Embed Size (px)
Citation preview

Starling:ASchedulerArchitectureforHighPerformanceCloudCompu8ng
HangQu,OmidMashayekhi,DavidTerei,PhilLevisPlaDormLabRetreat
June2,2016

HighPerformanceCompu8ng(HPC)
• Usemathema8calmodelstohelpunderstandthephysicalworld
SpaceX NOAA Pixar
– Demandhighfloa8ngpointcalcula8onthroughput– Takehours,daysorweekstosolveacomplexmodel– Operateonin-memorydata
• AlotofmachinelearningisHPC

HPCintheCloud
• HPChasstruggledtousecloudresources• Exis8ngHPCsoVwarehascertainexpecta8ons– Coresaresta8callyallocated,neverchange– Coresdonotfail– Everycorehasiden8calperformance
• Butclouddoesnotmeetthoseexpecta8ons.– Elas8cresources,dynamicallyreprovisioned– Expectsomefailures– Variableperformance

HPCinaCloudFramework? • Strawmansolu8on:runHPCcodesinsideacloudframework(e.g.,Spark,Hadoop,Naiad,etc.)– Frameworkhandlesallofthecloud’schallengesforyou:scheduling,failure,resourceadap8on
• Problem:tooslow(byordersofmagnitude)– Sparkcanschedule2,500tasks/second– TypicalHPCcomputetaskis10ms
• Eachcorecanexecute100tasks/second• Asingle18coremachinecanexecute1,800tasks/second
– Queuingtheoryandbatchprocessingmeanyouwanttooperatewellbelowthemaximumschedulingthroughput

Starling
• Schedulingarchitectureforhighperformancecloudcompu8ng(HPCC)
• Controllerdecidesdatadistribu8on,workersdecidewhattaskstoexecute– Insteadystate,noworker/controllercommunica8onexceptperiodicperformanceupdates
• Canscheduleupto120,000,000tasks/second.– Scaleslinearlywithnumberofcores
• HPCbenchmarksrun2.4-3.3faster

Outline
• HPCbackground• Starlingschedulingarchitecture• Evalua8on• Thoughtsandques8ons

HPCExample:FluidSimula8on
• Fluidismodeledasinterac8ngphysicalvariables.– Velocity,pressure,externalforces,levelset,density,viscosity,markerpar8cles(waterinterface,splashes,bubbles)…
• Valuesofeachphysicalvariablearesampledoverthesimulatedgeometricdomain.Eachcoreworksonseparatedomains.– Updateonephysicalvariableoneachdomain– Synchronizevariablevaluesatgeometricboundaries

