Embed Size (px)
Citation preview

STRUCTURE DETERMINATION AND BIOCHEMICAL CHARACTERIZATION OF NOVEL HUMAN
UBIQUITIN-LIKE DOMAINS.
by
Ryan Steven Doherty
A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy
Graduate Department of Medical Biophysics
University of Toronto
© Copyright by Ryan Steven Doherty 2015

ii
STRUCTURE DETERMINATION AND BIOCHEMICAL
CHARACTERIZATION OF NOVEL HUMAN
UBIQUITIN-LIKE DOMAINS
Ryan Steven Doherty
Doctor of Philosophy
Department of Medical Biophysics University of Toronto
2015
Abstract
The ubiquitin fold acts as a signaling modulator associated with regulating, trafficking, and
degrading proteins. The human genome encodes 398 ubiquitin-like domains (UBLs), of which a
couple dozen may act as covalent modifiers. Ubiquitin and ubiquitin-like domains have been
implicated in a number of malignancies, neuromuscular disorders, neurodegenerative disorders
and other human illnesses. Identifying the structural effects of sequence variations between
different ubiquitin-like homologues will provide insight into their varied functional pathways, since
the role of ubiquitin-like modifiers is typically mediated by protein-protein interactions. Structure
determination and analyses of ubiquitin-like homologues facilitates residue mapping and
comparative analysis of protein-protein interaction sites, which provide insight into the many roles
that ubiquitin-like homologues play in cellular processes. The aim of this thesis was to develop a
framework through which complete structural coverage of all human ubiquitin-like domains could
be achieved. To accomplish this, I defined the human ubiquitin-like fold family, identified ubiquitin-
like domain constructs amenable for NMR structure determination, solved two structures

iii
(NFATc2IP & ubiquilin-1) and characterized associated binding partners, and created a data
resource for human ubiquitin-like domains that enables clustering and associating protein
structures with physicochemical features and cellular function. I also collaborated with the North-
East Structural Genomics consortium (NESG) and the Structural Genomics Consortium (SGC),
through which the molecular structures of 17 ubiquitin-like domains were determined using
nuclear magnetic resonance (NMR) experiments and X-ray crystallography. Comparative
analysis of structurally characterized ubiquitin-like folds revealed potential interaction partners
with regions similar to known ubiquitin and SUMO interacting domains. Potential interaction
partners for NFATC2IP and ubiquilin-1 were validated experimentally using NMR titration
experiments. Comparative analysis of structural features of all ubiquitin-like homologues
facilitates further studies into the mechanisms of the ubiquitylation system, predicted protein-
protein interactions, and the identification of functional pathways associated with uncharacterized
ubiquitin-like domains.

iv
Acknowledgements
I would like to thank my supervisor Cheryl Arrowsmith for her ongoing support, advice and
mentorship over the years. I also appreciate the guidance and knowledge shared by my
supervisory committee members: Sirano Dhe-Paganon, Brian Raught, Jane McGlade, and
Zhaolei Zhang. I would also like to recognize the efforts and support from members of the
Arrowsmith lab, past and present, especially Adelinda Yee, Shili Duan, Scott Houliston, Sasha
Lemak, Aleks Gutmanas, Christophe Fares, Yi Sheng, Lilia Kaustov, Bin Wu, Seth Chitayat,
Sampath Srisailam, Murthy Karra, Jonathan Lukin, Natalie Nady, Jack Liao, Rob Laister, Melissa
Ho, Tony Semesi, and Maite Garcia.
This thesis would not have been possible without collaborations. For this reason, I would like to
thank Gaetano Montelione, John Everett, Mani Ravichandran, Yufeng Tong, Masoud Vedadi,
David Yim and Raymond Hui for their time, resources, feedback and help in key aspects of this
project.
I would also like to thank members of various University of Toronto communities who have
encouraged, supported and worked alongside me throughout this endeavor: Medical Biophysics
Graduate Student Association, 89 Chestnut Residence, Massey College, Massey Grand Rounds,
and Impact Centre.
Finally, I thank my family and friends for their patience, love and understanding. It is to you that I
dedicate this thesis.

v
Table of Contents
Abstract
Acknowledgements
Table of Contents
List of Tables
List of Figures
List of Appendices
List of Abbreviations
Chapter 1 - Introduction
1.1 Overview
1.2 Biological Significance of ubiquitin & ubiquitin-like modifiers
1.3 Protein Modification & ubiquitin
1.4 The ubiquitin Fold
1.5 Ubiquitin-like domains (UBLs)
1.6 Ubiquitin-like modifiers (UBM)
1.7 Ubiquitin-like structural domains
1.8 Ubiquitin Conjugation Cascade
1.9 Ubiquitin-binding domains & interactions
1.9.1 Ubiquitin Interacting Motif (UIM)
1.9.2 Coupling of Ubiquitin conjugation to Endoplasmic Reticulum Degradation (CUE)
1.9.3 Ubiquitin-Associated Domain (UBA)
1.9.4 Ubiquitin Conjugating Enzyme Variant (UEV)
1.9.5 Npl4 Zing Finger Motif (NZF)
1.9.6 GGA And Tom1 Domain (GAT)
1.9.7 Other Ubiquitin Binding Domains
1.9.8 SUMO Interacting Motif (SIM)
ii
iv
v
x
xi
xiii
xiv
1
1
2
2
3
4
6
9
9
11
11
12
12
12
13
13
13
13

vi
Table of Contents (continued)
1.9.9 Diversity among Ubiquitin-Binding Domains
1.10 Thesis Overview
1.10.1 Identify and obtain near-complete structural coverage of all human ubiquitin-like domains.
1.10.2 Exploring NFATc2IP:NFATc2 & ubiquilin-1:PIN2 protein-protein interactions
Chapter 2 - The Ubiquitin Fold: Leveraging structural genomics
2.1 Summary
2.2 Introduction
2.3 Methods
2.3.1 Identifying human ubiquitin-like domains
2.3.2 Validating putative human ubiquitin-like domains
2.3.3 Target selection
2.3.4 Construct design
2.3.5 Sample preparation
2.3.6 1H15N-HSQC screening of ubiquitin-like domains
2.4 Results & Discussion
2.4.1 Identifying unannotated human ubiquitin-like domains
2.4.2 Small-Scale Screening
2.4.3 Screening by 1H15N-HSQC
2.4.4 Structural Coverage - Completing the UBL Phylogenetic Tree
2.5 Conclusion
Chapter 3 - Solution NMR structure determination of human ubiquitin-like domains in NFATc2IP & ubiquilin-1
3.1 Introduction
3.1.1 NFATc2IP
3.1.2 Ubiquilin-1
14
15
15
15
17
18
18
21
21
22
24
25
26
26
27
27
29
29
31
36
37
38
38
39

vii
Table of Contents (continued)
3.1.3 Ubiquitin-like Fold
3.2 Experimental Procedures
3.2.1 NFATc2IP UBL domain NMR structure determination
3.2. 2 Ubiquilin-1 UBL domain NMR structure determination
3.2. 3 Comparative analysis of ubiquilin-1, NFATc2IP, ubiquitin & SUMO2
3.2. 4 Protein-protein interaction partner identification
3.2. 5 Binding interface analysis
3.3 Results & Discussion
3.3.1 Structure determination
3.3.2 Comparative analysis of ubiquilin-1, NFATc2IP & similar ubiquitin-like modifiers
3.3.2.1 Similar canonical ubiquitin-like modifiers: ubiquitin & SUMO-2
3.3.2.2 Structural comparison between ubiquilin-1 & NFATc2IP
3.3.2.3 Structural comparison between ubiquilin-1 & ubiquitin
3.3.2.4 Structural comparison between NFATc2IP & SUMO2
3.3.2.5 Structural differences between NFATc2IP_2nd & SUMO2
3.3.3 From Structure to Function: Exploring Protein-Protein Interactions involving ubiquitin-like domains
3.3.3.1 The ubiquitin-Interacting Motif interaction interface
3.3.3.2 Putative UIM Interaction Interface: Conserved Amino Acids
3.3.3.3 Putative UIM Interaction Interface: Similar Electrostatic Potential Distribution
3.3.3.4 Surveying Known UIM-Binding Partners
3.3.3.5 PIN1 – Peptidyl-Prolyl cis/trans Isomerase
3.3.3.6 Identifying a putative UIM in PIN1
3.3.3.7 Ubiquilin-1 & PIN1 NMR Titration
39
40
40
41
44
46
46
47
47
52
53
53
55
57
58
59
59
62
63
64
67
67
68

viii
Table of Contents (continued)
3.3.3.8 Analysis of the ubiquilin-1 & PIN1 interface
3.3.4 Binding-Partner Driven - Structural analysis of the SUMO-Interacting Motif binding interface
3.3.4.1 NFATc2IP Binding Partners
3.3.5 SUMO-Interacting Motif
3.3.5.1 Identifying putative SIMs in NFATc2
3.3.6 NFATc2IP:NFATc2 NMR titration
3.3.6.1 Analysis of the NFATc2IP:NFATc2 interface
3.4 Conclusion
Chapter 4 - Exploring UBLs & UBL-Interaction Motifs: Computational & Experimental analysis of ubiquilin, NFATc2IP, UIMs and SIMs.
4.1 Introduction
4.1.1 Database & comparative analysis
4.1.1.1 Similarities & differences between model family members
4.1.1.2 Common defining features for each modelling family
4.2 Experimental Procedures
4.2.1 UBL Database Development
4.2.2 Relating 17 structurally determined UBLs to nearest neighbours and model families
4.2.3 Secondary structure prediction & analysis
4.2.4 Relating structural features to functional pathways
4.3 Results
4.3.1 Structurally characterized ubiquitin-like domains
4.3.2 Nearest-neighbours of ubiquitin-like domains
4.3.3 Nearest-neighbours of structurally characterized UBMs
4.3.4 Grouping UBLs based on biological processes and molecular function
70
71
71
72
72
74
75
77
78
79
79
80
80
81
81
82
83
83
84
84
85
86
89

ix
Table of Contents (continued)
4.3.5 Grouping UBLs based on medical significance
4.3.5.1 Cellular localization
4.3.6 Grouping UBLs based on cell localization
4.4 Conclusion
Chapter 5 - Conclusion and Future Directions
5.1 Conclusions
5.2 Future Directions
5.2.1 Ubiquitin-like domain fold, NFATc2IP & ubiquilins
5.2.2 Ubiquitin-like domain structural genomics
5.2.3 Protein Domain family analyses
5.3 Concluding remarks
Chapter 6 - References
91
92
93
95
96
96
97
97
98
98
98
99

x
List of Tables
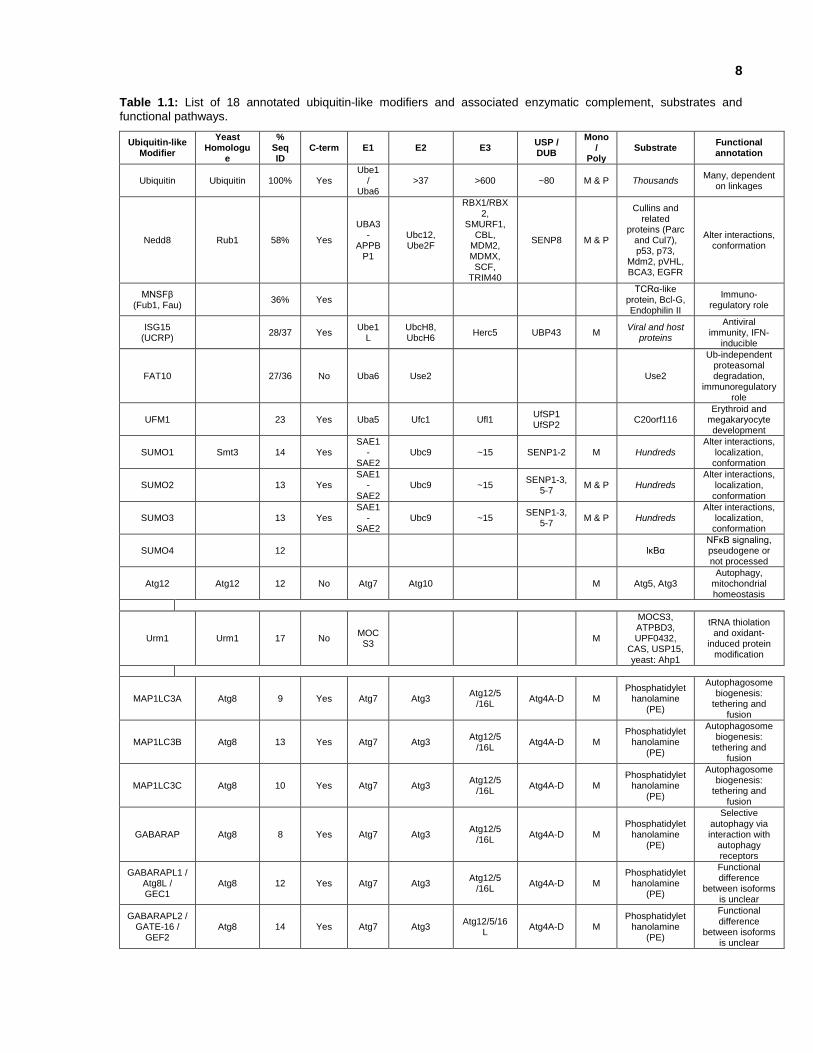
Table 1.1: List of 18 annotated ubiquitin-like modifiers, and associated enzymatic complement, substrates and functional pathways.
Table 1.2: Protein-protein interaction modes structurally characterized with experimentally determined binding affinities between UBLs and binding partners.
Table 2.1: Summary of small-scale expression screening of human ubiquitin-like domains structurally characterized and deposited in the PDB as part of this thesis.
Table 2.2: Summary of 1H15N-HSQC screening results for human ubiquitin-like domains. 10 ubiquitin-like domains were solved by NMR (red), and 7 ubiquitin-like domains were solved by X-ray crystallography (blue).
Table 2.3: All human ubiquitin-like domains that remain to be structurally determined, along with their most similar protein structure and biological significance.
Table 3.1: NMR data and refinement statistics.
Table 3.2: Secondary structure elements of NFATc2IP, ubiquilin-1, ubiquitin and SUMO1/2/3.
Table 3.3: Sequence similarity & identity between NFATc2IP, ubiquilin-1, ubiquitin and SUMO1/2/3/4.
Table 3.4: UIM:ubiquitin complexes deposited in the PDB, along with UIM sequence.
Table 3.5: Human proteins that contain at least one canonical UIM motif and observed to interact with ubiquitin, along with the number of supporting publications and supporting structural complexes that have been deposited in the PDB.
Table 3.6: Human proteins that contain at least one canonical UIM motif and observed to interact with members of the ubiquilin family (Turner et al., 2010).
Table 3.7: 17 human proteins that interact with both human ubiquitin and a member of the ubiquilin family, and that also contain at least one UIM motif.
Table 3.8: UIM motif and 4 variations of the UIM motif were used to identify 17 human proteins that interact with both human ubiquitin and a member of the ubiquilin family.
Table 4.1: Data sources for ubiquitin-like domain repository.
Table 4.2: Biological significance and functional annotation for each of the 17 ubiquitin-like domains structurally characterized for this project.
Table 4.3: Tissue and cell localization for each of the 17 UBL structurally characterized for this project.
Table 4.4: Structural alignment of lysines within ubiquitin and ubiquitin-like domains characterized within both cytoplasm and ER; nucleus, cytoplasm and ER; and only nucleus.
8
14
29
30
33
48
50
53
59
64
64
65
66
82
90
92
94

xi
List of Figures
Figure 1.1: Ribbon & molecular surface representations of the ubiquitin.
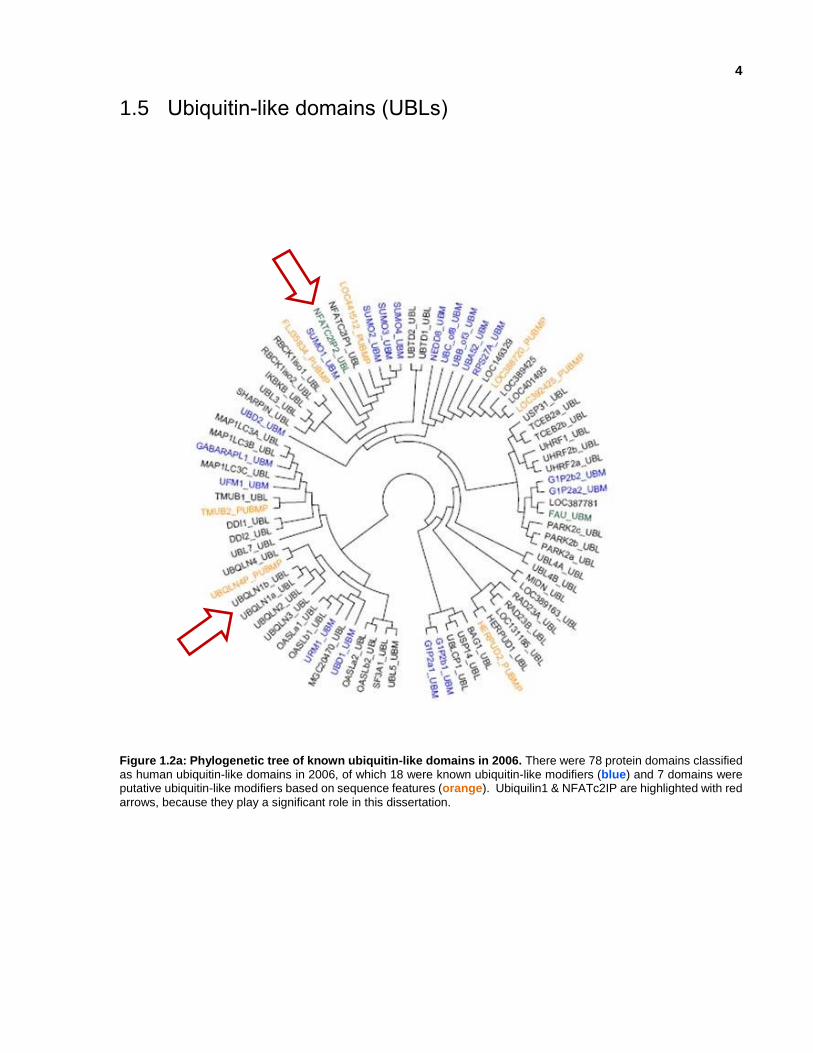
Figure 1.2a: Phylogenetic tree of known ubiquitin-like domains in 2006.
Figure 1.2b: Phylogenetic tree of known ubiquitin-like domains in 2015.
Figure 1.3: Ubiquitin-like modifier conjugation cascade.
Figure 1.4: Ubiquitin conjugation cascade.
Figure 2.1: Novel UBL discovery process.
Figure 2.2: Secondary & tertiary structures of Human ubiquilin-1.
Figure 2.3: Pseudo-multiple sequence alignment of human ubiquilin-1.
Figure 2.4: UBL target selection, preparation and screening process.
Figure 2.5: Pseudo-multiple sequence alignment of ubiquilin-1 for construct design.
Figure 2.6: Distribution of structurally characterized and uncharacterized UBLs.
Figure 2.7: Examples of 1H15N-HSQC screening results for human UBLs.
Figure 2.8: Clustering of human UBLs into groups based on sequence similarity.
Figure 3.1: Secondary structure and H-bond patterns of ubiquilin-1.
Figure 3.2: Secondary structure and H-bond patterns of NFATc2IP.
Figure 3.3: Ribbon diagrams of ubiquilin-1, NFATc2IP, ubiquitin, SUMO1, SUMO2 & SUMO3.
Figure 3.4: Molecular surfaces of ubiquilin-1.
Figure 3.5: Molecular surfaces of NFATc2IP.
Figure 3.6: UIM-interaction interface of ubiquilin-1 and NFATc2IP.
Figure 3.7: Similarities between ubiquilin-1 and NFATc2IP.
Figure 3.8: Similarities between ubiquilin-1 and ubiquitin.
Figure 3.9: Similarities between NFATc2IP and SUMO2.
Figure 3.10: UIM -helices from PSMD4, VPS27 and HGS.
Figure 3.11: Ubiqutin:PSMD4(UIM) complex.
3
4
5
10
10
21
22
23
24
25
28
30
31
49
49
50
51
51
52
54
56
58
60
61

xii
List of Figures (continued)
Figure 3.12: UBL residues within UIM-interaction interface.
Figure 3.13: Multiple sequence alignment of UBLs from ubiquilin family members.
Figure 3.14: Similarity tree based on electrostatic potential within 4 Å of UIM-binding interface.
Figure 3.15: Sequence alignment of UIMs within PSMD4, DNJB2, EPN1 and PIN1.
Figure 3.16: Putative human PIN1 UIM.
Figure 3.17: Ubiquilin-1:PIN1 NMR titration.
Figure 3.18: Putative ubiquilin-1:PIN1 interaction.
Figure 3.19: NFATc2 SUMO Interacting Motifs.
Figure 3.20: Diversity of SIM motifs.
Figure 3.21: NFATc2IP:NFATc2 NMR titration.
Figure 3.22: Electrostatic potential of NFATc2IP & SUMO2.
Figure 3.23: Electrostatic potential diversity between similar UBLs.
Figure 4.1: Database schema of ubiquitin-like domain repository.
Figure 4.2: Secondary & tertiary structures of 17 structurally characterized UBLs.
Figure 4.3: Nearest-neighbour clustering of UBLs displayed with proportional transformed branches.
Figure 4.4: UBLs with a structural fold similar to FUBI-1.
Figure 4.5: UBLs with a structural fold similar to the second UBL of ISG15.
Figure 4.6: UBLs with a structural fold similar to SF3A1.
Figure 4.7: Distribution of human UBLs based on cellular localization.
62
62
63
65
67
69
70
73
73
74
75
76
81
84
85
86
87
88
93

xiii
List of Appendices
Appendix I: All human genes that encode at least one ubiquitin-like domain.
Appendix II: All human genes and isoforms that encode ubiquitin-like domains.
Appendix III: 205 proteins observed to interact with both ubiquitin and at least one member of the ubiquilin family.
Appendix IV: 127 putative UIM sequences within 106 proteins that interact with both ubiquitin and at least one member of the ubiquilin family.
Appendix V: Six similarities trees of ubiquitin-like domains clustered based on electrostatic potential at varying distances (1 Å to 6 Å) from the UIM-binding interface, along with groups of ubiquitin-like domains that share strong electrostatic potential similarity at that specific range.
113
119
131
133
137

xiv
List of Abbreviations
AESOP Analysis of electrostatic similarities of proteins
CUE Coupling of ubiquitin conjugation to endoplasmic reticulum degradation
DUB De-ubiquitylating enzyme
DUIM Double-sided ubiquitin interacting motif
E1 Ubiquitin activating enzyme
E2 Ubiquitin conjugating enzyme
E3 Ubiquitin protein ligase
GAT GGA and Tom1 domain
GLUE GRAM-like ubiquitin binding in Eap45
IPTG Isopropyl-1-thio-D-galactopyranoside
MIU Motif interacting with ubiquitin
NESG North-east structural genomics consortium
NFAT Nuclear factor of activated T-cells
NMR Nuclear magnetic resonance
NZF Npl4 Zing Finger Motif
PAZ Polyubiquitin associated zinc finger
PE Phosphatidylethanolamine
PIN1 Peptidyl-prolyl cis/trans isomerase
PSSM Position-specific scoring matrix
SGC Structural genomics consortium
SIM SUMO interacting motif
UBA Ubiquitin-associated domain
UBD Ubiquitin-binding domain
UBL Ubiquitin-like domain
UBM Ubiquitin-like modifier

xv
List of Abbreviations (continued)
UEV Ubiquitin conjugating enzyme variant
UIM Ubiquitin interacting motif
VHS Vps27,Hrs,STAM

1
Chapter 1
Introduction
1.1 Overview
Ubiquitin, the original member of the ubiquitin-fold superfamily, is a highly conserved 76 residue
regulatory protein found in all eukaryotic cells. It was initially characterized as a post-translational
modification moiety that mediates ATP-dependent proteolytic degradation, yet has since been
recognized as a signaling modulator with multiple regulatory roles mediated by transient protein-
protein interactions. My research focuses on the similarities and variations between human
ubiquitin-like domains, and their influence on protein-protein interactions. My goal is to define the
family of ubiquitin-like domains in the human proteome and to understand the extent of the
diversity of amino acids within the protein-protein interaction interfaces of the ubiquitin-like
domain, and the insights into their functional pathways. The first chapter provides an introduction
to ubiquitin and ubiquitin-like domains, as well as a rationale for the aims of this thesis. Chapter
Two discusses structural genomics approaches that were implemented to facilitate the
experimental screening and determination of 17 human ubiquitin-like domains for this project.
Chapter Three describes the structure determination of the second ubiquitin-like domain of
NFATc2IP and the ubiquitin-like domain of ubiquilin-1, and introduces approaches for predicting
functional activity by combining their structural data with information about other ubiquitin-like
domains. This chapter also examines protein-protein interactions that were predicted between
NFATc2IP and NFATc2 through a predicted SIM-like interaction, as well as interactions between
ubiquilin-1 and PIN1 through a predicted UIM-like interaction. Chapter Four combines additional
analyses with the lessons learned from Chapters two and three to facilitate analyses and
predictions related to the set of human ubiquitin-like domains associated with the 17 ubiquitin-like
domains that were structurally characterized as part of this thesis. The final chapter of the
dissertation discusses the significance of these findings, relating observations to the entire human

2
ubiquitin-like domain superfamily, in addition to providing future directions and concluding
remarks.
1.2 Biological significance of ubiquitin & ubiquitin-like modifiers
Conjugation of ubiquitin and ubiquitin-like modifiers is necessary for the regulation and
translocation of proteins. Ubiquitin conjugation, also referred to as ubiquitylation, has been
implicated in having a regulatory role in cellular processes, such as protein degradation, cell cycle
control, transcription regulation, DNA damage repair, antigen processing, activation of
transcriptional factors and kinases, endocytosis, protein sorting, membrane trafficking, and stress
response (Haglund et al., 2005). Ubiquitylation is also involved in biological functions, such as
inflammation, cellular differentiation, and silencing the inactive X chromosome in female
mammals (de Napoles et al., 2004). The disruption of ubiquitin conjugation pathways has been
associated with various human illness, ranging from neurodegenerative disorders, developmental
abnormalities, autoimmune diseases, neuromuscular disorders and malignancies (Ciechanover
et al., 2004). UBMs are also involved in a variety of biological processes, including pathogenesis
of viruses and bacteria. Some UBMs protect against viruses, while other viruses depend on UBMs
for survival; and some bacteria effectors target ubiquitylation machinery (Angot et al., 2007).
1.3 Protein modification & ubiquitin
In 1975, ubiquitin was discovered and initially identified as a tag for targeted proteasomal
degradation (Schlesinger et al., 1975). Proteins are targeted for proteasomal degradation through
a process referred to as ubiquitylation, which involves covalent modification of a surface exposed
lysine by ubiquitin. It is a highly conserved 76 residue protein found only in eukaryotic cells.
Within humans, there are four genes that encode ubiquitin as two distinct gene classes: a poly-
Ub gene that encodes a precursor protein with tandemly repeated ubiquitin domains (ie. UBB and
UBC), and fusion precursor proteins in which a single ubiquitin domain is linked to a ribosomal
protein (ie. RPS27a and UBA52). The ubiquitin region of all four genes are entirely conserved,

3
suggesting that mutations are negatively selected. The covalent association between ubiquitin
with ribosomal proteins has been suggested to promote their association with ribosomes (Finley
et al., 1989). This is an interesting attribute, since the putative UBM FAU is also fused to a
ribosomal protein and the gene structure could relate to the functional activity of the protein.
1.4 The ubiquitin fold
Figure 1.1: Ribbon & molecular surface representations of ubiquitin. The secondary structure elements and
molecular surface of the ubiquitin fold are displayed from two orientations with conserved lysine amino acids displayed as cyan ball and stick representation.
The ubiquitin-fold consists of a 5-strand mixed -sheet that is intercalated by a 2-helix -helical
core (Figure 1.1). There are 5 key structural features of ubiquitin that are associated with its
biological activity: the C-terminal -RLRGG peptide, 7 lysine residues that could be involved in
poly-ubiquitin chain formation (Komander et al., 2009), a conserved leucine 8 / isoleucine 44 /
valine 70 triad involved in E1 and ubiquitin-binding domain interactions, histidine 68 involved in
E1-ubiquitin thioester formation, and protein-protein interaction interfaces associated with
interactions with ubiquitin-binding domains that regulate a variety of downstream molecular
pathways. These structural features were used when performing comparative analyses of UBLs.
4
1.5 Ubiquitin-like domains (UBLs)
Figure 1.2a: Phylogenetic tree of known ubiquitin-like domains in 2006. There were 78 protein domains classified as human ubiquitin-like domains in 2006, of which 18 were known ubiquitin-like modifiers (blue) and 7 domains were putative ubiquitin-like modifiers based on sequence features (orange). Ubiquilin1 & NFATc2IP are highlighted with red
arrows, because they play a significant role in this dissertation.

5
Figure 1.2b: Phylogenetic tree of known ubiquitin-like domains in 2015. There are 448 human ubiquitin-like
domains within human proteins identified through bioinformatics techniques described in this thesis; 18 of the domains are known ubiquitin-like modifiers [ : ATG8, FAU_1-1, ISG15_1-2, NEDD8_1-1, SUMO1_1-1, SUMO1_2-1, SUMO2_1-1,
SUMO2_2-1, SUMO3_1-1, UBB_1-1/UBC_1-1/RPS27A_1-1/UBA52_1-1, URM1_1-1, UBD_1-2 (aka FAT10), and UFM1_1-1], and 22 domains are putative ubiquitin-like modifiers based on sequence features [ : HERPUD2_1-1, PARK2_1-1/PARK2_2-1/PARK2_5-1, PARK2_2-2, PIK3CA_1-2, PTPN3_1-2, PTPN13_3-6/PTPN13_4-7, SF3A1_1-1, SHARPIN_1-1/SHARPIN_2-1/SHARPIN_3-1, TMUB2_1-1/TMUB2_2-2, SHROOM1_1-1/SHROOM1_2-1, USP40_3-1, USP5_1-1, VCPIP1_1-2, WDR48_1-1, and WDR48_5-1].

6
Within the human genome, there are 220 genes that encode 448 protein domains that share the
same structural fold as ubiquitin (Figure 1.2b); at the start of this project in 2006, there were 78
known human ubiquitin-like domains of which 18 were known ubiquitin-like modifiers and 7 were
putative ubiquitin-like modifiers (Figure 1.2a). Even with the same structural fold, they have
different binding partners and diverse biological functions in the host organism, as well as viral
and bacterial pathogens. Sixteen of these UBLs have been characterized as UBMs, which can
become conjugated to target proteins (Table 1.1). An additional 22 putative UBMs are predicted
to become conjugated to target proteins due to the presence of a characteristic C-terminal double-
glycine tail, but lack evidence of conjugated substrate formation. The remaining 410 UBLs contain
a ubiquitin-like fold along with other structural domains, and can modulate the ubiquitylation
pathway in some cases by competing with UBMs when interacting with proteins that contain
ubiquitin-binding domains (Hochstrasser et al., 2009).
1.6 Ubiquitin-like modifiers (UBM)
Until the 1990s, ubiquitin was thought to be the only post-translational modification that involved
the covalent linkage of a protein modifier. That was until ISG15/UCRP was discovered to undergo
a similar mechanism and became the first UBM studied in vitro (Loeb KR & Haas AL, 1992). Most
of the UBMs become conjugated to surface exposed lysines of target proteins through an
analogous but distinct enzymatic cascade. Many UBMs are associated with essential cellular
processes, yet the amount of functional information about them remains limited.
Of the UBMs that have been functionally characterized: SUMO targets lysines within conserved
motifs (ie. ФKXE, phosphorylation-dependent sumoylation motif & negatively charged amino acid-
dependent sumoylation motif) (Yang et al., 2006), and is involved in transcriptional regulation and
genome surveillance (Müller et al., 2004). NEDD8 modification is involved in cell cycle control
and in embryogenesis by up-regulating the activities of cullin-based E3 ligases (Pan et al., 2004).
Covalent attachment of Atg12 to Atg5 is essential for autophagy (Mizushima et al., 1998). Apg8,

7
MAP1LC3A, MAP1LC3B, MAP1LC3C, GABARAP, GABARAPL1, and GABARAPL2 are involved
in lipidation through a ubiquitylation-like system (Ichimura et al., 2000). UBL5 is a unique member
of the UBMs, since it contains a C-terminal double-tyrosine motif, instead of the characteristic
double-glycine. The structure of UBL5 was solved by NMR, and the overall fold was similar to
ubiquitin, even though they share only 17.5% sequence identity (McNally et al., 2003). However,
experimental evidence remains necessary to determine whether UBL5 conjugation occurs.
8
Table 1.1: List of 18 annotated ubiquitin-like modifiers and associated enzymatic complement, substrates and
functional pathways.
Ubiquitin-like Modifier
Yeast Homologu
e
% Seq ID
C-term E1 E2 E3 USP / DUB
Mono /
Poly Substrate
Functional annotation
Ubiquitin Ubiquitin 100% Yes Ube1
/ Uba6
>37 >600 ~80 M & P Thousands Many, dependent
on linkages
Nedd8 Rub1 58% Yes
UBA3-
APPBP1
Ubc12, Ube2F
RBX1/RBX2,
SMURF1, CBL,
MDM2, MDMX, SCF,
TRIM40
SENP8 M & P
Cullins and related
proteins (Parc and Cul7), p53, p73,
Mdm2, pVHL, BCA3, EGFR
Alter interactions, conformation
MNSFβ (Fub1, Fau)
36% Yes TCRα-like
protein, Bcl-G, Endophilin II
Immuno-regulatory role
ISG15 (UCRP)
28/37 Yes Ube1
L UbcH8, UbcH6
Herc5 UBP43 M Viral and host
proteins
Antiviral immunity, IFN-
inducible
FAT10 27/36 No Uba6 Use2 Use2
Ub-independent proteasomal degradation,
immunoregulatory role
UFM1 23 Yes Uba5 Ufc1 Ufl1 UfSP1 UfSP2
C20orf116 Erythroid and
megakaryocyte development
SUMO1 Smt3 14 Yes SAE1
-SAE2
Ubc9 ~15 SENP1-2 M Hundreds Alter interactions,
localization, conformation
SUMO2 13 Yes SAE1
-SAE2
Ubc9 ~15 SENP1-3,
5-7 M & P Hundreds
Alter interactions, localization,
conformation
SUMO3 13 Yes SAE1
-SAE2
Ubc9 ~15 SENP1-3,
5-7 M & P Hundreds
Alter interactions, localization,
conformation
SUMO4 12 IκBα NFκB signaling, pseudogene or not processed
Atg12 Atg12 12 No Atg7 Atg10 M Atg5, Atg3 Autophagy,
mitochondrial homeostasis
Urm1 Urm1 17 No MOCS3
M
MOCS3, ATPBD3, UPF0432,
CAS, USP15, yeast: Ahp1
tRNA thiolation and oxidant-
induced protein modification
MAP1LC3A Atg8 9 Yes Atg7 Atg3 Atg12/5
/16L Atg4A-D M
Phosphatidylethanolamine
(PE)
Autophagosome biogenesis:
tethering and fusion
MAP1LC3B Atg8 13 Yes Atg7 Atg3 Atg12/5
/16L Atg4A-D M
Phosphatidylethanolamine
(PE)
Autophagosome biogenesis:
tethering and fusion
MAP1LC3C Atg8 10 Yes Atg7 Atg3 Atg12/5
/16L Atg4A-D M
Phosphatidylethanolamine
(PE)
Autophagosome biogenesis:
tethering and fusion
GABARAP Atg8 8 Yes Atg7 Atg3 Atg12/5
/16L Atg4A-D M
Phosphatidylethanolamine
(PE)
Selective autophagy via interaction with
autophagy receptors
GABARAPL1 / Atg8L / GEC1
Atg8 12 Yes Atg7 Atg3 Atg12/5
/16L Atg4A-D M
Phosphatidylethanolamine
(PE)
Functional difference
between isoforms is unclear
GABARAPL2 / GATE-16 /
GEF2 Atg8 14 Yes Atg7 Atg3
Atg12/5/16L
Atg4A-D M Phosphatidylet
hanolamine (PE)
Functional difference
between isoforms is unclear

9
1.7 Ubiquitin-like structural domains (UBL)
The human genome contains 220 genes that encode proteins with at least one ubiquitin-like
domain, of which 38 can be classified as known or potential UBMs. The remaining non-modifying
UBLs could act as permanent structural features that facilitate protein targeting interactions to
regulate a variety of cellular activities that include transcription, translation, nuclear transport,
proteolysis, autophagy, antiviral pathways, and processes associated with poly-ubiquitylation,
such as endocytosis, membrane-protein trafficking, cell signaling and DNA repair (Grabbe & Dikic,
2009). There is no known generalizable function for the UBL fold, aside from mediating protein-
protein interactions and the role of the small set of UBMs.
1.8 Ubiquitin Conjugation Cascade
Ubiquitin and UBMs are conjugated to their target substrate through a series of enzymatic
reactions that result in conjugation of the C-terminus of ubiquitin-like fold to the -amino group of
a surface exposed lysine within the target substrate. The enzymes involved in this cascade
consist of an E1, an E2, and an E3 (Figure 1.3 & Figure 1.4). A computational analysis has
determined that there are 16 human E1s, 53 human E2s, 527 human E3s, and 184 human DUBs
(Xu & Peng, 2006; Semple CA, 2003).
The activating enzyme (E1) activates ubiquitin by catalyzing the ATP-dependent formation of a
thioester bond involving a free thiol of the catalytic Cys and the C-terminal glycine of ubiquitin,
which facilitates the transfer of the C-terminal glycine to a surface exposed Cys on a conjugating
enzyme (E2) (Figure 1.4). This is followed by either the C-terminal glycine of ubiquitin being
transferred to a Cys of a protein ligase (E3) or the formation of a covalent conjugation between
the C-terminal glycine and an -amino group of a surface exposed lysine within the target protein.
There are also some rare cases where the N-terminal amino group, a cysteine residue, a
threonine residue, or a serine residue within a target protein acts as ubiquitylation sites (Wang et
al., 2007).

10
Figure 1.3: Ubiquitin-like modifier conjugation cascade. Enzymes in the ubiquitin conjugation cascade consist of
E1, E2s, and in some cases E3s that are uniquely associated with specific UBMs (Hochstrasser M, 2000).
Figure 1.4: Ubiquitin conjugation cascade. The enzymatic cascade that mediates ubiquitin conjugation is similar for
all UBMs. It involves ATP, ubiquitin activating enzymes (E1), ubiquitin conjugating enzymes (E2), and ubiquitin ligases (E3), and results in the conjugation of the UBM to a surface exposed lysine on the target protein. Conjugation is a dynamic process, and de-ubiquitylating enzymes (DUBs) can release the UBM from the target protein.

11
1.9 Ubiquitin-binding domains & interactions
Ubiquitin-binding proteins are key players in modulating the downstream activity of UBM
conjugation. Ubiquitin-binding proteins contain regions that are 20 to 150 residues that non-
covalently interact with the members of ubiquitin-fold superfamily. Some ubiquitin-binding regions
are independent domains (ie. UBA, VHS, CUE), and other ubiquitin-binding regions consist of
individual secondary structure elements (ie. UIM and SIM). Ubiquitin-binding domains (UBDs)
were first identified as interaction partners of ubiquitin, but several UBD family members do not
interact with ubiquitin. The specificity of such ubiquitin-binding domain proteins could favour other
UBLs.
Many UBDs have been observed in the enzymatic components of the UBM cascade, as well as
in proteins that are involved in the downstream translocation or functional effect of protein
conjugation. Due to the transient nature of these interactions, binding is on the moderate to low
affinity scale; Kd of ~460uM for GRAM-like ubiquitin binding in Eap45 (GLUE)-monoubiquitin,
compared to an apparent Kd of ~0.03-9uM for UBA-polyubiquitin (Haglund et al., 2005). The
interaction itself appears to be controlled by post-translational modification of the UBD-containing
protein, accessibility of the ubiquitin-binding interface and accessibility of the UBD-binding
interface. A relevant example of UBD modulation involves RAD23, which shuttles conjugated
proteins to the proteasome. The RAD23-ubiquitin interaction is inhibited by the association of its
UBD with its UBL (Chen et al., 2001). Whether the role of UBL is to regulate UBD-ubiquitin or
UBD-UBM interactions has been explored through the course of this thesis.
1.9.1 Ubiquitin Interacting Motif (UIM), Motif Interacting with Ubiquitin (MIU) & Double-sided Ubiquitin Interacting Motif (DUIM)
The ubiquitin interacting motif (UIM) is the ubiquitin-interacting region of the S5A/RPN10
proteasomal subunit (Young et al., 1998). This UIM is a short ~20 aa -helical segment of a
protein. Through sequence analysis, putative human UIMs were identified and some of these

12
peptides were selected as putative UIM binding partners for ubiquitin and ubiquilin-1. Two
additional ubiquitin-interacting motifs are similar to the UIM: MIUs which bind in a manner almost
identical to the UIM:Ub interaction but in the opposite orientation, and DUIMs which consist of two
tandem UIMs.
1.9.2 Coupling of Ubiquitin conjugation to Endoplasmic Reticulum Degradation (CUE)
The coupling of ubiquitin conjugation to endoplasmic reticulum degradation domain was
discovered through yeast-two hybrid screening by two independent groups (Shih et al., 2003;
Donaldson et al., 2003), and structural analyses have resulted in 7 structures (ie. CUE2 [PDB_ID:
1OTR] & VPS9 [PDB_ID: 1P3Q]). The CUE domain consists of a three-helix bundle, from which
residues on two -helices interact with ubiquitin.
1.9.3 Ubiquitin-Associated Domain (UBA)
The ubiquitin-associated domain (UBA) was identified through bioinformatics analyses of
enzymes involved in ubiquitylation or deubiquitylation (Hoffmann et al., 1996). UBA interact with
both monoubiquitylated and polyubiquitylated proteins, and structural analyses have resulted in
45 structures (ie. Dsk2p [PDB_ID: 1WR1] & ubiquilin 3 [PDB_ID: 2DAH]). The UBA domain is
similar to the CUE domain in that it consists of a three-helix bundle, from which residues on two
-helices interact with ubiquitin.
1.9.4 Ubiquitin Conjugating Enzyme Variant (UEV)
The ubiquitin conjugating enzyme variant (UEV) proteins are homologous to E2s, but are inactive
because they lack the active site Cys. Even though they are catalytically inactive, they are able
to interact with ubiquitin through their conserved ubiquitin-binding interface (Koonin et al., 1997).
Structural analyses of UEV have resulted in 12 structures (ie. TSG101 [PDB_ID: 1S1Q] & VPS23
[PDB_ID: 1UZX]).

13
1.9.5 Npl4 Zing Finger Motif (NZF)
The Npl4 zinc finger (NZF) motif is also a zinc finger binding motif (Meyer et al., 2002; Wang et
al., 2003). Structural analyses of NZF have resulted in 3 structures [PDB_ID: 1Q5W, 1NJ3,
2PJH]. The NZF motif binds to ubiquitin through three residues that are located on loops
coordinated by strands ordered by the zinc ion.
1.9.6 GGA And Tom1 Domain (GAT)
The GGA and Tom1 (GAT) domain was discovered by two-hybrid screens (Shiba et al., 2004),
and structural analyses have resulted in 5 structures [PDB_ID: 1YD8, 1WR6, 1WRD, 2C7M, and
2C7N]. The GAT domain is similar to both the CUE and the UBA domains in that it consists of a
three-helix bundle, from which residues on two -helices interact with ubiquitin. However, the
orientation of the helices differ, such that the two -helices are parallel for GAT and are anti-
parallel in both CUE and UBA.
1.9.7 Other Ubiquitin Binding Domains
The GRAM-like ubiquitin binding in Eap45 (GLUE) domain has been structurally determined 4
times (Teo et al., 2006), and the Vps27,Hrs,STAM (VHS) domain has been structurally
determined 12 times (Hoffman et al., 2001). The polyubiquitin associated zinc finger (PAZ)
domain was discovered by two-hybrid screens, and was further characterized biochemically
(Hook et al., 2002).
1.9.8 SUMO Interacting Motif (SIM)
Binding partners and modes have been identified for some ubiquitin-like modifiers, such as the
SUMO-interacting Motif (SIM) that interacts with SUMO. The SIM is a short -strand that behaves
as a -sheet extension to that of SUMO.

