Embed Size (px)
Citation preview

Faculteit Letteren & Wijsbegeerte
Thomas Claesen
Style and Coordination in Literary Translation A case study of coordination style in Joseph Roth’s Hotel Savoy and its two Dutch translations
Masterproef voorgedragen tot het behalen van de graad van
Master in het Vertalen
2014
Promotor: Dr. Els Snick
Vakgroep Vertalen Tolken Communicatie


ABSTRACT
This study investigates coordination style as a feature of style in Joseph Roth’s German novel Hotel Savoy and its two Dutch translations, by Huib van Krimpen and Wilfred Oranje. Style is seen as a choice between alternative expressions, in casu the choice between syndetic, asyndetic and polysyndetic coordination (with one/no/several coordinating conjunctions, respectively). Previous research into style and translation can be divided into three paradigms: focusing on the source text author (e.g. House 1977, Parks 1998); focusing on specific linguistic features as traces of the translator in the target text, using a corpus-based method (e.g. Baker 2000, Winters 2005, Winters 2007); and focusing on the translator in a broader context (e.g. Berman 1995, Wallaert 2010). The present study combines elements from all three paradigms and uses an XML-based method to tag and process the parallel corpus, which comprises the three versions of the novel’s first thirteen chapters. It is found that in Roth’s text, 60.6% of all coordinations are syndetic, 36.4% asyndetic and 3.0% polysyndetic. Van Krimpen uses more syndeta and less asyndeta than Roth, Oranje even more syndeta and less asyndeta. Van Krimpen uses virtually the same amount of polysyndeta as Roth, while Oranje only uses them about half as much. Oranje changes Roth’s coordinated structures more often than van Krimpen does, both between different coordination styles and between coordinated and non-coordinated structures.

ACKNOWLEDGEMENTS
I would like to thank the following people for their contribution to this research and to my education in translation:
� Dr. Els Snick, for sharing her passion for translation, for introducing me to the work of Joseph Roth, for supervising this research, and for encouraging me to combine three research focuses at Ghent University Department of Translation, Interpreting and Communication as much as possible: Culture and Translation; Corpus-Based Translation Studies; and Language and Translation Technology;
� Prof. Dr. Sonia Vandepitte, for showing me the intricacies involved with translation, for reviewing an early version of the theoretical study of this dissertation, and for encouraging me to convert the three texts into a corpus;
� Dr. Lieve Macken and Nils Smeuninx, for their help with compiling the corpus; � Tom Vanassche, for proofreading this dissertation.
I would also like to thank L.J. Veen Klassiek (part of Atlas Uitgeverij) for sending me an electronic copy of Wilfred Oranje’s translation of Hotel Savoy.

5
TABLE OF CONTENTS
1 Introduction ........................................................................................................................ 7
2 Style .................................................................................................................................... 8
2.1 Defining Style .............................................................................................................. 8
2.2 Literature Review ...................................................................................................... 11
2.2.1 Research before 2000 ......................................................................................... 11
2.2.2 From 2000 onwards: corpus-based research ...................................................... 12
2.2.3 A different method ............................................................................................. 14
3 Roth’s Style ...................................................................................................................... 17
3.1 Hotel Savoy ............................................................................................................... 17
3.2 Investigating Roth’s Style ......................................................................................... 17
3.3 Coordinated Structures .............................................................................................. 18
3.4 Research Question and Hypotheses ........................................................................... 20
3.4.1 Research question ............................................................................................... 20
3.4.2 Hypotheses ......................................................................................................... 21
4 Data and Methodology ..................................................................................................... 23
4.1 Corpus ........................................................................................................................ 23
4.2 XML .......................................................................................................................... 24
4.3 Converting the XML Structure .................................................................................. 26
4.4 Tagging Coordinated Structures ................................................................................ 27
4.4.1 Example 1 ........................................................................................................... 28
4.4.2 Example 2 ........................................................................................................... 29
4.5 Filtering the Tagged Corpus with XSLT ................................................................... 30
4.5.1 Template 1: Separate .......................................................................................... 31
4.5.2 Template 2: Comparative ................................................................................... 32
5 Results and Discussion ..................................................................................................... 34
5.1 Separate Analysis ...................................................................................................... 34
5.1.1 Coordination style .............................................................................................. 34
5.1.2 Anaphorae .......................................................................................................... 36
5.2 Comparative Analysis ................................................................................................ 37
5.2.1 Coordination style compared ............................................................................. 37
5.2.2 Shifts between coordinated and non-coordinated structures .............................. 39
5.2.3 Additions ............................................................................................................ 43
5.3 Hypotheses ................................................................................................................. 44
6 Conclusion ........................................................................................................................ 47
7 References ........................................................................................................................ 49

6
8 Appendices ....................................................................................................................... 51
8.1 Appendix 1: Tagged XML Corpus ............................................................................ 51
8.2 Appendix 2: Template 1 (perauthor.xsl) ................................................................. 177
8.3 Appendix 3: Template 2 (chapdisplay.xsl) .............................................................. 178
8.4 Appendix 4: Template 2 Functions (chapdisplay_function.xsl) .............................. 180
8.5 Appendix 5: CSS Stylesheet (display.css) ............................................................... 187
8.6 Appendix 6: Shifts between Coordinated and Non-Coordinated Structures ........... 188
LIST OF TABLES
Table 1. Structure of a TMX <tu> element .............................................................................. 25
Table 2. Find and replace commands used to create a new XML structure ............................ 26
Table 3. XML elements used to tag coordinated structures ..................................................... 27
Table 4. Possible combinations of coordination styles between source and target texts. Three styles: S = syndetic, A = asyndetic, P = polysyndetic ............................................... 33
Table 5. Distribution of coordination style .............................................................................. 34
Table 6. Distribution of coordination style for coordinated sentences .................................... 34
Table 7. Distribution of coordination style for coordinated verb phrases ................................ 35
Table 8. Distribution of coordination style for coordinated noun phrases ............................... 35
Table 9. Distribution of coordination style for coordinated preposition phrases ..................... 35
Table 10. Distribution of coordination style for coordinated adjective phrases ...................... 35
Table 11. Distribution of coordination style for coordinated adverb phrases .......................... 35
Table 12. Distribution of coordination style for coordinated relative clauses ......................... 36
Table 13. Distribution of anaphorae ......................................................................................... 36
Table 14. Distribution of anaphorae per grammatical category of the coordinates ................. 37
Table 15. Comparison of coordination style between source and target texts ......................... 38
Table 16. Comparison of coordination style between Roth’s and van Krimpen’s texts .......... 39
Table 17. Comparison of coordination style between Roth’s and Oranje’s texts .................... 39
Table 18. Distribution of Roth’s coordinations translated as non-coordinations. 4 categories: (1) different conjunction, (2) durative verb + infinitive, (3) adjective > preposition phrase, (4) forming a compound ................................................................................ 41
Table 19. Distribution of non-coordinations translated as coordinations. 2 categories: (1) splitting a compound, (2) undefinites......................................................................... 42
Table 20. Distribution of additions .......................................................................................... 43
Table 21. Distribution of added full stops ................................................................................ 43
Table 22. Distribution of added/repeated personal pronouns................................................... 43
Table 23. Distribution of added/repeated prepositions ............................................................ 43
Table 24. Distribution of added/repeated relative pronouns .................................................... 43
Table 25. Distribution of anaphoric coordinations formed through addition in van Krimpen’s translation ................................................................................................................... 44
Table 26. Distribution of anaphoric coordinations formed through addition in Oranje’s translation ................................................................................................................... 44
Table 27. Comparison of coordination style between Roth and van Krimpen’s text, limited to coordinations containing additions ............................................................................ 45
Table 28. Comparison of coordination style between Roth and Oranje’s text, limited to coordinations containing additions ............................................................................ 45

7
1 INTRODUCTION
She [Ros Schwartz] said that when someone complained to a well-known Czech author that he had changed his style, his reply was, ‘No, I’ve changed my translator.’ (The Times, 2-12-1998, as cited in Baker 2000, p. 242)
When I read literature in translation, am I reading the author’s work or the translator’s?
That is the general, almost philosophical question lying at the basis of this research. Perhaps a
more nuanced question is at hand: How much of the author’s work am I reading and how
much of the translator’s? It seems plausible to assume that the story and plot one reads are the
author’s work, and that the language is the translator’s. There is, however, also a gray zone:
the question of style. Can style be translated? Do texts contain any traces of the translators
themselves?
The combination of style and translation has been studied from various angles:
focusing on the source text author (e.g. House 1977, Parks 1998); focusing on specific
linguistic features as traces of the translator in the target text (e.g. Baker 2000, Winters 2005,
Winters 2007); and focusing on the translator in a broader context (e.g. Berman 1995,
Wallaert 2010). Aiming to combine different elements drawn from these studies, the present
study investigates style in Joseph Roth’s German novel Hotel Savoy (1924) and its two Dutch
translations, one by Huib van Krimpen (1994) and one by Wilfred Oranje (2003). The
investigation of style is narrowed down to the investigation of one particular aspect: How
does Roth coordinate structures (with one/zero/several coordinating conjunctions) and how
do van Krimpen and Oranje treat the different styles of coordination in their translations?
This dissertation starts with a discussion of style in a general sense: how it has been
defined and how it has been researched, particularly with a link to translation (Chapter 2). The
next chapter focuses on Roth’s style and the aims and hypotheses of this study (Chapter 3).
Chapter 4 presents the corpus and the XML-based method used for this research. Finally, the
results are listed and discussed in Chapter 5. Throughout the dissertation, ‘>’ is used as an
abbreviation for ‘translated as’.

8
2 STYLE
2.1 Defining Style
In A Dictionary of Stylistics (Wales 1989), the definition of the lemma ‘style’ starts with the
observation that “[a]lthough style is used very frequently in LITERARY CRITICISM and
especially STYLISTICS (q.v.)1, it is very difficult to define” (Wales 1989, p. 435, emphasis
original). Wales then lists five possible meanings for style:
(1) At its simplest, style refers to the manner of EXPRESSION in writing or speaking, just as there is a manner of doing things, like playing squash or painting. We might talk of someone writing in an ‘ornate style’, or speaking in a ‘comic style’. For some people, style has EVALUATIVE connotations: style can be ‘good’ or ‘bad’.
(2) One obvious implication of (1) is that there are different styles in different SITUATIONS (e.g. comic v. turgid); also that the same activity can produce stylistic variation (no two people will have the same style in playing squash, or writing an essay). So style can be seen as variation in language use, whether LITERARY or non-literary. The term REGISTER (q.v.) is commonly used for those systematic variations in linguistic features common to particular non-literary situations, e.g. advertising, legal language, sports commentary. (…)
(3) In each case, style is seen as distinctive: in essence, the set or sum of linguistic features that seem to be characteristic: whether of register, genre or period, etc. Style is very commonly defined in this way, especially at the level of TEXT: the style of Keats’s Ode to a Nightingale, for example, or Jane Austen’s Emma. Stylistic features are basically features of language, so style in one sense is synonymous with language: we can speak equally of the ‘language’ of Ode to a
Nightingale. (…) When applied to the domain of an author’s entire oeuvre, style is the set of features peculiar to, or characteristic of an author: his or her ‘language habits’ or IDIOLECT (q.v.). (…)
(4) Clearly each author draws upon the general stock of the language in any given period; what makes styles distinctive is the CHOICE of items, and their distribution and patterning. (…)
(5) Another differential approach to style is to compare one set of features with another in terms of a DEVIATION from a NORM, a common approach in the 1960s (see Enkvist 1973). (…) [W]e match any text or piece of language against the linguistic norms of its genre, or its period, and the COMMON CORE of the language as a whole. Different texts will reveal different patterns of DOMINANT or FOREGROUNDED
FEATURES. (Wales 1989, pp. 435-437, emphasis original)
1 The abbreviation ‘q.v.’ stands for ‘quod vide’ and is used here to refer to other entries in A Dictionary of
Stylistics.

9
Enkvist (1964) gives an overview of different definitions that have been given to style. He
finds that there are six main categories definitions of style generally fit into. These are:
style as a shell surrounding a pre-existing core of thought or expression; as the choice between alternative expressions; as a set of individual characteristics; as deviations from a norm; as a set of collective characteristics; and as those relations among linguistic entities that are statable in terms of wider spans of text than the sentence. (Enkvist 1964, p. 12)
The cross-section of Wales’s (1989) and Enkvist’s (1964) overviews consists of four different
perspectives on style:
1. A manner of expression
2. A distinctive set of characteristics, be it for an individual or a text
3. A choice between alternative expressions
4. Deviations from a norm
All four perspectives can also be found in research on style and translation. The first two
(manner of expression and a distinctive set of characteristics) return in Baker’s definition of
style in Towards a Methodology for Investigating the Style of a Literary Translator (2000):
I understand style as a kind of thumb-print that is expressed in a range of linguistic – as well as non-linguistic features. […] In terms of translation, rather than original writing, the notion of style might include the (literary) translator’s choice of the type of material to translate, where applicable, and his or her consistent use of specific strategies, including the use of prefaces or afterwords, footnotes, glossing in the body of the text, etc. More crucially, a study of a translator’s style must focus on the manner of expression that is typical of a translator, rather than simply instances of open intervention. It must attempt to capture the translator’s characteristic use of language, his or her individual profile of linguistic habits, compared to other translators. Which means that style, as applied in this study, is a matter of patterning: it involves describing preferred or recurring patterns of linguistic behavior, rather than individual or one-off instances of intervention. (Baker 2000, p. 245, emphasis added)
Choice between alternative expressions, the third perspective on style, is linked to translation
in Mikhail Mikhailov and Miia Villikka’s research (2001). They search for what ‘translator
style’ can encompass and although they do not define a precise object of study, they do
explicitly choose the perspective of the typical choices a translator makes when several
equivalents are possible:

10
one important factor – the key focus area of this research – is the fact that many translation solutions must be decided upon independently2. […] [T]here are often more than just one suitable equivalent. Usage of these variants is in most cases solely up to the translator’s choice. (Mikhailov & Villikka 2001, p. 383)
Kirsten Malmkjær focuses on ‘translational stylistics’. She defines this concept in What
happened to God and the angels (2003), a study of the translational stylistics in Henry
William Dulcken’s English translations of Hans Christian Andersen’s works:
translational stylistics, as I understand it, is concerned to explain why, given the source text, the translation has been shaped in such a way that it comes to mean what it does. (Malmkjær 2003, p. 39)
An important element mentioned by Malmkjær is the relation between translator style and
source text influence. This can be connected to the fourth perspective on style, i.e. deviations
from a norm. The ‘norm’ then is the source text, and the deviations are the translation shifts.
This dissertation will see style as a matter of choice between alternative expressions. While
choices are a matter related to the process of writing and translating, each choice leaves a
textual trace. Therefore, choice can be studied using only texts, rather than having to observe
writing and translation processes.
Two kinds of style will be differentiated between in this research: author style and
translator style. Author style refers to the choices the source text author makes between
alternative expressions, or in other words: the traces the source text contains of the choices the
author made between alternative expressions. Translator style will have two meanings. In
the first sense, it can be regarded as the exact same thing as author style. This is the case when
translations are read and studied as texts on their own. Studying translations as standalone
texts can be fruitful, as most non-scholarly readers do not cross-reference translations with
their originals. In the second sense, translator style refers to the choices a translator makes
between translation equivalents, or in other words: the traces a translation contains of the
choices the translator made between translation equivalents. Both senses of translator style
have been used in previous research on style and translation, of which the next section gives
an overview.
2 ‘Independently’ here means ‘indepently from source text influence’.