MostHPCtoday(MPI) while(8me<dura8on){//locallycalculate,thenglobalmindt=calculate_dt();//locallycalculate,thenexchangeupdate_velocity(dt);//locallycalculate,thenexchangeupdate_levelset(dt);//locallycalculate,thenexchangeupdate_par8cles(dt);8me+=dt;}
Controlflowisexplicitineachprocess.Fullydistributedandnocentralbomleneck.Par88oningandcommunica8onissta8c.Asingleprocessfails,programcrashes.Runsasfastasslowestprocess.Assumeseverynoderunsatthesamespeed.
Problemsinthecloud
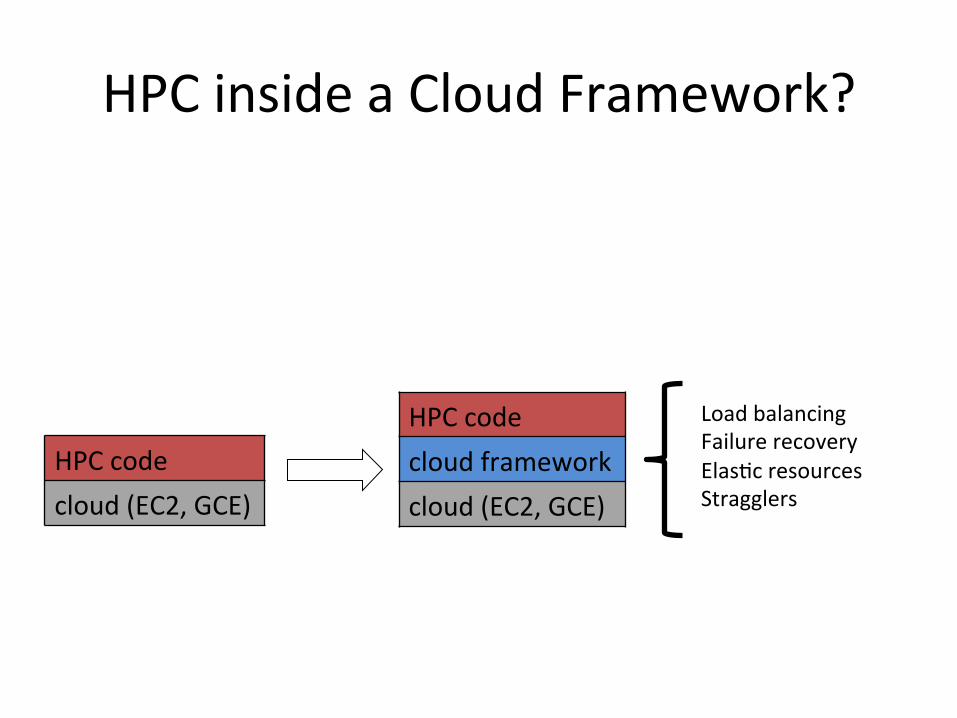
HPCinsideaCloudFramework?
HPCcode cloud(EC2,GCE)
HPCcode cloudframework cloud(EC2,GCE)
LoadbalancingFailurerecoveryElas8cresourcesStragglers
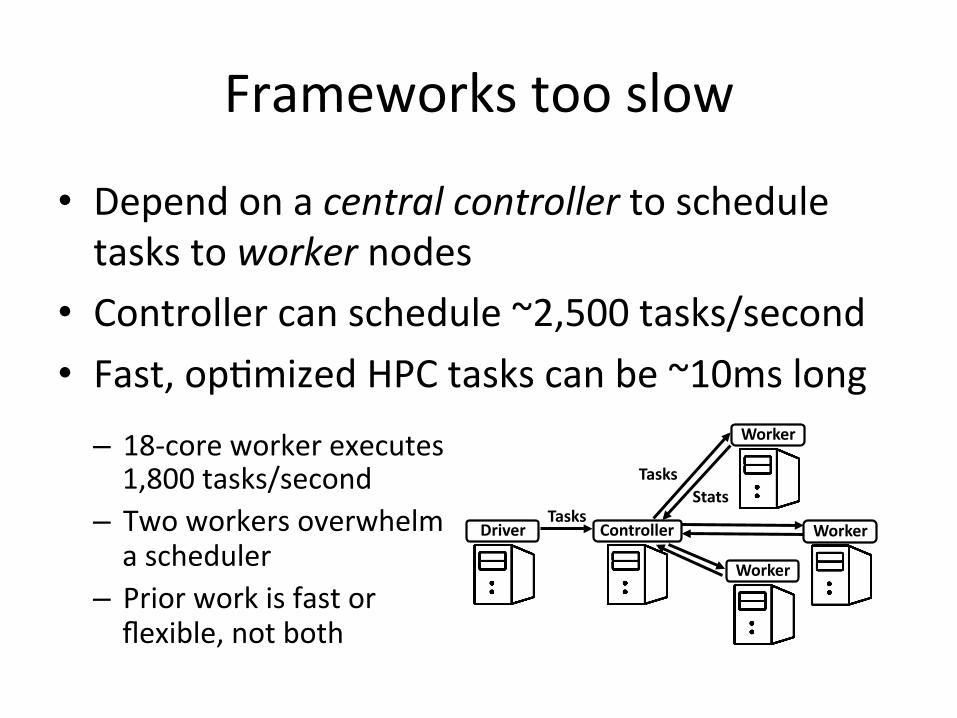
Frameworkstooslow
• Dependonacentralcontrollertoscheduletaskstoworkernodes
• Controllercanschedule~2,500tasks/second• Fast,op8mizedHPCtaskscanbe~10mslong
TasksController
Worker
Worker
Worker
Driver
TasksStats
– 18-coreworkerexecutes1,800tasks/second
– Twoworkersoverwhelmascheduler
– Priorworkisfastorflexible,notboth
Outline
• HPCbackground• Starlingschedulingarchitecture• Evalua8on• Thoughtsandques8ons

