Embed Size (px)
Citation preview

The Evolution of a Universal Genetic CodeAuthor(s): J. Tze-Fei WongSource: Proceedings of the National Academy of Sciences of the United States of America,Vol. 73, No. 7 (Jul., 1976), pp. 2336-2340Published by: National Academy of SciencesStable URL: http://www.jstor.org/stable/65766 .
Accessed: 06/05/2014 09:31
Your use of the JSTOR archive indicates your acceptance of the Terms & Conditions of Use, available at .http://www.jstor.org/page/info/about/policies/terms.jsp
.JSTOR is a not-for-profit service that helps scholars, researchers, and students discover, use, and build upon a wide range ofcontent in a trusted digital archive. We use information technology and tools to increase productivity and facilitate new formsof scholarship. For more information about JSTOR, please contact [email protected].
.
National Academy of Sciences is collaborating with JSTOR to digitize, preserve and extend access toProceedings of the National Academy of Sciences of the United States of America.
http://www.jstor.org
This content downloaded from 130.132.123.28 on Tue, 6 May 2014 09:31:47 AMAll use subject to JSTOR Terms and Conditions

Proc. Natl. Acad. Sci. USA Vol. 73, No. 7, pp. 2336-2340, July 1976 Biochemistry
The evolution of a universal genetic code (amino acids/translation/natural selection)
J. TZE-FEI WONG
Department of Biochemistry, University of Toronto, Toronto M5S 1A8, Canada
Communicated by J. Tuzo Wilson, May 3, 1976
ABSTRACT Some of the basic problems presented by the rapid evolution of a universal genetic code can be resolved by a mechanism of co-evolution of the code and the amino acids it serves.
The genetic code of protein synthesis assigns 64 triplet codons to amino acids and translational signals. Since the coding is universal amongst all prokaryotic and eukaryotic species for which there is evidence (1), it appears to have remained un- changed throughout the course of biological evolution. The code therefore stands as a faithful record of the events which at an early stage of the development of life on this planet had led to its emergence, selection, and fixation. Nirenberg et al. (2) first observed that some of the amino acids coded for by contiguous codons in the code are physically or metabolically related to each other. Sonneborn (3) and Woese (4) suggested that the physical relatedness could have accumulated through natural selection by virtue of the protection it offered against lethal ,mutations or translational errors. As for the question of whether or not the metabolic relatedness might be traceable to the origin of the code, an important step toward its resolution was taken when Pelc (5) and Dillon (6) suggested that the distribution of the codons amongst the amino acids could have been guided by potential conversions between the amino acids. Unfortu- nately, the postulated conversions were entirely based on the structural relatedness of the amino acids, and contradicted many of the actual metabolic conversions already known to occur in organisms. All of these proposals postulated an evolu- tionary origin for the genetic code, but did not provide any unambiguous prediction of codon distribution that can be tested against the distribution found in the code. This untestability renders it impossible to define the extent to which the apparent physical or structural relatedness between neighboring amino acids in the code may be the consequence of chance rather than evolution. Given the abundance of such relatedness amongst amino acids, even completely random allocations of code words would not be devoid of all elements of relatedness.
The co-evolution theory (7) of the genetic code overcomes this weakness of untestability. It proposes that the genetic code initially coded only for the small number of amino acids which were most easily formed in the primordial soup. These amino acids later served as precursors for the formation of other amino acids along prebiotic pathways which became enzymatized into the amino acid biosynthetic pathways of present day organisms. Each precursor subdivided its codons amongst its products, and this history of successive subdivisions determined the present boundaries of codon domains. The concession of codons from precursor to product requires the competitive attachment of the product to the tRNA of the precursor, or the covalent transformation of the precursor or its metabolite to the product while still attached to the tRNA. Both are familiar enough re- actions. Competitions between amino acids and analogues for
Abbreviation: ter, termination signal.
attachment to tRNAs are well known; and the covalent trans- formation of an amino acid on the tRNA also finds illustration either enzymically in the formylation of Met-tRNA (8), or nonenzymically in the desulfuration of Cys-tRNA (9). Since the biosynthetic relationships between amino acids in present day organisms are clearly defined, predictions could be made on this basis regarding the distribution of the codons for both precursor-product and sibling pairs of amino acids in the code. The excellent fit between both types of predictions and the genetic code excludes chance and establishes evolution as the originator of the code. The necessity for nonevolutionary origins such as frozen accident or infection from an extraterrestrial source (10) is removed.