11
2.2 Literature Review
In previous research on style and translation, three different paradigms can be observed:
firstly, studies focusing on the source text author; secondly, research into specific linguistic
features as traces of the translator in the target text, using a corpus-based method; and thirdly,
research focusing on the translator in a broader context. For each paradigm, two or three
representative studies are discussed.
2.2.1 Research before 2000
More traditional research on style and translation often focuses on how and to what extent a
translator or translation preserves the style of a source text or source text author. Baker (2000)
gives an overview of such studies and classifies them under “Style in Translation” (p. 242,
emphasis original). Most of her overview is dedicated to Juliane House’s research. House
(1977) creates a model to describe the source text style, to compare the translation to the
source text and to make observations about the two. Her model is based on the following
components:
� language user (focusing on the writer)
□ geographical origin
□ social class
□ time
� language use (focusing on the text)
□ medium
□ participation
□ social role relationship
□ social attitude
□ province
Most of these components are borrowed from Investigating English Style by Crystal and Davy
(1969). Their book focuses on linguistic variation in written and spoken language use in
everyday life, not necessarily in literary texts. Their theory and applications are based on
English, but according to the authors, it can also be used for other languages.
Baker points out that House does not study style systematically (Baker 2000, p. 242),
but that she only searches for stylistic differences between source and target texts, using the
abovementioned categories exclusively. The differences are then used to make statements
about the quality of the translation, hence the title of House’s book A Model for Translation

12
Quality Assessment. In contrast to House’s method, the present study will be merely
descriptive, not evaluative.
What is useful for the present research is that House uses methods to describe the style
of one text. When translator style is viewed as author style, the style of each text can be
described separately, regardless of whether it is the source text or a target text. The next step
lies in comparing the descriptions. Describing the style of each text separately is a method
that will be returned to in the Data and Methodology and the Results and Discussion sections.
Another relevant book that focuses on literary language and is reviewed by Baker, is
Translating Style by Tim Parks (1998). Each chapter treats a characteristic feature of one
work of English literature (i.e. an aspect of its style) and reviews how the Italian translation
treats this feature. The first chapter, for example, discusses excerpts from D.H. Lawrence’s
Women in Love where the author deviates from the linguistic norm, which Parks calls the
“unhousedness”: breaking out of the prison the linguistic norm can be experienced as (Parks
1998, p. 15). In other words, it discusses Lawrence’s idiosyncrasies. Then, Parks evaluates to
what extent the translator succeeds in preserving the “stylistic idiosyncrasies” (Parks 1998, p.
16) in Italian – usually hardly at all. Like House, Parks does not study style systematically: he
only selects one characteristic aspect. Another way in which Parks’s study is not systematic is
that it is anecdotic: the study is a selection of excerpts rather than a complete investigation of
every single instance of idiosyncratic language use.
2.2.2 From 2000 onwards: corpus-based research
Baker’s own research focuses on the traces translators themselves leave in the text, which she
calls “Style of Translation” (Baker 2000, p. 244, emphasis original). According to her, this has
not been done before because translation was seen as a reproductive rather than a creative
activity (p. 244). She searches the target text for patterns of both conscious and subconscious
decisions. Her innovation is that she uses a corpus to study style and translation.
The patterns Baker looks for are preferences a translator consistently shows for certain
words, structures or even punctuation when other equivalents are also possible. When we find
such preferences, we should try to answer the following questions:
(a) Is a translator’s preference for specific linguistic options independent of the style of the original author?; (b) Is it independent of general preferences of the source language, and possibly the norms or poetics of a given sociolect?; (c) If the answer is yes in both cases, is it possible to explain those preferences in terms of the social, cultural or ideological positioning of the individual translator? (Baker 2000, p. 248)

13
According to Baker, these are “’large’ questions” (2000, p. 248), to which she cannot find
answers in her paper, as her goal is only to develop a methodology to investigate translator
style3.
She does so as follows. Her corpus consists of a number of texts written by two
different translators and she searches the texts for “interesting patterns” (p. 248): patterns
related to type/token ratio; average sentence length; variation between different texts; and
reporting structures. She studies these patterns systematically, i.e. statistically. Translator 1
and 2 show characteristic preferences in the abovementioned categories. Baker interprets this
difference in the light of a general tendency of translator 1 to involve the reader more in the
story. The style of translator 2 is interpreted as an attempt to simplify the text for the reader.
Baker realizes that the possible source text influence on the patterns found needs to be
investigated, but does not do so herself, since that would extend beyond the scope of her
research. A category not attributable to source text influence is the (in English optional) use of
‘that’ as a subordinating conjunction after a reporting verb. It is not attributable to source text
influence as the use of a subordinating conjunction is necessary in the respective source
languages of translator 1 and 2 (Spanish and Portuguese; Arabic). Translator 1 uses ‘that’
systematically less than translator 2.
The next step in Baker’s investigation is to find possible explanations for the
differences. She considers the difficulty of the source text; the location of the translator (areas
where English is an official language vs. areas where English is a foreign language); and the
implied reader. However, in order to find a more complete explanation, the researcher has to
be able to determine which factors are unique for the translator and which are a result of
source text influence. Possible source text influences are related to specific source language
features, the poetics of a certain social group, and the style of the original author. She
concludes her paper with a number of questions:
1. How can we distinguish between elements attributable only to the translator and
elements attributable to source text style?
2. Should we try to make that distinction?
3. Should we look at different data? For example, different translations of the same
source text into the same target language. The difficulty with that is that “very few
texts are translated more than once into the same target language and during the same
period” (Baker 2000, pp. 261-262). When there is too much time in between two
3 Note that Baker’s definition of translator style differs from the one used in this study (see 2.1).

14
translations, differences in style can be attributed to the target language’s evolution or
the preferences of a socially or historically defined group of translators. Baker
concludes that it is unlikely we will ever be able to fix all variables so we can find
features unambiguously attributable to the translator and only the translator. But, she
remarks: “Perhaps we should not even try” (Baker 2000, p. 262).
The search for exclusive translator features is continued in Winters’s research (2005). She
adopts Baker’s definition of style and compares two German translations of F. Scott
Fitzgerald’s The Beautiful and Damned. In the translations she studies the use of modal
particles. These are good indicators of exclusive translator features, since modal particles
exist in the target but not in the source language. As Baker proposes, Winters compares two
translations of the same original. Moreover, both translations were published in the same year,
so time related preferences cannot account for differences in translation decisions. Apart from
modal particles, she also studies the use of ‘Sie’ and ‘du’ (formal and informal ‘you’), also a
feature of German that does not exist in English. Other elements she studies and for which
both translators show distinguishing preferences, are:
� the use of loan words
� the use of code switching
� the use of endnotes
� retaining or omitting source text repetitions
� retaining or changing the source text’s narrative focus
In a later study Winters (2007) returns to The Beautiful and Damned and its two translations,
now focusing on speech-act report verbs, and concludes that both translators therein show
distinguishing preferences as well. It should be noted that the last elements (loan words, code
switching, endnotes, repetitions, narrative focus and speech-act report verbs) are influenced
by the source text and therefore do not constitute exclusive translator features.
2.2.3 A different method
The corpus-based method is criticized by Ineke Wallaert in The Elephant in the Dark:
Corpus-Based Descriptions of Translator’s Style (2010). She specifically responds to
Winters’s 2007 article. If style is a kind of thumbprint (cf. Baker 2000), then studies such as
Winters’s have only been able to identify a few lines of that thumbprint, since they only
search for recurring patterns. Principally Wallaert has no objections to corpus-based research,
as long as the corpus is used as a tool to describe translations. She criticizes Winters’s study

15
of speech-act report verbs. A precise reason why Winters researches this specific topic is to be
found nowhere, so no textual reason in the original, nor in the target texts. According to
Wallaert, the central question of the research, i.e. what the recurring or preferred patterns are,
is not answered by Winters with a systematic and complete description of linguistic patterns –
which is exactly what corpus tools are capable of. According to Wallaert, studies such as
Winters’s lead to situations similar to the one described by Persian poet Rumi in his tale about
the elephant in the dark: Five wise men, who have never seen an elephant before, are asked to
touch the animal in the dark and to describe its nature. The wise man who touched the ear,
describes it as some sort of carpet, the person who touched the trunk compares it to a tubular
pipeline, etc. All of them touched a different part, so all of them have a different description
of the whole. One of the morals of the story is “that partial perceptions are apt to give
distorted pictures of the whole” (Wallaert 2010).
Wallaert does not only criticize; she presents a counterproposal. Her proposal follows
the paratextual method by Antoine Berman, as introduced in Pour une critique des
traductions: John Donne (1995). Berman stresses that the researcher first has to read the
source and target texts intensively and independently4. After this reading he or she can
formulate impressions and hypotheses. Next, Berman zooms in on the translating subject, the
individual, who inevitably has his or her own individual style. The theory of the translating
subject consists of four points of inquiry:
1. the position of the translator as a user of both source and target languages (“position
langagière”, Berman 1995, p. 75), as well as his or her personal literary preferences
2. the translator’s general stance in translation (“position traductive”, Berman 1995, p.
75), which can often be found in paratexts, such as prefaces, footnotes, general
comments on translation and translation reviews
3. The translating position often differs from translation project to translation project,
and the researcher has to search (again, in paratexts) for the vision a translator had for
a specific translation.
4. translator’s horizon: the literary practices of the target culture and the translation
norms at the time of translation
4 A truely ‘independent’ reading may be impossible, as a researcher is not likely to completely forget a different version of the same text (original or translation). However, what is meant here is that the texts are not compared yet.

16
The researcher then has to search the target text for traces of these four points, and can
interpret the traces with the information he or she has gathered. Based on the findings, the
previously formulated impressions and hypotheses can then obtain a scientific character.
After Wallaert has explained Berman’s technique, she applies it herself to Edgar Allen
Poe’s The Fall of the House of Usher and the French translation by Charles Baudelaire. After
reading the source and target text she formulates hypotheses and research questions related to
the narrator and ambiguity. Her method consists of a comparative analysis by laying the
(printed) texts next to each other and comparing them word for word. This is a time
consuming method, but, according to her, as time consuming as converting a source text and
its two translations into a corpus. As an answer to her hypotheses and research questions she
finds important traces of the translator not in patterns of linguistic behavior, but, on the
contrary, in “those one-off textual interventions which so many researchers insist on ignoring”
(Wallaert 2010). She concludes that the translation is less ambiguous and that the translated
narrator reacts differently to his environment and to Usher; he is less sceptic; imagines less;
and rationalizes more.

17
3 ROTH’S STYLE
3.1 Hotel Savoy
The present study investigates Austrian author Joseph Roth’s style in one of his first novels,
Hotel Savoy, and how two Dutch translators treat this style. As the discussion of style showed
(see 2.1), ‘style’ can relate to both an author and a text. In this paper, the terms ‘Joseph Roth’s
style’, ‘the style of Hotel Savoy’, and ‘Joseph Roth’s style in Hotel Savoy’ are used
interchangeably, as this study is limited to only that text. The translators’ styles and the styles
of their translations of Hotel Savoy will also be synonymous.
Joseph Roth was born in 1894 in Brody, in former Galicia, then part of the Austro-
Hungarian empire, now part of Ukraine. Working as a journalist, he spent most of his adult
life traveling across Europe. Hotel Savoy was his first novel printed in book form (1924),
telling the story of first-person narrator Gabriel Dan. In the aftermath of World War I, Dan
has been released from Russian war imprisonment in Siberia and is traveling west to go home.
On his way home he stops in the city where Hotel Savoy is located (which remains nameless
throughout the novel), because some of his relatives live there. He hopes to get some money
from them so he can continue his journey, but ends up staying much longer than anticipated.
In this socially criticizing novel Dan encounters many interesting characters who live higher
up in the hotel as they gradually become poorer.
Hotel Savoy was translated into Dutch twice: the first time by Dutchman Huib van
Krimpen in 1994, the second time by Dutchman Wilfred Oranje in 2003. Van Krimpen (1917-
2002) was a typographer and type designer who also worked as a translator (Els Snick,
personal communication, 26-5-2014). Oranje (1951-2011) was a translator who translated
works of, among others, Joseph Roth, Goethe, and Nietzsche, and the entire oeuvre of
Sigmund Freud (Schippers 2013, p. 237).
3.2 Investigating Roth’s Style
In order to determine a specific research question for this study, the three texts were first read
independently and intensively, as Wallaert (2010) and Berman (1995) advocate. One of the
features that catches the reader’s eye is the use of many enumerations and coordinated
structures throughout the entire novel, both in the source text and the target texts. This feature
is also commented on in the scientific literature on Joseph Roth, e.g. Joseph Roth als Stilist
(Hoffmann & Shchyhlevska 2013). In the first contribution in this collection, Hoffmann

