Embed Size (px)
DESCRIPTION
spss
Citation preview

Programiranje u SPSS-u
Uvod u korištenje programskog paketa SPSS
Sarajevo, Novembar 2011.
1

Problem:
Izvršiti deskriptnivnu analizu podataka dobijenih na osnovu rezultata ankete o pušenju.
Prilikom anketiranja korišten je slijedeći anketni upitnik:
Na vašem računaru nalazi se fajl Primjer_1.sav (c:\Obuka\Primjer_1.sav) u kome se nalaze rezultati ankete o pušenju koja je sprovedena na 5 domaćinstava.
Prilikom otvaranja fajla u SPSS-u otvorit će vam se direktni prikaz podataka (Slika 1.) ili pregled varijabli (Slika 2)
Redni broj domaćinstva _________________ (popunjava anketar)
ANKETA O PUŠENJU
Dobar dan, Zavod za javno zdravstvo sprovodi Anketu o pušenju, željeli bi vama i ostalim članovima vašeg domaćinstva postaviti nekoliko pitanja o pušenju.
R. broj osobe
Pol1-muški2-ženski
Koliko imate punih tj navršenih godina danas?(Za djecu do deset godina pitati roditelja ili staratelja)
Pitati osobe stare 10 i više godina
Koje je vaše obrazovanje?0 – bez obrazovanja1 – osnovno obrazovanje2 – srednje obrazovanje3 – visoko obrazovanje
Koliko u prosjeku dnevno popušite cigareta?
12345678
2
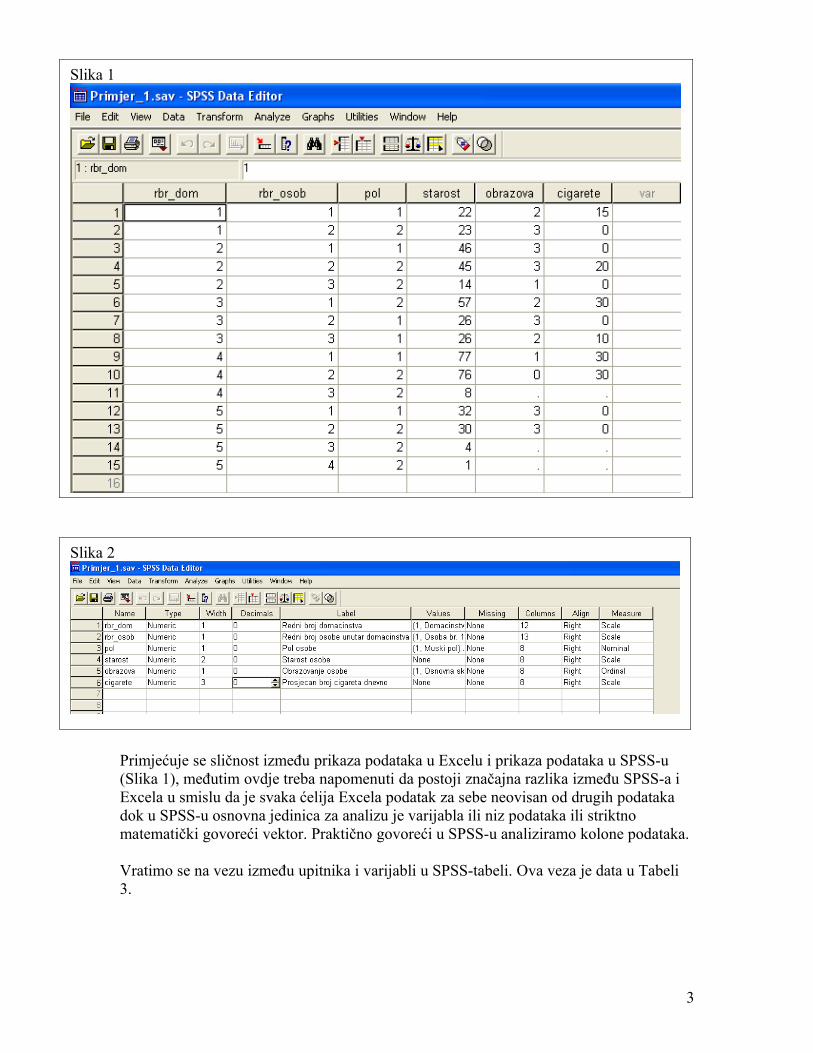
Primjećuje se sličnost između prikaza podataka u Excelu i prikaza podataka u SPSS-u (Slika 1), međutim ovdje treba napomenuti da postoji značajna razlika između SPSS-a i Excela u smislu da je svaka ćelija Excela podatak za sebe neovisan od drugih podataka dok u SPSS-u osnovna jedinica za analizu je varijabla ili niz podataka ili striktno matematički govoreći vektor. Praktično govoreći u SPSS-u analiziramo kolone podataka.
Vratimo se na vezu između upitnika i varijabli u SPSS-tabeli. Ova veza je data u Tabeli 3.
Slika 1
Slika 2
3

Uzmimo za primjer pitanje «Koje je vaše obrazovanje?». Ovom pitanju odgovara varijaba «obrazova» iz SPSS tabele. Ova varijabla je ordinalnog tipa budući da npr. osoba sa završenom srednjom školom ima više obrazovanja u odnosu na osobu sa samo završenom osnovnom školom ili u odnosu na osobu koja je bez obrazovanja, te da istovremeno ima manje obrazovanja u odnosu na osobu koja ima visoko obrazovanje.
Prije nego što pređemo na analizu podataka trebamo nešto reći o vrsti fajli koje se javljaju u SPSS-u.
Tabela 3Pitanje u upitnikuModaliteti odgovora u upitniku (values u SPSS-u)Programsko ime varijable u SPSS-u(niz znakova maksimalne duzine 8 znakova bez blanko znakova)SPSS tip varijableSPSS mjeraSPSS labela tj. Tekstualni opis varijable koji će se pojavljivati u izlaznim fajlama
m
Redni broj domaćinstvaBroj od 1 do ukupnog broja upitnikarbr_domNumerički tipSkala – može se tačno utvrditi razlika između dva elementaRedni broj domacinstva
u
Redni broj osobeOd 1 do 8rbr_osobNumerički tipSkalaRedni broj osobe unutar domacinstva
8
Pol1 za muški pol,2 za žeski polpolNumerički tipNominalni – ne može se utvrditi tačna razlika niti se može utvrdit odnos manje većePol osobe
o
Koliko imate punih tj navršenih godina danas?Od 0 pa do preko stotinu godinastarostNumerički tipSkalaStarost osobe
s
Koje je vaše obrazovanje?
