Embed Size (px)
DESCRIPTION
REGRESI SEDERHANA, metode kuadrat terkecil,
Citation preview

1
REGRESI SEDERHANA(DUA VARIABEL)
Pada model regresi linear sederhana yaitu variabel dependen hanya dijelaskan oleh satu variabel independen.Misalnya kita mempelajari: Pengeluaran konsumsi dengan pendapatan real. C = β0 + β1 Y β1 > 0 dimana C = konsumsi dan Y= pendapatan
β0 dan β1 adalah koefisien parameter βi
Jumlah permintaan dengan harga barang Y = β0 + β1 X β1 < 0 dimana Y = Jml permintaan dan X= harga barang
β0 dan β1 adalah koefisien parameter βi
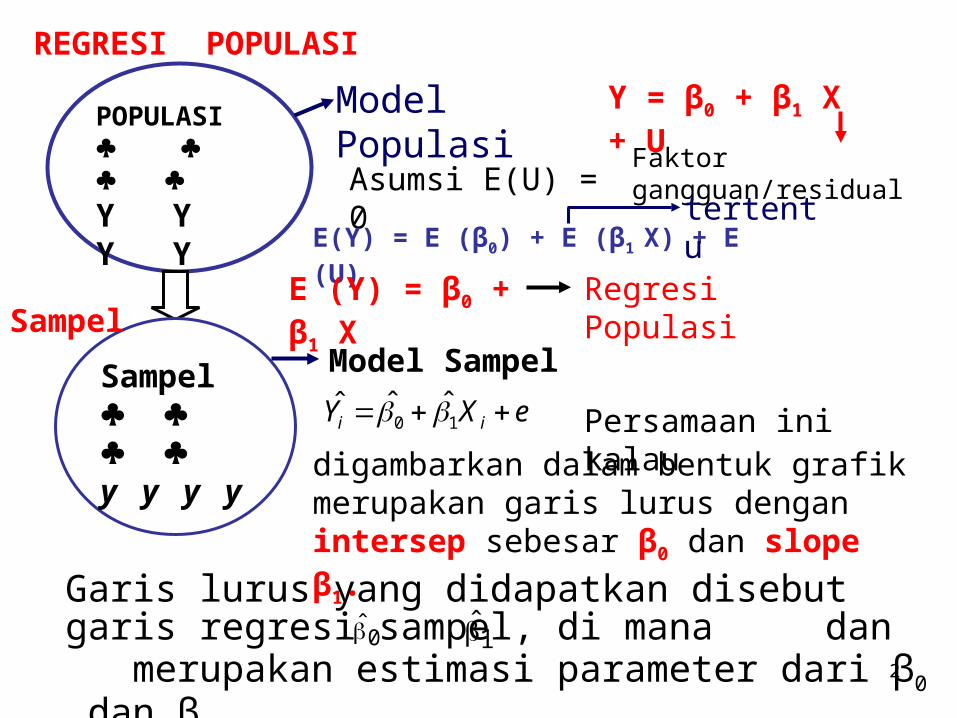
2
POPULASI Y Y Y Y
Sampel y y y y
REGRESI POPULASI
Sampel
Model Populasi Y = β0 + β1 X + U
Faktor gangguan/residualAsumsi E(U) = 0
E(Y) = E (β0) + E (β1 X) + E (U)tertentu
E (Y) = β0 + β1 X Regresi Populasi
Model Sampel
Persamaan ini kalaudigambarkan dalam bentuk grafik merupakan garis lurus dengan intersep sebesar β0 dan slope β1.
Garis lurus yang didapatkan disebut garis regresi sampel, di mana dan merupakan estimasi parameter dari β0 dan β1.
eXY ii 10ˆˆˆ
0 1

3
Regresi Sampel
Ŷ = mengestimate E(Y) ˆ
0 = mengestimate β0
= mengestimate β1 1
Ŷ disebut nilai prediksi (predicted value) dari Y. Nilai prediksi tidak sama dengan nilai aktualnya sehingga ditambahkan nilai residual dalam persamaan, Y = Ŷ + e
eXY ii 10ˆˆˆ
Xi
E(Y)= β0 + β1XX
XY 10ˆˆˆ
ee
A
Garis Regresi Populasi dan Sampel
E(Yi)

4
METODE KUADRAT TERKECIL (OLS= Ordinary Least Square)
Persoalan penting dalam membuat garis regresi sampel adalah bagaimana mendapatkan garis regresi yang baik sedekat mungkin dekat dengan datanya.
Metode OLS mempunyai beberapa sifat statistik yang sangat menarik yang membuatnya menjadi suatu metode analisis regresi yang paling kuat (powerful) dan populer. Untuk penjelasan kita lihat pada fungsi regresi sampel (FRS) dua variabel : eXY 10
ˆˆˆ

5
METODE KUADRAT TERKECIL (OLS= Ordinary Least Square)
Perbedaan nilai aktual dengan nilai prediksi disebut residual ( )dan dinyatakan dalam:
Metode OLS yang akan menjamin jumlah residual kuadrat sekecil mungkin dapat dijelaskan sebagai berikut:
iii eYY
ie
210
22
)(
)(
ii
iii
XY
YYe

6
METODE KUADRAT TERKECIL (OLS= Ordinary Least Square)
Melalui differensial parsial maka akan didapatkan estimator parameternya, hingga didapatkan:
2
2
221
)(
))((
)(ˆ
i
ii
i
ii
ii
iiii
X
YXXX
YYXX
XXn
YXYXn
XY
n
YXXn
YXXYX
nXi
ii
iiiii
i
2
2
22
2
0 )(ˆ

7
Metode OLS, menunjukkan jumlah residual kuadrat sekecil mungkin dapat dijelaskan sebagai berikut:
atau
Syarat
0)1()ˆˆ(20ˆ 10
0
2
XYe
1)
XnY 10ˆˆ …………… (1)
0)()ˆˆ(20ˆ 101
2
XXY
e
2)
210
ˆˆ XXXY ……….. (2)
22 )YY(e 210
2 )XˆˆY(e

8
Berdasarkan persamaan (1) dan (2) kita dapatkan nilai β0 dan β1 dengan mengalikan persamaan (1) dengan ∑X dan perasamaan (2) dengan n, sbb:
221 )(
ˆXXn
YXXYn
2)XX(
)YY)(XX(
X dan Yadalah rata-rata
21x
xyˆ
x = X – X
y = Y – Y
X10ˆ-Yˆ