14
1.9.9 Diversity among Ubiquitin-Binding Domains
From the structural studies of UBD-UBM interactions, some similarities have been observed.
However, there is a great diversity involving the tertiary folds of the protein involved in the
interaction; residues from individual and adjacent -helices, -strands, as well as loops interact
with ubiquitin or a ubiquitin-like domain (Table 1.2). The diversity amongst the binding modes
also changes across members within the same UBD families. However, one common feature
shared by many of the UBD interactions is that they usually extend along the isoleucine 44 face
of ubiquitin, which is highly conserved throughout evolution and to a minor extent between UBLs
(Haglund et al., 2005).
Table 1.2: Protein-protein interaction modes that have been structurally characterized with experimentally determined
binding affinities between UBLs and binding partners.
Ubiquitin Binding Type Size Affinity Example
PDB Reference
UIM / DUIM / MIU
Ubiquitin Interacting Motif
~20 aa ~100-400 µM
(mono or poly-Ub) ~30 µM (MIU)
1Q0W
Young P, 1998; Fisher RD, 2003;
Swanson KA, 2003; Wang QH, 2005
SIM SUMO Interacting Motif
~12 aa ~2-10 µM 2ASQ Song J, 2005;
Hecker CM, 2006
CUE Coupling of Ubiquitin conjugation to Endoplasmic Reticulum Degradation
42-43 aa ~2-160 µM (mono-Ub)
1P3Q, 1OTR
Donaldson KH, 2003; Kang RS, 2003; Prag G, 2003; Shih SC, 2003
GAT GGA And Tom1 Domain
135 aa ~180 µM
(mono-Ub) 1YD8
Shiba Y, 2004; Prag G, 2005
GLUE GRAM-like ubiquitin binding in Eap45
~135 aa ~460 µM
(mono-Ub) 2DX5 Teo H, 2006
NZF Npl4 Zing Finger Motif
~35 aa ~100-400 µM
(mono-Ub) 1Q5W
Meyer HH, 2002; Wang B, 20003; Alam SL, 2004;
A20 ZnF A20 ZnF Domain ~35 aa ~10-25 µM
2FID 2FIF 2G45
Lee S, 2006; Penengo L, 2006
UBC Ubiquitin Conjugating Catalytic Domain ~150 aa ~300 µM 2FUH Brzovic PS, 2006
UBA
Ubiquitin-Associated Domain
45-55 aa ~10-500 µM (mono-Ub) ~0.03-9 µM (poly-Ub)
2JY6, 1ZO6 Hofmann K, 1996;
PAZ (ZnF-UBP) Polyubiquitin Associated Zinc finger
~58 aa ~3 µM ~60 nM
2G45, 3IHP Hook SS, 2002; Boyault C, 2006;
Reyes-Turcu, 2006
UEV Ubiquitin Conjugating Enzyme Variant
~145 aa ~100-500 µM
(mono-Ub) 1S1Q
Koonin EV, 1997; Sundquist WI, 2004
VHS Vps27,Hrs,STAM
150 aa ~50 µM 2L0T, 3LDZ Hong YH, 2009

15
1.10 Thesis Overview
Ubiquitin plays a vital role in protein trafficking, protein degradation, and a variety of disease
pathways. Significant advances in the study of ubiquitin, ubiquitin-binding domains, UBLs,
ubiquitin-like modifiers, and ubiquitin conjugating enzymes have led to a better understanding of
the complexity of the ubiquitin and ubiquitin-like modifier conjugation system. However, there
remains a gap in knowledge associated with the overarching significance of the ubiquitin fold, and
the nature and function of many UBLs remains largely unexplored.
This thesis explores the size and scope of human UBLs, which led to a structure and biophysical
examination of 17 UBLs. Analysis of the 17 UBLs led to the analysis of two UBL-binding domains
that interact with two distinct UBLs (NFATc2IP & ubiquilin-1), as well as revealing the biochemical
relationship between these 17 UBLs with each other and within the full set of all UBLs.
1.10.1 Identify and obtain near-complete structural coverage of all human UBLs.
The first experimental component of this study focused on identifying the complete set of all
human UBLs encoded within the human genome, which allowed for a better understanding of the
breadth and sequence diversity of ubiquitin’s -grasp fold. Upon determination of the expansive
population of human UBLs, we obtained near-complete structural coverage of the ubiquitin-like
fold for the human proteome. This resulted in generating 100 modelling families of related UBLs
and experimental structural determination of 17 UBLs.
1.10.2 Exploring the NFATc2IP + NFATc2 protein-protein interaction and the ubiquilin-1 + PIN2 protein-protein interaction
To assist in understanding the structural and functional diversity of the ubiquitin-like domain,
computational analyses of NFATc2IP & ubiquilin protein sequences, molecular structures and
known binding partners were performed. This led to the deduction that NFATc2IP could interact
with NFATc2 via SIM-like interaction, which was validated using peptide-array and NMR titration

16
experiments. A similar series of computational analyses was performed using the ubiquilin-1
protein sequence and structure, which led to the deduction that PIN2 could interact with ubiquilin
via UIM-like interaction. This was validated using NMR titration experiments.

17
Chapter 2
The ubiquitin fold: leveraging structural genomics
Contributions: J. Everett performed clustering of UBLs into model families. A. Semesi, M. Garcia
& A. Yee assisted with cloning, small scale sample preparation & small scale expression/solubility
screening. J. Lukin, C. Fares, M. Karra, S. Srisalam, S. Houliston assisted with NMR data
acquisition and NMR titration. I performed large scale NMR sample preparation and NMR
screening, as well as remaining experiments and analyses under the guidance of CH. Arrowsmith.

18
Chapter 2
The ubiquitin fold: leveraging structural genomics
2.1 Summary
Structural genomics brings together information about not just the protein for which a structure is
obtained, but also sequentially similar homologues and even distantly related fold family
members. For this thesis, structural genomics provided the tools for gaining insight into the
diversity of the ubiquitin-like domain family. Bioinformatics and computational techniques were
leveraged to expand the set of known human ubiquitin-like domain containing genes, prioritize
subsets of human ubiquitin-like domain containing genes based on their structure’s role in domain
family structure coverage, and assist in construct design for structure determination. We used
nuclear magnetic resonance (NMR) spectroscopy to screen human UBLs for structure
determination, and subsequently determined the structures of 17 human UBLs using X-ray
Crystallography and NMR spectroscopy. As a result, the RCSB PDB now has 32% structural
coverage of human UBLs, and 82% structural coverage when taking into account homology
models of UBL domains that have at least 30% sequence identity over the enter length of the full
domain. Of the remaining 74 human UBLs that lack structural information, 30 are singletons and
are on average 36% similar & 23% identical to the most similar regions of protein structures within
the PDB. The UBLs structurally characterized for this project facilitate 3.7% structural coverage
of all human UBLs. When taking into account UBL homology models, the structural coverage is
6%. Structural analyses have also provided insight into families of related proteins. In particular,
structural analysis of the NFATc2IP and ubiquilin protein families revealed insight into protein-
protein interactions and facilitated the prediction of novel binding partners.
2.2 Introduction
One goal of structural genomics is to provide a high throughput framework for generating accurate
molecular structure representations of at least one member of large groups of protein domain

19
families. The molecular structure itself provides insight into functional attributes shared among
protein domain family members, functional variability within the protein domain family, as well as
structural templates for ligand docking studies, homology modeling, and molecular replacement
methods for solving X-ray crystal structures.
Two structural genomics groups that have made significant contributions to the PDB are the
NorthEast Structural Genomics Consortium (NESG) and the Structural Genomics Consortium
(SGC). In 2000, the Protein Structure Initiative was established to provide funding and direction
to 9 structural genomics centres. The NESG uses both NMR & X-ray crystallography for
elucidating the structures of eukaryotic proteins related to cancer biology, protein-protein
interaction networks, specific biochemical pathways, or implicated in specific human diseases.
The SGC is a public/private initiative that focuses on medically significant proteins related to
human health. From 2003 until Jan 2014, the NESG determined 1174 protein structures (516 by
NMR & 658 by X-ray crystallography), and from 2004 to Jan 2014 the SGC determined 1232
protein structures (28 by NMR & 1204 by X-ray crystallography). These initiatives implement a
similar parallel high-throughput structural genomics framework that focuses on structurally
characterizing a large number of protein targets from gene to structure.
Structural genomics efforts have had a significant impact on scientific innovations related to the
biological sciences and human health. In addition to the wealth of knowledge generated through
these efforts, structural genomics facilitates: methods development and optimization, improved
datasets related to known and potential drug target proteins for drug discovery programs, and
increased availability of purified proteins for reagent development (Weigelt, 2010).
This thesis leverages the strengths of structural genomics experimental methods to explore the
significance of structural variation within the ubiquitin-like domain family. The ubiquitin-like
domain family was chosen because of the large number of medically-significant members of the
family, the large number of uncharacterized ubiquitin-like domain containing genes, the stable

20
and soluble nature of ubiquitin, and the scientifically interesting questions surrounding the
ubiquitylation system that include the unknown role that UBLs play.
There remains a significant gap in understanding the role of UBLs, as well as the breadth of
cellular and molecular activity of the full length proteins that contain UBLs. There is also a gap in
knowledge related to the size of the ubiquitin-like domain fold-space. In 2005, 73 genes were
formally annotated as containing UBLs. By 2012, the list of formally annotated ubiquitin-like
domain containing genes expanded to 152 genes. By 2014, the list of formally annotated
ubiquitin-like domain containing genes expanded to 191 genes and 325 isoforms (Marchler-Bauer
et al., 2013). The expanded set of formally annotated ubiquitin-like domain containing genes
remains substantially smaller than the number of genes that were determined using a PSI-BLAST
batch approach for this thesis project. This gap in breadth presents a gap in knowledge of the full
extent of the ubiquitin-like domain family and its diversity.
This thesis tries to explore these gaps to provide insight and a possible explanation for the breadth
and diversity of the ubiquitin-like domain family, while demonstrating its significance through
molecular structure analysis. The first objective of the project was to identify all UBLs within the
human genome. Once all UBLs were identified, a strategy was developed to work towards
complete structural coverage of the ubiquitin-like domain family. Combining molecular biology
and structural biology techniques, along with knowledge of the molecular structure of each human
ubiquitin-like domain would provide insight into the various biochemical functions of UBLs and the
significance of variations between domains. The second objective of this chapter discusses how
we leveraged bioinformatics, molecular biology and structural biology techniques to screen UBLs
for structure determination by NMR and prioritize constructs to facilitate greater family coverage
with each newly solved structure.

21
2.3 Methods
2.3.1 Identifying human ubiquitin-like domains
An initial list of all identifiable human UBLs was compiled based on gene/domain annotation within
UniProtKB (UniProt Consortium, 2014), Human Protein Atlas (Uhlen et al., 2010), the Human
Protein Reference Database (Prasad et al., 2009), and the NCBI’s Conserved Domain Database
(consisting of SMART, Pfam, COGs, TIGRFAM, and PRK) (Marchler-Bauer et al., 2013). The
resulting list of 73 human UBLs was expanded to 645 distantly related human UBLs by performing
a batch of independent DELTA-BLAST sequence similarity searches of GenBank and Uniprot
using each member of the initial list of human ubiquitin-like domain. DELTA-BLAST is a modified
version of BLAST that uses RPS-BLAST to search for conserved domains from which a position-
specific scoring matrix (PSSM) is generated and used to search the sequence databases (Benson
et al., 2013; Boratyn et al., 2012).
Figure 2.1: Novel UBL discovery process. Unannotated UBLs were discovered though a series of DELTA-BLAST
searches of the NCBI Genbank and Uniprot human protein databases. The predicted secondary structure elements of putative UBLs was analyzed to confirm whether it was a legitimate UBLs, and legitimate UBLs were also used as input sequences for subsequent DELTA-BLAST searches.

22
2.3.2 Validating putative human ubiquitin-like domains
Figure 2.2: Secondary & tertiary structures of Human ubiquilin-1. Secondary structure elements of the human
ubiquitin-like domain containing protein ubiquilin-1 (UBQL1_HUMAN; sp|Q9UMX0).
Ubiquitin-like domains have a characteristic secondary structure consisting of 5 -strands and 3
-helical regions (Figure 2.2). Secondary structure elements were predicted using JPRED and
PSIPRED webservers for each full length protein that contains at least one of the 645 UBLs. A
sequence similarity search of the PDB was also performed using each full length ubiquitin-like
domain containing protein to determine whether any protein structures were deposited with a
similar amino acid sequence. A pseudo-multiple sequence alignment was generated for each
ubiquitin-like domain, bringing together information about the full length protein sequence,
predicted secondary structure elements, and similar proteins deposited in the RCSB PDB (Figure
2.3).
23
1---------11--------21--------31--------41--------51--------61--------71--------81--------91--------101-------111-------121-------131-------141-------151-------
OrigSeq :MAESGESGGPPGSQDSAAGAEGAGAPAAAASAEPKIMKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKTQNRPQDHSAQQTNTAGSNVTTSSTPNSNSTSGSATSNPFGLGGLGGLAGLSS
Jnet :-----------------------------------EEEEEEEE----EEEEE----HHHHHHHHHHHH-------EEEEE---------HHH--------EEEEEEE-----------------------------------------------------
Jhmm :-----------------------------------EEEEEEEE----EEEEEE----HHHHHHHHHH-------EEEEEE--EE----HHHHH-------EEEEEEE-----------------------------------------------------
Jpssm :-----------------------------------EEEEEEEE---EEEEEE----HHHHHHHHHHHHH------HEEH---------------------EEEEEEE-----------------------------------------------------
Jnet_25 :---------------BB-B----------------BB-BBBBB------B-B---B-B--BB--BB----B-B-BBBBBB-B-BB-----B--B-B---BBBBBBBBB--------B--B------BBB---------------BBBBBBBBBBBBBBB-
Jnet_5 :------------------------------------B-B-B----------------B--B---B----------B-BBB----------B----------BBBB----------------------------------------B---B----B--B--
Jnet_0 :-----------------------------------------------------------------------------BB----------------------B-B--------------------------------------------------------
Jnet Rel :9988877777777777777777777777777777606899871686078884077508999999998003787500000046006676000004467875488987436777777777777777777777777777777777777777777777777777
UBIQUITIN_HUMAN-JPRED -EEEEEE----EEEEEE-----HHHHHHHHHHH-------EEEEE--------------------EEEEEEE---- : Jnet
UBIQUITIN_HUMAN -EEEEEE----EEEEEE-----HHHHHHHHHHH-------EEEEE---EE-----HHHH------EEEEEEE---- : 1Q0W
SUMO1_HUMAN-JPRED ----------------------EEEEEEEE----EEEEEE----HHHHHHHHHHHHH-----EEEEEE--------------------EEEEEEEE------- : Jnet
SUMO1_HUMAN ----------------------EEEEEEEE---EEEEEEEE-----HHHHHHHHHHH-----EEEEE--------------------EEEEEEE--------- : 1A5R
161-------171-------181-------191-------201-------211-------221-------231-------241-------251-------261-------271-------281-------291-------301-------311-------
OrigSeq :LGLNTTNFSELQSQMQRQLLSNPEMMVQIMENPFVQSMLSNPDLMRQLIMANPQMQQLIQRNPEISHMLNNPDIMRQTLELARNPAMMQEMMRNQDRALSNLESIPGGYNALRRMYTDIQEPMLSAAQEQFGGNPFASLVSNTSSGEGSQPSRTENRDPL
Jnet :------------HHHH------HHHHHHHH--HHHHH----HHHHHHHH---HHHHHHHH-------------HHHHHHHHHH-HHHHHHHHHHHHHHHHH-------HHHHHHHHHHHHHHHHHHHH--------------------------------
Jhmm :------------HHHH-------HHHHHH---HHHH------HHHHHH----HHHHHHHH-------------HHHHHHHHHHHHHHHHHHHH--HHHHH--------HHHHHHHHHHHHHHHHHHHH--------------------------------
Jpssm :------------HHHHH-----HHHHHHHH--HHHHH----HHHHHHHHH--HHHHHHHH-------------HHHHHHHHH--HHHHHHHHHHHHHHHHH-------HHHHHHHHHHHHHHHHHHH---------------------------------
Jnet_25 :BBB----B--B---BB--B--BB-BBB-BB---BBB-BB--B-BB--BB--B--B--BB--BB-B---B----BB--BB-BB--B-BB--BB-----BB--B-BB-BB--BB--BB--B---BB-BB------BBBB-B--B------------B---BB
Jnet_5 :-------B-----------------B--------B--B------B-----------------------B-----B--B---B-------------------B-----B---B--B---B---B--B---------------------------------B
Jnet_0 :----------------------------------------------------------------------------------------------------------------------------------------------------------------
Jnet Rel :7777777776523453047874089999802356460477508999990055589998841413434677621789999984006899997470099987037887636899986899999999863056777777665667777777777777777777
321-------331-------341-------351-------361-------371-------381-------391-------401-------411-------421-------431-------441-------451-------461-------471-------
OrigSeq :PNPWAPQTSQSSSASSGTASTVGGTTGSTASGTSGQSTTAPNLVPGVGASMFNTPGMQSLLQQITENPQLMQNMLSAPYMRSMMQSLSQNPDLAAQMMLNNPLFAGNPQLQEQMRQQLPTFLQQMQNPDTLSAMSNPRAMQALLQIQQGLQTLATEAPGL
Jnet :--------------------------------------------------------------------HHHH-----HHHHHHHHHHH--HHHHHHHHH--------HHHHHHHHHHHHHHHHHH--HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH--
Jhmm :-----------------------------------------------------------------------------HHHHHHHHHHH--HHHHHHHHH--------HHHHHHHHHHHHHHHHHH--HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
Jpssm :----------------------EEE--------------------------------HH--------HHHHHH----HHHHHHHHHH---HHHHHHHHH--HHH---HHHHHHHHHHHHHHHHH---HHHHHHHHHHHHHHHHHHHHHHHHHHHHHH---
Jnet_25 :-BB------------B-----B--B------B--B--B-B-BBBBBBBBBBB-BBBB--BB--B--B---B--B--BBBBB-BB--BB-BB-BB--BB-BBBB---B--BB--B---BB-BB-BB----BB-BB-B--BB-BBB-BB-BB--B---BB-B
Jnet_5 :--B----------------------------------------B---B--B-----B-------------B--------B--BB---------B---B--BB-------B---B------B---B--------B----BB-BB---------B---BB-B
Jnet_0 :----------------------------------------------------------------------------------------------------------------------------------------------------------------
Jnet Rel :7777777777777777777774000267777777777777777777777777765410012577753000000067658999999860663589998614500005468999999748999873076589999868999999999999999987541000
481-------491-------501-------511-------521-------531-------541-------551-------561-------571-------581------ :
OrigSeq :IPGFTPGLGALGSTGGSSGTNGSNATPSENTSPTAGTTEPGHQQFIQQMLQALAGVNPQLQNPEVRFQQQLEQLSAMGFLNREANLQALIATGGDINAAIERLLGSQPS : OrigSeq
Jnet :------------------------------------------HHHHHHHH-------------HHHHHHHHHHHHH-----HHHHHHHHHH----HHHHHHHHH----- : Jnet
Jhmm :------------------------------------------HHHHHHH--------------HHHHHHHHHHHHH-----HHHHHHHHHH----HHHHHHHH------ : jhmm
Jpssm :------------------------------------------HHHHHHHHH-----------HHHHHHHHHHHHHH-----HHHHHHHHHH----HHHHHHHHH----- : jpssm
Jnet_25 :BBBBBBBBBBB--BBB---------B----B------B--BBBBBBBBBB-BBB-----B--B--BB--BB--B--BBB-B--BBB-BB-BB---BBBBB--B------ : Jnet_25
Jnet_5 :B--B-------------------------------------BB-BBB-B--B--------------B------B----------BB-BB------B-BBB--B------ : Jnet_5
Jnet_0 :----------------------------------------------------------------------------------------B-------------------- : Jnet_0
Jnet Rel :5677777777777777777777777777777777777777641788887004677877776507999999999986068866899999974588668999988026899 : Jnet Rel
Figure 2.3: Pseudo-multiple sequence alignment of human ubiquilin-1. Full length protein sequence and predicted secondary structure elements of the human
ubiquitin-like domain containing protein ubiquilin-1 (UBQL1_HUMAN; sp|Q9UMX0). The secondary structure elements for human ubiquitin & human SUMO1, as well as the predicted secondary structure elements for human ubiquitin & human SUMO1 are aligned with the ubiquitin-like domain of ubiquilin-1. Secondary structure elements were predicted using Jpred3.

24
Figure 2.4: UBL target selection, preparation and screening process. Legitimate UBLs were grouped into modeling
families, from which target UBLs were selected. For each target ubiquitin-like domain, constructs were designed with varying domain boundaries and protein samples were prepared using a parallel high-throughput batch approach. NMR screening was performed on ubiquitin-like domain samples that had sufficient expression and concentration. Ubiquitin-like domain samples with adequate 1H15N-HSQC spectra were re-expressed as 15N13C-labelled protein for full structure determination.
2.3.3 Target selection
A sequence similarity analysis was performed to group related UBLs. Modelling families were
generated that consist of subsets of UBLs in which the structure determination of one member of
the modelling family would facilitate a reliable structure prediction of all other members of the
modelling family using homology modelling techniques (Nair et al., 2009). This shortened the full
list of all UBLs to 76 ubiquitin-like domain targets after removing proteins whose structures have
already been deposited in the PDB, those that lack a homologue of sufficient sequence similarity,
and those for which DNA templates were not available. These UBLs were targeted for NMR
structure determination as described below.

25
2.3.4 Construct design
Multiple constructs were designed for each of the 76 UBLs to facilitate screening of solubility, yield
and NMR spectrum. The ubiquitin-like domain boundaries were defined using a pseudo-multiple
sequence alignment that contained sequence annotation, predicted secondary structure,
disordered regions, and all sequentially similar structurally characterized proteins within the PDB.
To facilitate protein purification using Ni2+ affinity chromatography, all constructs were generated
with a fused N-terminal poly-histidine tag. When necessary, constructs were redesigned based
on trends in small scale and NMR screening results.
21--------31--------41--------51--------61--------71--------81--------91--------101-------111------- OrigSeq : AEGAGAPAAAASAEPKIMKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKTQNRPQDHSAQQ
Jnet : ----------------EEEEEEEE----EEEEE----HHHHHHHHHHHH-------EEEEE---------HHH--------EEEEEEE------------
Jhmm : ----------------EEEEEEEE----EEEEEE----HHHHHHHHHH-------EEEEEE--EE----HHHHH-------EEEEEEE------------
Jpssm : ----------------EEEEEEEE---EEEEEE----HHHHHHHHHHHHH------HEEH---------------------EEEEEEE------------
Jnet_25 : ----------------BB-BBBBB------B-B---B-B--BB--BB----B-B-BBBBBB-B-BB-----B--B-B---BBBBBBBBB--------B--
Jnet_5 : -----------------B-B-B----------------B--B---B----------B-BBB----------B----------BBBB--------------
Jnet_0 : ----------------------------------------------------------BB----------------------B-B---------------
Jnet Rel : 7777777777777776068998716860788840775089999999980037875000000460066760000044678754889874367777777777
PSIPRED : cccccccccccccccccEEEEEEcccccEEEEEcccccHHHHHHHHHHHHccccccEEEEEccEEcccccHHHHcccccccEEEEEEEcccccccccccc
UBIQUITIN_HUMAN-JPRED -EEEEEE----EEEEEE-----HHHHHHHHHHH-------EEEEE--------------------EEEEEEE---- : Jnet
UBIQUITIN_HUMAN -EEEEEE----EEEEEE-----HHHHHHHHHHH-------EEEEE---EE-----HHHH------EEEEEEE---- : 1Q0W
SUMO1_HUMAN-JPRED --------EEEEEEEE----EEEEEE----HHHHHHHHHHHHH-----EEEEEE--------------------EEEEEEEE------- : Jnet
SUMO1_HUMAN --------EEEEEEEE---EEEEEEEE-----HHHHHHHHHHH-----EEEEE--------------------EEEEEEE--------- : 1A5R
OrigSeq : AEGAGAPAAAASAEPKIMKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKTQNRPQDHSAQQ
1J8C:A EPKI+KVTVKTPKEKEEFAVPENSSVQQFKE_ISKRFKS_TDQLVLIFAGKILKDQDTL_QHGIHDGLTVHLVIK (ID:95% SIM:96%)
1YQB:A __P_++KVTVKTPK+KE+F+V_+__++QQ_KEEIS+RFK+H_DQLVLIFAGKILKD_D+L+Q_G+_DGLTVHLVIK_Q+R (ID:68% SIM:85%)
1WX7:A A___+P_++KVTVKTPK+KE+F+V_+__++QQ_KEEIS+RFK+H_DQLVLIFAGKILKD_D+L+Q_G+_DGLTVHLVIK_Q+R (ID:66% SIM:84%)
2BWE:S +_+_+K+_++K_E__V___S+V_QFKE_I+K__________LI++GKILKD__T+__+_I_DG_+VHLV (ID:41% SIM:59%)
1YX5-B M++_VKT___K_____V__+_+++__K_+I__+_____DQ__LIFAGK_L+D__TLS_+_I____T+HLV++ (ID:36% SIM:54% GAP:1%)
Domain Boundaries:
Construct1 PKIMKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKTQNRP
Construct2 PKIMKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKTQNRPQD
Construct3 PKIMKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKT
Construct4 SAEPKIMKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKTQNRP
Construct5 SAEPKIMKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKTQNRPQD
Construct6 SAEPKIMKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKT
Construct7 MKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKTQNRP
Construct8 MKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKTQNRPQD
Construct9 MKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDTLSQHGIHDGLTVHLVIKT
Figure 2.5: Pseudo-multiple sequence alignment of ubiquilin-1 for construct design. Pseudo-multiple sequence
alignment of ubiquilin-1 showing residues 20-119 of the full length protein sequence corresponding to the ubiquitin-like domain region, as well as predicted secondary structure elements, similar proteins deposited in the RCSB PDB, and constructs with predicted ubiquitin-like domain boundaries.

26
2.3.5 Sample preparation
Small scale expression and purification of each construct was performed to determine sample
solubility and yield. For each target, samples with the best yield were regrown for NMR screening.
15N-labelled samples were expressed in E.coli, grown in batches of 12 x 0.5L using modified M9
minimal media containing 15NH4Cl as the sole nitrogen source supplemented with kanamycin at
37oC until an OD600 of 1.0 was reached. Protein expression was induced with isopropyl-1-thio-D-
galactopyranoside (IPTG) and the cells were incubated for 12-18 hours at 15oC. The cells were
lysed by sonication, and the cell debris was clarified by centrifugation. The poly-histidine tagged
UBLs were purified by modified batch/column Ni2+-affinity chromatography (Qiagen) in batches of
6-12 samples, and eluted to a final volume of 5 mL. Each sample was exchanged from elution
buffer into a NMR buffer using centrifugal concentrators. The standard NMR buffer consisted of
a MOPS-based buffer, however other buffers were used based on pH of sample, solubility and
resolution of NMR spectroscopy signal. The samples were concentrated to a volume of ~500 µL
and transferred to 5 mm NMR tubes, ~200 µL for 3 mm NMR tubes, or ~40 µL for 1 mm NMR
microprobe tubes. The volume and NMR tube selection depended on amount of sample
available, and necessary sample concentration for adequate NMR spectroscopy signal (Yee et
al., 2014).
2.3.6 1H15N-HSQC screening of ubiquitin-like domains
An 1H15N-HSQC spectrum was generated for each sample using a Bruker 800MHz AVANCE
spectrometer, or a Bruker 500MHz or Bruker 600MHz AVANCE spectrometer equipped with
automated sample changers. Samples were ranked based on peak intensity, dispersion and
percentage of total residues observed in each 1H15N-HSQC spectra (Yee et al., 2002). For
samples with inadequate 1H15N-HSQC spectra, new constructs were designed to improve domain
boundaries and/or NMR buffer conditions were optimized in an attempt to improve solubility.

27
2.4 Results & Discussion
2.4.1 Identifying unannotated human ubiquitin-like domains
The human genome contains 220 genes that encode proteins with UBLs, of which 147 were not
annotated as having the ubiquitin-fold at the time of analysis (Appendix I). These proteins contain
645 distantly related human UBLs that include those within isoforms produced by alternative
splicing. By eliminating identical sequences within isoforms, the pool of 645 putative UBLs can
be reduced to 398 unique UBL sequences. The goal of this project has been to obtain structural
coverage of all UBLs, without experimentally determining each of the 398 unique UBLs. To
accomplish this, the UBLs were grouped into 100 modelling families. Modelling families represent
groups of homologous protein domains that have similar structures, for which the experimental
structure of one of the members of the modelling family provides “modelling leverage” to facilitate
computation determination of protein structures for the remaining members of the modelling family
through the use of homology, or comparative, modelling methods (Arnold et al., 2006; Kiefer et
al., 2009; Peitsch, 1995; Pieper et al., 2011). Some studies have shown that sequence similarity
of >40% over >50 residues can provide models with heavy atom RMSD of <2.5 Å from the
experimental structure (Bhattacharya et al., 2008; Koh et al., 2003; Marti-Renom et al., 2000;
Marti-Renom et al., 2003). Modelling families are typically defined by such sequence similarity
and sequence coverage parameters, but the parameters used for homology model generation for
this thesis were modified to >20% over 90% because all of the domains are from the same
organism, all of the domain sequence lengths are 70 aa-120 aa in length, and there is a high level
of secondary structure element conservation shared among UBLs. Of the 100 modelling families,
there are 5 singletons (OASL_HUMAN, PARK2_HUMAN, IKKB_HUMAN, UBL7_HUMAN &
P3C2B_HUMAN), which correspond to modelling families that contain only one UBL.
28
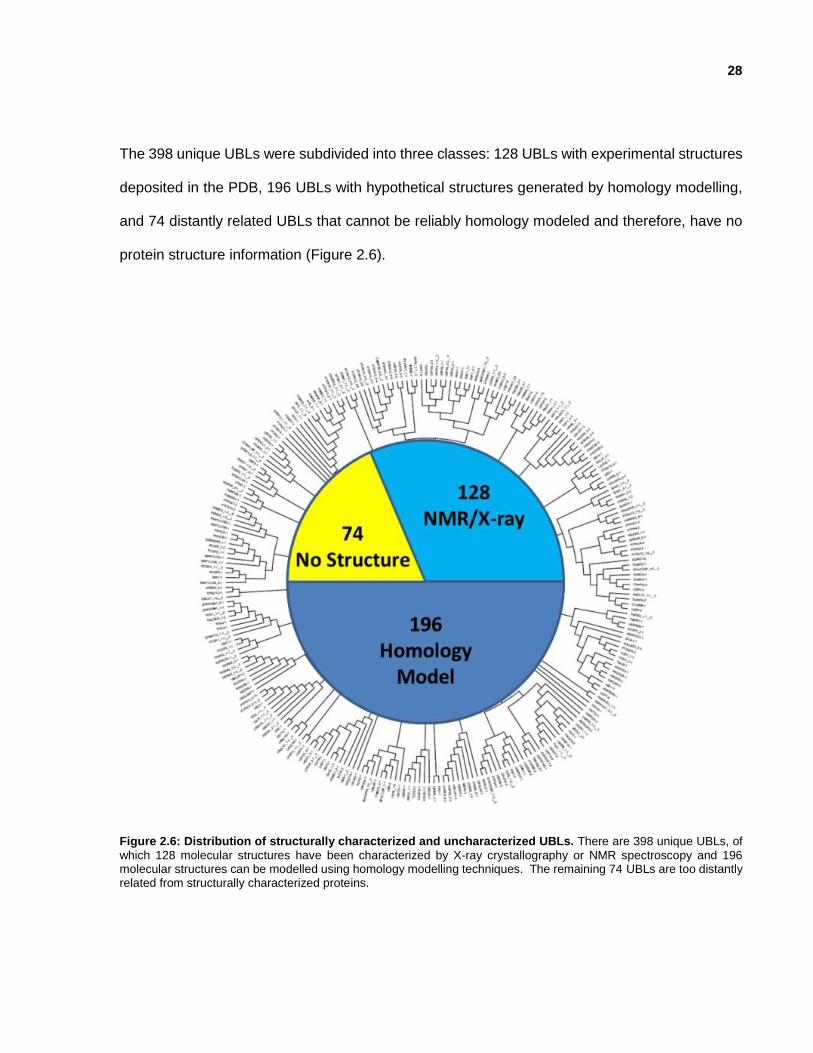
The 398 unique UBLs were subdivided into three classes: 128 UBLs with experimental structures
deposited in the PDB, 196 UBLs with hypothetical structures generated by homology modelling,
and 74 distantly related UBLs that cannot be reliably homology modeled and therefore, have no
protein structure information (Figure 2.6).
Figure 2.6: Distribution of structurally characterized and uncharacterized UBLs. There are 398 unique UBLs, of
which 128 molecular structures have been characterized by X-ray crystallography or NMR spectroscopy and 196 molecular structures can be modelled using homology modelling techniques. The remaining 74 UBLs are too distantly related from structurally characterized proteins.

29
2.4.2 Small-Scale Screening
The complete list of 645 human UBLs (corresponding to 398 unique UBLs) was reduced to 76
UBLs to be pursued for structure determination after removing domains that were structurally
characterized, domains that shared high sequence similarity, and domains for which reagents
were not readily availability. Between 9 to 12 UBL constructs were initially designed for each of
the 76 target proteins, and additional constructs were redesigned after taking into account the
results of small-scale expression and solubility screening. In total, 680 constructs were cloned,
resulting in 205 ubiquitin-like domain constructs with adequate expression and solubility for large-
scale 1H15N-HSQC Screening (Table 2.1).
Table 2.1: Summary of the small-scale expression screening of human UBLs that were structurally characterized and
deposited in the PDB as part of this thesis.
Gene Name
Expression Solubility
5 4 3 2 1 0 5 4 3 2 1 0
BRAF 17 15 2 1 3 25 1 6 2 4
FUBI 2 1 2 1 1
ISG15 16 6 2 1 4 15 6 1 2 1 4
HERPUD2 1 1
NFATc2IPN 1 1 2
NFATc2IPC 1 1
OTU1 1 1
PLXNC1 1 1 1 1
Ubiquilin-1 2 1 1
USP7 1 3 3 4 3
2.4.3 Screening by 1H15N-HSQC
NMR spectroscopy was used for screening protein constructs because samples amenable for
structure determination can be identified within minutes to hours of the protein being purified.
Protein constructs were expressed as poly-histidine-tagged 15N-labeled proteins, and purified
using a rapid batch purification protocol (Yee et al., 2002). 1H15N-HSQC spectra were classified
as poor, promising, good or excellent based on the number of peaks visible, the peaks:residues
ratio, and the signal:noise ratio. Poor 1H15N-HSQC spectra have no visible peaks or all peaks are
overlapping due the sample being an unfolded protein. Promising 1H15N-HSQC spectra may

30
consist of a partially folded protein that contains fewer than expected peaks, or inadequate peak
intensity. Good 1H15N-HSQC spectra show clear dispersion of peaks of equal intensity, an
equivalent number of peaks as amino acids, and adequate peak intensity for structure
determination. Excellent 1H15N-HSQC spectra are similar to the “Good” 1H15N-HSQC with
stronger peak intensity that would facilitate a shorter data collection period (Yee et al., 2002).
Figure 2.7: Examples of 1H15N-HSQC screening results for human UBLs. Sharpin 30 aa-154 aa resulted in a
HSQC classified as poor, FAT10 6 aa-165 aa resulted in a HSQC classified as promising, and FAT10 6 aa-89 aa resulted in a HSQC classified as good. Table 2.2: Summary of 1H15N-HSQC screening results for human UBLs. 10 UBLs were solved by NMR (red), and 7 UBLs were solved by X-ray crystallography (blue).
Gene Name 1H15N-HSQC quality PDB
BRAF promising-2 good-4 2L05 3NY5
FUBI good-4 2L7R
ISG15 2HJ8
HERPUD2 good-1 2KDB
MAP1ALC3 3ECI
NFATc2IP good-2 2L76
NFATc2IP good-1 2JXX
OTU1 good-1 2KZR
PLXNC1 3KUZ
RNF2/RING1B 3H8H
SF3A1 1ZKH
Ubiquilin-1 good-1 2KLC
Ubiquilin-3 1YQB
UHRF1 2FAZ
USP7 poor-1 good-1 2KVR
USP15 3PPA
Sharpin 30 aa-154 aa (poor) FAT10 6 aa-165 aa (promising) FAT10 6 aa-89 aa (good)

31
2.4.4 Structural Coverage - Completing the UBL Phylogenetic Tree
In 2005, there were 73 formally annotated UBLs, which has since grown to 191 formally annotated
ubiquitin-like domain-containing genes and 325 ubiquitin-like domain-containing isoforms
(Marchler et al., 2013). This increase in annotated domains was almost certain due, at least in
part, from the new structures of UBLs deposited in the PDB from work in this thesis; BRAF-1/-2
(PDB_ID: 2L05.A & PDB_ID: 3NY5.ABCD), FAU_1-1 (PDB_ID: 2L7R.A), HERPUD2_1-1
(PDB_ID: 2KDB.A), ISG15_1-2 (PDB_ID: 2HJ8.A), MAP1LC3A_1-1 (PDB_ID: 3ECI.AB),
NFATc2IP_1-1 (PDB_ID: 2L76.A), NFATc2IP_1-2 (PDB_ID: 2JXX.A), PLXNC1_1-2 (PDB_ID:
3KUZ.AB), RING1_2-1/-2 & RING1_2-2 (PDB_ID: 3H8H.A), SF3A1_1-1 (PDB_ID: 1ZKH.A),
UBQLN1_1-1 (PDB_ID: 2KLC.A), UBQLN3_1-1 (PDB_ID: 1YQB.A), UHRF1_1-1 (PDB_ID:
2FAZ.AB), USP15_1-1/-2/-3 & USP15_1-2 (PDB_ID: 3PPA.A) and USP7_1-3 (2KVR.A) (Table
2.2 & Figure 2.8).
Figure 2.8: Clustering of human UBLs into groups based on sequence similarity. Phylogenetic tree of all human
UBLs displaying sub-clustering into 5 groups based on UBL domain sequence similarity. UBLs structurally characterized for this project are labelled in blue alongside corresponding groups and PDB identifiers. Ubiquitin-like
modifiers and 3 putative ubiquitin-like modifiers structurally characterized for this project are underlined.

32
Nevertheless, our research has identified 398 unique UBLs in 220 human genes. When taking
into account isoforms and identical UBLs, there are 645 ubiquitin-like human protein domains. A
number of UBLs have low percent sequence identity, yet continue to share secondary structure
elements characteristic of the -grasp fold found in ubiquitin and UBLs. Our approach of
combining a BLAST sequence similarity search of human proteins followed by secondary
structure predictions and subsequent BLAST sequence similarity searches, allowed us to identify
putative UBLs. Some of the putative UBLs were not formally annotated at the time of analysis,
but have since been formally annotated, while 88 putative ubiquitin-like domain-containing
isoforms and 29 ubiquitin-like domain-containing genes have yet to be validated.
The ambitious goal of completing the structural coverage of all human UBLs through experimental
and computational means was not fully achieved, but 32% of human UBLs now have experimental
structures and an additional 49% of structural coverage has been achieved through 196
computationally determined homology models. The remaining 74 UBLs are too distantly related
to any of the experimentally characterized proteins within the PDB, and at least one member of
each modelling family will need to be experimentally characterized to complete the structural
coverage of all human UBLs (Table 2.3).

