Embed Size (px)
Citation preview

Topic #3: Lexical Analysis
EE 456 – Compiling Techniques
Prof. Carl Sable
Fall 2003

Lexical Analyzer and Parser

Why Separate?
• Reasons to separate lexical analysis from parsing:– Simpler design– Improved efficiency– Portability
• Tools exist to help implement lexical analyzers and parsers independently

Tokens, Lexemes, and Patterns
• Tokens include keywords, operators, identifiers, constants, literal strings, punctuation symbols
• A lexeme is a sequence of characters in the source program representing a token
• A pattern is a rule describing a set of lexemes that can represent a particular token

Attributes
• Attributes provide additional information about tokens
• Technically speaking, lexical analyzers usually provide a single attribute per token (might be pointer into symbol table)

Buffer
• Most lexical analyzers use a buffer• Often buffers are divided into two N
character halves• Two pointers used to indicate start and
end of lexeme• If pointer walks past end of either half of
buffer, other half of buffer is reloaded• A sentinel character can be used to
decrease number of checks necessary

Strings and Languages
• Alphabet – any finite set of symbols (e.g. ASCII, binary alphabet, or a set of tokens)
• String – A finite sequence of symbols drawn from an alphabet
• Language – A set of strings over a fixed alphabet
• Other terms relating to strings: prefix; suffix; substring; proper prefix, suffix, or substring (non-empty, not entire string); subsequence

Operations on Languages
• Union:• Concatenation:• Kleene closure:
–
– Zero or more concatenations
• Positive closure:
–
– One or more concatenations
M}tLsstLM in is and in is |{M}sLssML in is or in is |{
0
*
i
iLL
1i
iLL

Regular Expressions
• Defined over an alphabet Σ• ε represents {ε}, the set containing the empty string• If a is a symbol in Σ, then a is a regular expression
denoting {a}, the set containing the string a• If r and s are regular expressions denoting the
languages L(r) and L(s), then:– (r)|(s) is a regular expression denoting L(r)U L(s)– (r)(s) is a regular expression denoting L(r)L(s)– (r)* is a regular expression denoting (L(r))*
– (r) is a regular expression denoting L(r)
• Precedence: * (left associative), then concatenation (left associative), then | (left associative)

Regular Definitions
• Can give “names” to regular expressions
• Convention: names in boldface (to distinguish them from symbols)
letter A|B|…|Z|a|b|…|zdigit 0|1|…|9id letter (letter | digit)*

Notational Shorthands
• One or more instances: r+ denotes rr*
• Zero or one Instance: r? denotes r|ε• Character classes: [a-z] denotes [a|b|…|z]
digit [0-9]digits digit+
optional_fraction (. digits )?optional_exponent (E(+|-)? digits )?num digits optional_fraction optional_exponent

Limitations
• Can not describe balanced or nested constructs– Example, all valid strings of balanced
parentheses– This can be done with CFG
• Can not describe repeated strings– Example: {wcw|w is a string of a’s and b’s}– Can not denote with CFG either!

Grammar Fragment (Pascal)
stmt if expr then stmt| if expr then stmt else stmt| ε
expr term relop term| term
term id | num

Related Regular Definitions
if ifthen thenelse elserelop < | <= | = | <> | > | >=id letter ( letter | digit )*
num digit+ (. digit+ )? (E(+|-)? digit+ )?delim blank | tab | newlinews delim+

Tokens and Attributes
Regular Expression Token Attribute Value
ws - -
if if -
then then -
else else -
id id pointer to entry
num num pointer to entry
< relop LT
<= relop LE
= relop EQ
<> relop NE
> relop GT
=> relop GE

Transition Diagrams
• A stylized flowchart• Transition diagrams consist of states connected
by edges• Edges leaving a state s are labeled with input
characters that may occur after reaching state s• Assumed to be deterministic• There is one start state and at least one
accepting (final) state• Some states may have associated actions• At some final states, need to retract a character

Transition Diagram for “relop”

Identifiers and Keywords
• Share a transition diagram– After reaching accepting state, code
determines if lexeme is keyword or identifier– Easier than encoding exceptions in diagram
• Simple technique is to appropriately initialize symbol table with keywords

Numbers

Order of Transition Diagrams
• Transition diagrams tested in order
• Diagrams with low numbered start states tried before diagrams with high numbered start states
• Order influences efficiency of lexical analyzer

Trying Transition Diagrams
int next_td(void) { switch (start) { case 0: start = 9; break; case 9: start = 12; break; case 12: start = 20; break; case 20: start = 25; break; case 25: recover(); break; default: error("invalid start state"); }
/* Possibly additional actions here */
return start;}

Finding the Next Tokentoken nexttoken(void) { while (1) { switch (state) { case 0: c = nextchar(); if (c == ' ' || c=='\t' || c == '\n') { state = 0; lexeme_beginning++; } else if (c == '<') state = 1; else if (c == '=') state = 5 else if (c == '>') state = 6 else state = next_td();
break;
… /* 27 other cases here */