BestofBothWorlds
• Dependonacentralcontrollerto– Balanceload– Recoverfromfailures– Adapttochangingresources– Handlestragglers
• Dependonworkernodesto– Schedulecomputa8ons
• Recordercomputa8onstepsifneeded(trackdependencies)
– Exchangedata

ControlSignal
• Needadifferentcontrolsignalbetweencontrollerandworkerstoscheduletasks
• Intui8on:tasksexecutewheredataareresident– Datamovesonlyforloadbalancing/recovery
• Controllerdetermineshowdataaredistributed
• Workersgenerateandscheduletasksbasedonwhatdatatheyhave
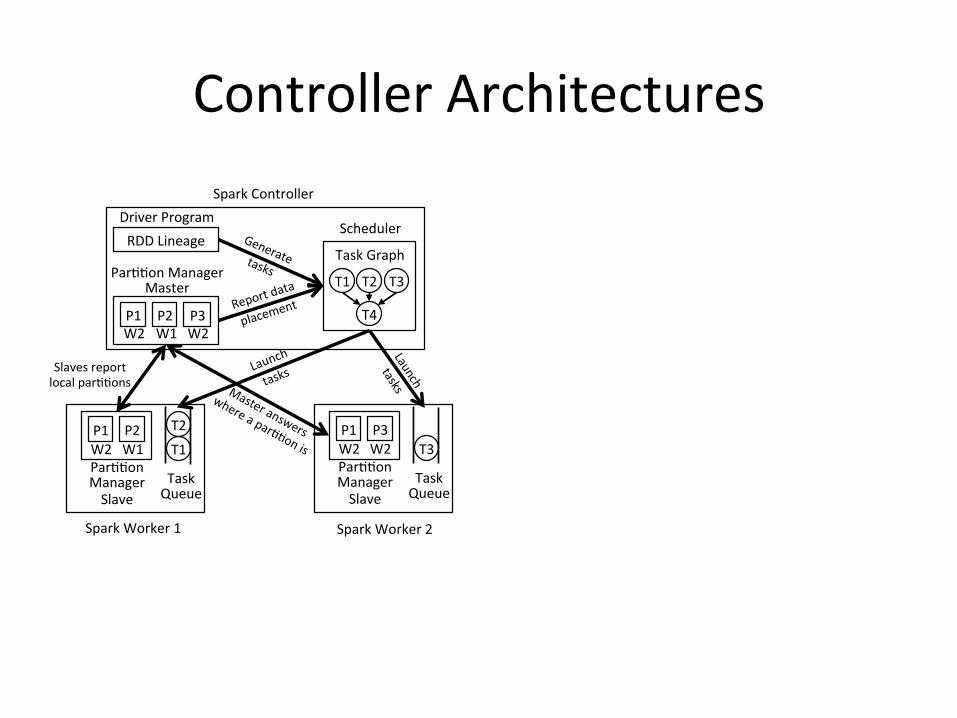
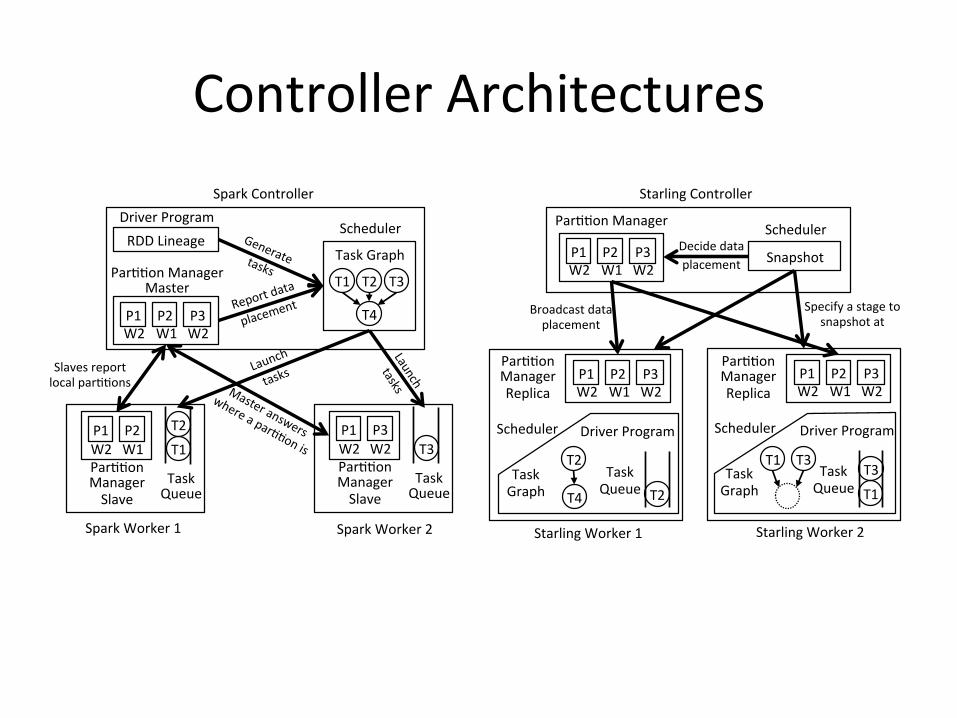
ControllerArchitectures
RDDLineage�DriverProgram�
Par//onManagerMaster�
P1� P3�W2� W2�
P2�W1�
T1� T2�
T4�
T3�
Scheduler�
TaskGraph�
Par//onManagerSlave�
P1�W2�
P2�W1� T1�
T2�
TaskQueue�
Reportdata
placement�
Slavesreportlocalpar//ons�
Par//onManagerSlave�
P1�W2�
P3�W2� T3�
TaskQueue�
SparkController�
SparkWorker1� SparkWorker2�
ControllerArchitectures
RDDLineage�DriverProgram�
Par//onManagerMaster�
P1� P3�W2� W2�
P2�W1�
T1� T2�
T4�
T3�
Scheduler�
TaskGraph�
Par//onManagerSlave�
P1�W2�
P2�W1� T1�
T2�
TaskQueue�
Reportdata
placement�
Slavesreportlocalpar//ons�
Par//onManagerSlave�
P1�W2�
P3�W2� T3�
TaskQueue�
SparkController�
SparkWorker1� SparkWorker2�
Par$$onManager�
P1� P3�W2� W2�
P2�W1�
Snapshot�
Scheduler�Decidedataplacement�
Broadcastdataplacement�
StarlingController�
StarlingWorker1� StarlingWorker2�
Par$$onManagerReplica�
P1� P3�W2� W2�
P2�W1�
T3�
Scheduler
Par$$onManagerReplica�
P1� P3�W2� W2�
P2�W1�
T1�TaskGraph
Specifyastagetosnapshotat�
T1�
T3�TaskQueue
DriverProgram
T4�
Scheduler
T2�TaskGraph T2�
TaskQueue
DriverProgram