33
Table 2.3: All human UBLs that remain to be structurally determined, along with their most similar protein structure
and biological significance.
UBL # Genes that
contain UBL PDB
ID PDB Protein Name
% Sequence
Identity
% Query Length
Medical Significance (OMIM, CGP, DiseaseHub)
# PPI partners
(BioGRID, HPRD, BIND)
# publications
(PubMed)
1 ANKUB1-2 3FIN-C 50S ribosomal protein L1 – Thermus thermophilus
30% 62%
- - 3
2 ANKUB1-3 3G4O-A Aerolysin
– Aeromonas hydrophila 40% 27%
3 ARAP1-3 2JKB-A Sialidase B
– Streptococcus pneumonia 27% 58% - 24 33
4 ARAP2-2 1U5F-A Src kinase-associated
phosphoprotein 2 – Mus musculus
23% 62%
- 1 14
5 ARAP2-3 1YZX-A Glutathione S-transferase kappa 1 – Homo sapiens
27% 59%
6 ARAP3-2 3L7U-A Nucleoside
diphosphate kinase A – Homo sapiens
33% 43% - 3 17
7 ARHGAP20 1U5L-A Major prion protein
– Trachemys scripta 27% 60% - 1 13
8 ASPSCR1_3 3LH5-A Tight junction protein ZO-1
– Homo sapiens 35% 65%
alveolar soft part sarcoma & renal cell carcinoma
12 28
9 EPB41L1_3-1 2HE7-A Band 4.1-like protein 3
– Homo sapiens 42% 60%
mental retardation
30 34
10 FRMD1_2-2 2DD4-B Thiocyanate hydrolase subunit
– Thiobacillus thioparus 44% 48% - 0 4
11
FRMD3_1-2 FRMD3_2-2 FRMD3_3-2 FRMD3_5-1 FRMD3_6-2 FRMD3_7-2 FRMD3_8-1 FRMD3_10-1
4K4K-A ORF:BACUNI_00621
– Bacteroides uniformis ATCC 8492
34% 54%
diabetic nephropathy & potential tumor
suppressor
- 10
12 FRMPD2_1-1 FRMPD2_2-1
3MEJ-A Putative transcriptional regulator
YwtF – Bacillus subtilis 22% 66%
- - 6
13 FRMPD2_4-1 1Q7X-A Tyrosine-protein phosphatase
non-receptor type 13 – Homo sapiens
47% 64%
14 MYLIP_2-1 2B50-A
Peroxisome proliferator-
activated receptor – Homo sapiens
34% 54% - 16 30
15 PAN2_1-1 PAN2_3-1
1E2Z-A Apocytochrome F
– Chlamydomonas reinhardtii 29% 66%
- 345 20 16
PAN2_1-2 PAN2_2-2 PAN2_3-2
2JWO-A V(D)J recombination-activating
protein 2 – Mus musculus 42% 29%
17 PAN2_1-3 PAN2_2-3 PAN2_3-3
4BUJ-B Superkiller protein 3
– Saccharomyces cerevisiae 32% 57%
18 PIK3C2B 2RD0-A
Phophatidylinositol 4,5-bisphophate 3-kinase catalytic
subunit isoform – Homo sapiens
32% 50% neoplasms 16 75
19 PIK3CG 3V65-B Low-density lipoprotein
receptor-related protein 4 – Rattus norvegicus
32% 55% longevity & HIV
pathways 36 380
20 PRIC285_1-1 2LU7-A Obscurin-like protein 1
– Homo sapiens 36% 67% - 7 16
21 PTPN13_1-2 PTPN13_3-2 PTPN13_4-3
3T30-B Nucleoplasmin-2 – Homo sapiens
22% (10% gap)
74% Systemic lupus erythematosus, lung cancer &
multiple sclerosis
34 79
22 PTPN13_3-8 PTPN13_4-9
1GAK-A Fertilization protein – Haliotis fulgens
27% 69%
23 PTPN14_1-3 4LXG-A / hydrolase
– Sphingomonas wittichii 24% 69%
breast neoplasms & lymphedema
38 31
24 PTPN21_1-2 4H1Z-A Enolase - Rhizobium meliloti 30% 48% Graves’ disease 8 14
25 PTPN3_1-2 1GG3-A Protein 4.1 – Homo sapiens 53.7% 53% - 12 28
26 RALGDS_1-1 RALGDS_2-1
1F1R-A 3,4-dihydroxyphenylacetate
2,3-dioxygenase – Iarthrobacter globiformis
31% 56% - 44 47
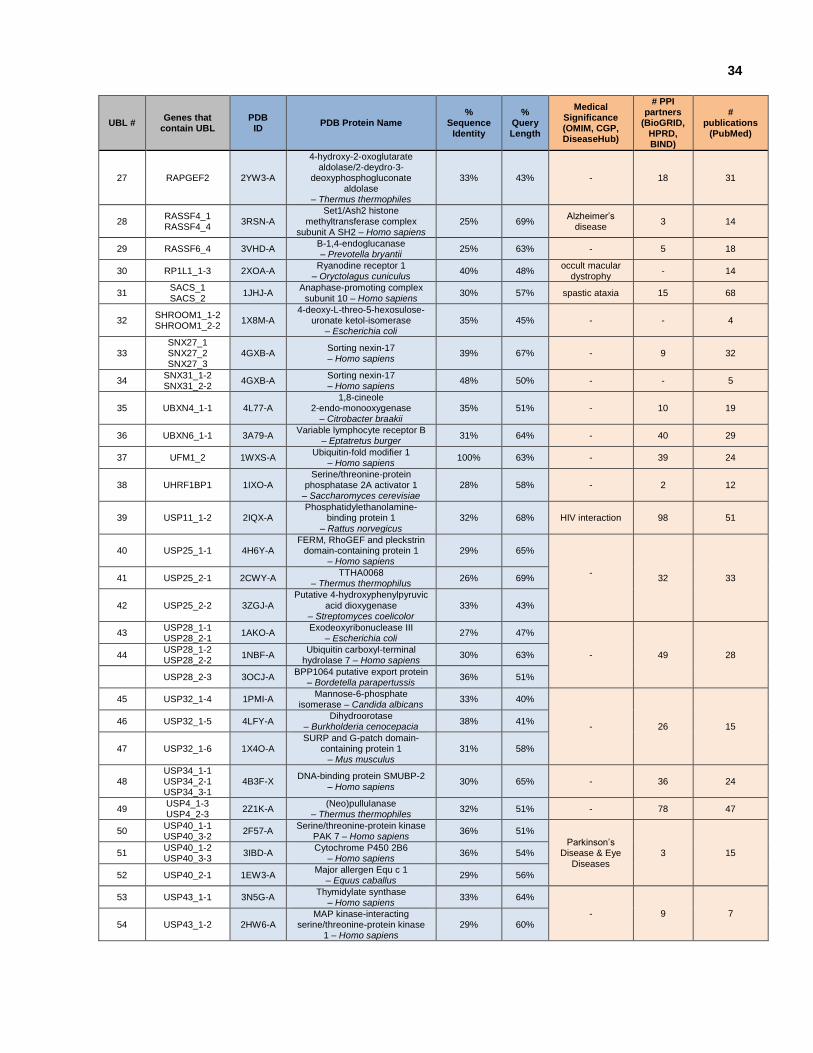
34
UBL # Genes that
contain UBL PDB
ID PDB Protein Name
% Sequence
Identity
% Query Length
Medical Significance (OMIM, CGP, DiseaseHub)
# PPI partners
(BioGRID, HPRD, BIND)
# publications
(PubMed)
27 RAPGEF2 2YW3-A
4-hydroxy-2-oxoglutarate aldolase/2-deydro-3-
deoxyphosphogluconate aldolase
– Thermus thermophiles
33% 43% - 18 31
28 RASSF4_1 RASSF4_4
3RSN-A Set1/Ash2 histone
methyltransferase complex subunit A SH2 – Homo sapiens
25% 69% Alzheimer’s
disease 3 14
29 RASSF6_4 3VHD-A B-1,4-endoglucanase – Prevotella bryantii
25% 63% - 5 18
30 RP1L1_1-3 2XOA-A Ryanodine receptor 1
– Oryctolagus cuniculus 40% 48%
occult macular dystrophy
- 14
31 SACS_1 SACS_2
1JHJ-A Anaphase-promoting complex
subunit 10 – Homo sapiens 30% 57% spastic ataxia 15 68
32 SHROOM1_1-2 SHROOM1_2-2
1X8M-A 4-deoxy-L-threo-5-hexosulose-
uronate ketol-isomerase – Escherichia coli
35% 45% - - 4
33 SNX27_1 SNX27_2 SNX27_3
4GXB-A Sorting nexin-17 – Homo sapiens
39% 67% - 9 32
34 SNX31_1-2 SNX31_2-2
4GXB-A Sorting nexin-17 – Homo sapiens
48% 50% - - 5
35 UBXN4_1-1 4L77-A 1,8-cineole
2-endo-monooxygenase – Citrobacter braakii
35% 51% - 10 19
36 UBXN6_1-1 3A79-A Variable lymphocyte receptor B
– Eptatretus burger 31% 64% - 40 29
37 UFM1_2 1WXS-A Ubiquitin-fold modifier 1
– Homo sapiens 100% 63% - 39 24
38 UHRF1BP1 1IXO-A Serine/threonine-protein
phosphatase 2A activator 1 – Saccharomyces cerevisiae
28% 58% - 2 12
39 USP11_1-2 2IQX-A Phosphatidylethanolamine-
binding protein 1 – Rattus norvegicus
32% 68% HIV interaction 98 51
40 USP25_1-1 4H6Y-A FERM, RhoGEF and pleckstrin
domain-containing protein 1 – Homo sapiens
29% 65%
-
32 33 41 USP25_2-1 2CWY-A TTHA0068
– Thermus thermophilus 26% 69%
42 USP25_2-2 3ZGJ-A Putative 4-hydroxyphenylpyruvic
acid dioxygenase – Streptomyces coelicolor
33% 43%
43 USP28_1-1 USP28_2-1
1AKO-A Exodeoxyribonuclease III
– Escherichia coli 27% 47%
- 49 28 44 USP28_1-2 USP28_2-2
1NBF-A Ubiquitin carboxyl-terminal
hydrolase 7 – Homo sapiens 30% 63%
USP28_2-3 3OCJ-A BPP1064 putative export protein
– Bordetella parapertussis 36% 51%
45 USP32_1-4 1PMI-A Mannose-6-phosphate
isomerase – Candida albicans 33% 40%
- 26 15 46 USP32_1-5 4LFY-A
Dihydroorotase – Burkholderia cenocepacia
38% 41%
47 USP32_1-6 1X4O-A SURP and G-patch domain-
containing protein 1 – Mus musculus
31% 58%
48 USP34_1-1 USP34_2-1 USP34_3-1
4B3F-X DNA-binding protein SMUBP-2
– Homo sapiens 30% 65% - 36 24
49 USP4_1-3 USP4_2-3
2Z1K-A (Neo)pullulanase
– Thermus thermophiles 32% 51% - 78 47
50 USP40_1-1 USP40_3-2
2F57-A Serine/threonine-protein kinase
PAK 7 – Homo sapiens 36% 51%
Parkinson’s Disease & Eye
Diseases 3 15 51
USP40_1-2 USP40_3-3
3IBD-A Cytochrome P450 2B6
– Homo sapiens 36% 54%
52 USP40_2-1 1EW3-A Major allergen Equ c 1
– Equus caballus 29% 56%
53 USP43_1-1 3N5G-A Thymidylate synthase
– Homo sapiens 33% 64%
- 9 7
54 USP43_1-2 2HW6-A MAP kinase-interacting
serine/threonine-protein kinase 1 – Homo sapiens
29% 60%

35
UBL # Genes that
contain UBL PDB
ID PDB Protein Name
% Sequence
Identity
% Query Length
Medical Significance (OMIM, CGP, DiseaseHub)
# PPI partners
(BioGRID, HPRD, BIND)
# publications
(PubMed)
55 USP47_1-4 1UF2-A Outer capsid protein P3
– Rice dwarf virus 26% 53%
- 12 26 56 USP47_2-3 4AWS-A NADH:flavin oxidoreductase
Sye1 – Shewanella oneidensis 57% 45%
57 USP47_2-4 3NWI-A Zinc transport protein ZntB – Salmonella typhimurium
35% 65%
58 USP48_2-3 3GB6-A Putative fructose-1,6-bisphosphate aldolase – Giardia intestinalis
35% 46%
- 10 24
59 USP48_5-1 1S70-A
Serine/threonine-protein
phosphatase PP1- catalytic subunit – Gallus gallus
27% 57%
60 USP48_5-2 2ISV-A Putative fructose-1,6-bisphosphate aldolase – Giardia intestinalis
35% 53%
61 USP48_6-1 3LAD-A Dihydrolipoyl dehydrogenase
– Azotobacter vinelandii 33% 57%
62 USP6_1-1 3UBF-A Neural-cadherin
– Drosophila melanogaster 26% 62%
aneurysmal bone cysts
15 30
63 USP6_1-2 4FN4-A Short chain dehydrogenase – Sulfolobus acidocaldarius
38% 55%
64 USP6_1-3 USP6_2-3
1K28-D Baseplate structural
protein Gp27 – Enterobacteria phage T4
31% 60%
65 USP6_2-2 1PGW-2 RNA2 polyprotein
– Bean-pod mottle virus 30% 69%
66 USP9X_1-3 USP9X_2-3
1VJV-A Ubiquitin carboxyl-terminal
hydrolase 6 – Saccharomyces cerevisiae
38% 62% Turner
syndrome 98 80
67 USP9Y_1-1 USP9Y_2-1
4NGU-A TRAP dicarboxylate transporter,
DctP subunit – Desulfovibrio desulfuricans
27% 64% Infertility /
azoospermia 6 30
68 USP9Y_1-3 USP9Y_2-3
2F1Z-A Ubiquitin carboxyl-terminal
hydrolase 7 – Homo sapiens 42% 62%
69 VCPIP1_1-1 4I15-A Class 1 phosphodiesterase
PDEB1 – Trypanosoma brucei 28% 69%
- 26 31
70 VCPIP1_1-3 3LXM-A Aspartate carbamoyltransferase
– Yersinia pestis 32% 51%
71 WDR48_1-1 WDR48_5-1
1LK5-A Ribose-5-phosphate isomerase
A – Pyrococcus horikoshii 31% 53%
- 70 28
72 WDR48_1-2 WDR48_5-2
1R8I-A TraC – Escherichia coli 23% 37%
73 WDR48_3-1 WDR48_4-1
2PBI-A Regulator of G-protein
signalling 9 – Mus musculus 28% 66%
74 WDR48_3-2 WDR48_4-2
1IDU-A Vanadium chloroperoxidase –
Curvularia inaequalis 33% 78%

36
2.5 Conclusion
The human genome contains 220 genes that encode 398 unique UBLs. At the time of the
analysis, 147 of the UBLs were not annotated as having the Ubiquitin-fold. The goal of this project
was to obtain structural coverage of all human UBLs, without experimentally determining each of
the 398 unique UBLs. This was facilitated by grouping the 398 UBLs into 100 modelling families
that represent homologous protein domains that have similar structures. NMR spectroscopy was
used to screen and prioritize UBLs for structure determination, and 17 human UBLs were
structurally characterized using X-ray Crystallography and NMR spectroscopy. As a result, the
RCSB PDB now has 32% structural coverage of human UBLs, and 82% structural coverage when
taking into account homology modelling. Of the 74 remaining human UBLs that lack structural
information, 30 are singletons and are 36% similar & 23% identical to protein structures in the
PDB. This project provided 3.7% coverage of the human UBLs through experimental structure
determination and 6% coverage when taking into account homology models. Structural analyses
also provide insight into families of related proteins. In particular, structural analysis of the
NFATc2IP and ubiquilin protein families revealed insight into protein-protein interactions and
facilitated the prediction of novel binding partners.

37
Chapter 3
Solution NMR structure determination of human Ubiquitin-like domains in NFATc2IP & Ubiquilin-1
Contributions: A. Semesi, M. Garcia & A. Yee assisted with cloning, small scale sample
preparation & small scale expression/solubility screening. C. Fares, M. Karra, S. Srisalam, S.
Houliston assisted with NMR data acquisition and NMR titration. B. Wu, A. Gutmanas & A. Lemak
assisted with NMR structure determination. I performed large scale NMR sample preparation and
NMR screening, as well as structure determination and subsequent analyses of NFATc2IP &
ubiquilin-1.

38
Chapter 3
Solution NMR structure determination of human Ubiquitin-like domains in NFATc2IP & Ubiquilin-1
3.1 Introduction
Ubiquitin-like domains from two human ubiquitin-like domain containing proteins, NFATc2IP and
Ubiquilin-1, were structurally determined using NMR spectroscopy. The ubiquitin-like domain of
human NFATc2IP (residues 342-419) and the ubiquitin-like domain of Ubiquilin-1 (residues 34-
112), both share the same -grasp domain architecture as Ubiquitin and other UBLs encoded
within the human genome.
Structure determination of these two protein structures was part of a collaborative effort that
resulted in the structure determination and characterization of 17 human ubiquitin-like domain
structures that have expanded our knowledge of the diversity of the ubiquitin fold.
3.1.1 NFATc2IP
NFATc2IP is involved in the Nuclear factor of activated T-cells (NFAT) signaling cascade, which
is important in immune response (Rengarajan et al., 2000). The NFAT family of transcription
factors (NFATc1, NFATc2, NFATc3, and NFATc4) are characterized by a Rel-homology region
and an NFAT-homology region (Macian F, 2005). NFATc2 interacts with NFATc2IP, and is
present in the cytoplasm prior to translocating to the nucleus upon T-cell receptor stimulation (Rao
et al., 1997). SUMO conjugation of NFATc2 leads to nuclear retention, regulation of
transcriptional activity and recruitment to nuclear SUMO-1 bodies (Nayak et al., 2009; Terui et al.,
2004). NFATc2 contains a putative SUMO interacting motif, which could be involved in the
association between NFATc2IP and NFATc2.

39
3.1.2 Ubiquilin-1
Ubiquilin-1 is one of the four members of the ubiquilin protein family. Ubiquilin proteins contain an
N-terminal ubiquitin-like domain and a C-terminal ubiquitin-associated domain, separated by ~450
aa (Mah et al., 2000). The central region of each member of the ubiquilin protein family contains
two STI1 motifs, capable of binding to heat shock proteins. Ubiquilin proteins physically associate
with proteasomes and ubiquitin ligases, and are thought to modulate protein degradation.
Ubiquilin-1 interacts with ubiquitin-interacting motifs (UIMs) in the proteasomal subunit S5A,
ataxin-3, HSJ1a, and EPS15 (Heir et al., 2006; Regan-Klapisz et al., 2005). Ubiquilin-1 also
interacts with CD47 and Gβγ, suggesting a role in integrating adhesion and signaling components
of cell migration (N'Diaye & Brown, 2003).
3.1.3 Ubiquitin-like Fold
The ubiquitin-like fold of both NFATc2IP & Ubiquilin-1 contain a 5-strand mixed -sheet that is
intercalated by an -helical core. Comparative analysis of both ubiquitin-like folds reveal minor
differences (1-2 aa) in loop lengths, and the most distinct difference is at the C-terminus of the -
helical core (Figure 3.3 & Table 3.2). The Ubiquilin-1 -helical core is 16 aa and contains a 2-
residue lysine 59 – serine 60 break that allows the three C-terminal residues of the -helix
(histidine 61, threonine 62, aspartic acid 63) to orient back into the fold.

40
3.2 Experimental Procedures
3.2.1 NFATc2IP UBL domain NMR structure determination
NMR screening was performed on a 78 residue construct of the 2nd ubiquitin-like domain of
NFATc2IP, and its HSQC spectra revealed that it was amenable for structure determination
(MGSSHHHHHHSSGLVPRGSTETSQQLQLRVQGKEKHQTLEVSLSRDSPLKTLMSHYEEAMGLSGRKLSFFFDGTK
LSGRELPADLGMESGDLIEVWG - SGC clone accession: ubh72.342.419.pET28-MHL_SDC088D093).
The NMR sample was expressed in E. coli BL21 (DE3) in a 125 mL flask containing M9 minimal
media (100 uM ZnSO4, 8.55 mM NaCl, 47.6 mM Na2HPO4, 22 mM KH2PO4 100 mM MgSO4, 2
mM biotin, 1.5 mM thiamine.HCl, 10 mM ZnSO4, and 0.1 M CaCl2), supplemented with 15NH4Cl,
13C6-D-glucose and 50 µg/mL kanamycin, and was inoculated from a glycerol stock of bacteria.
The flask was incubated on a shaker for 18 hours at 220 rpm at 37ºC before being transferred to
a 2L flask containing 1000 mL M9 minimal media supplemented with 50 µg/mL kanamycin, and
incubated at 37 ºC until an OD600 of 1.0 was reached. Protein expression was induced with 100
µM IPTG and the cells were incubated for 15.5 hours at 220rpm at 15ºC. Cell pellets were
obtained by centrifugation, and frozen in 50 mL Falcon tubes at -80ºC. The frozen cell pellets
were thawed by soaking in warm water before being resuspended in 40 mL lysis buffer (15.4 mM
tris.HCl, 100 uM ZnSO4 100uL, 0.5 mM NaCl, and 15 mM imidazole; pH 8.5.) and lysed by
sonication on ice. The lysate was clarified through centrifugation for 20 min at 4 ºC, and the
supernatant was mixed with 2 mL of Ni2+ affinity beads per 40 mL lysate. The mixture was shaken
for 20 minutes at 4 ºC, before undergoing centrifugation at 2000 rpm for 6 minutes. The
supernatant was decanted and the remaining resin was resuspended and washed twice with lysis
buffer, followed by two 5 mL cold buffer washes (15.4 mM tris.HCl, 100 uM ZnSO4 100uL, 0.5 mM
NaCl, and 30 mM imidazole; pH 8.5). The washed resin was transferred to a gravity filter column
and washed with an additional 2 mL of wash buffer. The purified protein was then eluted from the
resin with 5 mL of elution buffer (15.4 mM tris.HCl, 100 uM ZnSO4 100uL, 0.5 mM NaCl, and 500
mM imidazole; pH 8.5).

41
The purified protein was exchanged from elution buffer into MOPS-based NMR buffer (NMR buffer
for H2O experiments: pH 8.0, 10 mM MOPS, 500 mM NaCl, 1 mM benzamidine, 0.01% NaN3, 10
µM ZnSO4, 10% D2O, and 90% H2O; NMR buffer for D2O experiments: pH 8.0, 10 mM MOPS,
500 mM NaCl, 1 mM benzamidine, 0.01% NaN3, 10 µM ZnSO4, and 100% D2O) by
ultracentrifugation using 2 mL concentrators with a 3,000 molecular weight cut-off (VivaSpin 2
MES) at 3000 rpm, resulting in a final volume of 300 µL and final protein concentration of 0.9 mM.
The concentrated protein was then transferred to a 3 mm NMR tube.
A series of NMR spectra (3D HNCO, 3D HNCA, 3D CBCA(CO)NH, 3D HBHA(CO)NH, 2D 1H-
13C Constant Time HSQC, 3D 1H-13C NOESY, 3D 1H-15N NOESY, 3D 1H-13C Aromatic
NOESY, 3D (H)CCH-TOCSY, and 3D H(C)CH-TOCSY) were collected at 298K using a 500MHz
Bruker AVANCE spectrometer, a 600MHz Bruker AVANCE spectrometer and a 800MHz Bruker
AVANCE spectrometer. After data collection was performed on the unaligned sample, the purified
protein was aligned by titrating 12 mg/mL Pf1 co-solvent Protease-free Phage into the NMR
sample until 10 Hz proton splitting was observed. Spectra of aligned and unaligned spectra (2D
1H-15N IPAP HSQC) were obtained using the 500MHz Bruker AVANCE spectrometer and the
800MHz Bruker AVANCE spectrometer. NMR data was processed and analyzed using
TOPSPIN, NMRPipe, NMRDraw, SPARKY, Abacus/FMCGUI, CNS, TALOS, PALES, PSVS, and
WhatIF.(Delaglio et al., 1995; Goddard & Kneller; Lemak et al., 2011; Brünger et al., 1998;
Brünger AT, 2007; Shen et al., 2009; Zweckstetter & Bax, 2000; Bhattacharya A et al., 2007;
Vriend G, 1990)
3.2.2 Ubiquilin-1 UBL domain NMR structure determination
The process for NMR structure determination of Ubiquilin-1 was very similar to that of NFATc2IP,
with a few minor differences that included the use of the LEX fermentation system and non-
uniform sampling. The LEX fermentation system is a high-throughput bioreactor developed at the
Structural Genomics Consortium that consists of an enclosure that houses cell culture within

42
media bottles that are connected to an air manifold via a quick disconnect manual flow regulator
to ensure sufficient oxygenation and mixing of cells at a regulated temperature (Koehn & Hunt,
2009). Of the three constructs generated for ubiquilin-1, a 79 residue construct was determined
to be most amenable for structure determination by NMR (SGC clone accession:
ubqln1.034.112.p15Tvlic
MGSSHHHHHHSSGRENLYFQGPKIMKVTVKTPKEKEEFAVPENSSVQQFKEEISKRFKSHTDQLVLIFAGKILKDQDT
LSQHGIHDGLTVHLVIKTQNRP).
The NMR sample was expressed in E. coli BL21 (DE3) RIL in M9 minimal media supplemented
with biotin, thiamine, and 10 µM ZnSO4; 15NH4Cl and 13C-glucose were the sole nitrogen and
carbon source. Starter cultures (50 mL in a 250 mL flasks) were prepared with media
supplemented with 100 µL of glycerol stock and shaken overnight (18 hours) at 220 rpm at 37ºC.
The starter culture was used to inoculate 500 mL of growth media that was placed in a modified
LEX fermentation system at 37ºC until an OD600 of 1.0 was achieved. Protein expression was
induced with 1 mM IPTG and grown at room temperature for 15.5 hours. Cells were harvested
by centrifugation and frozen in 50 mL Falcon tubes at -80ºC. The frozen cell pellets were thawed,
resuspended in 25 mL lysis buffer (20 mM tris.HCl, 100 uM ZnSO4, 0.5 mM NaCl, and 15 mM
imidazole, pH 8.5) and lysed by sonication on ice. Lysate was clarified by centrifugation for 20
min at 4°C and the supernatant was mixed for 20 minutes at 4°C with 2 mL settled Ni2+ affinity
beads. Beads were batch-washed twice with 5 mL of cold wash buffer (20 mM tris.HCl, 100 uM
ZnSO4, 0.5 mM NaCl, and 30 mM imidazole, pH 8.5), spun at 2000 rpm for 6 minutes, transferred
to a column, and further washed with 2 mL of wash buffer. The purified protein was eluted with 5
mL of Elution buffer (20 mM tris.HCl, 100 uM ZnSO4, 0.5 mM NaCl, and 500 mM imidazole, pH
8.5). The purified protein was exchanged into NMR buffer (pH 7.0, 10 mM Tris-HCl, 300 mM
NaCl, 10 mM DTT, 1 mM benzamidine, 0.01% NaN3, 1x inhibitor cocktail (Roche), 10 µM ZnSO4,
10% D2O, and 90% H2O) and protein concentration was performed using VivaSpin concentrators

43
with a 5,000 molecular weight cut-off at 3000 rpm, resulting in a final volume of 300 µL and protein
concentration of 0.5 mM.
The purified protein was transferred to a 5 mm Shigemi NMR tube for data collection, and a series
of spectra (3D HNCO, 3D HNCA, 3D CBCA(CO)NH, 3D HBHA(CO)NH, 3D (H)CCH-TOCSY, 3D
H(C)CH-TOCSY, 13C-edited aliphatic NOESY, 13C-edited aromatic NOESY, 15N-edited NOESY-
HSQC, and 13C Constant Time HSQC) were collected at 25ºC on a 800 MHz Bruker AVANCE
spectrometer and a 600 MHz Bruker AVANCE spectrometer equipped with a z-shielded gradient
triple resonance cryoprobe. Chemical shifts were referenced to external DSS. All spectra were
non-uniformly sampled, and were processed using the NMRPipe, NMRDraw and
multidimensional decomposition software (Delaglio et al., 1995). The backbone assignments
were obtained using HNCO, CBCA(CO)NH, HBHA(CO)NH, HNCA and 15N-edited NOESY-HSQC
spectra. Aliphatic side chain assignments were obtained from H(C)CH-TOCSY, (H)CCH-TOCSY,
13C-edited aliphatic NOESY and 15N-edited NOESY-HSQC spectra. 36 H-N and 39 Ca-CO RDC
constraints were generated using SPARKY and PALES. NMR data was processed and analyzed
using TOPSPIN, NMRPipe, NMRDraw, SPARKY, MDD, FMCGUI, CYANA, CNS, TALOS,
PALES, and PSVS.
Distance restraints for structure calculations were derived from cross-peaks in 15N-edited NOESY-
HSQC, 13C-edited aliphatic and aromatic NOESY-HSQC spectra. NOE assignment and structure
calculations were performed using FMC-GUI and CYANA. The quality of the structure calculation
was assessed by NMR structure quality assessment scores (NMR PRF scores). The best 20 of
100 CYANA structures from the final cycle were selected and subjected to molecular dynamics
refinement in explicit water with RDC constraints using the program CNS. The structures were
inspected by PROCHECK and MolProbity using NESG validation software package PSVS.

44
3.2.3 Comparative analysis of Ubiquilin-1, NFATc2IP, Ubiquitin & SUMO2
Structural models (homology models and experimentally determined models) were inspected
using UCSF Chimera, and extraneous atoms removed (e.g. poly-histidine tag, water molecules,
other proteins/peptides, and residues that extended beyond the core ubiquitin-like domain)
(Petterson et al., 2004). The molecular structures of each structurally characterized Ubiquitin-like
domain were structurally aligned and superimposed using UCSF Chimera. Based on the
structural alignment, the corresponding core RMSD and C RMSD were calculated. Based on
both the structural alignment and secondary structure element alignment, a multiple sequence
alignment was generated.
Electrostatic potential distributions of 58 human UBLs were evaluated using the Analysis of
Electrostatic Similarities Of Proteins (AESOP) framework (Gorham et al., 2011). The x-ray crystal
structure coordinates of GABARAPL1(PDBID:2R2Q), NFATc2IP_2nd(PDBID:3RD2),
FAF1(PDBID:3QX1), USP15(PDBID:3PPA), TCEB2(PDBID:4B95), NSFL1C(PDBID:1S3S),
RNF2(PDBID:3H8H), UBXN7(PDBID:1WJ4), BRAF(PDBID:3NY5), NCF2(PDBID:1OEY),
PIK3CG(PDBID:3CST), OASL(PDBID:1WH3), RGL2(PDBID:4JGW), SUMO3(PDBID:2IO1),
PIK3CD(PDBID:4XE0), EPB41(PDBID:1GG3), EPB41L3(PDBID:2HE7), RALGDS(PDBID:2RGF),
ISG15(PDBID:3SDL), NF2(PDBID:1H4R), MAP1LC3A(PDBID:3ECI), MAP1LC3B(PDBID:3VTU),
UBQLN3(PDBID:1YQB), BAG1(PDBID:1WXV), UBL7(PDBID:1X1M), USP14(PDBID:2AYN),
RAD23A(PDBID:2WYQ), NEDD8(PDBID:4FBJ), UHRF1(PDBID:2FAZ), PIK3CA(PDBID:4JPS),
RDX(PDBID:1J19), UBIQUITIN(PDBID:3B0A & 4HK2), RAF1(PDBID:1GUA), and UBLCP1(PDBID:2M17)
were used for surface charge analysis (Berman et al., 2000). Representative models from 30
NMR ensembles were used: BRAF(PDBID:2L05), FAU(PDBID:2L7R), HERPUD1(PDBID:1WGD),
IQUB(PDBID:2DAF), ISG15(PDBID:2HJ8), NFATc2IP_1st(PDBID:2L76), NFATc2IP_2nd(PDBID:2JXX),
RAD23B(PDBID:1UEL), SF3A1(PDBID:1ZKH), SUMO1(PDBID:1A5R), SUMO2(PDBID:2AWT),
TBCB(PDBID: 2KJ6), UBIQUITIN(PDBID: 1Q0W & 1YX6), UBL3(PDBID: 1WGH), UBL4A(PDBID: 2DZI),
UBL5(PDBID: 1UH6), UBQLN1(PDBID: 2KLC), UBQLN2(PDBID: 1J8C), UBQLN3(PDBID: 1WX7),
UBTD2(PDBID: 1TTN), UBXN4(PDBID: 2KXJ), UFM1(PDBID: 1WXS), UHRF2(PDBID: 1WY8),

45
URM1(PDBID: 1WGK), USP7(PDBID: 2KVR), mouse ASPSCR1(PDBID: 2AL3), mouse RGL1(PDBID:
1EF5), mouse TMUB2(PDBID: 1WIA), and mouse UBFD1(PDBID:1V86).
Structural models were prepared for electrostatic potential calculations by determining partial
charges at a pH of 7.6 and van der Waals radii using PDB2PQR with the PARSE forcefield
(Dolinsky et al., 2007; Sitkoff et al., 1994). Electrostatic potentials were calculated using the
linearized Poisson Boltzmann equation,
where r represents discrete grid point positions within and around the protein, ε(r) is the dielectric
coefficient, ε0 is the vacuum permittivity, κ(r) is the ion accessibility function, ϕ(r) is the
electrostatic potential, e is the electron charge, κB is the Boltzmann constant, T is the temperature,
and z is the unit or partial charge at position δ(r − rr) (Davis et al., 1990). The Adaptive Poisson-
Boltzmann Solver (APBS) software package calculates electrostatic potential by embedding each
UBL in a grid, and solves the Poisson-Boltzmann equation to determine electrostatic potential at
each grid point based on assigned charge, dielectric coefficient, and ion accessibility (Baker et
al., 2001). The dielectric surface was defined using a sphere probe with a radius of 1.4 Å, and ion
accessibility surface was defined using a sphere probe with a radius of 2.0 Å. All UBLs were
superimposed within a unified grid dimensions (129 × 97 × 97 points) with calculated isopotential
contour surfaces plotted at ±1kbT/e. Electrostatic potentials were visualized using USCF Chimera
(Pettersen et al., 2004). Comparison of the spatial distributions of electrostatic potentials of the
UBLs were performed by generating a similarity distance matrix according to the metric:
where ϕA(i,j,k) and ϕB(i,j,k) are electrostatic potentials of proteins A and B, respectively, at a
common grid point (i,j,k), and N the number of grid points. This method implies that proteins
having a distance of 0 have identical spatial distributions of electrostatic potentials, whereas those
having a distance of 2 have completely different electrostatic potential spatial distributions.

46
3.2.4 Protein-protein interaction partner identification
The ScanProsite tool was used to search all human proteins for putative UIMs based on a series
of motifs with strict ([ED](3)-x(3)-[AG]-x(3)-S-x(2)-[ED]) and weak stringency ([ED]-x(3)-[AG]-x(6)-
S-x(2)-[ED]). The resulting lists of putative UIM-containing human proteins were compared to
experimentally known binding partners of ubiquitin, ubiquilin family members and isoforms.
Binding partners were identified by searching multiple protein-protein interaction databases
(BioGRID, iRefWeb, and Human Protein Reference Database) using protein name, uniprot ID,
and protein sequence (Turner et al., 2010). Multiple isoforms of ubiquilin family members and
NFATc2IP exist, and each isoform was included in the search. Human binding partners observed
to interact with non-human forms of ubiquilin and NFATc2IP were also considered in the analysis
of potential binding partners.
For proteins known or predicted to interact with ubiquilin-1 and NFATc2IP that lacked
experimental structures, secondary structure elements were predicted using the JPRED algorithm
for the full length protein of proteins (Cuff et al., 2000; Cole et al., 2008).
A difference approach was performed for identifying putative binding partners for NFATc2IP. Only
two binding partners were known for NFATc2IP. Therefore, bioinformatics analyses were
performed on both of these binding partners to identify possible modes of interaction related to
the ubiquitin fold. Secondary structure elements were predicted. Each -helix was analysed to
identify similarities with the canonical UIM. Each -strand was analysed to identify similarities
with the canonical SIM.
3.2.5 Binding interface analysis
UCSF Chimera was used to superimpose the newly characterized molecular structures of both
ubiquilin-1 and NFATc2IP onto known protein-protein interaction complexes involving
ubiquitin:UIM (PDBID: 1Q0W, 1P9D, 1UEL) and SUMO:SIM (PDBID: 2RPQ, 2ASQ & 2KQS).

47
Residues at varying distances from each atom of the UIM and SIM were annotated. Residues in
proximity to the UIM or SIM were further analysed for conservation or shared similar
physicochemical attributes as ubiquitin or SUMO2.
Molecular surfaces for each UBL were calculated, as well as hydrophobicity and electrostatic
potential distributions. Chemical characteristics near the UIM and SIM binding interfaces were
compared between UBLs, and key observations and residues were annotated.
3.3 Results & Discussion
3.3.1 Structure determination
High-quality NMR structures were obtained for both NFATc2IP & Ubiquilin-1. Their coordinates
were deposited in the Protein Data Bank on November 30th 2007 (NFATc2IP PDBID: 2JXX) and
June 30th 2009 (Ubiquilin-1 PDBID: 2KLC). Both structures consist of a compact globular -grasp
fold that contains 2 -helices and a 5-stranded -sheet with a C RMSD of 1.234Å for 39 core
residues, an overall RMSD of 1.234Å for all 69 aligned residues, and a structural distance
measurement (cutoff 5.0) of 34.382 (Figures 3.1 & 3.2). The -helical core is packed against one
side of the -sheet, and the Ubiquilin-1 -helix contains a 2-residue lysine 59 - serine 60 break
that allows the three C-terminal residues of the -helix (histidine 61, threonine 62, aspartic acid
63) to orient back into the fold (Figure 3.3). The second -helix of Ubiquilin-1 and NFATc2IP is
5-6 aa in length and situated at the top of the -sheet (Table 3.2).
The electrostatic potential distribution at pH 7 is significantly different between ubiquilin-1 and
NFATc2IP. Ubiquilin-1 is mostly positively charged and NFATc2IP is mostly negatively charged
(Figure 3.4 & 3.5). Both Ubiquilin-1 and NFATc2IP contain small hydrophobic patches, while
Ubiquilin-1 has a larger hydrophobicity patch within the region of residues valine 47, leucine 65,
valine 66, leucine 67, isoleucine 68, isoleucine 73, leucine 74, leucine 93, valine 94, and
isoleucine 95, which is within a few angstroms of the putative UIM-binding interface (Figure 3.6).

48
An analysis of each ubiquitin-like domain structure was performed to characterize similarities
between each molecular structure that was determined as part of this thesis. The molecular
structure analysis consisted of exploring four attributes: molecular surface characteristics,
electrostatic potential distribution, secondary structure elements, and protein-protein interaction
interfaces. The protein-protein interaction interface analysis focused on the UIM and SIM binding
interfaces, because the UIM region and SIM region of UBDs are amenable to identification using
computational analysis.
Table 3.1: NMR data and refinement statistics.
NFATc2IP Ubiquilin-1
NMR distance and dihedral constraints Distance constraints: Total NOE 2094 1997 Intra-residual 411 421 Sequential (|i-j| = 1) 556 566 Medium-range (2 ≤ |i-j| ≤ 4) 301 331 Long-range ( |i-j| ≥ 4) 826 679 Hydrogen bonds 0 24 Dihedral Angle constraints: 109 84
- phi 54 41
- psi 55 43
Structure statistics Violations (mean and s.d.) Distance constraints (Å) 0.038 +/- 0.004 0.016 +/- 0.001 Dihedral angle constraints (°) 3.680 +/- 6.088 0.855 +/- 0.130 Max. distance constraint violation (Å) 1.25 0.35 Max. dihedral angle violation (°) 152.43 5.74 Deviations from idealized geometry Bond lengths (Å) 1.235 +/- 0.007 1.256 +/- 0.005 Bond angles (°) 0.495 +/- 0.008 0.516 +/- 0.009 Impropers (°) 0.634 +/- 0.023 0.668 +/- 0.025 Ramachandran plot Most favoured regions (%) 87.5% 84.4% Allowed regions (%) 12.5% 14.3% Generously allowed regions (%) 0.1% 1.3% Disallowed regions (%) 0% 0.1% Average pairwise RMSD (Å) Heavy 1.57 +/- 0.25 1.15 +/- 0.10 Backbone 1.20 +/- 0.35 0.72 +/- 0.12
PDB accession ID 2JXX 2KLC BMRB accession ID 15576 16390
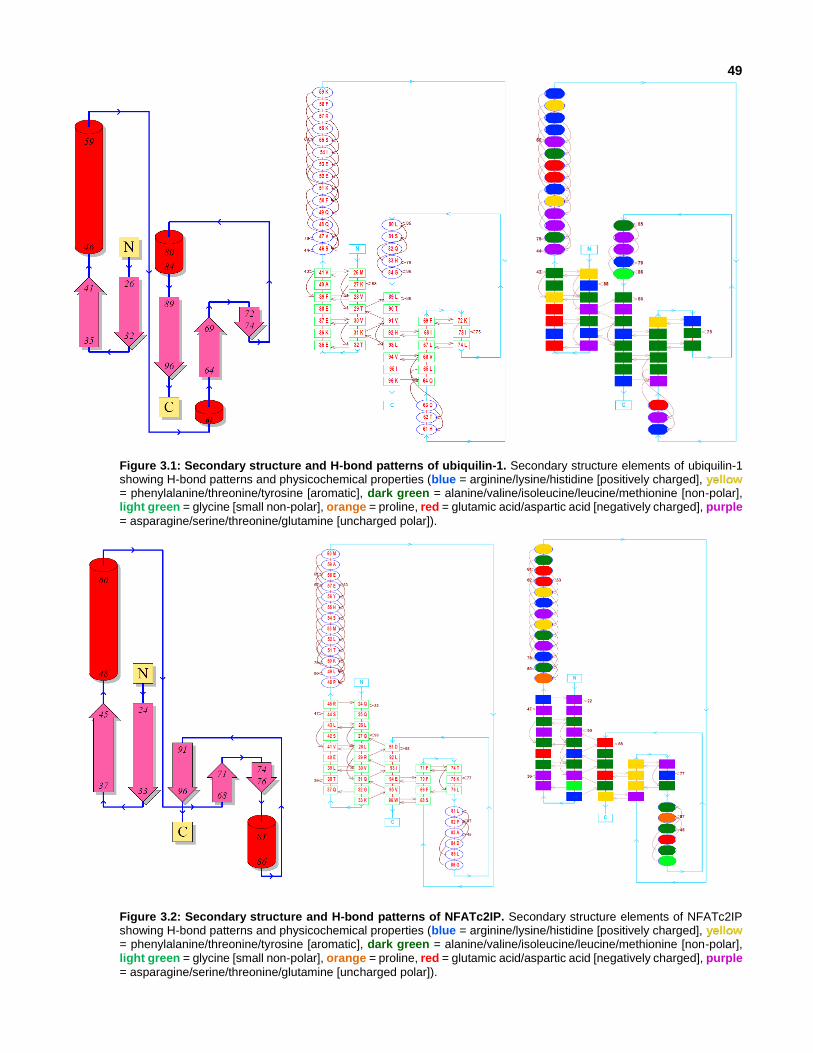
49
Figure 3.1: Secondary structure and H-bond patterns of ubiquilin-1. Secondary structure elements of ubiquilin-1 showing H-bond patterns and physicochemical properties (blue = arginine/lysine/histidine [positively charged], yellow = phenylalanine/threonine/tyrosine [aromatic], dark green = alanine/valine/isoleucine/leucine/methionine [non-polar], light green = glycine [small non-polar], orange = proline, red = glutamic acid/aspartic acid [negatively charged], purple
= asparagine/serine/threonine/glutamine [uncharged polar]).
Figure 3.2: Secondary structure and H-bond patterns of NFATc2IP. Secondary structure elements of NFATc2IP showing H-bond patterns and physicochemical properties (blue = arginine/lysine/histidine [positively charged], yellow = phenylalanine/threonine/tyrosine [aromatic], dark green = alanine/valine/isoleucine/leucine/methionine [non-polar], light green = glycine [small non-polar], orange = proline, red = glutamic acid/aspartic acid [negatively charged], purple
= asparagine/serine/threonine/glutamine [uncharged polar]).

