Embed Size (px)
Citation preview

What is Redshift ?

Secure
Fully Managed
MPP Data Warehouse
Based on Postgres 8.0.2
SQL interface
3000$ Data Warehouse
Analytics on Large scale Datasets
Peta-byte scale

DemoRDS vs Redshift
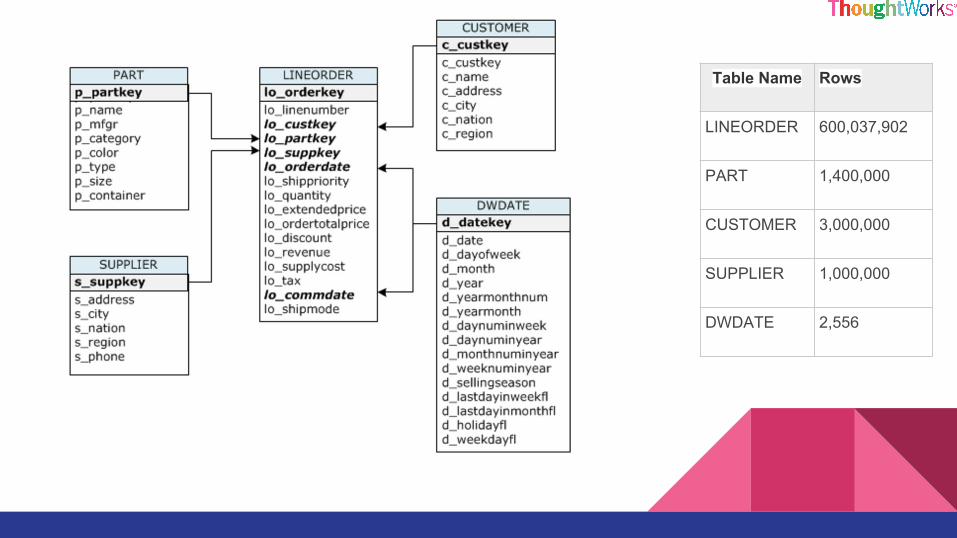
Table Name Rows
LINEORDER 600,037,902
PART 1,400,000
CUSTOMER 3,000,000
SUPPLIER 1,000,000
DWDATE 2,556

How is Redshift so fast ?
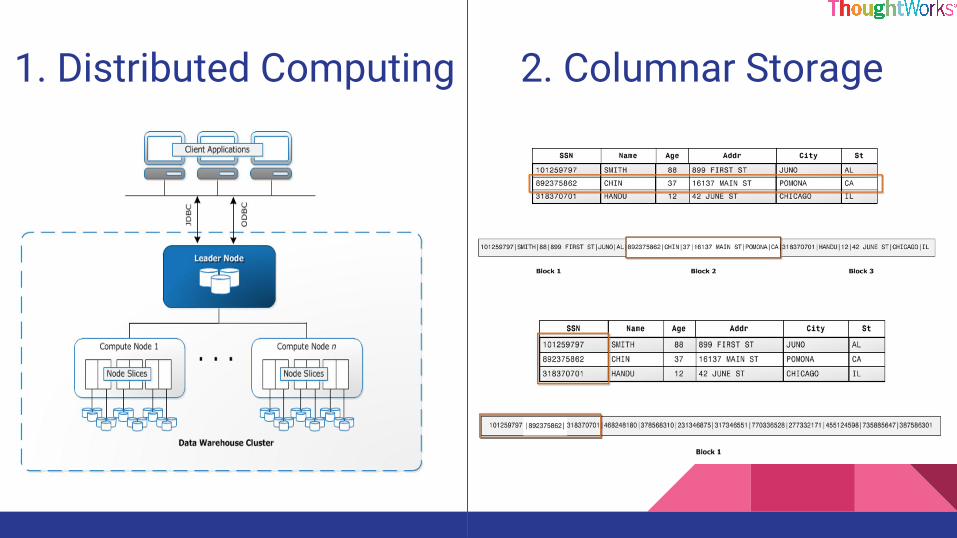
1. Distributed Computing 2. Columnar Storage

3. Data Compression 4. Large Block StorageRaw Default storage
ByteDict External dict of unique values
Delta Difference between the values
Runlength Count of repetitive values
Text Repetitive words in long text
Block Size of 1Mb as opposed to smaller block sizes in RDBMS

