Embed Size (px)
Citation preview

JOURNAL OF POLYMER SCIENCE: PAR1’ C NO. 12, PP. 235-248 (1966)
Translating the Genetic Code
PAUL DOTY, Harvard University, Cambridge, Massachusetts
In honoring Professor Mark on the occasion of his 70th birthday we have almost no alternative than to reflect in one way or another on the synthesis and properties of polymeric macromolecules. For it is this that has grown from an idea, a t the beginning of his career, to one of the largest sections of the advancing front of science and technology. Through his crucial vision and untiring devotion in this enterprise we have all gained enormously and we welcome this particularly pleasant occasion on which we can express our indebtedness.
My own contribution is very much in the mainstream of “the synthesis and properties of polymeric macromolecules” despite the fact that this is not evident in the title. This is because most of the polymerizations that take place in living systems involve an additional concept not usually evident in synthetic polymeric macromolecules. That is, the most im- portant macromolecules in living systems-proteins and nucleic acids- have a unique ordering of their monomeric components. Hence, the average composition and statistical distribution of nearest neighbors which serves to characterize typical copolymers must give way in biological systems to a unique specification of monomer sequence. And identical copies of these macromolecules must be made each time cells divide. Within the last few years the rather complicated way in which this “replica” polymerization is carried out has been elucidated. While this development has been carried on under the banner of biochemistry and molecular biology, it is inevitably built upon the broad base of polymer chemistry and would not have been possible without it. My aim is to give a summary of recent events in this field in a way that will make this connection evident.
At the risk of gross oversimplification, one can say that the decade of the fifties produced an entirely new view of the chemistry of living systems for the following reasons. In this period it became overwhelmingly evident that proteins were the supremely important molecules synthesized in the cell because they carried out the most delicate and essential functions of catalyzing thousands of chemical reactions to the proper extent and serving as highly specific carriers of essential small molecules. The main structural features of proteins were elucidated and the complete structure on one protein was obtained by 1961. This was myoglobin, shown in Figure 1, which consists of a single polypeptide chain that folds in a unique way due to the interplay of interactions :mong the various ainino acid residues,
235

236 1’. DOTY
Fig. 1. A view of the three-dimensional structure of the myoglobin molecule prepared from the work of Kendrew and his collaborators.’ (Courtesy of the Scientij’ic Ameri- can.)
the monomeric units, of which there are twenty. The function of this protein is to carry a molecule of 0% or COZ with just the tenacity needed by the living system. This is achieved by the nature of the binding site formed by one side of the heme group and several other amino acid residues that are uniquely positioned nearby. This is a, general situation: Host proteins seem to take up a unique configuration with one sniall region exhibiting the very specific function as the myoglobin example illustrates.
By the early fifties it had also become quite clear that these thousands of different protein molecules which collectively go a long way toward defining the entire nature of each kind of living species are not self-replicat- ing and often are not transferred to the next generation. They can there- fore only be synthesized in new cells and organisms if the instructions are contained in another type of macromolecule, and a mechanism is available for translating this into the sequence of amino acids in the proteins. The scheme that became evident in the fifties assigned the information specify- ing all the sequences in all the proteins characteristic of a given species to the deoxyribonucleic acid (DNA) of the species. This information had to be carried by a four-letter code in the linear DNA molecule since this mole- cule was a copolymer of four different nucleosides. Indeed, the forward thrust began when the molecular structure of DNA was elucidated in 1953

GENE'I'IC CODE 237
Fig. 2. An electron micrograph of DNA from a burst bacteriophage T2 virus.2
by Watson arid Crick. This showed it to be a double-stranded, helical molecule, the strands being held together by specific interactions between adenine (A) on one chain and thymine (T) on the other, and between gua- nine (G) on one chain and cytosine (C) on the other: No other pairing was possible and the two chains were perfectly complementary. Such molecules have a characteristic appearance in electron micrographs. One micrograph of a bacteriophage is shown in Figure 2. This is the entire DKA of this virus and has a degree of polymerization of about