ManagingMigra8ons
• Controllerdoesnotknowwhereworkersareintheprogram
• Workersdonotknowwhereeachotherareinprogram
• Whenadatapar88onmoves,Starlingneedstoensurethatdes8na8onpicksupwheresourceleVoff
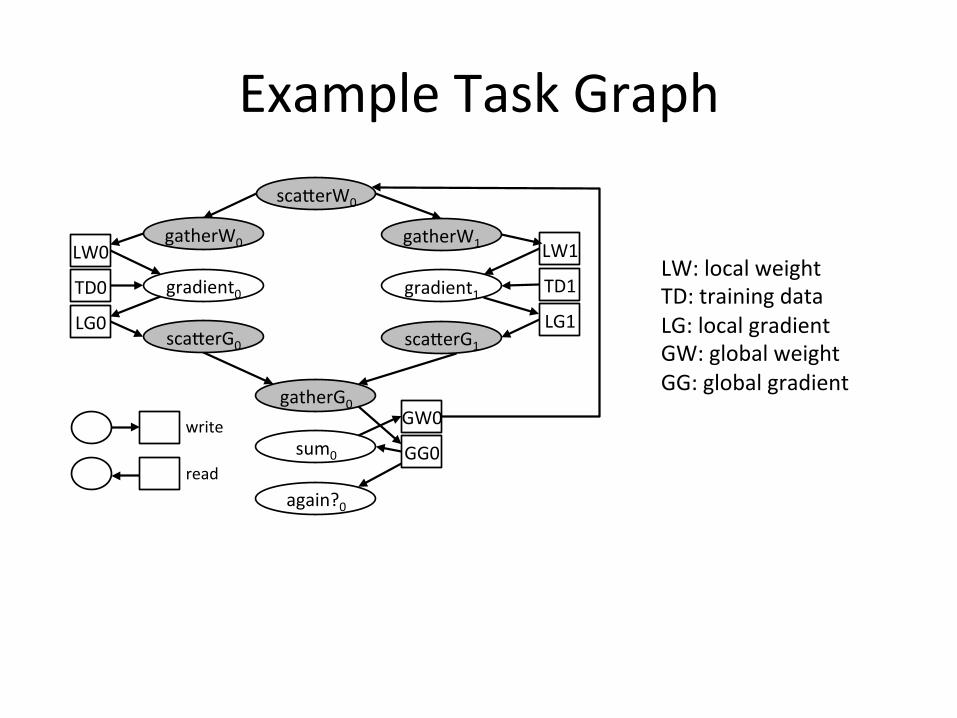
ExampleTaskGraph
write�
read�
sca*erW0�
sum0�
gatherG0�
again?0�
GW0�
GG0�
gatherW0�
gradient0�
sca*erG0�
LW0�
TD0�
LG0�
LW1�
TD1�
LG1�
gatherW1�
gradient1�
sca*erG1�
LW:localweightTD:trainingdataLG:localgradientGW:globalweightGG:globalgradient
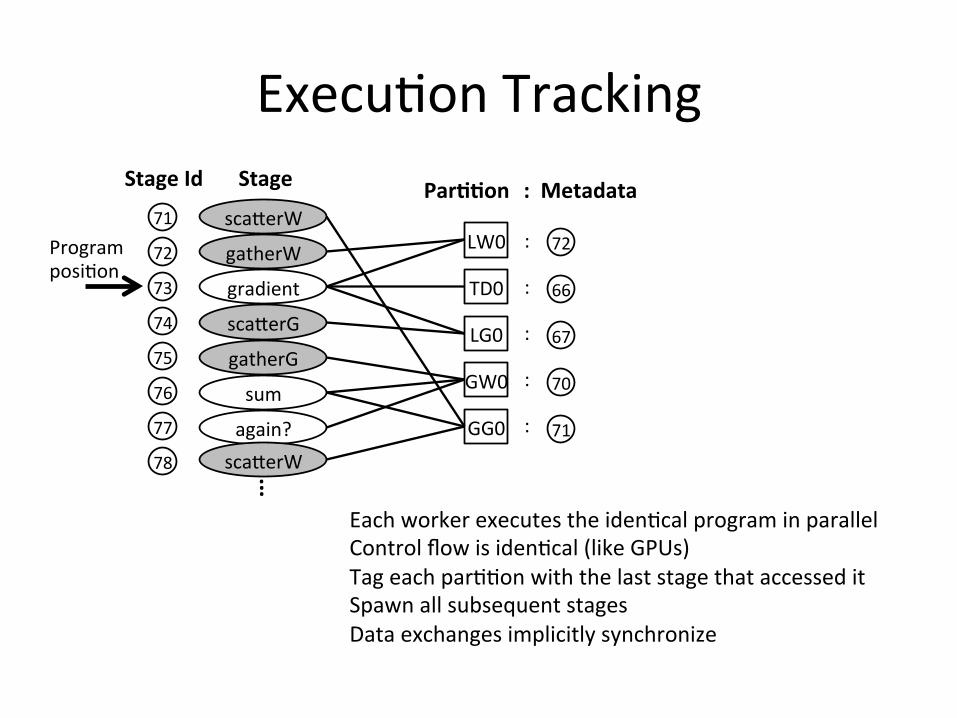
Execu8onTracking
sca$erW�
gatherG�
GG0�
GW0�
gatherW�
gradient�
sca$erG�
LW0�
TD0�
LG0�
:�
:��
:��
:��
:�sum�
again?�
StageId� Stage� Par++on�:Metadata�
Programposi;on�
sca$erW�
71�
72�
73�
74�
75�
76�
77�
78�
66�
72�
67�
70�
71�
...Eachworkerexecutestheiden8calprograminparallelControlflowisiden8cal(likeGPUs)Tageachpar88onwiththelaststagethataccesseditSpawnallsubsequentstagesDataexchangesimplicitlysynchronize
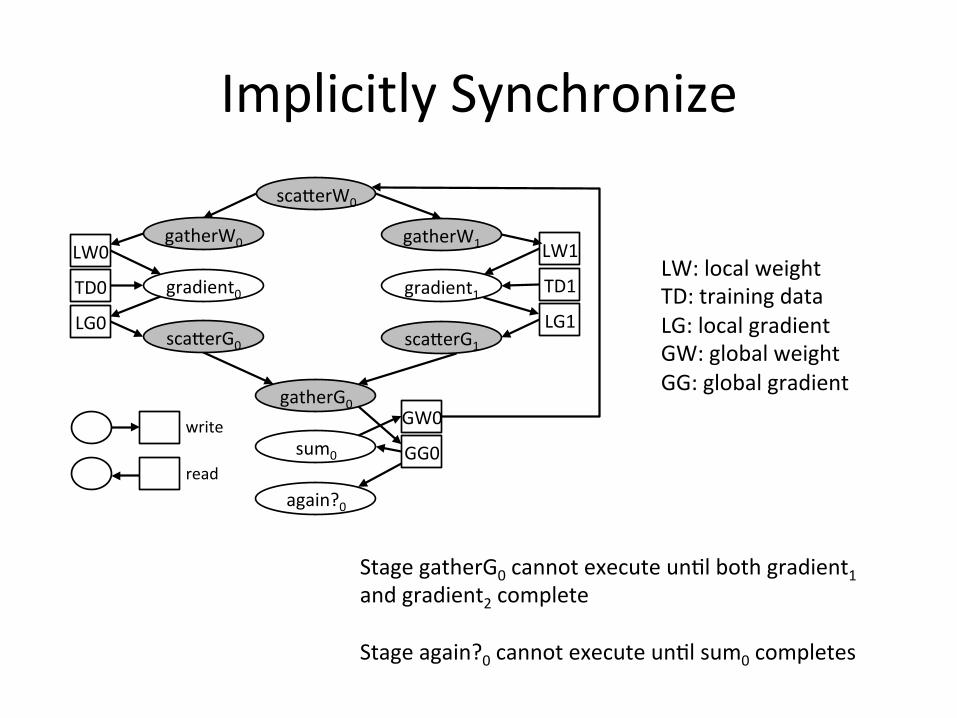
ImplicitlySynchronize
write�
read�
sca*erW0�
sum0�
gatherG0�
again?0�
GW0�
GG0�
gatherW0�
gradient0�
sca*erG0�
LW0�
TD0�
LG0�
LW1�
TD1�
LG1�
gatherW1�
gradient1�
sca*erG1�
LW:localweightTD:trainingdataLG:localgradientGW:globalweightGG:globalgradient
StagegatherG0cannotexecuteun8lbothgradient1andgradient2completeStageagain?0cannotexecuteun8lsum0completes

