Embed Size (px)
DESCRIPTION
Sebenta Estatística Aplicada à Psicologia
Citation preview
Andreia Martins
Modelo com VD contínua e um Preditor com mais de 2 Categorias: Problema
tipo 4 (Caso de amostras independentes)
Regressão Linear Múltipla com Mais de uma Dummy
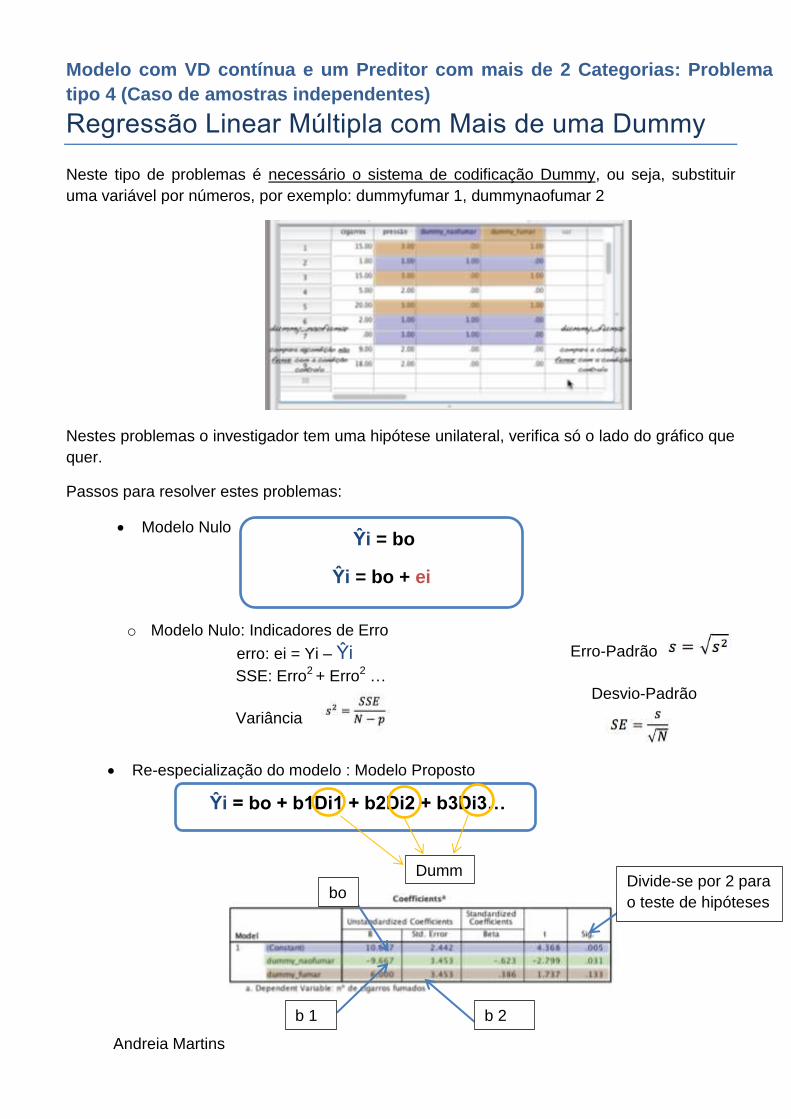
Neste tipo de problemas é necessário o sistema de codificação Dummy, ou seja, substituir
uma variável por números, por exemplo: dummyfumar 1, dummynaofumar 2
Nestes problemas o investigador tem uma hipótese unilateral, verifica só o lado do gráfico que
quer.
Passos para resolver estes problemas:
Modelo Nulo
o Modelo Nulo: Indicadores de Erro
erro: ei = Yi – Ŷi
SSE: Erro2 + Erro2 …
Variância
Erro-Padrão
Desvio-Padrão
Re-especialização do modelo : Modelo Proposto
Ŷi = bo
Ŷi = bo + ei
Ŷi = bo + b1Di1 + b2Di2 + b3Di3…
Dumm
y
b 1 b 2
bo Divide-se por 2 para
o teste de hipóteses
Andreia Martins
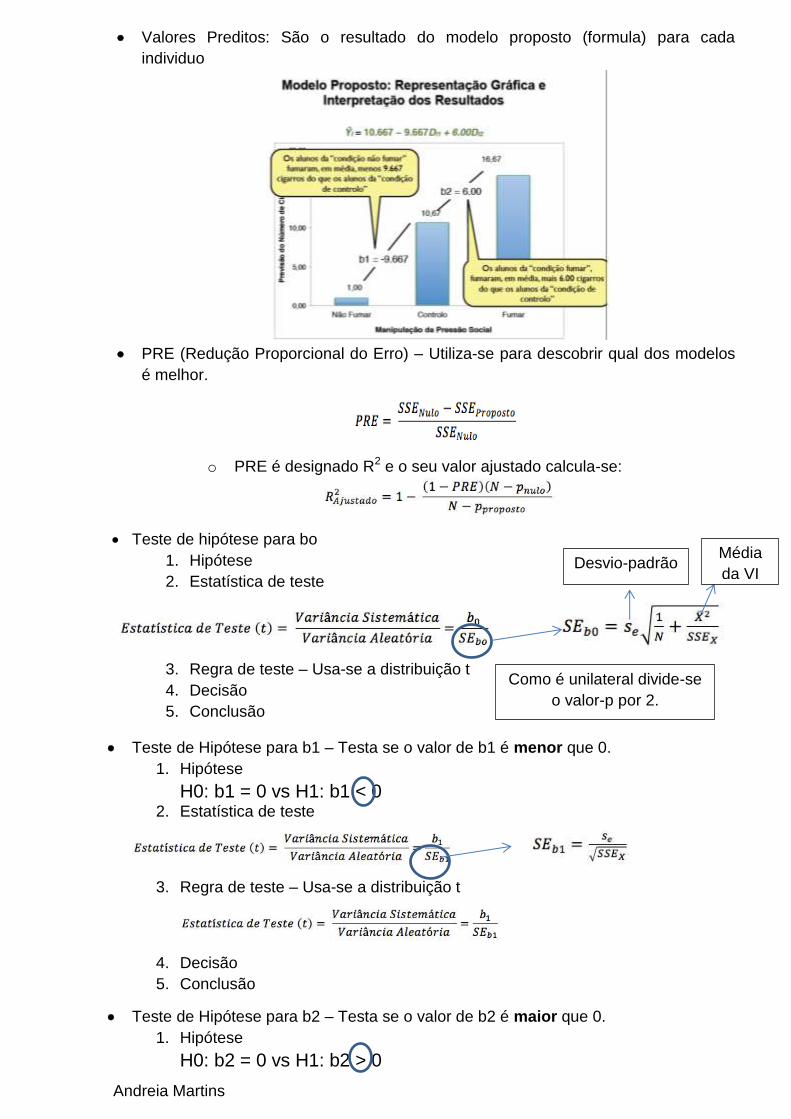
Valores Preditos: São o resultado do modelo proposto (formula) para cada
individuo
PRE (Redução Proporcional do Erro) – Utiliza-se para descobrir qual dos modelos
é melhor.
o PRE é designado R2 e o seu valor ajustado calcula-se:
Teste de hipótese para bo
1. Hipótese
2. Estatística de teste
3. Regra de teste – Usa-se a distribuição t
4. Decisão
5. Conclusão
Teste de Hipótese para b1 – Testa se o valor de b1 é menor que 0.
1. Hipótese
H0: b1 = 0 vs H1: b1 < 0 2. Estatística de teste
3. Regra de teste – Usa-se a distribuição t
4. Decisão
5. Conclusão
Teste de Hipótese para b2 – Testa se o valor de b2 é maior que 0.
1. Hipótese
H0: b2 = 0 vs H1: b2 > 0
Desvio-padrão Média
da VI
Como é unilateral divide-se
o valor-p por 2.

Andreia Martins
2. Estatística de teste
3. Regra de teste – Usa-se a distribuição t
4. Decisão
5. Conclusão
Teste de Hipótese para PRE (R, R2)
1. Hipótese
2. Estatística de teste
3. Regra de teste - Distribuição F de Snedecor com (p = número de
parâmetros estimados nos modelos):
gl do numerador (pProposto − pnulo), gl do denominador (N − pProposto)
4. Decisão
5. Conclusão
O coeficiente de regressão estandardizado (Beta)
o Passando b1 para Beta1
o Passando b2 para Beta2
One way ANOVA com Contrastes Planeados
O coeficiente de regressão estandardizado (Beta)
o Passando b1 para Beta1
o Passando b2 para Beta2
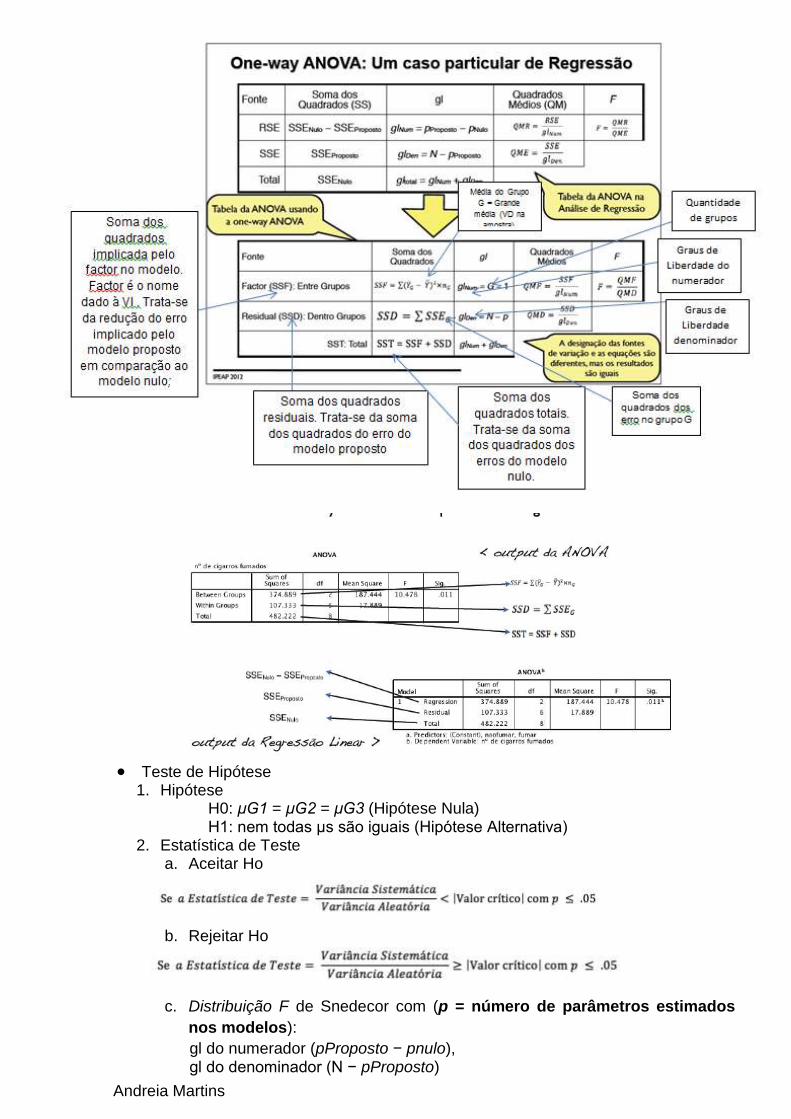
Análise menos complexa: análise de Variâncias com um Factor (One-way ANOVA)
o Análise de Variâncias Técnica estatística usada quando o teste de hipótese envolve a
comparação de duas ou mais médias; Foi desenvolvida pelo estatístico britânico Ronald Fisher (1918,1921) para
a análise de experimentos; Posteriormente, George W. Snedecor ampliou a utilização da técnica para
pesquisas baseadas em distribuições por amostragem, denominando-o estatística "F", em homenagem a Fisher.
ANOVA não se usa o teste t pois tem mais que 3 médias.