238 P. DOTY
DNA
DNA T G A A G I I I I I
L C A G C i G A
DNA
i G I I $ 4 : RNA A C i i C
Fig. 3. Diagram illustrating replication and transcription.
0 0 2(30S) + 2(50S) 2(70S) l(lO0S)
015 t 0.15 1.802 0.15 2.8 t 0.2 5.9 5 1.0
Fig. 4. The association of ribosomal particles together with the sedimentation constant and molecular weight of each form.8
500,000. A bacterial cell contains about 20-100 times as much DNA and a mammalian cell about 10,OOO times as much.
DNA was shown to replicate, with a conservation of its all-important base sequence, by virtue of the strands coming apart and serving as templates on which the other strands were synthesized thereby forming two exact copies of the ’
0rigin.d molecule. But the DNA was not the template from which the protein was synthesized. This function was performed by a second kind of nucleic acid, ribonucleic acid (RNA), which was also made on the DNA strand so as to consist of the complementary sequence. This newly formed RNA then separated and was taken up by the sites within the cells where protejns were synthesized, the ribosomes. These two steps, replication of DNA and transcription of its complementary sequence into the RNA, are !hewn diagrammatically in Figure 3.
The final step, that of translation, in which the information contained in the sequence of bases in the RNA dictate the order of assembly of amino acicf;s in protein synthesis, was not unraveled until quite recently. The early phase of this work (1958-1962) is best described in terms of the three different kinds of RNA that came to be recognized as essential participants in protein synthesis: ribosomal (r-RNA) , messenger (m-RNA), and trans- fer lor soluble (s-RNA)] RNA.
For some time it was known that protein synthesis occurred in particles known as ribosomes: These are composed of RNA and protein and seem to be of approximately the same composition and size in all living organ- isms. Their anatomy was explored in this period and although their detailed molecular structure is not yet known, their basic makeup in terms of two sub-particles has been elucidated. The results are displayed in
Two other key points were established in the fifties.

GENETIC CODE 239
I Ribonucleotides
V’ Q Ftee
\ Enzymatic /$ breakdown
Of m-RNA Pnlvoeotide chain
involved in protein synthesis
. +TRNA , r _ r _. 1s I
AA- AMP
f Z AA ATP
Fig. 5. Diagrammatic summary of protein synthesis.6
Figure 4 where the sedimentation coefficients are given in parentheses with the molecular weights below. It was quickly established that the 705 particle composed of one each of the two sub-particles was the active form on which protein synthesis occurs. The equilibrium shown are under control of the Mg++ concentration and hence this must be maintained within rather narrow limits to preserve the desired form of the ribosome.
For some time it had been believed that some kind of adaptor molecules must exist that would play the dual function of accepting a specific amino acid and offering it for insertion at the appropriate time by allowing another part of itself to be recognized by the “message” encoded in the RNA that is directing protein synthesis. Such adaptor molecules have been found, one to as many as four for each of the amino acids. These are small RNA molecules, only 25,000 in molecular weight, and containing unusual nucleotides in appreciable amounts. The sequence of one of these has just been determined by Holley and his colleague^.^
Finally we have the RNA, previously referred to, that contains the information for directing the assembly of amino acids and is made by direct template copying from the DNA: This is called messenger RNA. Previously it was thought that the whole RNA of the cell provided this function. But with the improved delineation that brought the other two forms into view it was found that the messenger RNA was indeed a minor component and in many cases a rather short-lived component.
With these three kinds of RNA defined, the other substances necessary for their functioning became clear. Thus, it became possible to envisage putting all of these items together in a test tube and carrying out protein

