Embed Size (px)
Citation preview

Statistiques avec R2 - Statistiques de base
Christophe Lalanne
Cours R (ESME), 2015 1

Synopsis
• Rappels sur la démarche inferentielle
• Split-Apply-Combine
• Comparaison de moyennes et de proportions
• Modèle linéaire
Cours R (ESME), 2015 2

Une tâche de dénombrement
Statisticians are applied philosophers. Philosophers argue how many angels can dance on the head of a needle; statisticians count them. Or rather, count how many can probably dance. (...) We can predict nothing with certainty but we can predict how uncertain our predictions will be, on average that is. Statistics is the science that tells us how. — Stephen Senn
Cours R (ESME), 2015 3

Démarche du test d'hypothèse
De manière générale, lorsque l'on s'intéresse à un effet particulier, l'idée est de postuler l'absence d'effet (hypothèse nulle, ) et de chercher à vérifier si les données observées sont compatibles ou non avec cette hypothèse. C'est le principe même de la démarche hypothético-déductive.
Cours R (ESME), 2015 4

Pour réaliser un tel test, il est nécessaire de construire une statistique de test, dont la distribution d'échantillonnage est connue (ou peut être approximée) sous , qui nous permettra de répondre à la question suivante : en supposant qu'il n'existe pas d'effet dans la population, quelle est la probabilité d'observer une statistique de test au moins aussi extrême que celle estimée à partir de l'échantillon choisi aléatoirement dans cette population ? Si cette probabilité se révèle "suffisamment petite", on concluera qu'il est vraisemblablement peu probable que le résultat observé soit dû simplement au hasard de l'échantillonnage.Cours R (ESME), 2015 5

Risques associés à un modèle décisionnel
Supposons que l'on est à prendre une décision concernant une hypothèse nulle. Le fameux "risque alpha" (type I) est le risque de conclure à tort à l'existence d'un effet alors qu'en réalité ce dernier n'existe pas.
À ce risque est typiquement associé, de manière asymétrique, le risque (type II) de ne pas rejeter lorsque celle-ci est en réalité fausse ; le complémentaire de ce risque est appelée la puissance. Cours R (ESME), 2015 6

Ces risques sont effectivement asymétriques :
• dans un essai thérapeutique, si l'on doit décider si un nouveau traitement est meilleur que le traitement courant, on cherche à minimiser le risque d'une mauvaise décision ( ). ;
• si à la fin de l'essai, on ne met en évidence aucune différences significatives, cela ne signifie pas que les traitements sont équivalents : il existe un risque $\beta$ qu'il existe une réelle différence entre les deux.
Cours R (ESME), 2015 7

Alternatives au paradigme fréquentiste
• méthode basée sur la vraisemblance: Utiliser les données pour l'arbitrage entre deux modèles alternatifs, "Quelle est la vraisemblance d'observer de telles données, étant donné le modèle postulé ?"
Cours R (ESME), 2015 8

• approche bayésienne: Utiliser des informations externes permettant de juger a priori quel modèle est le plus susceptible d'être vrai, i.e. utilisation d'une probabilité a priori qui sera mise à jour (en une probabilité a posteriori) au vu des données.
On préférerait souvent connaître plutôt que sous , même si 'the earth is round (p < .05).'
A Good P–value is Hard to Find: Why I’m a Bayesian When Time Allows (FE Harrell Jr, 2013).
Cours R (ESME), 2015 9

Formules R
Dans la plupart des cas, R repose sur l'usage de notation par formule pour les différentes étapes d'analyse d'un jeu de données : tidying + summarizing data, plotting, ou reporting
Ces formules permettent de décrire la relation entre les variables et sont à la base des modèles statistiques de base de R (modèles linéaires généralisés, arbres de décision, etc.).Les formules R (et les structures de type data frames, de facto) ont été implémentées en Python et Julia.
Cours R (ESME), 2015 10

Exemples :
• y ~ x : variable réponse y décrite par une variable explicative x (régression linéaire)
• y ~ 0 + x : idem sans terme d'ordonnée à l'origine
• y ~ x1*x2 : (equiv. à y ~ x1 + x2 + x1:x2) variable réponse y décrite par deux variable explicative x1 et x2 et leur interaction
• cbind(y1, y2) ~ x : deux variables réponses y1 et y2 décrites par une variable explicative x
Cours R (ESME), 2015 11

