Embed Size (px)
Citation preview

MySQL and Impala ecosystem:SQL friendly Hadoop

Agenda
•
•- SQL support
- Architecture
- Hadoop integration
•
2

●● Web portal, search engine in the Czech Republic● 30+ web services (news, email, media, listings…)● only Open Source technologies
●● PPC ads, Google AdWords competitor in Czech Republic
●● Software engineers, team leaders, database enthusiasts
● MySQL, HBASE, Hadoop, Analytics
● MySQL trainings, internal consultations
Who we are
2

●
Sklik.cz Statistics
3
MySQL
Hadoop
HBase client statistics

Apache Impala

Apache Impala (incubating) is...
•
•
•
•
•
6

Brief History
•
•
•
•
7

MySQL vs Impala
8

MySQL vs Impala: Purpose
9

MySQL vs Impala: Data
10

MySQL vs Impala: Environment
11

Impala Architecture

Why is Impala So Fast?
•
•
•
•
•
•13

Architecture
14client (JDBC, ODBC, impala-shell)
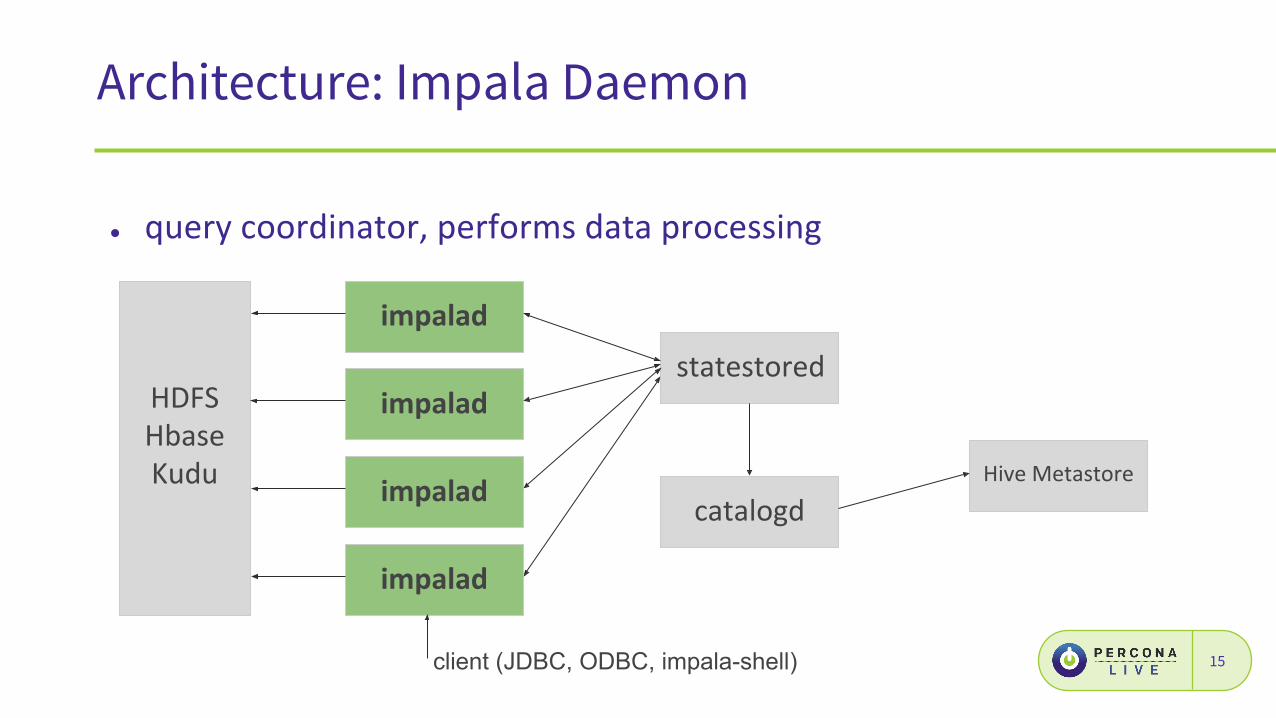
Architecture: Impala Daemon
●
15client (JDBC, ODBC, impala-shell)
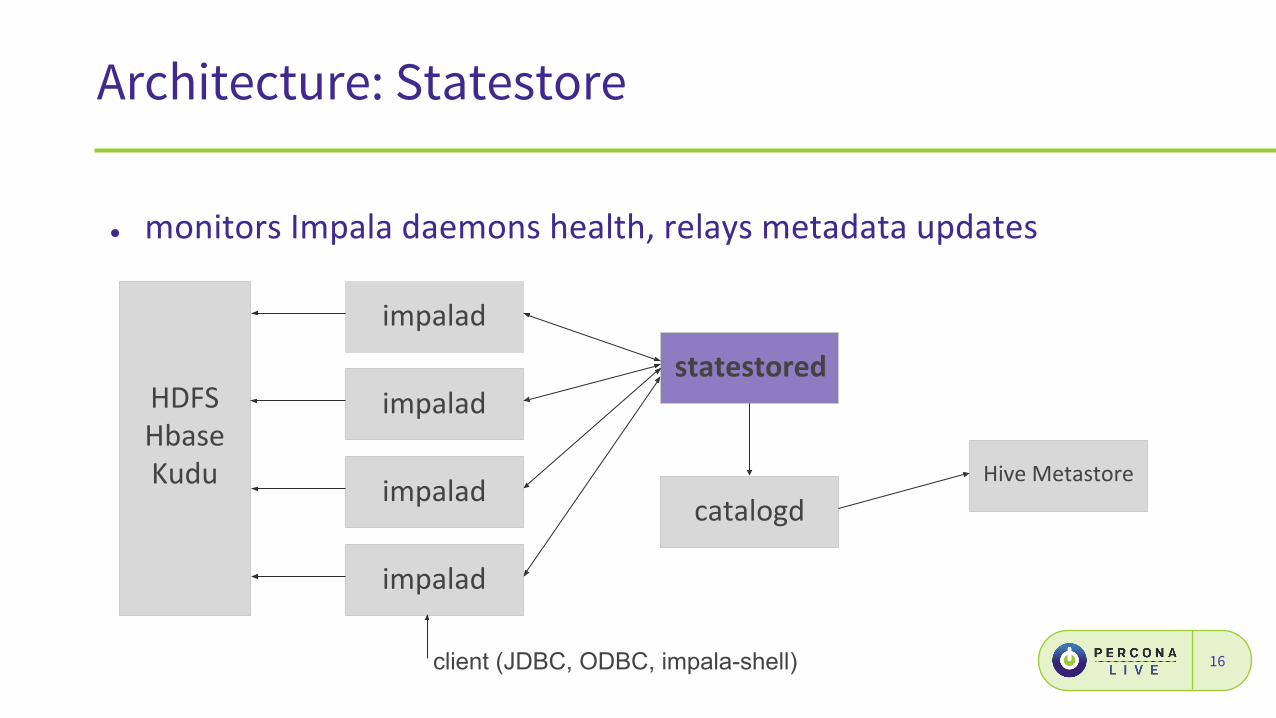
Architecture: Statestore
●
16client (JDBC, ODBC, impala-shell)

