) =n∑i=0
1− δ(s1[i], s2[i]) (5.6.1)
e quindi, in un certo senso, conta il numero di dierenze tra le due stringhe.Qui s1 ed s2 sono le stringhe che descrivono la colorazione corretta del grafo.Nella matrice é calcolata la distanza di ogni colorazione corretta da ognialtra, per il grafo che si sta studiando, la matrice é quindi simmetrica. Nellalibreria libgra la funzione hamming() é stata implementata come:
i f ( s t r l e n ( s1 )!= s t r l e n ( s2 ) )return −1;
else for ( i =0; i <(signed int ) s t r l e n ( s1 ) ; i++)
i f ( s1 [ i ] != s2 [ i ] ) hd++;
return hd ;
E' possibile apprezzare la transizione di clustering delle soluzioni e la dimin-uzione della dimensione del cluster centrale, al crescere della connettivitá.Nella gura 5.8 sono rappresentate, in tre dimensioni, le matrici di distanzadi gra da 512 nodi, in particolare di 160 soluzioni nelle prime due e di circa400 soluzioni nella terza, a 3 connettivitá diverse, ma comunque al di sopradella transizione di clustering. I plot hanno il numero progressivo di soluzionesugli assi x ed y, mentre sull'asse z é rappresentato il valore dell'elementodella matrice. Nei primi due graci le soluzioni sono state trovate in modosequenziale: una volta trovato un cluster l'algoritmo cerca di ottenere quantepiú soluzioni possibili all'interno di quel cluster, in modo da poterne apprez-zare, seppur in modo qualitativo, la dimensione. Nel terzo caso invece, unavolta trovata una soluzione il sistema viene portato ad una temperatura taleda randomizzare il nuovo cammino di discesa dell'energia. Si puó notare,in particolar modo nel terzo graco, un cluster gigante, e la presenza di 3cluster piccoli (il piú in alto ed il piú in basso sono i piú evidenti ed il terzo,meno evidente, subito al di sotto della componente grande).Interessante notare che un cluster grande di soluzioni si forma sempre tra

76 5. Algoritmi Monte Carlo e risultati numerici
soluzioni che hanno distanza media tra di loro 2/3N : questo é il cluster dipermutazione di colore. E' formato da soluzioni che, tra loro, sono uguali ameno della permutazione di due colori.
5.7 L'emergenza del k-Core
Come giá visto nei capitoli precedenti, in funzione della connettivitá si as-siste all'emergenza di un componente massivo e connesso, denito k-Core,composto dal sottografo massimale con grado minimo k. Trovare il k-Coredi un grafo ha importanza dal momento che, come ovvio, non é un problemacolorare nodi che hanno grado minore di q (il numero dei colori disponibili)mentre é chiaramente dicile colorare in modo corretto nodi che hanno gra-do uguale o maggiore a q.Il k-Core, quindi, rappresenta dal punto di vista della colorazione, il compo-nente piú dicile da colorare, e quando diventa parte consistente del grafo,impedisce la colorazione.Inoltre é possibile pensare di, una volta generato un grafo, colorare solo ilk-Core, e poi usare l'informazione sulla topologia originaria del grafo percolorare le foglie esterne al k-Core, che avendo grado minore di q, possonoessere trivialmente colorate.L'algoritmo per isolare il k-Core di un grafo é piuttosto semplice ed ha ilvantaggio di trovare un grafo nullo (nel caso in cui il k-Core non esista) op-pure un grafo che corrisponde al k-Core del grafo originario, come descrittoda [12], e quindi prova o meno la sua presenza o assenza. Si procede cosí:dato un grafo G in ingresso,
- si visita l'intero grafo e si rimuovono tutti i nodi di grado al piú k −1, chiamati vertici leggeri; nessuno di loro infatti puó appartenere alk-Core. Rimuovendo i vertici leggeri, si aggiornano anche le liste diadiacenza dei nodi rimasti.
- si ripete la stessa operazione no a che rimane o un grafo vuoto o ungrafo i cui vertici sono tutti pesanti (ovvero di grado almeno k).
I nodi rimasti, se ne sono rimasti, sono ovviamente appartenenti al k-Coredel grafo. Se non sono rimasti nodi, allora il k-Core non esiste (cioé é l'in-sieme vuoto). I risultati ottenuti sui gra generati sono compatibili con laletteratura citata in precedenza ([12]), come si puó vedere nella gura 5.5:l'apparizione del 3-Core per c ≈ 3.3 e da subito esso contiene circa il 27% deinodi del grafo.