L'utilisation de formules suppose qu'il est possible d'adresser individuellement chacune des variables du modèle, sans avoir à construire explicitement une matrice de design (model.matrix).
Il est parfois de nécessaire de restructurer ("reshape", melting/casting) le tableau de données pour opérer de manière plus simple sur les variables : melt (format "long") et cast (format "wide") : package reshape2.
Cours R (ESME), 2015 12

Structure de données (wide vs. long)
Dans le cas où l'on dispose de deux séries d'observations, on peut considérer deux façons de représenter les données. d <- data.frame(x1 = rnorm(n=5, mean=10, sd=1.5), x2 = rnorm(n=5, mean=12, sd=1.5))head(d, n = 3)
Deux colonnes désignant les deux séries d'observations. Or on n'a en réalité qu'une variable explicative.
Cours R (ESME), 2015 13

Solution alternative : faire apparaître explicitement la variable réponse (valeurs mesurées pour chaque unité) et la variable explicative (facteur de groupement).library(reshape2)dm <- melt(d) # switch from wide to long formathead(dm)
Option intéressantes : id.vars=, measure.vars=.
Cours R (ESME), 2015 14

Tests pour deux échantillons
Les tests pour deux échantillons sous R sont généralement suffixés par .test.
Exemple : {t, wilcox, prop, fisher, chisq}.test.
Ces tests statistiques ont des valeurs par défaut qu'il convient de vérifier avant l'application du test (e.g., var.equal = FALSE dans le cas du test t, ou correct = TRUE dans le cas du test du chi-deux).
Cours R (ESME), 2015 15

Usage:
t.test(x, ...)
## Default S3 method: t.test(x, y = NULL, alternative = c("two.sided", "less", "greater"), mu = 0, paired = FALSE, var.equal = FALSE, conf.level = 0.95, ...)
## S3 method for class 'formula' t.test(formula, data, subset, na.action, ...)
Cours R (ESME), 2015 16

Comparaison de deux moyennes
Cas de deux échantillons indépendants
Cours R (ESME), 2015 17

Illustration
data(birthwt)birthwt$smoke <- factor(birthwt$smoke, labels = c("No","Yes"))t.test(bwt ~ smoke, data = birthwt, var.equal = TRUE)
Cours R (ESME), 2015 18

Comparaison de deux moyennes (2)
Cas de deux échantillons appariés
Cours R (ESME), 2015 19