9
Asumsi-Asumsi Metode Kuadrat TerkecilAsumsi 1
Hubungan antara variabel Y (variabel dependen) dan X (variabel independen) adalah linear dalam parameter. Dalam hal ini β1 berhubungan linear dengan Y.
Asumsi 2
Variabel X adalah variabel tidak stokastik yang nilainya tetap. Nilai X adalah untuk berbagai observasi yang berulang-ulang, nilai X adalah tertentu. Jadi dengan sampel yang berulang-ulang nilai variabel independen (X) adalah tetap dengan kata lain variabel independen (X) adalah variabel yang dikontrol.
1080 140 210 300
(X1) (X2) (X3) (X4)
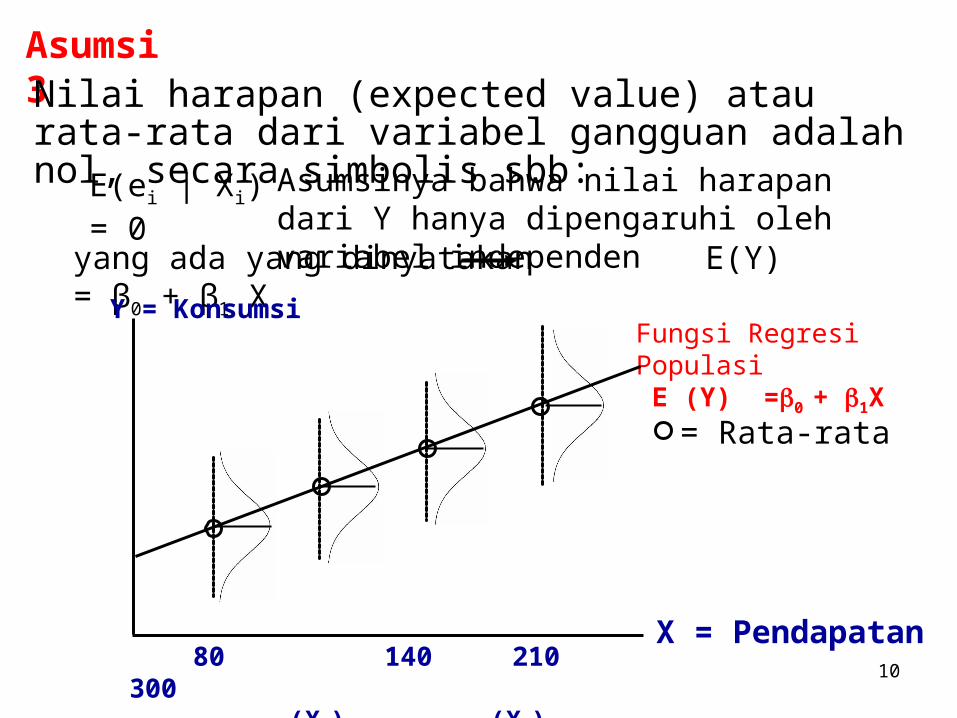
Asumsi 3Nilai harapan (expected value) atau rata-rata dari variabel gangguan adalah nol, secara simbolis sbb:
E(ei | Xi) = 0 Asumsinya bahwa nilai harapan dari Y hanya dipengaruhi oleh variabel independen
yang ada yang dinyatakan E(Y) = β0 + β1 X
Fungsi Regresi Populasi E (Y) =0 + 1X
= Rata-rata
X = Pendapatan
Y = Konsumsi
11
X3
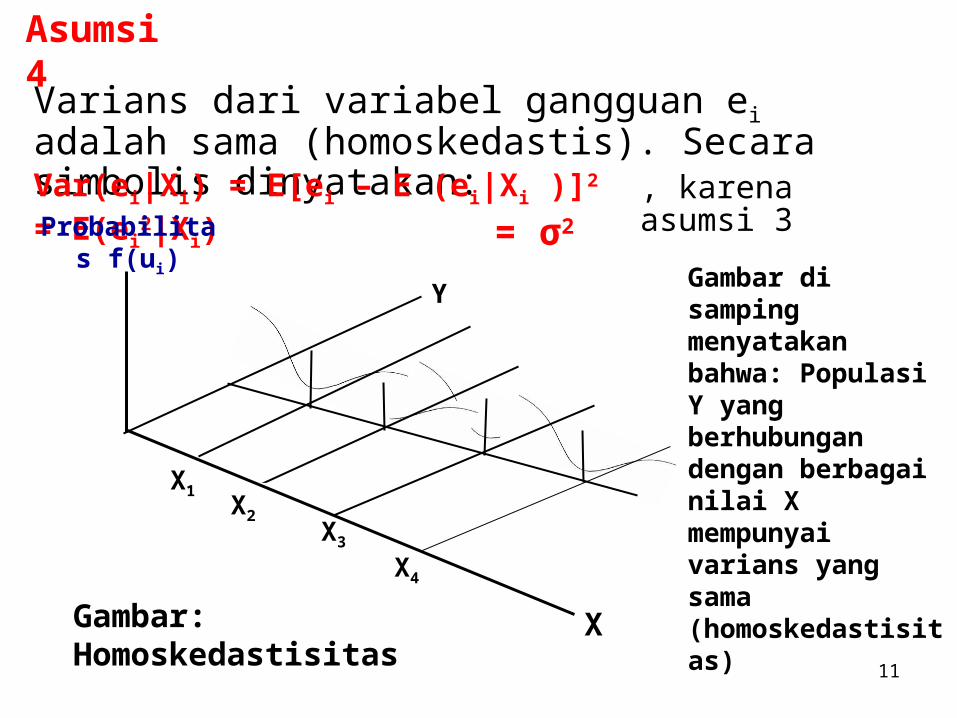
Asumsi 4
Varians dari variabel gangguan ei adalah sama (homoskedastis). Secara simbolis dinyatakan:Var(ei|Xi) = E[ei – E (ei|Xi )]2 = E(ei
2|Xi) , karena asumsi 3
= σ2
Y
X1X2
X4
Probabilitas f(ui) Gambar di samping
menyatakan bahwa: Populasi Y yang berhubungan dengan berbagai nilai X mempunyai varians yang sama (homoskedastisitas)
XGambar: Homoskedastisitas
12
X1
X2
X3
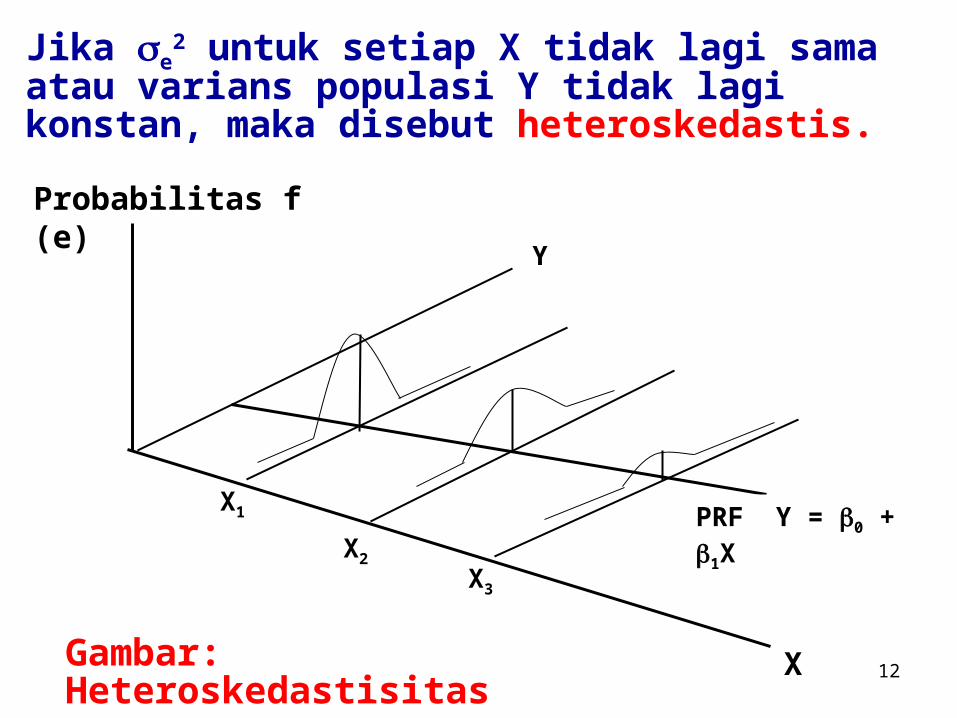
Jika e2 untuk setiap X tidak lagi sama atau varians
populasi Y tidak lagi konstan, maka disebut heteroskedastis.
Y
Probabilitas f (e)
PRF Y = 0 + 1X
XGambar: Heteroskedastisitas