50
Ubiquilin-1 NFATc2IP
Ubiquitin SUMO1 SUMO2 SUMO3
Figure 3.3: Ribbon diagrams of ubiquilin-1, NFATc2IP, ubiquitin, SUMO1, SUMO2 & SUMO3. Ubiquilin-1 and
NFATc2IP contain an -helical break, which also occurs in ubiquitin, SUMO1, SUMO2 and SUMO3.
Table 3.2: Secondary structure elements of NFATc2IP, ubiquilin-1, ubiquitin and SUMO1/2/3.
-strand 1
-strand 2
-helix 3
-strand 4
-strand 5
-helix 6
-strand 7
NFATc2IP_2nd 346-354
9 aa 4 aa
359-367 9 aa
2 aa
370-383 14 aa
6 aa
390-393 4 aa
2 aa
396-398 3 aa
4 aa
403-408 6 aa
4 aa
413-418 6 aa
Ubiquilin-1 26-32 7 aa
2 aa
35-41 7 aa
4 aa
46-61 16 aa
(gap)
2 aa
64-69 6 aa
2 aa
72-74 3 aa
5 aa
80-84 5 aa
4 aa
89-96 8 aa
Ubiquitin 2-6 5 aa
5 aa
12-16 5 aa
5 aa
22-39 18 aa
(gap)
1 aa
41-45 5 aa
2 aa
48-49 2 aa
5 aa
55-60 6 aa
5 aa
66-71 6 aa
SUMO1 21-28 7 aa
4 aa
32-39 7 aa
4 aa
44-55 10 aa
7 aa
62-65 4 aa
10aa
- - 76-80 5 aa
5 aa
86-92 7 aa
SUMO2 18-23 6 aa
5 aa
29-34 6 aa
5 aa
40-52 13 aa
6 aa
59-62 4 aa
2 aa
65-66 2 aa
15aa
82-83 2 aa
1 aa
85-87 3 aa
SUMO3 16-22 7 aa
5 aa
28-34 7 aa
4 aa
39-55 17 aa
(gap)
1 aa
57-61 5 aa
2 aa
64-65 2 aa
16a
82-87 6 aa
2 aa
90-91 2 aa
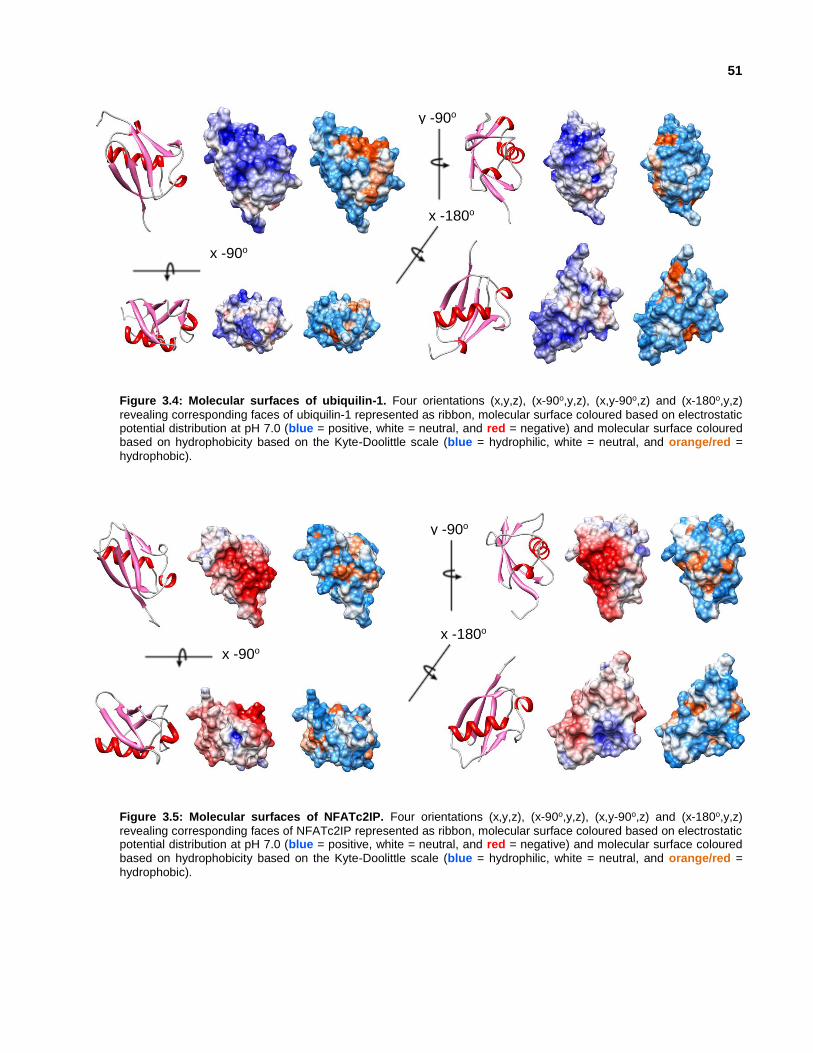
51
Figure 3.4: Molecular surfaces of ubiquilin-1. Four orientations (x,y,z), (x-90o,y,z), (x,y-90o,z) and (x-180o,y,z)
revealing corresponding faces of ubiquilin-1 represented as ribbon, molecular surface coloured based on electrostatic potential distribution at pH 7.0 (blue = positive, white = neutral, and red = negative) and molecular surface coloured based on hydrophobicity based on the Kyte-Doolittle scale (blue = hydrophilic, white = neutral, and orange/red =
hydrophobic).
Figure 3.5: Molecular surfaces of NFATc2IP. Four orientations (x,y,z), (x-90o,y,z), (x,y-90o,z) and (x-180o,y,z)
revealing corresponding faces of NFATc2IP represented as ribbon, molecular surface coloured based on electrostatic potential distribution at pH 7.0 (blue = positive, white = neutral, and red = negative) and molecular surface coloured based on hydrophobicity based on the Kyte-Doolittle scale (blue = hydrophilic, white = neutral, and orange/red =
hydrophobic).
x -90o
y -90o
x -180o
y -90o
x -180o
x -90o

52
Figure 3.6: UIM-interaction interface of ubiquilin-1 and NFATc2IP. A hydrophobic patch (orange) on ubiquilin-1 is
near the UIM-interaction interface, consisting of residues valine 47, leucine 65, valine 66, leucine 67, isoleucine 68, isoleucine 73, leucine 74, leucine 93, valine 94, and isoleucine 95. Four aliphatic residues (leucine 262, isoleucine 263, alanine 266, and isoleucine 267; pink) in the putative NFATc2 UIM peptide are closest to the hydrophobic patch.
3.3.2 Comparative analysis of ubiquilin-1, NFATc2IP & similar ubiquitin-like modifiers
The ubiquitin fold is the underlying characteristic that unifies all UBLs. However, structural and
physicochemical differences lead to the various functional pathways that UBLs are involved in.
To identify these differences, a comparative analysis of ubiquilin-1 and NFATc2IP was performed,
which was further expanded to include ubiquitin-like modifiers. Even with a core C RMSD of
1.234 Å (39 residues) and common secondary structure elements, the sequence identity between
ubiquilin-1 & NFATc2IP is 13% and the sequence similarity is 38%.
x +90o
x +90o

53
3.3.2.1 Similar canonical ubiquitin-like modifiers: ubiquitin & SUMO-2
The sequence identity/similarity between each ubiquitin-like domain and ubiquitin-like modifiers
was calculated. The closest canonical ubiquitin-like modifier for ubiquilin-1 is ubiquitin (35%
sequence identity & 54% sequence similarity), and the closest canonical ubiquitin-like modifier for
NFATc2IP is SUMO2 & SUMO4 (35% sequence identity & 55% sequence similarity) (Table 3.3).
Table 3.3: Sequence similarity & identity between NFATc2IP, ubiquilin-1, ubiquitin and SUMO1/2/3/4.
NFATc2IP ubiquilin-1 ubiquitin SUMO1 SUMO2 SUMO3 SUMO4
NFATc2IP_2nd 13%id (9) 11%id (8) 29%id (21) 35%id (28) 34%id (27) 35%id (28)
ubiquilin-1 13%id (9) 35%id (26) 19%id (15) 15%id (11) 15%id (11) 12%id (9)
NFATc2IP_2nd 38%sim (27) 41%sim (29) 54%sim (40) 55%sim (44) 53%sim (43) 55%sim (44)
ubiquilin-1 38%sim (27) 54%sim (40) 42%sim (33) 41%sim (30) 41%sim (30) 35%sim (26)
NFATc2IP_2nd 2%gaps (2) 1%gaps (1) 1%gaps (1) 1%gaps (1) 1%gaps (1) 1%gaps (1)
ubiquilin-1 2%gaps (2) 1%gaps (1) 1%gaps (1) 1%gaps (1) 1%gaps (1) 1%gaps (1)
3.3.2.2 Structural comparison between ubiquilin-1 & NFATc2IP
Ubiquilin-1 and NFATc2IP share 8 identical residues, 5 within secondary structure elements and
3 within loop regions. All three of the identical residues in loop regions are small & flexible, one
serine & two glycine amino acids. Most of the conserved residues are within the -sheet, however
conserved surface-exposed residues are scattered throughout the molecular surface of the
proteins (Figure 3.7). This may mean that residue conservation between Ubiquilin-1 and
NFATc2IP is related to the common fold and not shared binding partners.

54
Figure 3.7: Similarities between ubiquilin-1 and NFATc2IP. Ubiquilin-1 & NFATc2IP share 8 identical residues (5
within secondary structure elements) and 27 similar residues (12 within secondary structure elements). Molecular surface diagrams highlight all of the conserved (dark) & similar residues (light) within secondary structure (blue) or loops (green).
Ubiquilin-1 NFATc2IP 28-V Aliphatic 30-V 30-V Aliphatic 32-G 38-E Acidic 40-E 41-V Aliphatic 43-L 47-V Aliphatic 49-L 49-Q Polar/Uncharged 51-T 58-F Non-Polar/Uncharged 60-M 69-F Aromatic 71-F 74-L Aliphatic 76-L
Ubiquilin-1 NFATc2IP 84-G Aliphatic/Small 86-G 91-V Aliphatic 93-I 93-L Aliphatic 95-V
Outside Secondary Structure Elements 45-S Polar/Uncharged 47-S 71-G Aliphatic 73-G 88-G Aliphatic 90-G

55
3.3.2.3 Structural comparison between ubiquilin-1 & ubiquitin
Ubiquitin and ubiquilin-1 share 26 conserved residues, and the C-terminal -strand is almost
entirely conserved. Many residues are also conserved throughout the -sheet and major -helix.
Conserved residues exist on the major -helix turns that face the core of the fold. Conserved
surface-exposed residues are also visible on all faces of the protein, and a prominent patch of
conserved residues are within the UIM binding interface of ubiquitin. The presence of the region
of conserved residues could result in a common binding partner between ubiquitin and ubiquilin-
1. Analysis of protein-protein interaction databases revealed that 205 proteins interact with both
ubiquitin & at least one member of the ubiquilin family, while 2407 unique proteins have been
observed for ubiquitin, and 1512 unique proteins have been observed to interact with at least one
member of the ubiquilin family. At least one putative UIM has been observed in 106 of the 205
proteins known to interact with both ubiquitin and a member of the ubiquilin family (Appendix III).
Conserved residues outside secondary structure regions are found mostly at both the N-terminus
and C-terminus of the minor -helix (Figure 3.8).

56
z
z
Figure 3.8: Similarities between ubiquilin-1 and ubiquitin. Ubiquilin-1 & ubiquitin share 26 identical residues (20
within secondary structure elements) and 40 similar residues (29 within secondary structure elements). Molecular surface diagrams highlight all of the conserved (dark) & similar residues (light) within secondary structure (blue) or loops (green).
Ubiquilin-1 Ubiquitin 26-M Non-Polar/Uncharged 1-M 28-V Aliphatic 3-I 30-V Aliphatic 5-V 31-K + Charged 6-K 32-T Polar/Uncharged 7-T 41-V Aliphatic 17-V 46-S Polar/Uncharged 22-T 47-V Aliphatic 23-I 49-Q Polar/Uncharged 25-N 51-K + Charged 27-K 54-I Aliphatic 30-I 55-S Polar/Uncharged 31-Q 57-R + Charged 33-K 63-D - Charged 39-D 64-Q Polar/Uncharged 40-Q 67-L Aliphatic 43-L 68-I Aliphatic 44-I 69-F Non-Polar/Uncharged 45-F
Ubiquilin-1 Ubiquitin 72-K + Charged 48-K 74-L Aliphatic 50-L 80-L Aliphatic 56-L 81-S Polar/Uncharged 57-S 90-T Polar/Uncharged 66-T 91-V Aliphatic 67-L 92-H Aromatic 68-H 93-L Aliphatic 69-L 94-V Aliphatic 70-V 95-I Aliphatic 71-L 96-K + Charged 72-R
Outside Secondary Structure Elements 34-K + Charged 11-K 70-A Aliphatic 46-A 71-G Aliphatic 47-G 76-D - Charged 52-D 79-T Polar/Uncharged 55-T 85-I Aliphatic 61-I

57
3.3.2.4 Structural comparison between NFATc2IP & SUMO2
Structure conservation between NFATc2IP and SUMO2 is mostly within the -sheet and in loop
regions, with some conserved residues within the major -helix. The conserved loop residues
are at the C-terminus of the major -helix, and C-terminus of a couple of the -strands. Some
molecular-surface exposed conserved residues from loop regions are visible as patches, with
multiple conserved residues bordering the UIM binding interface and limited conservation within
the SIM binding interface (Figure 3.9). This may mean that there isn’t a commonly shared UIM
or SIM between NFATc2IP and SUMO2. However, conservation near the binding interfaces could
mean partial conservation between NFATc2IP binding partners and SUMO2 binding partners.
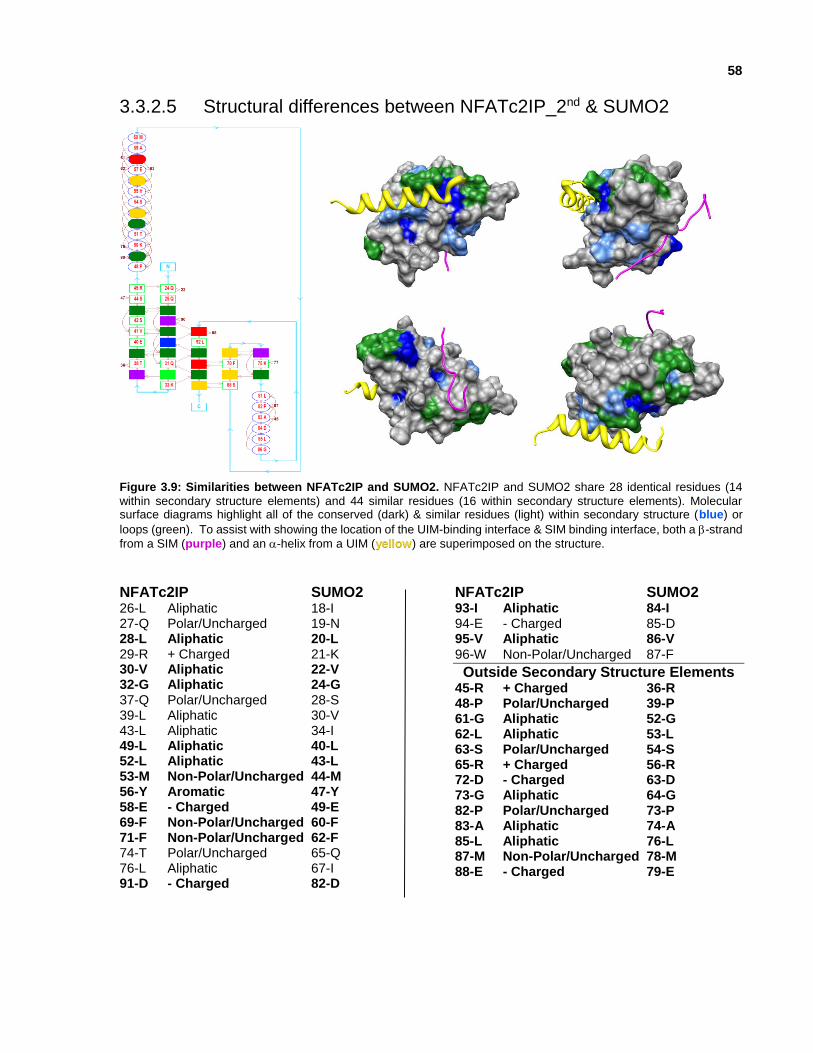
58
3.3.2.5 Structural differences between NFATc2IP_2nd & SUMO2
Figure 3.9: Similarities between NFATc2IP and SUMO2. NFATc2IP and SUMO2 share 28 identical residues (14
within secondary structure elements) and 44 similar residues (16 within secondary structure elements). Molecular surface diagrams highlight all of the conserved (dark) & similar residues (light) within secondary structure (blue) or
loops (green). To assist with showing the location of the UIM-binding interface & SIM binding interface, both a -strand
from a SIM (purple) and an -helix from a UIM (yellow) are superimposed on the structure.
NFATc2IP SUMO2 26-L Aliphatic 18-I 27-Q Polar/Uncharged 19-N 28-L Aliphatic 20-L 29-R + Charged 21-K 30-V Aliphatic 22-V 32-G Aliphatic 24-G 37-Q Polar/Uncharged 28-S 39-L Aliphatic 30-V 43-L Aliphatic 34-I 49-L Aliphatic 40-L 52-L Aliphatic 43-L 53-M Non-Polar/Uncharged 44-M 56-Y Aromatic 47-Y 58-E - Charged 49-E 69-F Non-Polar/Uncharged 60-F 71-F Non-Polar/Uncharged 62-F 74-T Polar/Uncharged 65-Q 76-L Aliphatic 67-I 91-D - Charged 82-D
NFATc2IP SUMO2 93-I Aliphatic 84-I 94-E - Charged 85-D 95-V Aliphatic 86-V
96-W Non-Polar/Uncharged 87-F
Outside Secondary Structure Elements 45-R + Charged 36-R 48-P Polar/Uncharged 39-P 61-G Aliphatic 52-G 62-L Aliphatic 53-L 63-S Polar/Uncharged 54-S 65-R + Charged 56-R 72-D - Charged 63-D 73-G Aliphatic 64-G 82-P Polar/Uncharged 73-P 83-A Aliphatic 74-A 85-L Aliphatic 76-L 87-M Non-Polar/Uncharged 78-M 88-E - Charged 79-E

59
3.3.3 From Structure to Function: Exploring Protein-Protein Interactions involving ubiquitin-like domains
As described in Chapter One, ubiquitin is known to be involved in many weak and transient
interactions. One of these interactions involves a UIM, which is an -helix found in hundreds of
known ubiquitin binding partners. The UIM is characterized by a conserved motif (E/D-E/D-E/D-
Φ-x-x-A-x-x-x-S-x-x-E/D; where Φ is a hydrophobic residue) (Fisher et al., 2003).
3.3.3.1 The Ubiquitin-Interacting Motif interaction interface
A few UIM:ubiquitin complexes have also been structurally characterized (Table 3.4). Two of the
UIM:ubiquitin complexes involve a UIM within the 26S proteasome non-ATPase regulatory
subunit 4 (Hofmann & Falquet, 2001). The 26S proteasome non-ATPase regulatory subunit 4
UIM does not fit the canonical UIM motif even though the binding mode and interaction features
remain the same. The key differences between the canonical UIM motif and the 26S proteasome
non-ATPase regulatory subunit 4 UIM include a glutamine neighbouring the conserved
hydrophobic residue within the acidic N-terminal region of the motif, and there are 4 amino acids
instead of the canonical 2-residue gap between the conserved serine and the acidic C-terminal
region.
Table 3.4: UIM:ubiquitin complexes deposited in the PDB, along with UIM sequence.
PDB_ID Year UIM-containing protein ubiquitin or ubiquitin-like domain UIM sequence
1UEL:B 2003
26S proteasome non-ATPase
regulatory subunit 4
P55036 UV excision repair protein
RAD23 homolog B (H.sapiens)
P54727 …EEEQIAYAMQMSLQGAE…
doesn’t fit canonical motif
1P9D:A 2003
26S proteasome non-ATPase
regulatory subunit 4
P55036 UV excision repair protein
RAD23 homolog A
(H.sapiens) P54725
…EEEQIAYAMQMSLQGAE…
doesn’t fit canonical motif
1Q0W:A 2003
Vacuolar protein sorting-
associated protein VPS27
P40343 ubiquitin (S.cerevisiae) P0CG63 …EDEEELIRKAIELSLKE…
2D3G:P 2005 HGS HRS O14964 ubiquitin (B. Taurus) P0CH28 …EEEELQLALALSQSEAEE…

60
Analysis of the UIM:ubiquitin complexes reveal structural conservation of acidic residues at the
termini of the UIM-containing-helix, as well as the general positioning of the conserved serine
residue and hydrophobic residues along the ubiquitin-facing surface of the UIM between the N-
terminal acidic residues and the conserved serine (Figure 3.10 & Figure 3.11).
Figure 3.10: UIM -helices from PSMD4, VPS27 and HGS. The UIMs from PSMD4, VPS27 and HGS were structurally characterized in complex with ubiquitin; acidic residues are red, basic residues are blue, hydrophobic residues are orange, and serine are green. Three conserved regions are highlighted: two acidic termini are highlighted with the blue box and the conserved serine highlighted by the green box.
PSMD4
1UEL / 1P9D
VPS27
1Q0W
HGS HRS
2D3G

61
Figure 3.11: Ubiqutin:PSMD4(UIM) complex. Ubiquitin residues within 3Å (isoleucine 68, isoleucine 73, alanine 70,
G71, H92) and 4Å (valine 66, isoleucine 68, alanine 70, G71, K72, isoleucine 73, H92, valine 94) of the UIM displayed as sticks.
Analysis of ubiquitin residues within proximity of the UIM, and corresponding residues within a
superimposed ubiquilin-1 molecular structure, reveal amino acid conservation; 6 out of 6 of
ubiquilin-1 residues at 3Å (isoleucine 68, isoleucine 73, alanine 70, G71, H92), and 14 out of 16
of ubiquilin-1 residues at 4Å (valine 66, isoleucine 68, alanine 70, G71, K72, isoleucine 73, H92,
valine 94). All of these conserved residues are also localized to interact with the hydrophobic
residues of the UIM (Figure 3.12).

62
Figure 3.12: UBL residues within UIM-interaction interface. This chart displays amino acids from ubiquitin, UBTD2
and ubiquilin-1 that are within 2Å, 3Å, and 4Å of each amino acid within the -helix from the PSMD4 UIM. Acidic amino acids are red, hydrophobic amino acids are green, and serine is blue. Black arrows identify amino acids that are
conserved between ubiquitin and ubiquilin-1.
3.3.3.2 Putative UIM Interaction Interface: Conserved Amino Acids
Within the ubiquitin-like domain of ubiquilin family members, there is residue conservation
between family members within two stretches of highly-conserved residues (10 aa in length & 14
aa in length) in both C-terminal -strands (Figure 3.13).
Figure 3.13: Multiple sequence alignment of UBLs from ubiquilin family members. Two conserved regions
correspond to amino acids within 4Å of UIM atoms.
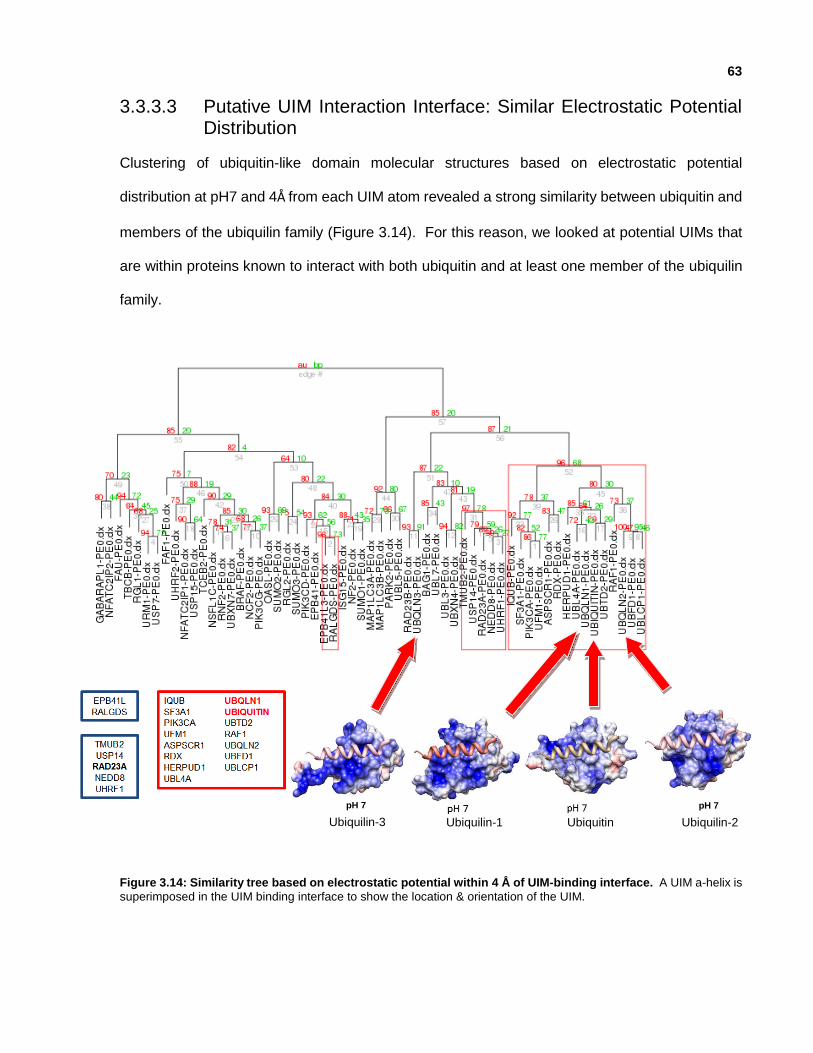
63
3.3.3.3 Putative UIM Interaction Interface: Similar Electrostatic Potential Distribution
Clustering of ubiquitin-like domain molecular structures based on electrostatic potential
distribution at pH7 and 4Å from each UIM atom revealed a strong similarity between ubiquitin and
members of the ubiquilin family (Figure 3.14). For this reason, we looked at potential UIMs that
are within proteins known to interact with both ubiquitin and at least one member of the ubiquilin
family.
Figure 3.14: Similarity tree based on electrostatic potential within 4 Å of UIM-binding interface. A UIM a-helix is
superimposed in the UIM binding interface to show the location & orientation of the UIM.
Ubiquitin Ubiquilin-1
pH 7
Ubiquilin-2
pH 7
Ubiquilin-3
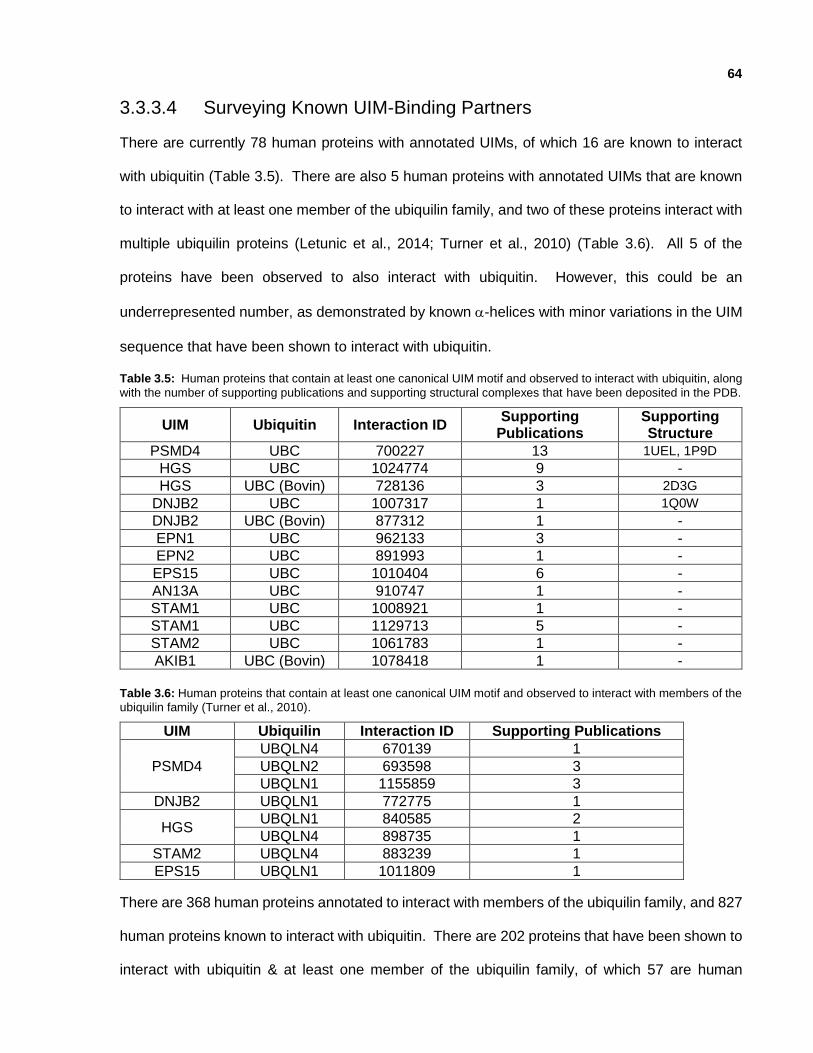
64
3.3.3.4 Surveying Known UIM-Binding Partners
There are currently 78 human proteins with annotated UIMs, of which 16 are known to interact
with ubiquitin (Table 3.5). There are also 5 human proteins with annotated UIMs that are known
to interact with at least one member of the ubiquilin family, and two of these proteins interact with
multiple ubiquilin proteins (Letunic et al., 2014; Turner et al., 2010) (Table 3.6). All 5 of the
proteins have been observed to also interact with ubiquitin. However, this could be an
underrepresented number, as demonstrated by known -helices with minor variations in the UIM
sequence that have been shown to interact with ubiquitin.
Table 3.5: Human proteins that contain at least one canonical UIM motif and observed to interact with ubiquitin, along
with the number of supporting publications and supporting structural complexes that have been deposited in the PDB.
UIM Ubiquitin Interaction ID Supporting
Publications Supporting Structure
PSMD4 UBC 700227 13 1UEL, 1P9D
HGS UBC 1024774 9 -
HGS UBC (Bovin) 728136 3 2D3G
DNJB2 UBC 1007317 1 1Q0W
DNJB2 UBC (Bovin) 877312 1 -
EPN1 UBC 962133 3 -
EPN2 UBC 891993 1 -
EPS15 UBC 1010404 6 -
AN13A UBC 910747 1 -
STAM1 UBC 1008921 1 -
STAM1 UBC 1129713 5 -
STAM2 UBC 1061783 1 -
AKIB1 UBC (Bovin) 1078418 1 -
Table 3.6: Human proteins that contain at least one canonical UIM motif and observed to interact with members of the
ubiquilin family (Turner et al., 2010).
UIM Ubiquilin Interaction ID Supporting Publications
PSMD4
UBQLN4 670139 1
UBQLN2 693598 3
UBQLN1 1155859 3
DNJB2 UBQLN1 772775 1
HGS UBQLN1 840585 2
UBQLN4 898735 1
STAM2 UBQLN4 883239 1
EPS15 UBQLN1 1011809 1
There are 368 human proteins annotated to interact with members of the ubiquilin family, and 827
human proteins known to interact with ubiquitin. There are 202 proteins that have been shown to
interact with ubiquitin & at least one member of the ubiquilin family, of which 57 are human

65
proteins. At least one putative UIM has been observed in 61 of the 202 proteins (17 of the 57
human proteins) known to interact with both ubiquitin & at least one member of the ubiquilin family
(Appendix III).
Table 3.7: 17 human proteins that interact with both human ubiquitin and a member of the ubiquilin family, and that
also contain at least one UIM motif.
ANCHR EPS15 PIN1 RD23A STAM1 UBP34
DNJB2 HD PSMD3 RNF11 STAM2 USP9X
EF1A1 HGS PSMD4 SAE2 UBE3A Analysis of bound UIM domains revealed variability within the canonical UIM motif. These include
a variable length stretch of residues between the N-terminal acidic residues and the conserved
alanine (ie. PSMD4 and DNJB2 have a stretch of 4 residues, while EPN1 has 3 residues that
separate the acidic residues from the alanine), and a variable length stretch of residues separates
the conserved serine and the C-terminal acidic residues (ie. PSMD4 has 4 residues, while DNJB2
and EPN1 have 2 residues that separate the serine from the C-terminal acidic residues). PIN1
had a few additional differences: hydrophobic residues within the N-terminal acidic residue
stretch, a glycine instead of a conserved alanine near the N-terminal acidic residue stretch, a
longer stretch of residues between the conserved glycine/alanine and the conserved serine, and
a single glycine to separate the conserved serine and C-terminal acidic residues (Figure 3.15).
PSMD4 EEEQIAYAMQMSLQGAE
DNJB2 EDEEELIRKAIELSLKE
EPN1 EEEELQLALALSQSEAEE
PIN1 TRTKEEALELINGYIQKIKSGEEDFESLAS
Figure 3.15: Sequence alignment of UIMs within PSMD4, DNJB2, EPN1 and PIN1. Sequence alignment of three
structurally characterized UIMs (PSMD4, DNJB2 and EPN1), as well as the putative UIM in PIN1. Acidic residues are red, basic residues are blue, hydrophobic residues are orange, and serine is green.
To take into account this variability, as well as variability introduced by the structural variance
between UBLs, 4 alternate UIM motifs were used when searching for putative UIMs in known
binding partners of both ubiquitin and members of the ubiquilin family (Table 3.8). Six of these
proteins have no molecular structure deposited in the PDB, while the remaining 11 proteins have
at least one structure within the PDB. PIN1 stands out because its molecular structure has been
deposited into the PDB 45 times (Table 3.8).
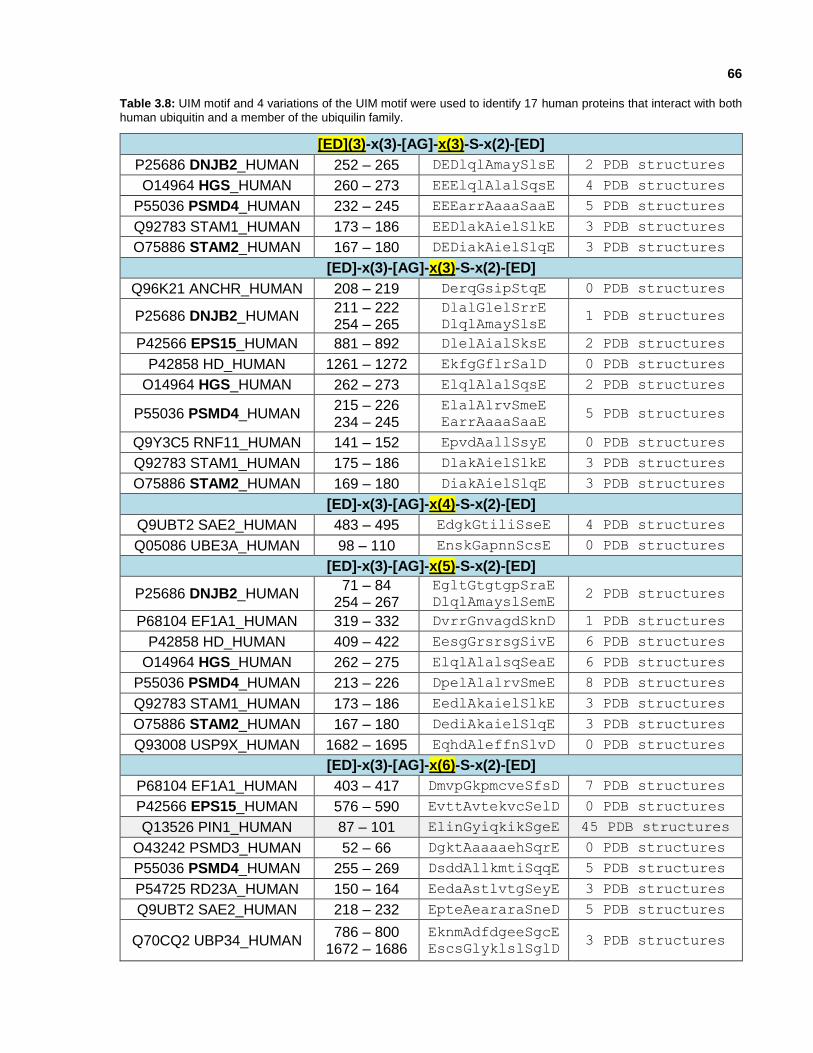
66
Table 3.8: UIM motif and 4 variations of the UIM motif were used to identify 17 human proteins that interact with both
human ubiquitin and a member of the ubiquilin family.
[ED](3)-x(3)-[AG]-x(3)-S-x(2)-[ED]
P25686 DNJB2_HUMAN 252 – 265 DEDlqlAmaySlsE 2 PDB structures
O14964 HGS_HUMAN 260 – 273 EEElqlAlalSqsE 4 PDB structures
P55036 PSMD4_HUMAN 232 – 245 EEEarrAaaaSaaE 5 PDB structures
Q92783 STAM1_HUMAN 173 – 186 EEDlakAielSlkE 3 PDB structures
O75886 STAM2_HUMAN 167 – 180 DEDiakAielSlqE 3 PDB structures
[ED]-x(3)-[AG]-x(3)-S-x(2)-[ED]
Q96K21 ANCHR_HUMAN 208 – 219 DerqGsipStqE 0 PDB structures
P25686 DNJB2_HUMAN 211 – 222 254 – 265
DlalGlelSrrE
DlqlAmaySlsE 1 PDB structures
P42566 EPS15_HUMAN 881 – 892 DlelAialSksE 2 PDB structures
P42858 HD_HUMAN 1261 – 1272 EkfgGflrSalD 0 PDB structures
O14964 HGS_HUMAN 262 – 273 ElqlAlalSqsE 2 PDB structures
P55036 PSMD4_HUMAN 215 – 226 234 – 245
ElalAlrvSmeE
EarrAaaaSaaE 5 PDB structures
Q9Y3C5 RNF11_HUMAN 141 – 152 EpvdAallSsyE 0 PDB structures
Q92783 STAM1_HUMAN 175 – 186 DlakAielSlkE 3 PDB structures
O75886 STAM2_HUMAN 169 – 180 DiakAielSlqE 3 PDB structures
[ED]-x(3)-[AG]-x(4)-S-x(2)-[ED]
Q9UBT2 SAE2_HUMAN 483 – 495 EdgkGtiliSseE 4 PDB structures
Q05086 UBE3A_HUMAN 98 – 110 EnskGapnnScsE 0 PDB structures
[ED]-x(3)-[AG]-x(5)-S-x(2)-[ED]
P25686 DNJB2_HUMAN 71 – 84
254 – 267
EgltGtgtgpSraE
DlqlAmayslSemE 2 PDB structures
P68104 EF1A1_HUMAN 319 – 332 DvrrGnvagdSknD 1 PDB structures
P42858 HD_HUMAN 409 – 422 EesgGrsrsgSivE 6 PDB structures
O14964 HGS_HUMAN 262 – 275 ElqlAlalsqSeaE 6 PDB structures
P55036 PSMD4_HUMAN 213 – 226 DpelAlalrvSmeE 8 PDB structures
Q92783 STAM1_HUMAN 173 – 186 EedlAkaielSlkE 3 PDB structures
O75886 STAM2_HUMAN 167 – 180 DediAkaielSlqE 3 PDB structures
Q93008 USP9X_HUMAN 1682 – 1695 EqhdAleffnSlvD 0 PDB structures
[ED]-x(3)-[AG]-x(6)-S-x(2)-[ED]
P68104 EF1A1_HUMAN 403 – 417 DmvpGkpmcveSfsD 7 PDB structures
P42566 EPS15_HUMAN 576 – 590 EvttAvtekvcSelD 0 PDB structures
Q13526 PIN1_HUMAN 87 – 101 ElinGyiqkikSgeE 45 PDB structures
O43242 PSMD3_HUMAN 52 – 66 DgktAaaaaehSqrE 0 PDB structures
P55036 PSMD4_HUMAN 255 – 269 DsddAllkmtiSqqE 5 PDB structures
P54725 RD23A_HUMAN 150 – 164 EedaAstlvtgSeyE 3 PDB structures
Q9UBT2 SAE2_HUMAN 218 – 232 EpteAeararaSneD 5 PDB structures
Q70CQ2 UBP34_HUMAN 786 – 800
1672 – 1686
EknmAdfdgeeSgcE
EscsGlyklslSglD 3 PDB structures

67
3.3.3.5 PIN1 – Peptidyl-Prolyl cis/trans Isomerase
Peptidyl-prolyl cis/trans isomerase (PIN1) regulates protein function by inducing a conformational
change of peptidyl-bonds in polypeptide chains after phosphorylation, and plays a significant role
in cell cycle regulation and cancer development (Lippens et al., 2007). PIN1 also regulates the
function and processing of Tau and APP, and is important for protecting against age-dependent
neurodegeneration. PIN1 is also the only gene known so far that, when deleted in mice, can
cause both tau and Aβ-related pathologies in an age-dependent manner that resembles human
Alzheimer’s disease (Liou et al., 2003).
PIN1 has been associated with ubiquitin through its ubiquitylation, and has been experimentally
observed to interact with ubiquilin-4 through a yeast-2-hybrid interaction (Lim et al., 2006).
However, the mode of that interaction remains unknown.
3.3.3.6 Identifying a putative UIM in PIN1
PIN1 consists of 14 secondary structure elements (10 -strands & 4 -helices). The putative UIM
is within the solvent-exposed -helix1.
EEALELINGYIQKIKSGEED
HHHHHHHHHHHHHHHHTSS-
Figure 3.16: Putative human PIN1 UIM. Human PIN1 protein with the putative UIM highlighted, along with corresponding UIM amino acid sequence highlighting conserved acidic residues (red), conserved glycine (green), and a conserved serine (blue).

68
The putative UIM identified within PIN1 contains non-canonical features; including hydrophobic
residues within the N-terminal acidic residue stretch (ie. …EEALELING…), a glycine instead of a
conserved alanine near the N-terminal acidic residue stretch (ie. …EEALELING…), and a longer
stretch of residues between the conserved glycine/alanine and the conserved serine (ie. 6
residues …GYIQKIKS… instead of 3 residues …GMQMS…, which corresponds to an extra turn in
the -helix).
PIN1 has been structurally characterized by X-ray crystallography and NMR with 45 structures
deposited in the PDB, and the putative UIM identified within PIN1 corresponds to an -helical
region of the protein (Figure 3.16). For this reason, one of the full length PIN1 constructs used
for structure determination by NMR was obtained and used for NMR titration to validate the
hypothesis that PIN1 contains a UIM that can interact with the ubiquilin-1 UIM-binding interface.
3.3.3.7 Ubiquilin-1 & PIN1 NMR Titration
NMR titration was performed using the ubiquitin-like domain of 15N-ubiquilin-1 (corresponding to
PDB-ID: 2KLC) and the full length PIN1 protein (corresponding to PDB-ID: 1NMV; BMRB: 5305).
2KLC was solved by NMR in TRIS buffer with NaCl, NaN3, benzamidine, ZnSO4, and DTT by our
group in 2009, and 1NMV was solved by NMR in phosphate buffer with DTT, EDTA and 50-100
mM sodium sulfate by Bayer et al. in 2003.
A series of NMR titrations were attempted at pH 6.5 and pH 7.0 in buffer optimized for an
UIM:ubiquitin interaction (50 mM sodium phosphate, 1 mM DTT, 10% D2O / 90% H2O) based on
the previously deposited UIM:ubiquitin complex [PDBID: 2RR9], but no chemical shift change was
visible. An additional NMR titration was performed at pH 8.0 in buffer optimized for ubiquilin-1
(10 mM TRIS, 300 mM sodium chloride, 0.01% sodium azide, 1 x inhibitor cocktail [Roche], 1 mM
benzamidine, 10 uM ZnSO4, 10 mM DTT, 10% D2O / 90% H2O) corresponding to the same buffer
used to determine ubiquilin-1 [PDBID: 2KLC], and 9 chemical shift peak changes were observed

69
at a 1:20 ubiquilin-1:PIN1 molar ratio. These peak shifts included D63, K72, isoleucine 73, leucine
74, Q82, H92, valine 94, and K96 (Figure 3.17). These results correspond to amino acids
predicted to be within the UIM binding site of ubiquilin-1 (Figure 3.18).
Figure 3.17: Ubiquilin-1:PIN1 NMR titration. HSQC (64 scans) from NMR titration from 1:0 ubiquilin-1:PIN1 (blue) to 1:20 ubiquilin-1:PIN1 (red); 150 µM 15N-ubiquilin-1 + 3 mM PIN1 at pH 8.0 (298K) in 40 µL sample volume with 50
mM sodium phosphate and 1 mM DTT.
K72 K72

70
3.3.3.8 Analysis of the ubiquilin-1 & PIN1 interface
Analysis of the ubiquilin-1:PIN1 interface reveals an extra -helical turn within the UIM resulting
from an additional three residues between the conserved glycine and conserved serine. The
UIM-binding region has several structural features: -strands 3, 4 & 5 curve around the UIM, a
phenylalanine & histidine are near the conserved serine of the UIM, and an isoleucine and valine
are near the leucine 262 – isoleucine 263 within the acidic N-terminal region of the UIM. The
molecular surface of the UIM-binding interface is positively charged, which could mediate an
interaction with the acidic residues at both termini of the UIM. The 9 residues corresponding to
the chemical shift changes in the NMR titration (aspartic acid 63, lysine 72, isoleucine 73, leucine
74, glutamine 82, histidine 92, valine 94, and lysine 96) are all within the UIM-interaction interface,
and all of the residues were predicted to interact with the UIM based on proximity to the putative
UIM-binding site, and comparative analysis of the UIM:ubiquitin complexes deposited in the PDB.
Analysis of the UBLs of ubiquilin family members reveal that 7 of the 9 residues are conserved
throughout the family. The two residues that are not conserved are isoleucine glutamine and
valine arginine. Both of these residues interact with the same isoleucine on the UIM, which is
next to the N-terminal acidic region of the UIM. This is the same region where hydrophobic
residues are inserted in the acidic region of the PIN1 UIM. Additional experiments are necessary
to validate and further characterize the ubiquilin-1:PIN1 interaction (Chapter Five).
Figure 3.18: Putative ubiquilin-1:PIN1 interaction. Ubiquilin-1 modelled with PIN1 (blue -helix) highlighting 9 stick
residues corresponding to chemical shift changes in the NMR titration.