Illustration
data(sleep)help(sleep)head(sleep)tail(sleep)x1 <- sleep$extra[sleep$group == 1]x2 <- sleep$extra[sleep$group == 2]t.test(x1, x2, paired = TRUE)
Cours R (ESME), 2015 20
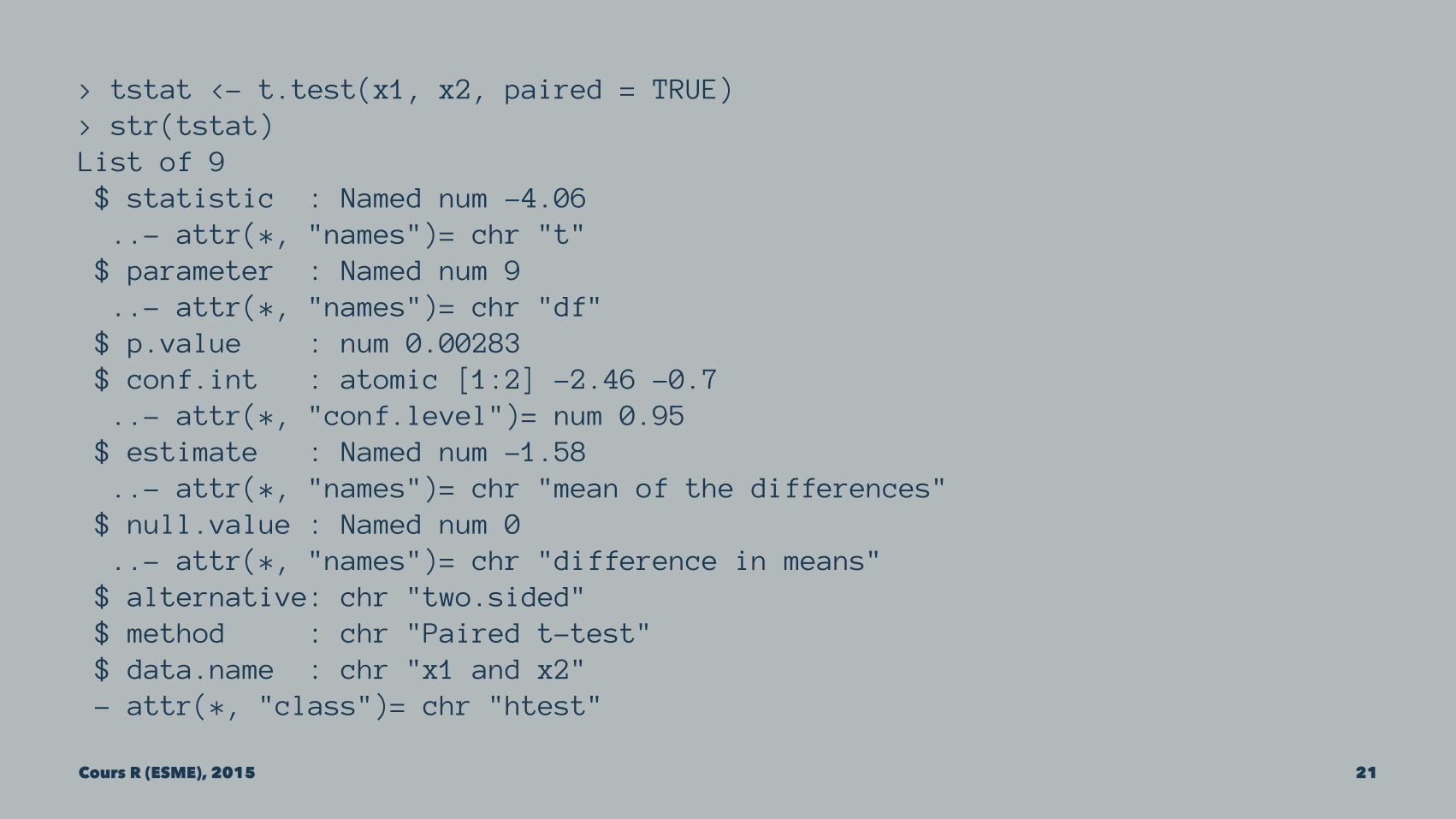
> tstat <- t.test(x1, x2, paired = TRUE)> str(tstat)List of 9 $ statistic : Named num -4.06 ..- attr(*, "names")= chr "t" $ parameter : Named num 9 ..- attr(*, "names")= chr "df" $ p.value : num 0.00283 $ conf.int : atomic [1:2] -2.46 -0.7 ..- attr(*, "conf.level")= num 0.95 $ estimate : Named num -1.58 ..- attr(*, "names")= chr "mean of the differences" $ null.value : Named num 0 ..- attr(*, "names")= chr "difference in means" $ alternative: chr "two.sided" $ method : chr "Paired t-test" $ data.name : chr "x1 and x2" - attr(*, "class")= chr "htest"
Cours R (ESME), 2015 21

