Embed Size (px)
DESCRIPTION
Ringkasan Cat Kuliah Analisa Epid Lanjut
Citation preview

RINGKASAN KULIAHAPLIKASI ANALISA EPIDEMIOLOGI LANJUT 1
Disusun oleh:Resthie Rachmanta Putri
NPM 1406519972
PJMK: Prof. Dr. dr. Bambang Sutrisna, MHSc
Peminatan Epidemiologi KlinikFakultas Kesehatan Masyarakat
Universitas Indonesia
JakartaApril 2015
KULIAH PENDAHULUAN

APLIKASI ANALISA EPIDEMIOLOGI LANJUT 114 FEBRUARI 2015
Alpha-error = false positive = disebut-sebut ada padahal tidak ada = “gosip”Beta-error = false negative = ada tapi tidak pernah disebut-sebut = “selingkuh”
Epidemiologi: ilmu tentang kependudukan. Epidemiologi merupakan suatu ilmu, tetapi juga merupakan suatu pendekatan.
Respons epidemiologi sesuatu yang menjadi masalah kalau bisa dihilangkan (eradikasi)
Penelitian S2-S3 umumnya tujuannya untuk mengungkap hubungan sebab-akibat.
Dalam epidemiologi, ada necessary condition dan ada contributing condition (contoh: penyakit TB, harus ada M. Tuberculosis, tapi tidak selalu M. Tuberculosis menjadi penyakit TB). Kondisi lain adalah sufficient condition (misalnya: buta bisa karena penyakit pada mata, bisa karena trauma, dll).
AAEL-1 fokusnya pada cross sectional dan case control. AAEL-2 fokusnya pada kohort.
Persiapkan proposal kasar, yang desainnya cross sectional atau case control. Pada UTS menyerahkan proposal kasar tersebut. Pada UAS, akan diberikan data set untuk diolah menghasilkan informasi yang diolah menjadi manuskrip untuk dipublikasi.
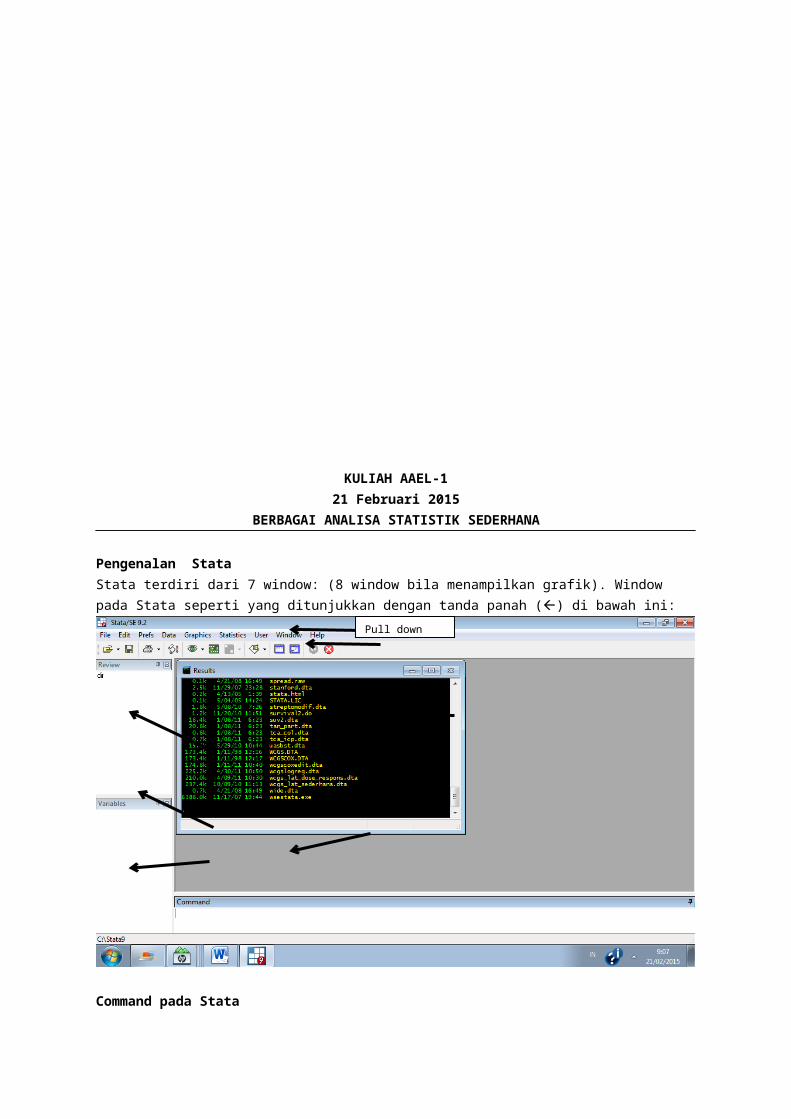
KULIAH AAEL-121 Februari 2015
BERBAGAI ANALISA STATISTIK SEDERHANA
Pengenalan StataStata terdiri dari 7 window: (8 window bila menampilkan grafik). Window pada Stata seperti yang ditunjukkan dengan tanda panah () di bawah ini:
Command pada StataSemua command stata selalu dalam huruf kecil
Untuk menutup stata: exit, clear Untuk melihat isi directory folder stata: dir Untuk menghapus variable: clear Untuk melihat variable yang ada di dlm memori stata: Buka file auto.dta,
kemudian di command: describe Untuk mentabulasi suatu variabel: tabu <nama variable> Untuk mendeskripsikan isi dari semua variabel: summarize / summ Untuk melihat jenis variabel: describe / descr Untuk melihat buku kode dari variabel: codebook
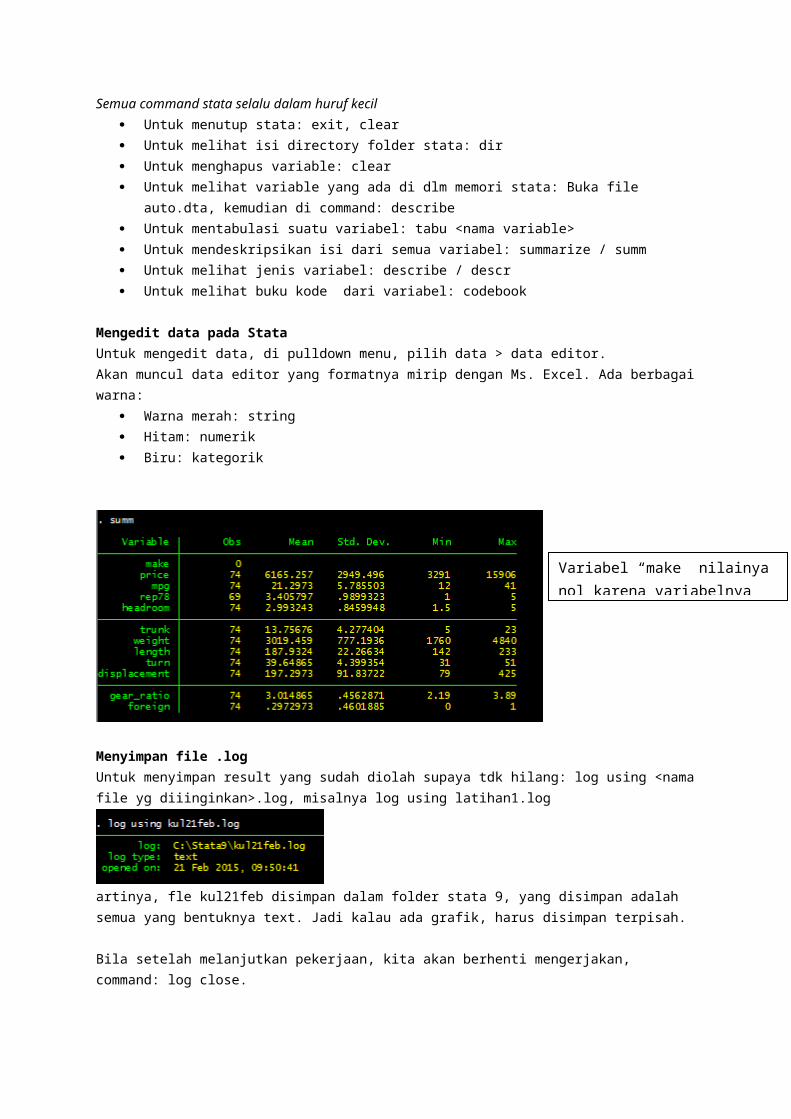
Mengedit data pada Stata Untuk mengedit data, di pulldown menu, pilih data > data editor.Akan muncul data editor yang formatnya mirip dengan Ms. Excel. Ada berbagai warna:
Warna merah: string Hitam: numerik Biru: kategorik
Pull down menu
Menyimpan file .logUntuk menyimpan result yang sudah diolah supaya tdk hilang: log using <nama file yg diiinginkan>.log, misalnya log using latihan1.log
artinya, fle kul21feb disimpan dalam folder stata 9, yang disimpan adalah semua yang bentuknya text. Jadi kalau ada grafik, harus disimpan terpisah.
Bila setelah melanjutkan pekerjaan, kita akan berhenti mengerjakan, command: log close.
Kelebihan .log file bisa dibuka dengan stata, notepad, ms.word.
Untuk menyambung pekerjaan yang sebelumnya sudah disimpan, command: log using <nama file yang sebelumnya dipakai>, append
Aplikasi command Stata
Variabel “make” nilainya nol karena variabelnya string.
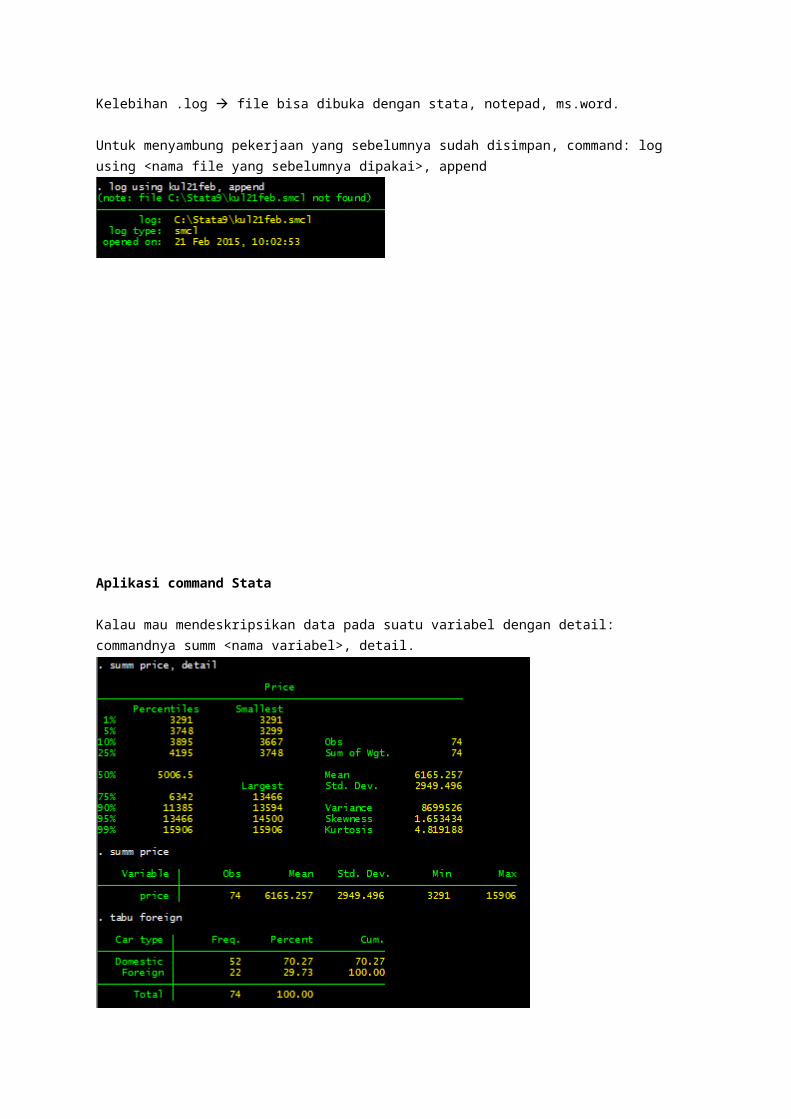
Kalau mau mendeskripsikan data pada suatu variabel dengan detail: commandnya summ <nama variabel>, detail.
Perbedaan summ dengan summ, detail:Summ yang ditampilkan hanya mean, nilai minimum, nilai maximum. Kalau summ, detail yang ditampilkan ada persentil, varians, skewness, kurtosis, dll.
Kalau datanya numerik, pakainya summarize. Kalau data kategorik, pakainya tabulate.
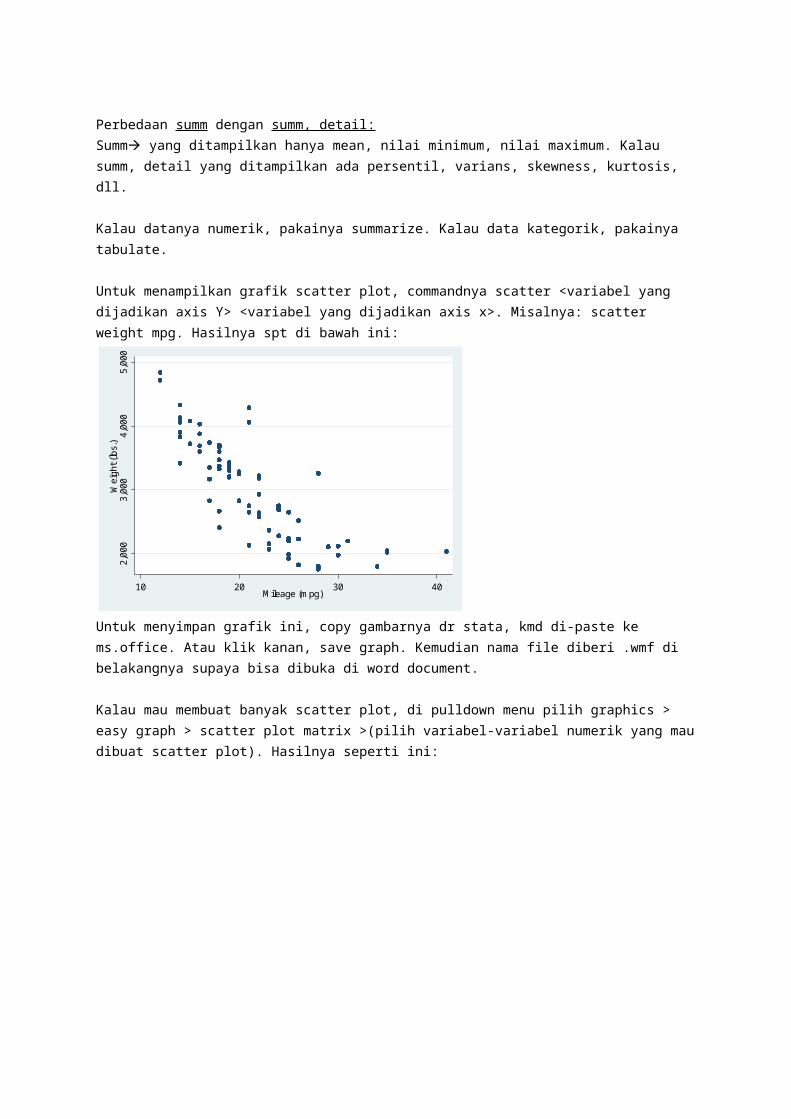
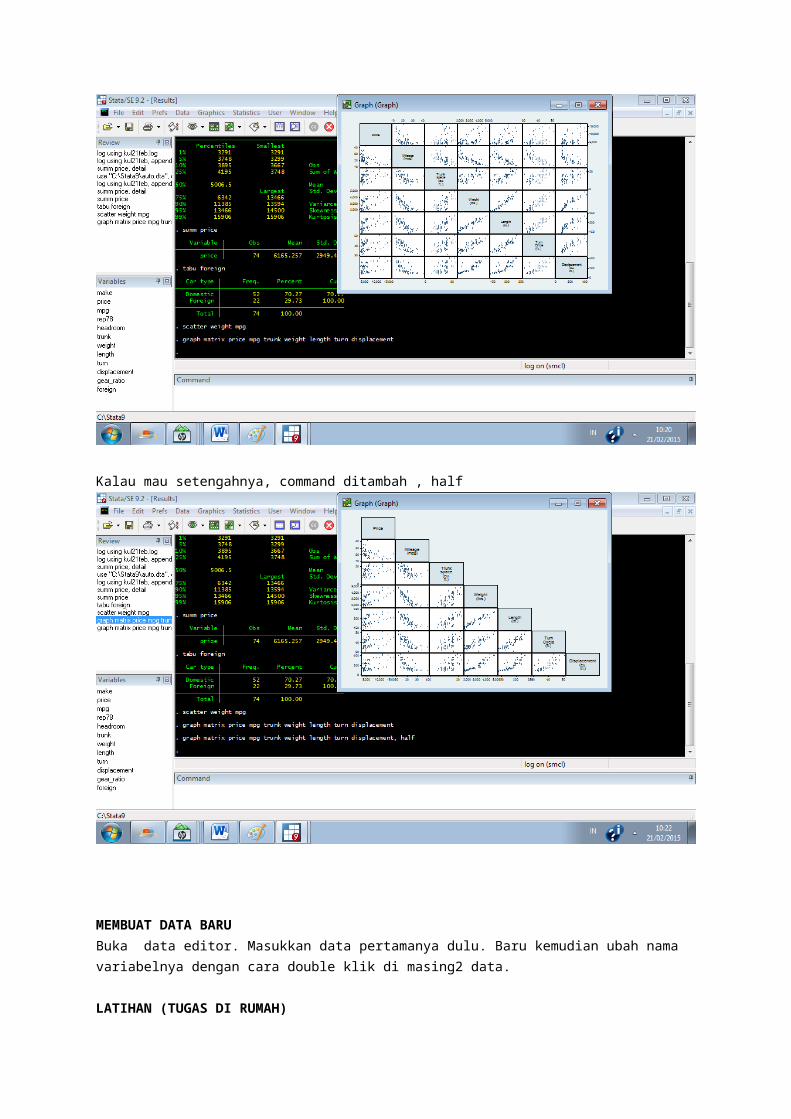
Untuk menampilkan grafik scatter plot, commandnya scatter <variabel yang dijadikan axis Y> <variabel yang dijadikan axis x>. Misalnya: scatter weight mpg. Hasilnya spt di bawah ini:
2,0
003
,000
4,0
005
,000
Wei
ght (
lbs.
)
10 20 30 40Mileage (mpg)
Untuk menyimpan grafik ini, copy gambarnya dr stata, kmd di-paste ke ms.office. Atau klik kanan, save graph. Kemudian nama file diberi .wmf di belakangnya supaya bisa dibuka di word document.
Kalau mau membuat banyak scatter plot, di pulldown menu pilih graphics > easy graph > scatter plot matrix >(pilih variabel-variabel numerik yang mau dibuat scatter plot). Hasilnya seperti ini:
Kalau mau setengahnya, command ditambah , half
MEMBUAT DATA BARUBuka data editor. Masukkan data pertamanya dulu. Baru kemudian ubah nama variabelnya dengan cara double klik di masing2 data.
LATIHAN (TUGAS DI RUMAH)1. Buat variabel baru low, mengkategorikan kelompok berat bayi lahir dari variabel bwt, dengan kategori:
a. BBL <2500 g=1b. BBL >= 2500 gram =2
2. Buat label pada variabel low dengan nama “bwt group”3. Buat label pada kategori low 1=”low”, 2=”normal”4. Buat variabel baru low2, mengganti nilai variabel low
a. 1 menjadi 0 dengan label “low”b. 2 menjadi 1 dengan label “normal”
5. Buat variabel baru ln_lwt berasal dari formulasi log natural variabel lwt.
KULIAH AAEL-128 FEBRUARI 2015
ANALISA TABEL 2X2
Tujuan AAEL-1:

Membuat manuskrip Membuat proposal penelitian dengan desain cross sectional atau case control Mampu mengolah data dengan STATA
Macam-macam research: Diagnostic research: mengembangkan alat diagnostik yang lebih sederhana tapi
valid Therapeutic research: mengembangkan obat-obatan untuk terapi (mll uji klinis) Prognostic research Etiologic research
Memulai research proposal:1. Menentukan topik yang Mau diteliti (causal model).2. Mengembangkan matriks fakta-hipotesis. Mana yg sudah jd fakta, mana yg mrpk
hipotesis, mana yg kontroversial? Kalau sudah jd fakta, tidak perlu diteliti lagi, kecuali mau bikin penelitian untuk membantah fakta.
3. Mengembangkan variabel-indicator matrix. Misalnya variabel status nutrisi, indikatornya BB/U, TB/U, BB/TB, metode pengukurannya bagaimana, dan referensinya.
4. Menentukan desain penelitian.5. Bagaimana prosedur samplingnya.6. Pilih metode statistik.
*buat dummy table sebelum ada data supaya tahu kira2 datanya akan menghasilkan informasi seperti apa.
Metode mengembangkan hipotesis: Method of difference Method of agreement Method of concomitant variant
Yang sering menjadi masalah dalam membuat penelitian:Masalah kesehatannya ada tapi masalah yang dicantumkan pada tesis tidak ada.
Komponen yang harus ada dalam introduksi proposal:1. Besaran masalah penelitian2. Kalau kita meneliti masalah tersebut, impactnya apa?3. Komponen masalah spesifik (yang dilakukan termasuk diagnostic/ prognostic/
therapeutic/ etiognostic research?)4. Elaborasi (dari berbagai kepustakaan, ada yang kontroversial atau tidak?)5. Kesenjangan (ada kesenjangan antara apa yang seharusnya dan apa yang sudah
ada)6. Lain-lain
Kalau penelitian banyak dilakukan, referensi sebaiknya 5 tahun terakhir.
LATIHAN STATALatihan stata hari ini: log using latihan28feb15.log.Buka file lowbwtff.dta.describe

.summ
Membuat variabel baru & menghapus variabel Membuat variabel baru diberi nama bblr: gen bblr=bwt Menghapus variabel bblr: drop bblr
Membuat histogramMenyimpan gambar graph sebaiknya dalam bentuk .wmf (windows metafile) bisa dibuka di ms.office.
.histogram ln_lwt, norm
0.5
11
.52
2.5
Den
sity
4.5 5 5.5ln_lwt
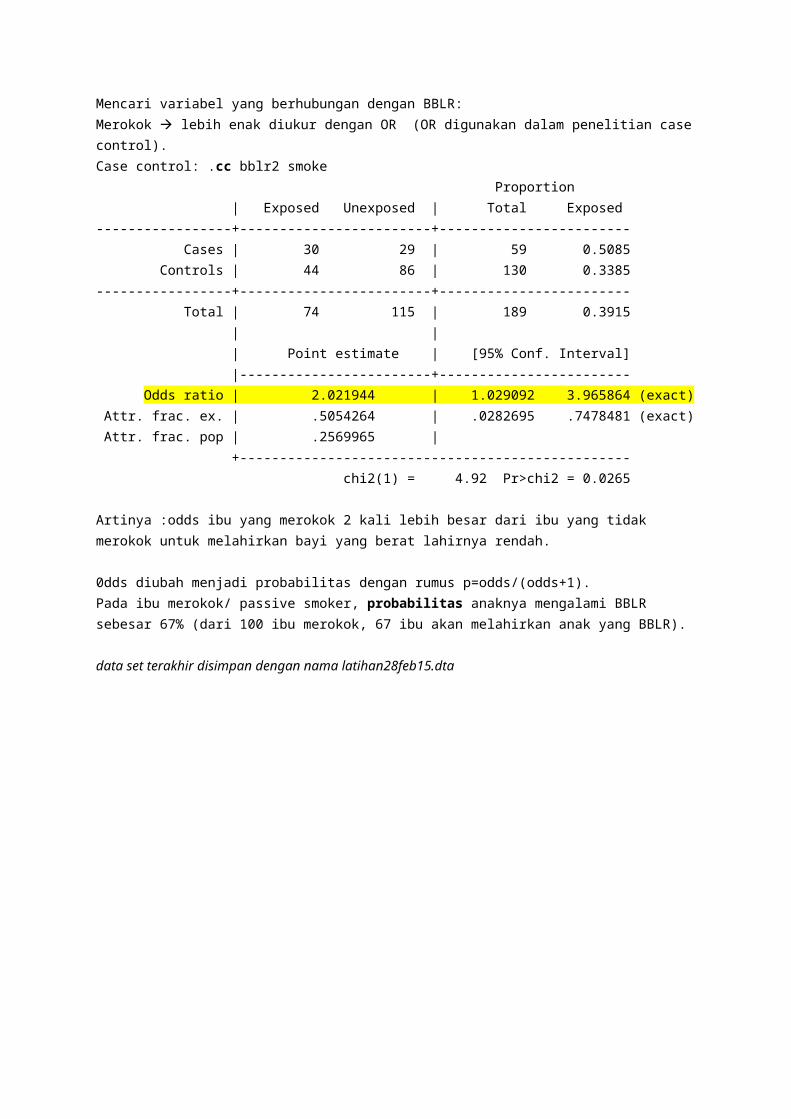
Odds RatioMencari variabel yang berhubungan dengan BBLR:Merokok lebih enak diukur dengan OR (OR digunakan dalam penelitian case control). Case control: .cc bblr2 smoke Proportion | Exposed Unexposed | Total Exposed-----------------+------------------------+------------------------ Cases | 30 29 | 59 0.5085 Controls | 44 86 | 130 0.3385-----------------+------------------------+------------------------ Total | 74 115 | 189 0.3915 | | | Point estimate | [95% Conf. Interval] |------------------------+------------------------ Odds ratio | 2.021944 | 1.029092 3.965864 (exact) Attr. frac. ex. | .5054264 | .0282695 .7478481 (exact) Attr. frac. pop | .2569965 | +------------------------------------------------- chi2(1) = 4.92 Pr>chi2 = 0.0265
Artinya :odds ibu yang merokok 2 kali lebih besar dari ibu yang tidak merokok untuk melahirkan bayi yang berat lahirnya rendah.
0dds diubah menjadi probabilitas dengan rumus p=odds/(odds+1). Pada ibu merokok/ passive smoker, probabilitas anaknya mengalami BBLR sebesar 67% (dari 100 ibu merokok, 67 ibu akan melahirkan anak yang BBLR).

data set terakhir disimpan dengan nama latihan28feb15.dta
KULIAH AAEL-17 MARET 2015
ANALISIS DASAR
Persiapan membuat proposal penelitian Referensi: membuat proposal penelitian, jilid 3 (Sopiyudin Dahlan).
Proposal penelitian yang baik: mengungkapkan sesuatu yang dilihat peneliti, tetapi tidak dilihat oleh orang lain.
Isi proposal penelitian:1. Judul penelitian biasanya belakangan saja dibuatnya.2. Latar belakang masalah menjelaskan kenapa kita mau meneliti hal ini,
besaran masalahnya. Kalau kita meneliti hal ini ada dampaknya ga? 3. Kepustakaan Komponen elaborasi, dilihat dari jurnal, artikel, dll untuk
menghasilkan kerangka teori dan kerangka konsep.4. Dst
JUDULApa: pertanyaan penelitianDi mana: subyek penelitian, lokasiKapan: waktu penelitian
LATAR BELAKANGPenjelasan ringkas identifikasi masalah menjadi masalah penelitian (piramida terbalik).
What is known What is unknown What is the aim of our study Why our study is important
RUMUSAN MASALAHRumusan masalah dlm bentuk pertanyaan penelitian.Outcome= f(determinant(s))
Pertanyaan terkait diagnostic research:Tujuan menentukan nilai diagnostik suatu indikator penyakit. Misalnya:
bagaimana manfaat MRI dan USG dalam deteksi dini kanker prostat? Prostate cancer prevalence=f(MRI and USG) Desain studi: cross sectional
Pertanyaan terkait etiognostic research:Tujuan mencari hubungan kausal. Misalnya:
Bagaimana risiko ca servix pada wanita dengan HPV(+)?
LATIHAN STATALog using latihan7mar15Pakai file lowbwff.dta
Mencari hubungan antar variabelMencari hubungan antara BBLR dengan variabel2 lainnya.Buat dulu tabel silang 2x2, misalnya antara merokok dengan BBLR.
Pakai command .cc (case control)

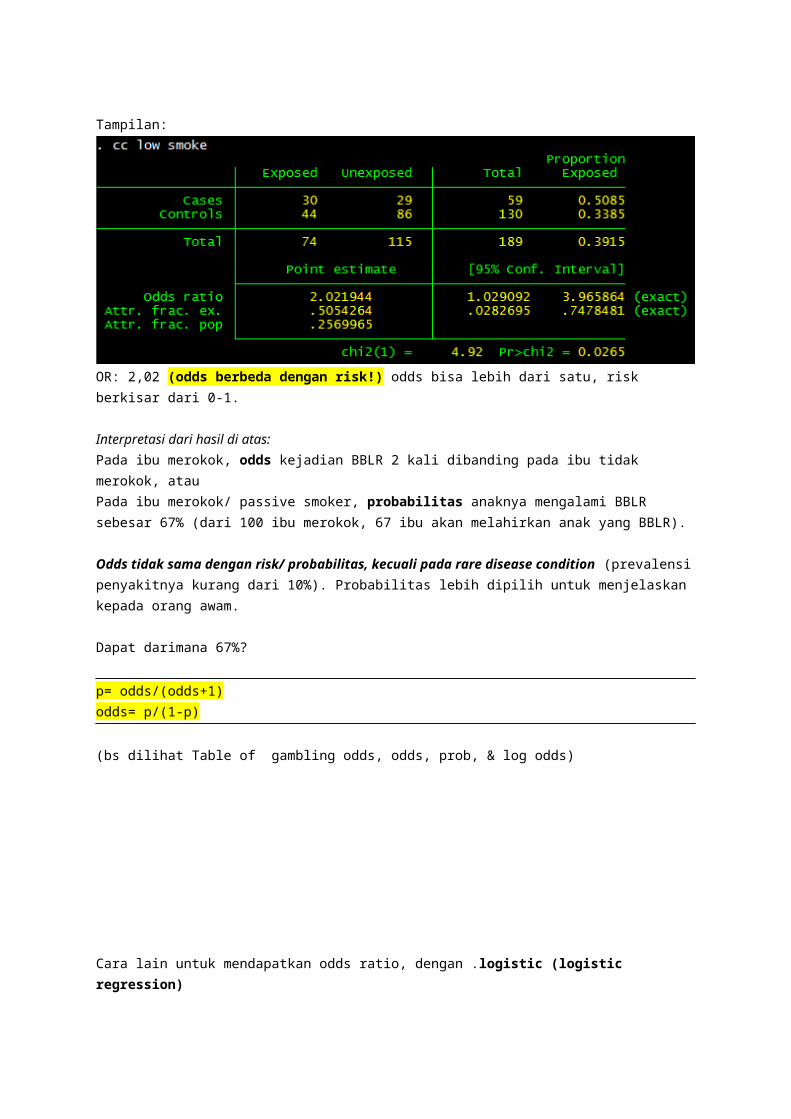
Tampilan:
OR: 2,02 (odds berbeda dengan risk!) odds bisa lebih dari satu, risk berkisar dari 0-1.
Interpretasi dari hasil di atas:Pada ibu merokok, odds kejadian BBLR 2 kali dibanding pada ibu tidak merokok, atauPada ibu merokok/ passive smoker, probabilitas anaknya mengalami BBLR sebesar 67% (dari 100 ibu merokok, 67 ibu akan melahirkan anak yang BBLR).
Odds tidak sama dengan risk/ probabilitas, kecuali pada rare disease condition (prevalensi penyakitnya kurang dari 10%). Probabilitas lebih dipilih untuk menjelaskan kepada orang awam.
Dapat darimana 67%?
p= odds/(odds+1)odds= p/(1-p)
(bs dilihat Table of gambling odds, odds, prob, & log odds)
Cara lain untuk mendapatkan odds ratio, dengan .logistic (logistic regression)
Hasil OR-nya sama dengan kalau menggunakan command .cc.