Quando se passa para Beta a constante
(bo) passa para 0, é 0 porque temos todas
as variáveis 0 e 0-0=0
Andreia Martins
Teste de Hipótese
1. Hipótese H0: μG1 = μG2 = μG3 (Hipótese Nula) H1: nem todas μs são iguais (Hipótese Alternativa)
2. Estatística de Teste a. Aceitar Ho
b. Rejeitar Ho
c. Distribuição F de Snedecor com (p = número de parâmetros estimados
nos modelos):
gl do numerador (pProposto − pnulo), gl do denominador (N − pProposto)

Andreia Martins
3. Regra de teste
4. Decisão
5. Conclusão
ANOVA é outra vertente de fazer o processo da Regressão Linear
Os resultados da ANOVA não nos dizem nada acerca do problema que o
investigador está a estudar! Para isso precisamos de fazer contrastes planeados.
o Comparação Planeadas
Sistema de comparação de médias usado quando o investigador tem hipóteses específicas para as diferenças entre as médias. Esse sistema é muitas vezes chamado “contrastes”. Abaixo temos um exemplo de codificação para comparações planeadas.
C1 = Compara o grupo 1 com o grupo 2; C2 = Compara o grupo 2 com o grupo 3.
Regras: A quantidade de contraste é igual ao número de graus de liberdade do numerador; A soma de cada contraste deve ser igual à zero.
Quadrados Médios
Factor
Quadrados Médios
Residual
Soma dos
quadrados Factor
Soma dos
quadrados Residual Soma dos
quadrados totais.

Andreia Martins
Contrastes Ortogonais o Sistema de comparação de médias usado quando o investigador tem hipóteses
específicas para as diferenças entre as médias. Abaixo temos um exemplo de codificação para contrastes.
Contraste 1 = Compara o grupo 1 com o grupo 3; Contraste 2 = Compara os grupos 1 e 3 (juntos) com o grupo 2. Regras: A quantidade de contraste é igual ao número de graus de liberdade do numerador; a soma de cada contraste deve ser igual à zero; a soma dos produtos entre os contrastes deve ser igual a zero.
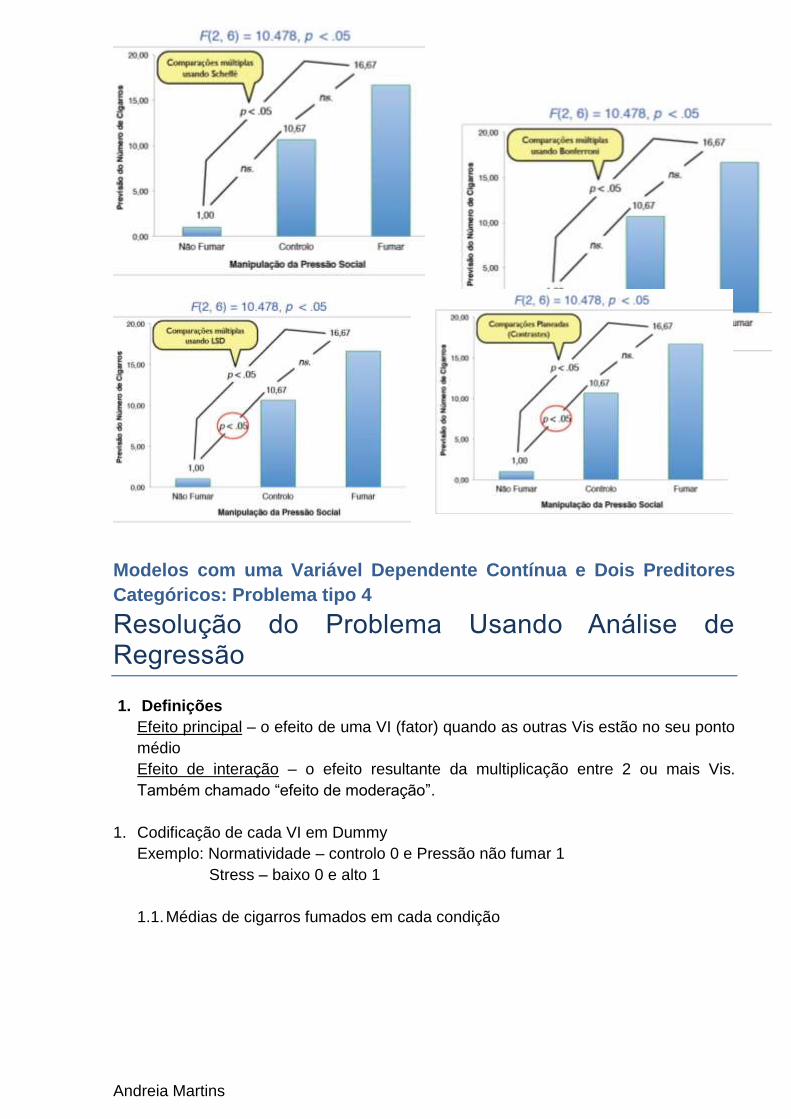
One-way Anova: Comparações Múltiplas (Post Hoc)
Sistema de comparação de médias quando o investigador não tem hipóteses
especificas para as diferenças entre as médias.
Todas as médias são comparadas umas contra as outras.
Exemplos:
o LSD – Least-Significant Difference (nada conservador)
o Duncan (pouco conservador)
o Bonferroni (conservador)
o Turkey (conservador)
o Scheffé (muito conservador)
Teste de Scheffé
o Devem ser consideradas diferentes todas as médias, quando:
Quadrado médio
Residual (dentro
dos grupos Número de
observações
num dos
grupos
(pressupõe
igual número
de
observações
em cada
grupo)
Quantidade de
grupos
Valor do F critico
ao nível de
significância
adotado
Andreia Martins
Modelos com uma Variável Dependente Contínua e Dois Preditores
Categóricos: Problema tipo 4
Resolução do Problema Usando Análise de Regressão
1. Definições
Efeito principal – o efeito de uma VI (fator) quando as outras Vis estão no seu ponto
médio