24.0 P. DOTY
synthesis outside the cell, in vitro. This was accomplished in 1961 and became the starting point for the exploration of the detailed understanding of protein synthesis that we now find ourselves involved with. Before taking this up let us look at the overall scheme that was revealed by the work at this stage. This is shown in Figure 5 where it can be seen that the messenger RNA attaches itself to the ribosome and the amino acids are brought to the point of assembly by the transfer RNA molecules. Specific interaction between the messenger RNA and the transfer RNA, mediated by the ribosome, insures that the message is read by the correct alignment of amino acids. Of course, several enzyme systems are involved in this assembly: to load the amino acid on to the transfer RNA and to add the amino acid to the growing peptide chain.
In 1955 Ochoa and Grunberg-Manago discovered an enzyme that catalyzed the polymerization of polyribonucleotides from nucleotide di- phosphates. With this it was possible to make polyribonucleotides having the same chain structure as natural RNA but composed of one, two, or more bases as desired; for copolymers the sequence n-as largely dictated by the composition of the polymerizing mixture. Thus homopolymers and copolymers became available and the question then arose if these could serve as messengers in place of the natural messenger RNA. When Nirenberg6 and then Ochoa’ with their collaborators found that in vitro systems deprived of messenger RNA began to incorporate amino acids into polypeptide products when a synthetic polynucleotide was added, a breakthrough was clearly evident. In the first instance, in 1961, the addition of polyuridylic acid (poly U) was found to produce poly- phenylalanine. Thus, some grouping of uridylic nucleotides coded for phenylalanine and the means of unraveling the genetic code, that is the sequence or sequences of bases in RNA that corresponded to the amino acids, was close at hand. With its elucidation was sure to come an under- standing of much of the molecular detail required for the assembly of amino acids into proteins in such a way that the instructions initiated back in the DNA are faithfully carried out.
For some time Crick* and others had insisted that the nature of the code ‘was probably such that three nucleotides, a triplet, coded for one amino acid. This followed from the fact that four bases allowed only 16 two-base groupings; with 20 amino acids to specify, this was not enough. With three bases, 64 combinations were possible. This was more than enough, but it saggested that several triplets might be used to designate a single amino acid, a situation described as degeneracy.
Against this background it was immediately of interest to see if simple copolynucleotides stimulated the incorporation of several amino acids. On the basis of a triplet code the frequency of occurrence of each possible triplet in a given copolymer could be predicted and these frequencies could then be matched against the amounts of amino acids incorporated. Ex- periments quickly showed that such a general prediction was borne out. In Figure 6 is shown the results of using a copolymer of adenylic acid (A)

GENETIC CODE 241
800
c 0) .- 4-
e n 9 600
2 E
.- u c
V ., 400 8
E a f
In 200
0 ._
0
m - s 3 3
‘0 10 20 30 40 50 60 70 80 90 100 Time (min.)
Fig. 6. The incorporat,ion of various amino acids stimii1at)ed by copoly AC (base com- posit#ion: 47% A, 53% C).g
and cytidylic acid (C) as the “mes~enger.”~ It is seen that six amino acids are incorporated from a pool in which all are present.
The analysis of the data obtained in this experiment is shown in Table I where the frequencies of doublets and triplets (code words) and relative incorporations are listed. It is seen that eight code words or triplets are
TABLE I Comparison between Amino Acids Incorporated and RNA
Code-Word Frequencies
Theoretical code-word frequency in poly AC Amino acids Frequency of containing 47y0 A and incorporated into C14 amino acids
53% c C14 Amino acid protein, ppmoles incorporated, %
AAA 10 .4 Lysine 183 10.8 AAC 11.7 Asparagine 192 11.6 ACA 11.7 Glutamine 157 9 . 3 CAA 11.7 Threonine 444 26 3 CCA 13.2 Histidine 159 9 . 4 ACC 13.2 Proline 550 32.6 CAC 13 .2 CCC 14.9
Total 1685 100.0