Melihat hubungan antara merokok, hipertensi dengan BBLR. Tampilan seperti di bawah ini:
Interpretasi:Kalau melihat tabel di atas, mana yg lebih berpengaruh terhadap BBLR? Merokok atau hipertensi??Yang lebih berpengaruh adalah hipertensi (dilihat dari ORnya lebih besar daripada ORnya smoke).Tetapi lihat juga 95%CInya. Meskipun OR smoke lebih rendah tapi CI-nya lebih sempit (1,08-3,84), dibanding CI-nya ht (1,01-11,5). Yang lebih reliable adalah smoke.
Lihat angka OR pada result dari .logistic low smoke ht berbeda dengan OR dari .logistic low smoke saja. Yang dari .logistic low smoke ht ORnya sudah diadjust (adjusted OR).
KULIAH AAEL-114 Maret 2015
ANALISIS DASAR
How to interpret scientific research and clinical trial resultsMelihat hasil penelitian, hal pertama yang dilakukan adalah menilai apakah penelitian ini riil atau by chance saja (signifikan atau tidak signifikan) dibantu oleh statistik. Bila secara statistik signifikan, maka mungkin hasil penelitian ini riil. Hal ini disebut juga ENDPOINT.
(P <0,05 yang kebetulan (by chance) <5%. Sisanya bukan kebetulan.)
RANDOMIZATION, beda antara random selection dan random allocation (pada penelitian eksperimental).
Fase I: in vitro atau percobaan pada hewan (is it safe?) Fase II: dose ranging (is it work?) Fase III: Trial ke manusia (is it better that the a Fase IV: Post marketing, melihat efek samping obat dll
BLINDED, terdiri dari: Single blind: yang menerima tidak tahu Double blind: yang menerima dan memberi tidak tahu Triple blind: yang menerima obat, yang memberi obat, dan yang mengukur efek
tidak tahu.Tujuan blinding adalah untuk menghilangkan selection bias.
INTENT-TO-TREAT (obat memang sengaja diberikan untuk kelompok tertentu), meliputi:Orang yang tidak mau mengikuti instruksi, can no longer be located, withdraw, did not receive treatment.
Loss to follow up jangan lebih dari 20%.
STUDY DESIGN2 jenis studi: deskriptif (menyangkut person, place, time) dan analitik (asosiasi).
Scientific approachMelihat sesuatu cari di literatur hipotesis study design collect data analisis data, terima/ tolak hipotesis publikasi dandapatkan scientific revies teori baru hipotesis lagi dst.
Eksperimen –randomized, terdiri dari: RCT dengan control placebo Ot reatment control Historical control (kontrolnya adalah dirinya sendiri) Active control
Sample size determination in health studies (WHO)
LATIHAN STATALog using latihan14mar15.log
Mengetahui hubungan low dengan ftv:

Interpretasi:Ftv terdiri dari 6 kategori. Kunjungan 0-6. Jadi interpretasinya adalah setiap kenaikan 1 unit dari ftv, akan meningkatkan odds dari low sebesar 0,87. (beda dengan interpretasi tabel 2x2, contohnya antara low dengan smoke)
Interpretasi:kalau logistic low smoke, smoke hanya terdiri dari 2 kategori, jadi tabelnya 2x2. Bisa diinterpretasikan langsung ORnya 2,02. Pada ibu merokok/ passive smoker, probabilitas anaknya mengalami BBLR sebesar 67% (dari 100 ibu merokok, 67 ibu akan melahirkan anak yang BBLR).
Interpretasi:

ternyata setelah melibatkan race, yang signifikan hanya race 2. Crude ORnya 2,02. Tapi setelah diadjust dengan mantel-haenzel combined, ORnya menjadi 3,08. Apakah bedanya lebih dari 10%? Kalau lebih dari 10%, berarti ada confounding.
Interpretasi:Awalnya OR low-smoke 2,02. Setelah diadjust dengan race, OR menjadi 3,05 (variabel race sudah dikendalikan). Jadi sebenarnya OR smoke-low adalah 3,05 setelah faktor ras dikendalikan.
Interpretasi: Setelah bebas dari variabel race, pt1, ht, ui, efek murni dari smoke thd BBLR adalah 2,69 dan signifikan.
KULIAH AAEL-128 Maret 2015
MENENTUKAN CUT OFF POINT DENGAN ROC
File : latihan28maret.log
CausationAda 2 komponen: sufficient cause & necessary cause
- Sufficient cause : precedes the disease, if the cause is present, the disease always occurs
- Necessary cause: if the cause is absent, the disease cannot occur, precedes the disease

Necessary and sufficient jarangOnly factor A DiseaseGenetic factors Sickle cell anemia
Necessary but not sufficientFaktor A + B + C disease, contohnya TB
Sufficient but not necessaryFaktor AFaktor B DiseaseFaktor CMisalnya: radiasi kanker
Neither sufficient nor necessaryFaktor A dan/atau Faktor BFaktor C dan/atau Faktor D DiseaseFaktor E dan/atau Faktor F
Bagaimana memastikan faktor risiko adalah kausal?Beberapa yang biasa dipakai (Hills Criteria)
- Temporal relationship: exposure precedes the disease- Strength of the association : measured by the relative risk (either the rate
ratio or the odds ratio)- Dose response relationship- Replication of the findings- Biologic plausibility- Consideration of alternate explanation- Cessation of exposure- Specificity of the association : makin spesifik asosiasi makin jelas hal
tersebut adalah penyebab
Lihat data set : lowbwtffPada variabel birth weight ditemukan bwt 2499.656… kita membagi birth weight menjadi <2500 gram (low birth weight) dan >=2500 gram (normal)Kita harus membuat data kontinyu menjadi data kategoriBagaimana membuat suatu data kontinyu menjadi kategori ?
- Lihat standard deviasiBwt 2944.656
Makin kecil standard deviasi maka data semakin homogen.
Bila data yang kita kumpulkan merupakan data kontinyu dalam jumlah banyak maka langkah selanjutnya adalah membuat summary statistic (rata-rata usia, pembagian jenis kelamin)Summary statistic bertujuan untuk mengangkat sesuatu yang awalnya tidak menarik menjadi menarik

Menentukan cut-off pointMenentukan angka 2500 dengan menentukan : titik valid (sensitive dan specific) untuk menentukan titik potong, yang baik yang imbang sensitivity dan specificityKalau terlalu specific yang banyak false negative, sedangkan terlalu sensitive terlalu banyak false positive.
Menentukan ROC, yaitu kurva yang merupakan gabungan antara sensitivitas (garis Y) dan spesifisitas (garis X)
Contoh :Harus menentukan variabel mana yang secara teori berperanMisalnya kita mulai dari variabel usiaMulai dengan:
Histogram ageHistogram age, norm
0.0
2.0
4.0
6.0
8.1
Den
sity
10 20 30 40 50Age of mother in years
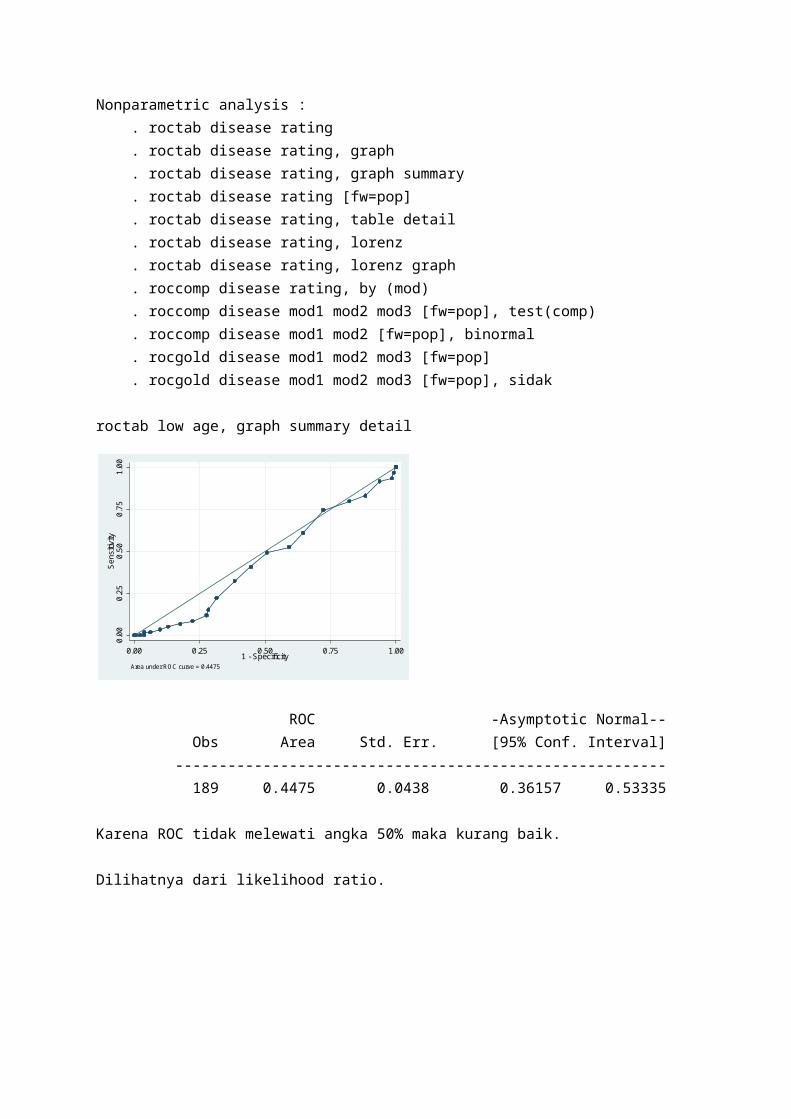
Help roctabNonparametric analysis : . roctab disease rating . roctab disease rating, graph . roctab disease rating, graph summary . roctab disease rating [fw=pop] . roctab disease rating, table detail . roctab disease rating, lorenz . roctab disease rating, lorenz graph . roccomp disease rating, by (mod) . roccomp disease mod1 mod2 mod3 [fw=pop], test(comp) . roccomp disease mod1 mod2 [fw=pop], binormal . rocgold disease mod1 mod2 mod3 [fw=pop] . rocgold disease mod1 mod2 mod3 [fw=pop], sidak

roctab low age, graph summary detail0
.00
0.2
50
.50
0.7
51
.00
Se
nsiti
vity
0.00 0.25 0.50 0.75 1.001 - Specificity
Area under ROC curve = 0.4475
ROC -Asymptotic Normal-- Obs Area Std. Err. [95% Conf. Interval] -------------------------------------------------------- 189 0.4475 0.0438 0.36157 0.53335
Karena ROC tidak melewati angka 50% maka kurang baik.
Dilihatnya dari likelihood ratio.
0.0
00
.25
0.5
00
.75
1.0
0S
ens
itivi
ty
0.00 0.25 0.50 0.75 1.001 - Specificity
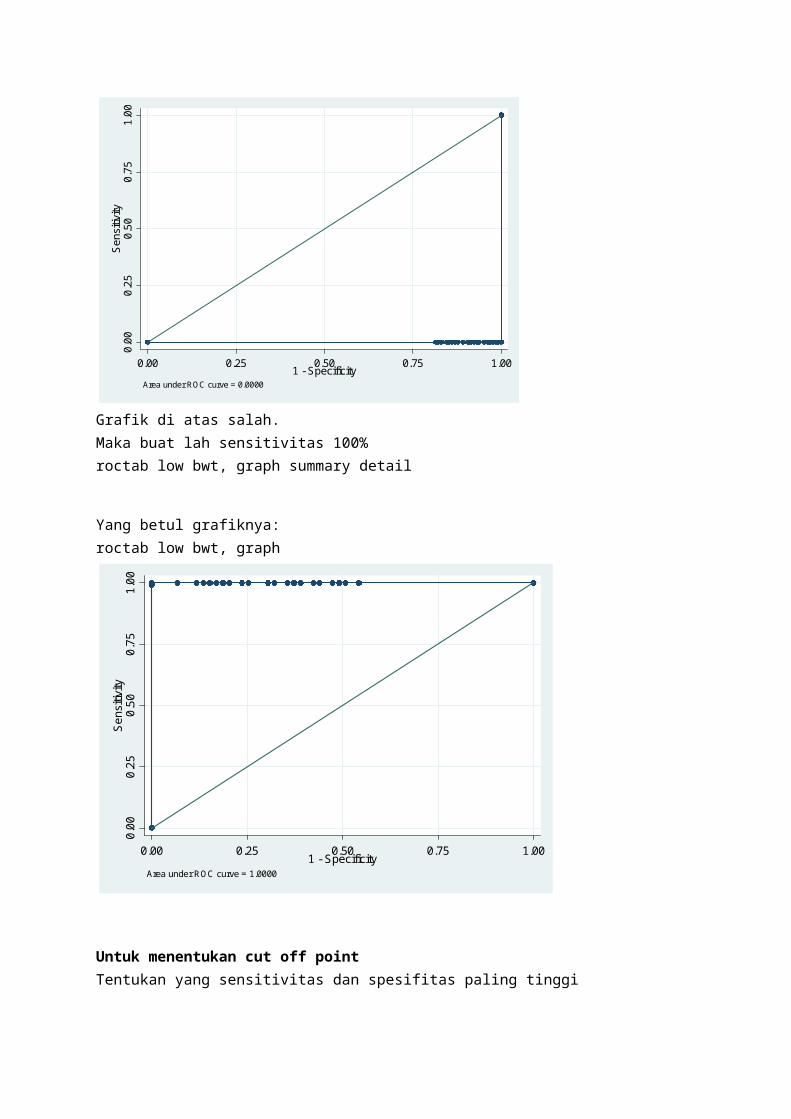
Area under ROC curve = 0.0000
Grafik di atas salah.Maka buat lah sensitivitas 100%roctab low bwt, graph summary detail
Yang betul grafiknya:roctab low bwt, graph

