Embed Size (px)
Citation preview

Sequence Local Alignment using Directed Acyclic Word Graph
Do Huy Hoang

SEQUENCE ALIGNMENT

Sequence Similarity
• Alignment–Arrange DNA/Protein sequences to show
the similarity• “” denotes the insertion/deletion event

Other variations
• Edit distance• Longest common substring• Affine gap scoring• Using scoring matrix (BLOSUM, PAM)

Alignment score computation
• Needleman–Wunsch – Dynamic programming
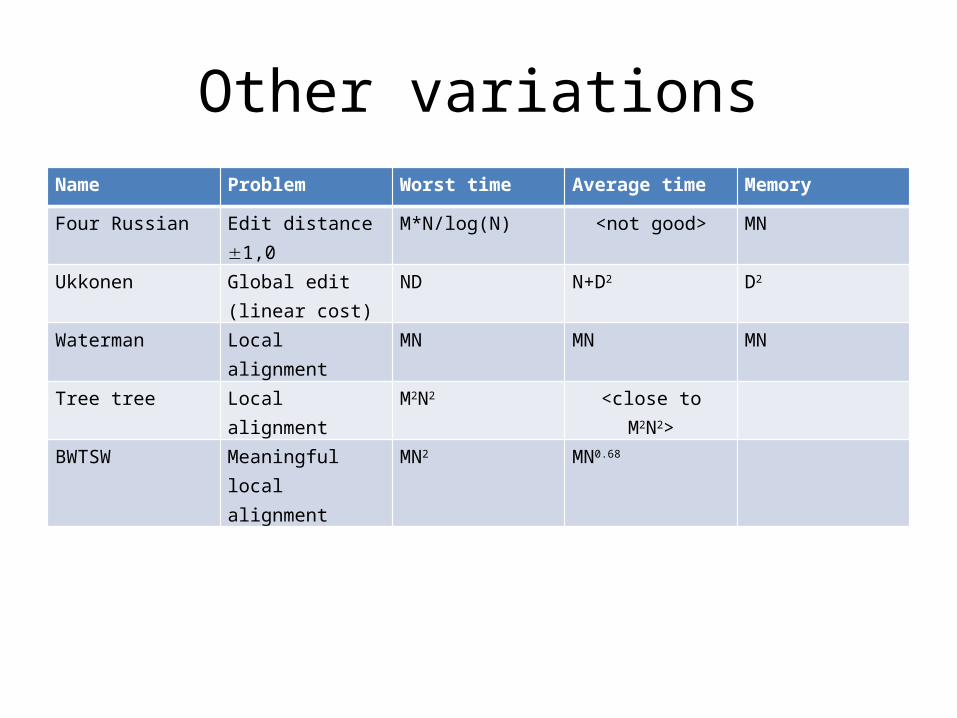
Other variationsName Problem Worst time Average time Memory
Four Russian Edit distance 1,0 M*N/log(N) <not good> MN
Ukkonen Global edit (linear cost)
ND N+D2 D2
Waterman Local alignment MN MN MN
Tree tree Local alignment M2N2 <close to M2N2>
BWTSW Meaningful local alignment
MN2 MN0.68

Local alignment
• Local alignment– Find the best alignments of two substring
from the sequences

BWTSW

• BWTSW– Motivation• Scoring 75% similarity• Local alignment table most are zero• Meaningful alignment
– Suffix tree– Meaningful alignment– Meaningful alignment with gap– How good is it?

Meaningful alignment (1)
• Sequences similarity sometimes implies functional similarity.
• Biologists is NOT usually interested in sequences with less than 70% similarity.
• BLAST score– Match = 1– Mismatch = -3– Open Gap = -5– Extending gap = -2

Meaningful alignment (2)
• BLAST score– Match = 1– Mismatch = -3– Open Gap = -5– Extending Gap = -2
– At least 70% match to have none zero score

Meaningful alignment (3)
• BLAST score– Match = 1– Mismatch = -3– Open Gap = -5– Extending Gap = -2
• How many none zero entries in the local alignment DP table?

How to improve?
• Idea:– Not storing zero score entries– Using suffix tree to prune off early

BWTSW details
• FM index for suffix tree representation• Prune zero entries• Store DP vector using linked list

Analysis
• Text length = N• Pattern length = M• Alphabet size =

Average running time (1)
• Let F(L) be the number of pairs of strings length L, which Score(S1,S2) > 0– Sizeof{(S1,S2) : Len(S1)=Len(S2)=L,
Score(S1,S2)>0}– F(L) counts the number of pairs of 75% identity.
• F(L) = sum(i=0..L/4, Binomial(L,i) * (-1)i) • F(L) k1k2
L
• F(log(N)) k3* N0.68

Average running time (2)
• Given S1, Pr(Score(S1,S2) > 0|S1) = F(L)/L
• For M < log(N)– The number of entries are– O(M * F(M)) < O(log(N)*F(log(N))
• For M > log (N)– O(M * N * F(M) / L)
• On average– Time = O(M*F(log(N))) = M * N0.68

DAWG

Possible improvement of BWTSW
• Worst case running time O(N2 M)– When M=N
– O(M N0.68+M3) When M is substring of N• What about ST vs. ST?