13
Gambar Heteroskedastisistas menunjukkan bahwa varians meningkat bersama dengan meningkatnya pendapatan. Jadi bisa dikatakan, keluarga yang lebih kaya secara rata-rata mengkonsumsi lebih banyak dari pada keluarga miskin, tetapi variabilitas belanja konsumsi keluarga yang kaya lebih besar.
Asumsi 5
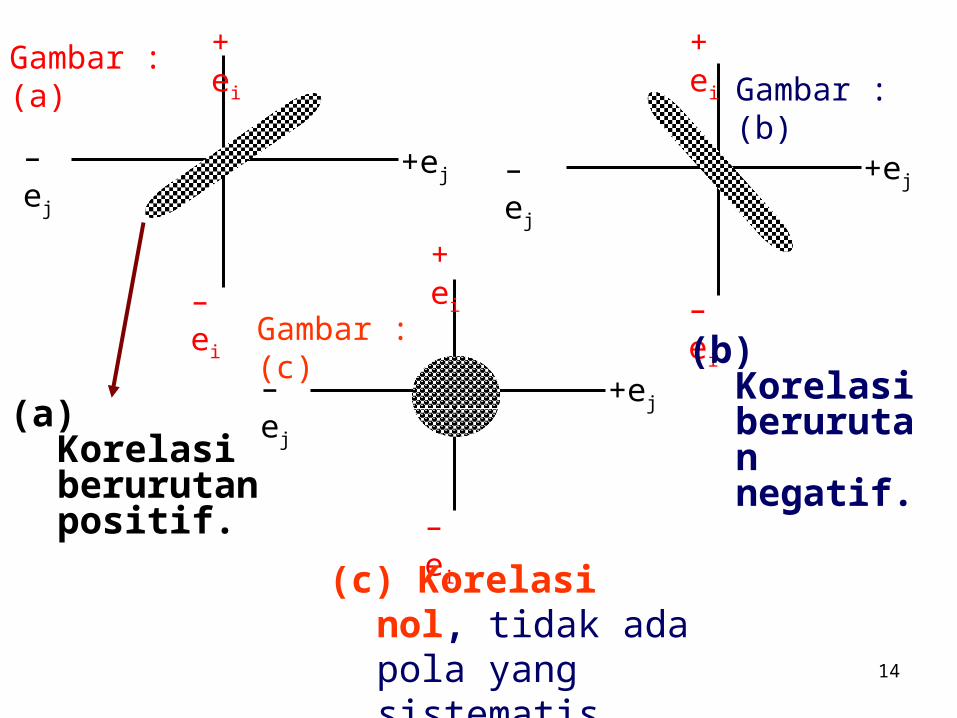
Tidak ada serial korelasi antara residual ei atau residual ei tidak saling berhubungan dengan ej yang lain. Secara simbolis :
Cov (ei, ej |Xi, Xj ) = E [ (ei – E(ei)|Xi)] [(ej – E (ej)|Xj)]
= E (ei |Xi ) ( ej |Xj ) =0
14
+ ei
+ ei
+ ei
– ei
– ei
– ei
– ej – ej
– ej
+ej +ej
Gambar : (a)Gambar : (b)
Gambar : (c)
(a) Korelasi berurutan positif.
(b) Korelasi berurutan negatif.
(c) Korelasi nol, tidak ada pola yang sistematis untuk e.
+ej

15
Asumsi 6Variabel gangguan ei berdistribusi normal
e (0 ;σ2)
Metode OLS menghasilkan regresi yang BLUE (Best Linear Unbiased Estimator)Suatu estimator β1 dikatakan mempunyai sifat BLUE, jika:1.Estimator β1 adalah linear, yaitu linear terhadap
variabel stokastik Y sebagai variabel dependen.2. Estimator β1 tidak bias, yaitu nilai rata-rata atau nilai
harapan E (β1) sama dengan β1 yang sebenarnya.
3. Estimator β1 mempunyai varian yang minimum (efisien).
16
Y (Konsumsi)
X (Pendapatan)X1
e1{
X2
}e2
*
*
*
X3
e3
*}e4
X4
XY 10
Y
Y
Y
Y
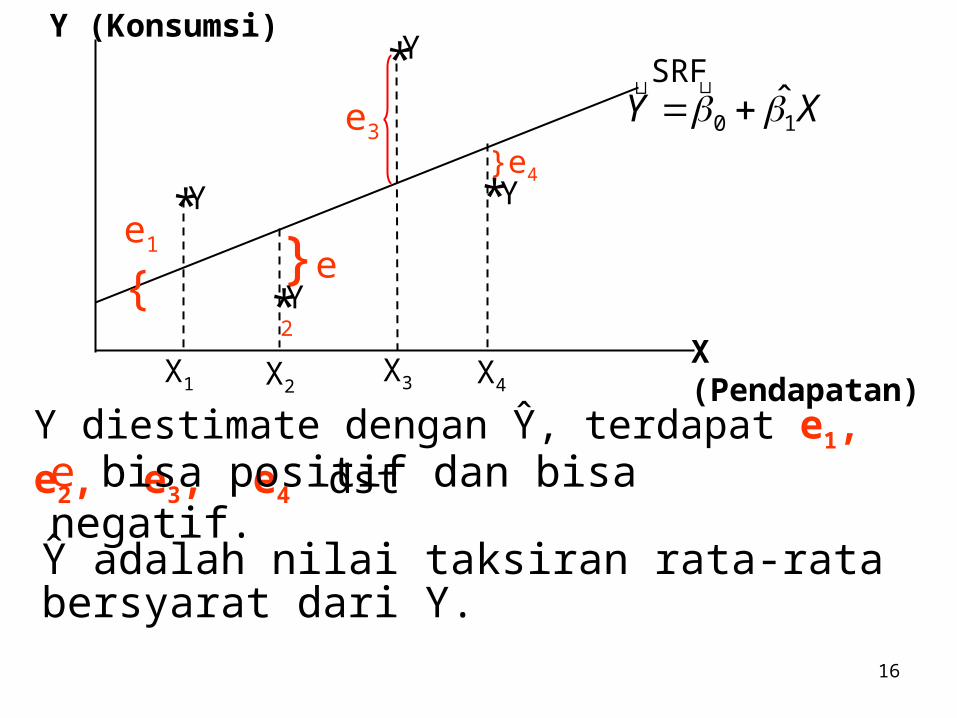
Y diestimate dengan Ŷ, terdapat e1, e2, e3, e4 dst e bisa positif dan bisa negatif.
Ŷ adalah nilai taksiran rata-rata bersyarat dari Y.
SRF

17
X dan Y sudah tentu, kita ingin menetapkan SRF sehingga sedekat mungkin dengan nilai Y yang sebenarnya (aktual). e2 = minimal. Jumlah kesalahan paling kecil disebut Metode Kuadrat Terkecil (OLS = Ordinary Least Squares)
ieXY 10ˆˆˆ Persamaan ini merupakan nilai
prediksi yang berbeda dengan nilai aktualnya.
Perbedaan nilai aktual dengan dengan nlai prediksi disebut residual (e), sehingga persamaan dapat ditulis kembali menjadi Y = Ŷ + e atau e = Y – Ŷ
Dalam bentuk persamaan yang lain e = Y – β0 – β1X ^ ^

18
Standard Error dari OLSEstimator yang diperoleh dari metode OLS adalah variabel yang sifatnya random, yaitu nilainya berubah dari satu sampel ke sampel lain. Kita membutuhkan ketepatan estimator dari β0 dan β1. Standard error mengukur ketepatan estimasi dari estimator β0 dan β1
Standard Error β0 dan β1 dihitung dengan rumus sebagai berikut:
2
22
0n
X)ˆ(Var
ix
)ˆ()ˆ( 00 VarSe

19
2
2
1)ˆ(Var x
)ˆ()ˆ( 11 VarSe
Rumus Varianskn
ei
2
2 n = ukuran data
k = banyaknya variabel
Rumus lain mencari varians:kn
xyy
12
2ˆ
∑e2 adalah jumlah residual kuadrat (residual sum of squares = RSS). n-k dikenal dengan derajat kebebasan atau degree of freedom (df).
Semakin kecil standard error maka semakin kecil variabilitas dari angka estimator, berarti semakin dipercaya nilai estimator yang didapat.