K
0 za osobe bez obrazovanja1 za osobe sa osnovnim obrazovanjm2 za osobe sa srednjim obrazovanjem3 za osobe sa visokim obrazovanjemobrazovaNumerički tipOrdinalni ne može se utvrditi tačna razlika ali se može utvrdit odnos manje većeObrazovanje osobe
r
Koliko u prosjeku dnevno popušite cigareta?Od 0 cigareta do preko stotinu u ekstremnim slučajevimacigareteNumerički tipSkalaProsječan broj cigareta dnevno
t
4
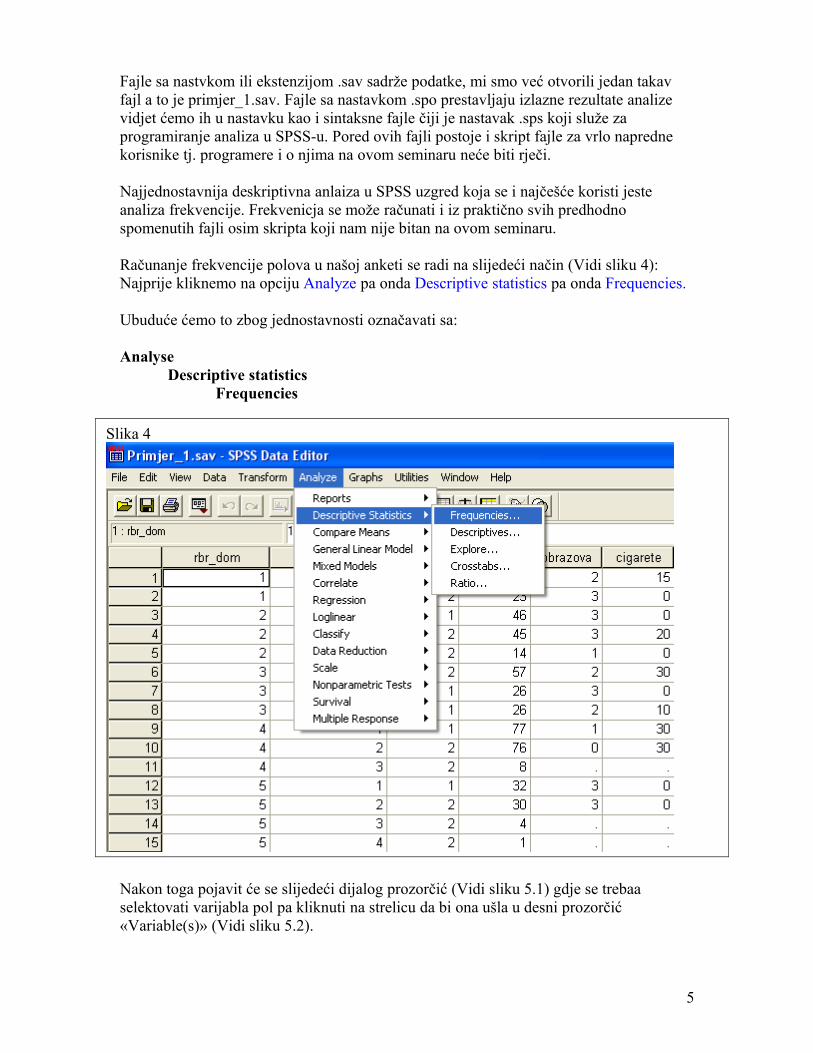
Fajle sa nastvkom ili ekstenzijom .sav sadrže podatke, mi smo već otvorili jedan takav fajl a to je primjer_1.sav. Fajle sa nastavkom .spo prestavljaju izlazne rezultate analize vidjet ćemo ih u nastavku kao i sintaksne fajle čiji je nastavak .sps koji služe za programiranje analiza u SPSS-u. Pored ovih fajli postoje i skript fajle za vrlo napredne korisnike tj. programere i o njima na ovom seminaru neće biti rječi.
Najjednostavnija deskriptivna anlaiza u SPSS uzgred koja se i najčešće koristi jeste analiza frekvencije. Frekvenicja se može računati i iz praktično svih predhodno spomenutih fajli osim skripta koji nam nije bitan na ovom seminaru.
Računanje frekvencije polova u našoj anketi se radi na slijedeći način (Vidi sliku 4): Najprije kliknemo na opciju Analyze pa onda Descriptive statistics pa onda Frequencies.
Ubuduće ćemo to zbog jednostavnosti označavati sa:
AnalyseDescriptive statistics
Frequencies
Nakon toga pojavit će se slijedeći dijalog prozorčić (Vidi sliku 5.1) gdje se trebaa selektovati varijabla pol pa kliknuti na strelicu da bi ona ušla u desni prozorčić «Variable(s)» (Vidi sliku 5.2).
Slika 4
5
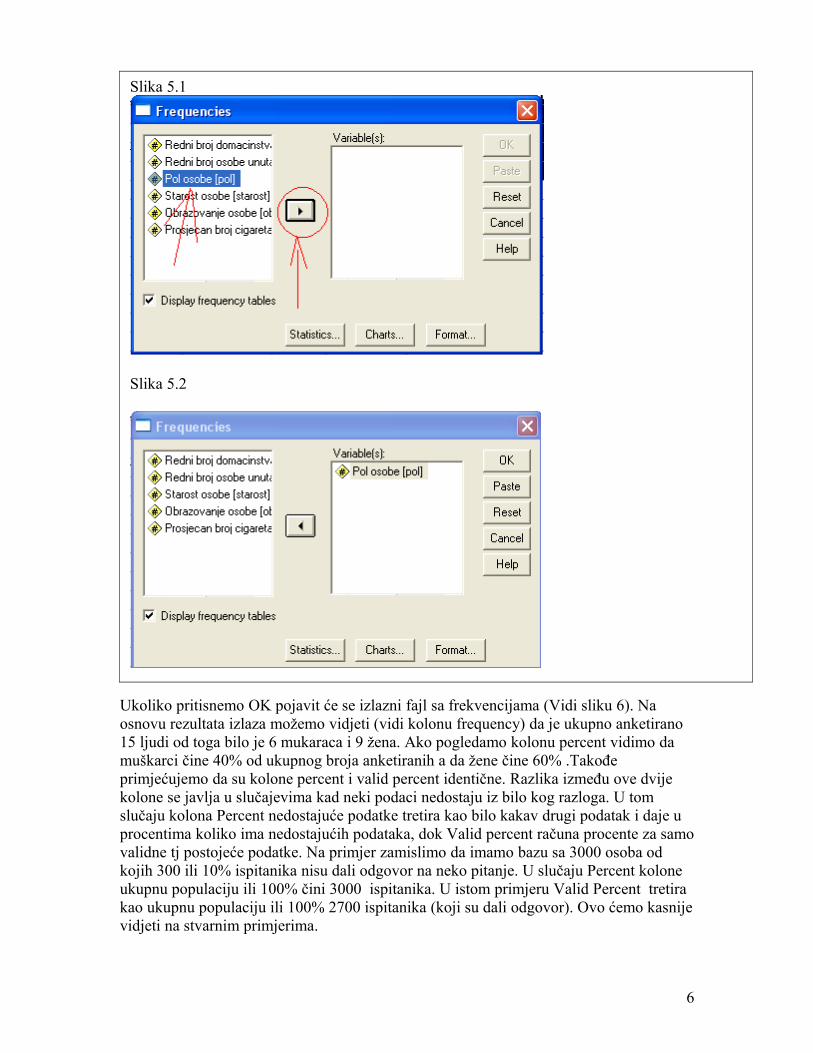
Ukoliko pritisnemo OK pojavit će se izlazni fajl sa frekvencijama (Vidi sliku 6). Na osnovu rezultata izlaza možemo vidjeti (vidi kolonu frequency) da je ukupno anketirano 15 ljudi od toga bilo je 6 mukaraca i 9 žena. Ako pogledamo kolonu percent vidimo da muškarci čine 40% od ukupnog broja anketiranih a da žene čine 60% .Takođe primjećujemo da su kolone percent i valid percent identične. Razlika između ove dvije kolone se javlja u slučajevima kad neki podaci nedostaju iz bilo kog razloga. U tom slučaju kolona Percent nedostajuće podatke tretira kao bilo kakav drugi podatak i daje u procentima koliko ima nedostajućih podataka, dok Valid percent računa procente za samo validne tj postojeće podatke. Na primjer zamislimo da imamo bazu sa 3000 osoba od kojih 300 ili 10% ispitanika nisu dali odgovor na neko pitanje. U slučaju Percent kolone ukupnu populaciju ili 100% čini 3000 ispitanika. U istom primjeru Valid Percent tretira kao ukupnu populaciju ili 100% 2700 ispitanika (koji su dali odgovor). Ovo ćemo kasnije vidjeti na stvarnim primjerima.