5.8. Distribuzione del grado dei nodi all'interno del k-Core 77
Figura 5.5: Dimensione del 3-core in funzione della connettivitá: l'apparizione del
3-core é intorno a c ≈ 3.3. A sinistra una misura media calcolata su gra di 2048
nodi, con circa 100 iterazioni, a destra un caso tipico, di un grafo con 2048 nodi.
La linea verticale indica, il punto di transizione COL/UNCOL
5.8 Distribuzione del grado dei nodi all'interno
del k-Core
Una misura interessante che si é fatta é la distribuzione del grado dei nodi al-l'interno del k-Core, supponendo che lí stia una chiave, seppur intuitiva, percapire il fenomeno di transizione COL/UNCOL. Difatti da sole l'emergenzae la crescita del k-Core come componente principale del grafo non bastano agiusticare l'esistenza della transizione di fase.Questa analisi viene fatta, partendo da un grafo, trovandone il 3-core, epoi analizzando, in funzione della connettivitá del grafo di partenza, la dis-tribuzione del grado dei nodi. Ci si aspetta che questa distribuzione siaPoissoniana, ma troncata per d < 3, ed eettivamente cosí é. Si nota unacosa interessante analizzando questa distribuzione: infatti, intorno al puntodi transizione COL/UNCOL, c'é un'inversione tra il grado piú probabile pri-ma della transizione, 3, ed il grado piú probabile dopo la transizione, 4, comesi nota nella gura 5.6. Questo é intuitivamente sensato, poiché se i nodia grado d < 3 sono immediatamente colorabili in tre colori, quelli a gradomaggiore di tre sono, via via che aumenta il grado, sempre piú un problemaper la colorazione del grafo. Per valutare questo, si puó calcolare l'integrale∫ ∞
0
pλ(k)(k − 2). (5.8.1)
che descrive, in funzione della connettivitá media del grafo λ il numero dinodi con almeno 3 vicini.

78 5. Algoritmi Monte Carlo e risultati numerici
Figura 5.6: Distribuzione del grado dei nodi all'interno del 3-core al variare della
connettivitá media del grafo di partenza. Da notare come, in un intorno del punto
di transizione COL/UNCOL (che é cq ∼ 4.69) la distribuzione si inverta: per
connettivitá media 4.7 sono piú probabili nodi di grado 4, mentre prima della
transizione, a 4.6, sono piú probabili nodi di grado 3.
5.9 Misura del diametro e del coeciente di
clustering
Come si é visto in 2.1.1 il diametro di un grafo é la distanza massimale trauna coppia qualsiasi di vertici. La distribuzione del diametro in una famigliadi gra random ad una certa p (e quindi ad una certa connettivitá media pernodo) é generalmente centrata intorno al valore:
d =ln(N)
ln(pN)=
ln(N)
ln(〈k〉), (5.9.1)
come precedentemente visto. La misura di questo indice é stata fatta seguen-do la denizione.
Anche per il coeciente di clustering la misura é stata fatta seguento ladenizione, e, da 2.1.1 é
Crand = p =〈k〉N. (5.9.2)
I risultati di queste misure sono visibili in gura 5.7.L'insieme di queste due misure fornisce un quadro dell'evoluzione di un graforandom: al crescere della connettivitá media il diametro del grafo diminuisce,dicendo cosi`, che la distanza tra i vertici del grafo diminuisce esponenzial-mente, mentre il coeciente di clustering aumenta linearmente. Questo for-nisce un'immagine chiara di cosa succede: il grafo si chiude sempre di piú su