242 P. DOTY
0 OH 1
OH OH
Fig. 7. The synthesis of polynucleotides; X = adenine, uracil, cystosine, guanine, hypoxanthine.
present in this copolymer and, assuming no preference in nearest neighbors, these eight triplets are present in roughly equal amounts. Of the six amino acids incorporated, two are used much more than the others which display about the same activity. Thus, one would tentatively con- clude that two of these, proline and threonine, were coded by two code words each and the other four amino acids, by one code word. By follow- ing this experiment, which was performed by others, using copolynucleo- tides of different composition a fairly good identification was made insofar as the constituent bases in the triplet is concerned. However, nothing can be deduced about the ordering of the bases within the triplet.
The consistency of the results obtained by this procedure supported the assumption that practically all of the triplets did correspond to amino acids, that is that the code was highly degenerate. Otherwise, many triplets would be inactive but since their composition was not known i t would not be possible to identify triplet frequencies with amino acids. During 1962 and 1963 this work was extended to provide a carefully coni- piled list of three-letter code words for the amino acids.
With this progress the stage was set for an attack on some very important unanswered problems. Chief among these were: (1) Can we obtain direct proof that the code words are triplets? (2) Can the triplet code words, with specific ordering of the three bases, be assigned for all 64 cases? (3) In what direction is the RNA chain “read?” (4) What are the suc- cessive steps of assembly (or polymerization) of the polypeptide chain on the ribosome? Is there a specific signal in terms of a certain nucleotide sequence for chain initiation and chain termination?
Three strategies were available for approaching a solution to this matter. One might be able to find the means by which trinucleotides could induce the specific binding of a particular amino acid, carried on its corresponding transfer RNA, and thereby identify nucleotide triplet with amino acid. This route was followed by Nirenberg and his co-workers. Alternatively, one might be able to make long polynucleotides with exactly repeating sequences. This has just been achieved by Khorana and his co-workers, Finally, one might make short oligonucleotides of known sequence and see if they could be induced to stimulate incorporation and yield analyzable products. Ochoa and his group as well as a group in my laboratory chose

GENETIC CODE 243
50 t 100 MM. C (pC),
No primer t- // '/ A
do -57cri- 70 ;o !o
0
Time (min.)
Fig. 8. The effect of oligocytidylic acids in priming the polymerization of uridine diphos- phate.
this route. The remainder of this article summarizes the present status of these three efforts.
Our own work began by seeking to understand the basic polymerization reaction so that short, tailor-made, oligomers could be produced. The reaction, catalyzed by the enzyme polynucleotide phosphorylase and mentioned earlier, is shown in Figure 7. Our first step was to exploit the earlier observation that with a particular preparation of the enzyme there was an absolute requirement for a primer, that is a small, preexisting oligo- nucleotide, that would serve for chain initiation. This effect can be seen in Figure 8 where oligomers of C (made by fractionating partially degraded poly C) are used for the polymerization of uridine diphosphate. Under ordinary conditions quite long chains of U grow from the priming oligo C, yielding blocks such as C,U,,. In order to reduce the chain length of the second block, an essential requirement of our procedure, we varied the NaCl concentration and achieved the desired effect.1° NaC1, 0.5M, quite effectively caused early chain termination so that a product such as
Codons from Two-Component Block Polymers
CpCpCpCpCpCpCpApApApApApAp.4
AAC ACC CCA CAA CAC ACA
AC AU A1 CU CI UI
Fig. 9. Triplet code words in a pair of reciprocal block oligonucleotides.