Efeito de interação – o efeito resultante da multiplicação entre 2 ou mais Vis.
Também chamado “efeito de moderação”.
1. Codificação de cada VI em Dummy
Exemplo: Normatividade – controlo 0 e Pressão não fumar 1
Stress – baixo 0 e alto 1
1.1. Médias de cigarros fumados em cada condição
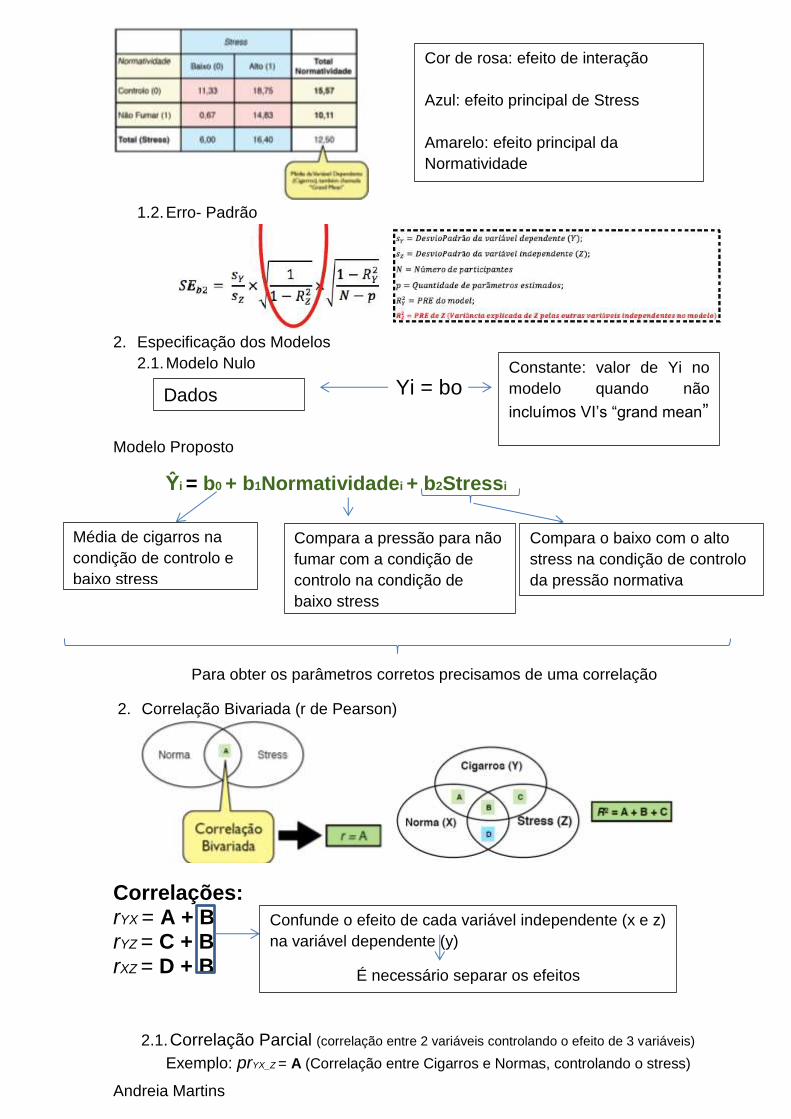
Andreia Martins
1.2. Erro- Padrão
2. Especificação dos Modelos
2.1. Modelo Nulo
Yi = bo
Modelo Proposto
Ŷi = b0 + b1Normatividadei + b2Stressi
Para obter os parâmetros corretos precisamos de uma correlação
2. Correlação Bivariada (r de Pearson)
Correlações: rYX = A + B rYZ = C + B rXZ = D + B
2.1. Correlação Parcial (correlação entre 2 variáveis controlando o efeito de 3 variáveis)
Exemplo: prYX_Z = A (Correlação entre Cigarros e Normas, controlando o stress)
Cor de rosa: efeito de interação
Azul: efeito principal de Stress
Amarelo: efeito principal da
Normatividade
Dados
previstos
Constante: valor de Yi no
modelo quando não
incluímos VI’s “grand mean”
Média de cigarros na
condição de controlo e
baixo stress
Compara a pressão para não
fumar com a condição de
controlo na condição de
baixo stress
Compara o baixo com o alto
stress na condição de controlo
da pressão normativa
Confunde o efeito de cada variável independente (x e z)
na variável dependente (y)
É necessário separar os efeitos
Andreia Martins
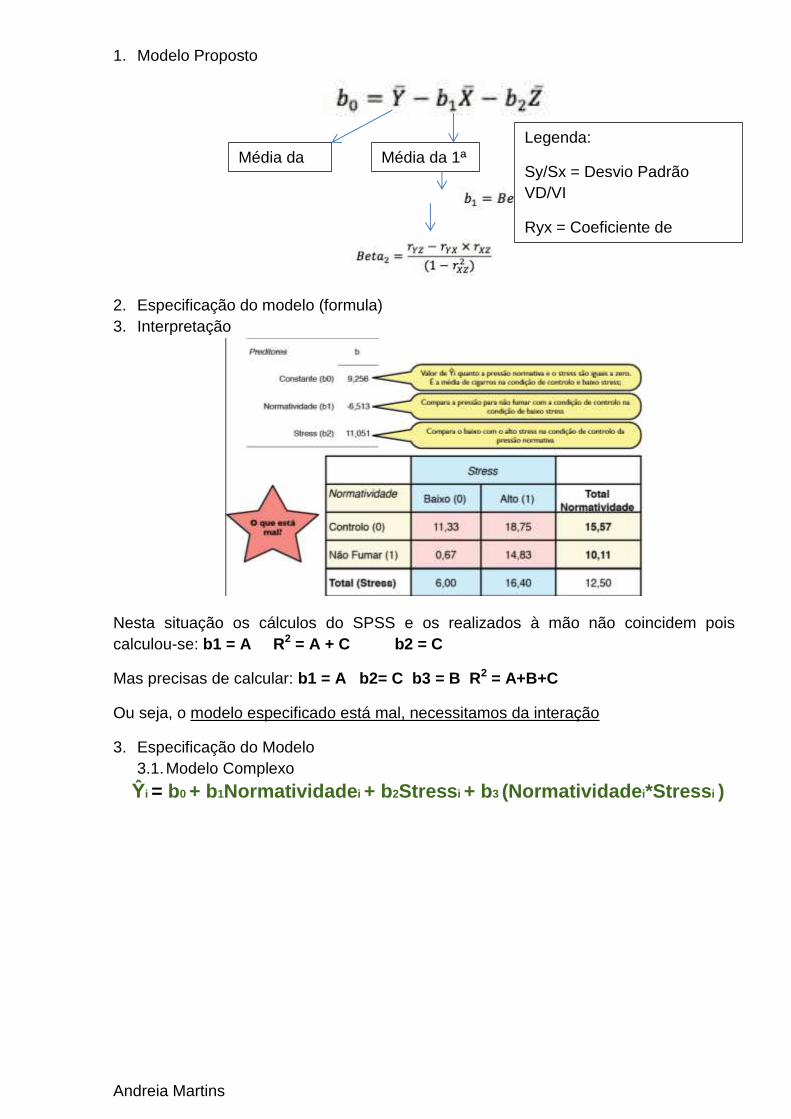
1. Modelo Proposto
2. Especificação do modelo (formula)
3. Interpretação
Nesta situação os cálculos do SPSS e os realizados à mão não coincidem pois
calculou-se: b1 = A R2 = A + C b2 = C
Mas precisas de calcular: b1 = A b2= C b3 = B R2 = A+B+C
Ou seja, o modelo especificado está mal, necessitamos da interação
3. Especificação do Modelo 3.1. Modelo Complexo
Ŷi = b0 + b1Normatividadei + b2Stressi + b3 (Normatividadei*Stressi )
Média da
VD
Média da 1ª
VI
Legenda:
Sy/Sx = Desvio Padrão
VD/VI
Ryx = Coeficiente de
correlação bivariada (r de
pearson) entre y e x
Andreia Martins
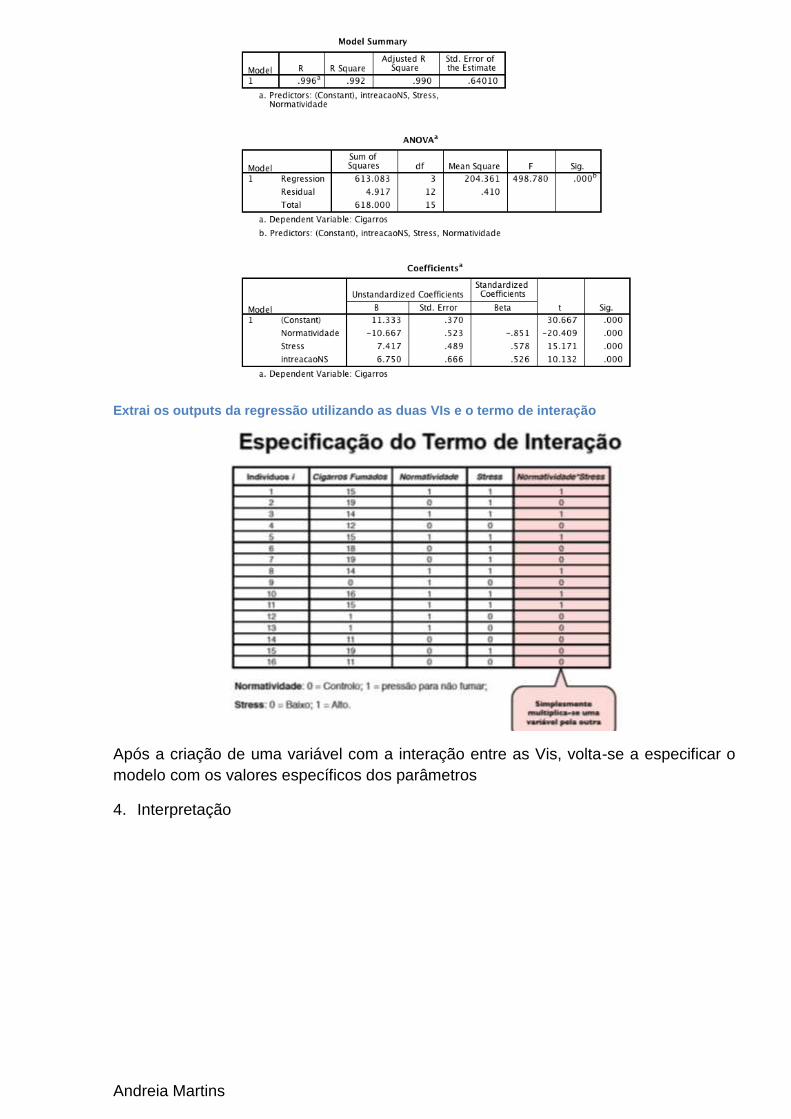
Extrai os outputs da regressão utilizando as duas VIs e o termo de interação
Após a criação de uma variável com a interação entre as Vis, volta-se a especificar o
modelo com os valores específicos dos parâmetros
4. Interpretação
Andreia Martins
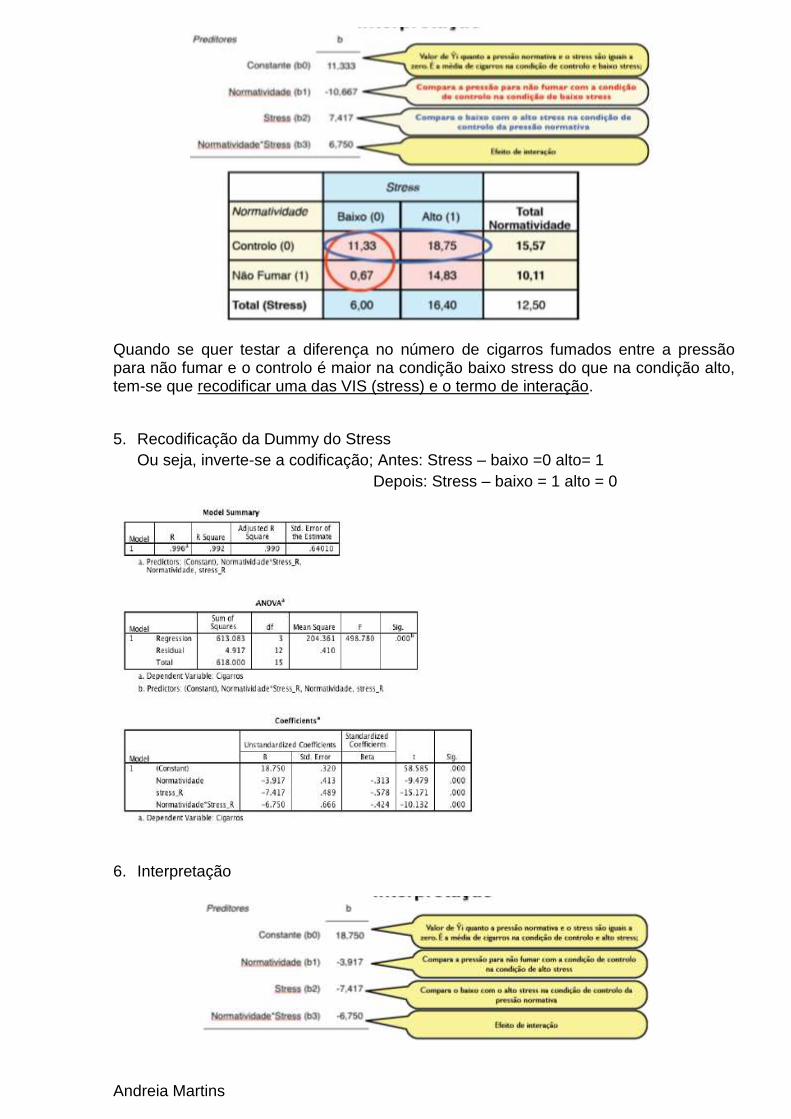
Quando se quer testar a diferença no número de cigarros fumados entre a pressão para não fumar e o controlo é maior na condição baixo stress do que na condição alto, tem-se que recodificar uma das VIS (stress) e o termo de interação.
5. Recodificação da Dummy do Stress
Ou seja, inverte-se a codificação; Antes: Stress – baixo =0 alto= 1
Depois: Stress – baixo = 1 alto = 0
6. Interpretação

Andreia Martins
Resolução do Problema Usando ANOVA Fatorial
1. Utilizar as duas Vis categorizadas com fatores
2. Interpretação da interação
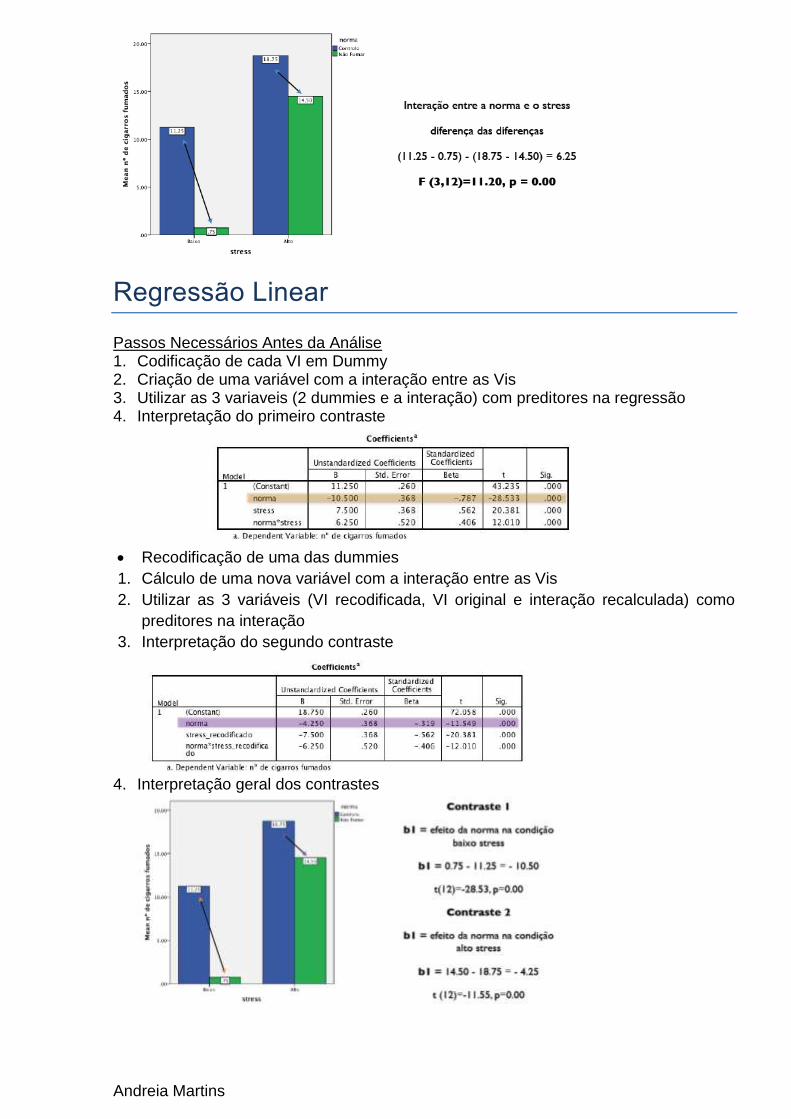
Andreia Martins
Regressão Linear