0.0
00
.25
0.5
00
.75
1.0
0S
ens
itivi
ty
0.00 0.25 0.50 0.75 1.001 - Specificity
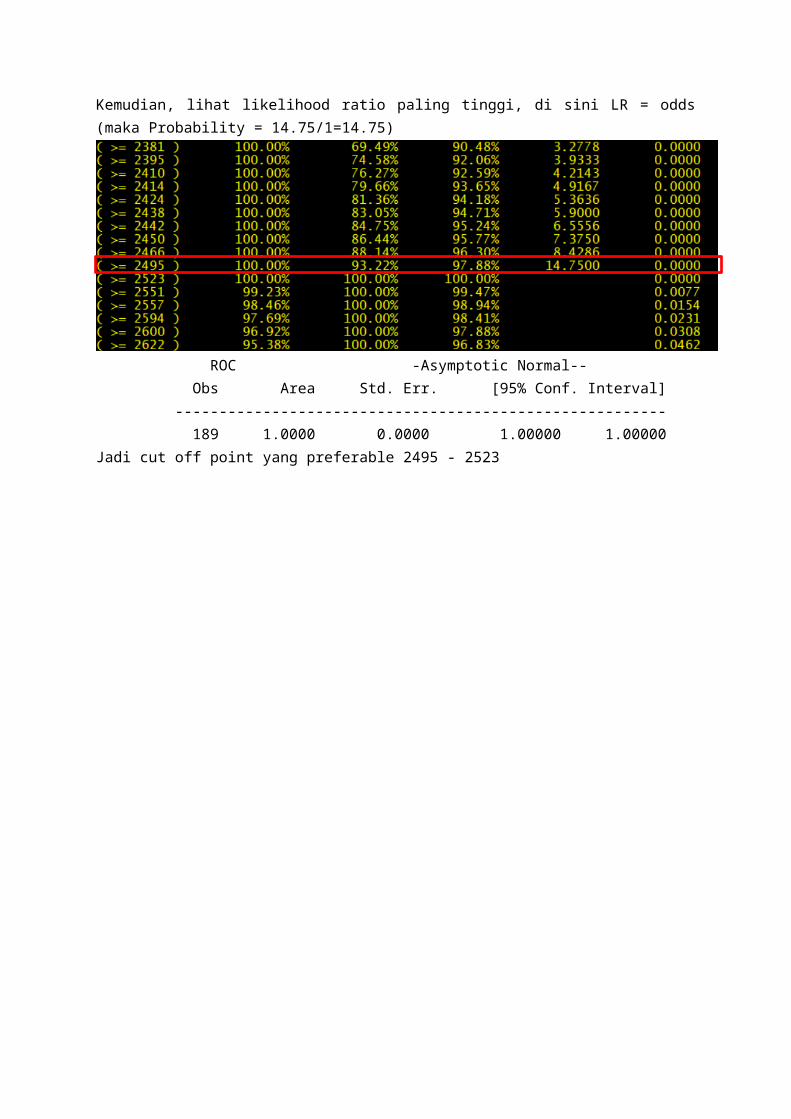
Area under ROC curve = 1.0000
Untuk menentukan cut off pointTentukan yang sensitivitas dan spesifitas paling tinggiKemudian, lihat likelihood ratio paling tinggi, di sini LR = odds (maka Probability = 14.75/1=14.75)
ROC -Asymptotic Normal-- Obs Area Std. Err. [95% Conf. Interval] -------------------------------------------------------- 189 1.0000 0.0000 1.00000 1.00000Jadi cut off point yang preferable 2495 - 2523

KULIAH AAEL-14 APRIL 2015
ANALISIS STRATIFIKASICONFOUNDING & INTERAKSI
Pada kerangka konsep, dilihat hubungan sebab akibat, apa yang menjadi penyebab utama. Lainnya menjadi faktor pengganggu.
Untuk mengendalikan confounding, dilakukan analisis stratifikasi.
ConfoundingConfound (mixing effect) efek yang bercampur, mana yang utama, mana yang pengganggu.Untuk mengendalikan salah satu efek dilakukanlah stratifikasi.
Confounding adalah covariate (berhubungan dengan akibat,dan berhubungan dengan sebab, tapi bukan variabel antara). Contoh sederhana: ada sekumpulan anak sedang bermain bola, bola memecahkan kaca jendela, sesaat itu semua bubar dan ada yang terlihat, jadi melihat yang mana yang penyebab utama (siapa yang memecahkan kaca jendela)
Bias confounding: contoh: melihat orang di dalam ruangan dari kaca jendela, tapi jendelanya kotor, tapi terlihatnya muka orang di dalam ruangan yang kotor. (yang menjadi bias confounding kaca jendela kotor)
Confounding remedies: matching, stratifikasi, restriksi, multivariate
Faktor A berkaitan dengan outcome, desain bisa retrospektif bisa prosepektif.
Confounding: faktor A outcomeTapi ada faktor B yang juga bisa menyebabkan outcomeDan faktor A serta B berhubunganApakah confounding itu dapat mendistorsi data, menjadi lebih besar atau lebih kecil
Contoh: kanker paru dengan kopiKanker paru dengan rokokMaka, yang mana rokok atau kopi yang menyebabkan kanker paru
Contoh : tukang bajaj berkurang pendengaran karena getaran atau suara
Interaksi : bisa menambah atau mengurangi (contoh di farmasi bisa sinergi atau antagonis)Interaksi bisa berbeda dengan confounding, Faktor A bisa menyebabkan outcomeInteraksi bisa menghilangkan atau menambahKalau ada confounding, interaksi bisa diabaikanRelation depends on particular values of factor B
Contoh:Outcome (+) outcome (-)
A (+) 3846 2000 (-) 1154 3000OR 5 Risk 5/6 = 80%Mau melihat apakah A itu murni atau tidak menjadi penyebab outcome.Maka dilakukan stratifikasi dibuat dua stratifikasi faktor B
Di strata 1, A bukan penyebab, karena nilai OR 1.0
Di strata 2, A bukan penyebab, karena nilai OR 1.0Kalau ada positive confounding maka yang dilaporkan data yang sudah distratifikasi jadi ternyata A bukan penyebab.Data A merupakan data crude, unadjusted data (simple)
Contoh 2:Nilai A, OR 1.0Setelah distratifikasi, faktor B,Nilai strata 1, RO 5.0Nilai strata 2, RO 5.0Situasi ini disebut negative confounding, maka faktor B merupakan penyebabIni namanya efek gabungan
Contoh 3:Faktor A (unadjusted) OR 1.71Dilakukan stratifikasi : strata 1, faktor B, OR 0.41 (protektif)
Strata 2, faktor B, OR 5.0 (menyebabkan)Ini namanya interaksi. Pada masing-masing strata sama, namun pada saat digabung (adjusted) bisa berbeda. Maka data yang ditampilkan adalah data yang sudah distratifikasi (qualitative interaction)
Kalau masing2 strata angkanya sama, kalau digabung (unadjusted dan adjusted) beda, itu CONFOUNDING
Kalau masing2 strata angkanya beda, beda, interaksi
Point estimateInterval estimate
Kalau sama lihat 95%CI
Kalau confounding harus di-adjustMaka harus dilkaukan stratifikasi mantel Haenzel, atau Woolf testConfounding : Data kasar dan data strata samaInteraction : data kasar dan data strata beda
Desain membuat restriksi Analisis dilkaukan stratifikasi lalau multivariate Kalau ada harus di stratifikasi
Kalau interaksi, tidak bisa dikontrol. Kalau ada interaksi sulitStop—sajikan data stratifikasi saja
Bila tidak ada interaksi, make summary (adjusted) risk estimate dengan Simple adjustment: direct, indirect, mantel haenzelRegression linier (, logistic (confirmatory)
Kalau kasus terlalu sedikit, banyakin control, untuk menimbulkan power yang sama (paling banyak 4 controls). Kapan dipakai controls lebih dari 2?Contoh: kanker esophagus (dapat kasus minimal, namun kontrolnya pasti sulit misalnya usia > 85 th tanpa kanker esophagus)
Simple (unadjusted)
strata B1
strata B2
1.9 1.8 2
lihat interval estimate, jika beda (interaction), jika tidak beda (confounding), tapi bisa bukan confounding dan bukan interaction, tergantung besar sample. Kalau interaction sajikan data yang stratifikasi
2.3 1.4 5.5 Interaksitidak perlu di-adjust
1.3 5.1 4.8 Confounding3.6 0.3 17.4 Interaksi1.1 0.37 0.54 Confounding2.8 1.7 3.8 Interaksi
Contoh :OR 2.37 dengan 95% CI 1.79-3.16Chi2(1) = 39.90 Data 3154 sampelProbabilitas terjadinya outcome dari case 2.37/3.37
Lalu dilakukan stratifikasi dari faktor USIAUsia < 48 Didapat OR 2.05Usia > 48 didapat OR 2.39
Dibuat stratanya dulu, mau tahu umur itu confounding atau bukan terhadap kepribadian.Maka dilakukan mantel haenzel, didapatkan Crude 2.37
MH 2.23Perbandingan Crude dan Mantel Haenzel= <10% bukan confoundingInstruksi Stata untuk MH:.cc chd ab, by (age_g)
Latihan StataBuat analisis stratifikasi dari variabel yang terdiri dari 3 kategori.Dari data lowbwtff.dtaVariabel yang terdiri dari 3 kategori adalah race, visit physician (ftv), ptl
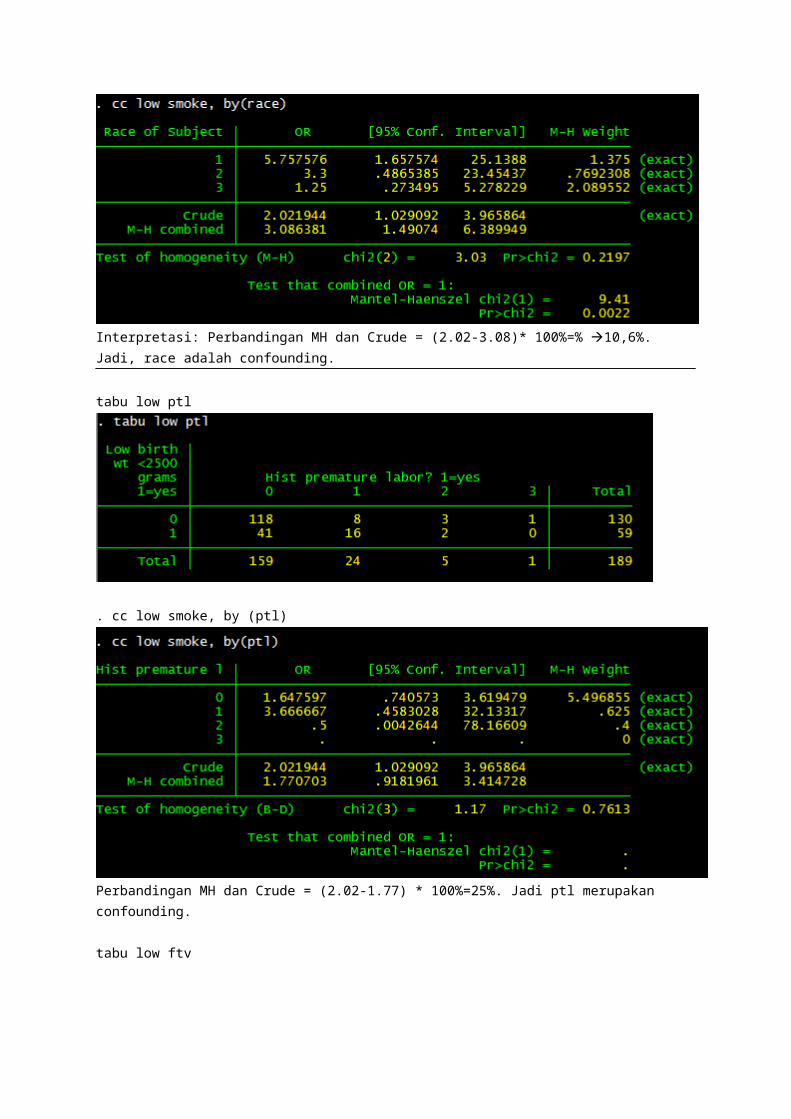
cc low smoke, by(race)
Interpretasi: Perbandingan MH dan Crude = (2.02-3.08)* 100%=% 10,6%. Jadi, race adalah confounding.
tabu low ptl

. cc low smoke, by (ptl)
Perbandingan MH dan Crude = (2.02-1.77) * 100%=25%. Jadi ptl merupakan confounding.
tabu low ftv
. cc low smoke, by (ftv)

Perbandingan MH dan Crude = (2.02-1.86) * 100% =16% ftv merupakan confounding.
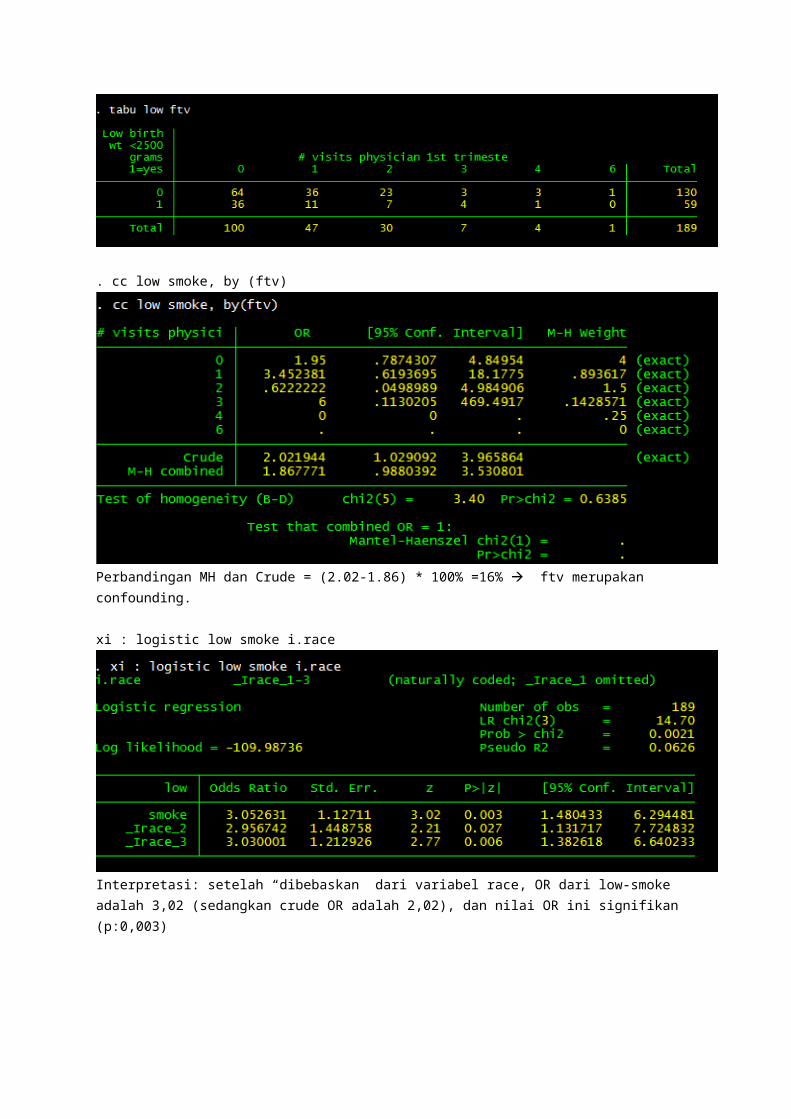
xi : logistic low smoke i.race
Interpretasi: setelah “dibebaskan” dari variabel race, OR dari low-smoke adalah 3,02 (sedangkan crude OR adalah 2,02), dan nilai OR ini signifikan (p:0,003)
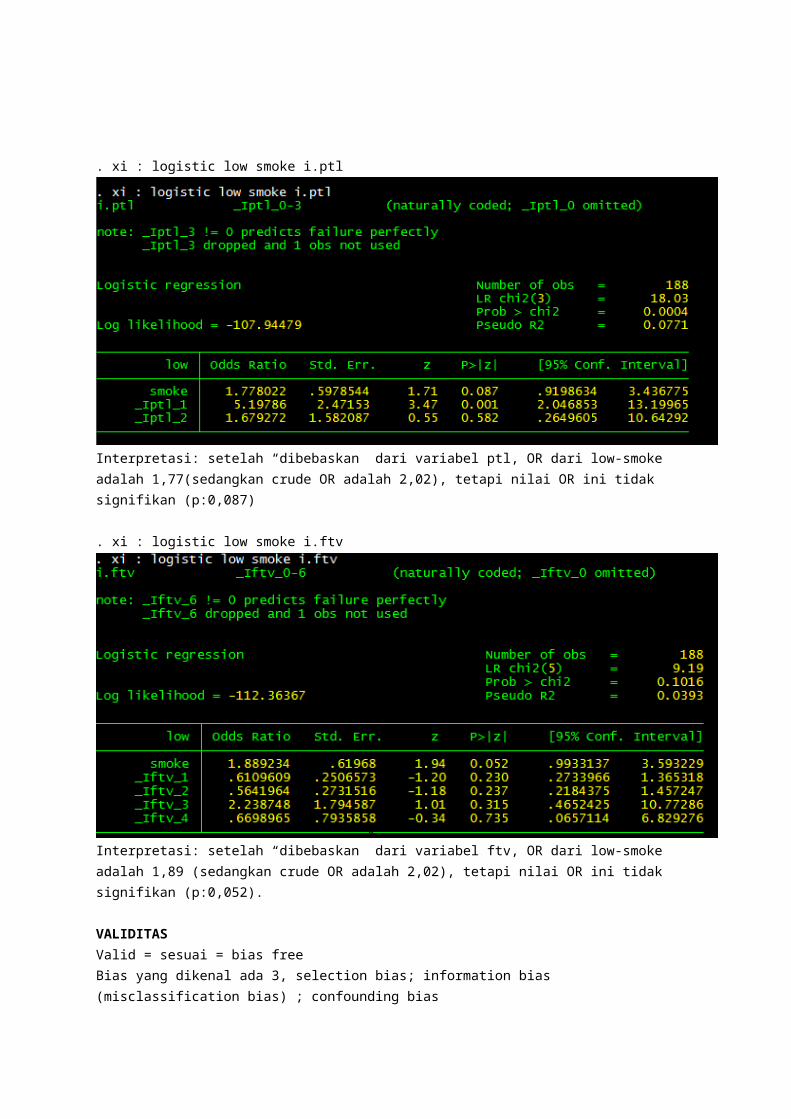
. xi : logistic low smoke i.ptl