The End of a Token
token nexttoken(void) { while (1) { switch (state) { … /* First 19 cases */
case 19: retract(); install_num(); return(NUM);
break;
… /* Final 8 cases */

Finite Automata
• Generalized transition diagrams that act as “recognizer” for a language
• Can be nondeterministic (NFA) or deterministic (DFA)– NFAs can have ε-transitions, DFAs can not– NFAs can have multiple edges with same
symbol leaving a state, DFAs can not– Both can recognize exactly what regular
expressions can denote

NFAs
• A set of states S• A set of input symbols Σ (input alphabet)• A transition function move that maps state,
symbol pairs to a set of states
• A single start state s0
• A set of accepting (or final) states F• An NFA accepts a string s if and only if there
exists a path from the start state to an accepting state such that the edge labels spell out s
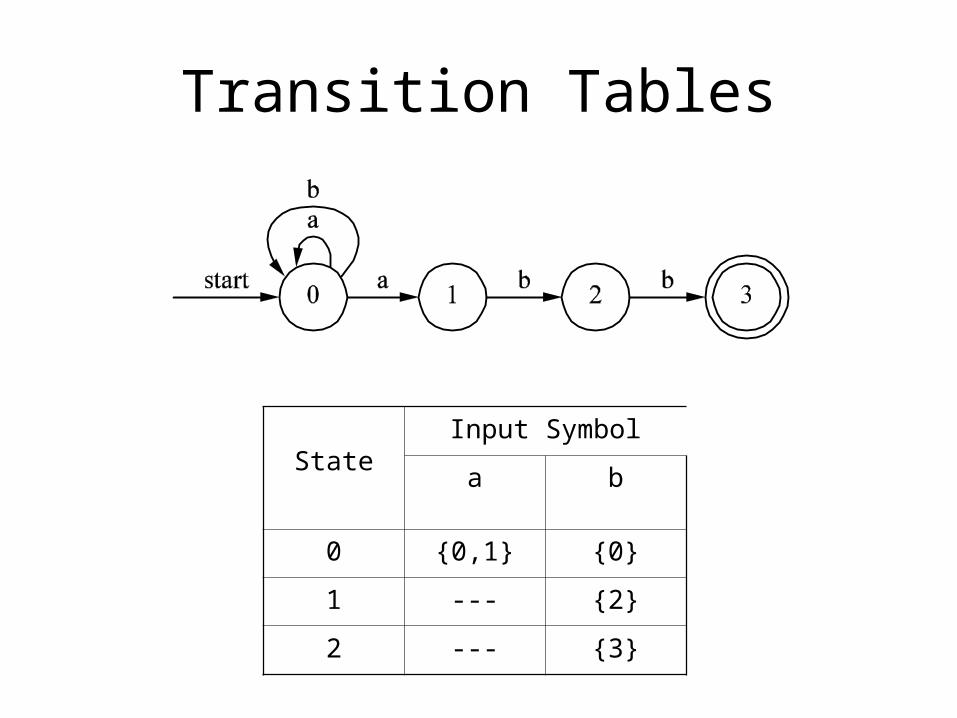
Transition Tables
StateInput Symbol
a b
0 {0,1} {0}
1 --- {2}
2 --- {3}
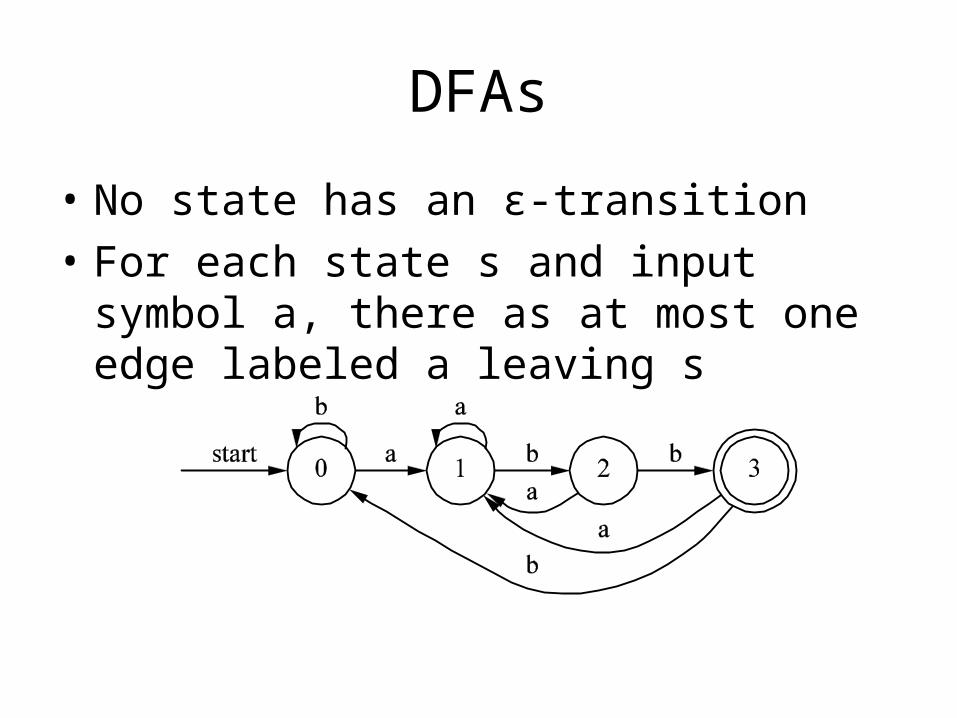
DFAs
• No state has an ε-transition
• For each state s and input symbol a, there as at most one edge labeled a leaving s