71
3.3.4 Binding-Partner Driven - Structural analysis of the SUMO-Interacting Motif binding interface
For NFATc2IP, a different approach was taken for identifying a potential binding partner. Instead
of searching for SIMs in known binding partners of both ubiquitin and ubiquilin, the sequence and
secondary structure of all known binding partners of NFATc2IP were analyzed to identify a
possible mode of interaction.
3.3.4.1 NFATc2IP Binding Partners
Human NFATc2 has been observed to interact with 28 human proteins, in addition to HIV tat and
HIV Vpr (Turner et al., 2010). Of the NFATc2-interacting proteins, only NFATc2IP contains two
UBLs. NFATc2IP has been observed to interact with 11 human proteins; B-ATF-3, NFATc2,
RNF4, SREK1, SUMO2, TRAF1/EBI6, TRAF2/TRAP3, TRAF3, TRAF5/RNF84, TRAF6/RNF85,
and ubiquitin (Turner et al., 2010). NFATc2IP contains an arginine-rich N-terminus and two UBLs
at its C-terminus. NFATc2IP is a homologue of yeast DNA repair factor RAD60, sharing 13%
sequence identity along the full length of the protein and 22% sequence identity between the
second ubiquitin-like domain of NFATc2IP and the lone ubiquitin-like domain of RAD60.
Our analyses revealed that SUMO2 and SUMO4 are the ubiquitin-like modifiers that are most
similar to NFATc2IP; 35% sequence identity and 55% sequence similarity (Table 3.3). Based on
the similarity between NFATc2IP and members of the SUMO family, we performed sequence
analysis of the known binding partners of NFATc2IP to determine whether there were -strands
similar to the canonical SIM motif.

72
3.3.5 Sumo-Interacting Motif (SIM)
The SUMO-interacting motif (SIM) was discovered as a protein-protein interaction related to
sumoylation, and the defining characteristics of the SIM have changed over time (Minty 2000,
Song 2004, Song 2005, Hannich 2005, Hecker 2006, Kerscher 2007, Perry 2008, Zhu 2008,
Makhnevych 2009). Initially, a SXS triplet motif was identified in 2000 as being important for
SUMO interaction, followed by a second hydrophobic core motif of V/I-X-V/I-V/I in 2004, and
further experimentation revealed that flanking acidic residues also play a role in SUMO:SIM
interactions (Minty 2000, Song 2004, Hannich 2005, Hecker 2006).
The functional role of the SIM has yet to be fully elucidated. However, it has been shown to be
involved in recruiting SUMO-modified Ubc9 to facilitate sumoylation of the SIM-containing protein.
Structurally, the SIM interaction consists of a -sheet extension, and is a stronger interaction when
compared to other binding modes involving the ubiquitin-fold (Chapter One).
3.3.5.1 Identifying putative SIMs in NFATc2
Full length human NFATc2 consists of 18 secondary structure elements (3 -helices & 15 -
strands). Our analysis of its secondary structure elements revealed that two of the -strands have
characteristics similar to that of the SIM. These include amino acids similar to the hydrophobic
V/I-X-V/I-V/I region, and acidic residues nearby. Analysis of the molecular structure of NFATc2
deposited in the PDB reveal that both of the putative SIM-containing -strands are solvent-
exposed (Figure 3.19).

73
Figure 3.19: NFATc2 SUMO Interacting Motifs. Human NFATc2 protein with two putative SIMs highlighted, along
with corresponding SIM amino acid sequences highlighting secondary structure elements and underlined residues associated with the SIM sequence motif.
Analysis of molecular structures of the SIM:SUMO interaction deposited in the PDB have revealed
that there is variability among residues within the V/I-X-V/I-V/I motif, as well as other characteristic
amino acids associated with SIMs (Figure 3.20). This demonstrates that sequence alone cannot
act as a means to identify putative SIMs. However, the propensity for -strand formation is shared
between SIMs.
2ASQ (PIASx) – kvdVIDLtiessd
---EEE--TTSS-
2KQS (DAXX) - peeIIVLsdsd
-------------
2RPQ (ATP7IP)- ssgVIDLtmddee
----EE--SS---
2MP2 (RNF4) - gdeIVdLtcesle
- S------S-----
Figure 3.20: Diversity of SIM motifs. Sequence alignment of experimentally characterized SIM:SUMO structural
complexes reveals variability within the V/I-X-V/I-V/I motif.
We performed an NMR titration between NFATc2IP and the putative SIM1 region of NFATc2
knowing that an interaction between both proteins has already been observed, and because the
putative SIM region is within a secondary structure element has residues similar to the SIM motif
and is solvent exposed.
GHPVVQLHGYMENKPLGLQIFIG
--EEEEEE-----EEEEEEEEEE SGRIVSLQTASNPIECSQRS
----EEE-------------

74
3.3.6 NFATc2IP:NFATc2 NMR titration
NMR titration was performed using the ubiquitin-like domain of 15N-NFATc2IP (corresponding to
PDB-ID: 2JXX) and a 15 residue peptide of the putative SIM motif within NFATc2 (corresponding
to residues S-554 to S-573 in PDB-ID: 1S9K.C).
A series of NMR titrations were attempted at pH 6.5 and pH 7.0 in buffer optimized for a
NFATc2IP:NFATc2 interaction (50 mM sodium phosphate, 1 mM DTT, 10% D2O / 90% H2O)
based on the previously deposited NFATc2 protein, but no chemical shift change was visible until
1:20 molar ratio. These peak shifts consisted of 2 major peak shifts (glutamine 37 & threonine
38) and 4 minor peak shifts (glycine 32, leucine 39, alanine 59 & tryptophan 96) (Figure 3. 21).
These results correspond to amino acid residues predicted to be within the UIM binding site of
ubiquilin-1 (Figure 3.22 & Figure 3.23).
Figure 3.21: NFATc2IP:NFATc2 NMR titration. HSQC from NMR titration from 1:0 NFATc2IP:NFATc2 (red) to 1:20 NFATc2IP:NFATc2 (blue).
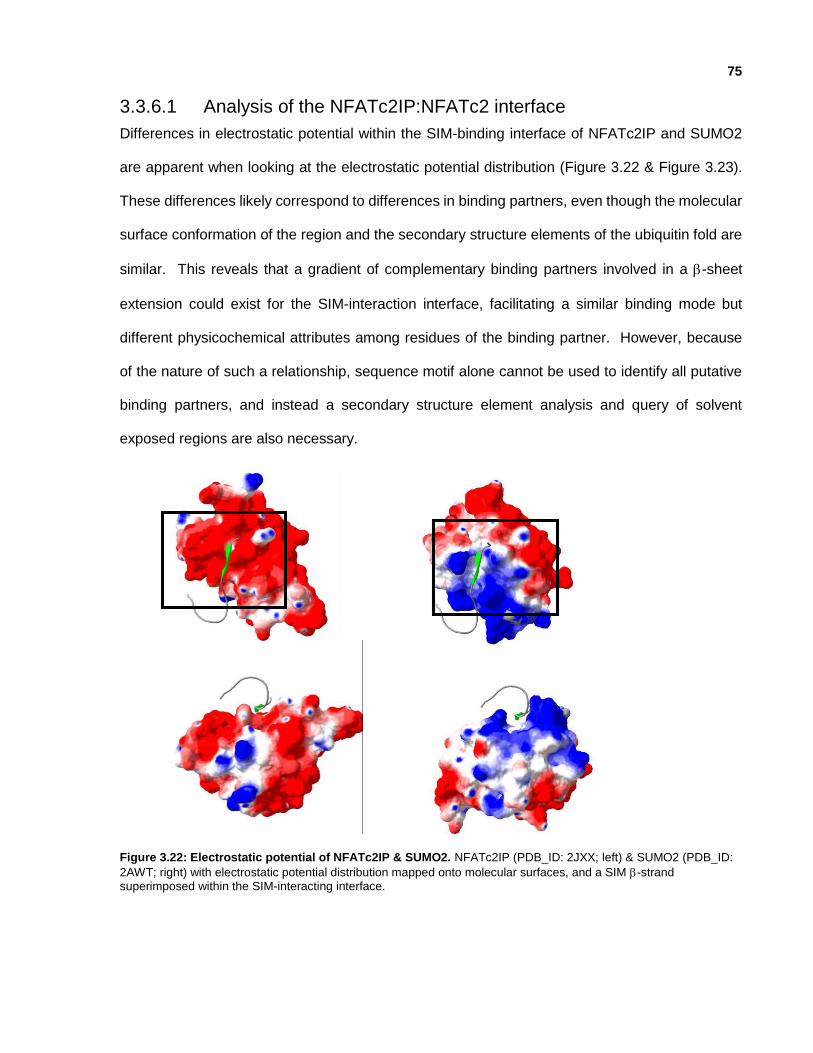
75
3.3.6.1 Analysis of the NFATc2IP:NFATc2 interface
Differences in electrostatic potential within the SIM-binding interface of NFATc2IP and SUMO2
are apparent when looking at the electrostatic potential distribution (Figure 3.22 & Figure 3.23).
These differences likely correspond to differences in binding partners, even though the molecular
surface conformation of the region and the secondary structure elements of the ubiquitin fold are
similar. This reveals that a gradient of complementary binding partners involved in a -sheet
extension could exist for the SIM-interaction interface, facilitating a similar binding mode but
different physicochemical attributes among residues of the binding partner. However, because
of the nature of such a relationship, sequence motif alone cannot be used to identify all putative
binding partners, and instead a secondary structure element analysis and query of solvent
exposed regions are also necessary.
Figure 3.22: Electrostatic potential of NFATc2IP & SUMO2. NFATc2IP (PDB_ID: 2JXX; left) & SUMO2 (PDB_ID:
2AWT; right) with electrostatic potential distribution mapped onto molecular surfaces, and a SIM -strand superimposed within the SIM-interacting interface.

76
Figure 3.23: Electrostatic potential diversity between similar UBLs. The ubiquitin-fold consists of a β-sheet
intercalated by an α-helical core. Electrostatic potential mapping reveals a different charge distribution at the SIM-binding interface of NFATc2IP-2 despite domain sequence similarity. There are 2 SIM-like regions of NFATc2 that may interact with NFATc2IP despite lacking a negative charge typical of SIM motifs.

77
3.4 Conclusion
The molecular structures of NFATc2IP & ubiquilin-1 were determined by NMR spectroscopy,
putative binding modes (SIM & UIM) were identified through structural analysis of similar ubiquitin-
like modifiers, and interactions with binding partners (NFATc2 & PIN1) and were validated through
NMR titration. NFATc2IP was predicted to interact with its binding partner NFATc2 in a SIM-like
-strand extension interaction. Ubiquilin-1 was predicted to interact with its binding partner PIN1
in a UIM-like -helical mediated interaction. These results suggest that a structure-based
approach can be useful for identifying potential interaction partners and mechanisms in the
ubiquitin fold superfamily.

78
Chapter 4
Exploring UBLs & UBL-Interaction Motifs: Computational & Experimental analysis of ubiquilin, NFATc2IP, UIMs and
SIMs.
Contributions: D. Yim & Z. Zhang developed the UBL database and web service. I designed the
UBL database and web service, identified data sources, and performed analyses of UBL data
under the guidance of CH. Arrowsmith.

79
Chapter 4
Exploring UBLs & UBL-Interaction Motifs: Computational & Experimental analysis of ubiquilin, NFATc2IP, UIMs and
SIMs.
4.1 Introduction
This research project was to obtain near complete structural coverage of human UBLs, without
experimentally determining each of the 398 unique UBLs. This was partly facilitated by grouping
the UBLs into 100 modelling families that represent homologous protein domains with similar
structures (Chapter Two). NMR spectroscopy was used to screen and prioritize UBLs for
structure determination, and 17 human UBLs were structurally characterized using X-ray
Crystallography and NMR spectroscopy. The RCSB PDB now has 32% structural coverage of
human UBLs based on structures experimentally determined by X-ray Crystallography and NMR
spectroscopy, and 82% when taking into account homology modelling. This chapter explores
similarities between UBLs, focusing on each of the 17 human UBLs that were structurally
characterized for this project and related UBLs. This chapter also discusses the 74 remaining
human UBLs that lack structural information, and provides hypotheses for further study.
4.1.1 Database & comparative analysis
Information about each ubiquitin-like domain was compiled from multiple databases to generate
a repository that would allow for detailed analysis of relationships between sequence, structure
and function of each protein domain. A detailed analysis focused on UBLs that were structurally
determined as part of the project, and members of associated modeling families. A relational
database facilitated identification of trends and hypothesis generation

80
4.1.1.1 Similarities & differences between model family members
Molecular features from UIM-binding & SIM-binding interfaces were identified and compared
within and across modelling families. Full domain and binding-interface localized electrostatic
potential distribution clustering was also performed to identify UBLs that shared similar
physicochemical characteristics
In addition to comparing molecular features of protein-protein interaction interfaces on the
ubiquitin-like domain, our analyses extended to grouping together UBLs that shared common
putative protein-protein interaction partners mentioned in literature.
A variety of other features were annotated to identify other similarities and differences between
members of each model family. These data included conserved residues, sequence similarity,
functional residues (ie. lysines for poly-ubiquitin chains), phosphorylation sites, hydrophobic
patches, GO-terms, and full length protein domain structure.
4.1.1.2 Common defining features for each modelling family
Common defining features provide insight into shared attributes of members of each modelling
family. These features could also identify functional attributes, binding partners, or other
characteristics shared between UBLs. This is particularly important for the ubiquitin-like domain
superfamily, since 35.5% of human proteins containing UBLs have no known functional
annotations. Additional significance arises from 54 human UBLs associated with disease
pathways.

81
4.2 Experimental Procedures
4.2.1 UBL Database Development
A MySQL relational database was developed to contain information about all UBLs and related
proteins. The database includes a framework consisting of PHP scripts that facilitate aggregation
of online resources (Appendix 1.1.1 & Figure 4.1), and a web-based user interface for displaying
and accessing the information.
Figure 4.1: Database schema of ubiquitin-like domain repository.
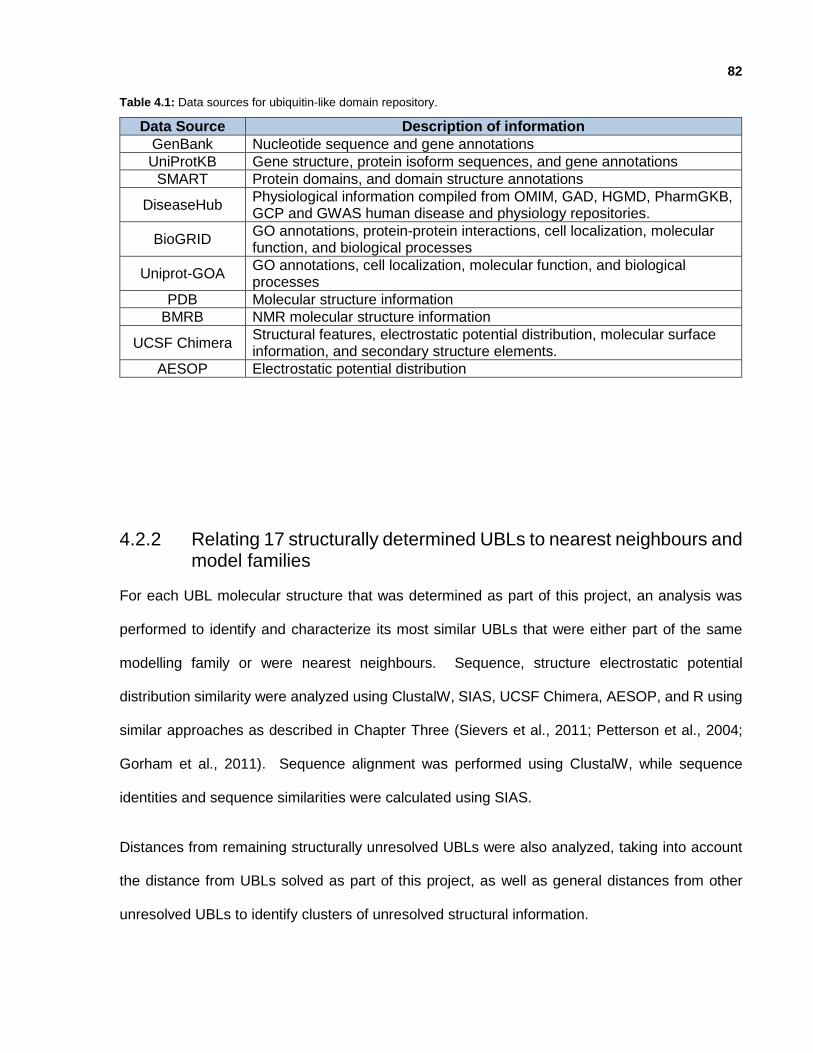
82
Table 4.1: Data sources for ubiquitin-like domain repository.
Data Source Description of information
GenBank Nucleotide sequence and gene annotations
UniProtKB Gene structure, protein isoform sequences, and gene annotations
SMART Protein domains, and domain structure annotations
DiseaseHub Physiological information compiled from OMIM, GAD, HGMD, PharmGKB, GCP and GWAS human disease and physiology repositories.
BioGRID GO annotations, protein-protein interactions, cell localization, molecular function, and biological processes
Uniprot-GOA GO annotations, cell localization, molecular function, and biological processes
PDB Molecular structure information
BMRB NMR molecular structure information
UCSF Chimera Structural features, electrostatic potential distribution, molecular surface information, and secondary structure elements.
AESOP Electrostatic potential distribution
4.2.2 Relating 17 structurally determined UBLs to nearest neighbours and model families
For each UBL molecular structure that was determined as part of this project, an analysis was
performed to identify and characterize its most similar UBLs that were either part of the same
modelling family or were nearest neighbours. Sequence, structure electrostatic potential
distribution similarity were analyzed using ClustalW, SIAS, UCSF Chimera, AESOP, and R using
similar approaches as described in Chapter Three (Sievers et al., 2011; Petterson et al., 2004;
Gorham et al., 2011). Sequence alignment was performed using ClustalW, while sequence
identities and sequence similarities were calculated using SIAS.
Distances from remaining structurally unresolved UBLs were also analyzed, taking into account
the distance from UBLs solved as part of this project, as well as general distances from other
unresolved UBLs to identify clusters of unresolved structural information.

83
4.2.3 Secondary structure prediction & analysis
The protein domains within each human ubiquitin-like domain containing protein were annotated,
and clustered based on similar full length protein domain architecture. Protein domains were
identified using information from UniprotKB, PROSITE, SMART & NCBI GenBank, and plotted
using PROSITE MyDomains (Galperin et al., 2015; Sigrist et al., 2012; Letunic et al., 2014;
Benson et al., 2013).
The architecture of all UBLs were compared at the sequence-level using secondary-structure
sequence alignment, as well as at the structural level using UCSF Chimera (Petterson et al.,
2004).
4.2.4 Relating structural features to functional pathways
For each human ubiquitin-like domain, gene ontology annotations for cellular localization and
functional annotation were retrieved from Uniprot-GOA QuickGO (Huntley et al., 2015). Clusters
of human UBLs grouped based on common functional activity and/or cellular localization were
analyzed using UCSF Chimera to identify common molecular features (Petterson et al., 2004).

84
4.3 Results
4.3.1 Structurally characterized ubiquitin-like domains
Comparison of molecular structures of the 17 UBLs solved for this project revealed a few structural
variations. These include extended loops (between β-strand1 & β-strand2, β-strand2 & -helix1),
additional/missing -helicles, and a missing β-strand4. Structural analysis also revealed
conserved amino acids associated with the fold (Figure 4.2).
Figure 4.2: Secondary & tertiary structures of 17 structurally characterized UBLs. Ribbon diagrams of 17
ubiquitin-like domain structures solved for this project, along with corresponding secondary structure architecture.

85
4.3.2 Nearest-neighbours of ubiquitin-like domains
Clustering all UBLs based on sequence similarity reveals 5 groups and 30 subgroups (Figure 4.3).
Each of the groups contains at least one UBMs, with the majority of UBMs within Group I and the
largest proportion of structurally uncharacterized UBLs within Group IV.
Figure 4.3: Nearest-neighbour clustering of UBLs displayed with proportional transformed branches. Ubiquitin-like domains structurally determined for this project are highlighted in blue. Ubiquitin-like modifiers and
putative ubiquitin-like modifiers are underlined.

86
4.3.3 Nearest-neighbours of structurally characterized UBMs
Three of the structurally characterized UBLs were ubiquitin-like modifiers (FUBI-1, ISG15-2, and
SF3A1-1). To identify UBLs that may regulate ubiquitin-like modifiers by competing for binding
partners, a nearest-neighbour analysis was performed on FUBI-1, ISG15-2 and SF3A1-1.
Ubiquitin-like domains with structures with an RMSD of less than 2Å were compared to UBLs with
similar electrostatic potential and low RMSD (Figure 4.4, Figure 4.5, Figure 4.6).
Figure 4.4: UBLs with a structural fold similar to FUBI-1. There are 21 structurally characterized UBLs with an
RMSD of less than 2Å when compared to FUBI-1.
Twelve UBLs share similar electrostatic potential distribution as FUBI-1, of which 3 (highlighted
in red) have a fold with an RMSD of less than 2Å when compared to FUBI-1: UBIML_1-1,
UBIML_2-1, ISG15-2, PARK2_1-1, PARK2_2-1, PARK2_5-1, IQUB_1-1, IQUB_2-1, UBL7-1,
UBLCP1-1, USP14-1, and UBFD1-1.

87
Figure 4.5: UBLs with a structural fold similar to the second UBL of ISG15. There are 25 structurally
characterized UBLs with an RMSD of less than 2Å when compared to ISG15-2.
Thirteen UBLs share similar electrostatic potential distribution as ISG15-2, of which 5 (highlighted
in red) have a fold with an RMSD of less than 2Å when compared to ISG15-2: UHRF2_1-1,
UHRF2_2-1, UBA52-1, UBB-1, UBC-1, RPS27A-1, NEDD8-1, ANUBL1-1, RAD23A-1, RAD23B-
1, UBL4A-1, UBL4B-1, and UHRF1-1.

88
Figure 4.6: UBLs with a structural fold similar to SF3A1. There are 25 structurally characterized UBLs with an
RMSD of less than 2Å when compared to SF3A1-1
Three UBLs share similar electrostatic potential distribution as SF3A1-1, of which none have a
fold with an RMSD of less than 2Å when compared to SF3A1-1: TBCB-1, USP40_3-1, and
USP47_2-3.

89
4.3.4 Grouping UBLs based on biological processes and molecular function
Many UBLs are uncharacterized, with 62.77% of UBLs having biological process annotations and
64.5% of UBLs having molecular function annotations within the GO repository. A pool of 145
UBLs are associated with a total of 369 unique biological processes and 149 UBLs are associated
with 133 unique molecular functions (Huntley et al., 2015). Up to 53 biological processes and 9
molecular functions are associated with an individual UBL. Similarly to cellular localization,
biological process attribution and molecular function are associated with full length UBL-
containing proteins, and not each individual UBL domain. As a result, factors associated with
functional activity could result from molecular features in other domains within the full length
protein.

90
Table 4.2: Biological significance, functional annotation, and UBL group for each of the 17 UBLs structurally
characterized for this project.
Protein Method PDB ID
UBL Group
Biological Significance Function
SF3A1 NMR 1ZKH V Spliceosome gene regulation: nuclear
mRNA 3'-splice site recognition
ISG15 NMR 2HJ8 I Innate immune response activated
by interferon-& interferon- signaling protein
MAP1ALC3 Xray 3ECI II endomembrane system apoptosis: autophagy
HERPUD2 NMR 2KDB III Endoplasmic Reticulum protein binding
RNF2/RING1B Xray 3H8H I & III E3 ligase of lysine 119 on histone
H2A Transcription
PLXNC1 Xray 3KUZ I Receptor related to immune
modulation during virus infection signaling protein
USP7 Xray 2KVR II
Deubiquitylates proteins; prevents MDM2 self-ubiquitylation and enhances MDM2 E3 activity
towards p53 and its proteasomal degradation
protein binding: ubiquitinyl hydrolase 1
NFATc2IP_1st NFATc2IP_2nd
NMR 2L76 2JXX
I
Down-regulates poly-SUMO chain formation by UBE2I/UBC9, and
involved in expression of cytokine genes in T-cells
transcription
protein binding
BRAF (N-term)
Xray NMR
2L05 3NY5
I
Vemurafenib (approved by FDA in 2011) was first drug to target B-RAF for treatment of late-stage
melanoma; B-RAF is a Raf kinase and regulates MAP kinase/ERKs signaling pathway, which affects cell division, differentiation and
secretion.
transferase: non-specific serine/threonine protein
kinase
FUBI NMR 2L7R II C-term is ribosomal protein S30
and N-term is a UBL intracellular, ribosome and
translation
USP15 Xray 3PPA I
Ubiquitin-specific protease that targets lysine 48-linked poly-Ub
chains; Targets ubiquitylated APC and human papillomavirus type 16
protein E6
ubiquitin thioesterase activity
UHRF1 Xray 2FAZ I
E3 ubiquitin ligase involved in methylation-dependent
transcriptional regulation. Important for G1/S transition and possibly chromosomal stability and DNA
repair.
ligase activity
Ubiquilin 1 NMR 2KLC I
Modulates accumulation of presenilin protein, and is found in
lesions associated with Alzheimer’s and Parkinson’s disease. Also
associated with: neurodegenerative diseases, ALS,
Dementia, Ataxia, Huntington’s Disease & Lung Adenocarcinoma.
protein binding
Ubiquilin 3 Xray 1YQB I N/A signaling protein

91
4.3.5 Grouping UBLs based on medical significance
Some UBLs are associated with medically significant functional pathways based on annotations
within DiseaseHub, a tool that aggregates gene-disease associations from OMIM, GAD, HGMD,
PharmGKB, CGP and GWAS (DiseaseHub; http://zldev.ccbr.utoronto.ca/~ddong/diseaseHub). A
pool of 54 UBLs are associated with a total of 103 medically significant functional pathways. The
specific role of each UBL domain remains unknown in many cases. Similar to cellular localization,
medical significance is associated with full length UBL-containing proteins, and not individual UBL
domains. Based on medical significance, 6 structurally uncharacterized and distant UBLs can be
prioritized for functional significance (BRAF, PCGF2, PIK3C2A, PIK3C2B, USP40 and USP6).
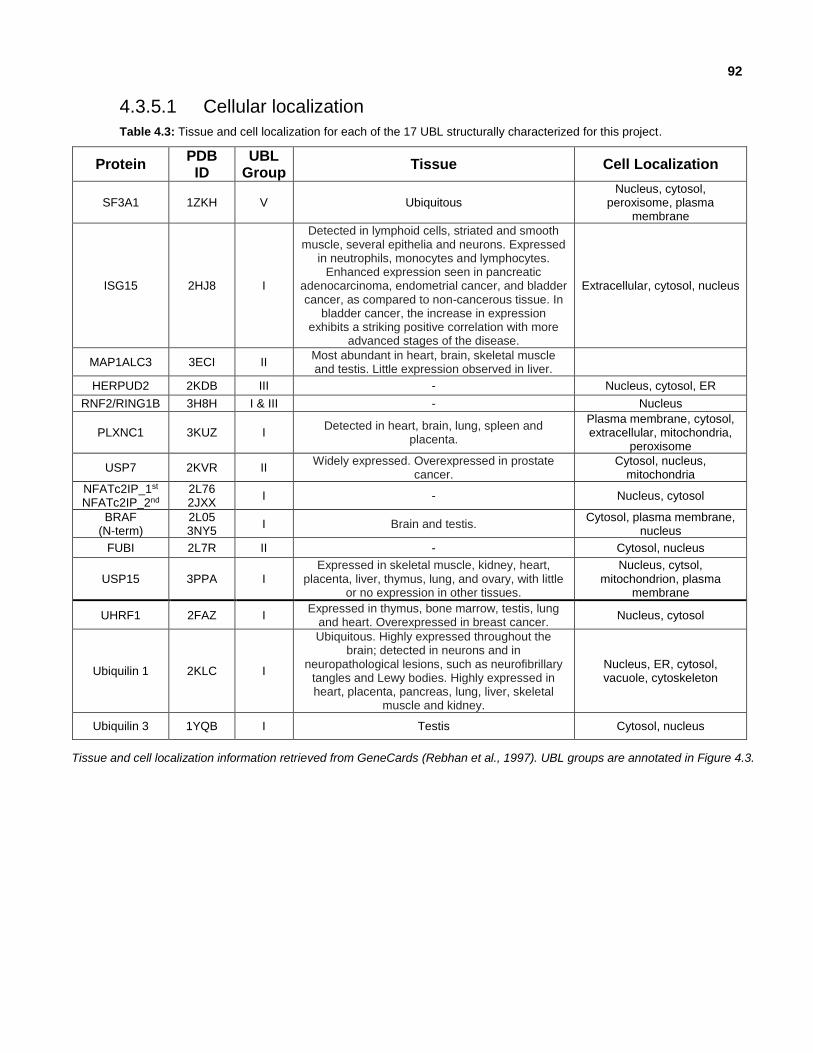
92
4.3.5.1 Cellular localization
Table 4.3: Tissue and cell localization for each of the 17 UBL structurally characterized for this project.
Protein PDB ID
UBL Group
Tissue Cell Localization
SF3A1 1ZKH V Ubiquitous Nucleus, cytosol,
peroxisome, plasma membrane
ISG15 2HJ8 I
Detected in lymphoid cells, striated and smooth muscle, several epithelia and neurons. Expressed
in neutrophils, monocytes and lymphocytes. Enhanced expression seen in pancreatic
adenocarcinoma, endometrial cancer, and bladder cancer, as compared to non-cancerous tissue. In
bladder cancer, the increase in expression exhibits a striking positive correlation with more
advanced stages of the disease.
Extracellular, cytosol, nucleus
MAP1ALC3 3ECI II Most abundant in heart, brain, skeletal muscle and testis. Little expression observed in liver.
HERPUD2 2KDB III - Nucleus, cytosol, ER
RNF2/RING1B 3H8H I & III - Nucleus
PLXNC1 3KUZ I Detected in heart, brain, lung, spleen and
placenta.
Plasma membrane, cytosol, extracellular, mitochondria,
peroxisome
USP7 2KVR II Widely expressed. Overexpressed in prostate
cancer. Cytosol, nucleus,
mitochondria
NFATc2IP_1st NFATc2IP_2nd
2L76 2JXX
I - Nucleus, cytosol
BRAF (N-term)
2L05 3NY5
I Brain and testis. Cytosol, plasma membrane,
nucleus
FUBI 2L7R II - Cytosol, nucleus
USP15 3PPA I Expressed in skeletal muscle, kidney, heart,
placenta, liver, thymus, lung, and ovary, with little or no expression in other tissues.
Nucleus, cytsol, mitochondrion, plasma
membrane
UHRF1 2FAZ I Expressed in thymus, bone marrow, testis, lung
and heart. Overexpressed in breast cancer. Nucleus, cytosol
Ubiquilin 1 2KLC I
Ubiquitous. Highly expressed throughout the brain; detected in neurons and in
neuropathological lesions, such as neurofibrillary tangles and Lewy bodies. Highly expressed in heart, placenta, pancreas, lung, liver, skeletal
muscle and kidney.
Nucleus, ER, cytosol, vacuole, cytoskeleton
Ubiquilin 3 1YQB I Testis Cytosol, nucleus
Tissue and cell localization information retrieved from GeneCards (Rebhan et al., 1997). UBL groups are annotated in Figure 4.3.

93
4.3.6 Grouping UBLs based on cell localization
Upon analysis of all 231 UBL-containing proteins, 65.8% of UBLs have cell localization
annotations within the GO repository. This pool of 152 UBLs are associated with a total of 110
unique cellular regions, and up to 10 cellular regions are associated with a single UBL. Cell
localization is a significant attribute to consider when characterizing a protein, since it provides
insight into possible protein-protein interactions and functional pathways associated with that
particular cell localization, and also provides insight into the chemical environment (ie. pH). Cell
localization data for UBLs was analyzed a few different ways. First, the geographic distribution
of UBLs within the cell was analyzed, and the most common cellular locations for UBLs were the
nucleus, cytoplasm and ER (Figure 4.7). Of the UBLs that have been characterized to exist in the
cytoplasm, nucleus and/or ER, 90 UBLs are structurally characterized (bold blue font), and 12
are UBMs (underlined bold blue font).
Figure 4.7: Distribution of human UBLs based on cellular localization.
There are a few caveats to this approach. For example, cell localization is based on the full length
protein, which would affect any direct correlation between cell localization and specific protein
domains; and 34.2% of UBL-containing proteins lack information about cellular localization.

94
However, taking into account molecular structure data, specifically electrostatic potential
distribution mapped onto the molecular surface, the influence of pH on the binding interfaces and
structural features could be elucidated.
Table 4.4: Structural alignment of lysines within structurally characterized ubiquitin and ubiquitin-like domains
characterized within both cytoplasm and ER; cytoplasm & nucleus; nucleus, cytoplasm and ER; and only nucleus.
Cellular Localization Number of UBLs lysine-6 lysine-11 lysine-27 lysine-29 lysine-33 lysine-48 lysine-63
ER & Cytoplasm 3 2 1 0 1 2 1 1
Nucleus 14 1 4 7 9 6 2 1
Cytoplasm, ER & Nucleus
21 7 7 12 6 7 12 6
Cytoplasm 18 4 1 9 5 8 6 3
Nucleus & Cytoplasm 29 8 8 16 11 9 8 7
none of the above 10 4 2 8 2 1 3 1
Of the 21 UBLs associated with the ER, 4 UBLs are found to only be associated with the cytoplasm
and ER; GABARAP, GABARAPL1, HSPA13 and VCPIP1. The ubiquitin-like domain of
GABARAP and GABARAPL1 have been structurally characterized. VCPIP1 contains two
putative UBLs; there are distantly related protein structures for fragments of the first ubiquitin-like
domain of VCPIP1, and a homology model can be generated for the second ubiquitin-like domain.
However, the homology model for the second ubiquitin-like domain of VCPIP1 has a low
confidence C-terminal tail due to template sequence alignment gaps. Homology models were not
generated for HSPA13 nor VCPIP1_1-1 because low quality homology models would have been
generated.
Structural analysis of the homology model of VCPIP1, GABARAP and GABARAPL1 reveal
structural alignment of lysine 53 in VCPIP1 with poly-ubiquitin chain target lysine 48 of ubiquitin,
and lysine 35 & lysine 66 of GABARAP and GABARAPL1 with lysine 6 & lysine 33 of ubiquitin.
Comparative analysis of the molecular surface of each ubiquitin-like domain structure at pH 7.2
revealed no major hydrophobic patches nor electrostatic potential patches across all structures.
However, this could be due to the small sample size of only two structurally characterized UBLs
and one homology model for this group of UBLs.

95
Structural analysis of UBLs found within the nucleus provide richer pool of information. There
was structural information for 14 UBLs, of which 8 structures were generated using homology
modelling techniques. Analysis of electrostatic potential distribution grouped the proteins into 3
subgroupings: UBLs with surfaces that are mostly positively charged (PCGF1_1-1, PCGF2_1-1,
PCGF3_1-1, PCGF5_1-1, SF3A1_1-1), UBLs with a large conserved negatively charged patch
(PCGF5_1-1, PCGF6_1-1, PCGF6_2-2, USP31_1-1), UBLs with mixed distribution of negatively
& positively charged residues (UHRF1_1-1, UHRF2_1-1, UBLCP1_1-1, SUMO2_1-1, PCGF6_1-
1, PCGF6_2-2). Some small hydrophobic patches were identified for small subgroupings of
UBLs, but nothing significant to characterize the full group of UBLs. Similar to the group of UBLs
within the ER, there is also a subset of nuclear UBLs that have structurally conserved lysines in
regions corresponding to lysine 6, lysine 33, and lysine 48 of ubiquitin (Table 4.4).
4.4 Conclusion
Information about the ubiquitin-like domain family has been compiled as a resource for generating
hypotheses about ubiquitin-like domain containing proteins, and the role of the UBLs in
uncharacterized proteins based on structural similarity analyses that could be associated with
potential protein-protein interaction interfaces. Multiple approaches were pursued for grouping
UBLs; these included clustering based on sequence similarity, structural features, and functional
characterization. Based on the analyses that were performed, a framework was generated to
explore molecular diversity of protein domains and putative members of protein domain families.
Structurally unresolved UBLs were ranked based on the amount and significance of information
generated by subsequence structural analyses. The top 10 UBLs recommended for future
characterization are ANKUB1-2, FRMD1_2-2, FRMPD2_1-1, SHROOM1_1-2, SNX31_1-2,
USP9X_1-3, USP11_1-2, SACS_1, PAN2_1-1, PAN2_1-2, PAN2_1-3, PIK3CG and PTPN13_1-2.

96
Chapter 5
Conclusion and Future Directions
5.1 Conclusions
Over the course of this thesis project, I investigated the scope and diversity of the ubiquitin fold
among human ubiquitin-like domains. This revealed a functionally diverse superfamily of 448
protein domains, related to one another in terms of structural fold and secondary structure
elements. The functional diversity of the 448 human UBLs was efficiently surveyed by grouping
related UBLs into modelling families. As a result, 680 DNA constructs representing 76 UBL
domains were expressed in E.coli for small-scale screening of protein expression and solubility,
of which 205 UBL domain constructs were further screened by NMR spectroscopy. 17 UBLs with
high novel leverage were selected for molecular structure determination based on protein
expression and solubility screening results. The structurally characterized UBLs were surveyed
and compared with structurally characterized UBMs, revealing amino acid variability and
complementarity that maintains the protein fold while diversifying the chemical environment of
protein-protein interaction interfaces.
Aggregating and analyzing these distant features facilitated correlations and predicted
relationships based on structural features. Two of these predictions, the second ubiquitin-like
domain of NFATc2IP interacting with the second SIM of NFATc2, as well as the ubiquitin-like
domain of ubiquilin-1 interacting with a putative UIM of PIN1, were screened by NMR titration
(Chapter Three). Changes in chemical shifts of residues at or near the putative binding site
validate the predicted interaction, and also demonstrate the potential for ubiquitin-like domains to
have interactions that are similar to known binding partners of ubiquitin and ubiquitin-like modifiers
yet complement the interaction interface of the ubiquitin-like fold. The significance of these
interactions are yet to be characterized, but could be related to shared functional activity, common

97
functional pathways, modulation of ubiquitin-like modifier activity, or could be involved in
mediating ubiquitin-like modifier conjugation of ubiquitin-like domain containing proteins.
5.2 Future Directions
5.2.1 Ubiquitin-like domain fold, NFATc2IP & ubiquilins
In order to better understand the significance of conserved residues on maintaining the ubiquitin
fold and the characteristic secondary structure elements, a series of mutagenesis experiments
could be performed. Mutagenesis could also be performed on amino acids within binding
interfaces to explore complementarity between ubiquitin-like domains and binding partners. For
NFATc2IP, the amino acids would include those identified in the NMR titration experiments;
glutamine 37, threonine 38, glycine 32, leucine 39, alanine 59, and tryptophan 96. For ubiquilin-
1, the amino acids would include aspartic acid 63, lysine 72, isoleucine 73, leucine 74, glutamine
82, histidine 92, valine 94, and lysine 96.
NMR titration experiments were performed using isolated ubiquitin-like domains and fragments of
binding partner proteins, and should be repeated using full length proteins (NFATc2IP, NFATc2,
ubiquilin-1, and PIN1). The full length NFATc2IP protein contains tandem NFATc2IP ubiquitin-
like domains, and a comparative analysis can be performed as a tandem NFATc2IP ubiquitin-like
domain fragment. NFATc2IP and ubiquilin-1 genes each have multiple protein family members
and isoforms, and similar experiments can be performed on each of these members to determine
whether binding specificity extends to other family members and/or isoforms.
Ubiquilin-1 has been observed in the cytoplasm, nucleus and ER, while NFATc2IP has been
observed in the cytoplasm and nucleus. Subtle differences in the chemical environments of each
cellular compartment could impact the electrostatic surface potential at binding interfaces and
impact protein-protein interactions. For this reason, experiments involving pH titration and the
impact on protein-protein interactions could be explored. Similarity, phosphorylation and post-

98
translational modification sites exist on NFATc2IP, NFATc2, ubiquilin-1 and PIN1, and
experiments could be performed to determine whether phosphorylation or other post-translational
modifications affect binding affinities.
Based on fold conservation and structural feature similarity, competition analysis with similar
ubiquitin-like domains could be performed (ubiquitin, UBL4A & UBTD2 for ubiquilin-1) to
determine whether the ubiquitin-like domains compete to interact with PIN1 for ubiquilin-1. A
matrix of similar competition analyses could be performed using additional binding partners.
5.2.2 Ubiquitin-like domain structural genomics
270 ubiquitin-like domains remain to be structurally determined for structural completeness, which
becomes 74 when taking into account homology models. I’d recommend a strategy for completing
structural coverage which is prioritized based on structural coverage & functional significance. This
would consist of screening and characterizing the following ubiquitin-like domains: ANKUB1-2,
FRMD1_2-2, FRMPD2_1-1, SHROOM1_1-2, SNX31_1-2, USP9X_1-3, USP11_1-2, SACS_1,
PAN2_1-1, PAN2_1-2, PAN2_1-3, PIK3CG, and PTPN13_1-2.
5.2.3 Protein Domain family analyses
Our systematic approach of surveying, selecting, screening, structural determination, and
analysis could be performed on a variety of different protein families to explore the amino acid
and structural diversity of any group of proteins, whether fold superfamily or structural motif.
5.3 Concluding remarks
My structural genomics analysis of human ubiquitin-like domains demonstrates the value of: (1)
NMR 1H15N-HSQC screening for amenability for structure determination; (2) modelling family
analysis and homology model generation to assist in completing structural coverage of a protein
family; and (3) utilizing relational databases and structure-driven hypothesis generation to predict
putative binding partners.

99
6.0 References
Angot A, Vergunst A, Genin S, and Peeters N. “Exploitation of eukaryotic ubiquitin signaling
pathways by effectors translocated by bacterial type III and type IV secretion systems.” PLoS
pathogens 3, no. 1 (2007): e3.
Arnold K, Bordoli L, Kopp J, and Schwede T. "The SWISS-MODEL Workspace: A web-based
environment for protein structure homology modelling." Bioinformatics 22 (2006): 195-201.
Baker NA, Sept D, Joseph S, Holst MJ, and McCammon JA. "Electrostatics of nanosystems:
application to microtubules and the ribosome." Proceedings of the National Academy of Sciences
of the United States of America 98 (2001): 10037–10041.
Benson, DA, Cavanaugh M, Clark K, Karsch-Mizrachi I, Lipman DJ, Ostell J, and Sayers EW.
"GenBank." Nucleic Acids Research 41, no. Database Issue (2013): D36-D42.
Berman HM, Westbrook J, Feng Z, Gilliland G, Bhat TN, Weissig H, Shindyalov IN, and Bourne
PE. "The Protein Data Bank". Nucleic Acids Research 28 (2000): 235–242.
Bhattacharya, A, Tejero R, and Montelione GT. "Evaluating protein structures determined by
structural genomics consortia." Proteins: Structure, Function, and Bioinformatics 66, no. 4 (2007):
778-795.
Bhattacharya, A, Wunderlich Z, Monleon D, Tejero R, and Montelione GT. "Assessing model
accuracy using the homology modeling automatically software." Proteins 70 (2008): 105-118.
Boratyn, Grzegorz M, Schaffer AA, Agarwala R, Altschul SF, Lipman DJ, and Madden TL.
"Domain enhanced lookup time accelerated BLAST." Biology Direct 7, no. 1 (2012): 12.