SpawningandExecu8ngLocalTasks
• Metadataforeachdatapar88onisthelaststagethatreadsfromorwritestoit
• AVerfinishingatask,aworker:– Updatesmetadata– Examinestaskcandidatesthatoperateondatapar88onsgeneratedbythecompletedtask
– Putsacandidatetaskintoareadyqueueifalldatapar88onitoperatesonare(1)localand(2)modifiedbytherighttasks

Outline
• HPCbackground• Starlingschedulingarchitecture• Evalua8on• Thoughtsandques8ons

Evalua8onQues8on
• Doeshighschedulingthroughput¢ralcontrolhelpimproveperformance?– Logis8cregression– K-means,PageRank– Lassen– PARSECfluidanimate
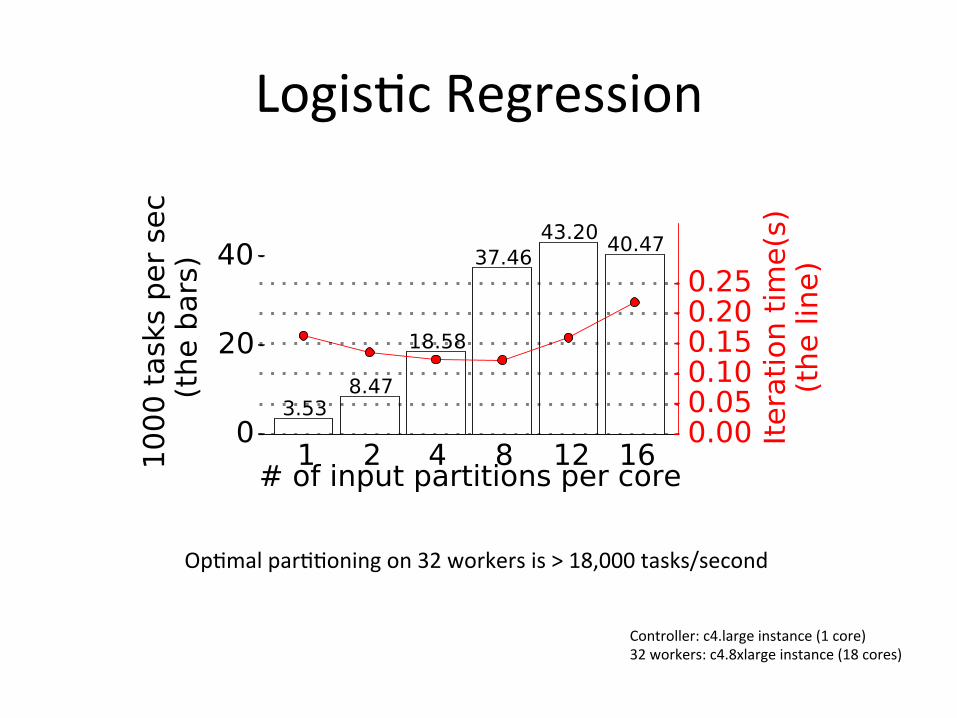
Logis8cRegression
Op8malpar88oningon32workersis>18,000tasks/second
Controller:c4.largeinstance(1core)32workers:c4.8xlargeinstance(18cores)
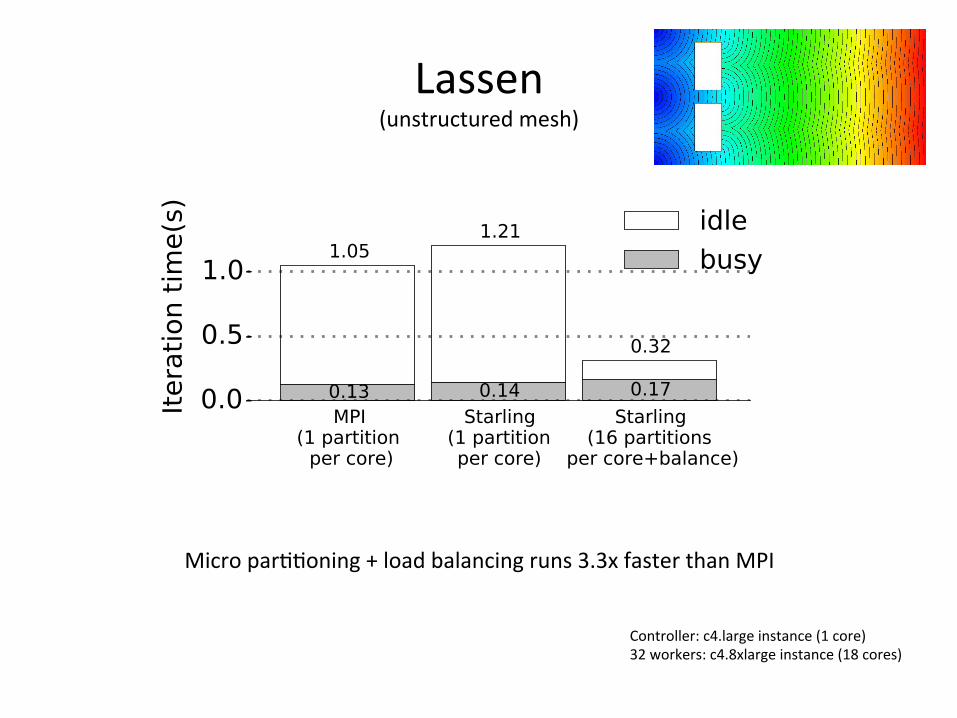