20
Dari e Y Y ii eyy ii ˆasumsi e dan y independen
222 )()()(
ˆ
iiii
iiii
ii
yyyyyy
kuadratnyanpenjumlahatotalyyyyyy
ydikurangikemudian
eyy
TSSESS + RSS = (Total Sum Squares)
(Residual Sum Squares)(Explained Sum Squares)
KOEFISIEN DETERMINASI
RSSESSTSSingatYY
eR
atauYY
YY
TSS
ESSR
i
i
i
i
,)(
1
)(
)(
2
2
2
2
2
2

21
Berdasarkan TSS=ESS+RSS
Nilai determinasi dapat didefinisikan sebagai proposri atau persentase dari total variasi variabel dependen Y yang dijelaskan oleh garis regresi (variabel independen X). Jika garis regresi tepat pada semua data Y maka ESS sama dengan TSS sehingga nilai determinasi = 1, sedangkan jika garis regresi tepat pada rata-rata nilai Y maka ESS = 0 sehingga nilai determinasinya sama dengan nol. Dengan demikian nilia koefisien determinasi ini terletak antara 0 dan 1.

22
Koefisien Determinasi r2 0 ≤ r2 ≤ 1
Semakin mendekati angka 1 maka semakin baik garis regresi, karena mampu menjelaskan data aktualnya. Semaikn mendekati angka nol maka garis regresi kurang baik atau tidak baik.
Y X
Venn Diagram
IndependenY X
Pengaruh X terhadap Y
X Semakin besar irisan semakin besar pengaruh X terhadap Y.
23
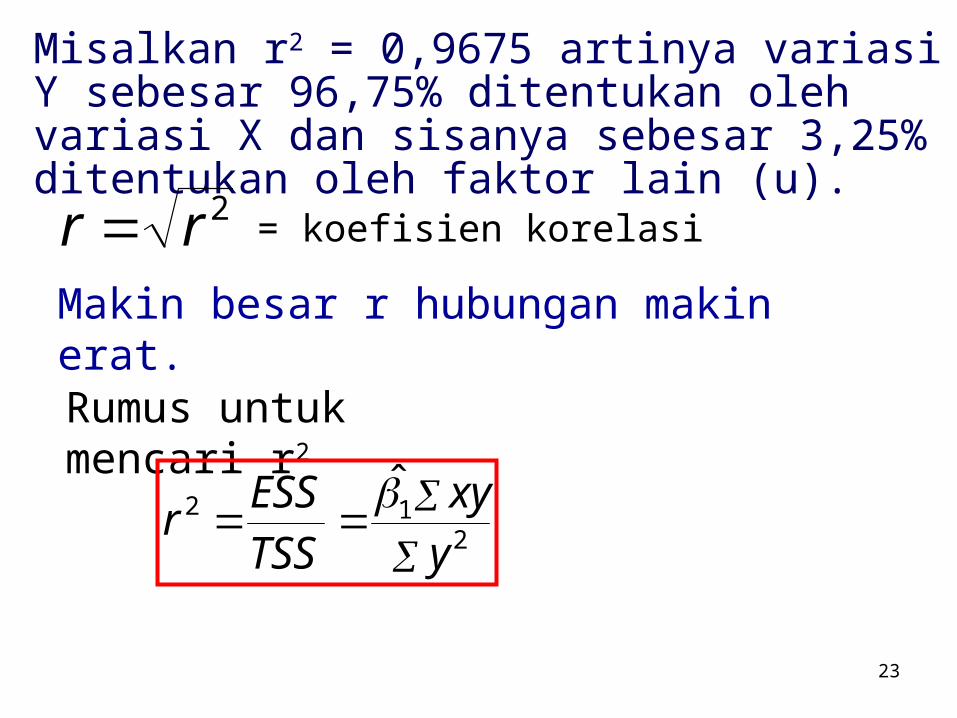
Misalkan r2 = 0,9675 artinya variasi Y sebesar 96,75% ditentukan oleh variasi X dan sisanya sebesar 3,25% ditentukan oleh faktor lain (u).
2rr = koefisien korelasi
Makin besar r hubungan makin erat.
Rumus untuk mencari r2
212
ˆ
yxy
TSSESS
r
24
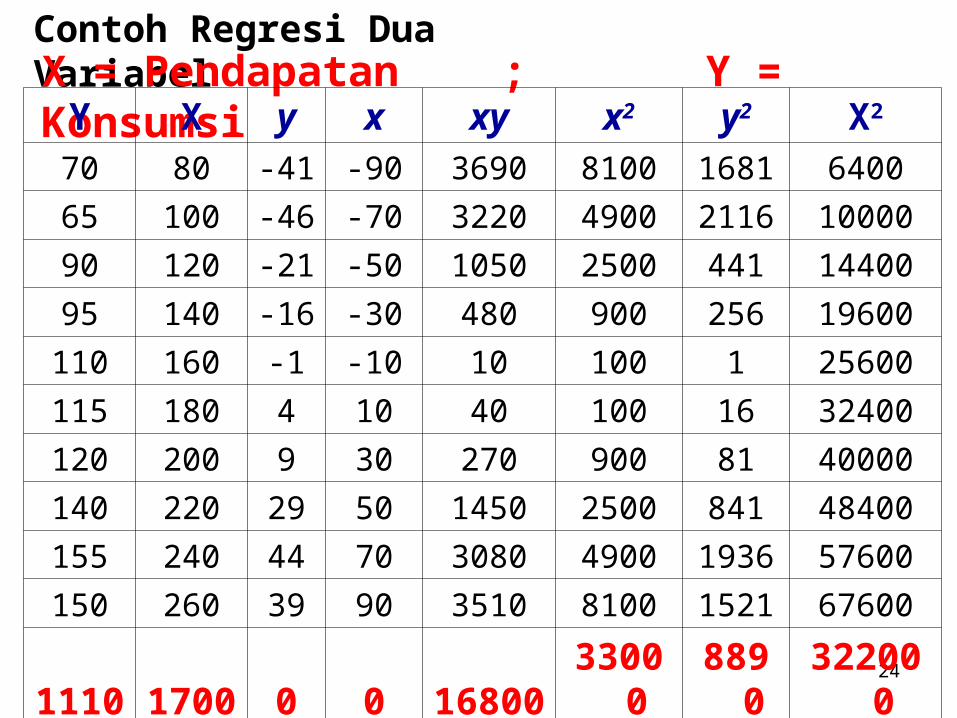
Contoh Regresi Dua VariabelX = Pendapatan ; Y = Konsumsi
Y X y x xy x2 y2 X2
70 80 -41 -90 3690 8100 1681 6400
65 100 -46 -70 3220 4900 2116 10000
90 120 -21 -50 1050 2500 441 14400
95 140 -16 -30 480 900 256 19600
110 160 -1 -10 10 100 1 25600
115 180 4 10 40 100 16 32400
120 200 9 30 270 900 81 40000
140 220 29 50 1450 2500 841 48400
155 240 44 70 3080 4900 1936 57600
150 260 39 90 3510 8100 1521 67600
1110 1700 0 0 16800 33000 8890 322000

25
11110110.1
nY
Y 170
10700.1
nX
X
51,05091,0000.33800.16
21
xxy
45,24)170(5091,0111-Y 10 XRegresi Ŷ = 24,45 + 0,51X
knxyy
1
22ˆ
Varianskn
e
22 atau
14,42210
)800.16(5091,08890ˆ 1
22
knxyy
0013,0001276,0000.3314,42
)( 2
2
1 x
Var