Since evolution as we know it operates within the framework of a universal genetic code, the evolution of the universal code itself necessarily presents unfamiliar mechanistic problems that are compounded by the speed of the process. The assignment of the 64 codons in the code likely had to be settled within far less than two billion years, allowing far less than 32 million years per codon. This was not a long time span, considering that the establishment of just a single change of amino acid per 100 residues of known protein sequences required on the average about five million years (11). Accordingly, the purpose of this study is to resolve on the basis of the co-evolution mechanism some of the basic questions raised by the rapid emergence of a universal genetic code, undoubtedly one of the most complex achievements of the primordial biosphere.
Economy of co-evolution
The selection of the present-day universal genetic code must satisfy three fundamental requirements: it had to be accom- plished quickly; it had to provide an adequate basis for the phenomenal success of life on earth; and it had to be unique. Of these, the rate of evolution depends on many factors, fore- most of which being the magnitude of the task of natural se- lection. One way of gauging this task is to count the number of numerically equivalent codes potentially out of which a unique selection is to be made, treating as equivalent any code that assigns the same size of packages of codons to the amino acids as the universal code. The number of equivalent codes gener- ated depends on the evolutionary route by which the codons are distributed. Two different routes may be compared in this regard, with use in each case of the same hypergeometric al- gorithm to calculate the equivalent codes.
Route I applies if the 20 amino acids and the ter (termina- tion) signal are all present at the start of evolution, ready to be assigned a group of codons. The 64 codons are assigned to them in the same size of packages as assigned by the universal code, and the sequence of assignment follows in a descending order the size of the packages. At each assignment, the multiplicity of similar assignments that can be made is estimated to the nearest integer, and this indicates the order of magnitude of the selection that has to be exercised at that step. Accordingly, since
2336
This content downloaded from 130.132.123.28 on Tue, 6 May 2014 09:31:47 AMAll use subject to JSTOR Terms and Conditions
Biochemistry: Wong Proc. Natl. Acad. Sci. USA 73 (1976) 2337
Leu and Arg have the largest codon packages in the universal code, assignment begins with them. Giving Leu six codons out of a total of 64 yields a multiplicity of 64/6, or approximately 11. This leaves behind 58 codons, and giving six of these to Arg yields a multiplicity of 58/6, or approximately 10. This leaves behind 52 codons, and giving four codons to each of Val, Ser, Pro, Thr, Ala, and Gly, successively, yields the multiplicities of 13, 12, 11, 10, 9, and 8. Giving three of the remaining 28 codons to Ile yields an approximate multiplicity of 9, and as- signing two of the remaining 25 to each of Phe, T'yr, ter, His, Gln, Asn, Lys, Asp, Glu, Cys, and again to Ser yields the mul- tiplicities of 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, and 3. Giving the final three codons one each to Met, ter, and Trp brings the multi- plicities of 3, 2, and 1. Multiplying all 23 multiplicities gives the number of equivalent codes as 2.29 X 1019.
Route II applies to the co-evolution theory, which postulates that at first the 64 codons are partitioned only between the seven starting amino acids. The assignments in desceinding order according to the size of the codon packages are: 16 for Glu; 14 for Asp; 10 for Val; seven for Ser; four for each of Phe, Ala, and Gly; two for ter; another two for Ser; and another one for ter. The respective multiplicities for these assignments are 4, 3, 3, 3, 4, 3, 2, 3, 2, and 1. The codons of each precursor amino acid are next subdivided amongst its products. Thus, the 16 Glu codons are subdivided to give six to Arg, four to Pro, four to Gln, and finally two to Glu itself; this incurs the respective multi- plicities of 3, 3, 2, and 1. The 14 Asp codons are subdivided to give eight to Thr, and two to each of Asn, Lys, and Asp itself; this incurs the respective multiplicities of 2, 3, 2, anid 1. The 10 codons of Val are subdivided to give six to Leu and four to Val; the multiplicities are 2 and 1, respectively. The 7-codon Ser domain is subdivided to give four to Ser, two to Cys, and one to Trp; the multiplicities are 2, 2, and 1, respectively. The four codons of Phe are evenly split between Phe and Tyr, rendering multiplicities of 2 and 1. At this stage, the codon domains of Thr and Gln requires further subdivision: that of Thr to give four codons to Thr itself, three to Ile, and one to Met, with respective multiplicities of 2, 1, and 1; and that of Gln to give two codons to His and two to Gln itself, with respective multiplicities of 2 and 1. Multiplying together all 30 multiplicities gives the number of equivalent codes as only 2.15 X 108, which is still a large number, but no longer forbiddingly large. The reduction of equivalent codes in Route II compared to Route I means that the evolutionary pathway described by the co-evolution theory makes possible a drastic economy in terms of t:he amount of natural selection required to bring about the unique selection of one universal code. This economy stems from the restriction imposed on codon distribution by the linkage between amino acid evolution and genetic code evolution. Its large magnitude depends on both the suggested number of starting amino acids as well as the process of subdivision of codon domains. This conclusion can be demonstrated more rigoroujsly with a mathematically simple model.