5.10. Divisore 79
Figura 5.7: A sinistra: andamento del coeciente di clustering in funzione
della connettivitá media. A destra: andamento del diametro in funzione della
connettivitá media.
se stesso, aumentando il numero di archi e le connessioni tra i nodi.
Il fatto che i gra random di Erdös-Rényi abbiano diametro piccolo e chetale parametro diminuisca al crescere della connettiviá media per nodo nonstupisce, dal momento che nel limite di p→ 1 il grafo casuale tende al grafocompleto di ordine N , ma colpisce il parallelismo con i network complessistudiati da Barabási e Albert in [11], con la dierenza che la distribuzionedel grado dei nodi é per questi ultimi una legge del tipo P (k) ∼ k−γ. Esempidi questi network complessi sono il World-Wide Web, Internet, i gra dicollaborazione scientica e reti ecologiche e neurali, seppur con diversi γ.
5.10 Divisore
Pur non avendo nulla a che vedere con la sica del sistema che si sta stu-diando, si sono sviluppati un algoritmo ed un programma che rendono pos-sibile la parallelizzazione della colorazione di un grafo: tale parallelizzazioneé necessaria per poter aggiornare su IANUS le colorazioni del grafo in modoparallelo.Il divisore, infatti, ha il compito di riordinare e rinominare il grafo in modoche, scelto un k arbitrario, che per IANUS é ssato a 64, blocchi di k nodiscritti di seguito del grafo non contengano nodi adiacenti tra loro. Si trattaquindi di scorrere il grafo e spostare i nodi in nuove posizioni, all'internodell'array, in modo che non ci siano adiacenze all'interno del blocco di k no-di. Questo puó essere fatto in diversi modi: scorrendo il grafo e spostandoin modo casuale verso il basso, in altri blocchi, i nodi che hanno adiacenze

80 5. Algoritmi Monte Carlo e risultati numerici
Figura 5.8: Plot in 3 dimensioni della matrice delle distanze per un grafo di 512
nodi: le soluzioni appaiono chiaramente clusterizzate.
Figura 5.9: Probabilitá di successo dell'algoritmo di divisione random in funzione
della dimensione del grafo (il colore) e della dimensione del blocco k di nodi non
adiancenti che si vuol generare.

5.10. Divisore 81
all'interno dello stesso blocco, e poi, una volta nito il grafo, rinominando inodi in modo che il numero del nodo corrisponda alla sua posizione nell'arraydei nodi, e di conseguenza modicando le liste di adiancenza con i nuovi nu-meri dei nodi; in altro modo si possono sfruttare le proprietá topologiche delgrafo, mettendo all'interno dello stesso blocco nodi che hanno connettivitácrescenti o decrescenti: questo si puó fare ordinando il grafo in modo che inodi siano ordinati per connettivitá crescente o descrescente e poi prendendonodi con diversa connettivitá, mettendoli poi all'interno di un blocco. Fattoquesto é opportuno vericare la condizione di non adiancenza, e, nel casospostare nodi che non la vericano.Mentre il primo modo non é detto che si raggiunga una risposta in un tempoaccettabile, soprattutto per gra grandi (cioé potrebbe non riuscire nell'op-erazione di divisione e metterci comunque molto tempo), per il secondo larisposta sulla fattibilitá della divisione é piú veloce, ma non é sempre possi-bile riuscire: questo é vero in ogni caso, dipendendo solamente ed in modoforte dalla topologia del grafo particolare che é stato generato. Data la naturarandomica del primo algoritmo, lo stesso grafo puó ottenere un insuccesso oun successo in modo casuale: per questo motivo valutare la sua ecienza écosa piuttosto dicile. Nella gura 5.9 sono rappresentate le probabilitá disuccesso dell'algoritmo di divisione random.