Thompson’s Construction
• Method of converting a regular expression into an NFA
• Start with two simple rules– For ε, construct NFA:
– For each a in Σ, construct NFA:
• Next will inductively apply a more complex rule until entire we obtain NFA for entire expression

Complex Rule, Part 1
• For the regular expression s|t, such that N(s) and N(t) are NFAs for s and t, construct the following NFA N(s|t):

Complex Rule, Part 2
• For the regular expression st, construct the composite NFA N(st):
N(S) N(T)
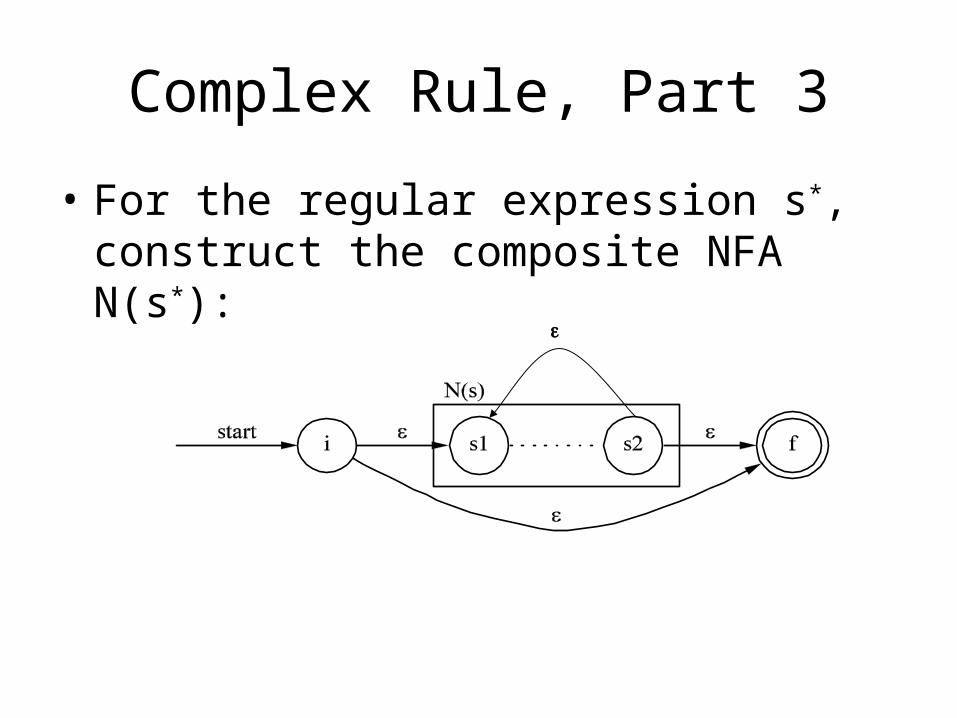
Complex Rule, Part 3
• For the regular expression s*, construct the composite NFA N(s*):

Complex Rule, Part 4
• For the parenthesized regular expression (s), use N(s) itself as the NFA

Example: r = (a|b)*abb

Functions ε-closure and move
• ε-closure(s) is the set of NFA states reachable from NFA state s on ε-transitions alone
• ε-closure(T) is the set of NFA states reachable from any NFA state s in T on ε-transitions alone
• move(T,a) is the set of NFA states to which there is a transition on input a from any NFA state s in T

Computing ε-closure
push all states in T onto stackinitialize ε-closure(T) to Twhile stack is not empty
pop t from top of stackfor each state u with an ε-transition from t
if u is not in ε-closure(T) thenadd u to ε-closure(T)push u onto stack

Subset Construction (NFA to DFA)
initialize Dstates to unmarked ε-closure(s0)while there is an unmarked state T in Dstates
mark Tfor each input symbol a
U := ε-closure(move(T,a))if U is not in Dstates
add U as unmarked state to DstatesDtran[T,a] := U

Constructed DFA

Simulating a DFA
s := s0
c := nextcharwhile c != eof do
s := move(s, c)c := nextchar
endif s is in F then
return “yes”else
return “no”

Simulating an NFA
S := ε-closure({s0})a := nextcharwhile a != eof do
S := ε-closure(move(S,a))a := nextchar
if S ∩ F != Øreturn “yes”
elsereturn “no”

Space/Time Tradeoff (Worst Case)
Space Time
NFA O(|r|) O(|r|*|x|)
DFA O(2|r|) O(|x|)

• First use Thompson’s Construction to convert RE to NFA
• Then there are two choices:– Use subset construction to convert NFA to
DFA, then simulate the DFA– Simulate the NFA directly
• You won’t have to worry about any of this while programming, Lex will take care of it!
Simulating a Regular Expression





