Architecture: Catalog
●
17client (JDBC, ODBC, impala-shell)

Architecture: Hive Metastore
●
18client (JDBC, ODBC, impala-shell)

Architecture: Data Storage Layer
●
19client (JDBC, ODBC, impala-shell)

Data storage formats
•
•
•
•
•
20

Parquet file format
•
•
•
•
•
21
Row Group 1row 1 col 1row 2 col 1row 3 col 1row 4 col 1
row 1 col 2row 2 col 2row 3 col 2row 4 col 2
row 1 col 3row 2 col 3row 3 col 3row 4 col 3
\\\\
Row Group 2row 5 col 1

Partitioning and schema proposal
•
•
•
•
22
2014 2015 2016
… WHERE year = 2016

Impala SQL support

SQL Support
•
•
•
•
•
24
$ impala-shell
[impala1.test:21000] > USE db_example;
Query: USE db_example;
Database changed.
[impala1.test:21000] > SELECT * FROM example;
Query: SELECT * FROM example;
+-----+----------+
| Day | Audience |
+-----+----------+
| 20 | 122 |
+-----+----------+
| 21 | 129 |
+-----+----------+
2 rows in set (0.18 sec)

Use Your Favorite SELECT...
25
●
●
…
●
●
●
●

Data Manipulation
26
● …
● …
●
●
●
●
●

How to Write the Data?
• … …
• … …
• …
• …
•
• …27

Impala Data Types
•
•
•
•
28

Kick Out From Your DDL...
•
•
•
•
•
29

Impala Specific DDL
•
•
•
30
CREATE TABLE … PARTITIONED BY (column int)
CREATE TABLE … AS PARQUETCREATE TABLE … AS TEXTFILE SEPARATED BY “,”
COMPUTE STATS mytableREFRESH mytableINVALIDATE METADATA

Hadoop Integration

Hadoop integration
•
2
HDFS Kudu
SparkMapReduce Tez
SqoopImport/export
HiveHQL
ImpalaSQL
HBaseNo SQL
StormStream
Hue / ODBC / ...
ImpalaSQL