Slika 5.1
Slika 5.2
6
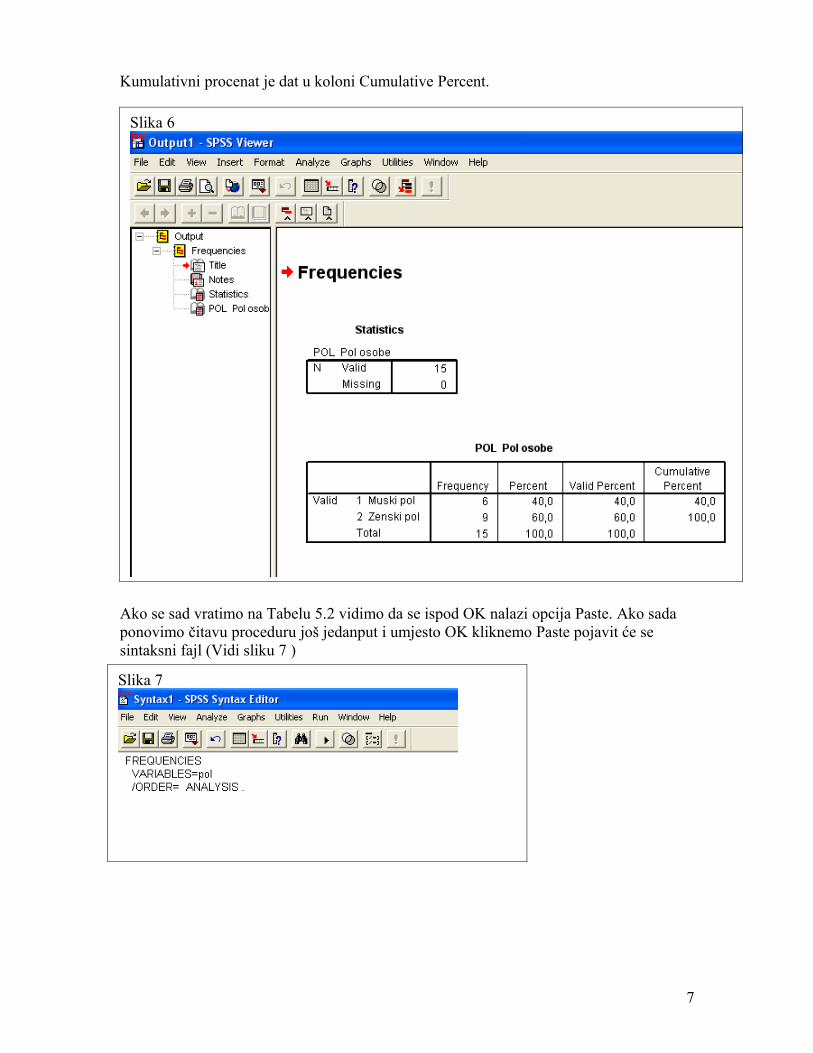
Kumulativni procenat je dat u koloni Cumulative Percent.
Ako se sad vratimo na Tabelu 5.2 vidimo da se ispod OK nalazi opcija Paste. Ako sada ponovimo čitavu proceduru još jedanput i umjesto OK kliknemo Paste pojavit će se sintaksni fajl (Vidi sliku 7 )
Slika 6
Slika 7
7
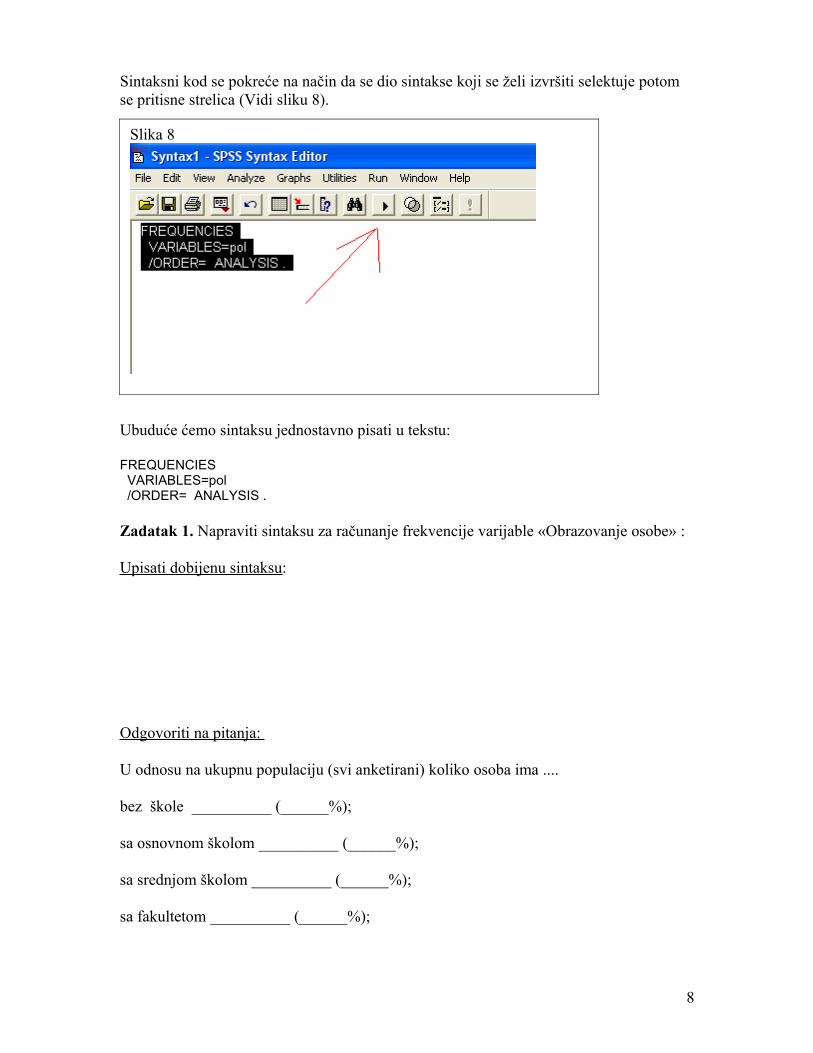
Sintaksni kod se pokreće na način da se dio sintakse koji se želi izvršiti selektuje potom se pritisne strelica (Vidi sliku 8).
Ubuduće ćemo sintaksu jednostavno pisati u tekstu:
FREQUENCIES VARIABLES=pol /ORDER= ANALYSIS .