Passos Necessários Antes da Análise 1. Codificação de cada VI em Dummy 2. Criação de uma variável com a interação entre as Vis 3. Utilizar as 3 variaveis (2 dummies e a interação) com preditores na regressão 4. Interpretação do primeiro contraste
Recodificação de uma das dummies
1. Cálculo de uma nova variável com a interação entre as Vis
2. Utilizar as 3 variáveis (VI recodificada, VI original e interação recalculada) como
preditores na interação
3. Interpretação do segundo contraste
4. Interpretação geral dos contrastes
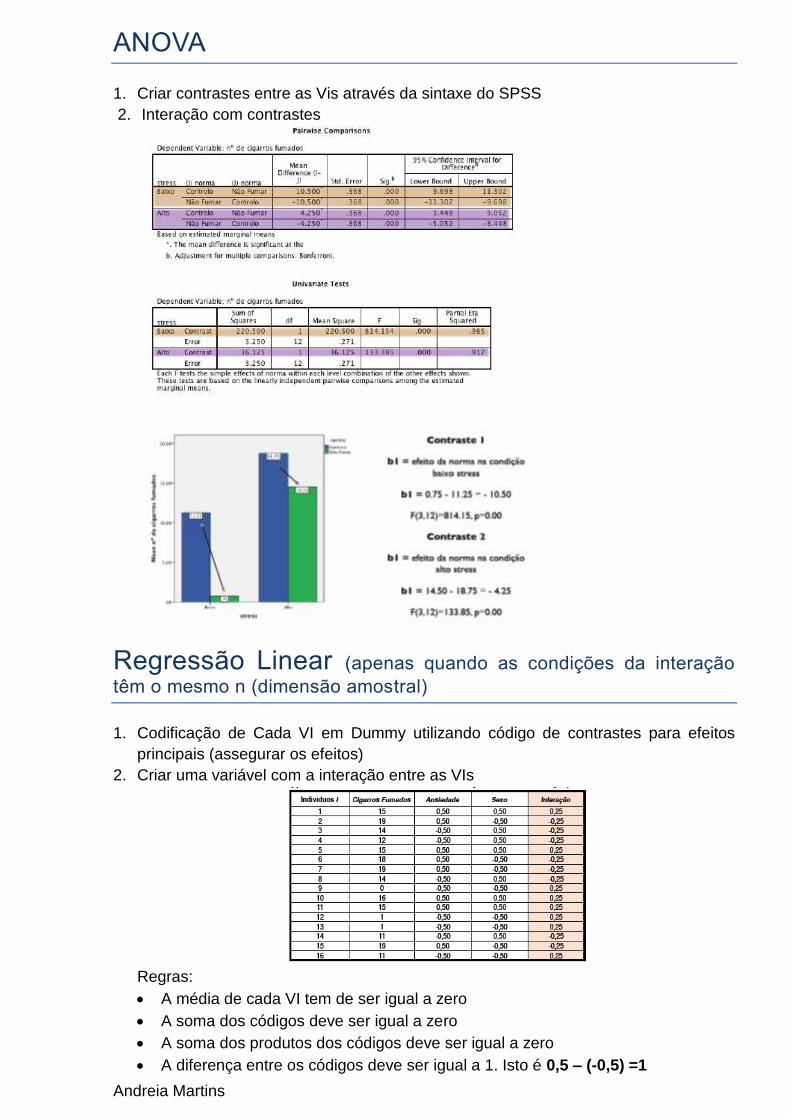
Andreia Martins
ANOVA
1. Criar contrastes entre as Vis através da sintaxe do SPSS
2. Interação com contrastes
Regressão Linear (apenas quando as condições da interação
têm o mesmo n (dimensão amostral)
1. Codificação de Cada VI em Dummy utilizando código de contrastes para efeitos
principais (assegurar os efeitos)
2. Criar uma variável com a interação entre as VIs
Regras:
A média de cada VI tem de ser igual a zero
A soma dos códigos deve ser igual a zero
A soma dos produtos dos códigos deve ser igual a zero
A diferença entre os códigos deve ser igual a 1. Isto é 0,5 – (-0,5) =1
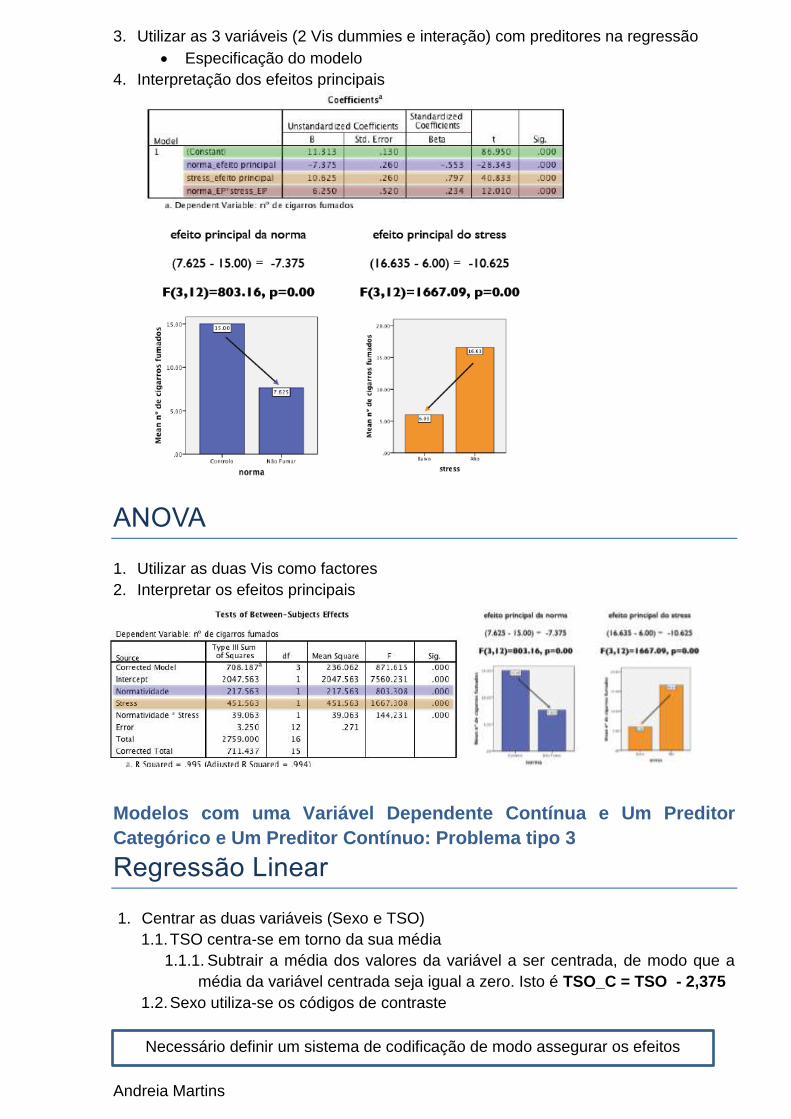
Andreia Martins
3. Utilizar as 3 variáveis (2 Vis dummies e interação) com preditores na regressão
Especificação do modelo
4. Interpretação dos efeitos principais
ANOVA
1. Utilizar as duas Vis como factores
2. Interpretar os efeitos principais
Modelos com uma Variável Dependente Contínua e Um Preditor
Categórico e Um Preditor Contínuo: Problema tipo 3
Regressão Linear
1. Centrar as duas variáveis (Sexo e TSO)
1.1. TSO centra-se em torno da sua média
1.1.1. Subtrair a média dos valores da variável a ser centrada, de modo que a
média da variável centrada seja igual a zero. Isto é TSO_C = TSO - 2,375
1.2. Sexo utiliza-se os códigos de contraste
Necessário definir um sistema de codificação de modo assegurar os efeitos
principais
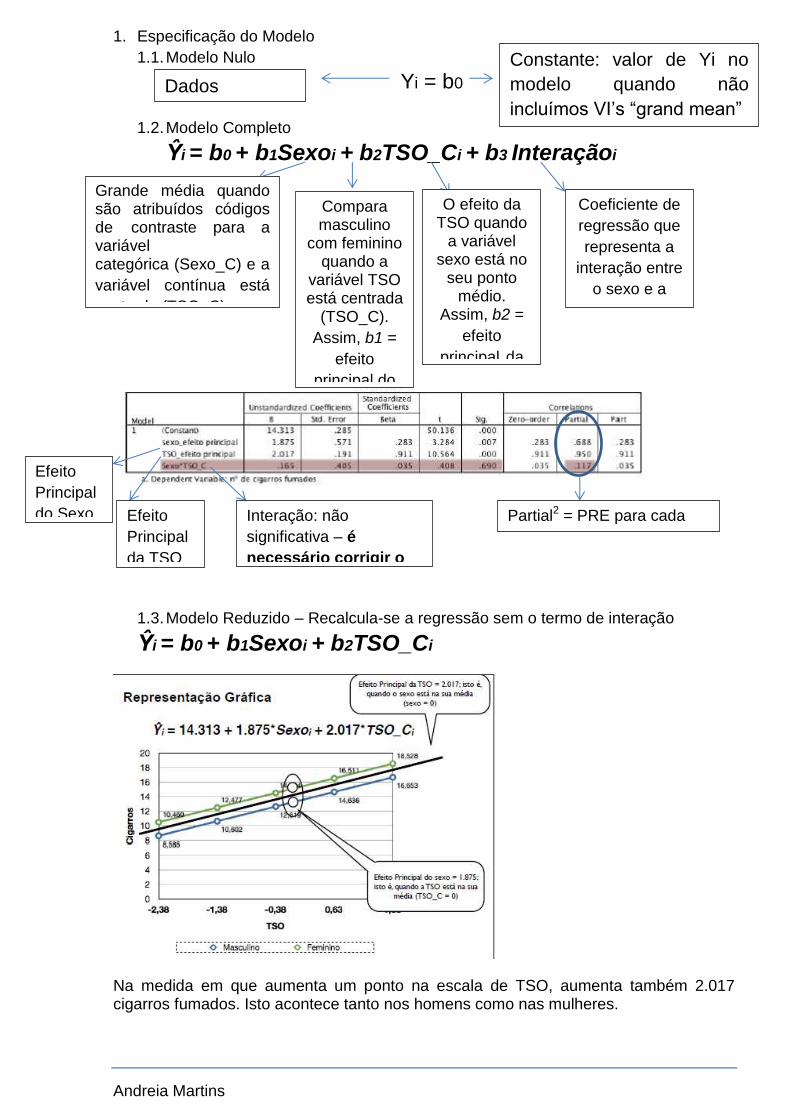
Andreia Martins
1. Especificação do Modelo
1.1. Modelo Nulo
Yi = b0
1.2. Modelo Completo
Ŷi = b0 + b1Sexoi + b2TSO_Ci + b3 Interaçãoi
1.3. Modelo Reduzido – Recalcula-se a regressão sem o termo de interação
Ŷi = b0 + b1Sexoi + b2TSO_Ci
Na medida em que aumenta um ponto na escala de TSO, aumenta também 2.017 cigarros fumados. Isto acontece tanto nos homens como nas mulheres.
Dados
previstos
Constante: valor de Yi no
modelo quando não
incluímos VI’s “grand mean”
Grande média quando são atribuídos códigos de contraste para a variável categórica (Sexo_C) e a
variável contínua está
centrada (TSO_C)
Compara masculino
com feminino quando a
variável TSO está centrada
(TSO_C).
Assim, b1 =
efeito
principal do sexo;
O efeito da TSO quando
a variável sexo está no
seu ponto médio.
Assim, b2 =
efeito
principal da
TSO;
Coeficiente de
regressão que
representa a interação entre
o sexo e a
TSO.