26
036,00013,0)ˆ()ˆ( 11 VarSe
1184,41)000.33(10
)000.322(14,42)( 2
22
0
xnX
Var = 41,12
Regresi Ŷ = 24,45 + 0,51 X
(6,41) (0,036) Standardeviasi
41,612,41)( 00 VarS
0,962079 890.8
88,85528.890
(16.800) 5091,0ˆ2
12
yxy
r
= 0,9621
27
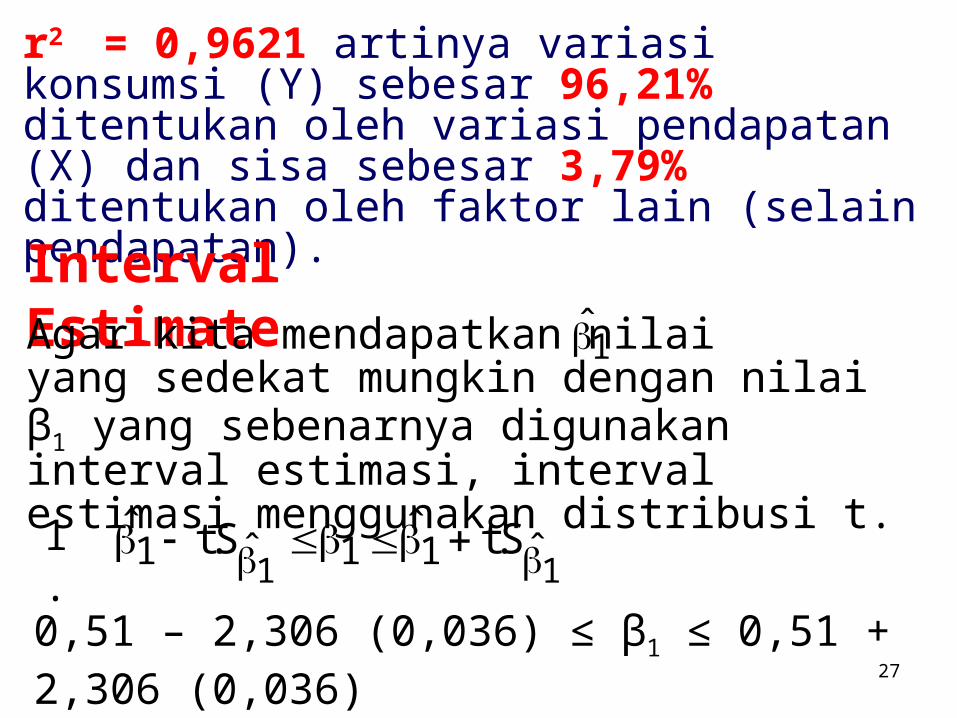
r2 = 0,9621 artinya variasi konsumsi (Y) sebesar 96,21% ditentukan oleh variasi pendapatan (X) dan sisa sebesar 3,79% ditentukan oleh faktor lain (selain pendapatan).
Interval EstimateAgar kita mendapatkan nilai yang sedekat mungkin dengan nilai β1 yang sebenarnya digunakan interval estimasi, interval estimasi menggunakan distribusi t.
11ˆ11ˆ1 S.tˆS.tˆ 1.
0,51 – 2,306 (0,036) ≤ β1 ≤ 0,51 + 2,306 (0,036)
1

28
0,51 – 0,083 ≤ β1 ≤ 0,51 + 0,083
0,43 ≤ β1 ≤ 0,59
0ˆ0ˆ S.tS.t 000 2.
24,45 – 2,306 (6,41) ≤ β0 ≤ 24,45 + 2,306(6,41)
24,45 – 14,781 ≤ β0 ≤ 24,45 + 14,781
9,67 ≤ β0 ≤ 39,23
2
22
22hit
2 ˆkn
21
3. Varian (σ2)
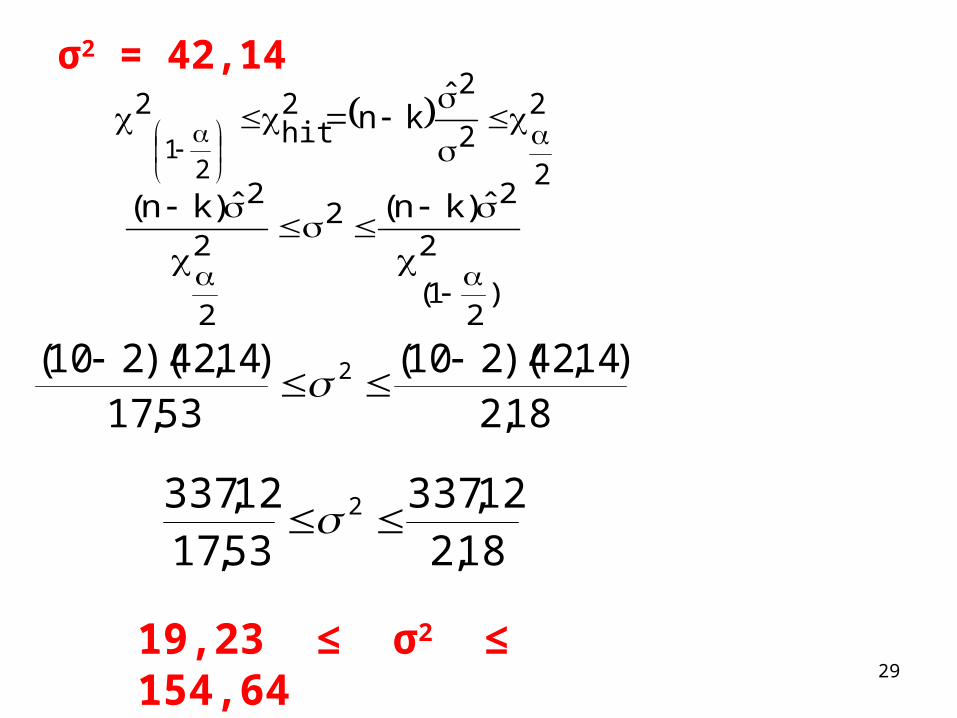
29
σ2 = 42,14
2
22
22hit
2 ˆkn
21
2
)2
1(
22
2
2
2 ˆ)kn(ˆ)kn(
18,2)14,42)(210(
53,17)14,42)(210( 2
18,212,337
53,1712,337 2
19,23 ≤ σ2 ≤ 154,64

30
Latihan Penggunaan OLS• Dipunyai data jumlah permintaan mobil di dealer
Daihatsu (Y) dan harganya (X) dengan datanya seperti terlihat pada tabel berikut:
X(Juta)
120 121,2 123,8 123,9 123,9 124,2 124,8 125 125,7 125,9 126
Y(unit)
1250 1300 1312 1324 1345 1365 1334 1367 1378 1499 1500
1. Tentukan estimasi parameter-parameternya (dengan metode OLS) jika persoalan tsb memenuhi persamaan regresi
2. Berapakah nilai koefisien determinasinya?
3. Tentukan nilai standar errornya
4. Jelaskan interpretasi anda berdasarkan soal no 1 -3.

31
DISKUSI KELOMPOK1. Dipunyai belanja harian seorang mahasiswa (Y)
dan harganya (X) dengan datanya seperti terlihat pada tabel berikut:
X(ribu)
700 750 760 760 740 780 785 790 800
Y(ribu)
690 700 740 755 760 760 775 780 800
1. Tentukan estimasi parameter-parameternya (dengan metode OLS) jika persoalan tsb memenuhi persamaan regresi
2. Berapakah nilai koefisien determinasinya?
3. Tentukan nilai standar errornya
4. Jelaskan interpretasi anda berdasarkan soal no 1 -3.