Zadatak 1. Napraviti sintaksu za računanje frekvencije varijable «Obrazovanje osobe» :
Upisati dobijenu sintaksu:
Odgovoriti na pitanja:
U odnosu na ukupnu populaciju (svi anketirani) koliko osoba ima ....
bez škole __________ (______%);
sa osnovnom školom __________ (______%);
sa srednjom školom __________ (______%);
sa fakultetom __________ (______%);
Slika 8
8

Koliko osoba nije dalo odgovor __________ (______%);
U odnosu na ciljnu populaciju (osobe stare 10 i više godina) koliko osoba ima ....
bez škole __________ (______%);
sa osnovnom školom __________ (______%);
sa srednjom školom __________ (______%);
sa fakultetom __________ (______%);
Koliko osoba nije nije dalo odgovor __________ (______%);
Zadatak 2: napraviti sintaksu i izračunati koliko muškaraca a koliko žena u ukupnoj populaciji ima sa završenim fakultetom.
Rješenje ovog zadatka je ukrštanje varijabli «pol» i «obrazova».
AnalyseDescriptive statistics
Crosstabs
Jednu varijablu trebamo staviti u prozorčić Raw(s) npr. «pol» a drugu u «Column(s)»
Kada «zalijepimo» sintaksu dobijam slijedeći sintaksni kod:
CROSSTABS /TABLES=pol BY obrazova /FORMAT= AVALUE TABLES /CELLS= COUNT .
Rješenje: Nakon pokretanja sintakse dobijemo da 3 anketirana muškarca i 3 anketirane žene iz uzorka imaju završen fakultet.
Izlaz/output 9:
POL Pol osobe * OBRAZOVA Obrazovanje osobe Crosstabulation
Count
OBRAZOVA Obrazovanje osobe
Total01 Osnovna
skola2 Srednja
skola 3 UniverzitetPOL Pol osobe
1 Muski pol 0 1 2 3 62 Zenski pol 1 1 1 3 6
Total 1 2 3 6 129
Pitanje: Da li primjećujeto nešto neobićno u predhodnoj tabeli?
Odgovor:
Pitanje: Šta možemo napraviti da u tabeli imamo 15 osoba umjesto 12.
Odgovor: Prilikom ukrštanja podataka SPSS ukršta samo one podatke za koje postoje vrijednosti u «obje» varijable. U našem slučaju tri osobe su imale nedostajuće vrijednosti u varijabli «obrazova». Radi se o troje djece koje nismo pitali za nivo obrazovanja budući da imaju manje od 10 godina i očigledno da nisu završili osnovnu školu. Ovoj djeci treba da na mjesto nedostajućih podataka u varijabli obrazvanja stavimo vrijednost «0» koja odgovara modalitetu «osobe bez obrazovanja».
Za zamjenu podataka koristimo naredbu «Recode»
TransformRecode
Into same variable
Potom varijablu «Obrazovanje osobe» «ubacimo» u prozorčić «Variables:» nakon toga će se aktivirati dugme «Old and New Values» klikom na ovo dugme otvara se slijedeći prozor koji se saastoji od dva dijela «Old Value» i «New Value». U dijelu «Old Value» «zakačit» ćemo opciju «System-missing» a u dijelu «New Value» «zakačit» ćemo opciju «Value» i upisati «0» (Vidi sliku 10).
Slika 10
10
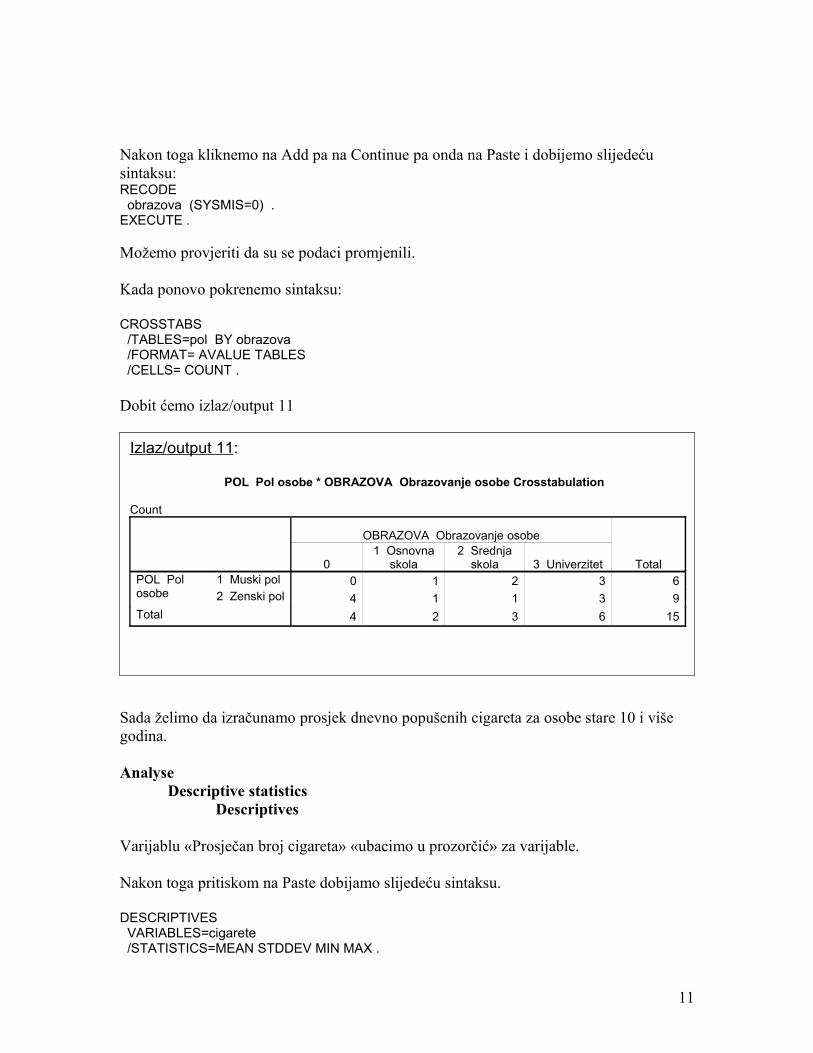
Nakon toga kliknemo na Add pa na Continue pa onda na Paste i dobijemo slijedeću sintaksu:RECODE obrazova (SYSMIS=0) .EXECUTE .
Možemo provjeriti da su se podaci promjenili.
Kada ponovo pokrenemo sintaksu:
CROSSTABS /TABLES=pol BY obrazova /FORMAT= AVALUE TABLES /CELLS= COUNT .
Dobit ćemo izlaz/output 11
Sada želimo da izračunamo prosjek dnevno popušenih cigareta za osobe stare 10 i više godina.
AnalyseDescriptive statistics
Descriptives
Varijablu «Prosječan broj cigareta» «ubacimo u prozorčić» za varijable.
Nakon toga pritiskom na Paste dobijamo slijedeću sintaksu.
DESCRIPTIVES VARIABLES=cigarete /STATISTICS=MEAN STDDEV MIN MAX .
Izlaz/output 11:
POL Pol osobe * OBRAZOVA Obrazovanje osobe Crosstabulation
Count
OBRAZOVA Obrazovanje osobe
Total01 Osnovna
skola2 Srednja
skola 3 UniverzitetPOL Pol osobe
1 Muski pol 0 1 2 3 62 Zenski pol 4 1 1 3 9
Total 4 2 3 6 15
11
Odgovorite na pitanja
Kolki je prosjek varijable? _________________Kolki je minimum varijable? ____________________Koliki je maksimum varijable? ____________________Kolika je standardna devijacija varijable? ____________________
No nas ne interesuje samo prosječan broj popušenih cigareta za ukupnu populaciju, nego nas interesuje i prosjek npr. po polu.