100
Boyault C, Gilquin B, Zhang Y, Rybin V, Garman E, Meyer-Klaucke W, Matthias P, Müller CW,
and Khochbin S. “HDAC6–p97/VCP controlled polyubiquitin chain turnover.” The EMBO journal
25, no. 14 (2006): 3357-3366.
Brzovic PS, Lissounov A, Christensen DE, Hoyt DW, and Klevit RE. “A UbcH5/ubiquitin
noncovalent complex is required for processive BRCA1-directed ubiquitination.” Mol. Cell 21
(2006): 873–880.
Brünger AT, Adams PD, Clore GM, DeLano WL, Gros P, Grosse-Kunstleve RW, Jiang J-S,
Kuszewski J, Nilges M, Pannu NS, Read RJ, Rice LM, Simonson T, Warren GL. "Crystallography
& NMR system: A new software suite for macromolecular structure determination." Acta
Crystallographica Section D: Biological Crystallography 54, no. 5 (1998): 905-921.
Brünger AT. "Version 1.2 of the Crystallography and NMR system." Nature protocols 2, no. 11
(2007): 2728-2733.
Chen L, Shinde U, Ortolan TG, and Madura K. “Ubiquitin‐associated (UBA) domains in Rad23
bind ubiquitin and promote inhibition of multi‐ubiquitin chain assembly.” EMBO reports 2, no. 10
(2001): 933-938.
Ciechanover A, and Schwartz AL. “The ubiquitin system: pathogenesis of human diseases and
drug targeting.” Biochimica et Biophysica Acta (BBA)-Molecular Cell Research 1695, no. 1 (2004):
3-17.
Cole C, Barber JD, and Barton GJ. "The Jpred 3 secondary structure prediction server" Nucleic
Acids Res. 36, suppl. 2 (2008): W197-W201.
Cuff JA, and Barton GJ. "Application of Enhanced Multiple Sequence Alignment Profiles to
Improve Protein Secondary Structure Prediction." PROTEINS: Structure, Function and Genetics
40 (2000): 502-511.

101
Davis ME, McCammon JA "Electrostatics in biomolecular structure and dynamics." Chem. Rev.
90 (1990): 509–521.
de Napoles M, Mermoud JE, Wakao R, Tang YA, Endoh M, Appanah R, Nesterova TB, Silva J,
Otte AP, Vidal M, Koseki H, and Brockdorff N. “Polycomb group proteins Ring1A/B link
ubiquitylation of histone H2A to heritable gene silencing and X inactivation.” Developmental cell
7, no. 5 (2004): 663-676.
Delaglio F, Grzesiek S, Vuister GW, Zhu G, Pfeifer J, and Bax AD. "NMRPipe: a multidimensional
spectral processing system based on UNIX pipes." Journal of biomolecular NMR 6, no. 3 (1995):
277-293.
Dolinsky TJ, Czodrowski P, Li H, Nielsen JE, Jensen JH, Klebe G, Baker NA. "PDB2PQR:
expanding and upgrading automated preparation of biomolecular structures for molecular
simulations." Nucleic Acids Research 35 (2007): W522–W525.
Donaldson KM, Yin H, Gekakis N, Supek F, and Joazeiro CA. “Ubiquitin signals protein trafficking
via interaction with a novel ubiquitin binding domain in the membrane fusion regulator, Vps9p.”
Current biology 13, no. 3 (2003): 258-262.
Finley D, Bartel B, and Varshavsky A. “The tails of ubiquitin precursors are ribosomal proteins
whose fusion to ubiquitin facilitates ribosome biogenesis.” Nature 338, no. 6214 (1989): 394-401.
Fisher RD, Wang B, Alam SL, Higginson DS, Robinson H, Sundquist WI, & Hill CP. "Structure
and ubiquitin binding of the ubiquitin-interacting motif." Journal of Biological Chemistry 278, no.
31 (2003): 28976-28984.
Goddard TD & Kneller DG. "SPARKY 3", University of California, San Francisco.

102
Gorham Jr RD, Kieslich CA, Morikis D. "Electrostatic Clustering and Free Energy Calculations
Provide a Foundation for Protein Design and Optimization." Annals of Biomedical Engineering 39,
no. 4 (2011): 1252–1263.
Grabbe C & Dikic I. "Functional roles of ubiquitin-like domain (ULD) and ubiquitin-binding domain
(UBD) containing proteins." Chemical reviews 109, no. 4 (2009): 1481-1494.
Haglund K, and Dikic I. “Ubiquitylation and cell signaling.” The EMBO journal 24, no. 19 (2005):
3353-3359.
Hannich JT, Lewis A, Kroetz MB, Li SJ, Heide H, Emili A, and Hochstrasser M. "Defining the
SUMO-modified proteome by multiple approaches in Saccharomyces cerevisiae." Journal of
Biological Chemistry 280, no. 6 (2005): 4102-4110.
Hecker CM, Rabiller M, Haglund K, Bayer P, and Dikic I. “Specification of SUMO1-and SUMO2-
interacting motifs.” Journal of Biological Chemistry 281, no. 23 (2006): 16117-16127.
Heir R, Ablasou C, Dumontier E, Elliott M, Fagotto-Kaufmann C, Bedford FK. "The UBL domain
of PLIC-1 regulates aggresome formation." EMBO reports 7, 12 (2006): 1252-1258.
Hochstrasser M. “Origin and function of ubiquitin-like proteins.” Nature 458, no. 7237 (2009): 422-
429.
Hochstrasser, M. "Evolution and function of ubiquitin-like protein-conjugation systems." Nature
cell biology 2, no. 8 (2000): E153-E157.
Hofmann K & Bucher P. "The UBA domain: a sequence motif present in multiple enzyme classes
of the ubiquitination pathway." Trends in biochemical sciences 21, no. 5 (1996): 172-173.

103
Hofmann K & Falquet L. “A ubiquitin-interacting motif conserved in components of the
proteasomal and lysosomal protein degradation systems.” Trends in biochemical sciences 26, no.
6 (2001): 347-350.
Hong YH, Ahn HC, Lim J, Kim HM, Ji HY, Lee S, Kim JH, Park EY, Song HK, and Lee BJ.
“Identification of a novel ubiquitin binding site of STAM1 VHS domain by NMR spectroscopy.”
FEBS letters 583, no. 2 (2009): 287-292.
Hook SS, Orian A, Cowley SM, and Eisenman RN. “Histone deacetylase 6 binds polyubiquitin
through its zinc finger (PAZ domain) and copurifies with deubiquitinating enzymes.” Proceedings
of the National Academy of Sciences 99, no. 21 (2002): 13425-13430.
Ichimura Y, Takayoshi K, Toshifumi T, Yoshinori S, Yasutsugu S, Naotada I, Noboru M, et al. "A
ubiquitin-like system mediates protein lipidation." Nature 408, no. 6811 (2000): 488-492.
Kang RS, Daniels CM, Francis SA, Shih SC, Salerno WJ, Hicke L, and Radhakrishnan I. “Solution
structure of a CUE–ubiquitin complex reveals a conserved mode of ubiquitin binding.” Cell 113
(2003): 621–630.
Kerscher O. "SUMO junction—what's your function?." EMBO reports 8, no. 6 (2007): 550-555.
Kiefer F, Arnold K, Künzli M, Bordoli L, and Schwede T. "The SWISS-MODEL Repository and
associated resources.” Nucleic Acids Research 37 (2009): D387-D392.
Ko HS, Uehara T, Tsuruma K, and Nomura Y. "Ubiquilin interacts with ubiquitylated proteins and
proteasome through its ubiquitin-associated and ubiquitin-like domains." FEBS letters 566, no. 1
(2004): 110-114.

104
Koehn J & Hunt I. "High-Throughput Protein Production (HTPP): a review of enabling technologies
to expedite protein production." In High Throughput Protein Expression and Purification, pp. 1-18.
Humana Press, 2009.
Koh IYY, Eyrich VA, Marti-Renom MA, Przybylski D, Madhusudhan MS, Eswar N, Grana O, Pazos
F, Valencia A, Sali A, and Rost B. "EVA: evaluation of protein structure prediction servers."
Nucleic Acids Research 31, no. 13 (2003): 3311-3315.
Komander D. “The emerging complexity of protein ubiquitination.” Biochemical Society
Transactions 37, no. Pt 5 (2009): 937-953.
Koonin EV & Abagyan RA. “TSG101 may be the prototype of a class of dominant negative
ubiquitin regulators.” Nature genetics 16, no. 4 (1997): 330-331.
Lee S, Tsai YC, Mattera R, Smith WJ, Kostelansky MS, Weissman AM, Bonifacino JS, and Hurley
JH. “Structural basis for ubiquitin recognition and autoubiquitination by Rabex-5.” Nature Struct.
Mol. Biol. 13, (2006): 264–271.
Lemak A, Gutmanas A, Chitayat S, Karra M, Farès C, Sunnerhagen M, and Arrowsmith CH. "A
novel strategy for NMR resonance assignment and protein structure determination." Journal of
biomolecular NMR 49, no. 1 (2011): 27-38.
Letunic I, Doerks T, and Bork P. "SMART: recent updates, new developments and status in 2015."
Nucleic Acids Research 43, no. D1 (2014): D257-D260.
Liou YC, Sun A, Ryo A, Zhou XZ, Yu ZX, Huang HK, Uchida T, Bronson R, Bing G, Li X, Hunter
T, and Lu KP. "Role of the prolyl isomerase Pin1 in protecting against age-dependent
neurodegeneration" Nature 424, no. 6948 (2003): 556-561.

105
Lim J, Hao T, Shaw C, Patel AJ, Szabó G, Rual JF, Fisk CJ, Li N, Smolyar A, Hill DE, Barabási
AL, Vidal M, and Zoghbi HY. "A protein–protein interaction network for human inherited ataxias
and disorders of Purkinje cell degeneration." Cell 125, no. 4 (2006): 801-814.
Lippens G, Landrieu I, and Smet C. "Molecular mechanisms of the phospho‐dependent prolyl
cis/trans isomerase Pin1." FEBS journal 274, no. 20 (2007): 5211-5222.
Loeb KR & Haas AL. "The interferon-inducible 15-kDa ubiquitin homolog conjugates to
intracellular proteins." Journal of Biological Chemistry 267, no. 11 (1992): 7806-7813.
Macian F. "NFAT proteins: key regulators of T-cell development and function." Nature Reviews
Immunology 5, no. 6 (2005): 472-484.
Mah AL, Perry G, Smith MA, and Monteiro MJ. "Identification of ubiquilin, a novel presenilin
interactor that increases presenilin protein accumulation." The Journal of cell biology 151, no. 4
(2000): 847-862.
Makhnevych T, Sydorskyy Y, Xin X, Srikumar T, Vizeacoumar FJ, Jeram SM, Li Z, Bahr S,
Andrews BJ, Boone C, and Raught B. "Global map of SUMO function revealed by protein-protein
interaction and genetic networks." Molecular cell 33, no. 1 (2009): 124-135.
Marchler-Bauer A, Zheng C, Chitsaz F, Derbyshire MK, Geer LY, Geer RC, Gonzales NR, Gwadz
M, Hurwitz DI, Lanczycki CJ, Lu F, Lu S, Marchler GH, Song JS, Thanki N, Yamashita RA, Zhang
D, and Bryant SH. "CDD: conserved domains and protein three-dimensional structure." Nucleic
acids research 41, no. D1 (2013): D348-D352.
Marti-Renom MA, Madhusudhan MS, Fiser A, Rost B, and Sali A. "Reliability of assessment of
protein structure prediction methods." Structure 10 (2002): 435-440.

106
Marti-Renom MA, Stuart A, Fiser A, Sanchez R, Melo F, and Sali A. "Comparative protein
structure modeling of genes and genomes." Annual Review of Biophysics and Biomolecular
Structure 29 (2000): 291-325.
McNally T, Huang Q, Janis RS, Liu Z, Olejniczak ET, and Reilly RM. "Structural analysis of UBL5,
a novel ubiquitin-like modifier." Protein science 12, no. 7 (2003): 1562-1566.
Meyer HH, Wang Y, and Warren G. “Direct binding of ubiquitin conjugates by the mammalian p97
adaptor complexes, p47 and Ufd1–Npl4.” The EMBO journal 21, no. 21 (2002): 5645-5652.
Minty A, Dumont X, Kaghad M, and Caput D. "Covalent Modification of p73α by SUMO-1 two-
hybrid screening with p73 identifies novel SUMO-1-interacting proteins and a SUMO-1 interacting
motif." Journal of Biological Chemistry 275, no. 46 (2000): 36316-36323.
Mizushima N, Noda T, Yoshimori T, Tanaka Y, Ishii T, George MD, Klionsky DJ, Ohsumi M, and
Ohsumi Y. "A protein conjugation system essential for autophagy." Nature 395, no. 6700 (1998):
395-398.
Müller S, Ledl A, and Schmidt D. "SUMO: a regulator of gene expression and genome integrity."
Oncogene 23, no. 11 (2004): 1998-2008.
N'Diaye EN & Brown EJ. "The ubiquitin-related protein PLIC-1 regulates heterotrimeric G protein
function through association with Gβγ." The Journal of cell biology 163, no. 5 (2003): 1157-1165.
Nair, Rajesh, Liu J, Soong TT, Acton TB, Everett JK, Kouranov A, Fiser A, Godzik A, Jaroszewski
L, Orengo C, Montelione GT, and Rost B. "Structural genomics is the largest contributor of novel
structural leverage." Journal of Structural and Functional Genomics 10, no. 2 (2009): 181-191.
Nayak A, Glöckner-Pagel J, Vaeth M, Schumann JE, Buttmann M, Bopp T, Schmitt E, Serfling E
and Berberich-Siebelt F. "Sumoylation of the transcription factor NFATc1 leads to its subnuclear

107
relocalization and interleukin-2 repression by histone deacetylase" Journal of Biological Chemistry
284, no. 16 (2009): 10935-10946.
Pan ZQ, Kentsis A, Dias DC, Yamoah K, and Wu K. "Nedd8 on cullin: building an expressway to
protein destruction." Oncogene 23, no. 11 (2004): 1985-1997.
Peitsch, MC. "Protein modeling by E-mail." Nature Biotechnology 13 (1995): 658-660.
Penengo L, Mapelli M, Murachelli AG, Confalonieri S, Magri L, Musacchio A, Di Fiore PP, Polo S,
and Schneider TR. “Crystal structure of the ubiquitin binding domains of rabex-5 reveals two
modes of interaction with ubiquitin.” Cell 124 (2006): 1183–1195.
Perry JJP, Tainer JA, and Boddy MN. "A SIM-ultaneous role for SUMO and ubiquitin." Trends in
biochemical sciences 33, no. 5 (2008): 201-208.
Pettersen EF, Goddard TD, Huang CC, Couch GS, Greenblatt DM, Meng EC, and Ferrin TE
"UCSF Chimera–a visualization system for exploratory research and analysis." J. Comput. Chem
25 (2004): 1605–1612.
Pieper U, Webb BM, Barkan DT, Schneidman-Duhovny D, Schlessinger A, Braberg H, Yang Z,
Meng EC, Pettersen EF, Huang CC, Datta RS, Sampathkumar P, Madhusudhan MS, Sjolander
K, Ferrin TE, Burley SK, and Sali A. "MODBASE, a database of annotated comparative protein
structure models and associated resources." Nucleic Acids Research 39 (2011): 465-474.
Prag G, Misra S, Jones EA, Ghirlando R, Davies BA, Horazdovsky BF, and Hurley JH.
“Mechanism of ubiquitin recognition by the CUE domain of Vps9p.” Cell 113 (2003): 609–620.
Prag G, Lee SH, Mattera R, Arighi CN, Beach BM, Bonifacino JS, and Hurley JH. “Structural
mechanism for ubiquitinated-cargo recognition by the Golgi-localized, gamma-ear-containing,

108
ADP-ribosylation-factor-binding proteins.” Proceedings of the National Academy of Sciences of
the United States of America 102 (2005): 2334–2339.
Prasad TSK, Goel R, Kandasamy K, Keerthikumar S, Kumar S, Mathivanan S, Telikicherla D,
Raju R, Shafreen B, Venugopal A, Balakrishnan L, Marimuthu A, Banerjee S, Somanathan DS,
Sebastian A, Rani S, Ray S, Kishore CJH, Kanth S, Ahmed M, Kashyap MK, Mohmood R,
Ramachandra YL, Krishna V, Rahiman BA, Mohan S, Ranganathan P, Ramabadran S,
Chaerkady R, and Pandey A. "Human Protein Reference Database - 2009 Update." Nucleic Acids
Research 37 (2009): D767-D772.
Rao A, Luo C, and Hogan PG. “Transcription factors of the NFAT family: regulation and function.”
Annual review of immunology 15, no. 1 (1997): 707-747.
Rebhan M, Chalifa-Caspi V, Prilusky J, and Lancet D. "GeneCards: integrating information about
genes, proteins and diseases." Trends in Genetics 13, no. 4 (1997): 163.
Regan-Klapisz E, Sorokina I, Voortman J, de Keizer P, Roovers RC, Verheesen P, Urbé S, Fallon
L, Fon EA, Verkleij A, Benmerah A, and van Bergen en Henegouwen PM. "Ubiquilin recruits
Eps15 into ubiquitin-rich cytoplasmic aggregates via a UIM-UBL interaction." Journal of cell
science 118, no. 19 (2005): 4437-4450.
Rengarajan J, Mittelstadt PR, Mages HW, Gerth AJ, Kroczek RA, Ashwell JD, and Glimcher LH.
“Sequential involvement of NFAT and Egr transcription factors in FasL regulation.” Immunity 12,
no. 3 (2000): 293-300.
Reyes-Turcu FE, Horton JR, Mullally JE, Heroux A, Cheng X, and Wilkinson KD. “The ubiquitin
binding domain ZnF UBP recognizes the C-terminal diglycine motif of unanchored ubiquitin.” Cell
124, no. 6 (2006): 1197-1208.

109
Schlesinger DH, Goldstein G, and Niall HD. “Complete amino acid sequence of ubiquitin, an
adenylate cyclase stimulating polypeptide probably universal in living cells.” Biochemistry 14, no.
10 (1975): 2214-2218.
Semple CA. “The comparative proteomics of ubiquitination in mouse.” Genome Research 13
(2003): 1389–1394.
Shen Y, Delaglio F, Cornilescu G, and Bax A. "TALOS+: a hybrid method for predicting protein
backbone torsion angles from NMR chemical shifts." Journal of biomolecular NMR 44, no. 4
(2009): 213-223.
Shiba Y, Katoh Y, Shiba T, Yoshino K, Takatsu H, Kobayashi H, Shin HW, Wakatsuki S, and
Nakayama K. “GAT (GGA and Tom1) domain responsible for ubiquitin binding and ubiquitination.”
Journal of Biological Chemistry 279, no. 8 (2004): 7105-7111.
Shih SC, Prag G, Francis SA, Sutanto MA, Hurley JH, and Hicke L. “A ubiquitin‐binding motif
required for intramolecular monoubiquitylation, the CUE domain.” The EMBO Journal 22, no. 6
(2003): 1273-1281.
Shimodaira H. "An approximately unbiased test of phylogenetic tree selection." System. Biol. 51
(2002): 492–508.
Shimodaira H. "Approximately unbiased test of regions using multistep-multiscale bootstrap
resampling." Ann. Statist. 32 (2004): 2616–2641.
Sitkoff D, Sharp KA, Honig B. "Accurate calculation of hydration free energies using macroscopic
solvent models." J. Phys. Chem. 98 (1994): 1978–1988.

110
Song J, Durrin LK, Wilkinson TA, Krontiris TG, and Chen Y. "Identification of a SUMO-binding
motif that recognizes SUMO-modified proteins." Proceedings of the National Academy of
Sciences of the United States of America 101, no. 40 (2004): 14373-14378.
Song J, Zhang Z, Hu W, and Chen Y. “Small ubiquitin-like modifier (SUMO) recognition of a SUMO
binding motif: a reversal of the bound orientation.” J.Biol.Chem. 280 (2005): 40122-40129.
Sundquist WI, Schubert HL, Kelly BN, Hill GC, Holton JM, and Hill CP. “Ubiquitin recognition by
the human TSG101 protein.” Mol. Cell 13 (2004): 783–789.
Swanson KA, Kang RS, Stamenova SD, Hicke L, and Radhakrishnan I. “Solution structure of
Vps27 UIM-ubiquitin complex important for endosomal sorting and receptor downregulation.”
EMBO J. 22 (2003): 4597–4606.
Teo H, Gill DJ, Sun J, Perisic O, Veprintsev DB, Vallis Y, Emr SD, and Williams RL. “ESCRT-I
core and ESCRT-II GLUE domain structures reveal role for GLUE in linking to ESCRT-I and
membranes.” Cell 125, no. 1 (2006): 99-111.
Terui Y, Saad N, Jia S, McKeon F, and Yuan J. "Dual role of sumoylation in the nuclear localization
and transcriptional activation of NFAT1." Journal of Biological Chemistry 279 (2004): 28257-
28265.
Turner B, Razick S, Turinsky AL, Vlasblom J, Crowdy EK, Cho E, Morrison K, Donaldson IM, and
Wodak SJ. "iRefWeb: interactive analysis of consolidated protein interaction data and their
supporting evidence." Database (2010): baq023.
Uhlen M, Oksvold P, Fagerberg L, Lundberg E, Jonasson K, Forsberg M, Zwahlen M, Kampf C,
Wester K, Hober S, Wernerus H, Björling L, and Ponten F. "Towards a knowledge-based Human
Protein Atlas." Nature Biotechnology 28, no. 12 (2010): 1248-1250.

111
UniProt Consortium. "Activities at the Universal Protein Resource (UniProt)." Nucleic Acids
Research 42, no. D1 (2014): D191-D198.
Varadan R, Assfalg M, Raasi S, Pickart C, and Fushman D. “Structural determinants for selective
recognition of a lys48-linked polyubiquitin chain by a UBA domain.” Mol. Cell 18 (2005): 687–698.
Vriend, G. "WHAT IF: a molecular modeling and drug design program." Journal of molecular
graphics 8, no. 1 (1990): 52-56.
Wang B, Alam SL, Meyer HH, Payne M, Stemmler TL, Davis DR, and Sundquist WI. “Structure
and ubiquitin interactions of the conserved zinc finger domain of Npl4.” Journal of Biological
Chemistry 278, no. 22 (2003): 20225-20234.
Wang QH, Young P, and Walters KJ. “Structure of S5a bound to monoubiquitin provides a model
for polyubiquitin recognition.” J. Mol. Biol. 348 (2005): 727–739.
Wang X, Herr RA, Chua WJ, Lybarger L, Wiertz EJHJ, and Hansen TH. "Ubiquitination of serine,
threonine, or lysine residues on the cytoplasmic tail can induce ERAD of MHC-I by viral E3 ligase
mK3." The Journal of cell biology 177, no. 4 (2007): 613-624.
Weigelt J. "Structural genomics—impact on biomedicine and drug discovery." Experimental cell
research 316, no. 8 (2010): 1332-1338.
Xu P & Peng J. "Dissecting the ubiquitin pathway by mass spectrometry." Biochimica et
Biophysica Acta (BBA)-Proteins and Proteomics 1764, no. 12 (2006): 1940-1947.
Yang SH, Galanis A, Witty J, and Sharrocks AD. "An extended consensus motif enhances the
specificity of substrate modification by SUMO." The EMBO journal 25, no. 21 (2006): 5083-5093.

112
Yee A, Chang X, Pineda-Lucena A, Wu B, Semesi A, Le B, Ramelot T, Lee GM, Bhattacharyya
S, Gutierrez P, Denisov A, Lee CH, Cort JR, Kozlov G, Liao J, Finak G, Chen L, Wishart D, Lee
W, McIntosh LP, Gehring K, Kennedy MA, Edwards AM, and Arrowsmith CH. "An NMR approach
to structural proteomics." Proceedings of the National Academy of Sciences 99, no. 4 (2002):
1825-1830.
Yee AA, Semesi A, Garcia M, and Arrowsmith CH. "Screening proteins for NMR suitability. In
Structural Genomics and Drug Discovery." Springer New York (2014): 169-178.
Young P, Deveraux Q, Beal RE, Pickart CM, and Rechsteiner M. "Characterization of two
polyubiquitin binding sites in the 26 S protease subunit 5a". Journal of Biological Chemistry 273,
no. 10 (1998): 5461–5467.
Zhu J, Zhu S, Guzzo CM, Ellis NA, Sung KS, Choi CY, and Matunis MJ. "Small ubiquitin-related
modifier (SUMO) binding determines substrate recognition and paralog-selective SUMO
modification." Journal of Biological Chemistry 283, no. 43 (2008): 29405-29415.
Zweckstetter M & Bax A. "Prediction of sterically induced alignment in a dilute liquid crystalline
phase: aid to protein structure determination by NMR." Journal of the American Chemical Society
122, no. 15 (2000): 3791-3792.

113
7.0 Appendix
Appendix I: All human genes that encode at least one ubiquitin-like domain.
Gene Name Protein Name HUGO HGNC
NCBI GeneID
EC EnzymeID
UniProt ID UniProt Name
ANKRD60 Ankyrin repeat domain-containing protein 60 16217 140731 - Q9BZ19 ANR60_HUMAN
ANKUB1-1/-2/-3 ANKUB1 389161 29642 - A6NFN9 ANKUB_HUMAN
ANUBL1-1 AN1-type zinc finger protein 4 23504 93550 - Q86XD8 ZFAN4_HUMAN
APBB1IP Amyloid beta A4 precursor protein-binding family B member
1-interacting protein 17379 54518 - Q7Z5R6 AB1IP_HUMAN
ARAF-1 Serine/threonine-protein kinase A-Raf 646 369 2.7.11.1 P10398 ARAF_HUMAN
ARAP1 Arf-GAP with Rho-GAP domain, ANK repeat and PH domain-
containing protein 1 16925 116985 - Q96P48 ARAP1_HUMAN
ARAP2 Arf-GAP with Rho-GAP domain, ANK repeat and PH domain-
containing protein 2 16924 116984 - Q8WZ64 ARAP2_HUMAN
ARAP3 Arf-GAP with Rho-GAP domain, ANK repeat and PH domain-
containing protein 3 24097 64411 - Q8WWN8 ARAP3_HUMAN
ARHGAP20 Rho GTPase-activating protein 20 18357 57569 - Q9P2F6 RHG20_HUMAN
ASPSCR1_1-1 Tether containing UBX domain for GLUT4 13825 79058 - Q9BZE9 ASPC1_HUMAN
ATG12 Ubiquitin-like protein ATG12 588 9140 - O94817 ATG12_HUMAN
ATG3-1 Ubiquitin-like-conjugating enzyme ATG3 20962 64422 6.3.2.- Q9NT62 ATG3_HUMAN
ATG7_1-1 Ubiquitin-like modifier-activating enzyme ATG7 16935 10533 - O95352 ATG7_HUMAN
BAG1_1-1 BAG family molecular chaperone regulator 1 937 573 - Q99933 BAG1_HUMAN
BAG6_1-1 Large proline-rich protein BAG6 13919 7917 - P46379 BAG6_HUMAN
BMI1-1 Polycomb complex protein BMI-1 1066 648 - P35226 BMI1_HUMAN
BRAF-1/-2 Serine/threonine-protein kinase B-raf 1097 673 2.7.11.1 P15056 BRAF_HUMAN
CLK4 Dual specificity protein kinase CLK4 13659 57396 2.7.12.1 Q9HAZ1 CLK4_HUMAN
DCDC1 Doublecortin domain-containing protein 1 20625 341019 - P59894 DCDC1_HUMAN
DCDC2 Doublecortin domain-containing protein 2 18141 51473 - Q9UHG0 DCDC2_HUMAN
DCDC2B Doublecortin domain-containing protein 2B 32576 149069 - A2VCK2 DCD2B_HUMAN
DCDC2C Doublecortin domain-containing protein 2C 32696 728597 - A8MYV0 DCD2C_HUMAN
DCDC5 Doublecortin domain-containing protein 5 24799 100506627 - Q6ZRR9 DCDC5_HUMAN
DCLK1 Serine/threonine-protein kinase DCLK1 2700 9201 2.7.11.1 O15075-2 DCLK1_HUMAN
DCLK2 Serine/threonine-protein kinase DCLK2 19002 166614 2.7.11.1 Q8N568 DCLK2_HUMAN
DCX Neuronal migration protein doublecortin 2714 1641 - O43602 DCX_HUMAN
DDI1-1 Protein DDI1 homolog 1 18961 414301 - Q8WTU0 DDI1_HUMAN
DDI2_1-1 Protein DDI1 homolog 2 24578 84301 - Q5TDH0 DDI2_HUMAN
DGKQ Diacylglycerol kinase theta 2856 1609 2.7.1.107 P52824 DGKQ_HUMAN
EPB41L1_1-1 Band 4.1-like protein 1 3378 2036 - Q9H4G0 E41L1_HUMAN
EPB41L2-1 Band 4.1-like protein 2 3379 2037 - O43491 E41L2_HUMAN
EPB41L3_1-1 Band 4.1-like protein 3 3380 23136 - Q9Y2J2 E41L3_HUMAN
EPB41L4A Band 4.1-like protein 4A 13278 64097 - Q9HCS5 E41LA_HUMAN
EPB41L4B_1 Band 4.1-like protein 4B 19818 54566 - Q9H329 E41LB_HUMAN
EPB41L5_1-1 Band 4.1-like protein 5 19819 57669 - Q9HCM4 E41L5_HUMAN
FAF1_1-1 FAS-associated factor 1 3578 11124 - Q9UNN5 FAF1_HUMAN
114
Gene Name Protein Name HUGO HGNC
NCBI GeneID
EC EnzymeID
UniProt ID UniProt Name
FAF2-1 FAS-associated factor 2 24666 23197 - Q96CS3 FAF2_HUMAN
FARP2_1-1 FERM, RhoGEF and pleckstrin domain-containing protein 2 16460 9855 - O94887 FARP2_HUMAN
FAU_1-1 Ubiquitin-like protein FUBI 3597 2197 - P35544 UBIM_HUMAN
FRMD1_1-1 FERM domain-containing protein 1 21240 79981 - Q8N878 FRMD1_HUMAN
FRMD3_1-1/-2 FERM domain-containing protein 3 24125 257019 - A2A2Y4 FRMD3_HUMAN
FRMD4A_1-1 FERM domain-containing protein 4A 25491 55691 - Q9P2Q2 FRM4A_HUMAN
FRMD4B_1-1 FERM domain-containing protein 4B 24886 23150 - Q9Y2L6 FRM4B_HUMAN
FRMD5_1-1/-2 FERM domain-containing protein 5 28214 84978 - Q7Z6J6 FRMD5_HUMAN
FRMD6_1-1 FERM domain-containing protein 6 19839 122786 - Q96NE9 FRMD6_HUMAN
FRMD7_1-1 FERM domain-containing protein 7 8079 90167 - Q6ZUT3 FRMD7_HUMAN
FRMPD2_1-1 FERM and PDZ domain-containing protein 2 28572 143162 - Q68DX3 FRPD2_HUMAN
GABARAP Gamma-aminobutyric acid receptor-associated protein 4067 11337 - O95166 GBRAP_HUMAN
GABARAPL1_1-1 Gamma-aminobutyric acid receptor-associated protein-like 1 4068 23710 - Q9H0R8 GBRL1_HUMAN
GABARAPL2 Gamma-aminobutyric acid receptor-associated protein-like 2 13291 11345 - P60520 GBRL2_HUMAN
GRB10 Growth factor receptor-bound protein 10 4564 2887 - Q13322 GRB10_HUMAN
GRB14 Growth factor receptor-bound protein 14 4565 2888 - Q14449 GRB14_HUMAN
GRB7 Growth factor receptor-bound protein 7 4567 2886 - Q14451 GRB7_HUMAN
HERPUD1_1-1 Homocysteine-responsive endoplasmic reticulum-resident
ubiquitin-like domain member 1 protein 13744 9709 - Q15011 HERP1_HUMAN
HERPUD2_1-1 Homocysteine-responsive endoplasmic reticulum-resident
ubiquitin-like domain member 2 protein 21915 64224 - Q9BSE4 HERP2_HUMAN
HSPA13 Heat shock 70 kDa protein 13 11375 6782 - P48723 HSP13_HUMAN
IKBKB_1-1 Inhibitor of nuclear factor kappa-B kinase subunit 5960 3551 2.7.11.10 O14920 IKKB_HUMAN
IQUB_1-1 IQ and ubiquitin-like domain-containing protein 21995 154865 - Q8NA54 IQUB_HUMAN
ISG15_1-1/-2 Ubiquitin-like protein ISG15 4053 9636 - P05161 ISG15_HUMAN
MAP1LC3A_1-1 Microtubule-associated proteins 1A/1B light chain 3A 6838 84557 - Q9H492 MLP3A_HUMAN
MAP1LC3B Microtubule-associated proteins 1A/1B light chain 3B 13352 81631 - Q9GZQ8 MLP3B_HUMAN
MAP1LC3B2 Microtubule-associated proteins 1A/1B light chain 3 2 34390 643246 - A6NCE7 MP3B2_HUMAN
MAP1LC3C Microtubule-associated proteins 1A/1B light chain 3C 13353 440738 - Q9BXW4 MLP3C_HUMAN
MDP1_1 Magnesium-dependent phosphatase 1 28781 145553 3.1.3.48 Q86V88 MGDP1_HUMAN
MIDN Midnolin 16298 90007 - Q504T8 MIDN_HUMAN
MLLT4_1 Afadin 7137 4301 - P55196 AFAD_HUMAN
MOCS2 Molybdopterin synthase sulfur carrier subunit 7193 4338 - O96033 MOC2A_HUMAN
MYLIP_1-1 E3 ubiquitin-protein ligase MYLIP 21155 29116 6.3.2.- Q8WY64 MYLIP_HUMAN
MYO9A_1 Unconventional myosin-Ixa 7608 4649 - B2RTY4 MYO9A_HUMAN
MYO9B_1-1 Unconventional myosin-Ixb 7609 4650 - Q13459 MYO9B_HUMAN
NAE1_1-1 NEDD8-activating enzyme E1 regulatory subunit 621 8883 - Q13564 ULA1_HUMAN
NCF2_1-1 Neutrophil cytosol factor 2 7661 4688 - P19878 NCF2_HUMAN
NEDD8 NEDD8 7732 4738 - Q15843 NEDD8_HUMAN
NF2_1 Merlin 7773 4771 - P35240 MERL_HUMAN
NFATC2IP_1 NFATC2-interacting protein 25906 84901 - Q8NCF5 NF2IP_HUMAN
NPLOC4_1 Nuclear protein localization protein 4 homolog 18261 55666 - Q8TAT6 NPL4_HUMAN
NSFL1C_1 NSFL1 cofactor p47 15912 55968 - Q9UNZ2 NSF1C_HUMAN
OASL_1 2'-5'-oligoadenylate synthase-like protein 8090 8638 - Q15646 OASL_HUMAN

115
Gene Name Protein Name HUGO HGNC
NCBI GeneID
EC EnzymeID
UniProt ID UniProt Name
PAN2_1-1/-2/-3 Retinol dehydrogenase 14 19979 57665 1.1.1.- Q9HBH5 RDH14_HUMAN
PARK2_1 E3 ubiquitin-protein ligase parkin 8607 5071 6.3.2.- O60260 PRKN2_HUMAN
PCGF1_1-1 Polycomb group RING finger protein 1 17615 84759 - Q9BSM1 PCGF1_HUMAN
PCGF2_1-1 Polycomb group RING finger protein 2 12929 7703 - P35227 PCGF2_HUMAN
PCGF3_1-1 Polycomb group RING finger protein 3 10066 10336 - Q3KNV8 PCGF3_HUMAN
PCGF5_1-1 Polycomb group RING finger protein 5 28264 84333 - Q86SE9 PCGF5_HUMAN
PCGF6_1-1 Polycomb group RING finger protein 6 21156 84108 - Q9BYE7 PCGF6_HUMAN
PIK3C2A Phosphatidylinositol 4-phosphate 3-kinase C2
domain-containing subunit 8971 5286 2.7.1.154 O00443 P3C2A_HUMAN
PIK3C2B Phosphatidylinositol 4-phosphate 3-kinase C2
domain-containing subunit 8972 5287 2.7.1.154 O00750 P3C2B_HUMAN
PIK3CA Phosphatidylinositol 4,5-bisphosphate 3-kinase
catalytic subunit isoform 8975 5290 2.7.1.153 P42336 PK3CA_HUMAN
PIK3CB Phosphatidylinositol 4,5-bisphosphate 3-kinase
catalytic subunit isoform 8976 5291 2.7.1.153 P42338 PK3CB_HUMAN
PIK3CD Phosphatidylinositol 4,5-bisphosphate 3-kinase
catalytic subunit isoform 8977 5293 2.7.1.153 O00329 PK3CD_HUMAN
PIK3CG Phosphatidylinositol 4,5-bisphosphate 3-kinase
catalytic subunit isoform 8978 5294 2.7.1.153 P48736 PK3CG_HUMAN
PLXNC1_1-1/-2 Plexin-C1 9106 10154 - O60486 PLXC1_HUMAN
HELZ2_1-1/-2/-3 Helicase with zinc finger domain 2 (PRIC285) 30021 85441 3.6.4.- Q9BYK8 PR285_HUMAN
PTPN13_1-1/-2/-3 Tyrosine-protein phosphatase non-receptor type 13 9646 5783 3.1.3.48 Q12923 PTN13_HUMAN
PTPN14 Tyrosine-protein phosphatase non-receptor type 14 9647 5784 3.1.3.48 Q15678 PTN14_HUMAN
PTPN21_1-1/-2/-3 Tyrosine-protein phosphatase non-receptor type 21 9651 11099 3.1.3.48 Q16825 PTN21_HUMAN
PTPN3_1-1/-2 Tyrosine-protein phosphatase non-receptor type 3 9655 5774 3.1.3.48 P26045 PTN3_HUMAN
PTPN4_1-1/-2/-3 Tyrosine-protein phosphatase non-receptor type 4 9656 5775 3.1.3.48 P29074 PTN4_HUMAN
RAD23A UV excision repair protein RAD23 homolog A 9812 5886 - P54725 RD23A_HUMAN
RAD23B UV excision repair protein RAD23 homolog B 9813 5887 - P54727 RD23B_HUMAN
RAF1_1 RAF proto-oncogene serine/threonine-protein kinase 9829 5894 2.7.11.1 P04049 RAF1_HUMAN
RALGDS_1-1/-2 Ral guanine nucleotide dissociation stimulator 9842 5900 - Q12967 GNDS_HUMAN
RAPGEF2 Rap guanine nucleotide exchange factor 2 16854 9693 - Q9Y4G8 RPGF2_HUMAN
RAPGEF4_1 Rap guanine nucleotide exchange factor 4 16626 11069 - Q8WZA2 RPGF4_HUMAN
RAPH1_1 Ras-associated and pleckstrin homology domains-
containing protein 1 14436 65059 - Q70E73 RAPH1_HUMAN
RASIP1 Ras-interacting protein 1 24716 54922 - Q5U651 RAIN_HUMAN
RASSF1_1 Ras association domain-containing protein 1 9882 11186 - Q9NS23 RASF1_HUMAN
RASSF2 Ras association domain-containing protein 2 9883 9770 - P50749 RASF2_HUMAN
RASSF3_1 Ras association domain-containing protein 3 14271 283349 - Q86WH2 RASF3_HUMAN
RASSF4_1 Ras association domain-containing protein 4 20793 83937 - Q9H2L5 RASF4_HUMAN
RASSF5_1 Ras association domain-containing protein 5 17609 83593 - Q8WWW0 RASF5_HUMAN
RASSF6_1 Ras association domain-containing protein 6 20796 166824 - Q6ZTQ3 RASF6_HUMAN
RASSF7_1 Ras association domain-containing protein 7 1166 8045 - Q02833 RASF7_HUMAN
RASSF8_1 Ras association domain-containing protein 8 13232 11228 - Q8NHQ8 RASF8_HUMAN
RASSF9 Ras association domain-containing protein 9 15739 9182 - O75901 RASF9_HUMAN
RBCK1_1-1/-2 RanBP-type and C3HC4-type zinc finger-containing
protein 1 15864 10616 6.3.2.- Q9BYM8 HOIL1_HUMAN
RDX_1-1 Radixin 9944 5962 - P35241 RADI_HUMAN
RGL1_1-1 Ral guanine nucleotide dissociation stimulator-like 1 30281 23179 - Q9NZL6 RGL1_HUMAN
RGL2_1-1 Ral guanine nucleotide dissociation stimulator-like 2 9769 5863 - O15211 RGL2_HUMAN

116
Gene Name Protein Name HUGO HGNC
NCBI GeneID
EC EnzymeID
UniProt ID UniProt Name
RGL3_1-1 Ral guanine nucleotide dissociation stimulator-like 3 30282 57139 - Q3MIN7 RGL3_HUMAN
RGS12_1 Regulator of G-protein signaling 12 9994 6002 - O14924 RGS12_HUMAN
RGS14_1 Regulator of G-protein signaling 14 9996 10636 - O43566 RGS14_HUMAN
RIN1_1 Ras and Rab interactor 1 18749 9610 - Q13671 RIN1_HUMAN
RIN2_1 Ras and Rab interactor 2 18750 54453 - Q8WYP3 RIN2_HUMAN
RIN3_1 Ras and Rab interactor 3 18751 79890 - Q8TB24 RIN3_HUMAN
RING1_1-1/-2 E3 ubiquitin-protein ligase RING1 10018 6015 6.3.2.- Q06587 RING1_HUMAN
RING2_1-1 E3 ubiquitin-protein ligase RING2 10061 6045 6.3.2.- Q99496 RING2_HUMAN
RP1 Oxygen-regulated protein 1 10263 6101 - P56715 RP1_HUMAN
RP1L1_1 Retinitis pigmentosa 1-like 1 protein 15946 94137 - Q8IWN7 RP1L1_HUMAN
RPS27A_1-1 Ubiquitin-40S ribosomal protein S27a 10417 6233 - P62979 RS27A_HUMAN
RSG1_1-1/2 REM2- and Rab-like small GTPase 1 28127 79363 - Q9BU20 RSG1_HUMAN
SACS_1 Sacsin 10519 26278 - Q9NZJ4 SACS_HUMAN
SAE1_1-1 SUMO-activating enzyme subunit 1 30660 10055 - Q9UBE0 SAE1_HUMAN
SAE2 SUMO-activating enzyme subunit 2 30661 10054 6.3.2.- Q9UBT2 SAE2_HUMAN
SF3A1_1-1 Splicing factor 3A subunit 1 10765 10291 - Q15459 SF3A1_HUMAN
SHARPIN_1-1/-2 Sharpin 25321 81858 - Q9H0F6 SHRPN_HUMAN
SHROOM1 Shroom1 24084 134549 - Q2M3G4 SHRM1_HUMAN
SNRNP25 U11/U12 small nuclear ribonucleoprotein 25 kDa protein 14161 79622 - Q9BV90 SNR25_HUMAN
SNX27_1 Sorting nexin-27 20073 81609 - Q96L92 SNX27_HUMAN
SNX31_1 Sorting nexin-31 28605 169166 - Q8N9S9 SNX31_HUMAN
SUMO1_1-1/-2 Small ubiquitin-related modifier 1 12502 7341 - P63165 SUMO1_HUMAN
SUMO2_1-1 Small ubiquitin-related modifier 2 11125 6613 - P61956 SUMO2_HUMAN
SUMO3_1-1 Small ubiquitin-related modifier 3 11124 6612 - P55854 SUMO3_HUMAN
SUMO4_1-1 Small ubiquitin-related modifier 4 21181 387082 - Q6EEV6 SUMO4_HUMAN
TBCB_1-1 Tubulin-folding cofactor B 1989 1155 - Q99426 TBCB_HUMAN
TBCE Tubulin-specific chaperone E 11582 6905 - Q15813 TBCE_HUMAN
TBCEL Tubulin-specific chaperone cofactor E-like protein 28115 219899 - Q5QJ74 TBCEL_HUMAN
TCEB2_1-1 Transcription elongation factor B polypeptide 2 11619 6923 - Q15370 ELOB_HUMAN
TECR_1 Very-long-chain enoyl-CoA reductase 4551 9524 1.3.1.93 Q9NZ01 TECR_HUMAN
TIAM1 T-lymphoma invasion and metastasis-inducing protein 1 11805 7074 - Q13009 TIAM1_HUMAN
TIAM2_1 T-lymphoma invasion and metastasis-inducing protein 2 11806 26230 - Q8IVF5 TIAM2_HUMAN
TMUB1_1-1 Transmembrane and ubiquitin-like domain-containing
protein 1 21709 83590 - Q9BVT8 TMUB1_HUMAN
TMUB2_1-1 Transmembrane and ubiquitin-like domain-containing
protein 2 28459 79089 - Q71RG4 TMUB2_HUMAN
UBA1 Ubiquitin-like modifier-activating enzyme 1 12469 7317 - P22314 UBA1_HUMAN
UBA3_1 NEDD8-activating enzyme E1 catalytic subunit 12470 9039 6.3.2.- Q8TBC4 UBA3_HUMAN
UBA5_1 Ubiquitin-like modifier-activating enzyme 5 23230 79876 - Q9GZZ9 UBA5_HUMAN
UBA6_1 Ubiquitin-like modifier-activating enzyme 6 25581 55236 - A0AVT1 UBA6_HUMAN
UBA7 Ubiquitin-like modifier-activating enzyme 7 12471 7318 - P41226 UBA7_HUMAN
UBA52_1-1 Ubiquitin-60S ribosomal protein L40 12458 7311 - P62987 RL40_HUMAN
UBAC1 Ubiquitin-associated domain-containing protein 1 30221 10422 - Q9BSL1 UBAC1_HUMAN