Alternative non-paramétrique
Cours R (ESME), 2015 22

Split-Apply-Combine
(...) break up a big problem into manageable pieces, operate on each piece independently and then put all the pieces back together.— Hadley Wickham
Packages plyr ou dplyr.Wickham, H (2011). The Split-Apply-Combine Strategy for Data Analysis. Journal of Statistical Software, 40.
Cours R (ESME), 2015 23
Fichier auto.txtmake,price,mpg,rep78,headroom,trunk,weight,length,turn,displacement,gear_ratio,foreignAMC Concord,4099.0,22.0,3.0,2.5,11.0,2930,186.0,40.0,121.0,3.57999992371,0AMC Pacer,4749.0,17.0,3.0,3.0,11.0,3350,173.0,40.0,258.0,2.52999997139,0AMC Spirit,3799.0,22.0,-999.0,3.0,12.0,2640,168.0,35.0,121.0,3.07999992371,0Buick Century,4816.0,20.0,3.0,4.5,16.0,3250,196.0,40.0,196.0,2.93000006676,0Buick Electra,7827.0,15.0,4.0,4.0,20.0,4080,222.0,43.0,350.0,2.41000008583,0Buick LeSabre,5788.0,18.0,3.0,4.0,21.0,3670,218.0,43.0,231.0,2.73000001907,0Buick Opel,4453.0,26.0,-999.0,3.0,10.0,2230,170.0,34.0,304.0,2.86999988556,0...
Cours R (ESME), 2015 24
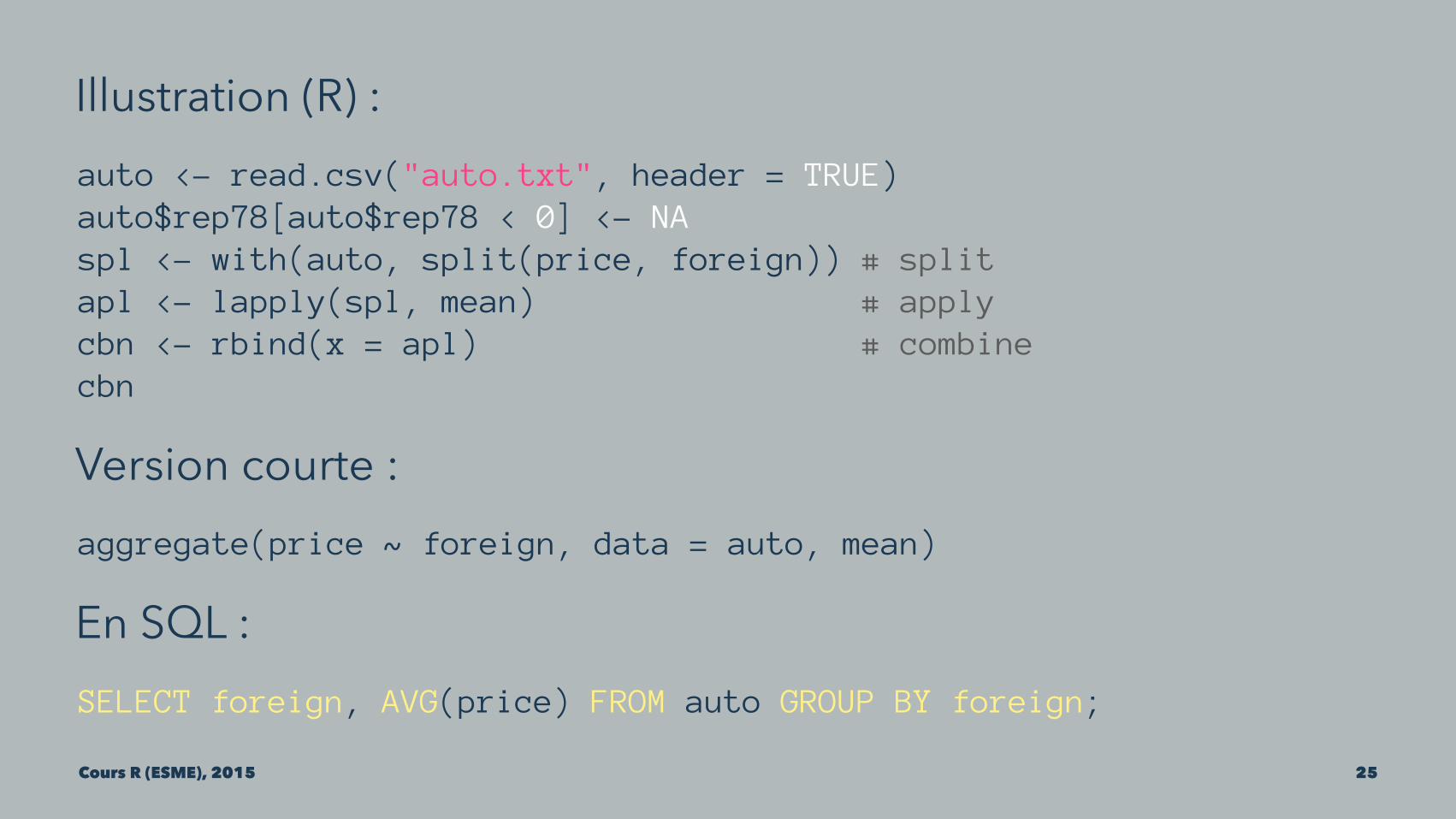
Illustration (R) :auto <- read.csv("auto.txt", header = TRUE)auto$rep78[auto$rep78 < 0] <- NAspl <- with(auto, split(price, foreign)) # splitapl <- lapply(spl, mean) # applycbn <- rbind(x = apl) # combinecbn
Version courte :aggregate(price ~ foreign, data = auto, mean)
En SQL :SELECT foreign, AVG(price) FROM auto GROUP BY foreign;
Cours R (ESME), 2015 25