Efeito
Principal
do Sexo Efeito
Principal
da TSO
Interação: não
significativa – é
necessário corrigir o
modelo
Partial2 = PRE para cada
variável
Andreia Martins
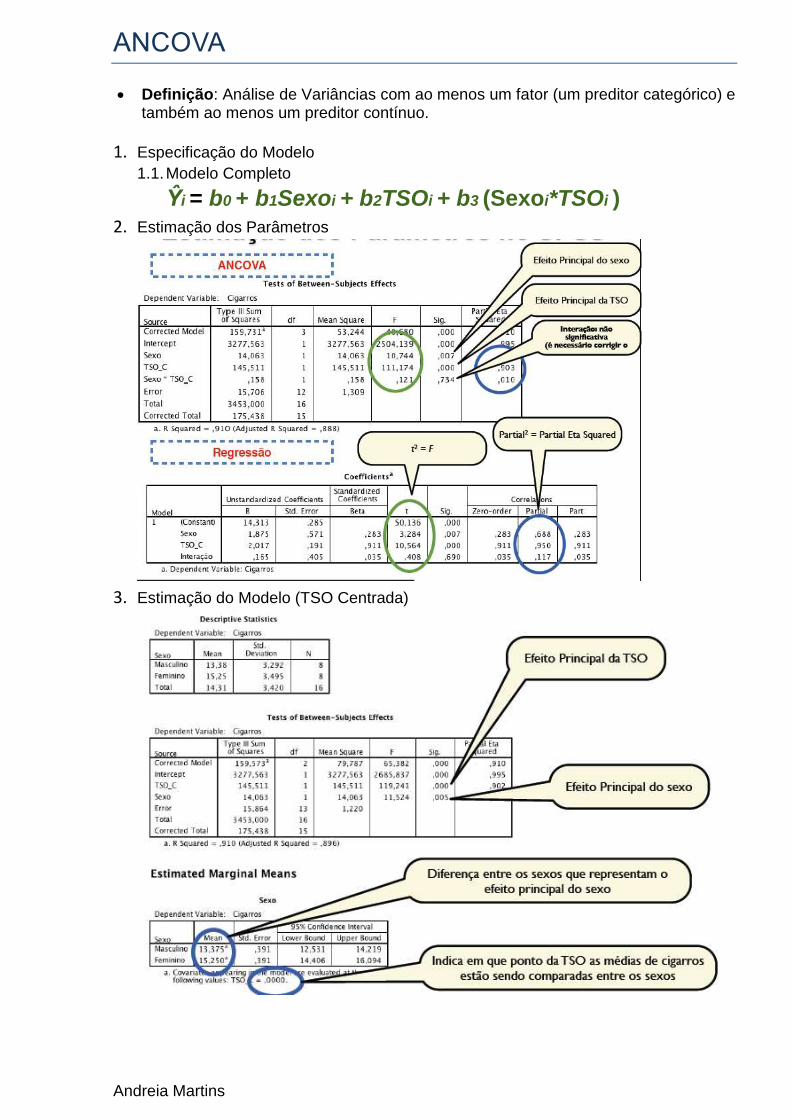
ANCOVA
Definição: Análise de Variâncias com ao menos um fator (um preditor categórico) e também ao menos um preditor contínuo.
1. Especificação do Modelo
1.1. Modelo Completo
Ŷi = b0 + b1Sexoi + b2TSOi + b3 (Sexoi*TSOi )
2. Estimação dos Parâmetros
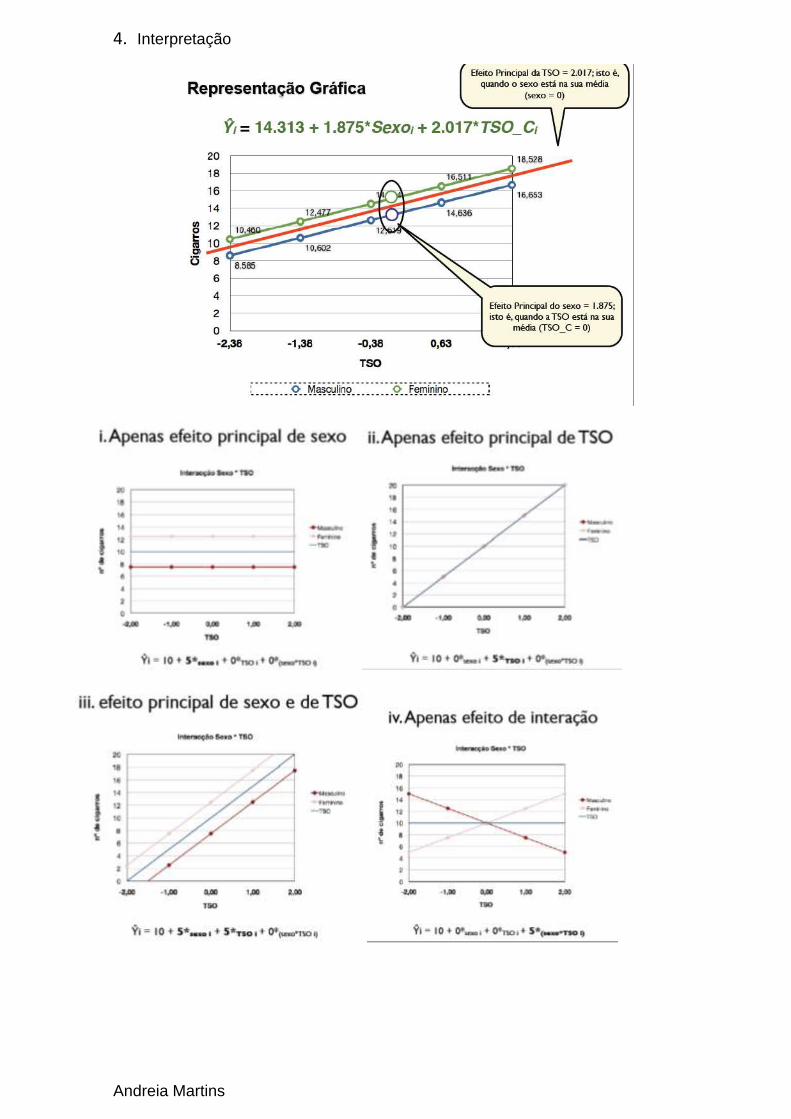
3. Estimação do Modelo (TSO Centrada)
Andreia Martins
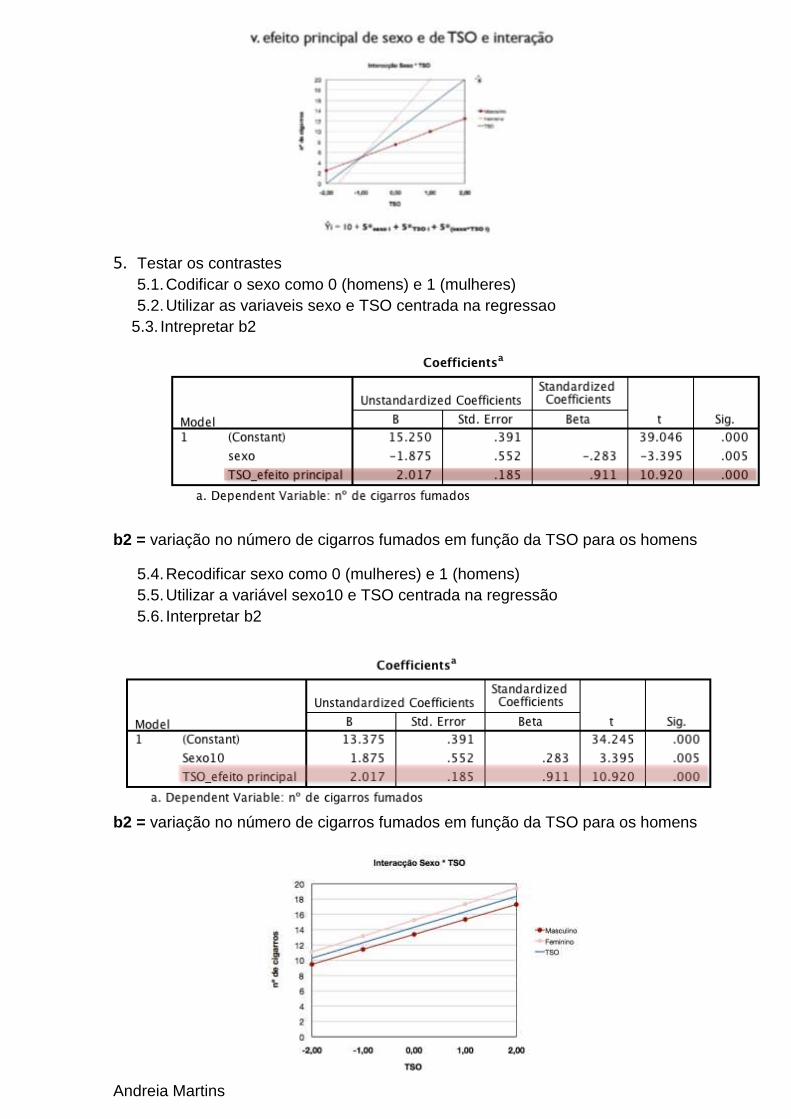
4. Interpretação
Andreia Martins
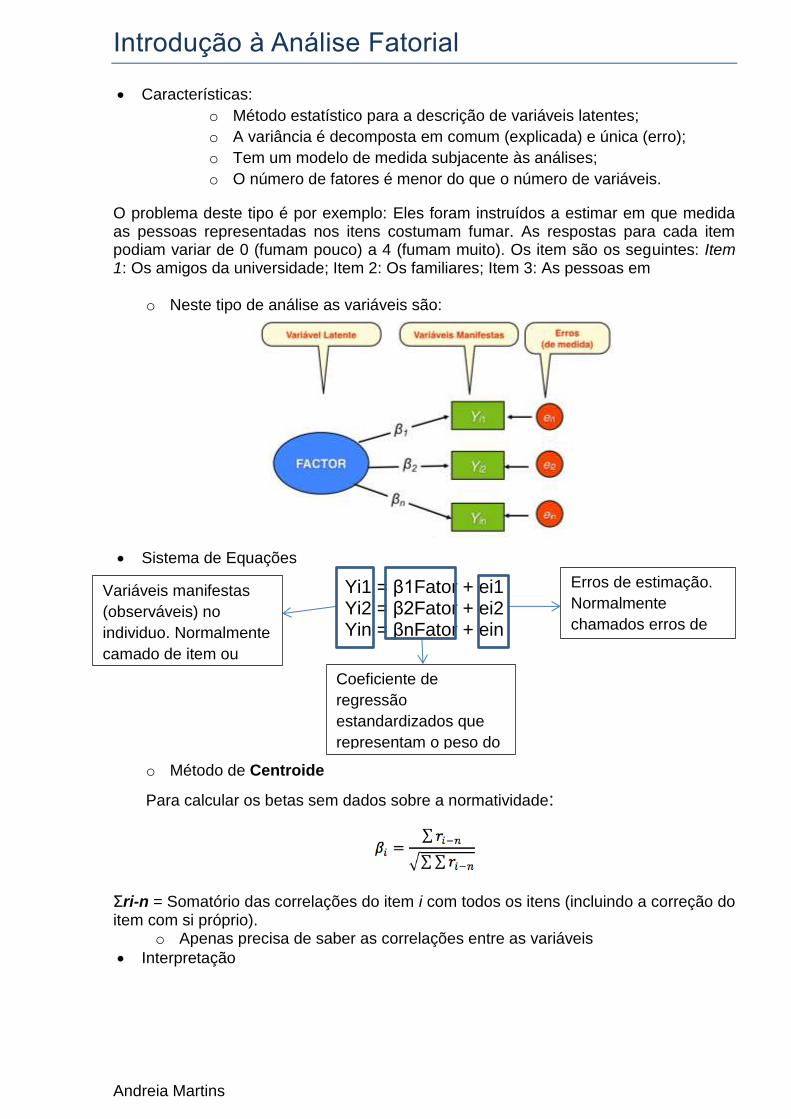
5. Testar os contrastes
5.1. Codificar o sexo como 0 (homens) e 1 (mulheres)
5.2. Utilizar as variaveis sexo e TSO centrada na regressao
5.3. Intrepretar b2
b2 = variação no número de cigarros fumados em função da TSO para os homens
5.4. Recodificar sexo como 0 (mulheres) e 1 (homens)
5.5. Utilizar a variável sexo10 e TSO centrada na regressão
5.6. Interpretar b2
b2 = variação no número de cigarros fumados em função da TSO para os homens
Andreia Martins
Introdução à Análise Fatorial
Características:
o Método estatístico para a descrição de variáveis latentes;
o A variância é decomposta em comum (explicada) e única (erro);
o Tem um modelo de medida subjacente às análises;
o O número de fatores é menor do que o número de variáveis.