244 P. DOTY
Codons from Three-Component Block Polymers
I + p i CpCpCpCpCpCpC
CPCPCPCPCPCPCPAPA CPCPCPCPCPCPCPAPAPA
A CpCpCpCpCpCpCpA + UDP -* CpCpCpCpCpCpCpApUpUp.. . + Pi
1:
2:
1.0 M Na+; 1 mM Mg++ and PNPase
0.5 M Na+; 10 m N Mg++ and PNPase
Fig. 10. The preparation of block oligonucleotides with internal heterogeneous triplet code words. Reaction 1: 1.OM Na+, 1 mM. Mg++, and PNPase; reaction 2: 0.5M Na+, 10 mM. Mg++, and PNPase.
C A , C&, C&, and C6A4, as a mixture, could be obtained. It was then quite easy to fractionate this into the pure components. Any of these products could then be used again as primer to make for example, CsAIUs. The bar over the final subscript indicates that this is an average value (number-average). Fractionation into pure components is again possible, but it is seldom required for reasons that will be seen. The code words (or codons) that become available in two- and three-component blocks are illustrated in Figures 9 and 10 together with the scheme of preparation in the later case.
The determination of a code word can often be made by using two re- ciprocal blocks as summarized in Table 11. For example, it is known from the earlier copolymer studies that copoly CU incorporates leucine and hence one or more of its code words is composed of these two bases. The incorporation experiments shown in Table II indicate that one such codon must be either CCU or CUU. Since other work assigns CCU to proline, CUU must be a leucine code word. In this way a number of code words have been identified. l1 Meanwhile, however, more rapid progress was made by Nirenberg using a binding technique to which we now turn.
Last fall Nirenberg and Leder12 devised a clever method of detecting specific interaction between trinucleotides and amino acid bound to transfer RNR. Their work showed that most trinucleotides can be bound on ribosomes much as messenger RNA is bound and in this state
TABLE I1 Effect of Block Sequence for Internally Coded Amino Acid
Total Blank Net counts/min. counts/min. counts/min.
COU13 3329 1189 2140 UlOC56 1157 1189 - 32
-
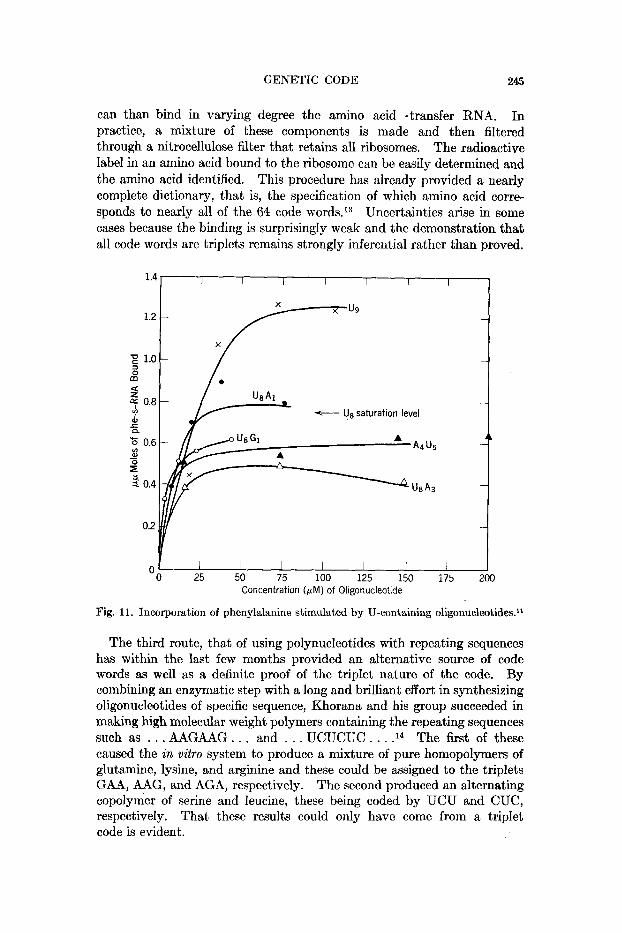
GENETIC CODE 245
can than bind in varying degree the amino acid-transfer RNA. In practice, a mixture of these components is made and then filtered through a nitrocellulose filter that retains all ribosomes. The radioactive label in an amino acid bound to the ribosome can be easily determined and the amino acid identified. This procedure has already provided a nearly complete dictionary, that is, the specification of which amino acid corre- sponds to nearly all of the 64 code words.13 Uncertainties arise in some cases because the binding is surprisingly weak and the demonstration that all code words are triplets remains strongly inferential rather than proved.
1.4
1.2
z 1.0 m a g 0.8 Y) - U8 saturation level d,
3 0
z
r Q
Y) 0.6
- B t' 0.4
0.2
0 25 50 75 100 125 150 i75 2 Concentration (&M) of Oligonucleotlde
0
Fig. 11. Incorporation of phenylalanine stimulated by U-containing oligonucleotides.ll
The third route, that of using polynucleotides with repeating sequences has within the last few months provided an alternative source of code words as well as a definite proof of the triplet nature of the code. By combining an enzymatic step with a long and brilliant effort in synthesizing oligonucleotides of specific sequence, Khorana and his group succeeded in making high molecular weight polymers containing the repeating sequences such as . . . AAGAAG . . . and . . . UCUCUC . . . .14 The first of these caused the in vitro system to produce a mixture of pure homopolymers of glutamine, lysine, and arginine and these could be assigned to the triplets GAA, AAG, and AGA, respectively. The second produced an alternating copolymer of serine and leucine, these being coded by UCU and CUC, respectively. That these results could only have come from a triplet code is evident.