Apache Kudu (incubating)
33
●
●
●
●
●
●
● Source: Cloudera Blog

Other Big Data SQL
●
○○○
●
○
●
○
●
○○
34

Apache Hive
●
35

●
●
Apache Drill
36
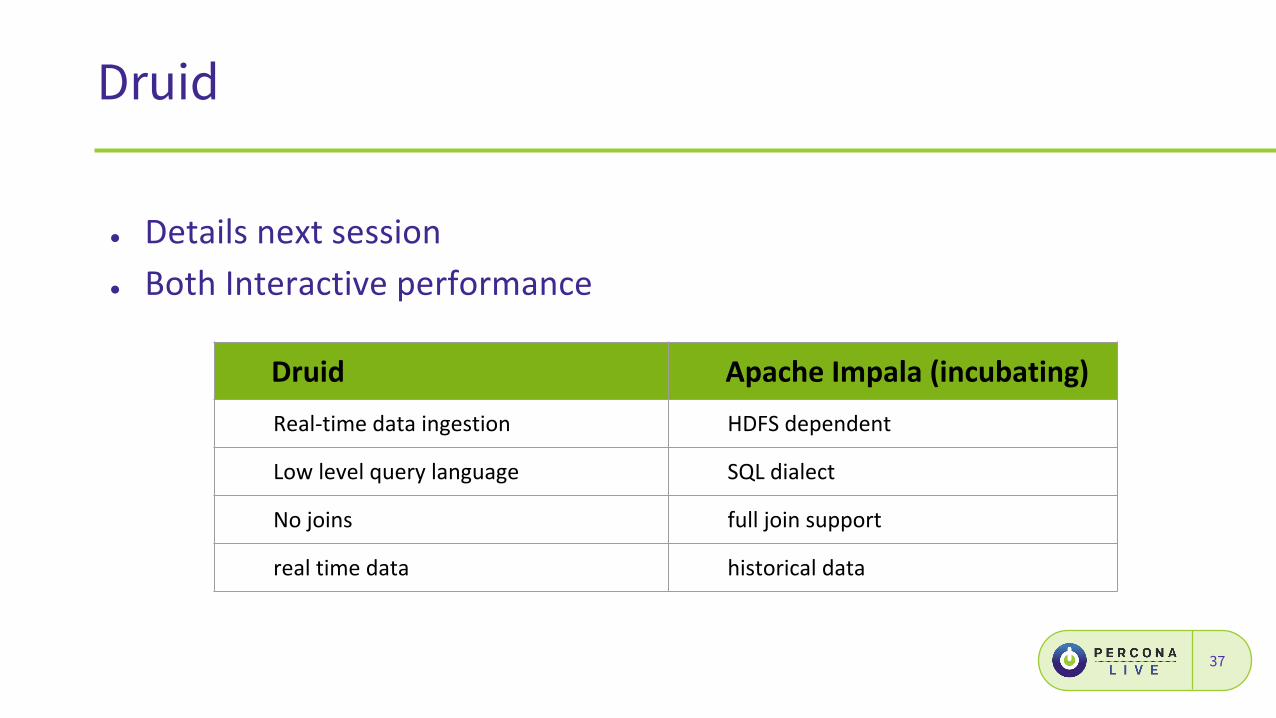
Druid
●
●
37

MariaDB Column Store
●
38

Our use case
●○ Only for internal use, several queries per hour○ No client reports○ Billions of rows
●○ Group by (web, zone, position,..)○ Period (from one day up to all period)○ aggregated daily, weekly, yearly reports
●2

Yahoo! use case
●
●○ Asynchronous client report○ Around 15k request/hour, totally 6TB of data
●○ couldn’t handle the use case
●
2

SELECT question FROM audience;
41












![Chapter 1: Installing and Configuring Spark · Chapter 7: Structured Streaming with PySpark [ 60 ] [ 61 ] [ 62 ] ... Spark Drill Impala HBase Arrow Memory Parquet Cassandra Kudu Model](https://img.dokumen.tips/doc/110x75/5ec9185e5263de629b5d9d4a/chapter-1-installing-and-configuring-spark-chapter-7-structured-streaming-with.jpg)
![KUDU PCP - Schlumberger · KUDU PCP KUDU Elastomer Relative Specifications Elastomer† KUDU Reference Hardness Shore A Max. Temperature, degF [degC] Sand Resistance H 2 S Resistance](https://img.dokumen.tips/doc/110x75/5b2c266f7f8b9a6d188bcaef/kudu-pcp-kudu-pcp-kudu-elastomer-relative-specifications-elastomer-kudu.jpg)