Interpretasi: setelah “dibebaskan” dari variabel ptl, OR dari low-smoke adalah 1,77(sedangkan crude OR adalah 2,02), tetapi nilai OR ini tidak signifikan (p:0,087)
. xi : logistic low smoke i.ftv
Interpretasi: setelah “dibebaskan” dari variabel ftv, OR dari low-smoke adalah 1,89 (sedangkan crude OR adalah 2,02), tetapi nilai OR ini tidak signifikan (p:0,052).
VALIDITASValid = sesuai = bias freeBias yang dikenal ada 3, selection bias; information bias (misclassification bias) ; confounding biasAda satu bias yang sistematik yaitu sampling bias.Contoh: pengisian kuosioner recall bias (information bias)
Contoh Selection bias pada case control : Memilih kasus dan control terkait determinanSelection of cases or controls is related to determinant.Yang paling sulit adalah selection bias (bias saat seleksi), contoh case control. Yang sulit di kanker paru dan hubungannya dengan merokok di grup kasus, sedangkan di grup

control yang bukan kanker paru (tapi kalau dipilih bronchitis bisa saja dipengaruih merokok. Contoh lain: diare dengan makan gado-gado , control : diare dan tidak diare (misalnya dipilih sampel orang Belanda, kontrolnya orang Indonesia)Selection bias dapat dicegah saat design.Selection bias tidak dapat dicegah saat analisis data.
Selection bias pada cohort:Selection of determinant groups is related to outcomeFraktur dan hubungannya dengan rokok di negara barat bisa ada kaitannya dengan osteoporosis.Sedangkan di Indonesia lebih kaitannya dengan usia muda (trauma).
KULIAH AAEL-111 April 2015
BIASDOSE-RESPONSE RELATIONSHIP
Penelitian Eksperimen + Non-eksperimenAnalytic: case control, cohort, experiment
Case control vs cohort: Case-control dimulai dari kasus Cohort dimulai dari exposure- sekelompok orang yang exposed diikuti dalam
periode waktu tertentu (konsep epidemiologi: exposed dan non-exposed) Nested case-control : kasus control yang ”disarangkan” dalam cohort yang
sedang berjalan, tapi dasarnya tetap cohort. Contoh: sekelompok pekerja tambang saat awal masuk pasti dilakukan skrining kesehatan dan diambil darah yang disimpan di suhu -70C. pada suatu saat, diambil sampel darah dari beberapa sampel. Diambil beberapa orang yang dikelompokkan dalam kelompok kasus dan kelompok control. (tapi saat studi kohort berlangsung).
Latar belakang:- Besar masalah- Masalah spesifik (mau meneliti etiognostik/diagnostik/prognostic)
Yang paling sulit : selection bias (pada desain penelitian case control atau cross sectional)Pada case control: yang sulit memilih kelompok control karena diharapkan tidak berkaitan dengan determinan. Contoh: menentukan faktor determinan dari kanker paru (grup kasus), kemudian memilih kelompok control dengan diagnosis penyakit jantung coroner. Padahal determinan dari dua kelompok tersebut sama yaitu merokok.
Analisis dasar : cut off point, mean-median,dllAttributable fraction (pop.) = 0.4 bila merokok dihilangkan di populasi dapat menghilangkan risiko penyakit sebesar 40% di populasiAttributable fraction (exp). = 0.5 antara expo dan non-expo, jika merokok dihilangkan akan menghilangkan risiko sebesar 50%
Kalau confounding, kelompok 1 dan kelompok 2 - SAMAContoh: pada kelompok 1 OR 2.1 (95% Ci 1.3 – 3.1)Pada kelompok 2 OR (2.9 (95% CI 1.4-3.0)Lihat juga range CI-nya, kedua angka OR di atas di dalam range CI, maka sama , maka CONFOUNDING
Untuk menganalisa adanya confounding, menggunakan stratiikasi. Masuk ke bagian Mentel-Haenszel analisis Lihat perbandingan antara crude dan MH Bila test homogenicity, tidak signifikan, maka kedua kelompok tersebut homogen.
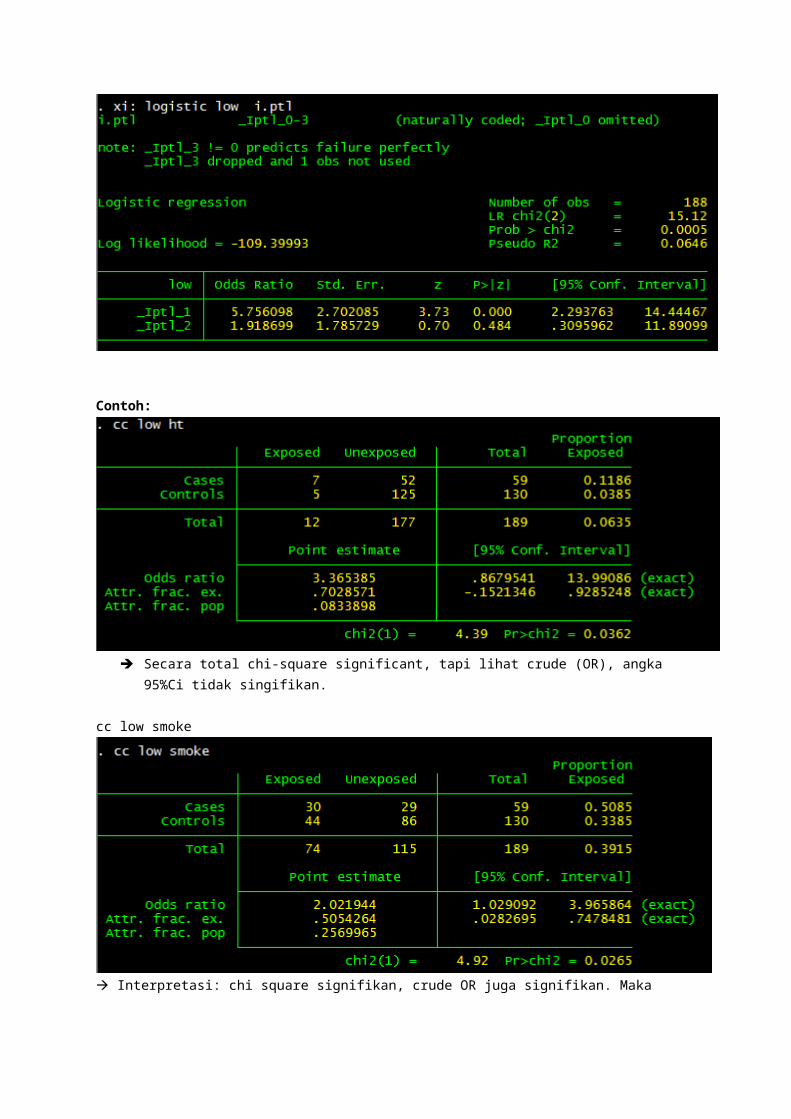
Contoh instruksi STATA untuk dapat OR crude :cc var1 var2
ANALISIS DOSE-RESPONSE.xi: logistic chd i. chol_gLogistic regressionDidapatkan tabel, lihat nilai OR risk=OR/OR+1
Dilakukan analisis dose response sebagai : kriteria untuk menyatakan ada hubungan sebab akibat (strength of association, -- lihat Kriteria Hill)
Contoh:. xi : logistic low i.ptl
Contoh:
Secara total chi-square significant, tapi lihat crude (OR), angka 95%Ci tidak singifikan.
cc low smoke
Interpretasi: chi square signifikan, crude OR juga signifikan. Maka dapat diinterpretasikan, dengan merokok dihilangkan dapat memengaruhi low bwt sebesar 25%
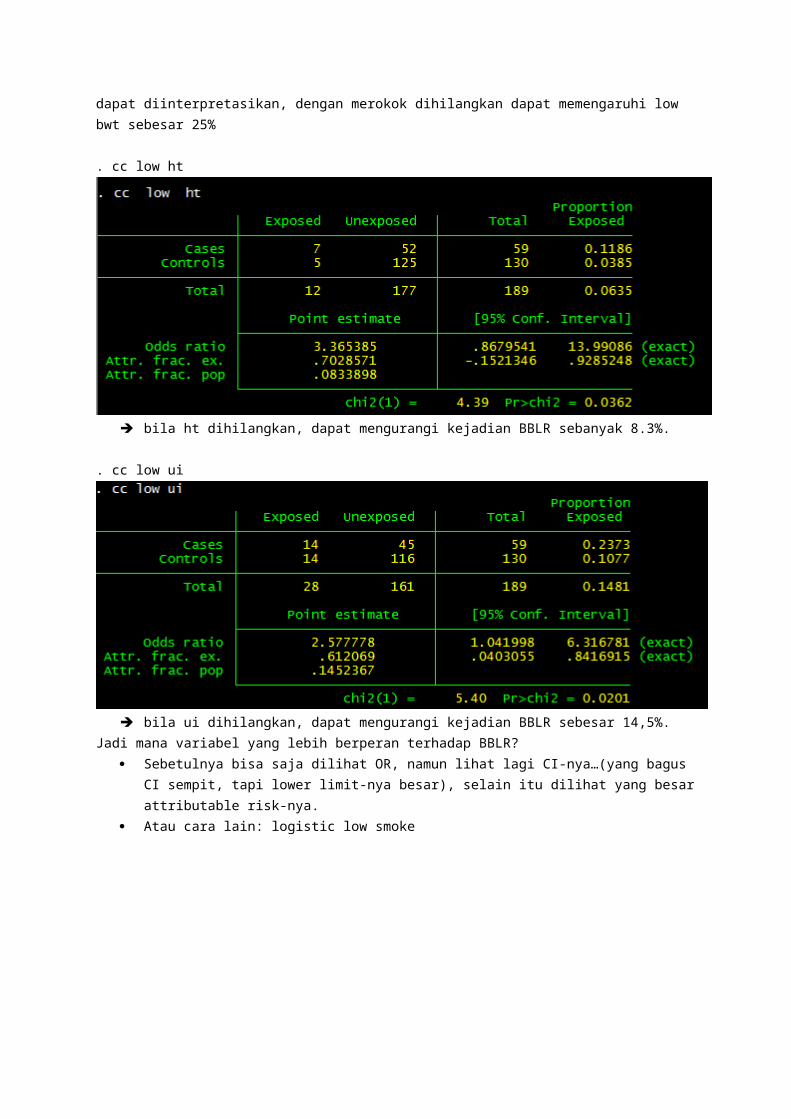
. cc low ht
bila ht dihilangkan, dapat mengurangi kejadian BBLR sebanyak 8.3%.
. cc low ui
bila ui dihilangkan, dapat mengurangi kejadian BBLR sebesar 14,5%.Jadi mana variabel yang lebih berperan terhadap BBLR?
Sebetulnya bisa saja dilihat OR, namun lihat lagi CI-nya…(yang bagus CI sempit, tapi lower limit-nya besar), selain itu dilihat yang besar attributable risk-nya.

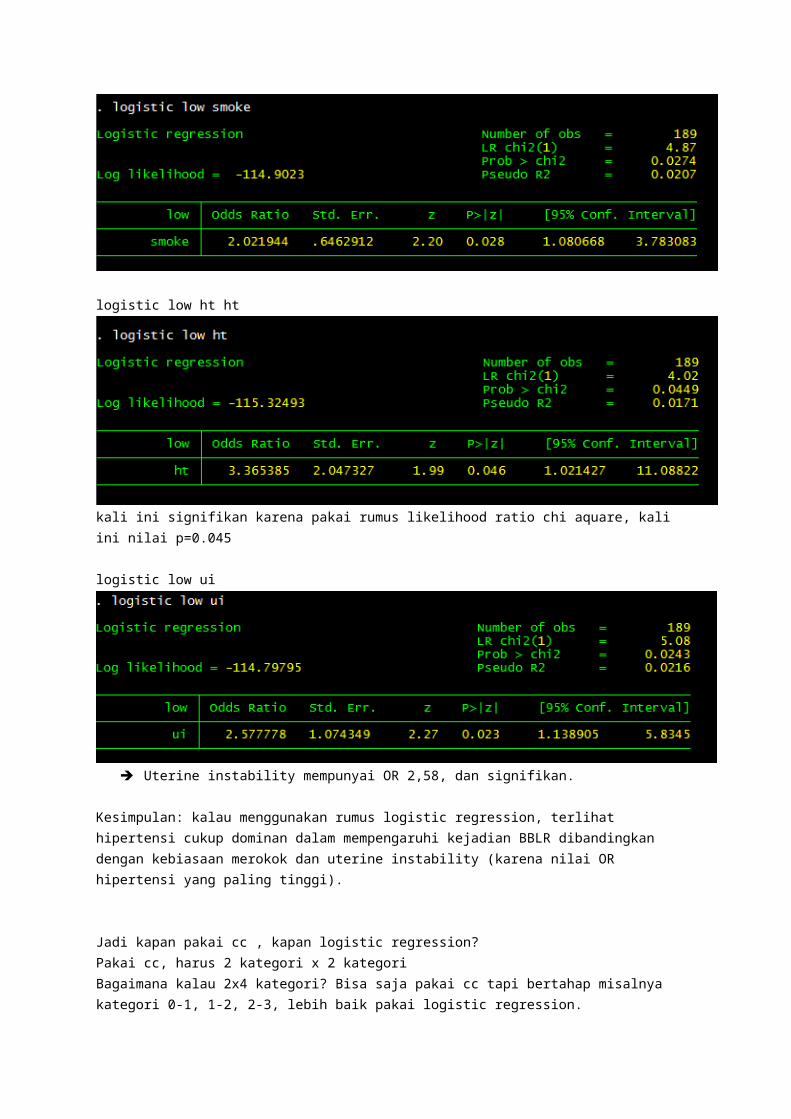
Atau cara lain: logistic low smoke
logistic low ht ht
kali ini signifikan karena pakai rumus likelihood ratio chi aquare, kali ini nilai p=0.045
logistic low ui
Uterine instability mempunyai OR 2,58, dan signifikan.
Kesimpulan: kalau menggunakan rumus logistic regression, terlihat hipertensi cukup dominan dalam mempengaruhi kejadian BBLR dibandingkan dengan kebiasaan merokok dan uterine instability (karena nilai OR hipertensi yang paling tinggi).
Jadi kapan pakai cc , kapan logistic regression?Pakai cc, harus 2 kategori x 2 kategoriBagaimana kalau 2x4 kategori? Bisa saja pakai cc tapi bertahap misalnya kategori 0-1, 1-2, 2-3, lebih baik pakai logistic regression.
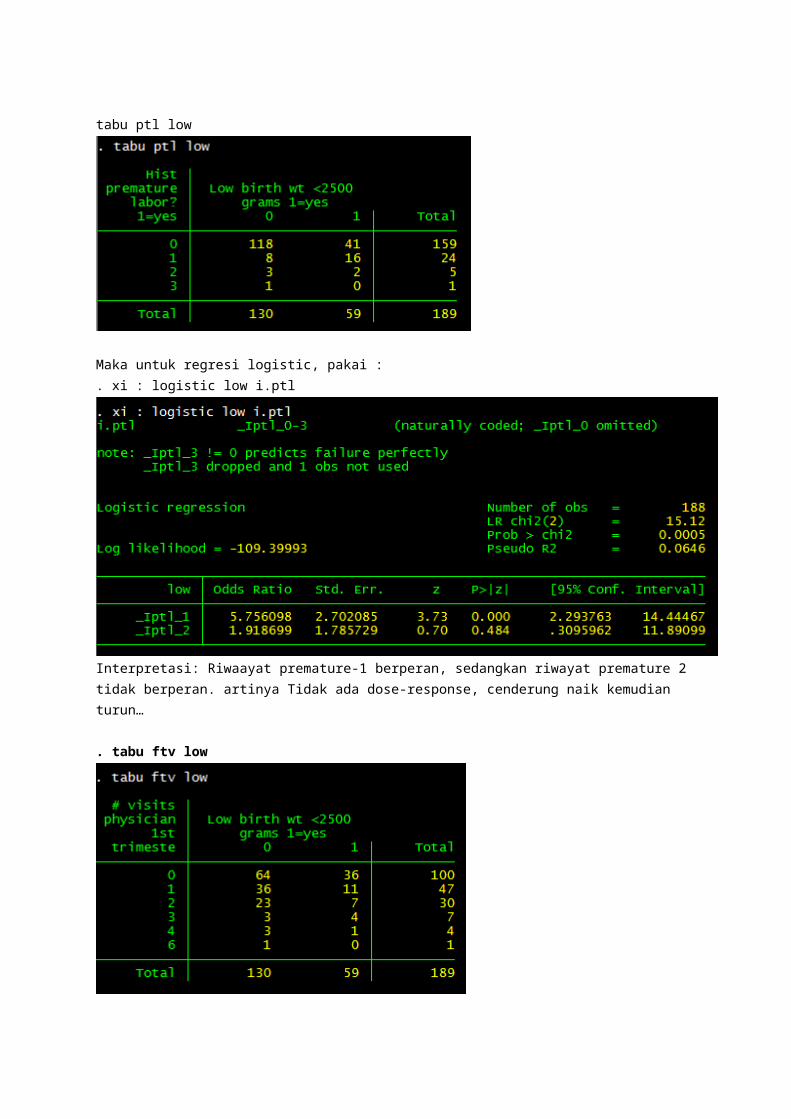
tabu ptl low