Da bi izračunali prosjek po polu potrebno je da «podjelimo» analize na analize za osobe muškog pola i analize za osobe ženskog pola.
Podjela izlaznih analiza po nekom kriterijumu u SPSS-u se vrši koristeći komandu SPLIT FILE.
DataSplit file
Potom zakačimo opciju «Compare Groups» i u prozorčić za varijable ubacima varijablu Pol osobe(Vidi sliku 12).
Slika 12
12

Kada «zalijepimo» sintaksu dobijemo slijedeći sintaksni kod:
SORT CASES BY pol .SPLIT FILE LAYERED BY pol .
Kada pokrenemo ovaj kod nećemo dobiti nikakav izlaz. Ovo je u stvari samo poruka kompjuteru da «djeli» analize.
Medjutim kad nakon pokretanja ovog koda pokrenemo predhodni kod za računanje prosjeka:
DESCRIPTIVES VARIABLES=cigarete /STATISTICS=MEAN STDDEV MIN MAX .
dobit ćemo slijedeći izlaz (Vidi izlaz/output 13).
U nadalje sve analize koje budu bile rađene bit će podjeljene na muškarce i žene.
Ukidanje ove opcije je slično kao i pokretanje ove opciju:
DataSplit file
S tim da zakačimo opciju «Analyse all cases, do not create groups» i ako zalijepimo ovu opciju dobit ćemo slijedeći sintaksni kod:
SPLIT FILE OFF.
Recimo sada da se interesujemo za osobe starije od 10 godina koje puše koliko puše. Ovo nije moguće uraditi direktno SPLIT FILE komandom budući da nemamo varijablu koja nam ukazuje na osobe koje puše preko 10 cigareta.
Izlaz/output 13: Descriptive Statistics
POL Pol osobe N Minimum Maximum MeanStd.
Deviation1 Muski pol CIGARETE
Prosjecan broj cigareta dnevno
6 0 30 9,17 12,007
Valid N (listwise) 6 2 Zenski pol CIGARETE
Prosjecan broj cigareta dnevno
6 0 30 13,33 15,055
Valid N (listwise) 6
13
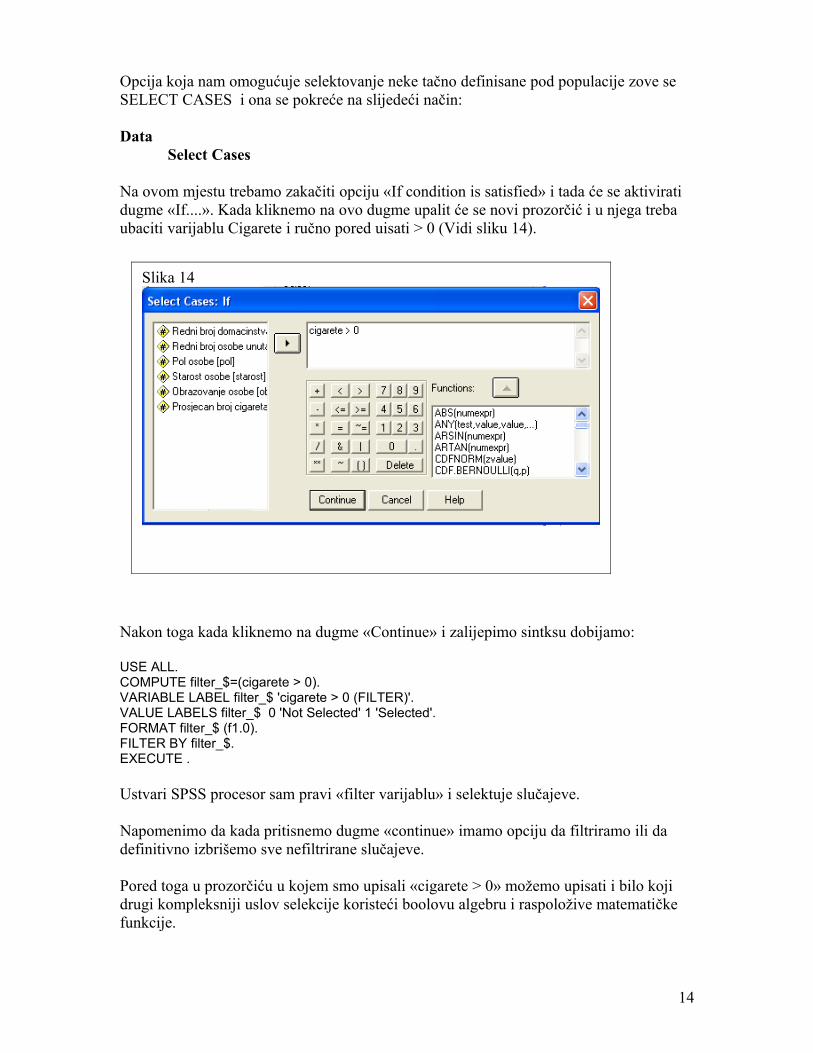
Opcija koja nam omogućuje selektovanje neke tačno definisane pod populacije zove se SELECT CASES i ona se pokreće na slijedeći način:
DataSelect Cases
Na ovom mjestu trebamo zakačiti opciju «If condition is satisfied» i tada će se aktivirati dugme «If....». Kada kliknemo na ovo dugme upalit će se novi prozorčić i u njega treba ubaciti varijablu Cigarete i ručno pored uisati > 0 (Vidi sliku 14).
Nakon toga kada kliknemo na dugme «Continue» i zalijepimo sintksu dobijamo:
USE ALL.COMPUTE filter_$=(cigarete > 0).VARIABLE LABEL filter_$ 'cigarete > 0 (FILTER)'.VALUE LABELS filter_$ 0 'Not Selected' 1 'Selected'.FORMAT filter_$ (f1.0).FILTER BY filter_$.EXECUTE .
Ustvari SPSS procesor sam pravi «filter varijablu» i selektuje slučajeve.
Napomenimo da kada pritisnemo dugme «continue» imamo opciju da filtriramo ili da definitivno izbrišemo sve nefiltrirane slučajeve.
Pored toga u prozorčiću u kojem smo upisali «cigarete > 0» možemo upisati i bilo koji drugi kompleksniji uslov selekcije koristeći boolovu algebru i raspoložive matematičke funkcije.
Slika 14
14

Nakon pokretanja ove sintakse i predhodne sintakse za proračun prosjeka popušenih cigareta:
DESCRIPTIVES VARIABLES=cigarete /STATISTICS=MEAN STDDEV MIN MAX .
Dobijamo slijedeći izlaz/output 15:
Jasno se može uočiti da se ovdje nalazi 6 osoba koje konzumiraju cigarete (Vidi sliku 16).
Slično kao i slučaju sa filtriranjem opcija selektovanja podataka se treba ukinuti kada želimo anlalizirati nanovo sve podatke.
Sintaksni kod koji odgovara ukidanju opcije filtriranja je:
FILTER OFF.USE ALL.EXECUTE .
Izlaz/output 15 Descriptive Statistics
N Minimum Maximum Mean Std. DeviationCIGARETE Prosjecan broj cigareta dnevno 6 10 30 22,50 8,803
Valid N (listwise) 6
Slika 16
15
Da bi izračunali koliko cigareta ukupno troši svako od posmatranih 5 domaćinstava, najprije trebamo definisati pojam primarnog ključa.
Primarni ključ je jedna ili kombinacija više varijabli koja na jedinstven način određuje određenu kategoriju ili jedinicu populacije.