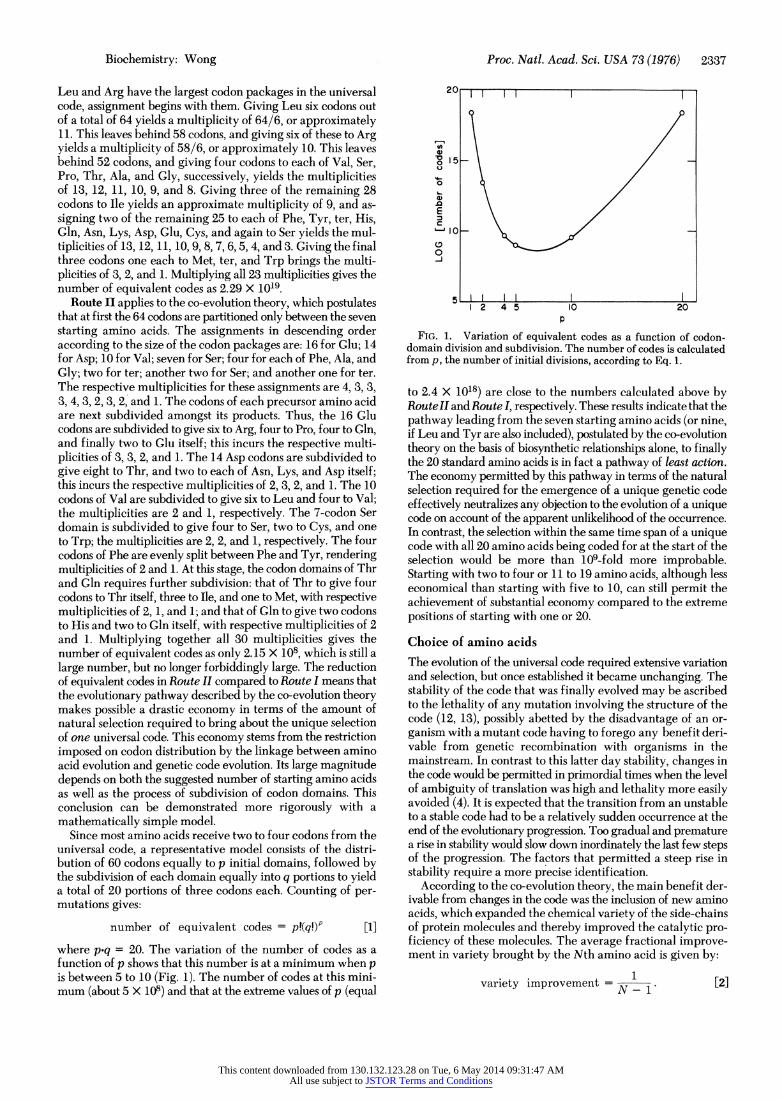
Since most amino acids receive two to four codons from the universal code, a representative model consists of the distri- bution of 60 codons equally to p initial domains, followed by the subdivision of each domain equally into q portions to yield a total of 20 portions of three codons each. Cournting of per- mutations gives:
number of equivalent codes = p!(q!) [1]
where p*q = 20. The variation of the number of codes as a function of p shows that this number is at a minimlum when p is between 5 to 10) (Fig. 1). The number of codes at this mini- mum (about 5 X 108) and that at the extreme values of p (equal
20 I I I 1 1
0 AX 0)
E
0
1 2 4 5 10 20 p
FIG. 1. Variation of equivalent codes as a function of codon- domain division and subdivision. The number of codes is calculated from p, the number of initial divisions, according to Eq. 1.