246 P. DOTY
The Nirenberg-Leder binding technique offered an opportunity to see how effectively our oligonucleotides participated in the first step of this reaction, that of the messenger binding to the ribosome. Some results with U-containing oligomers is shown in Figure 11 where the amount of phenylalanine, coded by UUU, is plotted against the amount of oligo- n~c1eotide.l~ Us is seen to reach a high level of binding, not far short of what poly U itself displays. However, the replacement of a 3' terminal residue with A or G diminishes the binding of phenylalanine but does not eliminate it. This shows that the codon containing the other nucleotide can occupy the site to which the transfer RNA attaches but that binding at the 3' end is not by any means exclusive. Replacement a t the other end of the oligonucleotide, the 5' end in contrast to the 3' end, also de- presses the binding of phenylalanine-transfer RNA but does not eliminate it. The conclu- sion to be drawn from these experiments is that neither the 3' nor the 5' terminal triplet constitutes a mandatory coding site for the initiation of chain growth. Attachment of messengers of this type can be at any loca- tion along the chain, some preference probably being given to those triplets that have a stronger binding capacity. Thus, in actual messenger RNA there must be some encoded information that signals chain initiation at the end or at specified points within the chain, but these have not yet been reproduced in the synthetic messenger oligonucleotides.
If the choice of a triplet reading frame within an oligonucleotide is es- sentially random, then we would expect that internal triplets would also code. Thus, the block A4Uj, which contains internally the triplets AAU and AUU, should code for a t least one amino acid other than phenylalanine and lysine." Among the several amino acids tested, we have found that isoleucine is coded by this block, but not by its reciprocal block, U,A,. It remains to be determined which of these two internal triplets codes for isoleucine. To decide this we conducted binding experiments using as messengers the trinucleotides AAU and AUU, but did not observe a significant stimulation with either which thus made the assignment of this codon impossible by the binding technique. However, we found that the oligonucleotide UAU, bound a small but reproducible amount of iso- leucine-transfer RNA. Now, UAU? contains two possible triplets for isoleucine, AUU and UAU, but we have established that the latter codes for tyrosine. Thus, studies with trinucleotides have shown that both UAU and UAC specifically stimulate the binding of tyrosine-transfer RNA. We conclude, then, that AUU is the correct coding triplet for isoleucine, and that internal triplets in block oligonucleotides can stimulate the bind- ing of the corresponding amino acid-transfer RNA's.
The question remains as to why the trinucleotide AUU failed to stimulate binding of isoleucine-transfer RNA, while longer chains containing the AUU sequence were quite active. We have interpreted this phenomenon as indicating that nucleotide residues adjacent to the triplet which is ac- tually engaged in coding can increase the stability of the complex between
Hence, the 5' end is not an exclusive binding site either.