117
Gene Name Protein Name HUGO HGNC
NCBI GeneID
EC EnzymeID
UniProt ID UniProt Name
UBB_1-1 Polyubiquitin-B 12463 7314 - P0CG47 UBB_HUMAN
UBC_1-1 Polyubiquitin-C 12468 7316 - P0CG48 UBC_HUMAN
UBD_1-1/-2 Ubiquitin D 18795 10537 - O15205 UBD_HUMAN
UBFD1_1-1/-2 Ubiquitin domain-containing protein UBFD1 30565 56061 - O14562 UBFD1_HUMAN
UBIML_1-1 Putative ubiquitin-like protein FUBI-like protein
ENSP00000310146 - - - A6NDN8 UBIML_HUMAN
UBL3_1-1 Ubiquitin-like protein 3 12504 5412 - O95164 UBL3_HUMAN
UBL4A_1-1 Ubiquitin-like protein 4A 12505 8266 - P11441 UBL4A_HUMAN
UBL4B_1-1 Ubiquitin-like protein 4B 32309 164153 - Q8N7F7 UBL4B_HUMAN
UBL5_1-1 Ubiquitin-like protein 5 13736 59286 - Q9BZL1 UBL5_HUMAN
UBL7_1-1 Ubiquitin-like protein 7 28221 84993 - Q96S82 UBL7_HUMAN
UBLCP1_1-1/-2/-3 Ubiquitin-like domain-containing CTD phosphatase 1 28110 134510 3.1.3.16 Q8WVY7 UBCP1_HUMAN
UBQLN1_1-1 Ubiquilin-1 12508 29979 - Q9UMX0 UBQL1_HUMAN
UBQLN2_1-1 Ubiquilin-2 12509 29978 - Q9UHD9 UBQL2_HUMAN
UBQLN3_1-1 Ubiquilin-3 12510 50613 - Q9H347 UBQL3_HUMAN
UBQLN4_1-1 Ubiquilin-4 1237 56893 - Q9NRR5 UBQL4_HUMAN
UBQLNL_1-1 Ubiquilin-like protein 28294 143630 - Q8IYU4 UBQLN_HUMAN
UBTD1_1-1 Ubiquitin domain-containing protein 1 25683 80019 - Q9HAC8 UBTD1_HUMAN
UBTD2_1-1 Ubiquitin domain-containing protein 2 24463 92181 - Q8WUN7 UBTD2_HUMAN
UBXN1_1-1 UBX domain-containing protein 1 18402 51035 - Q04323 UBXN1_HUMAN
UBXN2A_1-1/-2 UBX domain-containing protein 2A 27265 165324 - P68543 UBX2A_HUMAN
UBXN2B_1-1/-2 UBX domain-containing protein 2B 27035 137886 - Q14CS0 UBX2B_HUMAN
UBXN4_1-1/-2 UBX domain-containing protein 4 14860 23190 - Q92575 UBXN4_HUMAN
UBXN6_1-1/-2 UBX domain-containing protein 6 14928 80700 - Q9BZV1 UBXN6_HUMAN
UBXN7_1-1/-2 UBX domain-containing protein 7 29119 26043 - O94888 UBXN7_HUMAN
UBXN8_1-1 UBX domain-containing protein 8 30307 7993 - O00124 UBXN8_HUMAN
UBXN10_1-1 UBX domain-containing protein 10 26354 127733 - Q96LJ8 UBX10_HUMAN
UBXN11_1 UBX domain-containing protein 11 30600 91544 - Q5T124 UBX11_HUMAN
UFM1_1-1 Ubiquitin-fold modifier 1 20597 51569 - P61960 UFM1_HUMAN
UHRF1_1-1 E3 ubiquitin-protein ligase UHRF1 12556 29128 6.3.2.- Q96T88 UHRF1_HUMAN
UHRF1BP1 UHRF1-binding protein 1 21216 54887 - Q6BDS2 URFB1_HUMAN
UHRF2_1-1 E3 ubiquitin-protein ligase UHRF2 12557 115426 6.3.2.- Q96PU4 UHRF2_HUMAN
URM1_1-1 Ubiquitin-related modifier 1 28378 81605 - Q9BTM9 URM1_HUMAN
USP11_1-1/-2 Ubiquitin carboxyl-terminal hydrolase 11 12609 8237 3.4.19.12 P51784 UBP11_HUMAN
USP14_1-1/-2 Ubiquitin carboxyl-terminal hydrolase 14 12612 9097 3.4.19.12 P54578 UBP14_HUMAN
USP15_1-1/-2/-3 Ubiquitin carboxyl-terminal hydrolase 15 12613 9958 3.4.19.12 Q9Y4E8 UBP15_HUMAN
USP20_1-1/-2 Ubiquitin carboxyl-terminal hydrolase 20 12619 10868 3.4.19.12 Q9Y2K6 UBP20_HUMAN
USP21_1-1 Ubiquitin carboxyl-terminal hydrolase 21 12620 27005 3.4.19.12 Q9UK80 UBP21_HUMAN
USP24_1-1/-2 Ubiquitin carboxyl-terminal hydrolase 24 12623 23358 3.4.19.12 Q9UPU5 UBP24_HUMAN
USP25_1-1/-2/-3 Ubiquitin carboxyl-terminal hydrolase 25 12624 29761 3.4.19.12 Q9UHP3 UBP25_HUMAN
USP28_1-1/-2 Ubiquitin carboxyl-terminal hydrolase 28 12625 57646 3.4.19.12 Q96RU2 UBP28_HUMAN
USP31_1-1 Ubiquitin carboxyl-terminal hydrolase 31 20060 57478 3.4.19.12 Q70CQ4 UBP31_HUMAN
USP32 Ubiquitin carboxyl-terminal hydrolase 32 19143 84669 3.4.19.12 Q8NFA0 UBP32_HUMAN

118
Gene Name Protein Name HUGO HGNC
NCBI GeneID
EC EnzymeID
UniProt ID UniProt Name
USP34 Ubiquitin carboxyl-terminal hydrolase 34 20066 9736 3.4.19.12 Q70CQ2 UBP34_HUMAN
USP4_1-1/-2/-3/-4 Ubiquitin carboxyl-terminal hydrolase 4 12627 7375 3.4.19.12 Q13107 UBP4_HUMAN
USP40_1-1/-2 Ubiquitin carboxyl-terminal hydrolase 40 20069 55230 3.4.19.12 Q9NVE5 UBP40_HUMAN
USP43 Ubiquitin carboxyl-terminal hydrolase 43 20072 124739 3.4.19.12 Q70EL4 UBP43_HUMAN
USP47 Ubiquitin carboxyl-terminal hydrolase 47 20076 55031 3.4.19.12 Q96K76 UBP47_HUMAN
USP48_1-1/-2 Ubiquitin carboxyl-terminal hydrolase 48 18533 84196 3.4.19.12 Q86UV5 UBP48_HUMAN
USP5_1-1 Ubiquitin carboxyl-terminal hydrolase 5 12628 8078 3.4.19.12 P45974 UBP5_HUMAN
USP6 Ubiquitin carboxyl-terminal hydrolase 6 12629 9098 3.4.19.12 P35125 UBP6_HUMAN
USP7 Ubiquitin carboxyl-terminal hydrolase 7 12630 7874 3.4.19.12 Q93009 UBP7_HUMAN
USP8_1-1/-2/-3 Ubiquitin carboxyl-terminal hydrolase 8 12631 9101 3.4.19.12 P40818 UBP8_HUMAN
USP9X_1-1/-2/-3 Probable ubiquitin carboxyl-terminal hydrolase FAF-X 12632 8239 3.4.19.12 Q93008 USP9X_HUMAN
USP9Y_1-1/-2/-3 Probable ubiquitin carboxyl-terminal hydrolase FAF-Y 12633 8287 3.4.19.12 O00507 USP9Y_HUMAN
VCPIP1_1-1/-2/-3 Deubiquitinating protein VCIP135 30897 80124 3.4.19.12 Q96JH7 VCIP1_HUMAN
WDR48_1-1/-2 WD repeat-containing protein 48 30914 57599 - Q8TAF3 WDR48_HUMAN
YOD1_1-1 Ubiquitin thioesterase OTU1 25035 55432 3.4.19.12 Q5VVQ6 OTU1_HUMAN
119
Appendix II: All human genes & isoforms that encode ubiquitin-like domains.
Gene Name Protein Name UniProt ID UniProt Name
ANKRD60 Ankyrin repeat domain-containing protein 60 Q9BZ19 ANR60_HUMAN
ANKUB1-1/-2/-3 ANKUB1 A6NFN9 ANKUB_HUMAN
ANUBL1-1 AN1-type zinc finger protein 4 Q86XD8 ZFAN4_HUMAN
APBB1IP Amyloid beta A4 precursor protein-binding family B member 1-interacting protein Q7Z5R6 AB1IP_HUMAN
ARAF-1 Serine/threonine-protein kinase A-Raf P10398 ARAF_HUMAN
ARAP1 Arf-GAP with Rho-GAP domain, ANK repeat and PH domain-containing protein 1 Q96P48 ARAP1_HUMAN
ARAP2 Arf-GAP with Rho-GAP domain, ANK repeat and PH domain-containing protein 2 Q8WZ64 ARAP2_HUMAN
ARAP3 Arf-GAP with Rho-GAP domain, ANK repeat and PH domain-containing protein 3 Q8WWN8 ARAP3_HUMAN
ARHGAP20 Rho GTPase-activating protein 20 Q9P2F6 RHG20_HUMAN
ASPSCR1_1-1 Tether containing UBX domain for GLUT4 Q9BZE9 ASPC1_HUMAN
ASPSCR1_2-1 Q9BZE9-2 ASPC1_HUMAN
ASPSCR1_3 Q9BZE9-3 ASPC1_HUMAN
ATG12 Ubiquitin-like protein ATG12 O94817 ATG12_HUMAN
ATG3_1-1 Ubiquitin-like-conjugating enzyme ATG3 Q9NT62 ATG3_HUMAN
ATG7_1-1 Ubiquitin-like modifier-activating enzyme ATG7 O95352 ATG7_HUMAN
ATG7_2-1 O95352-2 ATG7_HUMAN
ATG7_3-1 O95352-3 ATG7_HUMAN
BAG1_1-1 BAG family molecular chaperone regulator 1 Q99933 BAG1_HUMAN
BAG1_2-1 Q99933-2 BAG1_HUMAN
BAG1_3-1 Q99933-3 BAG1_HUMAN
BAG1_4-1 Q99933-4 BAG1_HUMAN
BAG6_1-1 Large proline-rich protein BAG6 P46379 BAG6_HUMAN
BAG6_2-1 P46379-2 BAG6_HUMAN
BAG6_3-1 P46379-3 BAG6_HUMAN
BMI1_1-1 Polycomb complex protein BMI-1 P35226 BMI1_HUMAN
BRAF_1-1/-2 Serine/threonine-protein kinase B-raf P15056 BRAF_HUMAN
CLK4_1-1 Dual specificity protein kinase CLK4 Q9HAZ1 CLK4_HUMAN
DCDC1_1-1 Doublecortin domain-containing protein 1 P59894 DCDC1_HUMAN
DCDC2_1-1 Doublecortin domain-containing protein 2 Q9UHG0 DCDC2_HUMAN
DCDC2B_1-1 Doublecortin domain-containing protein 2B A2VCK2 DCD2B_HUMAN
DCDC2C_1-1 Doublecortin domain-containing protein 2C A8MYV0 DCD2C_HUMAN
DCDC5 Doublecortin domain-containing protein 5 Q6ZRR9 DCDC5_HUMAN
DCLK1_1-1 Serine/threonine-protein kinase DCLK1 O15075-2 DCLK1_HUMAN
DCLK2_1-1 Serine/threonine-protein kinase DCLK2 Q8N568 DCLK2_HUMAN
DCX_1-1 Neuronal migration protein doublecortin O43602 DCX_HUMAN
DCX_2-1 O43602-2 DCX_HUMAN
DDI1_1-1 Protein DDI1 homolog 1 Q8WTU0 DDI1_HUMAN
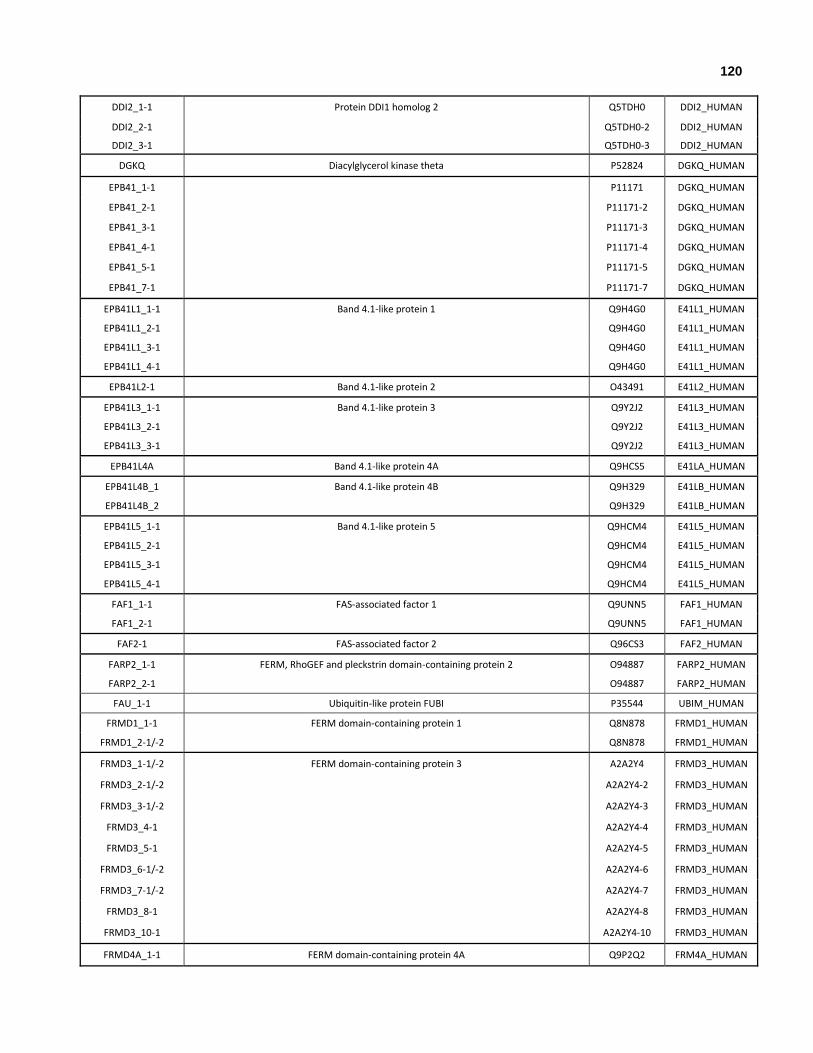
120
DDI2_1-1 Protein DDI1 homolog 2 Q5TDH0 DDI2_HUMAN
DDI2_2-1 Q5TDH0-2 DDI2_HUMAN
DDI2_3-1 Q5TDH0-3 DDI2_HUMAN
DGKQ Diacylglycerol kinase theta P52824 DGKQ_HUMAN
EPB41_1-1 P11171 DGKQ_HUMAN
EPB41_2-1 P11171-2 DGKQ_HUMAN
EPB41_3-1 P11171-3 DGKQ_HUMAN
EPB41_4-1 P11171-4 DGKQ_HUMAN
EPB41_5-1 P11171-5 DGKQ_HUMAN
EPB41_7-1 P11171-7 DGKQ_HUMAN
EPB41L1_1-1 Band 4.1-like protein 1 Q9H4G0 E41L1_HUMAN
EPB41L1_2-1 Q9H4G0 E41L1_HUMAN
EPB41L1_3-1 Q9H4G0 E41L1_HUMAN
EPB41L1_4-1 Q9H4G0 E41L1_HUMAN
EPB41L2-1 Band 4.1-like protein 2 O43491 E41L2_HUMAN
EPB41L3_1-1 Band 4.1-like protein 3 Q9Y2J2 E41L3_HUMAN
EPB41L3_2-1 Q9Y2J2 E41L3_HUMAN
EPB41L3_3-1 Q9Y2J2 E41L3_HUMAN
EPB41L4A Band 4.1-like protein 4A Q9HCS5 E41LA_HUMAN
EPB41L4B_1 Band 4.1-like protein 4B Q9H329 E41LB_HUMAN
EPB41L4B_2 Q9H329 E41LB_HUMAN
EPB41L5_1-1 Band 4.1-like protein 5 Q9HCM4 E41L5_HUMAN
EPB41L5_2-1 Q9HCM4 E41L5_HUMAN
EPB41L5_3-1 Q9HCM4 E41L5_HUMAN
EPB41L5_4-1 Q9HCM4 E41L5_HUMAN
FAF1_1-1 FAS-associated factor 1 Q9UNN5 FAF1_HUMAN
FAF1_2-1 Q9UNN5 FAF1_HUMAN
FAF2-1 FAS-associated factor 2 Q96CS3 FAF2_HUMAN
FARP2_1-1 FERM, RhoGEF and pleckstrin domain-containing protein 2 O94887 FARP2_HUMAN
FARP2_2-1 O94887 FARP2_HUMAN
FAU_1-1 Ubiquitin-like protein FUBI P35544 UBIM_HUMAN
FRMD1_1-1 FERM domain-containing protein 1 Q8N878 FRMD1_HUMAN
FRMD1_2-1/-2 Q8N878 FRMD1_HUMAN
FRMD3_1-1/-2 FERM domain-containing protein 3 A2A2Y4 FRMD3_HUMAN
FRMD3_2-1/-2 A2A2Y4-2 FRMD3_HUMAN
FRMD3_3-1/-2 A2A2Y4-3 FRMD3_HUMAN
FRMD3_4-1 A2A2Y4-4 FRMD3_HUMAN
FRMD3_5-1 A2A2Y4-5 FRMD3_HUMAN
FRMD3_6-1/-2 A2A2Y4-6 FRMD3_HUMAN
FRMD3_7-1/-2 A2A2Y4-7 FRMD3_HUMAN
FRMD3_8-1 A2A2Y4-8 FRMD3_HUMAN
FRMD3_10-1 A2A2Y4-10 FRMD3_HUMAN
FRMD4A_1-1 FERM domain-containing protein 4A Q9P2Q2 FRM4A_HUMAN

121
FRMD4B_1-1 FERM domain-containing protein 4B Q9Y2L6 FRM4B_HUMAN
FRMD5_1-1/-2 FERM domain-containing protein 5 Q7Z6J6 FRMD5_HUMAN
FRMD5_2-1 Q7Z6J6-2 FRMD5_HUMAN
FRMD6_1-1 FERM domain-containing protein 6 Q96NE9 FRMD6_HUMAN
FRMD6_2-1 Q96NE9-2 FRMD6_HUMAN
FRMD7_1-1 FERM domain-containing protein 7 Q6ZUT3 FRMD7_HUMAN
FRMPD2_1-1 FERM and PDZ domain-containing protein 2 Q68DX3 FRPD2_HUMAN
FRMPD2_2-1 Q68DX3-2 FRPD2_HUMAN
FRMPD2_4-1/-2 Q68DX3-4 FRPD2_HUMAN
FRMPD2_5-1 Q68DX3-5 FRPD2_HUMAN
GABARAP Gamma-aminobutyric acid receptor-associated protein O95166 GBRAP_HUMAN
GABARAPL1_1-1 Gamma-aminobutyric acid receptor-associated protein-like 1 Q9H0R8 GBRL1_HUMAN
GABARAPL1_2-1 Q9H0R8-2 GBRL1_HUMAN
GABARAPL2 Gamma-aminobutyric acid receptor-associated protein-like 2 P60520 GBRL2_HUMAN
GRB10 Growth factor receptor-bound protein 10 Q13322 GRB10_HUMAN
GRB14 Growth factor receptor-bound protein 14 Q14449 GRB14_HUMAN
GRB7 Growth factor receptor-bound protein 7 Q14451 GRB7_HUMAN
HERPUD1_1-1 Homocysteine-responsive endoplasmic reticulum-resident ubiquitin-like domain member
1 protein Q15011 HERP1_HUMAN
HERPUD1_2-1 Q15011-2 HERP1_HUMAN
HERPUD1_3-1 Q15011-3 HERP1_HUMAN
HERPUD2_1-1 Homocysteine-responsive endoplasmic reticulum-resident ubiquitin-like domain member
2 protein Q9BSE4 HERP2_HUMAN
HSPA13 Heat shock 70 kDa protein 13 P48723 HSP13_HUMAN
IKBKB_1-1 Inhibitor of nuclear factor kappa-B kinase subunit O14920 IKKB_HUMAN
IQUB_1-1 IQ and ubiquitin-like domain-containing protein Q8NA54 IQUB_HUMAN
IQUB_2-1 Q8NA54-2 IQUB_HUMAN
ISG15_1-1/-2 Ubiquitin-like protein ISG15 P05161 ISG15_HUMAN
MAP1LC3A_1-1 Microtubule-associated proteins 1A/1B light chain 3A Q9H492 MLP3A_HUMAN
MAP1LC3A_2-1 Q9H492-2 MLP3A_HUMAN
MAP1LC3B Microtubule-associated proteins 1A/1B light chain 3B Q9GZQ8 MLP3B_HUMAN
MAP1LC3B2 Microtubule-associated proteins 1A/1B light chain 3 2 A6NCE7 MP3B2_HUMAN
MAP1LC3C Microtubule-associated proteins 1A/1B light chain 3C Q9BXW4 MLP3C_HUMAN
MDP1_1 Magnesium-dependent phosphatase 1 Q86V88 MGDP1_HUMAN
MDP1_2 Q86V88 MGDP1_HUMAN
MDP1_3 Q86V88 MGDP1_HUMAN
MIDN Midnolin Q504T8 MIDN_HUMAN

122
MLLT4_1 Afadin P55196 AFAD_HUMAN
MLLT4_2 P55196-2 AFAD_HUMAN
MLLT4_3 P55196-3 AFAD_HUMAN
MLLT4_4 P55196-4 AFAD_HUMAN
MLLT4_5 P55196-5 AFAD_HUMAN
MLLT4_6 P55196-6 AFAD_HUMAN
MOCS2 Molybdopterin synthase sulfur carrier subunit O96033 MOC2A_HUMAN
MYLIP_1-1 E3 ubiquitin-protein ligase MYLIP Q8WY64 MYLIP_HUMAN
MYLIP_2-1 Q8WY64 MYLIP_HUMAN
MYO9A_1 Unconventional myosin-Ixa B2RTY4 MYO9A_HUMAN
MYO9A_2 B2RTY4 MYO9A_HUMAN
MYO9A_3 B2RTY4 MYO9A_HUMAN
MYO9A_4 B2RTY4 MYO9A_HUMAN
MYO9B_1-1 Unconventional myosin-Ixb Q13459 MYO9B_HUMAN
MYO9B_2-1 Q13459 MYO9B_HUMAN
NAE1_1-1 NEDD8-activating enzyme E1 regulatory subunit Q13564 ULA1_HUMAN
NAE1_2-1 Q13564 ULA1_HUMAN
NCF2_1-1 Neutrophil cytosol factor 2 P19878 NCF2_HUMAN
NEDD8 NEDD8 Q15843 NEDD8_HUMAN
NF2_1 Merlin P35240 MERL_HUMAN
NF2_2 P35240 MERL_HUMAN
NF2_3 P35240 MERL_HUMAN
NF2_4 P35240 MERL_HUMAN
NF2_5 P35240 MERL_HUMAN
NF2_7 P35240 MERL_HUMAN
NF2_8 P35240 MERL_HUMAN
NF2_9 P35240 MERL_HUMAN
NFATC2IP_1 NFATC2-interacting protein Q8NCF5 NF2IP_HUMAN
NFATC2IP_2 Q8NCF5-2 NF2IP_HUMAN
NFATC2IP_3 Q8NCF5-3 NF2IP_HUMAN
NPLOC4_1 Nuclear protein localization protein 4 homolog Q8TAT6 NPL4_HUMAN
NPLOC4_2 Q8TAT6 NPL4_HUMAN
NSFL1C_1 NSFL1 cofactor p47 Q9UNZ2 NSF1C_HUMAN
NSFL1C_2 Q9UNZ2 NSF1C_HUMAN
NSFL1C_3 Q9UNZ2 NSF1C_HUMAN
NSFL1C_4 Q9UNZ2 NSF1C_HUMAN
OASL_1 2'-5'-oligoadenylate synthase-like protein Q15646 OASL_HUMAN
OASL_2 Q15646-2 OASL_HUMAN
PAN2_1-1/-2/-3 Retinol dehydrogenase 14 Q9HBH5 RDH14_HUMAN
PAN2_2-1/-2/-3 Q9HBH5-2 RDH14_HUMAN
PAN2_3-1/-2/-3 Q9HBH5-3 RDH14_HUMAN
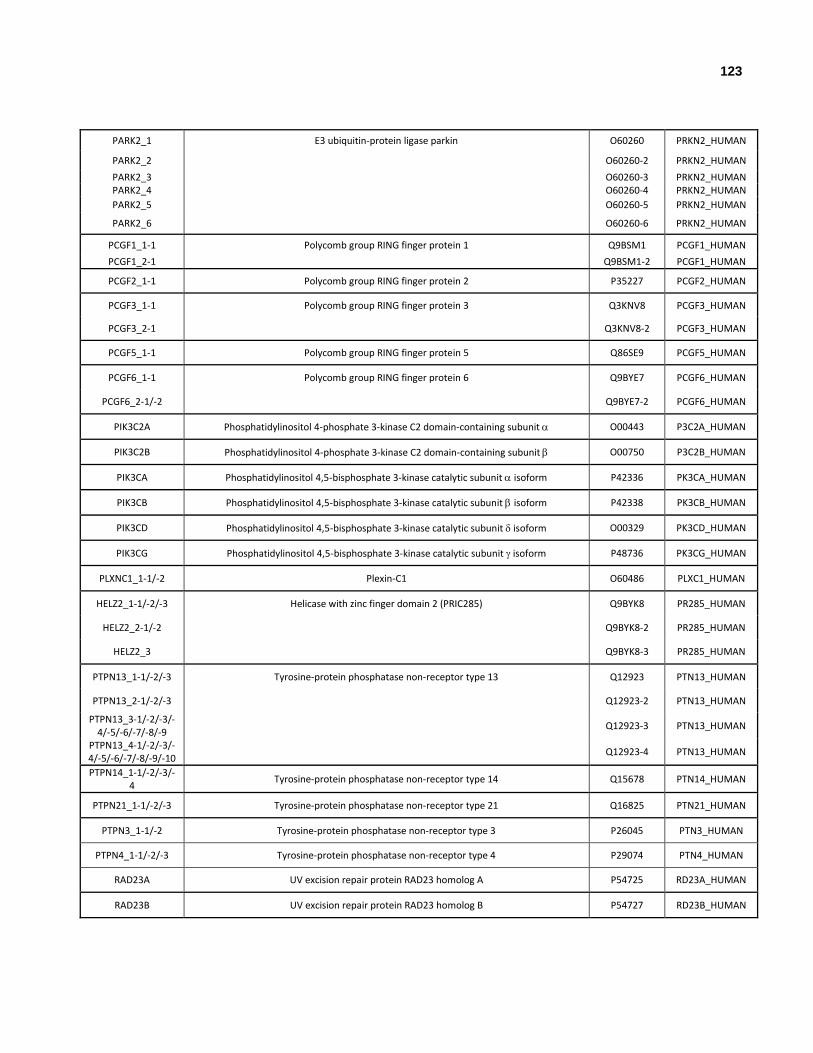
123
PARK2_1 E3 ubiquitin-protein ligase parkin O60260 PRKN2_HUMAN
PARK2_2 O60260-2 PRKN2_HUMAN
PARK2_3 O60260-3 PRKN2_HUMAN PARK2_4 O60260-4 PRKN2_HUMAN
PARK2_5 O60260-5 PRKN2_HUMAN
PARK2_6 O60260-6 PRKN2_HUMAN
PCGF1_1-1 Polycomb group RING finger protein 1 Q9BSM1 PCGF1_HUMAN
PCGF1_2-1 Q9BSM1-2 PCGF1_HUMAN
PCGF2_1-1 Polycomb group RING finger protein 2 P35227 PCGF2_HUMAN
PCGF3_1-1 Polycomb group RING finger protein 3 Q3KNV8 PCGF3_HUMAN
PCGF3_2-1 Q3KNV8-2 PCGF3_HUMAN
PCGF5_1-1 Polycomb group RING finger protein 5 Q86SE9 PCGF5_HUMAN
PCGF6_1-1 Polycomb group RING finger protein 6 Q9BYE7 PCGF6_HUMAN
PCGF6_2-1/-2 Q9BYE7-2 PCGF6_HUMAN
PIK3C2A Phosphatidylinositol 4-phosphate 3-kinase C2 domain-containing subunit O00443 P3C2A_HUMAN
PIK3C2B Phosphatidylinositol 4-phosphate 3-kinase C2 domain-containing subunit O00750 P3C2B_HUMAN
PIK3CA Phosphatidylinositol 4,5-bisphosphate 3-kinase catalytic subunit isoform P42336 PK3CA_HUMAN
PIK3CB Phosphatidylinositol 4,5-bisphosphate 3-kinase catalytic subunit isoform P42338 PK3CB_HUMAN
PIK3CD Phosphatidylinositol 4,5-bisphosphate 3-kinase catalytic subunit isoform O00329 PK3CD_HUMAN
PIK3CG Phosphatidylinositol 4,5-bisphosphate 3-kinase catalytic subunit isoform P48736 PK3CG_HUMAN
PLXNC1_1-1/-2 Plexin-C1 O60486 PLXC1_HUMAN
HELZ2_1-1/-2/-3 Helicase with zinc finger domain 2 (PRIC285) Q9BYK8 PR285_HUMAN
HELZ2_2-1/-2 Q9BYK8-2 PR285_HUMAN
HELZ2_3 Q9BYK8-3 PR285_HUMAN
PTPN13_1-1/-2/-3 Tyrosine-protein phosphatase non-receptor type 13 Q12923 PTN13_HUMAN
PTPN13_2-1/-2/-3 Q12923-2 PTN13_HUMAN
PTPN13_3-1/-2/-3/-4/-5/-6/-7/-8/-9
Q12923-3 PTN13_HUMAN
PTPN13_4-1/-2/-3/-4/-5/-6/-7/-8/-9/-10
Q12923-4 PTN13_HUMAN
PTPN14_1-1/-2/-3/-4
Tyrosine-protein phosphatase non-receptor type 14 Q15678 PTN14_HUMAN
PTPN21_1-1/-2/-3 Tyrosine-protein phosphatase non-receptor type 21 Q16825 PTN21_HUMAN
PTPN3_1-1/-2 Tyrosine-protein phosphatase non-receptor type 3 P26045 PTN3_HUMAN
PTPN4_1-1/-2/-3 Tyrosine-protein phosphatase non-receptor type 4 P29074 PTN4_HUMAN
RAD23A UV excision repair protein RAD23 homolog A P54725 RD23A_HUMAN
RAD23B UV excision repair protein RAD23 homolog B P54727 RD23B_HUMAN
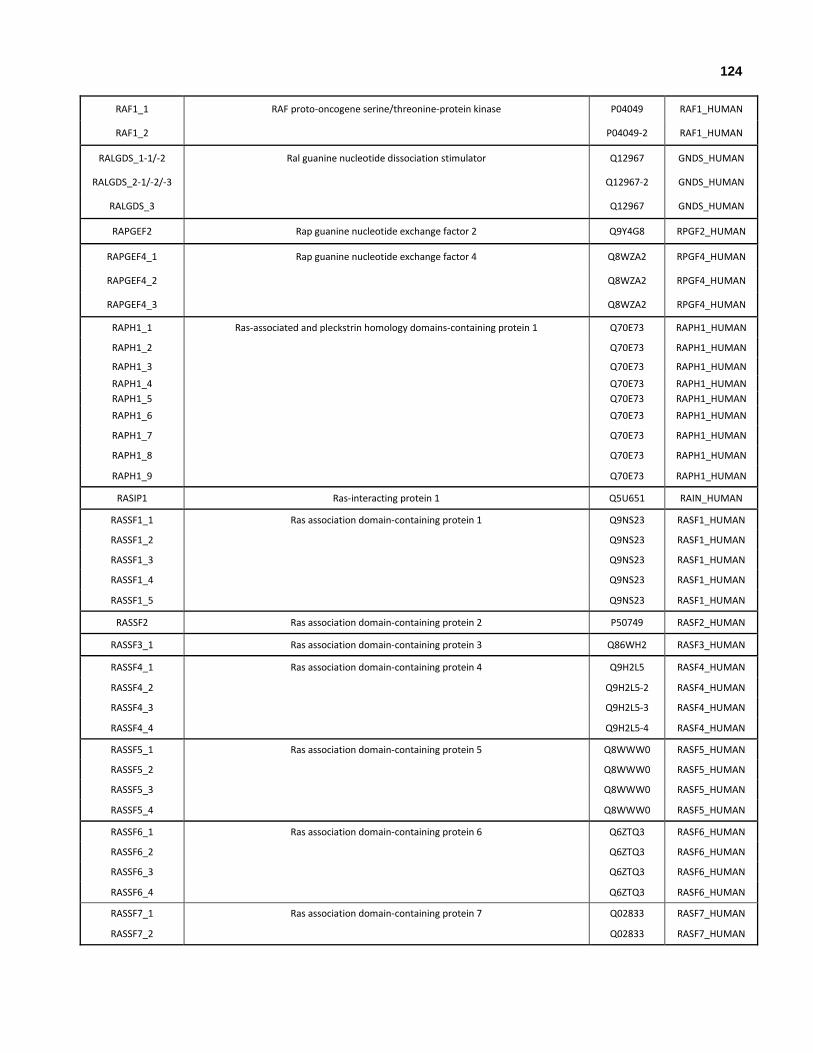
124
RAF1_1 RAF proto-oncogene serine/threonine-protein kinase P04049 RAF1_HUMAN
RAF1_2 P04049-2 RAF1_HUMAN
RALGDS_1-1/-2 Ral guanine nucleotide dissociation stimulator Q12967 GNDS_HUMAN
RALGDS_2-1/-2/-3 Q12967-2 GNDS_HUMAN
RALGDS_3 Q12967 GNDS_HUMAN
RAPGEF2 Rap guanine nucleotide exchange factor 2 Q9Y4G8 RPGF2_HUMAN
RAPGEF4_1 Rap guanine nucleotide exchange factor 4 Q8WZA2 RPGF4_HUMAN
RAPGEF4_2 Q8WZA2 RPGF4_HUMAN
RAPGEF4_3 Q8WZA2 RPGF4_HUMAN
RAPH1_1 Ras-associated and pleckstrin homology domains-containing protein 1 Q70E73 RAPH1_HUMAN
RAPH1_2 Q70E73 RAPH1_HUMAN
RAPH1_3 Q70E73 RAPH1_HUMAN
RAPH1_4 Q70E73 RAPH1_HUMAN
RAPH1_5 Q70E73 RAPH1_HUMAN
RAPH1_6 Q70E73 RAPH1_HUMAN
RAPH1_7 Q70E73 RAPH1_HUMAN
RAPH1_8 Q70E73 RAPH1_HUMAN
RAPH1_9 Q70E73 RAPH1_HUMAN
RASIP1 Ras-interacting protein 1 Q5U651 RAIN_HUMAN
RASSF1_1 Ras association domain-containing protein 1 Q9NS23 RASF1_HUMAN
RASSF1_2 Q9NS23 RASF1_HUMAN
RASSF1_3 Q9NS23 RASF1_HUMAN
RASSF1_4 Q9NS23 RASF1_HUMAN
RASSF1_5 Q9NS23 RASF1_HUMAN
RASSF2 Ras association domain-containing protein 2 P50749 RASF2_HUMAN
RASSF3_1 Ras association domain-containing protein 3 Q86WH2 RASF3_HUMAN
RASSF4_1 Ras association domain-containing protein 4 Q9H2L5 RASF4_HUMAN
RASSF4_2 Q9H2L5-2 RASF4_HUMAN
RASSF4_3 Q9H2L5-3 RASF4_HUMAN
RASSF4_4 Q9H2L5-4 RASF4_HUMAN
RASSF5_1 Ras association domain-containing protein 5 Q8WWW0 RASF5_HUMAN
RASSF5_2 Q8WWW0 RASF5_HUMAN
RASSF5_3 Q8WWW0 RASF5_HUMAN
RASSF5_4 Q8WWW0 RASF5_HUMAN
RASSF6_1 Ras association domain-containing protein 6 Q6ZTQ3 RASF6_HUMAN
RASSF6_2 Q6ZTQ3 RASF6_HUMAN
RASSF6_3 Q6ZTQ3 RASF6_HUMAN
RASSF6_4 Q6ZTQ3 RASF6_HUMAN
RASSF7_1 Ras association domain-containing protein 7 Q02833 RASF7_HUMAN
RASSF7_2 Q02833 RASF7_HUMAN
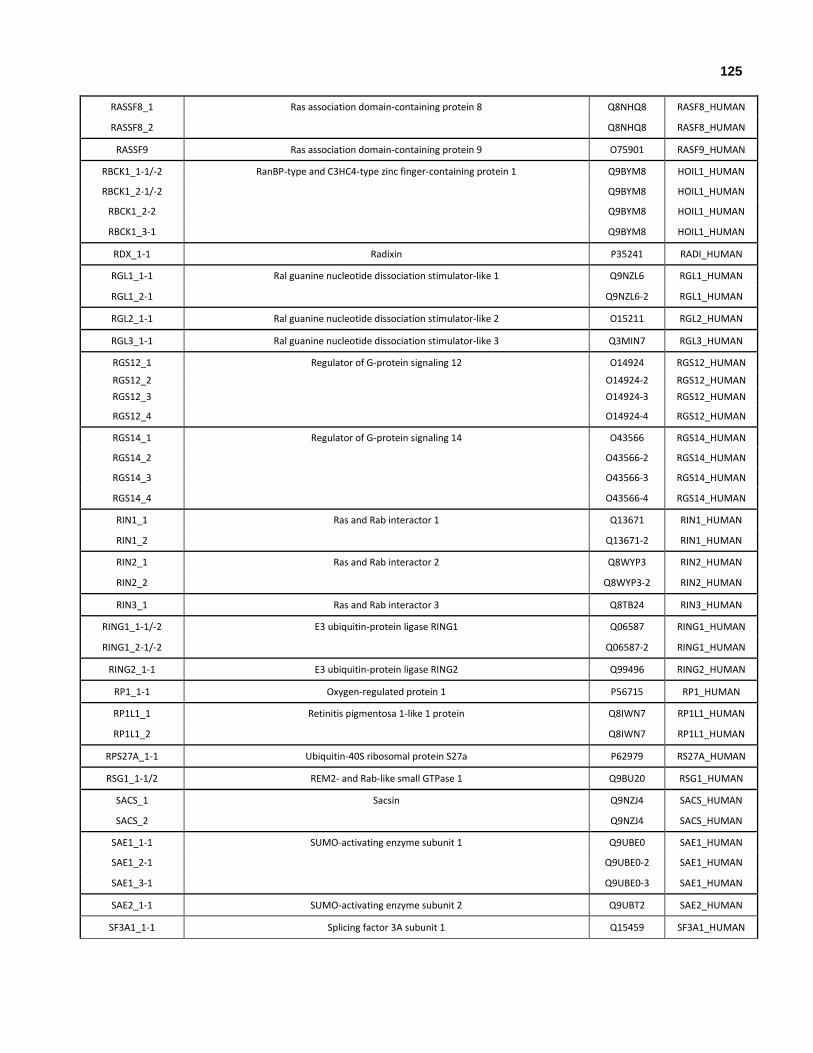
125
RASSF8_1 Ras association domain-containing protein 8 Q8NHQ8 RASF8_HUMAN
RASSF8_2 Q8NHQ8 RASF8_HUMAN
RASSF9 Ras association domain-containing protein 9 O75901 RASF9_HUMAN
RBCK1_1-1/-2 RanBP-type and C3HC4-type zinc finger-containing protein 1 Q9BYM8 HOIL1_HUMAN
RBCK1_2-1/-2 Q9BYM8 HOIL1_HUMAN
RBCK1_2-2 Q9BYM8 HOIL1_HUMAN
RBCK1_3-1 Q9BYM8 HOIL1_HUMAN
RDX_1-1 Radixin P35241 RADI_HUMAN
RGL1_1-1 Ral guanine nucleotide dissociation stimulator-like 1 Q9NZL6 RGL1_HUMAN
RGL1_2-1 Q9NZL6-2 RGL1_HUMAN
RGL2_1-1 Ral guanine nucleotide dissociation stimulator-like 2 O15211 RGL2_HUMAN
RGL3_1-1 Ral guanine nucleotide dissociation stimulator-like 3 Q3MIN7 RGL3_HUMAN
RGS12_1 Regulator of G-protein signaling 12 O14924 RGS12_HUMAN
RGS12_2 O14924-2 RGS12_HUMAN
RGS12_3 O14924-3 RGS12_HUMAN
RGS12_4 O14924-4 RGS12_HUMAN
RGS14_1 Regulator of G-protein signaling 14 O43566 RGS14_HUMAN
RGS14_2 O43566-2 RGS14_HUMAN
RGS14_3 O43566-3 RGS14_HUMAN
RGS14_4 O43566-4 RGS14_HUMAN
RIN1_1 Ras and Rab interactor 1 Q13671 RIN1_HUMAN
RIN1_2 Q13671-2 RIN1_HUMAN
RIN2_1 Ras and Rab interactor 2 Q8WYP3 RIN2_HUMAN
RIN2_2 Q8WYP3-2 RIN2_HUMAN
RIN3_1 Ras and Rab interactor 3 Q8TB24 RIN3_HUMAN
RING1_1-1/-2 E3 ubiquitin-protein ligase RING1 Q06587 RING1_HUMAN
RING1_2-1/-2 Q06587-2 RING1_HUMAN
RING2_1-1 E3 ubiquitin-protein ligase RING2 Q99496 RING2_HUMAN
RP1_1-1 Oxygen-regulated protein 1 P56715 RP1_HUMAN
RP1L1_1 Retinitis pigmentosa 1-like 1 protein Q8IWN7 RP1L1_HUMAN
RP1L1_2 Q8IWN7 RP1L1_HUMAN
RPS27A_1-1 Ubiquitin-40S ribosomal protein S27a P62979 RS27A_HUMAN
RSG1_1-1/2 REM2- and Rab-like small GTPase 1 Q9BU20 RSG1_HUMAN
SACS_1 Sacsin Q9NZJ4 SACS_HUMAN
SACS_2 Q9NZJ4 SACS_HUMAN
SAE1_1-1 SUMO-activating enzyme subunit 1 Q9UBE0 SAE1_HUMAN
SAE1_2-1 Q9UBE0-2 SAE1_HUMAN
SAE1_3-1 Q9UBE0-3 SAE1_HUMAN
SAE2_1-1 SUMO-activating enzyme subunit 2 Q9UBT2 SAE2_HUMAN
SF3A1_1-1 Splicing factor 3A subunit 1 Q15459 SF3A1_HUMAN