to 2.4 X 1018) are close to the numbers calculated above by RouteII and Route I, respectively. These results indicate that the pathway leading from the seven starting amino acids (or nine, if Leu and Tyr are also included), postulated by the co-evolution theory on the basis of biosynthetic relationships alone, to finally the 20 standard amino acids is in fact a pathway of least action. The economy permitted by this pathway in terms of the natural selection required for the emergence of a unique genetic code effectively neutralizes any objection to the evolution of a unique code on account of the apparent unlikelihood of the occurrence. In contrast, the selection within the same time span of a unique code with all 20 amino acids being coded for at the start of the selection would be more than 109-fold more improbable. Starting with two to four or 11 to 19 amino acids, although less economical than starting with five to 10, can still permit the achievement of substantial economy compared to the extreme positions of starting with one or 20.
Choice of amino acids
The evolution of the universal code required extensive variation and selection, but once established it became unchanging. The stability of the code that was finally evolved may be ascribed to the lethality of any mutation involving the structure of the code (12, 13), possibly abetted by the disadvantage of an or- ganism with a mutant code having to forego any benefit deri- vable from genetic recombination with organisms in the mainstream. In contrast to this latter day stability, changes in the code would be permitted in primordial times when the level of ambiguity of translation was high and lethality more easily avoided (4). It is expected that the transition from an unstable to a stable code had to be a relatively sudden occurrence at the end of the evolutionary progression. Too gradual and premature a rise in stability would slow down inordinately the last few steps of the progression. The factors that permitted a steep rise in stability require a more precise identification.
According to the co-evolution theory, the main benefit der- ivable from changes in the code was the inclusion of new amino acids, which expanded the chemical variety of the side-chains of protein molecules and thereby improved the catalytic pro- ficiency of these molecules. The average fractional improve- ment in variety brought by the Nth amino acid is given by:
variety improvement = N_- 1* [21
This content downloaded from 130.132.123.28 on Tue, 6 May 2014 09:31:47 AMAll use subject to JSTOR Terms and Conditions
2338 Biochemistry: Wong Proc. Natl. Acad. Sci. USA 73 (1976)
However, as the new product amino acid takes over some of the tRNAs and codons of its precursor and replaces the precursor in some positions in protein sequences, it introduces some dis- turbance, or noise, into the sequences. The impact of the re- placement is small if the replacement is gradual and limited, or in some instances even preceded by a posttranslational conversion of some precursor residues, e.g., Glu, on proteins into the product form, e.g., Gln (T. Hofmann, personal communi- cation). In general, since the precursor occupies an average of 1/(N - 1) of all amino acid residues in the translated proteins, the noise created by the replacement is given by:
replacement noise = N 0 l [31
where 0 is small for small impact and large for large impact, but cannot exceed unity. Provided that 0 does not vary too greatly for different new amino acids, comparison of Eqs. 2 and 3 in- dicates that the balance between the benefit provided by the improvement in variety and the resistance posed by the re- placement noise need not vary much with N.