Tuning
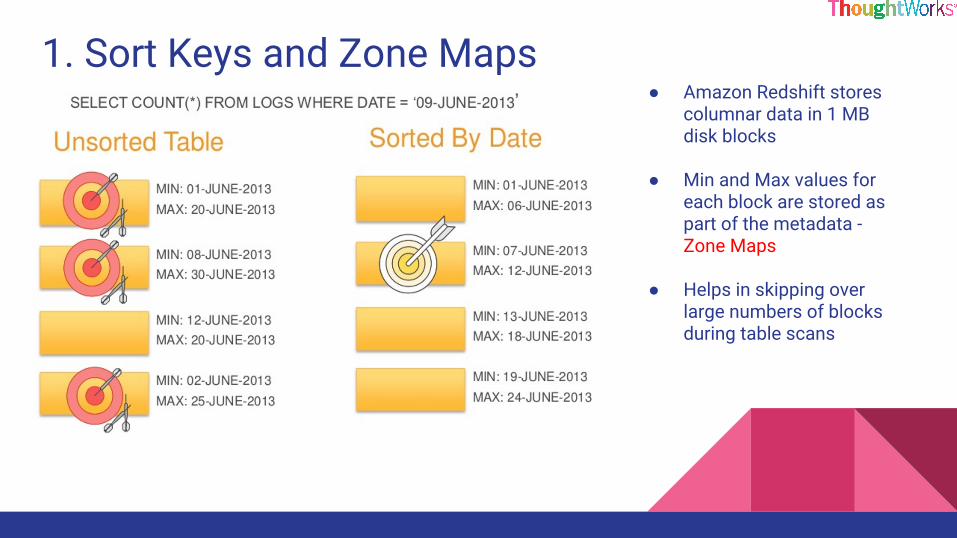
1. Sort Keys and Zone Maps● Amazon Redshift stores
columnar data in 1 MB disk blocks
● Min and Max values for each block are stored as part of the metadata - Zone Maps
● Helps in skipping over large numbers of blocks during table scans