126
SHARPIN_1-1/-2 Sharpin Q9H0F6 SHRPN_HUMAN
SHARPIN_2-1/-2 Q9H0F6-2 SHRPN_HUMAN
SHARPIN_3-1 Q9H0F6-3 SHRPN_HUMAN
SHROOM1_1 Shroom1 Q2M3G4 SHRM1_HUMAN
SHROOM1_2 Q2M3G4-2 SHRM1_HUMAN
SNRNP25 U11/U12 small nuclear ribonucleoprotein 25 kDa protein Q9BV90 SNR25_HUMAN
SNX27_1 Sorting nexin-27 Q96L92 SNX27_HUMAN
SNX27_2 Q96L92 SNX27_HUMAN
SNX27_3 Q96L92 SNX27_HUMAN
SNX31_1 Sorting nexin-31 Q8N9S9 SNX31_HUMAN
SNX31_2 Q8N9S9-2 SNX31_HUMAN
SUMO1_1-1/-2 Small ubiquitin-related modifier 1 P63165 SUMO1_HUMAN
SUMO2_1-1 Small ubiquitin-related modifier 2 P61956 SUMO2_HUMAN
SUMO2_2-1 P61956 SUMO2_HUMAN
SUMO3_1-1 Small ubiquitin-related modifier 3 P55854 SUMO3_HUMAN
SUMO4_1-1 Small ubiquitin-related modifier 4 Q6EEV6 SUMO4_HUMAN
TBCB_1-1 Tubulin-folding cofactor B Q99426 TBCB_HUMAN
TBCE Tubulin-specific chaperone E Q15813 TBCE_HUMAN
TBCEL Tubulin-specific chaperone cofactor E-like protein Q5QJ74 TBCEL_HUMAN
TCEB2_1-1 Transcription elongation factor B polypeptide 2 Q15370 ELOB_HUMAN
TECR_1 Very-long-chain enoyl-CoA reductase Q9NZ01 TECR_HUMAN
TIAM1 T-lymphoma invasion and metastasis-inducing protein 1 Q13009 TIAM1_HUMAN
TIAM2_1 T-lymphoma invasion and metastasis-inducing protein 2 Q8IVF5 TIAM2_HUMAN
TIAM2_2 Q8IVF5 TIAM2_HUMAN
TIAM2_4 Q8IVF5 TIAM2_HUMAN
TIAM2_5 Q8IVF5 TIAM2_HUMAN
TMUB1_1-1 Transmembrane and ubiquitin-like domain-containing protein 1 Q9BVT8 TMUB1_HUMAN
TMUB2_1-1 Transmembrane and ubiquitin-like domain-containing protein 2 Q71RG4 TMUB2_HUMAN
TMUB2_2-1/-2 Q71RG4-2 TMUB2_HUMAN
TMUB2_3-1 Q71RG4 TMUB2_HUMAN
TMUB2_4-1 Q71RG4 TMUB2_HUMAN
UBA1 Ubiquitin-like modifier-activating enzyme 1 P22314 UBA1_HUMAN
UBA3_1 NEDD8-activating enzyme E1 catalytic subunit Q8TBC4 UBA3_HUMAN
UBA3_2 Q8TBC4 UBA3_HUMAN
UBA5_1 Ubiquitin-like modifier-activating enzyme 5 Q9GZZ9 UBA5_HUMAN
UBA5_2 Q9GZZ9 UBA5_HUMAN
UBA6_1 Ubiquitin-like modifier-activating enzyme 6 A0AVT1 UBA6_HUMAN
UBA6_2 A0AVT1-2 UBA6_HUMAN
UBA7 Ubiquitin-like modifier-activating enzyme 7 P41226 UBA7_HUMAN
UBA52_1-1 Ubiquitin-60S ribosomal protein L40 P62987 RL40_HUMAN

127
UBAC1 Ubiquitin-associated domain-containing protein 1 Q9BSL1 UBAC1_HUMAN
UBB_1-1 Polyubiquitin-B P0CG47 UBB_HUMAN
UBC_1-1 Polyubiquitin-C P0CG48 UBC_HUMAN
UBD_1-1/-2 Ubiquitin D O15205 UBD_HUMAN
UBFD1_1-1/-2 Ubiquitin domain-containing protein UBFD1 O14562 UBFD1_HUMAN
UBIML_1-1 Putative ubiquitin-like protein FUBI-like protein ENSP00000310146 A6NDN8 UBIML_HUMAN
UBIML_2-1 A6NDN8-2 UBIML_HUMAN
UBL3_1-1 Ubiquitin-like protein 3 O95164 UBL3_HUMAN
UBL4A_1-1 Ubiquitin-like protein 4A P11441 UBL4A_HUMAN
UBL4B_1-1 Ubiquitin-like protein 4B Q8N7F7 UBL4B_HUMAN
UBL5_1-1 Ubiquitin-like protein 5 Q9BZL1 UBL5_HUMAN
UBL7_1-1 Ubiquitin-like protein 7 Q96S82 UBL7_HUMAN
UBLCP1_1-1/-2/-3 Ubiquitin-like domain-containing CTD phosphatase 1 Q8WVY7 UBCP1_HUMAN
UBQLN1_1-1 Ubiquilin-1 Q9UMX0 UBQL1_HUMAN
UBQLN1_2-1 Q9UMX0 UBQL1_HUMAN
UBQLN2_1-1 Ubiquilin-2 Q9UHD9 UBQL2_HUMAN
UBQLN3_1-1 Ubiquilin-3 Q9H347 UBQL3_HUMAN
UBQLN4_1-1 Ubiquilin-4 Q9NRR5 UBQL4_HUMAN
UBQLN4_2-1 Q9NRR5 UBQL4_HUMAN
UBQLNL_1-1 Ubiquilin-like protein Q8IYU4 UBQLN_HUMAN
UBQLNL_2-1 Q8IYU4 UBQLN_HUMAN
UBTD1_1-1 Ubiquitin domain-containing protein 1 Q9HAC8 UBTD1_HUMAN
UBTD2_1-1 Ubiquitin domain-containing protein 2 Q8WUN7 UBTD2_HUMAN
UBXN1_1-1 UBX domain-containing protein 1 Q04323 UBXN1_HUMAN
UBXN1_2-1 Q04323 UBXN1_HUMAN
UBXN2A_1-1/-2 UBX domain-containing protein 2A P68543 UBX2A_HUMAN
UBXN2B_1-1/-2 UBX domain-containing protein 2B Q14CS0 UBX2B_HUMAN
UBXN4_1-1/-2 UBX domain-containing protein 4 Q92575 UBXN4_HUMAN
UBXN6_1-1/-2 UBX domain-containing protein 6 Q9BZV1 UBXN6_HUMAN
UBXN6_2-1 Q9BZV1-2 UBXN6_HUMAN
UBXN7_1-1/-2 UBX domain-containing protein 7 O94888 UBXN7_HUMAN
UBXN8_1-1 UBX domain-containing protein 8 O00124 UBXN8_HUMAN
UBXN8_2-1 O00124 UBXN8_HUMAN
UBXN8_3-1 O00124 UBXN8_HUMAN
UBXN10_1-1 UBX domain-containing protein 10 Q96LJ8 UBX10_HUMAN

128
UBXN11_1 UBX domain-containing protein 11 Q5T124 UBX11_HUMAN
UBXN11_2 Q5T124 UBX11_HUMAN
UBXN11_3 Q5T124 UBX11_HUMAN
UBXN11_4 Q5T124 UBX11_HUMAN
UBXN11_5 Q5T124 UBX11_HUMAN
UBXN11_8 Q5T124 UBX11_HUMAN
UFM1_1-1 Ubiquitin-fold modifier 1 P61960 UFM1_HUMAN
UFM1_2-1 P61960 UFM1_HUMAN
UHRF1_1-1 E3 ubiquitin-protein ligase UHRF1 Q96T88 UHRF1_HUMAN
UHRF1BP1 UHRF1-binding protein 1 Q6BDS2 URFB1_HUMAN
UHRF2_1-1 E3 ubiquitin-protein ligase UHRF2 Q96PU4 UHRF2_HUMAN
UHRF2_2-1 Q96PU4 UHRF2_HUMAN
URM1_1-1 Ubiquitin-related modifier 1 Q9BTM9 URM1_HUMAN
URM1-2 Q9BTM9 URM1_HUMAN
USP11_1-1/-2 Ubiquitin carboxyl-terminal hydrolase 11 P51784 UBP11_HUMAN
USP11_1-2 P51784 UBP11_HUMAN
USP14_1-1/-2 Ubiquitin carboxyl-terminal hydrolase 14 P54578 UBP14_HUMAN
USP14_1-2 P54578 UBP14_HUMAN
USP15_1-1/-2/-3 Ubiquitin carboxyl-terminal hydrolase 15 Q9Y4E8 UBP15_HUMAN
USP15_1-2 Q9Y4E8 UBP15_HUMAN
USP15_1-3 Q9Y4E8 UBP15_HUMAN
USP15_2-1/-2/-3 Q9Y4E8-2 UBP15_HUMAN
USP15_2-2 Q9Y4E8-2 UBP15_HUMAN
USP15_2-3 Q9Y4E8-2 UBP15_HUMAN
USP15_3-1/-2/-3 Q9Y4E8-3 UBP15_HUMAN
USP15_3-2 Q9Y4E8-3 UBP15_HUMAN
USP15_3-3 Q9Y4E8-3 UBP15_HUMAN
USP20_1-1/-2 Ubiquitin carboxyl-terminal hydrolase 20 Q9Y2K6 UBP20_HUMAN
USP20_1-2 Q9Y2K6 UBP20_HUMAN
USP21_1-1 Ubiquitin carboxyl-terminal hydrolase 21 Q9UK80 UBP21_HUMAN
USP21_3-1 Q9UK80-3 UBP21_HUMAN
USP24_1-1/-2 Ubiquitin carboxyl-terminal hydrolase 24 Q9UPU5 UBP24_HUMAN
USP24_1-2 Q9UPU5 UBP24_HUMAN
USP25_1-1/-2/-3 Ubiquitin carboxyl-terminal hydrolase 25 Q9UHP3 UBP25_HUMAN
USP25_1-2 Q9UHP3 UBP25_HUMAN
USP25_1-3 Q9UHP3 UBP25_HUMAN
USP25_2-1/-2/-3 Q9UHP3 UBP25_HUMAN
USP25_2-2 Q9UHP3 UBP25_HUMAN
USP25_2-3 Q9UHP3 UBP25_HUMAN
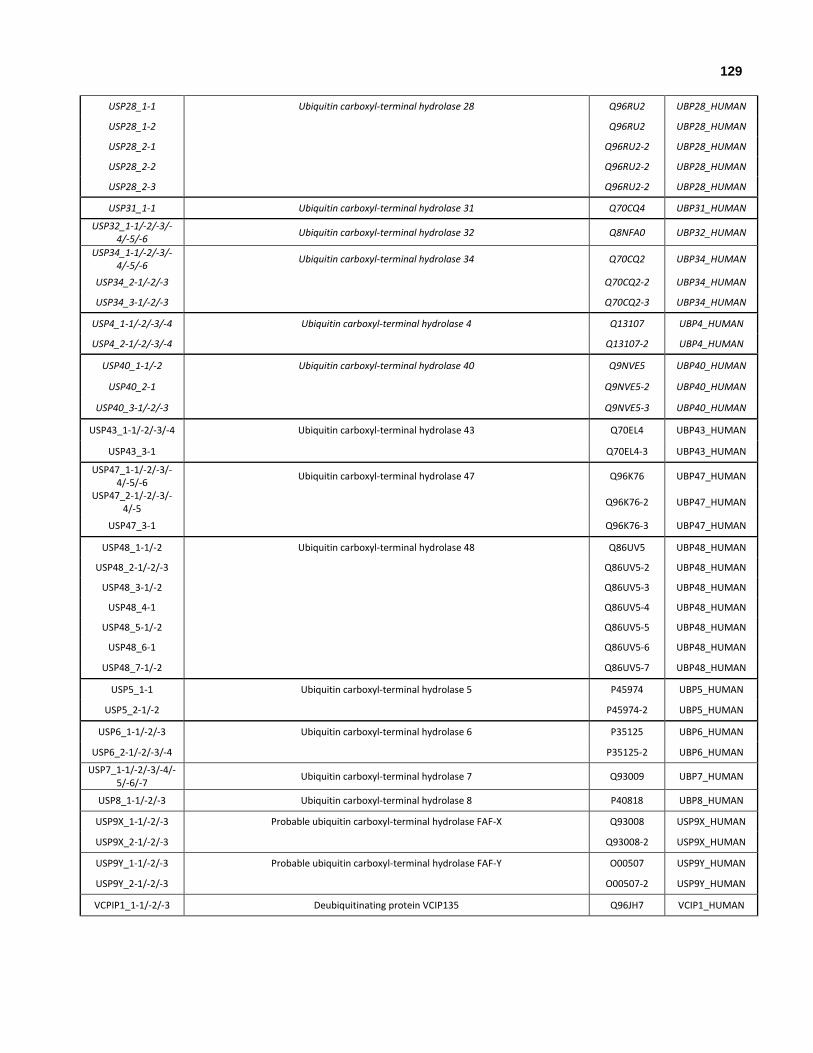
129
USP28_1-1 Ubiquitin carboxyl-terminal hydrolase 28 Q96RU2 UBP28_HUMAN
USP28_1-2 Q96RU2 UBP28_HUMAN
USP28_2-1 Q96RU2-2 UBP28_HUMAN
USP28_2-2 Q96RU2-2 UBP28_HUMAN
USP28_2-3 Q96RU2-2 UBP28_HUMAN
USP31_1-1 Ubiquitin carboxyl-terminal hydrolase 31 Q70CQ4 UBP31_HUMAN
USP32_1-1/-2/-3/-4/-5/-6
Ubiquitin carboxyl-terminal hydrolase 32 Q8NFA0 UBP32_HUMAN
USP34_1-1/-2/-3/-4/-5/-6
Ubiquitin carboxyl-terminal hydrolase 34 Q70CQ2 UBP34_HUMAN
USP34_2-1/-2/-3 Q70CQ2-2 UBP34_HUMAN
USP34_3-1/-2/-3 Q70CQ2-3 UBP34_HUMAN
USP4_1-1/-2/-3/-4 Ubiquitin carboxyl-terminal hydrolase 4 Q13107 UBP4_HUMAN
USP4_2-1/-2/-3/-4 Q13107-2 UBP4_HUMAN
USP40_1-1/-2 Ubiquitin carboxyl-terminal hydrolase 40 Q9NVE5 UBP40_HUMAN
USP40_2-1 Q9NVE5-2 UBP40_HUMAN
USP40_3-1/-2/-3 Q9NVE5-3 UBP40_HUMAN
USP43_1-1/-2/-3/-4 Ubiquitin carboxyl-terminal hydrolase 43 Q70EL4 UBP43_HUMAN
USP43_3-1 Q70EL4-3 UBP43_HUMAN
USP47_1-1/-2/-3/-4/-5/-6
Ubiquitin carboxyl-terminal hydrolase 47 Q96K76 UBP47_HUMAN
USP47_2-1/-2/-3/-4/-5
Q96K76-2 UBP47_HUMAN
USP47_3-1 Q96K76-3 UBP47_HUMAN
USP48_1-1/-2 Ubiquitin carboxyl-terminal hydrolase 48 Q86UV5 UBP48_HUMAN
USP48_2-1/-2/-3 Q86UV5-2 UBP48_HUMAN
USP48_3-1/-2 Q86UV5-3 UBP48_HUMAN
USP48_4-1 Q86UV5-4 UBP48_HUMAN
USP48_5-1/-2 Q86UV5-5 UBP48_HUMAN
USP48_6-1 Q86UV5-6 UBP48_HUMAN
USP48_7-1/-2 Q86UV5-7 UBP48_HUMAN
USP5_1-1 Ubiquitin carboxyl-terminal hydrolase 5 P45974 UBP5_HUMAN
USP5_2-1/-2 P45974-2 UBP5_HUMAN
USP6_1-1/-2/-3 Ubiquitin carboxyl-terminal hydrolase 6 P35125 UBP6_HUMAN
USP6_2-1/-2/-3/-4 P35125-2 UBP6_HUMAN
USP7_1-1/-2/-3/-4/-5/-6/-7
Ubiquitin carboxyl-terminal hydrolase 7 Q93009 UBP7_HUMAN
USP8_1-1/-2/-3 Ubiquitin carboxyl-terminal hydrolase 8 P40818 UBP8_HUMAN
USP9X_1-1/-2/-3 Probable ubiquitin carboxyl-terminal hydrolase FAF-X Q93008 USP9X_HUMAN
USP9X_2-1/-2/-3 Q93008-2 USP9X_HUMAN
USP9Y_1-1/-2/-3 Probable ubiquitin carboxyl-terminal hydrolase FAF-Y O00507 USP9Y_HUMAN
USP9Y_2-1/-2/-3 O00507-2 USP9Y_HUMAN
VCPIP1_1-1/-2/-3 Deubiquitinating protein VCIP135 Q96JH7 VCIP1_HUMAN

130
WDR48_1-1/-2 WD repeat-containing protein 48 Q8TAF3 WDR48_HUMAN
WDR48_2-1 Q8TAF3-2 WDR48_HUMAN
WDR48_3-1/-2/-3 Q8TAF3-3 WDR48_HUMAN
WDR48_4-1/-2/-3 Q8TAF3-4 WDR48_HUMAN
WDR48_5-1/-2 Q8TAF3-5 WDR48_HUMAN
YOD1_1-1 Ubiquitin thioesterase OTU1 Q5VVQ6 OTU1_HUMAN
YOD1_2-1 Q5VVQ6 OTU1_HUMAN
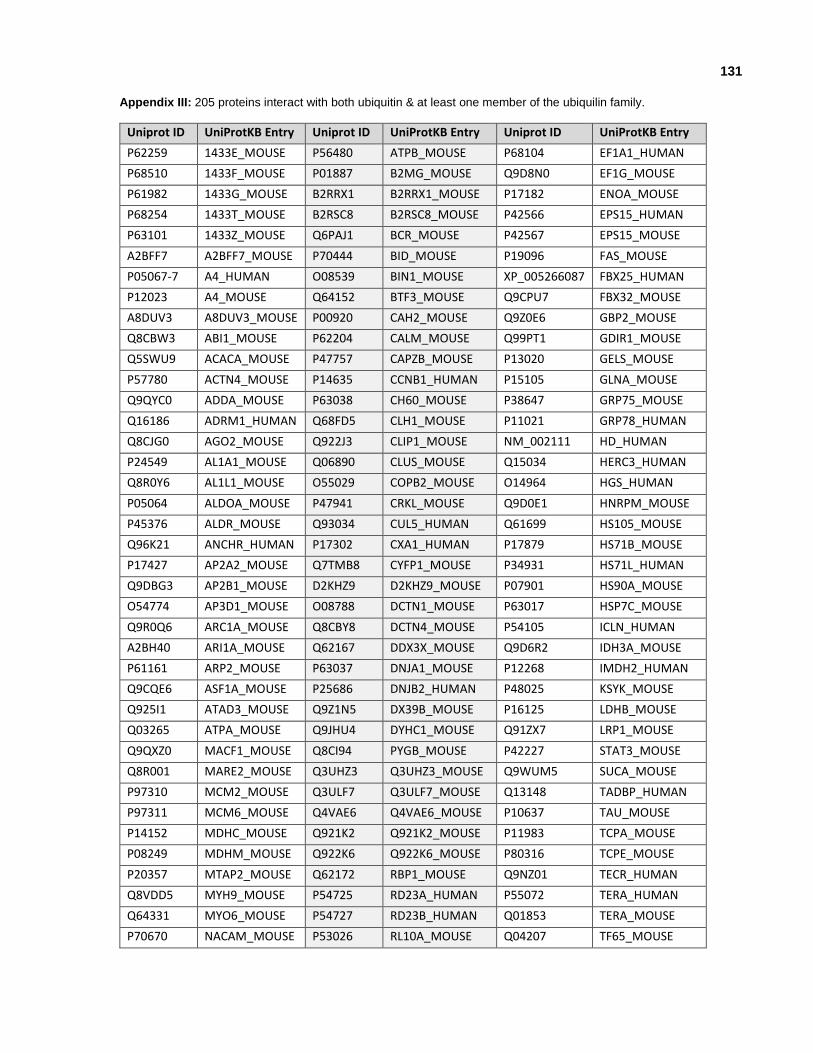
131
Appendix III: 205 proteins interact with both ubiquitin & at least one member of the ubiquilin family.
Uniprot ID UniProtKB Entry Uniprot ID UniProtKB Entry Uniprot ID UniProtKB Entry
P62259 1433E_MOUSE P56480 ATPB_MOUSE P68104 EF1A1_HUMAN
P68510 1433F_MOUSE P01887 B2MG_MOUSE Q9D8N0 EF1G_MOUSE
P61982 1433G_MOUSE B2RRX1 B2RRX1_MOUSE P17182 ENOA_MOUSE
P68254 1433T_MOUSE B2RSC8 B2RSC8_MOUSE P42566 EPS15_HUMAN
P63101 1433Z_MOUSE Q6PAJ1 BCR_MOUSE P42567 EPS15_MOUSE
A2BFF7 A2BFF7_MOUSE P70444 BID_MOUSE P19096 FAS_MOUSE
P05067-7 A4_HUMAN O08539 BIN1_MOUSE XP_005266087 FBX25_HUMAN
P12023 A4_MOUSE Q64152 BTF3_MOUSE Q9CPU7 FBX32_MOUSE
A8DUV3 A8DUV3_MOUSE P00920 CAH2_MOUSE Q9Z0E6 GBP2_MOUSE
Q8CBW3 ABI1_MOUSE P62204 CALM_MOUSE Q99PT1 GDIR1_MOUSE
Q5SWU9 ACACA_MOUSE P47757 CAPZB_MOUSE P13020 GELS_MOUSE
P57780 ACTN4_MOUSE P14635 CCNB1_HUMAN P15105 GLNA_MOUSE
Q9QYC0 ADDA_MOUSE P63038 CH60_MOUSE P38647 GRP75_MOUSE
Q16186 ADRM1_HUMAN Q68FD5 CLH1_MOUSE P11021 GRP78_HUMAN
Q8CJG0 AGO2_MOUSE Q922J3 CLIP1_MOUSE NM_002111 HD_HUMAN
P24549 AL1A1_MOUSE Q06890 CLUS_MOUSE Q15034 HERC3_HUMAN
Q8R0Y6 AL1L1_MOUSE O55029 COPB2_MOUSE O14964 HGS_HUMAN
P05064 ALDOA_MOUSE P47941 CRKL_MOUSE Q9D0E1 HNRPM_MOUSE
P45376 ALDR_MOUSE Q93034 CUL5_HUMAN Q61699 HS105_MOUSE
Q96K21 ANCHR_HUMAN P17302 CXA1_HUMAN P17879 HS71B_MOUSE
P17427 AP2A2_MOUSE Q7TMB8 CYFP1_MOUSE P34931 HS71L_HUMAN
Q9DBG3 AP2B1_MOUSE D2KHZ9 D2KHZ9_MOUSE P07901 HS90A_MOUSE
O54774 AP3D1_MOUSE O08788 DCTN1_MOUSE P63017 HSP7C_MOUSE
Q9R0Q6 ARC1A_MOUSE Q8CBY8 DCTN4_MOUSE P54105 ICLN_HUMAN
A2BH40 ARI1A_MOUSE Q62167 DDX3X_MOUSE Q9D6R2 IDH3A_MOUSE
P61161 ARP2_MOUSE P63037 DNJA1_MOUSE P12268 IMDH2_HUMAN
Q9CQE6 ASF1A_MOUSE P25686 DNJB2_HUMAN P48025 KSYK_MOUSE
Q925I1 ATAD3_MOUSE Q9Z1N5 DX39B_MOUSE P16125 LDHB_MOUSE
Q03265 ATPA_MOUSE Q9JHU4 DYHC1_MOUSE Q91ZX7 LRP1_MOUSE
Q9QXZ0 MACF1_MOUSE Q8CI94 PYGB_MOUSE P42227 STAT3_MOUSE
Q8R001 MARE2_MOUSE Q3UHZ3 Q3UHZ3_MOUSE Q9WUM5 SUCA_MOUSE
P97310 MCM2_MOUSE Q3ULF7 Q3ULF7_MOUSE Q13148 TADBP_HUMAN
P97311 MCM6_MOUSE Q4VAE6 Q4VAE6_MOUSE P10637 TAU_MOUSE
P14152 MDHC_MOUSE Q921K2 Q921K2_MOUSE P11983 TCPA_MOUSE
P08249 MDHM_MOUSE Q922K6 Q922K6_MOUSE P80316 TCPE_MOUSE
P20357 MTAP2_MOUSE Q62172 RBP1_MOUSE Q9NZ01 TECR_HUMAN
Q8VDD5 MYH9_MOUSE P54725 RD23A_HUMAN P55072 TERA_HUMAN
Q64331 MYO6_MOUSE P54727 RD23B_HUMAN Q01853 TERA_MOUSE
P70670 NACAM_MOUSE P53026 RL10A_MOUSE Q04207 TF65_MOUSE

132
Uniprot ID UniProtKB Entry Uniprot ID UniProtKB Entry Uniprot ID UniProtKB Entry
P15532 NDKA_MOUSE P47963 RL13_MOUSE Q8QZT1 THIL_MOUSE
Q8TAT6 NPL4_HUMAN Q9CR57 RL14_MOUSE P19438 TNR1A_HUMAN
P35486 ODPA_MOUSE Q9D8E6 RL4_MOUSE P20333 TNR1B_HUMAN
P29341 PABP1_MOUSE P62987 RL40_HUMAN P17751 TPIS_MOUSE
P49586 PCY1A_MOUSE P47911 RL6_MOUSE P21107 TPM3_MOUSE
Q9WU78 PDC6I_MOUSE P12970 RL7A_MOUSE Q12933 TRAF2_HUMAN
P12382 PFKAL_MOUSE P14869 RLA0_MOUSE Q9R1R2 TRIM3_MOUSE
Q13526 PIN1_HUMAN Q96GF1 RN185_HUMAN Q9QZE7 TSNAX_MOUSE
Q9QXS1 PLEC_MOUSE Q9Y3C5 RNF11_HUMAN P62837 UB2D2_HUMAN
P63330 PP2AA_MOUSE P70336 ROCK2_MOUSE P61077 UB2D3_HUMAN
P35700 PRDX1_MOUSE P38886 RPN10_YEAST P0CG48, NP_066289
UBC_HUMAN
Q61171 PRDX2_MOUSE O48726 RPN13_ARATH P49459-3 UBE2A_HUMAN
P97313 PRKDC_MOUSE P62281 RS11_MOUSE P63146 UBE2B_HUMAN
P62334 PRS10_MOUSE P25444 RS2_MOUSE Q05086 UBE3A_HUMAN
P62192 PRS4_MOUSE P62908 RS3_MOUSE P11441 UBL4A_HUMAN
P54775 PRS6B_MOUSE E9Q401 RYR2_MOUSE Q70CQ2 UBP34_HUMAN
P35998 PRS7_HUMAN Q9UBT2 SAE2_HUMAN Q9UMX0 UBQL1_HUMAN
P62196 PRS8_MOUSE O43865 SAHH2_HUMAN Q9UHD9 UBQL2_HUMAN
P25787 PSA2_HUMAN P42208 SEPT2_MOUSE P15374 UCHL3_HUMAN
P60900 PSA6_HUMAN P28661 SEPT4_MOUSE Q13564 ULA1_HUMAN
Q9QUM9 PSA6_MOUSE Q9R1T4 SEPT6_MOUSE Q9C0B0 UNK_HUMAN
Q3TXS7 PSMD1_MOUSE O55131 SEPT7_MOUSE XP_005272733 USP9X_HUMAN
Q13200 PSMD2_HUMAN P84022 SMAD3_HUMAN Q9WV55 VAPA_MOUSE
Q8VDM4 PSMD2_MOUSE Q920B9 SP16H_MOUSE P20152 VIME_MOUSE
O43242 PSMD3_HUMAN Q62261 SPTB2_MOUSE P62960 YBOX1_MOUSE
P14685 PSMD3_MOUSE P16546 SPTN1_MOUSE P39447 ZO1_MOUSE
P55034 PSMD4_ARATH O60232 SSA27_HUMAN O95218-2 ZRAB2_HUMAN
P55036, P55036-2
PSMD4_HUMAN Q92783 STAM1_HUMAN
Q05920 PYC_MOUSE O75886 STAM2_HUMAN
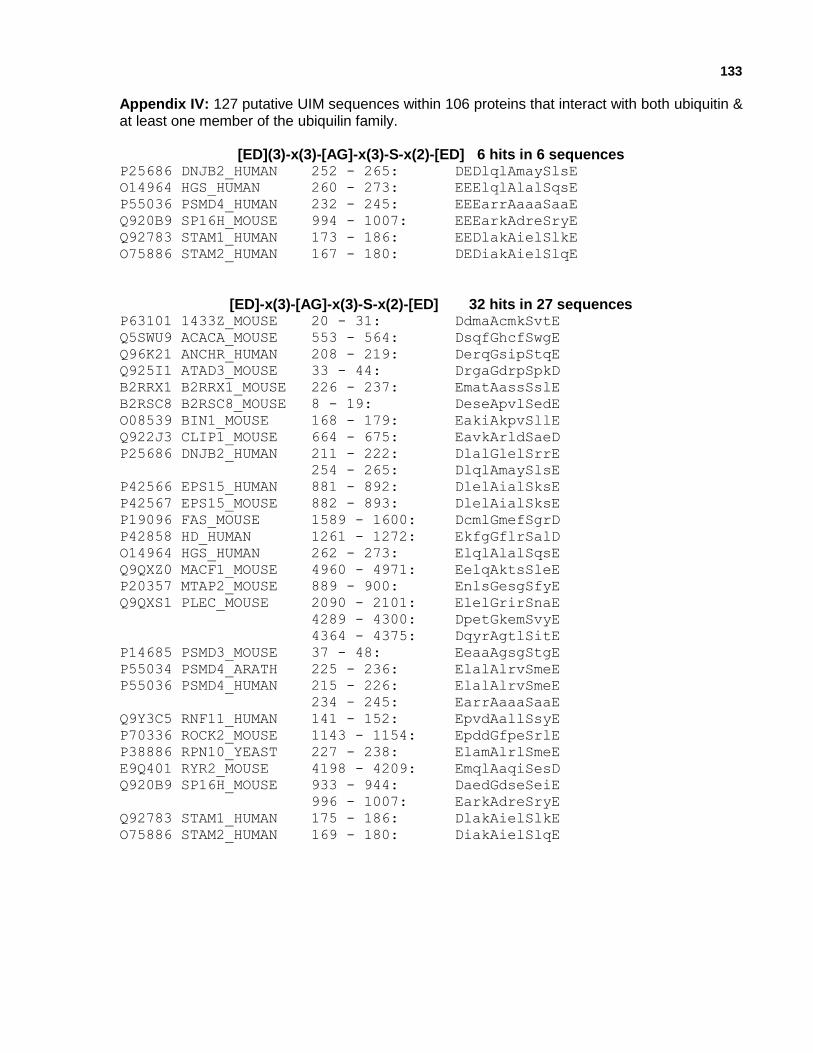
133
Appendix IV: 127 putative UIM sequences within 106 proteins that interact with both ubiquitin & at least one member of the ubiquilin family.
[ED](3)-x(3)-[AG]-x(3)-S-x(2)-[ED] 6 hits in 6 sequences P25686 DNJB2_HUMAN 252 - 265: DEDlqlAmaySlsE
O14964 HGS_HUMAN 260 - 273: EEElqlAlalSqsE
P55036 PSMD4_HUMAN 232 - 245: EEEarrAaaaSaaE
Q920B9 SP16H_MOUSE 994 - 1007: EEEarkAdreSryE
Q92783 STAM1_HUMAN 173 - 186: EEDlakAielSlkE
O75886 STAM2_HUMAN 167 - 180: DEDiakAielSlqE
[ED]-x(3)-[AG]-x(3)-S-x(2)-[ED] 32 hits in 27 sequences P63101 1433Z_MOUSE 20 - 31: DdmaAcmkSvtE
Q5SWU9 ACACA_MOUSE 553 - 564: DsqfGhcfSwgE
Q96K21 ANCHR_HUMAN 208 - 219: DerqGsipStqE
Q925I1 ATAD3_MOUSE 33 - 44: DrgaGdrpSpkD
B2RRX1 B2RRX1_MOUSE 226 - 237: EmatAassSslE
B2RSC8 B2RSC8_MOUSE 8 - 19: DeseApvlSedE
O08539 BIN1_MOUSE 168 - 179: EakiAkpvSllE
Q922J3 CLIP1_MOUSE 664 - 675: EavkArldSaeD
P25686 DNJB2_HUMAN 211 - 222: DlalGlelSrrE
254 - 265: DlqlAmaySlsE
P42566 EPS15_HUMAN 881 - 892: DlelAialSksE
P42567 EPS15_MOUSE 882 - 893: DlelAialSksE
P19096 FAS_MOUSE 1589 - 1600: DcmlGmefSgrD
P42858 HD_HUMAN 1261 - 1272: EkfgGflrSalD
O14964 HGS_HUMAN 262 - 273: ElqlAlalSqsE
Q9QXZ0 MACF1_MOUSE 4960 - 4971: EelqAktsSleE
P20357 MTAP2_MOUSE 889 - 900: EnlsGesgSfyE
Q9QXS1 PLEC_MOUSE 2090 - 2101: ElelGrirSnaE
4289 - 4300: DpetGkemSvyE
4364 - 4375: DqyrAgtlSitE
P14685 PSMD3_MOUSE 37 - 48: EeaaAgsgStgE
P55034 PSMD4_ARATH 225 - 236: ElalAlrvSmeE
P55036 PSMD4_HUMAN 215 - 226: ElalAlrvSmeE
234 - 245: EarrAaaaSaaE
Q9Y3C5 RNF11_HUMAN 141 - 152: EpvdAallSsyE
P70336 ROCK2_MOUSE 1143 - 1154: EpddGfpeSrlE
P38886 RPN10_YEAST 227 - 238: ElamAlrlSmeE
E9Q401 RYR2_MOUSE 4198 - 4209: EmqlAaqiSesD
Q920B9 SP16H_MOUSE 933 - 944: DaedGdseSeiE
996 - 1007: EarkAdreSryE
Q92783 STAM1_HUMAN 175 - 186: DlakAielSlkE
O75886 STAM2_HUMAN 169 - 180: DiakAielSlqE

134
[ED]-x(3)-[AG]-x(4)-S-x(2)-[ED] 25 hits in 20 sequences P68510 1433F_MOUSE 136 - 148: EvasGekknSvvE
P24549 AL1A1_MOUSE 138 - 150: DkihGqtipSdgD
O54774 AP3D1_MOUSE 884 - 896: EelaAstitSpkD
A2BH40 ARI1A_MOUSE 2131 - 2143: DlilAtppfSrlE
Q6PAJ1 BCR_MOUSE 850 - 862: DyerAewreSirE
O08788 DCTN1_MOUSE 875 - 887: EqiyGspssSpyE
965 - 977: ElseAnvrlSllE
P63037 DNJA1_MOUSE 74 - 86: EggaGggfgSpmD
P19096 FAS_MOUSE 1358 - 1370: EvqpApsllSqeE
P38647 GRP75_MOUSE 244 - 256: DlggGtfdiSilE
Q9QXZ0 MACF1_MOUSE 105 - 117: DlrdGhnliSllE
3823 - 3835: EqyaAslarSeaE
Q9QXS1 PLEC_MOUSE 217 - 229: DlrdGhnliSllE
2360 - 2372: EvteAarqrSqvE
P62192 PRS4_MOUSE 382 - 394: DlimAkddlSgaD
P14685 PSMD3_MOUSE 50 - 62: DgkaAatehSqrE
Q3UHZ3 Q3UHZ3_MOUSE 180 - 192: EseeGnsaeSaaE
Q62172 RBP1_MOUSE 83 - 95: EgyaAfqedSsgD
415 - 427: DlqgGikdlSkeE
Q9UBT2 SAE2_HUMAN 483 - 495: EdgkGtiliSseE
P28661 SEPT4_MOUSE 2 - 14: DhslGwqgnSvpE
Q920B9 SP16H_MOUSE 140 - 152: DkfpGefmkSwsD
930 - 942: EgsdAedgdSesE
Q62261 SPTB2_MOUSE 1600 - 1612: DaaeAeawmSeqE
Q05086 UBE3A_HUMAN 98 - 110: EnskGapnnScsE

135
[ED]-x(3)-[AG]-x(5)-S-x(2)-[ED] 30 hits in 26 sequences Q5SWU9 ACACA_MOUSE 945 - 958: DshaAtlnrkSerE
P45376 ALDR_MOUSE 217 - 230: DrpwAkpedpSllE
B2RRX1 B2RRX1_MOUSE 224 - 237: EqemAtaassSslE
Q6PAJ1 BCR_MOUSE 325 - 338: DsggGytpdcSsnE
P00920 CAH2_MOUSE 19 - 32: DfpiAngdrqSpvD
P63037 DNJA1_MOUSE 268 - 281: EalcGfqkpiStlD
P25686 DNJB2_HUMAN 71 - 84: EgltGtgtgpSraE
254 - 267: DlqlAmayslSemE
Q9JHU4 DYHC1_MOUSE 3952 - 3965: DeqfGiwldsSspE
P68104 EF1A1_HUMAN 319 - 332: DvrrGnvagdSknD
P42858 HD_HUMAN 409 - 422: EesgGrsrsgSivE
O14964 HGS_HUMAN 262 - 275: ElqlAlalsqSeaE
Q91ZX7 LRP1_MOUSE 2807 - 2820: EsvtAgclynStcD
Q8VDD5 MYH9_MOUSE 1153 - 1166: DstaAqqelrSkrE
Q64331 MYO6_MOUSE 1234 - 1247: ErcgGiqylqSaiE
Q9QXS1 PLEC_MOUSE 1200 - 1213: EpspAaptlrSelE
2037 - 2050: EerlAqlrkaSesE
P54775 PRS6B_MOUSE 361 - 374: EdyvArpdkiSgaD
P55034 PSMD4_ARATH 223 - 236: DpelAlalrvSmeE
309 - 322: DlalAlqmsmSgeE
P55036 PSMD4_HUMAN 213 - 226: DpelAlalrvSmeE
Q62172 RBP1_MOUSE 19 - 32: EhgsGltrtpSseE
83 - 96: EgyaAfqedsSgdE
P38886 RPN10_YEAST 225 - 238: DpelAmalrlSmeE
E9Q401 RYR2_MOUSE 3702 - 3715: EdddGeeevkSfeE
Q62261 SPTB2_MOUSE 1378 - 1391: DankAelftqScaD
Q92783 STAM1_HUMAN 173 - 186: EedlAkaielSlkE
O75886 STAM2_HUMAN 167 - 180: DediAkaielSlqE
Q93008 USP9X_HUMAN 1682 - 1695: EqhdAleffnSlvD
Q9WV55 VAPA_MOUSE 143 - 156: EpskAvplnaSkqD

136
[ED]-x(3)-[AG]-x(6)-S-x(2)-[ED] 34 hits in 27 sequences
A2BH40 ARI1A_MOUSE 117 - 131: EppgGgggggsSssD
Q6PAJ1 BCR_MOUSE 324 - 338: EdsgGgytpdcSsnE
P62204 CALM_MOUSE 7 - 21: EeqiAefkeafSlfD
Q922J3 CLIP1_MOUSE 661 - 675: DsleAvkarldSaeD
O55029 COPB2_MOUSE 593 - 607: EyqtAvmrrdfSmaD
Q9JHU4 DYHC1_MOUSE 4621 - 4635: DfeiAtkedprSfyE
P68104 EF1A1_HUMAN 403 - 417: DmvpGkpmcveSfsD
P42566 EPS15_HUMAN 576 - 590: EvttAvtekvcSelD
P19096 FAS_MOUSE 584 - 598: EvacGyadgclSqrE
Q91ZX7 LRP1_MOUSE 1353 - 1367: DwiaGniywveSnlD
2630 - 2644: DcedAsdemncSatD
3967 - 3981: DwvaGnvywtdSgrD
Q9QXZ0 MACF1_MOUSE 2199 - 2213: DtsvGlrsefkSehD
2685 - 2699: DmatGkrvtlaSalE
6870 - 6884: DrvkAlitehqSfmE
P97310 MCM2_MOUSE 790 - 804: DvnmAirvmmeSfiD
P20357 MTAP2_MOUSE 7 - 21: DegkAphwtsaSltE
Q64331 MYO6_MOUSE 702 - 716: DlmqGgfpsraSfhE
Q13526 PIN1_HUMAN 87 - 101: ElinGyiqkikSgeE
P97313 PRKDC_MOUSE 2041 - 2055: DfstGvqsysySsqD
O43242 PSMD3_HUMAN 52 - 66: DgktAaaaaehSqrE
P55036 PSMD4_HUMAN 255 - 269: DsddAllkmtiSqqE
Q62172 RBP1_MOUSE 452 - 466: EtkiAqeiaslSkeD
P54725 RD23A_HUMAN 150 - 164: EedaAstlvtgSeyE
P38886 RPN10_YEAST 194 - 208: EgssGmgafggSggD
E9Q401 RYR2_MOUSE 1859 - 1873: EeegGtpekeiSieD
3337 - 3351: DhlkAeargdmSeaE
Q9UBT2 SAE2_HUMAN 218 - 232: EpteAeararaSneD
Q920B9 SP16H_MOUSE 930 - 944: EgsdAedgdseSeiE
Q62261 SPTB2_MOUSE 2063 - 2077: EksaAtwderfSalE
2148 - 2162: EmvnGaaeqrtSskE
P16546 SPTN1_MOUSE 1604 - 1618: DrirGvidmgnSliE
Q70CQ2 UBP34_HUMAN 786 - 800: EknmAdfdgeeSgcE
1672 - 1686: EscsGlyklslSglD

137
Appendix V: Six similarities trees of ubiquitin-like domains clustered based on electrostatic potential at varying
distances (1Å to 6Å) from the UIM-binding interface, along with groups of ubiquitin-like domains that share strong electrostatic potential similarity at that specific range.





