18
observes that Roth very consciously uses certain rhetorical devices, such as inversion,
enumeration and phrasal modification, “um auch seine Leser immer wieder auf die Bedeutung
der formalen Seite seiner Texte zu lenken” [“in order to always again point out also to his
readers the meaning of the formal aspect of his texts” (Translation, TC)] (Hoffmann 2013, p.
55). The article pays special attention to rhetorical devices often used by Roth, which include
enumerations (often of adjectives), anaphorae, and parallel structures (pp. 50-54). All of these
contribute to the sensory, visual style of Joseph Roth, one of the three main features of Joseph
Roth’s style: “Forschung und Kritik preisen [Roths] bildhaften, musikalischen und biblischen
Stil” [“Studies and criticism praise [Roth’s] pictorial, musical and biblical style” (Translation,
TC)] (Hoffman & Shchyhlevska 2013, p. 15).
3.3 Coordinated Structures
Not only are coordinated structures numerous, they are also often coordinated without any
coordinating conjunction. This dissertation adopts Huddleston and Pullum’s (2006) definition
of coordination:
a relation holding between two or more elements of equal syntactic status. None is a dependent of any other, and none is a head – coordination is a non-headed construction. We call the elements or parts coordinates. (…) The words that mark the relation – most commonly the words and and or – are called coordinators. (p. 199, emphasis original)
There are three different ways to mark coordination: syndetic, asyndetic and polysyndetic:
The major contrast is between syndetic coordination, which contains at least one coordinator, and asyndetic coordination, which does not. In constructions with more than two coordinates there is a further contrast within syndetic coordination between the default simple syndetic, which has a single coordinator marking the final coordinate, and polysyndetic, where all non-initial coordinates are marked by a coordinator (which must be the same for all of them). (Huddleston & Pullum 2006, p. 202, emphasis original)
The above terms will be used throughout this dissertation to refer to the different styles of
coordination. However, from a terminological standpoint no distinction will be made between
‘syndetic’ and ‘simple syndetic’. Only ‘syndetic’ coordinations will be considered, which will
always refer to coordinations with one coordinator. ‘Polysyndetic’ then implies that the
coordination counts at least three coordinates. Furthermore, Huddleston and Pullum’s
definition of ‘polysyndetic’ will not be used. Instead, the following definition from A
Dictionary of Stylistics will be adopted:

19
polysyndeton describes the MARKED use of several CONJUNCTIONS in succession (especially the same one) particularly for CO-ORDINATE CLAUSES or phrases. (Wales 1989, p. 365, emphasis original)
The main difference between this definition and the one by Huddleston and Pullum is that this
definition does not require all but the first coordinate to be introduced by a coordinator. It
only requires several coordinators, in other words: more than one coordinator. This is more
valuable for programming purposes.
Asyndetic coordinations are also an entry in A Dictionary of Stylistics (Wales 1989, p.
40). The Dictionary lists synonyms for both asyndetic and polysyndetic coordinations:
respectively ‘asyndeton’ and ‘polysyndeton’, which will be used throughout this paper.
‘Syndeton’ will be used to refer to syndetic coordinations. Furthermore, in A Dictionary of
Stylistics, asyndeton and polysyndeton are labeled rhetorical devices. The study of Roth’s use
of different coordination styles then also becomes a study of the rhetorical devices he uses.
The three styles of coordination are now illustrated. The following sentence is taken from the
first chapter of Hotel Savoy and demonstrates syndetic coordination: “Ich kehre aus
dreijähriger Kriegsgefangenschaft zurück, habe in einem sibirischen Lager gelebt und bin
durch russische Dörfer und Städte gewandert” [“I return from three years of war
imprisonment, lived in a Siberian prison camp, and wandered through Russian villages and
cities” (Translation5, TC)] (Roth 1924, emphasis added). It actually contains two
coordinations: the first one consists of coordinated sentences6, the second one of coordinated
noun phrases (‘Dörfer und Städte’). For this demonstration, only the first coordination is
relevant. The same sentence coordinated asyndetically would be: ‘Ich kehre aus dreijähriger
Kriegsgefangenschaft zurück, habe in einem sibirischen Lager gelebt, bin durch russische
Dörfer und Städte gewandert.’ And finally, the rewritten polysyndetic version would look as
follows: ‘Ich kehre aus dreijähriger Kriegsgefangenschaft zurück und habe in einem
sibirischen Lager gelebt und bin durch russische Dörfer und Städte gewandert.’
During the first reading of the source text, many coordinations were found to be asyndetic.
Both translations also contain numerous asyndetic coordinations, but after a comparison of the
5 All English translations of German and Dutch text excerpts are primarily aimed at illustrating the coordinated structures and coordination styles involved. 6 The coordinates can be interpreted either as sentences or verb phrases. They are classified here as coordinated sentences because all verbs have satellites, appearing to be sentences with the repeated subject in ellipsis. However, classifying the coordinates as verb phrases is equally valuable.

20
first chapter across all three texts, Oranje showed to sometimes change asyndeta into syndeta,
for example:
Text Excerpt 1
die mächtigen Brüste einer Frau, die man unterwegs getroffen, ins Moos gelegt hat, die weiße Pracht ihrer Schenkel (Roth 1924, ch. 1)
> de imposante borsten, de prachtige blanke dijen van een vrouw die ik onderweg ben tegengekomen en in het mos heb gevlijd (Oranje 2003, p. 8, emphasis added)
Furthermore, both translators also add elements, such as the possessive second-person
pronoun ‘je’ in the following example:
Text Excerpt 2
So vieles kann man in sich saugen und dennoch unverändert an Körper, Gang und Gehaben bleiben.
> Zoveel kun je in jezelf opzuigen terwijl je lichaam, je gang en je gedrag hetzelfde blijven. (van Krimpen 1994, p. 6, emphasis added)
> Je kunt zoveel in je opzuigen, zonder dat je lichaam, je manier van lopen en gedragen veranderen. (Oranje 2003, p. 8, emphasis added)
Because of the structure the translators chose, in both translations ‘je’ is necessary before the
first noun phrase (‘lichaam’), but the repetition really makes it an addition. Moreover, van
Krimpen repeats the addition with each coordinated noun phrase, making the coordination an
anaphora7. Throughout the first chapter, van Krimpen adds more elements than Oranje. There
are several instances where the former repeats the added element to form an anaphora.
3.4 Research Question and Hypotheses
3.4.1 Research question
After the first readings of all three texts, and a comparison of the first chapter, the specific
research question for this research could be formulated: How does Roth coordinate structures
(syndetically/asyndetically/polysyndetically) and how do van Krimpen and Oranje treat the
different styles of coordination in their translations?
7 ‘Anaphora’ is defined in A Dictionary of Stylistics as “a popular FIGURE OF SPEECH involving REPETITION of the same word at the beginning of successive clauses, sentences or verses” (Wales 1989, p. 23, emphasis original). In this research, this definition is adopted, but with one adaption: a popular figure of speech involving repetition of the same word at the beginning of successive coordinates in a coordinated structure.

21
The fact that polysyndetic structures are researched, implies that this study will only
investigate coordinations with German ‘und’ and ‘oder’, and Dutch ‘en’ and ‘of’ (‘and’ and
‘or’, respectively), because only these two coordinating conjunctions can be repeated within
the same coordination (cf. Huddleston & Pullum 2006, p. 202). As a consequence, only
asyndeta consisting of coordinates that can be coordinated by ‘and’ or ‘or’ are researched.
With regard to the definition of author style and translator style in the first sense, this
research focuses on the choice the original author and the translators make. With regard to
translator style in the second sense, this study investigates the choice van Krimpen and Oranje
make when translating a certain coordination style: whether they choose to retain that
coordination style or whether they change it to one of the other two styles of coordination.
3.4.2 Hypotheses
In order to formulate more nuanced hypotheses than hypotheses based on the comparison of
one chapter, the first three chapters were compared.8 This comparison unveiled some other
phenomena worth noting: van Krimpen also changes asyndeta into syndeta and sometimes
splits up coordinated structures into two sentences, both translators compensate by changing
some syndeta into asyndeta, and they both sometimes change syndeta and asyndeta into non-
coordinated structures. Thus the following hypotheses were formulated:
� Hypothesis 1:
Both van Krimpen and Oranje sometimes change asyndeta into syndeta, but Oranje
more so than van Krimpen.
� Hypothesis 2:
Both van Krimpen and Oranje show a limited quantity of compensation by changing
syndeta into asyndeta.
� Hypothesis 3:
When an asyndeton is translated as an asyndeton, both van Krimpen and Oranje
sometimes add (a repetition of) elements.
� Hypothesis 4:
When elements are added in the translation, van Krimpen sometimes repeats them to
form an anaphora.
8 This comparison is only a quick comparison by laying the three texts next to each other, scanning the first three chapters for coordinations, and only taking rudimentary notes. It differs from the in-depth corpus-based method used for this research and described in the next chapter.

22
� Hypothesis 5:
Both van Krimpen and Oranje sometimes change coordinated structures into non-
coordinated structures.
This investigation of style shall not only prove the above hypotheses right or wrong
(qualitative research), it shall also fill in the terms ‘sometimes’ and ‘a limited quantity’ more
precisely (quantitative research).
An added hypothesis is the retranslation hypothesis, which
claims that later translations of a given (literary) work into a given target language tend to get closer to the source text. The idea goes back to Goethe, but has been much debated. Some evidence supports the claim, but much evidence does not. (Chesterman 2010, p. 177)
In the case of Hotel Savoy, the retranslation hypothesis proposes that Oranje’s translation is
closer to Roth’s text than van Krimpen’s translation is. Staying within the scope of this
research, the distance between translations and original will be tested on the level of
coordination.

23
4 DATA AND METHODOLOGY
While a specific research question for this study was determined using Wallaert’s (2010) and
Berman’s (1995) first steps of research, the here-described methodology is based on a
combination of methods used by Parks (1998) and Baker (2000): like Parks’s study, the
analysis focuses on a characteristic feature of the original, and the method used is a corpus-
based method such as Baker proposes. The strength of combining elements from all three
paradigms lies in the fact that the corpus-based method allows for a systematic description
rather than an anecdotic one, and that there is a concrete textual cause to research
coordination style specifically.
4.1 Corpus
The parallel corpus consists of three texts: the German source text, Joseph Roth’s Hotel
Savoy, and the two Dutch translations, one by Huib van Krimpen and one by Wilfred Oranje.
A digital version of the source text was already available. As Roth passed away in 1939 the
copyright has expired and the full text is available online at Der Spiegel’s Projekt Gutenberg-
DE. The book is divided into 4 parts (‘Bücher’), totaling in 30 chapters. For this research only
the first part is used, which consists of about 13,000 words in 13 chapters.
In an attempt to digitalize the translations as efficiently as possible, contact was sought
with the publishers to request a digital version of the books. Van Krimpen’s translation was
published in 1994 by Uitgeverij Bas Lubberhuizen. Mr. Lubberhuizen responded to the
request that he was not able to send a digital copy of the book, as he believed this particular
book was probably still written on a typewriter (personal communication, 10-3-2014).
Therefore a hard copy of the book had to be scanned and run through OCR software, ABBEY
FineReader in the case of this study.
Oranje’s translation was published in 2003 by L.J. Veen Klassiek. For this dissertation
the second edition, printed in 2013, is used. The publisher responded to the request that they
were able to send an electronic version of the book on the condition that a non-disclosure
agreement was signed. They sent a PDF file, which the OCR software converted into a text
format.
The three documents were aligned using the freeware LF Aligner. The advantage this
program has over some other alignment software is that it can align several translations of the
same source text at the same time. It can also export the aligned files to a TMX file
(Translation Memory eXchange, the format used to exchange translation memories between

24
different computer-aided translation tools). TMX files are XML documents. The following
section gives a brief introduction to XML, after which the presentation of corpus and
methodology is continued.
4.2 XML
XML stands for eXtensible Markup Language and is a markup language similar to HTML
“designed to transport and store data” (W3Schools c). The ‘extensible’ means users have to
create their own tags, which is not the case with HTML. Other examples of XML-based file
formats are TBX (TermBase eXchange) and one of the possible output formats of the
Stanford Log-linear Part-Of-Speech Tagger.
An XML document consists of elements and text. Elements are represented by
opening and closing tags, e.g. respectively <body> and </body>. XML documents must contain
a root element, which contains all other elements. Elements have a hierarchal structure and
the relationships between elements are described with terms such as ‘parent’, ‘child’, ‘sibling’
and ‘descendant’ (W3Schools b). Elements can contain either child elements or text. They can
also have attributes, which are declared within the tag. The following example contains the
first 28 lines of code of the aligned corpus TMX file:
Code Excerpt 1
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE tmx SYSTEM "tmx14.dtd">
<tmx version="1.4">
<header
creationtool="LF Aligner"
creationtoolversion="4.05"
datatype="unknown"
segtype="sentence"
adminlang="RO"
srclang="RO"
o-tmf="TW4Win 2.0 Format"
>
</header>
<body>
<tu creationdate="20140318T135659Z" creationid="LF Aligner 4.05">
<tuv xml:lang="RO"><seg>Erstes Buch</seg></tuv>
<tuv xml:lang="VK"><seg>EERSTE BOEK</seg></tuv>
<tuv xml:lang="OR"><seg>Eerste deel</seg></tuv> </tu>
<tu creationdate="20140318T135659Z" creationid="LF Aligner 4.05">
<tuv xml:lang="RO"><seg>I</seg></tuv>
<tuv xml:lang="VK"><seg>1</seg></tuv>

25
<tuv xml:lang="OR"><seg>I</seg></tuv> </tu>
<tu creationdate="20140318T135659Z" creationid="LF Aligner 4.05">
<tuv xml:lang="RO"><seg>Ich komme um zehn Uhr vormittags im Hotel Savoy an.
Ich war entschlossen, ein paar Tage oder eine Woche
auszuruhen.</seg></tuv>
<tuv xml:lang="VK"><seg>Ik kom om tien uur in de ochtend bij Hotel Savoy aan.
Ik had me voorgenomen een paar dagen of een week uit te
rusten.</seg></tuv>
<tuv xml:lang="OR"><seg>Ik kom om tien uur 's ochtends bij Hotel Savoy
aan. Ik had me voorgenomen een paar dagen of een week uit te
rusten.</seg></tuv> </tu>
This code excerpt starts with the XML declaration and document type declaration, followed
by the root element, <tmx>.The root element has two child elements: <header> and <body>.
The <header> element has attributes containing meta information (e.g. creationtool="LF
Aligner"), and the aligned segments are stored in the <body> element. Aligned segments are
grouped in translation units (<tu>), which have the following structure:
Element Name Tag Attributes
Translation Unit <tu> creationdate, creationid
Translation Unit Variant <tuv> xml:lang
Segment <seg>
Table 1. Structure of a TMX <tu><tu><tu><tu> element
Every row represents a child element of the element listed in the preceding row. The
Translation Unit can be seen as a collection of all variants of an aligned segment, along with
all additional information. There is one Translation Variant per language, and the Segment
contains the actual text of the aligned segment. A difference is made between <tuv> and <seg>
to allow for other elements, such as notes (<note>) to also be stored inside a <tuv>.9
The translation units contain some child elements and (child elements’) attributes
irrelevant for this research, i.e. the creation date, the creation ID and the <seg> element. Note
that the xml:lang normally specifies the language of the variant. As seen in Code Excerpt 1,
the actual languages are not declared, because that would result in one German and two Dutch
variants. Since differences between the two Dutch variants are important for this research,
fake language codes were chosen, actually representing the author10 of each variant: ‘RO’ for
Roth, ‘VK’ for van Krimpen, and ‘OR’ for Oranje.
9 The <note> element is not included in Table 1 because the TMX file does not contain any notes. Furthermore, the <note> element will not return in what follows. 10 ‘Author’ is here interpreted in a broad sense and refers to the person who wrote the variant, regardless of whether it concerns the (source text) author or a translator.