• What we used in BWTSW is Suffix Trie (not suffix tree).– #Prove it#
• Suffix trie has O(N2)nodes
• DAWG is a similar structure with O(N) nodes
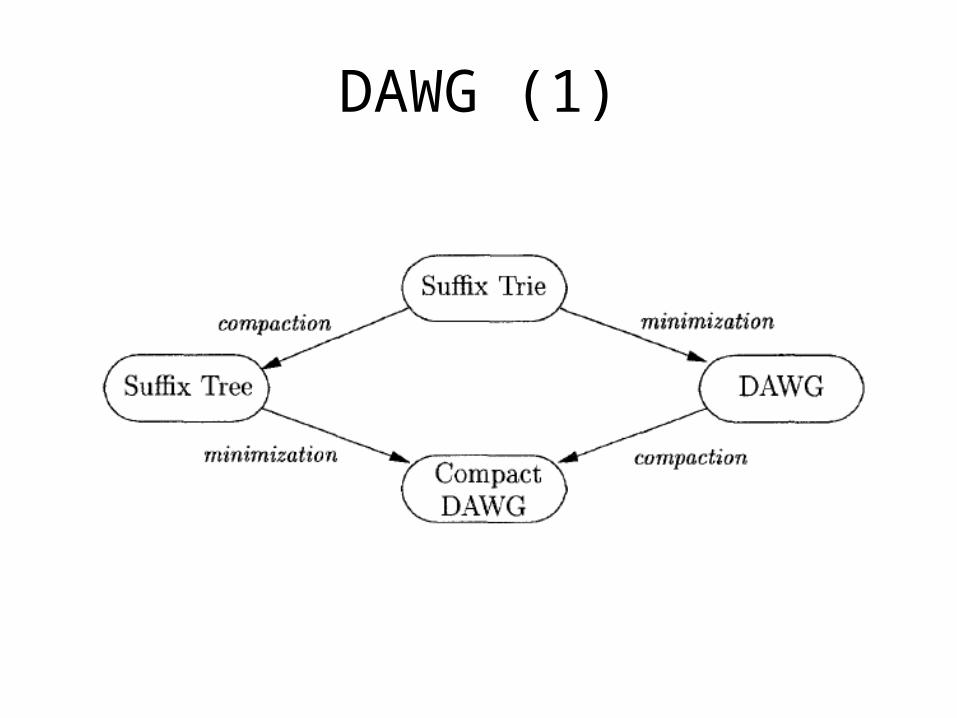
DAWG (1)