Corrélation linéaire
cor.test(..., method=c("pearson", "spearman"))
Cours R (ESME), 2015 26

Modèle linéaire
Expliquer les variations observées au niveau d'une variable réponse ("dépendante") numérique, , en fonction de variables prédictrices ("indépendantes"), , pouvant être de nature qualitative ou quantitative.
Exemples : analyse de variance à un ou plusieurs facteurs, régression linéaire simple et multiple, analyse de covariance.
Cours R (ESME), 2015 27

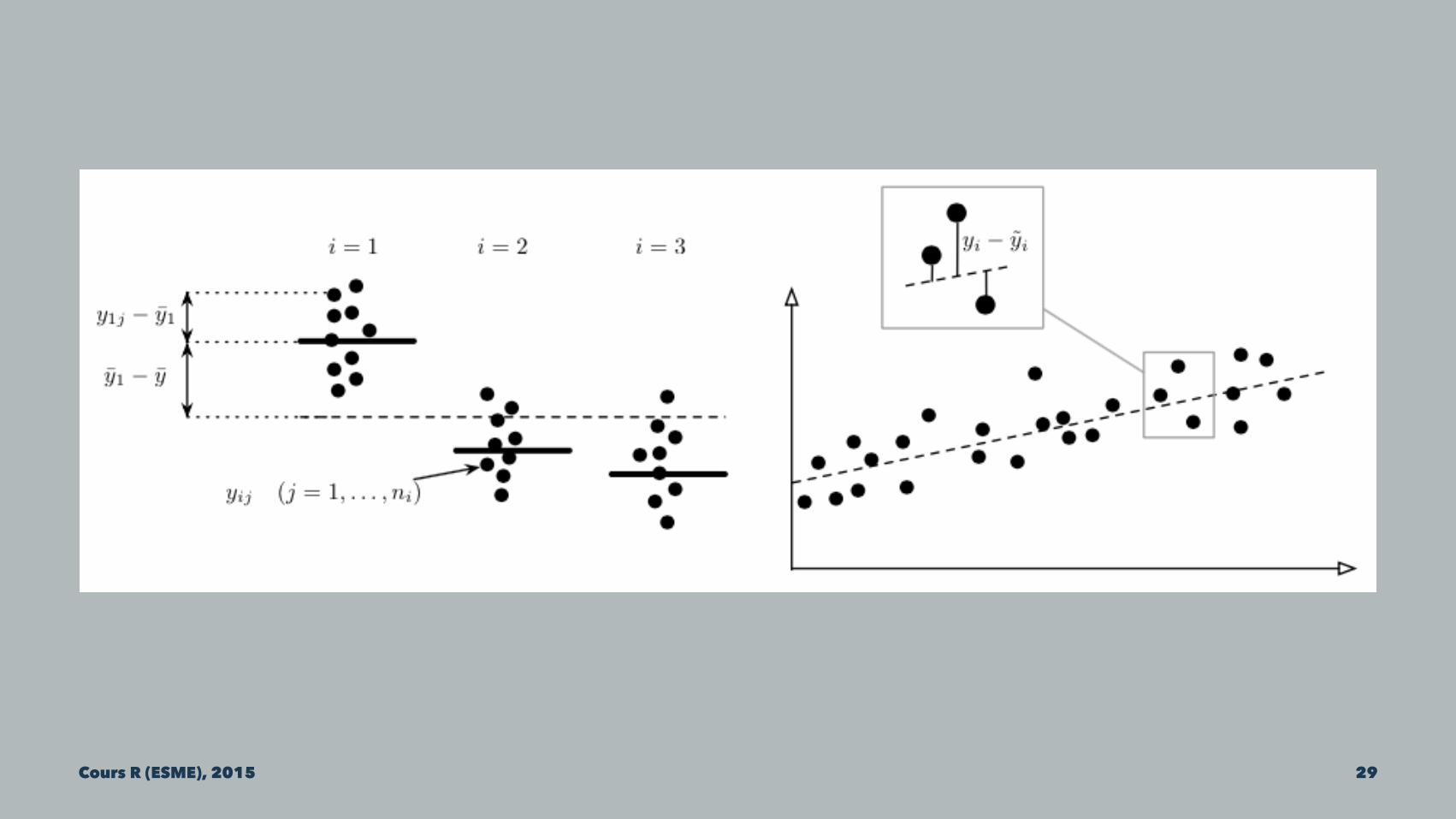
L'idée revient toujours à considérer qu'il existe une part systématique et une part aléatoire (résidus) dans ces variations. Le modèle linéaire permet de formaliser la relation entre et les , en séparant ces deux sources afin d'estimer la contribution relative des dans les fluctuations de .
é é
Le modèle théorique relie fonctionnellement la réponse aux prédicteurs de manière additive : . Cours R (ESME), 2015 28
Cours R (ESME), 2015 29