26
4.3 Converting the XML Structure
The next step in processing the corpus consisted of transforming the TMX structure into a
new XML structure fit to the needs of this research. To create that structure, the following
‘find and replace’ commands were executed in Notepad++, a freeware text editor:
Find Replace by
1 <tu creationdate=".*" creationid=".*"> <tu>
2 <seg>
3 </seg>
4 <tuv xml:lang="RO"> \t<tuv author="ro">
5 <tuv xml:lang="VK"> \t<tuv author="vk">
6 <tuv xml:lang="OR"> \t<tuv author="or">
7 </tu> \n</tu>
Table 2. Find and replace commands used to create a new XML structure
The above commands delete the redundant information: the translation unit’s creation date
and creation ID, as well as the <seg> tags (rows 1-3). They also change the variant’s xml:lang
attribute into an author attribute, making the XML structure semantically more transparent
(rows 4-6). In rows 4 through 7, the \t and \n respectively add tabs and line breaks to the
code. These are merely for visual clarity’s sake. The <tmx>, <header> and <body> elements
were also irrelevant. The root element <tmx> was replaced by the <book> element. Child
elements of <book> are chapters (<chap>) with attribute id. The new document structure is
demonstrated below:
Code Excerpt 2
<?xml version="1.0" encoding="utf-8" ?>
<book>
<chap id="1">
<tu>
<tuv author="ro">Ich komme um zehn Uhr vormittags im Hotel Savoy
an. Ich war entschlossen, ein paar Tage oder eine Woche
auszuruhen.</tuv>
<tuv author="vk">Ik kom om tien uur in de ochtend bij Hotel Savoy
aan. Ik had me voorgenomen een paar dagen of een week uit te
rusten.</tuv>
<tuv author="or">Ik kom om tien uur 's ochtends bij Hotel
Savoy aan. Ik had me voorgenomen een paar dagen of een week uit te
rusten.</tuv>
</tu>

27
This is only an excerpt. Respecting the XML syntax, the <chap> element is closed by </chap>
before a new chapter begins, and </book> ends the document.
4.4 Tagging Coordinated Structures
The bulk of the work consisted in tagging all coordinated structures within a <tuv>. To this
end a set of new tags was created, which is listed in the following table:
Element Name Tag Attributes
Coordinated Structure <c> elcat ana
Coordinated Element <el>
Coordinating Conjunction11 <cc>
Addition (in the target texts) <add>
Table 3. XML elements used to tag coordinated structures
The <c> element can have two attributes. Firstly, the elcat attribute specifies the grammatical
category of the coordinated elements, allowing for an investigation of potential differences in
coordination style between different grammatical categories. The following categories occur
throughout the book:
� sen sentence
� vp verb phrase
� np noun phrase
� pp preposition phrase
� adjp adjective phrase
� advp adverb phrase
� relcl relative clause
When the elements belong to a different category than the ones listed, the elcat attribute is
left blank (elcat=””).
Secondly, the ana attribute indicates whether a coordinated structure is an anaphora.
This attribute is only specified in case of an anaphoric coordination. The following two
examples illustrate the tagging of coordinated structures. The full, tagged corpus can be found
in Appendix 1.
11 In Huddleston and Pullum’s (2006, see 3.3) terminology, ‘coordinated element’ and ‘coordinating conjunction’ are called ‘coordinate’ and ‘coordinator’ respectively. The terms ‘coordinate’ and ‘coordinator’ are not used in the XML structure, since all tags are abbreviations formed by the initial letter(s) of the terms. ‘Coordination’, ‘coordinate’ and ‘coordinator’ would then result in untransparent tags. Moreover, ‘cc’ is also the tag used in the Penn Treebank POS tagset (cf. Marcus, Marcinkiewicz & Santorini 1993).

28
4.4.1 Example 1
The first example treats one of the opening sentences of the book: “Ich trage eine russische
Bluse, die mir jemand geschenkt hat, eine kurze Hose, die ich von einem verstorbenen
Kameraden geerbt habe, und Stiefel, immer noch brauchbare, an deren Herkunft ich mich
selbst nicht mehr erinnere.” (Roth 1924, ch. 1) This sentence contains one coordinated
structure, the elements of which are noun phrases. The following code excerpt contains the
tagged version:
Code Excerpt 3
Ich trage <c elcat="np"><el>eine russische Bluse, die mir jemand geschenkt
hat,</el> <el>eine kurze Hose, die ich von einem verstorbenen Kameraden
geerbt habe,</el> <cc>und</cc> <el>Stiefel, immer noch brauchbare, an deren
Herkunft ich mich selbst nicht mehr erinnere.</el></c>
The <c> element has one attribute and four child elements. The attribute specifies that the
grammatical category of the elements (elcat) is a noun phrase ("np"). Of the four child
elements, three are coordinated elements (<el>) and one is the coordinating conjunction (<cc>)
“und”.
The above excerpt only contains the tagged source text segment. The complete
translation unit is printed below:
Code Excerpt 4
<tu>
<tuv author="ro">Ich trage <c elcat="np"><el>eine russische Bluse,
die mir jemand geschenkt hat,</el> <el>eine kurze Hose, die ich von
einem verstorbenen Kameraden geerbt habe,</el> <cc>und</cc>
<el>Stiefel, immer noch brauchbare, an deren Herkunft ich mich
selbst nicht mehr erinnere.</el></c></tuv>
<tuv author="vk">Ik draag <c elcat="np"><el>een Russische kiel die
iemand me gegeven heeft,</el> <el>een korte broek die ik van een
gestorven kameraad heb geërfd</el> <cc>en</cc> <el>nog altijd
bruikbare laarzen, waarvan ik zelf niet meer weet hoe ik er aan ben
gekomen.</el></c></tuv>
<tuv author="or">Ik draag <c elcat="np"><el>een Russische kiel die
iemand mij cadeau heeft gedaan,</el> <el>een korte broek die ik van
een gestorven kameraad heb geërfd,</el> <cc>en</cc> <el>nog altijd
bruikbare laarzen waarvan ik zelf niet meer weet hoe ik eraan
gekomen ben.</el></c></tuv>
</tu>

29
In Code Excerpt 4, it can be seen that both translations also contain one <c> element, of which
the coordinated elements are noun phrases as well (elcat="np"), and which also contain one
coordinating conjunction, i.e. “en”, tagged “<cc>en</cc>”.
4.4.2 Example 2
XML allows its elements to be nested, so coordinated structures within coordinated structures
can be tagged as well. Consider the following example:
Code Excerpt 5
<tu>
<tuv author="ro"><c elcat="sen"><el>Aus dem siebenten Stock sind
alle Einwohner verschwunden,</el> <el>offen stehn die Türen,</el>
<el>dargeboten ist dem Blick <c elcat="np"><el>alle kümmerliche
Häuslichkeit,</el> <el>eilig zusammengeraffte Bündel,</el>
<el>Haufen von Zeitungspapier über verbotenen
Gegenständen</el></c>.</el></c></tuv>
<tuv author="vk"><c elcat="sen"><el>Op de zevende verdieping zijn
alle bewoners verdwenen,</el> <el>de deuren staan open,</el> <el>de
armzalige huiselijkheid is voor ieder zichtbaar: <c
elcat="np"><el>haastig bij elkaar gegaarde bundels,</el> <el>oude
kranten over verboden voorwerpen</el></c>.</el></c></tuv>
<tuv author="or"><c elcat="sen"><el>Van de zevende verdieping zijn
alle bewoners verdwenen,</el> <el>de deuren staan open,</el> <el><c
elcat="np"><el>al het armoedige huisraad,</el> <el>haastig
bijeengeraapte bundeltjes,</el> <el>stapels krantenpapier over
verboden voorwerpen</el></c>,</el> <el>alles ligt daar <c
elcat="adjp"><el>open</el> <cc>en</cc>
<el>bloot</el></c>.</el></c></tuv>
</tu>
The German variant consists of three coordinated sentences, the third of which contains three
coordinated noun phrases. Schematically:
� Aus dem siebenten Stock sind alle Einwohner verschwunden,
� offen stehn die Türen,
� dargeboten ist dem Blick
□ alle kümmerliche Häuslichkeit,
□ eilig zusammengeraffte Bündel,
□ Haufen von Zeitungspapier über verbotenen Gegenständen.
Van Krimpen’s translation has a similar structure, while Oranje’s translation adds a third
coordination, i.e. the coordinated adjectives ‘open en bloot’. This last instance demonstrates
that each variant is tagged independently from the two other variants within the same

30
translation unit. In other words: rather than tagging all coordinated structures in the source
text and then only looking for the equivalents in the target texts, all coordinated structures are
tagged, regardless of whether they have corresponding structures in the other <tuv>’s.
4.5 Filtering the Tagged Corpus with XSLT
After all coordinated structures were tagged in XML, they were processed by XSLT
templates. XSLT stands for eXtensible Stylesheet Language Transformations and “can
add/remove elements and attributes to or from the output file. You can also rearrange and sort
elements, perform tests and make decisions about which elements to hide and display, and a
lot more” (W3Schools a). So while XML is used to store information, XSLT is the language
used to display (‘Stylesheet’) and transform (‘Transformations’) this information. The general
principles behind the code are explained here. The full XSLT (and CSS) code can be found in
Appendices 2 through 5.
XSLT is used to determine whether a structure is coordinated syndetically,
asyndetically or polysyndetically. In order to determine that, the template counts how many
<cc> elements (coordinating conjunctions) are child elements of a <c> (coordination). An
asyndeton contains zero <cc>’s, a syndeton contains one, and a polysyndeton contains more
than one. Respective examples are:
Code Excerpt 6
<tuv author="ro"><c elcat="sen"><el>Ich genieße das Schweben,</el>
<el>berechne, wieviel Stufen ich mühsam erklimmen müßte, wenn ich nicht in
diesem Prachtlift säße,</el> <cc>und</cc> <el>werfe <c
elcat="np"><el>Bitterkeit,</el> <el>Armut,</el> <el>Wanderung,</el>
<el>Heimatlosigkeit,</el> <el>Hunger,</el> <el>Vergangenheit des
Bettlers</el></c> hinunter - tief, woher es mich, den Emporschwebenden,
nimmermehr erreichen kann.</el></c></tuv>
This <tuv> contains one syndeton and one asyndeton. The first <c> element (<c
elcat="sen">) contains exactly one <cc> child element, making it a syndetic coordination.
The second <c> element (<c elcat="np">) comprises asyndetically coordinated noun phrases,
as it contains zero <cc> child elements.
Code Excerpt 7
<c elcat="np"><el>Kanner</el> <cc>und</cc> <el>Neuner</el> <cc>und</cc>
<el>Siegmund Fink</el> <cc>und</cc> <el>Frau Jetti Kupfer</el></c>