As the code evolves, however, the translational apparatus also would be subject to improvement by natural selection and tend toward lower ambiguity, or noise. One simple model of this decrease in noise is that it decreases linearly between N = 8 and N = 21:
translation noise _a - (a - w)(N - 8) [4] (21 - 8)
where a is the translation noise at N = 8 and-c the noise at N = 21. The stability of the code depends most of all on the fol- lowing quotient:
_replacemnent noise stability quotient = tralatin noise [5] translation noise
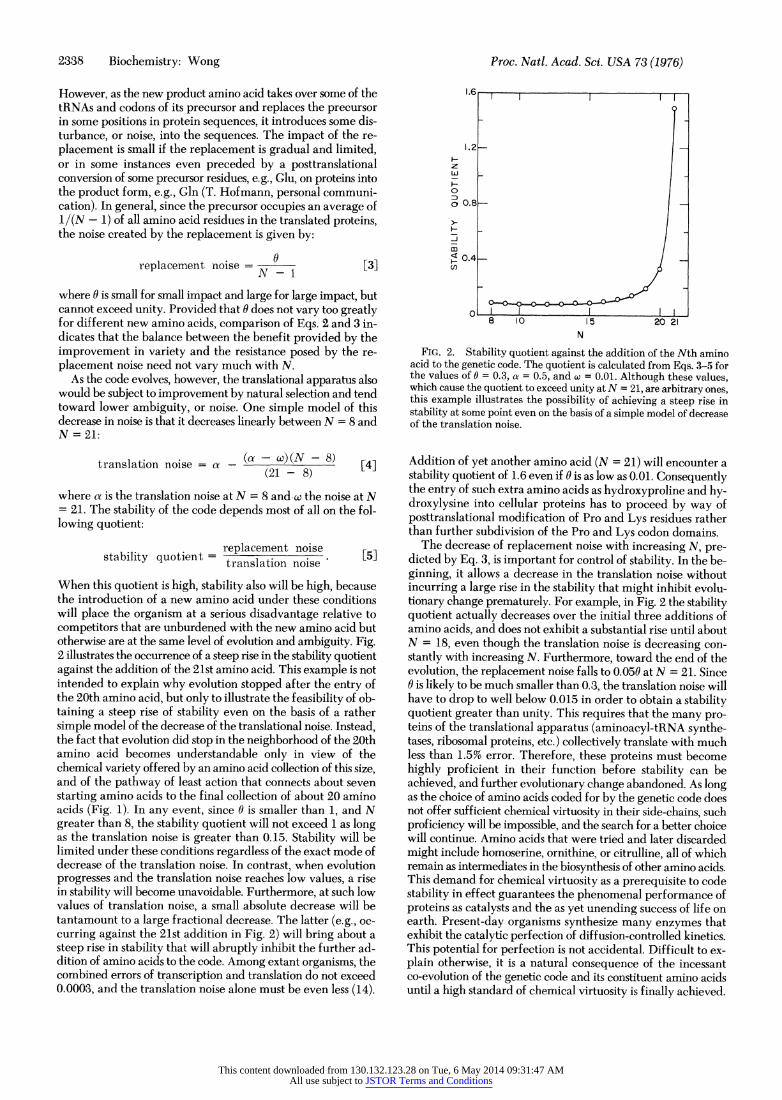
When this quotient is high, stability also will be high, because the introduction of a new amino acid under these conditions will place the organism at a serious disadvantage relative to competitors that are unburdened with the new amino acid but otherwise are at the same level of evolution and ambiguity. Fig. 2 illustrates the occurrence of a steep rise in the stability quotient against the addition of the 21st amino acid. This example is not intended to explain why evolution stopped after the entry of the 20th amino acid, but only to illustrate the feasibility of ob- taining a steep rise of stability even on the basis of a rather simple model of the decrease of the translational noise. Instead, the fact that evolution did stop in the neighborhood of the 20th amino acid becomes understandable only in view of the chemical variety offered by an amino acid collection of this size, and of the pathway of least action that connects about seven starting amino acids to the final collection of about 20 amino acids (Fig. 1). In any event, since 0 is smaller than 1, and N greater than 8, the stability quotient will not exceed 1 as long as the translation noise is greater than 0.15. Stability will be limited under these conditions regardless of the exact mode of decrease of the translation noise. In contrast, when evolution progresses and the translation noise reaches low values, a rise in stability will become unavoidable. Furthermore, at such low values of translation noise, a small absolute decrease will be tantamount to a large fractional decrease. The latter (e.g., oc- curring against the 21st addition in Fig. 2) will bring about a steep rise in stability that will abruptly inhibit the further ad- dition of amino acids o tohe code. Among extant organisms, the combined errors of trXanscription and translation do not exceed 0.0003, and the translation noise alone must be even less (14).
S ~~~~~II
z _
F-I 0
0.8_
m a 0.4-
8 l0 15 20 21
N
FIG. 2. Stability quotient against the addition of the Nth amino acid to the genetic code. The quotient is calculated from Eqs. 3-5 for the values of 0 = 0.3, a = 0.5, and w = 0.01. Although these values, which cause the quotient to exceed unity at N = 21, are arbitrary ones, this example illustrates the possibility of achieving a steep rise in stability at some point even on the basis of a simple model of decrease of the translation noise.