Maka untuk regresi logistic, pakai :. xi : logistic low i.ptl
Interpretasi: Riwaayat premature-1 berperan, sedangkan riwayat premature 2 tidak berperan. artinya Tidak ada dose-response, cenderung naik kemudian turun…
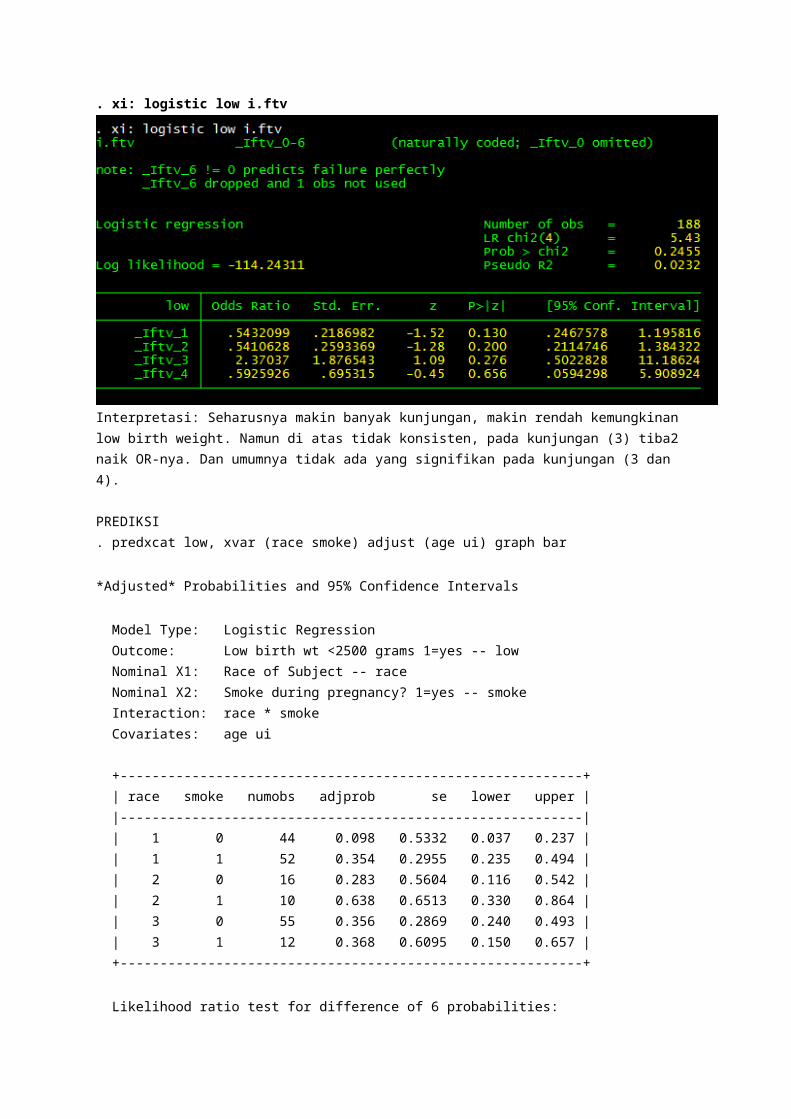
. tabu ftv low
. xi: logistic low i.ftv