31
In Code Excerpt 7, the names of the characters are coordinated polysyndetically, as the <c>
element contains more than one <cc> child element.
Counting <cc> child elements is the basic principle underlying the two XSLT
templates used to obtain the results for this research. Both templates are now discussed.
4.5.1 Template 1: Separate
The first template filters and lists coordinated structures for each author separately. It
generates an HTML display of all coordinated structures found in e.g. Roth’s text. The HTML
file is divided into four sections: all coordinations; only syndetic coordinations; only
asyndetic coordinations; and only polysyndetic coordinations. The following figure is a
screenshot from Roth’s coordinated structures:
Figure 1. Template 1 displaying all of Roth’s coordinations
As the screenshot demonstrates, the template automatically numbers all coordinated
structures, so the researcher does not have to do any manual counting. The menu on the left
allows for easy navigation through the different sections.
To switch to the other authors, only one variable needs to be changed in the template’s
source code. Other (usually uncomplicated) changes in the code can filter the results further,
e.g.: listing anaphorae only, listing anaphoric coordinations formed by addition only, listing
noun phrases only, listing everything but noun phrases.
32
4.5.2 Template 2: Comparative
The second template is used for comparative research and has a more complex source code
than the first one. Its general function is to list the source text’s coordinated structures with
their corresponding structures in the target texts. In order to do this, the template performs a
series of commands on every single <tu> in the corpus.
Firstly, it searches the Roth <tuv>’s for descendant12 <c> elements. Then, it searches
the other two <tuv>’s (within the same translation unit) for corresponding <c> elements. This
correspondence is structural, not semantic. For example, if the Roth <tuv> contains three <c>
child elements, which we can label C.1, C.2, and C.313, and of which the second <c> contains
another two <c> child elements, labeled C.2.a and C.2.b, then Oranje’s equivalent for the
C.2.b structure provided by the template will be the <tuv author="or">’s second child <c>’s
second child <c> – regardless of whether the C.2.b structure in Oranje’s <tuv> is the actual
translation of the C.2.b structure in Roth’s <tuv>.
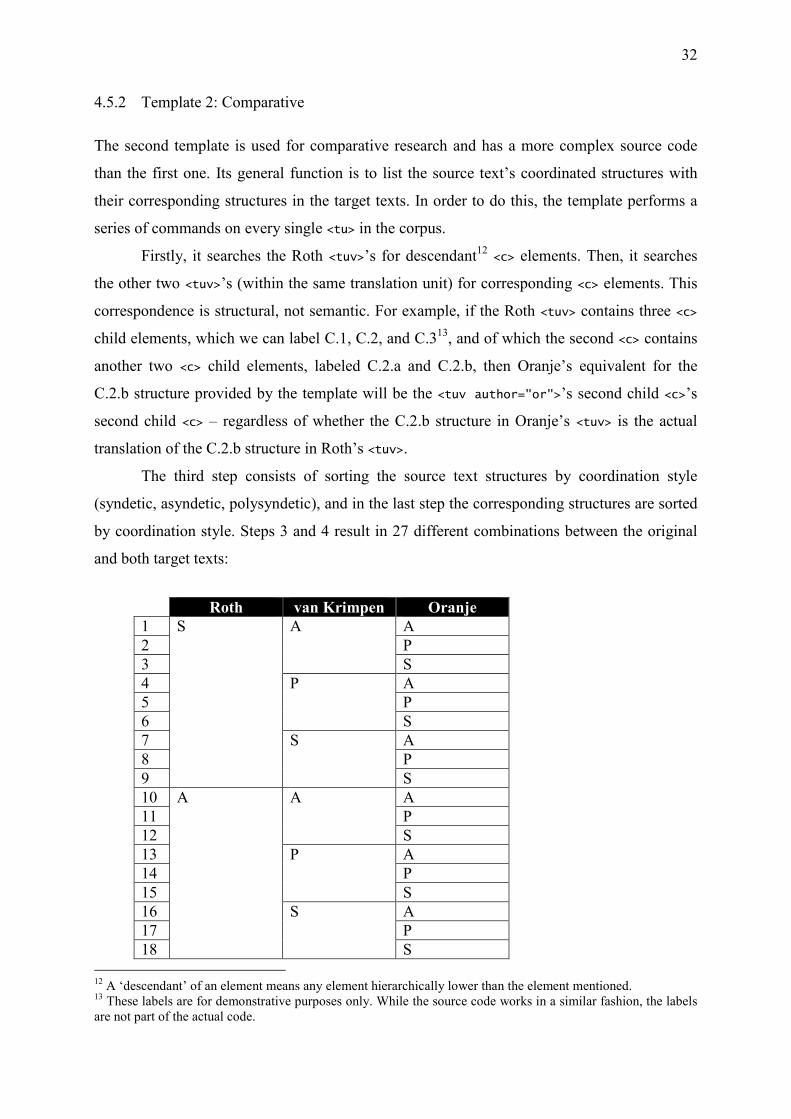
The third step consists of sorting the source text structures by coordination style
(syndetic, asyndetic, polysyndetic), and in the last step the corresponding structures are sorted
by coordination style. Steps 3 and 4 result in 27 different combinations between the original
and both target texts:
Roth van Krimpen Oranje
1 S A A 2 P 3 S 4 P
A
5 P 6 S 7 S
A
8 P 9 S 10 A A
A
11 P 12 S 13 P
A
14 P 15 S 16 S
A
17 P 18 S
12 A ‘descendant’ of an element means any element hierarchically lower than the element mentioned. 13 These labels are for demonstrative purposes only. While the source code works in a similar fashion, the labels are not part of the actual code.