U našem slučaju jedinica populacije je jedna osoba unutar datog domaćinstva.
Svaka osoba je na jedinstven način određena rednim brojem domaćinstva i rednim brojem osobe unutar domaćinstva. Na taj način primarni ključ za osobe su varijable rbr_dom i rbr_osob.
No recimo da nas ne interesuju pojave na nivou osobe nego na nivou domaćinstva. U tom slučaju primarni ključ za domaćinstva je jednostavno redni broj domaćinstva (rbr_dom).
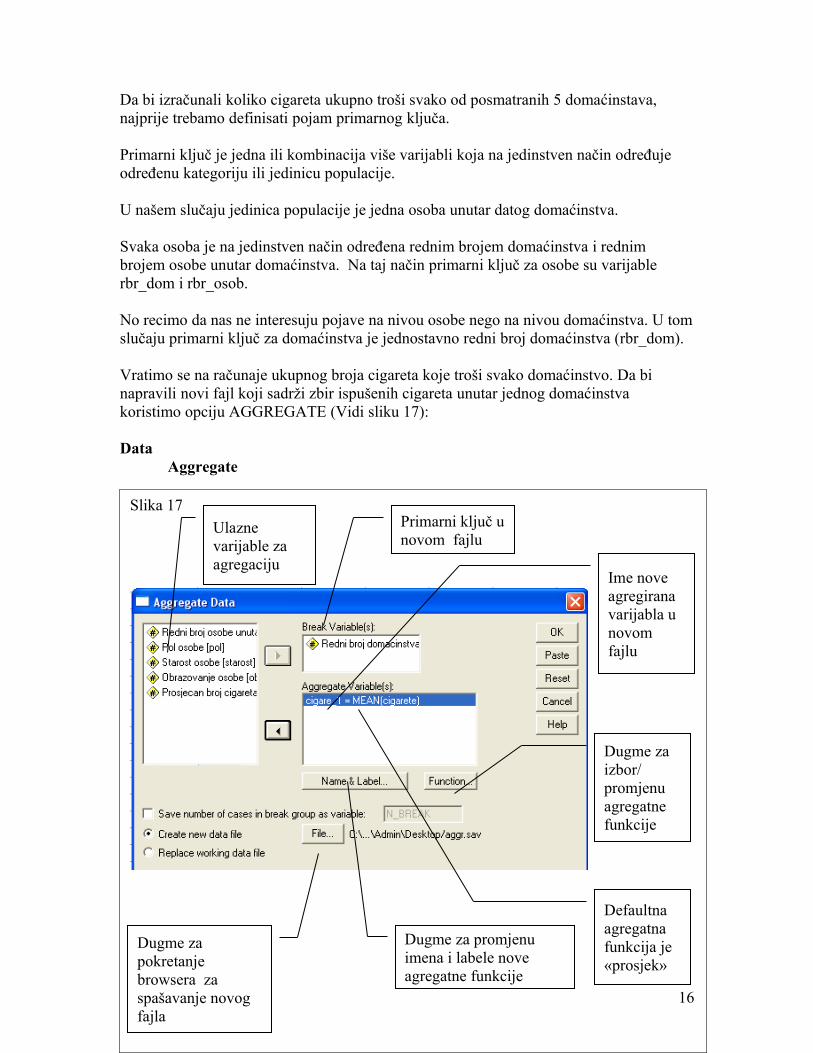
Vratimo se na računaje ukupnog broja cigareta koje troši svako domaćinstvo. Da bi napravili novi fajl koji sadrži zbir ispušenih cigareta unutar jednog domaćinstva koristimo opciju AGGREGATE (Vidi sliku 17):
DataAggregate
Slika 17Primarni ključ u novom fajlu
Dugme za izbor/ promjenu agregatne funkcije
Ime nove agregirana varijabla u novom fajlu
Defaultna agregatna funkcija je «prosjek»
Dugme za promjenu imena i labele nove agregatne funkcije
Dugme za pokretanje browsera za spašavanje novog fajla
Ulazne varijable za agregaciju
16
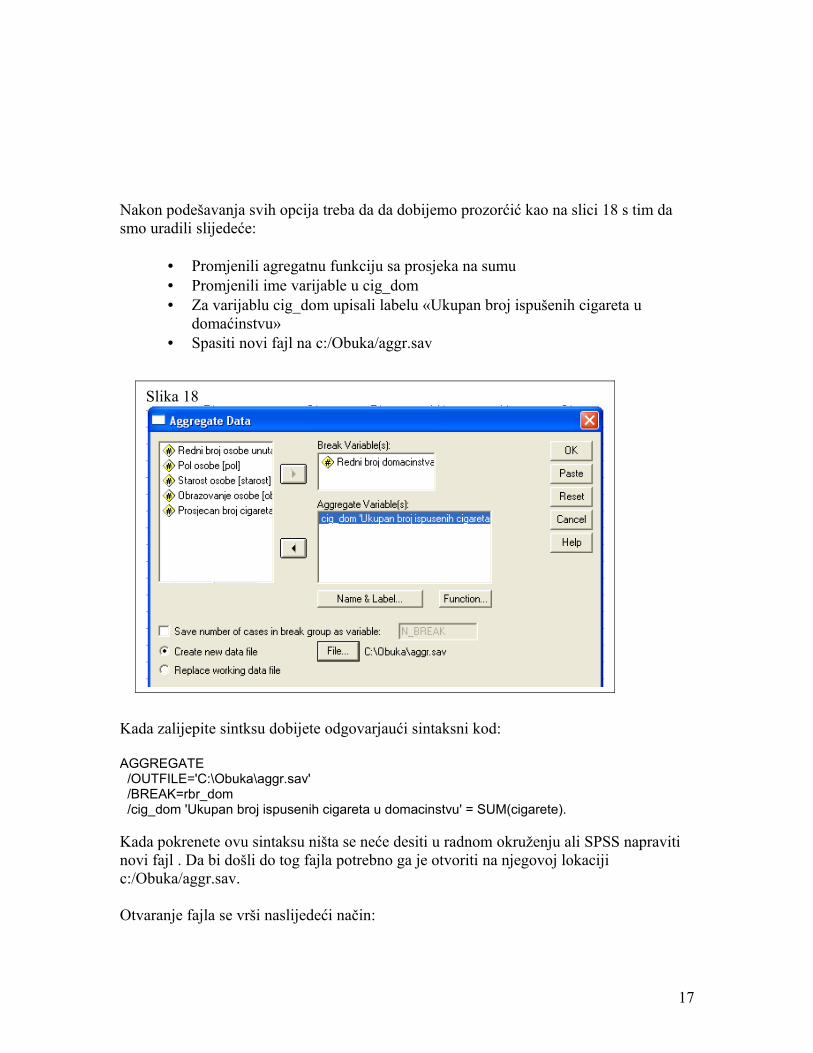
Nakon podešavanja svih opcija treba da da dobijemo prozorćić kao na slici 18 s tim da smo uradili slijedeće:
• Promjenili agregatnu funkciju sa prosjeka na sumu• Promjenili ime varijable u cig_dom• Za varijablu cig_dom upisali labelu «Ukupan broj ispušenih cigareta u
domaćinstvu»• Spasiti novi fajl na c:/Obuka/aggr.sav
Kada zalijepite sintksu dobijete odgovarjaući sintaksni kod:
AGGREGATE /OUTFILE='C:\Obuka\aggr.sav' /BREAK=rbr_dom /cig_dom 'Ukupan broj ispusenih cigareta u domacinstvu' = SUM(cigarete).