Compound Sort Key
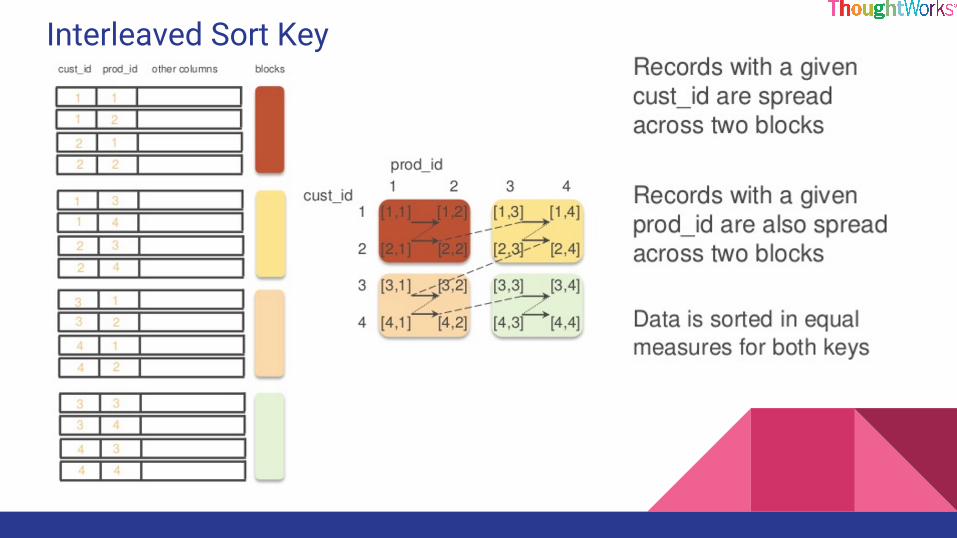
Interleaved Sort Key

Choosing a Sort Key
● Timestamp Column
● Range or Equality filtering on specific column
● Join Column
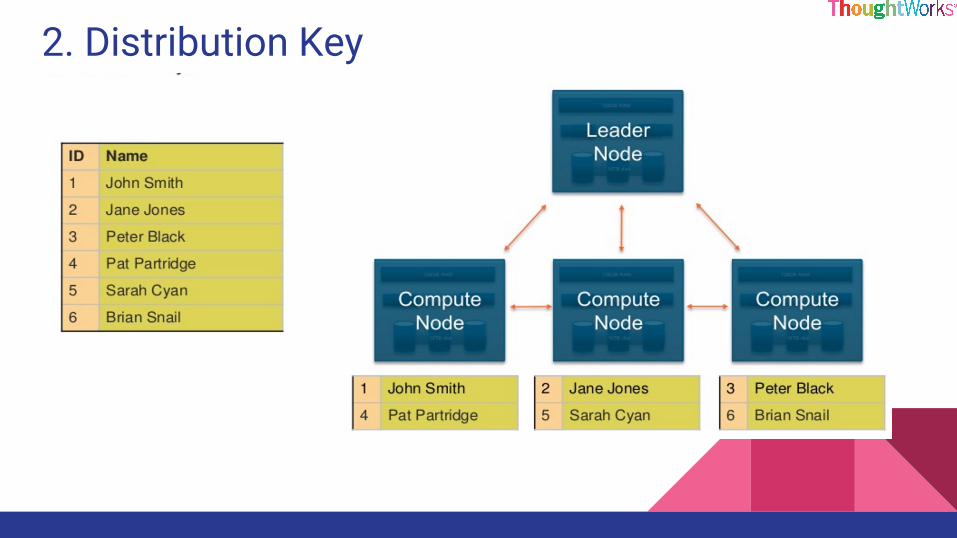
2. Distribution Key

Effect of distribution on query performance
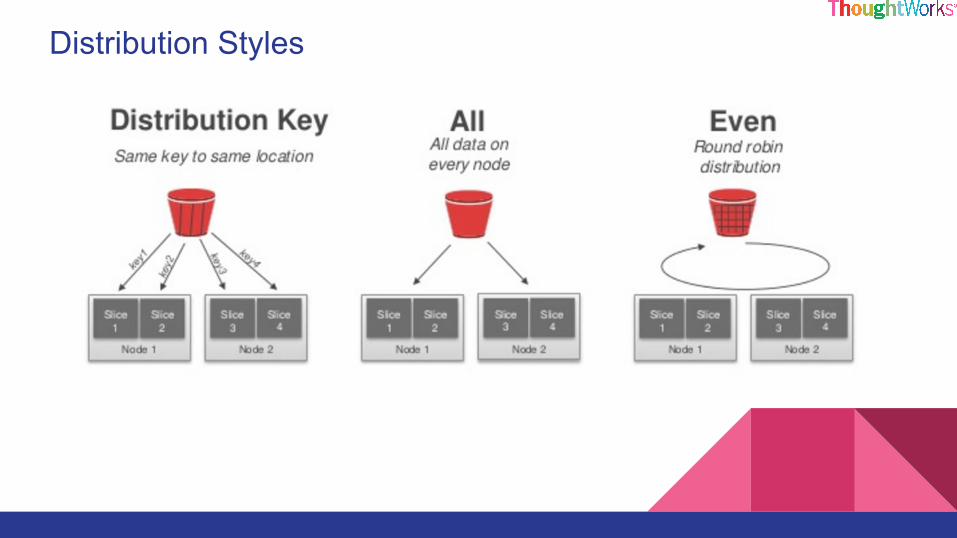
Distribution Styles

Integration with other tools

● EMR
● RDS
● Spark
● ETL - SnapLogic,
Treasure data

Where not to use it ?

● Using it for something non-analytics○ It is not for OLTP operations
● When you have small queries like select * from <table>
● When you have constraints, indexes or table partitioning
● When you have many concurrent users accessing same
cluster○ Limit of 50 concurrent users

Gotchas

● Data loading into Redshift○ Only S3, DynamoDB, EMR and Data-Pipeline supported parallely
● Concurrent queries downgrades performance○ More load more latency
● Cluster resizing○ Read only mode while resizing
○ Does not easily scale up for dynamic workloads

● Multi-AZ deployments not supported○ Cluster unavailable until power and network access to the AZ are
restored
● Frequent Deletes & Updates
○ Every UPDATE = DELETE + INSERT
○ Vacuum to the rescue
● Can not apply compression after table is created

References

● http://docs.aws.amazon.com/redshift/latest/dg/welcome.html
● https://www.periscopedata.com/blog/redshift-and-rds-postgres-benchmarke
d.html
● http://blog.blazeclan.com/what-is-amazon-redshift-11-key-points-remember/
● https://redshiftuser.wordpress.com/
● http://engineering.thinknear.com/blog/2015/01/21/understanding-the-decisi
on-to-move-from-aws-emr-slash-hive-to-redshift/
● http://www.eshioji.co.uk/2013/07/a-simplistic-redshift-trouble-shooting.html





