32
DISKUSI KELOMPOK
2. Berdasarkan pengamatan 10 sampel diperoleh data sebagai
berikut:
132100,32200,205500,1700,1110
22
YXYXXY iiii
Dengan koefisien korelasi r = 0,9758, tetapi pada pemeriksaan ulang dijumpai bahwa dua pasang pengamatan tercatat
Y X
90 120
140 220
Y X
80 110
150 210
Seharusnya
Apa pengaruh kesalahan tadi terhadap r? Berapakah r yang benar?

33
DISKUSI KELOMPOK3. Tabel berikut memberikan informasi tingkat pekerja yang ke luar
negeri sari pekerjaan per 100 karyawan (Y) salam sektor produksi dan tingkat pengangguran (X) dalam sektor produksi di Arab Saudi untuk periode tahun 1995-2007
Y X
1,3 6,2
1,2 7,8
1,4 5,8
1,4 5,7
1,5 5,0
1,9 4,0
2,6 3,2
2,3 3,6
2,5 3,3
2,7 3,3
2,1 5,6
1,8 6,8
2,2 5,6
Berdasarkan tabel tersebut diperoleh hasil analisis varians (AOV) sebagai berikut
Sumber
Variasi
SS Df MSS
Karena
Regresi
2,153 1 2,153
Karena
Residual
1,144 11 0,104
Total 3,297 12
Ujilah hipotesis nol bahwa tingkat keluarnya karyawan tidak berhubungan secara linier dengan tingkat pengangguran

34
Uji HipotesisSeseorang yang melakukan penelitian lebih banyak menggunakan data sampel daripada data populasi. Dalam menguji kebenaran hipotesis dari data sampel, statistika mengembangkan dengan uji–t. Hal yang penting dalam uji-t menggunakan satu sisi atau dua sisi.
Contoh 1:
Apakah Pendapatan (X) mempengaruhi Konsumsi (Y) secara signifikan?Maka kita buat Regresi: XY 10
Hipotesis: Ho: β1 = 0 (X tidak mempengaruhi Y)
H1 : β1 ≠ 0

35
Hitung :
Gunakan tabel-t : Terima Ho
0,0250,025
- 2,306 2,306
Karena thitung = 14,17 > 2,306Maka tolak Ho, artinya pendapatan (X) mempengaruhi konsumsi (Y) signifikan.
Contoh 2:
Apakah β1 = MPC > 0,30 Coba tes dengan satu sisi.
Buat Hipotesis: Ho: β1 ≤ 0,30
H1 : β1 > 0,30
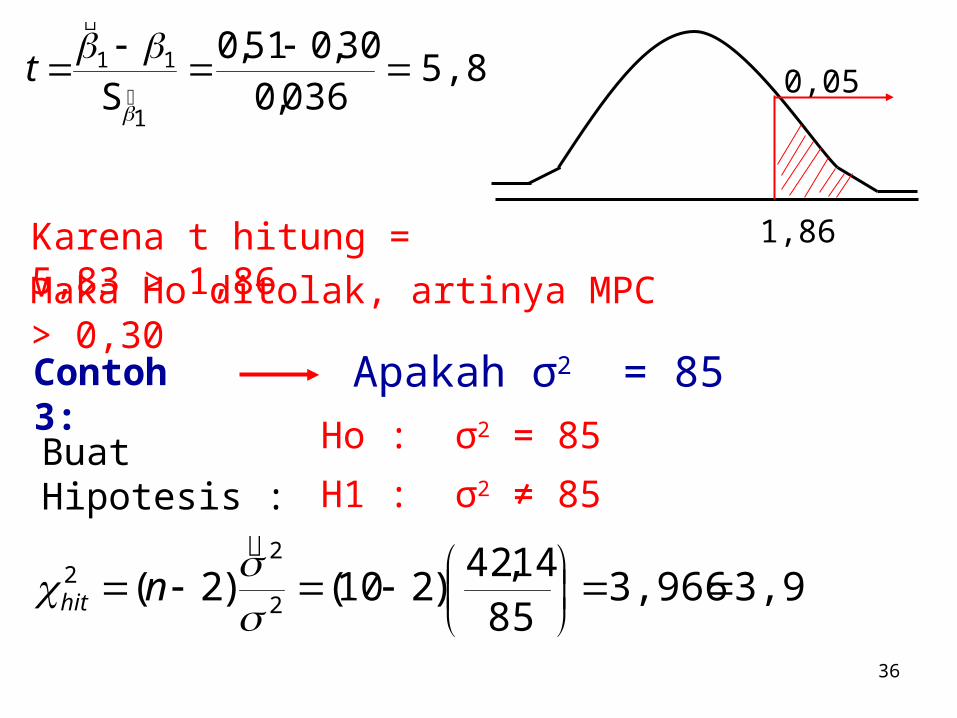
14,17 036,051,0
S
1
1
t
36
0,05
1,86
5,83 036,0
30,051,0S
1
11
t
Karena t hitung = 5,83 > 1,86
Maka Ho ditolak, artinya MPC > 0,30
Contoh 3: Apakah σ2 = 85
Buat Hipotesis : Ho : σ2 = 85
H1 : σ2 ≠ 85
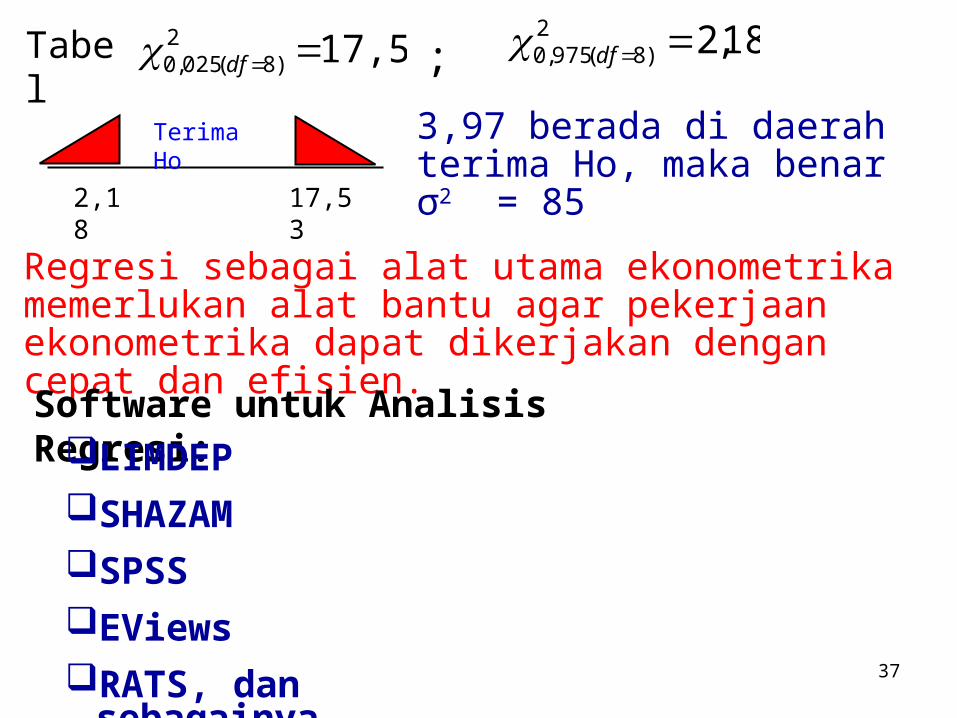
3,97 3,966 85
14,42)210()2( 2
22
nhit
37
Tabel 17,53 2)8(025,0 df 18,22
)8(975,0 df;
3,97 berada di daerah terima Ho, maka benar σ2 = 85
2,18 17,53
Terima Ho
Regresi sebagai alat utama ekonometrika memerlukan alat bantu agar pekerjaan ekonometrika dapat dikerjakan dengan cepat dan efisien.
Software untuk Analisis Regresi:LIMDEPSHAZAMSPSSEViewsRATS, dan sebagainya.