Addition of yet another amino acid (N = 21) will encounter a stability quotient of 1.6 even if 0 is as low as 0.01. Consequently the entry of such extra amino acids as hydroxyproline and hy- droxylysine into cellular proteins has to proceed by way of posttranslational modification of Pro and Lys residues rather than further subdivision of the Pro and Lys codon domains.
The decrease of replacement noise with increasing N, pre- dicted by Eq. 3, is important for control of stability. In the be- ginning, it allows a decrease in the translation noise without incurring a large rise in the stability that might inhibit evolu- tionary change prematurely. For example, in Fig. 2 the stability quotient actually decreases over the initial three additions of amino acids, and does not exhibit a substantial rise until about N = 18, even though the translation noise is decreasing con- stantly with increasing N. Furthermore, toward the end of the evolution, the replacement noise falls to 0.050 at N = 21. Since 0 is likely to be much smaller than 0.3, the translation noise will have to drop to well below 0.015 in order to obtain a stability quotient greater than unity. This requires that the many pro- teins of the translational apparatus (aminoacyl-tRNA synthe- tases, ribosomal proteins, etc.) collectively translate with much less than 1.5% error. Therefore, these proteins must become highly proficient in their function before stability can be achieved, and further evolutionary change abandoned. As long as the choice of amino acids coded for by the genetic code does not offer sufficient chemical virtuosity in their side-chains, such proficiency will be impossible, and the search for a better choice will continue. Amino acids that were tried and later discarded might include homoserine, ornithine, or citrulline, all of which remain as intermediates in the biosynthesis of other amino acids. This demand for chemical virtuosity as a prerequisite to code stability in effect guarantees the phenomenal performance of proteins as catalysts and the as yet unending success of life on earth. Present-day organisms synthesize many enzymes that exhibit the catalytic perfection of diffusion-controlled kinetics. This potential for perfection is not accidental. Difficult to ex- plain otherwise, it is a natural consequence of the incessant co-evolution of the genetic code and its constituent amino acids until a high standard of chemical virtuosity is finally achieved.
This content downloaded from 130.132.123.28 on Tue, 6 May 2014 09:31:47 AMAll use subject to JSTOR Terms and Conditions

Biochemistry: Wong Proc. Natl. Acad. Sci. USA 73(1976) 2339
Table 1. Stages of bio-organic evolution
Stage (tentative age, 109 years ago) Genetic code Major activity
Primordial soup (<4.5) None Accumulation of organic compounds
Protobionts (>3.5) Formation of primitive code for 7 amino acids Appearance of primitive cellular structure and metabolism
Paleokaryotes (3.5-2.5)* Formation of universal code for 20 amino acids Establishment of universal designs of biochemical structures, pathways, and mechanisms
Prokaryotes and eukaryotes (<2.5) Universal code Adaptive diversification and specia- tion
* Available microfossil evidence (18) suggests that the microfossils from 3.5 to 2.5 x 109 years ago are heterogeneous in size (range of 1-203 ,um), whereas those from 2.5 to 1.5 x 109 years ago are strikingly more homogeneous (range of 1-20 kum). One possible interpretation of this otherwise puzzling discontinuity might be that the earlier heterogeneity was due to the experimentation and diversity amongst the paleokaryotic genotypes, and the later homogeneity due to the fundamental universality amongst the early prokaryotic genotypes. Size diversity once again became prominent after 1.5 x 109 years ago with the emergence of the eukaryotes.
Evolution of paleokaryotes Since organisms with widely divergent genetic codes would not produce viable genetic recombinants, the genetic code is a useful criterion for distinguishing between two f undamental kinds of organisms: prokaryotes and eukaryotes that use the universal genetic code; paleokaryotes that use a genetic code significantly different from the universal code. There may still be extant paleokaryotes, but so far they have eluded detection. In contrast, when the prototype prokaryote first appeared, its competitors in the biosphere would all be paleokaryotes, most likely with advanced genotypes not too different in capability from the prokaryotic one. The unique selection of the universal code thus requires the elimination in time of all, or nearly all, paleokaryotes. In times of Darwinian evolution mnany species flourished and many perished, but the selection of a single ge- notype accompanied by the extinction of all others throughout the fauna, flora, and microflora of the biosphere has never been known to occur. Certainly the prokaryotes are highly diversi- fied: in terms of the (G + C)/(A + T) ratio of their DNAs, they are even more widely ranging in their diversification than the eukaryotes. Why then did the paleokaryotes before them fail to diversify, adapt, and escape total elimination by the one mutant line with its prokaryotic genetic code?
