Embed Size (px)
Citation preview

Shared Memory Parallelization
Outline
• What is shared memory parallelization?
• OpenMP• Fractal Example• False Sharing• Variable scoping• Examples on sharing and
synchronization

Shared Memory Parallelization
• All processors can access all the memory in the parallel system
• The time to access the memory may not be equal for all processors - not necessarily a flat memory
• Parallelizing on a SMP does not reduce CPU time - it reduces wallclock time
• Parallel execution is achieved by generating threads which execute in parallel
• Number of threads is independent of the number of processors

Shared Memory Parallelization
• Overhead for SMP parallelization is large (100-200 sec)- size of parallel work construct must be significant enough to overcome overhead
• SMP parallelization is degraded by other processes on the node - important to be dedicated on the SMP node
• Remember Amdahl's Law - Only get a speedup on code that is parallelized

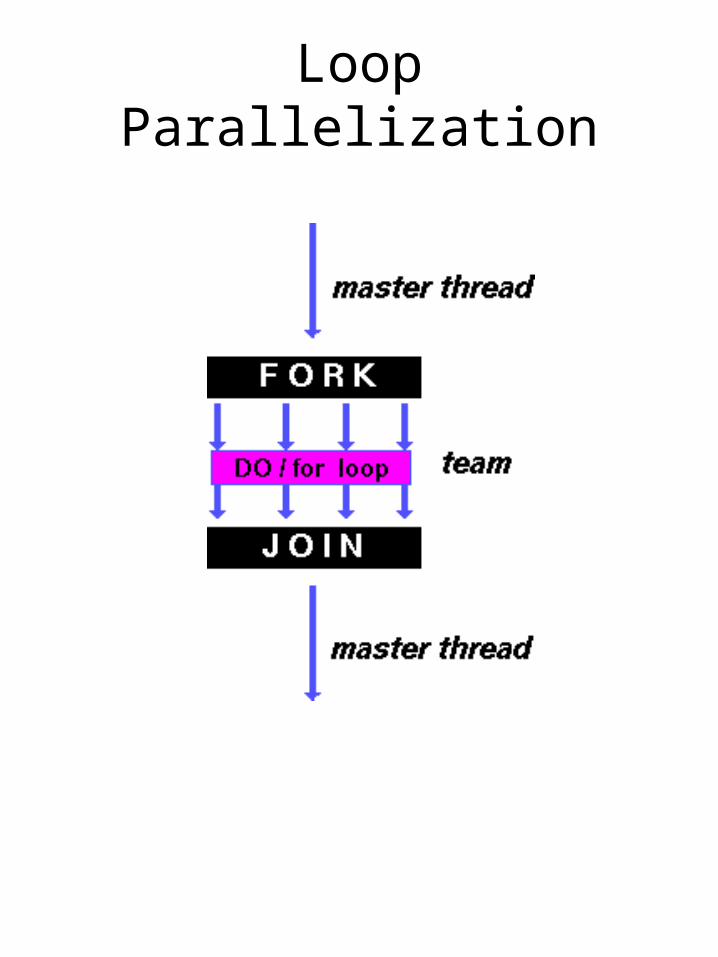
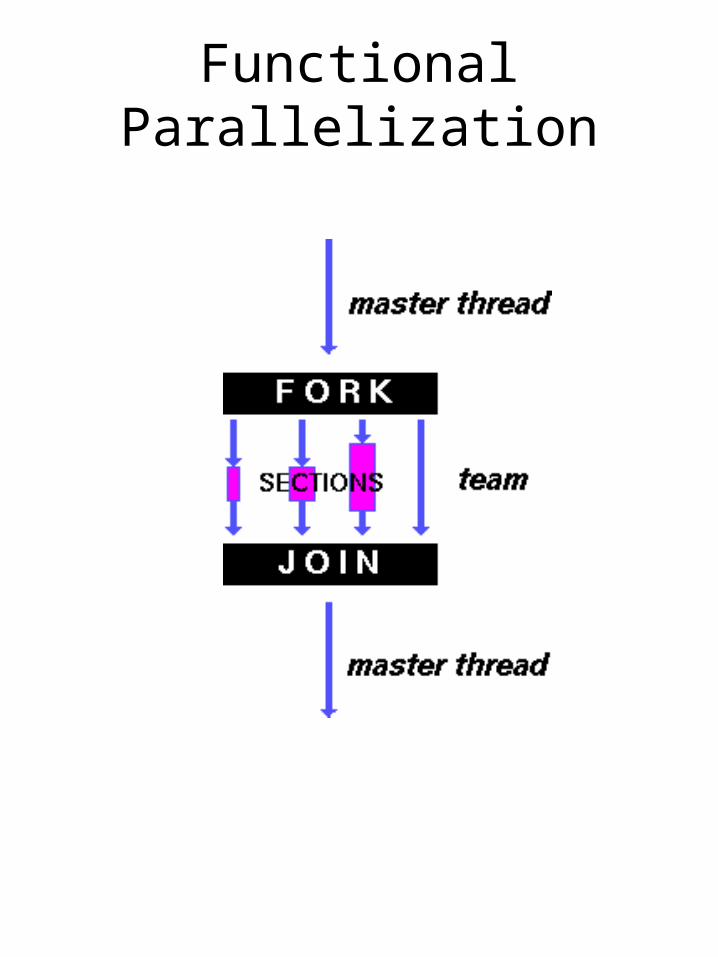
Fork-Join Model1.All OpenMP programs begin as a single process: the master thread
2.FORK: the master thread then creates a team of parallel threads
3.Parallel region statements executed in parallel among the various team threads
4.JOIN: threads synchronize and terminate, leaving only the master thread