33
19 P A
A 20 P 21 S 22 P
A
23 P 24 S 25 S
A
26 P 27 S Table 4. Possible combinations of coordination styles between source and target texts. Three styles: S =
syndetic, A = asyndetic, P = polysyndetic
The following image is a screenshot from the second template:
Figure 2. Template 2 displaying coordination styles compared between the three texts
The menu on the left navigates through all 27 possible combinations of coordinated structures
between the three texts (see Table 4). The first column contains Roth’s source text, the second
column van Krimpen’s target text, the third column Oranje’s target text.
The described system’s structural correspondence – rather than a semantic
correspondence – has a disadvantage: there is no guarantee that the (structurally)
corresponding coordinations are the actual translations of the source text coordinations.
However, one factor increases the chance that the structures listed as translations are in fact
the translations: the principle that the system searches within the same translation unit, which
is an aligned segment. Despite this principle, some false correspondences do exist. These
occur when the amount of <c> elements within the van Krimpen and/or Oranje <tuv>’s differs
from the amount of <c> elements within the Roth <tuv>. The <tuv>’s containing potential false
correspondences are marked by the template and have to be manually processed by the
researcher. As false correspondences indicate that the translator(s) either added or deleted one
or more coordinated structures, they form a separate set of structures worth closer
examination and discussed in the Results and Discussion section (see 5.2.2).
34
5 RESULTS AND DISCUSSION
5.1 Separate Analysis
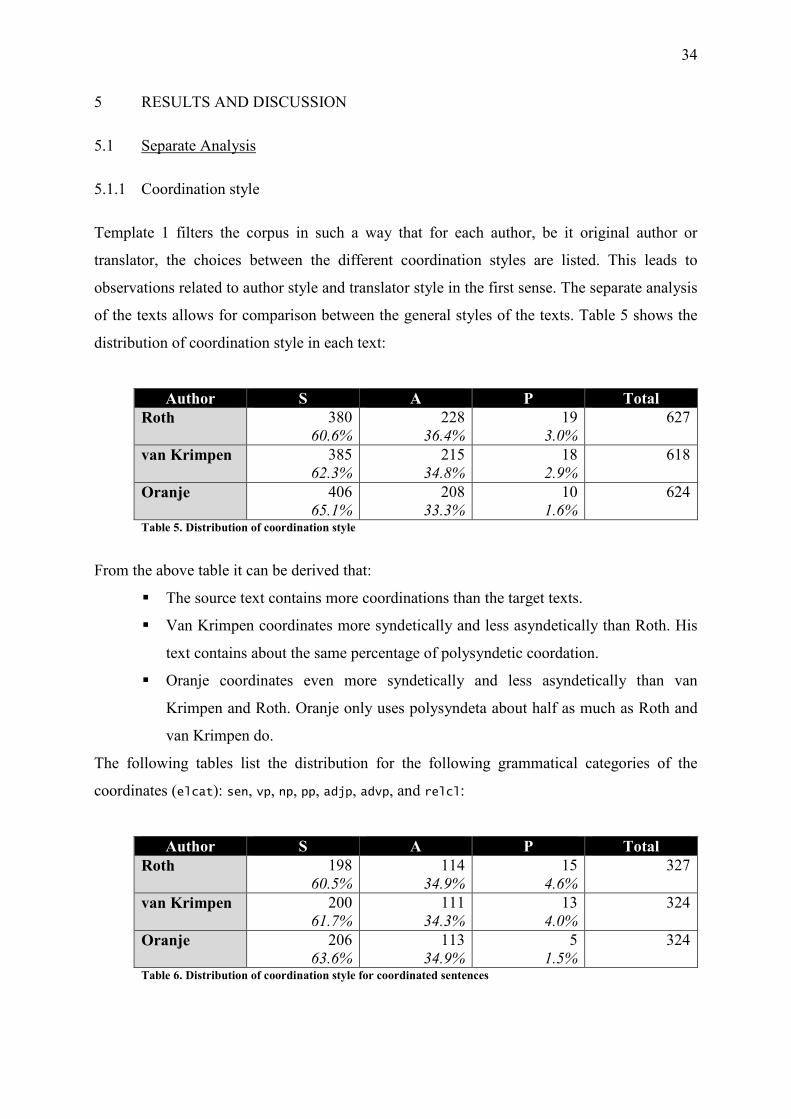
5.1.1 Coordination style
Template 1 filters the corpus in such a way that for each author, be it original author or
translator, the choices between the different coordination styles are listed. This leads to
observations related to author style and translator style in the first sense. The separate analysis
of the texts allows for comparison between the general styles of the texts. Table 5 shows the
distribution of coordination style in each text:
Author S A P Total
Roth 380 60.6%
228 36.4%
19 3.0%
627
van Krimpen 385 62.3%
215 34.8%
18 2.9%
618
Oranje 406 65.1%
208 33.3%
10 1.6%
624
Table 5. Distribution of coordination style
From the above table it can be derived that:
� The source text contains more coordinations than the target texts.
� Van Krimpen coordinates more syndetically and less asyndetically than Roth. His
text contains about the same percentage of polysyndetic coordation.
� Oranje coordinates even more syndetically and less asyndetically than van
Krimpen and Roth. Oranje only uses polysyndeta about half as much as Roth and
van Krimpen do.
The following tables list the distribution for the following grammatical categories of the
coordinates (elcat): sen, vp, np, pp, adjp, advp, and relcl:
Author S A P Total
Roth 198 60.5%
114 34.9%
15 4.6%
327
van Krimpen 200 61.7%
111 34.3%
13 4.0%
324
Oranje 206 63.6%
113 34.9%
5 1.5%
324
Table 6. Distribution of coordination style for coordinated sentences
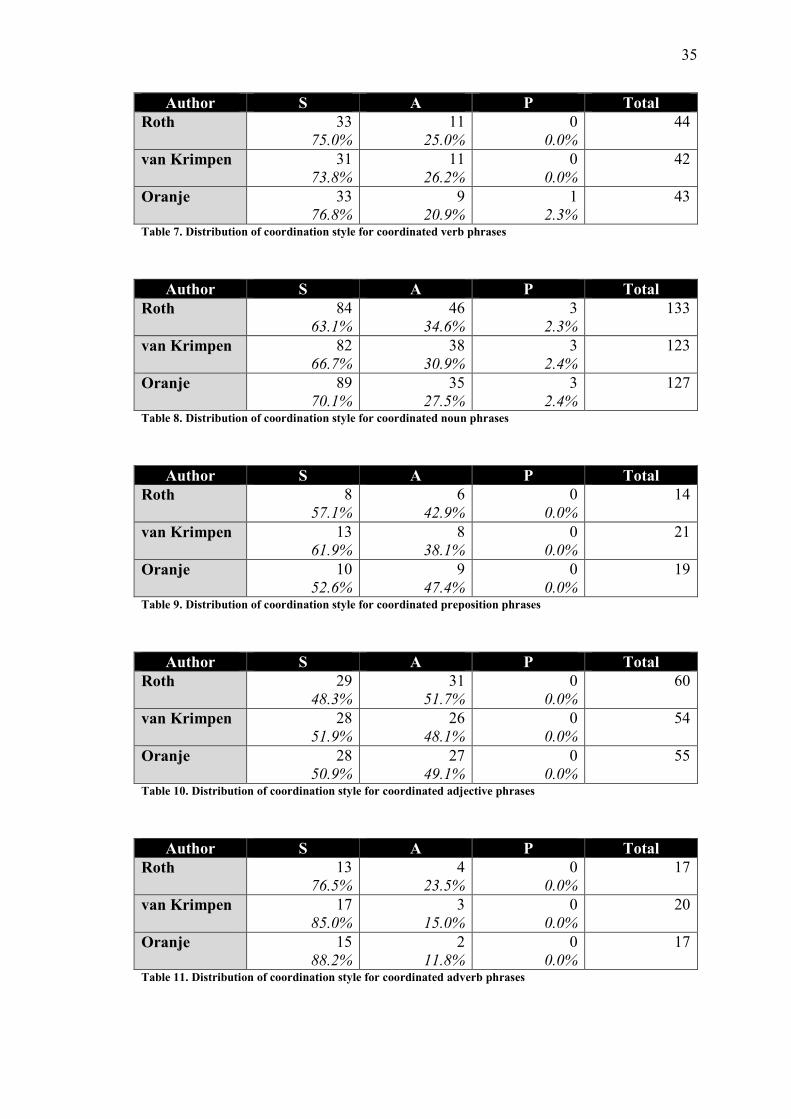
35
Author S A P Total
Roth 33 75.0%
11 25.0%
0 0.0%
44
van Krimpen 31 73.8%
11 26.2%
0 0.0%
42
Oranje 33 76.8%
9 20.9%
1 2.3%
43
Table 7. Distribution of coordination style for coordinated verb phrases
Author S A P Total
Roth 84 63.1%
46 34.6%
3 2.3%
133
van Krimpen 82 66.7%
38 30.9%
3 2.4%
123
Oranje 89 70.1%
35 27.5%
3 2.4%
127
Table 8. Distribution of coordination style for coordinated noun phrases
Author S A P Total
Roth 8 57.1%
6 42.9%
0 0.0%
14
van Krimpen 13 61.9%
8 38.1%
0 0.0%
21
Oranje 10 52.6%
9 47.4%
0 0.0%
19
Table 9. Distribution of coordination style for coordinated preposition phrases
Author S A P Total
Roth 29 48.3%
31 51.7%
0 0.0%
60
van Krimpen 28 51.9%
26 48.1%
0 0.0%
54
Oranje 28 50.9%
27 49.1%
0 0.0%
55
Table 10. Distribution of coordination style for coordinated adjective phrases
Author S A P Total
Roth 13 76.5%
4 23.5%
0 0.0%
17
van Krimpen 17 85.0%
3 15.0%
0 0.0%
20
Oranje 15 88.2%
2 11.8%
0 0.0%
17
Table 11. Distribution of coordination style for coordinated adverb phrases
36
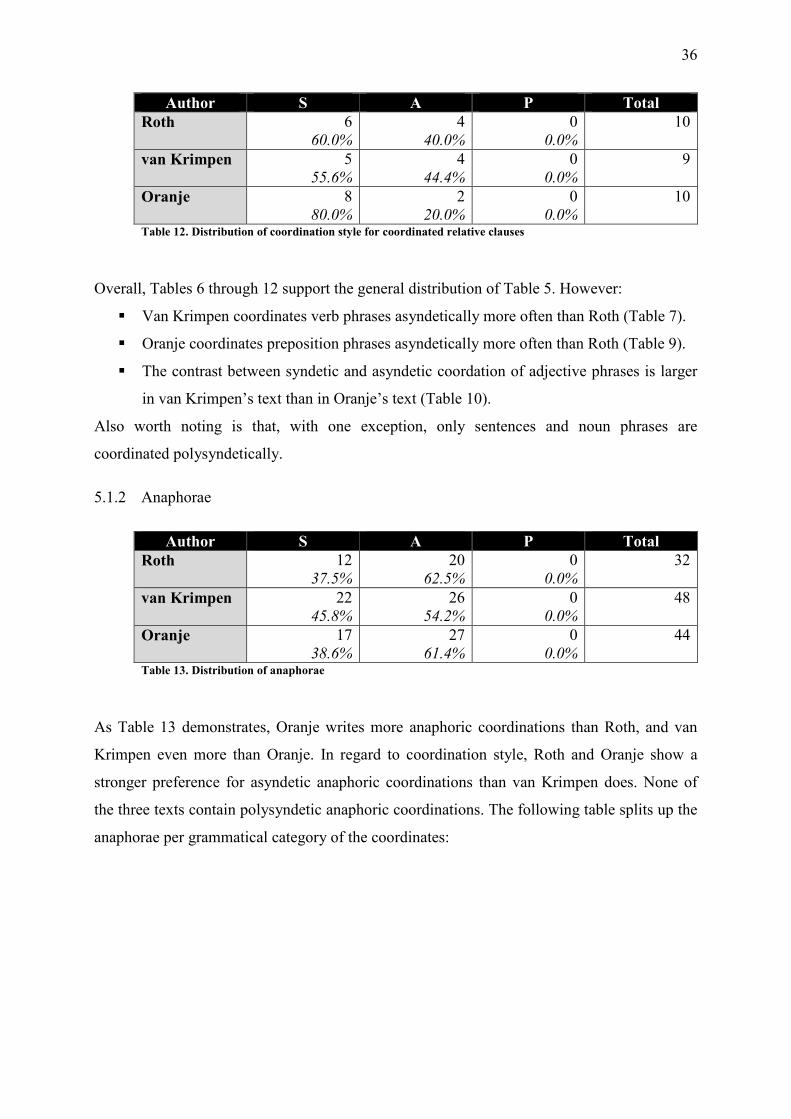
Author S A P Total
Roth 6 60.0%
4 40.0%
0 0.0%
10
van Krimpen 5 55.6%
4 44.4%
0 0.0%
9
Oranje 8 80.0%
2 20.0%
0 0.0%
10
Table 12. Distribution of coordination style for coordinated relative clauses
Overall, Tables 6 through 12 support the general distribution of Table 5. However:
� Van Krimpen coordinates verb phrases asyndetically more often than Roth (Table 7).
� Oranje coordinates preposition phrases asyndetically more often than Roth (Table 9).
� The contrast between syndetic and asyndetic coordation of adjective phrases is larger
in van Krimpen’s text than in Oranje’s text (Table 10).
Also worth noting is that, with one exception, only sentences and noun phrases are
coordinated polysyndetically.
5.1.2 Anaphorae
Author S A P Total
Roth 12 37.5%
20 62.5%
0 0.0%
32
van Krimpen 22 45.8%
26 54.2%
0 0.0%
48
Oranje 17 38.6%
27 61.4%
0 0.0%
44
Table 13. Distribution of anaphorae
As Table 13 demonstrates, Oranje writes more anaphoric coordinations than Roth, and van
Krimpen even more than Oranje. In regard to coordination style, Roth and Oranje show a
stronger preference for asyndetic anaphoric coordinations than van Krimpen does. None of
the three texts contain polysyndetic anaphoric coordinations. The following table splits up the
anaphorae per grammatical category of the coordinates:
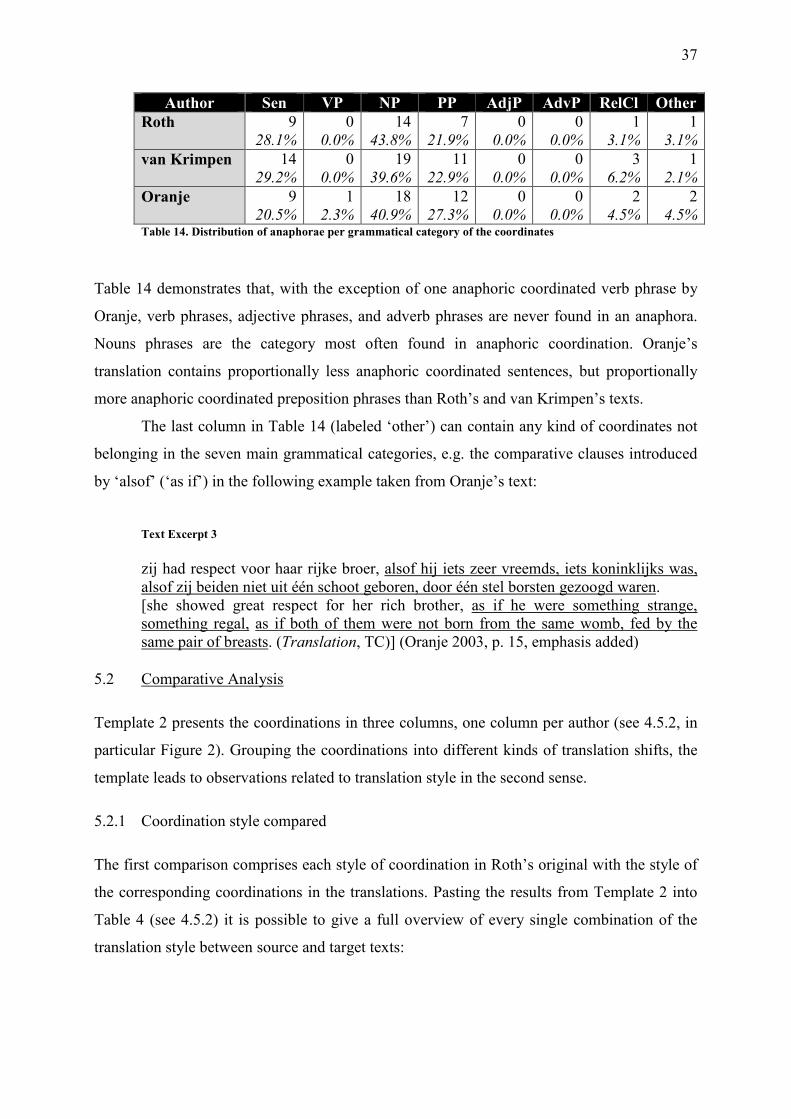
37
Author Sen VP NP PP AdjP AdvP RelCl Other
Roth 9 28.1%
0 0.0%
14 43.8%
7 21.9%
0 0.0%
0 0.0%
1 3.1%
1 3.1%
van Krimpen 14 29.2%
0 0.0%
19 39.6%
11 22.9%
0 0.0%
0 0.0%
3 6.2%
1 2.1%
Oranje 9 20.5%
1 2.3%
18 40.9%
12 27.3%
0 0.0%
0 0.0%
2 4.5%
2 4.5%
Table 14. Distribution of anaphorae per grammatical category of the coordinates
Table 14 demonstrates that, with the exception of one anaphoric coordinated verb phrase by
Oranje, verb phrases, adjective phrases, and adverb phrases are never found in an anaphora.
Nouns phrases are the category most often found in anaphoric coordination. Oranje’s
translation contains proportionally less anaphoric coordinated sentences, but proportionally
more anaphoric coordinated preposition phrases than Roth’s and van Krimpen’s texts.
The last column in Table 14 (labeled ‘other’) can contain any kind of coordinates not
belonging in the seven main grammatical categories, e.g. the comparative clauses introduced
by ‘alsof’ (‘as if’) in the following example taken from Oranje’s text:
Text Excerpt 3
zij had respect voor haar rijke broer, alsof hij iets zeer vreemds, iets koninklijks was, alsof zij beiden niet uit één schoot geboren, door één stel borsten gezoogd waren. [she showed great respect for her rich brother, as if he were something strange, something regal, as if both of them were not born from the same womb, fed by the same pair of breasts. (Translation, TC)] (Oranje 2003, p. 15, emphasis added)
5.2 Comparative Analysis
Template 2 presents the coordinations in three columns, one column per author (see 4.5.2, in
particular Figure 2). Grouping the coordinations into different kinds of translation shifts, the
template leads to observations related to translation style in the second sense.
5.2.1 Coordination style compared
The first comparison comprises each style of coordination in Roth’s original with the style of
the corresponding coordinations in the translations. Pasting the results from Template 2 into
Table 4 (see 4.5.2) it is possible to give a full overview of every single combination of the
translation style between source and target texts:
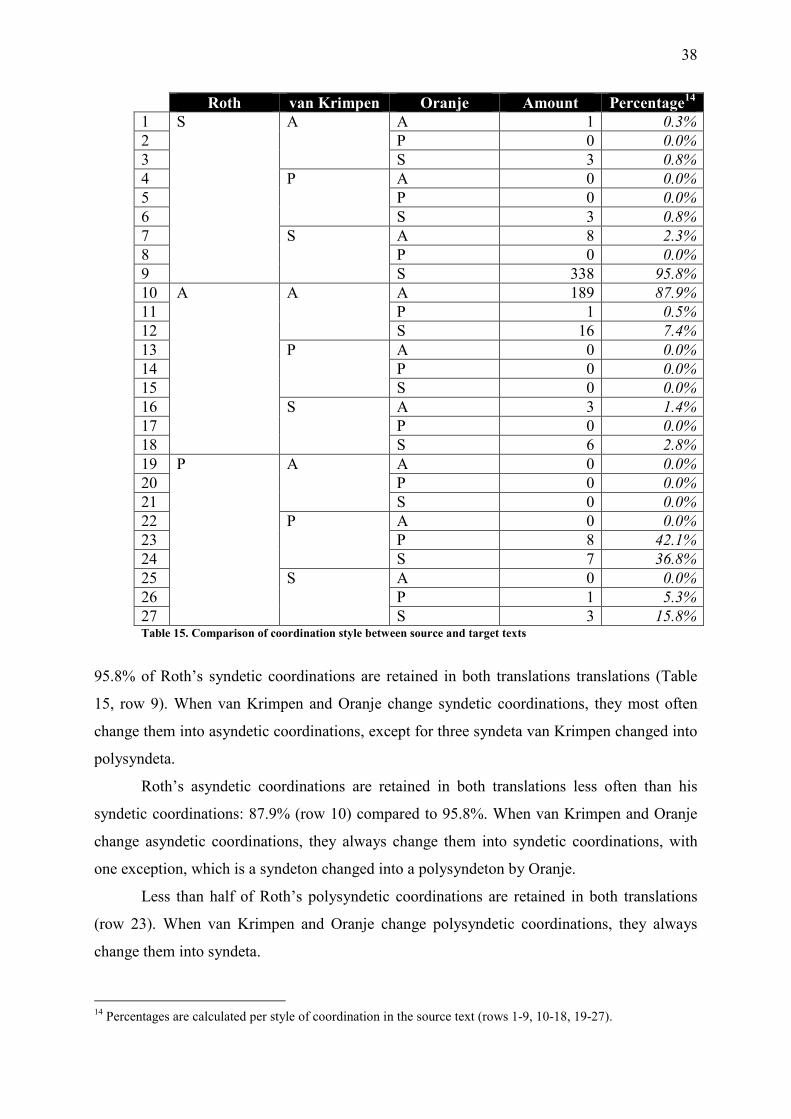
38
Roth van Krimpen Oranje Amount Percentage14
1 S A A 1 0.3%
2 P 0 0.0%
3 S 3 0.8%
4 P A 0 0.0%
5 P 0 0.0%
6 S 3 0.8%
7 S A 8 2.3%
8 P 0 0.0%
9 S 338 95.8%
10 A A A 189 87.9%
11 P 1 0.5%
12 S 16 7.4%
13 P A 0 0.0%
14 P 0 0.0%
15 S 0 0.0%
16 S A 3 1.4%
17 P 0 0.0%
18 S 6 2.8%
19 P A A 0 0.0%
20 P 0 0.0%
21 S 0 0.0%
22 P A 0 0.0%
23 P 8 42.1%
24 S 7 36.8%
25 S A 0 0.0%
26 P 1 5.3%
27 S 3 15.8% Table 15. Comparison of coordination style between source and target texts
95.8% of Roth’s syndetic coordinations are retained in both translations translations (Table
15, row 9). When van Krimpen and Oranje change syndetic coordinations, they most often
change them into asyndetic coordinations, except for three syndeta van Krimpen changed into
polysyndeta.
Roth’s asyndetic coordinations are retained in both translations less often than his
syndetic coordinations: 87.9% (row 10) compared to 95.8%. When van Krimpen and Oranje
change asyndetic coordinations, they always change them into syndetic coordinations, with
one exception, which is a syndeton changed into a polysyndeton by Oranje.
Less than half of Roth’s polysyndetic coordinations are retained in both translations
(row 23). When van Krimpen and Oranje change polysyndetic coordinations, they always
change them into syndeta.
14 Percentages are calculated per style of coordination in the source text (rows 1-9, 10-18, 19-27).
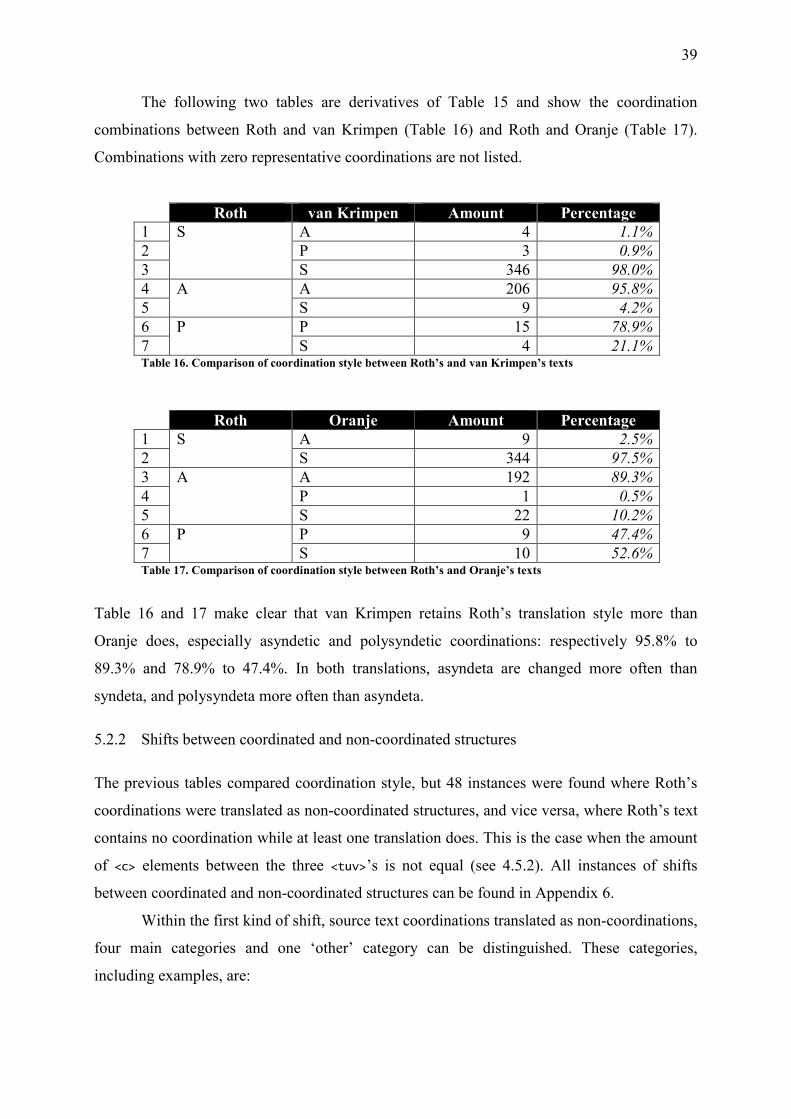
39
The following two tables are derivatives of Table 15 and show the coordination
combinations between Roth and van Krimpen (Table 16) and Roth and Oranje (Table 17).
Combinations with zero representative coordinations are not listed.
Roth van Krimpen Amount Percentage
1 S A 4 1.1%
2 P 3 0.9%
3 S 346 98.0%
4 A A 206 95.8%
5 S 9 4.2%
6 P P 15 78.9%
7 S 4 21.1% Table 16. Comparison of coordination style between Roth’s and van Krimpen’s texts
Roth Oranje Amount Percentage
1 S A 9 2.5%
2 S 344 97.5%
3 A A 192 89.3%
4 P 1 0.5%
5 S 22 10.2%
6 P P 9 47.4%
7 S 10 52.6% Table 17. Comparison of coordination style between Roth’s and Oranje’s texts
Table 16 and 17 make clear that van Krimpen retains Roth’s translation style more than
Oranje does, especially asyndetic and polysyndetic coordinations: respectively 95.8% to
89.3% and 78.9% to 47.4%. In both translations, asyndeta are changed more often than
syndeta, and polysyndeta more often than asyndeta.
5.2.2 Shifts between coordinated and non-coordinated structures
The previous tables compared coordination style, but 48 instances were found where Roth’s
coordinations were translated as non-coordinated structures, and vice versa, where Roth’s text
contains no coordination while at least one translation does. This is the case when the amount
of <c> elements between the three <tuv>’s is not equal (see 4.5.2). All instances of shifts
between coordinated and non-coordinated structures can be found in Appendix 6.
Within the first kind of shift, source text coordinations translated as non-coordinations,
four main categories and one ‘other’ category can be distinguished. These categories,
including examples, are:

40
1. Different conjunction
Sometimes syndetic coordinations are translated as structures containing a different
conjunction, e.g.:
Text Excerpt 4
Santschin ist plötzlich erkrankt. ‚Plötzlich‘, sagen alle Leute und wissen nicht, daß Santschin zehn Jahre lang unaufhörlich gestorben ist. [Santschin suddenly fell ill. ‘Suddenly’, people say, and don’t know that Santschin had been dying ceaselessly for the past ten years. (Translation, TC)] (Roth 1924, ch. 9, emphasis added)
> Santschin is plotseling ziek geworden. ‘Plotseling,’ zegt iedereen, maar ze weten niet dat Santschin al tien jaar voortdurend gestorven is. [Santschin suddenly fell ill. ‘Suddenly’, people say, but they don’t know that Santschin had been dying ceaselessly for the past ten years. (Translation, TC)] (van Krimpen 1994, p. 42, emphasis added)
Although van Krimpen’s translation still contains a coordinating conjunction, this
conjunction cannot be repeated to form a polysyndeton. The shift from ‘und’ (‘and’) to
‘maar’ (‘but’) therefore limits the choice of coordination style, making it a different
structure than the source text structure.
2. Durative verb + infinitive
Some of Roth’s syndetic coordinations with the structure [durative verb + ‘und’ +
active verb] are translated as the Dutch structure [durative verb + ‘te’ + active verb
(infinitive)], as in the following example:
Text Excerpt 5
Als wir das Tor des Friedhofs erreicht hatten, stand Xaver Zlotogor da, der Magnetiseur, und zankte mit dem Friedhofsverwalter. [When we had reached the cemetery gate, Xaver Zlotogor, the magnetizer, stood there and argued with the cemetery administrator. (Translation, TC)] (Roth 1924, ch. 10, emphasis added)
> Toen we de poort van de begraafplaats hadden bereikt, stond Xaver Zlotogor, de magnetiseur, daar ruzie te maken met de beheerder van de begraafplaats. [When we had reached the cemetery gate, Xaver Zlotogor, the magnetizer, stood there, arguing15 with the cemetery administrator. (Translation, TC)] (Oranje 2003, p. 56)
15 Although the English structure [durative verb’,’ active verb (-ing form)] represents a relation between the verbs not entirely the same as the Dutch structure [durative verb + ‘te’ + active verb (infinitive)], both structures are close enough to illustrate the shift.
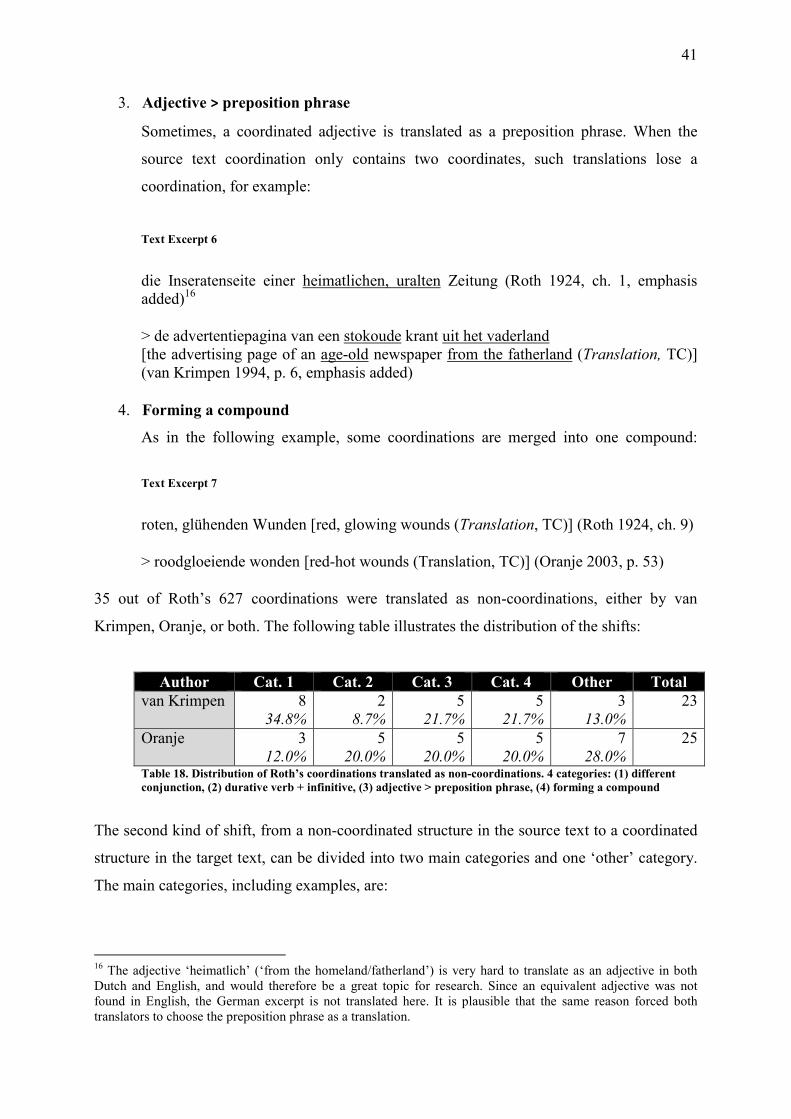
41
3. Adjective > preposition phrase
Sometimes, a coordinated adjective is translated as a preposition phrase. When the
source text coordination only contains two coordinates, such translations lose a
coordination, for example:
Text Excerpt 6
die Inseratenseite einer heimatlichen, uralten Zeitung (Roth 1924, ch. 1, emphasis added)16
> de advertentiepagina van een stokoude krant uit het vaderland [the advertising page of an age-old newspaper from the fatherland (Translation, TC)] (van Krimpen 1994, p. 6, emphasis added)
4. Forming a compound
As in the following example, some coordinations are merged into one compound:
Text Excerpt 7
roten, glühenden Wunden [red, glowing wounds (Translation, TC)] (Roth 1924, ch. 9)
> roodgloeiende wonden [red-hot wounds (Translation, TC)] (Oranje 2003, p. 53)
35 out of Roth’s 627 coordinations were translated as non-coordinations, either by van
Krimpen, Oranje, or both. The following table illustrates the distribution of the shifts:
Author Cat. 1 Cat. 2 Cat. 3 Cat. 4 Other Total
van Krimpen 8 34.8%
2 8.7%
5 21.7%
5 21.7%
3 13.0%
23
Oranje 3 12.0%
5 20.0%
5 20.0%
5 20.0%
7 28.0%
25
Table 18. Distribution of Roth’s coordinations translated as non-coordinations. 4 categories: (1) different
conjunction, (2) durative verb + infinitive, (3) adjective > preposition phrase, (4) forming a compound
The second kind of shift, from a non-coordinated structure in the source text to a coordinated
structure in the target text, can be divided into two main categories and one ‘other’ category.
The main categories, including examples, are:
16 The adjective ‘heimatlich’ (‘from the homeland/fatherland’) is very hard to translate as an adjective in both Dutch and English, and would therefore be a great topic for research. Since an equivalent adjective was not found in English, the German excerpt is not translated here. It is plausible that the same reason forced both translators to choose the preposition phrase as a translation.

42
1. Splitting a compound
This first category of the second kind is the counterpart of category 4 of the first kind:
the translations split up some compounds into coordinated structures, e.g.:
Text Excerpt 8
Er lag auf dem Bauch, streckte alle viere von sich und war tot. [He was lying on his stomach, extended all fours, and was dead. (Translation, TC)] (Roth 1924, ch. 9, emphasis added)
> Hij lag op zijn buik, strekte zijn armen en benen en was dood. [He was lying on his stomach, extended his arms and legs, and was dead. (Translation, TC)] (Oranje 2003, p. 49, emphasis added)
Text Excerpt 8 shows that ‘compound’ is used in a broader sense than only compound
nouns. Here it denotes non-coordinated expressions with ‘compound’ referents.
2. Undefinites
Some non-coordinated undefinites are translated as coordinations, e.g.:
Text Excerpt 9
Er sprach eine Stunde von allen Dingen und nichts von unserem Geschäft. [For an hour, he talked about various things and said nothing about our business. (Translation, TC)] (Roth 1924, ch. 13, emphasis added)
> Hij praatte een uur lang over koetjes en kalfjes en zei niets over onze transactie. [For an hour, he talked about this and that and said nothing about our transaction. (Translation, TC)] (van Krimpen 1994, p. 70, emphasis added)
13 non-coordinations were translated as coordinations, either by van Krimpen, Oranje, or
both. The following table shows the distribution of the shifts:
Author Cat. 1 Cat. 2 Other Total
van Krimpen 4 40.0%
3 30.0%
3 30.0%
10
Oranje 4 36.4%
3 27.2%
4 36.4%
11
Table 19. Distribution of non-coordinations translated as coordinations. 2 categories: (1) splitting a
compound, (2) undefinites
Adding the results of Tables 18 and 19, it becomes clear that Oranje’s translation contains
slightly more shifts between coordinations and non-coordinations than van Krimpen’s
translation does.
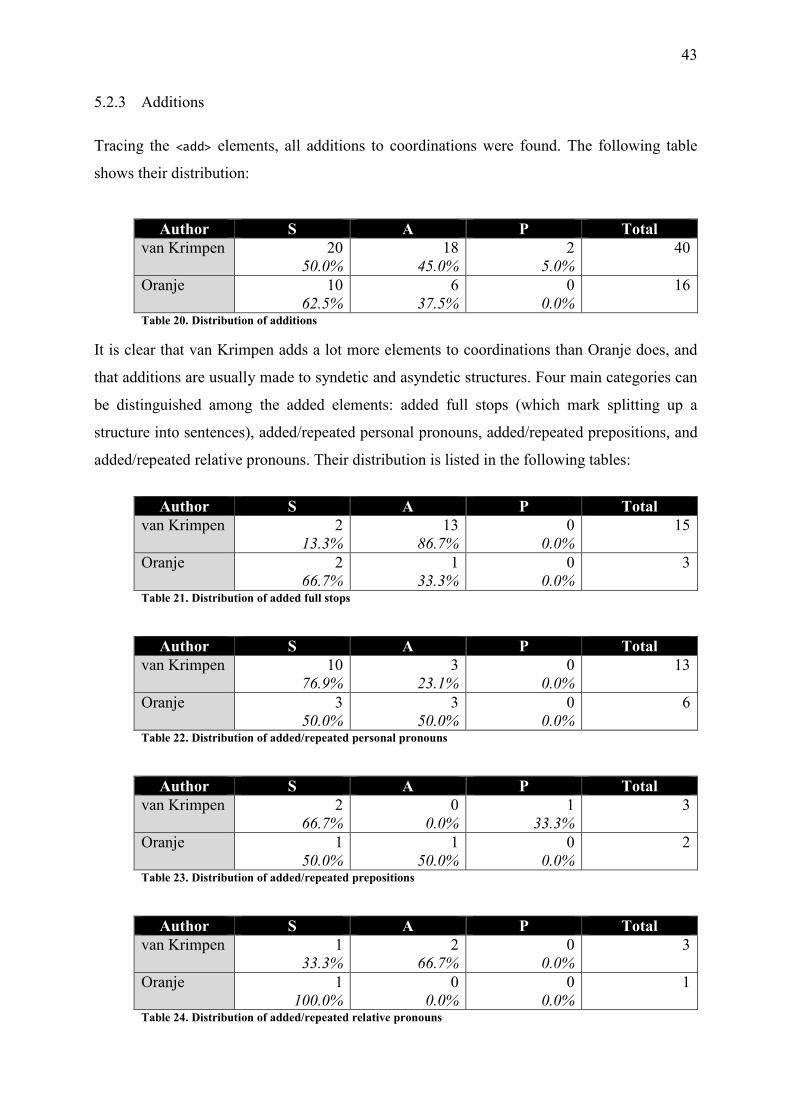
43
5.2.3 Additions
Tracing the <add> elements, all additions to coordinations were found. The following table
shows their distribution:
Author S A P Total
van Krimpen 20 50.0%
18 45.0%
2 5.0%
40
Oranje 10 62.5%
6 37.5%
0 0.0%
16
Table 20. Distribution of additions
It is clear that van Krimpen adds a lot more elements to coordinations than Oranje does, and
that additions are usually made to syndetic and asyndetic structures. Four main categories can
be distinguished among the added elements: added full stops (which mark splitting up a
structure into sentences), added/repeated personal pronouns, added/repeated prepositions, and
added/repeated relative pronouns. Their distribution is listed in the following tables:
Author S A P Total
van Krimpen 2 13.3%
13 86.7%
0 0.0%
15
Oranje 2 66.7%
1 33.3%
0 0.0%
3
Table 21. Distribution of added full stops
Author S A P Total
van Krimpen 10 76.9%
3 23.1%
0 0.0%
13
Oranje 3 50.0%
3 50.0%
0 0.0%
6
Table 22. Distribution of added/repeated personal pronouns
Author S A P Total
van Krimpen 2 66.7%
0 0.0%
1 33.3%
3
Oranje 1 50.0%
1 50.0%
0 0.0%
2
Table 23. Distribution of added/repeated prepositions
Author S A P Total
van Krimpen 1 33.3%
2 66.7%
0 0.0%
3
Oranje 1 100.0%
0 0.0%
0 0.0%
1
Table 24. Distribution of added/repeated relative pronouns