Cours R (ESME), 2015 30

Illustration
n <- 10x <- runif(n, 0, 10)y <- 5.1 + 1.8 * x + rnorm(n)lm(y ~ x)
Méthodes (S3) associées : summary, coef, confint, anova, predict, fitted, resid Défaut : print
Valable également pour les GLM.
Cours R (ESME), 2015 31
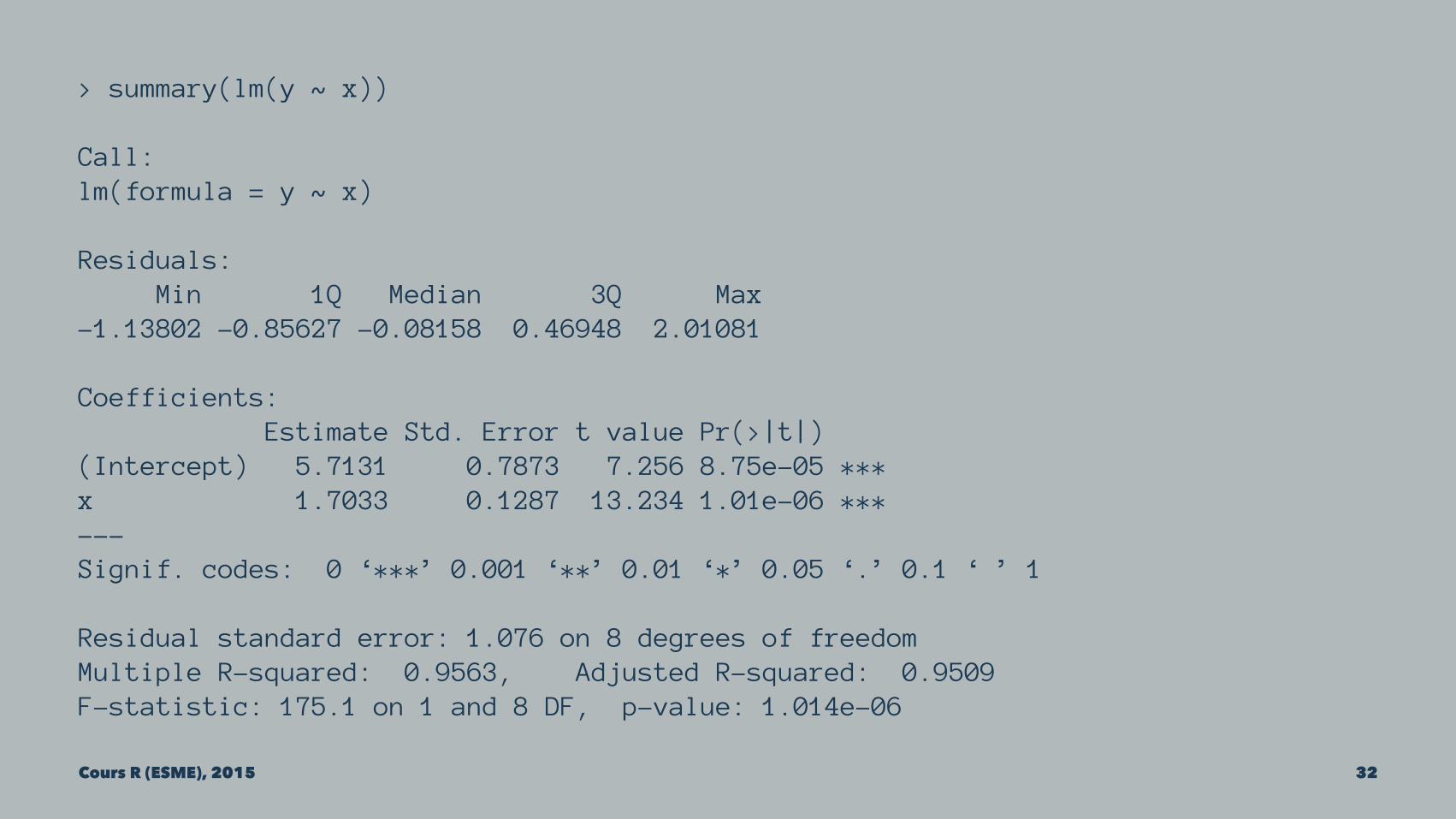
> summary(lm(y ~ x))
Call:lm(formula = y ~ x)
Residuals: Min 1Q Median 3Q Max-1.13802 -0.85627 -0.08158 0.46948 2.01081
Coefficients: Estimate Std. Error t value Pr(>|t|)(Intercept) 5.7131 0.7873 7.256 8.75e-05 ***x 1.7033 0.1287 13.234 1.01e-06 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.076 on 8 degrees of freedomMultiple R-squared: 0.9563, Adjusted R-squared: 0.9509F-statistic: 175.1 on 1 and 8 DF, p-value: 1.014e-06
Cours R (ESME), 2015 32