Kada pokrenete ovu sintaksu ništa se neće desiti u radnom okruženju ali SPSS napraviti novi fajl . Da bi došli do tog fajla potrebno ga je otvoriti na njegovoj lokaciji c:/Obuka/aggr.sav.
Otvaranje fajla se vrši naslijedeći način:
Slika 18
17

FileOpen
Data
Na ovom mjestu browser-om treba da pronađete c:/Obuka/aggr.sav, ako kliknete na OK fajl će se otvoriti no ako zalijepite sintaksu dobit ćete slijedeći sintaksni kod:
GET FILE='C:\Obuka\aggr.sav'.
Ovaj kod je važan jer se nalazi na početku svih sintaksnih fajli. Kad ga naučite napamet prelazite u fazu direktnog programiranje sintaksnih fajli bez korištenja padajućih menija što je i početak naprednog korištenja SPSS-a.
Automatsko spašavanje nekog fajla je slično kao i otvaranje s tim da se koristi slijedeća sintaksa:
SAVE OUTFILE='C:\Obuka\.....'.
Još jedna značajna sintaksna naredba koju nismo koristili je komentar.
Komentar izgleda ovako u SPSS-u:
*Ovo je komentar.
Vratimo se na naš novi fajl sa cigaretama kada se otvori on izgleda ovako (Vidi sliku: 19).
Slika 19
18

Primjetimo da SPSS procesor nedostajuće podatke tretira kao nule.
Sada nas interesuje da vidimo koliko ljudi živi u domaćinstvima u kojima se puši manje od 30 cigareta dnevno.
Ovo možemo izračunati u dvije faze:1. Svakoj osobi dodijeliti ukupan broj cigareta koje se puše u datom domaćinstvu.2. Napraviti novu (indikatorsku ili dummy ) varijablu koja ima vrijednost 1 ako
osoba živi u domaćinstvu u kojem se puši ispod 30 cigareta odnosno koja ima vrijednost nula ako se puši 30 i više cigareta dnevno.
Fazu 1 ćemo uraditi pomći opcije MERGE ili povezivanje dvaju različitih fajli u jedan fajl.Na tekući tj. fajl koji je otvoren u ovom momentu kačimo neki drugi fajl na slijedeći način:
DataMerge files
Add Varibles...
Nakon ovog izbora padajućeg menija i izbora fajla kojeg želimo nakačiti (u našem slučaju c:/Obuka/aggr.sav) otvara se slijedeći prozor (Vidi sliku: 20)
Slika 20Varijable koje se dupliraju u oba fajla. Jedna ili više njih su primarni ključ u fajlu kojeg kačimo, neke se jednostavno dupliraju i biće jednostavno izbačene
(*) varijable u tekućem fajlu(+) varijable u fajlu koji će biti nakačen
Mjesto gdje se upisuje primarni ključ
Vrsta veze među fajlovima
19
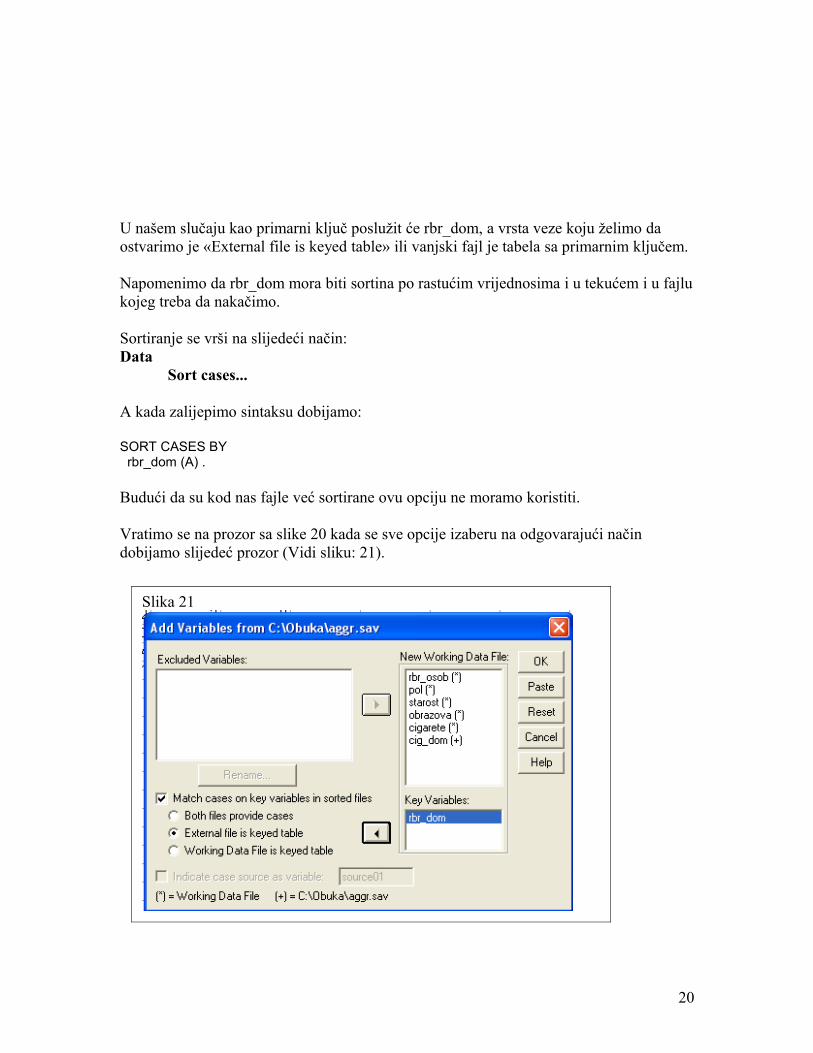
U našem slučaju kao primarni ključ poslužit će rbr_dom, a vrsta veze koju želimo da ostvarimo je «External file is keyed table» ili vanjski fajl je tabela sa primarnim ključem.
Napomenimo da rbr_dom mora biti sortina po rastućim vrijednosima i u tekućem i u fajlu kojeg treba da nakačimo.
Sortiranje se vrši na slijedeći način:Data
Sort cases...
A kada zalijepimo sintaksu dobijamo:
SORT CASES BY rbr_dom (A) .
Budući da su kod nas fajle već sortirane ovu opciju ne moramo koristiti.
Vratimo se na prozor sa slike 20 kada se sve opcije izaberu na odgovarajući način dobijamo slijedeć prozor (Vidi sliku: 21).