44
Tables 21 through 24 demonstrate that the addition of full stops and the addition and
repetition of personal pronouns are the main shifts that make up the big difference between
van Krimpen’s and Oranje’s translations.
Some additions turn non-anaphoric coordinations in the source text into anaphorae in
the target texts. This only occurs when the source text coordination style is retained, and only
in syndetic and asyndetic coordinations. The following two tables contain the number of
occurrences in both translations:
Roth van Krimpen Amount
S S 6 A A 4 Table 25. Distribution of anaphoric coordinations formed through addition in van Krimpen’s translation
Roth Oranje Amount
S S 2 A A 1 Table 26. Distribution of anaphoric coordinations formed through addition in Oranje’s translation
Tables 25 and 26 show that van Krimpen uses addition more than three times as much as
Oranje to form new anaphoric coordinations.
5.3 Hypotheses
Using the results from section 5.2, the hypotheses formulated in section 3.4.2 can be
answered, since all of them relate to comparative analysis.
� Hypothesis 1:
Both van Krimpen and Oranje sometimes change asyndeta into syndeta, but Oranje
more so than van Krimpen.
This hypothesis was found to be correct. As demonstrated in Tables 16 and 17, Oranje
changes 10.2% of all asyndeta into syndeta, whereas van Krimpen makes the same change
only 4.2% of the time.
� Hypothesis 2:
Both van Krimpen and Oranje show a limited quantity of compensation by changing
syndeta into asyndeta.

45
This hypothesis was found to be correct. Tables 16 and 17 show that van Krimpen
compensates (by changing syndeta into asyndeta) 1.1% of the time (4 instances) and Oranje
2.5% of the time (9 instances).
� Hypothesis 3:
When an asyndeton is translated as an asyndeton, both van Krimpen and Oranje
sometimes add (a repetition of) elements.
In order to validate this hypothesis, two additional tables of data are needed. Table 27
contains a comparison of coordination style between Roth’s and van Krimpen’s texts, limited
to coordinations containing additions. Table 28 contains the comparison between Roth and
Oranje:
Roth van Krimpen Amount Percentage
1 S S 19 45.2%
2 A A 22 52.4%
3 P S 1 2.4% Table 27. Comparison of coordination style between Roth and van Krimpen’s text, limited to coordinations
containing additions
Roth Oranje Amount Percentage
1 S A 2 11.8%
2 S S 9 52.9%
3 A A 5 29.4%
4 P S 1 5.9% Table 28. Comparison of coordination style between Roth and Oranje’s text, limited to coordinations
containing additions
Tables 27 and 28 prove Hypothesis 3 to be correct: both van Krimpen and Oranje sometimes
add elements when they translate asyndeta as asyndeta. They also add elements when they
translate other coordination styles and when they change coordination styles.
Asyndeton>asyndeton translation, however, is the biggest representative of additions in van
Krimpen’s translation. This is not true for Oranje’s translation, where most elements are
added to syndeton>syndeton translation.

46
� Hypothesis 4:
When elements are added in the translation, van Krimpen sometimes repeats them to
form an anaphora.
This hypothesis was found to be correct, but the phenomenon is not limited to van Krimpen.
Oranje also repeats added elements to form anaphorae. However, van Krimpen does so more
than three times as much (10 instances) as Oranje (3 instances, see Tables 25 and 26).
� Hypothesis 5:
Both van Krimpen and Oranje sometimes change coordinated structures into non-
coordinated structures.
This hypothesis was found to be correct. 35 out of Roth’s 627 coordinations (5.6%) were
translated as non-coordinations, either by van Krimpen, Oranje, or both. The reverse shift also
occurs (see 5.2.2).
� Retranslation hypothesis
“[L]ater translations of a given (literary) work into a given target language tend to get
closer to the source text” (Chesterman 2010, p. 177).”
This hypothesis was found to be wrong. On the level of coordination, Oranje changes more
than van Krimpen, both in shifting between different styles of coordination (see 5.2.1) and in
shifting between coordinated and non-coordinated structures (5.2.2).

47
6 CONCLUSION
This study has sought to investigate how Roth coordinates elements and how van Krimpen
and Oranje treat the different styles of coordination in their translations. In the first thirteen
chapters of Hotel Savoy, Roth uses syndeta in 60.6% of the cases, asyndeta in 36.4% of the
cases and polysyndeta in 3.0% of the cases. Van Krimpen uses more syndeta (62.3%), less
asyndeta (34.8%) and virtually the same amount of polysyndeta (2.9%). Oranje shows an
even stronger preference for syndeta (65.1%) and a slightly weaker preference for asyndeta
(33.3%), but he only uses about half as many polysyndeta compared to Roth and van Krimpen
(1.6% compared to 3.0% and 2.9%, respectively). Even though the percentages differ, the
differences are small enough for a reader only reading a translation to get much the same
impression of how syndetic and asyndetic Hotel Savoy is. However, readers of Oranje’s
translation would get a different impression of how polysyndetic the novel is in comparison to
the readers of Roth’s original or van Krimpen’s translation. Compared to readers of the
German source text, Oranje’s readership would also get the impression that the coordinations
are more anaphoric. This impression would be even stronger in van Krimpen’s readership.
Looking at how the three styles of coordination are treated in the translations, it
became clear that polysyndeta are changed to a different coordination style the most, followed
by asyndeta, and then syndeta. Oranje changes the style of coordination more often than van
Krimpen does. Translation shifts also occur between coordinated and non-coordinated
structures. Here too, Oranje’s text contains more changes compared to the original than van
Krimpen’s text does. Combining the fact that Oranje changes structures more often than van
Krimpen does with the fact that the amount of syndetic and asyndetic coordinations is
virtually the same across all three texts, it is as if Oranje takes a detour to arrive at the same
destination – losing some polysyndeta along the way.
Returning to the general question how much of the author’s and how much of the
translator’s work one reads when reading a translation, the overall answer is that, on the level
of coordination style, a reader of van Krimpen’s translation reads about 94% of Roth’s work,
while a reader of Oranje’s translation reads about 89% of Roth’s work. However, Oranje’s
work partly compensates for this difference by shifting between different coordination styles
and between coordinated and non-coordinated structures, so that about the same amount of
syndetic and asyndetic style is reached. This compensation can be seen as Oranje’s respecting
the spirit, rather than the letter of Roth’s text.

48
Because of the limited scope of this study, no explanation for the differences was sought, nor
an explanation for the source text features. Combining the reviewed translation literature
further, future research can use the paratextual method described by Berman (1995) to find
satisfactory reasons and to get a more complete description of the whole elephant (cf.
Wallaert 2010). As Wallaert indicates, explanations following the four points of inquiry into
style (see 2.2.3) can, depending on the translator, comprise an entire volume of their own.
Also because of the scope of this study, the corpus has been limited to about 50,000
words. This dissertation can be considered a pilot study for research into coordination style
and translation, and the method used may well constitute the most important part of this study.
Further research into coordination style can use the same XML-based method to tag larger
corpora. A standard corpus can be tagged in order to determine a normal distribution between
syndetic, asyndetic and polysyndetic coordination. This would allow research into
coordination style to investigate style not only as a matter of choice, but also as a deviation
from a norm.
Hopefully in the future, the method used can be automated further. The templates filter
and present the results automatically, but the tagging has to be done manually. At the moment
of writing, POS taggers and other automated systems are not capable of identifying
coordinated structures. Asyndetic structures will most likely form the biggest challenge to be
identified, since they are unmarked by coordinating conjunctions. Until computer programs
can automatically identify all kinds of linguistic structures, the partly automated, partly
manual XML-based method will remain a useful tool to tackle problems similar to the one
presented in this research.

49
7 REFERENCES
Original and translations
Roth, J. (1924). Hotel Savoy. In Der Spiegel, Projekt Gutenberg-DE. Available online at http://gutenberg.spiegel.de/buch/4272/1 through http://gutenberg.spiegel.de/buch/4272/30.
Roth, J. (1924). Hotel Savoy. Amsterdam: Bas Lubberhuizen. (Trans. Huib van Krimpen 1994.)
Roth, J. (1924). Hotel Savoy. Amsterdam & Antwerpen: L.J. Veen Klassiek. (Transl. Wilfred Oranje 2003. 2nd edition: 2013.)
Software used
ABBEY FineReader, http://www.abbyy.com. LF Aligner, http://sourceforge.net/projects/aligner. Notepad++, http://notepad-plus-plus.org. Works cited
Baker, A. (2000). Towards a Methodology for Investigating the Style of a Literary Translator. Target, 12(2), 241-266.
Berman, A. (1995). Pour une critique des traductions: John Donne. Paris: Gallimard. Chesterman, A. (2010) Translation universals. In Yves Gambier & Luc van Doorslaer (Eds.),
Handbook of translation studies: Volume 1 (pp. 175-179). Amsterdam: John Benjamins.
Crystal, D. & Davy, D. (1969). Investigating English Style. London: Longman. Enkvist, N. E. (1964) On Defining Style: An Essay in Applied Linguistics. In John Spencer
(Ed.), Linguistics and Style (pp. 1-56). London: Oxford University Press. Hoffmann, N. & Shchyhlevska, N. (2013) Einleitung. In Nora Hoffmann & Natalia
Shchyhlevska (Eds.), Joseph Roth als Stilist (pp. 13-20). Heidelberg: Winter. Hoffmann, N. (2013) Joseph Roth zum Stil – zum Stil Joseph Roths. Ein doppelter Überblick.
In Nora Hoffmann & Natalia Shchyhlevska (Eds.), Joseph Roth als Stilist (pp. 23-57). Heidelberg: Winter.
House, J. (1977). A Model for Translation Quality Assessment. Tübingen: Gunter Narr. (2nd edition: 1981.)
Huddleston, R. & Pullum, G.K. (2006). Coordination and Subordination. In Bas Aarts & April McMahon (Eds.), The Handbook of English Linguistics (pp. 198-219). Oxford: Blackwell.
Malmkjær, K. (2003). What happened to God and the angels. An exercise in translational stylistics. Target, 15(1), 37-58.
Marcus, M. P., Marcinkiewicz, M. A. & Santorini, B. (1993Z). Building a large annotated corpus of English: The Penn Treebank. Computational linguistics, 19(2), 313-330.
Mikhailov, M. & Villikka, M. (2001). Is there such a thing as a translator’s style?. In Rayson, P., Wilson, A., McEnery, T. (Eds.), Proceedings of the Corpus Linguistics 2001
conference (pp. 378-386). Lancaster University: UCREL Technical Papers. Parks, T. (1998). Translating Style. A Literary Approach to Translation, A Translation
Approach to Literature. London & Washington: Cassell. (2nd edition: 2007.)

50
Schippers, E. (2013) Joseph Roth zum Stil – zum Stil Joseph Roths. Ein doppelter Überblick. In Nora Hoffmann & Natalia Shchyhlevska (Eds.), Joseph Roth als Stilist (pp. 237-238). Heidelberg: Winter.
W3Schools a. Displaying XML with XSLT. http://www.w3schools.com/xml/xml_xsl.asp (04-05-2014).
W3Schools b. XML Tree. http://www.w3schools.com/xml/xml_tree.asp (13-05-2014). W3Schools c. XML Tutorial. http://www.w3schools.com/xml/default.ASP (02-05-2014). Wales, K. (1989). A Dictionary of Stylistics. Essex: Longman. (Paperback edition, 4th
impression 1995.) Wallaert, I. (2010). The Elephant in the Dark. Corpus-Based Descriptions of Translators’
Style. Les Cahiers du GEPE, 2010(2). Available online at http://www.cahiersdugepe.fr/index1641.php.
Winters, M. (2005). A corpus-based study of translator style. Oeser’s and Orth-Guttmann’s
German translations of F. Scott Fitzgerald’s The Beautiful and Damned. Unpublished PhD thesis, Dublin City University, Dublin. Available online at http://doras.dcu.ie/17626/1/Marion_Winters.pdf.
Winters, M. (2007). F. Scott Fitzgerald’s Die Schönen und Verdammten. A corpus-based study of speech-act report verbs as a feature of translators’ style. Meta: Journal des
traducteurs, 52(3), 412-425.





