DAWG (2)
• DAWG: Directed Acyclic Word Graph• DAWG is a cyclic automata that recognizes all
the sub-strings of the given string.
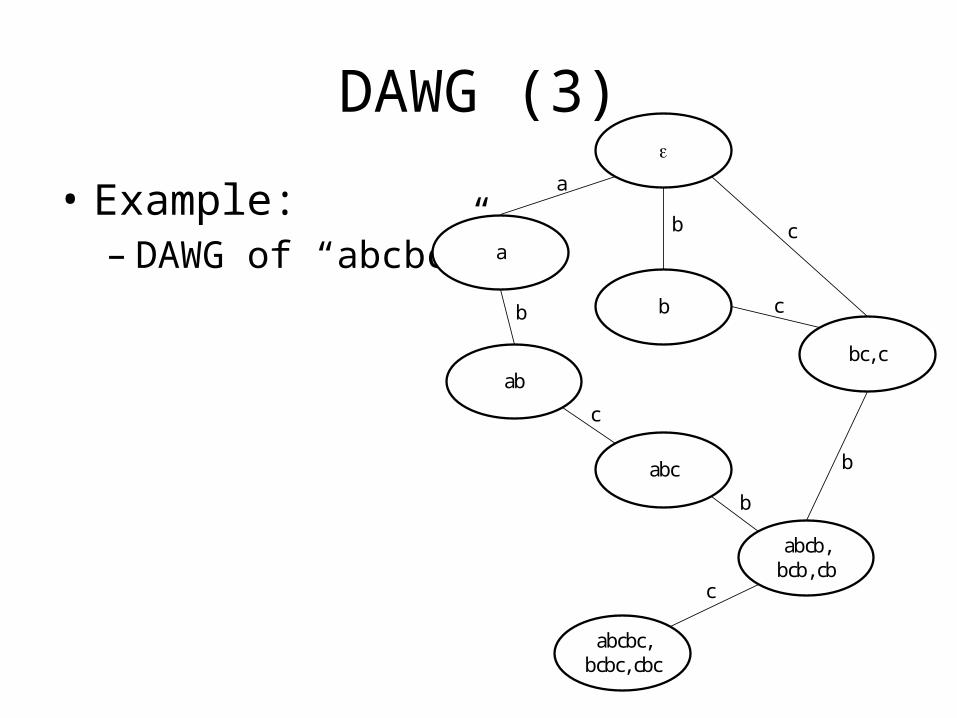
DAWG (3)
• Example:– DAWG of “abcbc”
a
b
bc, cab
abc
abcb, bcb, cb
abcbc, bcbc, cbc
a
b c
cb
c
b
b
c
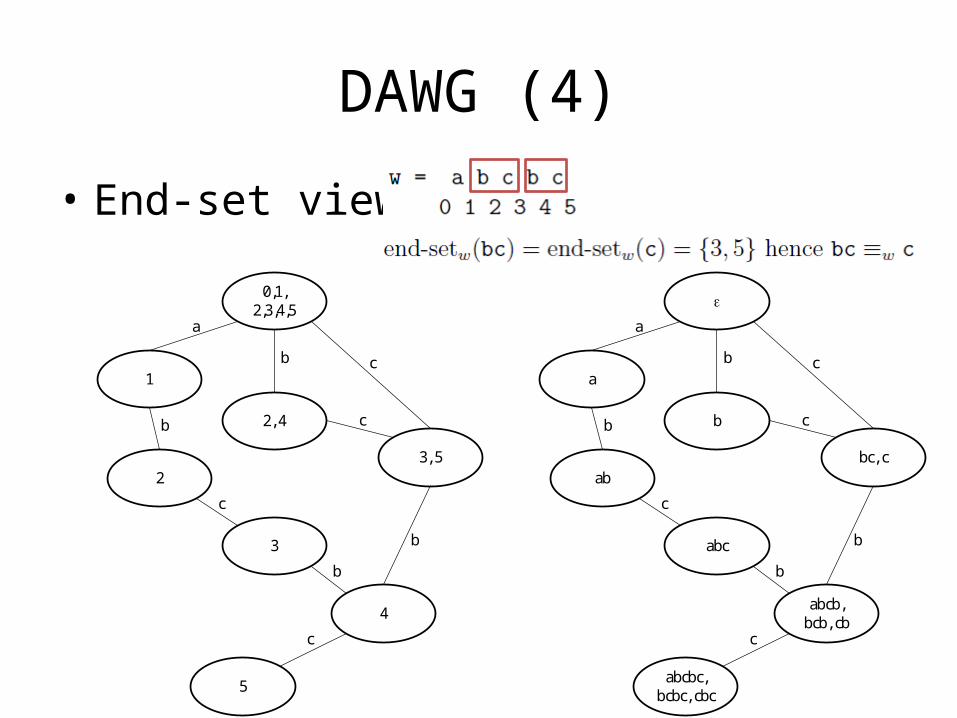
DAWG (4)
• End-set view
0,1, 2,3,4,5
1
2, 4
3, 52
3
4
5
a
b c
cb
c
b
b
c
a
b
bc, cab
abc
abcb, bcb, cb
abcbc, bcbc, cbc
a
b c
cb
c
b
b
c
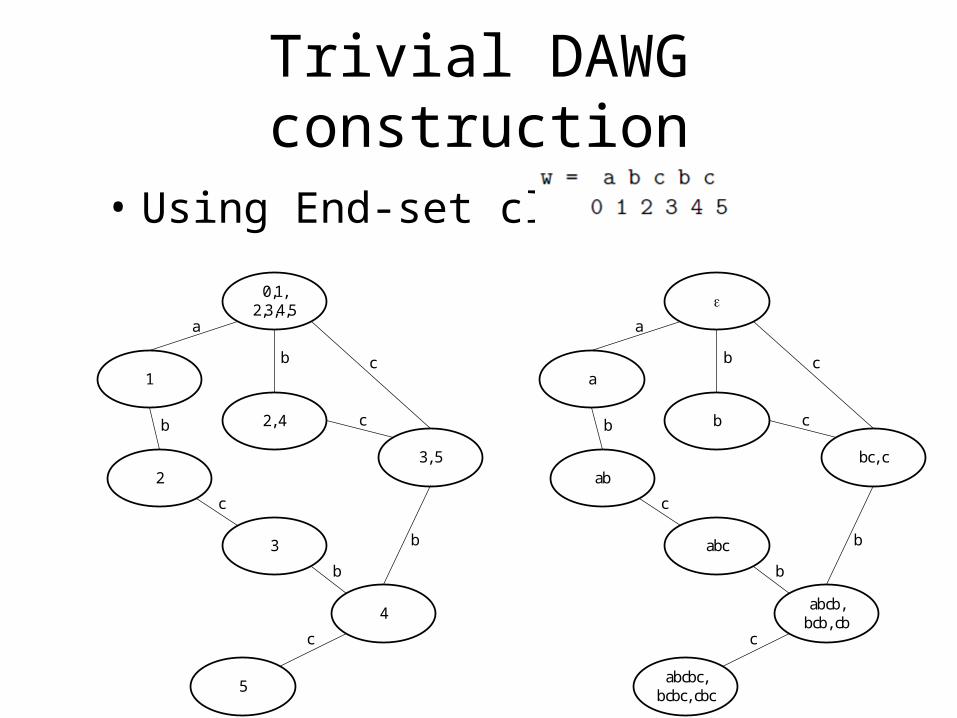
Trivial DAWG construction
• Using End-set class
0,1, 2,3,4,5
1
2, 4
3, 52
3
4
5
a
b c
cb
c
b
b
c
a
b
bc, cab
abc
abcb, bcb, cb
abcbc, bcbc, cbc
a
b c
cb
c
b
b
c