Interpretasi: Seharusnya makin banyak kunjungan, makin rendah kemungkinan low birth weight. Namun di atas tidak konsisten, pada kunjungan (3) tiba2 naik OR-nya. Dan umumnya tidak ada yang signifikan pada kunjungan (3 dan 4).
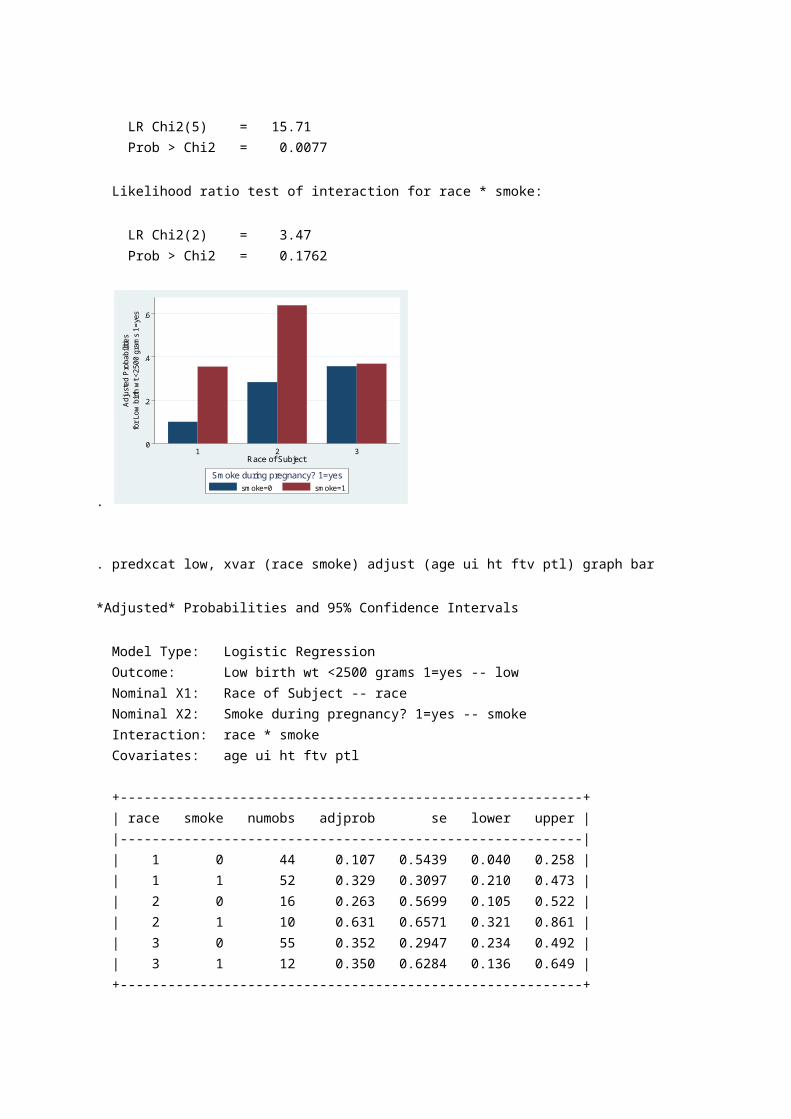
PREDIKSI. predxcat low, xvar (race smoke) adjust (age ui) graph bar *Adjusted* Probabilities and 95% Confidence Intervals Model Type: Logistic Regression Outcome: Low birth wt <2500 grams 1=yes -- low Nominal X1: Race of Subject -- race Nominal X2: Smoke during pregnancy? 1=yes -- smoke Interaction: race * smoke Covariates: age ui
+----------------------------------------------------------+ | race smoke numobs adjprob se lower upper | |----------------------------------------------------------| | 1 0 44 0.098 0.5332 0.037 0.237 | | 1 1 52 0.354 0.2955 0.235 0.494 | | 2 0 16 0.283 0.5604 0.116 0.542 | | 2 1 10 0.638 0.6513 0.330 0.864 | | 3 0 55 0.356 0.2869 0.240 0.493 | | 3 1 12 0.368 0.6095 0.150 0.657 | +----------------------------------------------------------+ Likelihood ratio test for difference of 6 probabilities: LR Chi2(5) = 15.71 Prob > Chi2 = 0.0077 Likelihood ratio test of interaction for race * smoke: LR Chi2(2) = 3.47
Prob > Chi2 = 0.1762
.
0
.2
.4
.6
for
Low
bir
th w
t <2
500
gra
ms
1=
yes
1 2 3
Ad
just
ed
Pro
bab
ilitie
s
Race of Subject
smoke=0 smoke=1
Smoke during pregnancy? 1=yes
. predxcat low, xvar (race smoke) adjust (age ui ht ftv ptl) graph bar *Adjusted* Probabilities and 95% Confidence Intervals Model Type: Logistic Regression Outcome: Low birth wt <2500 grams 1=yes -- low Nominal X1: Race of Subject -- race Nominal X2: Smoke during pregnancy? 1=yes -- smoke Interaction: race * smoke Covariates: age ui ht ftv ptl
+----------------------------------------------------------+ | race smoke numobs adjprob se lower upper | |----------------------------------------------------------| | 1 0 44 0.107 0.5439 0.040 0.258 | | 1 1 52 0.329 0.3097 0.210 0.473 | | 2 0 16 0.263 0.5699 0.105 0.522 | | 2 1 10 0.631 0.6571 0.321 0.861 | | 3 0 55 0.352 0.2947 0.234 0.492 | | 3 1 12 0.350 0.6284 0.136 0.649 | +----------------------------------------------------------+ Likelihood ratio test for difference of 6 probabilities: LR Chi2(5) = 12.90 Prob > Chi2 = 0.0244 Likelihood ratio test of interaction for race * smoke: LR Chi2(2) = 3.06 Prob > Chi2 = 0.2162
.
0
.2
.4
.6fo
r Lo
w b
irth
wt <
250
0 gr
am
s 1
=ye
s
1 2 3
Ad
just
ed
Pro
bab
ilitie
s
Race of Subject
smoke=0 smoke=1Smoke during pregnancy? 1=yes
. predxcat low, xvar (ftv smoke) adjust (age ui ht race ptl) graph bar(2 missing values generated)(2 missing values generated)(2 missing values generated)(2 missing values generated)(2 missing values generated) *Adjusted* Probabilities and 95% Confidence Intervals Model Type: Logistic Regression Outcome: Low birth wt <2500 grams 1=yes -- low Nominal X1: # visits physician 1st trimeste -- ftv Nominal X2: Smoke during pregnancy? 1=yes -- smoke Interaction: ftv * smoke Covariates: age ui ht race ptl
+---------------------------------------------------------+ | ftv smoke numobs adjprob se lower upper | |---------------------------------------------------------| | 0 0 55 0.234 0.3596 0.131 0.383 | | 0 1 45 0.412 0.3491 0.261 0.581 | | 1 0 35 0.147 0.4973 0.061 0.313 | | 1 1 12 0.480 0.6286 0.212 0.760 | | 2 0 19 0.263 0.5579 0.107 0.515 | | 2 1 11 0.283 0.8048 0.075 0.657 | | 3 0 3 0.331 1.2613 0.040 0.854 | | 3 1 4 0.801 1.1962 0.279 0.977 | | 4 0 3 0.310 1.3287 0.032 0.859 | | 4 1 1 . . . . | | 6 1 1 . . . . | +---------------------------------------------------------+ Likelihood ratio test for difference of 12 probabilities: LR Chi2(8) = 11.92 Prob > Chi2 = 0.1547 Likelihood ratio test of interaction for ftv * smoke: LR Chi2(3) = 2.25
Prob > Chi2 = 0.5226
.
0
.2
.4
.6
.8
for
Low
bir
th w
t <2
500
gra
ms
1=
yes
0 1 2 3 4 6
Ad
just
ed
Pro
bab
ilitie
s
# visits physician 1st trimeste
smoke=0 smoke=1Smoke during pregnancy? 1=yes
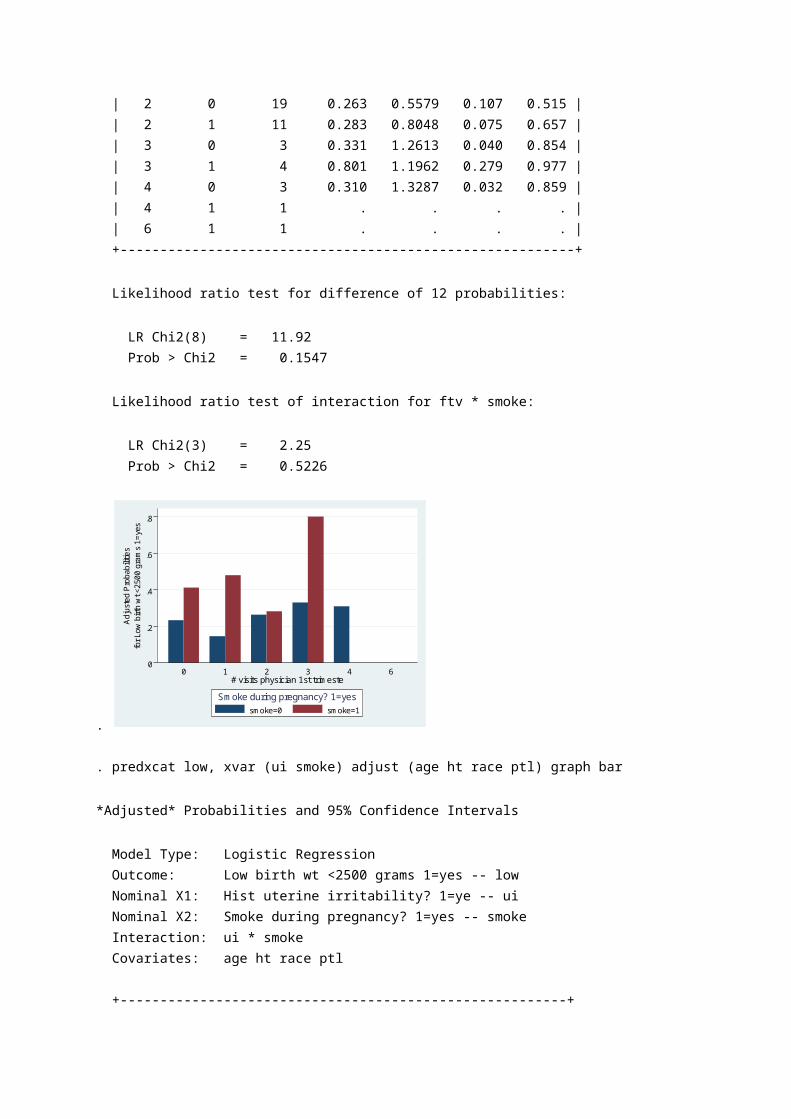
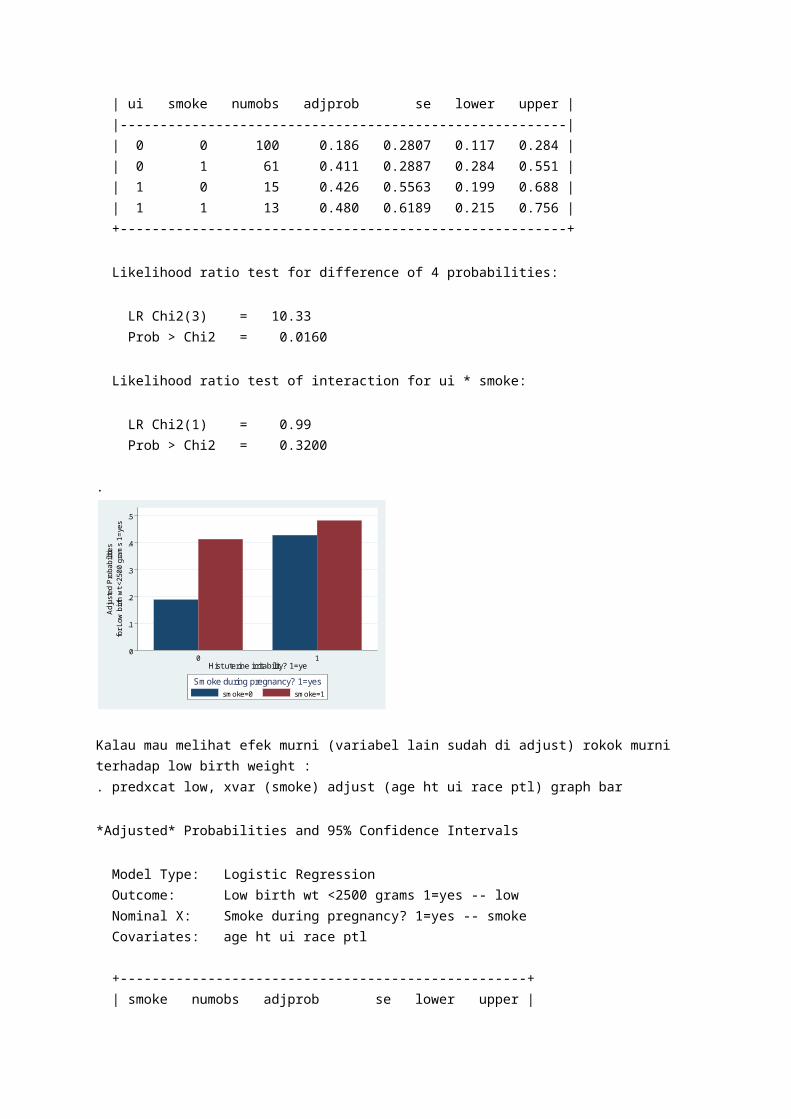
. predxcat low, xvar (ui smoke) adjust (age ht race ptl) graph bar *Adjusted* Probabilities and 95% Confidence Intervals Model Type: Logistic Regression Outcome: Low birth wt <2500 grams 1=yes -- low Nominal X1: Hist uterine irritability? 1=ye -- ui Nominal X2: Smoke during pregnancy? 1=yes -- smoke Interaction: ui * smoke Covariates: age ht race ptl
+--------------------------------------------------------+ | ui smoke numobs adjprob se lower upper | |--------------------------------------------------------| | 0 0 100 0.186 0.2807 0.117 0.284 | | 0 1 61 0.411 0.2887 0.284 0.551 | | 1 0 15 0.426 0.5563 0.199 0.688 | | 1 1 13 0.480 0.6189 0.215 0.756 | +--------------------------------------------------------+ Likelihood ratio test for difference of 4 probabilities: LR Chi2(3) = 10.33 Prob > Chi2 = 0.0160 Likelihood ratio test of interaction for ui * smoke: LR Chi2(1) = 0.99 Prob > Chi2 = 0.3200
.
0
.1
.2
.3
.4
.5fo
r Lo
w b
irth
wt <
250
0 gr
am
s 1
=ye
s
0 1
Ad
just
ed
Pro
bab
ilitie
s
Hist uterine irritability? 1=ye
smoke=0 smoke=1
Smoke during pregnancy? 1=yes
Kalau mau melihat efek murni (variabel lain sudah di adjust) rokok murni terhadap low birth weight :. predxcat low, xvar (smoke) adjust (age ht ui race ptl) graph bar *Adjusted* Probabilities and 95% Confidence Intervals Model Type: Logistic Regression Outcome: Low birth wt <2500 grams 1=yes -- low Nominal X: Smoke during pregnancy? 1=yes -- smoke Covariates: age ht ui race ptl
+---------------------------------------------------+ | smoke numobs adjprob se lower upper | |---------------------------------------------------| | 0 115 0.217 0.2534 0.144 0.313 | | 1 74 0.419 0.2682 0.299 0.549 | +---------------------------------------------------+ Likelihood ratio test for difference of 2 probabilities: LR Chi2(1) = 6.24 Prob > Chi2 = 0.0125
0
.1
.2
.3
.4
for
Low
bir
th w
t <2
500
gra
ms
1=
yes
0 1
Ad
just
ed
Pro
bab
ilitie
s
Smoke during pregnancy? 1=yes
Interpretasi : Prediksi variabel kategori (terjadinya low), dengan variabel utama (smoke), dan variabel lain di adjust (age, race, ht, ui, ptl), dan sajikan data dalam grafik bar. Dengan mempertimbangkan adanya interaksi, bila tidak merokok, probabilitas low birth weight 21.7% dengan 95%CI 14.4%-31.3%. Bila merokok, meningkatkan probabilitas low birth weight menjadi 41.9% dengan 95%CI 29.9-54.9%.
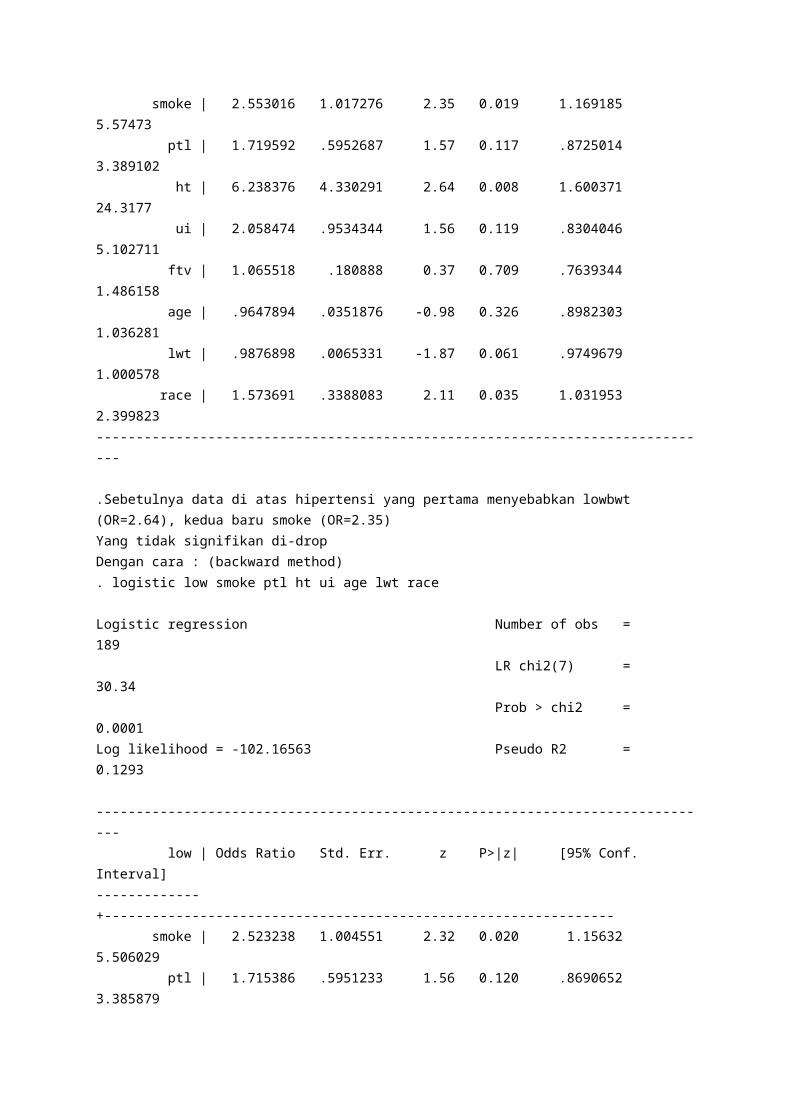
Sebetulnya… command yang “manual”. logistic low smoke ptl ht ui ftv age lwt race
Logistic regression Number of obs = 189 LR chi2(8) = 30.48 Prob > chi2 = 0.0002Log likelihood = -102.09641 Pseudo R2 = 0.1299
------------------------------------------------------------------------------ low | Odds Ratio Std. Err. z P>|z| [95% Conf. Interval]-------------+---------------------------------------------------------------- smoke | 2.553016 1.017276 2.35 0.019 1.169185 5.57473 ptl | 1.719592 .5952687 1.57 0.117 .8725014 3.389102 ht | 6.238376 4.330291 2.64 0.008 1.600371 24.3177 ui | 2.058474 .9534344 1.56 0.119 .8304046 5.102711 ftv | 1.065518 .180888 0.37 0.709 .7639344 1.486158 age | .9647894 .0351876 -0.98 0.326 .8982303 1.036281 lwt | .9876898 .0065331 -1.87 0.061 .9749679 1.000578 race | 1.573691 .3388083 2.11 0.035 1.031953 2.399823------------------------------------------------------------------------------
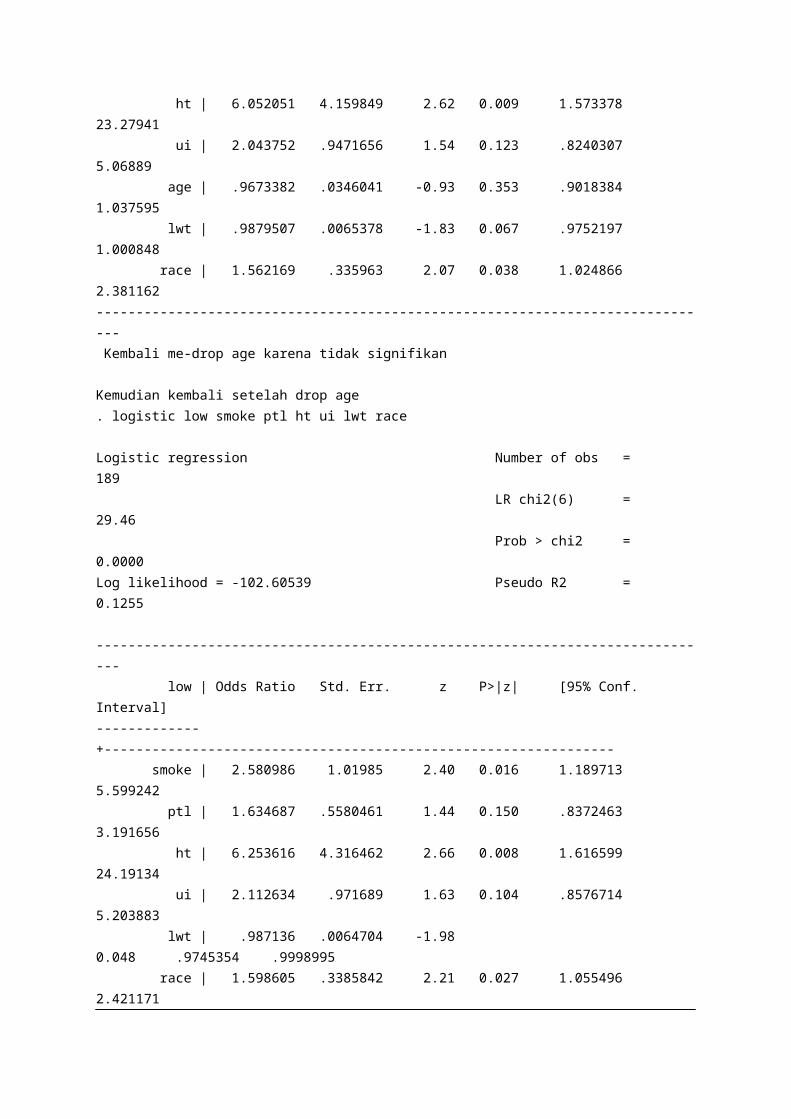
.Sebetulnya data di atas hipertensi yang pertama menyebabkan lowbwt (OR=2.64), kedua baru smoke (OR=2.35)Yang tidak signifikan di-dropDengan cara : (backward method). logistic low smoke ptl ht ui age lwt race
Logistic regression Number of obs = 189 LR chi2(7) = 30.34 Prob > chi2 = 0.0001Log likelihood = -102.16563 Pseudo R2 = 0.1293
------------------------------------------------------------------------------ low | Odds Ratio Std. Err. z P>|z| [95% Conf. Interval]-------------+---------------------------------------------------------------- smoke | 2.523238 1.004551 2.32 0.020 1.15632 5.506029 ptl | 1.715386 .5951233 1.56 0.120 .8690652 3.385879 ht | 6.052051 4.159849 2.62 0.009 1.573378 23.27941 ui | 2.043752 .9471656 1.54 0.123 .8240307 5.06889 age | .9673382 .0346041 -0.93 0.353 .9018384 1.037595 lwt | .9879507 .0065378 -1.83 0.067 .9752197 1.000848 race | 1.562169 .335963 2.07 0.038 1.024866 2.381162------------------------------------------------------------------------------ Kembali me-drop age karena tidak signifikan
Kemudian kembali setelah drop age. logistic low smoke ptl ht ui lwt race
Logistic regression Number of obs = 189 LR chi2(6) = 29.46 Prob > chi2 = 0.0000
Log likelihood = -102.60539 Pseudo R2 = 0.1255
------------------------------------------------------------------------------ low | Odds Ratio Std. Err. z P>|z| [95% Conf. Interval]-------------+---------------------------------------------------------------- smoke | 2.580986 1.01985 2.40 0.016 1.189713 5.599242 ptl | 1.634687 .5580461 1.44 0.150 .8372463 3.191656 ht | 6.253616 4.316462 2.66 0.008 1.616599 24.19134 ui | 2.112634 .971689 1.63 0.104 .8576714 5.203883 lwt | .987136 .0064704 -1.98 0.048 .9745354 .9998995 race | 1.598605 .3385842 2.21 0.027 1.055496 2.421171
Masih ada yang tidak signifikan
. logistic low smoke ht ui lwt race
Logistic regression Number of obs = 189 LR chi2(5) = 27.33 Prob > chi2 = 0.0000Log likelihood = -103.67021 Pseudo R2 = 0.1165
------------------------------------------------------------------------------ low | Odds Ratio Std. Err. z P>|z| [95% Conf. Interval]-------------+---------------------------------------------------------------- smoke | 2.841152 1.10446 2.69 0.007 1.326176 6.086782 ht | 6.335655 4.341321 2.69 0.007 1.653982 24.26902 ui | 2.390032 1.075332 1.94 0.053 .9895275 5.772707 lwt | .9862774 .0064069 -2.13 0.033 .9737997 .998915 race | 1.619502 .3404269 2.29 0.022 1.072643 2.445165------------------------------------------------------------------------------Makin berat ibu, makin kecil OR terjadinya bayi berat badan rendah (OR -0.98, p=0.033, 95%CI 0.97-0.99)
Kemudian baru lanjut ke command predxcat
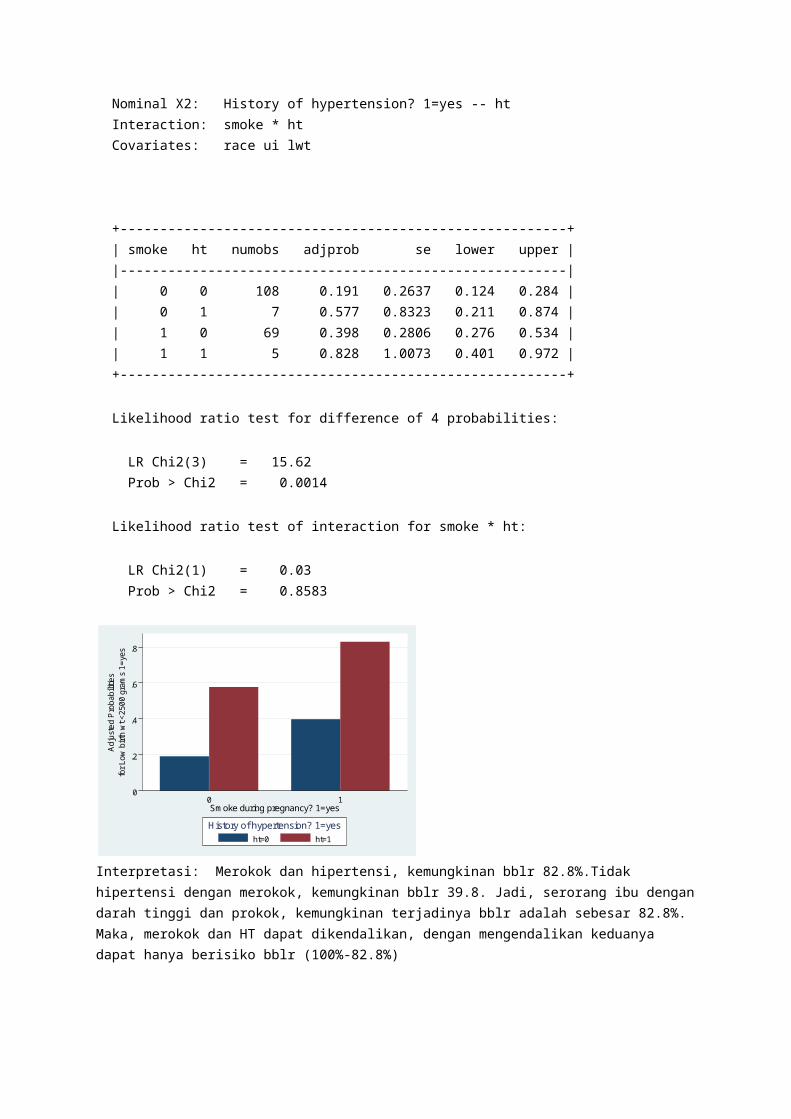
. predxcat low, xvar (smoke ht) adjust (race ui lwt) graph bar *Adjusted* Probabilities and 95% Confidence Intervals Model Type: Logistic Regression Outcome: Low birth wt <2500 grams 1=yes -- low Nominal X1: Smoke during pregnancy? 1=yes -- smoke Nominal X2: History of hypertension? 1=yes -- ht Interaction: smoke * ht Covariates: race ui lwt
+--------------------------------------------------------+ | smoke ht numobs adjprob se lower upper | |--------------------------------------------------------| | 0 0 108 0.191 0.2637 0.124 0.284 |