The co-evolution theory requires that one out of more than 108 equivalent codes be selected, a near-tripling of amino acid variety, and two rounds of subdivision of codon-domains during the paleokaryotic age. Therefore, there could be no shortage of genetic variation and experimentation amongst the paleokaryotes, and the paucity of their offsprings could not be due to some unknown mechanism restricting mutational change. Instead, the reason for this paucity may best be sought from the probable conditions of life of the paleokaryotes. Coming after the primordial soup and the protobionts postu- lated by Oparin (15), the paleokaryotes began likely some three to four billion years ago with a highly ambiguous primitive code for about seven abundant amino acids from the primordial soup, and achieved at the end a highly unambigu-ous code for twenty amino acids (Table 1). Other fundamental features of the cellular machinery also underwent comparable progress, culminating in the many biochemical designs which likewise became universal, e.g., the DNA/RNA systemr of replication and transcription, the lipoprotein cell membrane, use of ATP and other co-enzymes, and basic metabolic pathways such as the glycolytic sequence. At various times, innovations in these designs would be introduced, bringing smaller rnicro-advances or larger macro-advances into the system. Because of the dis- creteness of biochemical designs, it may be expected that
macro-advances were by no means rare. Although they are difficult to identify in retrospect, an example might be the in- phase coupling between DNA replication and cell division, the invention of active transport, or the extension of the glycolytic sequence beyond pyruvate to include an NAD+ regeneration step. Each paleokaryotic macro-advance improved some fun- damental. cell function, and not merely some specialized ad- aptation to local environment as was the case with most prokaryotic and eukaryotic macro-advances. Consequently, any macro-advance achieved by one paleokaryote conferred upon it a selective advantage over all other paleokaryotes rather than just over a few local competitors. Furthermore, evidence suggests that heterotrophy evolved amongst organisms before autotrophy (16). Toward the end of the heterotrophic eon, when the small organic compounds accumulated in the primordial soup were rapidly exhausted, competition amongst the het- erotrophic paleokaryotes would be totally unrelenting. Thus, strong selection of a small number of genotypes with the latest macro-advances, rather than wide-ranging diversification, would be the norm at this juncture. This strong selection ulti- mately permitted the emergence of only one line of prototype prokaryote with its perfected universal biochemical designs. Once this basic perfection was achieved, then and only then the highly individualistic adaptation to local environments took over as the overriding factor of evolution. Given the hetero- geneity of local environments on this planet, together with the spread of autotrophy which allowed a moderation of compe- tition and the establishment of ecological balance between genotypes, the spectacular diversification of prokaryotes and eukaryotes became the order of the new age.
The occurrence of macro-advances in basic cellular functions thus favored the narrowing of genotypes and the final emer- gence of some universal genetic code. We also may enquire whether the emergence of the particular code of current usage might have benefited from macro-advances within the design of the code itself. Inspection of the code reveals at least two late improvements which could have been instrumental to the ultimate ascendency of the present code. First, according to the co-evolution theory both His and Met received their codons from a second subdivision of some codon-domain, and both Trp and Met received only one codon. Therefore, these amino acids were likely very late arrivals. This conclusion is supported by the observations that they are neither readily formed from electric discharge through a simulated prebiotic atmosphere nor as yet detected on meteorites (17), and are absent from some primitive ferredoxins (16). Furthermore, they are the exclusive sources of imidazole, thioether, and indole side-chains on pro-
This content downloaded from 130.132.123.28 on Tue, 6 May 2014 09:31:47 AMAll use subject to JSTOR Terms and Conditions

2340 Biochemistry: Wong Proc. Natl. Acad. Sci. USA 73 (1976)
AUGE {internal Met or Thr}
AUG4 internal Met N-terminal fMet
AUG'-'{~N-terminal fMet)
FIG. 3. Alternate pathways for acquiring the two-function state of the AUG codon.
teins. Accordingly, the provisions for one or more of His, Met, and Trp late in the evolution process could confer an important advantage to the present code over competitors which lacked such provisions.