O problema deste tipo é por exemplo: Eles foram instruídos a estimar em que medida as pessoas representadas nos itens costumam fumar. As respostas para cada item podiam variar de 0 (fumam pouco) a 4 (fumam muito). Os item são os seguintes: Item 1: Os amigos da universidade; Item 2: Os familiares; Item 3: As pessoas em
o Neste tipo de análise as variáveis são:
Sistema de Equações
Yi1 = β1Fator + ei1 Yi2 = β2Fator + ei2 Yin = βnFator + ein
o Método de Centroide
Para calcular os betas sem dados sobre a normatividade:
Σri-n = Somatório das correlações do item i com todos os itens (incluindo a correção do item com si próprio).
o Apenas precisa de saber as correlações entre as variáveis
Interpretação
Variáveis manifestas
(observáveis) no
individuo. Normalmente
camado de item ou
indicador Coeficiente de
regressão
estandardizados que
representam o peso do
fator em cada item
Erros de estimação.
Normalmente
chamados erros de
medida

Andreia Martins
Múltiplos Fatores
O problema base: O investidor considera que estes itens medem dimensões diferentes da adição, especificamente: 3 deles medem a Normatividade, outros 3 a Compulsão, e finalmente outros e a Atitude em relação ao consumo.
Rotação Ortogonal
Sistema de Equações – Fatores ortogonais
Ci1 = β11Fator1 + β12Fator2 + β13Fator3 + ei1 Ci2 = β21Fator1 + β22Fator2 + β23Fator3 + ei2 Ci3 = β31Fator1 + β32Fator2 + β33Fator3 + ei3 Ai1 = β41Fator1 + β42Fator2 + β43Fator3 + ei4 Ai2 = β51Fator1 + β42Fator2 + β53Fator3 + ei5 Ai3 = β61Fator1 + β42Fator2 + β63Fator3 + ei6
Estimação dos parâmetros
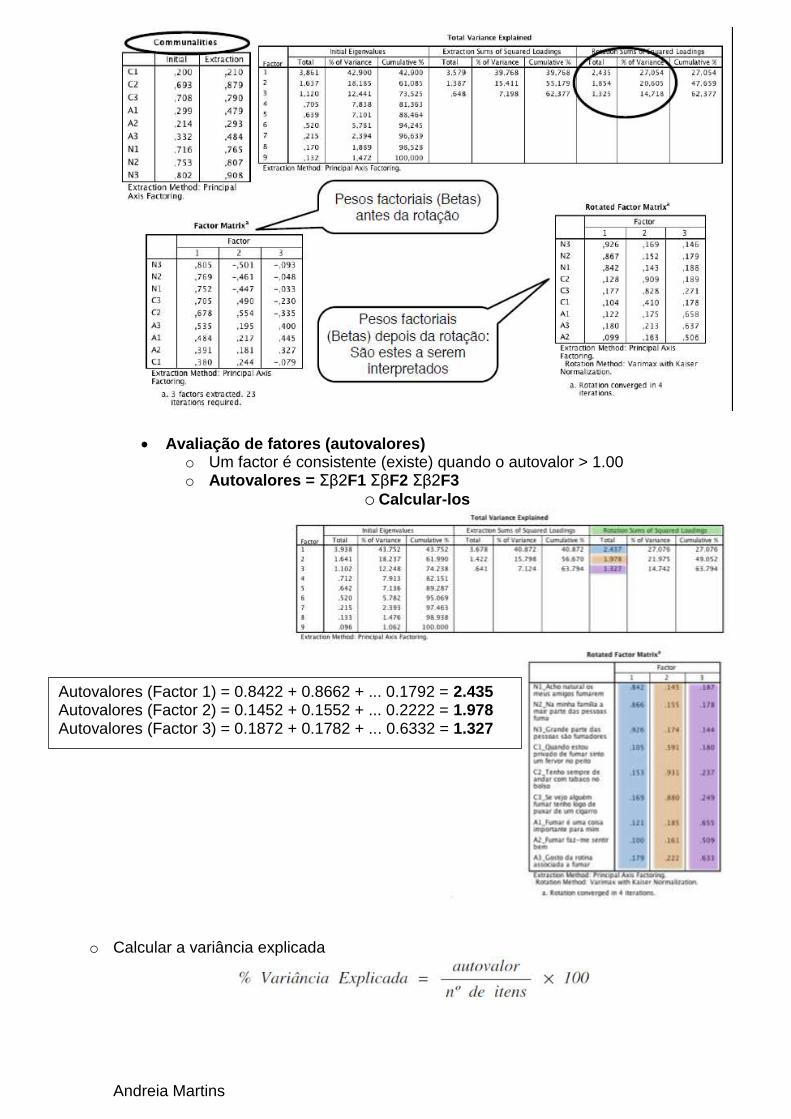
Andreia Martins
Avaliação de fatores (autovalores) o Um factor é consistente (existe) quando o autovalor > 1.00 o Autovalores = Σβ2F1 ΣβF2 Σβ2F3
o Calcular-los
o Calcular a variância explicada
Autovalores (Factor 1) = 0.8422 + 0.8662 + ... 0.1792 = 2.435 Autovalores (Factor 2) = 0.1452 + 0.1552 + ... 0.2222 = 1.978 Autovalores (Factor 3) = 0.1872 + 0.1782 + ... 0.6332 = 1.327
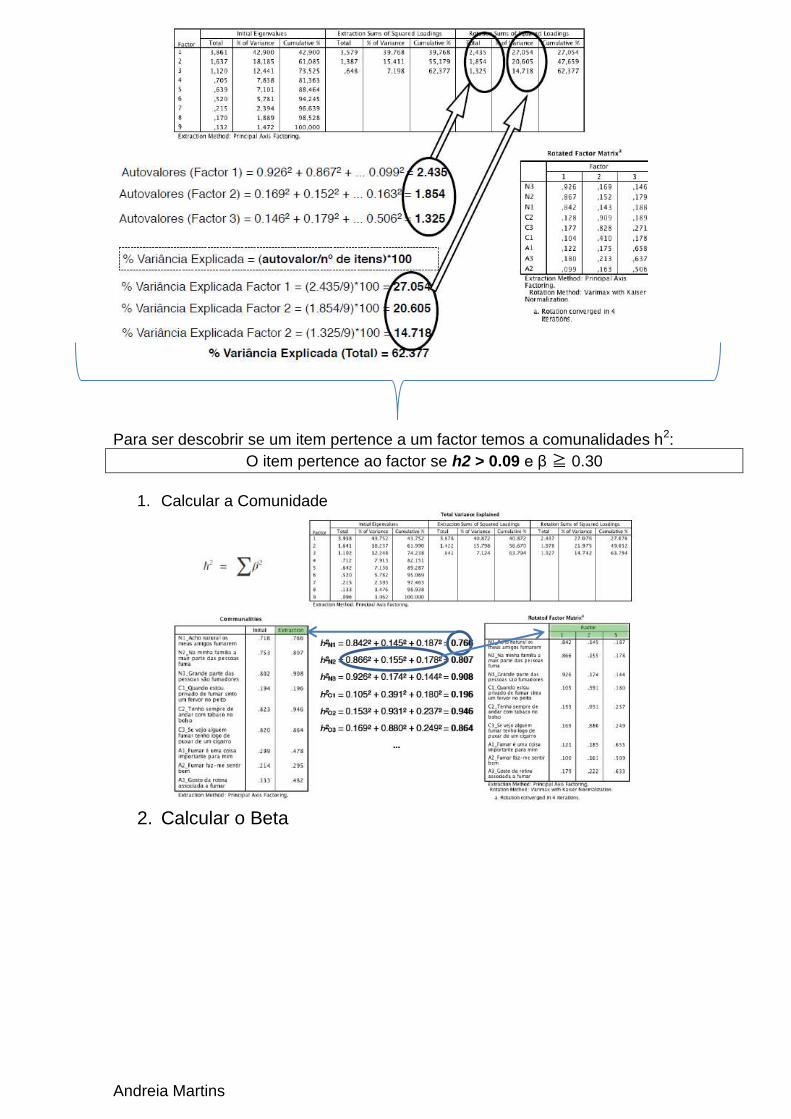
Andreia Martins
Para ser descobrir se um item pertence a um factor temos a comunalidades h2:
O item pertence ao factor se h2 > 0.09 e β ≧ 0.30
1. Calcular a Comunidade
2. Calcular o Beta
Andreia Martins
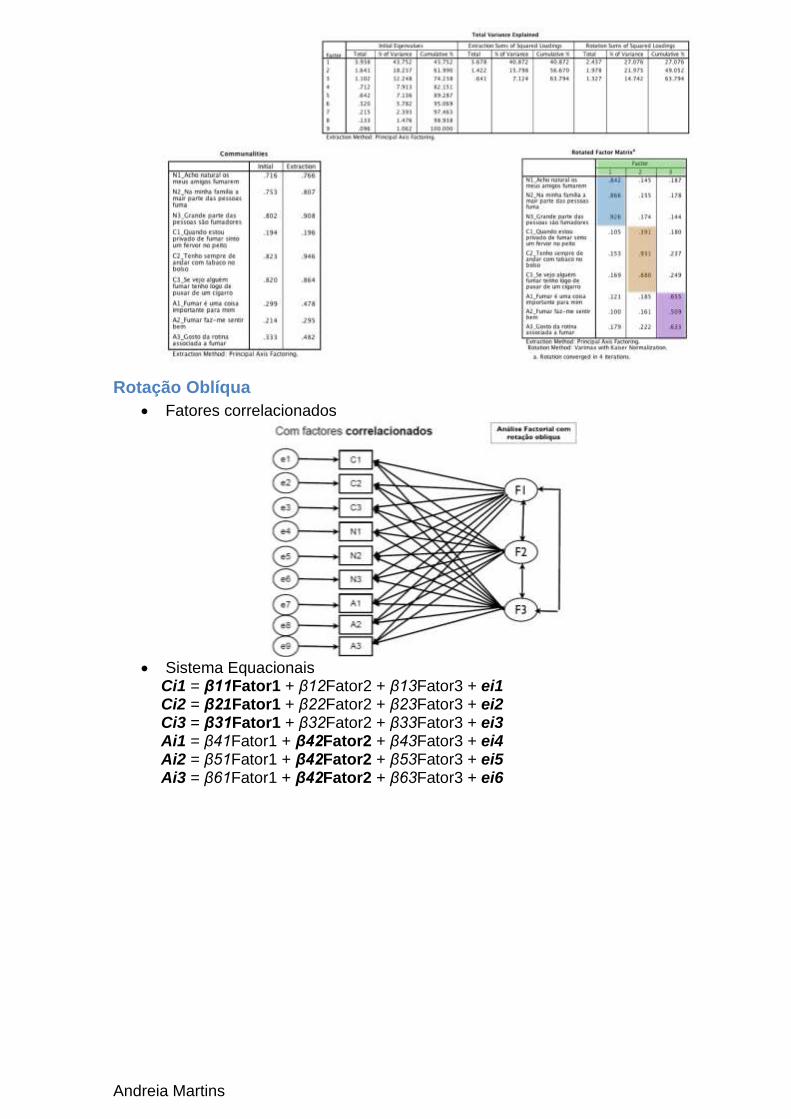
Rotação Oblíqua
Fatores correlacionados
Sistema Equacionais
Ci1 = β11Fator1 + β12Fator2 + β13Fator3 + ei1 Ci2 = β21Fator1 + β22Fator2 + β23Fator3 + ei2 Ci3 = β31Fator1 + β32Fator2 + β33Fator3 + ei3 Ai1 = β41Fator1 + β42Fator2 + β43Fator3 + ei4 Ai2 = β51Fator1 + β42Fator2 + β53Fator3 + ei5 Ai3 = β61Fator1 + β42Fator2 + β63Fator3 + ei6
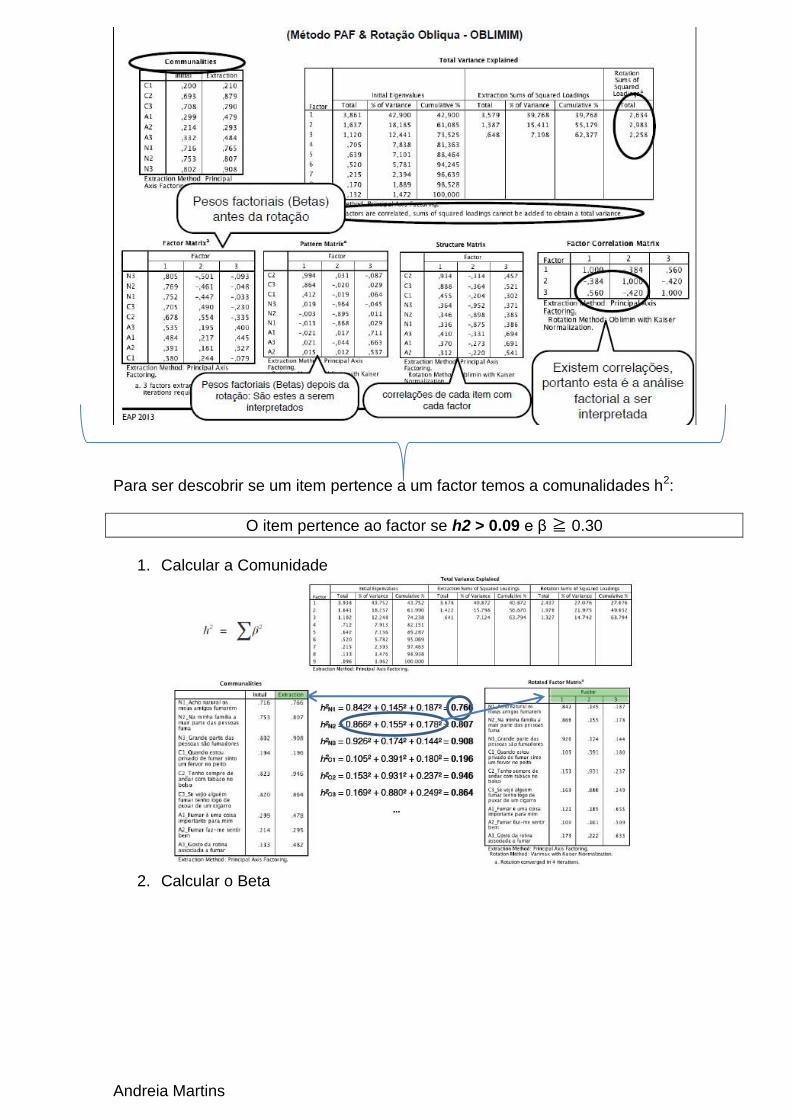
Andreia Martins
Para ser descobrir se um item pertence a um factor temos a comunalidades h2:
O item pertence ao factor se h2 > 0.09 e β ≧ 0.30
1. Calcular a Comunidade
2. Calcular o Beta

Andreia Martins
Análise Não Paramétrica (tipo 4)
Problemas: O investigador quer saber se o nível de ansiedade influencia a classificação que os alunos obtêm num exame de matemática. Ele quer testar a hipótese de que o nível de ansiedade moderada leva os alunos a obterem melhores resultados. Para testar esta hipótese, o investigador manipulou a ansiedade (baixa vs. moderada) enquanto os alunos realizavam o exame. Em seguida, observou a classificação obtida por cada aluno no exame.