38
Ringkasan Hasil Regresi: Ŷ = 24,45 + 0,51X
Sumber Variasi
df Sum Squares (SS)
Mean Squares(MS)
F hitung
Regresi k – 1 = 1 ESS = β1 ∑xy =
8552,73
EMS = SS/df = 8552,73
EMS/RMS= 8552,73/42,16 =
202,87
Error n – k = 8 RSS = 337,27 RMS = RSS/df =
42,16
Total n – 1 = 9 TSS = ∑y2 = 8890
Secara manual perhitungan dengan rumus-rumus:
Tabel F0,05 (1,8) = 5,32
Kesimpulan: Karena Fhitung= 202,87> F0,05(1,8) = 5,32,
maka Ho ditolak, artinya pendapatan mempengaruhi konsumsi signifikan.
Tabel ANAVA
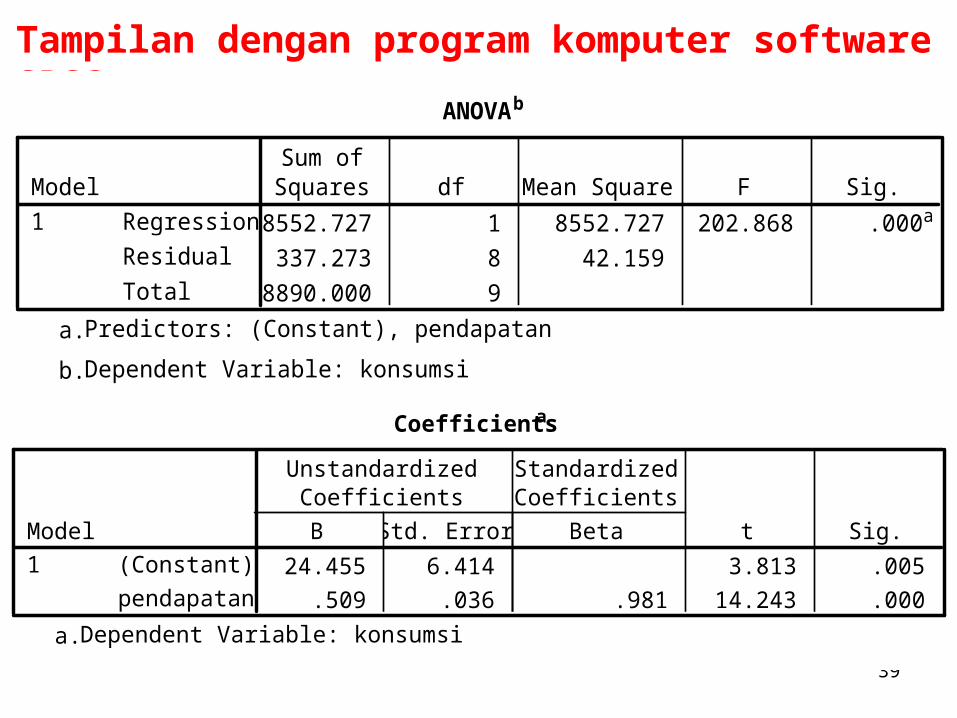
39
Tampilan dengan program komputer software SPSS
ANOVAb
8552.727 1 8552.727 202.868 .000a
337.273 8 42.159
8890.000 9
Regression
Residual
Total
Model1
Sum ofSquares df Mean Square F Sig.
Predictors: (Constant), pendapatana.
Dependent Variable: konsumsib.
Coefficientsa
24.455 6.414 3.813 .005
.509 .036 .981 14.243 .000
(Constant)
pendapatan
Model1
B Std. Error
UnstandardizedCoefficients
Beta
StandardizedCoefficients
t Sig.
Dependent Variable: konsumsia.

40
Model Summary
.981a .962 .957 6.49300Model1
R R SquareAdjustedR Square
Std. Error ofthe Estimate
Predictors: (Constant), pendapatana.
R2 = 0,962 artinya variasi Y (konsumsi) sebesar 96,20% ditentukan oleh variasi X (pendapatan) dan sisanya sebesar 3,80% ditentukan oleh faktor lain (U) yang tidak diteliti.
Penghitungan secara Manual:
0,962079 890.8
88,85528.890
(16.800) 5091,0ˆ2
12
yxy
r
Dibulatkan menjadi 0,9621
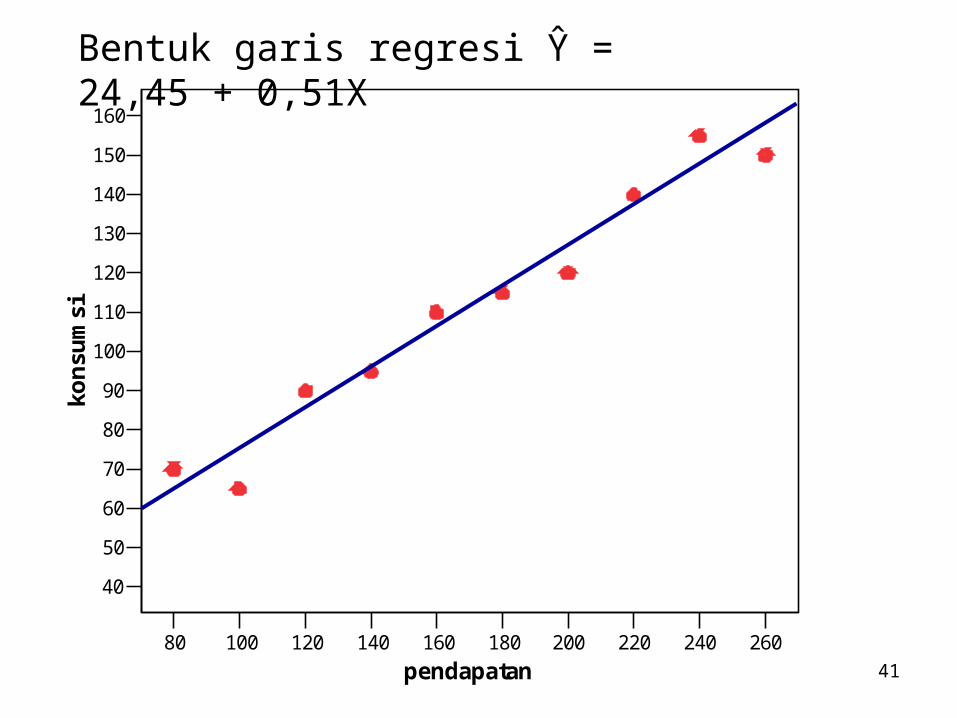
41
80 100 120 140 160 180 200 220 240 260
pendapatan
40
50
60
70
80
90
100
110
120
130
140
150
160
kon
sum
siBentuk garis regresi Ŷ = 24,45 + 0,51X

42
FORECASTING
Ŷ0 mengestimate E(Y)
Untuk X0 = 100 Ŷ0 = 24,45 + 0,51 (100) = 75,45
Ŷ0 – tSŶ0 ≤ E (Y) ≤ Ŷ0 + tSŶ0
2
202
Yx
XX
n
1ˆS
0
33000
)170100(101
14,422
=
= 3,24
t0,025(df=8) = 2,306
Ŷ0 – tSŶ0 ≤ E (Y) ≤ Ŷ0 + tSŶ0
Ŷ0 mengestimate nilai individual