DAWG properties
• For |w|>2, the Directed Acyclic Word Graph for w has at most 2|w|-1 states, and 3|w|-4 edges
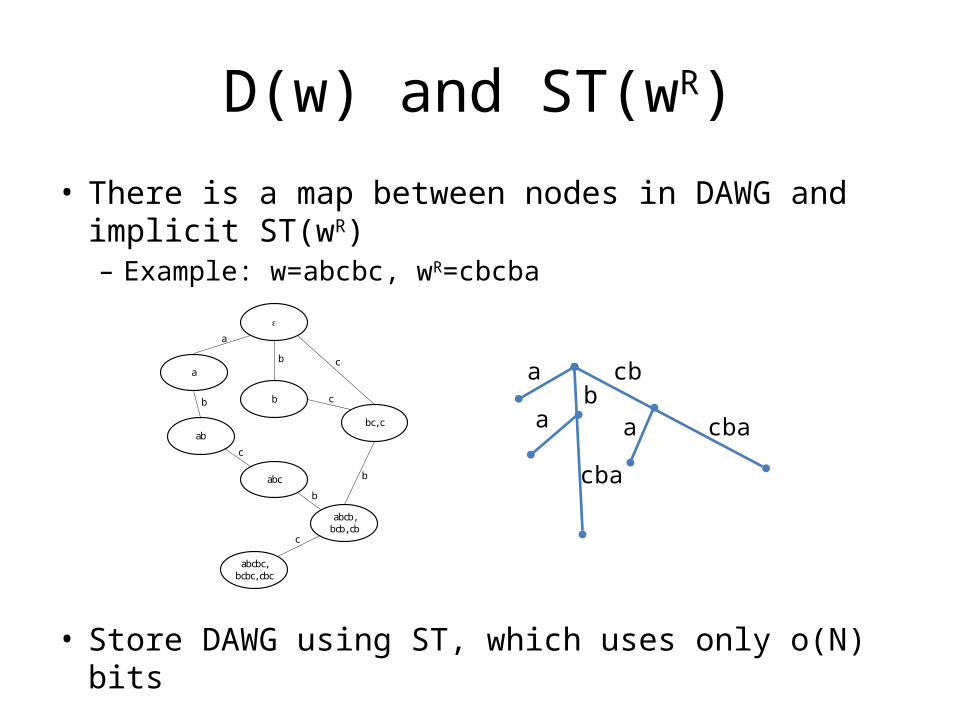
D(w) and ST(wR)
• There is a map between nodes in DAWG and implicit ST(wR)– Example: w=abcbc, wR=cbcba
• Store DAWG using ST, which uses only o(N) bits
a
ab
cb
cbaa
cba
a
b
bc, cab
abc
abcb, bcb, cb
abcbc, bcbc, cbc
a
b c
cb
c
b
b
c

D(w) and ST(wR) (2)list all incoming edges of node q in Dw using ST(w^R)

Local Alignment using DAWG
• Basis
• Induction

Extensions
• Meaningful alignment using DAWG– Prune the nodes whose Score is less than zero
• Shortest path pruning style• Cache log(N) nodes the worst case running
time is M*N*log(N), average case is the same for M << N.





