Second, the late-assigned AUG codon also serves two func- tions. The two simplest pathways for acquiring this two-func- tion state are shown in Fig. 3. According to Pathway I, initially the code would lack a proper initiation codon. Therefore wrong-frame initiation of translation would be widespread, polycistronic mRNA ineffective, and placement of a regulatory untranslated sequence at the 5' terminus of mRNA disallowed. According to Pathway II, initially the code could not translate internal AUG. Therefore, internal mutations to AUG would inhibit translation without release of the polypeptide product, thereby inactivating the ribosome. In either case the attainment of the two-function state of AUG could be a macro-advance that served to secure universality for the present code. Parallel considerations apply to the GUG codon as well.
In conclusion, the co-evolution theory provides not only an explanation of the structure of the genetic code, but also a pathway of least action toward the unique selection of the code, an identification of new amino acid variety as the main benefit of evolutionary change, enough starting amino acids to initiate the synthesis of catalytically useful proteins, a means for finally ensuring chemical virtuosity amongst the coded amino acids, and late changes in the code endowed with the potential of a macro-advance facilitating the acquisition of universality. It will be important to determine if other proposals can be' con- structed to offer fundamental advantages of comparable magnitude. Failing such alternatives, the chances might be remote that the development of life form would forego a
mechanism of co-evolution of its coding and coded units of genetic information, either on earth or elsewhere in the uni- verse.
I wish to thank Drs. C. S. Hanes and L. Siminovitch for valuable discussions. This study was supported by the Medical Research Council of Canada.
1. Ycas, M. (1969) in The Biological Code (North-Holland Co., Amsterdam and London), pp. 254-260.
2. Nirenberg, M. W., Jones, 0. W., Leder, P., Clark, B. F. C., Sly, W. S. & Pestka, S. (1963) Cold Spring Harbor Symp. Quant. Biol. 28,549-557.
3. Sonneborn, T. M. (1965) in Evolving Genes and Proteins, eds. Bryson, V. & Vogel, H. J. (Academic Press, New York), pp. 337-397.
4. Woese, C. (1965) in The Genetic Code (Harper and Row, New York), pp. 156-160.
5. Pelc, S. R. (1965) Nature 207,597-599. 6. Dillon, L. S. (1973) Bot. Rev. 39, 301-345. 7. Wong, J. T. (1975) Proc. Natl. Acad. Sci USA 72, 1909-1912. 8. Marcker, K. & Sanger, F. (1964) J. Mol. Biol. 8, 835-840. 9. Chapeville, F., Lipmann, F., von Ehrenstein, G., Weisblum, B.,
Ray, W. Y., Jr. & Benzer, S. (1962) Proc. Natl. Acad. Sci. USA 48, 1086-1092.
10. Crick, F. H. C. & Orgel, L. E. (1973) Icarus 19,341-346. 11. McLaughlin, P. J. & Dayhoff, M. 0. (1972) in Atlas of Protein
Sequence and Structure, ed. Dayhoff, M. 0. (National Bio- medical Research Foundation, Washington, D.C.), Vol. 5, pp. 47-52.
12. Hinegardner, R. T. & Engelberg, J. (1963) Science 142, 1083- 1085.
13. Crick, F. H. C. (1963) Progr. Nucl. Acid Res. Mol. Biol. 1, 163-217.
14. Loftfield, R. B. (1963) Biochem. J. 89, 82-92. 15. Oparin, A. I. (1968) in Genesis and Evolutionary Development
of Life (Academic Press, New York and London), pp. 127- 152.
16. Hall, D. O., Cammack, R. & Rao, K. K. (1971) Nature 233, 136-138.
17. Wolman, Y., Haverland, W. J. & Miller, S. L. (1972) Proc. Natl. Acad. Sci. USA 69, 809-811.
18. Schopf, J. W. (1975) in Chemical Evolution of the Precambrian (Laboratory of Chemical Evolution, University of Maryland, College Park, Md.), pp. 30-33.
This content downloaded from 130.132.123.28 on Tue, 6 May 2014 09:31:47 AMAll use subject to JSTOR Terms and Conditions





