Slika 21
20
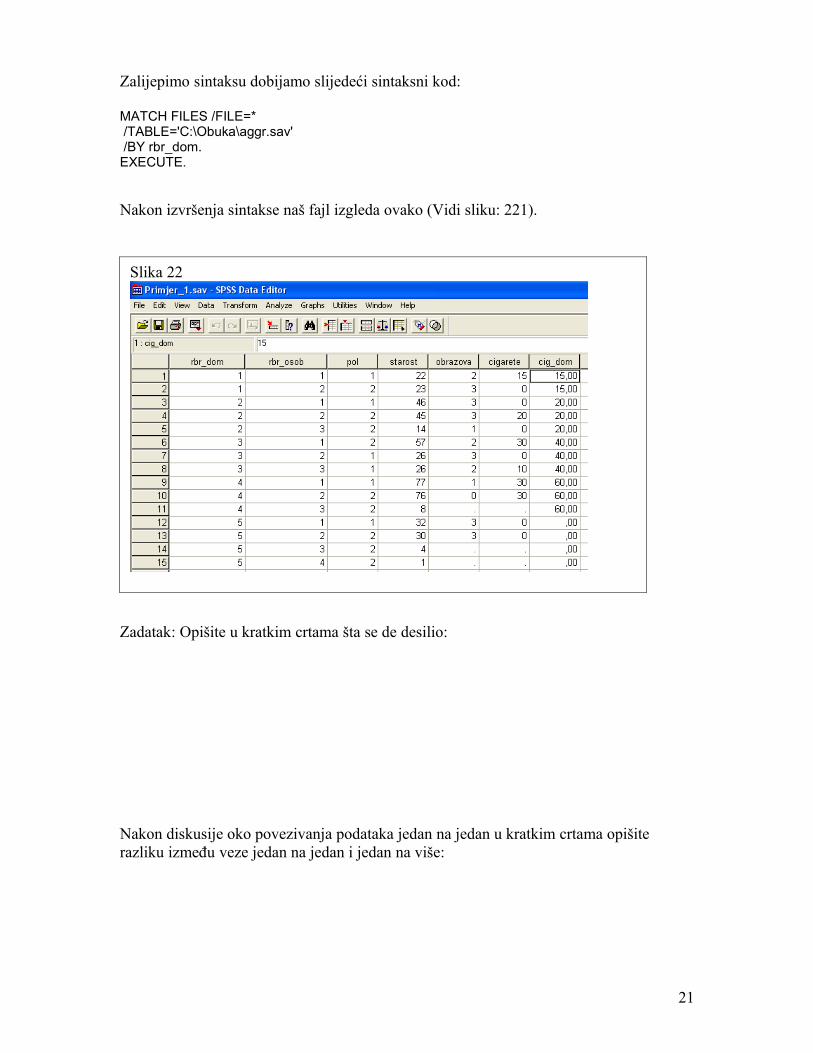
Zalijepimo sintaksu dobijamo slijedeći sintaksni kod:
MATCH FILES /FILE=* /TABLE='C:\Obuka\aggr.sav' /BY rbr_dom.EXECUTE.
Nakon izvršenja sintakse naš fajl izgleda ovako (Vidi sliku: 221).
Zadatak: Opišite u kratkim crtama šta se de desilio:
Nakon diskusije oko povezivanja podataka jedan na jedan u kratkim crtama opišite razliku između veze jedan na jedan i jedan na više:
Slika 22
21
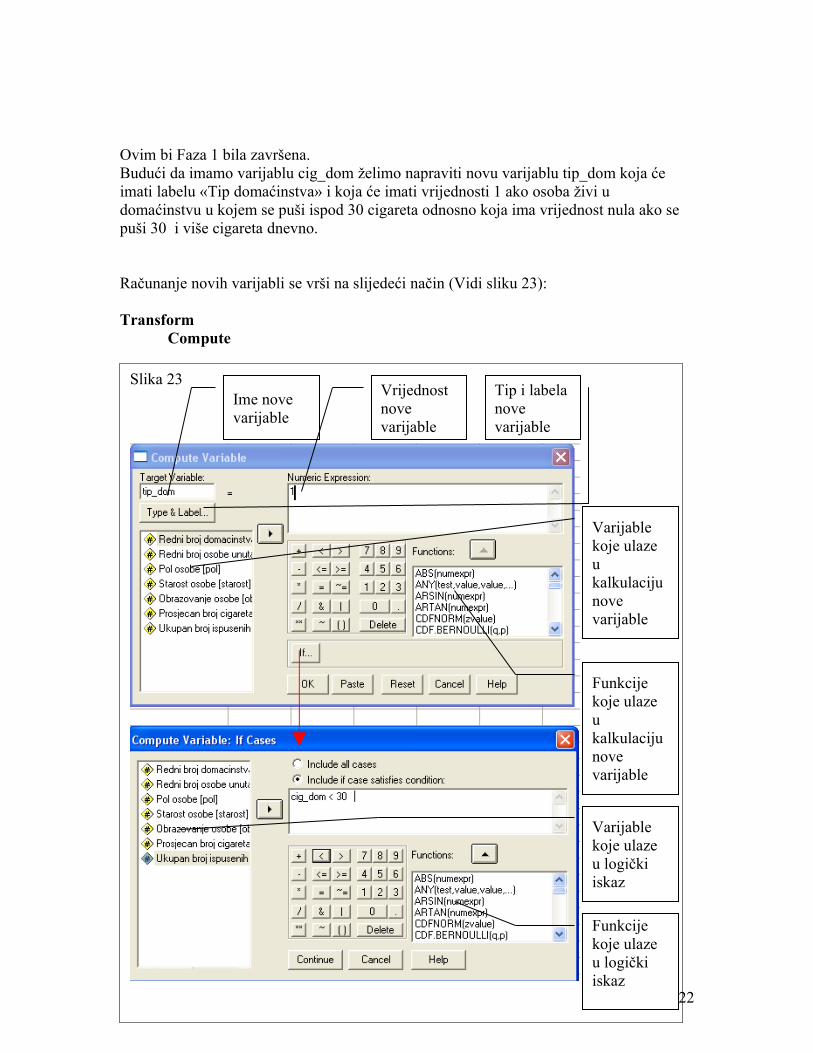
Ovim bi Faza 1 bila završena.Budući da imamo varijablu cig_dom želimo napraviti novu varijablu tip_dom koja će imati labelu «Tip domaćinstva» i koja će imati vrijednosti 1 ako osoba živi u domaćinstvu u kojem se puši ispod 30 cigareta odnosno koja ima vrijednost nula ako se puši 30 i više cigareta dnevno.
Računanje novih varijabli se vrši na slijedeći način (Vidi sliku 23):
TransformCompute
Slika 23Ime nove varijable
Vrijednost nove varijable
Tip i labela nove varijable
Varijable koje ulaze u kalkulaciju nove varijable
Funkcije koje ulaze u kalkulaciju nove varijable
Varijable koje ulaze u logički iskaz
Funkcije koje ulaze u logički iskaz
22

Kada zalijepimo sintaksu dobijemo slijedeći sintaksni kod:
EXECUTE.IF (cig_dom < 30 ) tip_dom = 1 .EXECUTE .
Primjetim da će ova naredba generisati vrijednost 1 i nedostajuće vrijednosti:
Zadatak: Napisati kod koji generira vrijednost «nula» za varijablu tip_dom i pokrenuti sintaksu.
Slijedeća sintaksa dodjeljuje automatski labele vrijednostima varijable tip_dom.
VALUE LABELS tip_dom1 "Manje od 30"2 "30 i vise".Execute.
U kratkim crtama objasnite sta radi varijable Execute.
Upisite sintaksu za racunanje frekvencije varijable tip_dom koja u isto vrijeme i crta graf te frekvencije.
23

Problem: Napraviti sintaksni fajl koji istovremeno računa sve ove analize.
Na osnovu dobijenih analiza napisati kratki sintetski izvještaj o rezultatima ankete.
24

25


















![katalog obuka [ pdf ]](https://img.dokumen.tips/doc/110x75/5854acda1a28abfa39909bc1/katalog-obuka-pdf-.jpg)