GENETIC CODE 247
0.6 I I I I I
I I I I 20 40 60
Concentration (WM.) of Oligonucleotide
Fig. 12. The binding of leucine-trtrnsfer RNA with relevant oligonucleotides."
amino-acyl-s-RNA, triplet, and ribosome. The mechanism by which this extra stability is achieved may be through the ability of these adjacent nucleotide residues to interact with the m-RNA binding site on the 30s ribosome.
This stabilization effect has enabled us to determine coding triplets for other amino acid-transfer RNA's which are unable to bind in the presence of trinucleotides. As is shown in Figure 12 the trinucleotide CUU does not stimulate the binding of leucine-transfer RNA, whereas longer oligo- nucleotides containing the CUU sequence, such as C1UI and C1U4 are quite effective in promoting binding. It is also clear that the coding of leucine is unambiguous in our system, since A1U3 and AlU4 fail to promote binding. Thus, it is seen that the stability of the coding complex involving amino acid-transfer RNA, triplet, and ribosome varies widely from one amino acid to the next. We have found two trinucleotides which are very active in this respect. These are AAA for lysine and AUG for methionine, the latter being the more active of the two. The possibility that these are related to the signal for chain initiation is being examined.
The only remaining question that can be touched on here is the direction in which the RNA chain is read, from the 3' to the 5' end or vice versa. While some early reports favored the 3'-5' direction, stronger evidence supporting the opposite direction is now accumulating. One source in- volves some very elegant genetic experiments by Okada and Streisinger which cannot be presented here. Another is the report from Whaba and Ochoa and their collaborators in which A29C>1 was shown to produce a poly- peptide with asparagine (coded by AAC) in the C terminal position. Our own efforts point in this same direction. (Indeed, following the presenta- tion of this lecture we were able to demonstrate that A3U3 generates the dipeptide lysylphenylalanine.) l5 Thus, the peptide chain, which is known to grow from the N terminal to the C terminal direction is read from the 5' to the 3' direction of the RNR chain.

248 P. DOTY
This more detailed discussion at the end serves to show the rapid con- vergence that is taking place in understanding the molecular aspects of protein synthesis. A dictionary of the genetic code, completely agreeable to all, should be available very shortly. And, the technical improvement in synthesizing or isolating pure sequences of nucleotides should make possible the synthesis of polypeptides and even proteins, including many not heretofore existing in nature, before many more years have passed. That this remarkable thrust forward was greatly propelled by the use of copolynucleotides and more generally by the concepts of linear polymer molecules that have been the special province of Professor Mark seems reason enough for bringing this story before you in this context.
In closing, it is important to emphasize that this exposition has been documented and referenced in only a casual way: Many investigators have not been appropriately recognized for their contributions.
Among my own colleagues, Drs. Robert E. Thach and T. A. Sundararajan deserve The work in our laboratory is supported by the National Science especial credit.
Foundation (GB 1328) and the National Institutes of Health (HD-01229).
References 1. Kendrew, J. C., H. C. Watson, B. E. Strandberg, R. E. Dickerson, D. C. Phillips,
2. Kleinschmidt, A. K., D. Lang, D. Jacherts, arid R. K. Zahn, Biochem. Biophys.
3. Kurland, C. G., J . MoZ. Biol., 2, 83 (1960). 4. Holley, R. W., J. Apgar, G. Everett, J. Madison, M. Marquisse, S. Merrill, J.
5. Watson, J. D., Bull. SOC. Chim. Biol., 46, 1399 (1964). 6. Matthaei, J. H., and M. Nirenberg, Proc. Nutl. Acad. Sci. U. S., 47, 1580 (1961). 7. Lengyel, P., J. F. Speyer, and S. Ochoa, ibid., 47,1936 (1961). 8. Crick, F. H. C., Adv. Nucleic Acid Res., 1, 164 (1963). 9. Nirenberg, M., 0. Jones, P. Leder, B. Clark, W. Sly, and S. Pestka, Cold Spring
arid V. C . Shore, Nature, 190, 663 (1961).
Acta, 61, 857 (1962).
Penswick, and A. Zamir, Science, 147, 1462 (1965).
Harbor Symposia on Quantitative Biology, 28, 549 (1963). 10. Thach, R. E., and P. Doty, Science, 147, 1310 (1965). 11. Thach, R. E., T. A. Sundararajan, and P. Doty, Federation Proc., 24,409 (1965). 12. Nirenberg, M., and M. Leder, Science, 145, 1399 (1964). 13. Nirenberg, M., P. Leder, M. Bernfield, R. Brimacomb, J. Trupin, F. Kottman,
14. Thach, R. E., and T. A. Siiridararajan ibid., 53, 1021 (1966). 15. Thach, R. E., M. A. Cecere, T. A. Sundararajan, and P. Doty, Natl. Acad. Sci.,
and C. O’Neal, Proc. Natl. Acud. Sci. U . S., 53, 1161 (1965).
54, 1167 (1965).





