As variáveis têm de ser ordinais (rank)
Estimação dos Parâmetros
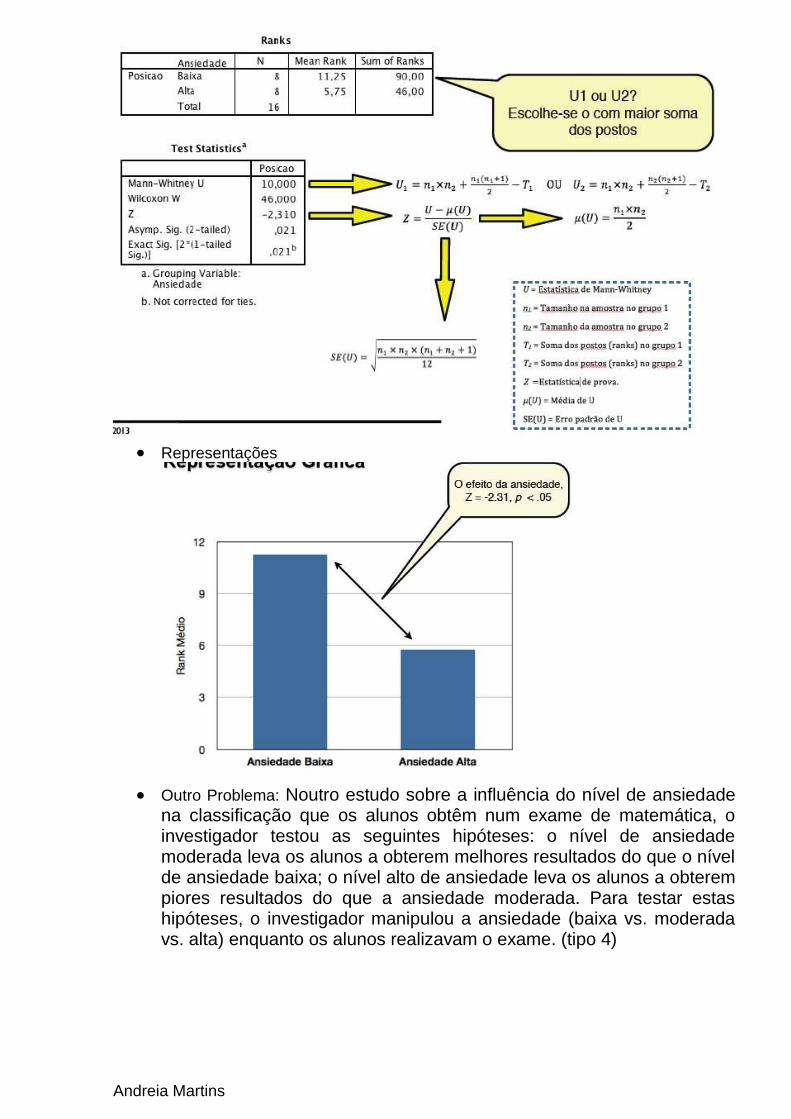
Andreia Martins
Representações
Outro Problema: Noutro estudo sobre a influência do nível de ansiedade
na classificação que os alunos obtêm num exame de matemática, o investigador testou as seguintes hipóteses: o nível de ansiedade moderada leva os alunos a obterem melhores resultados do que o nível de ansiedade baixa; o nível alto de ansiedade leva os alunos a obterem piores resultados do que a ansiedade moderada. Para testar estas hipóteses, o investigador manipulou a ansiedade (baixa vs. moderada vs. alta) enquanto os alunos realizavam o exame. (tipo 4)
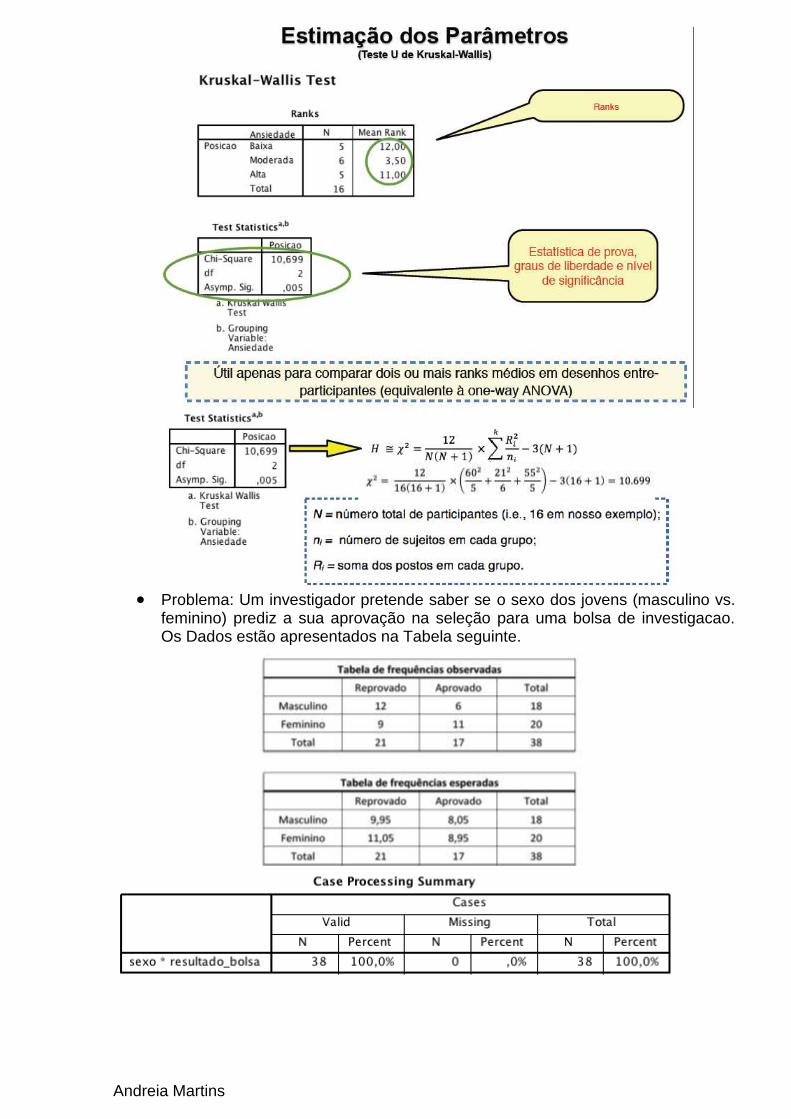
Andreia Martins
Problema: Um investigador pretende saber se o sexo dos jovens (masculino vs.
feminino) prediz a sua aprovação na seleção para uma bolsa de investigacao. Os Dados estão apresentados na Tabela seguinte.
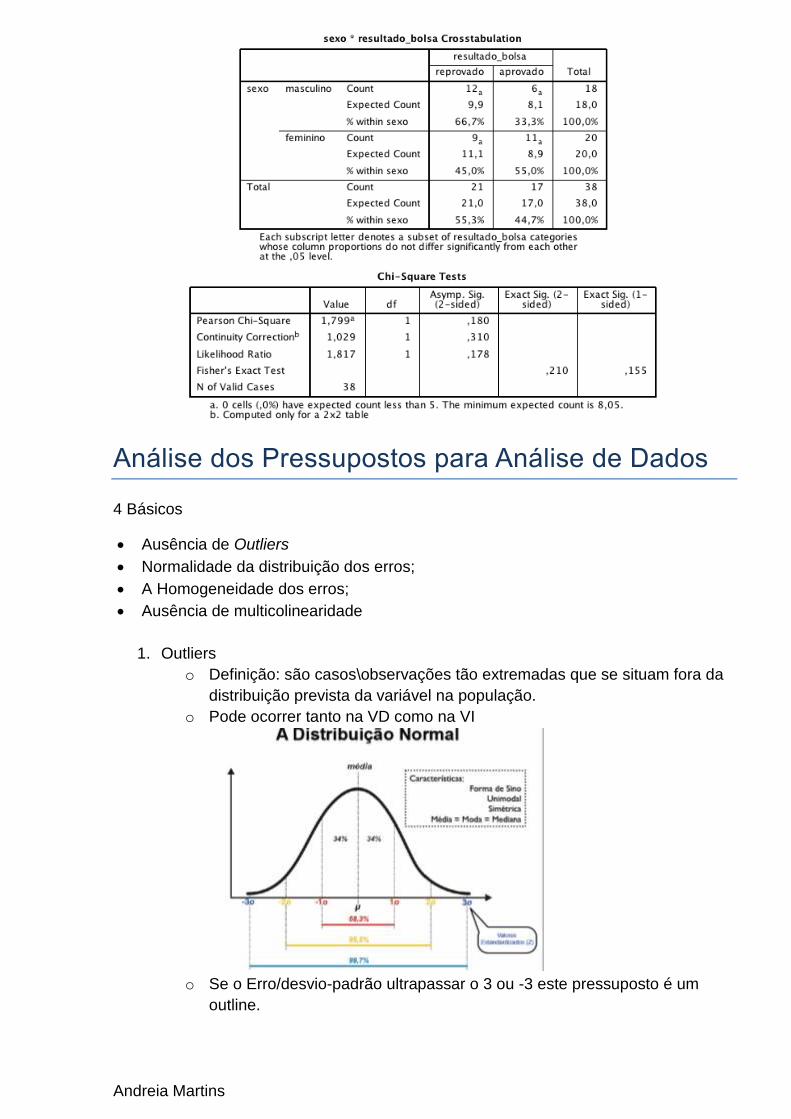
Andreia Martins
Análise dos Pressupostos para Análise de Dados
4 Básicos
Ausência de Outliers
Normalidade da distribuição dos erros;
A Homogeneidade dos erros;
Ausência de multicolinearidade
1. Outliers
o Definição: são casos\observações tão extremadas que se situam fora da
distribuição prevista da variável na população.
o Pode ocorrer tanto na VD como na VI
o Se o Erro/desvio-padrão ultrapassar o 3 ou -3 este pressuposto é um
outline.