43
Rumus Individual
2
202
Yx
XX
n
11ˆS
0
33000
)170100(101
114,422
=
= 7,25
I. 75,45 – 2,306 (3,24) ≤ E (Y) ≤ 75,45 + 2,306 (3,24)
67,98 ≤ E (Y) ≤ 82,92
II. 75,45 – 2,306 (7,25) ≤ Y ≤ 75,45 + 2,306 (7,25)
58,73 ≤ Y ≤ 92,17

44
ueXY 110 Metode OLS tidak berlaku
Model ini harus dibuat linear dengan log-nya.
ln Y = ln β0 + β1 ln X1 + U (Linear dalam log), maka OLS berlaku.(Model log – log)
Beberapa Model Regresi dalam log
XY lnˆˆln 10 1. log - log
Jika X bertambah 1%, maka Y bertambah β1%

45
XY lnˆˆˆ10 2. linear - log
Jika X bertambah 1%, maka Y bertambah β1 unit
3. XY 10ˆˆln log - linear
Jika X bertambah 1 unit, maka Y bertambah β1%
Misalnya:GNP
0 1 2 3 4t = time
1985ln GNP = 6,96 +0,027 t
t bertambah 1 tahun, GNP bertambah 2,7% (rate ofgrowth)
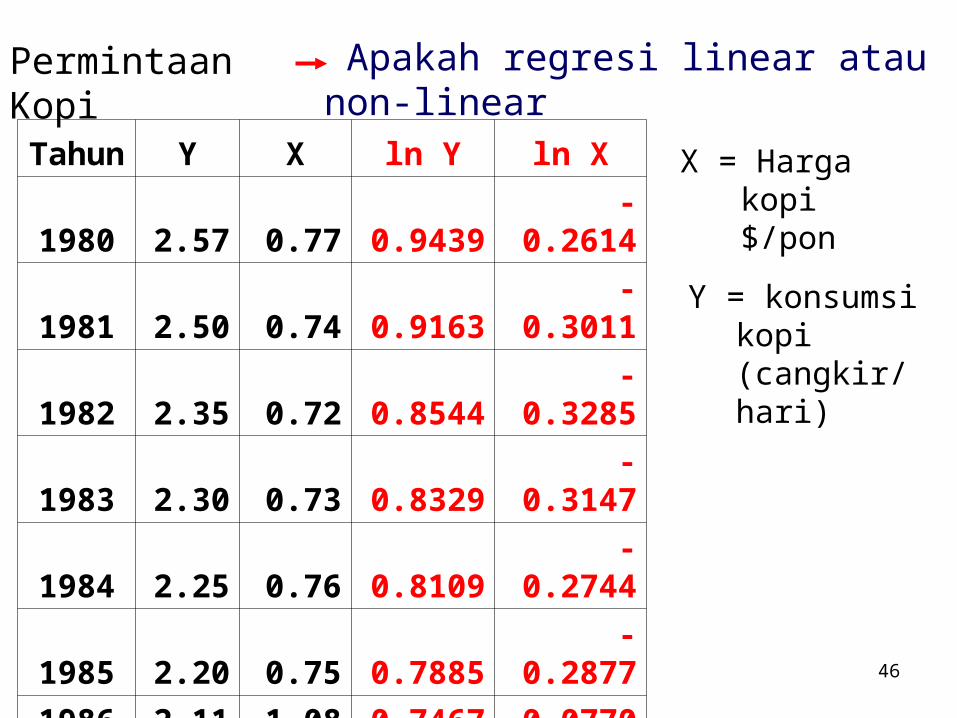
46
Tahun Y X ln Y ln X
1980 2.57 0.77 0.9439 -0.2614
1981 2.50 0.74 0.9163 -0.3011
1982 2.35 0.72 0.8544 -0.3285
1983 2.30 0.73 0.8329 -0.3147
1984 2.25 0.76 0.8109 -0.2744
1985 2.20 0.75 0.7885 -0.2877
1986 2.11 1.08 0.7467 0.0770
1987 1.94 1.81 0.6627 0.5933
1988 1.97 1.39 0.6780 0.3293
1989 2.06 1.20 0.7227 0.1823
1990 2.02 1.17 0.7031 0.1570
Permintaan Kopi Apakah regresi linear atau non-linear
X = Harga kopi $/pon
Y = konsumsi kopi (cangkir/ hari)

47
Model Summary
.814a .663 .625 .12870Model1
R R SquareAdjustedR Square
Std. Error ofthe Estimate
Predictors: (Constant), Xa.
I. Model Regresi Linear Output Komputer
Coefficientsa
2.691 .122 22.127 .000
-.480 .114 -.814 -4.206 .002
(Constant)
X
Model1
B Std. Error
UnstandardizedCoefficients
Beta
StandardizedCoefficients
t Sig.
Dependent Variable: Ya.
Ŷ = 2,691 – 0,480 Xr2 = 0,6630, artinya variasi Y sebesar 66,30% dipengaruhi oleh variasi X.
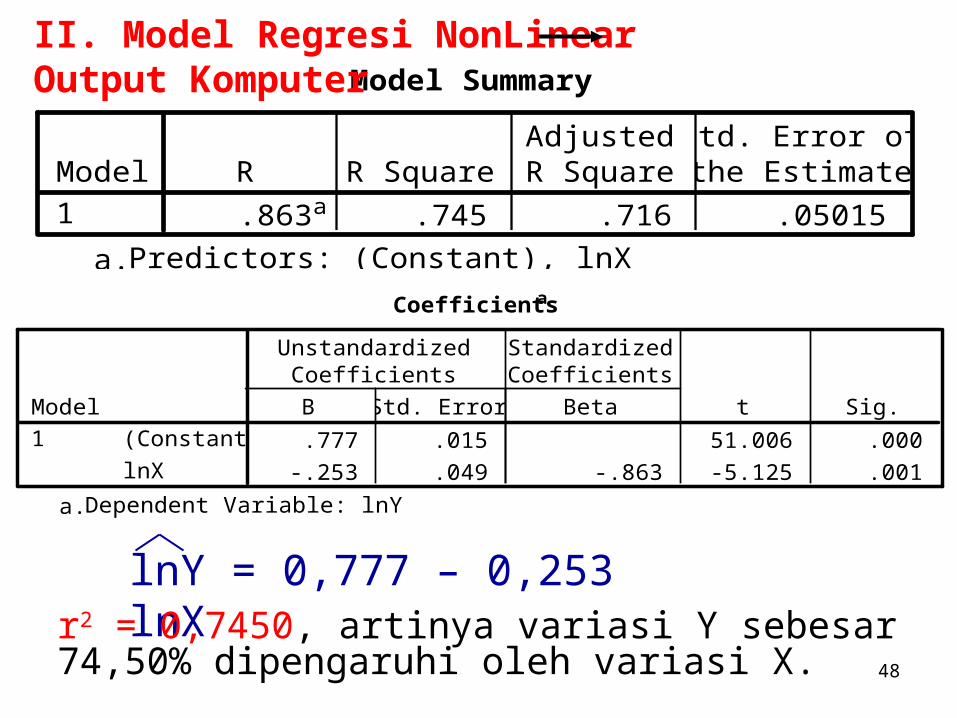
48
Model Summary
.863a .745 .716 .05015Model1
R R SquareAdjustedR Square
Std. Error ofthe Estimate
Predictors: (Constant), lnXa.
II. Model Regresi NonLinear Output Komputer
Coefficientsa
.777 .015 51.006 .000
-.253 .049 -.863 -5.125 .001
(Constant)
lnX
Model1
B Std. Error
UnstandardizedCoefficients
Beta
StandardizedCoefficients
t Sig.
Dependent Variable: lnYa.
lnY = 0,777 – 0,253 lnXr2 = 0,7450, artinya variasi Y sebesar 74,50% dipengaruhi oleh variasi X.





