82 5. Algoritmi Monte Carlo e risultati numerici

6Conclusioni
In questa tesi si é studiato il problema di colorabilitá di un grafo random,utilizzando un approccio di tipo Monte Carlo, con cui sono stati riottenutialcuni risultati giá noti in letteratura. In particolare si é vericato:
- l'esistenza della transizione COL/UNCOL, ed il valore del parametro cintorno a tale transizione, anche in funzione della grandezza del grafo.
- l'esistenza delle altre transizioni, in particolare quella di clusterizzazione
- l'esistenza, la soglia a cui appare e la dimensione del k-core di un grafo,con particolare attenzione al 3-core.
- la distribuzione delle soluzioni di colorazione
I risultati ottenuti sono, in larga parte e con ottimo accordo, compatibilicon i risultati presenti in letteratura.
E' ora in corso l'adattamento del codice della simulazione Monte Carloin modo da poterlo utilizzare sul calcolatore dedicato IANUS, sviluppato incollaborazione tra l'Universitá di Ferrara, l'Universitá di Roma 1 e l'Istitutodi Bioinformatica e Fisica dei Sistemi Complessi dell'Universitá di Zaragoza.Con tale sistema si potrá studiare il comportamento a grandi N di questigra, con una accuratezza stastistica dell'ordine di 100 volte superiore aquella possibile con strumenti di calcolo tradizionali.

84 6. Conclusioni

Bibliograa
[1] Birkho, G.D., A Determinant Formula for the Number of Ways of
Coloring a Map, Ann. Math. 14, 42-46, 1912
[2] Whitney, H., A logical expansion in mathematics, Bull. Amer. Math.Soc. 38, 572-579, 1932
[3] Whitney, H., The coloring of graphs, Annals of Math. (2) 33, 688-718,1932
[4] Whitney, H., A set of topological invariants for graphs, Amer. J. Math.55, 231-235, 1933
[5] Tutte, W.T., A ring in graph theory, Proc. Cambridge Philos. Soc. 43,26-40, 1947
[6] Tutte, W.T., A contribution to the theory of chromatic polynomials, Can.J. Math. 6, 80, 1954
[7] Sokal, A., Chromatic Polynomials, Potts Models and All That, 1999
[8] Kasteleyn, P.W. e Fortuin, C.M., Phase transitions in lattice systems
with random local properties, J Phys Soc Japan 26(Suppl.), 11-14, 1969
[9] Fortuin, C.M. e Kasteleyn, P.W., On the random-cluster model.
I.Introduction and relation to other models, Physica 57, 536-564 ,1972
[10] Welsh, D.J.A., Complexity: Knots, Colourings, and Counting,Cambridge University Press, Cambridge-New York, 1993
[11] Albert, R. e Barabási, A-L., Statistical Mechanics of Complex Networks,Review of Modern Physics, 74, 47, 2002
[12] Pittel, B., Spencer, J., Wormald, N., Sudden Emergence of a Giant k-Core in a Random Graph, Journal of Combinatorial Theory, Series B67, 111-151 1996
85

86 BIBLIOGRAFIA
[13] uczak, T., Size and Connectivity of the k-Core of a Random Graph,Discrete Math., 91, 61-68, 1991
[14] Luczak, M., Svante, J., A Simple Solution to the k-Core Problem,arXiv.org:math/0508453
[15] Cain, J. e Wormald, N., Encores on cores, Electronic J. Combinatorics13 (2006), R81, 13
[16] Dong, F.M., Koh, K.M., Leo, K.L., Chromatic Polynomials and
Chromaticity of Graphs, World Scientic
[17] Zdeborová, L., Krzakaªa, F., Phase Transition in the Coloring of
Random Graphs, arXiv:0704/1269v1 [cond-mat.dis.nn]
[18] Montanari, A., Semerjian, G., Large Scale Rearrangements to Mode
Coupling Phenomenology, Phys. Rev. Lett. 94, 247201 2005
[19] Newman, M.E.J., Barkema, G.T., Monte Carlo Methods in Statistical
Physics Oxford University Press, 2002
[20] Mulet, R., Pagnani, A., Weigt, M., Zecchina, R., Coloring Random
Graph, Phys. Rev. Lett. 89, 268701 2002
[21] Bollobás, B., Modern Graph Theory, Springer-Verlag 1984
[22] Bollobás, B., Random Graphs Second Edition, Cambridge UniversityPress 2001
[23] Mezard, M., Parisi, G., Zecchina, R., Analytic and Algorithmic Solutionsof Random Satisability Problems, Science 297, 812 2002
[24] uczak, T., Pittel, B., Weirman, J.C., The Structure of a Random
Graph at the Point of the Phase Transition, Transaction of the AmericanMathematical Society, 341, 2, 1994