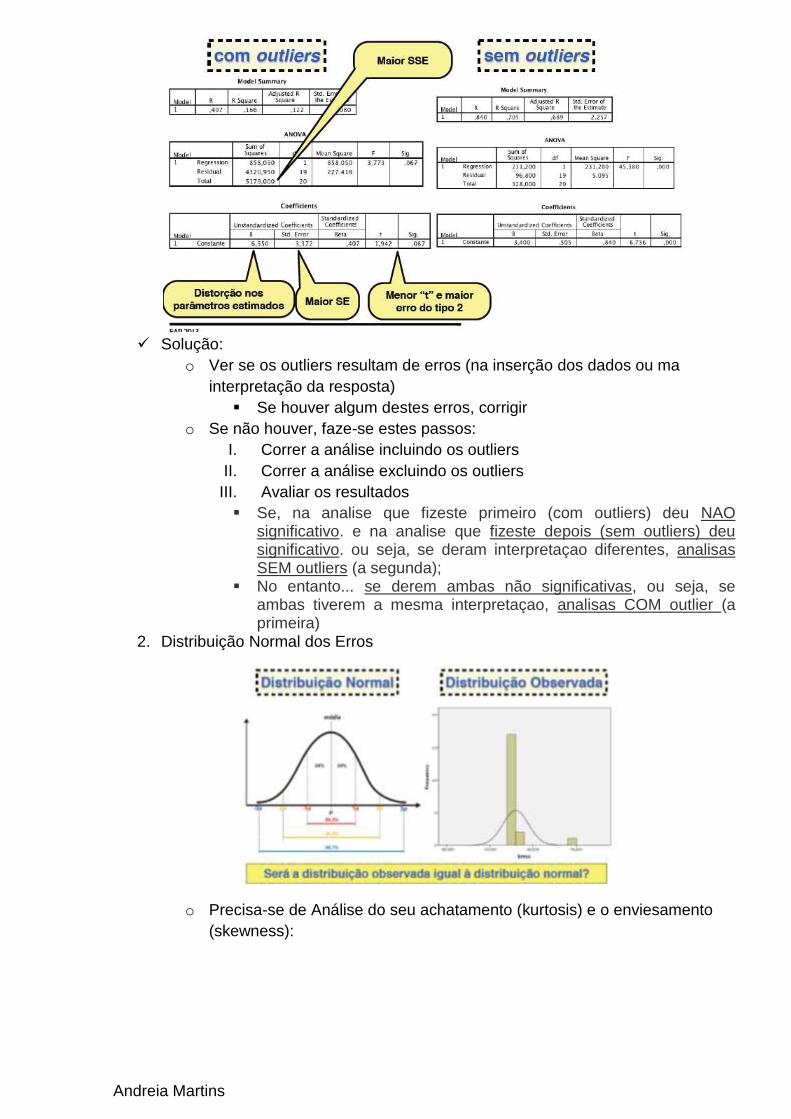
Andreia Martins
Solução:
o Ver se os outliers resultam de erros (na inserção dos dados ou ma
interpretação da resposta)
Se houver algum destes erros, corrigir
o Se não houver, faze-se estes passos:
I. Correr a análise incluindo os outliers
II. Correr a análise excluindo os outliers
III. Avaliar os resultados
Se, na analise que fizeste primeiro (com outliers) deu NAO significativo. e na analise que fizeste depois (sem outliers) deu significativo. ou seja, se deram interpretaçao diferentes, analisas SEM outliers (a segunda);
No entanto... se derem ambas não significativas, ou seja, se ambas tiverem a mesma interpretaçao, analisas COM outlier (a primeira)
2. Distribuição Normal dos Erros
o Precisa-se de Análise do seu achatamento (kurtosis) e o enviesamento
(skewness):

Andreia Martins
Ou então fazemos pelo Teste de Kolmogorov-Smirnov
Solução:
o Transformação da variável dependente:
Andreia Martins
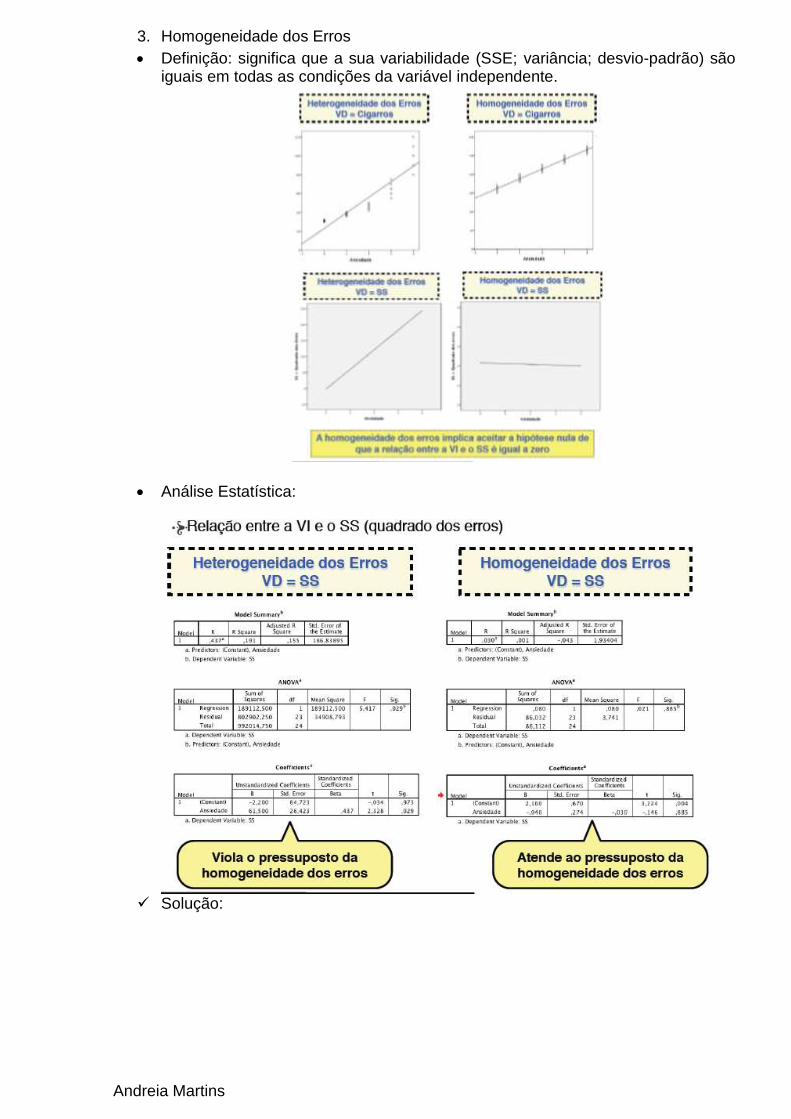
3. Homogeneidade dos Erros
Definição: significa que a sua variabilidade (SSE; variância; desvio-padrão) são iguais em todas as condições da variável independente.
Análise Estatística:
Solução:
Andreia Martins
o Escolhe-se o erro que se aproxima mais do zero
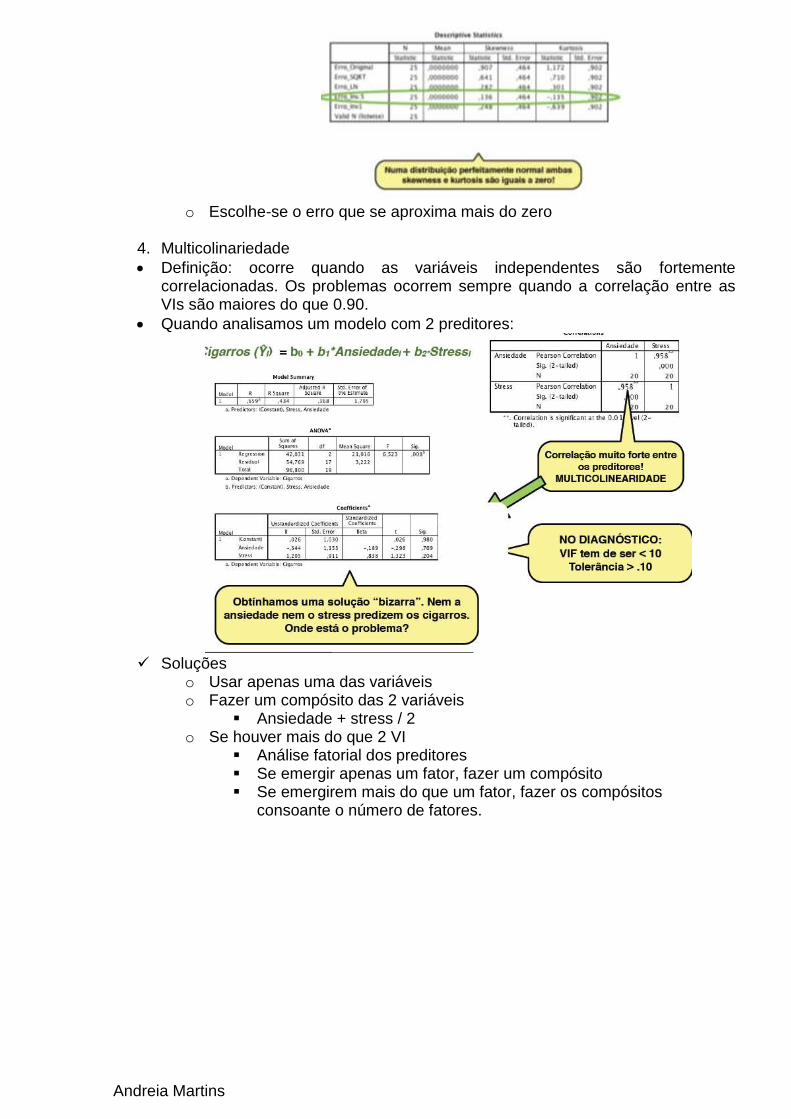
4. Multicolinariedade
Definição: ocorre quando as variáveis independentes são fortemente correlacionadas. Os problemas ocorrem sempre quando a correlação entre as VIs são maiores do que 0.90.
Quando analisamos um modelo com 2 preditores:
Soluções
o Usar apenas uma das variáveis o Fazer um compósito das 2 variáveis
Ansiedade + stress / 2 o Se houver mais do que 2 VI
Análise fatorial dos preditores Se emergir apenas um fator, fazer um compósito Se emergirem mais do que um fator, fazer os compósitos
consoante o número de fatores.
















![Silabo Primer Semestre 2010 Eap Contabilidad[1]](https://img.dokumen.tips/doc/110x75/5571f86249795991698d5057/silabo-primer-semestre-2010-eap-contabilidad1.jpg)



![Procedimiento Conexion Red Wifi EAP[1]](https://img.dokumen.tips/doc/110x75/5571f24049795947648c6477/procedimiento-conexion-red-wifi-eap1.jpg)