Lassen(unstructuredmesh)
Micropar88oning+loadbalancingruns3.3xfasterthanMPI
Controller:c4.largeinstance(1core)32workers:c4.8xlargeinstance(18cores)
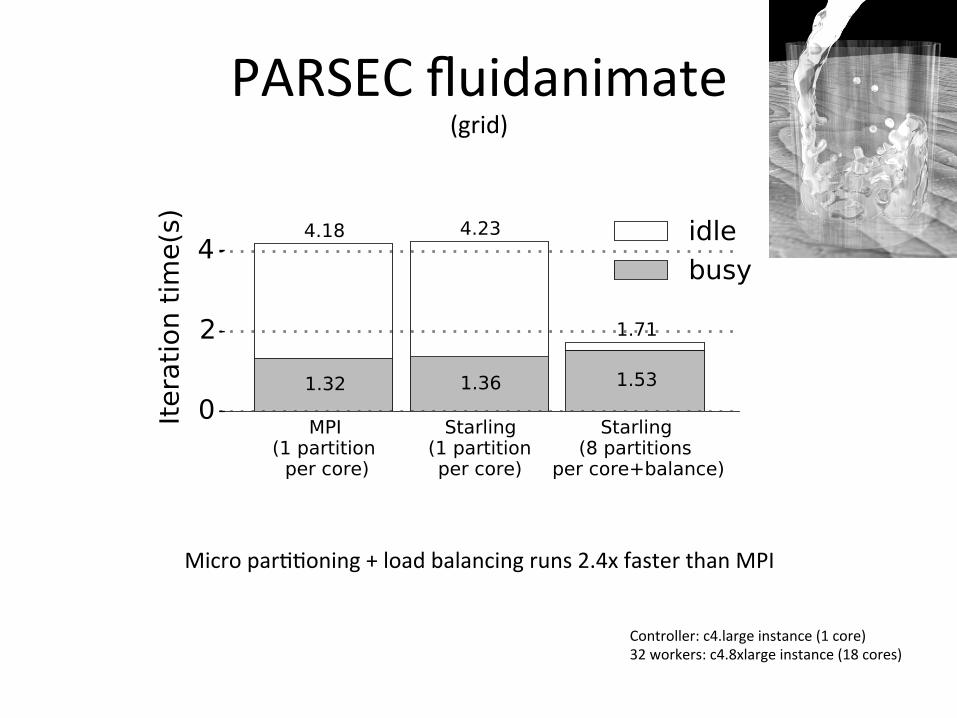
PARSECfluidanimate(grid)
Micropar88oning+loadbalancingruns2.4xfasterthanMPI
Controller:c4.largeinstance(1core)32workers:c4.8xlargeinstance(18cores)

Outline
• HPCbackground• Starlingschedulingarchitecture• Evalua8on• Thoughtsandques8ons

Thoughts
• Manynewercloudcompu8ngworkloadsresembledhighperformancecompu8ng– I/Oboundworkloadsareslow– CPUboundworkloadsarefast
• Nextgenera8onsystemswilldrawfromboth– Cloudcompu8ng:varia8on,comple8on8me,failure,programmingmodels,systemdecomposi8on
– HPC:scalability,performance

Thankyou!





