OpenMP
• 1997: group of hardware and software vendors announced their support for OpenMP, a new API for multi-platform shared-memory programming (SMP) on UNIX and Microsoft Windows NT platforms.
• www.openmp.org• OpenMP parallelism specified
through the use of compiler directives which are imbedded in C/C++ or Fortran source code. IBM does not yet support OpenMP for C++.

OpenMP
How is OpenMP typically used?• OpenMP is usually used to
parallelize loops:– Find your most time consuming
loops.– Split them up between threads.
• Better scaling can be obtained using OpenMP parallel regions, but can be tricky!
Loop Parallelization
Functional Parallelization

Fractal Example
!$OMP PARALLEL!$OMP DO SCHEDULE(RUNTIME)do i=0,inos ! Long loop do k=1,niter ! Short loop if(zabs(z(i)).lt.lim) then if(z(i).eq.dcmplx(0.,0.)) then z(i)=c(i) else z(i)=z(i)**alpha+c(i) endif kount(i)=k else exit endif end doend do!$OMP END PARALLEL

Fractal Example (cont’d)
Can also define parallel region thus:
!$OMP PARALLEL DO SCHEDULE(RUNTIME)do i=0,inos ! Long loop do k=1,niter ! Short loop ... end doend do
C syntax:
#pragma omp parallel forfor(i=0; i <= inos; i++)for(k=1; j <= niter; k++) {...}

Fractal Example (cont’d)
• Number of threads is machine-dependent, or can be set at runtime by setting an environment variable
• SCHEDULE clause specifies how the iterations of the loop are divided among the threads:– STATIC: the loop iterations divided
into contiguous chunks of equal size.– DYNAMIC: iterations are broken into
chunks of specified size (default 1). As each thread finishes its work it dynamically obtains the next set of iterations.
– RUNTIME: the schedule determined at runtime
– GUIDED

Fractal Example (cont’d)
Compilation:• xlf90_r -qsmp=omp prog.f• cc_r -qsmp=omp prog.c• Threaded version of compilers will
perform automatic parallelization of your program unless you specify otherwise using the -qsmp=omp (or noauto) option
• Program will run on four processors unless specified otherwise by setting the XLSMPOPTS=parthds= environment variable
• Default schedule is STATIC. Try setting it to DYNAMIC with: export XLSMPOPTS="SCHEDULE=dynamic”– This will assign loop iterations in chunks of 1.
Try a larger chunk size (and get better performance), for example 40: export XLSMPOPTS="SCHEDULE=dynamic=40"

Fractal Example (cont’d)
Tradeoff between Load Balancing and Reduced Overhead
• The larger the size (GRANULARITY) of the piece of work, the lower the overall thread overhead.
• The smaller the size (GRANULARITY) of the piece of work, the better the dynamically scheduled load balancing
• Watch out for FALSE SHARING: chunk size smaller than cache line

False Sharing
• IBM Power3 cache line is 128 Bytes (16 8-Byte words)
!$OMP PARALLEL DO
do I=1,50 A(I)=B(I)+C(I)enddo
say A(1-13)starts on cache line– then some of A(14-20)will be on
first cache line so won’t be accessible until first thread finished
Solution: set chunk size of 32 so won’t have overlap on other cache line