Cours R (ESME), 2015 33

Application
1. Écrire une fonction permettant de simuler des données pour étudier la régression ou la corrélation linéaire.
2. Vérifier les intervalles de confiance asymptotiques renvoyés par R lorsqu'on utilise lm avec ceux que l'on pourrait calculer par bootstrap (échantillonnage avec remise).
3. Faire une régression linéaire en considérant les variables bwt et race pour le jeu de données birthwt du package MASS.
Cours R (ESME), 2015 34

Interpréter un modèle de régression
Cas de l'analyse de covariance
L'analyse de covariance consiste à tester différents niveaux d'un facteur en présence d'un ou plusieurs co-facteurs continus. La variable réponse et ces co-facteurs sont supposées reliés, et l'objectif est d'obtenir une estimation des réponses corrigée pour les éventuelles différences entre groupes (au niveau des cofacteurs).
Cours R (ESME), 2015 35

Cours R (ESME), 2015 36

Estimation des paramètres des modèles avec et sans interaction :data(anorexia)anorexia$Treat <- relevel(anorexia$Treat, ref="Cont")anorex.aov0 <- aov(Postwt ~ Prewt + Treat, data=anorexia)anorex.aov1 <- aov(Postwt ~ Prewt * Treat, data=anorexia)summary(anorex.aov0)
Comparaison de modèles :anova(anorex.aov0, anorex.aov1)
Cours R (ESME), 2015 37

Le modèle sans interaction (coef(anorex.aov0)) s'écrit
Pour les patientes du groupe contrôle, , alors que pour celles du groupe
FT, . Ceci correspond bien à l'idée que l'effet de Prewt est le même pour toutes les patientes et que le facteur de groupe induit simplement un changement moyen (+4.10 ou +8.66) par rapport au groupe contrôle.
Cours R (ESME), 2015 38

Pour le modèle avec interaction avec Prewt centré, on a
Cours R (ESME), 2015 39





