| 0 1 7 0.577 0.8323 0.211 0.874 | | 1 0 69 0.398 0.2806 0.276 0.534 | | 1 1 5 0.828 1.0073 0.401 0.972 | +--------------------------------------------------------+ Likelihood ratio test for difference of 4 probabilities: LR Chi2(3) = 15.62 Prob > Chi2 = 0.0014 Likelihood ratio test of interaction for smoke * ht: LR Chi2(1) = 0.03 Prob > Chi2 = 0.8583
0
.2
.4
.6
.8
for
Low
bir
th w
t <2
500
gra
ms
1=
yes
0 1
Ad
just
ed
Pro
bab
ilitie
s
Smoke during pregnancy? 1=yes
ht=0 ht=1History of hypertension? 1=yes
Interpretasi: Merokok dan hipertensi, kemungkinan bblr 82.8%.Tidak hipertensi dengan merokok, kemungkinan bblr 39.8. Jadi, serorang ibu dengan darah tinggi dan prokok, kemungkinan terjadinya bblr adalah sebesar 82.8%. Maka, merokok dan HT dapat dikendalikan, dengan mengendalikan keduanya dapat hanya berisiko bblr (100%-82.8%)
Untuk memprediksi merokok dengan usia 30 tahun, probabilitas untuk terjadi hipertensi:. predcalc ht, xvar (smoke=1 age=30) model
Logistic regression Number of obs = 189 LR chi2(2) = 0.08 Prob > chi2 = 0.9615Log likelihood = -44.653551 Pseudo R2 = 0.0009
------------------------------------------------------------------------------ ht | Odds Ratio Std. Err. z P>|z| [95% Conf. Interval]-------------+---------------------------------------------------------------- smoke | 1.111855 .6738534 0.17 0.861 .3389745 3.646946 age | .9879358 .0570646 -0.21 0.834 .88219 1.106357Model: Logistic RegressionOutcome: History of hypertension? 1=yes -- htX Values: smoke=1 age=30Num. Obs: 189
Predicted Value and 95% CI for ht: 0.0623 (0.0191, 0.1850)
. predcalc ht, xvar (smoke=1 ui=0 age=30) model
note: ui != 0 predicts failure perfectly ui dropped and 28 obs not used
Logistic regression Number of obs = 161 LR chi2(2) = 0.19 Prob > chi2 = 0.9101Log likelihood = -42.60503 Pseudo R2 = 0.0022
------------------------------------------------------------------------------ ht | Odds Ratio Std. Err. z P>|z| [95% Conf. Interval]-------------+---------------------------------------------------------------- smoke | 1.189476 .7253058 0.28 0.776 .3600142 3.929996 age | .9812369 .056471 -0.33 0.742 .8765698 1.098402
Model: Logistic RegressionOutcome: History of hypertension? 1=yes -- htX Values: smoke=1 ui=0 age=30Num. Obs: 161
Predicted Value and 95% CI for ht: 0.0729 (0.0230, 0.2077)
Hitung prediksi bblr kalau merokok, ui=0, usia=35 tahun:. predcalc ht, xvar (smoke=1 ui=0 age=35) model
note: ui != 0 predicts failure perfectly ui dropped and 28 obs not used
Logistic regression Number of obs = 161 LR chi2(2) = 0.19 Prob > chi2 = 0.9101Log likelihood = -42.60503 Pseudo R2 = 0.0022
------------------------------------------------------------------------------ ht | Odds Ratio Std. Err. z P>|z| [95% Conf. Interval]-------------+---------------------------------------------------------------- smoke | 1.189476 .7253058 0.28 0.776 .3600142 3.929996 age | .9812369 .056471 -0.33 0.742 .8765698 1.098402------------------------------------------------------------------------------
Model: Logistic RegressionOutcome: History of hypertension? 1=yes -- htX Values: smoke=1 ui=0 age=35Num. Obs: 161
Predicted Value and 95% CI for ht: 0.0667 (0.0138, 0.2671)
Kalau 35 tahun 6%, dengan range 0.4%-45% karena sampel sedikit.
AAEL 118 April 2015
Analisis pada Studi Cross-sectional dan penentuan kontrol pada desain studi case control
Jenis-jenis bias: Information bias Selection bias

Confounding bias Sample bias
Dari antara keempat bias ini, yang bisa diperbaiki atau dikontrol hanyalah confounding bias. Bias lainnya sebisa mungkin dihindari sejak penentuan desain studi.
Desain dasar epidemiologi: cross sectional & longitudinal (case control/ kohort/ eksperimental). Yang membedakan adalah cross sectional melihat suatu kejadian sebagai suatu potret pada suatu saat tertentu, sedangkan studi longitudinal melihat kejadian dalam suatu rentang waktu.
Bagaimana menganalitikkan studi cross sectional?Desain studi cross sectional tetapi pendekatannya bisa dengan case control/ kohort, analisa dapat menggunakan prevalence odds ratio (POR) atau prevalence ratio (PR).POR suatu studi cross sectional yang diperlakukan sebagai case control.PR suatu studi cross sectional yang diperlakukan sebagai kohort.(Referensi: Buku Practical epidemiology).
Kapan studi cross sectional (CS) dijadikan case control (CC)?CS dijadikan CC, caranya: memotret kasus dan exposurenya, dan memotret bukan kasus dan exposurenya.Contoh: TBC-gizi buruk, caranya: cari kasus TBC, diukur data BB, TB, Hb dengan asumsi gizi buruk sebagai penyebab TBC. Kemudian cari kasus bukan TBC, diukur BB, TB, Hb.Yang menjadi permasalahan, akan timbul pertanyaan gizi buruk menyebabkan TBC atau TBC yang meyebabkan gizi buruk? ini merupakan kelemahan dari studi cross sectional dan studi case control. Studi yang bisa memastikan mana yang penyebab adalah kohort.
TBC merupakan salah satu penyakit menular yang unik. Karena risk of infection ≠ risk of developing the disease. Berbeda dengan campak atau varicella, risk of infection = risk of developing the disease.
Tidak semua penyakit infeksi menular. Ada penyakit infeksi yang tidak menular, contohnya tetanus.
Strategy for Mathematical Modeling Membuat perencanaan logis membuat estimasi hubungan antara exposure
dengan outcome.
Langkah-langkah modeling:1. Menentukan exposure, potential confounder, dan potential interaction (tentukan
dulu sebab-sebab dan akibat, dari antara sebab-sebab yang ada, mana yang merupakan variabel pengganggu? Dari antara variabel-variabel pengganggu, mana yang confounder, mana yang interaction?)
2. Buat full model yang terdiri dari exposure, confounder, interaction. (confounder merupakan variabel yang sama dengan variabel utama tapi dapat mengganggu variabel utama dengan akibat). Contoh: merokok dan PJK. Orang merokok lebih berisiko PJK. Tetapi umur juga berpengaruh dengan PJK. Makin tua umur, makin tinggi risiko PJK. Adakah interaksi antara umur dengan merokok? Minum kopi berhubungan dengan PJK, apa benar? Minum kopi berhubungan dengan merokok, tapi apa minum kopi berhubungan langsung dengan PJK? harus dibuat full modelnya dulu. Sebisa mungkin interaksi disederhanakan menjadi 2-3 interaksi.
3. Coba mengeliminasi potential interaction yang tidak signifikan secara statistik. Estimasi terbaik adalah meng-adjust efek dari semua confounder. Jika tidak ada interaksi, coonfounding diassess dengan membandingkan OR yang crude dengan OR adjusted dari full model. Kalau >10%, pakai OR yang adjusted.
Elemen dari strategi modeling: Seleksi variabel (sebanyak mungkin variabel yang berhub dengan outcome
dimasukkan) Coding variabel Seleksi model Evaluasi interaksi Evaluasi confounding Estimasi titik dan interval Uji hipotesis Assess model fit Pertimbangkan bentuk model yang lain
Seleksi potential confounder:List of potential confounnder should be limited to previously demonstrated independent risk factors for the disease. When no prior information on risk factors, potential confounders may be limited to demographic info, such as age, sex, race.
Relationship between log odds and probability, bentuknya harusnya seperti huruf S. kalau seperti itu, bisa menggunakan logistic model. Kalau bentuknya garis lurus, pakainya regresi linier.
Sama dengan model probabilitas: p = odds/(odds+1)
Regression Analysis Syarat: data X dan Y adalah variabel kuantitatif.
Yang dicari adalah β0 dan β1 -> disebut koefisien regresi.
Homoscedasticity: value dari Y tidak bergantung pada value X yang lain
R menyatakan kuatnya hubungan antara x dan Y. Nilai r yang positif menunjukkan korelasi yang positif, makin besar x, makin besar y. Sedangkan nilai r yang negatif menunjukkan korelasi negatif, makin besar x, makin kecil y.
Latihan Statadata anscombe.dtalog using latihan18april.log
0,5
1
Jadi, berdasarkan di atas: Persamaan regresi liniernya Y1= 3 + 0,5X1
R2=0,67, artinya 2/3 untuk terjadinya Y ditentukan oleh variabel X jadi variabel X cukup penting.
Dari mana dapat angka R2? R2 = Model/ Residual = 27,51/13,76. Bagaimana korelasinya (R)? R=√0,6665 = 0,82 strong correlation. Signifikankah X sebagai determinan dari Y? Dilihat dari Prob > F untuk degree of
freedom 1 dari 9 adalah 0,0022 signifikan.
Pertanyaannya, model ini cocok ga? Dapat dijawab dengan membuat grafik.
Garis ini hanyalah garis imajiner
Coba perintah regress y2 x2, kemudian y3 x3, kemudian y4 x4! (lihat angka koefisien regresi, R, dan R-squarednya hampir sama semuanya!)

Grafik regresi y2 x2. twoway (lfitci y2 x2) (scatter y2 x2)
24
68
10
12
4 6 8 10 12 14x2
95% CI Fitted valuesy2
Kalau lihat model y2 x2, baik koefisien regresi, R2, maupun Rnya, nilaiya hampir sama dengan regresi y1 x1. Mana yang lebih baik??? LIHAT GRAFIKNYA.
Grafik y1 x1, titik-titiknya tersebar merata di sekitar garis imajiner. Sedangkan pada grafik y2 x2, titik-titiknya tidak tersebar merata, dan cenderung membentuk parabola.
Jangan hanya melihat koefisien regresi, R, dan R2, tetapi juga harus melihat gambaran grafiknya.
Grafik y3 x3:
46
81
01
2
4 6 8 10 12 14x3
95% CI Fitted valuesy3
Grafik y3 x3, bentuknya seperti garis lurus tetapi tidak tersebar merata di sekitar garis imajiner. Kenapa?? Karena ada 1 outlier, yang membuat garis imajinernya tidak sejalan dengan titik2nya.
outlier

51
01
5
5 10 15 20x4
95% CI Fitted valuesy4
Grafik y4 x4, hampir semua titik berkumpul di satu tempat.
Kesimpulan: tidak semua data kontinyu cocok untuk digunakan sebagai model regresi linier! Setiap membuat model regresi linier, harus dipastikan bahwa model tersebut memenuhi asumsi dasar regresi linier: NORMALITY, LINEARITY, HOMOSCEDASTICITY, INDEPENDENCE.
Jadi bila kita mempunyai data seperti di atas, model mana yang akan paling baik untuk diambil?Koefisien regresi, R, dan R2 memiliki nilai yang hampir sama. Namun melihat sebaran titik-titik di grafik, yang paling sesuai untuk model regresi linier adalah data Y1 X1.
Bagaimana membuat matriks korelasi dari data-data di atas?

Bagaimana membuat matriks grafik dari data-data di atas?
y1
x1
y2
x2
y3
x3
y4
x4
4 6 8 10
5
10
15
5 10 15
4
6
8
10
4 6 8 10
5
10
15
5 10 15
5
10
15
5 10 15
5
10
15
5 10 15
5
10
15
5 10 15
10
15
20





