Variable Scoping• Most difficult part of Shared
Memory Parallelization– What memory is Shared– What memory is Private - each
processor has its own copy
• Compare MPI: all variables are private
• Variables are shared by default, except:– loop indices– scalars, and arrays whose subscript
is constant with respect to PARALLEL DO, that are set and then used in loop)

How does sharing work?
THREAD 1: increment(x){ x = x + 1;}
THREAD 1:
10 LOAD A, (x address)
20 ADD A, 130 STORE A, (x
address)
THREAD 2: increment(x) {
x = x + 1;
}
THREAD 2: 10 LOAD A, (x
address) 20 ADD A, 1 30 STORE A, (x
address)
X initially 0
Result could be 1 or 2
Need synchronization

Variable Scoping exampleread *,nsum = 0.0call random (b)call random (c)!$OMP PARALLEL!$OMP PRIVATE (i,sump )!$OMP SHARED (a,b,n,c,sum)sump = 0.0!$OMP DOdo i=1,na(i) = sqrt(b(i)**2+c(i)**2)sump = sump + a(i)enddo!$OMP CRITICALsum = sum + sump!$OMP ENDCRITICAL!$OMP END PARALLELend

Scoping example #2read *,nsum = 0.0call random (b)call random (c)!$OMP PARALLEL DO!$OMP&PRIVATE (i)!$OMP&SHARED (a,b,n)!$OMP&REDUCTION (+:sum)do i=1,na(i) = sqrt(b(i)**2+c(i)**2)sum = sum + a(i)Enddo!$OMP PARALLEL ENDDOend
Each processor needs
a separate copy of i
everything else is
Shared

Variable Scoping
• Global variables are SHARED among threads– Fortran: COMMON blocks, SAVE
variables, MODULE variables– C: variables “visible” when #pragma omp parallel encountered, static variables declared within a parallel region
• But not everything is shared...– Stack variables in sub-programs
called from parallel regions are PRIVATE
– Automatic variables within a statement block are PRIVATE.

Hello World #1 (correct)
PROGRAM HELLOINTEGER TID, OMP_GET_THREAD_NUM!$OMP PARALLEL PRIVATE(TID)TID = OMP_GET_THREAD_NUM()PRINT *, 'Hello World from thread =
', TID...!$OMP END PARALLELEND

Hello World #2 (incorrect)
PROGRAM HELLOINTEGER TID, OMP_GET_THREAD_NUM!$OMP PARALLEL TID = OMP_GET_THREAD_NUM()PRINT *, 'Hello World from thread =
', TID...!$OMP END PARALLELEND

Hello World #3 (incorrect)
PROGRAM HELLOINTEGER TID, OMP_GET_THREAD_NUMTID = OMP_GET_THREAD_NUM()PRINT *, 'Hello World from thread =
', TID!$OMP PARALLEL ...!$OMP END PARALLELEND

Another Variable Scoping Example
subroutine example4(n,m,a,b,c)real*8 a(100,100),B(100,100),c(100)integer n,ireal*8 sum!$OMP PARALLEL DO!$OMP PRIVATE (j,i,c)!$OMP SHARED (a,b,m,n)do j=1,mdo i=2,n-1c(i) = sqrt(1.0+b(i,j)**2)enddodo i=1,na(i,j) = sqrt(b(i,j)**2+c(i)**2)enddoenddoendEach processor needs a separate copy of j,i,c
everything else is Shared. What about c?
c(1) and c(n)?

Another Variable Scoping Example (cont’d)
subroutine example4(n,m,a,b,c)real*8 a(100,100),B(100,100),c(100)integer n,ireal*8 sum!$OMP PARALLEL DO!$OMP PRIVATE (j,i)!$OMP SHARED (a,b,m,n)!$OMP FIRSTPRIVATE (c)do j=1,mdo i=2,n-1c(i) = sqrt(1.0+b(i,j)**2)enddodo i=1,na(i,j) = sqrt(b(i,j)**2+c(i)**2)enddoenddoendNeed First Value of c. Master copies it's
c array to all threads prior to DO loop

Another Variable Scoping Example (cont’d)
What if last value of c is needed?
• Use LASTPRIVATE clause

References
• www.openmp.org• ASCI Blue training :
http://www.llnl.gov/computing/tutorials/workshops/workshop/
• EWOMP ‘99: http://www.it.lth.se/ewomp99/
programme.html
• EWOMP ‘00: http://www.epcc.ed.ac.uk/ewomp2000/proceedings.html
• Multimedia tutorial at Boston University: http://scv.bu.edu/SCV/Tutorials/
OpenMP/





























